
The Rapid Non-Destructive Detection of Adulteration and Its Degree of Tieguanyin by Fluorescence Hyperspectral Technology


Abstract
:1. Introduction
2. Materials and Methods
2.1. Selection of Adulterated Tea
2.2. Fluorescence Hyperspectral Image Acquisition
2.3. Region of Interest Extraction
2.4. Spectral Pretreatment
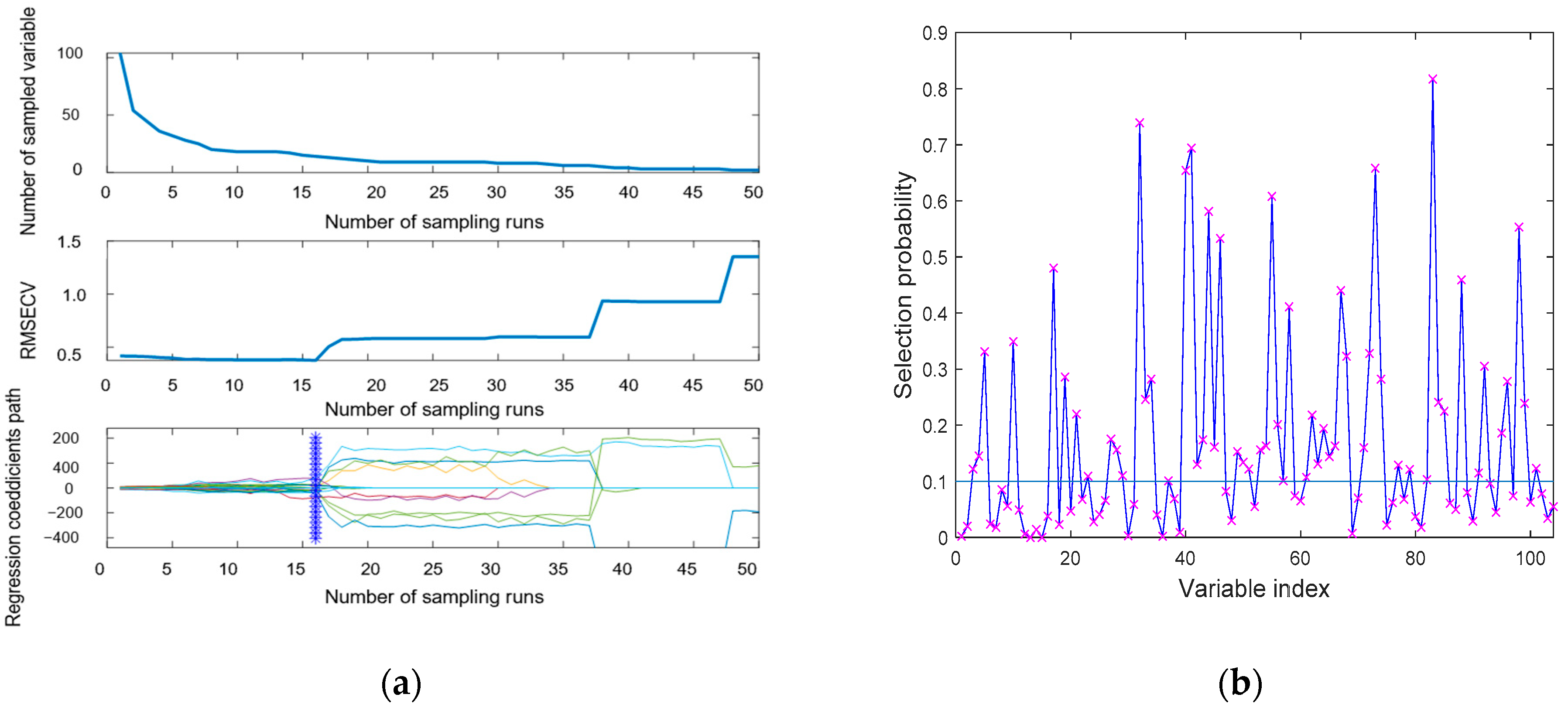
2.5. Spectral Characteristic Wavelength Selection
2.6. Support Vector Machine (SVM)
2.7. Performance Evaluation of the Model
3. Results
3.1. Characterization of Fluorescence Spectra
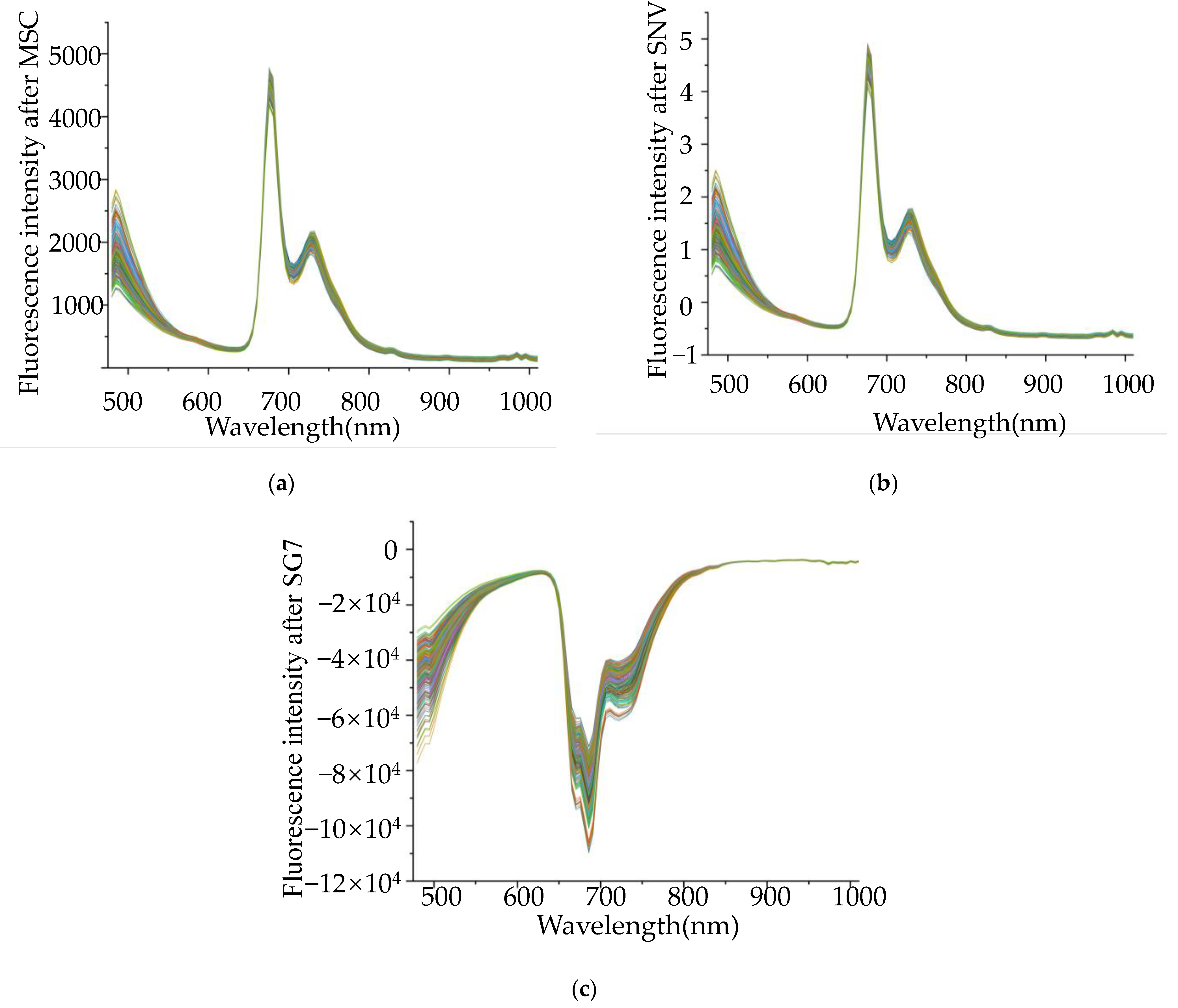
3.2. Result of Spectral Preprocessing
3.3. Result of Classification
3.3.1. Two-Class Discriminant Models
3.3.2. Six-Class Discriminant Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Hu, Y.; Xu, L.; Huang, P.; Luo, X.; Wang, P.; Kang, Z. Reliable Identification of Oolong Tea Species: Nondestructive Testing Classification Based on Fluorescence Hyperspectral Technology and Machine Learning. Agriculture 2021, 11, 1106. [Google Scholar] [CrossRef]
- Huang, Z.; Sanaeifar, A.; Tian, Y.; Liu, L.; Zhang, D.; Wang, H.; Ye, D.; Li, X. Improved generalization of spectral models associated with Vis-NIR spectroscopy for determining the moisture content of different tea leaves. J. Food Eng. 2021, 293, 110374. [Google Scholar] [CrossRef]
- Ge, X.; Sun, J.; Lu, B.; Chen, Q.; Xun, W.; Jin, Y. Classification of oolong tea varieties based on hyperspectral imaging technology and BOSS-LightGBM model. J. Food Process Eng. 2019, 42, e13289. [Google Scholar] [CrossRef]
- Jiang, H.; Xu, W.; Chen, Q. Determination of tea polyphenols in green tea by homemade color sensitive sensor combined with multivariate analysis. Food Chem. 2020, 319, 126584. [Google Scholar] [CrossRef] [PubMed]
- Ren, G.; Liu, Y.; Ning, J.; Zhang, Z. Assessing black tea quality based on visible–near infrared spectra and kernel-based methods. J. Food Compos. Anal. 2021, 98, 103810. [Google Scholar] [CrossRef]
- Li, Q.; Zeng, J.; Lin, L.; Zhang, J.; Zhu, J.; Yao, L.; Wang, S.; Yao, Z.; Wu, Z. Low risk of category misdiagnosis of rice syrup adulteration in three botanical origin honey by ATR-FTIR and general model. Food Chem. 2020, 332, 127356. [Google Scholar] [CrossRef]
- Tao, F.; Liu, L.; Kucha, C.; Ngadi, M. Rapid and non-destructive detection of cassava flour adulterants in wheat flour using a handheld MicroNIR spectrometer. Biosyst. Eng. 2021, 203, 34–43. [Google Scholar] [CrossRef]
- Zhang, S.; Takano, J.; Murayama, N.; Tominaga, M.; Abe, T.; Park, I.; Seol, J.; Ishihara, A.; Tanaka, Y.; Yajima, K.; et al. Subacute Ingestion of Caffeine and Oolong Tea Increases Fat Oxidation without Affecting Energy Expenditure and Sleep Architecture: A Randomized, Placebo-Controlled, Double-Blinded Cross-Over Trial. Nutrients 2020, 12, 3671. [Google Scholar] [CrossRef]
- Rust, A.; Marini, F.; Allsopp, M.; Williams, P.J.; Manley, M. Application of ANOVA-simultaneous component analysis to quantify and characterise effects of age, temperature, syrup adulteration and irradiation on near-infrared (NIR) spectral data of honey. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 253, 119546. [Google Scholar] [CrossRef]
- Tomioka, Y.; Arakawa, T.; Akuta, T.; Nakagawa, M.; Ishibashi, M. Analysis of proteins by agarose native gel electrophoresis in the presence of solvent additives. Int. J. Biol. Macromol. 2021, 198, 26–36. [Google Scholar] [CrossRef]
- Morimoto, J.; Rosso, M.C.; Kfoury, N.; Bicchi, C.; Cordero, C.; Robbat, A. Untargeted/Targeted 2D Gas Chromatography/Mass Spectrometry Detection of the Total Volatile Tea Metabolome. Molecules 2019, 24, 3757. [Google Scholar] [CrossRef] [Green Version]
- Sanaeifar, A.; Li, X.; He, Y.; Huang, Z.; Zhan, Z. A data fusion approach on confocal Raman microspectroscopy and electronic nose for quantitative evaluation of pesticide residue in tea. Biosyst. Eng. 2021, 210, 206–222. [Google Scholar] [CrossRef]
- Tabara, K.; Watanabe, K.; Shigeto, H.; Yamamura, S.; Kishi, T.; Kitamatsu, M.; Ohtsuki, T. Fluorophore-PNA-Quencher/Quencher-DNA probe for miRNA detection. Bioorg. Med. Chem. Lett. 2021, 51, 128359. [Google Scholar] [CrossRef]
- Kucharska, M.; Grabka, J. A review of chromatographic methods for determination of synthetic food dyes. Talanta 2010, 80, 1045–1051. [Google Scholar] [CrossRef] [PubMed]
- Saber, R.A.; Attia, A.K.; Salem, W.M. Thermal analysis study of antihypertensive drugs telmisartan and cilazapril. Adv. Pharm. Bull. 2014, 4, 283–287. [Google Scholar] [CrossRef] [PubMed]
- Burger, A. Differential thermal analysis and differential scanning calorimetry: Basis, methods and use. Pharm. Unserer Zeit 1982, 11, 177–189. [Google Scholar] [CrossRef] [PubMed]
- Allen, B.; Gaskin, K.; Stewart, P. Measurement of body composition by in-vivo neutron-activation analysis. Med. J. Aust. 1986, 145, 307. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.-Y.; Wang, S.-T.; Wang, J.-Z.; Cheng, Q.; Wu, X.-J.; Kong, D.-M. Rapid detection of the authenticity and adulteration of sesame oil using excitation-emission matrix fluorescence and chemometric methods. Food Control 2020, 112, 107145. [Google Scholar] [CrossRef]
- Hu, C.D.; Liang, Y.Z.; Guo, F.Q.; Li, X.R.; Wang, W.P. Determination of Essential Oil Composition from Osmanthus fragrans Tea by GC-MS Combined with a Chemometric Resolution Method. Molecules 2010, 15, 3683–3693. [Google Scholar] [CrossRef]
- Huang, G.; Yuan, L.M.; Shi, W.; Chen, X.; Chen, X. Using one-class autoencoder for adulteration detection of milk powder by infrared spectrum. Food Chem. 2022, 372, 131219. [Google Scholar] [CrossRef]
- Kelis Cardoso, V.G.; Poppi, R.J. Cleaner and faster method to detect adulteration in cassava starch using Raman spectroscopy and one-class support vector machine. Food Control 2021, 125, 107917. [Google Scholar] [CrossRef]
- Liu, Z.; Xie, H.L.; Chen, L.; Huang, J.H. An Improved Weighted Partial Least Squares Method Coupled with Near Infrared Spectroscopy for Rapid Determination of Multiple Components and Anti-Oxidant Activity of Pu-Erh Tea. Molecules 2018, 23, 1058. [Google Scholar] [CrossRef] [Green Version]
- Cebi, N.; Yilmaz, M.T.; Sagdic, O. A rapid ATR-FTIR spectroscopic method for detection of sibutramine adulteration in tea and coffee based on hierarchical cluster and principal component analyses. Food Chem. 2017, 229, 517–526. [Google Scholar] [CrossRef] [PubMed]
- Jamwal, R.; Amit; Kumari, S.; Sharma, S.; Kelly, S.; Cannavan, A.; Singh, D.K. Recent trends in the use of FTIR spectroscopy integrated with chemometrics for the detection of edible oil adulteration. Vib. Spectrosc. 2021, 113, 103222. [Google Scholar] [CrossRef]
- Wei, X.; He, J.-C.; Ye, D.-P.; Jie, D.-F. Navel Orange Maturity Classification by Multispectral Indexes Based on Hyperspectral Diffuse Transmittance Imaging. J. Food Qual. 2017, 2017, 1023498. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.; Qiu, Q.; Wang, Y.; Wang, Y.; Lu, Y.; Fan, D.; Wang, X. Rapid Identification of Different Grades of Huangshan Maofeng Tea Using Ultraviolet Spectrum and Color Difference. Molecules 2020, 25, 4665. [Google Scholar] [CrossRef]
- Ciursă, P.; Pauliuc, D.; Dranca, F.; Ropciuc, S.; Oroian, M. Detection of honey adulterated with agave, corn, inverted sugar, maple and rice syrups using FTIR analysis. Food Control 2021, 130, 108266. [Google Scholar] [CrossRef]
- Weng, S.; Guo, B.; Tang, P.; Yin, X.; Pan, F.; Zhao, J.; Huang, L.; Zhang, D. Rapid detection of adulteration of minced beef using Vis/NIR reflectance spectroscopy with multivariate methods. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2020, 230, 118005. [Google Scholar] [CrossRef]
- Abamba Omwange, K.; Al Riza, D.F.; Saito, Y.; Suzuki, T.; Ogawa, Y.; Shiraga, K.; Giametta, F.; Kondo, N. Potential of front face fluorescence spectroscopy and fluorescence imaging in discriminating adulterated extra-virgin olive oil with virgin olive oil. Food Control 2021, 124, 107906. [Google Scholar] [CrossRef]
- Luo, X.; Xu, L.J.; Huang, P.; Wang, Y.C.; Liu, J.; Hu, Y.; Wang, P.; Kang, Z.L. Nondestructive Testing Model of Tea Polyphenols Based on Hyperspectral Technology Combined with Chemometric Methods. Agriculture 2021, 11, 673. [Google Scholar] [CrossRef]
- Li, Y.; Sun, J.; Wu, X.; Lu, B.; Wu, M.; Dai, C. Grade Identification of Tieguanyin Tea Using Fluorescence Hyperspectra and Different Statistical Algorithms. J. Food Sci. 2019, 84, 2234–2241. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Xiong, Y.; Huang, J.; Zhou, J.; Zhang, B. Accurate prediction of soluble solid content of apples from multiple geographical regions by combining deep learning with spectral fingerprint features. Postharvest Biol. Technol. 2019, 156, 110943. [Google Scholar] [CrossRef]
- Huang, F.; Song, H.; Guo, L.; Guang, P.; Yang, X.; Li, L.; Zhao, H.; Yang, M. Detection of adulteration in Chinese honey using NIR and ATR-FTIR spectral data fusion. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2020, 235, 118297. [Google Scholar] [CrossRef]
- Huang, Y.; Dong, W.; Sanaeifar, A.; Wang, X.; Luo, W.; Zhan, B.; Liu, X.; Li, R.; Zhang, H.; Li, X. Development of simple identification models for four main catechins and caffeine in fresh green tea leaf based on visible and near-infrared spectroscopy. Comput. Electron. Agric. 2020, 173, 105388. [Google Scholar] [CrossRef]
- Li, Q.; Zeng, J.; Lin, L.; Zhang, J.; Zhu, J.; Yao, L.; Wang, S.; Du, J.; Wu, Z. Mid-infrared spectra feature extraction and visualization by convolutional neural network for sugar adulteration identification of honey and real-world application. LWT 2021, 140, 110856. [Google Scholar] [CrossRef]
- Xia, Y.; Fan, S.; Tian, X.; Huang, W.; Li, J. Multi-factor fusion models for soluble solid content detection in pear (Pyrus bretschneideri ‘Ya’) using Vis/NIR online half-transmittance technique. Infrared Phys. Technol. 2020, 110, 103443. [Google Scholar] [CrossRef]
- Wang, Y.-J.; Jin, G.; Li, L.-Q.; Liu, Y.; Kianpoor Kalkhajeh, Y.; Ning, J.-M.; Zhang, Z.-Z. NIR hyperspectral imaging coupled with chemometrics for nondestructive assessment of phosphorus and potassium contents in tea leaves. Infrared Phys. Technol. 2020, 108, 103365. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Cheng, J.; Wang, J.; Sun, X.; Sun, S.; Zhang, Z. Enhanced cross-category models for predicting the total polyphenols, caffeine and free amino acids contents in Chinese tea using NIR spectroscopy. LWT 2018, 96, 90–97. [Google Scholar] [CrossRef]
- Zhang, D.; Yang, Y.; Chen, G.; Tian, X.; Wang, Z.; Fan, S.; Xin, Z. Nondestructive evaluation of soluble solids content in tomato with different stage by using Vis/NIR technology and multivariate algorithms. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 248, 119139. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Ye, Y.; Yang, C.; An, T.; Jiang, Y.; Ye, Y.; Li, Y.; Yang, Y. Rapid detection of catechins during black tea fermentation based on electrical properties and chemometrics. Food Biosci. 2021, 40, 100855. [Google Scholar] [CrossRef]
- Li, L.; Huang, J.; Wang, Y.; Jin, S.; Li, M.; Sun, Y.; Ning, J.; Chen, Q.; Zhang, Z. Intelligent evaluation of storage period of green tea based on VNIR hyperspectral imaging combined with chemometric analysis. Infrared Phys. Technol. 2020, 110, 103450. [Google Scholar] [CrossRef]
- Ke, J.; Rao, L.; Zhou, L.; Chen, X.; Zhang, Z. Non-destructive determination of volatile oil and moisture content and discrimination of geographical origins of Zanthoxylum bungeanum Maxim. by hyperspectral imaging. Infrared Phys. Technol. 2020, 105, 103185. [Google Scholar] [CrossRef]
- Wang, P.; Liu, J.; Xu, L.J.; Huang, P.; Luo, X.; Hu, Y.; Kang, Z.L. Classification of Amanita Species Based on Bilinear Networks with Attention Mechanism. Agriculture 2021, 11, 393. [Google Scholar] [CrossRef]
- Huang, Y.; Dong, W.; Chen, Y.; Wang, X.; Luo, W.; Zhan, B.; Liu, X.; Zhang, H. Online detection of soluble solids content and maturity of tomatoes using Vis/NIR full transmittance spectra. Chemom. Intell. Lab. Syst. 2021, 210, 104243. [Google Scholar] [CrossRef]
- Liu, Y.L.Y.-d.; Lin, X.L.X.-d.; Gao, H.G.H.-g.; Wang, S.W.S.; Gao, X.G.X. Research on Tea Cephaleuros Virescens Kunze Model Based on Chlorophyll Fluorescence Spectroscopy. Spectrosc. Spectr. Anal. 2021, 41, 2129–21314. [Google Scholar] [CrossRef]
- Li, X.L.; Zhou, R.Q.; Xu, K.W.; Xu, J.; Jin, J.J.; Fang, H.; He, Y. Rapid Determination of Chlorophyll and Pheophytin in Green Tea Using Fourier Transform Infrared Spectroscopy. Molecules 2018, 23, 1010. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Tieguanyin | Benshan |
|---|---|---|
| 0 | 100% | 0% |
| 1 | 90% | 10% |
| 2 | 80% | 20% |
| 3 | 70% | 30% |
| 4 | 60% | 40% |
| 5 | 50% | 50% |
| Methods | Sensitivity | Specificity | Accuracy | Time | |
|---|---|---|---|---|---|
| RAW | Calibration | 75.86% | 100.00% | 95.63% | 1.9588 |
| Prediction | 84.21% | 100.00% | 96.25% | ||
| SNV | Calibration | 100.00% | 100.00% | 100.00% | 2.1267 |
| Prediction | 89.47% | 100.00% | 97.50% | ||
| MSC | Calibration | 100.00% | 100.00% | 100.00% | 1.7759 |
| Prediction | 94.74% | 98.36% | 97.50% | ||
| SG-7 | Calibration | 100.00% | 100.00% | 100.00% | 1.7861 |
| Prediction | 100.00% | 100.00% | 100.00% |
| SG7 | Number | Sensitivity | Specificity | Accuracy | Time (s) | |
|---|---|---|---|---|---|---|
| SPA | 41 | Calibration | 100.00% | 100.00% | 100.00% | 1.2147 |
| Prediction | 98.51% | 100.00% | 98.75% | |||
| CARS | 11 | Calibration | 100.00% | 100.00% | 100.00% | 1.2088 |
| Prediction | 100.00% | 100.00% | 100.00% | |||
| RF | 44 | Calibration | 100.00% | 100.00% | 100.00% | 1.1935 |
| Prediction | 100.00% | 94.74% | 100.00% | |||
| UVE | 41 | Calibration | 100.00% | 100.00% | 100.00% | 1.1829 |
| Prediction | 100.00% | 100.00% | 100.00% |
| Preprocessing | Methods | Number | Class Accuracy | Overall Accuracy | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0% | 10% | 20% | 30% | 40% | 50% | Time | ||||
| RAW | NO | 104 | 100.00% | 100.00% | 100.00% | 100.00% | 59.09% | 100.00% | 93.18% | 0.01396 |
| SPA | 33 | 100.00% | 100.00% | 78.57% | 81.82% | 45.45% | 100.00% | 84.31% | 0.01396 | |
| CARS | 19 | 100.00% | 100.00% | 78.57% | 100.00% | 36.36% | 78.57% | 82.25% | 0.01296 | |
| RF | 60 | 100.00% | 100.00% | 78.57% | 100.00% | 36.36% | 78.57% | 82.25% | 0.01396 | |
| UVE | 41 | 100.00% | 100.00% | 78.57% | 100.00% | 45.45% | 100.00% | 87.34% | 0.01300 | |
| MSC | NO | 104 | 100.00% | 100.00% | 92.86% | 100.00% | 68.18% | 100.00% | 93.51% | 0.01097 |
| SPA | 34 | 100.00% | 94.74% | 64.29% | 100.00% | 54.55% | 78.57% | 82.03% | 0.00801 | |
| CARS | 11 | 100.00% | 100.00% | 71.43% | 72.73% | 40.91% | 78.57% | 77.27% | 0.00798 | |
| RF | 55 | 100.00% | 100.00% | 71.43% | 100.00% | 63.64% | 92.86% | 87.99% | 0.00898 | |
| UVE | 34 | 100.00% | 100.00% | 71.43% | 100.00% | 59.09% | 85.71% | 86.04% | 0.00997 | |
| SNV | NO | 104 | 100.00% | 100.00% | 92.86% | 100.00% | 68.18% | 100.00% | 93.51% | 0.00798 |
| SPA | 27 | 100.00% | 100.00% | 85.71% | 81.82% | 54.55% | 85.71% | 84.63% | 0.00698 | |
| CARS | 14 | 100.00% | 100.00% | 78.57% | 100.00% | 45.45% | 71.43% | 82.58% | 0.00499 | |
| RF | 57 | 100.00% | 100.00% | 92.86% | 100.00% | 72.73% | 100.00% | 94.27% | 0.00698 | |
| UVE | 46 | 100.00% | 100.00% | 64.29% | 100.00% | 59.09% | 85.71% | 84.85% | 0.00698 | |
| SG | NO | 104 | 100.00% | 100.00% | 85.71% | 100.00% | 45.45% | 100.00% | 88.53% | 0.00898 |
| SPA | 41 | 100.00% | 100.00% | 71.42% | 72.73% | 31.82% | 71.43% | 74.57% | 0.00798 | |
| CARS | 11 | 100.00% | 100.00% | 92.86% | 72.73% | 45.45% | 100.00% | 85.17% | 0.00698 | |
| RF | 44 | 100.00% | 100.00% | 78.57% | 90.91% | 45.45% | 92.86% | 84.63% | 0.00798 | |
| UVE | 41 | 100.00% | 100.00% | 78.57% | 81.82% | 36.36% | 85.71% | 80.41% | 0.00898 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Kang, Z. The Rapid Non-Destructive Detection of Adulteration and Its Degree of Tieguanyin by Fluorescence Hyperspectral Technology. Molecules 2022, 27, 1196. https://doi.org/10.3390/molecules27041196
Hu Y, Kang Z. The Rapid Non-Destructive Detection of Adulteration and Its Degree of Tieguanyin by Fluorescence Hyperspectral Technology. Molecules. 2022; 27(4):1196. https://doi.org/10.3390/molecules27041196
Chicago/Turabian StyleHu, Yan, and Zhiliang Kang. 2022. "The Rapid Non-Destructive Detection of Adulteration and Its Degree of Tieguanyin by Fluorescence Hyperspectral Technology" Molecules 27, no. 4: 1196. https://doi.org/10.3390/molecules27041196