





Comput. Sci. Math. Forum 2023, 8(1), 99; https://doi.org/10.3390/cmsf2023008099 - 10 Apr 2024
Abstract
►
Show Figures
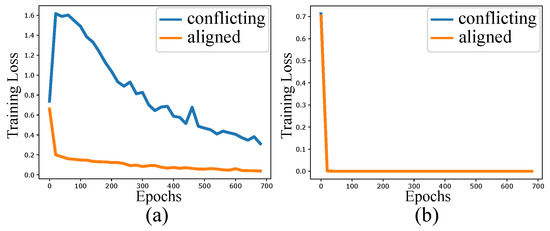
Current encryption technologies mostly rely on complex algorithms or difficult mathematical problems to improve security. Therefore, it is difficult for these encryption technologies to possess both high security and high efficiency, which are two properties that people desire. Trying to solve this dilemma,
[...] Read more.
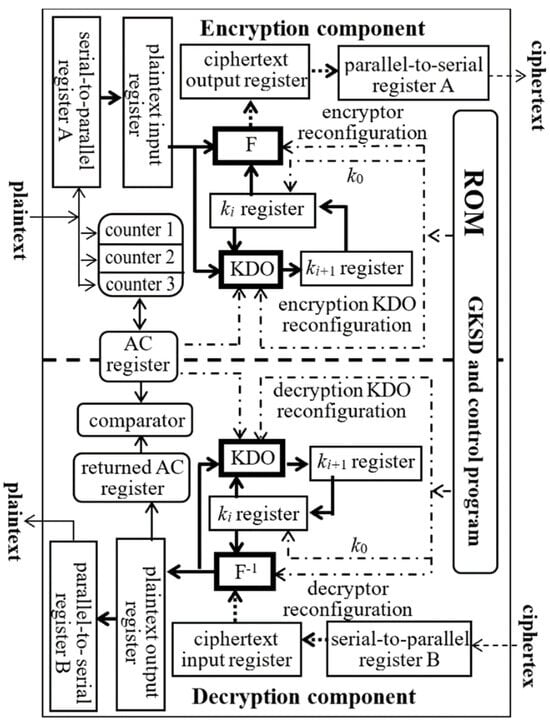
Current encryption technologies mostly rely on complex algorithms or difficult mathematical problems to improve security. Therefore, it is difficult for these encryption technologies to possess both high security and high efficiency, which are two properties that people desire. Trying to solve this dilemma, we built a new encryption technology, called configurable encryption technology (CET), based on the typical structure of reconfigurable quaternary logic operator (RQLO) that was invented in 2018. We designed the CET as a block cipher for symmetric encryption, where we use four 32-quit RQLO typical structures as the encryptor, decryptor, and two key derivation operators. Taking advantage of the reconfigurability of the RQLO typical structure, the CET can automatically reconfigure the keys and symbol substitution rules of the encryptor and decryptor after each encryption operation. We found that a chip containing about 70,000 transistors and 500 MB of nonvolatile memory could provide all the CET devices and generalized keys needed for any user’s lifetime, to implement a practical one-time pad encryption technology. We also developed a strategy to solve the current key distribution problem with prestored generalized key source data and on-site appointment codes. The CET is expected to provide a theoretical basis and core technology for using the RQLO to build a new cryptographic system with high security, fast encryption/decryption speed, and low manufacturing cost.
Full article
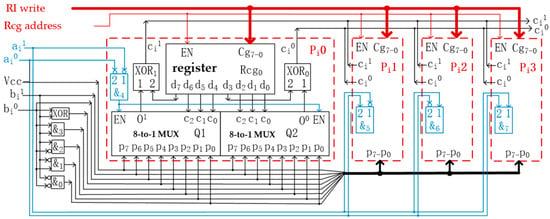
Figure 1


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}