





Sensors 2024, 24(8), 2552; https://doi.org/10.3390/s24082552 - 16 Apr 2024
Viewed by 311
Abstract
►
Show Figures
Accurate and reliable pose estimation of boom-type roadheaders is the key to the forming quality of the tunneling face in coal mines, which is of great importance to improve tunneling efficiency and ensure the safety of coal mine production. The multi-laser-beam target-based visual
[...] Read more.
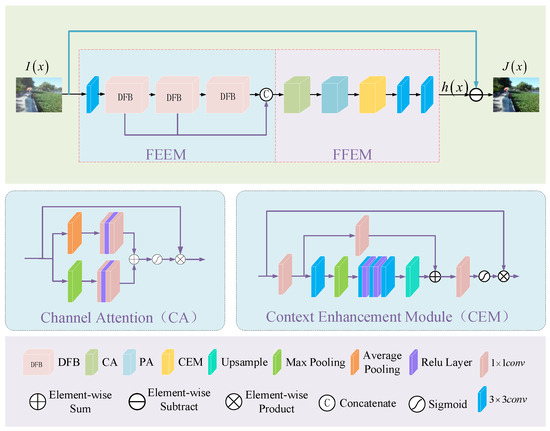
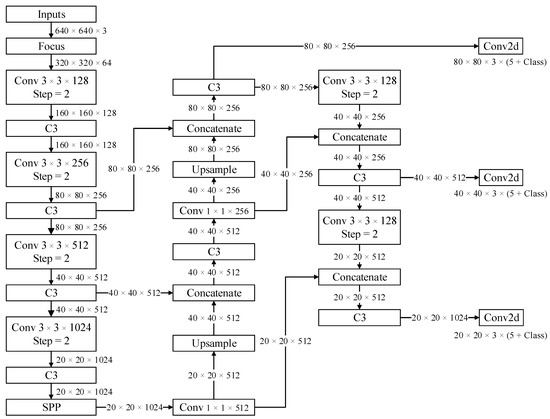
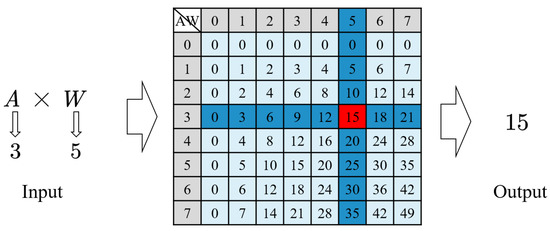
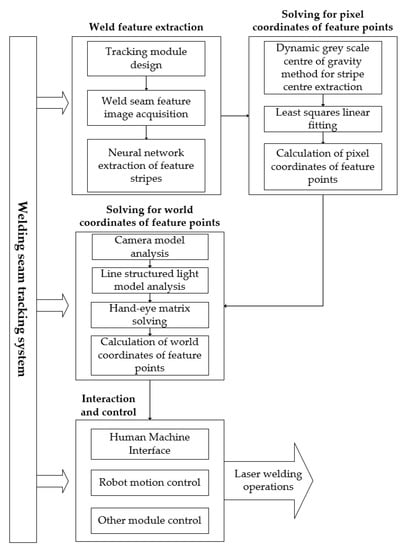
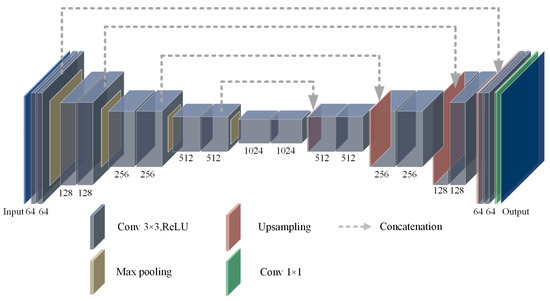
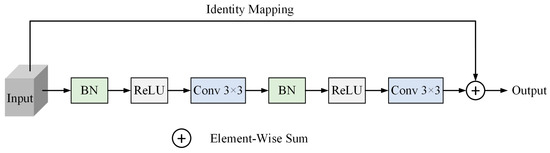
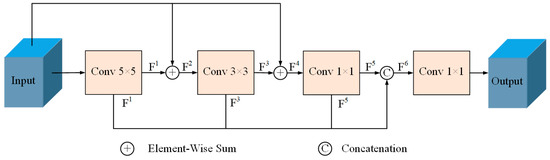
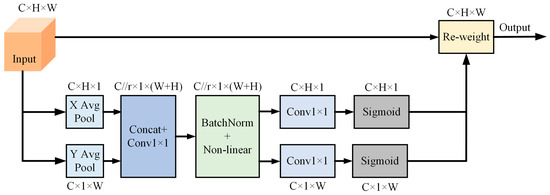
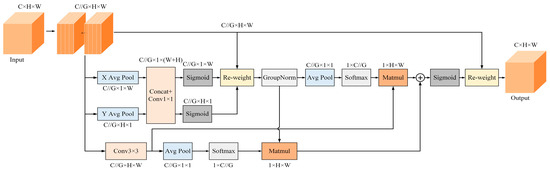
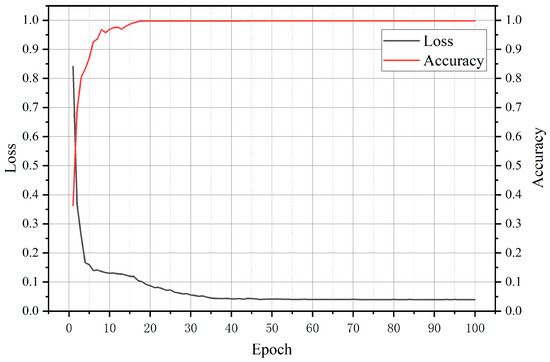
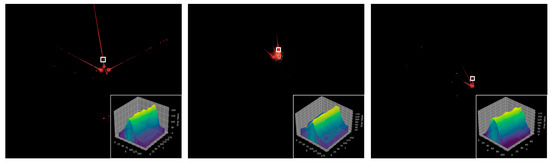
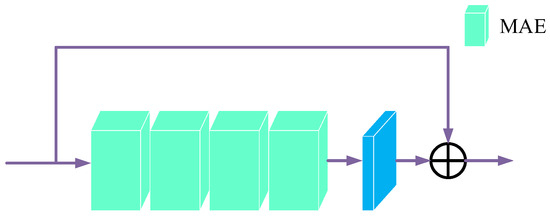
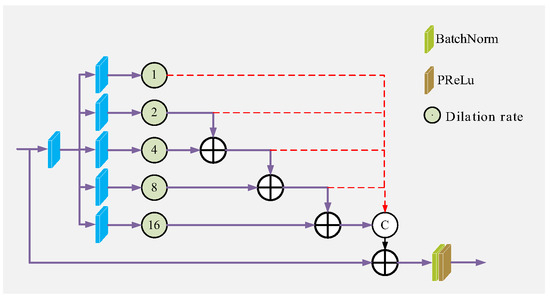
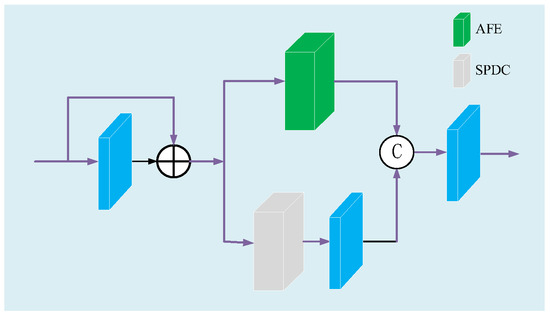
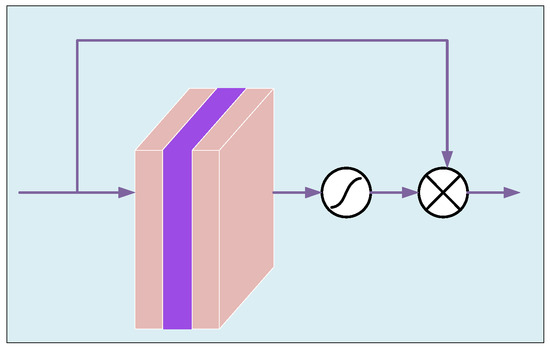
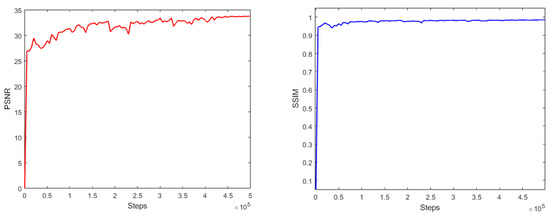
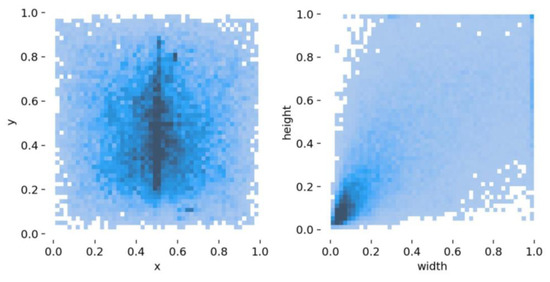
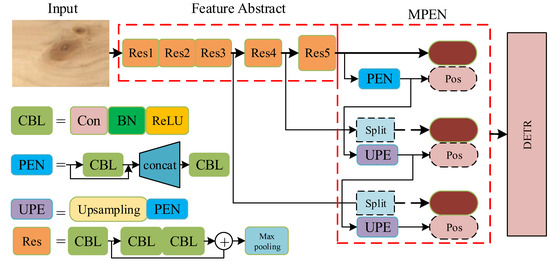
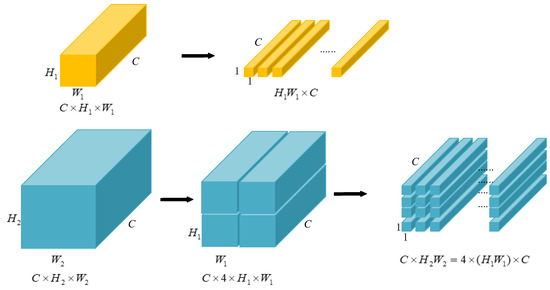
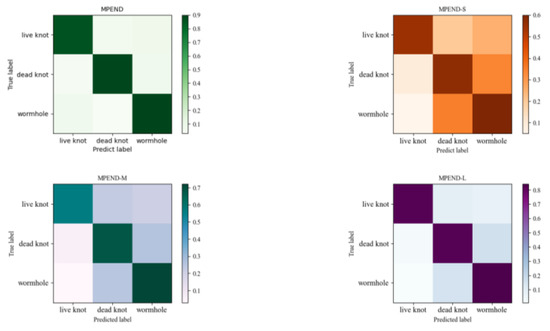
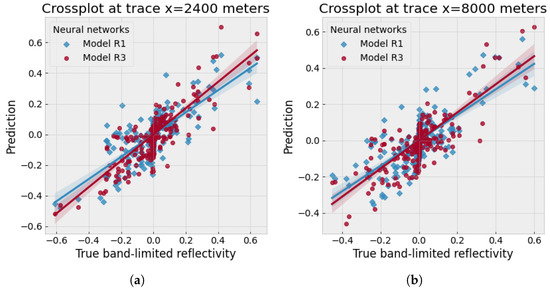
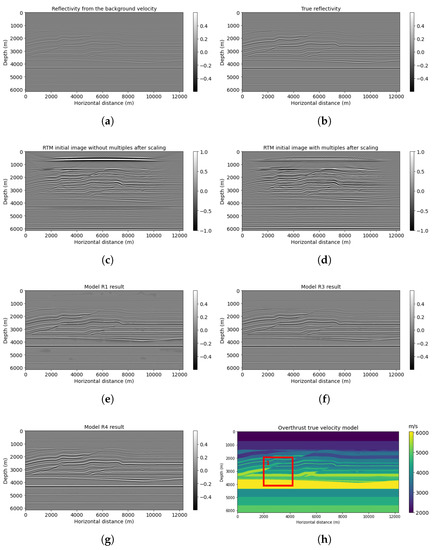
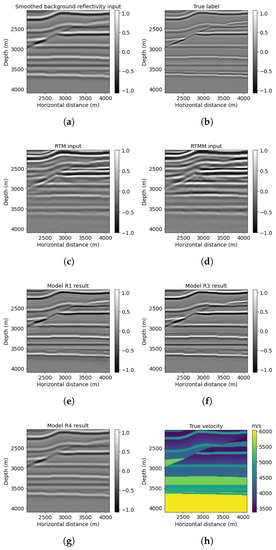
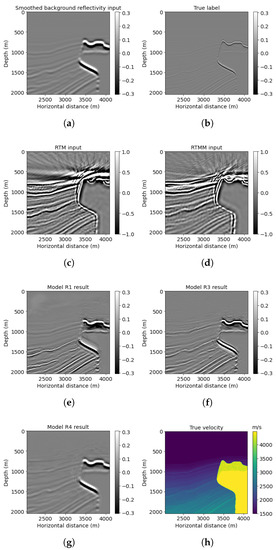
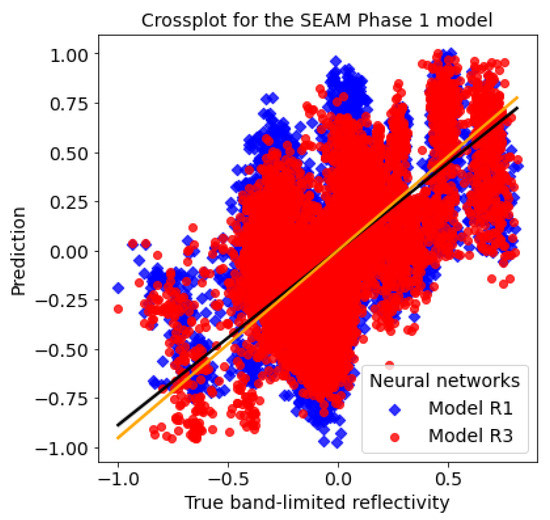
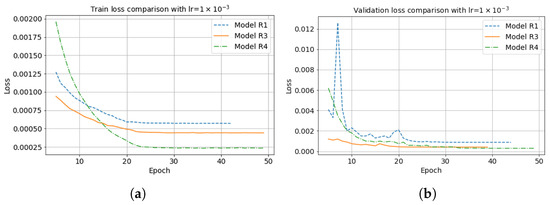
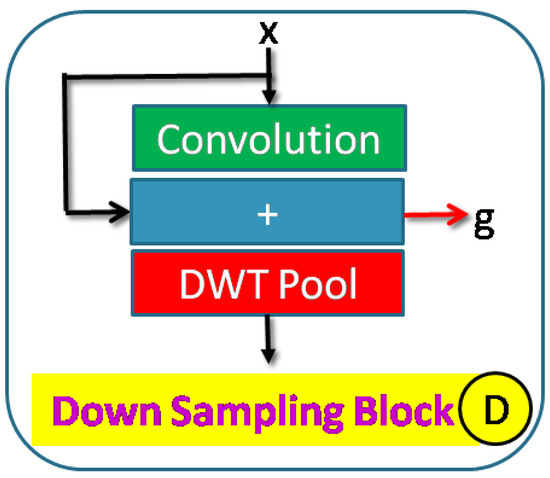
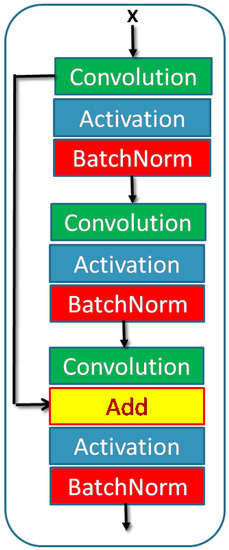
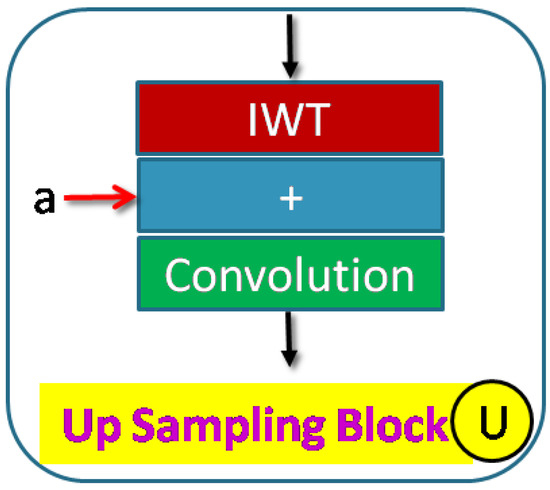
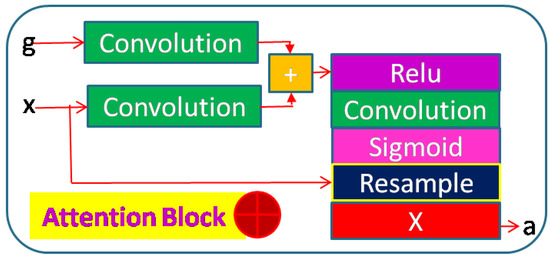
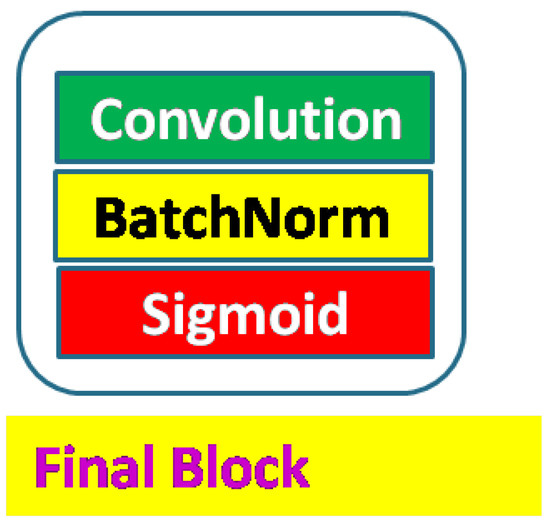
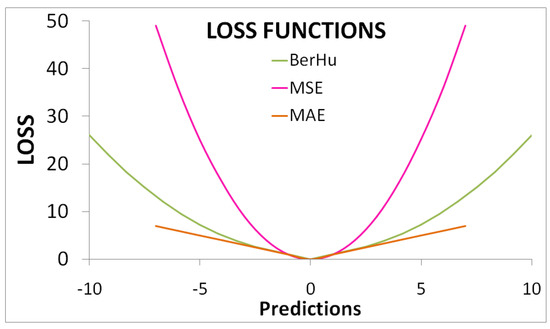
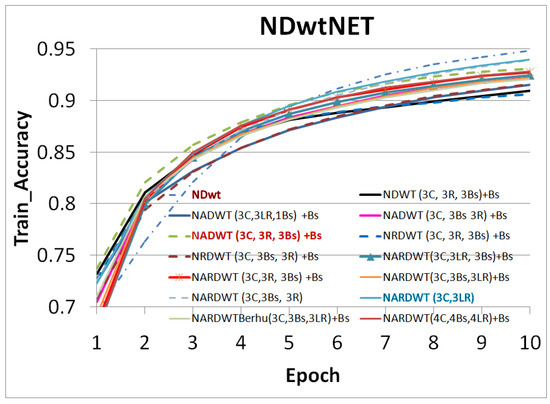
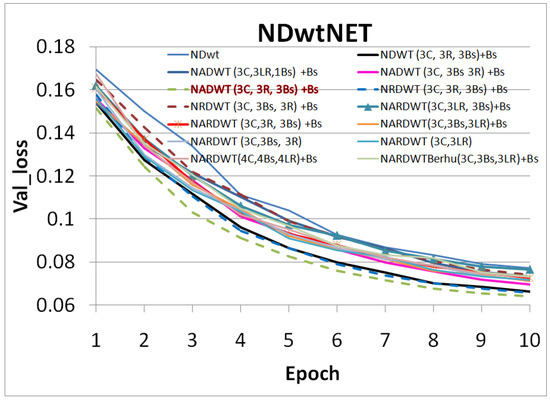
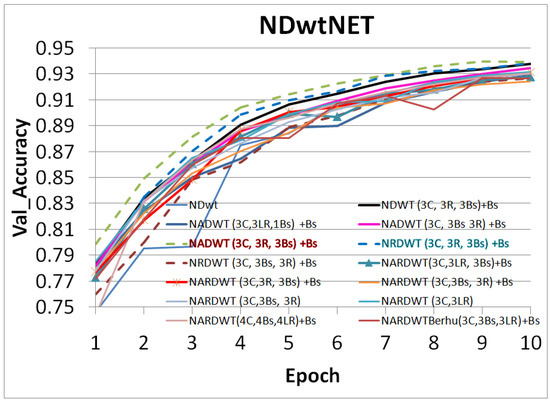
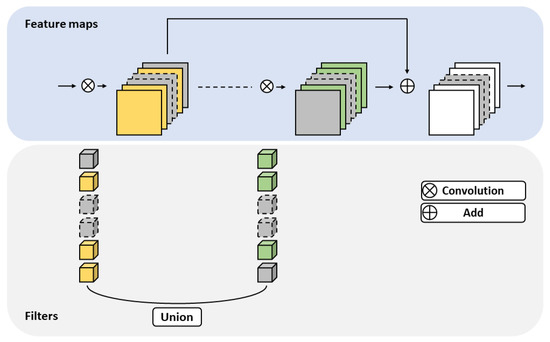
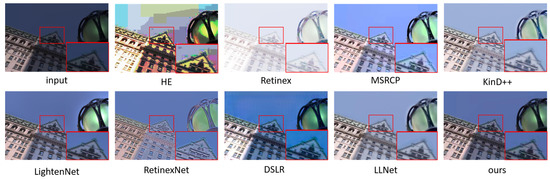
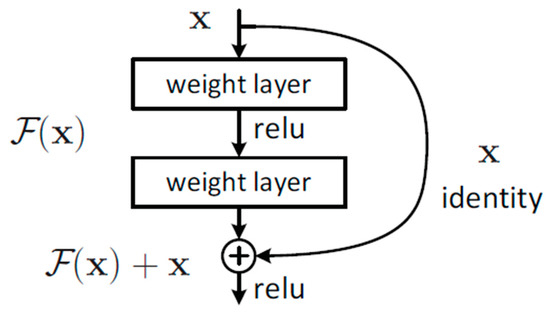
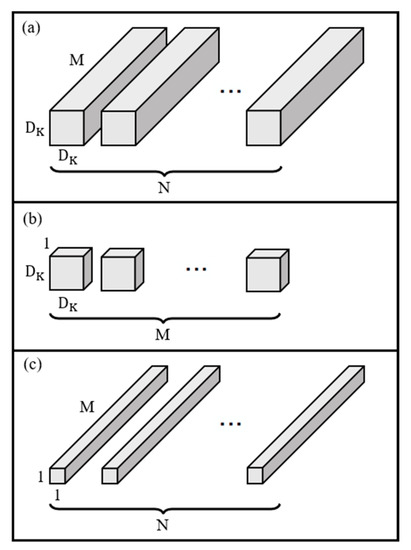
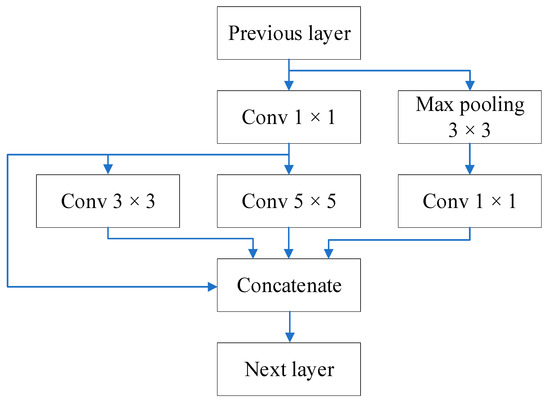
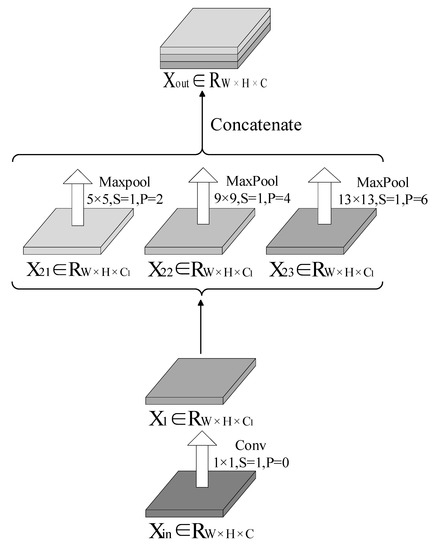
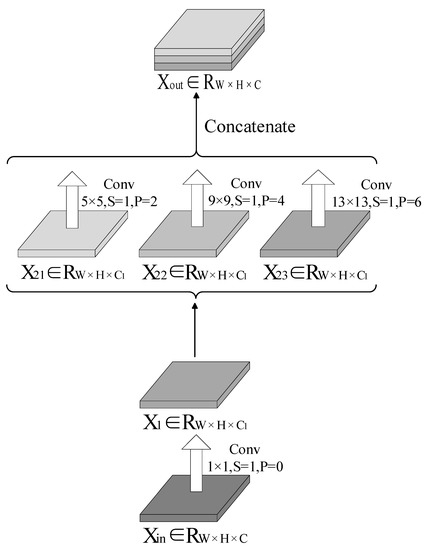
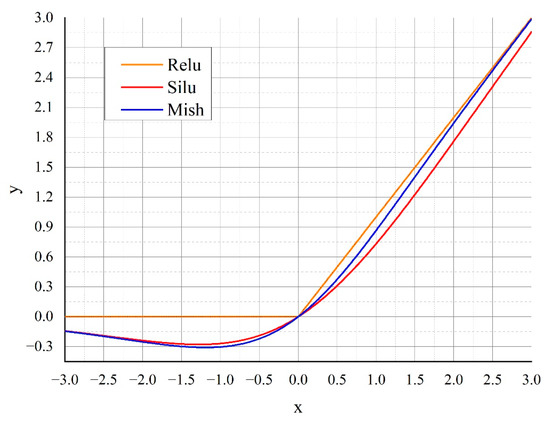
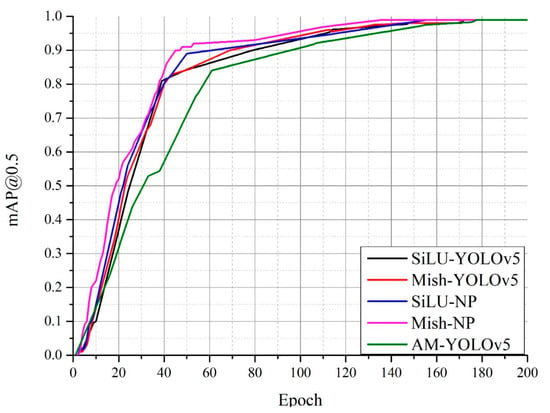
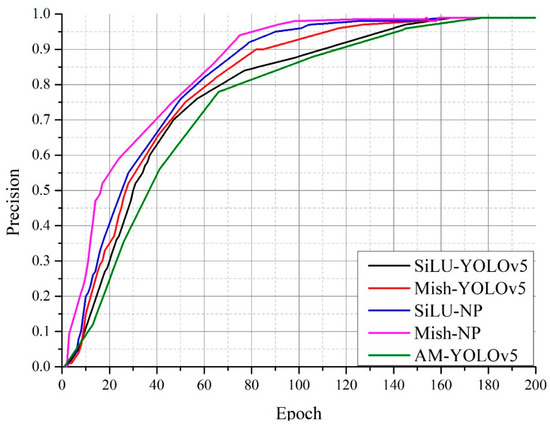
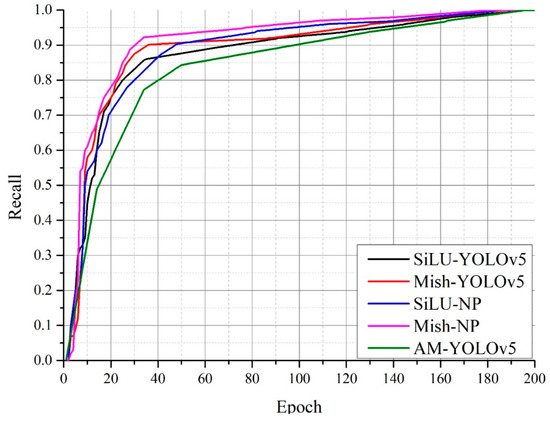
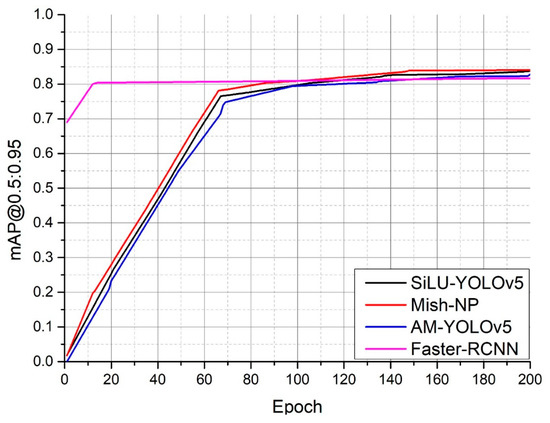
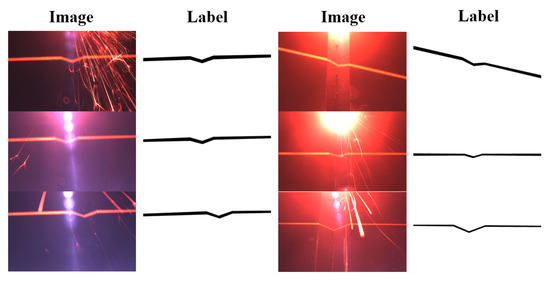
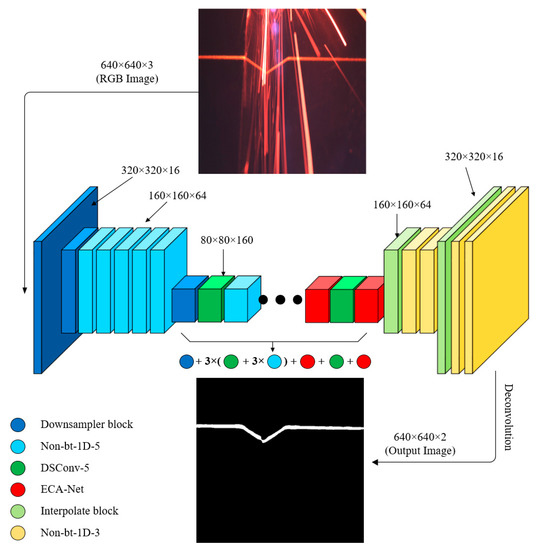
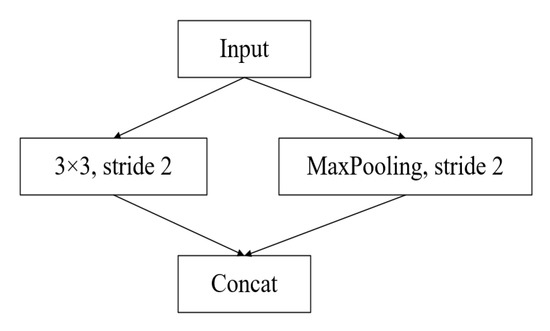
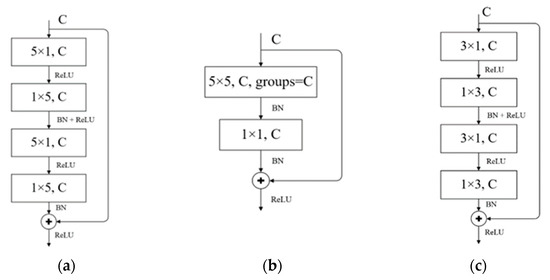
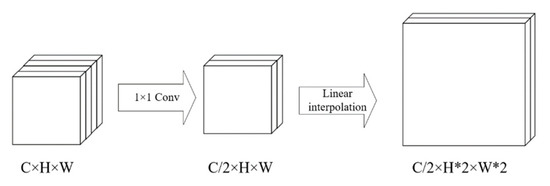
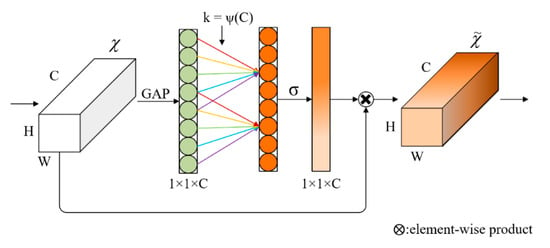
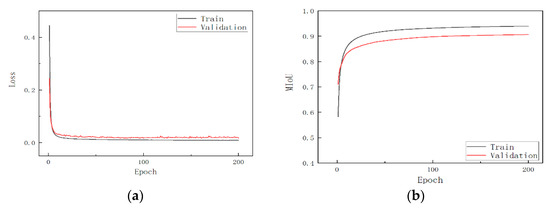
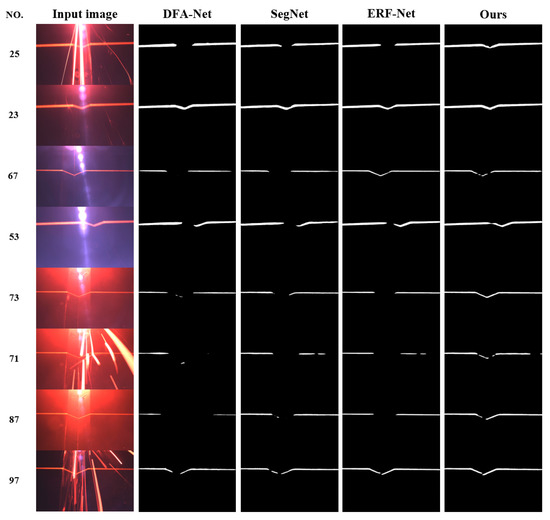
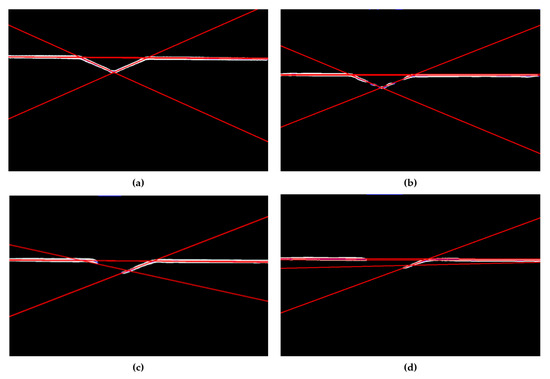
Accurate and reliable pose estimation of boom-type roadheaders is the key to the forming quality of the tunneling face in coal mines, which is of great importance to improve tunneling efficiency and ensure the safety of coal mine production. The multi-laser-beam target-based visual localization method is an effective way to realize accurate and reliable pose estimation of a roadheader body. However, the complex background interference in coal mines brings great challenges to the stable and accurate segmentation and extraction of laser beam features, which has become the main problem faced by the long-distance visual positioning method of underground equipment. In this paper, a semantic segmentation network for underground laser beams in coal mines, RCEAU-Net, is proposed based on U-Net. The network introduces residual connections in the convolution of the encoder and decoder parts, which effectively fuses the underlying feature information and improves the gradient circulation performance of the network. At the same time, by introducing cascade multi-scale convolution in the skipping connection section, which compensates for the lack of contextual semantic information in U-Net and improves the segmentation effect of the network model on tiny laser beams at long distance. Finally, the introduction of an efficient multi-scale attention module with cross-spatial learning in the encoder enhances the feature extraction capability of the network. Furthermore, the laser beam target dataset (LBTD) is constructed based on laser beam target images collected from several coal mines, and the proposed RCEAU-Net model is then tested and verified. The experimental results show that, compared with the original U-Net, RCEAU-Net can ensure the real-time performance of laser beam segmentation while increasing the Accuracy by 0.19%, Precision by 2.53%, Recall by 22.01%, and Intersection and Union Ratio by 8.48%, which can meet the requirements of multi-laser-beam feature segmentation and extraction under complex backgrounds in coal mines, so as to further ensure the accuracy and stability of long-distance visual positioning for boom-type roadheaders and ensure the safe production in the working face.
Full article

Figure 1



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}