1. Introduction
The development of online trading platforms has made online shopping more common, with an increasing number of consumers choosing to buy the products and services they need online. The theory of consumer risk reduction holds that consumers’ consumption behavior is to find ways to reduce risks. In order to reduce risks, many people will collect as much information about products as possible to increase their understanding of the product. Under the special form of online shopping, a large number of reviews published by other consumers is undoubtedly the most effective way for consumers to understand the product. Therefore, online product reviews on social platforms have become an important reference for consumers when making purchase decisions [
1].
In circumstances driven by opportunism, some unscrupulous merchants deliberately mislead consumers by hiring users to manipulate online reviews. These users are actually fake users who make up fake transactions with fake reviews and even have some interactive behaviors with each other. In 2018, Mafengwo, a well-known Chinese social travel platform, pointed out that 18 million of the 21 million comments published were plagiarized from other websites. The comment time of 15,000 accounts was extremely unreasonable, and the plagiarism rate was as high as 85%. The fake review problem was subsequently acknowledged [
2]. In recent years, these fake users have gradually shown the characteristics of grouping and concealment, that is, multiple people secretly collude with each other and try to control the evaluation of the target product. This kind of group of people is usually called the “e-commerce water army” [
3] or “review spammer groups” [
4]. According to Chen et al. [
5], the “Internet water army” refers to a specific group of users employed by interest organizations or individuals to post purposeful comments and articles on the Internet. Compared with individual spammers, the e-commerce “water army” has greater negative effects and more destructive effects. They rely on social networks to form groups and create fictitious business transactions, which not only bring great trouble to consumers when shopping online but also reduce consumers’ credibility of product brands and disrupt a fair and orderly e-commerce environment. First of all, for the platform, the water army will greatly damage its reputation and reduce its credibility. For example, the above-mentioned Mafengwo platform has been criticized for its false reviews. Secondly, for shops, the water army will cause opportunistic shops to get bonuses while honest merchants have mediocre incomes. Consequently, herd and comparison mentalities will cause shops that originally stuck to the bottom line to fall. Finally, for users, the water army will reduce the user’s ability to judge when shopping and disrupt the user’s purchase decision. Therefore, with such dire consequences, it is particularly important to adopt corresponding intervention strategies to effectively detect water army.
In related research, the usual method is to use graph-based models to detect internet spammers or review spammer groups. The main idea is to create a user relationship graph with users as nodes and determine the edge weights between nodes based on suspicious relationships between users. Different grouping methods are employed [
1,
6,
7,
8,
9,
10] subsequently to excavate candidate water army groups from the graph, and then such candidate groups are sorted to obtain the final result according to some evaluation metrics. For example, Wang et al. [
1,
6] find k-connected sub-graphs in a user relationship graph recursively as candidate review spammer groups. Similarly, Xu et al. [
7] and Wang et al. [
8] also adopt CPM and LDA methods, respectively, to identify candidate review spammer groups in a user graph. Generally, the focus of current research is to find review spammer groups from the graph structure after the user relationship graph is built, neglecting the comprehensive analysis and refinement of the collusive relationships between users, which are important clues to the existence of the “water army” on social platforms. Additionally, collusive relationships refer to a group of people who cooperate to publish deceptive reviews to manipulate the reputation of the target product [
11], which is the premise and basis for building a user relationship graph model. The reason is that the edge weights between nodes in a user relationship graph are mainly reflected by the collusive relationships between users. Therefore, the collusive relationships between users, when fully examined, will directly affect the accuracy of the final performance of water army group detection.
Currently, some studies have tried to extract collusive relationships between users from the metadata of user reviews, such as rating, review time, or product consistency [
6,
7,
8,
9,
10,
11]. Among them, Wang et al. [
6,
8] considered the user review time difference and rating difference when building the user relationship graph and, based on this, defined “co-review collusiveness,” which is used to describe the degree of user collusion. Xu et al. [
7] considered the review time interval and rating deviation, gave a set of calculation methods, and then established a suspicious reviewer graph. Additionally, Ye et al. [
9] extracted multiple interactive behavior indicators and user behavior indicators to establish a weighted graph. The number of common comments, rating of similarity, etc., are considered. Similarly, Zhang et al. [
10] also consider the number of common comments and rating similarity to construct a weighted graph. Xu et al. [
11] considered target consistency, rating consistency, activity consistency, etc. to obtain the collusion relationship between users. This shows that user interactive behavior indicators can be examined to serve as edge weights to mine user collusive relationships. Although these researches indicate that there are some important complicity clues of fake users reflected in user content and user behavior, as far as we know, has started to analyze collusive relationships of the “water army” in an e-commerce environment from such two aspects. Thus, it provides some enlightenment for us to fully mine collusive relationships between users from such two aspects.
On the basis of the above analysis, current research has identified the following gaps in the water army identification problem: (1) Most studies focus on the identification method after the user-weighted graph is established but ignore the influence of the edge weight setting method on the final result when the user-weighted graph is established. In other words, there is currently no research that discusses the effect of water army recognition under different edge weight settings. (2) Most studies only consider a few indicators to measure the collusion relationship between users, and no research has conducted a comprehensive analysis and refinement of the collusion relationship between users.
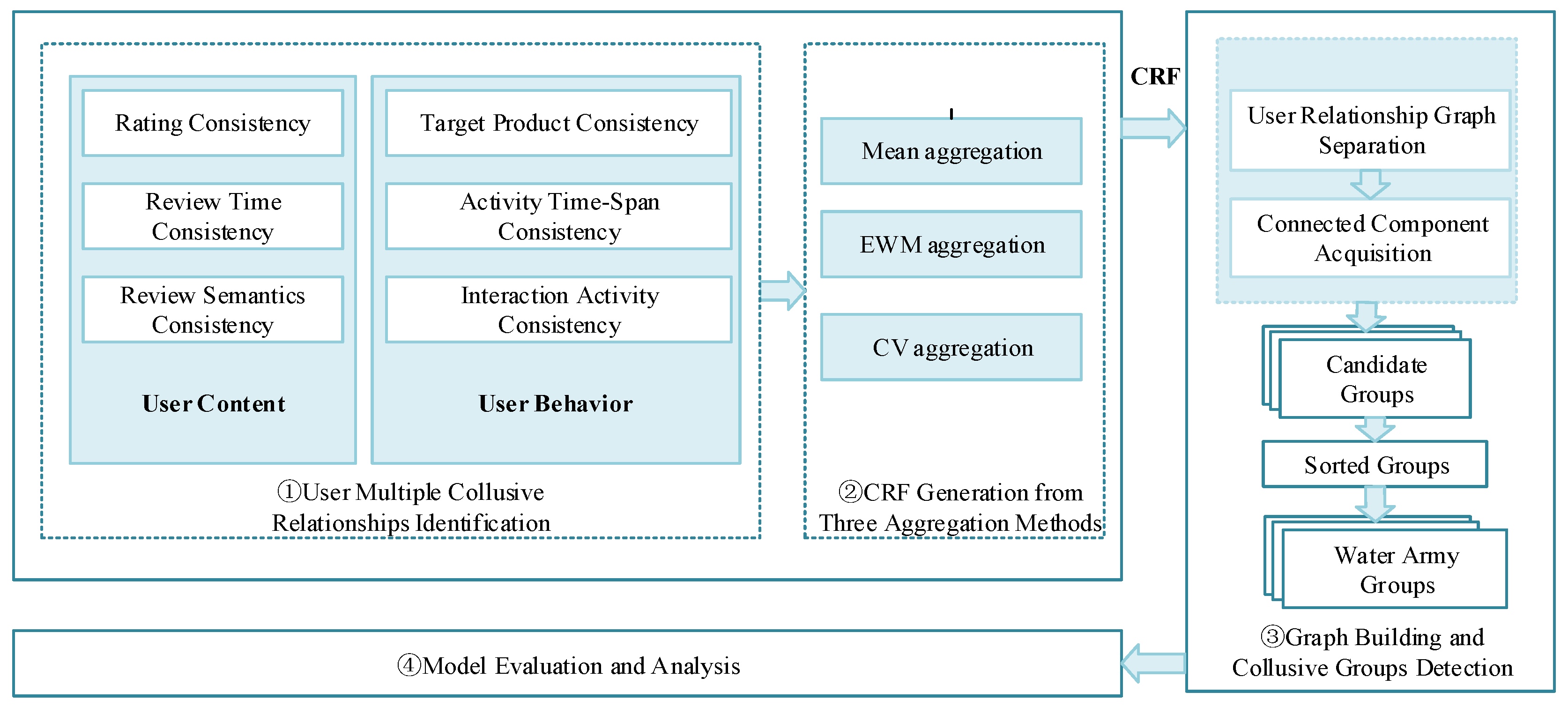
Therefore, in order to make up for the above deficiencies, this paper focuses on the problem of weight setting when establishing a user-weighted graph in the process of water army identification. First, in view of the fact that user collusive relationships have an important impact on the results of e-commerce water army detection, this study focuses on the identification and extraction of multiple collusive relationships among users. Six kinds of user collusive relationships are first proposed from the aspects of user content and user behavior. Firstly, the popular pre-trained model of Bert (Bidirectional Encoder Representations from Transformers) is used to explore whether the content semantics between users are collusive. Secondly, in order to effectively utilize these identified multiple user collusive relationships into a user graph model, this paper introduces for the first time three methods, including the mean method, the entropy weight method, and the variation coefficient method, to generate the collusive relationship factor (CRF) between users as the edge weights to build a user collusive relationship graph model. In combination with the graph grouping method and comprehensive evaluation rules to rank candidate sub-graphs, good results are achieved in the task of water army detection on the Mafengwo platform.
2. Related Work
In the existing research, the detection methods of e-commerce water army or review spammer groups can be divided into three categories: based on user content or behavior characteristics, based on group structural characteristics, and combining user behavior and structural characteristics.
The detection methods based on user content or behavior characteristics assume that users with some peculiar behaviors increase the probability that they belong to the “water army”. Lim et al. [
12] believe that users in the same group are more likely to post reviews with the same rating on their products within a short time of the product release and that there is a rating bias among normal users. In addition, Xu et al. [
13,
14,
15] point out that users in the same group will tend to be similar in behavioral characteristics and text characteristics, such as the similarity of reviewers’ ratings or content semantics on the same product and the deviation of the review’s published time. Guo et al. [
16] designed a comprehensive set of features to compare the water army against normal users on different dimensions and built an ensemble detection model to find the water army. Further, Ji et al. [
17] focused on product rating distribution, proposed a method called GSDB (Group Spam Detection Algorithm Based on Review Burst), and confirmed the effectiveness of the method. Hussain et al. [
18] proposed the Spam Group Detection (SGD) method, which identifies suspected spam groups based on the similarity of the activities of all reviewers, taking into account their review time and rating. The results show that the proposed methods outperformed the existing approaches when compared in terms of accuracy. Liu et al. [
19] analyzed the behavioral characteristics of users and used the user2vec algorithm to represent users as vectors to identify the user population. In addition, the field of water army recognition is also diverse. For example, Zhang et al. [
20] proposed a multi-view feature expression and recognition model for cultural products and designed the model according to the unique characteristics of the cultural product field. Wang et al. [
21] focused on Weibo and used different feature extraction methods to design methods to identify Weibo’s water army. In this type of method based on user content and behavior characteristics, when studying water army detection problems, researchers often focus more on the differences between water army and normal users in some behaviors or comment content. They regard each user as an independent individual without considering the possible internal connection between users, that is, they seldom consider the group characteristics of the water army. Consequently, some researchers began to identify water army groups from user structural characteristics based on the relationship between users.
The detection method based on group structure features obtains the network connections between users, reviews, and products. Mukherjee et al. [
22,
23] use the frequent itemset mining method to obtain the network between users and commodities so as to find candidate groups and establish a ranking model to obtain the final groups. Akoglu et al. [
24] rank fake reviewers through the network effect between reviewers and products and obtain review spammer groups by clustering the induced sub-graphs of fake reviewers and corresponding products. Additionally, Ye et al. [
25] propose a Network Footprint Score (NFS) to explore the abnormality of the behavior of reviewers and use the GroupStainer algorithm to cluster review spammer groups. Yu et al. [
26] establish connections among users, groups, and merchants, calculate the group false degree through the iterative relationship between the three, and obtain spammer groups after sorting. Zhang et al. [
27] improve FIM and unsupervised ranking methods and propose an identification method for reviewing spammer groups based on cosine patterns and heterogeneous information networks. Rukari et al. [
28] used frequent item mining (FIM) to extract candidates from the spammer community and then used PU-Learning to identify actual spammer groups from these candidates. Li et al. [
29] proposed a framework to discover the overlapping community from the emotional social network and detect “water armies” in communities. Soni et al. [
30] performed the hyperparameter optimization of various unsupervised deep learning algorithms, such as self-organizing maps and restricted Boltzmann machines, on the reviewer graph data, and the experimental results showed that the projected method can detect the group of fake reviewers with reasonable accuracy. Furthermore, Li et al. [
31] proposed a reviewer suspiciousness ranking algorithm based on community discovery and TrustRank. On the basis of the supernetwork theory, Jothi et al. [
32] proposed a model for detecting “water army” and demonstrated its effectiveness. In summary, this detection method based on structural features is essentially designed to discover water armies from the graph structure or network structure. The focus on the associations between users can effectively identify user groups with collusive relationships. However, this method also has a problem. Ordinary users sometimes have group characteristics. For example, some users with similar interests are often very similar in the graph structure, but these users do not meet the definition of a “water army.” In this case, it seems that only focusing on structural features cannot meet the requirements. At this time, it is necessary to comprehensively consider both user behavior features and structural features.
The detection methods that combine group behavior and structural features are the most common in current research. The idea behind this method is to design and construct a graph based on the behavioral characteristics of suspicious groups and to identify spammer groups on the new network. Choo et al. [
33] construct a user relationship graph through the interaction between users and further discover groups through the emotional relationships in the user interaction process. Li et al. [
34] construct a graph based on user behavior characteristics, using the method of graph clustering to identify review spammer groups. Zhang et al. [
10] construct a user relationship graph by correlating the behavioral characteristics of each user and using the Louvain community discovery algorithm to obtain final groups. In addition, after identifying fake users, Cao et al. [
35] use the hierarchical clustering method to obtain review spammer groups based on the indicators of user collusion awareness. Similarly, Xu et al. [
7] and Wang et al. [
8] use the CPM and LDA methods to identify candidate groups, respectively, after mining user collusive relationships to construct a user-weighted graph. Thahira et al. [
36] extracted features from metadata and proposed a framework based on these features. In combining metadata and structural features, the method shows good results. He et al. [
37] proposed a semi-supervised approach combining network structure features and user attribute features for identifying the Internet “water army.” This method uses the graph embedding algorithm to obtain the user’s network structure features, which together with the defined user attribute features constitute the detection feature set. Results showed that the accuracy can reach 95.15%. According to the results of previous experiments, this method of combining group behavior and structural features is more comprehensive and can often achieve better results than the previous two methods. As a result of this, this kind of method begins to receive the attention of numerous researchers.
The above-mentioned research provides an important reference for “water army” detection in the e-commerce environment, but there is still some room for improvement. Firstly, current research in e-commerce water army focuses more on identifying collusive groups from the graph structure after the user relationship graph is constructed, making the structure feature of sub-groups, not the user collusive relationships, the focus of this type of research. Secondly, the clues in user review content are less concerned by the existing literature. Although some studies have used some text features before constructing the user relationship graph, most of them focus on the metadata features such as review time and review rating. The clues related to content semantics have not been fully explored. Finally, most of the researches analyze the relationships between users from the single aspect of user content or user behavior, not a combination of examining these two aspects. Further, the methods to comprehensively infer multiple collusive relationships between users and how to aggregate these collusive relationships into a user relationship graph have not yet been deeply explored.
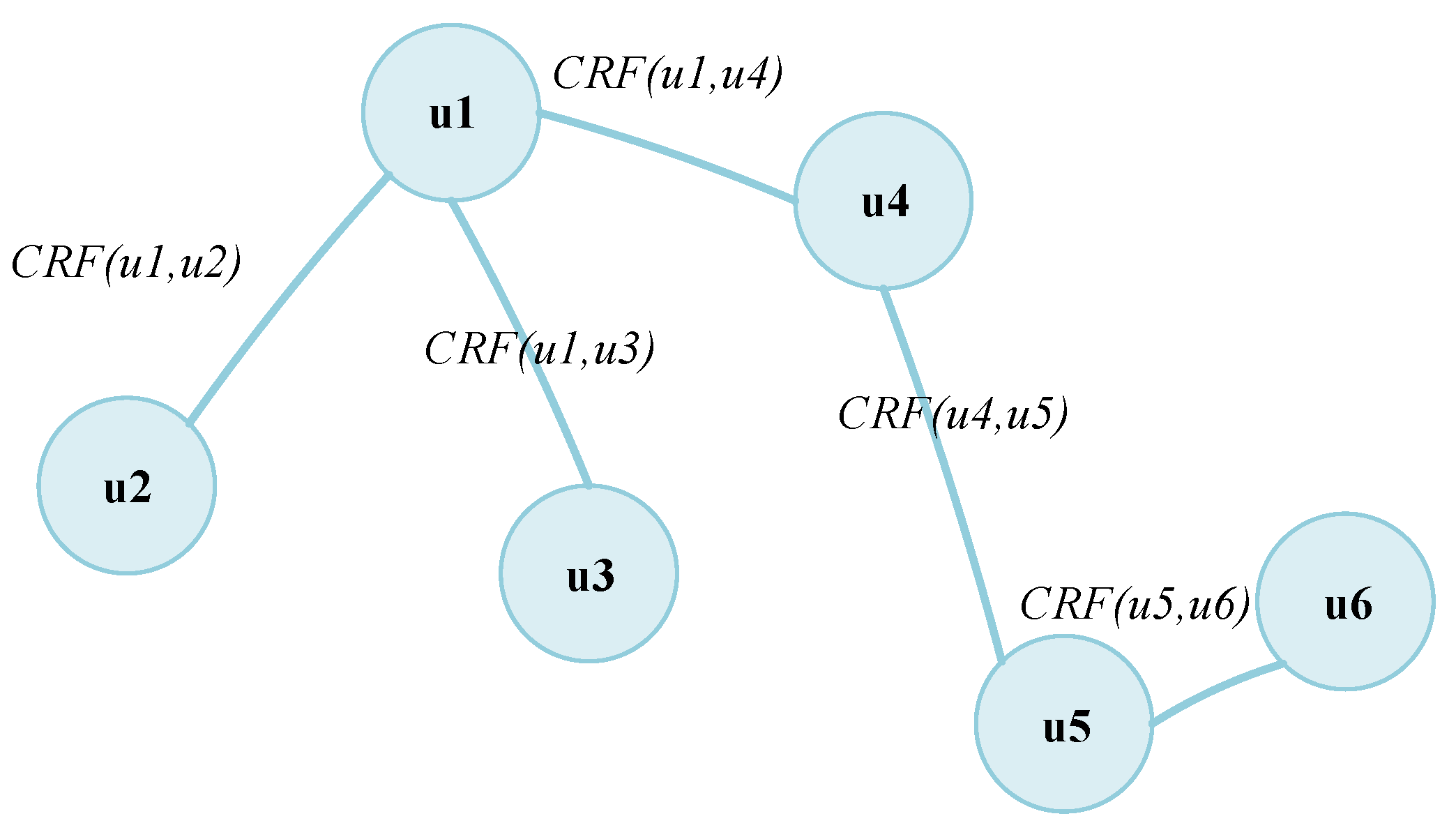
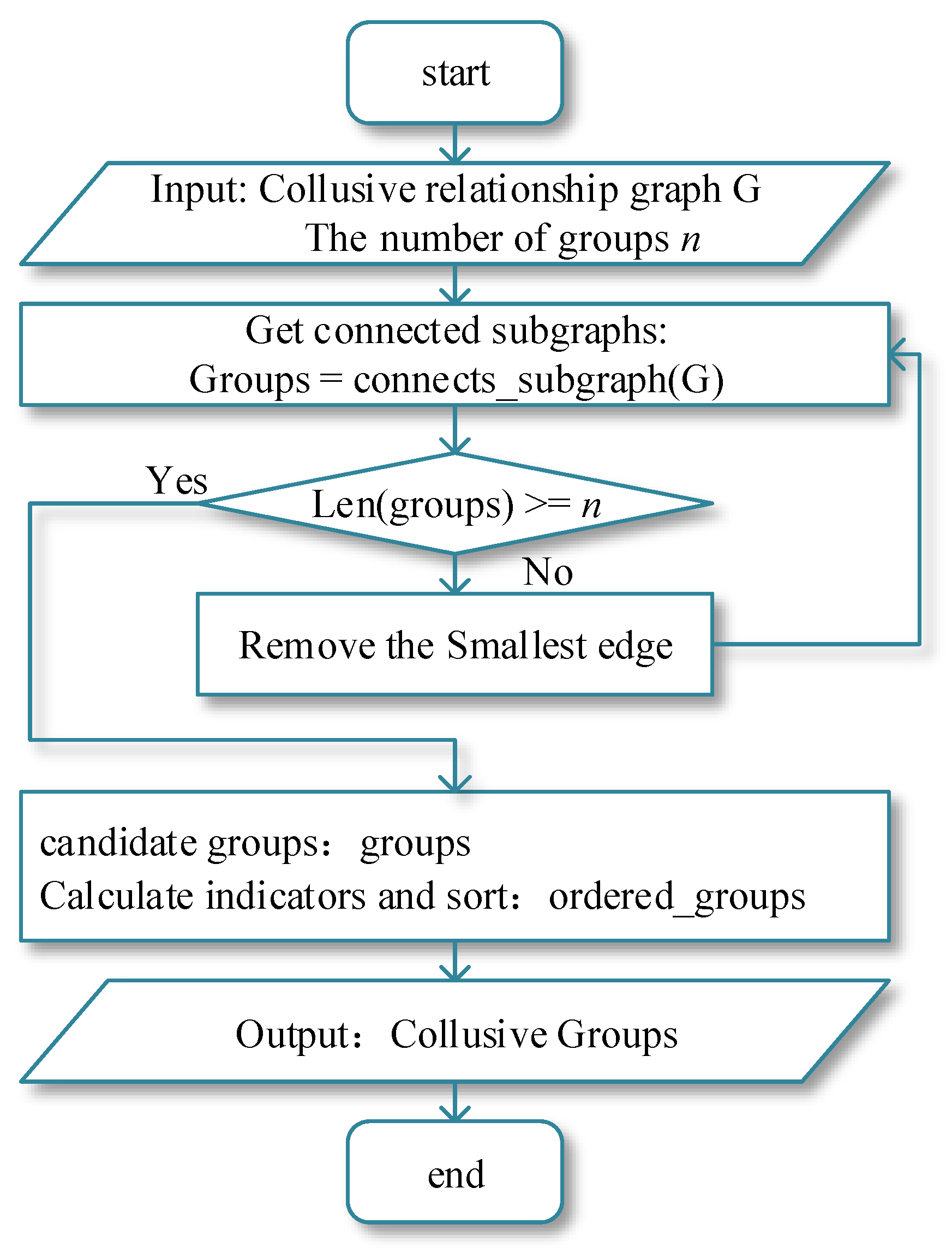
Therefore, in order to make up for the above deficiencies, this paper defines six kinds of user collusive relationships from the two aspects of user content and user behavior. On the one hand, it was inferred that the published review content and review metadata from some users are highly consistent, such as similar text semantics, the same rating, and a close review time. On the other hand, the examinations carried out on the behaviors of some users are highly consistent on the same online platform, such as reviews of the same product, similar interactive behaviors, or the activity time-span. Further, three aggregation methods, including the mean value method, the entropy weight method, and the coefficient of variation method, are employed, respectively, to quantify the degree of collusion between users, which is called the “user collusive relationship factor” (CRF). In addition, the user CRF is applied to serve as the edge weight between two nodes in a user collusive relationship graph, which is subsequently divided into multiple connected candidate sub-graphs according to the edge weights. Lastly, combined with the graph clustering method and the comprehensive evaluation rules employed on the candidate sub-graphs, the final review of the water army groups is effectively obtained.
The remainder of this research is organized as follows:
Section 3 describes the research framework and discusses the extraction process of user-collusive relationships. Additionally,
Section 4 presents the building for the user graph and sub-graph grouping method in detail.
Section 5 discusses the experiment setup and the research results. Last,
Section 6 provides the conclusions and limitations of the research.
6. Discussion, Implications, and Conclusions
6.1. Discussion
In recent times, almost everyone has experience with online shopping. There are many commodities and services on the Internet that can meet people’s various needs. The variety of products and the convenience of purchasing online make online shopping more and more popular. However, making the right purchase decisions and buy the products they really want has become a concern for consumers. Generally speaking, when there is a clear shopping need, consumers will inevitably shop around, and they tend to pay more attention to the comments of other consumers on the relevant product pages, which will largely affect their final decision. For this reason, a special group has emerged—the water army. For the purpose of profit, they often unite to publish a large number of comments on the target product so as to interfere with consumers’ purchase decisions. The flooding of army groups with water is extremely harmful and will have a negative impact on platforms, shops, and consumers. Therefore, this paper focuses on the identification of water army groups.
First of all, aiming at the research gap of in-depth mining of user collusion relationships neglected in the current water army identification method, this paper focuses on the in-depth mining of the collusive relationships between users, mainly including user content and user behavior. Among them, user content includes three collusive relationships that measure the consistency of two users’ review content: rating consistency, review time consistency, and review semantic consistency. The user behavior includes three collusive relationships: target product consistency, activity time-span consistency, and interaction activity consistency. They measure the consistency of two users’ comment behaviors. If two users show strong consistency on these indicators, it is more likely that the two users belong to the same water army group. Secondly, in view of the research gap that exists because the current research ignores the impact of the edge weight setting method on the final recognition result, this paper uses the mean, EWM, and CV methods to aggregate the above-mentioned user collusive relationships. Then, we design the user collusive relationship factor CRF, which is used to measure the collusion strength between two users, and use the CRF value as the weight of the connection between users when building the user relationship graph. In addition, the impact of different aggregation methods on the final recognition results is discussed in the experimental study section, which fills the existing research gap. Contrary to previous research, the building of the user relationship graph in our research focuses on exploring the recognition effects of different user collusive factor calculation methods. Additionally, from the results, the user collusive factor facilitates the graph clustering method to discover connected components and obtain candidate groups, which heavily relies on the edge weights in the user-weighted graph. The experimental results show that our method in this paper is more suitable for a water detection task than complex group discovering methods such as CPM, LDA, or community discovery algorithms.
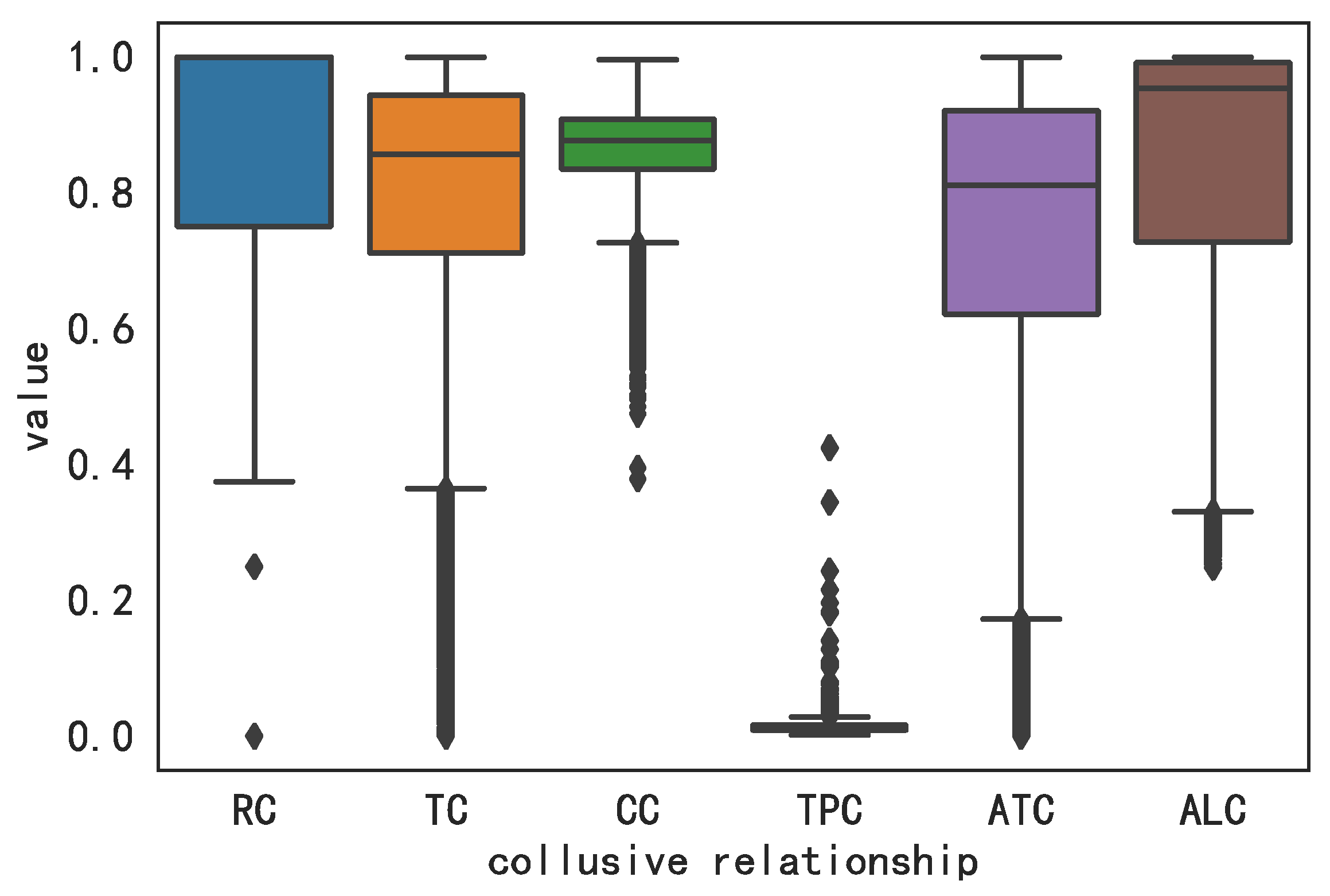
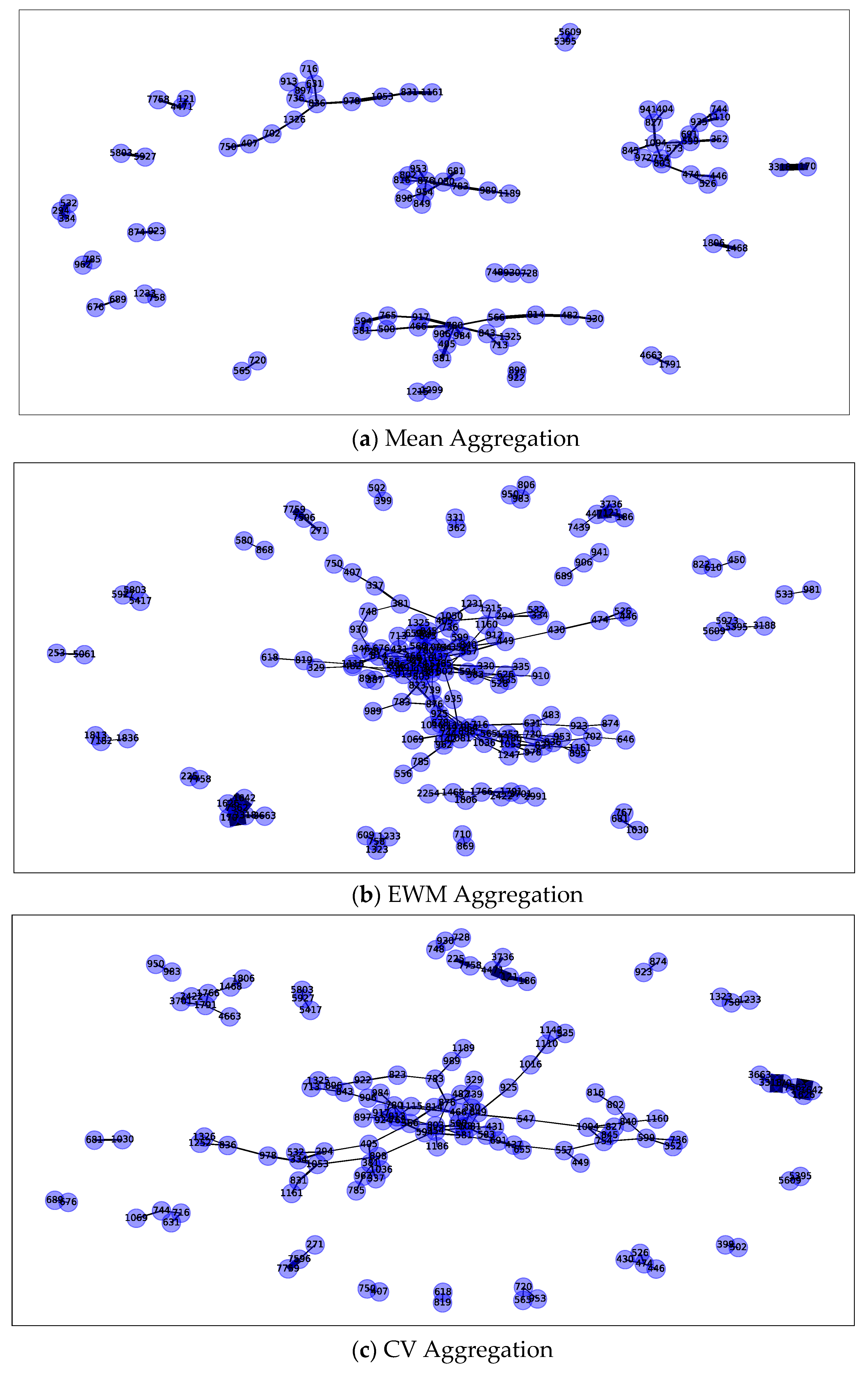
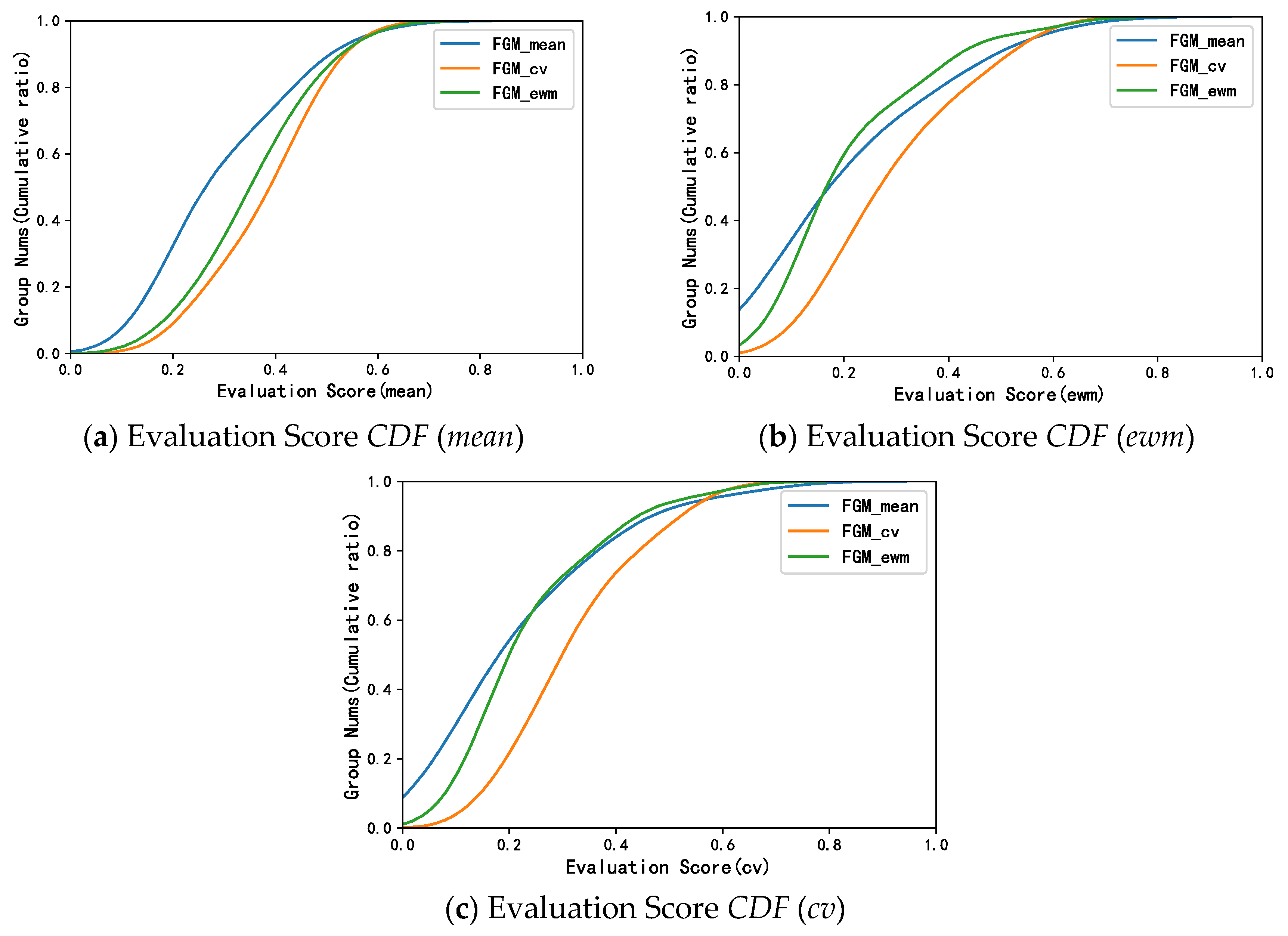
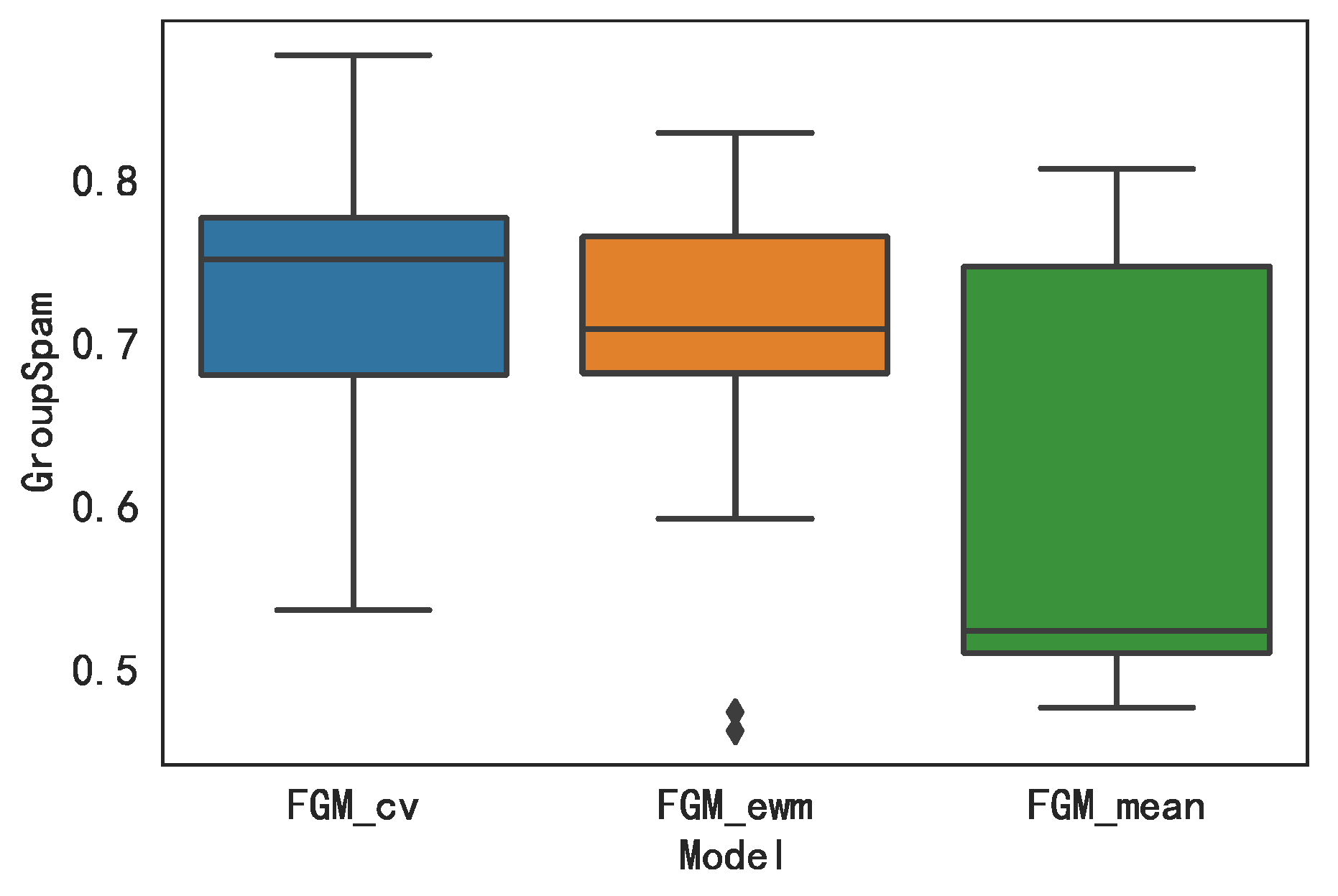
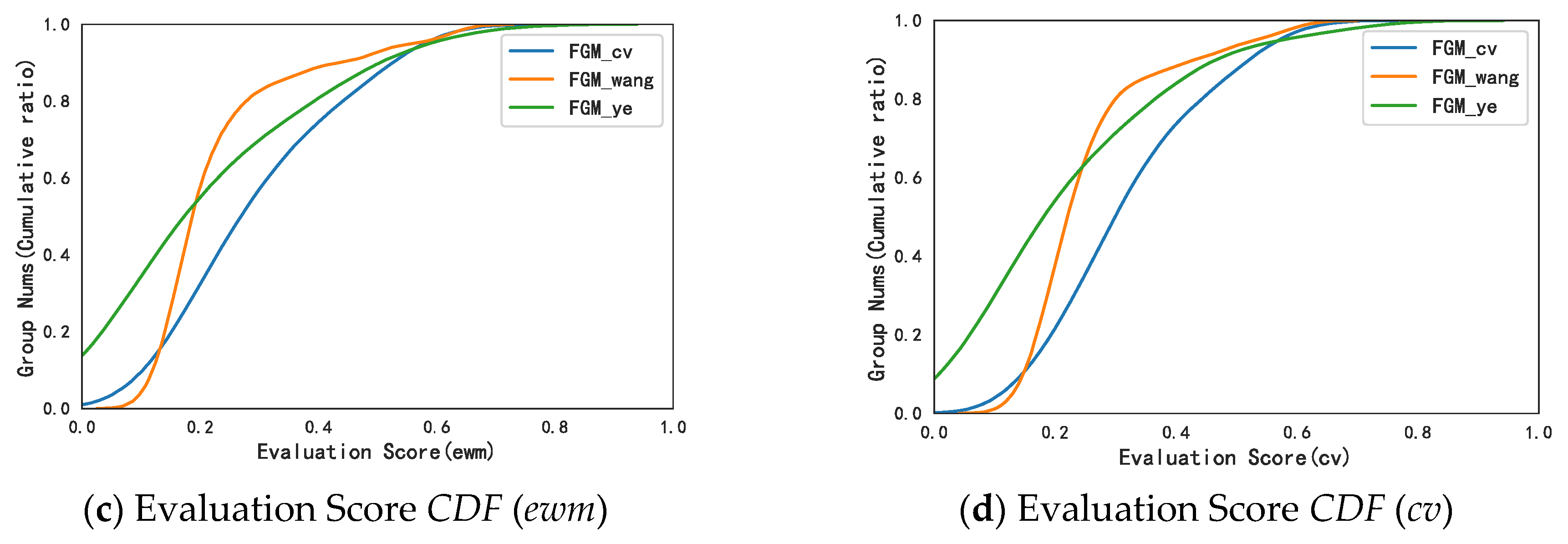
In the part about the experimental study, this article first introduces the dataset and experimental settings used in the research. To obtain the relevant data about hotels and their reviews obtained from the Mafengwo platform, we give the labelling rules to experts to label. In the end, the experimental data contains a total of 279 users, 7931 hotels, and 16,734 reviews. A descriptive statistical analysis was carried out on six collusive relationships, and the analysis results confirmed the effectiveness of these indicators. Next, we show the water army recognition results under the three aggregation methods and analyze the consistency of the three results. The results show that, compared with other methods, the water army group obtained by the model built after the aggregation of the CV method is more abundant and comprehensive. On this basis, based on the evaluation metrics mentioned in
Section 4.2.1, we draw and show the cumulative distribution function diagram of the three models of
,
, and
. It can be seen that no matter what kind of evaluation score is used,
performs the best (the curve is further to the right). Furthermore, in the calculated
value of the three model results, the results show that the
value of
reaches 0.7160, which is the largest compared to the
values of, 0.6107 and 0.6990 for
and
, respectively. Finally, after the above analysis, we came to the conclusion that the
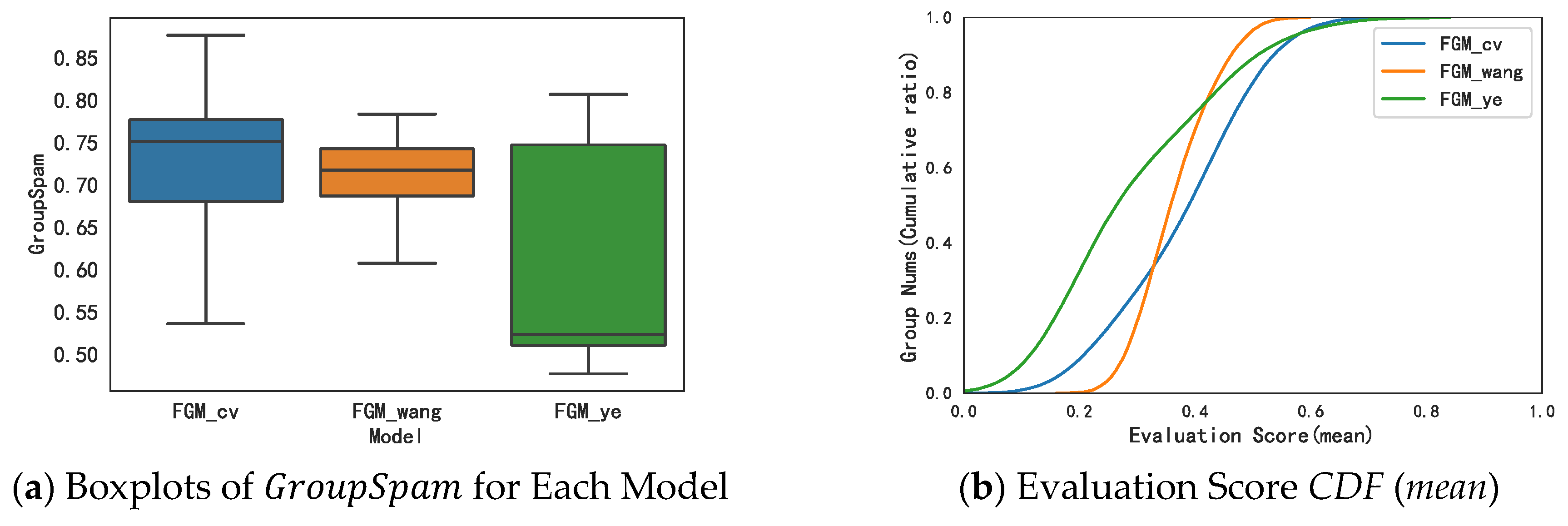
model obtained more effective results in the collusive group identification task. In order to verify the effectiveness of the method proposed in this paper, we compared the method in this paper with the methods of Wang et al. [
8], Ye et al. [
9], etc., and set the edge weight setting method as the only variable. The results show that our optimal model
is significantly better and more stable than the other two baseline models, implying that
CRF weight is efficient in detecting collusive relationships between users. In addition, compared with previous studies [
6,
9,
10,
12,
24], this paper proposes three new collusive relationships: review semantics consistency (
RSC), activity sime-span consistency (
ATC), and interaction activity consistency (
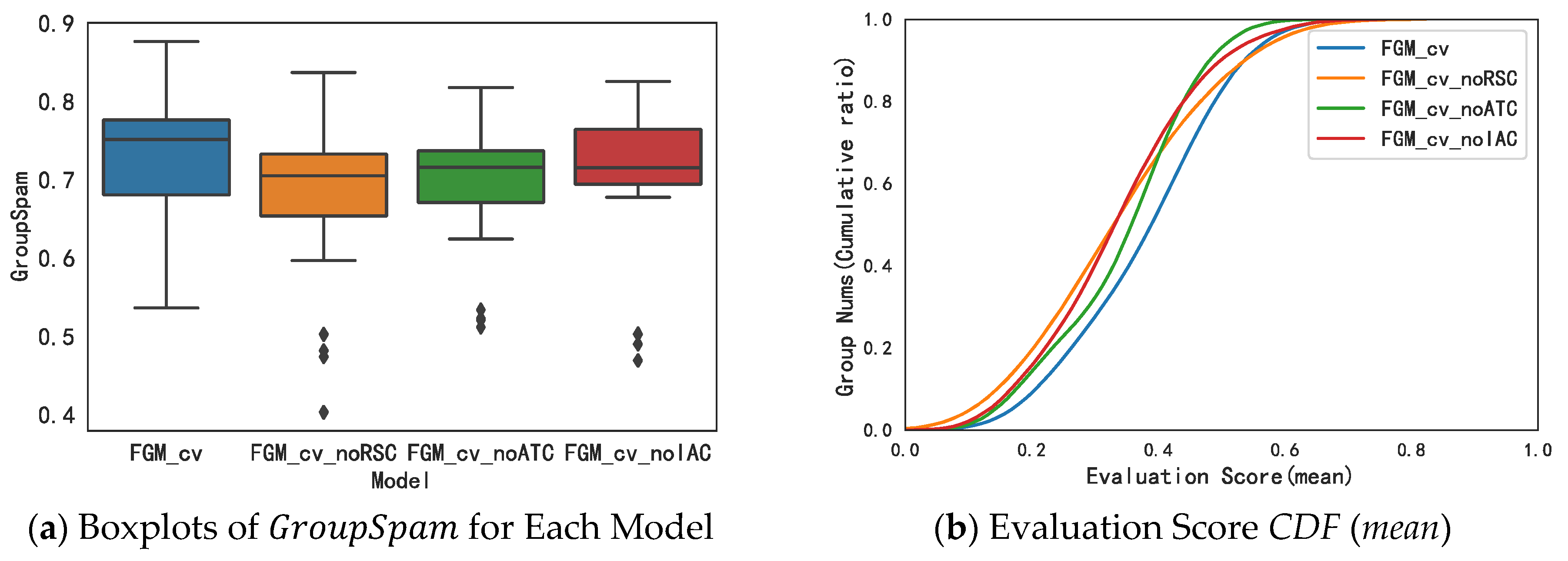
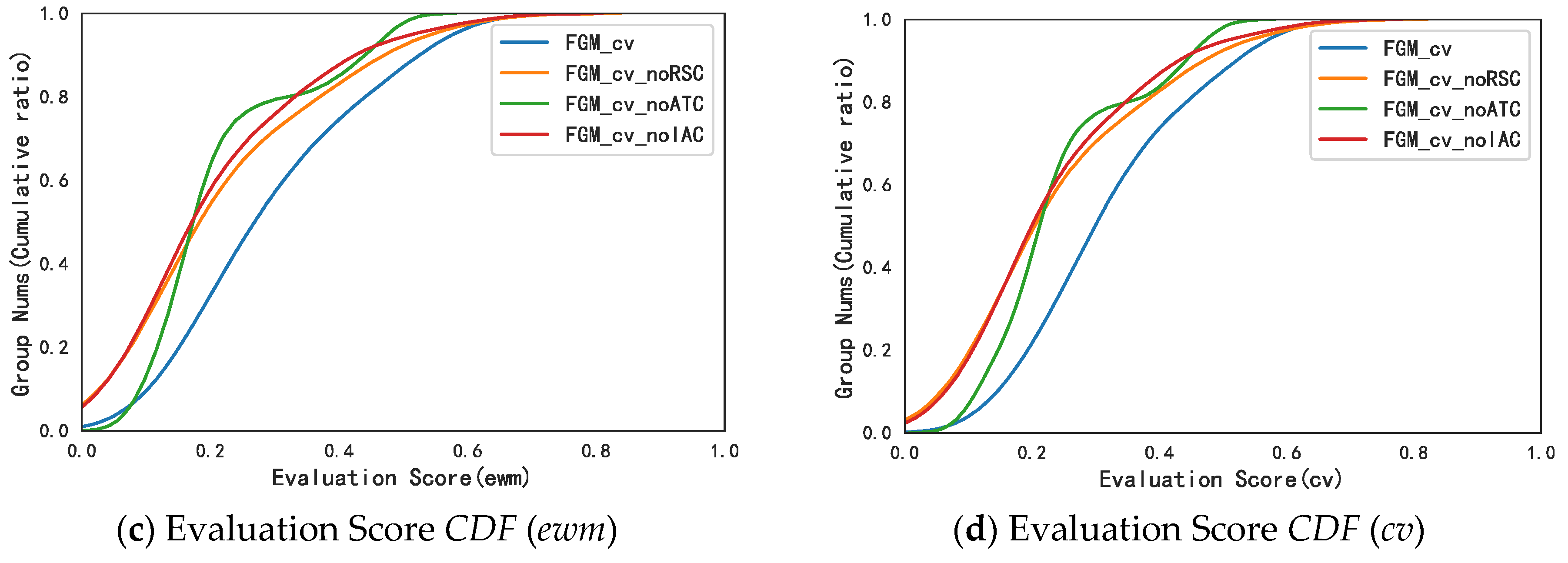
IAC). In order to confirm the effectiveness of these newly proposed collusive relationships, we compared the collusive group recognition effect in the cases of deleting this indicator and not deleting this indicator. The final result shows that retaining these indicators can achieve better results, and the importance of each indicator is
RSC >
ATC >
IAC.
6.2. Implications and Conclusions
The identification of the “water army” is of great significance. First of all, on the platform side, when fake reviews seriously endanger the healthy development of online trading platforms, identifying the “water army” can help the platform to regulate user behavior in a timely manner and adopt corresponding intervention strategies [
40], which will help the platform regain the trust of consumers. Secondly, in terms of merchants, identifying the “water army” can effectively prevent malicious competition among merchants, prevent the phenomenon of getting good reviews but poor products, and help form a clean and orderly online shopping environment. Finally, on the user side, consumer defense theory [
41] pointed out that when consumers realize that they have been deceived, they will engage in appropriate defensive behaviors, including negative reactions and mistrust behaviors, thereby reducing the risk of being deceived again. On the basis of this theory, identifying the information army can help improve users’ information discrimination abilities and help users avoid the influence of false information brought by fake reviews.
The main work and innovation of this research are reflected in the following three aspects: Firstly, in view of the problem of focusing on candidate group mining and ignoring the measurement method of user collusive relationships when setting edge weights in the research of graph-based spammer group identification, this paper focuses on the measurement of user collusive relationship factors; Secondly, several experiments were carried out to explore the optimal method for setting user collusive relationship factors. Finally, the factors were identified, and their effectiveness on the task of e-commerce water army group identification was verified. Furthermore, this study has the following limitations: (1) Due to the limitations of computer computing power, this study only performed the group identification task on a small amount of user data, and whether it can achieve ideal results in the face of a large number of users needs further verification. (2) This paper uses the mean aggregation, EWM aggregation, and CV aggregation to calculate the edge weight. Future research would have to be conducted to find out the possibilities of other, more effective weight calculation methods. Next, we will focus on the above limitations and further explore methods to improve the identification of water army groups.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}