Data Fusion Using Improved Support Degree Function in Aquaculture Wireless Sensor Networks


Abstract
:1. Introduction
2. Related Work
3. Enhancing Data Quality Based on Data Fusion Mechanism
3.1. Overview of Data Correction
| Algorithm 1. Data Correction | |
| INPUT: Original data of dissolved oxygen content, O = {o1, o2, …, on}; | |
| OUTPUT: Fused Data (XFuse); | |
| 1: | BEGIN |
| 2: | Xi = [xi1, xi2, …, xit]←consistency checking of oi; |
| 3: | for i = 1, j = 2:n |
| 4: | compute Dist(Xi, Xj); |
| 5: | sij = DTWS-ISD(Xi, Xj); |
| 6: | wj = sij/sum(sij); |
| 7: | end for |
| 8: | ; |
| 9: | XFuse = X1′; |
| 10: | END |
| 11: | ReturnXFuse; |
3.2. Data Consistency Detection
3.3. The Support Function
- (1)
- sup(a, b) ∈ [0, 1]
- (2)
- sup(a, b) = sup(b, a)
- (3)
- If |a − b| < |x − y|, then sup(a, b) > sup(x, y), a, b, x, y > 0
3.4. Weighted Fusion Based on Improved Support Degree
3.4.1. Improved Support Degree
3.4.2. Improved Support Degree Function Based on DTW Distance (DTW-ISD)
- (1)
- Boundary condition: The warping path from w1 = (1, 1) to wk = (m, n).
- (2)
- Continuity condition: The steps are confined to the points in the distance matrix with a − a′ ≤ 1 and b − b′ ≤ 1, wk = (a, b) and wk−1 = (a′, b′)
- (3)
- Monotonicity condition: For wk = (a, b) and wk−1 = (a′, b′), a − a′ ≥ 0 and b − b′ ≥ 0.
3.4.3. ISD Function Based on DTW Distance and Time Series Segmentation
3.5. Data Fusion Based on DTWS-ISD Function
4. Experiments
4.1. Data Preparation
4.1.1. Data Collection
4.1.2. The Analysis of Data Consistency Checking
4.2. Time Series Segmentation and Analysis
5. Results and Discussion
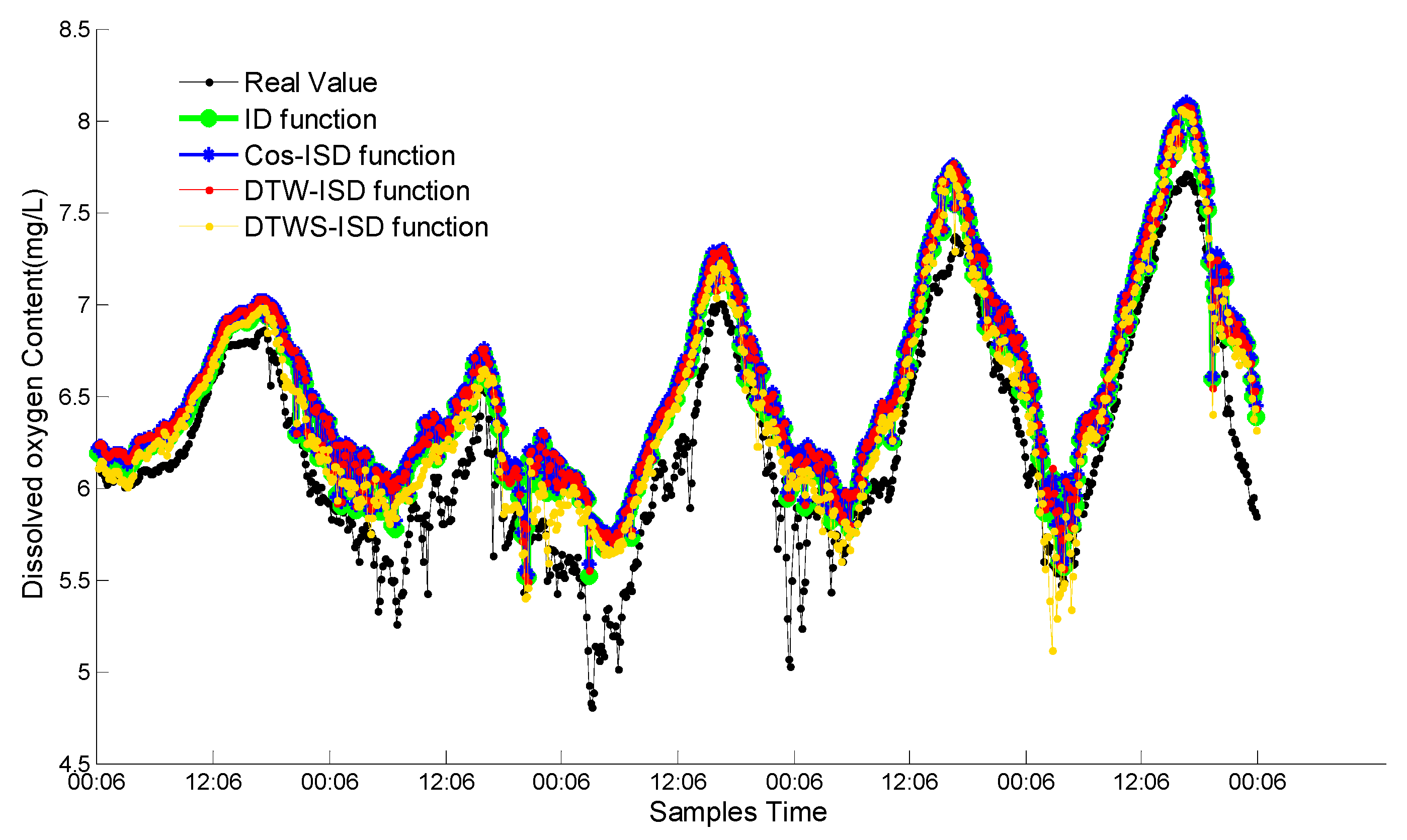
5.1. The Best Proposed Function
5.2. Comparison with Existing Methods
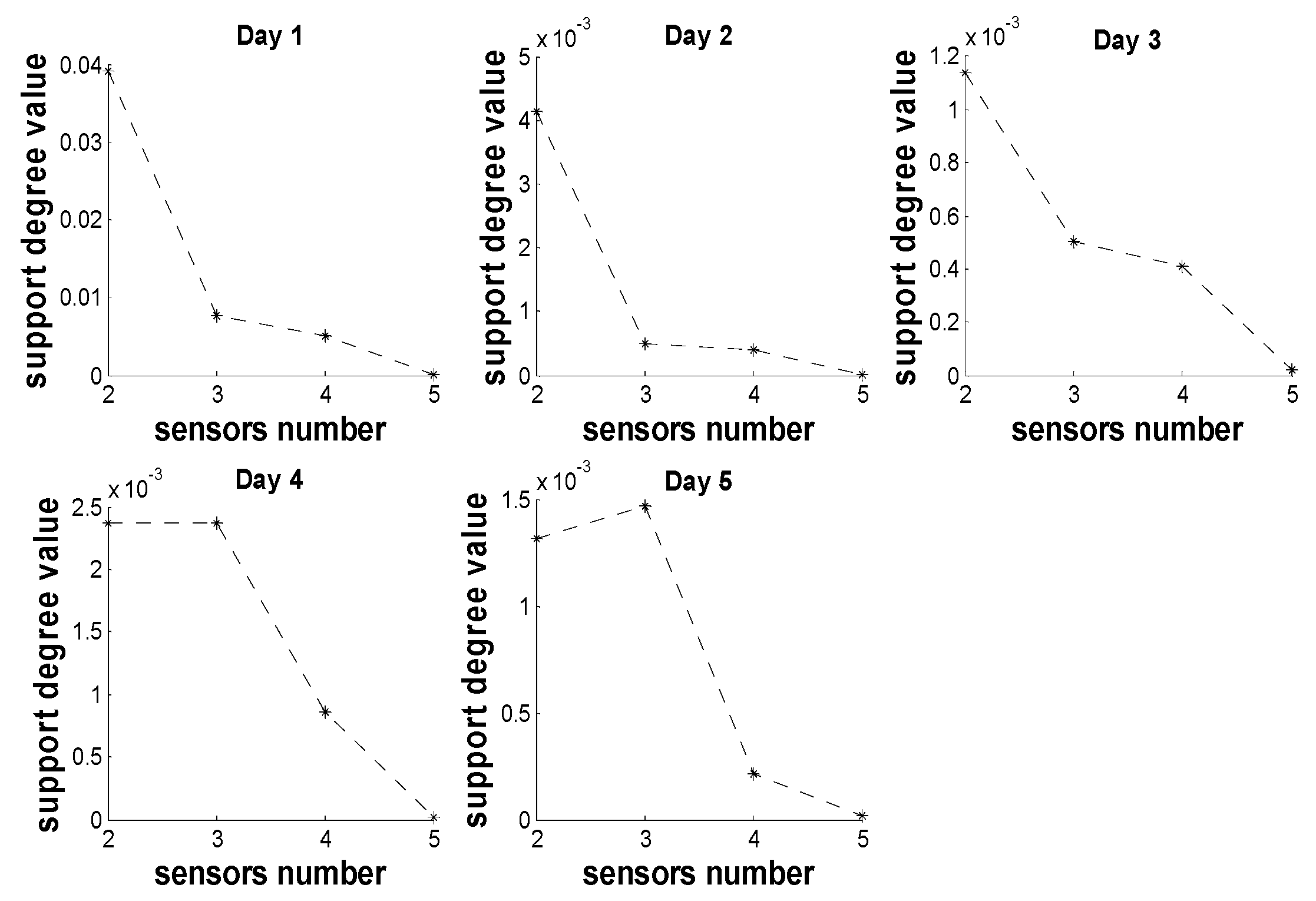
5.3. Analysis of Correlation between Sensors’ Distribution and Mutual Support Degree
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Boukerche, A.; Oliveira, H.A.B.; Nakamura, E.F.; Loureiro, A.A.F. Secure localization algorithms for wireless sensor networks. IEEE Commun. Mag. 2008, 46, 96–101. [Google Scholar] [CrossRef]
- Lu, Z.J.; Xiang, Q.; Xu, L. An application case study on multi-sensor data fusion system for intelligent process monitoring. Procedia CIRP 2014, 17, 721–725. [Google Scholar] [CrossRef]
- Wang, T.; Bhuiyan, M.Z.A.; Wang, G.; Rahman, M.A.; Wu, J.; Cao, J. Big data reduction for a smart city’s critical infrastructural health monitoring. IEEE Commun. Mag. 2018, 56, 128–133. [Google Scholar] [CrossRef]
- Han, G.J.; Liu, L.; Jiang, J.F.; Shu, L.; Hancke, G. Analysis of Energy-Efficient Connected Target Coverage Algorithms for Industrial Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2017, 13, 135–143. [Google Scholar] [CrossRef]
- Bai, X.; Wang, Z.; Sheng, L.; Wang, Z. Reliable data fusion of hierarchical wireless sensor networks with asynchronous measurement for greenhouse monitoring. IEEE Trans. Control Syst. Technol. 2018, 99, 1–11. [Google Scholar] [CrossRef]
- Qiu, T.; Qiao, R.; Wu, D.O. EABS: An Event-Aware Backpressure Scheduling Scheme for Emergency Internet of Things. IEEE Trans. Mob. Comput. 2018, 17, 72–84. [Google Scholar] [CrossRef]
- Bhuiyan, M.Z.A.; Cao, J.; Wang, G. Deploying wireless sensor networks with fault tolerance for structural health monitoring. IEEE Trans. Comput. 2015, 64, 382–395. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, G.X.; Liu, A.F.; Bhuiyan, M.Z.A.; Jin, Q. A secure IoT service architecture with an efficient balance dynamics based on cloud and edge computing. IEEE Internet Things J. 2018. [Google Scholar] [CrossRef]
- Wang, T.; Zeng, J.D.; Lai, Y.X.; Cai, Y.Q.; Tian, H.; Chen, Y.H.; Wang, B.W. Data collection from WSNs to the cloud based on mobile Fog elements. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Qiu, T.; Zheng, K.; Song, H.; Han, M.; Kantarci, B. A local-optimization emergency scheduling scheme with self-recovery for smart grid. IEEE Trans. Ind. Inform. 2017, 13, 3195–3205. [Google Scholar] [CrossRef]
- Kolanowski, K.; Świetlicka, A.; Kapela, R.; Pochmara, J.; Rybarczyk, A. Multisensor data fusion using elman neural networks. Appl. Math. Comput. 2017, 319, 236–244. [Google Scholar] [CrossRef]
- Majumder, S.; Pratihar, D.K. Multi-sensors data fusion through fuzzy clustering and predictive tools. Expert Syst. Appl. 2018, 107, 165–172. [Google Scholar] [CrossRef]
- Wei, W.; Liang, J.Y. Information fusion in rough set theory: An overview. Inf. Fusion 2019, 48, 107–118. [Google Scholar] [CrossRef]
- Aitsaadi, N.; Aitsaadi, N.; Aitsaadi, N.; Oukhellou, L. Fusion-based surveillance WSN deployment using dempster-shafer theory. J. Netw. Comput. Appl. 2016, 64, 154–166. [Google Scholar]
- Askarian, M.; Zarghami, R.; Jalali-Farahani, F.; Mostoufi, N. Fusion of micro-macro data for fault diagnosis of a sweetening unit using bayesian network. Chem. Eng. Res. Des. 2016, 115, 325–334. [Google Scholar] [CrossRef]
- Gao, B.; Hu, G.; Gao, S.; Zhong, Y.; Gu, C. Multi-sensor optimal data fusion based on the adaptive fading unscented kalman filter. Sensors 2018, 18, 488. [Google Scholar] [CrossRef] [PubMed]
- Safari, S.; Shabani, F.; Dan, S. Multirate multisensor data fusion for linear systems using kalman filters and a neural network. Aerosp. Sci. Technol. 2014, 39, 465–471. [Google Scholar] [CrossRef]
- Lopez-Molina, C.; Montero, J.; Bustince, H.; Baets, B.D. Self-adapting weighted operators for multiscale gradient fusion. Inf. Fusion 2018, 44, 136–146. [Google Scholar] [CrossRef]
- Chang, F.J.; Chiang, Y.M.; Tsai, M.J.; Shieh, M.C.; Hsu, K.L.; Sorooshian, S. Watershed rainfall forecasting using neuro-fuzzy networks with the assimilation of multi-sensor information. J. Hydrol. 2014, 508, 374–384. [Google Scholar] [CrossRef]
- Geng, K.K.; Chulin, N.A. Applications of multi-height sensors data fusion and fault-tolerant kalman filter in integrated navigation system of UAV. Proc. Comput. Sci. 2017, 103, 231–238. [Google Scholar] [CrossRef]
- Davood, I.; Abawajy, J.H.; Sara, G.; Tutut, H. A data fusion method in wireless sensor networks. Sensors 2015, 15, 2964–2979. [Google Scholar]
- Yager, R.R. The power average operator. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2001, 31, 724–731. [Google Scholar] [CrossRef]
- Xiong, Y.; Shen, M.; Lu, M.; Liu, Y.; Sun, Y.; Liu, L. Algorithm of real time data fusion for greenhouse WSN system. Trans. Chin. Soc. Agric. Eng. 2012, 28, 160–166. (In Chinese) [Google Scholar]
- Duan, Q.; Xiao, X.; Liu, Y.; Zhang, L.; Wang, K. Data fusion method of livestock and poultry breeding internetof things based on improved support function. Trans. Chin. Soc. Agric. Eng. 2017, 33 (Suppl. 1), 239–245. (In Chinese) [Google Scholar]
- Wang, T.; Zhou, J.Y.; Liu, A.F.; Bhuiyan, M.Z.A.; Wang, G.J.; Jia, W.J. Fog-based computing and storage offloading for data synchronization in IoT. IEEE Internet Things 2018. [Google Scholar] [CrossRef]
- Angelov, P.; Yager, R. Density-based averaging—A new operator for data fusion. Inf. Sci. 2013, 222, 163–174. [Google Scholar] [CrossRef]
- Senjean, B.; Knecht, S.; Jensen, H.J.A.; Fromager, E. Linear interpolation method in ensemble kohn-sham and range-separated density-functional approximations for excited states. Phys. Rev. A 2015, 92, 012518. [Google Scholar] [CrossRef]
- Bianco, A.M.; Ben, M.G.; Martínez, E.J.; Yohai, V.J. Outlier detection in regression models with arima errors using robust estimates. J. Forecast. 2010, 20, 565–579. [Google Scholar] [CrossRef]
- Hill, D.J.; Minsker, B.S. Anomaly detection in streaming environmental sensor data: A data-driven modeling approach. Environ. Model. Softw. 2010, 1014–1022. [Google Scholar] [CrossRef]
- Wang, J.; Pagani, L.; Leach, R.K.; Zeng, W.; Colosimo, B.M.; Zhou, L. Study of weighted fusion methods for the measurement of surface geometry. Precis. Eng. 2017, 47, 111–121. [Google Scholar] [CrossRef] [Green Version]
- Zhou, D.; Yu, Z.; Zhang, H.; Weng, S. A novel grey prognostic model based on markov process and grey incidence analysis for energy conversion equipment degradation. Energy 2016, 109, 420–429. [Google Scholar] [CrossRef]
- Feng, L.S.; Ming, X.N.; Jeffery, F. On new models of grey incidence analysis based on visual angle of similarity and nearness. Syst. Eng.-Theory Pract. 2010, 30, 881–887. (In Chinese) [Google Scholar]
- Adwan, S.; Alsaleh, I.; Majed, R. A new approach for image stitching technique using dynamic time warping (dtw) algorithm towards scoliosis x-ray diagnosis. Measurement 2016, 84, 32–46. [Google Scholar] [CrossRef]
- Long, X.; Fonseca, P.; Foussier, J.; Haakma, R. Using dynamic time warping for sleep and wake discrimination. In Proceedings of the 2012 IEEE-EMBS International Conference on Biomedical and Health Informatics, Hong Kong, China, 5–7 January 2012; pp. 886–889. [Google Scholar]
- Górecki, T.; Łuczak, M. Non-isometric transforms in time series classification using dtw. Knowl. Based. Syst. 2014, 61, 98–108. [Google Scholar] [CrossRef]
- Meesrikamolkul, W.; Niennattrakul, V.; Ratanamahatana, C.A. Multiple shape-based template matching for time series data. In Proceedings of the 2011 8th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Khon Kaen, Thailand, 17–19 May 2011; pp. 464–467. [Google Scholar]
- Cai, Q.; Chen, L.; Sun, J. Piecewise statistic approximation based similarity measure for time series. Knowl. Based Syst. 2015, 85, 181–195. [Google Scholar] [CrossRef]
- Niennattrakul, V.; Srisai, D.; Ratanamahatana, C.A. Shape-based template matching for time series data. Knowl. Based Syst. 2012, 26, 1–8. [Google Scholar] [CrossRef]
- Benyahya, L.; Hilaire, A.S.; Quarda, B.M.J.T.; Bobee, B.; Nedushan, B.A. Modeling of water temperatures based on stochastic approaches: Case study of the Deschutes River. J. Environ. Eng. Sci. 2007, 6, 437–448. [Google Scholar] [CrossRef]
- Liao, H.; Xu, Z. Approaches to manage hesitant fuzzy linguistic information based on the cosine distance and similarity measures for HFLTSs and their application in qualitative decision making. Expert Syst. Appl. 2015, 42, 5328–5336. [Google Scholar] [CrossRef]
- Moujahid, D.; Elharrouss, O.; Tairi, H. Visual object tracking via the local soft cosine similarity. Pattern Recogn. Lett. 2018, 110, 79–85. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | ISD | Cos-ISD | DTW-ISD | DTWS-ISD |
|---|---|---|---|---|
| Time(s) | 0.0153 | 0.0063 | 2.4351 | 0.0192 |
| MAE | 0.3028 | 0.5018 | 0.2445 | 0.2328 |
| Metrics | Gauss | D | SN | DTWS-ISD |
|---|---|---|---|---|
| Time(s) | 0.0172 | 0.0166 | 0.0161 | 0.0192 |
| MAE | 0.3066 | 0.3324 | 0.3306 | 0.2328 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, P.; Li, G.; Yuan, Y.; Kuang, L. Data Fusion Using Improved Support Degree Function in Aquaculture Wireless Sensor Networks. Sensors 2018, 18, 3851. https://doi.org/10.3390/s18113851
Shi P, Li G, Yuan Y, Kuang L. Data Fusion Using Improved Support Degree Function in Aquaculture Wireless Sensor Networks. Sensors. 2018; 18(11):3851. https://doi.org/10.3390/s18113851
Chicago/Turabian StyleShi, Pei, Guanghui Li, Yongming Yuan, and Liang Kuang. 2018. "Data Fusion Using Improved Support Degree Function in Aquaculture Wireless Sensor Networks" Sensors 18, no. 11: 3851. https://doi.org/10.3390/s18113851