Knowledge Graphs for Search and Recommendation
Share This Topical Collection
Editors
 Dr. Pierpaolo Basile
Dr. Pierpaolo Basile
Dr. Pierpaolo Basile
E-Mail
Website
Collection Editor
Department of Computer Science, Università degli Studi di Bari Aldo Moro, 70121 Bari BA, Italy
Interests: natural language processing; entity linking; information retrieval; recommender systems
 Dr. Annalina Caputo
Dr. Annalina Caputo
Dr. Annalina Caputo
E-Mail
Website
Collection Editor
School of Computing, Dublin City University Glasnevin Campus, Glasnevin, Dublin 9, Ireland
Interests: intelligent information access; text representation and information retrieval; natural language processing
Topical Collection Information
Dear Colleagues,
The MDPI Information journal invites submissions to a Topical Collection on “Knowledge Graphs for Search and Recommendation”.
The availability of large publicly available knowledge graph resources, such as Freebase, DBpedia, Wikidata, Yago, and Babelnet, has fostered new research directions, tasks, and application, in search and recommendation systems. Knowledge graphs are at the forefront of applications that try to bridge the semantic gap between structured and unstructured information in order to open new possibilities to represent, visualize, query, interact, and in general, make sense of information.
More recently, search and recommendation systems have benefited from developments in deep learning and graph embeddings, which have inspired new approaches to semantic matching, feature extraction, cold-start and long-tail problems, algorithm transparency and interpretability, entity, facet, and exploratory search.
This Topical Collection welcomes submissions that provide new perspectives, introduce new challenges and tasks, as well as overview articles on the use of knowledge graphs in information retrieval and recommendation systems.
Dr. Pierpaolo Basile
Dr. Annalina Caputo
Collection Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Information is an international peer-reviewed open access monthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1600 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- Knowledge graph representation and acquisition for search and recommendation
- Knowledge graph embeddings for search and recommendation
- Entity linking for search and recommendation
- Knowledge graph-based query expansion
- Knowledge graph-based information extraction
- Question answering over knowledge graphs
- Facet and exploratory search through knowledge graphs
- Result diversification through knowledge graphs
- Conversational systems based on knowledge graphs
- Knowledge graphs for recommendation explanation and transparency
- Entity and expert retrieval
- Application of knowledge graphs to retrieval and recommendation on specific domains: cultural heritage and digital humanities, medical, legal, etc.
Published Papers (21 papers)
Open AccessArticle
Enhancing Personalized Educational Content Recommendation through Cosine Similarity-Based Knowledge Graphs and Contextual Signals
by
Christos Troussas, Akrivi Krouska, Panagiota Tselenti, Dimitrios K. Kardaras and Stavroula Barbounaki
Viewed by 1413
Abstract
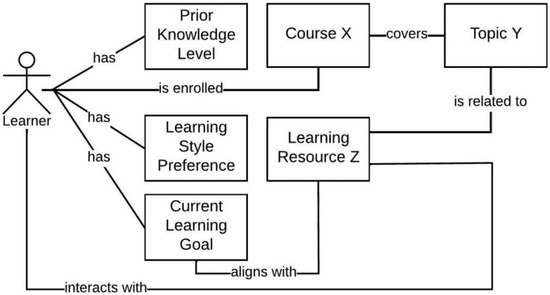
The extensive pool of content within educational software platforms can often overwhelm learners, leaving them uncertain about what materials to engage with. In this context, recommender systems offer significant support by customizing the content delivered to learners, alleviating the confusion and enhancing the
[...] Read more.
The extensive pool of content within educational software platforms can often overwhelm learners, leaving them uncertain about what materials to engage with. In this context, recommender systems offer significant support by customizing the content delivered to learners, alleviating the confusion and enhancing the learning experience. To this end, this paper presents a novel approach for recommending adequate educational content to learners via the use of knowledge graphs. In our approach, the knowledge graph encompasses learners, educational entities, and relationships among them, creating an interconnected framework that drives personalized e-learning content recommendations. Moreover, the presented knowledge graph has been enriched with contextual signals referring to various learners’ characteristics, such as prior knowledge level, learning style, and current learning goals. To refine the recommendation process, the cosine similarity technique was employed to quantify the likeness between a learner’s preferences and the attributes of educational entities within the knowledge graph. The above methodology was incorporated in an intelligent tutoring system for learning the programming language Java to recommend content to learners. The software was evaluated with highly promising results.
Full article
►▼
Show Figures
Open AccessArticle
Efficient Non-Sampling Graph Neural Networks
by
Jianchao Ji, Zelong Li, Shuyuan Xu, Yingqiang Ge, Juntao Tan and Yongfeng Zhang
Viewed by 1105
Abstract
A graph is a widely used and effective data structure in many applications; it describes the relationships among nodes or entities. Currently, most semi-supervised or unsupervised graph neural network models are trained based on a very basic operation called negative sampling. Usually, the
[...] Read more.
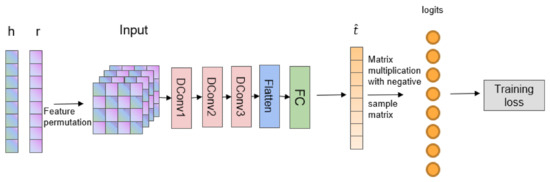
A graph is a widely used and effective data structure in many applications; it describes the relationships among nodes or entities. Currently, most semi-supervised or unsupervised graph neural network models are trained based on a very basic operation called negative sampling. Usually, the purpose of the learning objective is to maximize the similarity between neighboring nodes while minimizing the similarity between nodes that are not close to each other. Negative sampling can reduce the time complexity by sampling a small fraction of the negative nodes instead of using all of the negative nodes when optimizing the objective. However, sampling of the negative nodes may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such disadvantages, we provide an efficient Non-Sampling Graph Neural Network (NS-GNN) framework. The main idea is to use all the negative samples when optimizing the learning objective to avoid the sampling process. Of course, directly using all of the negative samples may cause a large increase in the model training time. To mitigate this problem, we rearrange the origin loss function into a linear form and take advantage of meticulous mathematical derivation to reduce the complexity of the loss function. Experiments on benchmark datasets show that our framework can provide better efficiency at the same level of prediction accuracy compared with existing negative sampling-based models.
Full article
►▼
Show Figures
Open AccessArticle
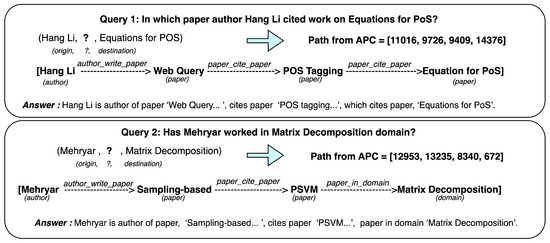
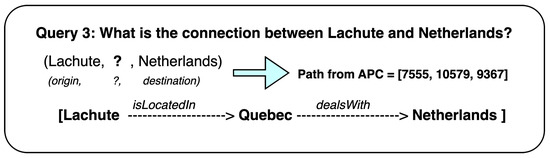
Auction-Based Learning for Question Answering over Knowledge Graphs
by
Garima Agrawal, Dimitri Bertsekas and Huan Liu
Cited by 2 | Viewed by 1704
Abstract
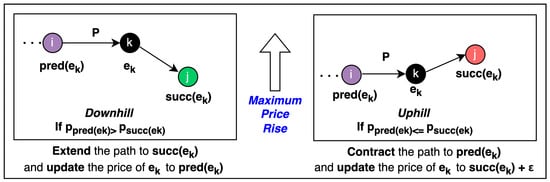
Knowledge graphs are graph-based data models which can represent real-time data that is constantly growing with the addition of new information. The question-answering systems over knowledge graphs (KGQA) retrieve answers to a natural language question from the knowledge graph. Most existing KGQA systems
[...] Read more.
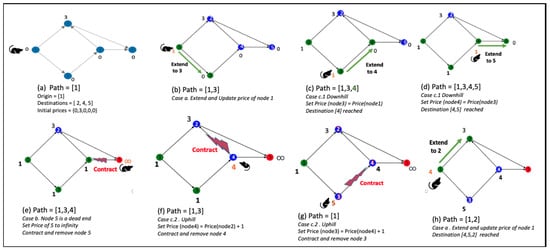
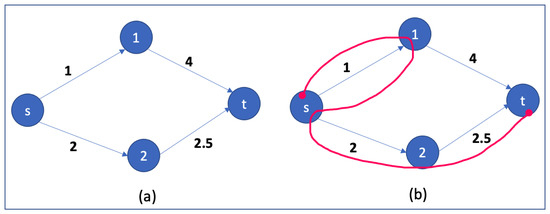
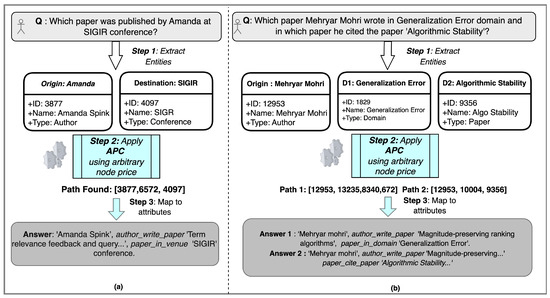
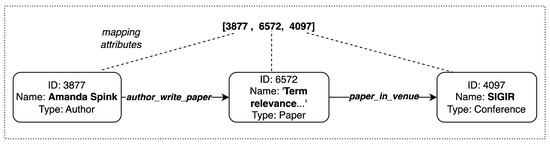
Knowledge graphs are graph-based data models which can represent real-time data that is constantly growing with the addition of new information. The question-answering systems over knowledge graphs (KGQA) retrieve answers to a natural language question from the knowledge graph. Most existing KGQA systems use static knowledge bases for offline training. After deployment, they fail to learn from unseen new entities added to the graph. There is a need for dynamic algorithms which can adapt to the evolving graphs and give interpretable results. In this research work, we propose using new auction algorithms for question answering over knowledge graphs. These algorithms can adapt to changing environments in real-time, making them suitable for offline and online training. An auction algorithm computes paths connecting an origin node to one or more destination nodes in a directed graph and uses node prices to guide the search for the path. The prices are initially assigned arbitrarily and updated dynamically based on defined rules. The algorithm navigates the graph from the high-price to the low-price nodes. When new nodes and edges are dynamically added or removed in an evolving knowledge graph, the algorithm can adapt by reusing the prices of existing nodes and assigning arbitrary prices to the new nodes. For subsequent related searches, the “learned” prices provide the means to “transfer knowledge” and act as a “guide”: to steer it toward the lower-priced nodes. Our approach reduces the search computational effort by 60% in our experiments, thus making the algorithm computationally efficient. The resulting path given by the algorithm can be mapped to the attributes of entities and relations in knowledge graphs to provide an explainable answer to the query. We discuss some applications for which our method can be used.
Full article
►▼
Show Figures
Open AccessArticle
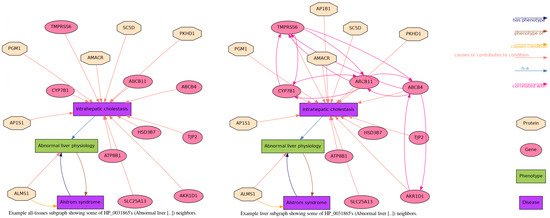
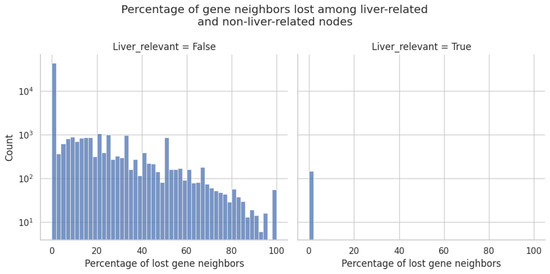
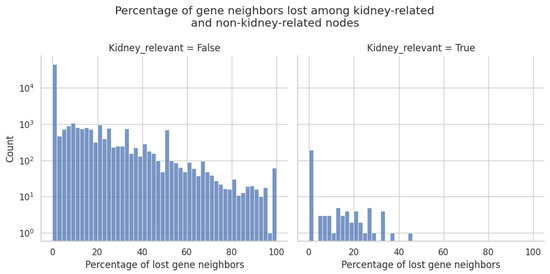
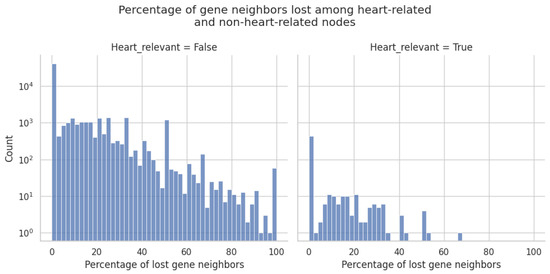
A Tissue-Specific and Toxicology-Focused Knowledge Graph
by
Ignacio J. Tripodi, Lena Schmidt, Brian E. Howard, Deepak Mav and Ruchir Shah
Cited by 1 | Viewed by 1611
Abstract
Molecular biology-focused knowledge graphs (KGs) are directed graphs that integrate information from heterogeneous sources of biological and biomedical data, such as ontologies and public databases. They provide a holistic view of biology, chemistry, and disease, allowing users to draw non-obvious connections between concepts
[...] Read more.
Molecular biology-focused knowledge graphs (KGs) are directed graphs that integrate information from heterogeneous sources of biological and biomedical data, such as ontologies and public databases. They provide a holistic view of biology, chemistry, and disease, allowing users to draw non-obvious connections between concepts through shared associations. While these massive graphs are constructed using carefully curated ontologies and annotations from public databases, much of the information relating the concepts is context specific. Two important variables that determine the applicability of a given ontology annotation are the species and (especially) the tissue type in which it takes place. Using a data-driven approach and the results from thousands of high-quality gene expression samples, we have constructed tissue-specific KGs (using liver, kidney, and heart as examples) that empirically validate the annotations provided by ontology curators. The resulting human-centered KGs are designed for toxicology applications but are generalizable to other areas of human biology, addressing the issue of tissue specificity that often limits the applicability of other large KGs. These knowledge graphs can serve as valuable tools for generating transparent explanations of experimental results in the form of mechanistic hypotheses that are highly relevant to the studied tissue. Because the data-driven relations are derived from a large collection of human in vitro data, these KGs are particularly well suited for in vitro toxicology applications.
Full article
►▼
Show Figures
Open AccessArticle
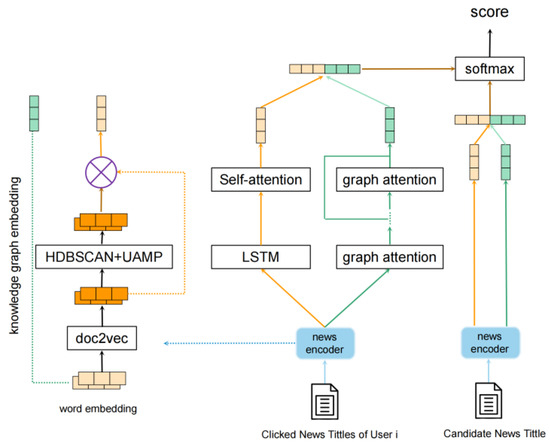
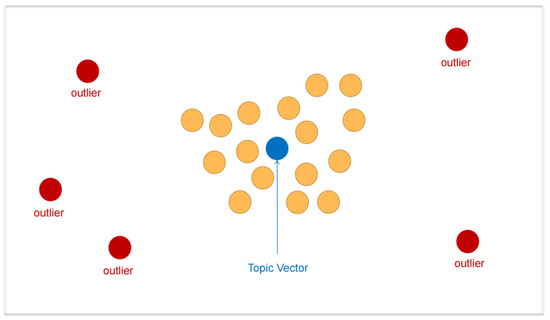
News Recommendation Based on User Topic and Entity Preferences in Historical Behavior
by
Haojie Zhang and Zhidong Shen
Cited by 4 | Viewed by 2806
Abstract
A news-recommendation system is designed to deal with massive amounts of news and provide personalized recommendations for users. Accurately modeling of news and users is the key to news recommendation. Researchers usually use auxiliary information such as social networks or item attributes to
[...] Read more.
A news-recommendation system is designed to deal with massive amounts of news and provide personalized recommendations for users. Accurately modeling of news and users is the key to news recommendation. Researchers usually use auxiliary information such as social networks or item attributes to learn about news and user representation. However, existing recommendation systems neglect to explore the rich topics in the news. This paper considered the knowledge graph as the source of side information. Meanwhile, we used user topic preferences to improve recommendation performance. We proposed a new framework called NRTEH that was based on topic and entity preferences in user historical behavior. The core of our approach was the news encoder and the user encoder. Two encoders in NRTEH handled news titles from two perspectives to obtain news and user representation embedding: (1) extracting explicit and latent topic features from news and mining user preferences for them; and (2) extracting entities and propagating users’ potential preferences in the knowledge graph. Experiments on a real-world dataset validated the effectiveness and efficiency of our approach.
Full article
►▼
Show Figures
Open AccessArticle
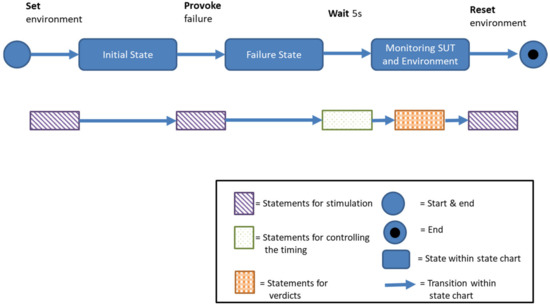
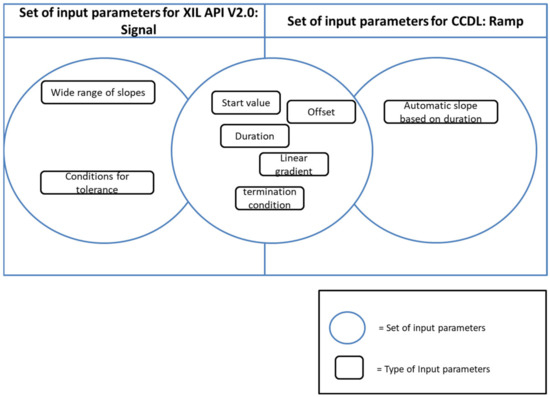
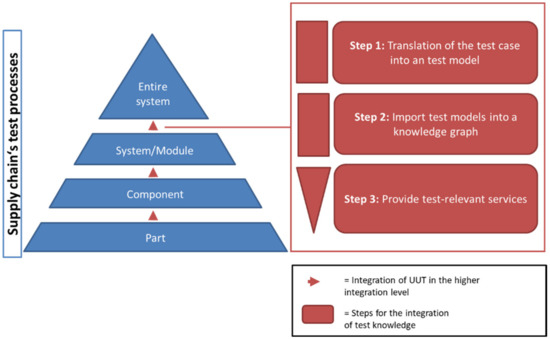
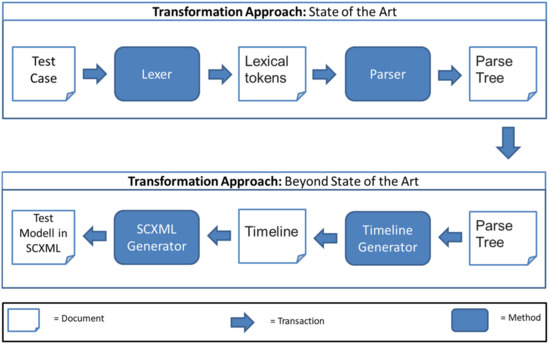
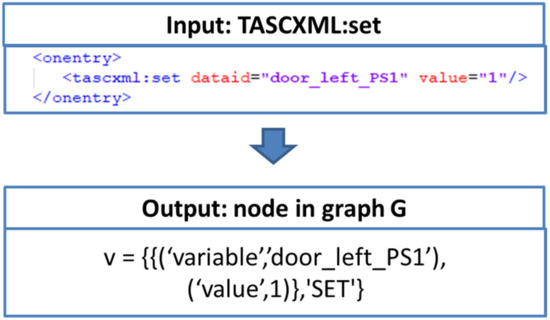
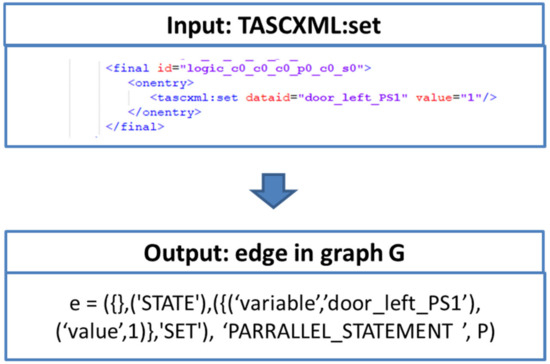
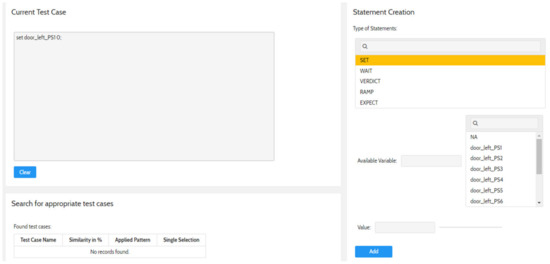
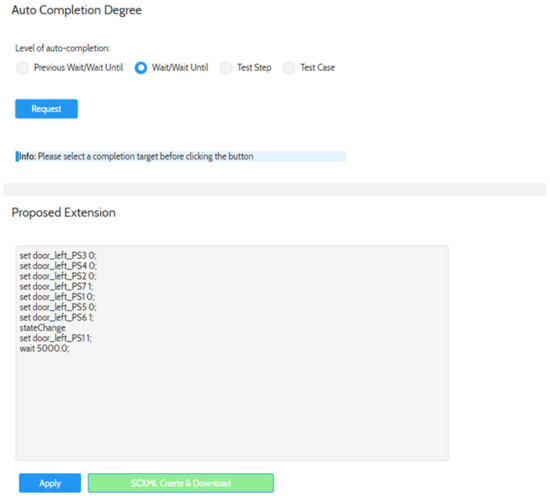
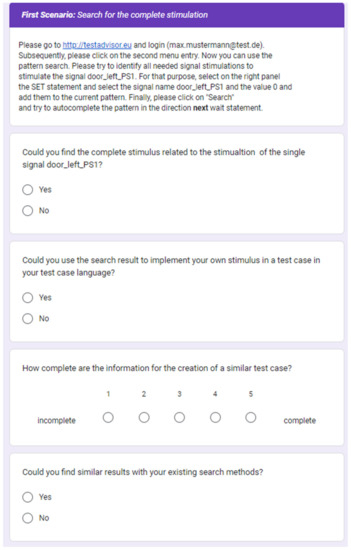
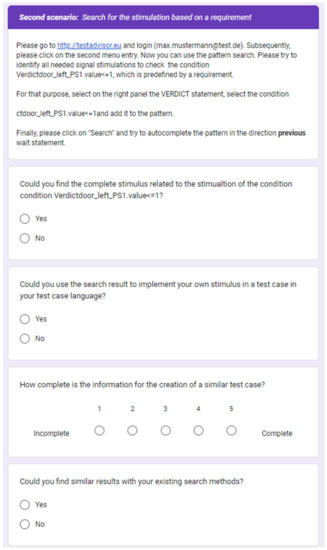
The Faceted and Exploratory Search for Test Knowledge
by
Marco Franke, Klaus-Dieter Thoben and Beate Ehrhardt
Viewed by 1492
Abstract
Heterogeneous test processes concerning test goals and test script languages are an integral part of mechatronic systems development in supply chains. Here, test cases are written in a multitude of different test script languages. The translation between test script languages is possible, a
[...] Read more.
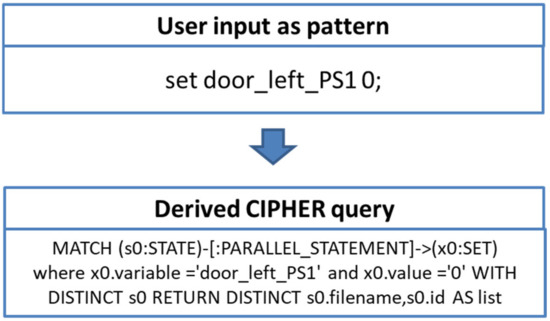
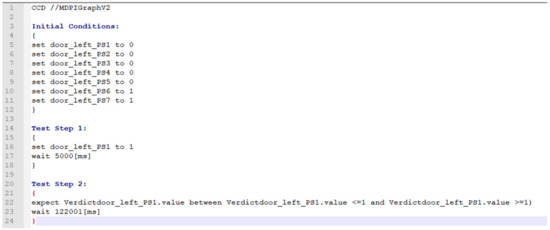
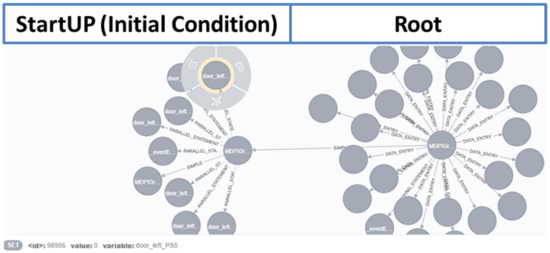
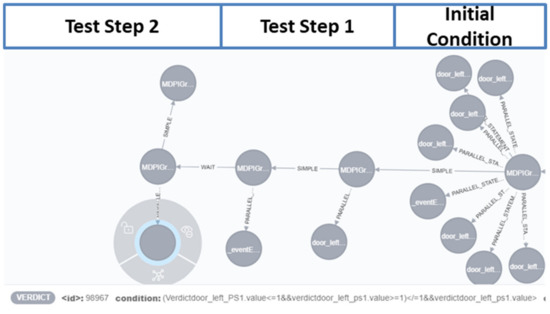
Heterogeneous test processes concerning test goals and test script languages are an integral part of mechatronic systems development in supply chains. Here, test cases are written in a multitude of different test script languages. The translation between test script languages is possible, a joint understanding and a holistic view of the mechatronic system as a system under test is only achieved in the minds of experienced test engineers. This joined-up information is called test knowledge and is the key input for test automation and in turn, it is essential for reducing the cost of product development. Persisted test knowledge enables the search for patterns semi-automatically without reading countless test cases and enables the auto-completion of essential parts of test cases. In this paper, we developed a knowledge graph that aggregates all the test knowledge automatically and integrates it into the test processes. We derived an explorative search that simplifies the test case creation. For that purpose, a corresponding user-friendly query language, and unidirectional translation capabilities were developed that translates a test case into a graph tailored to the target audience of test engineers. We demonstrated the usage and impact of this approach by evaluating it on test cases from aircraft cabin doors.
Full article
►▼
Show Figures
Open AccessArticle
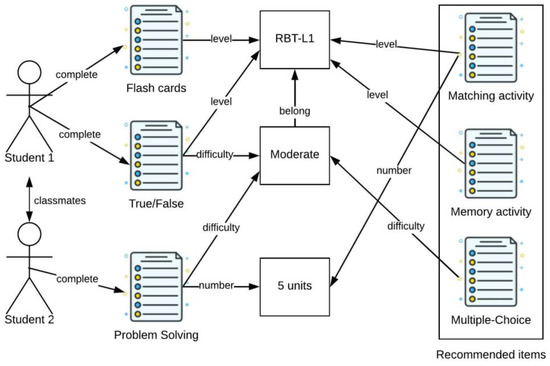
Path-Based Recommender System for Learning Activities Using Knowledge Graphs
by
Christos Troussas and Akrivi Krouska
Cited by 9 | Viewed by 3304
Abstract
Recommender systems can offer a fertile ground in e-learning software, since they can assist users by presenting them with learning material in which they can be more interested, based on their preferences. To this end, in this paper, we present a new method
[...] Read more.
Recommender systems can offer a fertile ground in e-learning software, since they can assist users by presenting them with learning material in which they can be more interested, based on their preferences. To this end, in this paper, we present a new method for a knowledge-graph-based, path-based recommender system for learning activities. The suggested approach makes better learning activity recommendations by using connections between people and/or products. By pre-defining meta-paths or automatically mining connective patterns, our method uses the student-learning activity graph to find path-level commonalities for learning activities. The path-based approach can provide an explanation for the result as well. Our methodology is used in an intelligent tutoring system with Java programming as the domain being taught. The system keeps track of user behavior and can recommend learning activities to students using a knowledge-graph-based recommender system. Numerous metadata, such as kind, complexity, and number of questions, are used to describe each activity. The system has been evaluated with promising results that highlight the effectiveness of the path-based recommendations for learning activities, while preserving the pedagogical affordance.
Full article
►▼
Show Figures
Open AccessArticle
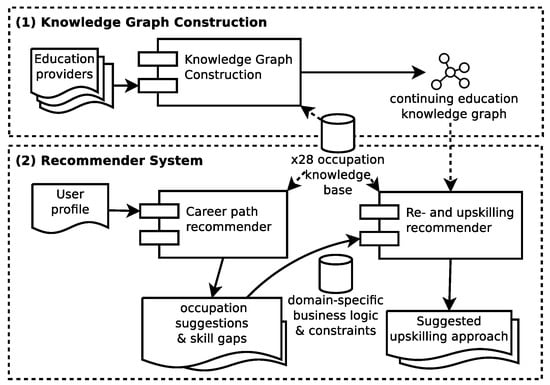
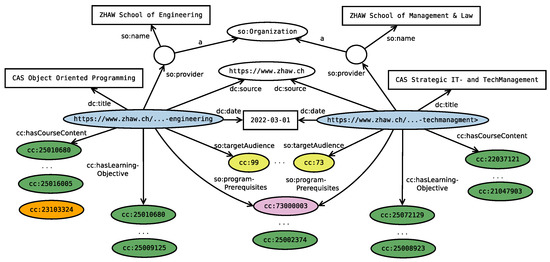
Building Knowledge Graphs and Recommender Systems for Suggesting Reskilling and Upskilling Options from the Web
by
Albert Weichselbraun, Roger Waldvogel, Andreas Fraefel, Alexander van Schie and Philipp Kuntschik
Cited by 3 | Viewed by 3730
Abstract
As advances in science and technology, crisis, and increased competition impact labor markets, reskilling and upskilling programs emerged to mitigate their effects. Since information on continuing education is highly distributed across websites, choosing career paths and suitable upskilling options is currently considered a
[...] Read more.
As advances in science and technology, crisis, and increased competition impact labor markets, reskilling and upskilling programs emerged to mitigate their effects. Since information on continuing education is highly distributed across websites, choosing career paths and suitable upskilling options is currently considered a challenging and cumbersome task. This article, therefore, introduces a method for building a comprehensive knowledge graph from the education providers’ Web pages. We collect educational programs from 488 providers and leverage entity recognition and entity linking methods in conjunction with contextualization to extract knowledge on entities such as prerequisites, skills, learning objectives, and course content. Slot filling then integrates these entities into an extensive knowledge graph that contains close to 74,000 nodes and over 734,000 edges. A recommender system leverages the created graph, and background knowledge on occupations to provide a career path and upskilling suggestions. Finally, we evaluate the knowledge extraction approach on the CareerCoach 2022 gold standard and draw upon domain experts for judging the career paths and upskilling suggestions provided by the recommender system.
Full article
►▼
Show Figures
Open AccessArticle
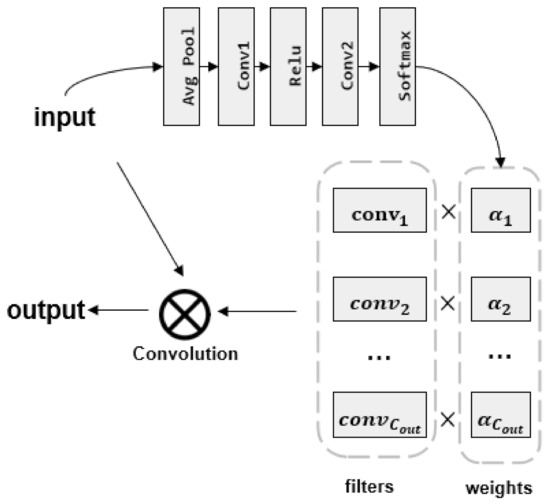
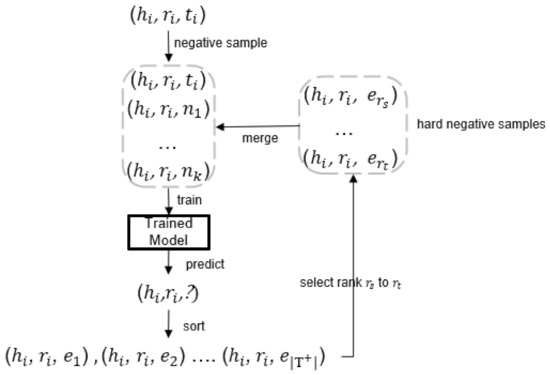
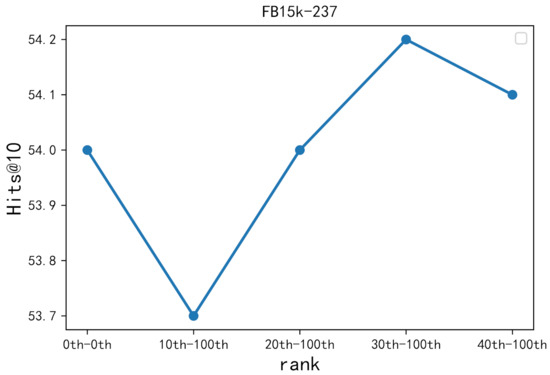
A Dynamic Convolutional Network-Based Model for Knowledge Graph Completion
by
Haoliang Peng and Yue Wu
Cited by 4 | Viewed by 2561
Abstract
Knowledge graph embedding can learn low-rank vector representations for knowledge graph entities and relations, and has been a main research topic for knowledge graph completion. Several recent works suggest that convolutional neural network (CNN)-based models can capture interactions between head and relation embeddings,
[...] Read more.
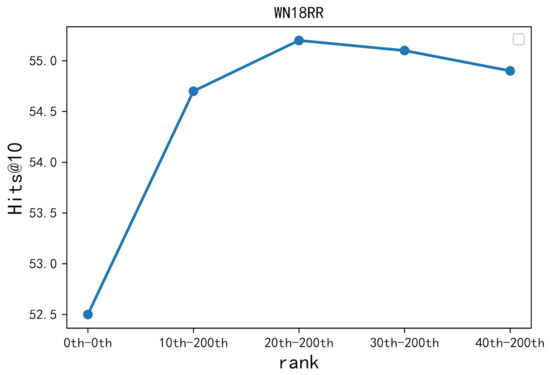
Knowledge graph embedding can learn low-rank vector representations for knowledge graph entities and relations, and has been a main research topic for knowledge graph completion. Several recent works suggest that convolutional neural network (CNN)-based models can capture interactions between head and relation embeddings, and hence perform well on knowledge graph completion. However, previous convolutional network models have ignored the different contributions of different interaction features to the experimental results. In this paper, we propose a novel embedding model named DyConvNE for knowledge base completion. Our model DyConvNE uses a dynamic convolution kernel because the dynamic convolutional kernel can assign weights of varying importance to interaction features. We also propose a new method of negative sampling, which mines hard negative samples as additional negative samples for training. We have performed experiments on the data sets WN18RR and FB15k-237, and the results show that our method is better than several other benchmark algorithms for knowledge graph completion. In addition, we used a new test method when predicting the Hits@1 values of WN18RR and FB15k-237, named specific-relationship testing. This method gives about a 2% relative improvement over models that do not use this method in terms of Hits@1.
Full article
►▼
Show Figures
Open AccessArticle
Mean Received Resources Meet Machine Learning Algorithms to Improve Link Prediction Methods
by
Jibouni Ayoub, Dounia Lotfi and Ahmed Hammouch
Cited by 4 | Viewed by 1891
Abstract
The analysis of social networks has attracted a lot of attention during the last two decades. These networks are dynamic: new links appear and disappear. Link prediction is the problem of inferring links that will appear in the future from the actual state
[...] Read more.
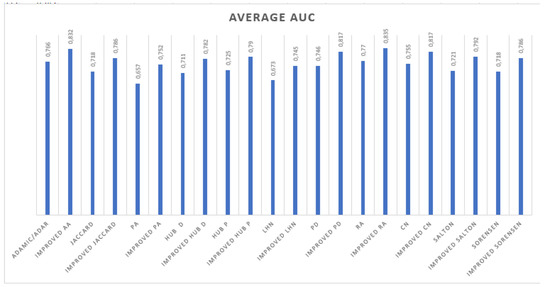
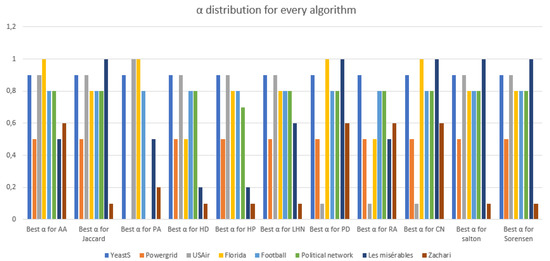
The analysis of social networks has attracted a lot of attention during the last two decades. These networks are dynamic: new links appear and disappear. Link prediction is the problem of inferring links that will appear in the future from the actual state of the network. We use information from nodes and edges and calculate the similarity between users. The more users are similar, the higher the probability of their connection in the future will be. The similarity metrics play an important role in the link prediction field. Due to their simplicity and flexibility, many authors have proposed several metrics such as Jaccard, AA, and Katz and evaluated them using the area under the curve (AUC). In this paper, we propose a new parameterized method to enhance the AUC value of the link prediction metrics by combining them with the mean received resources (MRRs). Experiments show that the proposed method improves the performance of the state-of-the-art metrics. Moreover, we used machine learning algorithms to classify links and confirm the efficiency of the proposed combination.
Full article
►▼
Show Figures
Open AccessArticle
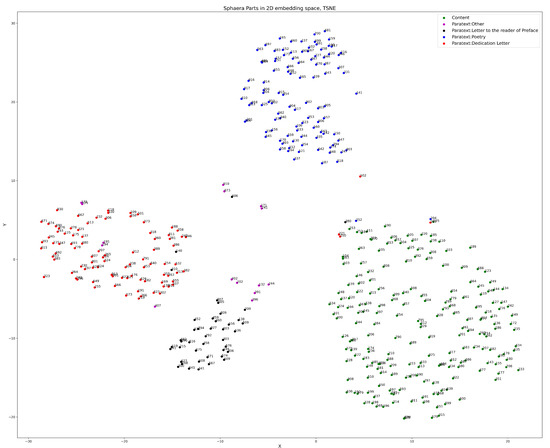
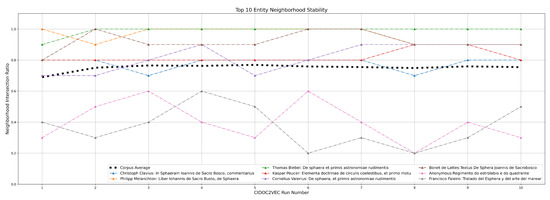
CIDOC2VEC: Extracting Information from Atomized CIDOC-CRM Humanities Knowledge Graphs
by
Hassan El-Hajj and Matteo Valleriani
Cited by 5 | Viewed by 3564
Abstract
The development of the field of digital humanities in recent years has led to the increased use of knowledge graphs within the community. Many digital humanities projects tend to model their data based on CIDOC-CRM ontology, which offers a wide array of classes
[...] Read more.
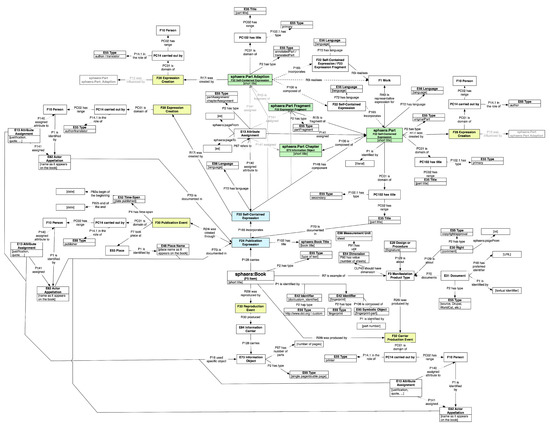
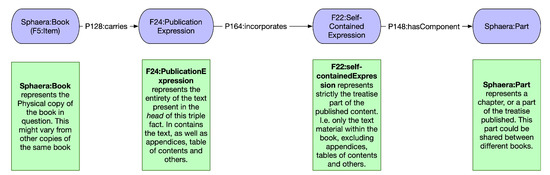
The development of the field of digital humanities in recent years has led to the increased use of knowledge graphs within the community. Many digital humanities projects tend to model their data based on CIDOC-CRM ontology, which offers a wide array of classes appropriate for storing humanities and cultural heritage data. The CIDOC-CRM ontology model leads to a knowledge graph structure in which many entities are often linked to each other through chains of relations, which means that relevant information often lies many hops away from their entities. In this paper, we present a method based on graph walks and text processing to extract entity information and provide semantically relevant embeddings. In the process, we were able to generate similarity recommendations as well as explore their underlying data structure. This approach was then demonstrated on the
Sphaera Dataset which was modeled according to the CIDOC-CRM data structure.
Full article
►▼
Show Figures
Open AccessArticle
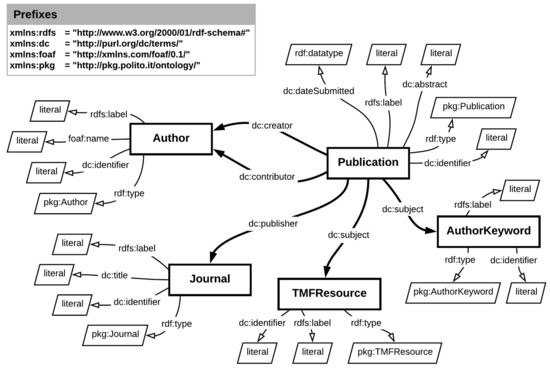
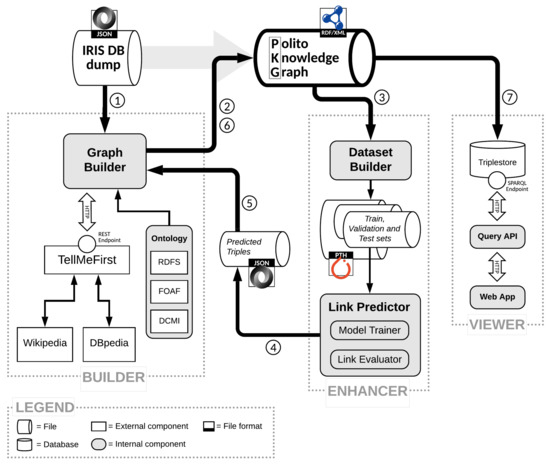
The Geranium Platform: A KG-Based System for Academic Publications
by
Giovanni Garifo, Giuseppe Futia, Antonio Vetrò and Juan Carlos De Martin
Viewed by 2316
Abstract
Knowledge Graphs (KGs) have emerged as a core technology for incorporating human knowledge because of their capability to capture the relational dimension of information and of its semantic properties. The nature of KGs meets one of the vocational pursuits of academic institutions, which
[...] Read more.
Knowledge Graphs (KGs) have emerged as a core technology for incorporating human knowledge because of their capability to capture the relational dimension of information and of its semantic properties. The nature of KGs meets one of the vocational pursuits of academic institutions, which is sharing their intellectual output, especially publications. In this paper, we describe and make available the Polito Knowledge Graph (PKG) –which semantically connects information on more than 23,000 publications and 34,000 authors– and Geranium, a semantic platform that leverages the properties of the PKG to offer advanced services for search and exploration. In particular, we describe the Geranium recommendation system, which exploits Graph Neural Networks (GNNs) to suggest collaboration opportunities between researchers of different disciplines. This work integrates the state of the art because we use data from a real application in the scholarly domain, while the current literature still explores the combination of KGs and GNNs in a prototypal context using synthetic data. The results shows that the fusion of these technologies represents a promising approach for recommendation and metadata inference in the scholarly domain.
Full article
►▼
Show Figures
Open AccessArticle
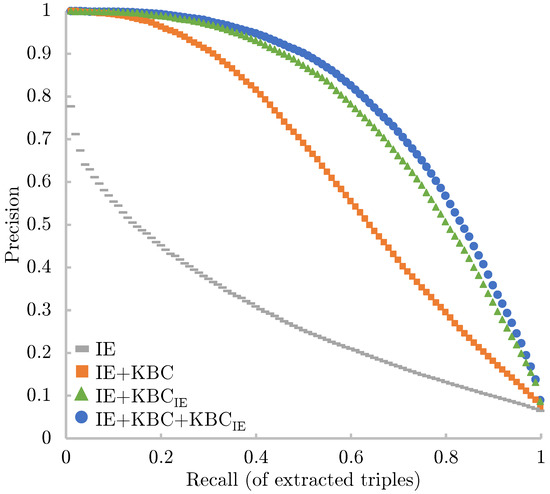
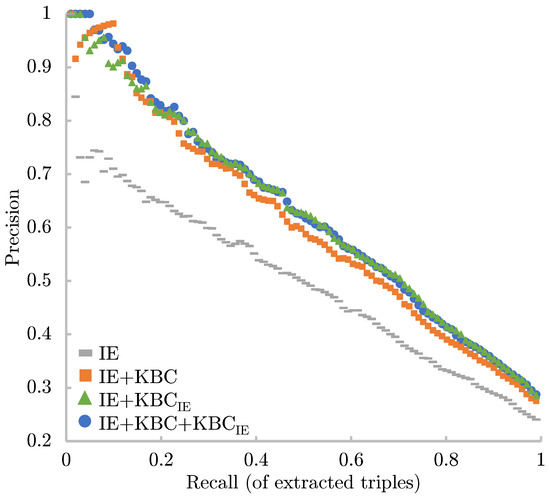
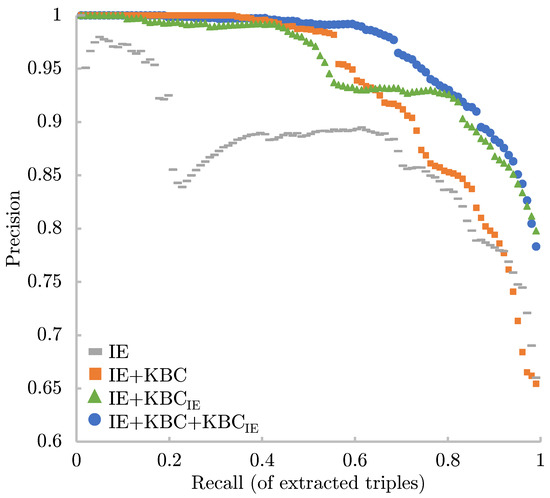
Populating Web-Scale Knowledge Graphs Using Distantly Supervised Relation Extraction and Validation
by
Sarthak Dash, Michael R. Glass, Alfio Gliozzo, Mustafa Canim and Gaetano Rossiello
Cited by 1 | Viewed by 2155
Abstract
In this paper, we propose a fully automated system to extend knowledge graphs using external information from web-scale corpora. The designed system leverages a deep-learning-based technology for relation extraction that can be trained by a distantly supervised approach. In addition, the system uses
[...] Read more.
In this paper, we propose a fully automated system to extend knowledge graphs using external information from web-scale corpora. The designed system leverages a deep-learning-based technology for relation extraction that can be trained by a distantly supervised approach. In addition, the system uses a deep learning approach for knowledge base completion by utilizing the global structure information of the induced KG to further refine the confidence of the newly discovered relations. The designed system does not require any effort for adaptation to new languages and domains as it does not use any hand-labeled data, NLP analytics, and inference rules. Our experiments, performed on a popular academic benchmark, demonstrate that the suggested system boosts the performance of relation extraction by a wide margin, reporting error reductions of 50%, resulting in relative improvement of up to 100%. Furthermore, a web-scale experiment conducted to extend DBPedia with knowledge from Common Crawl shows that our system is not only scalable but also does not require any adaptation cost, while yielding a substantial accuracy gain.
Full article
►▼
Show Figures
Open AccessReview
Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey
by
Mohammad Yani and Adila Alfa Krisnadhi
Cited by 17 | Viewed by 6257
Abstract
Simple questions are the most common type of questions used for evaluating a knowledge graph question answering (KGQA). A simple question is a question whose answer can be captured by a factoid statement with one relation or predicate. Knowledge graph question answering (KGQA)
[...] Read more.
Simple questions are the most common type of questions used for evaluating a knowledge graph question answering (KGQA). A simple question is a question whose answer can be captured by a factoid statement with one relation or predicate. Knowledge graph question answering (KGQA) systems are systems whose aim is to automatically answer natural language questions (NLQs) over knowledge graphs (KGs). There are varieties of researches with different approaches in this area. However, the lack of a comprehensive study to focus on addressing simple questions from all aspects is tangible. In this paper, we present a comprehensive survey of answering simple questions to classify available techniques and compare their advantages and drawbacks in order to have better insights of existing issues and recommendations to direct future works.
Full article
►▼
Show Figures
Open AccessReview
A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions
by
Janneth Chicaiza and Priscila Valdiviezo-Diaz
Cited by 72 | Viewed by 11242
Abstract
In recent years, the use of recommender systems has become popular on the web. To improve recommendation performance, usage, and scalability, the research has evolved by producing several generations of recommender systems. There is much literature about it, although most proposals focus on
[...] Read more.
In recent years, the use of recommender systems has become popular on the web. To improve recommendation performance, usage, and scalability, the research has evolved by producing several generations of recommender systems. There is much literature about it, although most proposals focus on traditional methods’ theories and applications. Recently, knowledge graph-based recommendations have attracted attention in academia and the industry because they can alleviate information sparsity and performance problems. We found only two studies that analyze the recommendation system’s role over graphs, but they focus on specific recommendation methods. This survey attempts to cover a broader analysis from a set of selected papers. In summary, the contributions of this paper are as follows: (1) we explore traditional and more recent developments of filtering methods for a recommender system, (2) we identify and analyze proposals related to knowledge graph-based recommender systems, (3) we present the most relevant contributions using an application domain, and (4) we outline future directions of research in the domain of recommender systems. As the main survey result, we found that the use of knowledge graphs for recommendations is an efficient way to leverage and connect a user’s and an item’s knowledge, thus providing more precise results for users.
Full article
►▼
Show Figures
Open AccessArticle
Collective and Informal Learning in the ViewpointS Interactive Medium
by
Philippe Lemoisson, Stefano A. Cerri, Vincent Douzal, Pascal Dugénie and Jean-Philippe Tonneau
Cited by 2 | Viewed by 2295
Abstract
Collective learning has been advocated to be at the source for innovation, particularly as serendipity seems historically to have been the driving force not only behind innovation, but also behind scientific discovery and artistic creation. Informal learning is well known to represent the
[...] Read more.
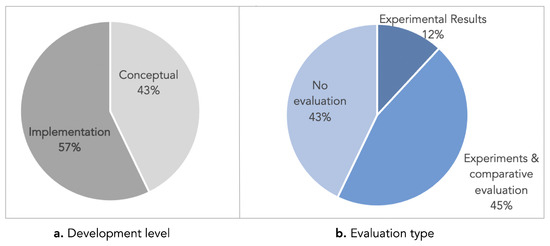
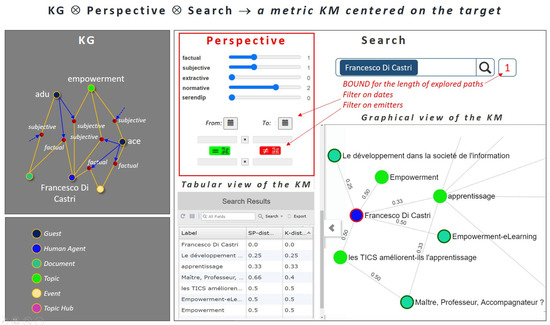
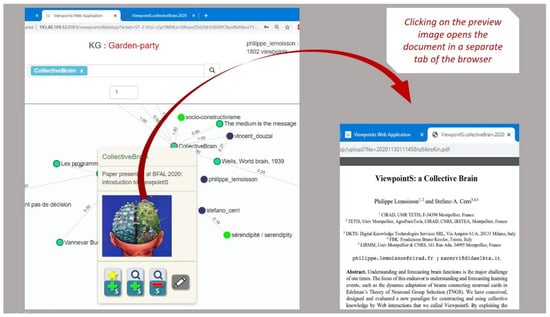
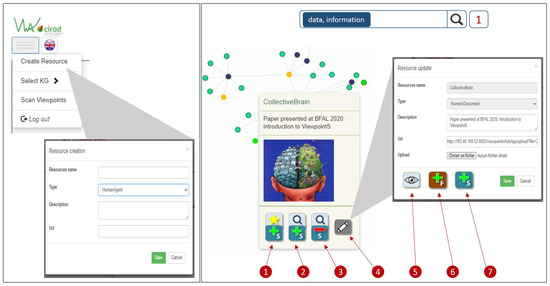
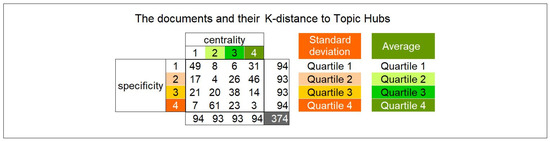
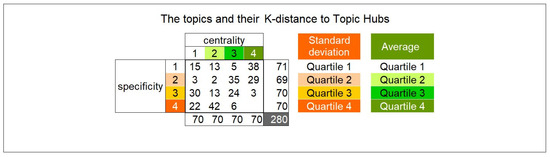
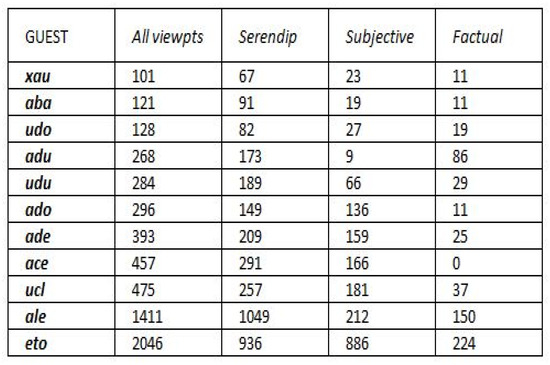
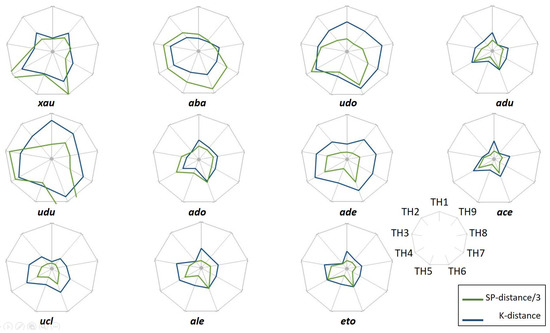
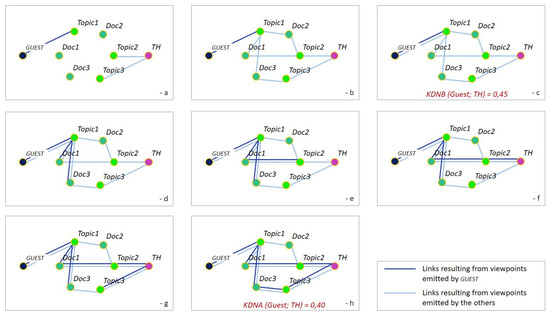
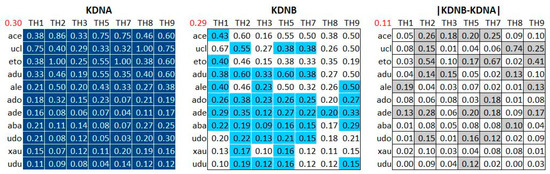
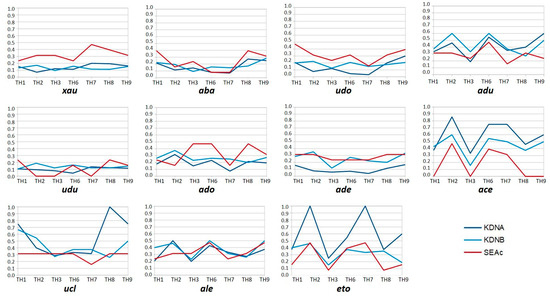
Collective learning has been advocated to be at the source for innovation, particularly as serendipity seems historically to have been the driving force not only behind innovation, but also behind scientific discovery and artistic creation. Informal learning is well known to represent the most significant learning effects in humans, far better than its complement: formal learning with predefined objectives. We have designed an approach—ViewpointS—based on a digital medium—the ViewpointS Web Application—that enables and enhances the processes for sharing knowledge within a group and is equipped with metrics aimed at assessing collective and informal learning. In this article, we introduce by giving a brief state of the art about collective and informal learning, then outline our approach and medium, and finally, present and exploit a real-life experiment aimed at evaluating the ViewpointS approach and metrics.
Full article
►▼
Show Figures
Open AccessArticle
Conversation Concepts: Understanding Topics and Building Taxonomies for Financial Services
by
John P. McCrae, Pranab Mohanty, Siddharth Narayanan, Bianca Pereira, Paul Buitelaar, Saurav Karmakar and Rajdeep Sarkar
Cited by 2 | Viewed by 2975
Abstract
Knowledge graphs are proving to be an increasingly important part of modern enterprises, and new applications of such enterprise knowledge graphs are still being found. In this paper, we report on the experience with the use of an automatic knowledge graph system called
[...] Read more.
Knowledge graphs are proving to be an increasingly important part of modern enterprises, and new applications of such enterprise knowledge graphs are still being found. In this paper, we report on the experience with the use of an automatic knowledge graph system called Saffron in the context of a large financial enterprise and show how this has found applications within this enterprise as part of the “Conversation Concepts Artificial Intelligence” tool. In particular, we analyse the use cases for knowledge graphs within this enterprise, and this led us to a new extension to the knowledge graph system. We present the results of these adaptations, including the introduction of a semi-supervised taxonomy extraction system, which includes analysts in-the-loop. Further, we extend the kinds of relations extracted by the system and show how the use of the BERTand ELMomodels can produce high-quality results. Thus, we show how this tool can help realize a smart enterprise and how requirements in the financial industry can be realised by state-of-the-art natural language processing technologies.
Full article
►▼
Show Figures
Open AccessArticle
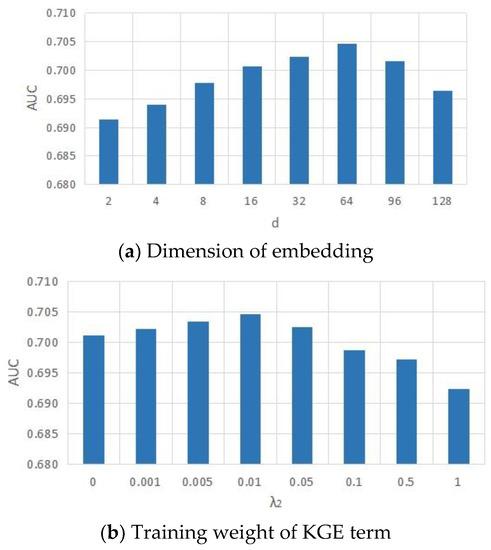
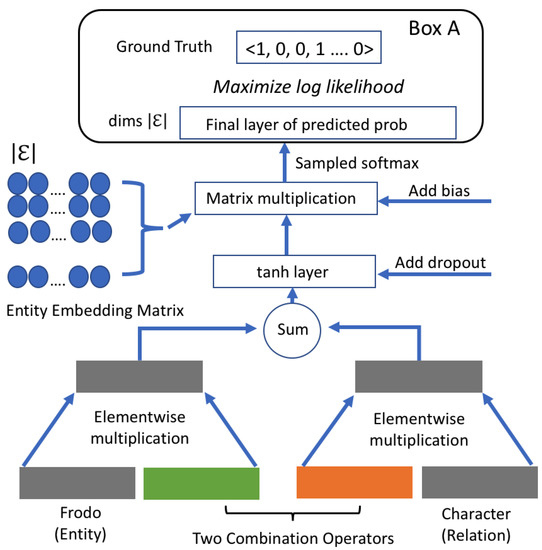
On Training Knowledge Graph Embedding Models
by
Sameh K. Mohamed, Emir Muñoz and Vit Novacek
Cited by 2 | Viewed by 3866
Abstract
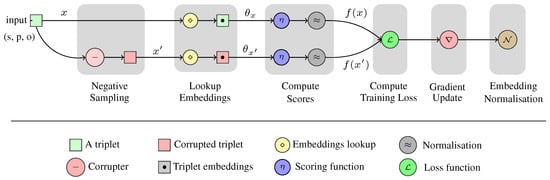
Knowledge graph embedding (KGE) models have become popular means for making discoveries in knowledge graphs (e.g., RDF graphs) in an efficient and scalable manner. The key to success of these models is their ability to learn low-rank vector representations for knowledge graph entities
[...] Read more.
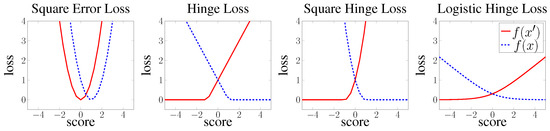
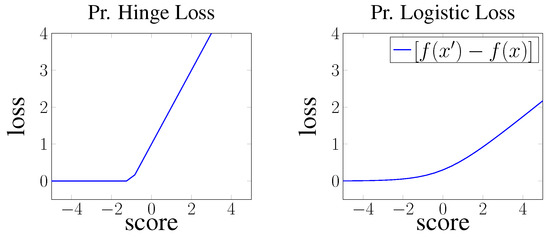
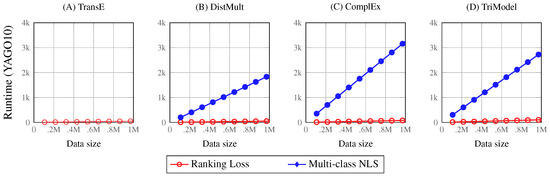
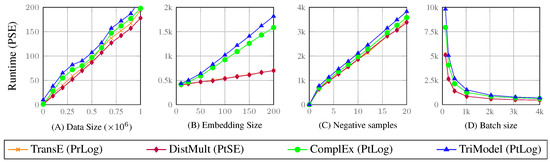
Knowledge graph embedding (KGE) models have become popular means for making discoveries in knowledge graphs (e.g., RDF graphs) in an efficient and scalable manner. The key to success of these models is their ability to learn low-rank vector representations for knowledge graph entities and relations. Despite the rapid development of KGE models, state-of-the-art approaches have mostly focused on new ways to represent embeddings interaction functions (i.e., scoring functions). In this paper, we argue that the choice of other training components such as the loss function, hyperparameters and negative sampling strategies can also have substantial impact on the model efficiency. This area has been rather neglected by previous works so far and our contribution is towards closing this gap by a thorough analysis of possible choices of training loss functions, hyperparameters and negative sampling techniques. We finally investigate the effects of specific choices on the scalability and accuracy of knowledge graph embedding models.
Full article
►▼
Show Figures
Open AccessArticle
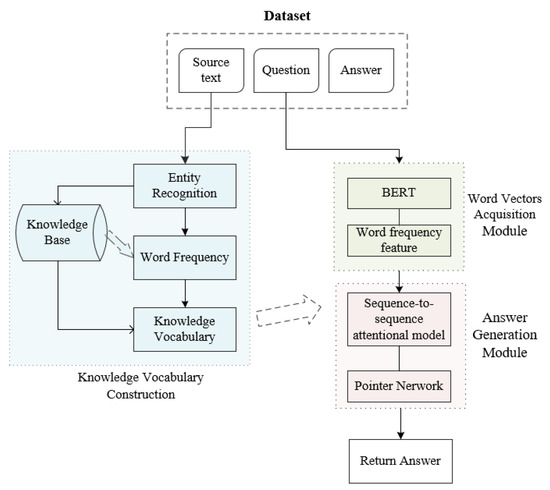
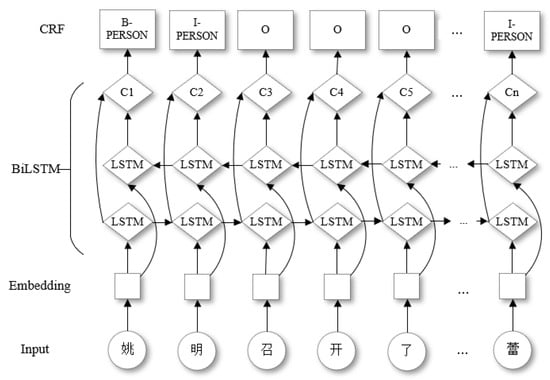
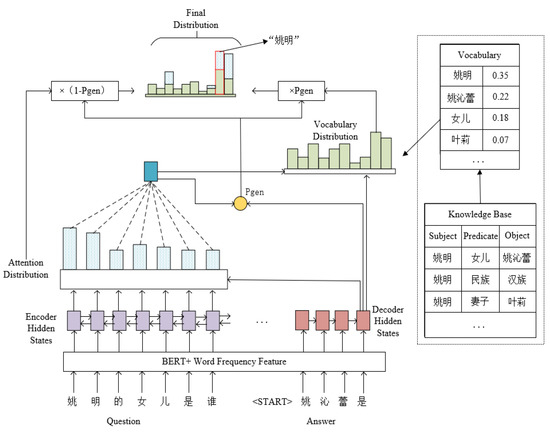
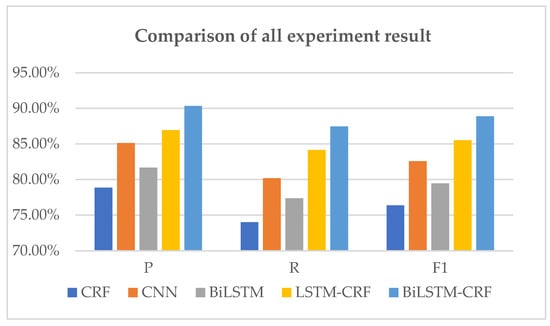
Research on Automatic Question Answering of Generative Knowledge Graph Based on Pointer Network
by
Shuang Liu, Nannan Tan, Yaqian Ge and Niko Lukač
Cited by 3 | Viewed by 3558
Abstract
Question-answering systems based on knowledge graphs are extremely challenging tasks in the field of natural language processing. Most of the existing Chinese Knowledge Base Question Answering(KBQA) can only return the knowledge stored in the knowledge base by extractive methods. Nevertheless, this processing does
[...] Read more.
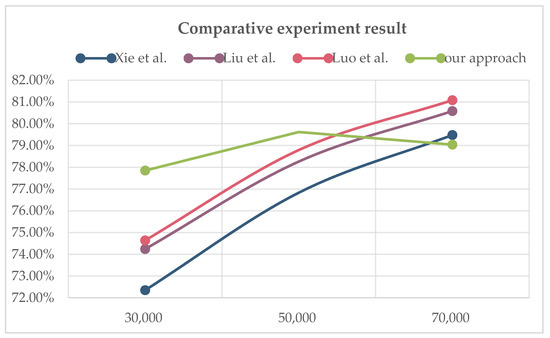
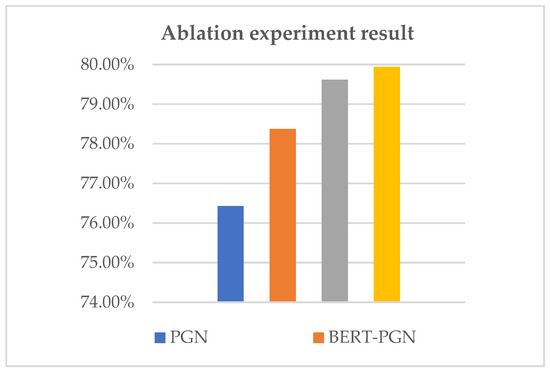
Question-answering systems based on knowledge graphs are extremely challenging tasks in the field of natural language processing. Most of the existing Chinese Knowledge Base Question Answering(KBQA) can only return the knowledge stored in the knowledge base by extractive methods. Nevertheless, this processing does not conform to the reading habits and cannot solve the Out-of-vocabulary(OOV) problem. In this paper, a new generative question answering method based on knowledge graph is proposed, including three parts of knowledge vocabulary construction, data pre-processing, and answer generation. In the word list construction, BiLSTM-CRF is used to identify the entity in the source text, finding the triples contained in the entity, counting the word frequency, and constructing it. In the part of data pre-processing, a pre-trained language model BERT combining word frequency semantic features is adopted to obtain word vectors. In the answer generation part, one combination of a vocabulary constructed by the knowledge graph and a pointer generator network(PGN) is proposed to point to the corresponding entity for generating answer. The experimental results show that the proposed method can achieve superior performance on WebQA datasets than other methods.
Full article
►▼
Show Figures
Open AccessArticle
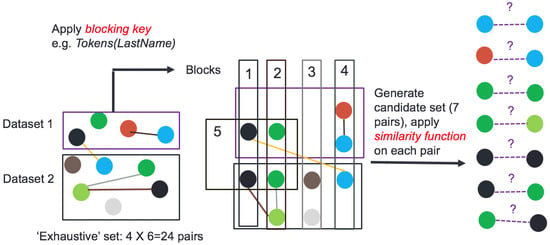
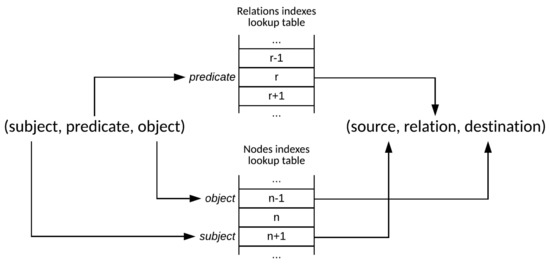
Unsupervised DNF Blocking for Efficient Linking of Knowledge Graphs and Tables
by
Mayank Kejriwal
Cited by 2 | Viewed by 2921
Abstract
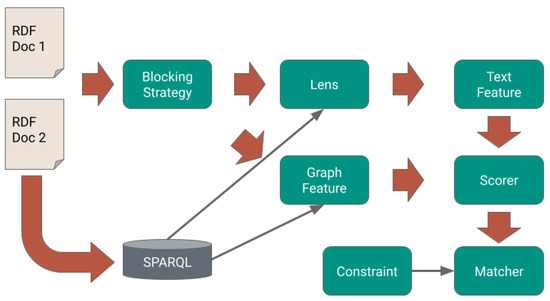
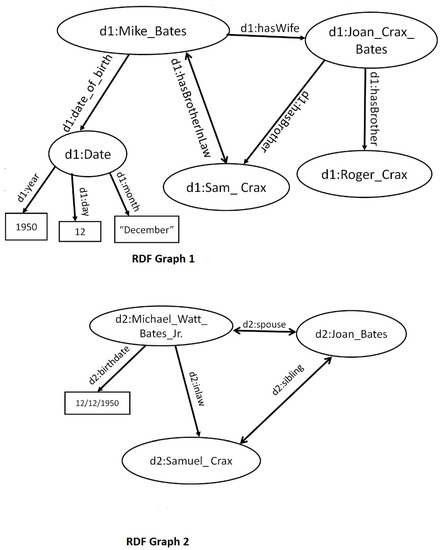
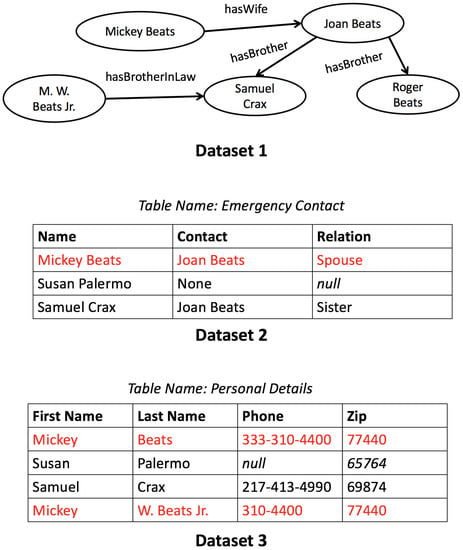
Entity Resolution (ER) is the problem of identifying co-referent entity pairs across datasets, including knowledge graphs (KGs). ER is an important prerequisite in many applied KG search and analytics pipelines, with a typical workflow comprising two steps. In the first ’blocking’ step, entities
[...] Read more.
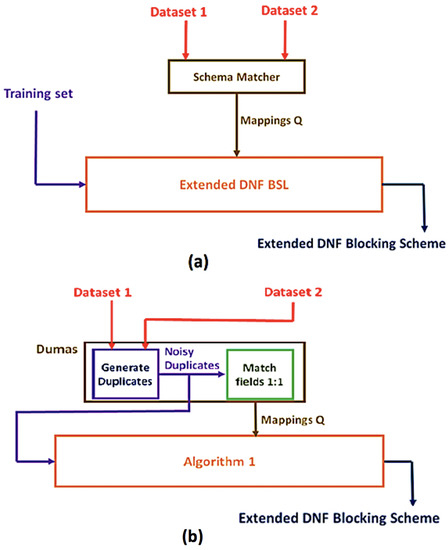
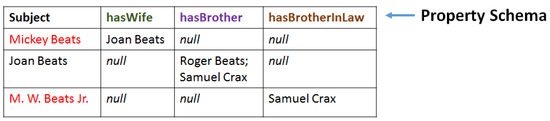
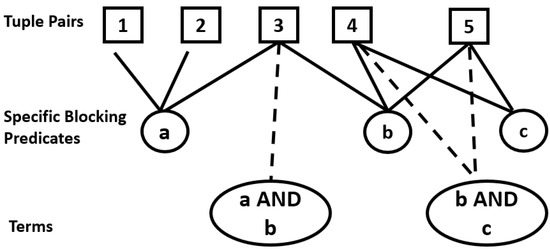
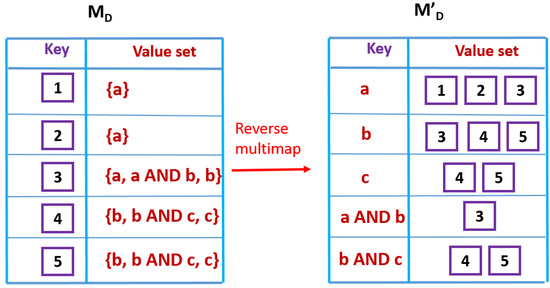
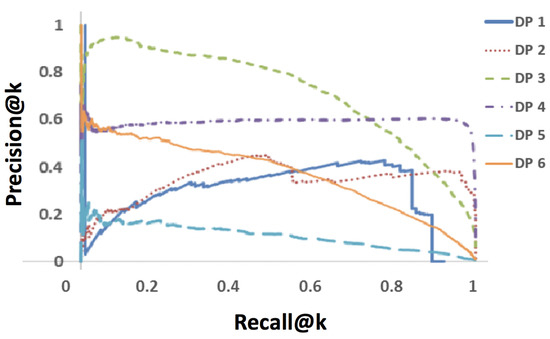
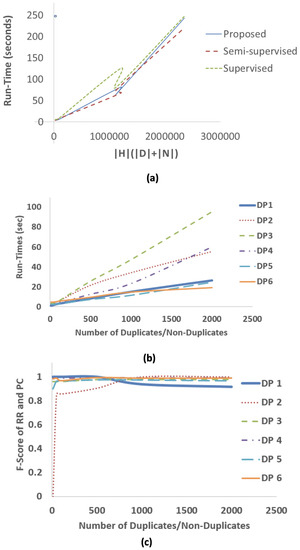
Entity Resolution (ER) is the problem of identifying co-referent entity pairs across datasets, including knowledge graphs (KGs). ER is an important prerequisite in many applied KG search and analytics pipelines, with a typical workflow comprising two steps. In the first ’blocking’ step, entities are mapped to blocks. Blocking is necessary for preempting comparing all possible pairs of entities, as (in the second ‘similarity’ step) only entities within blocks are paired and compared, allowing for significant computational savings with a minimal loss of performance. Unfortunately, learning a blocking scheme in an unsupervised fashion is a non-trivial problem, and it has not been properly explored for heterogeneous, semi-structured datasets, such as are prevalent in industrial and Web applications. This article presents an unsupervised algorithmic pipeline for learning Disjunctive Normal Form (DNF) blocking schemes on KGs, as well as structurally heterogeneous tables that may not share a common schema. We evaluate the approach on six real-world dataset pairs, and show that it is competitive with supervised and semi-supervised baselines.
Full article
►▼
Show Figures
Open AccessArticle
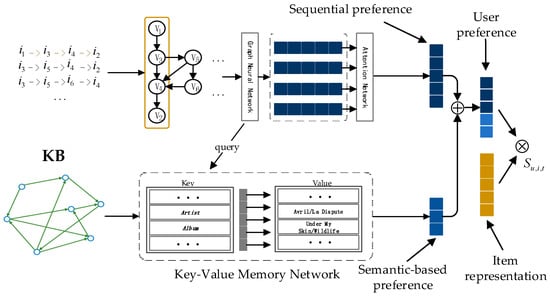
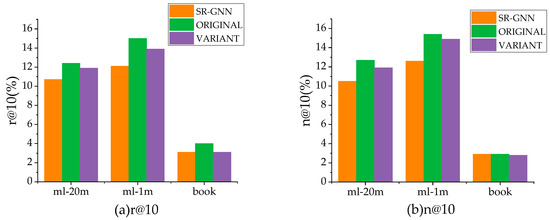
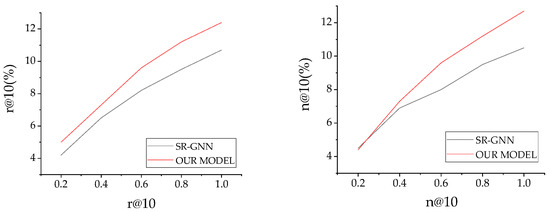
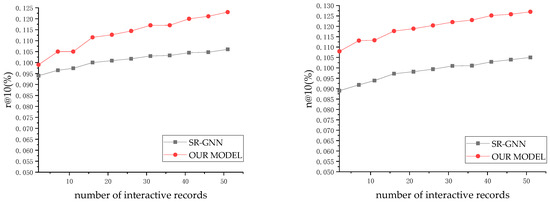
Knowledge-Enhanced Graph Neural Networks for Sequential Recommendation
by
Baocheng Wang and Wentao Cai
Cited by 20 | Viewed by 6261
Abstract
With the rapid increase in the popularity of big data and internet technology, sequential recommendation has become an important method to help people find items they are potentially interested in. Traditional recommendation methods use only recurrent neural networks (RNNs) to process sequential data.
[...] Read more.
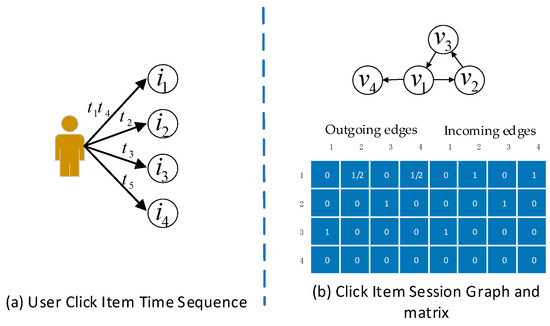
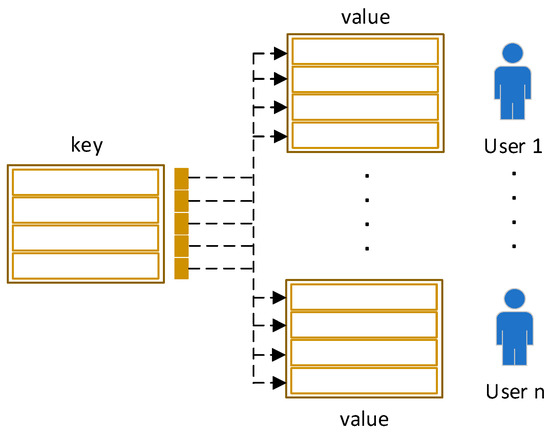
With the rapid increase in the popularity of big data and internet technology, sequential recommendation has become an important method to help people find items they are potentially interested in. Traditional recommendation methods use only recurrent neural networks (RNNs) to process sequential data. Although effective, the results may be unable to capture both the semantic-based preference and the complex transitions between items adequately. In this paper, we model separated session sequences into session graphs and capture complex transitions using graph neural networks (GNNs). We further link items in interaction sequences with existing external knowledge base (KB) entities and integrate the GNN-based recommender with key-value memory networks (KV-MNs) to incorporate KB knowledge. Specifically, we set a key matrix to many relation embeddings that learned from KB, corresponding to many entity attributes, and set up a set of value matrices storing the semantic-based preferences of different users for the corresponding attribute. By using a hybrid of a GNN and KV-MN, each session is represented as the combination of the current interest (i.e., sequential preference) and the global preference (i.e., semantic-based preference) of that session. Extensive experiments on three public real-world datasets show that our method performs better than baseline algorithms consistently.
Full article
►▼
Show Figures
Planned Papers
The below list represents only planned manuscripts. Some of these
manuscripts have not been received by the Editorial Office yet. Papers
submitted to MDPI journals are subject to peer-review.
Title: Hierarchical Classification of Semantic Answer Types For Short Text Questions
Authors: Remzi Çelebi
Affiliation: Institute of Data Science, Maastricht University
Abstract: Question answering systems have recently become integrated with many smart devices and search engines. One of the methods to filter irrelevant results and improve general search and retrieval performance in question answering systems is to predict the type of answer. Predicting granular answer types for a question from a big ontology is a greater challenge due to the large number of possible types. Here we present our approach to response type prediction using the datasets provided for the International Semantic Web Conference (ISWC 2020) SMART Task Challenge. The task consists of training data of questions, categories, and types from large ontologies, and the challenge participants are asked to provide the categories and types from the WikiData and the DBpedia ontologies questions in the test dataset. The DBpedia dataset contains 17,571 training questions and 4,393 test questions, and the WikiData dataset has 18,251 training questions and 4,571 test questions. We propose a 3-step approach to tackle the challenge task. We start by building a classifier that predicts the category of the types and build another classifier just for resource types. The second model will predict the most general (frequent) type for each question, ignoring the type hierarchy. For these two models, we use a multi-class text classification algorithm built-in fastai library. Next, we train a third classifier to find more specific types (sub-types) for each question based on the previous predicted general types. This problem is modeled as a binary classification where the given generic type and specific type match the question in the positive examples, but not for negative examples. On the DBpedia test set, we achieve a score of 0.62 with NDCG@5 metric and 0.61 with NDCG@10 metric.
Title: Unsupervised DNF Blocking for Efficient Linking of Knowledge Graphs and Tables
Authors: Mayank Kejriwal
Affiliation: Department of Industrial and Systems Engineering, and a Research Lead at the USC Information Sciences Institute
Abstract: Entity Resolution concerns identifying co-referent entity pairs across datasets, including knowledge graphs (KG). A typical workflow comprises two steps, and is an important step in an applied KG search and analytics pipeline. In the first step, a blocking method uses a one-many function called a blocking scheme to map entities to blocks. In the second step, entities sharing a block are paired and compared. Current Disjunctive Normal Form blocking scheme learners (DNF-BSLs) apply only to structurally homogeneous tables. We present an unsupervised algorithmic pipeline for learning DNF blocking schemes on Resource Description Framework (RDF) graph datasets, as well as structurally heterogeneous tables. Previous DNF-BSLs are admitted as special cases. We evaluate the pipeline on six real-world dataset pairs. Unsupervised results are shown to be competitive with supervised and semi-supervised baselines. To the best of our knowledge, this is the first unsupervised DNF-BSL that admits RDF graphs and structurally heterogeneous tables as inputs, thereby enabling many more applications of a heterogeneous nature.
Title: Collaboration Spotting X - Retrieving, Analyzing and Reporting Through Network Data Analysis
Authors: Christian Guetl; Aleksandar Bobic
Affiliation: --
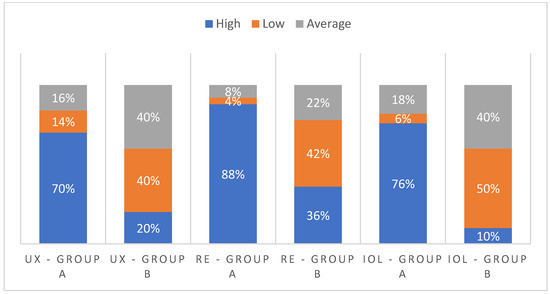
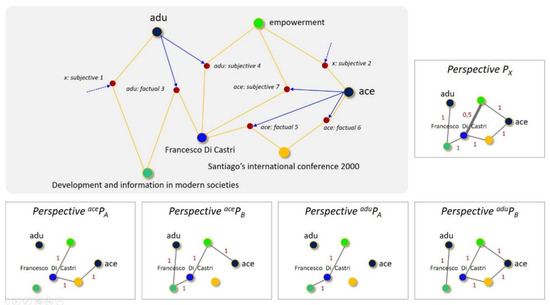
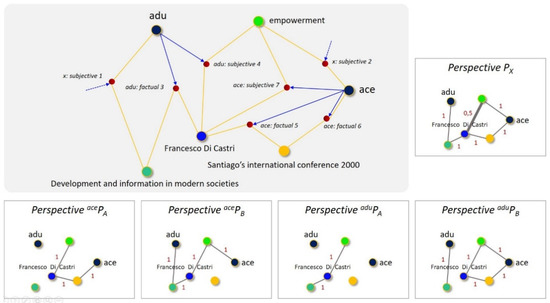
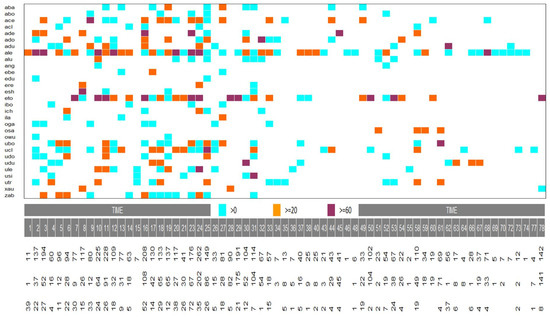
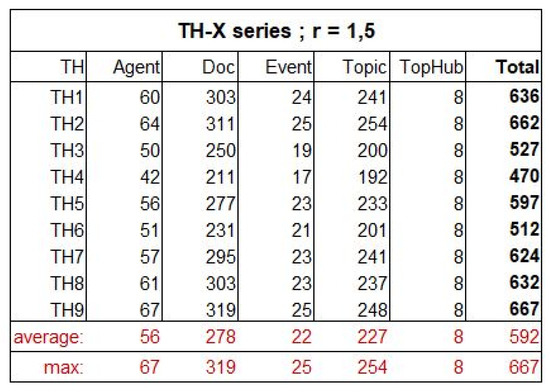
Abstract: Extracting insights from data is a complicated process that usually includes multiple steps, from retrieving and transforming to exploring and interpreting. To the best of our knowledge, most of today's tools that focus on such processes are either inaccessible due to their complicated nature, proprietary and expensive, or focus on traditional data representations that do not adequately represent connections in data. To address these issues as part of this work, we introduce Collaboration Spotting X, an open source network-based visual analytics tool which enables users to perform exploratory searching, data analysis and insight extraction. A preliminary tool evaluation was conducted through use cases, user surveying, interaction data tracking, and expert interviews. Despite the complexity and lower usability scores of the UI the users seem to have experienced positive emotions thought using the tool and recognised its potential.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}