
Development, High-Throughput Profiling, and Biopanning of a Large Phage Display Single-Domain Antibody Library
 ,
, 
Abstract
:1. Introduction
2. Results
2.1. Construction of an Alpaca Single-Domain Antibody (VHH) Phage Display Library
2.2. NGS of the Constructed Alpaca VHH Phage Display Library
2.3. Analysis of Germline Usage in the Alpaca VHH Phage Display Library
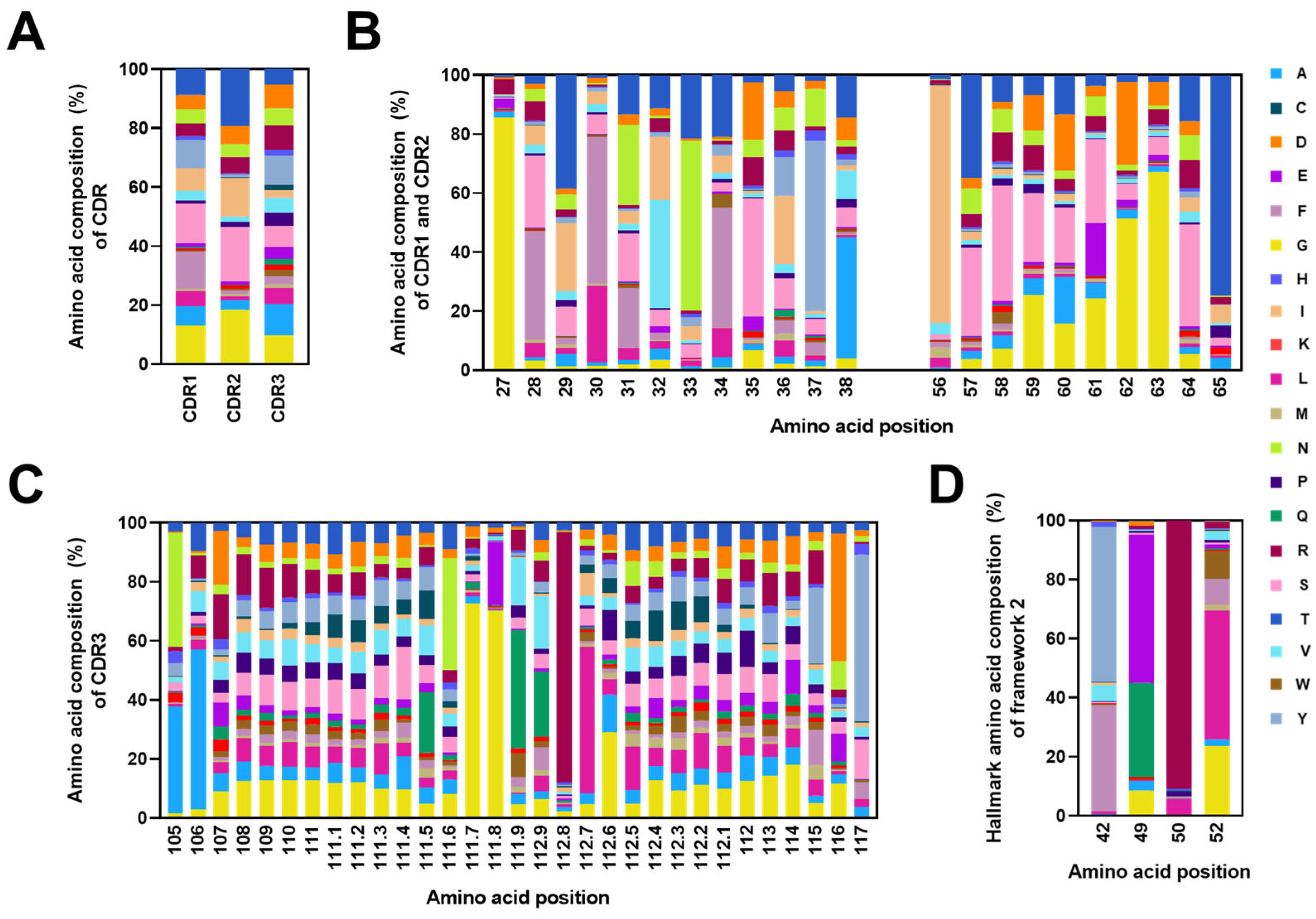
2.4. Analysis of CDRs and the FR2 Characteristics in Alpaca VHHs within the Constructed Library
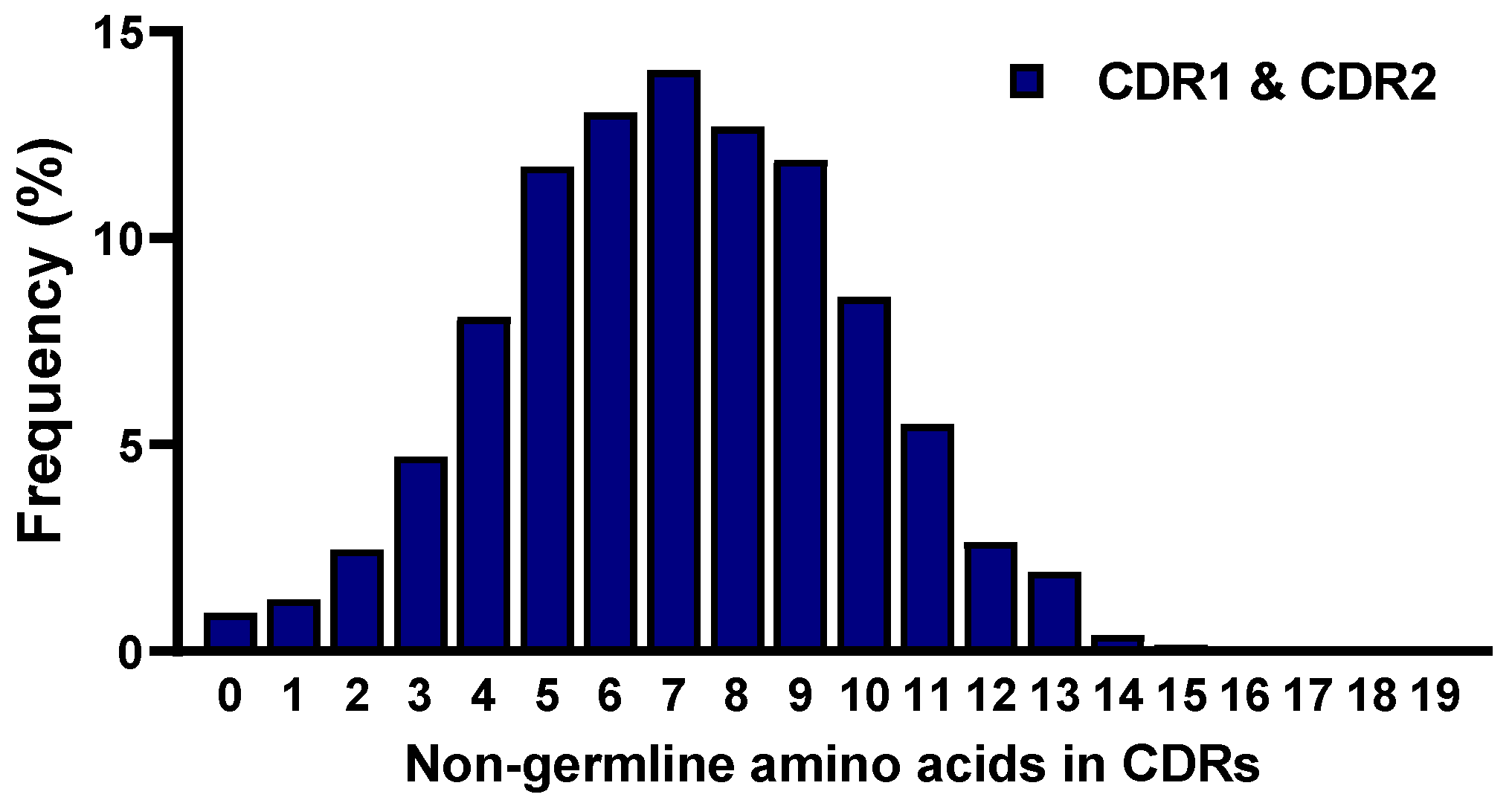
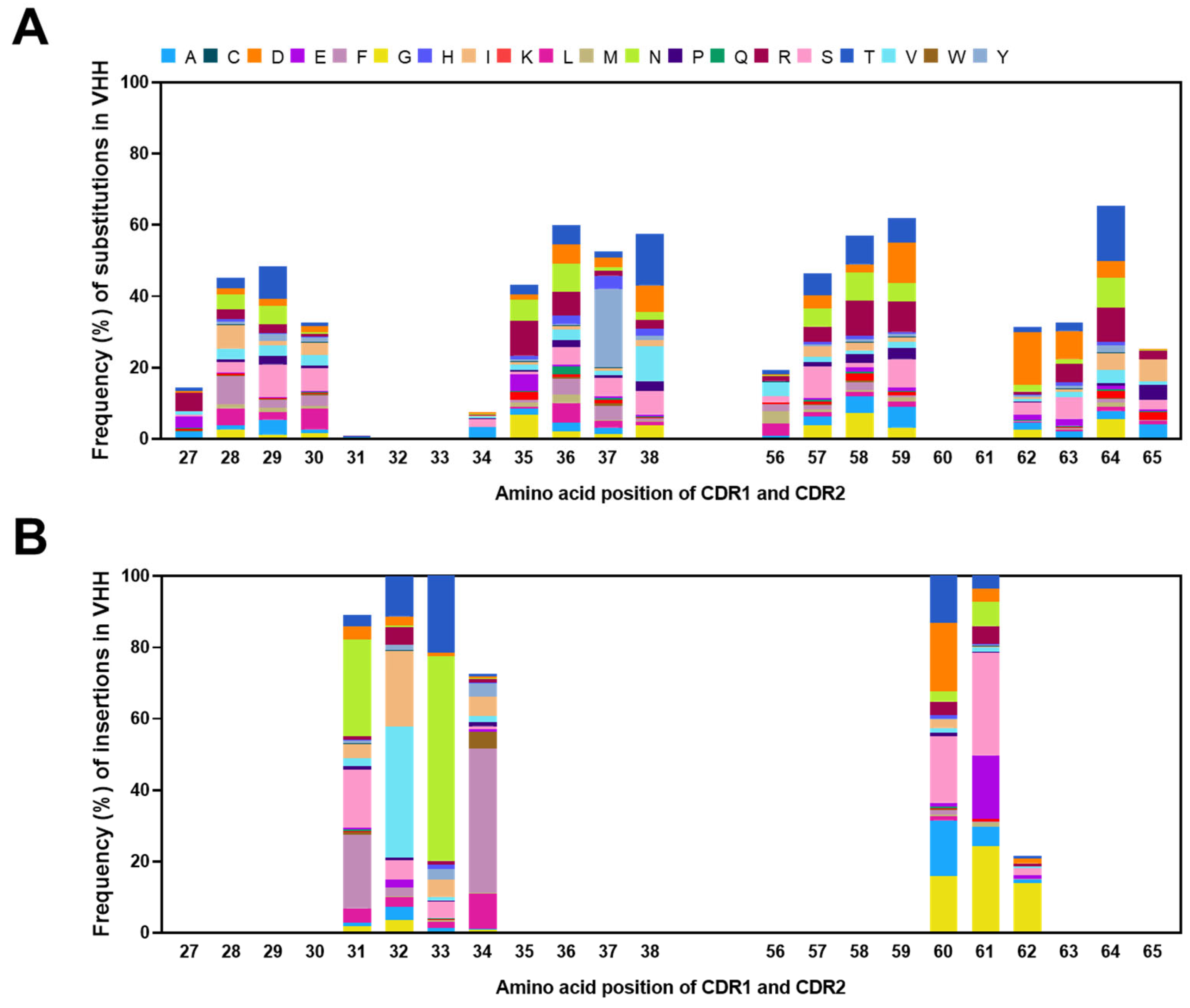
2.5. Frequencies of Mutations in CDRs
2.6. Selection of Antigen-Specific VHH Antibodies from the Constructed Library
3. Discussion
4. Materials and Methods
4.1. Construction of an Alpaca Single-Domain Antibody (VHH) Library
4.2. Next-Generation Sequencing of the Antibody Library
4.3. Analysis of the Antibody Library
4.4. Rescue of the VHH-Displaying Phage
4.5. Selection of VHHs from a Phage Display Antibody Library
4.6. Phage ELISA
4.7. Production and Purification of Selected VHHs
4.8. Determination of the Binding Kinetics of Selected VHHs
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quinteros, D.A.; Bermúdez, J.M.; Ravetti, S.; Cid, A.; Allemandi, D.A.; Palma, S.D. Chapter 25—Therapeutic use of monoclonal antibodies: General aspects and challenges for drug delivery. In Nanostructures for Drug Delivery; Elsevier: Amsterdam, The Netherlands, 2017; pp. 807–833. [Google Scholar]
- Bannas, P.; Hambach, J.; Koch-Nolte, F. Nanobodies and Nanobody-Based Human Heavy Chain Antibodies as Antitumor Therapeutics. Front. Immunol. 2017, 8, 1603. [Google Scholar] [CrossRef] [PubMed]
- Cong, Y.; Devoogdt, N.; Lambin, P.; Dubois, L.J.; Yaromina, A. Promising Diagnostic and Therapeutic Approaches Based on VHHs for Cancer Management. Cancers 2024, 16, 371. [Google Scholar] [CrossRef] [PubMed]
- Hamers-Casterman, C.; Atarhouch, T.; Muyldermans, S.; Robinson, G.; Hammers, C.; Songa, E.B.; Bendahman, N.; Hammers, R. Naturally occurring antibodies devoid of light chains. Nature 1993, 363, 446–448. [Google Scholar] [CrossRef] [PubMed]
- Padlan, E.A. Anatomy of the antibody molecule. Mol. Immunol. 1994, 31, 169–217. [Google Scholar] [CrossRef] [PubMed]
- Muyldermans, S. Nanobodies: Natural Single-Domain Antibodies. Annu. Rev. Biochem. 2013, 82, 775–797. [Google Scholar] [CrossRef] [PubMed]
- Fugmann, S.D.; Lee, A.I.; Shockett, P.E.; Villey, I.J.; Schatz, D.G. The RAG Proteins and V(D)J Recombination: Complexes, Ends, and Transposition. Annu. Rev. Immunol. 2000, 18, 495–527. [Google Scholar] [CrossRef] [PubMed]
- Smider, V.; Chu, G. The end-joining reaction in V(D)J recombination. Semin. Immunol. 1997, 9, 189–197. [Google Scholar] [CrossRef]
- Muyldermans, S.; Atarhouch, T.; Saldanha, J.; Barbosa, J.A.R.G.; Hamers, R. Sequence and structure of VH domain from naturally occurring camel heavy chain immunoglobulins lacking light chains. Protein Eng. Des. Sel. 1994, 7, 1129–1135. [Google Scholar] [CrossRef]
- Revets, H.; De Baetselier, P.; Muyldermans, S. Nanobodies as novel agents for cancer therapy. Expert Opin. Biol. Ther. 2005, 5, 111–124. [Google Scholar] [CrossRef]
- Debie, P.; Lafont, C.; Defrise, M.; Hansen, I.; van Willigen, D.M.; van Leeuwen, F.W.B.; Gijsbers, R.; D’Huyvetter, M.; Devoogdt, N.; Lahoutte, T.; et al. Size and affinity kinetics of nanobodies influence targeting and penetration of solid tumours. J. Control. Release 2020, 317, 34–42. [Google Scholar] [CrossRef]
- Dumoulin, M.; Conrath, K.; Van Meirhaeghe, A.; Meersman, F.; Heremans, K.; Frenken, L.G.J.; Muyldermans, S.; Wyns, L.; Matagne, A. Single-domain antibody fragments with high conformational stability. Protein Sci. 2002, 11, 500–515. [Google Scholar] [CrossRef] [PubMed]
- Van der Linden, R.H.J.; Frenken, L.G.J.; de Geus, B.; Harmsen, M.M.; Ruuls, R.C.; Stok, W.; de Ron, L.; Wilson, S.; Davis, P.; Verrips, C.T. Comparison of physical chemical properties of llama VHH antibody fragments and mouse monoclonal antibodies. Biochim. Et Biophys. Acta (BBA)—Protein Struct. Mol. Enzymol. 1999, 1431, 37–46. [Google Scholar] [CrossRef]
- Conrath, K.; Vincke, C.; Stijlemans, B.; Schymkowitz, J.; Decanniere, K.; Wyns, L.; Muyldermans, S.; Loris, R. Antigen Binding and Solubility Effects upon the Veneering of a Camel VHH in Framework-2 to Mimic a VH. J. Mol. Biol. 2005, 350, 112–125. [Google Scholar] [CrossRef]
- Chothia, C.; Novotný, J.; Bruccoleri, R.; Karplus, M. Domain association in immunoglobulin molecules: The packing of variable domains. J. Mol. Biol. 1985, 186, 651–663. [Google Scholar] [CrossRef] [PubMed]
- Harmsen, M.M.; Ruuls, R.C.; Nijman, I.J.; Niewold, T.A.; Frenken, L.G.J.; de Geus, B. Llama heavy-chain V regions consist of at least four distinct subfamilies revealing novel sequence features. Mol. Immunol. 2000, 37, 579–590. [Google Scholar] [CrossRef]
- Maass, D.R.; Sepulveda, J.; Pernthaner, A.; Shoemaker, C.B. Alpaca (Lama pacos) as a convenient source of recombinant camelid heavy chain antibodies (VHHs). J. Immunol. Methods 2007, 324, 13–25. [Google Scholar] [CrossRef]
- Gonzalez-Sapienza, G.; Rossotti, M.A.; Tabares-da Rosa, S. Single-Domain Antibodies As Versatile Affinity Reagents for Analytical and Diagnostic Applications. Front. Immunol. 2017, 8, 288027. [Google Scholar] [CrossRef] [PubMed]
- Chanier, T.; Chames, P. Nanobody Engineering: Toward Next Generation Immunotherapies and Immunoimaging of Cancer. Antibodies 2019, 8, 13. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Fan, Z.; Shao, L.; Kong, X.; Hou, X.; Tian, D.; Sun, Y.; Xiao, Y.; Yu, L. Nanobody-derived nanobiotechnology tool kits for diverse biomedical and biotechnology applications. Int. J. Nanomed. 2016, 11, 3287–3303. [Google Scholar] [CrossRef]
- Bao, C.; Gao, Q.; Li, L.-L.; Han, L.; Zhang, B.; Ding, Y.; Song, Z.; Zhang, R.; Zhang, J.; Wu, X.-H. The Application of Nanobody in CAR-T Therapy. Biomolecules 2021, 11, 238. [Google Scholar] [CrossRef]
- Jin, B.K.; Odongo, S.; Radwanska, M.; Magez, S. Nanobodies: A Review of Generation, Diagnostics and Therapeutics. Int. J. Mol. Sci. 2023, 24, 5994. [Google Scholar] [CrossRef] [PubMed]
- Koide, S. Engineering of recombinant crystallization chaperones. Curr. Opin. Struct. Biol. 2009, 19, 449–457. [Google Scholar] [CrossRef]
- Rasmussen, S.G.F.; Choi, H.-J.; Fung, J.J.; Pardon, E.; Casarosa, P.; Chae, P.S.; DeVree, B.T.; Rosenbaum, D.M.; Thian, F.S.; Kobilka, T.S.; et al. Structure of a nanobody-stabilized active state of the β2 adrenoceptor. Nature 2011, 469, 175–180. [Google Scholar] [CrossRef]
- Hollifield, A.L.; Arnall, J.R.; Moore, D.C. Caplacizumab: An anti–von Willebrand factor antibody for the treatment of thrombotic thrombocytopenic purpura. Am. J. Health-Syst. Pharm. 2020, 77, 1201–1207. [Google Scholar] [CrossRef] [PubMed]
- Martin, T.; Usmani, S.Z.; Berdeja, J.G.; Agha, M.; Cohen, A.D.; Hari, P.; Avigan, D.; Deol, A.; Htut, M.; Lesokhin, A.; et al. Ciltacabtagene Autoleucel, an Anti-B-cell Maturation Antigen Chimeric Antigen Receptor T-Cell Therapy, for Relapsed/Refractory Multiple Myeloma: CARTITUDE-1 2-Year Follow-Up. J. Clin. Oncol. Off. J. Am. Soc. Clin. Oncol. 2023, 41, 1265–1274. [Google Scholar] [CrossRef]
- Keam, S.J. Ozoralizumab: First Approval. Drugs 2023, 83, 87–92. [Google Scholar] [CrossRef]
- Boder, E.T.; Wittrup, K.D. Yeast surface display for screening combinatorial polypeptide libraries. Nat. Biotechnol. 1997, 15, 553–557. [Google Scholar] [CrossRef] [PubMed]
- Gunneriusson, E.; Samuelson, P.; Uhlen, M.; Nygren, P.A.; Stähl, S. Surface display of a functional single-chain Fv antibody on staphylococci. J. Bacteriol. 1996, 178, 1341–1346. [Google Scholar] [CrossRef] [PubMed]
- Stafford, R.L.; Matsumoto, M.L.; Yin, G.; Cai, Q.; Fung, J.J.; Stephenson, H.; Gill, A.; You, M.; Lin, S.H.; Wang, W.D.; et al. In vitro Fab display: A cell-free system for IgG discovery. Protein Eng. Des. Sel. PEDS 2014, 27, 97–109. [Google Scholar] [CrossRef]
- Smith, G.P. Filamentous Fusion Phage: Novel Expression Vectors That Display Cloned Antigens on the Virion Surface. Science 1985, 228, 1315–1317. [Google Scholar] [CrossRef]
- Smith, G.P.; Petrenko, V.A. Phage Display. Chem. Rev. 1997, 97, 391–410. [Google Scholar] [CrossRef] [PubMed]
- Azzazy, H.M.E.; Highsmith, W.E. Phage display technology: Clinical applications and recent innovations. Clin. Biochem. 2002, 35, 425–445. [Google Scholar] [CrossRef] [PubMed]
- McCafferty, J.; Griffiths, A.D.; Winter, G.; Chiswell, D.J. Phage antibodies: Filamentous phage displaying antibody variable domains. Nature 1990, 348, 552–554. [Google Scholar] [CrossRef]
- Kumar, R.; Parray, H.A.; Shrivastava, T.; Sinha, S.; Luthra, K. Phage display antibody libraries: A robust approach for generation of recombinant human monoclonal antibodies. Int. J. Biol. Macromol. 2019, 135, 907–918. [Google Scholar] [CrossRef]
- Zheng, B.; Yang, Y.; Chen, L.; Wu, M.; Zhou, S. B-cell receptor repertoire sequencing: Deeper digging into the mechanisms and clinical aspects of immune-mediated diseases. iScience 2022, 25, 105002. [Google Scholar] [CrossRef]
- Hoehn, K.B.; Fowler, A.; Lunter, G.; Pybus, O.G. The Diversity and Molecular Evolution of B-Cell Receptors during Infection. Mol. Biol. Evol. 2016, 33, 1147–1157. [Google Scholar] [CrossRef]
- Erasmus, M.F.; D’Angelo, S.; Ferrara, F.; Naranjo, L.; Teixeira, A.A.; Buonpane, R.; Stewart, S.M.; Nastri, H.G.; Bradbury, A.R.M. A single donor is sufficient to produce a highly functional in vitro antibody library. Commun. Biol. 2021, 4, 350. [Google Scholar] [CrossRef]
- Goodwin, S.; McPherson, J.D.; McCombie, W.R. Coming of age: Ten years of next-generation sequencing technologies. Nat. Rev. Genet. 2016, 17, 333–351. [Google Scholar] [CrossRef] [PubMed]
- Schadt, E.E.; Turner, S.; Kasarskis, A. A window into third-generation sequencing. Hum. Mol. Genet. 2010, 19, R227–R240. [Google Scholar] [CrossRef]
- Yang, Y.; Xie, B.; Yan, J. Application of Next-Generation Sequencing Technology in Forensic Science. Genom. Proteom. Bioinform. 2014, 12, 190–197. [Google Scholar] [CrossRef]
- Rouet, R.; Jackson, K.J.L.; Langley, D.B.; Christ, D. Next-Generation Sequencing of Antibody Display Repertoires. Front. Immunol. 2018, 9, 118. [Google Scholar] [CrossRef]
- Arbabi-Ghahroudi, M. Camelid Single-Domain Antibodies: Historical Perspective and Future Outlook. Front. Immunol. 2017, 8, 315863. [Google Scholar] [CrossRef]
- Liu, B.; Yang, D. Easily Established and Multifunctional Synthetic Nanobody Libraries as Research Tools. Int. J. Mol. Sci. 2022, 23, 1482. [Google Scholar] [CrossRef]
- Muyldermans, S. A guide to: Generation and design of nanobodies. FEBS J. 2021, 288, 2084–2102. [Google Scholar] [CrossRef]
- Perelson, A.S.; Oster, G.F. Theoretical studies of clonal selection: Minimal antibody repertoire size and reliability of self-non-self discrimination. J. Theor. Biol. 1979, 81, 645–670. [Google Scholar] [CrossRef]
- Perelson, A.S. Immune Network Theory. Immunol. Rev. 1989, 110, 5–36. [Google Scholar] [CrossRef]
- Lee, C.M.Y.; Iorno, N.; Sierro, F.; Christ, D. Selection of human antibody fragments by phage display. Nat. Protoc. 2007, 2, 3001–3008. [Google Scholar] [CrossRef]
- Liu, Y.; Yi, L.; Li, Y.; Wang, Z. Characterization of heavy-chain antibody gene repertoires in Bactrian camels. J. Genet. Genom. 2023, 50, 38–45. [Google Scholar] [CrossRef]
- Li, X.; Duan, X.; Yang, K.; Zhang, W.; Zhang, C.; Fu, L.; Ren, Z.; Wang, C.; Wu, J.; Lu, R.; et al. Comparative Analysis of Immune Repertoires between Bactrian Camel’s Conventional and Heavy-Chain Antibodies. PLoS ONE 2016, 11, e0161801. [Google Scholar] [CrossRef]
- Frigotto, L.; Smith, M.E.; Brankin, C.; Sedani, A.; Cooper, S.E.; Kanwar, N.; Evans, D.; Svobodova, S.; Baar, C.; Glanville, J.; et al. Codon-Precise, Synthetic, Antibody Fragment Libraries Built Using Automated Hexamer Codon Additions and Validated through Next Generation Sequencing. Antibodies 2015, 4, 88–102. [Google Scholar] [CrossRef]
- Lu, R.-M.; Hwang, Y.-C.; Liu, I.J.; Lee, C.-C.; Tsai, H.-Z.; Li, H.-J.; Wu, H.-C. Development of therapeutic antibodies for the treatment of diseases. J. Biomed. Sci. 2020, 27, 1. [Google Scholar] [CrossRef] [PubMed]
- Bashir, S.; Paeshuyse, J. Construction of Antibody Phage Libraries and Their Application in Veterinary Immunovirology. Antibodies 2020, 9, 21. [Google Scholar] [CrossRef] [PubMed]
- Tu, Z.; Huang, X.; Fu, J.; Hu, N.; Zheng, W.; Li, Y.; Zhang, Y. Landscape of variable domain of heavy-chain-only antibody repertoire from alpaca. Immunology 2020, 161, 53–65. [Google Scholar] [CrossRef]
- Tu, Z.; Xu, Y.; He, Q.; Fu, J.; Liu, X.; Tao, Y. Isolation and characterisation of deoxynivalenol affinity binders from a phage display library based on single-domain camelid heavy chain antibodies (VHHs). Food Agric. Immunol. 2012, 23, 123–131. [Google Scholar] [CrossRef]
- Lu, Q.; Zhang, Z.; Li, H.; Zhong, K.; Zhao, Q.; Wang, Z.; Wu, Z.; Yang, D.; Sun, S.; Yang, N.; et al. Development of multivalent nanobodies blocking SARS-CoV-2 infection by targeting RBD of spike protein. J. Nanobiotechnol. 2021, 19, 33. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Zhang, F.; Lu, Y.; Hu, H.; Wang, J.; Guo, C.; Deng, Q.; Liao, C.; Wu, Q.; Hu, T.; et al. Highly potent multivalent VHH antibodies against Chikungunya isolated from an alpaca naïve phage display library. J. Nanobiotechnol. 2022, 20, 231. [Google Scholar] [CrossRef] [PubMed]
- Moreno, E.; Valdés-Tresanco, M.S.; Molina-Zapata, A.; Sánchez-Ramos, O. Structure-based design and construction of a synthetic phage display nanobody library. BMC Res. Notes 2022, 15, 124. [Google Scholar] [CrossRef]
- Deschaght, P.; Vintém, A.P.; Logghe, M.; Conde, M.; Felix, D.; Mensink, R.; Gonçalves, J.; Audiens, J.; Bruynooghe, Y.; Figueiredo, R.; et al. Large Diversity of Functional Nanobodies from a Camelid Immune Library Revealed by an Alternative Analysis of Next-Generation Sequencing Data. Front. Immunol. 2017, 8, 420. [Google Scholar] [CrossRef]
- Sabir, J.S.M.; Atef, A.; El-Domyati, F.M.; Edris, S.; Hajrah, N.; Alzohairy, A.M.; Bahieldin, A. Construction of naïve camelids VHH repertoire in phage display-based library. Comptes Rendus Biol. 2014, 337, 244–249. [Google Scholar] [CrossRef]
- Ponsel, D.; Neugebauer, J.; Ladetzki-Baehs, K.; Tissot, K. High Affinity, Developability and Functional Size: The Holy Grail of Combinatorial Antibody Library Generation. Molecules 2011, 16, 3675–3700. [Google Scholar] [CrossRef]
- Aughan, T.; Willams, A.; Prichard, K.J.N.B. Human antibodies with sub-nanomolar affinities isolated from a large non-immunized phage display library. Nat. Biotechnol. 1996, 14, 309–314. [Google Scholar] [CrossRef] [PubMed]
- Ling, M.M. Large Antibody Display Libraries for Isolation of High-Affinity Antibodies. Comb. Chem. High Throughput Screen. 2003, 6, 421–432. [Google Scholar] [CrossRef] [PubMed]
- North, B.; Lehmann, A.; Dunbrack, R.L. A New Clustering of Antibody CDR Loop Conformations. J. Mol. Biol. 2011, 406, 228–256. [Google Scholar] [CrossRef] [PubMed]
- Weisser, N.E.; Hall, J.C. Applications of single-chain variable fragment antibodies in therapeutics and diagnostics. Biotechnol. Adv. 2009, 27, 502–520. [Google Scholar] [CrossRef] [PubMed]
- Kang, T.H.; Seong, B.L. Solubility, Stability, and Avidity of Recombinant Antibody Fragments Expressed in Microorganisms. Front. Microbiol. 2020, 11, 552011. [Google Scholar] [CrossRef] [PubMed]
- Tadokoro, T.; Tsuboi, H.; Nakamura, K.; Hayakawa, T.; Ohmura, R.; Kato, I.; Inoue, M.; Tsunoda, S.-I.; Niizuma, S.; Okada, Y.; et al. Thermostability and binding properties of single-chained Fv fragments derived from therapeutic antibodies. bioRxiv 2024. [Google Scholar] [CrossRef]
- Asaadi, Y.; Jouneghani, F.F.; Janani, S.; Rahbarizadeh, F. A comprehensive comparison between camelid nanobodies and single chain variable fragments. Biomark. Res. 2021, 9, 87. [Google Scholar] [CrossRef]
- Valdés-Tresanco, M.S.; Valdés-Tresanco, M.E.; Molina-Abad, E.; Moreno, E. NbThermo: A new thermostability database for nanobodies. Database 2023, 2023, baad021. [Google Scholar] [CrossRef]
- European Medicines Agency, Cablivi (Caplacizumab): Summary of Product Characteristics. 2018. Available online: https://www.ema.europa.eu/en/documents/assessment-report/cablivi-epar-public-assessment-report_en.pdf (accessed on 22 April 2024).
- Zak, K.M.; Grudnik, P.; Magiera, K.; Dömling, A.; Dubin, G.; Holak, T.A. Structural Biology of the Immune Checkpoint Receptor PD-1 and Its Ligands PD-L1/PD-L2. Structure 2017, 25, 1163–1174. [Google Scholar] [CrossRef]
- van de Donk, N.W.; Janmaat, M.L.; Mutis, T.; Lammerts van Bueren, J.J.; Ahmadi, T.; Sasser, A.K.; Lokhorst, H.M.; Parren, P.W. Monoclonal antibodies targeting CD38 in hematological malignancies and beyond. Immunol. Rev. 2016, 270, 95–112. [Google Scholar] [CrossRef]
- Pescovitz, M.D. Rituximab, an Anti-CD20 Monoclonal Antibody: History and Mechanism of Action. Am. J. Transplant. 2006, 6 Pt 1, 859–866. [Google Scholar] [CrossRef]
- Zhang, J.; Kobert, K.; Flouri, T.; Stamatakis, A. PEAR: A fast and accurate Illumina Paired-End reAd mergeR. Bioinformatics 2014, 30, 614–620. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.W.; Cho, A.H.; Shin, H.G.; Jang, S.H.; Cho, S.Y.; Lee, Y.R.; Lee, S. Development and Characterization of Phage Display-Derived Monoclonal Antibodies to the S2 Domain of Spike Proteins of Wild-Type SARS-CoV-2 and Multiple Variants. Viruses 2023, 15, 174. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Antigen | Antibody (VHH) | Ka (1/Ms) | Kd (1/s) | KD (nM) | Tm (°C) | CDR3 Length | Germline V Gene | Germline J Gene |
|---|---|---|---|---|---|---|---|---|
| Human PD-L1 | K113.1 | 2.36 × 104 | 9.36 × 10−5 | 3.96 | 66.7 | 8 | IGHV3S53 | IGHJ4 |
| K113.2 | 1.48 × 105 | 9.23 × 10−4 | 6.22 | 76.4 | 8 | IGHV3S53 | IGHJ4 | |
| SARS-CoV-2 B.1.617.2 RBD | K114.1 | 1.96 × 105 | 1.41 × 10−3 | 7.19 | 68.3 | 19 | IGHV3-3 | IGHJ4 |
| K114.2 | 2.30 × 105 | 2.53 × 10−3 | 11.0 | 66.4 | 19 | IGHV3-3 | IGHJ4 | |
| K114.3 | 3.57 × 105 | 3.56 × 10−3 | 9.98 | 62.4 | 9 | IGHV3S1 | IGHJ6 | |
| K114.4 | 1.19 × 105 | 4.24 × 10−3 | 35.7 | 64.1 | 9 | IGHV3S1 | IGHJ6 | |
| K114.5 | 2.87 × 105 | 6.54 × 10−3 | 22.8 | 68.8 | 13 | IGHV3S53 | IGHJ6 | |
| K114.6 | 3.60 × 105 | 2.98 × 10−3 | 8.28 | 60.5 | 9 | IGHV3S1 | IGHJ6 | |
| SARS-CoV-2 BA.2 RBD | K115.1 | 2.80 × 105 | 2.66 × 10−3 | 9.21 | 71.6 | 12 | IGHV3S53 | IGHJ4 |
| K115.2 | 2.57 × 105 | 4.20 × 10−4 | 1.63 | 72.9 | 17 | IGHV3-3 | IGHJ6 | |
| K115.3 | 1.53 × 105 | 6.86 × 10−4 | 4.48 | 77.5 | 12 | IGHV3S53 | IGHJ4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.E.; Cho, A.H.; Hwang, J.H.; Kim, J.W.; Yang, H.R.; Ryu, T.; Jung, Y.; Lee, S. Development, High-Throughput Profiling, and Biopanning of a Large Phage Display Single-Domain Antibody Library. Int. J. Mol. Sci. 2024, 25, 4791. https://doi.org/10.3390/ijms25094791
Lee HE, Cho AH, Hwang JH, Kim JW, Yang HR, Ryu T, Jung Y, Lee S. Development, High-Throughput Profiling, and Biopanning of a Large Phage Display Single-Domain Antibody Library. International Journal of Molecular Sciences. 2024; 25(9):4791. https://doi.org/10.3390/ijms25094791
Chicago/Turabian StyleLee, Hee Eon, Ah Hyun Cho, Jae Hyeon Hwang, Ji Woong Kim, Ha Rim Yang, Taehoon Ryu, Yushin Jung, and Sukmook Lee. 2024. "Development, High-Throughput Profiling, and Biopanning of a Large Phage Display Single-Domain Antibody Library" International Journal of Molecular Sciences 25, no. 9: 4791. https://doi.org/10.3390/ijms25094791