Visual and Thermal Image Processing for Facial Specific Landmark Detection to Infer Emotions in a Child-Robot Interaction

 , , , and
, , , and
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Experimental Procedure
3.2. Contact-Free Emotion Recognition
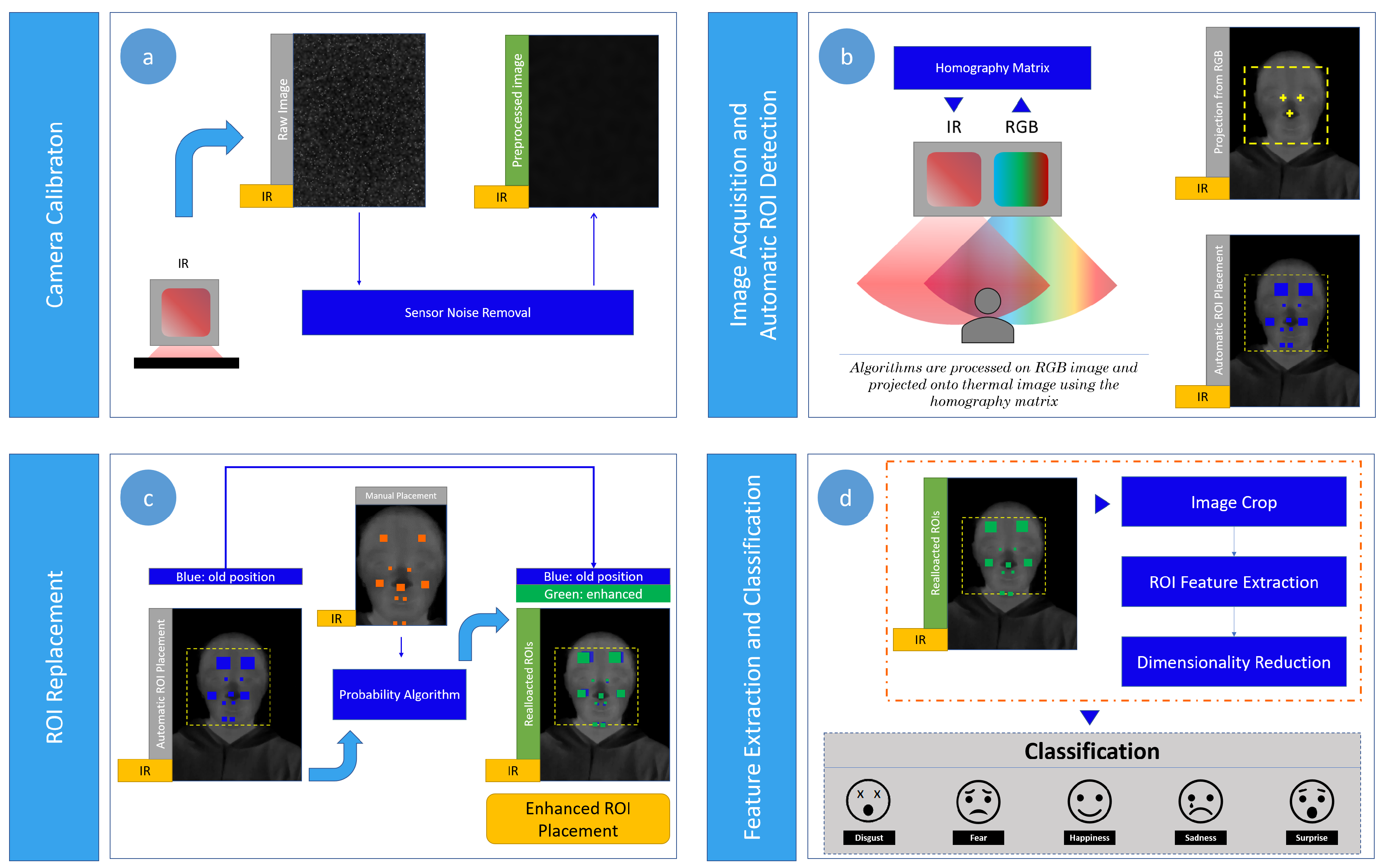
3.2.1. Camera System and N-MARIA
3.2.2. Camera Calibration
3.2.3. Image Acquisition and Pre-Processing
3.2.4. Face Landmark Detection
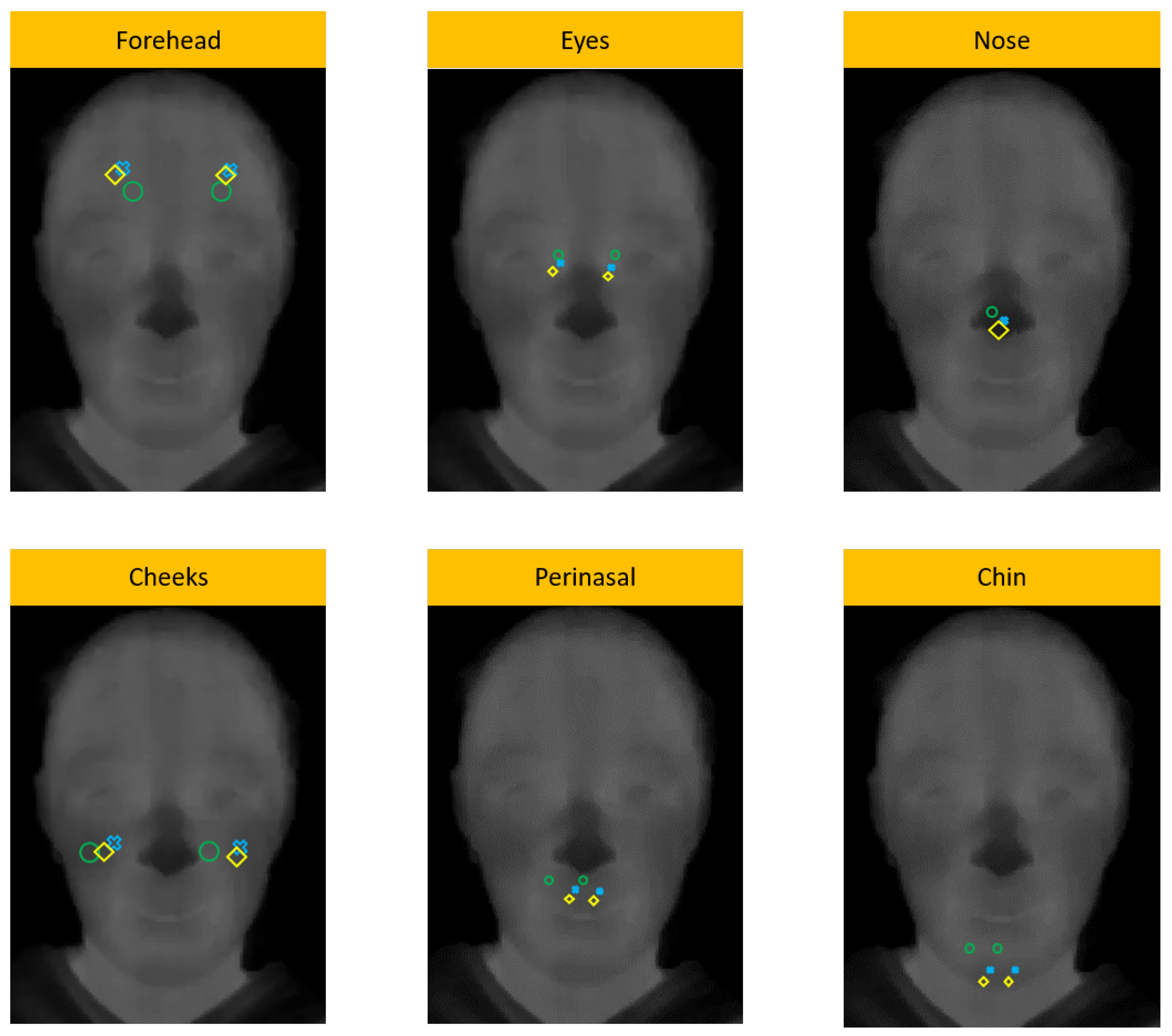
3.2.5. Automatic ROI Detection
3.2.6. ROI Location Correction
3.2.7. Feature Extraction
3.2.8. Dimensionality Reduction and Emotion Classification
3.3. Statistical Evaluation
4. Results
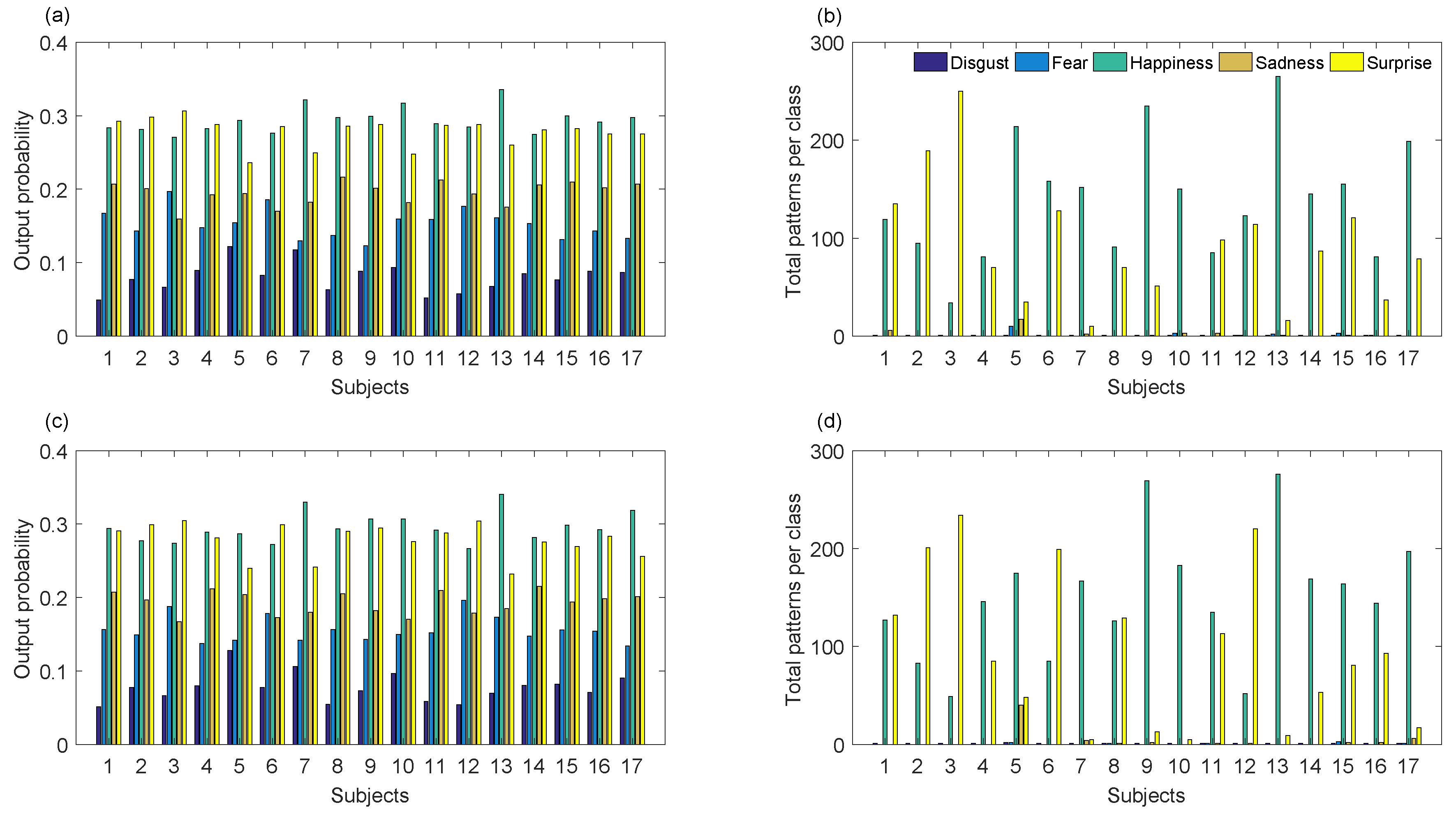
4.1. Automatic ROI Location
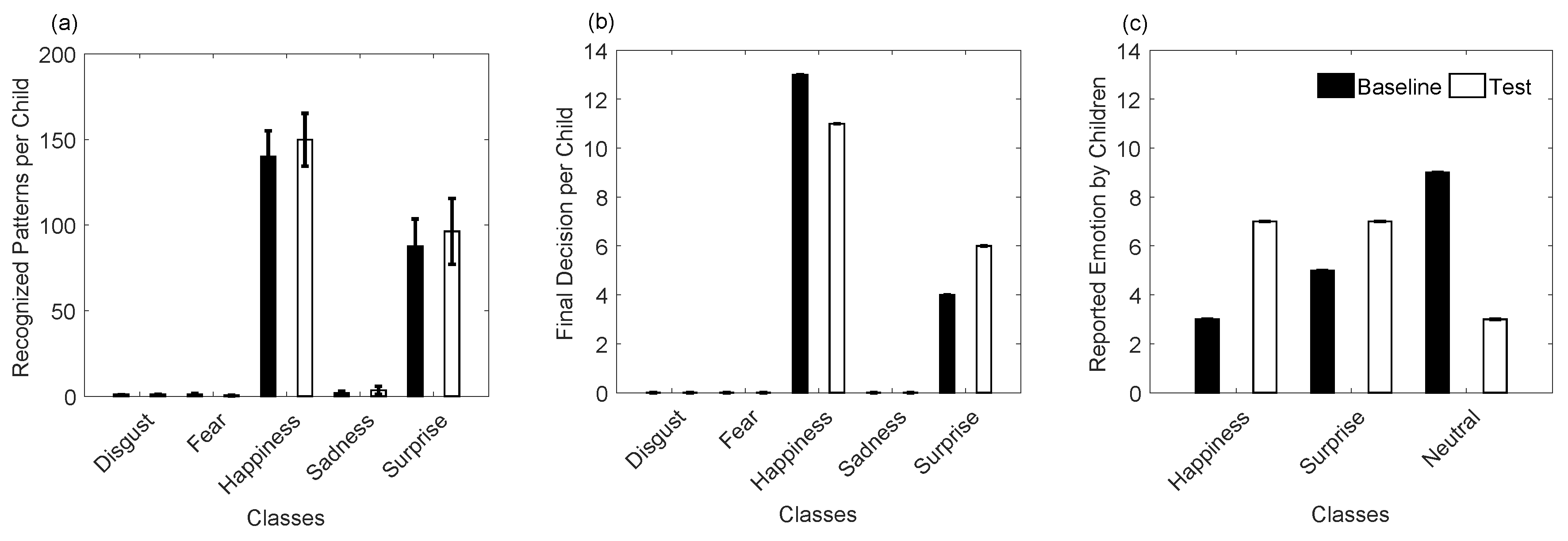
4.2. Emotion Recognition
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gunes, H.; Celiktutan, O.; Sariyanidi, E. Live human–robot interactive public demonstrations with automatic emotion and personality prediction. Philos. Trans. R. Soc. B 2019, 374, 20180026. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.S.; Berkovits, L.D.; Bernier, E.P.; Leyzberg, D.; Shic, F.; Paul, R.; Scassellati, B. Social Robots as Embedded Reinforcers of Social Behavior in Children with Autism. J. Autism Dev. Disord. 2012, 43, 1038–1049. [Google Scholar] [CrossRef] [PubMed]
- Valadao, C.; Caldeira, E.; Bastos-Filho, T.; Frizera-Neto, A.; Carelli, R. A New Controller for a Smart Walker Based on Human-Robot Formation. Sensors 2016, 16, 1116. [Google Scholar] [CrossRef] [PubMed]
- Picard, R.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef]
- Conn, K.; Liu, C.; Sarkar, N.; Stone, W.; Warren, Z. Affect-sensitive assistive intervention technologies for children with autism: An individual-specific approach. In Proceedings of the RO-MAN 2008—The 17th IEEE International Symposium on Robot and Human Interactive Communication, Munich, Germany, 1–3 August 2008. [Google Scholar]
- Shier, W.A.; Yanushkevich, S.N. Biometrics in human-machine interaction. In Proceedings of the 2015 International Conference on Information and Digital Technologies, Zilina, Slovakia, 7–9 July 2015. [Google Scholar]
- Goulart, C.; Valadao, C.; Caldeira, E.; Bastos, T. Brain signal evaluation of children with Autism Spectrum Disorder in the interaction with a social robot. Biotechnol. Res. Innov. 2018. [Google Scholar] [CrossRef]
- Latif, M.T.; Yusof, M.; Fatai, S. Emotion Detection from Thermal Facial Imprint based on GLCM Features. ARPN J. Eng. Appl. Sci. 2016, 11, 345–349. [Google Scholar]
- Sariyanidi, E.; Gunes, H.; Cavallaro, A. Automatic analysis of facial affect: A survey of registration, representation, and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1113–1133. [Google Scholar] [CrossRef] [PubMed]
- Ko, B. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef]
- Rusli, N.; Sidek, S.N.; Yusof, H.M.; Latif, M.H.A. Non-Invasive Assessment of Affective States on Individual with Autism Spectrum Disorder: A Review. In IFMBE Proceedings; Springer: Singapore, 2015; pp. 226–230. [Google Scholar]
- Petrantonakis, P.C.; Hadjileontiadis, L.J. Emotion recognition from EEG using higher order crossings. IEEE Trans. Inf. Technol. Biomed. 2009, 14, 186–197. [Google Scholar] [CrossRef]
- Basu, A.; Routray, A.; Shit, S.; Deb, A.K. Human emotion recognition from facial thermal image based on fused statistical feature and multi-class SVM. In Proceedings of the 2015 Annual IEEE India Conference (INDICON), New Delhi, India, 17–20 December 2015. [Google Scholar]
- Ghimire, D.; Jeong, S.; Lee, J.; Park, S.H. Facial expression recognition based on local region specific features and support vector machines. Multimed. Tools Appl. 2017, 76, 7803–7821. [Google Scholar] [CrossRef]
- Perikos, I.; Paraskevas, M.; Hatzilygeroudis, I. Facial Expression Recognition Using Adaptive Neuro-fuzzy Inference Systems. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Happy, S.; Routray, A. Automatic facial expression recognition using features of salient facial patches. IEEE Trans. Affect. Comput. 2014, 6, 1–12. [Google Scholar] [CrossRef]
- Goulart, C.; Valadao, C.; Delisle-Rodriguez, D.; Caldeira, E.; Bastos, T. Emotion analysis in children through facial emissivity of infrared thermal imaging. PLoS ONE 2019, 14, e0212928. [Google Scholar] [CrossRef] [PubMed]
- Cruz-Albarran, I.A.; Benitez-Rangel, J.P.; Osornio-Rios, R.A.; Morales-Hernandez, L.A. Human emotions detection based on a smart-thermal system of thermographic images. Infrared Phys. Technol. 2017, 81, 250–261. [Google Scholar] [CrossRef]
- Wang, S.; Shen, P.; Liu, Z. Facial expression recognition from infrared thermal images using temperature difference by voting. In Proceedings of the 2012 IEEE 2nd International Conference on Cloud Computing and Intelligence Systems, Hangzhou, China, 30 October–1 November 2012; Volume 1, pp. 94–98. [Google Scholar]
- Pop, F.M.; Gordan, M.; Florea, C.; Vlaicu, A. Fusion based approach for thermal and visible face recognition under pose and expresivity variation. In Proceedings of the 9th RoEduNet IEEE International Conference, Sibiu, Romania, 24–26 June 2010; pp. 61–66. [Google Scholar]
- Ioannou, S.; Gallese, V.; Merla, A. Thermal infrared imaging in psychophysiology: Potentialities and limits. Psychophysiology 2014, 51, 951–963. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, Y. Face detection and eyeglasses detection for thermal face recognition. SPIE Proc. 2012, 8300, 83000C. [Google Scholar]
- Wang, S.; Liu, Z.; Lv, S.; Lv, Y.; Wu, G.; Peng, P.; Chen, F.; Wang, X. A Natural Visible and Infrared Facial Expression Database for Expression Recognition and Emotion Inference. IEEE Trans. Multimed. 2010, 12, 682–691. [Google Scholar] [CrossRef]
- Choi, J.S.; Bang, J.; Heo, H.; Park, K. Evaluation of fear using nonintrusive measurement of multimodal sensors. Sensors 2015, 15, 17507–17533. [Google Scholar] [CrossRef] [PubMed]
- Lajevardi, S.M.; Hussain, Z.M. Automatic facial expression recognition: Feature extraction and selection. Signal Image Video Process. 2012, 6, 159–169. [Google Scholar] [CrossRef]
- Jabid, T.; Kabir, M.H.; Chae, O. Robust facial expression recognition based on local directional pattern. ETRI J. 2010, 32, 784–794. [Google Scholar] [CrossRef]
- Kabir, M.H.; Jabid, T.; Chae, O. A local directional pattern variance (LDPv) based face descriptor for human facial expression recognition. In Proceedings of the 2010 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August–1 September 2010; pp. 526–532. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Robust facial expression recognition using local binary patterns. In Proceedings of the IEEE International Conference on Image Processing 2005, Genova, Italy, 14 September 2005; Volume 2, p. II–370. [Google Scholar]
- Shan, C.; Gritti, T. Learning Discriminative LBP-Histogram Bins for Facial Expression Recognition. In Proceedings of the British Machine Vision Conference 2008, Leeds, UK, 1–4 September 2008; pp. 1–10. [Google Scholar]
- Song, M.; Tao, D.; Liu, Z.; Li, X.; Zhou, M. Image ratio features for facial expression recognition application. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 40, 779–788. [Google Scholar] [CrossRef]
- Zhang, L.; Tjondronegoro, D. Facial expression recognition using facial movement features. IEEE Trans. Affect. Comput. 2011, 2, 219–229. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Jiang, B.; Martinez, B.; Valstar, M.F.; Pantic, M. Decision level fusion of domain specific regions for facial action recognition. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1776–1781. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1867–1874. [Google Scholar]
- Zhao, X.; Zhang, S. Facial expression recognition based on local binary patterns and kernel discriminant isomap. Sensors 2011, 11, 9573–9588. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wang, X.; Han, S.; Wang, J.; Park, D.S.; Wang, Y. Improved Real-Time Facial Expression Recognition Based on a Novel Balanced and Symmetric Local Gradient Coding. Sensors 2019, 19, 1899. [Google Scholar] [CrossRef] [PubMed]
- Giacinto, A.D.; Brunetti, M.; Sepede, G.; Ferretti, A.; Merla, A. Thermal signature of fear conditioning in mild post traumatic stress disorder. Neuroscience 2014, 266, 216–223. [Google Scholar] [CrossRef] [PubMed]
- Marzec, M.; Koprowski, R.; Wróbel, Z. Methods of face localization in thermograms. Biocybern. Biomed. Eng. 2015, 35, 138–146. [Google Scholar] [CrossRef]
- Trujillo, L.; Olague, G.; Hammoud, R.; Hernandez, B. Automatic Feature Localization in Thermal Images for Facial Expression Recognition. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)—Workshops, San Diego, CA, USA, 21–23 September 2005. [Google Scholar]
- Nhan, B.; Chau, T. Classifying Affective States Using Thermal Infrared Imaging of the Human Face. IEEE Trans. Biomed. Eng. 2010, 57, 979–987. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV library. Dr Dobb’s J. Softw. Tools 2000, 25, 120–125. [Google Scholar]
- Malis, E.; Vargas, M. Deeper Understanding of the Homography Decomposition for Vision-Based Control. Ph.D. Thesis, INRIA, Sophia Antipolis Cedex, France, 2007. [Google Scholar]
- Budzier, H.; Gerlach, G. Calibration of uncooled thermal infrared cameras. J. Sens. Sens. Syst. 2015, 4, 187–197. [Google Scholar] [CrossRef] [Green Version]
- Martínez, A.M.; Kak, A.C. Pca versus lda. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef]
- Friedman, J.H. Regularized discriminant analysis. J. Am. Stat. Assoc. 1989, 84, 165–175. [Google Scholar] [CrossRef]
- Kwon, O.W.; Chan, K.; Hao, J.; Lee, T.W. Emotion recognition by speech signals. In Proceedings of the Eighth European Conference on Speech Communication and Technology, Geneva, Switzerland, 1–4 September 2003. [Google Scholar]
- Bamidis, P.D.; Frantzidis, C.A.; Konstantinidis, E.I.; Luneski, A.; Lithari, C.; Klados, M.A.; Bratsas, C.; Papadelis, C.L.; Pappas, C. An integrated approach to emotion recognition for advanced emotional intelligence. In International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2009; pp. 565–574. [Google Scholar]
- Ververidis, D.; Kotropoulos, C.; Pitas, I. Automatic emotional speech classification. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, pp. I–593. [Google Scholar]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Japkowicz, N.; Shah, M. Evaluating Learning Algorithms: A Classification Perspective; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Boucenna, S.; Gaussier, P.; Andry, P.; Hafemeister, L. A robot learns the facial expressions recognition and face/non-face discrimination through an imitation game. Int. J. Soc. Robot. 2014, 6, 633–652. [Google Scholar] [CrossRef]
- Busso, C.; Deng, Z.; Yildirim, S.; Bulut, M.; Lee, C.M.; Kazemzadeh, A.; Lee, S.; Neumann, U.; Narayanan, S. Analysis of emotion recognition using facial expressions, speech and multimodal information. In Proceedings of the 6th International Conference on Multimodal Interfaces, State College, PA, USA, 13–15 October 2004; pp. 205–211. [Google Scholar]
- Pantic, M.; Rothkrantz, L.J. Toward an affect-sensitive multimodal human-computer interaction. Proc. IEEE 2003, 91, 1370–1390. [Google Scholar] [CrossRef] [Green Version]
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Essa, I.A.; Pentland, A.P. Coding, analysis, interpretation, and recognition of facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 757–763. [Google Scholar] [CrossRef]
- Mase, K. Recognition of facial expression from optical flow. IEICE Trans. Inf. Syst. 1991, 74, 3474–3483. [Google Scholar]
- Yacoob, Y.; Davis, L. Computing Spatio-Temporal Representations of Human Faces. Ph.D. Thesis, Department of Computer Science, University of Maryland, College Park, MD, USA, 1994. [Google Scholar]
- Lee, C.M.; Yildirim, S.; Bulut, M.; Kazemzadeh, A.; Busso, C.; Deng, Z.; Lee, S.; Narayanan, S. Emotion recognition based on phoneme classes. In Proceedings of the Eighth International Conference on Spoken Language Processing, Jeju Island, Korea, 4–8 October 2004. [Google Scholar]
- Nwe, T.L.; Wei, F.S.; De Silva, L.C. Speech based emotion classification. In Proceedings of the IEEE Region 10 International Conference on Electrical and Electronic Technology, TENCON 2001 (Cat. No. 01CH37239), Singapore, 19–22 August 2001; Volume 1, pp. 297–301. [Google Scholar]
- Mehta, D.; Siddiqui, M.F.H.; Javaid, A.Y. Facial emotion recognition: A survey and real-world user experiences in mixed reality. Sensors 2018, 18, 416. [Google Scholar] [CrossRef]
- Bharatharaj, J.; Huang, L.; Mohan, R.; Al-Jumaily, A.; Krägeloh, C. Robot-Assisted Therapy for Learning and Social Interaction of Children with Autism Spectrum Disorder. Robotics 2017, 6, 4. [Google Scholar] [CrossRef]
- Kosonogov, V.; Zorzi, L.D.; Honoré, J.; Martínez-Velázquez, E.S.; Nandrino, J.L.; Martinez-Selva, J.M.; Sequeira, H. Facial thermal variations: A new marker of emotional arousal. PLoS ONE 2017, 12, e0183592. [Google Scholar] [CrossRef] [PubMed]
- Yoshitomi, Y.; Miyaura, T.; Tomita, S.; Kimura, S. Face identification using thermal image processing. In Proceedings of the 6th IEEE International Workshop on Robot and Human Communication, RO-MAN’97 SENDAI, Sendai, Japan, 29 September–1 October 1997; pp. 374–379. [Google Scholar] [CrossRef]
- Wang, S.; He, M.; Gao, Z.; He, S.; Ji, Q. Emotion recognition from thermal infrared images using deep Boltzmann machine. Front. Comput. Sci. 2014, 8, 609–618. [Google Scholar] [CrossRef]
- Bijalwan, V.; Balodhi, M.; Gusain, A. Human emotion recognition using thermal image processing and eigenfaces. Int. J. Eng. Sci. Res. 2015, 5, 34–40. [Google Scholar]
- Yoshitomi, Y.; Miyawaki, N.; Tomita, S.; Kimura, S. Facial expression recognition using thermal image processing and neural network. In Proceedings of the 6th IEEE International Workshop on Robot and Human Communication, RO-MAN’97 SENDAI, Sendai, Japan, 29 September–1 October 1997. [Google Scholar] [CrossRef]
- Vukadinovic, D.; Pantic, M. Fully Automatic Facial Feature Point Detection Using Gabor Feature Based Boosted Classifiers. In Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 12 October 2005. [Google Scholar]
- Di Nuovo, A.; Conti, D.; Trubia, G.; Buono, S.; Di Nuovo, S. Deep Learning Systems for Estimating Visual Attention in Robot-Assisted Therapy of Children with Autism and Intellectual Disability. Robotics 2018, 7, 25. [Google Scholar] [CrossRef]
- Suk, M.; Prabhakaran, B. Real-time mobile facial expression recognition system—A case study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 132–137. [Google Scholar]
- Deshmukh, S.; Patwardhan, M.; Mahajan, A. Survey on real-time facial expression recognition techniques. IET Biom. 2016, 5, 155–163. [Google Scholar] [CrossRef]
- Gu, W.; Xiang, C.; Venkatesh, Y.; Huang, D.; Lin, H. Facial expression recognition using radial encoding of local Gabor features and classifier synthesis. Pattern Recognit. 2012, 45, 80–91. [Google Scholar] [CrossRef]
- Liu, C.; Wechsler, H. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. IEEE Trans. Image Process. 2002, 11, 467–476. [Google Scholar] [PubMed]
- Boda, R.; Priyadarsini, M.; Pemeena, J. Face detection and tracking using KLT and Viola Jones. ARPN J. Eng. Appl. Sci. 2016, 11, 13472–13476. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference ROIs | Located ROIs |
|---|---|
| Head | , , , |
| Eyes | , , , , , |
| Nose | , , , , |
| Features | Equations |
|---|---|
| 1. Mean value of the whole ROI | , |
| 2. Variance form the whole ROI, organized in a vector | , |
| 3. Median of the whole ROI, organized as a vector | , |
| 4. Mean of variance values in rows | , |
| 5. Mean of median values in rows | , |
| 6. Mean of variance values in columns | , |
| 7. Mean of median values in columns | , |
| 8. Difference from each item in consecutive frames |
| Disgust | Fear | Happiness | Sadness | Surprise | |
|---|---|---|---|---|---|
| TPR (%) | 90.02 ± 1.91 | 87.25 ± 2.37 | 87.55 ± 2.12 | 74.69 ± 2.77 | 86.93 ± 2.12 |
| FPR (%) | 3.07 ± 0.49 | 4.17 ± 0.57 | 4.61 ± 0.69 | 3.42 ± 0.78 | 2.93 ± 0.50 |
| ACC (%) | 85.29 ± 1.16 | ||||
| Kappa (%) | 81.26 ± 1.46 | ||||
| Disgust | Fear | Happiness | Sadness | Surprise | |
|---|---|---|---|---|---|
| TPR (%) | 89.93 ± 1.88 | 88.22 ± 2.38 | 86.36 ± 2.09 | 76.15 ± 2.80 | 87.14 ± 2.15 |
| FPR (%) | 2.80 ± 0.47 | 3.48 ± 0.47 | 5.40 ± 0.83 | 3.42 ± 0.81 | 2.42 ± 0.44 |
| ACC (%) | 85.75 ± 1.16 | ||||
| Kappa (%) | 81.84 ± 1.46 | ||||
| Studies | Volunteers | Age | ACC (%) | Summary |
|---|---|---|---|---|
| Cruz-Albarran et al. [18] | 25 | 19 to 33 | 89.90 | Fuzzy algorithm, IF-THEN rules and top-down hierarquical classifier. The analyzed emotions were joy, disgust, anger, fear and sadness. |
| Basu et al. [13] | 26 | 11 to 32 | 87.5 | Histogram feature extraction and multiclass support vector machine (SVM). The Kotani Thermal Facial Expression database was used to detect emotions of anger, fear, happiness, and sadness. |
| Nhan and Chau [41] | 12 | 21 to 27 | 80.0 | Comparison between baseline and affective states. High and low arousal and valence are compared with the baseline. |
| Wang et al. [65] | 38 | 17 to 31 | 62.90 | Deep Boltzmann Machine to find positive or negative valence. |
| Bijalwan et al. [66] | 1 | N/A | 97.0 | Model for expression recognition in thermal images. Application of PCA for recognizing happiness, anger, disgust, sadness and neutral emotions. |
| Yoshitomi et al. [67] | 1 | N/A | 90.0 | Neural Networks and Backpropagation algorithms that recognize emotions of happiness, surprise and neutral state. |
| Kosonogov et al. [63] | 24 | 20 to 24 | N/A | Studied tip of nose thermal variation in volunteers with images from International Affective Picture System (IAPS) which found that positive or negative images showed more temperature change compared with neutral images |
| Vukadinovic and Pantic [68] | 200 | 18 to 50 | N/A | Algorithm to find facial ROIs. A Viola-Jones adapted algorithm (that applies GentleBoost instead of AdaBoost) was used. For facial feature extraction Gabor wavelet filter was used. No emotion classes were studied, only the facial points for ROI detection. |
| Bharatharaj et al. [62] | 9 | 6 to 16 | N/A | AMRM (indirect teaching method) was studied using a parrot-inspired robot and the Oxford emotion API to recognize and classify emotions in ASD children. Most of them appeared to be happy with the robot. |
| Mehta et al. [61] | 3 | N/A | 93.8% | Microsoft HoloLens (MHL) system was used to detect emotions achieving a high accuracy to detect happiness, sadness, anger, surprise and neutral emotions. |
| Our proposal | 28 | 7 to 11 | 85.75% | PCA and LDA were used on our database, published in [17], to recognize happiness, sadness, fear, surprise and disgust. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goulart, C.; Valadão, C.; Delisle-Rodriguez, D.; Funayama, D.; Favarato, A.; Baldo, G.; Binotte, V.; Caldeira, E.; Bastos-Filho, T. Visual and Thermal Image Processing for Facial Specific Landmark Detection to Infer Emotions in a Child-Robot Interaction. Sensors 2019, 19, 2844. https://doi.org/10.3390/s19132844
Goulart C, Valadão C, Delisle-Rodriguez D, Funayama D, Favarato A, Baldo G, Binotte V, Caldeira E, Bastos-Filho T. Visual and Thermal Image Processing for Facial Specific Landmark Detection to Infer Emotions in a Child-Robot Interaction. Sensors. 2019; 19(13):2844. https://doi.org/10.3390/s19132844
Chicago/Turabian StyleGoulart, Christiane, Carlos Valadão, Denis Delisle-Rodriguez, Douglas Funayama, Alvaro Favarato, Guilherme Baldo, Vinícius Binotte, Eliete Caldeira, and Teodiano Bastos-Filho. 2019. "Visual and Thermal Image Processing for Facial Specific Landmark Detection to Infer Emotions in a Child-Robot Interaction" Sensors 19, no. 13: 2844. https://doi.org/10.3390/s19132844