Software Engineering: Computer Science and System
A project collection of Applied Sciences (ISSN 2076-3417). This project collection belongs to the section "Computing and Artificial Intelligence".
Papers displayed on this page all arise from the same project. Editorial decisions were made independently of project staff and handled by the Editor-in-Chief or qualified Editorial Board members.
Viewed by 86321
Share This Project Collection
Editor
Project Overview
Dear Colleagues,
Software is fast becoming an integral part of our everyday life and is gradually impacting human beings and society. It involves programming languages, databases, software development tools, system platforms, standards, design patterns, and so on.
In modern society, software is used in many ways. Typical types of software include e-mail clients, embedded systems, HMIs, office suites, operating systems, compilers, databases, and games. At the same time, computer software finds application in almost all industries, such as manufacturing, agriculture, banking, aviation, and government departments. Furthermore the software plays an extremely important role in scientific research: instruments control software, data analysis, scientific results publishing. These applications have promoted the development of the economy and society as well as the efficiency of work and life.
This Special Issue aims to advance the state of the art by gathering original research in the field of software-intensive systems, fundamental connections between software engineering and information theory, and, especially, sustainable software product lines.
Dr. Vito Conforti
Guest Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Applied Sciences is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- mathematics and computer science
- software industry
- software engineering
- software for the science research
Related Special Issue
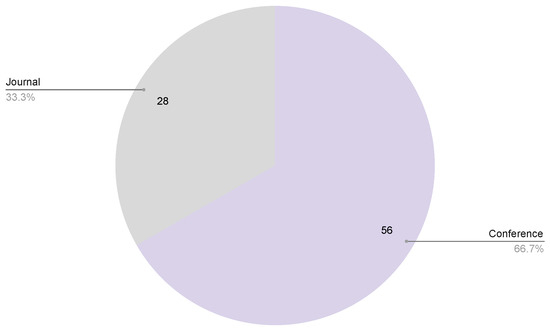
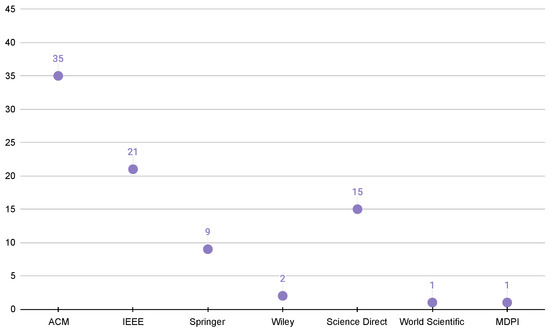
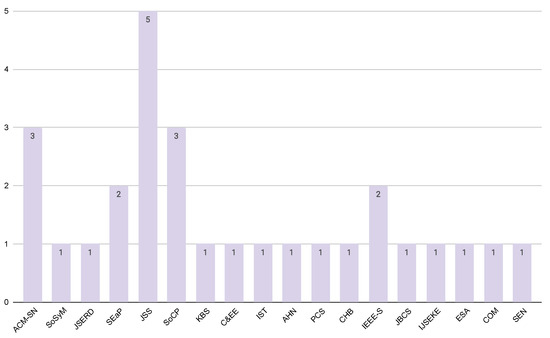
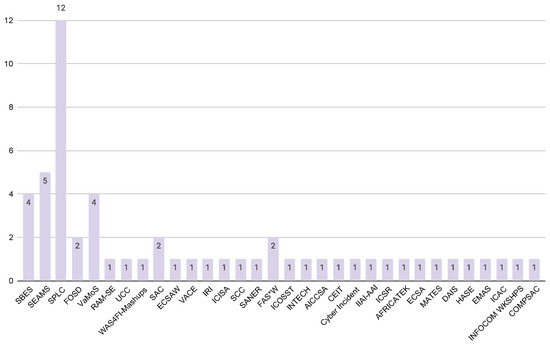
Published Papers (30 papers)
Open AccessArticle
Adaptive Test Suits Generation for Self-Adaptive Systems Using SPEA2 Algorithm
by
Muhammad Abid Jamil, Mohamed K. Nour, Saud S. Alotaibi, Mohammad Jabed Hussain, Syed Mutiullah Hussaini and Atif Naseer
Viewed by 788
Abstract
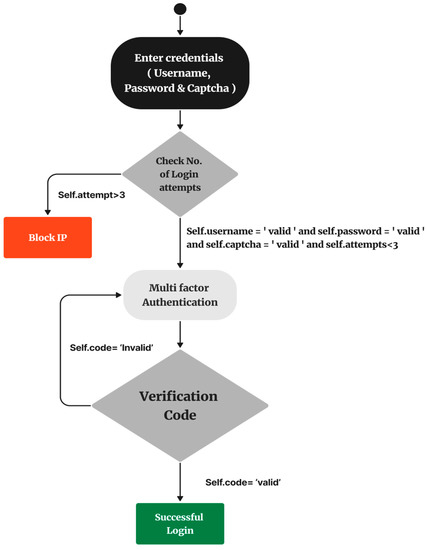
Self-adaptive systems are capable of reconfiguring themselves while in use to reduce the risks forced by environments for which they may not have been specifically designed. Runtime validation techniques are required because complex self-adaptive systems must consistently offer acceptable behavior for important services.
[...] Read more.
Self-adaptive systems are capable of reconfiguring themselves while in use to reduce the risks forced by environments for which they may not have been specifically designed. Runtime validation techniques are required because complex self-adaptive systems must consistently offer acceptable behavior for important services. The runtime testing can offer further confidence that a self-adaptive system will continue to act as intended even when operating in unknowable circumstances. This article introduces an evolutionary framework that supports adaptive testing for self-adaptive systems. The objective is to ensure that the adaptive systems continue to operate following its requirements and that both test plans and test cases continuously stay relevant to shifting operational conditions. The proposed approach using the Strength Pareto Evolutionary Algorithm 2 (SPEA2) algorithm facilitates both the execution and adaptation of runtime testing operations.
Full article
►▼
Show Figures
Open AccessArticle
Open-Source Software Development in Cheminformatics: A Qualitative Analysis of Rationales
by
Johannes Pernaa, Aleksi Takala, Veysel Ciftci, José Hernández-Ramos, Lizethly Cáceres-Jensen and Jorge Rodríguez-Becerra
Viewed by 1421
Abstract
This qualitative research explored the rationales of open-source development in cheminformatics. The objective was to promote open science by mapping out and categorizing the reasons why open-source development is being carried out. This topic is important because cheminformatics has an industrial background and
[...] Read more.
This qualitative research explored the rationales of open-source development in cheminformatics. The objective was to promote open science by mapping out and categorizing the reasons why open-source development is being carried out. This topic is important because cheminformatics has an industrial background and open-source is the key solution in promoting the growth of cheminformatics as an independent academic field. The data consisted of 87 research articles that were analyzed using qualitative content analysis. The analysis produced six rationale categories: (1) Develop New Software, (2) Update Current Features, Tools, or Processes, (3) Improve Usability, (4) Support Open-source Development and Open Science, (5) Fulfill Chemical Information Needs, and (6) Support Chemistry Learning and Teaching. This classification can be used in designing rationales for future software development projects, which is one of the largest research areas in cheminformatics. In particular, there is a need to develop cheminformatics education for which software development can serve as an interesting multidisciplinary framework.
Full article
Open AccessArticle
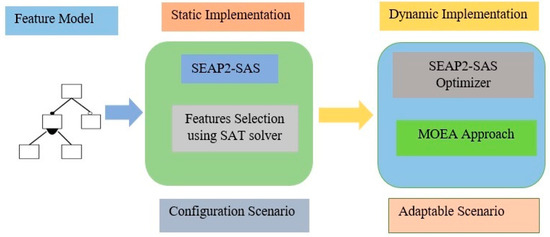
Software Product Line Maintenance Using Multi-Objective Optimization Techniques
by
Muhammad Abid Jamil, Mohamed K. Nour, Saud S. Alotaibi, Mohammad Jabed Hussain, Syed Mutiullah Hussaini and Atif Naseer
Cited by 2 | Viewed by 867
Abstract
Currently, software development is more associated with families of configurable software than the single implementation of a product. Due to the numerous possible combinations in a software product line, testing these families of software product lines (SPLs) is a difficult undertaking. Moreover, the
[...] Read more.
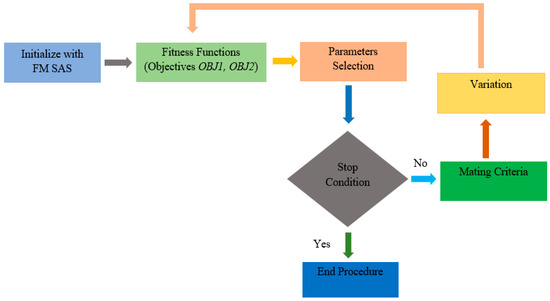
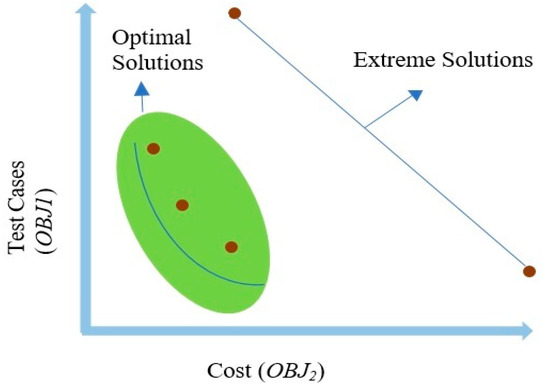
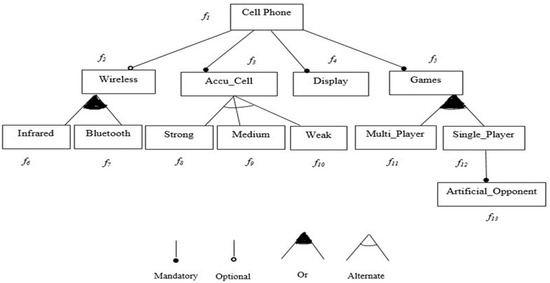
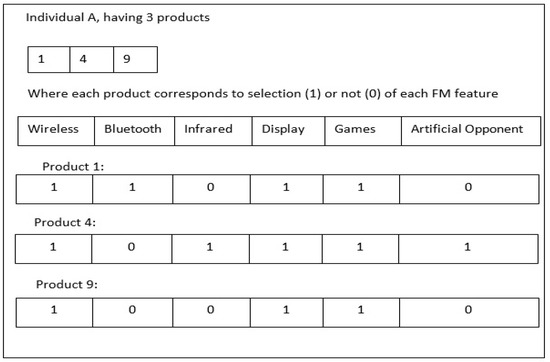
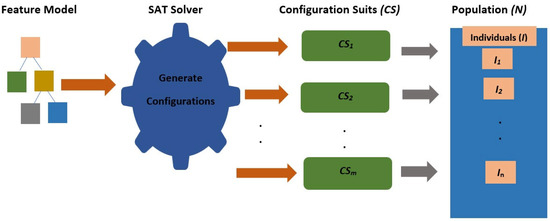
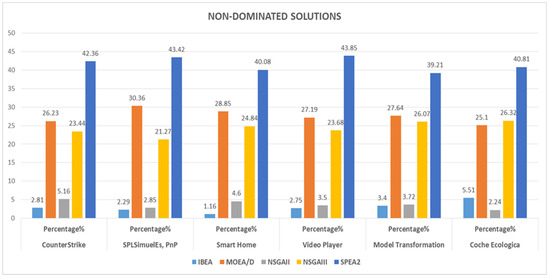
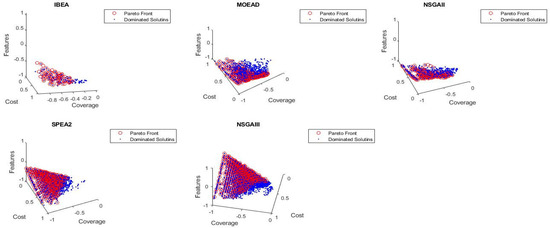
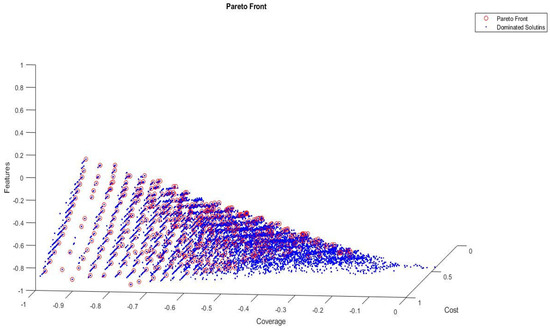
Currently, software development is more associated with families of configurable software than the single implementation of a product. Due to the numerous possible combinations in a software product line, testing these families of software product lines (SPLs) is a difficult undertaking. Moreover, the presence of optional features makes the testing of SPLs impractical. Several features are presented in SPLs, but due to the environment’s time and financial constraints, these features are rendered unfeasible. Thus, testing subsets of configured products is one approach to solving this issue. To reduce the testing effort and obtain better results, alternative methods for testing SPLs are required, such as the combinatorial interaction testing (CIT) technique. Unfortunately, the CIT method produces unscalable solutions for large SPLs with excessive constraints. The CIT method costs more because of feature combinations. The optimization of the various conflicting testing objectives, such as reducing the cost and configuration number, should also be considered. In this article, we proposed a search-based software engineering solution using multi-objective evolutionary algorithms (MOEAs). In particular, the research was applied to different types of MOEA method: the Indicator-Based Evolutionary Algorithm (IBEA), Multi-objective Evolutionary Algorithm based on Decomposition (MOEA/D), Non-dominant Sorting Genetic Algorithm II (NSGAII), NSGAIII, and Strength Pareto Evolutionary Algorithm 2 (SPEA2). The results of the algorithms were examined in the context of distinct objectives and two quality indicators. The results revealed how the feature model attributes, implementation context, and number of objectives affected the performances of the algorithms.
Full article
►▼
Show Figures
Open AccessArticle
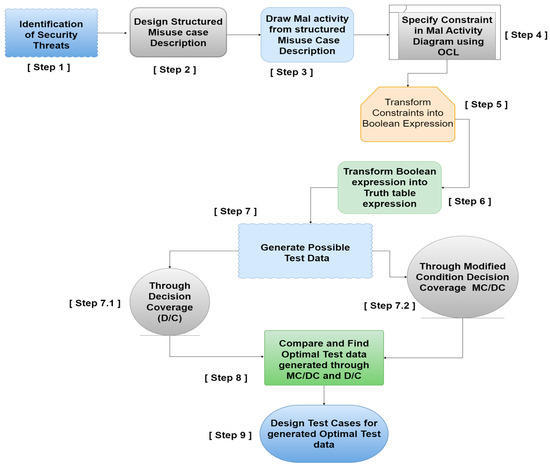
Maximizing Test Coverage for Security Threats Using Optimal Test Data Generation
by
Talha Hussain, Rizwan Bin Faiz, Mohammad Aljaidi, Adnan Khattak, Ghassan Samara, Ayoub Alsarhan and Raed Alazaidah
Cited by 1 | Viewed by 911
Abstract
As time continues to advance, the need for robust security threat mitigation has become increasingly vital in software. It is a constant struggle to maximize test coverage through optimal data generation. We conducted explanatory research to maximize test coverage of security requirements as
[...] Read more.
As time continues to advance, the need for robust security threat mitigation has become increasingly vital in software. It is a constant struggle to maximize test coverage through optimal data generation. We conducted explanatory research to maximize test coverage of security requirements as modeled in the structured misuse case description (SMCD). The acceptance test case is designed through the structured misuse case description for mitigation of security threats. Mal activity is designed from SMCD upon which constraints are specified in object constraint language (OCL) in order to minimize human dependency and improve consistency in the optimal test case design. The study compared two state-of-the-art test coverage maximization approaches through optimal test data generation. It was evident through the results that MC/DC generated optimal test data, i.e., n + 1 test conditions in comparison to the decision coverage approach, i.e., 2
n test conditions for security threats. Thus, MC/DC resulted in a significantly lower number of test cases yet maximized test coverage of security threats. We, therefore, conclude that MC/DC maximizes test coverage through optimal test data in comparison to decision coverage at the design level for security threat mitigation.
Full article
►▼
Show Figures
Open AccessArticle
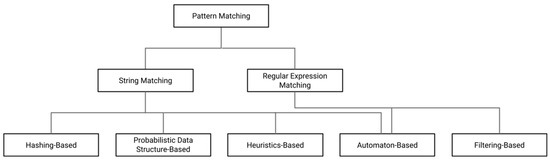
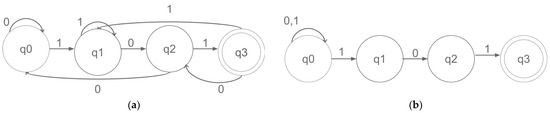
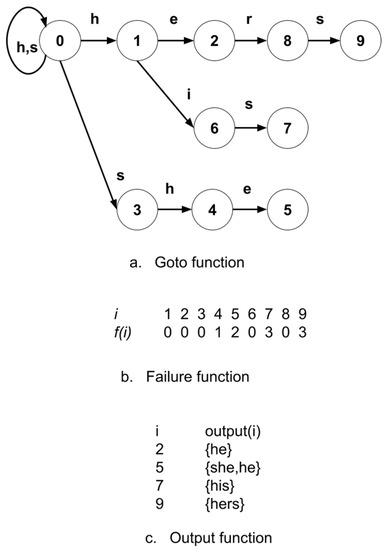
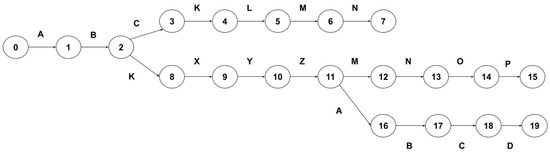
Accelerating Pattern Matching Using a Novel Multi-Pattern-Matching Algorithm on GPU
by
Merve Çelebi and Uraz Yavanoğlu
Cited by 1 | Viewed by 1105
Abstract
Nowadays, almost all network traffic is encrypted. Attackers hide themselves using this traffic and attack over encrypted channels. Inspections performed only on packet headers and metadata are insufficient for detecting cyberattacks over encrypted channels. Therefore, it is important to analyze packet contents in
[...] Read more.
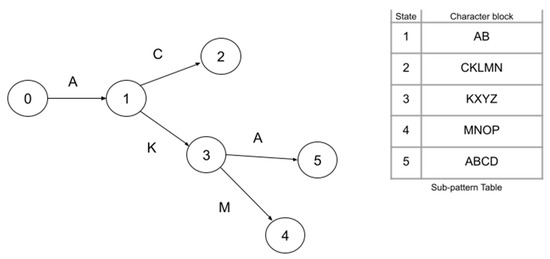
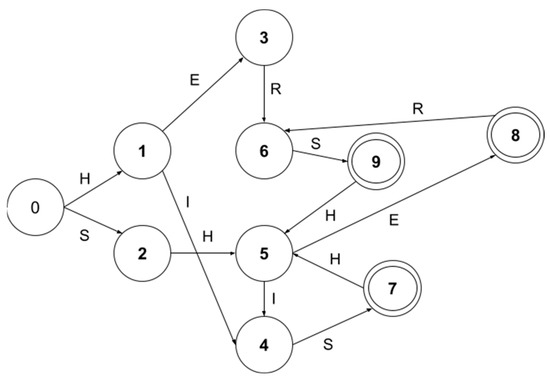
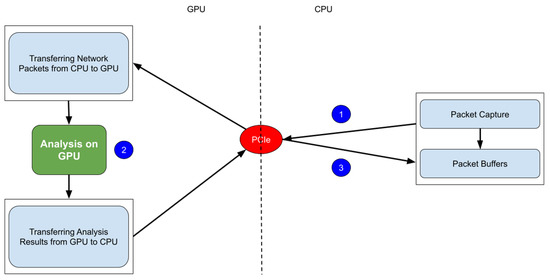
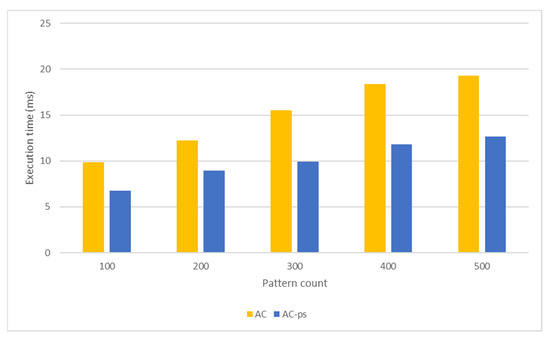
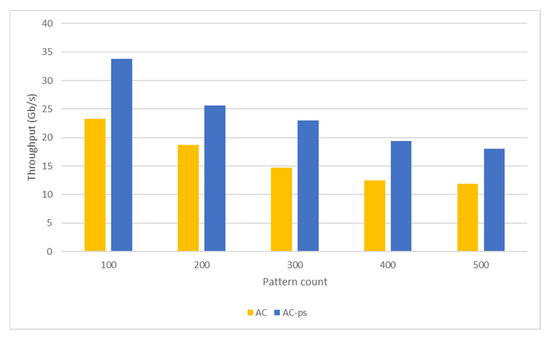
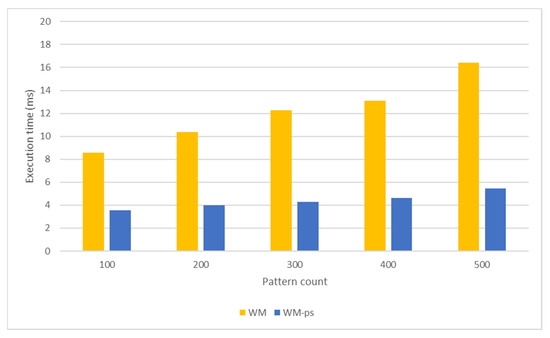
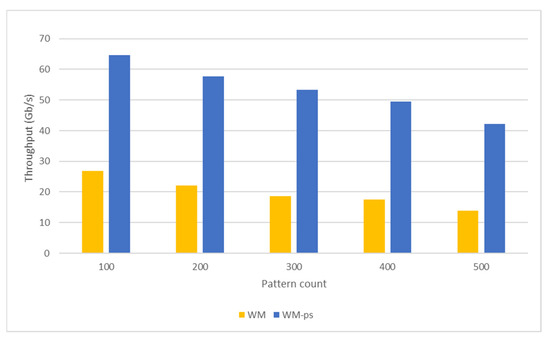
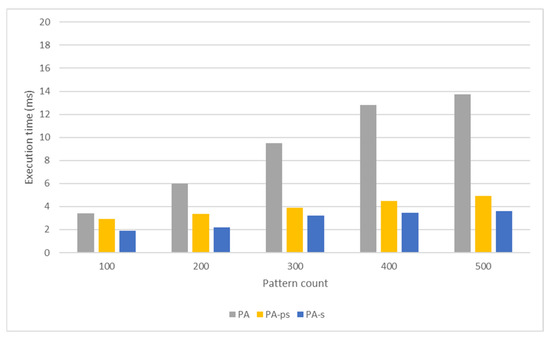
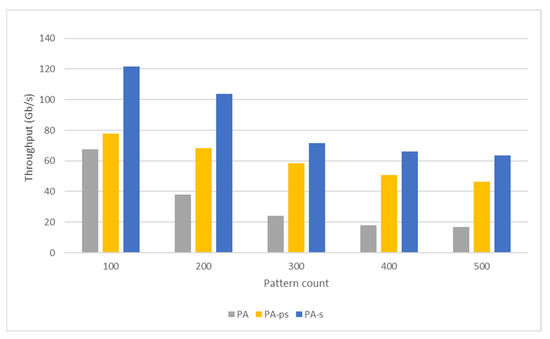
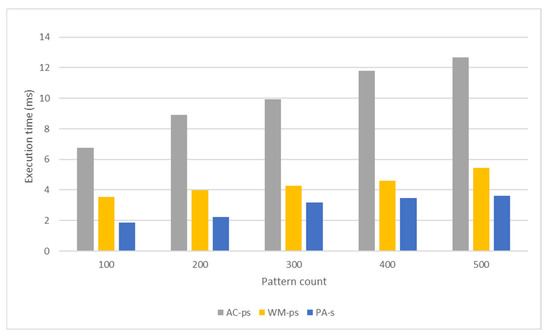
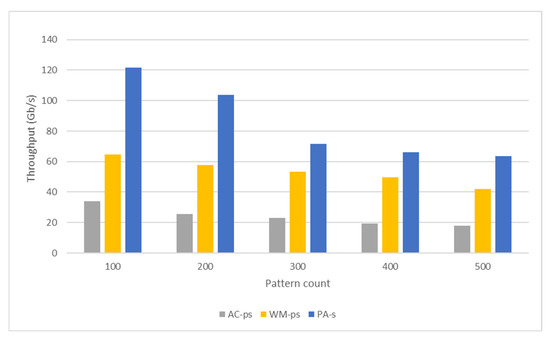
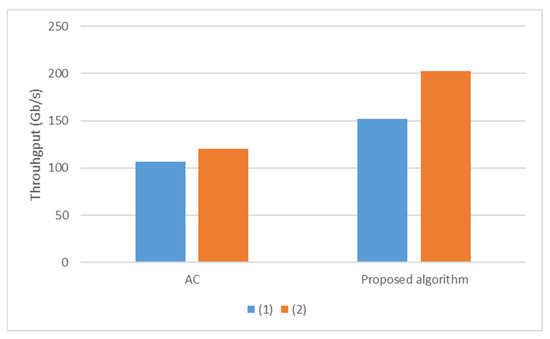
Nowadays, almost all network traffic is encrypted. Attackers hide themselves using this traffic and attack over encrypted channels. Inspections performed only on packet headers and metadata are insufficient for detecting cyberattacks over encrypted channels. Therefore, it is important to analyze packet contents in applications that require control over payloads, such as content filtering, intrusion detection systems (IDSs), data loss prevention systems (DLPs), and fraud detection. This technology, known as deep packet inspection (DPI), provides full control over the communication between two end stations by keenly analyzing the network traffic. This study proposes a multi-pattern-matching algorithm that reduces the memory space and time required in the DPI pattern matching compared to traditional automaton-based algorithms with its ability to process more than one packet payload character at once. The pattern-matching process in the DPI system created to evaluate the performance of the proposed algorithm (PA) is conducted on the graphics processing unit (GPU), which accelerates the processing of network packets with its parallel computing capability. This study compares the PA with the Aho-Corasick (AC) and Wu–Manber (WM) algorithms, which are widely used in the pattern-matching process, considering the memory space required and throughput obtained. Algorithm tables created with a dataset containing 500 patterns use 425 and 688 times less memory space than those of the AC and WM algorithms, respectively. In the pattern-matching process using these tables, the PA is 3.5 and 1.5 times more efficient than the AC and WM algorithms, respectively.
Full article
►▼
Show Figures
Open AccessArticle
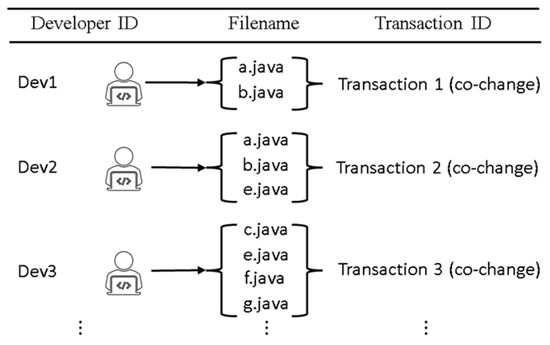
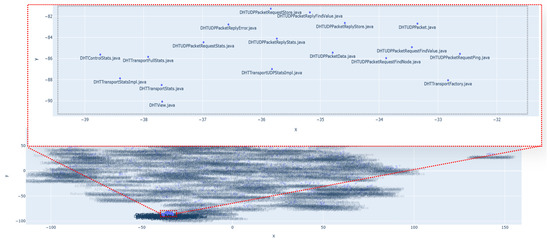
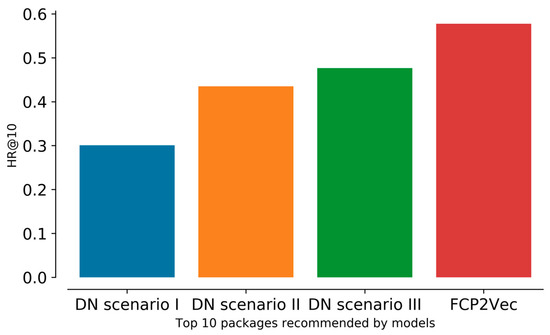
FCP2Vec: Deep Learning-Based Approach to Software Change Prediction by Learning Co-Changing Patterns from Changelogs
by
Hamdi Abdurhman Ahmed and Jihwan Lee
Cited by 1 | Viewed by 900
Abstract
As software systems evolve, they become more complex and larger, creating challenges in predicting change propagation while maintaining system stability and functionality. Existing studies have explored extracting co-change patterns from changelog data using data-driven methods such as dependency networks; however, these approaches suffer
[...] Read more.
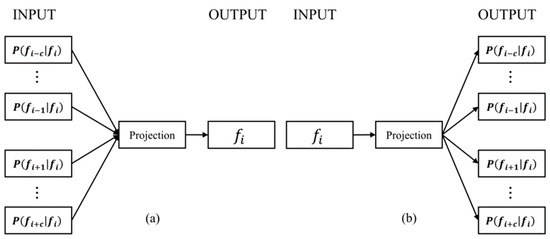
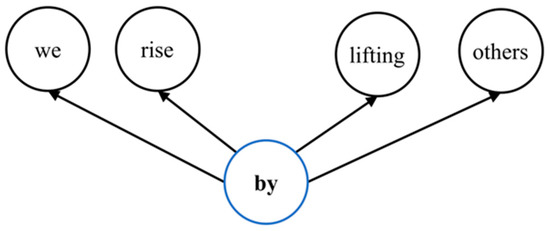
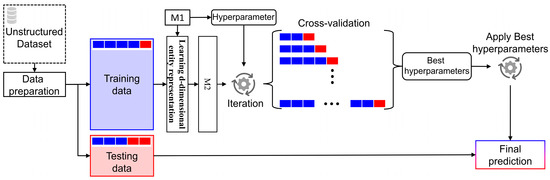
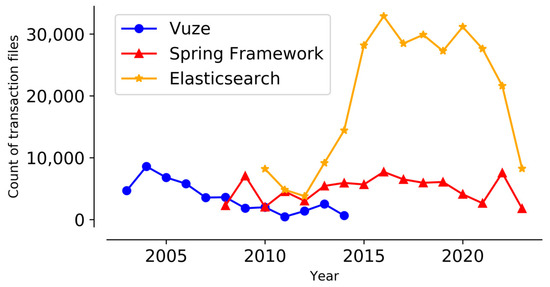
As software systems evolve, they become more complex and larger, creating challenges in predicting change propagation while maintaining system stability and functionality. Existing studies have explored extracting co-change patterns from changelog data using data-driven methods such as dependency networks; however, these approaches suffer from scalability issues and limited focus on high-level abstraction (package level). This article addresses these research gaps by proposing a file-level change propagation to vector (FCP2Vec) approach. FCP2Vec is a recommendation system designed to aid developers by suggesting files that may undergo change propagation subsequently, based on the file being presently worked on. We carried out a case study utilizing three publicly available datasets: Vuze, Spring Framework, and Elasticsearch. These datasets, which consist of open-source Java-based software development changelogs, were extracted from version control systems. Our technique learns the historical development sequence of transactional software changelog data using a skip-gram method with negative sampling and unsupervised nearest neighbors. We validate our approach by analyzing historical data from the software development changelog for more than ten years. Using multiple metrics, such as the normalized discounted cumulative gain at K (NDCG@K) and the hit ratio at K (HR@K), we achieved an average HR@K of 0.34 at the file level and an average HR@K of 0.49 at the package level across the three datasets. These results confirm the effectiveness of the FCP2Vec method in predicting the next change propagation from historical changelog data, addressing the identified research gap, and show a 21% better accuracy than in the previous study at the package level.
Full article
►▼
Show Figures
Open AccessArticle
Toward a Comprehensive Understanding and Evaluation of the Sustainability of E-Health Solutions
by
Azza Alajlan and Malak Baslyman
Viewed by 1473
Abstract
Digital health transformation (DHT) has been deployed rapidly worldwide, and many e-health solutions are being invented and improved on an accelerating basis. Healthcare already faces many challenges in terms of reducing costs and allocating resources optimally, while improving provided services. E-solutions in healthcare
[...] Read more.
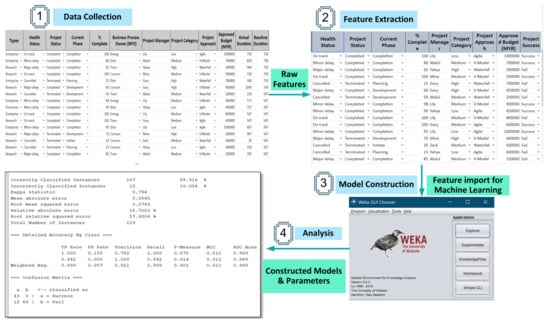
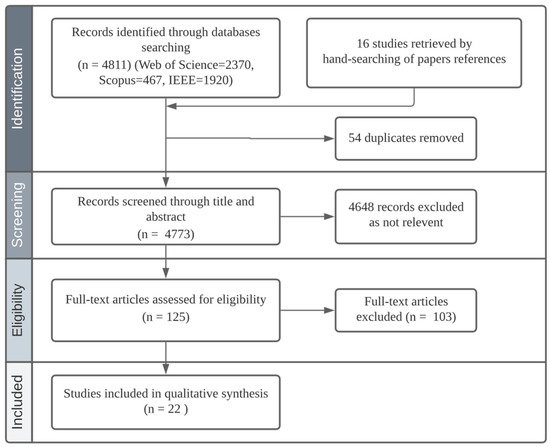
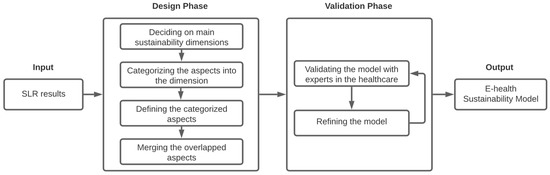
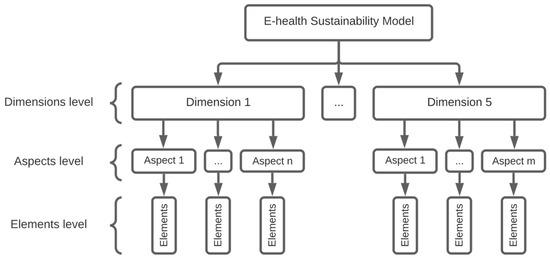
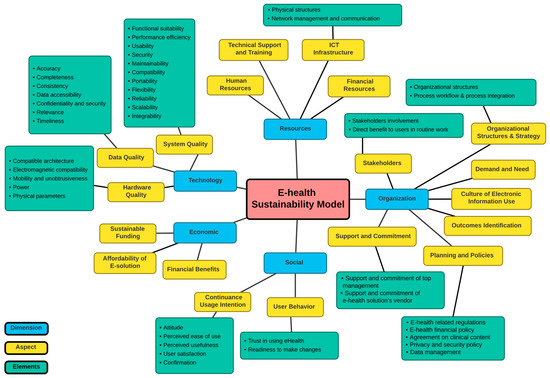
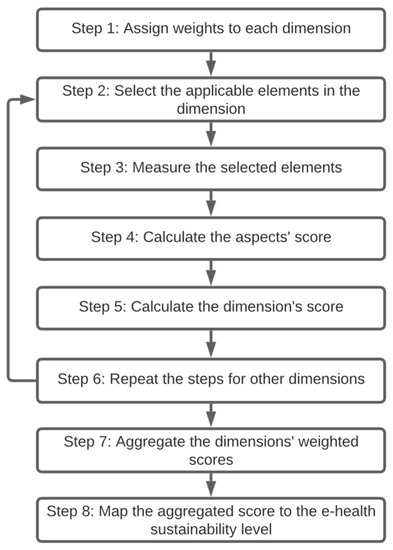
Digital health transformation (DHT) has been deployed rapidly worldwide, and many e-health solutions are being invented and improved on an accelerating basis. Healthcare already faces many challenges in terms of reducing costs and allocating resources optimally, while improving provided services. E-solutions in healthcare can be a key enabler for improvements while controlling the budget; however, if the sustainability of those solutions is not assessed, many resources directed towards e-solutions and the cost of adoption/implementation will be wasted. Thus, it is important to assess the sustainability of newly proposed or already in-use e-health solutions. In the literature, there is a paucity of empirically driven comprehensive sustainability models and assessment tools to guide practices in real-world cases. Hence, this study proposes a comprehensive sustainability model for e-health solutions to assess the essential sustainability aspects of e-health solutions and anticipate the likelihood of their sustainability. To build the model, a systematic literature review (SLR) was conducted to extract the e-health sustainability dimensions and elements. In addition, the SLR analyzes the existing definitions of sustainability in healthcare and sustainability assessment methods. The proposed sustainability model has five dimensions, namely; technology, organization, economic, social, and resources. Each dimension has aspects that provide another level of required detail to assess sustainability. In addition, an assessment method was developed for this model to assess the aspects of each dimension, resulting in the overall prediction of the e-health solution’s sustainability level. The sustainability model and the assessment method were validated by three experts in terms of comprehensiveness and applicability to be used in healthcare. Furthermore, a case study was conducted on a Hospital Information System (HIS) of a hospital in Saudi Arabia to evaluate the sustainability model and its assessment method. The sustainability model and assessment method were illustrated to be effective in evaluating the sustainability of e-solutions and more comprehensive and systematic than the evaluation used in the hospital.
Full article
►▼
Show Figures
Open AccessReview
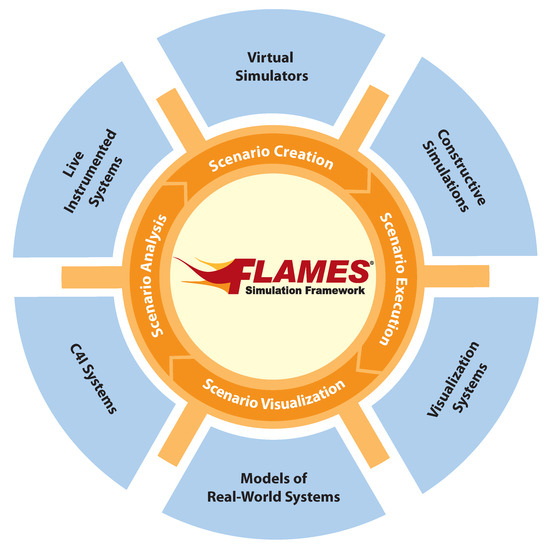
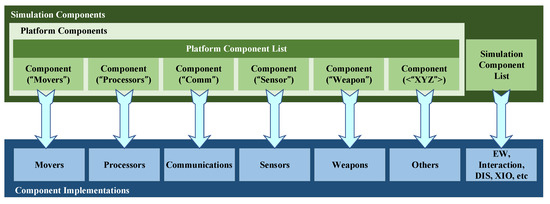
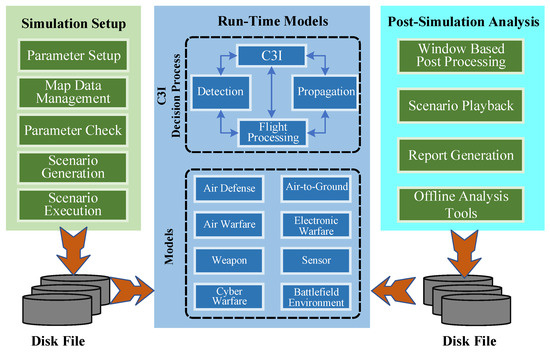
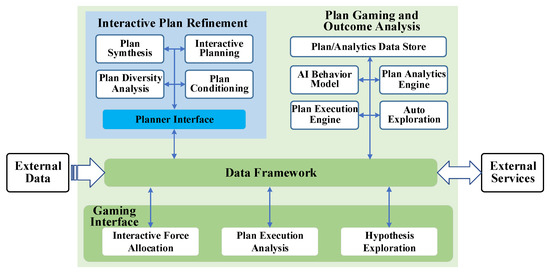
Review of the Research Progress in Combat Simulation Software
by
Fengshun Lu, Xingzhi Hu, Bendong Zhao, Xiong Jiang, Duoneng Liu, Jianqi Lai and Zhiren Wang
Cited by 1 | Viewed by 2228
Abstract
To address the new functional requirements brought by the introduction of new weapons and new combat modes, a comprehensive survey of the research progress in the area of combat simulation software is performed from the perspective of software engineering. First, the top-level specification,
[...] Read more.
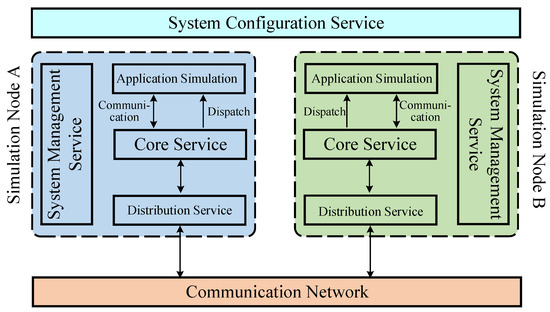
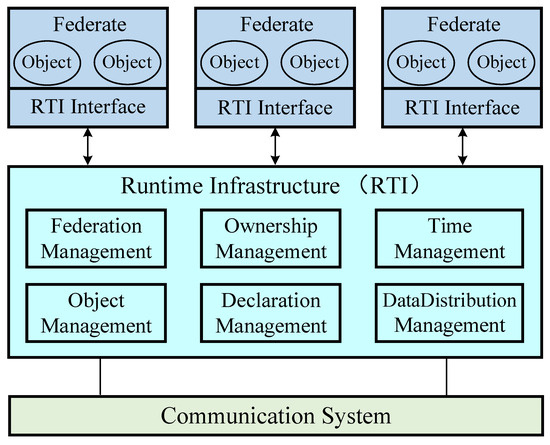
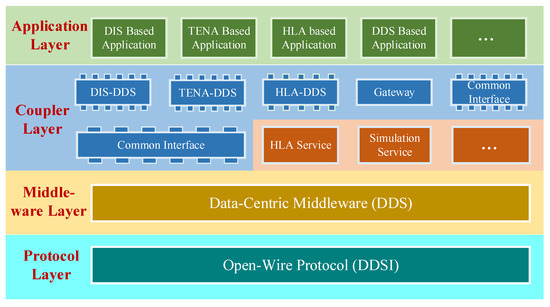
To address the new functional requirements brought by the introduction of new weapons and new combat modes, a comprehensive survey of the research progress in the area of combat simulation software is performed from the perspective of software engineering. First, the top-level specification, simulation engine, and simulation framework of combat simulation software are reviewed. Then, several typical combat simulation software systems are demonstrated, and the relevant software frameworks are analyzed. Finally, combining the application prospect of artificial intelligence, metaverse, and other new technologies in combat simulation, the development trends of combat simulation software are presented, namely intellectualization, adaptation to an LVC (live, virtual, and constructive) system, and a more game-based experience. Based on a comprehensive comparison between the mentioned simulation frameworks, we believe that the AFSIM (Advanced framework for simulation, integration, and modeling) and the E-CARGO (Environments—classes, agents, roles, groups, and objects) are appropriate candidates for developing distributed combat simulation software.
Full article
►▼
Show Figures
Open AccessArticle
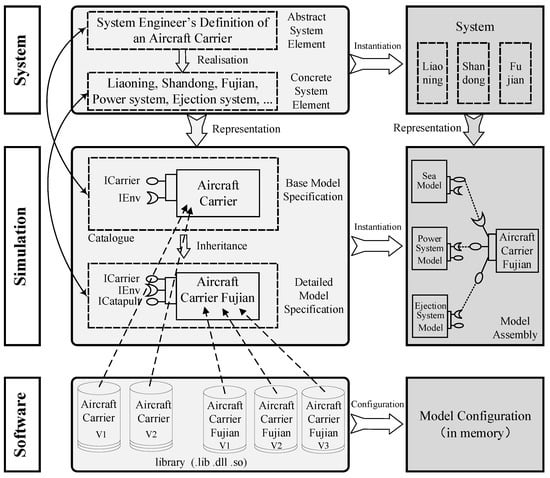
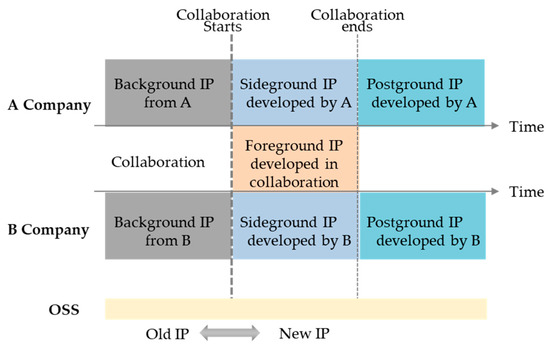
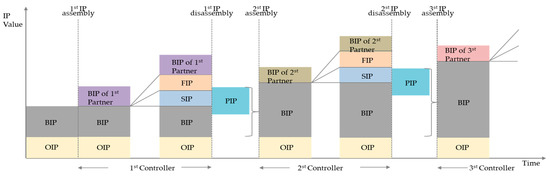
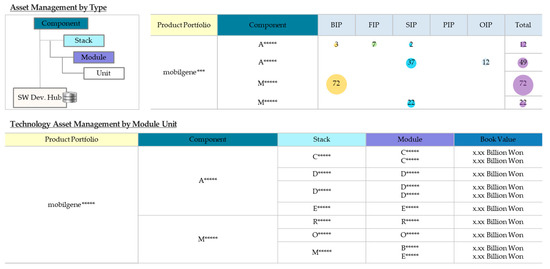
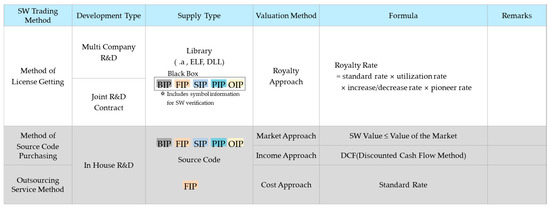
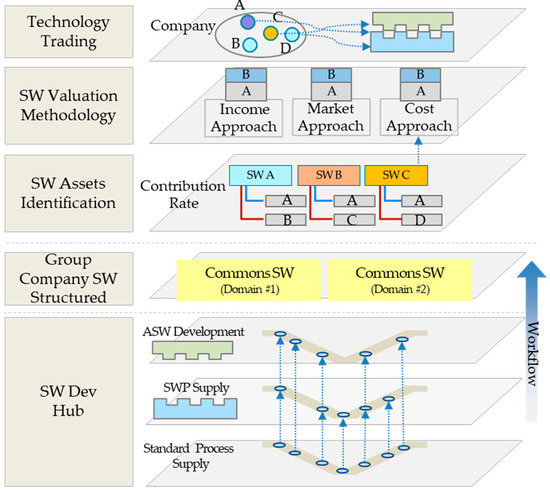
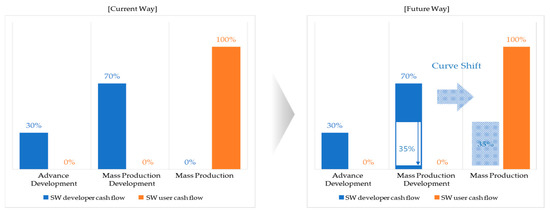
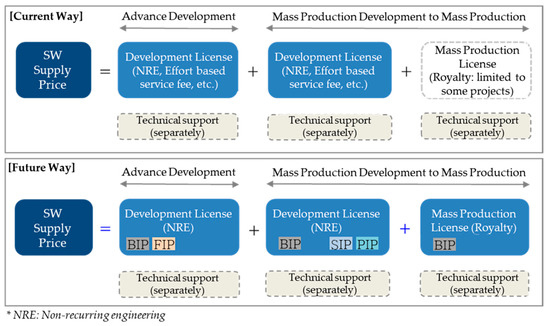
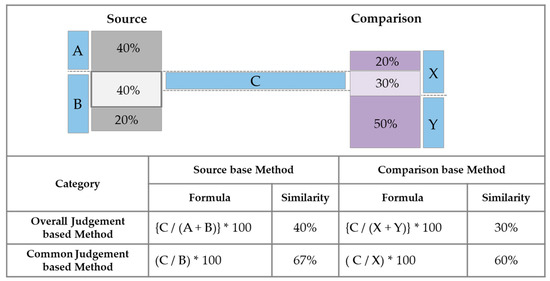
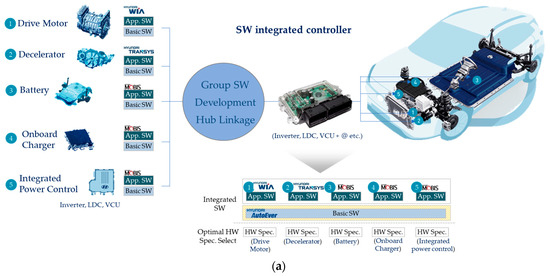
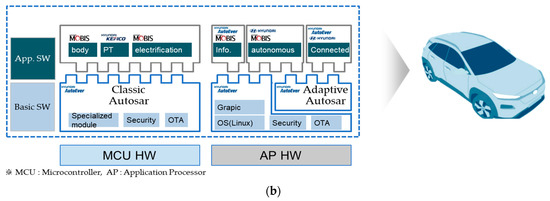
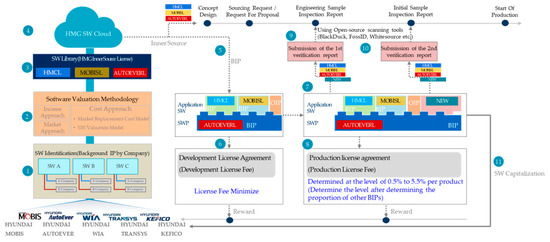
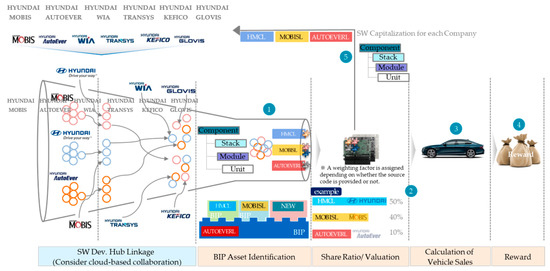
A Method for Managing Software Assets in the Automotive Industry (Focusing on the Case of Hyundai Motor Company and Parts Makers)
by
Changhan Ryu and Sungryong Do
Cited by 2 | Viewed by 3694
Abstract
We propose a method for managing software assets in the automotive industry to enhance software competitiveness and to reduce development costs. The ownership of software assets in the automotive industry is held by automotive parts companies, making it challenging to exchange these technologies.
[...] Read more.
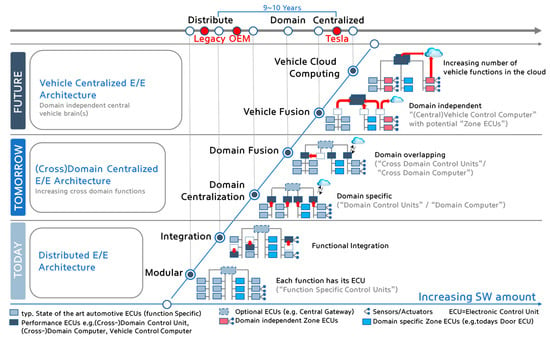
We propose a method for managing software assets in the automotive industry to enhance software competitiveness and to reduce development costs. The ownership of software assets in the automotive industry is held by automotive parts companies, making it challenging to exchange these technologies. Moreover, the criteria for determining software assets are often unclear, resulting in difficulties in integrating automotive software and implementing over-the-air updates. To address these issues, we suggest breaking down black-boxed software assets into tradable components, valuating them, and introducing the concept of exchanging software technology assets. Additionally, we provide a structured approach for recycling used software assets and establish a software asset management system for registration and tracking. Our proposed approach can help traditional automotive OEMs narrow the technology gap with automakers such as Tesla and improve their software competitiveness in the automotive industry. This paper contributes to the advancement of software asset management practices in the automotive industry, and provides insights into the integration of automotive software and over-the-air updates.
Full article
►▼
Show Figures
Open AccessArticle
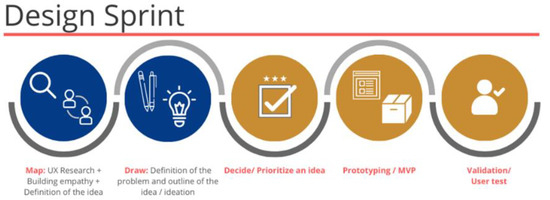
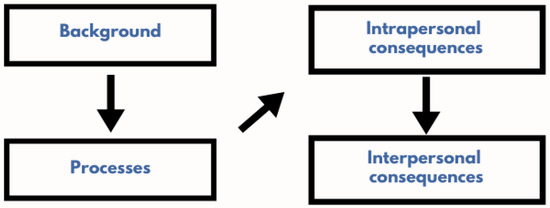
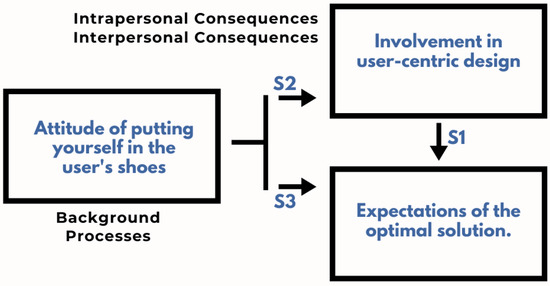
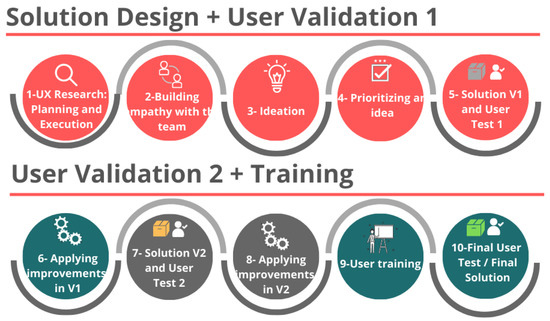
Measuring Empathy in Technical Teams to Improve the UX Quality of Innovative Technological Solutions
by
Samira e Silva Amaral Ribeiro, Maria Elizabeth Sucupira Furtado, Adriano Albuquerque and Gleidson Sobreira Leite
Viewed by 1237
Abstract
Developing the empathy of a technical team for target users has been a practice to innovate solutions centered on the experience they can provide to their users. However, there are few studies focused on the impact of empathy practices on solution design. In
[...] Read more.
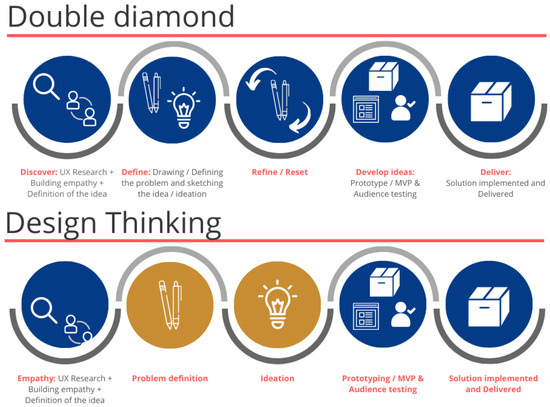
Developing the empathy of a technical team for target users has been a practice to innovate solutions centered on the experience they can provide to their users. However, there are few studies focused on the impact of empathy practices on solution design. In order to contribute to the study of the art regarding the construction of empathy in technical teams to improve the user experience quality in developing technical solutions, this research analyzes the effectiveness of building empathy in technical teams in a case study of the electricity sector, which was based on a process concerning validations with users. The results showed that, in the perception of a group of technicians, there was an improvement in the quality of empathy for their target users and had an impact on the team’s engagement to carry out human-computer interaction practices and, consequently, on the quality of use of the developed solution.
Full article
►▼
Show Figures
Open AccessArticle
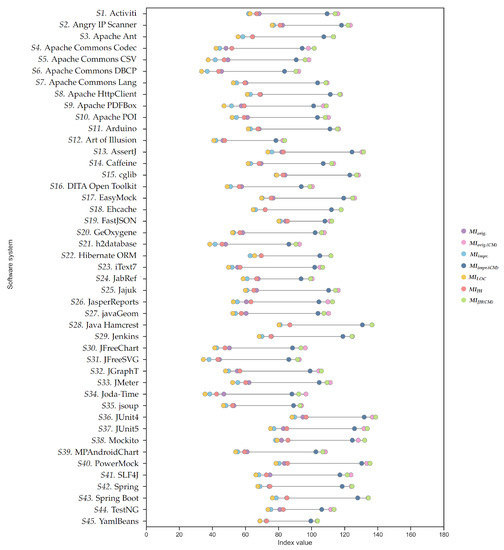
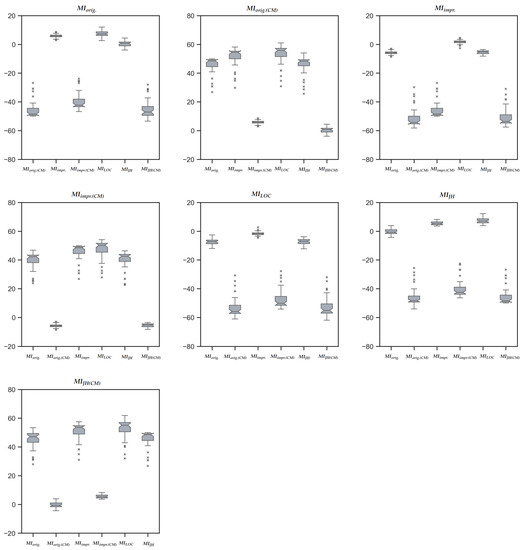
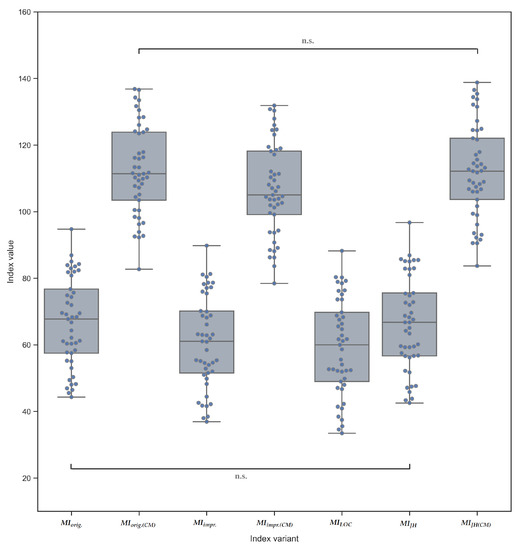
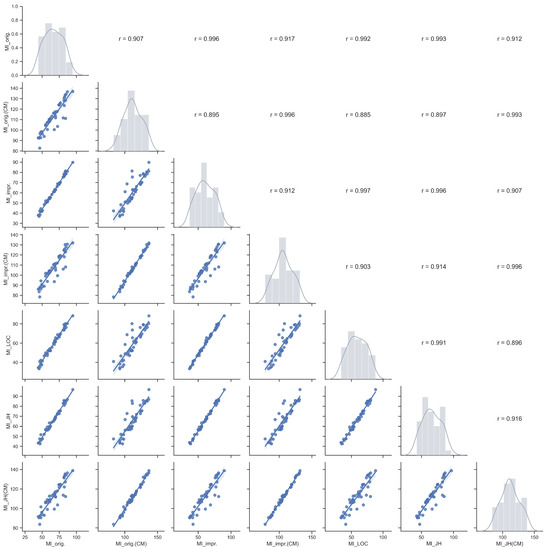
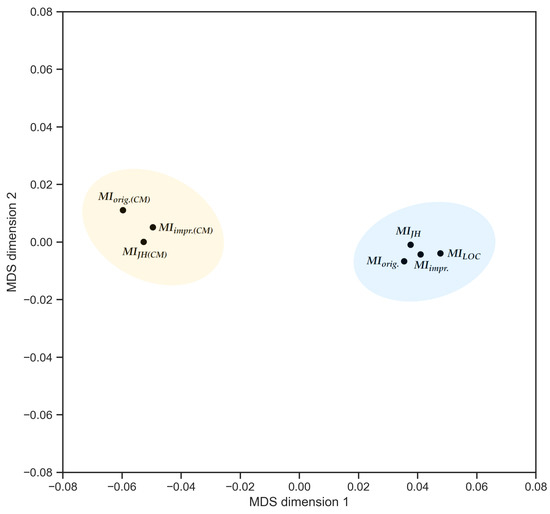
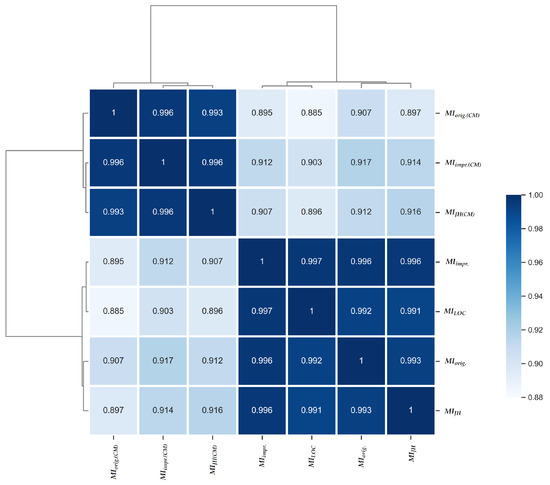
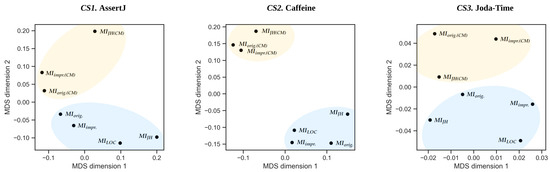
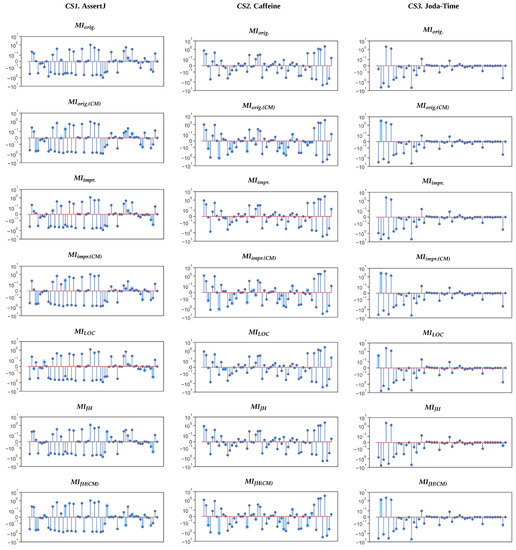
Exploring Maintainability Index Variants for Software Maintainability Measurement in Object-Oriented Systems
by
Tjaša Heričko and Boštjan Šumak
Cited by 3 | Viewed by 2647
Abstract
During maintenance, software systems undergo continuous correction and enhancement activities due to emerging faults, changing environments, and evolving requirements, making this phase expensive and time-consuming, often exceeding the initial development costs. To understand and manage software under development and maintenance better, several maintainability
[...] Read more.
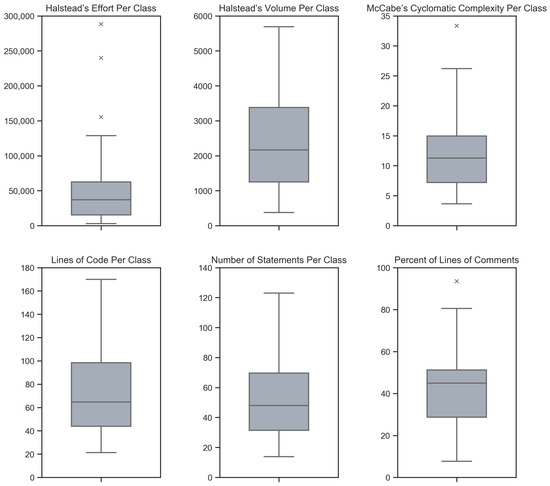
During maintenance, software systems undergo continuous correction and enhancement activities due to emerging faults, changing environments, and evolving requirements, making this phase expensive and time-consuming, often exceeding the initial development costs. To understand and manage software under development and maintenance better, several maintainability measures have been proposed. The Maintainability Index is commonly used as a quantitative measure of the relative ease of software maintenance. There are several Index variants that differ in the factors affecting maintainability (e.g., code complexity, software size, documentation) and their given importance. To explore the variants and understand how they compare when evaluating software maintainability, an experiment was conducted with 45 Java-based object-oriented software systems. The results showed that the choice of the variant could influence the perception of maintainability. Although different variants presented different values when subjected to the same software, their values were strongly positively correlated and generally indicated similarly how maintainability evolved between releases and over the long term. Though, when focusing on fine-grained results posed by the Index, the variant selection had a larger impact. Based on their characteristics, behavior, and interrelationships, the variants were divided into two distinct clusters, i.e., variants that do not consider code comments in their calculation and those that do.
Full article
►▼
Show Figures
Open AccessArticle
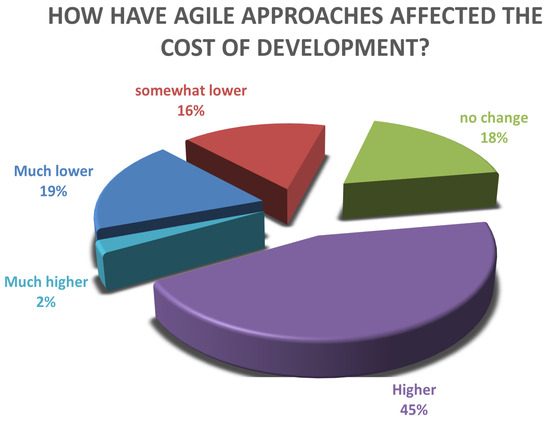
The Impact of Agile Methodology on Project Success, with a Moderating Role of Person’s Job Fit in the IT Industry of Pakistan
by
Rubab Wafa, Muhammad Qasim Khan, Fazal Malik, Akmalbek Bobomirzaevich Abdusalomov, Young Im Cho and Roman Odarchenko
Cited by 15 | Viewed by 8690
Abstract
Computing software plays an essential role in almost every sector of the digital age, but the process of efficient software development still faces several challenges. Effective software development methodology can be the difference between the success and failure of a software project. This
[...] Read more.
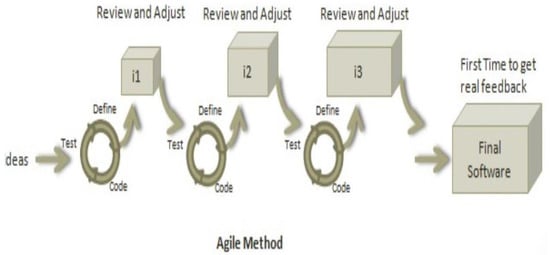
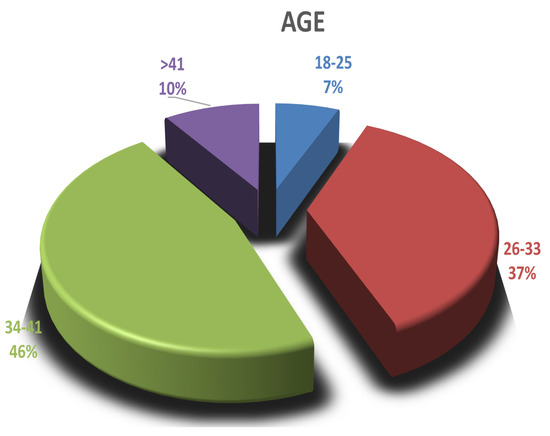
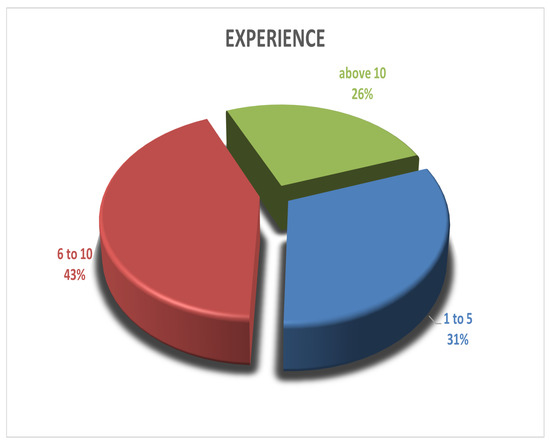
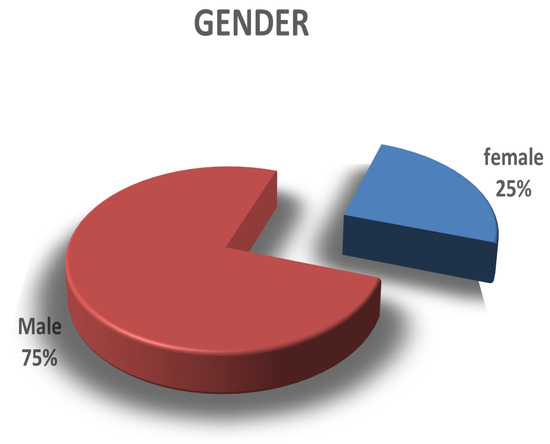
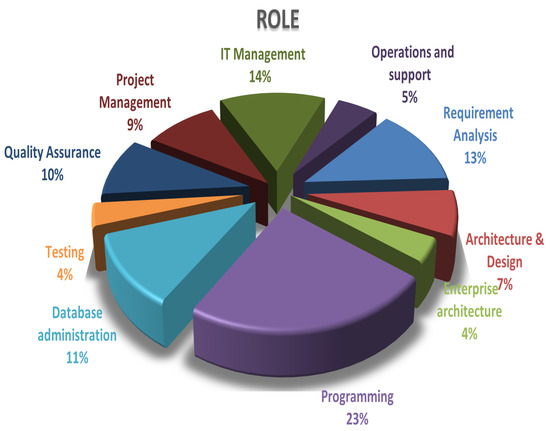
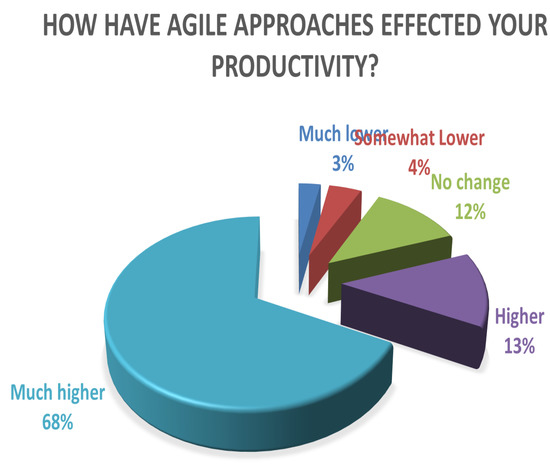
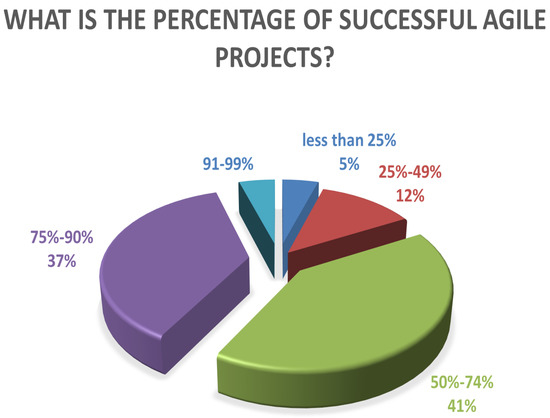
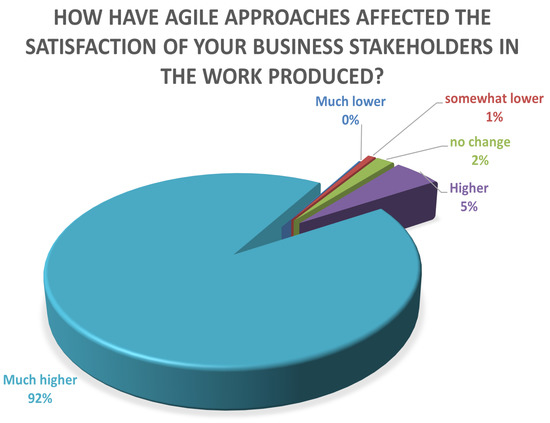
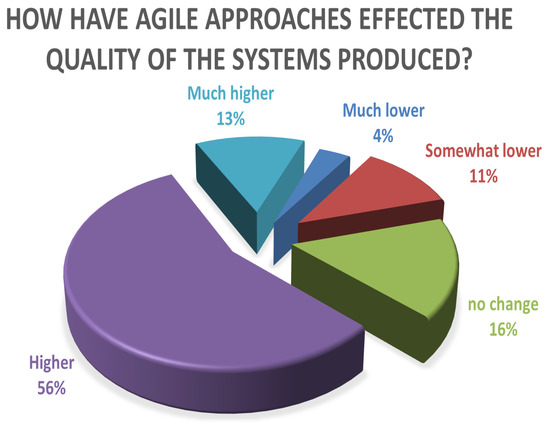
Computing software plays an essential role in almost every sector of the digital age, but the process of efficient software development still faces several challenges. Effective software development methodology can be the difference between the success and failure of a software project. This research aims to evaluate the overall impact of Agile Software Development (ASD) on the individual, organizational, software development, and project management dimensions. For this purpose, we surveyed several software development professionals from a variety of backgrounds (experience, location, and job ranks) to explore the impact of ASD on the IT industry of Pakistan. Our analysis of the collected information is two folds. First, we summarized the findings from our surveys graphically clearly show the opinions of our survey respondents regarding the effectiveness of the Agile methodology for software development. Secondly, we utilized quantitative measures to analyze the same data statistically. A comparison is drawn between the graphical and statistical analysis to verify the reliability of our findings. Our findings suggest the existence of a strong relationship between effective software development and the use of Agile processes. Our analysis shows that the job fit of software development professionals and ASD are critical factors for software development project success in terms of cost, quality, stakeholders satisfaction, and time. Although the study focuses on the IT industry of Pakistan, the findings can be generalized easily to other developing IT industries worldwide.
Full article
►▼
Show Figures
Open AccessArticle
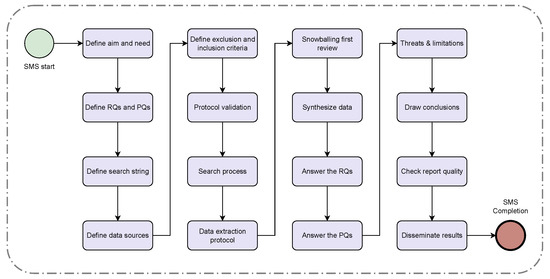
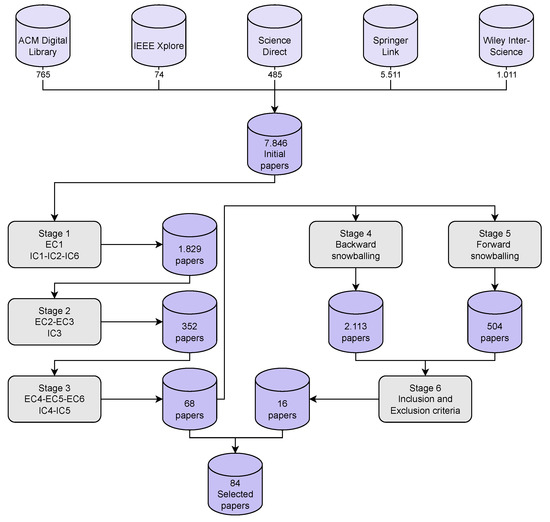
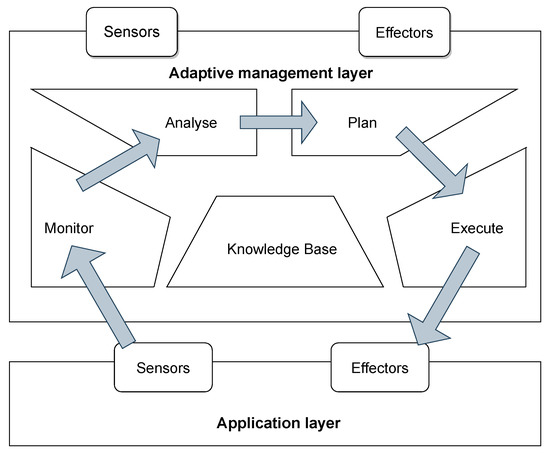
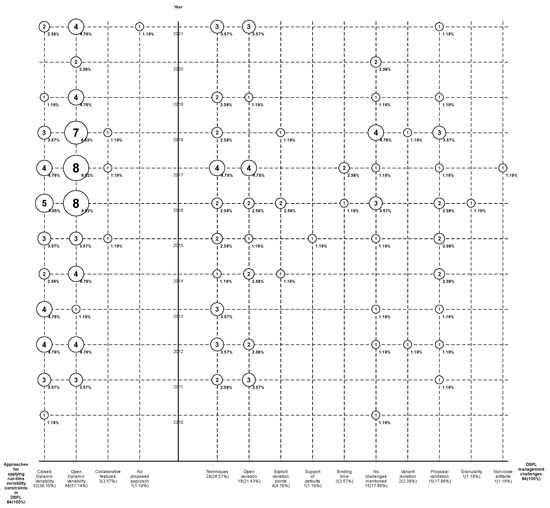
Variability Management in Dynamic Software Product Lines for Self-Adaptive Systems—A Systematic Mapping
by
Oscar Aguayo and Samuel Sepúlveda
Cited by 3 | Viewed by 2652
Abstract
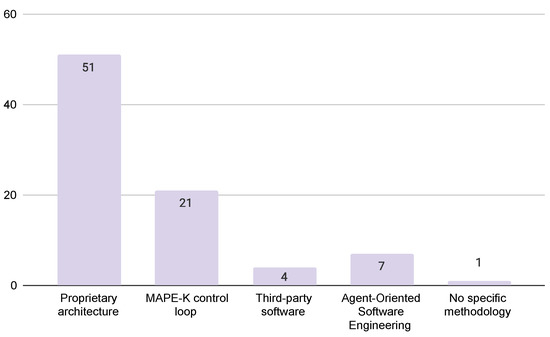
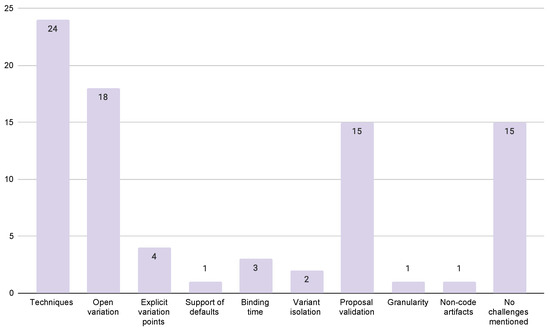
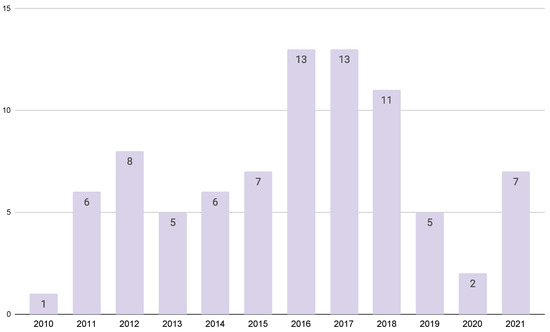
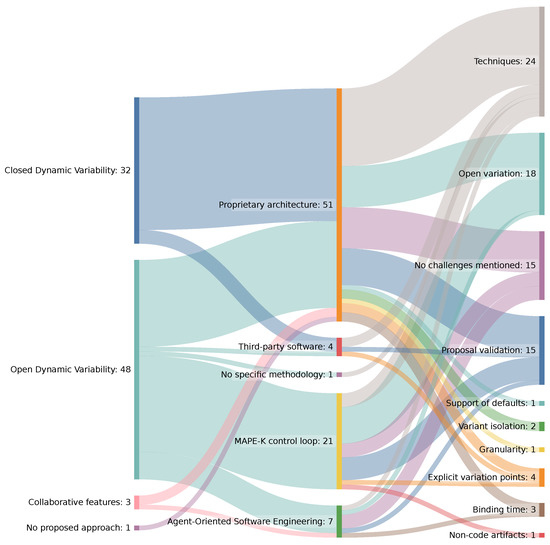
Context: Dynamic software product lines (DSPLs) have considerably increased their adoption for variability management for self-adaptive systems. The most widely used models for managing the variability of DSPLs are the MAPE-K control loop and context-aware feature models (CFMs). Aim: In this paper, we
[...] Read more.
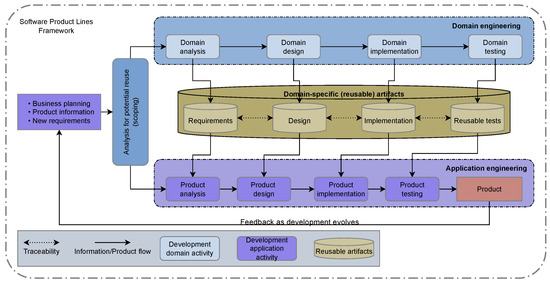
Context: Dynamic software product lines (DSPLs) have considerably increased their adoption for variability management for self-adaptive systems. The most widely used models for managing the variability of DSPLs are the MAPE-K control loop and context-aware feature models (CFMs). Aim: In this paper, we review and synthesize evidence of using variability constraint approaches, methodologies, and challenges for DSPL. Method: We conducted a systematic mapping, including three research questions. This study included 84 papers published from 2010 to 2021. Results: The main results show that open-dynamic variability shows a presence in 57.1% of the selected papers, and on the other hand, closed-dynamic variability appears in 38.1%. The most commonly used methodology for managing a DSPL environment is based on proprietary architectures (60.7%), where the use of CFMs predominates. For open-dynamic variability approaches, the MAPE-K control loop is mainly used. The main challenges in DSPL management are based on techniques (28.6%) and open variation (21.4%). Conclusions: Open-dynamic variability has prevailed over the years as the primary approach to managing variability in DSPL, where its primary methodology is the MAPE-K control loop. Response RQ3 requires further review.
Full article
►▼
Show Figures
Open AccessArticle
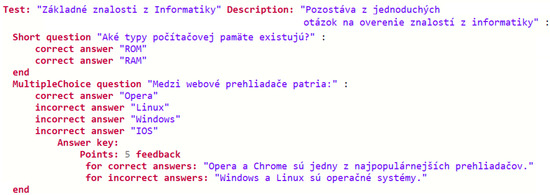
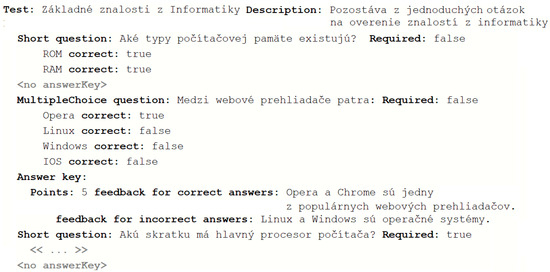
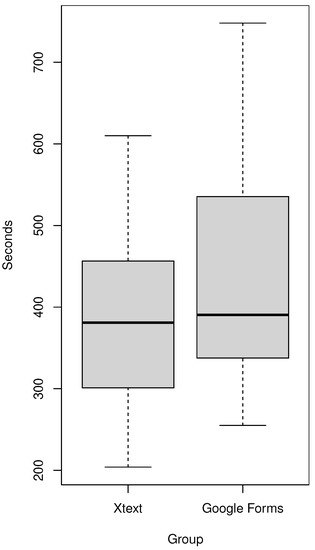
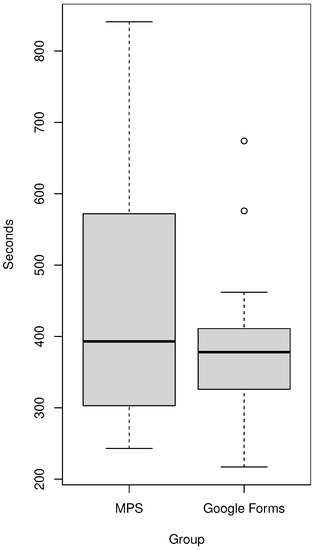
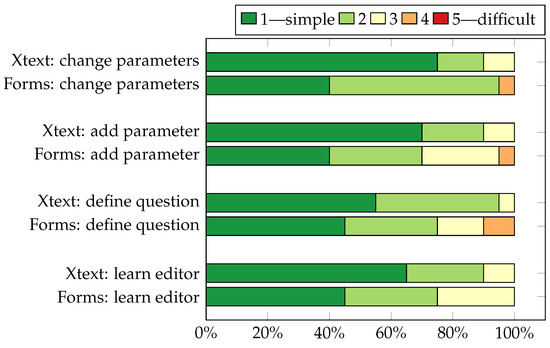
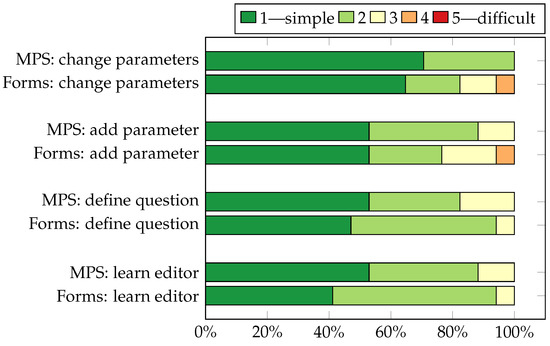
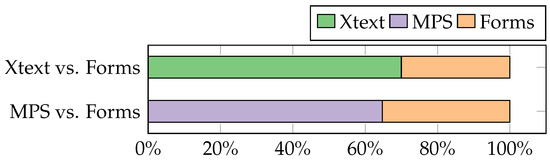
Experimental Comparison of Editor Types for Domain-Specific Languages
by
Sergej Chodarev, Matúš Sulír, Jaroslav Porubän and Martina Kopčáková
Cited by 3 | Viewed by 1286
Abstract
The editor type can influence the user experience for a domain-specific language, but empirical evaluation of this factor is still quite limited. In this paper, we present the results of our empirical study, in which we compare the productivity of users with different
[...] Read more.
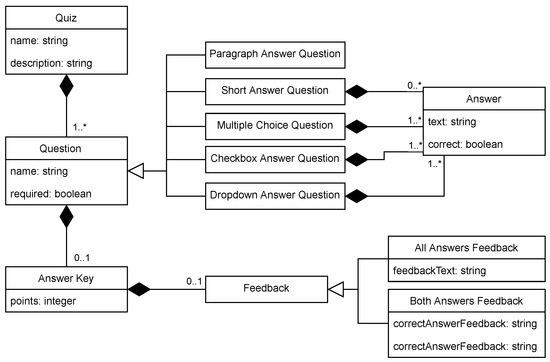
The editor type can influence the user experience for a domain-specific language, but empirical evaluation of this factor is still quite limited. In this paper, we present the results of our empirical study, in which we compare the productivity of users with different kinds of editors for the same domain-specific language. We chose the domain of quiz definitions and used three editors: a text editor with syntax highlighting and code completion developed with the Xtext framework, a projectional editor created using JetBrains MPS, and an existing form-based editor—Google Forms. The study was performed on 37 graduate students of computer science. The measured time was lower for the text editor than for the form-based editor, and the form-based editor’s time was lower than the projectional one’s; however, the results were statistically insignificant. The experiment was also complemented with a survey providing insight into the perception of different editor types by users.
Full article
►▼
Show Figures
Open AccessArticle
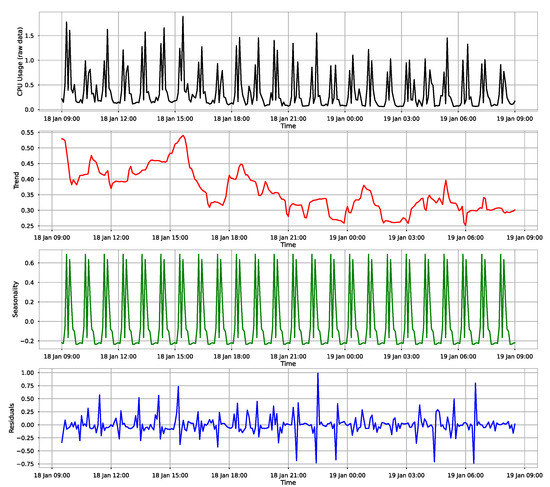
A System for Sustainable Usage of Computing Resources Leveraging Deep Learning Predictions
by
Marius Cioca and Ioan Cristian Schuszter
Cited by 1 | Viewed by 1171
Abstract
In this paper, we present the benefit of using deep learning time-series analysis techniques in order to reduce computing resource usage, with the final goal of having greener and more sustainable data centers. Modern enterprises and agile ways-of-working have led to a complete
[...] Read more.
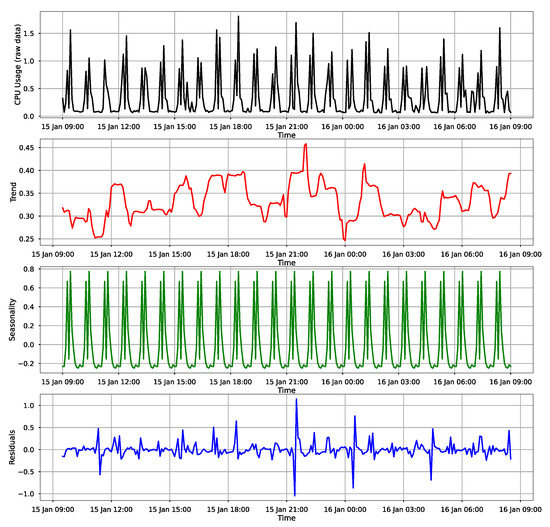
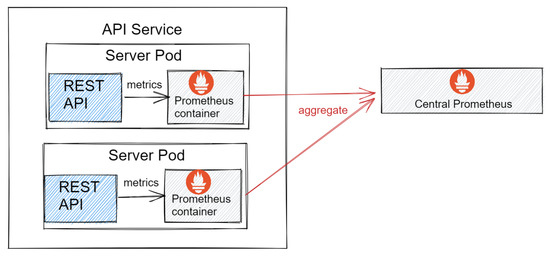
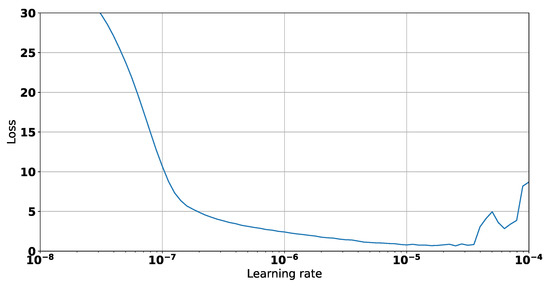
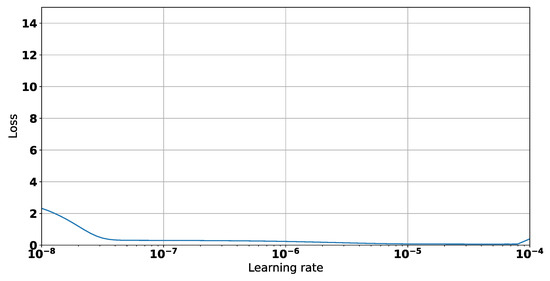
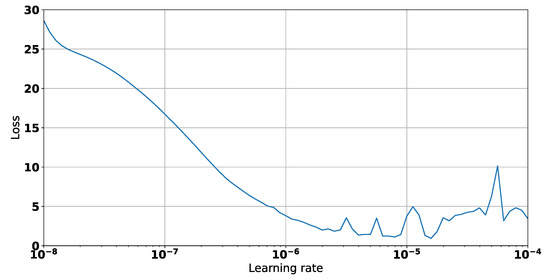
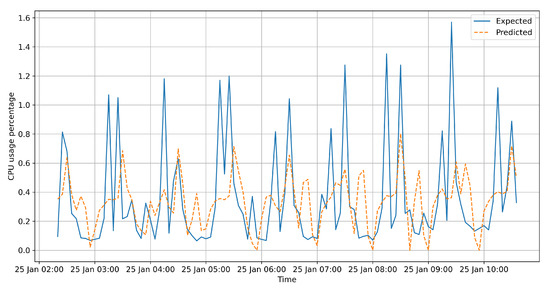
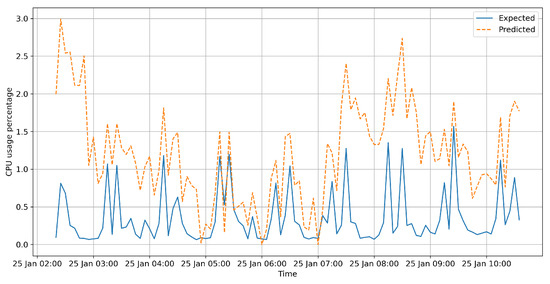
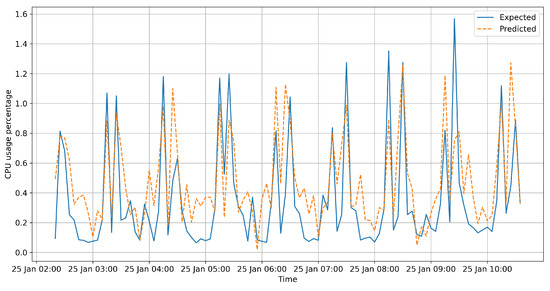
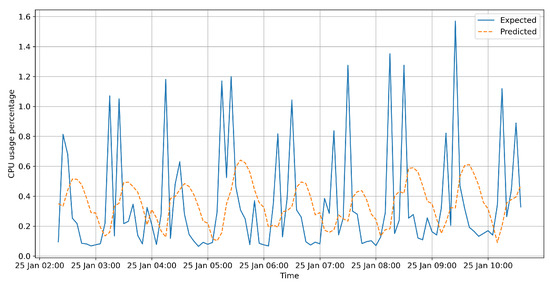
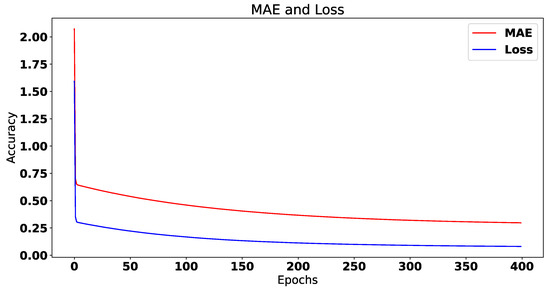
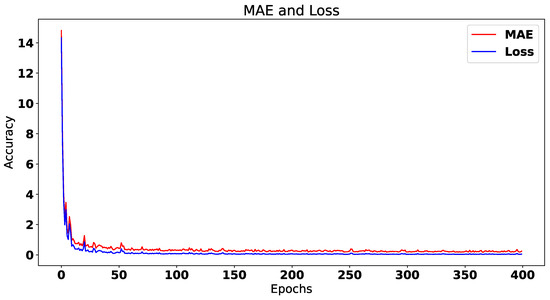
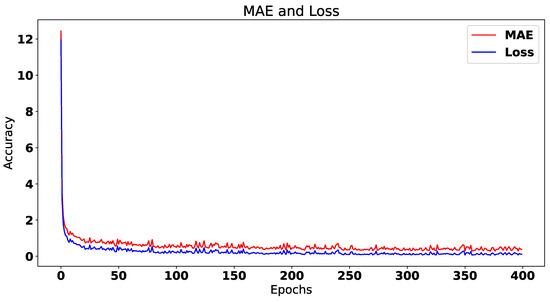
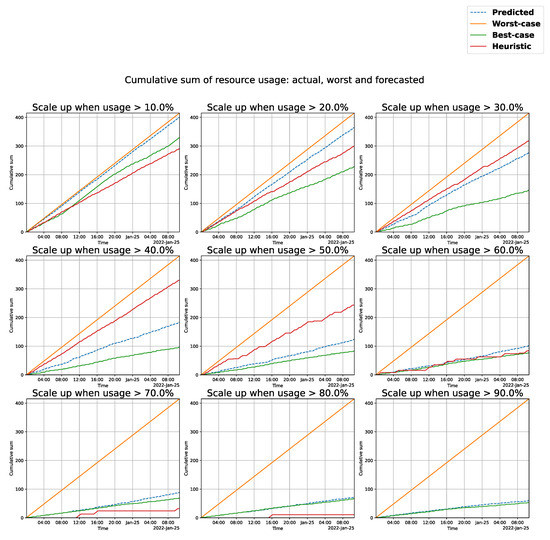
In this paper, we present the benefit of using deep learning time-series analysis techniques in order to reduce computing resource usage, with the final goal of having greener and more sustainable data centers. Modern enterprises and agile ways-of-working have led to a complete revolution of the way that software engineers develop and deploy software, with the proliferation of container-based technology, such as Kubernetes and Docker. Modern systems tend to use up a large amount of resources, even when idle, and intelligent scaling is one of the methods that could be used to prevent waste. We have developed a system for predicting and influencing computer resource usage based on historical data of real production software systems at CERN, allowing us to scale down the number of machines or containers running a certain service during periods that have been identified as idle. The system leverages recurring neural network models in order to accurately predict the future usage of a software system given its past activity. Using the data obtained from conducting several experiments with the forecasted data, we present the potential reductions on the carbon footprint of these computing services, from the perspective of CPU usage. The results show significant improvements to the computing power usage of the service (60% to 80%) as opposed to just keeping machines running or using simple heuristics that do not look too far into the past.
Full article
►▼
Show Figures
Open AccessArticle
A Conceptual Model of Factors Influencing Customer Relationship Management in Global Software Development: A Client Perspective
by
Kausar-Nasreen Khattak, Mansoor Ahmed, Naeem Iqbal, Murad-Ali Khan, Imran and Jungsuk Kim
Cited by 2 | Viewed by 2914
Abstract
The software development industry or organizations increasingly emerging day by day have adopted global software development (GSD) practices due to the large significance of outsourcing. These industries face many challenges due to a lack of understanding customer perspective in the GSD environment. For
[...] Read more.
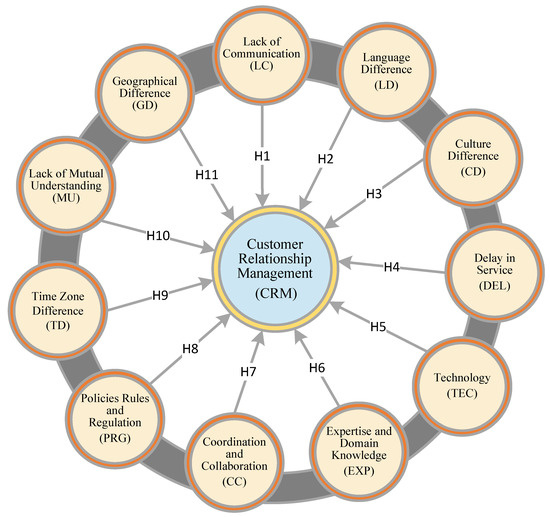
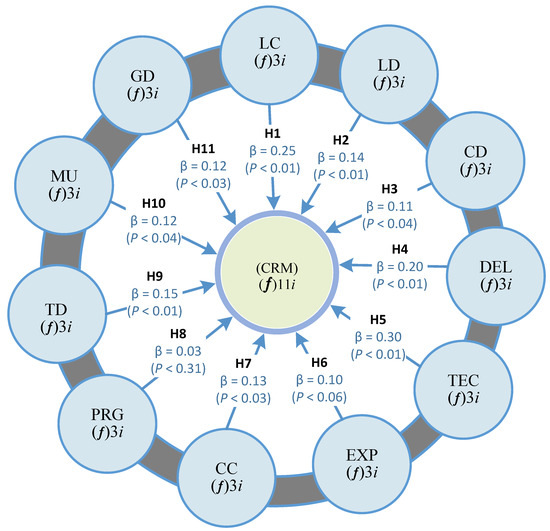
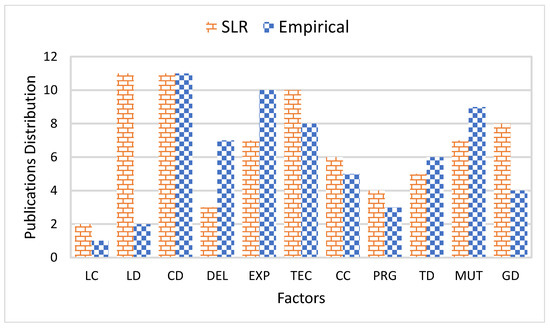
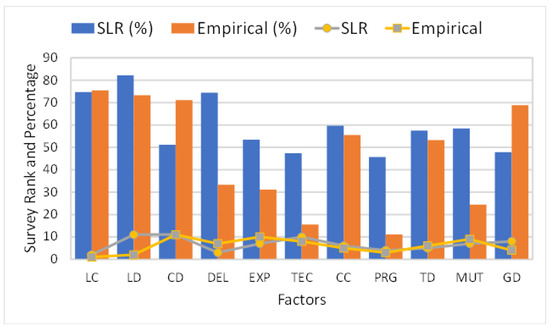
The software development industry or organizations increasingly emerging day by day have adopted global software development (GSD) practices due to the large significance of outsourcing. These industries face many challenges due to a lack of understanding customer perspective in the GSD environment. For any organization, the customer is the major stakeholder, and customer relationship management (CRM) plays a vital role in customer satisfaction with software development projects. These challenges create serious risks for any software development project’s success. Thus, CRM is a crucial challenge in the success of software projects in the GSD environment. This research study aims to address the factors that negatively influence CRM implementation in the global context and proposes a conceptual model based on the identified factors for enhancing software product quality. The systematic literature review (SLR) phase investigates the potential barriers to CRM implementation in GSD. Based on identified barriers, an initial conceptual model is developed. The proposed conceptual model is validated using a questionnaire survey of the GSD industry and CRM practitioners of Pakistan. Statistical analysis and several suitable tests are also performed to develop the final conceptual model for CRM implementation in the GSD environment. This research is performed from the client’s perspective. The results are promising and accommodating to avoid any software project failure due to customer-related issues in a GSD environment.
Full article
►▼
Show Figures
Open AccessArticle
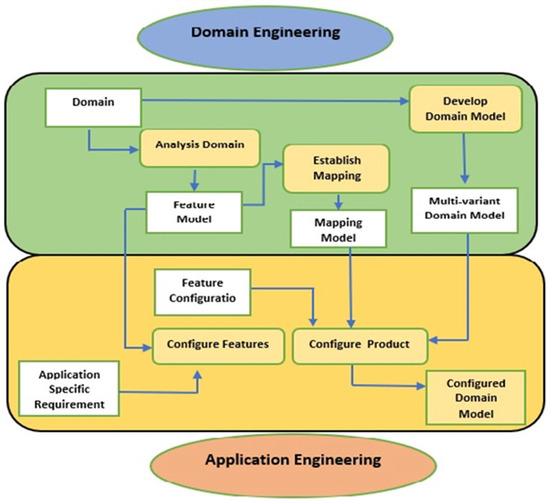
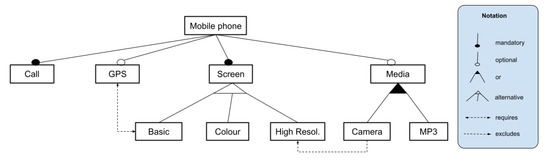
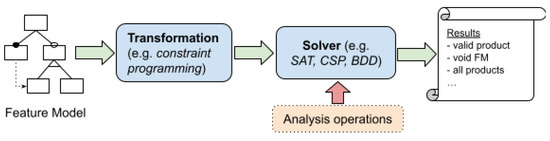
Reasoning Algorithms on Feature Modeling—A Systematic Mapping Study
by
Samuel Sepúlveda and Ania Cravero
Cited by 2 | Viewed by 1976
Abstract
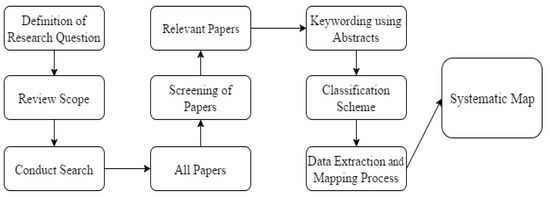
Context: Software product lines (SPLs) have reached a considerable level of adoption in the software industry. The most commonly used models for managing the variability of SPLs are feature models (FMs). The analysis of FMs is an error-prone, tedious task, and it is
[...] Read more.
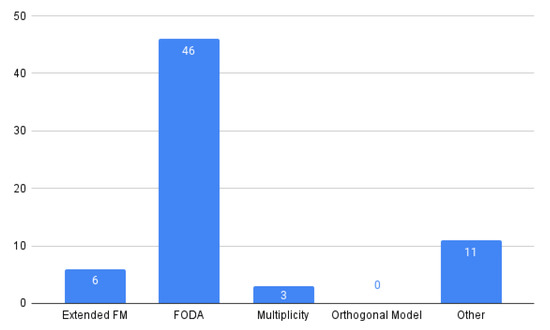
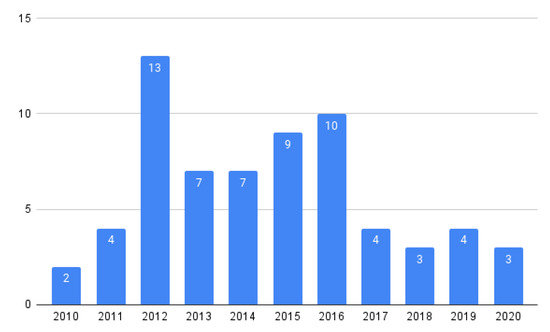
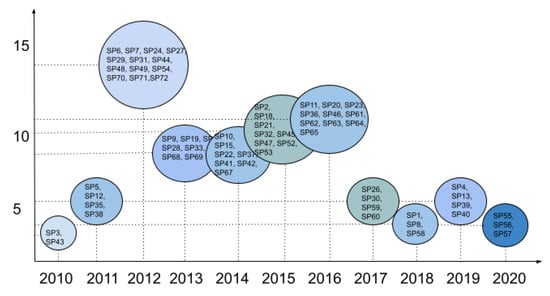
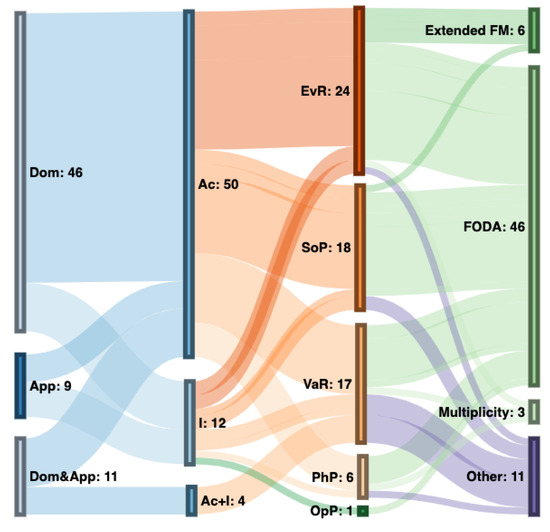
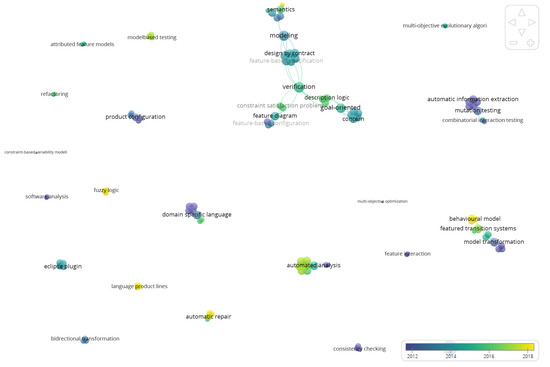
Context: Software product lines (SPLs) have reached a considerable level of adoption in the software industry. The most commonly used models for managing the variability of SPLs are feature models (FMs). The analysis of FMs is an error-prone, tedious task, and it is not feasible to accomplish this task manually with large-scale FMs. In recent years, much effort has been devoted to developing reasoning algorithms for FMs. Aim: To synthesize the evidence on the use of reasoning algorithms for feature modeling. Method: We conducted a systematic mapping study, including six research questions. This study included 66 papers published from 2010 to 2020. Results: We found that most algorithms were used in the domain stage (70%). The most commonly used technologies were transformations (18%). As for the origins of the proposals, they were mainly rooted in academia (76%). The FODA model continued to be the most frequently used representation for feature modeling (70%). A large majority of the papers presented some empirical validation process (90%). Conclusion: We were able to respond to the RQs. The FODA model is consolidated as a reference within SPLs to manage variability. Responses to RQ2 and RQ6 require further review.
Full article
►▼
Show Figures
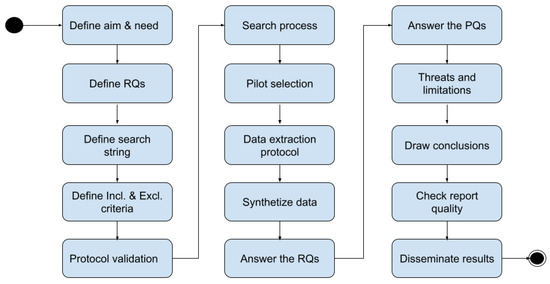
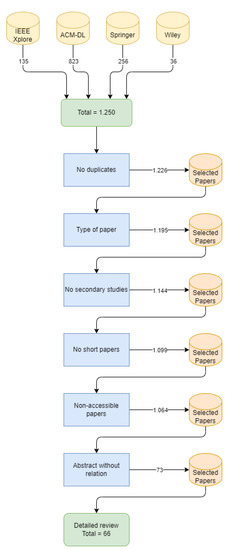
Open AccessSystematic Review
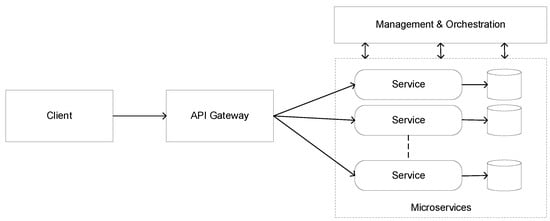
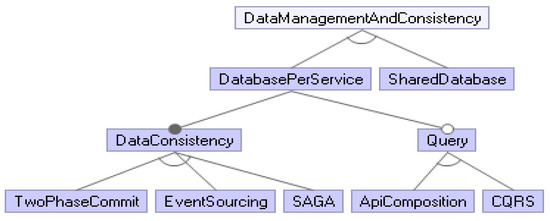
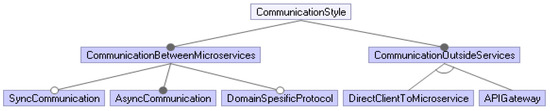
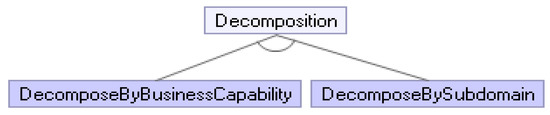
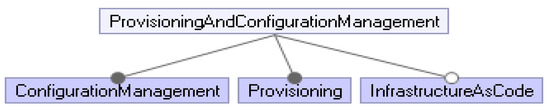
Challenges and Solution Directions of Microservice Architectures: A Systematic Literature Review
by
Mehmet Söylemez, Bedir Tekinerdogan and Ayça Kolukısa Tarhan
Cited by 5 | Viewed by 5574
Abstract
Microservice architecture (MSA) is an architectural style for distributed software systems, which promotes the use of fine-grained services with their own lifecycles. Several benefits of MSA have been reported in the literature, including increased modularity, flexible configuration, easier development, easier maintenance, and increased
[...] Read more.
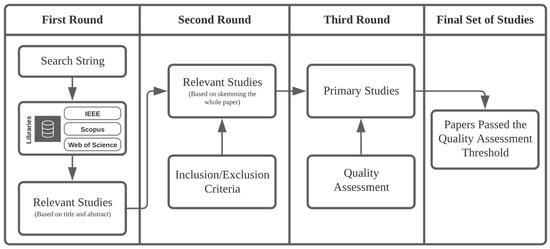
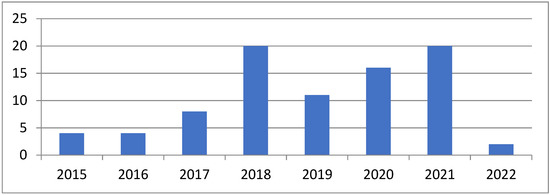
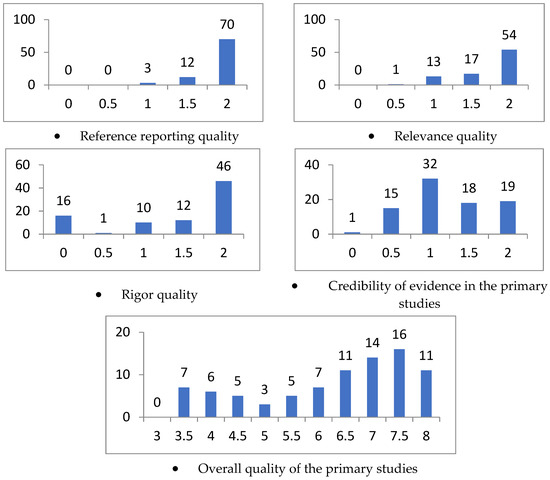
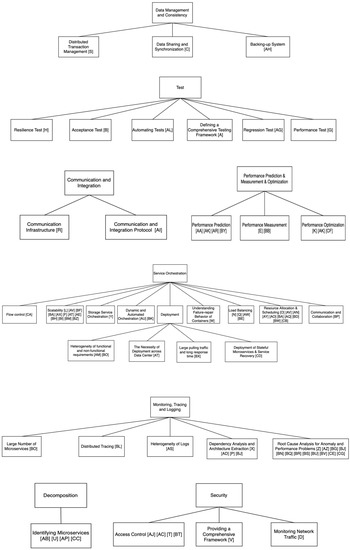
Microservice architecture (MSA) is an architectural style for distributed software systems, which promotes the use of fine-grained services with their own lifecycles. Several benefits of MSA have been reported in the literature, including increased modularity, flexible configuration, easier development, easier maintenance, and increased productivity. On the other hand, the adoption of MSA for a specific software system is not trivial and a number of challenges have been reported in the literature. These challenges should be evaluated carefully concerning project requirements before successful MSA adoption. Unfortunately, there has been no attempt to systematically review and categorize these challenges and the potential solution directions. This article aims at identifying the state of the art of MSA and describing the challenges in applying MSA together with the identified solution directions. A systematic literature review (SLR) is performed using the published literature since the introduction of MSA in 2014. Overall, 3842 papers were discovered using a well-planned review protocol, and 85 of them were selected as primary studies and analyzed regarding research questions. Nine basic categories of challenges were identified and detailed into 40 sub-categories, for which potential solution directions were explored. MSA seems feasible, but the identified challenges could impede the expected benefits when not taken into account. This study identifies and synthesizes the reported challenges and solution directions, but further research on these directions is needed to leverage the successful MSA adoption.
Full article
►▼
Show Figures
Open AccessArticle
Feature-Driven Characterization of Microservice Architectures: A Survey of the State of the Practice
by
Mehmet Söylemez, Bedir Tekinerdogan and Ayça Kolukısa Tarhan
Cited by 2 | Viewed by 2823
Abstract
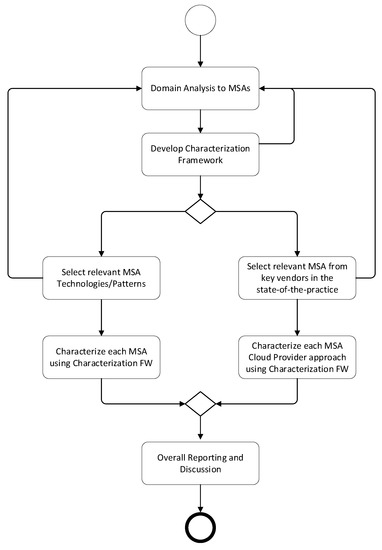
With the need for increased modularity and flexible configuration of software modules, microservice architecture (MSA) has gained interest and momentum in the last 7 years. As a result, MSA has been widely addressed in the literature and discussed from various perspectives. In addition,
[...] Read more.
With the need for increased modularity and flexible configuration of software modules, microservice architecture (MSA) has gained interest and momentum in the last 7 years. As a result, MSA has been widely addressed in the literature and discussed from various perspectives. In addition, several vendors have provided their specific solutions in the state of the practice, each with its challenges and benefits. Yet, selecting and implementing a particular approach is not trivial and requires a broader overview and guidance for selecting the proper solution for the given situation. Unfortunately, no study has been provided that reflects on and synthesizes the key features and challenges of the current MSA solutions in the state of the practice. To this end, this article presents a feature-driven characterization of micro-service architectures that identifies and synthesizes the key features of current MSA solutions as provided by the key vendors. A domain-driven approach is adopted in which a feature model is presented defining the common and variant features of the MSA solutions. Further, a comparative analysis of the solution approaches is provided based on the proposed feature model.
Full article
►▼
Show Figures
Open AccessArticle
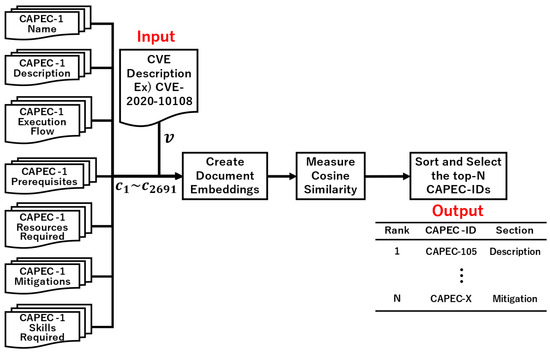
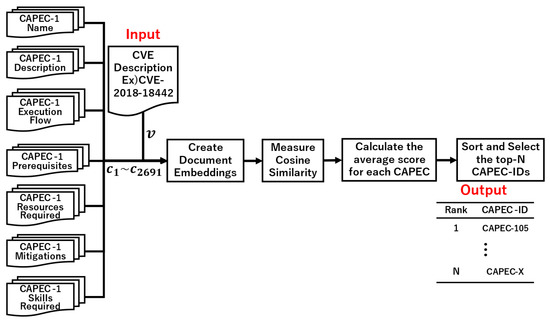
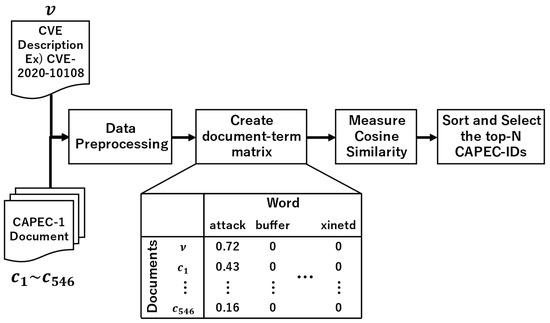
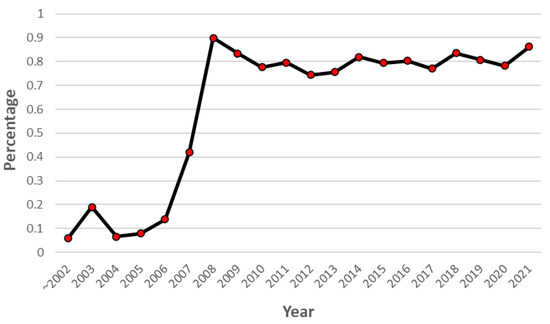
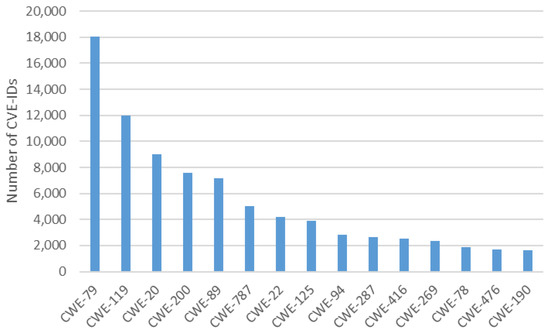
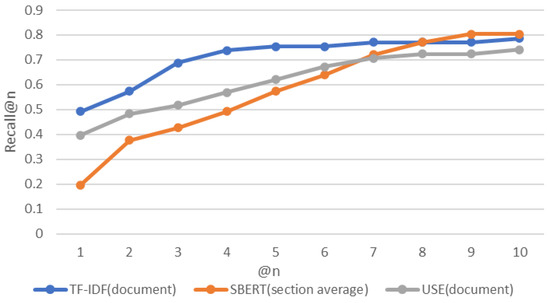
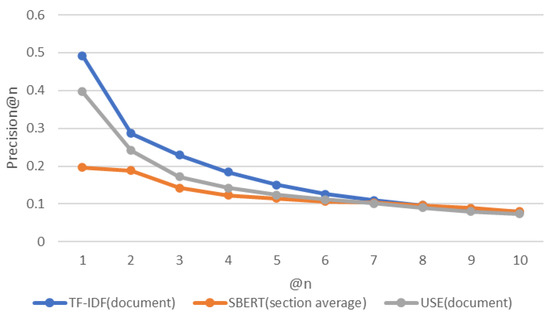
Comparative Evaluation of NLP-Based Approaches for Linking CAPEC Attack Patterns from CVE Vulnerability Information
by
Kenta Kanakogi, Hironori Washizaki, Yoshiaki Fukazawa, Shinpei Ogata, Takao Okubo, Takehisa Kato, Hideyuki Kanuka, Atsuo Hazeyama and Nobukazu Yoshioka
Cited by 6 | Viewed by 3443
Abstract
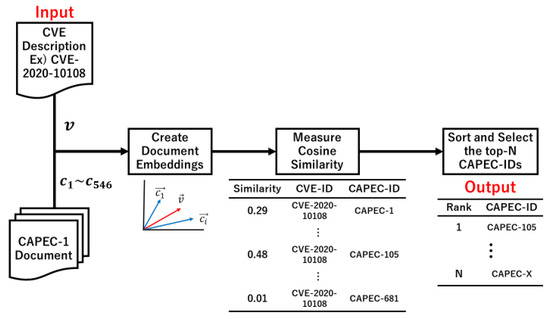
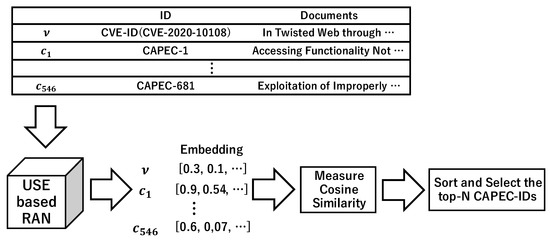
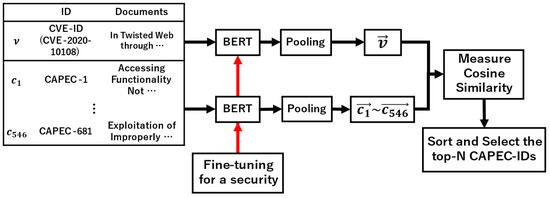
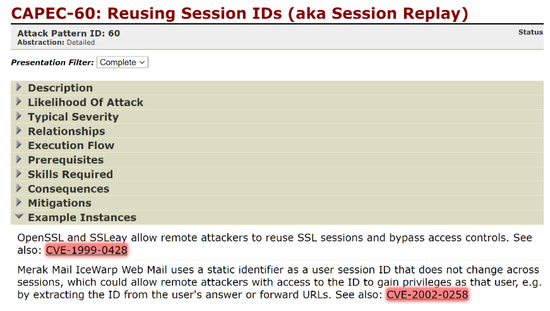
Vulnerability and attack information must be collected to assess the severity of vulnerabilities and prioritize countermeasures against cyberattacks quickly and accurately. Common Vulnerabilities and Exposures is a dictionary that lists vulnerabilities and incidents, while Common Attack Pattern Enumeration and Classification is a dictionary
[...] Read more.
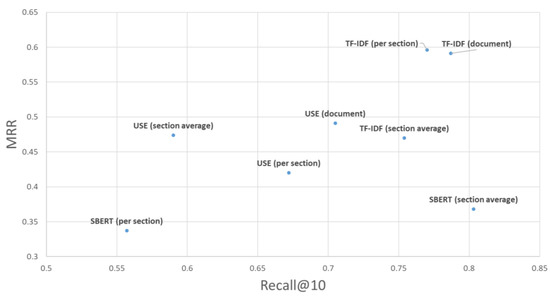
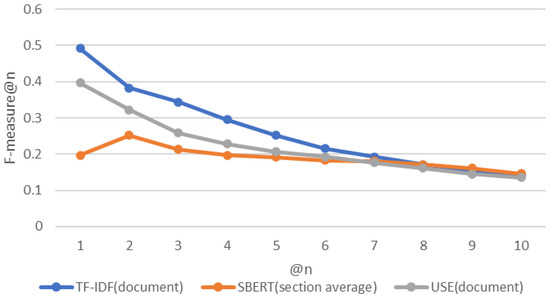
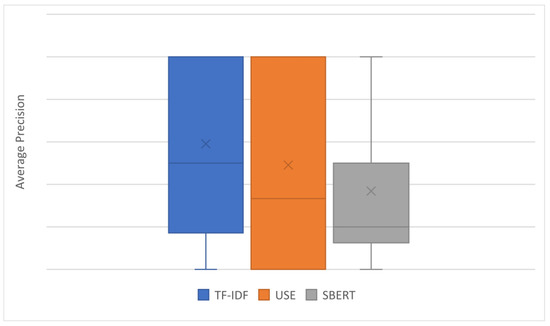
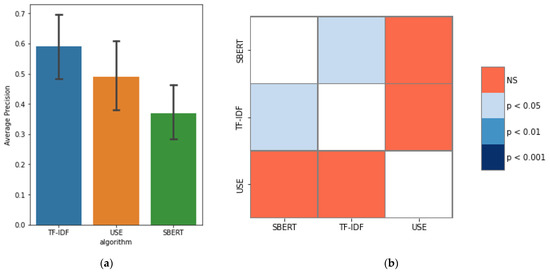
Vulnerability and attack information must be collected to assess the severity of vulnerabilities and prioritize countermeasures against cyberattacks quickly and accurately. Common Vulnerabilities and Exposures is a dictionary that lists vulnerabilities and incidents, while Common Attack Pattern Enumeration and Classification is a dictionary of attack patterns. Direct identification of common attack pattern enumeration and classification from common vulnerabilities and exposures is difficult, as they are not always directly linked. Here, an approach to directly find common links between these dictionaries is proposed. Then, several patterns, which are combinations of similarity measures and popular algorithms such as term frequency–inverse document frequency, universal sentence encoder, and sentence BERT, are evaluated experimentally using the proposed approach. Specifically, two metrics, recall and mean reciprocal rank, are used to assess the traceability of the common attack pattern enumeration and classification identifiers associated with 61 identifiers for common vulnerabilities and exposures. The experiment confirms that the term frequency–inverse document frequency algorithm provides the best overall performance.
Full article
►▼
Show Figures
Open AccessArticle
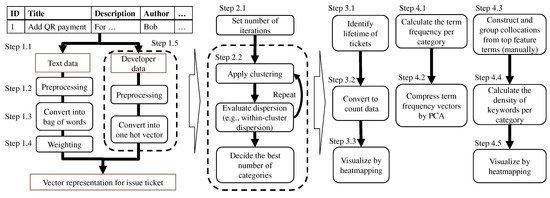
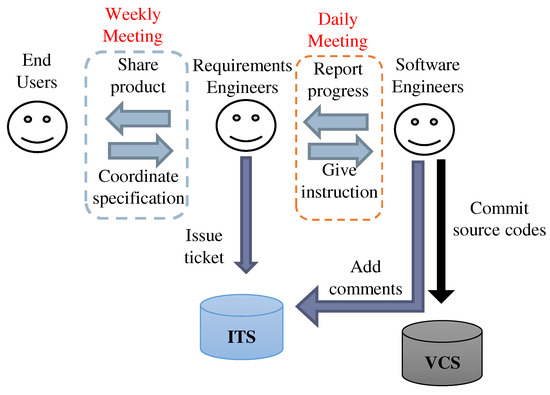
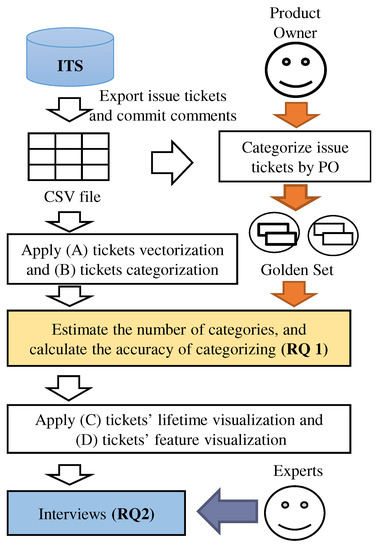
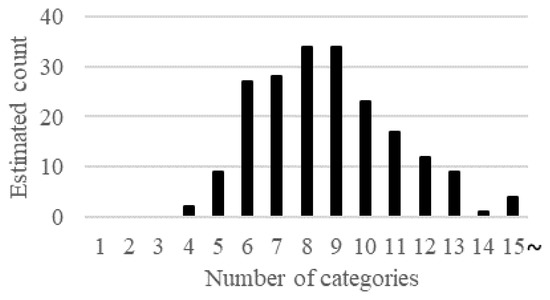
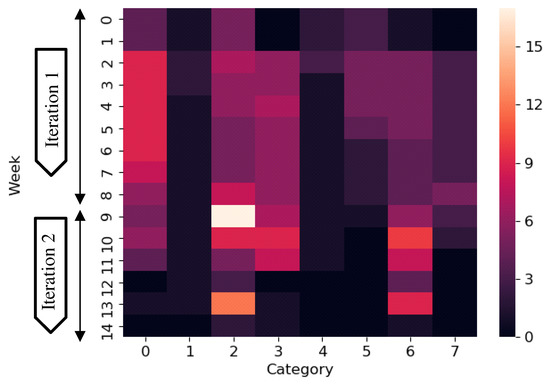
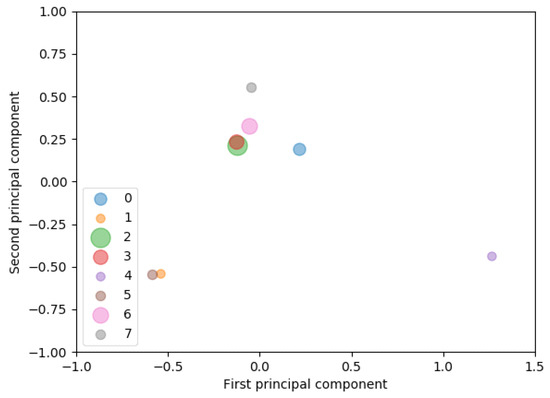
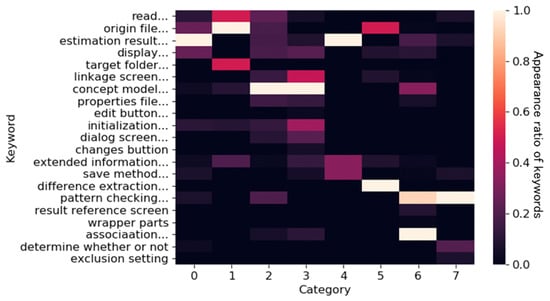
Categorization and Visualization of Issue Tickets to Support Understanding of Implemented Features in Software Development Projects
by
Ryo Ishizuka, Hironori Washizaki, Naohiko Tsuda, Yoshiaki Fukazawa, Saori Ouji, Shinobu Saito and Yukako Iimura
Viewed by 2427
Abstract
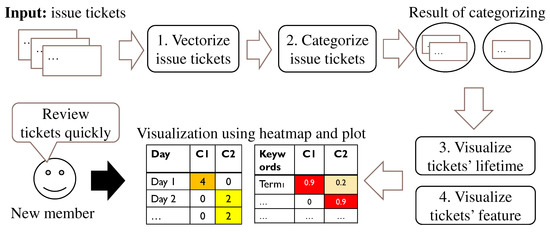
Background: In most software projects, new members must comprehend the features already implemented since they are usually assigned during the project period. They often read software documents (e.g., flowcharts and data models), but such documents tend not to be updated after they are
[...] Read more.
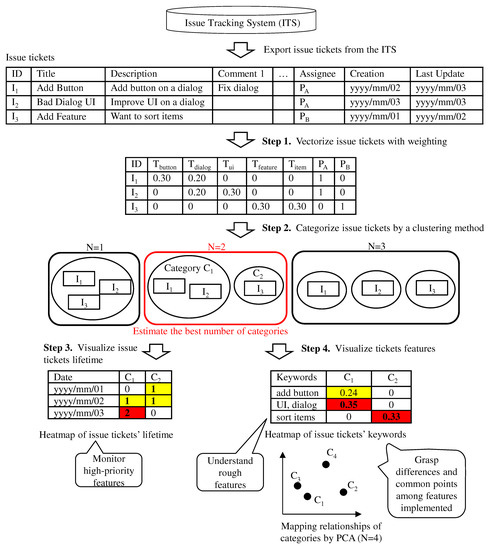
Background: In most software projects, new members must comprehend the features already implemented since they are usually assigned during the project period. They often read software documents (e.g., flowcharts and data models), but such documents tend not to be updated after they are created. Herein we focus on tickets issued because they are created as a project evolves and include the latest information of the implemented features. Aim: The purpose of this paper is to clarify the way of helping new members understand the implemented features of a project by using tickets. Methodology: We propose a novel method to categorize tickets by clustering and visualizing the characteristics of each category via heatmapping and principal component analysis (PCA). Our method estimates the number of categories and categorizes issue tickets (tickets) automatically. Moreover, it has two visualizations. Ticket lifetime visualization shows the time series change to review tickets quickly, while ticket feature visualization shows the relationships among ticket categories and keywords of ticket categories using heatmapping and PCA. Results: To evaluate the effectiveness of our method, we implemented a case study. Specifically, we applied our method to an industrial software development project and interviewed the project members and external experts. Furthermore, we conducted an experiment to clarify the effectiveness of our method compared with a non-tool-assist method by letting subjects comprehend the target project, which is the same as that of the case study. These studies confirm our method supports experts’ and subjects’ comprehension of the project and its features by examining the ticket category lifetimes and keywords. Implication: Newcomers during project onboarding can utilize tickets to comprehend implemented features effectively if the tickets are appropriately structured and visualized. Conclusions: The original contribution of this paper is the proposal of the project feature comprehension method by visualizing the multi-dimensional nature of requirements in an organized and structured way based on available tickets and the result of its application to the industrial project.
Full article
►▼
Show Figures
Open AccessArticle
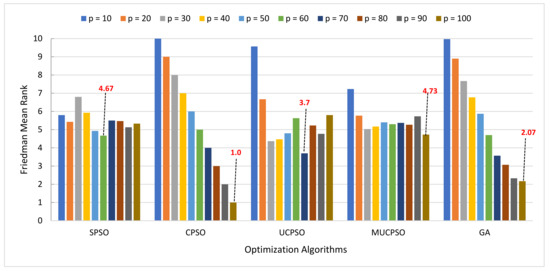
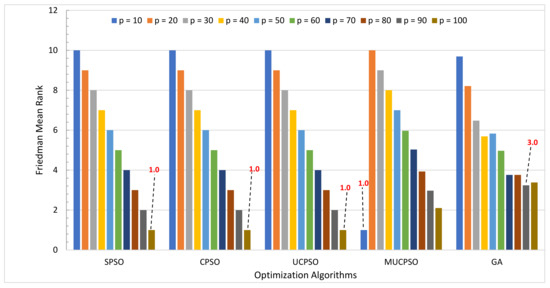
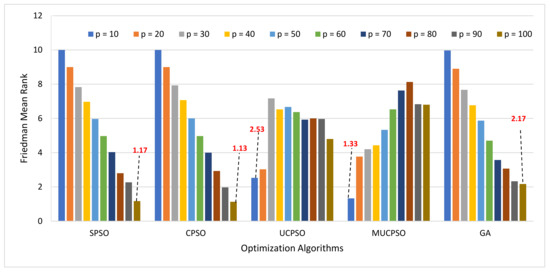
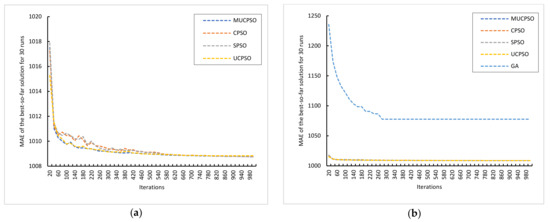
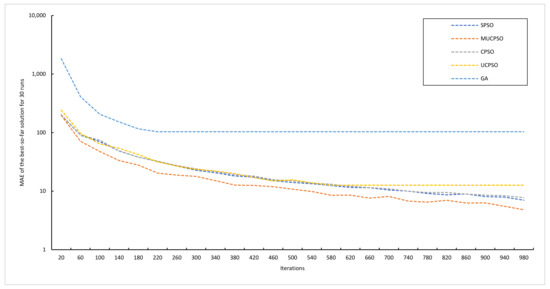
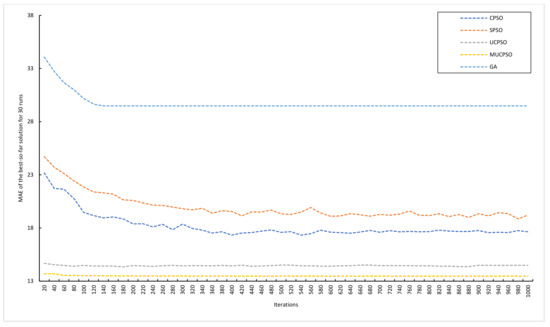
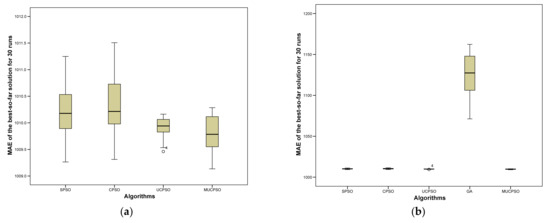
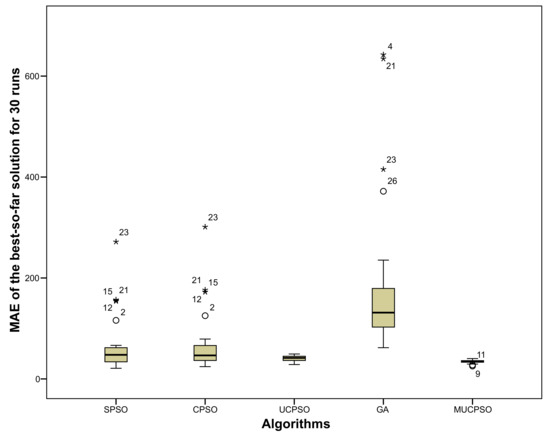
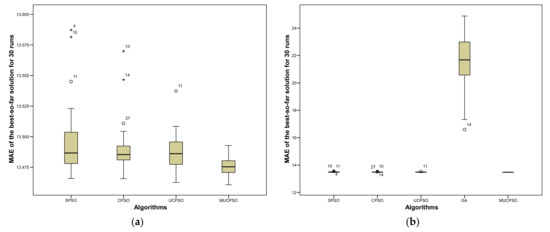
MUCPSO: A Modified Chaotic Particle Swarm Optimization with Uniform Initialization for Optimizing Software Effort Estimation
by
Ardiansyah Ardiansyah, Ridi Ferdiana and Adhistya Erna Permanasari
Cited by 14 | Viewed by 1905
Abstract
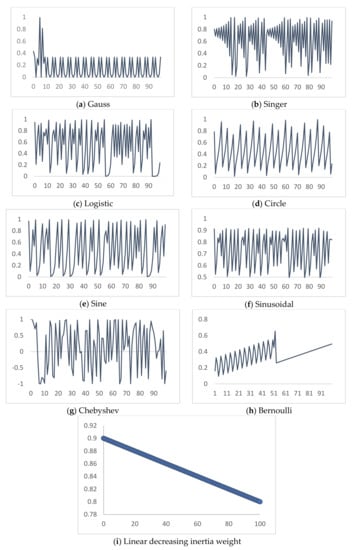
Particle Swarm Optimization is a metaheuristic optimization algorithm widely used across a broad range of applications. The algorithm has certain primary advantages such as its ease of implementation, high convergence accuracy, and fast convergence speed. Nevertheless, since its origin in 1995, Particle swarm
[...] Read more.
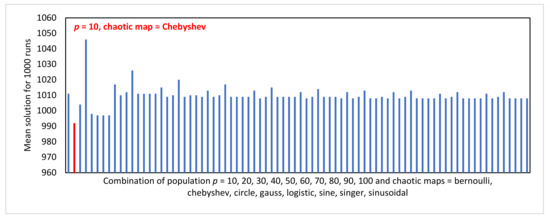
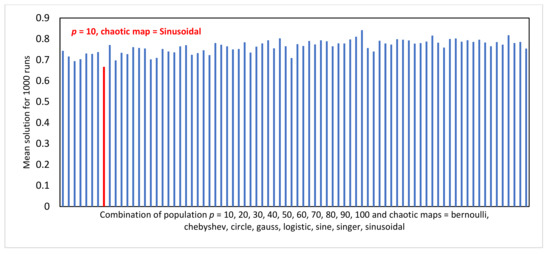
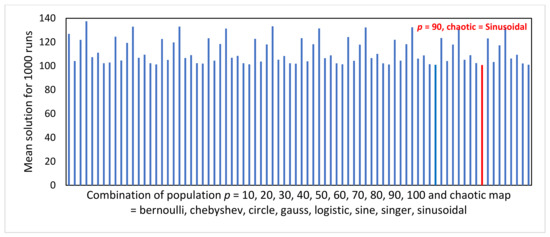
Particle Swarm Optimization is a metaheuristic optimization algorithm widely used across a broad range of applications. The algorithm has certain primary advantages such as its ease of implementation, high convergence accuracy, and fast convergence speed. Nevertheless, since its origin in 1995, Particle swarm optimization still suffers from two primary shortcomings, i.e., premature convergence and easy trapping in local optima. Therefore, this study proposes modified chaotic particle swarm optimization with uniform particle initialization to enhance the comprehensive performance of standard particle swarm optimization by introducing three additional schemes. Firstly, the initialized swarm is generated through a uniform approach. Secondly, replacing the linear inertia weight by introducing the nonlinear chaotic inertia weight map. Thirdly, by applying a personal learning strategy to enhance the global and local search to avoid trap in local optima. The proposed algorithm is examined and compared with standard particle swarm optimization, two recent particle swarm optimization variants, and a nature-inspired algorithm using three software effort estimation methods as benchmark functions: Use case points, COCOMO, and Agile. Detailed investigations prove that the proposed schemes work well to develop the proposed algorithm in an exploitative manner, which is created by a uniform particle initialization and avoids being trapped on the local optimum solution in an explorative manner and is generated by a personal learning strategy and chaotic-based inertia weight.
Full article
►▼
Show Figures
Open AccessArticle
Techniques for Calculating Software Product Metrics Threshold Values: A Systematic Mapping Study
by
Alok Mishra, Raed Shatnawi, Cagatay Catal and Akhan Akbulut
Cited by 5 | Viewed by 2777
Abstract
Several aspects of software product quality can be assessed and measured using product metrics. Without software metric threshold values, it is difficult to evaluate different aspects of quality. To this end, the interest in research studies that focus on identifying and deriving threshold
[...] Read more.
Several aspects of software product quality can be assessed and measured using product metrics. Without software metric threshold values, it is difficult to evaluate different aspects of quality. To this end, the interest in research studies that focus on identifying and deriving threshold values is growing, given the advantage of applying software metric threshold values to evaluate various software projects during their software development life cycle phases. The aim of this paper is to systematically investigate research on software metric threshold calculation techniques. In this study, electronic databases were systematically searched for relevant papers; 45 publications were selected based on inclusion/exclusion criteria, and research questions were answered. The results demonstrate the following important characteristics of studies: (a) both empirical and theoretical studies were conducted, a majority of which depends on empirical analysis; (b) the majority of papers apply statistical techniques to derive object-oriented metrics threshold values; (c) Chidamber and Kemerer (CK) metrics were studied in most of the papers, and are widely used to assess the quality of software systems; and (d) there is a considerable number of studies that have not validated metric threshold values in terms of quality attributes. From both the academic and practitioner points of view, the results of this review present a catalog and body of knowledge on metric threshold calculation techniques. The results set new research directions, such as conducting mixed studies on statistical and quality-related studies, studying an extensive number of metrics and studying interactions among metrics, studying more quality attributes, and considering multivariate threshold derivation.
Full article
►▼
Show Figures
Open AccessArticle
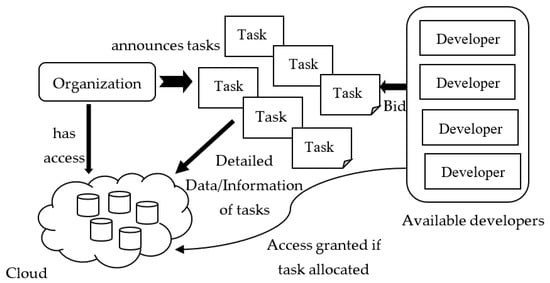
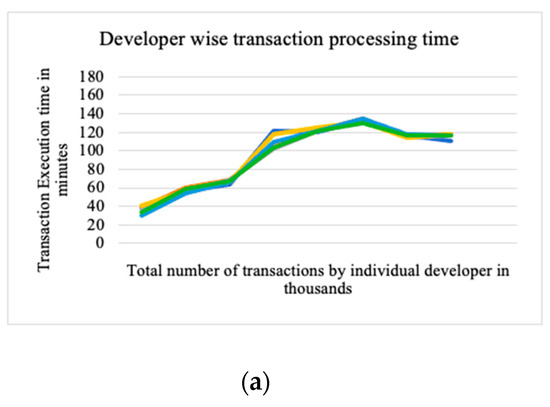
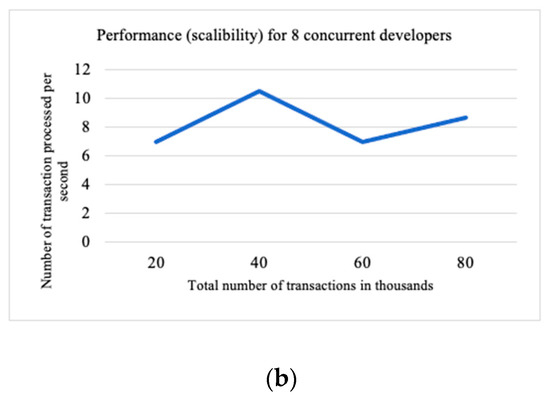
A Decentralized Framework for Managing Task Allocation in Distributed Software Engineering
by
Chetna Gupta and Varun Gupta
Cited by 2 | Viewed by 2026
Abstract
In distributed software development, planning and managing fair and transparent task allocation is both critical and challenging. The objective of this paper is to propose a decentralized blockchain-oriented, transparent task allocation framework to improve the quality of the task allocation process. It addresses
[...] Read more.
In distributed software development, planning and managing fair and transparent task allocation is both critical and challenging. The objective of this paper is to propose a decentralized blockchain-oriented, transparent task allocation framework to improve the quality of the task allocation process. It addresses the concerns of (i) enhancing collaboration, (ii) inhibiting knowledge vaporization, and (iii) reducing documentation problems. The proposed method is a novel two-fold process: First, it identifies and categorizes tasks exhibiting different dependencies and complexities to create equal task clusters based on their dependency type, difficulty, cost, and time. Second, it uses a blockchain-oriented framework to broadcast, check bid validity, allow developers to bid on tasks matching their roles and expertise, evaluate, and announce the winner for task allocation using smart contracts. Results of experimentation, surveys, and interviews with software practitioners conclude that the proposed solution is transparent and effective in allocating tasks (with Cranach’s alpha of 0.894) at a low cost of contract execution in a distributed software development environment. Overall, the proposed approach will have a positive and significant impact in industrial settings.
Full article
►▼
Show Figures
Open AccessArticle
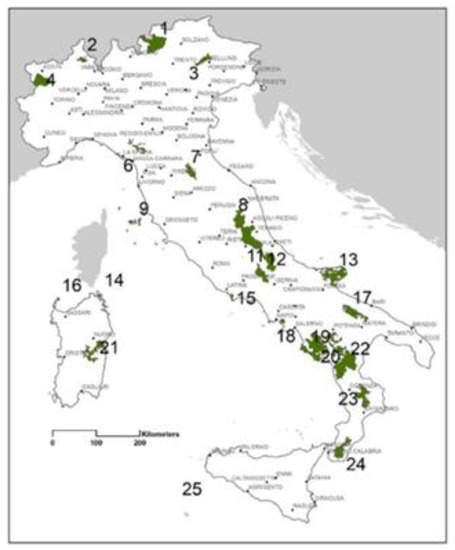
Sensitivity Analysis of PROMETHEE II for the Evaluation of Environmental Websites
by
Katerina Kabassi and Aristotelis Martinis
Cited by 13 | Viewed by 1879
Abstract
The quality of content and the attractiveness of an environmental website can create an environmentally friendly attitude before one visits a secured area. However, a website should be evaluated to ensure that its goal is met. For this reason, the websites of environmental
[...] Read more.
The quality of content and the attractiveness of an environmental website can create an environmentally friendly attitude before one visits a secured area. However, a website should be evaluated to ensure that its goal is met. For this reason, the websites of environmental content have been evaluated using a combination of AHP and PROMETHEE II. More specifically, the websites of environmental content that have been selected to be evaluated are the websites of the national parks of Italy. The main contribution of the particular paper is on comparing PROMETHEE II with three other common MCDM models (SAW, WPM, TOPSIS) and performing a sensitivity analysis to make the comparison more thorough. As a result, the conclusions drawn by this experiment involve the appropriateness of PROMETHEE II for the ranking of environmental websites as well as the robustness of the different MCDM models. The experiment revealed that the PROMETHEE II model was found to be very effective in ranking environmental websites and is the most robust model compared to the other ones. Furthermore, the evaluation of the websites of national parks in Italy revealed that the electronic presence of national parks is at an early stage.
Full article
►▼
Show Figures
Open AccessArticle
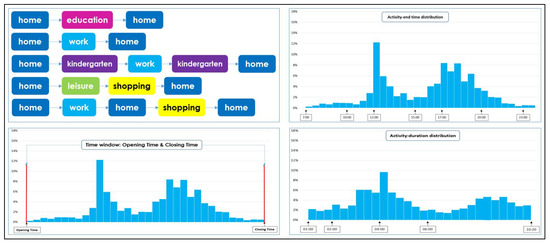
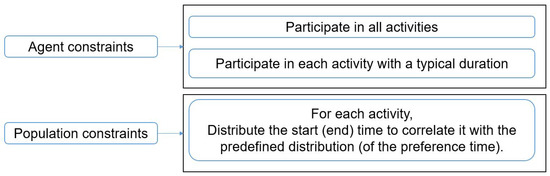
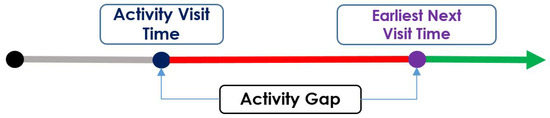
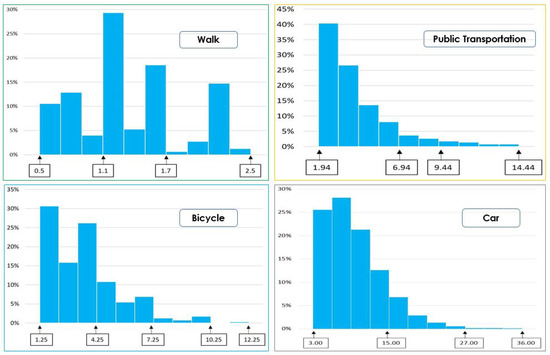
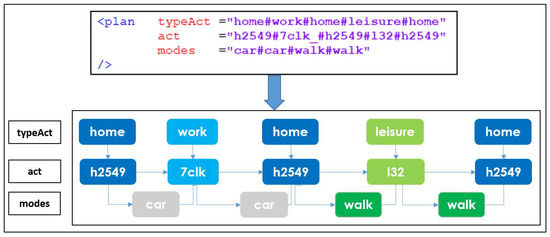
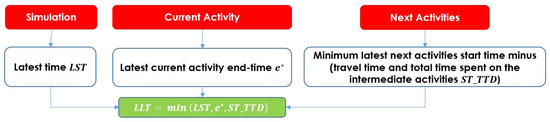
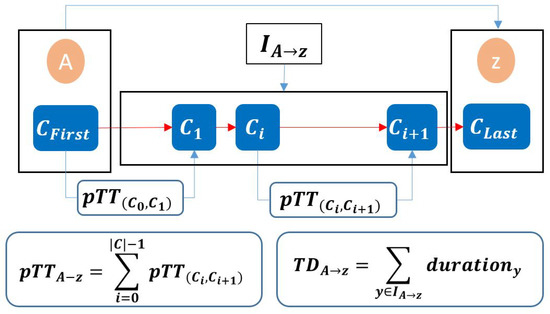
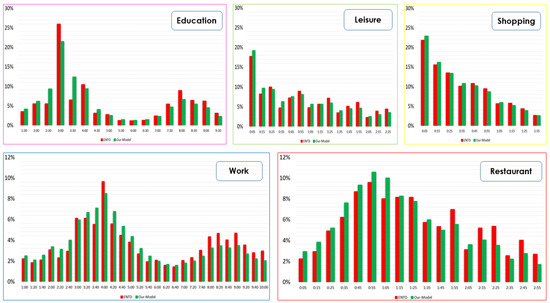
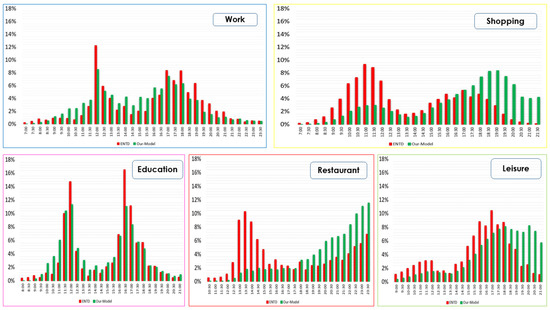
Modeling Activity-Time to Build Realistic Plannings in Population Synthesis in a Suburban Area
by
Younes Delhoum, Rachid Belaroussi, Francis Dupin and Mahdi Zargayouna
Cited by 2 | Viewed by 1608
Abstract
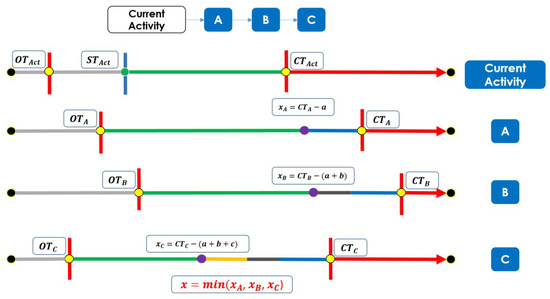
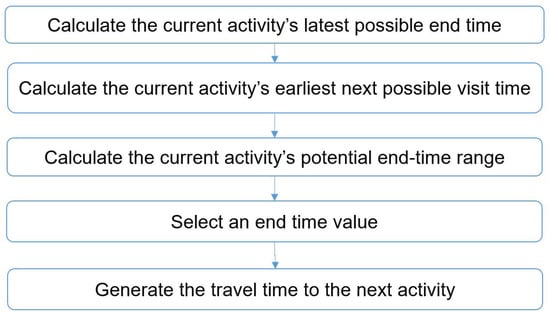
In their daily activity planning, travelers always considers time and space constraints such as working or education hours and distances to facilities that can restrict the location and time-of-day choices of other activities. In the field of population synthesis, current demand models lack
[...] Read more.
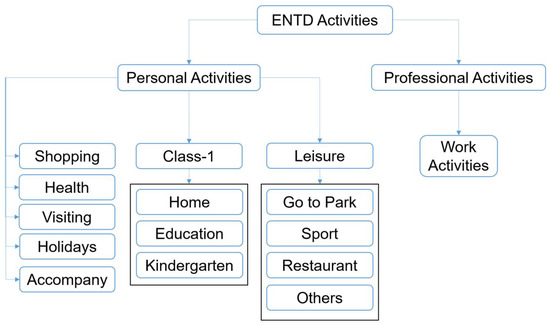
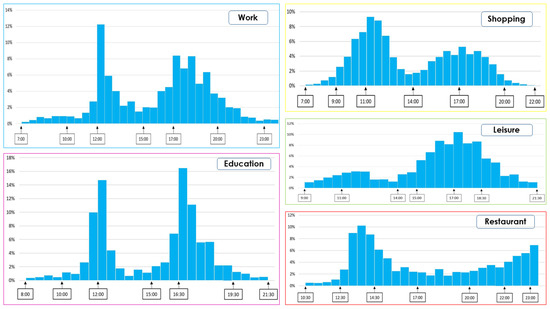
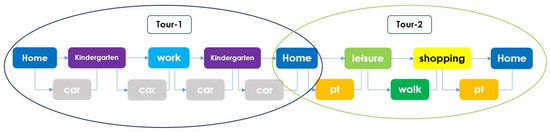
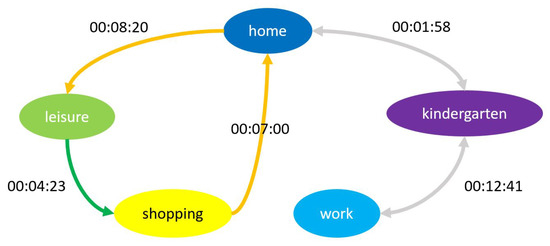
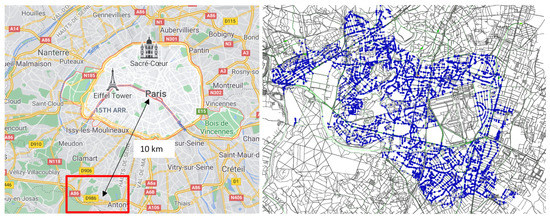
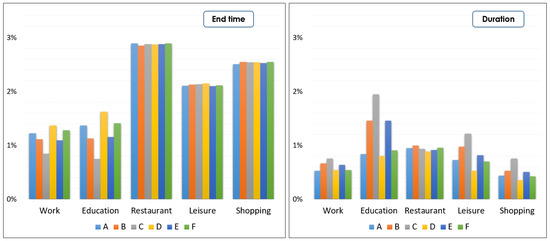
In their daily activity planning, travelers always considers time and space constraints such as working or education hours and distances to facilities that can restrict the location and time-of-day choices of other activities. In the field of population synthesis, current demand models lack dynamic consistency and often fail to capture the angle of activity choices at different times of the day. This article presents a method for synthetic population generation with a focus on activity-time choice. Activity-time choice consists mainly in the activity’s starting time and its duration, and we consider daily planning with some mandatory home-based activity: the chain of other subsequent activities a traveler can participate in depends on their possible end-time and duration as well as the travel distance from one another and opening hours of commodities. We are interested in a suburban area with sparse data available on population, where a discrete choice model based on utilities cannot be implemented due to the lack of microeconomic data. Our method applies activity-hours distributions extracted from the public census, with a limited corpus, to draw the time of a potential next activity based on the end-time of the previous one, predicted travel times, and the successor activities the agent wants to participate in during the day. We show that our method is able to construct plannings for 126k agents over five municipalities, with chains of activity made of work, education, shopping, leisure, restaurant and kindergarten, which fit adequately real-world time distributions.
Full article
►▼
Show Figures
Open AccessArticle
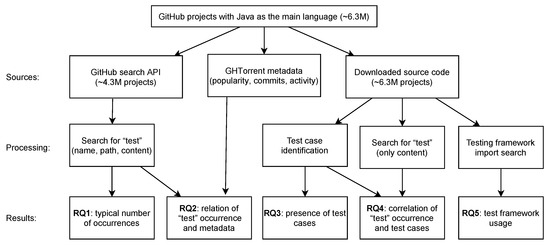
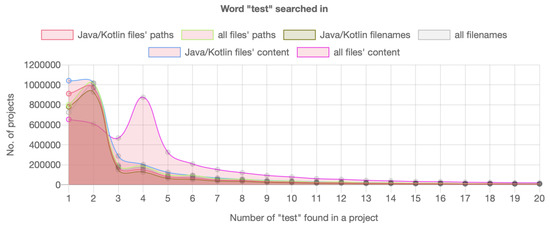
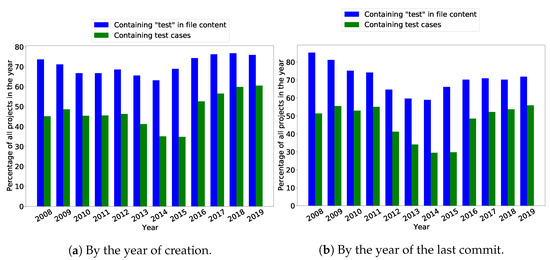
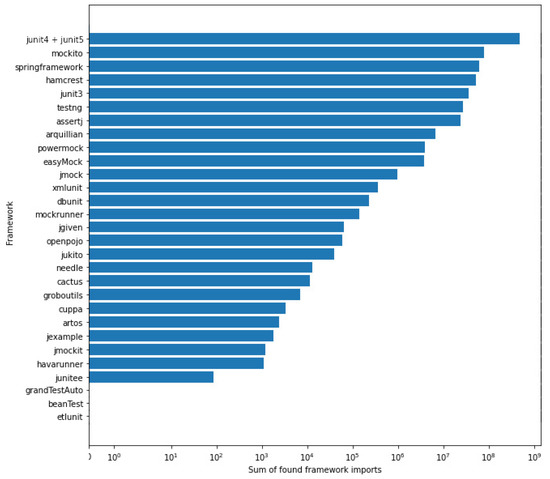
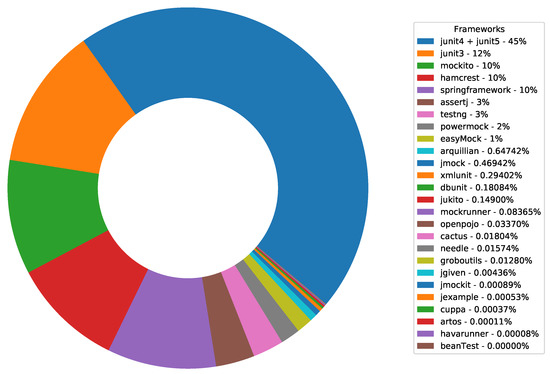
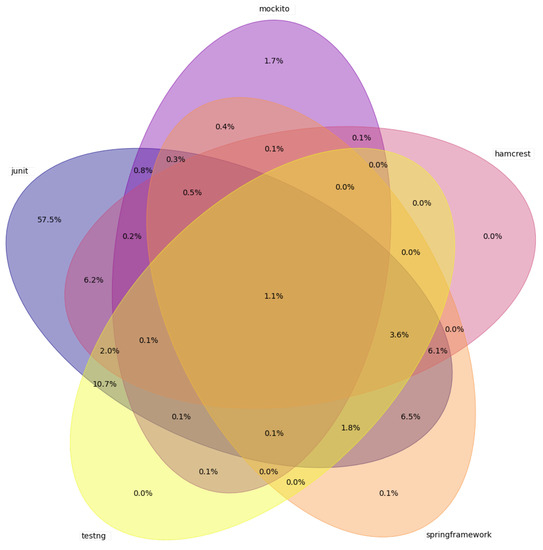
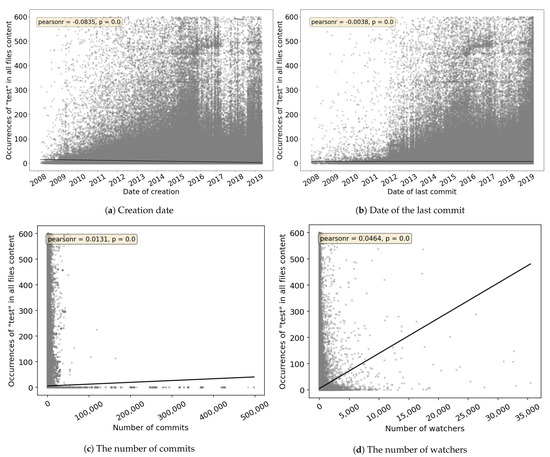
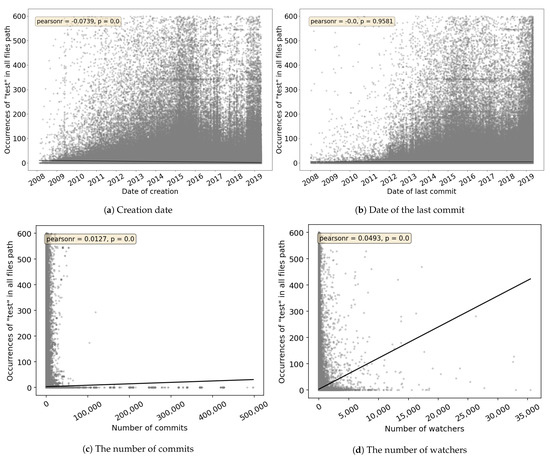
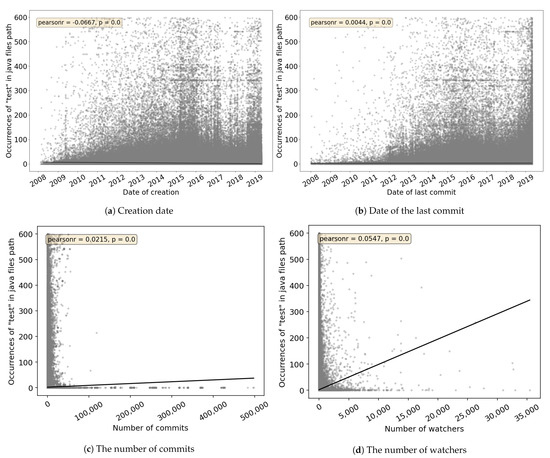
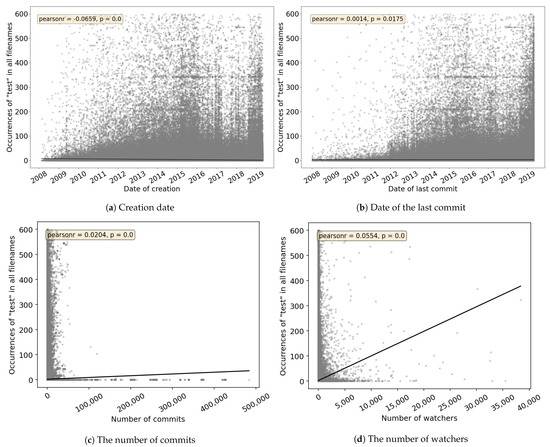
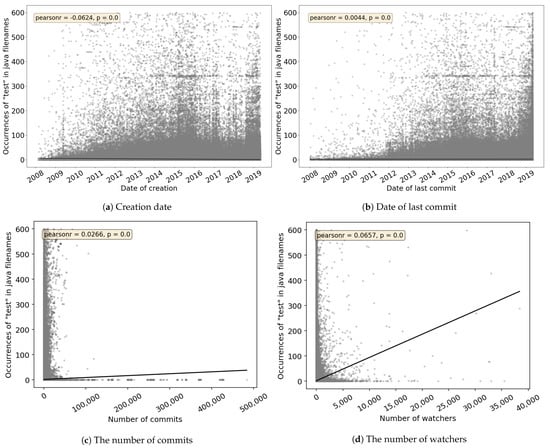
Empirical Study of Test Case and Test Framework Presence in Public Projects on GitHub
by
Matej Madeja, Jaroslav Porubän, Sergej Chodarev, Matúš Sulír and Filip Gurbáľ
Cited by 1 | Viewed by 1936
Abstract
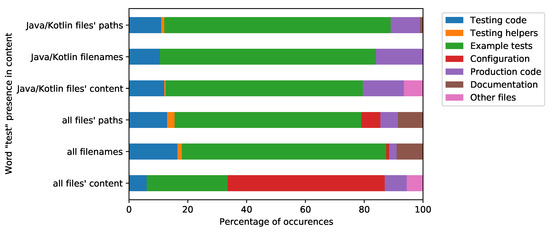
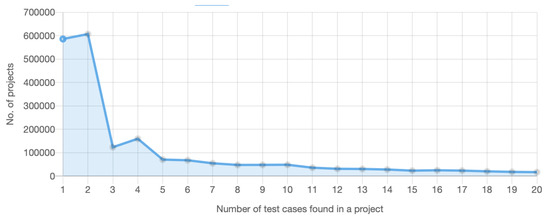
Automated tests are often considered an indicator of project quality. In this paper, we performed a large analysis of 6.3 M public GitHub projects using Java as the primary programming language. We created an overview of tests occurrence in publicly available GitHub projects
[...] Read more.
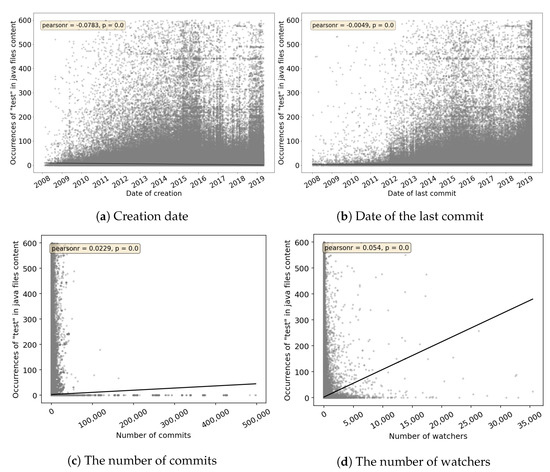
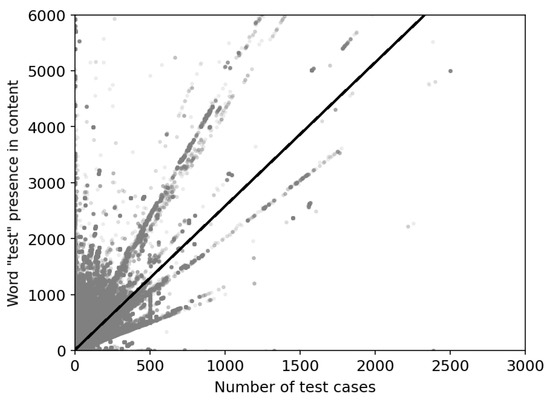
Automated tests are often considered an indicator of project quality. In this paper, we performed a large analysis of 6.3 M public GitHub projects using Java as the primary programming language. We created an overview of tests occurrence in publicly available GitHub projects and the use of test frameworks in them. The results showed that 52% of the projects contain at least one test case. However, there is a large number of example tests that do not represent relevant production code testing. It was also found that there is only a poor correlation between the number of the word “test” in different parts of the project (e.g., file paths, file name, file content, etc.) and the number of test cases, creation date, date of the last commit, number of commits, or number of watchers. Testing framework analysis confirmed that JUnit is the most used testing framework with a 48% share. TestNG, considered the second most popular Java unit testing framework, occurred in only 3% of the projects.
Full article
►▼
Show Figures
Open AccessArticle
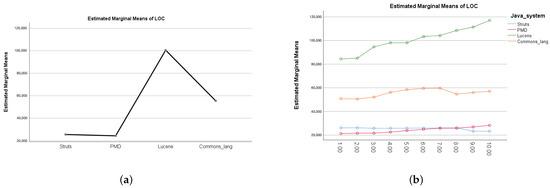
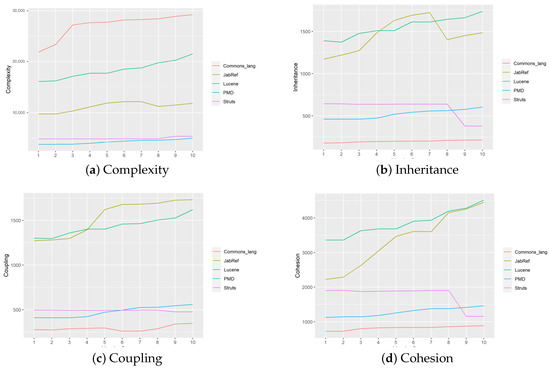
Internal Quality Evolution of Open-Source Software Systems
by
Mamdouh Alenezi
Cited by 3 | Viewed by 1931
Abstract
The evolution of software is necessary for the success of software systems. Studying the evolution of software and understanding it is a vocal topic of study in software engineering. One of the primary concepts of software evolution is that the internal quality of
[...] Read more.
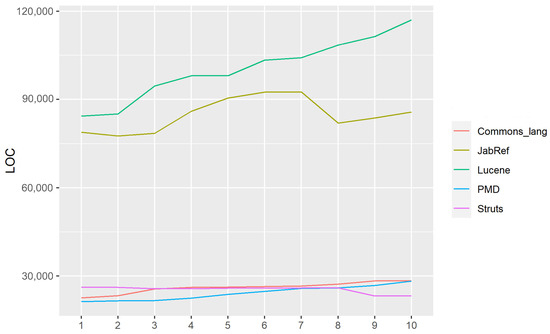
The evolution of software is necessary for the success of software systems. Studying the evolution of software and understanding it is a vocal topic of study in software engineering. One of the primary concepts of software evolution is that the internal quality of a software system declines when it evolves. In this paper, the method of evolution of the internal quality of object-oriented open-source software systems has been examined by applying a software metric approach. More specifically, we analyze how software systems evolve over versions regarding size and the relationship between size and different internal quality metrics. The results and observations of this research include: (i) there is a significant difference between different systems concerning the LOC variable (ii) there is a significant correlation between all pairwise comparisons of internal quality metrics, and (iii) the effect of complexity and inheritance on the LOC was positive and significant, while the effect of Coupling and Cohesion was not significant.
Full article
►▼
Show Figures
Open AccessArticle
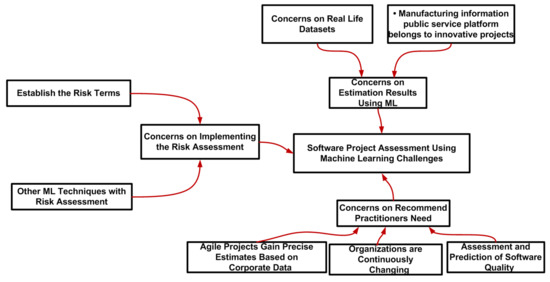
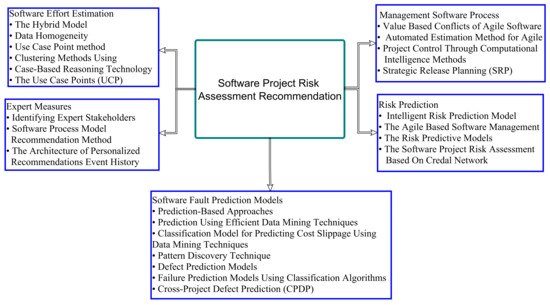
Software Project Management Using Machine Learning Technique—A Review
by
Mohammed Najah Mahdi, Mohd Hazli Mohamed Zabil, Abdul Rahim Ahmad, Roslan Ismail, Yunus Yusoff, Lim Kok Cheng, Muhammad Sufyian Bin Mohd Azmi, Hayder Natiq and Hushalini Happala Naidu
Cited by 16 | Viewed by 13210
Abstract
Project management planning and assessment are of great significance in project performance activities. Without a realistic and logical plan, it isn’t easy to handle project management efficiently. This paper presents a wide-ranging comprehensive review of papers on the application of Machine Learning in
[...] Read more.
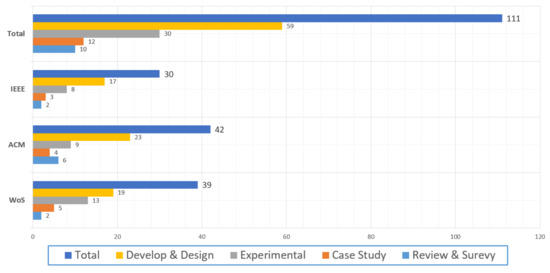
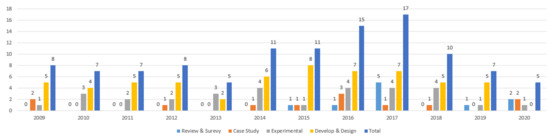
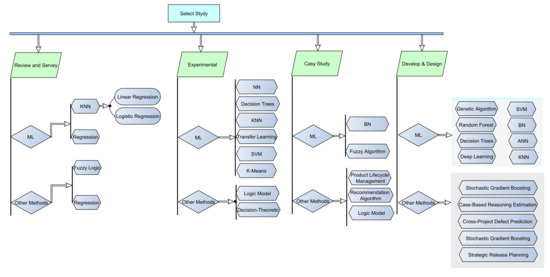
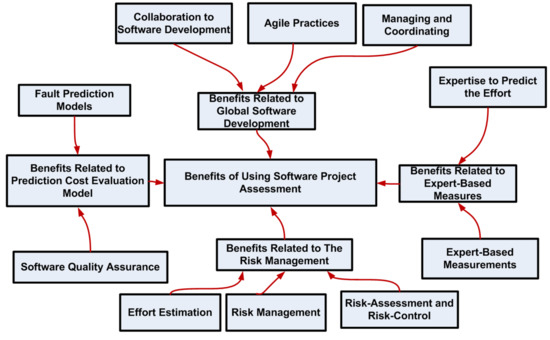
Project management planning and assessment are of great significance in project performance activities. Without a realistic and logical plan, it isn’t easy to handle project management efficiently. This paper presents a wide-ranging comprehensive review of papers on the application of Machine Learning in software project management. Besides, this paper presents an extensive literature analysis of (1) machine learning, (2) software project management, and (3) techniques from three main libraries, Web Science, Science Directs, and IEEE Explore. One-hundred and eleven papers are divided into four categories in these three repositories. The first category contains research and survey papers on software project management. The second category includes papers that are based on machine-learning methods and strategies utilized on projects; the third category encompasses studies on the phases and tests that are the parameters used in machine-learning management and the final classes of the results from the study, contribution of studies in the production, and the promotion of machine-learning project prediction. Our contribution also offers a more comprehensive perspective and a context that would be important for potential work in project risk management. In conclusion, we have shown that project risk assessment by machine learning is more successful in minimizing the loss of the project, thereby increasing the likelihood of the project success, providing an alternative way to efficiently reduce the project failure probabilities, and increasing the output ratio for growth, and it also facilitates analysis on software fault prediction based on accuracy.
Full article
►▼
Show Figures
Open AccessArticle
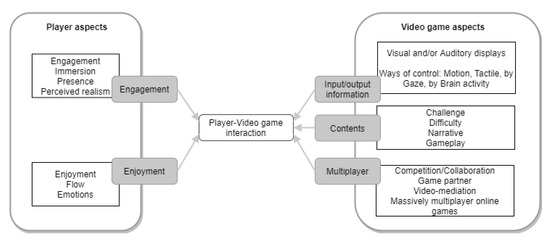
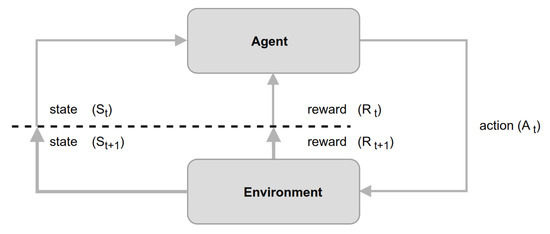
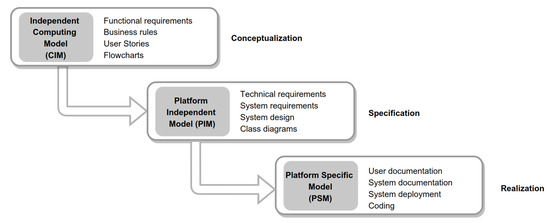
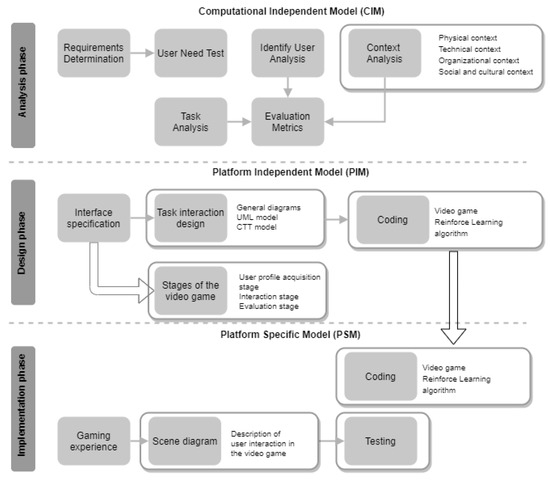
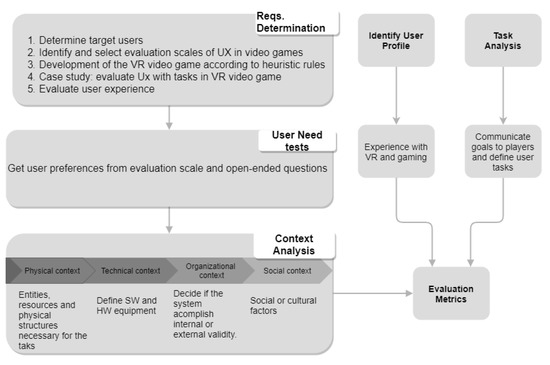
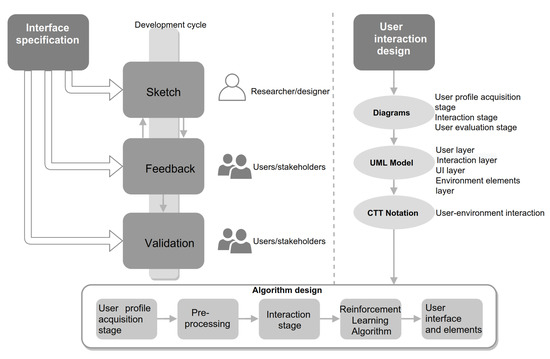
Model-Driven Approach of Virtual Interactive Environments for Enhanced User Experience
by
Héctor Cardona-Reyes, Jaime Muñoz-Arteaga, Andres Mitre-Ortiz and Klinge Orlando Villalba-Condori
Cited by 2 | Viewed by 2895
Abstract
The video game and entertainment industry has been growing in recent years, particularly those related to Virtual Reality (VR). Therefore, video game creators are looking for ways to offer and improve realism in their applications in order to improve user satisfaction. In this
[...] Read more.
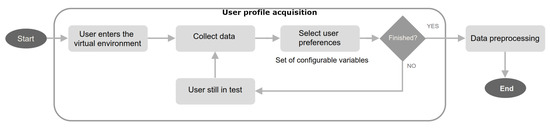
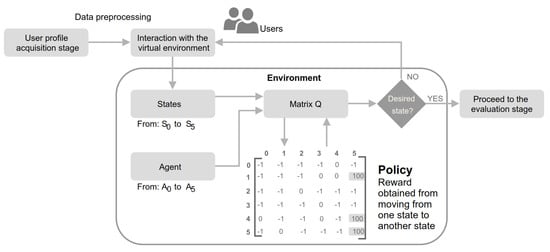
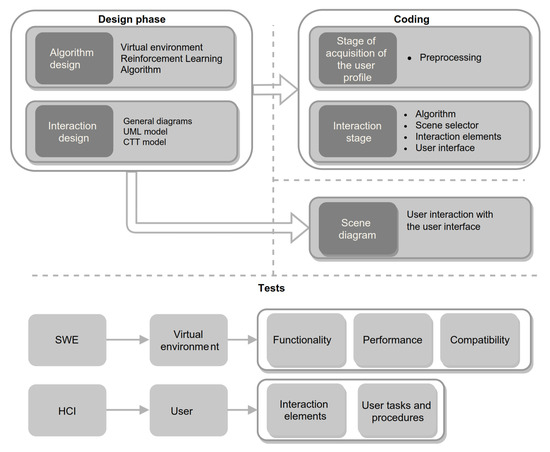
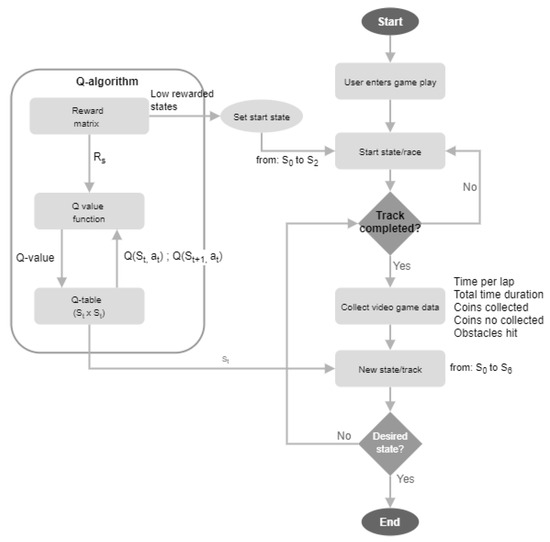
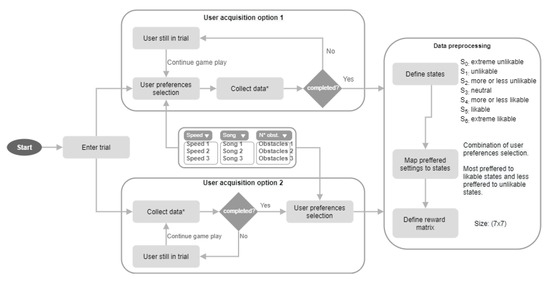
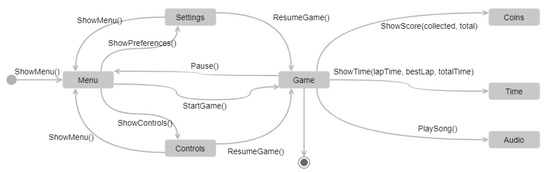
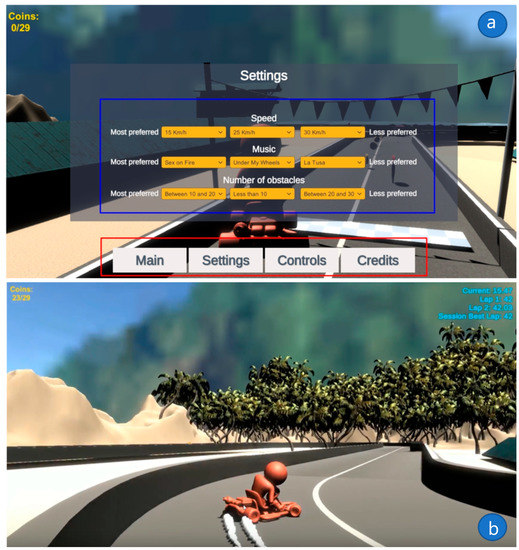
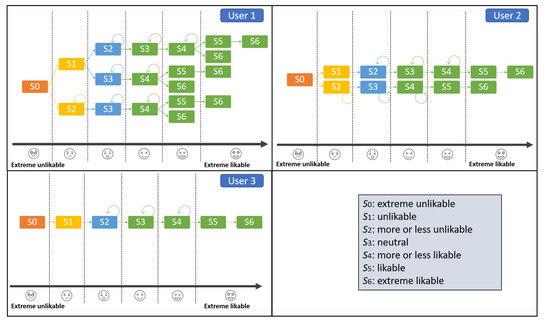
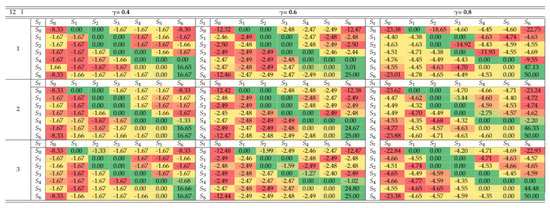
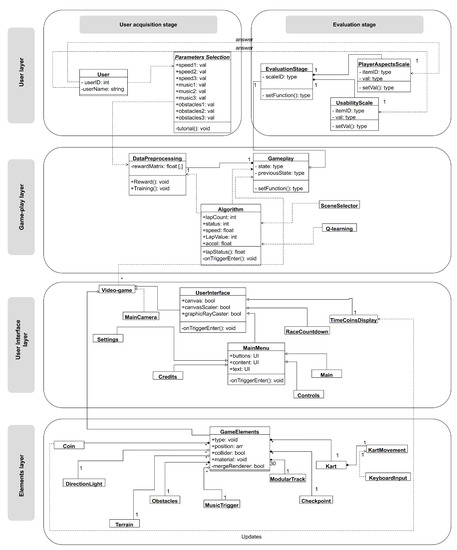
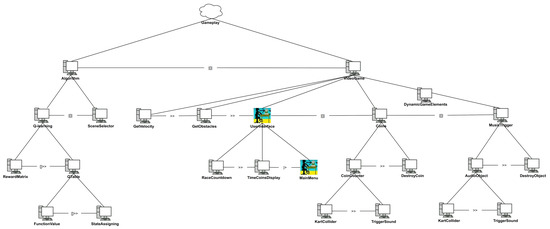
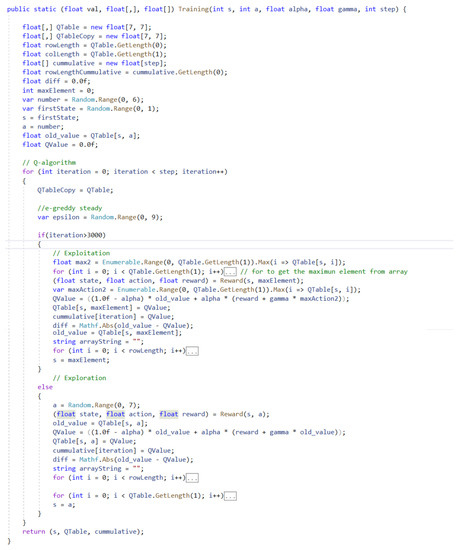
The video game and entertainment industry has been growing in recent years, particularly those related to Virtual Reality (VR). Therefore, video game creators are looking for ways to offer and improve realism in their applications in order to improve user satisfaction. In this sense, it is of great importance to have strategies to evaluate and improve the gaming experience in a group of people, without considering the fact that users have different preferences and, coupled with this, also seeks to achieve satisfaction in each user. In this work, we present a model to improve the user experience in a personal way through reinforcement learning (RL). Unlike other approaches, the proposed model adjusts parameters of the virtual environment in real-time based on user preferences, rather than physiological data or performance. The model design is based on the Model-Driven Architecture (MDA) approach and consists of three main phases: analysis phase, design phase, and implementation phase. As results, a simulation experiment is presented that shows the transitions between undesired satisfaction states to desired satisfaction states, considering an approach in a personal way.
Full article
►▼
Show Figures
Planned Papers
The below list represents only planned manuscripts. Some of these
manuscripts have not been received by the Editorial Office yet. Papers
submitted to MDPI journals are subject to peer-review.
Title: Bibliometric Assessment of SE concerning 15 Knowledge Areas identified by Software Engineering Body of Knowledge (SWEBoK) over 7 years (2015 - 2021)
Author:
Highlights: Inclusion of 15 Knowledge Areas (KAs) defined by SWEBoK Analysis based on collaboration amongst countries Analysis of multi-disciplinary research areas Analysis based on distinguished time frames Language-based analysis of articles Connectedness amongst research studies on the basis of keywords Highly cited papers-based analysis
Title: Reviewing Automated Anaysis of Feature Model solutions for the Product Configuration
Author:
Highlights: To identify, evaluate, and classify research work from 2010 to 2020 regarding the minimal conflict set detection, minimal diagnosis, and product completion for the automated analysis of feature model product configuration.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}