Genome-Scale Analysis of Homologous Genes among Subgenomes of Bread Wheat (Triticum aestivum L.)


Abstract
:1. Introduction
2. Results
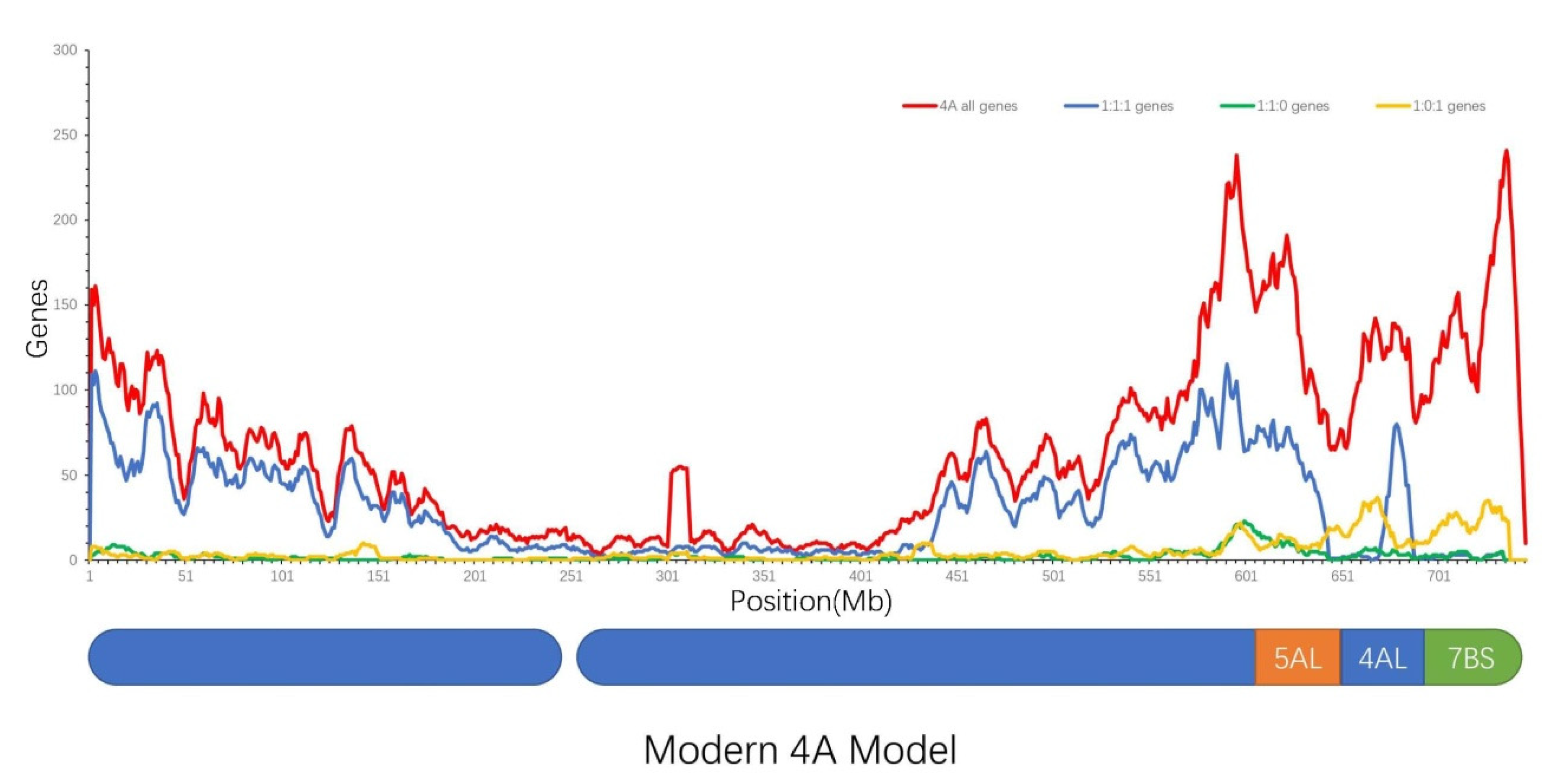
2.1. Homologous Gene Density of Wheat Chromosomes
2.2. Distribution of Homologous Genes on Wheat Chromosomes
2.2.1. Regional Distribution of 1:1:1 Homologous Genes
2.2.2. Regional Distribution of 1:1:0 Homologous Genes
2.2.3. Regional Distribution of 0:1:1 Homologous Genes
2.2.4. Regional Distribution of 1:0:1 Homologous Genes
2.3. Homologous Gene Correlations between the A, B and D Subgenomes of Wheat
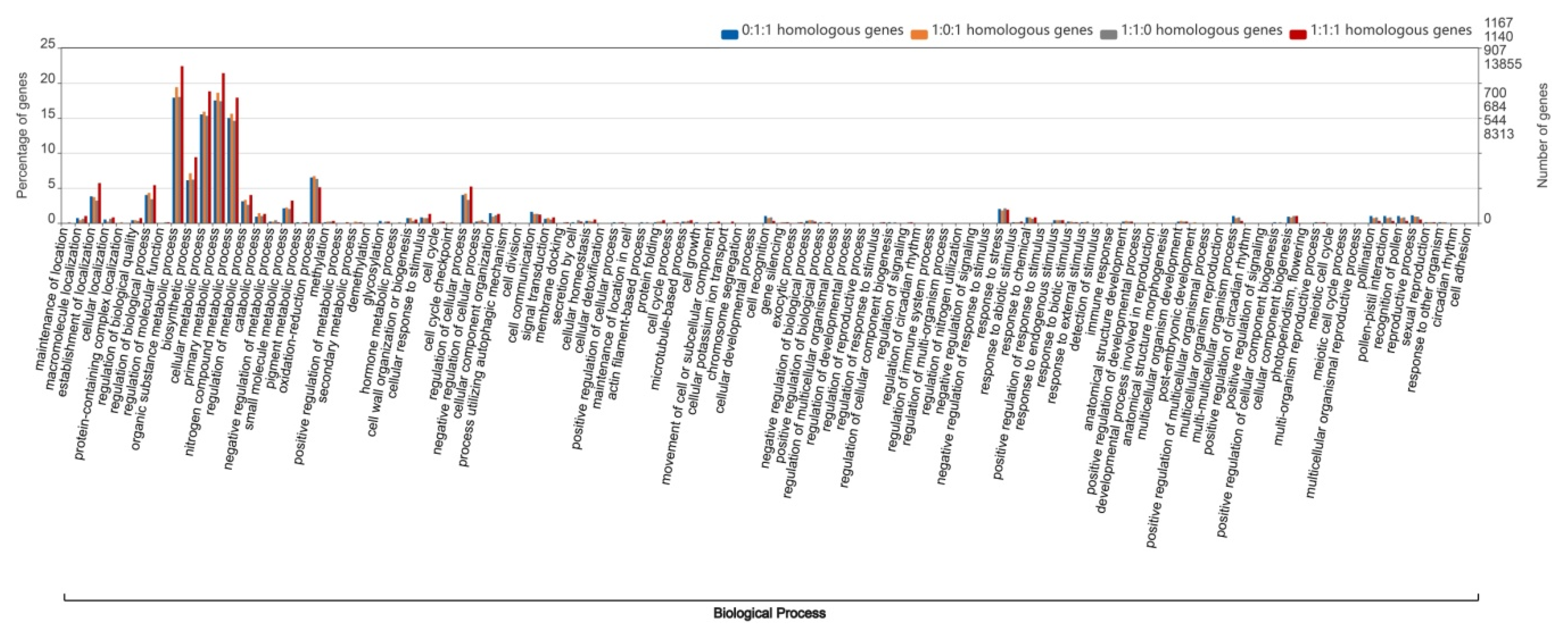
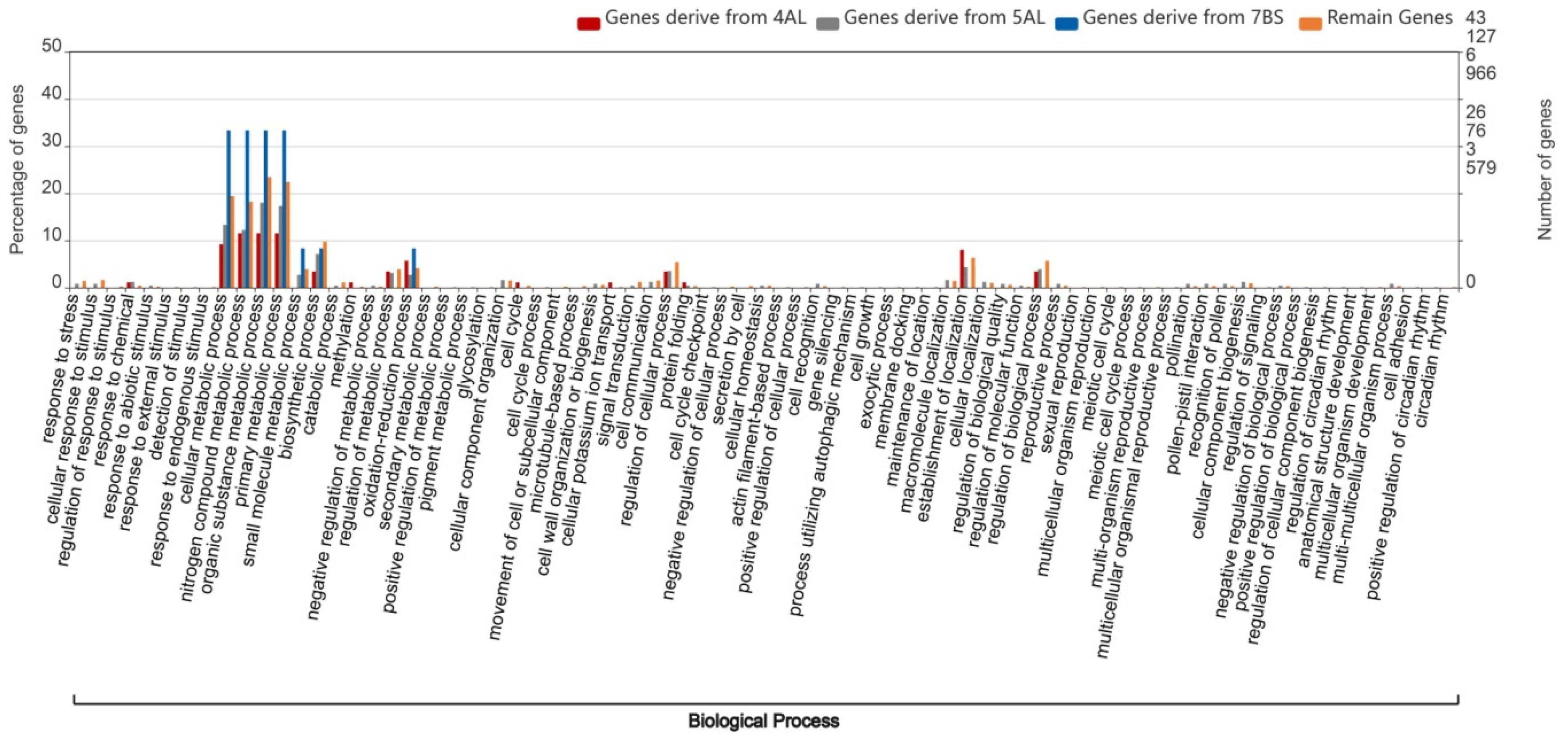
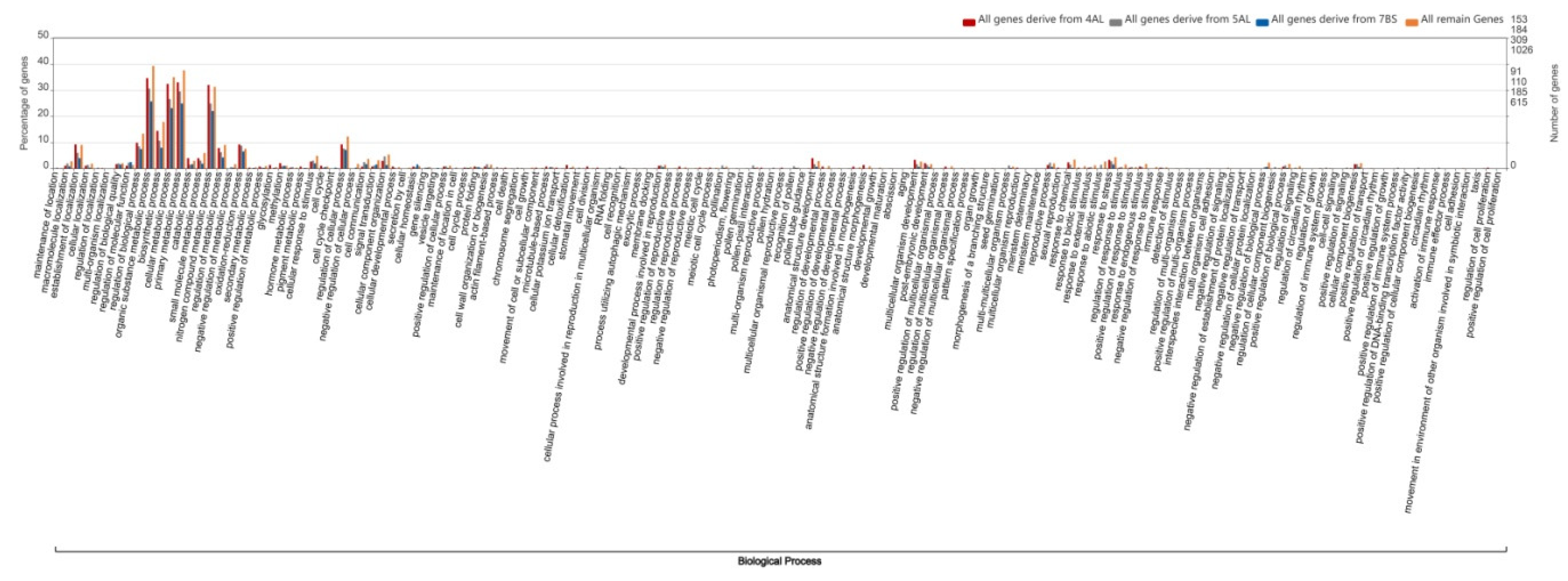
2.4. Gene Ontology Analysis of Wheat Homologous Genes
3. Discussion
4. Materials and Methods
4.1. Experimental Materials
4.2. Parameter Optimization for Illustrating Gene Distribution
4.3. The Distribution and Correspondence (Circle Map) between Homologous Genes
4.4. GO Analysis
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Peng, J.H.; Sun, D.F.; Nevo, E. Wild emmer wheat, Triticum dicoccoides, occupies a pivotal position in wheat domestication process. Aust. J. Crop. Sci. 2011, 5, 1127–1143. [Google Scholar]
- Ray, D.K.; Mueller, N.D.; West, P.C.; Foley, J.A. Yield Trends Are Insufficient to Double Global Crop Production by 2050. PLoS ONE 2013, 8, e66428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shewry, P.R. Wheat. J. Exp. Bot. 2009, 60, 1537–1553. [Google Scholar] [CrossRef] [PubMed]
- Glover, N.M.; Redestig, H.; Dessimoz, C. Homoeologs: What Are They and How Do We Infer Them? Trends Plant Sci. 2016, 21, 609–621. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marcussen, T.; Sandve, S.R.; Heier, L.; Spannagl, M.; Pfeifer, M.; Jakobsen, K.S.; Wulff, B.B.; Steuernagel, B.; Mayer, K.F.X.; Olsen, O.-A.; et al. Ancient hybridizations among the ancestral genomes of bread wheat. Science 2014, 345, 1250092. [Google Scholar] [CrossRef]
- Naranjo, T.; Roca, A.; Goicoechea, P.G.; Giraldez, R. Arm homoeology of wheat and rye chromosomes. Genome 1987, 29, 873–882. [Google Scholar] [CrossRef]
- Danilova, T.V.; Friebe, B.; Gill, B.S. Development of a wheat single gene FISH map for analyzing homoeologous relationship and chromosomal rearrangements within the Triticeae. Theor. Appl. Genet. 2014, 127, 715–730. [Google Scholar] [CrossRef] [Green Version]
- International Wheat Genome Sequencing. A chromosome-based draft sequence of the hexaploid bread wheat (Triticum aestivum) genome. Science 2014, 345, 1251788. [Google Scholar] [CrossRef]
- The International Wheat Genome Sequencing Consortium (IWGSC); Appels, R.; Eversole, K.; Stein, N.; Feuillet, C.; Keller, B.; Rogers, J.; Pozniak, C.J.; Choulet, F.; Distelfeld, A.; et al. Shifting the limits in wheat research and breeding using a fully annotated reference genome. Science 2018, 361, eaar7191. [Google Scholar] [CrossRef] [Green Version]
- Naz, A.; Dadshani, S.; Ballvora, A.; Pillen, K.; Léon, J. Genetic Analysis and Transfer of Favorable Exotic QTL Alleles for Grain Yield Across D Genome Using Two Advanced Backcross Wheat Populations. Front. Plant Sci. 2019, 10, 711. [Google Scholar] [CrossRef]
- Ma, J.; Stiller, J.; Berkman, P.J.; Wei, Y.; Rogers, J.; Feuillet, C.; Dolezel, J.; Mayer, K.F.X.; Eversole, K.; Zheng, Y.-L.; et al. Sequence-Based Analysis of Translocations and Inversions in Bread Wheat (Triticum aestivum L.). PLoS ONE 2013, 8, e79329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, J.; Stiller, J.; Wei, Y.; Zheng, Y.-L.; Devos, K.M.; Dolezel, J.; Liu, C. Extensive pericentric rearrangements in the bread wheat (Triticum aestivum L.) genotype "Chinese Spring" revealed from chromosome shotgun sequence data. Genome Boil. Evol. 2014, 6, 3039–3048. [Google Scholar] [CrossRef] [PubMed]
- Huo, N.; Zhu, T.; Zhang, S.; Mohr, T.; Luo, M.-C.; Lee, J.-Y.; Distelfeld, A.; Altenbach, S.; Gu, Y.Q. Rapid evolution of α-gliadin gene family revealed by analyzing Gli-2 locus regions of wild emmer wheat. Funct. Integr. Genom. 2019, 19, 993–1005. [Google Scholar] [CrossRef] [Green Version]
- He‡, F.; Pasam, R.; Shi, F.; Kant, S.; Keeble-Gagnère, G.; Kay, P.; Forrest, K.; Fritz, A.; Hucl, P.; Wiebe, K.; et al. Exome sequencing highlights the role of wild-relative introgression in shaping the adaptive landscape of the wheat genome. Nat. Genet. 2019, 51, 896–904. [Google Scholar] [CrossRef]
- Danilova, T.V.; Akhunova, A.R.; Akhunov, E.; Friebe, B.; Gill, B.S. Major structural genomic alterations can be associated with hybrid speciation inAegilops markgrafii(Triticeae). Plant J. 2017, 92, 317–330. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martis, M.M.; Zhou, R.; Haseneyer, G.; Schmutzer, T.; Vrána, J.; Kubaláková, M.; König, S.; Kugler, K.G.; Scholz, U.; Hackauf, B.; et al. Reticulate Evolution of the Rye Genome [W] [OPEN]. Plant Cell 2013, 25, 3685–3698. [Google Scholar] [CrossRef] [Green Version]
- Hori, K.; Takehara, S.; Nankaku, N.; Sato, K.; Sasakuma, T.; Takeda, K. Barley EST Markers Enhance Map Saturation and QTL Mapping in Diploid Wheat. Breed. Sci. 2007, 57, 39–45. [Google Scholar] [CrossRef]
- Grewal, S.; Yang, C.; Hubbart-Edwards, S.; Scholefield, D.; Ashling, S.; Burridge, A.J.; King, I.P.; King, J. Characterisation of Thinopyrum bessarabicum chromosomes through genome-wide introgressions into wheat. Theor. Appl. Genet. 2017, 131, 389–406. [Google Scholar] [CrossRef] [Green Version]
- Nelson, J.C.; Sorrells, M.E.; Van-Deynze, A.E.; Lu, Y.H.; Atkinson, M.; Bernard, M.; Leroy, P.; Faris, J.D.; Anderson, J.A. Molecular Mapping of Wheat: Major Genes and Rearrangements in Homoeologous Groups 4, 5, and 7. Genetics 1995, 141, 721–731. [Google Scholar]
- Devos, K.M.; Dubcovsky, J.; Dvořák, J.; Chinoy, C.N.; Gale, M.D. Structural evolution of wheat chromosomes 4A, 5A, and 7B and its impact on recombination. Theor. Appl. Genet. 1995, 91, 282–288. [Google Scholar] [CrossRef] [Green Version]
- Mickelson-Young, L.; Endo, T.R.; Gill, B.S. A cytogenetic ladder-map of the wheat homoeologous group-4 chromosomes. Theor. Appl. Genet. 1995, 90, 1007–1011. [Google Scholar] [CrossRef] [PubMed]
- Endo, T.R.; Gill, B.S. The Deletion Stocks of Common Wheat. J. Hered. 1996, 87, 295–307. [Google Scholar] [CrossRef]
- Dvorak, J.; Wang, L.; Zhu, T.; Jorgensen, C.M.; Luo, M.-C.; Deal, K.R.; Gu, Y.Q.; Gill, B.S.; Distelfeld, A.; Devos, K.M.; et al. Reassessment of the evolution of wheat chromosomes 4A, 5A, and 7B. Theor. Appl. Genet. 2018, 131, 2451–2462. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naranjo, T. The Effect of Chromosome Structure upon Meiotic Homologous and Homoeologous Recombinations in Triticeae. Agronomy 2019, 9, 552. [Google Scholar] [CrossRef] [Green Version]
- Choulet, F.; Alberti, A.; Theil, S.; Glover, N.; Barbe, V.; Daron, J.; Pingault, L.; Sourdille, P.; Couloux, A.; Paux, E.; et al. Structural and functional partitioning of bread wheat chromosome 3B. Science 2014, 345, 1249721. [Google Scholar] [CrossRef] [PubMed]
- Lukaszewski, A.J.; Kopecký, D.; Linc, G. Inversions of chromosome arms 4AL and 2BS in wheat invert the patterns of chiasma distribution. Chromosoma 2011, 121, 201–208. [Google Scholar] [CrossRef]
- Coruzzi, G. Nitrogen and Carbon Nutrient and Metabolite Signaling in Plants. Plant Physiol. 2001, 125, 61–64. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.-W.; Dai, T.-B.; Cai, J.; Jiang, D.; Cao, W.-X. Characteristics of Dry Matter Accumulation and Translocation During the Wheat Genetic Improvement and Their Relationship to Grain Yield. Sci. Agric. Sin. 2012, 45, 801–808. [Google Scholar]
- Wang, L.H.; Zuo, S.Y.; Wei, S.; Li, J. Differences in flag leaf nitrogen metabolism and grain protein formation among triticale varieties after anthesis. Plant Physiol. J. 2018, 54, 401–410. [Google Scholar]
- Masclaux-Daubresse, C.; Daniel-Vedele, F.; Dechorgnat, J.; Chardon, F.; Gaufichon, L.; Suzuki, A. Nitrogen uptake, assimilation and remobilization in plants: Challenges for sustainable and productive agriculture. Ann. Bot. 2010, 105, 1141–1157. [Google Scholar] [CrossRef] [Green Version]
- Tang, H.; Song, Y.; Guo, J.; Wang, J.; Zhang, L.; Niu, N.; Ma, S.; Zhang, G.; Zhao, H. Physiological and metabolome changes during another development in wheat (Triticum aestivum L.). Plant Physiol. Biochem. 2018, 132, 18–32. [Google Scholar] [CrossRef] [PubMed]
- Ramirez-Gonzalez, R.H.; Borrill, P.; Lang, D.; Harrington, S.A.; Brinton, J.; Venturini, L.; Davey, M.; Jacobs, J.; Van Ex, F.; Pasha, A.; et al. The transcriptional landscape of polyploid wheat. Science 2018, 361, eaar6089. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chromosome Name | Total Number of Homologous Genes | Chromosome Length (Mb) | Homologous Gene Density (Gene Number/Mb) |
|---|---|---|---|
| 1A | 2451 | 594.10 | 4.1 |
| 1B | 2455 | 689.85 | 3.6 |
| 1D | 2453 | 495.45 | 5.0 |
| 2A | 3186 | 780.80 | 4.1 |
| 2B | 3183 | 801.26 | 4.0 |
| 2D | 3186 | 651.85 | 4.9 |
| 3A | 2911 | 750.84 | 3.9 |
| 3B | 2928 | 830.83 | 3.5 |
| 3D | 2918 | 615.55 | 4.7 |
| 4A | 2287 | 744.59 | 3.1 |
| 4B | 2295 | 673.62 | 3.4 |
| 4D | 2301 | 509.86 | 4.5 |
| 5A | 3081 | 709.77 | 4.3 |
| 5B | 3058 | 713.15 | 4.3 |
| 5D | 3060 | 566.08 | 5.4 |
| 6A | 2140 | 618.08 | 3.5 |
| 6B | 2156 | 720.99 | 3.0 |
| 6D | 2143 | 473.59 | 4.5 |
| 7A | 2418 | 736.71 | 3.3 |
| 7B | 2399 | 750.62 | 3.2 |
| 7D | 2413 | 638.69 | 3.8 |
| Chromosome Name | Total Number of Homologous Genes | Chromosome Length(Mb) | Homologous Gene Density (Gene Number/Mb) |
|---|---|---|---|
| 1A | 200 | 594.10 | 0.3 |
| 1B | 208 | 689.85 | 0.3 |
| 2A | 294 | 780.80 | 0.4 |
| 2B | 292 | 801.26 | 0.4 |
| 3A | 293 | 750.84 | 0.4 |
| 3B | 316 | 830.83 | 0.4 |
| 4A | 170 | 744.59 | 0.2 |
| 4B | 209 | 673.62 | 0.3 |
| 5A | 314 | 709.77 | 0.4 |
| 5B | 249 | 713.15 | 0.3 |
| 6A | 297 | 618.08 | 0.5 |
| 6B | 305 | 720.99 | 0.4 |
| 7A | 246 | 736.71 | 0.3 |
| 7B | 235 | 750.62 | 0.3 |
| Chromosome Name | Total Number of Homologous Genes | Chromosome Length (Mb) | Homologous Gene Density (Gene Number/Mb) |
|---|---|---|---|
| 1B | 291 | 689.85 | 0.4 |
| 1D | 298 | 495.45 | 0.6 |
| 2B | 425 | 801.26 | 0.5 |
| 2D | 435 | 651.85 | 0.7 |
| 3B | 416 | 830.83 | 0.5 |
| 3D | 408 | 615.55 | 0.7 |
| 4B | 177 | 673.62 | 0.3 |
| 4D | 183 | 509.86 | 0.4 |
| 5B | 405 | 713.15 | 0.6 |
| 5D | 426 | 566.08 | 0.8 |
| 6B | 301 | 720.99 | 0.4 |
| 6D | 293 | 473.59 | 0.6 |
| 7B | 320 | 750.62 | 0.4 |
| 7D | 292 | 638.69 | 0.5 |
| Chromosome Name | Total Number of Homologous Genes | Chromosome Length (Mb) | Homologous Gene Density (Gene Number/Mb) |
|---|---|---|---|
| 1A | 218 | 594.10 | 0.4 |
| 1D | 230 | 495.45 | 0.5 |
| 2A | 366 | 780.80 | 0.5 |
| 2D | 371 | 651.85 | 0.6 |
| 3A | 322 | 750.84 | 0.4 |
| 3D | 330 | 615.55 | 0.5 |
| 4A | 400 | 744.59 | 0.5 |
| 4D | 175 | 509.86 | 0.3 |
| 5A | 272 | 709.77 | 0.4 |
| 5D | 284 | 566.08 | 0.5 |
| 6A | 236 | 618.08 | 0.4 |
| 6D | 238 | 473.59 | 0.5 |
| 7A | 467 | 736.71 | 0.6 |
| 7D | 653 | 638.69 | 1.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, C.; Dong, Z.; Zhang, T.; Wu, J.; Yu, S.; Zeng, Q.; Han, D.; Tong, W. Genome-Scale Analysis of Homologous Genes among Subgenomes of Bread Wheat (Triticum aestivum L.). Int. J. Mol. Sci. 2020, 21, 3015. https://doi.org/10.3390/ijms21083015
Zhou C, Dong Z, Zhang T, Wu J, Yu S, Zeng Q, Han D, Tong W. Genome-Scale Analysis of Homologous Genes among Subgenomes of Bread Wheat (Triticum aestivum L.). International Journal of Molecular Sciences. 2020; 21(8):3015. https://doi.org/10.3390/ijms21083015
Chicago/Turabian StyleZhou, Caie, Zhaonian Dong, Ting Zhang, Jianhui Wu, Shizhou Yu, Qingdong Zeng, Dejun Han, and Wei Tong. 2020. "Genome-Scale Analysis of Homologous Genes among Subgenomes of Bread Wheat (Triticum aestivum L.)" International Journal of Molecular Sciences 21, no. 8: 3015. https://doi.org/10.3390/ijms21083015