3.1. FTIR Spectra on Stainless Steel
Mean FTIR spectra of all dry bacterial cells collected from the stainless steel substrate at the concentration of 10 OD were obtained and the baseline was removed by performing asymmetric least squares smoothing, with the resultant spectra presented in
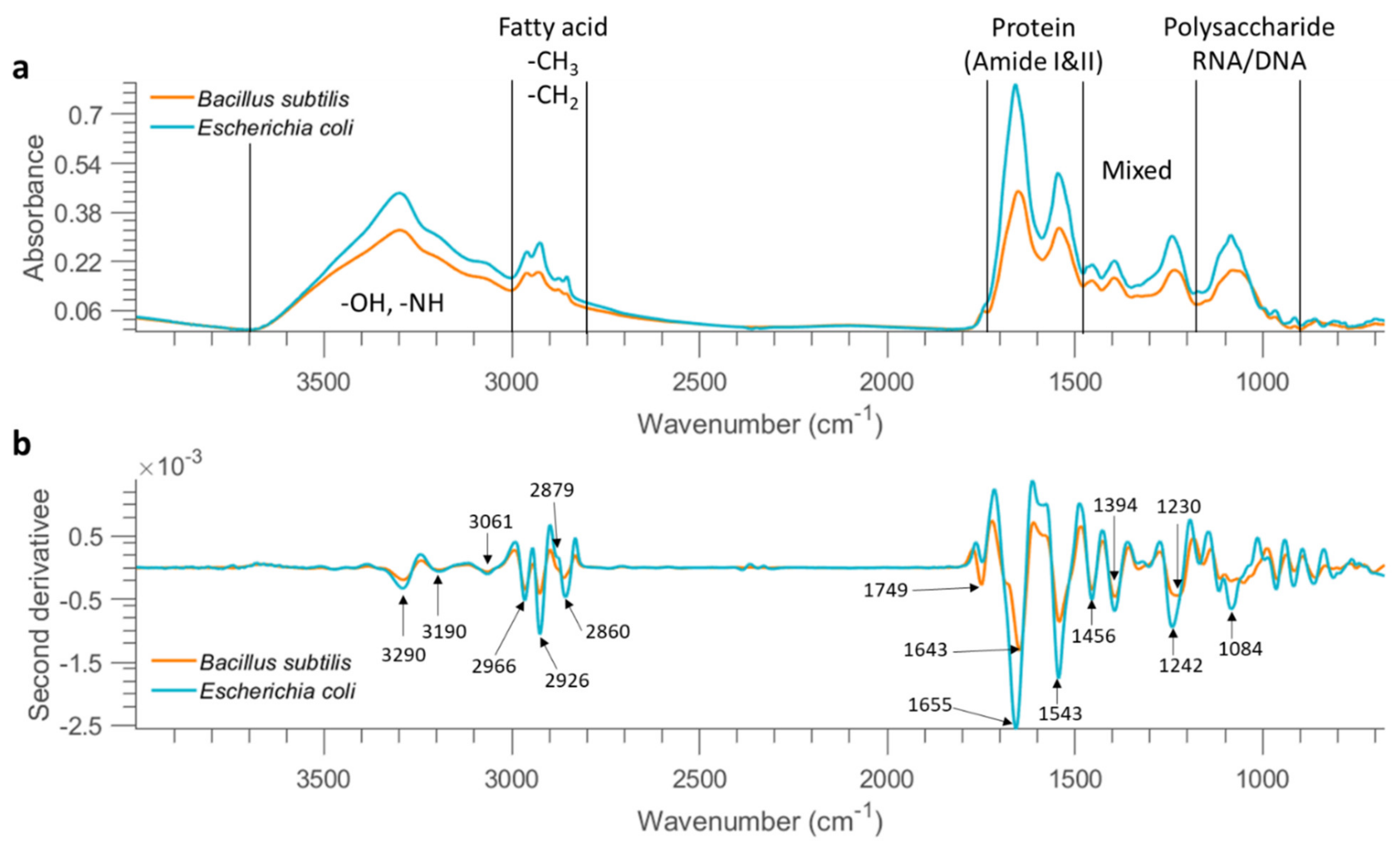
Figure 1a. As can be seen, FTIR spectroscopy provides mid-infrared spectral fingerprints of bacterial cells, originating from the different functional groups related to proteins, lipids, and carbohydrates. The acquired FTIR spectra of microbial cells are a superposition of contributions from all biomolecules found in a cell, making it challenging to find out the specific contribution from any particular biomolecules or molecular groups. The entire spectral range can be subdivided into five non-overlapping sub-regions according to specific chemical constituents, as shown in
Figure 1a.
A broad band with a peak at 3300 cm
−1 corresponds to O–H and N–H stretching vibrations. The 3000–2800 cm
−1 region is dominated by the C–H stretching vibrations in fatty acids, as seen from
Table 3 which lists band assignment based on the literature. The 1700–1500 cm
−1 region represents amide I and amide II arising from various proteins and peptides. The 1500–1200 cm
−1 region has multiple mixed contributions from proteins, fatty acids, and phosphate-carrying compounds, while the 1200–900 cm
−1 region represents RNA/DNA with vibrations coming from PO
2− in combination with C–O–C stretching of polysaccharides in the cell wall [
16].
The displayed spectra show similar patterns over the entire spectral range for
E. coli and
B. subtilis, suggesting similarity of the functional group chemistry of both types of bacterial cells studied. Overall, the mean spectrum of
E. coli demonstrates stronger absorption across the whole wavenumber range. This observation is well supported by higher cell counts observed in selected samples of
E.coli (5.75 logCFU/mL) as compared to
B.subtilis (3.72 logCFU/mL) at 0.1 OD. Similarly, for samples prepared on 23 and 24 September 2020, the cell counts at 1 OD ranged between 7.91–7.85 logCFU/mL for
E.coli while a lower viable cell count of 6.48–6.66 logCFU/mL was found for
B.subtilis (
Table S1 of
Supplementary Materials). The differences between the nature of the two bacteria, their shape & size as well as their multiplication/growth cycles may have further contributed to these variations.
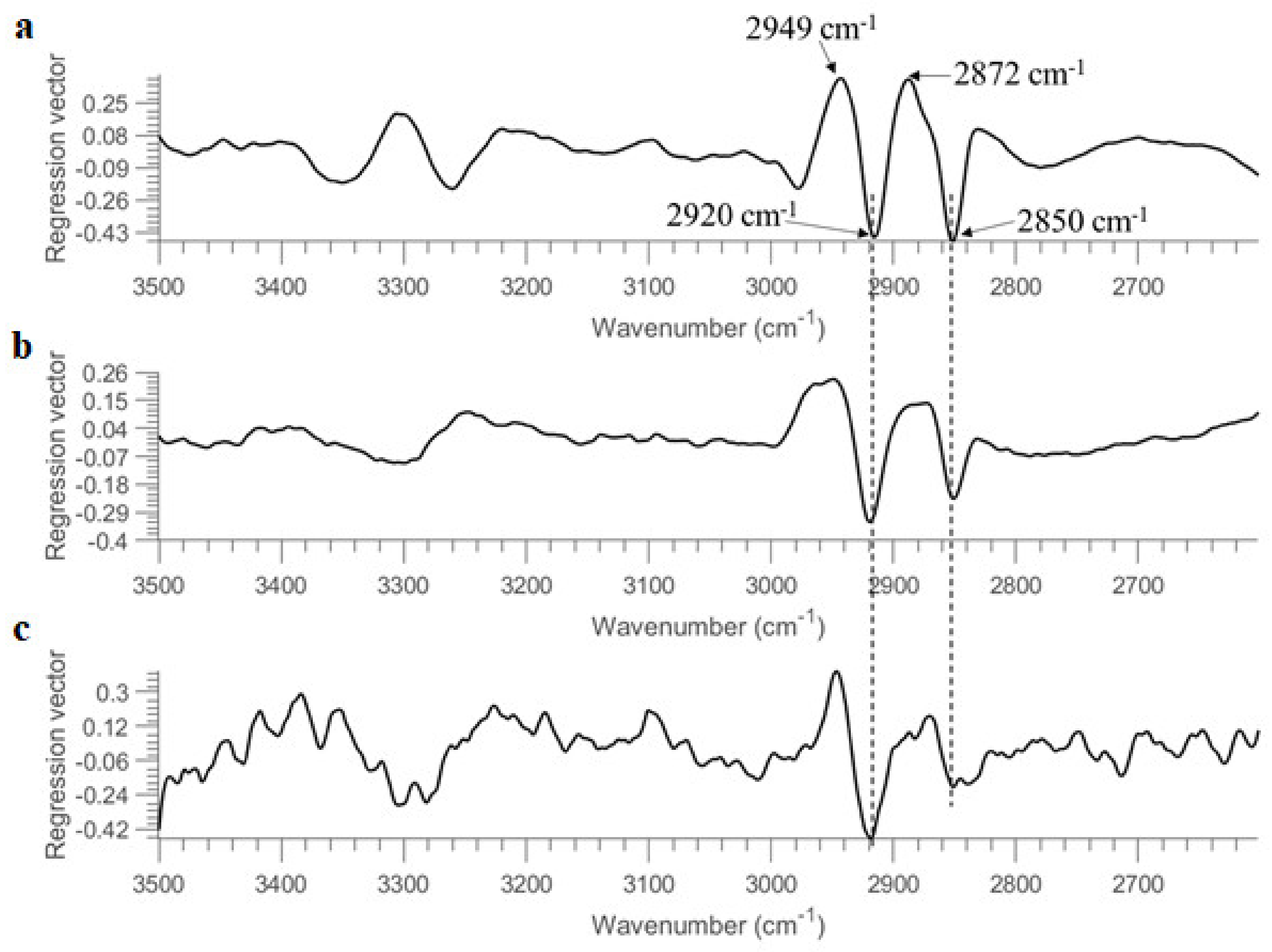
Savitzky–Golay second derivative transformation (window size = 25 points and the polynomial order = 3) was applied to the raw mean spectra at the concentration of 10 OD (as shown in
Figure 1b) to enhance the separation of overlapping bands. The broad band in the 3500–3000 cm
−1 range consists of three minor bands at 3290 cm
−1, 3190 cm
−1, and 3061 cm
−1. A series of bands are also observed between 3000 and 2800 cm
−1; bands at 2926 and 2860 cm
−1 can be assigned to CH
2 stretching, while 2966 and 2879 cm
−1 can be related to CH
3 stretching, according to the literature (
Table 3). The intensity ratio of CH
3 groups to CH
2 groups is observed higher in
B. subtilis based on the mean second derivative spectra (
Figure 1b), possibly because Gram-negative bacteria differ physically from Gram-positive bacteria, the former having an additional (outer) membrane, leading to distinct differences in fatty acid chains [
19]. As a further step, we obtained the second derivative spectrum for each pixel and computed the ratio of 2966 cm
−1 (CH
3 group) to 2926 cm
−1 (CH
2 group). A two-sample
t-test confirmed that this ratio was significantly higher in
B. subtilis than that of
E.coli at 10 OD and 1 OD (
p < 0.01). However, the ratio between the two bacterial strains was not significantly different when the bacterial concentration reached 0.1 OD (
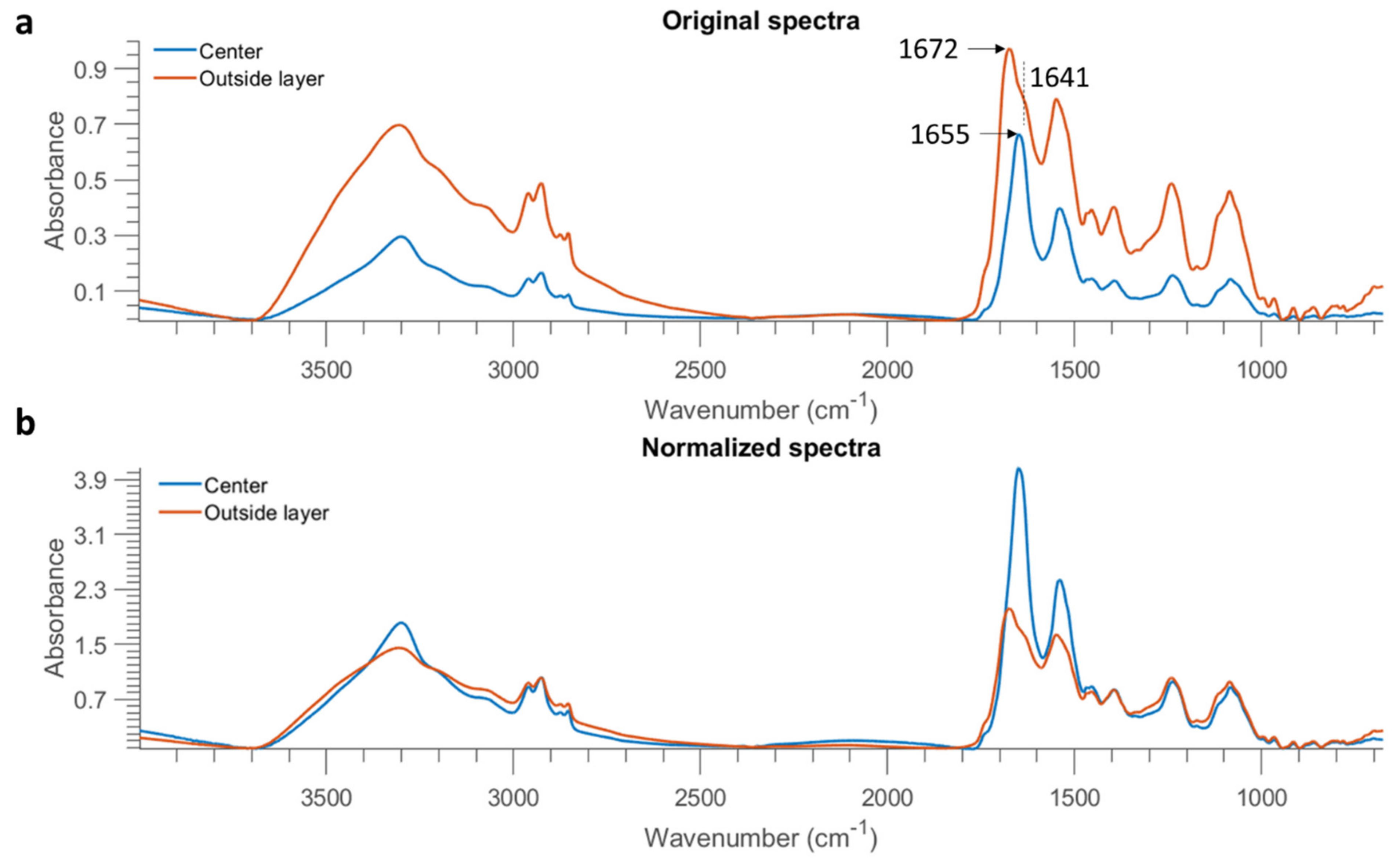
p > 0.01). The carboxylic groups of bacterial cells exhibit distinct bands at ~1749 cm
−1 due to the C=O stretching. Observable differences between these two bacterial strains are found in amide groups showing two intense bands in the 1700–1500 cm
−1 range, indicating variations in the composition and structure of proteins and peptides. Another distinct feature arises from asymmetric P=O stretch with a peak at 1242 cm
−1 for
E. coli and 1230 cm
−1 for
B. subtilis. In addition, this band, representing the contribution of phospholipids from the cell membrane, appears broader for
B. subtilis. In addition, differences in terms of band shape and peak position are observable in the spectral region of 1200–1000 cm
−1 due to the combined contributions from polysaccharides and nucleic acids.
Mean spectra of each replicate of 10 OD samples are also plotted in
Figure S3 to examine the repeatability. These 8 replicates were obtained from 4 independent experiments (see details in
Table 1). From
Figure S3, it is evident that substantial spectral variation among replicates is observed, although spectral profiles are similar across the entire range. An observable peak shift appears in the amide I and II groups, suggesting molecular structure changes in proteins and peptides and thus significant variations in bacterial cells cultured from different experiments, which will pose a challenge for the subsequent classification.
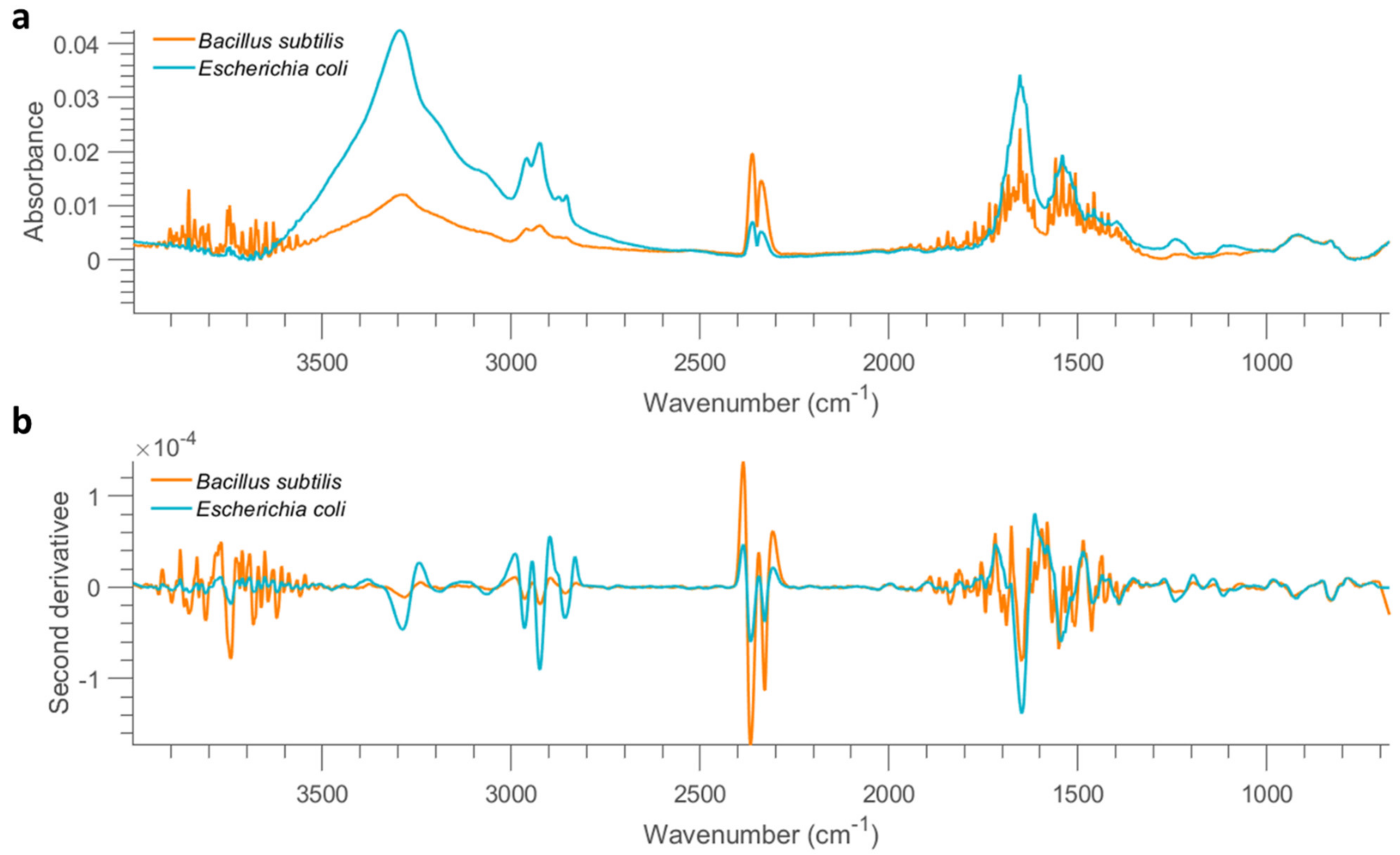
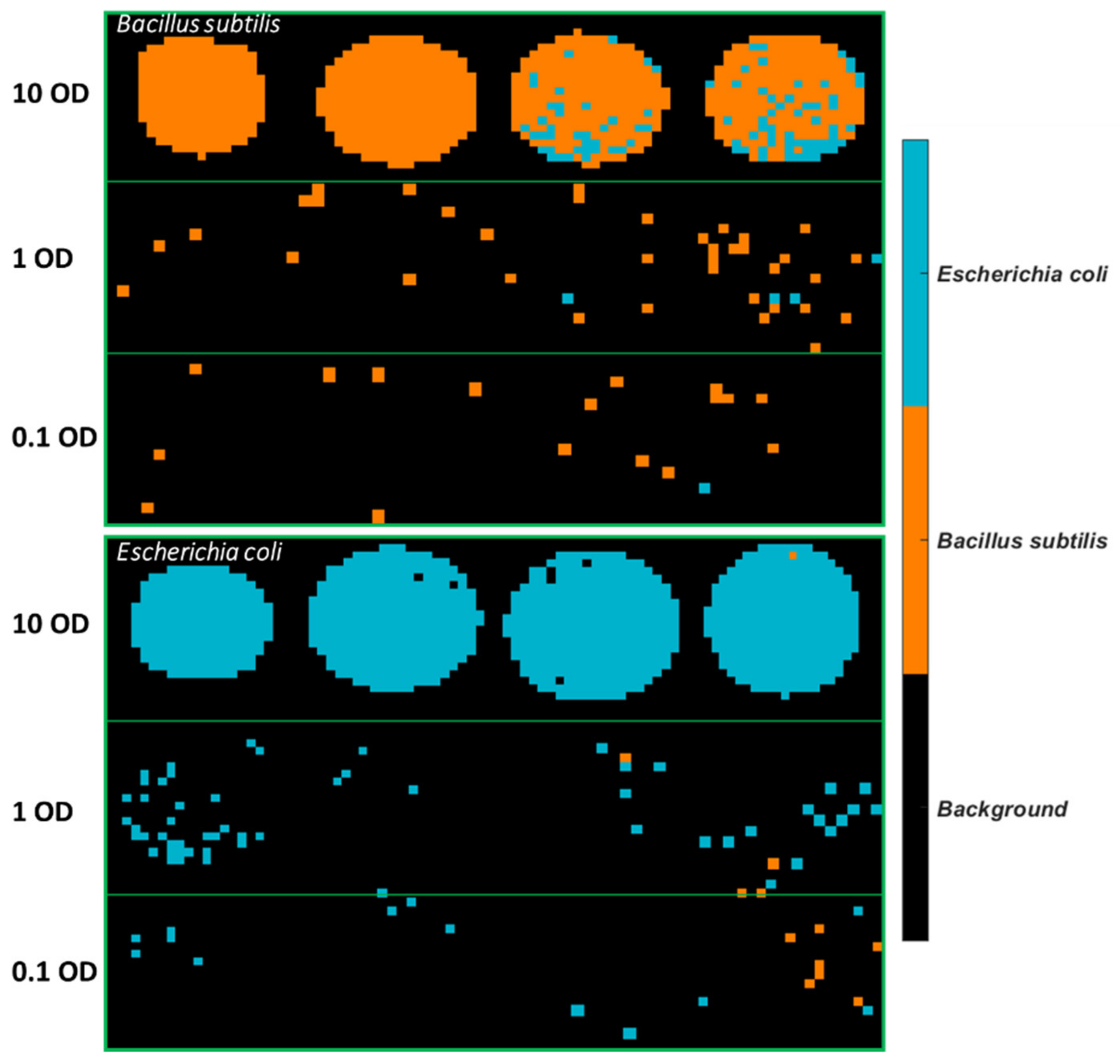
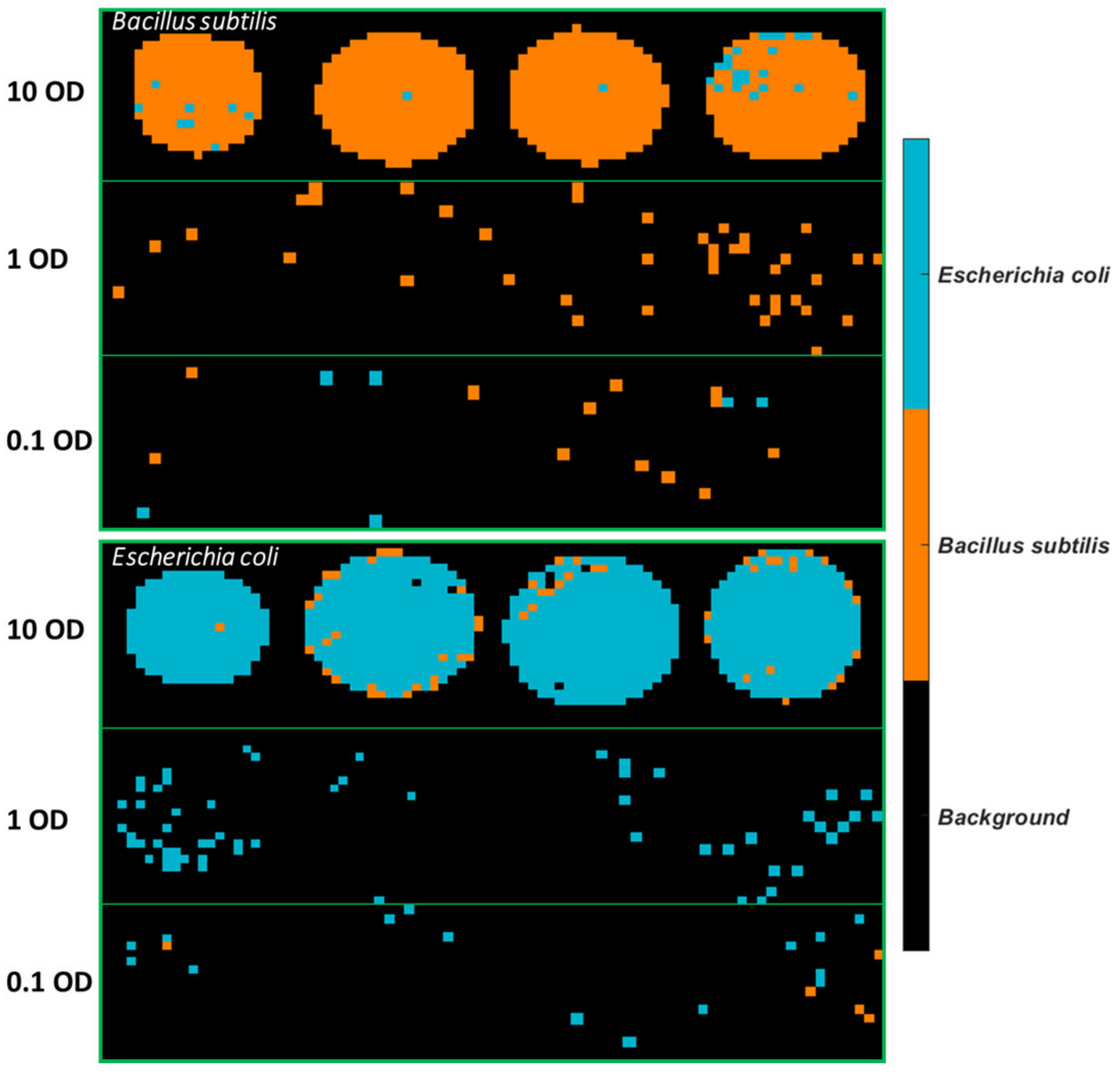
One sample image was randomly selected from each concentration and the pixel spectra of this sample (without baseline correction) were extracted, as displayed in
Figure S4. The pixel spectra of stainless steel are plotted in
Figure S5 for comparison. Stainless steel presents no prominent spectral features except the baseline slope and environmental interferences. Infrared light scatters when interacting with the rough surface of stainless steel, and this scattering effect is greater at lower wavelengths, leading to a sloping baseline. The pixel spectra of bacterial cells are also influenced by this baseline effect. It is also found that spectra of bacterial cells especially from lower concentrations suffer from environmental interferences although efforts were made to maintain a stable environment (e.g., keep lab door closed during the whole scanning period, continuous gas nitrogen purging, background spectra collection and removal every 10 min). This is because atmospheric water vapour and carbon dioxide (CO
2) strongly absorb in the infrared region and they can interfere in the spectral regions of 4000–3600 cm
−1, 2500–2000 cm
−1, and 1650–1400 cm
−1. Spectral profiles indicate that fewer pixels are found to show bacterial features as the concentration decreases. Particularly, pixels of 0.001 OD exhibit nothing but the spectra of stainless steel, suggesting that the FTIR instrumental detection limit has been reached at this concentration. In this sense, samples at 0.001 OD are excluded from the following analysis and modelling procedure.
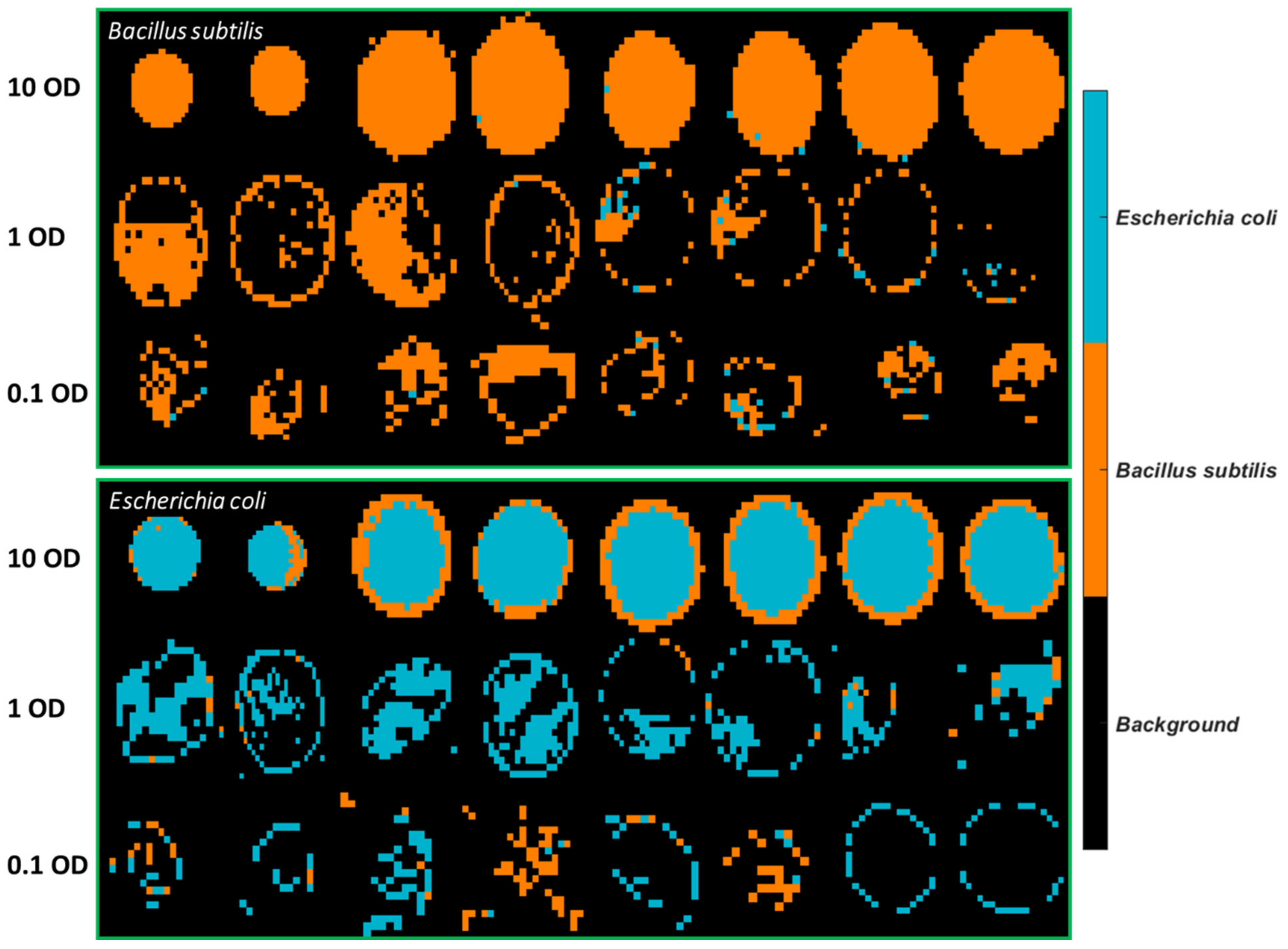
Mean spectra of all dry bacterial cells for each concentration are plotted in
Figure S6. Weaker absorption over the entire spectral region is evidenced as the concentration of bacterial cells drops. Due to the dominance of spectral features at 10 OD, the characteristic absorbance bands are unnoticeable for the mean spectra of lower concentrations. As a result, normalization is performed by dividing the intensity at 2926 cm
−1 (CH
2 stretching) and the outcome is shown in
Figure S7. It is found that the mean spectrum of 0.1 OD is heavily affected by the environmental interference and the baseline correction is less satisfying. At 0.1 OD, amide groups within the spectral domain of 1700–1500 cm
−1 are compromised by the occurrence of water vapour interference. Moreover, spectral features below 1200 cm
−1 are less apparent at a lower concentration.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}