PARSUC: A Parallel Subsampling-Based Method for Clustering Remote Sensing Big Data


Abstract
:1. Introduction
2. Method
2.1. Traditional Parallelization Strategy
2.2. PARSUC
2.2.1. Subsampling Step
2.2.2. Filtering Step
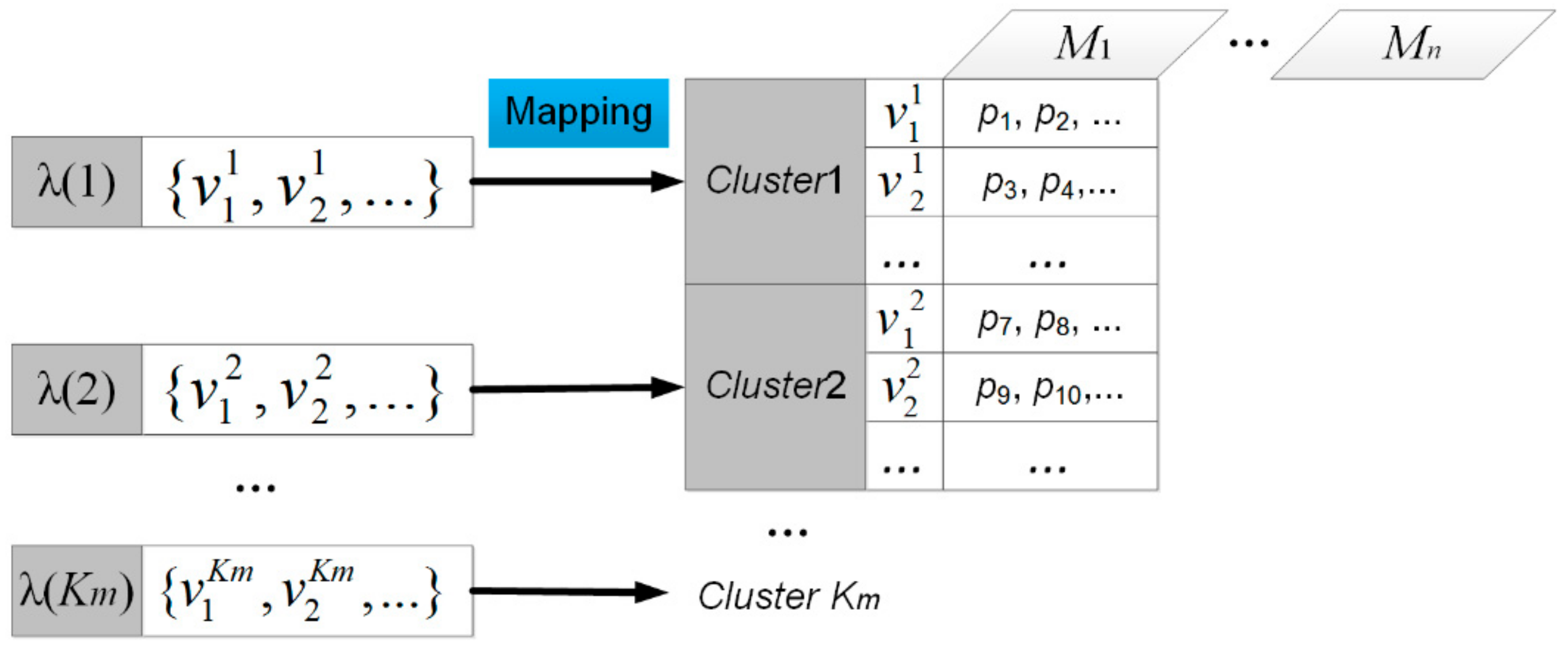
2.2.3. Mapping Step
3. Implementation
4. Results
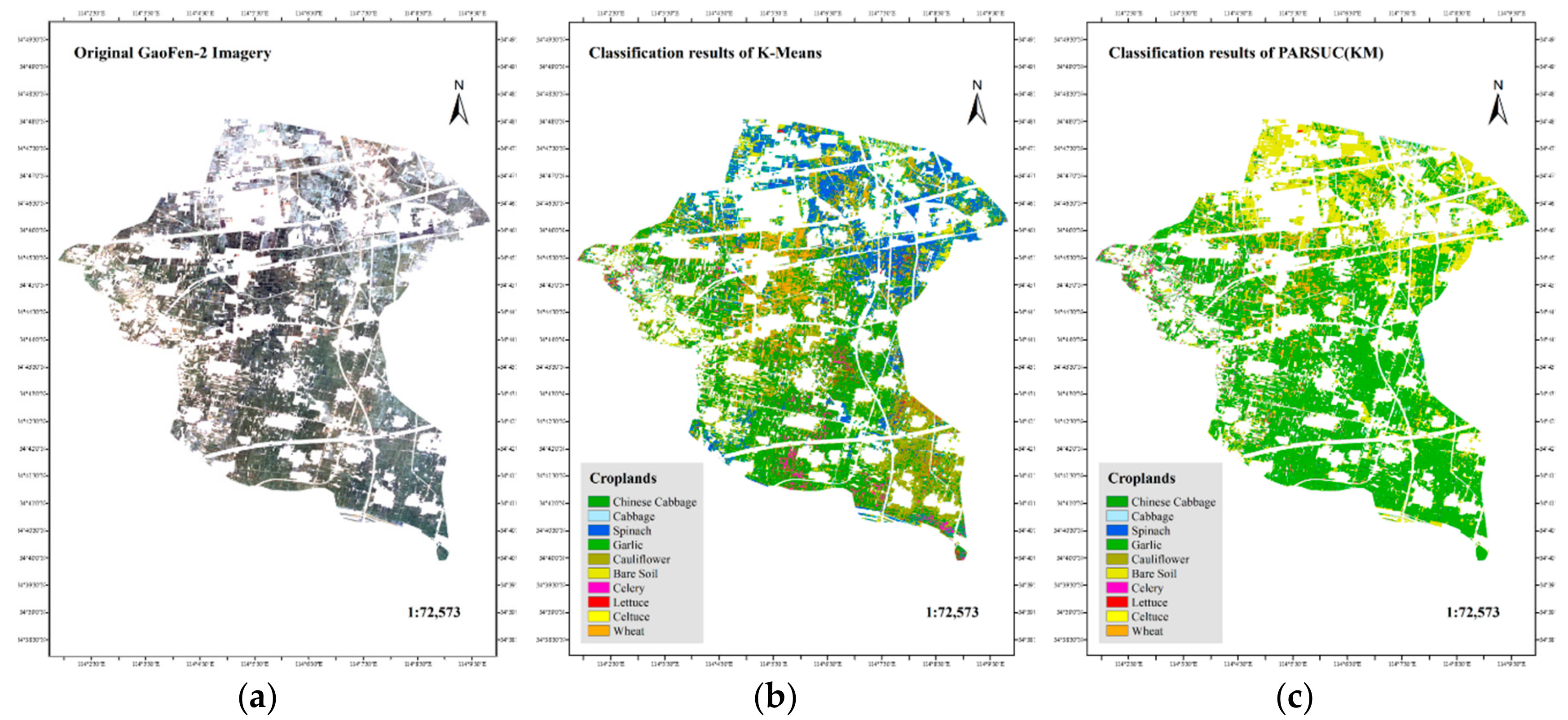
4.1. Accuracy Validation
4.2. Accuracy Validation by Two Cases
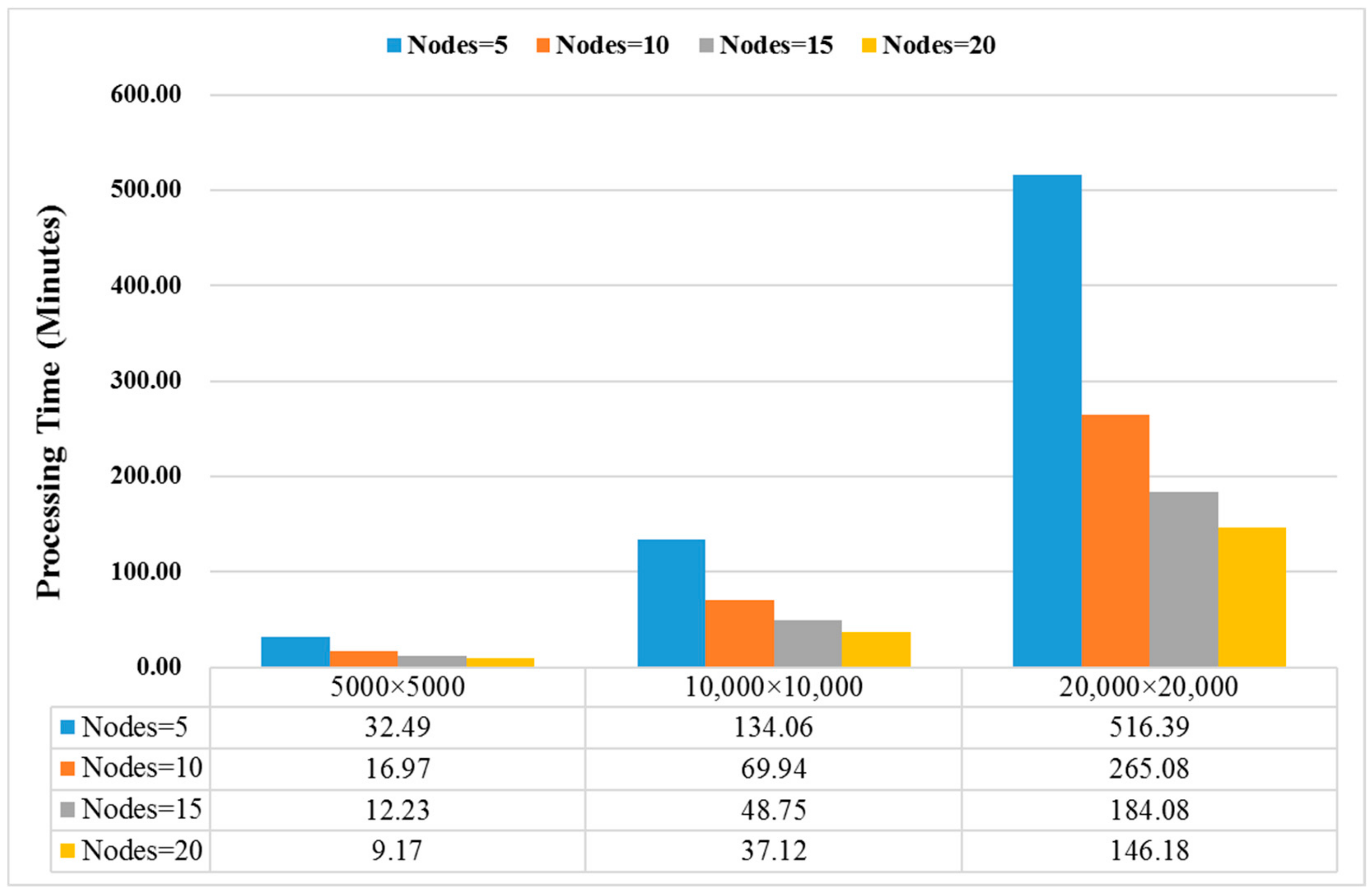
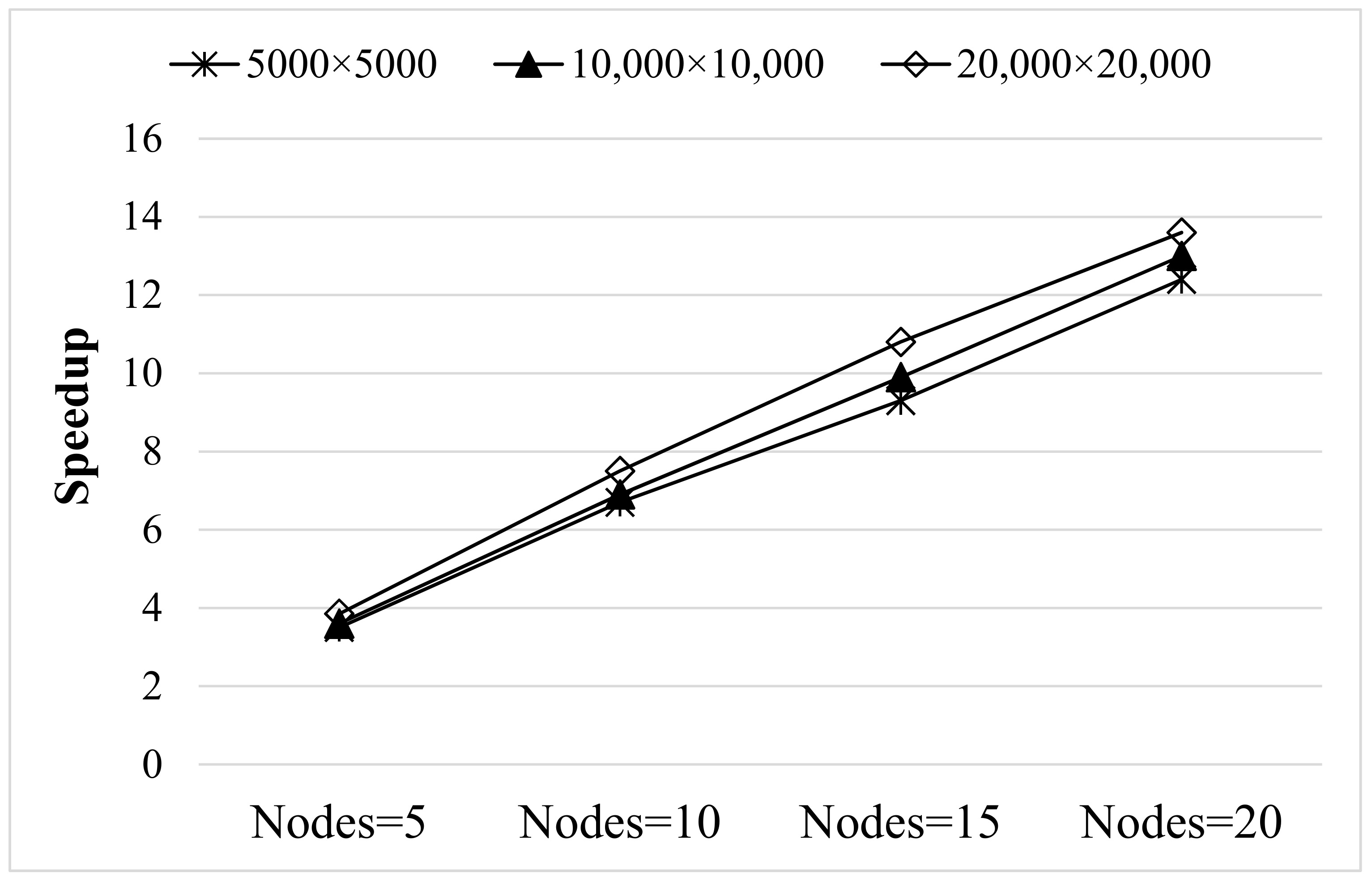
4.3. Time Cost
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, J.G.; Kang, M. Geospatial big data: Challenges and opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big data and cloud computing: innovation opportunities and challenges. Int. J. Digit. Earth. 2017, 10, 13–53. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Liu, P.; Di, L.; Du, Q.; Wang, L. Remote Sensing Big Data: Theory, Methods and Applications. Remote Sens. 2018, 10, 711. [Google Scholar] [CrossRef]
- Ye, D.; Li, Y.; Tao, C.; Xie, X.; Wang, X. Multiple feature hashing learning for large-scale remote sensing image retrieval. ISPRS Int. J. Geo-Inf. 2017, 6, 364. [Google Scholar] [CrossRef]
- Jo, J.; Lee, K.-W. High-Performance Geospatial Big Data Processing System Based on MapReduce. ISPRS Int. J. Geo-Inf. 2018, 7, 399. [Google Scholar] [CrossRef]
- Li, Z.; Yang, C.; Liu, K.; Hu, F.; Jin, B. Automatic Scaling Hadoop in the Cloud for Efficient Process of Big Geospatial Data. ISPRS Int. J. Geo-Inf. 2016, 5, 173. [Google Scholar] [CrossRef]
- Xia, H.; Karimi, H.; Meng, L. Parallel implementation of Kaufman’s initialization for clustering large remote sensing images on clouds. Comput. Environ. Urban Syst. 2017, 61, 153–162. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; pp. 1–32. [Google Scholar]
- MacQueen, J.B. Some methods for classification and analysis of multivariate observations. In Proceedings of Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Ball, G.; Hall, J. ISODATA, A Novel Method of Data Analysis and Pattern Classification, Technical Report; Stanford Research Institute: Menlo Park, CA, USA, 1965; pp. 1–61. [Google Scholar]
- HajKacem, M.; N’cir, C. One-pass MapReduce-based clustering method for mixed large scale data. J. Intell. Inf. Syst. 2017, 52, 1–18. [Google Scholar] [CrossRef]
- Tsapanos, N.; Tefas, A.; Nikolaidis, N.; Pitas, I. A distributed framework for trimmed kernel k-means clustering. Pattern Recognit. 2015, 48, 2685–2698. [Google Scholar] [CrossRef]
- Zerhari, B.; Lahcen, A.A.; Mouline, S. Big data clustering: Algorithms and challenges. In Proceedings of the International Conference on Big Data, Cloud and Applications, Tetuan, Morocco, 25–26 May 2015. [Google Scholar]
- Shirkhorshidi, A.; Aghabozorgi, S.; Wah, T.; Herawan, T. Big Data Clustering: A Review. In Proceedings of the International Conference on Computational Science and Its Applications, Guimarães, Portugal, 30 June–3 July 2014; pp. 707–720. [Google Scholar]
- Wang, X.; Hamilton, H. DBRS: A Density-based spatial clustering method with random sampling. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Seoul, Korea, 30 April–2 May 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 563–575. [Google Scholar]
- Rocke, D.; Dai, J. Sampling and subsampling for cluster analysis in data mining: With applications to sky survey data. Data Min. Knowl. Discov. 2003, 7, 215–232. [Google Scholar] [CrossRef]
- Han, J.; Luo, M. Bootstrapping K-means for big data analysis. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014; pp. 591–596. [Google Scholar]
- Vanderzee, D.; Ehrichlich, D. Sensitivity of ISODATA to change in sampling procedures and processing parameters when applied to AVHRR time-series NDVI Data. Int. J. Remote Sens. 1995, 16, 673–686. [Google Scholar] [CrossRef]
- Fern, X.Z.; Brodley, C.E. Random projection for high dimensional clustering: A cluster ensemble approach. In Proceedings of the Twentieth International Conference on Machine Learning (ICML), Washington, DC, USA, 21–24 August 2003; pp. 186–193. [Google Scholar]
- Ding, C.; He, X.; Zha, H.; Simon, H. Adaptive dimension reduction for clustering high dimensional data. In Proceedings of the International Conference on Data Mining (ICDM), Maebashi City, Japan, 9–12 December 2002; pp. 1–8. [Google Scholar]
- Boutsidis, C.; Zouzias, A.; Drineas, P. Random projections for k-means clustering. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 6–9 December 2010; pp. 298–306. [Google Scholar]
- Zhang, J.; Wu, G.; Hu, X.; Li, S.; Hao, S. A Parallel K-means Clustering Algorithm with MPI. In Proceedings of the 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Tianjin, China, 9–11 December 2011; pp. 60–64. [Google Scholar]
- Xu, X.; Jäger, J.; Kriegel, H.-P. A Fast Parallel Clustering Algorithm for Large Spatial Databases. Data Min. Knowl. Discov. 1999, 3, 263–290. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Zhao, W.; Ma, H.; He, Q. Parallel k-means clustering based on MapReduce. In Proceedings of the IEEE International Conference on Cloud Computing, Beijing, China, 1–4 December 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 674–679. [Google Scholar]
- Shahrivari, S.; Jalili, S. Single-pass and linear-time k-means clustering based on MapReduce. Inf. Syst. 2016, 60, 1–12. [Google Scholar] [CrossRef]
- Kim, Y.; Shim, K.; Kim, M.-S.; Sup Lee, J. DBCURE-MR: An efficient density-based clustering algorithm for large data using MapReduce. Inf. Syst. 2014, 42, 15–35. [Google Scholar] [CrossRef]
- Maulik, U.; Sarkar, A. Efficient parallel algorithm for pixel classification in remote sensing imagery. GeoInformatica. 2012, 16, 391–407. [Google Scholar] [CrossRef]
- Du, Z.; Gu, Y.; Zhang, C.; Zhang, F.; Liu, R.; Sequeira, J.; Li, W. ParSymG: a parallel clustering approach for unsupervised classification of remotely sensed imagery. Int. J. Digit. Earth. 2017, 10, 471–489. [Google Scholar] [CrossRef]
- Ye, F.; Shi, X. Parallelizing ISODATA Algorithm for Unsupervised Image Classification on GPU. Modern Accelerator Technologies for Geographic Information Science; Springer: Boston, MA, USA, 2013; pp. 145–156. [Google Scholar]
- Li, B.; Zhao, H.; Lv, Z. Parallel ISODATA clustering of remote sensing images based on MapReduce. In Proceedings of the 2010 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Huangshan, China, 10–12 October 2010; pp. 380–383. [Google Scholar]
- Lv, Z.; Hu, Y.; Zhong, H.; Wu, J.; Li, B.; Zhao, H. Parallel K-means clustering of remote sensing images based on MapReduce. In Proceedings of the International Conference on Web Information Systems and Mining, Sanya, China, 23–24 October 2010; pp. 162–170. [Google Scholar]
- Mohebi, A.; Aghabozorgi, S.; Wah, T.Y.; Herawan, T.; Yahyapour, R. Iterative big data clustering algorithms: A review. Softw. Pract. Exp. 2016, 46, 107–129. [Google Scholar] [CrossRef]
- Bu, Y.; Howe, B.; Balazinska, M.; Ernst, M.D. HaLoop: Efficient iterative data processing on large clusters. Proc. VLDB Endow. 2010, 3, 285–296. [Google Scholar] [CrossRef]
- Davidson, I.; Satyanarayana, A. Speeding up K-Means clustering using bootstrap averaging. In Proceedings of the 2003 International Conference on Data Mining Workshop on Clustering Large Data Sets, Melbourne, FL, USA, 19–22 November 2003; pp. 16–25. [Google Scholar]
- Hore, P.; Hall, L.O.; Goldgof, D.B. A scalable framework for cluster ensembles. Pattern Recognit. 2009, 42, 676–688. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prim, R.C. Shortest connection networks and some generalizations. Bell Syst. Tech. J. 1957, 36, 1389–1401. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ρ = 1% | ρ = 2% | ρ = 5% | ρ = 10% | ρ = 20% | ρ = 30% | |
|---|---|---|---|---|---|---|
| B = 10 | 44.0 | 25.8 | 9.5 | 5.0 | 1.2 | 1.0 |
| B = 20 | 46.1 | 21.5 | 11.2 | 4.2 | 0.5 | 0.6 |
| B = 30 | 43.3 | 31.7 | 7.8 | 4.6 | 1.1 | 1.0 |
| B = 40 | 44.6 | 26.9 | 10.3 | 4.9 | 0.7 | 0.9 |
| 2 × median | 3 × median | 4 × median | 5 × median | |
|---|---|---|---|---|
| Ithreshold | 0.17 | 0.53 | 0.62 | 0.96 |
| 500 × 500 | 1000 × 1000 | 2000 × 2000 | 3000 × 3000 | 4000 × 4000 | |
|---|---|---|---|---|---|
| PARSUC(KM) | 2.11 × 108 | 7.6 × 108 | 1.35 × 109 | 5.61 × 109 | 0.23 × 1010 |
| K-means | 2.19 × 108 | 7.72 × 108 | 1.96 × 109 | 6.33 × 109 | 0.96 × 1010 |
| 500 × 500 | 1000 × 1000 | 2000 × 2000 | 3000 × 3000 | 4000 × 4000 | |
|---|---|---|---|---|---|
| PARSUC(ISO) | 2.51 × 108 | 8.80 × 108 | 2.06 × 109 | 6.92 × 109 | 0.93 × 1010 |
| ISODATA | 2.36 × 108 | 8.84 × 108 | 2.14 × 109 | 7.76 × 109 | 1.66 × 1010 |
| Image Size | Nodes = 5 | Nodes = 10 | Nodes = 15 | Nodes = 20 | ||||
|---|---|---|---|---|---|---|---|---|
| PARSUC | MPC | PARSUC | MPC | PARSUC | MPC | PARSUC | MPC | |
| 5000 × 5000 | 32.49 | 87.47 | 16.97 | 50.44 | 12.23 | 37.45 | 9.17 | 27.34 |
| 10,000 × 10,000 | 134.06 | 305.61 | 69.94 | 169.88 | 48.75 | 122.49 | 37.12 | 92.25 |
| 20,000 × 20,000 | 516.39 | 1088.78 | 265.08 | 577.16 | 184.08 | 407.16 | 146.18 | 323.37 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, H.; Huang, W.; Li, N.; Zhou, J.; Zhang, D. PARSUC: A Parallel Subsampling-Based Method for Clustering Remote Sensing Big Data. Sensors 2019, 19, 3438. https://doi.org/10.3390/s19153438
Xia H, Huang W, Li N, Zhou J, Zhang D. PARSUC: A Parallel Subsampling-Based Method for Clustering Remote Sensing Big Data. Sensors. 2019; 19(15):3438. https://doi.org/10.3390/s19153438
Chicago/Turabian StyleXia, Huiyu, Wei Huang, Ning Li, Jianzhong Zhou, and Dongying Zhang. 2019. "PARSUC: A Parallel Subsampling-Based Method for Clustering Remote Sensing Big Data" Sensors 19, no. 15: 3438. https://doi.org/10.3390/s19153438