Novelty Detection Classifiers in Weed Mapping: Silybum marianum Detection on UAV Multispectral Images

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
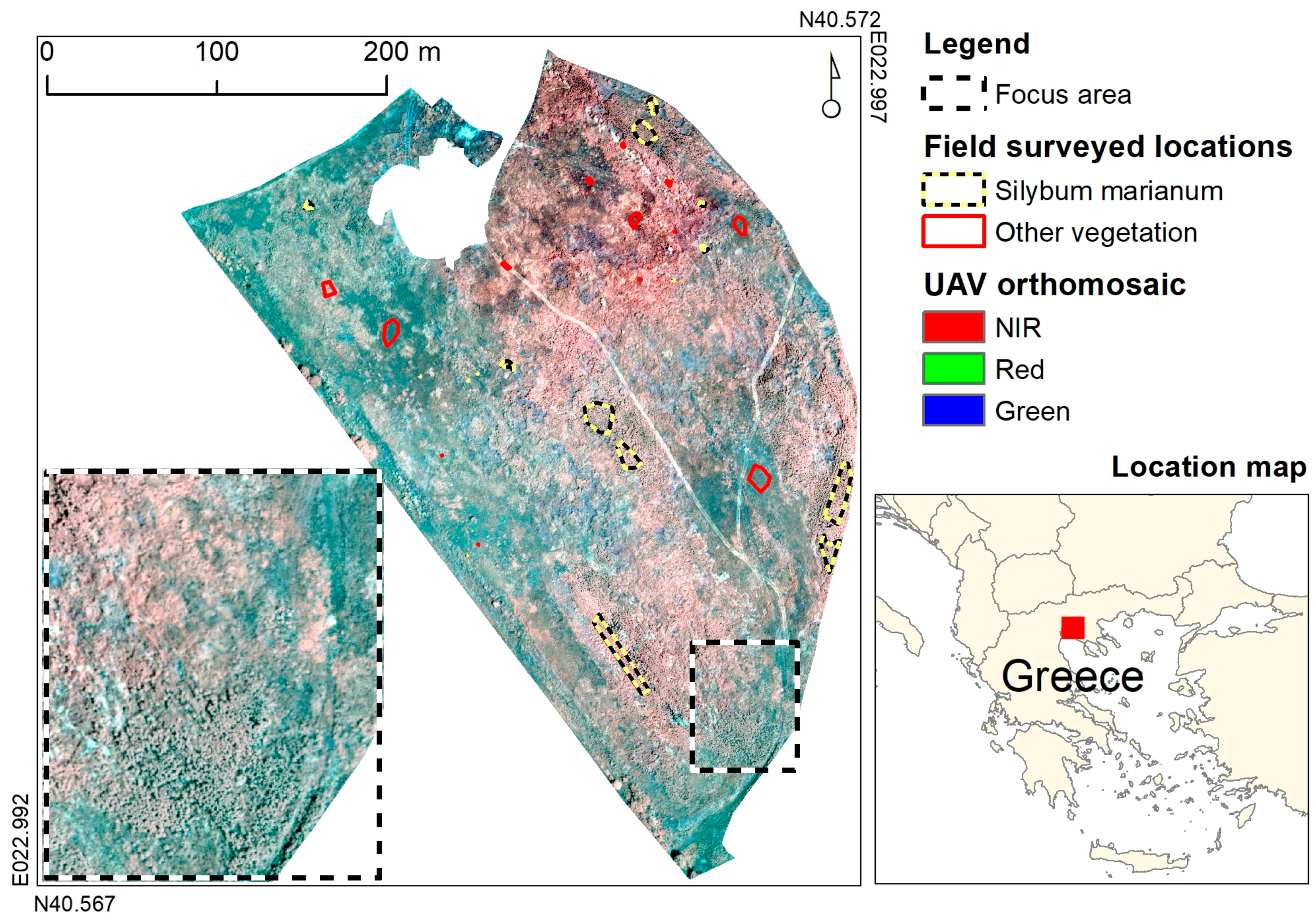
2.1. Experimental Study Location
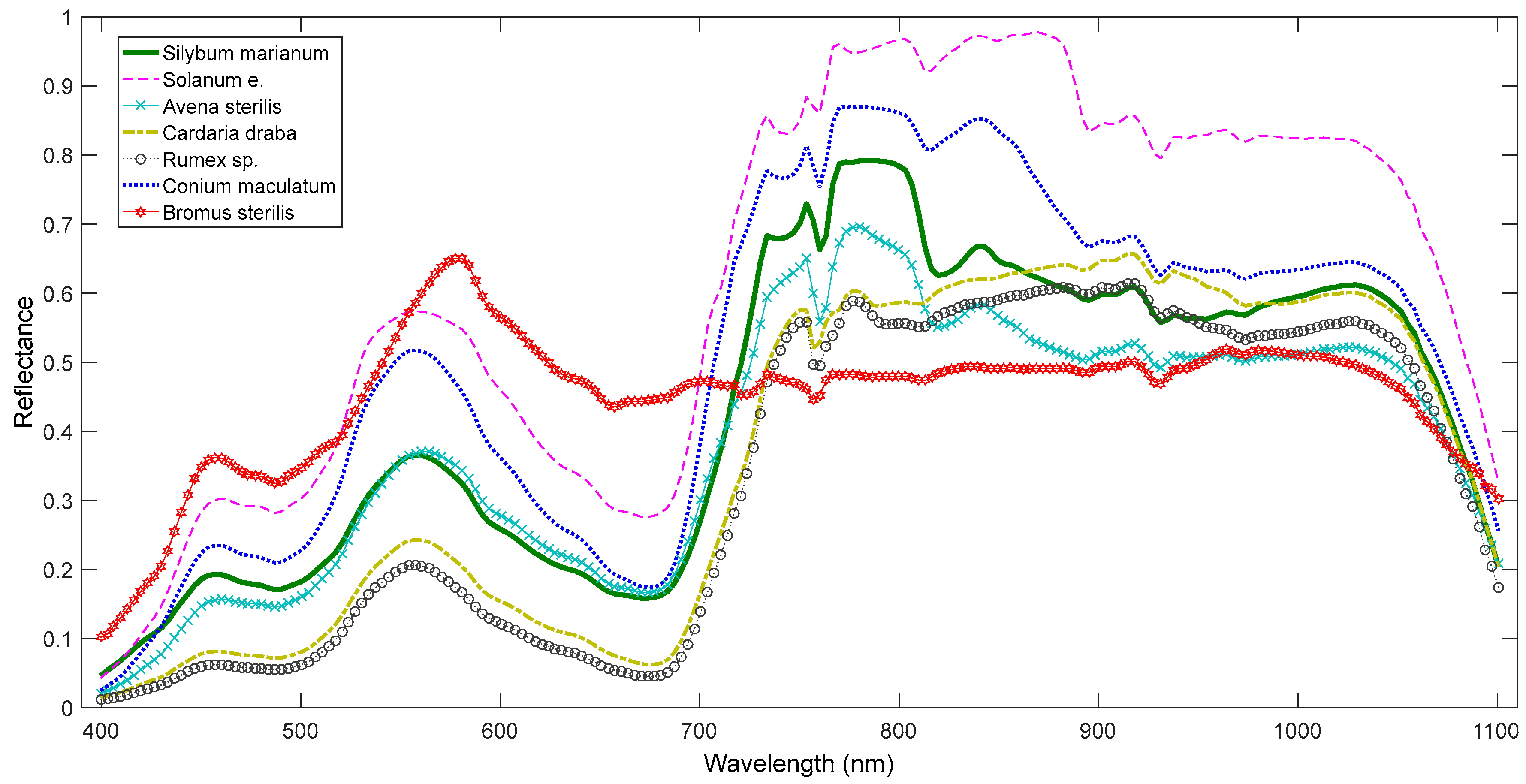
2.2. Datasets
2.3. Novelty Detector Classifiers
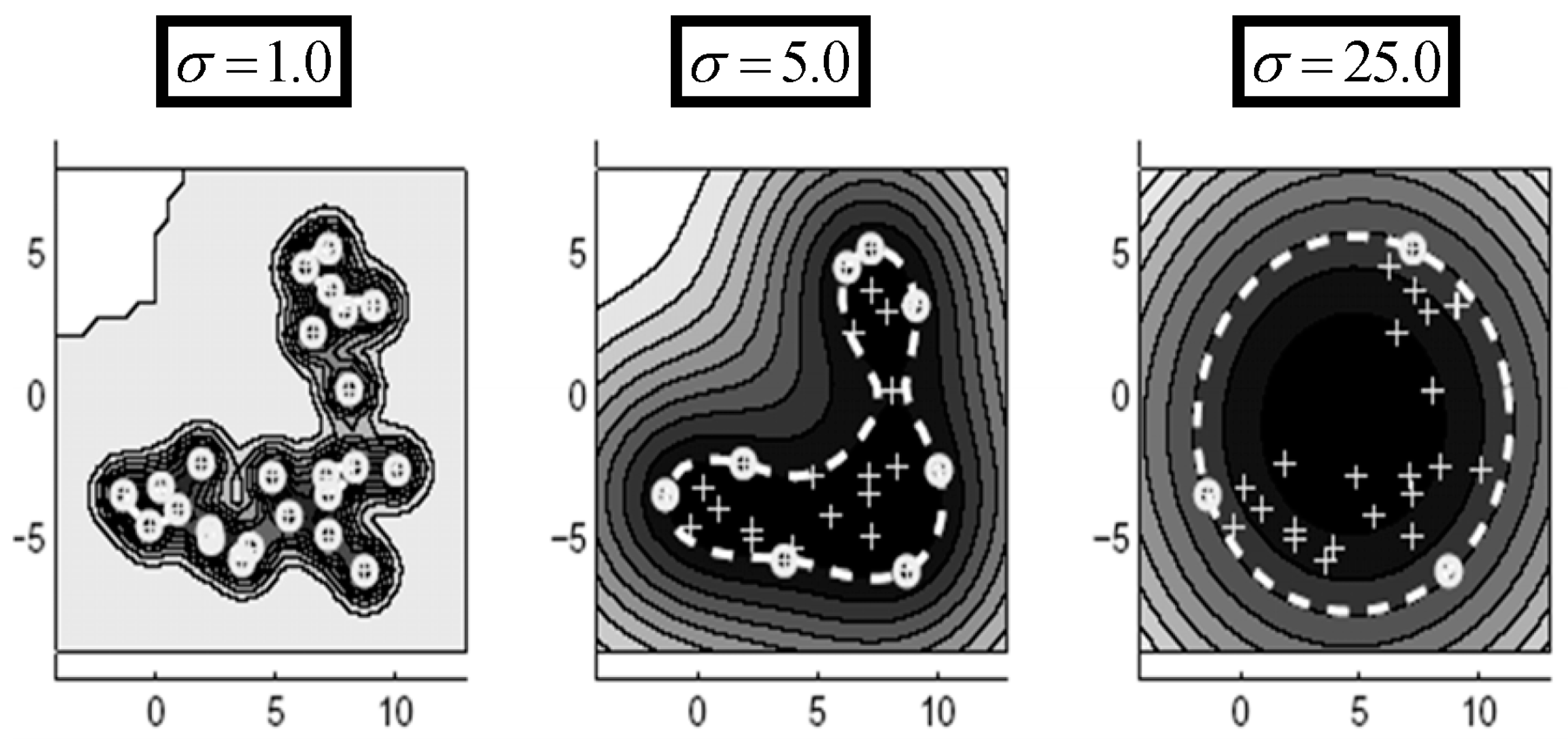
2.3.1. OC-SVM
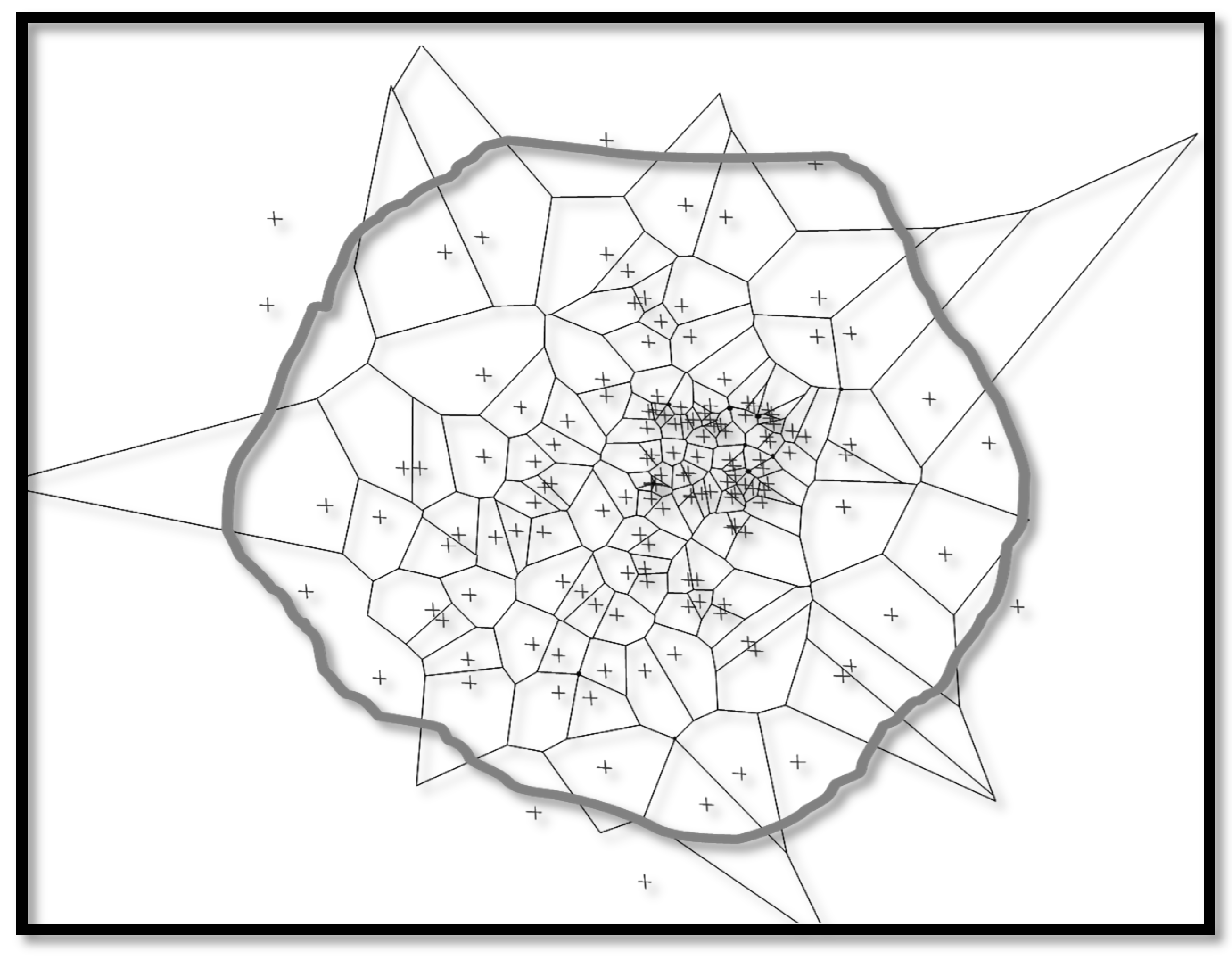
2.3.2. One Class Self-Organizing Map (OC-SOM)
- Data_distances_sorted = sort(distances);
- Fraction = round(fraction_targets × length(target_set));
- Threshold = (Data_distances_sorted(fraction) + Data _distances_sorted(fraction + 1))/2;
2.3.3. Auto-Encoders
2.3.4. OC-PCA
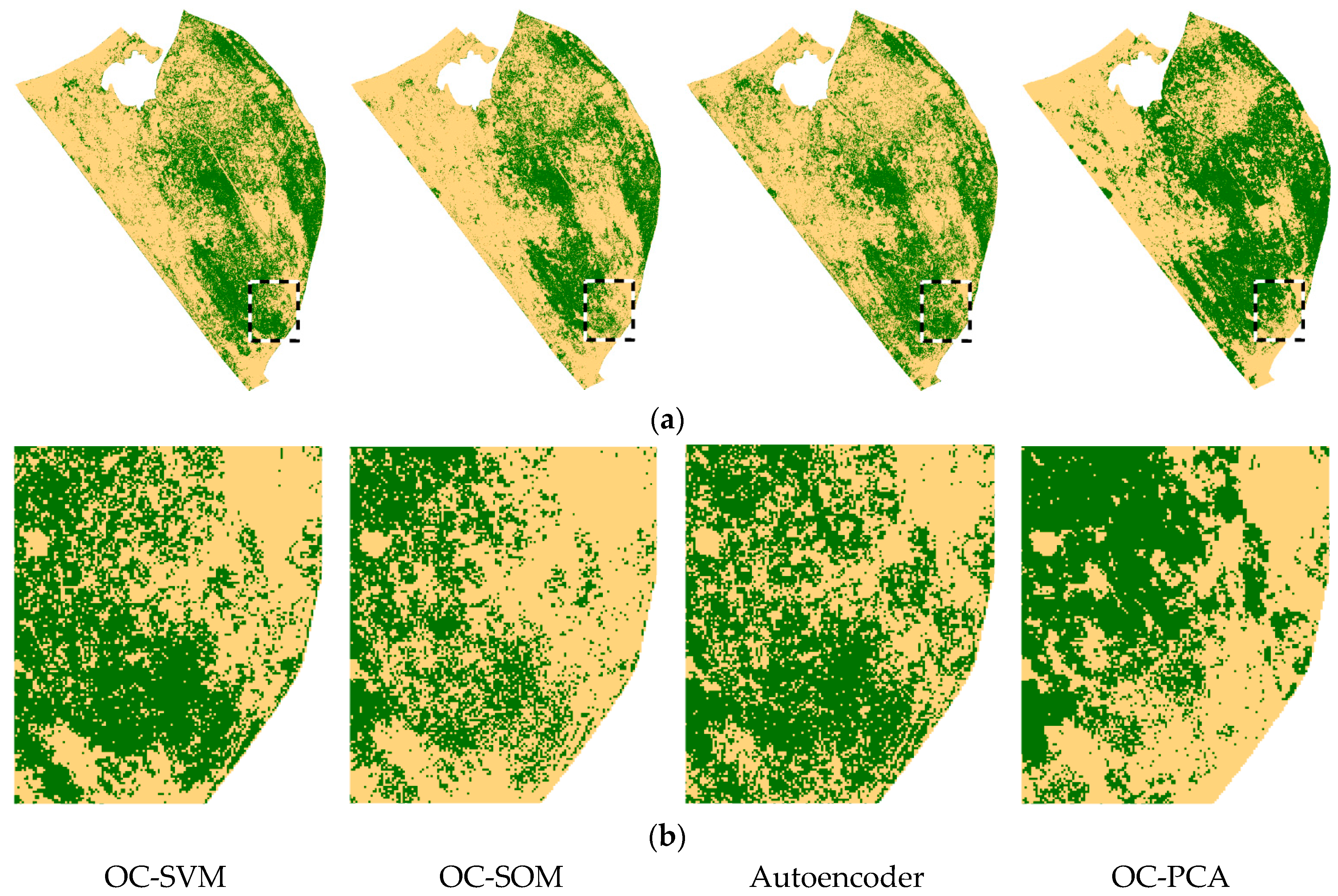
3. Results and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Thorp, K.; Tian, L. A review on remote sensing of weeds in agriculture. Precis. Agric. 2004, 5, 477–508. [Google Scholar] [CrossRef]
- Zhang, Y.; Slaughter, D.C.; Staab, E.S. Robust hyperspectral vision-based classification for multi-season weed mapping. ISPRS J. Photogramm. Remote Sens. 2012, 69, 65–73. [Google Scholar] [CrossRef]
- Åstrand, B.; Baerveldt, A.-J. An agricultural mobile robot with vision-based perception for mechanical weed control. Auton. Robots 2002, 13, 21–35. [Google Scholar] [CrossRef]
- Waske, B.; van der Linden, S.; Benediktsson, J.A.; Rabe, A.; Hostert, P. Sensitivity of support vector machines to random feature selection in classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2880–2889. [Google Scholar] [CrossRef]
- Ahmed, F.; Al-Mamun, H.A.; Bari, A.H.; Hossain, E.; Kwan, P. Classification of crops and weeds from digital images: A support vector machine approach. Crop Prot. 2012, 40, 98–104. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory; John Wiley & Sons, Inc.: New York, NY, USA, 1998. [Google Scholar]
- Sluiter, R. Mediterranean Land Cover Change: Modelling and Monitoring Natural Vegetation Using Gis and Remote Sensing; Utrecht University: Utrecht, The Netherlands, 2005. [Google Scholar]
- Im, J.; Jensen, J.R. A change detection model based on neighborhood correlation image analysis and decision tree classification. Remote Sens. Environ. 2005, 99, 326–340. [Google Scholar] [CrossRef]
- Dihkan, M.; Guneroglu, N.; Karsli, F.; Guneroglu, A. Remote sensing of tea plantations using an svm classifier and pattern-based accuracy assessment technique. Int. J. Remote Sens. 2013, 34, 8549–8565. [Google Scholar] [CrossRef]
- Crupi, V.; Guglielmino, E.; Milazzo, G. Neural-network-based system for novel fault detection in rotating machinery. Modal Anal. 2004, 10, 1137–1150. [Google Scholar] [CrossRef]
- Tax, D.M.J. One-Class Classification. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2001. [Google Scholar]
- Parsons, W.T.; Cuthbertson, E. Noxious Weeds of Australia; CSIRO Publishing: Melbourne, Victoria, Australia, 2001. [Google Scholar]
- Tucker, J.M.; Cordy, D.R.; Berry, L.J.; Harvey, W.A.; Fuller, T.C. Nitrate Poisoning in Livestock; University of California: Oakland, CA, USA, 1961. [Google Scholar]
- Khan, M.A.; Kalsoom, U.; Khan, M.I.; Khan, R.; Khan, S.A. Screening the allelopathic potential of various weeds. Pak. J. Weed Sci. Res. 2011, 11, 73–81. [Google Scholar]
- Tamouridou, A.; Alexandridis, T.; Pantazi, X.; Lagopodi, A.; Kashefi, J.; Moshou, D. Evaluation of uav imagery for mapping silybum marianum weed patches. Int. J. Remote Sens. 2017, 38, 2246–2259. [Google Scholar]
- Pantazi, X.; Tamouridou, A.; Alexandridis, T.; Lagopodi, A.; Kashefi, J.; Moshou, D. Evaluation of hierarchical self-organising maps for weed mapping using uas multispectral imagery. Comput. Electron. Agric. 2017, 139, 224–230. [Google Scholar] [CrossRef]
- Peña, J.M.; Torres-Sánchez, J.; de Castro, A.I.; Kelly, M.; López-Granados, F. Weed mapping in early-season maize fields using object-based analysis of unmanned aerial vehicle (UAV) images. PLoS ONE 2013, 8, e77151. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Ortiz, M.; Gutiérrez, P.A.; Peña, J.M.; Torres-Sánchez, J.; Hervás-Martínez, C.; López-Granados, F. An experimental comparison for the identification of weeds in sunflower crops via unmanned aerial vehicles and object-based analysis. In Proceedings of the 13th International Work-Conference on Artificial Neural Networks (IWANN), Palma de Mallorca, Spain, 6 June 2015; Rojas, I., Joya, G., Catala, A., Eds.; Springer: Palma de Mallorca, Spain, 2015; pp. 252–262. [Google Scholar]
- Torres-Sánchez, J.; López-Granados, F.; De Castro, A.I.; Peña-Barragán, J.M. Configuration and specifications of an unmanned aerial vehicle (UAV) for early site specific weed management. PLoS ONE 2013, 8, e58210. [Google Scholar] [CrossRef] [PubMed]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Scholkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Saunders, R.; Gero, J.S. A curious design agent: A computational model of novelty-seeking behaviour in design. In Proceedings of the Sixth Conference on Computer-Aided Architectural Design Research in Asia (CAADRIA 2001), Sydney, Australia, 19–21 April 2001; pp. 345–350. [Google Scholar]
- Japkowicz, N.; Myers, C.; Gluck, M. A Novelty Detection Approach to Classification; International Joint Conference on Artificial Intelligence (IJCAI 95): Montreal, QC, Canada, 1995; pp. 518–523. [Google Scholar]
- Hertz, J.A.; Krogh, A.S.; Palmer, R.G. Introduction to the Theory of Neural Computation; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1991. [Google Scholar]
- Baldi, P.; Hornik, K. Neural networks and principal component analysis: Learning from examples without local minima. Neural Netw. 1989, 2, 53–58. [Google Scholar] [CrossRef]
- Bourlard, H.; Kamp, Y. Auto-association by multilayer perceptrons and singular value decomposition. Biol. Cybern. 1988, 59, 291–294. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Metternicht, G. Geospatial Technologies and the Management of Noxious Weeds in Agricultural and Rangelands Areas of Australia; University of South Australia: Mawson Lakes, SA, Australia, 2007. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Prediction | |||||
|---|---|---|---|---|---|
| Classifier (Overall Accuracy %) | Actual Observations | S. marianum (Pixels) | Other Vegetation (Pixels) | User’s Accuracy (%) | Producer’s Accuracy (%) |
| OC-SVM σ = 2.5 (96.05) | S. marianum | 416 | 25 | 97.88 | 94.33 |
| Other vegetation | 9 | 410 | 94.25 | 97.85 | |
| OC-SOM, 8 × 8 (94.65) | S. marianum | 404 | 37 | 97.82 | 91.61 |
| Other vegetation | 9 | 410 | 91.72 | 97.85 | |
| Autoencoder, 8 hidden (94.30) | S. marianum | 416 | 25 | 94.55 | 94.33 |
| Other vegetation | 24 | 395 | 94.05 | 94.27 | |
| OC-PCA (90.00) | S. marianum | 390 | 51 | 91.76 | 88.44 |
| Other vegetation | 35 | 384 | 88.28 | 91.65 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alexandridis, T.K.; Tamouridou, A.A.; Pantazi, X.E.; Lagopodi, A.L.; Kashefi, J.; Ovakoglou, G.; Polychronos, V.; Moshou, D. Novelty Detection Classifiers in Weed Mapping: Silybum marianum Detection on UAV Multispectral Images. Sensors 2017, 17, 2007. https://doi.org/10.3390/s17092007
Alexandridis TK, Tamouridou AA, Pantazi XE, Lagopodi AL, Kashefi J, Ovakoglou G, Polychronos V, Moshou D. Novelty Detection Classifiers in Weed Mapping: Silybum marianum Detection on UAV Multispectral Images. Sensors. 2017; 17(9):2007. https://doi.org/10.3390/s17092007
Chicago/Turabian StyleAlexandridis, Thomas K., Afroditi Alexandra Tamouridou, Xanthoula Eirini Pantazi, Anastasia L. Lagopodi, Javid Kashefi, Georgios Ovakoglou, Vassilios Polychronos, and Dimitrios Moshou. 2017. "Novelty Detection Classifiers in Weed Mapping: Silybum marianum Detection on UAV Multispectral Images" Sensors 17, no. 9: 2007. https://doi.org/10.3390/s17092007