Speech Enhancement of Mobile Devices Based on the Integration of a Dual Microphone Array and a Background Noise Elimination Algorithm

Abstract
:1. Introduction
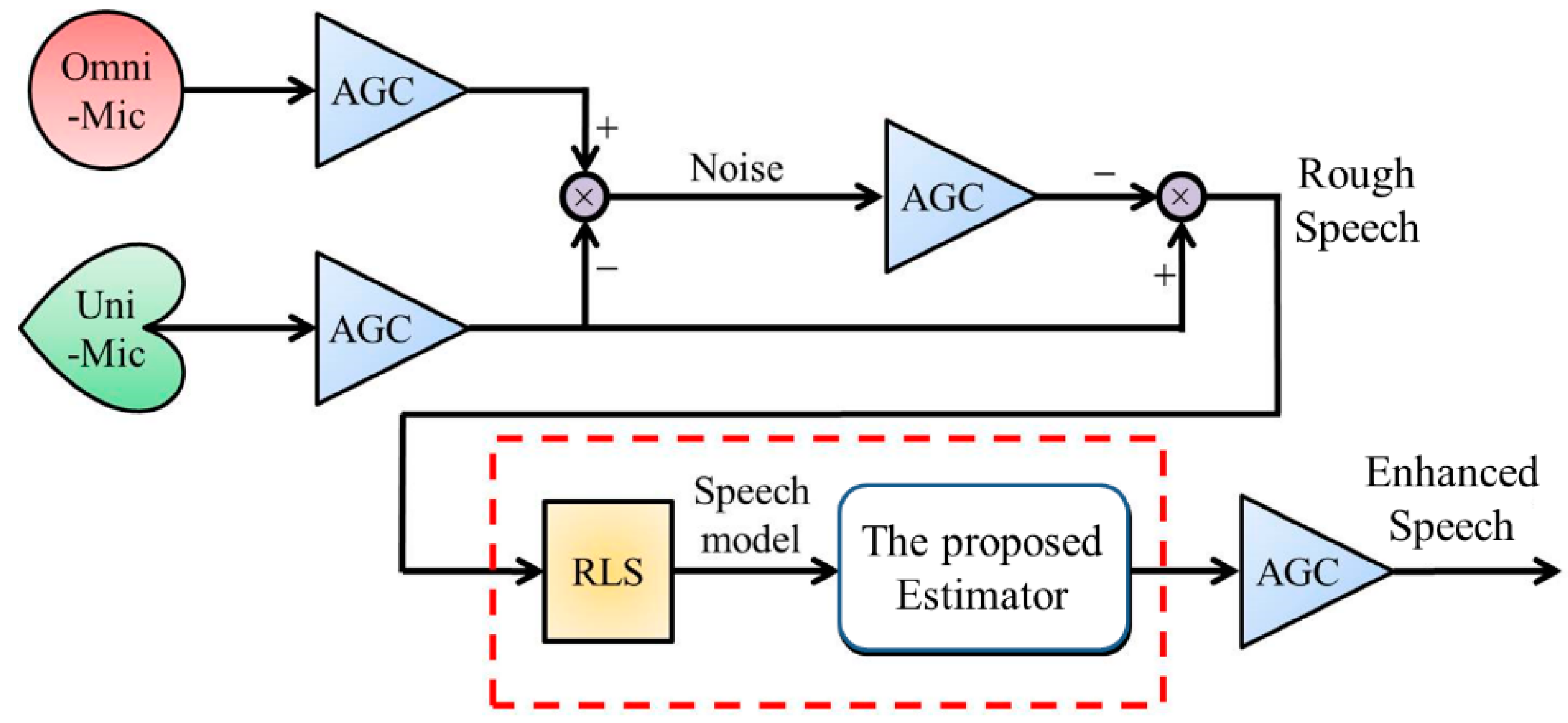
2. Speech Enhancement Process for Mobile Devices
2.1. Introduction of Overall Speech Enhancement Process
2.2. Background Noise Whitening and Extraction of a Rough Speech
2.3. System Identification: Recursive Least-Squares Identification Algorithm
2.4. H2 Estimator Design
2.5. Estimation Gain L2 of H2 Estimator
- Step 1.
- Assume the covariance matrices of vs(t) and ws(t) are identity matrices, and ∆ is a constant matrix.
- Step 2.
- Solve the LMI in Equation (23) for getting the matrices P2 and Y2.
- Step 3.
- Calculate the estimation gain L2 = P2−1 Y2.
- Step 4.
- Construct the optimal H2 estimator by Equation (13) as below
3. Practical Implementation and Performance Verification
3.1. Enhanced SNR and Perceptual Evaluation of Speech Quality
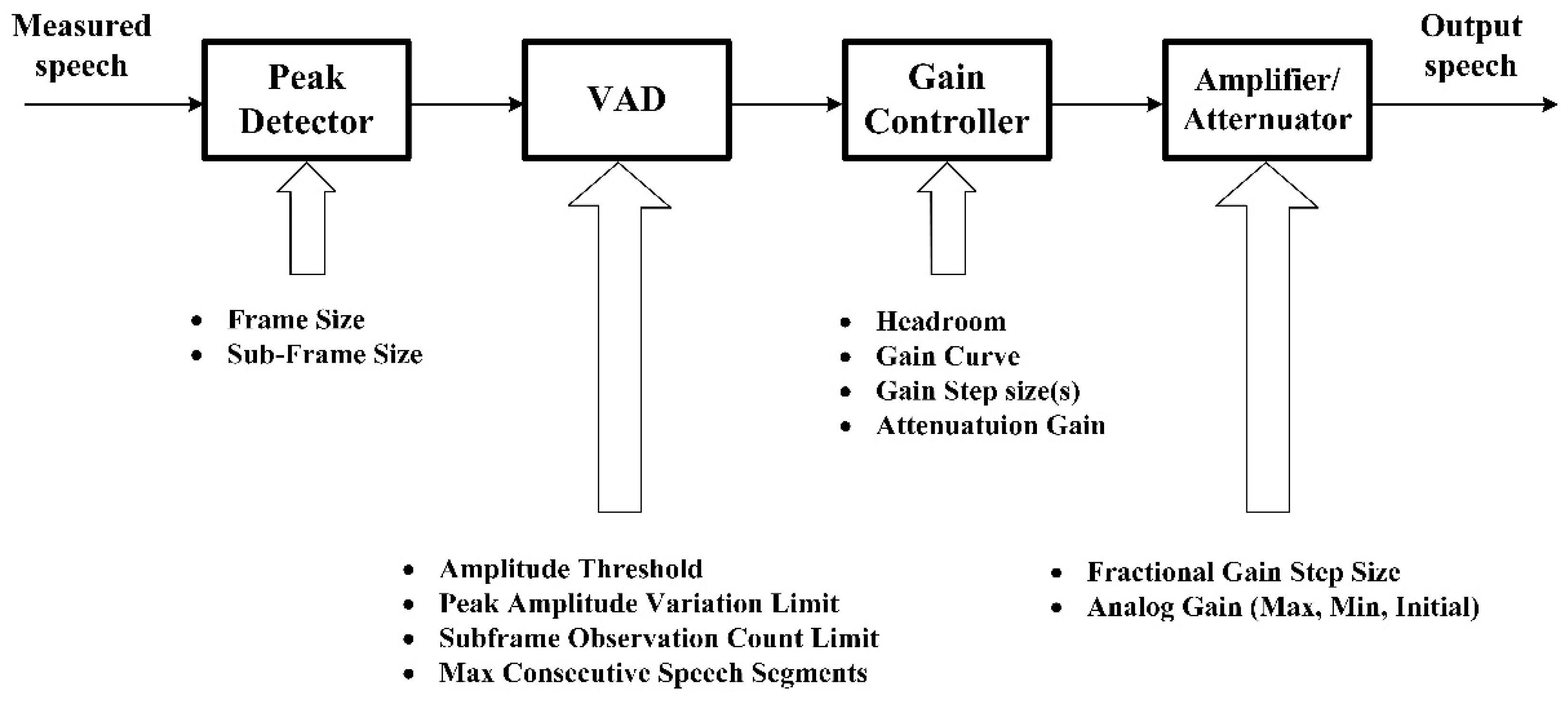
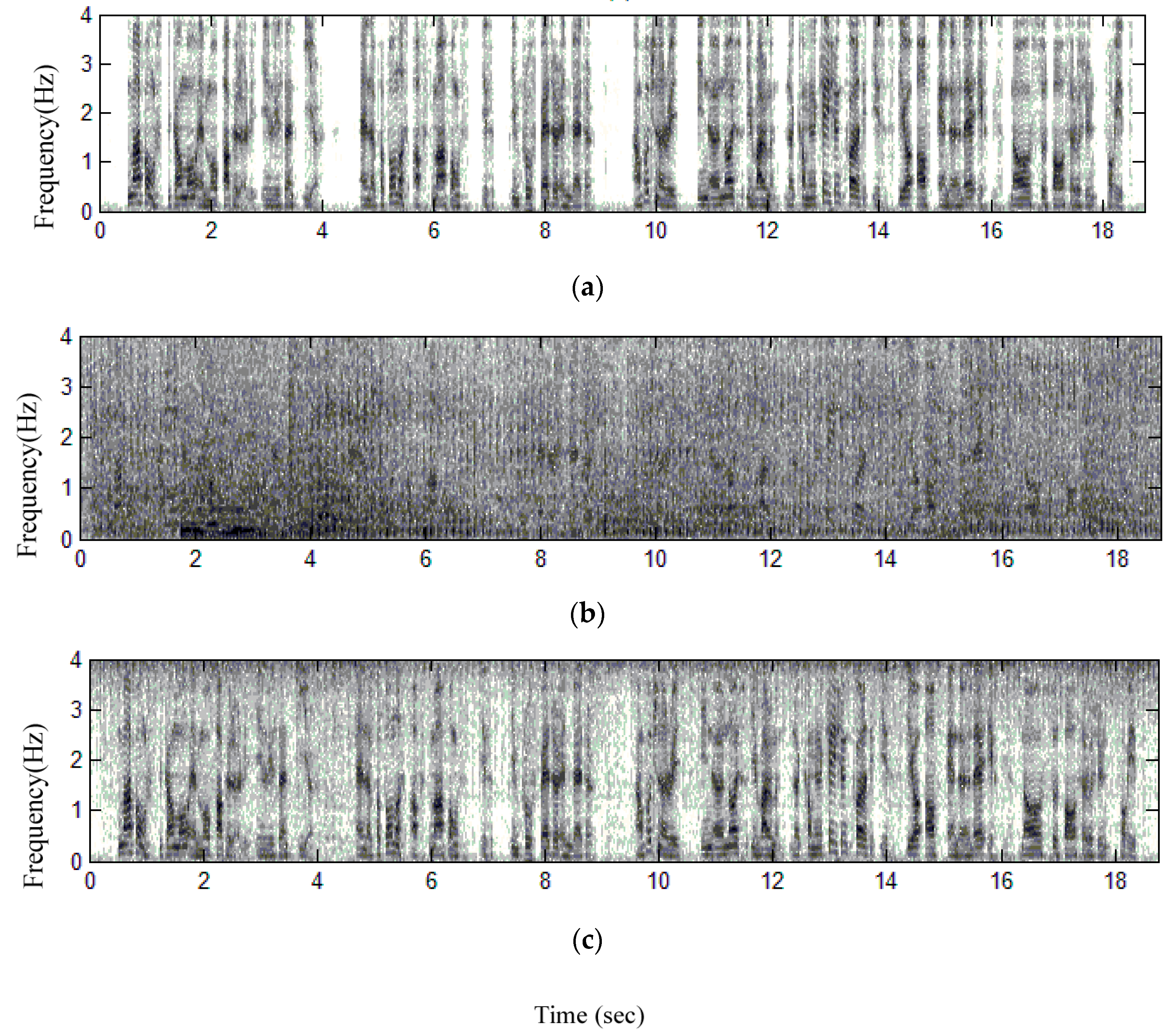
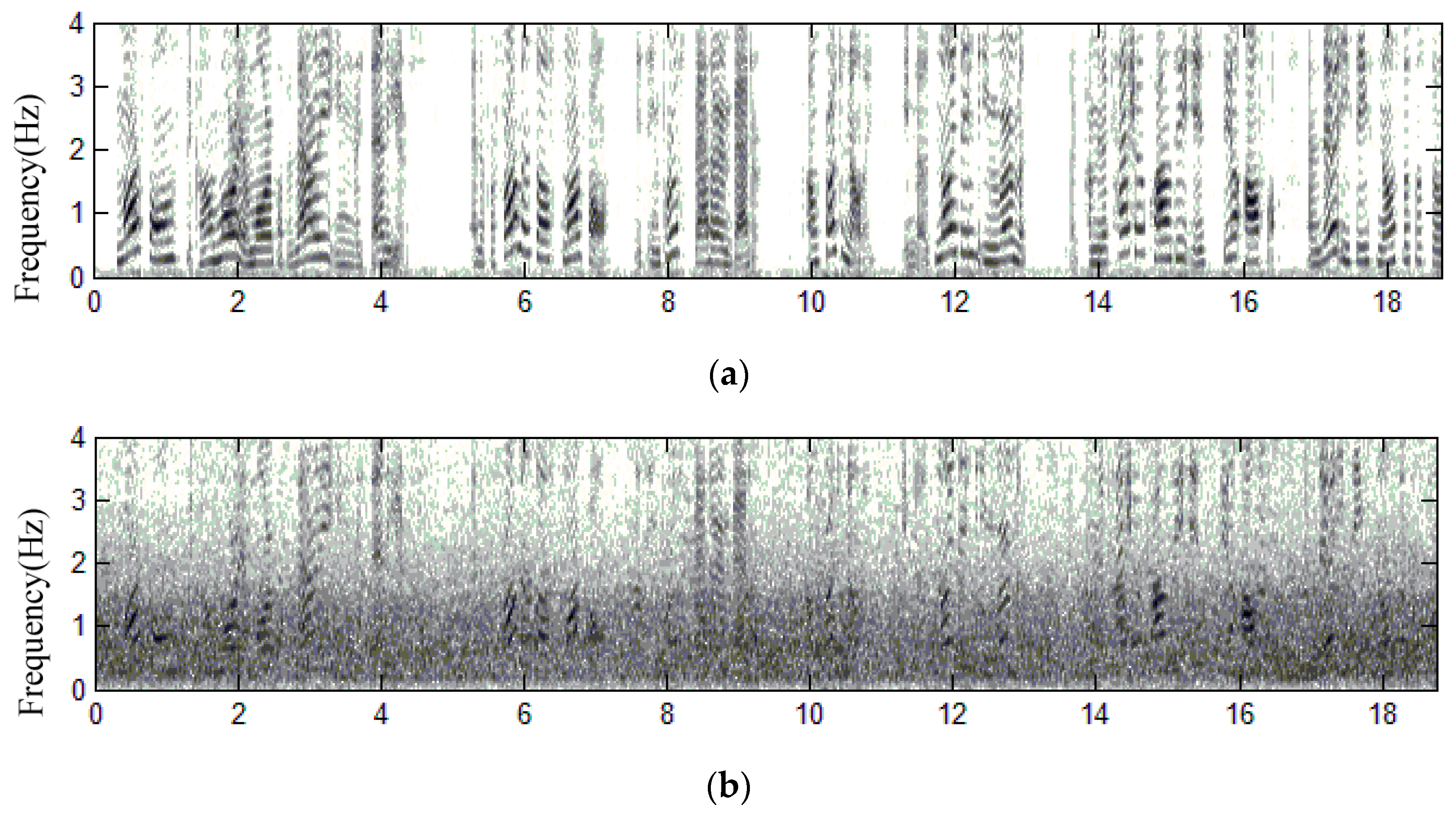
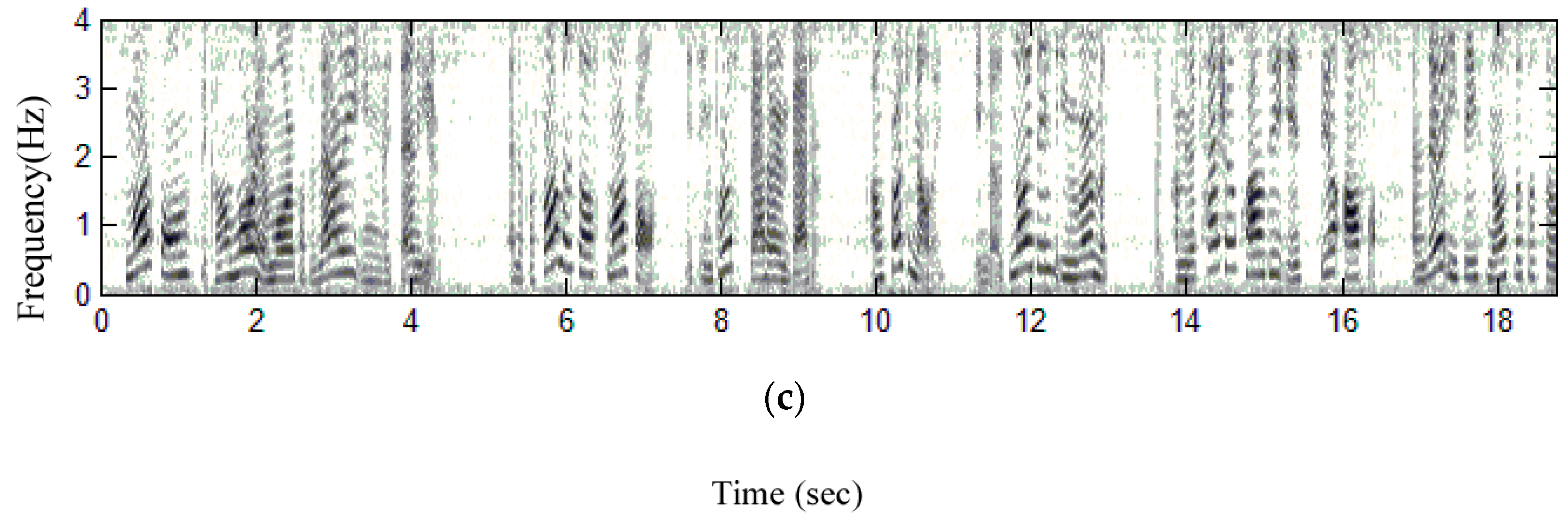
3.2. Practical Implementation and Performance Verification
3.3. Initialization of the Practical Realization
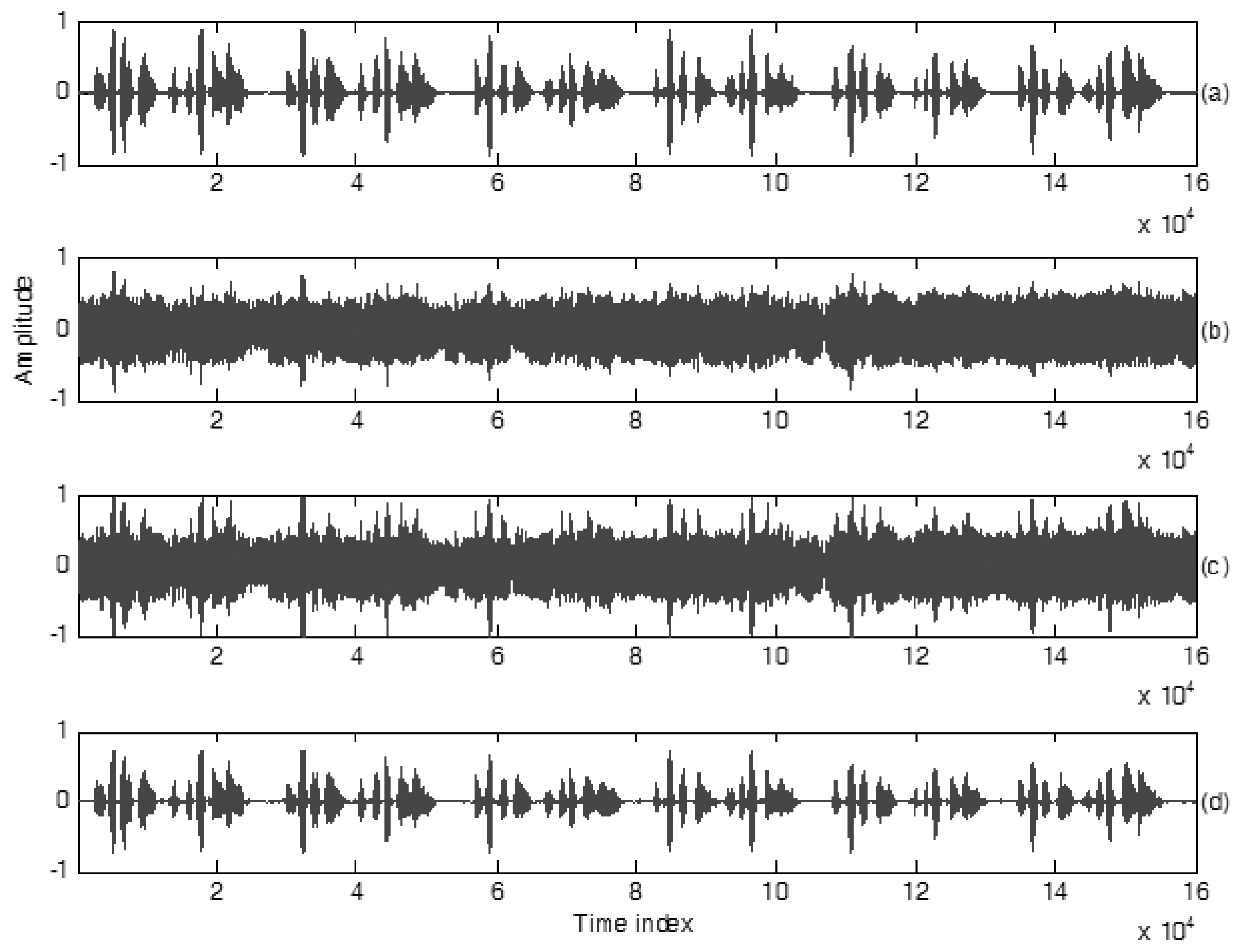
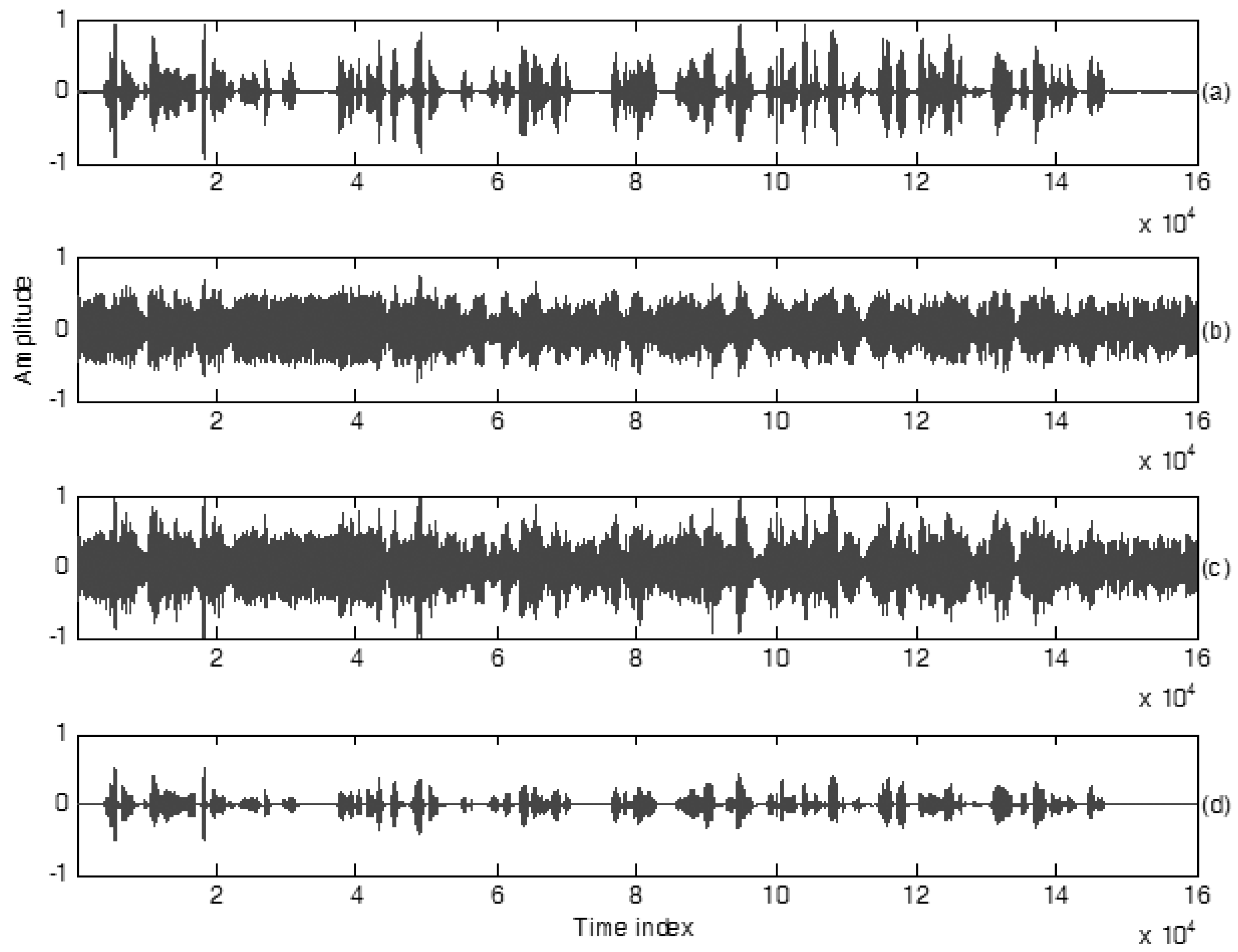
3.4. Practical Test of This Proposed Method for a Phrase
4. Conclusions
Acknowledgments
Conflicts of Interest
References
- Mosayyebpour, S.; Esmaeili, M.; Gulliver, T.A. Single-microphone early and late reverberation suppression in noisy speech. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 322–335. [Google Scholar] [CrossRef]
- Gabrea, M.; Grivel, E.; Najun, M. A single microphone Kalman filter-based noise canceller. IEEE Signal Process. Lett. 1999, 6, 55–57. [Google Scholar] [CrossRef]
- Mingyang, W.; Wang, D. A two-stage algorithm for one-microphone reverberant speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 774–784. [Google Scholar] [CrossRef]
- Ishaq, R.; Zapirain, B.G.; Shahid, M.; Lovstrom, B. Subband modulator Kalman filtering for single channel speech enhancement. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Griffiths, L.; Jim, C. An alternative approach to linearly constrained adaptive beamforming. IEEE Trans. Antennas Propag. 1982, 30, 27–34. [Google Scholar] [CrossRef]
- Hoshuyama, O.; Sugiyama, A.; Hirano, A. A robust adaptive beamformer for microphone arrays with a blocking matrix using constrained adaptive filters. IEEE Trans. Signal Process. 1999, 47, 2677–2684. [Google Scholar] [CrossRef]
- Herbordt, W.; Kellermann, W. Analysis of blocking matrices for generalized sidelobe cancellers for non-stationary broadband signals. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Orlando, FL, USA, 13–17 May 2002. [Google Scholar]
- Jeub, M.; Herglotz, C.; Nelke, C.; Beaugeant, C.; Vay, P. Noise reduction for dual-microphone mobile phones exploition power lever differences. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Gannot, S. Speech processing utilizing the Kalman filter. IEEE Trans. Instrum. Meas. Mag. 2012, 15, 10–14. [Google Scholar] [CrossRef]
- Goh, Z.; Tan, K.C.; Tan, B.T.G. Kalman-filtering speech enhancement method based on a voiced-unvoiced speech model. Speech Audio Process. 1999, 7, 510–524. [Google Scholar]
- Labarre, D.; Grivel, E.; Najim, M.; Christov, N. Dual H∞ algorithms for signal processing—Application to speech enhancement. IEEE Trans. Signal Process. 2007, 55, 5195–5208. [Google Scholar] [CrossRef]
- Chen, B.S.; Chen, W.H.; Wu, H.L. Robust H2/H∞ Global Linearization Filter Design for Nonlinear Stochastic Systems. IEEE Trans. Circuits Syst. I Regul. Pap. 2008, 56, 144–1454. [Google Scholar]
- Tseng, C.S.; Chen, B.S. H∞ fuzzy estimation for a class of nonlinear discrete-time dynamic systems. IEEE Trans. Signal Process. 2001, 49, 2605–2619. [Google Scholar] [CrossRef]
- Hu, J.S.; Lee, M.T.; Yang, C.H. Robust adaptive beamformer for speech enhancement using the second-order extended H∞ filter. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 39–50. [Google Scholar]
- Nagata, Y.; Abe, M.; Fujioka, T. Speech enhancement based on auto gain control. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 177–190. [Google Scholar] [CrossRef]
- Bessaoudi, T.; Khemiri, K.; Hmida, F.B.; Gossa, M. Recursive least-squares estimation for the joint input-state estimation of linear discrete time systems with unknown input. In Proceedings of the 2011 8th International Multi-Conference on Systems, Signals and Devices (SSD), Sousse, Tunisia, 22–25 March 2011. [Google Scholar]
- Chen, B.S.; Tsai, C.L.; Chen, Y.F. Mixed H2/H∞ filtering design in multirate transmultiplexer systems: LMI approach. IEEE Trans. Signal Process. 2001, 49, 2693–2701. [Google Scholar] [CrossRef]
- Boyd, S.; el Ghaoui, L.; Feron, E.; Balakrishnan, V. Linear Matrix Inequalities in System and Control Theory; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1994; pp. 1–5. [Google Scholar]
- MathWorks: Linear Matrix Inequality, LMI Solvers. Available online: http://www.mathworks.com/help/robust/lmis.html?requestedDomain=www.mathworks.com (accessed on 17 November 2017).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value |
|---|---|---|
| Initial values of estimator states | ||
| The coefficient covariance | ||
| Constant matrix |
| , |
| Type | Final Cross-Correlation | E-SNR | PESQ | |
|---|---|---|---|---|
| Scenario 1 | Pure Speech: A Phrase | 0.91 | 18.3 dB | 3.78 |
| English Song: Let it go, female singer Idina Menzel | ||||
| Scenario 2 | Pure Speech: A Phrase | 0.92 | 18.6 dB | 3.84 |
| English Song: Free loop, male singer Daniel Powter | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-Y. Speech Enhancement of Mobile Devices Based on the Integration of a Dual Microphone Array and a Background Noise Elimination Algorithm. Sensors 2018, 18, 1467. https://doi.org/10.3390/s18051467
Chen Y-Y. Speech Enhancement of Mobile Devices Based on the Integration of a Dual Microphone Array and a Background Noise Elimination Algorithm. Sensors. 2018; 18(5):1467. https://doi.org/10.3390/s18051467
Chicago/Turabian StyleChen, Yung-Yue. 2018. "Speech Enhancement of Mobile Devices Based on the Integration of a Dual Microphone Array and a Background Noise Elimination Algorithm" Sensors 18, no. 5: 1467. https://doi.org/10.3390/s18051467