Dear Colleagues,
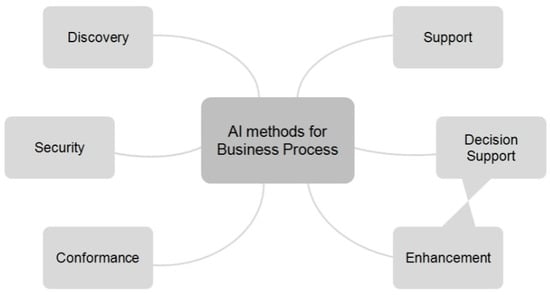
Researchers are invited to contribute with research work that presents original scientific results, concepts, and methods in the field of data mining applied to various domains, such as Healthcare, Software Development, Logistics and Human Resources. We are especially interested in how the data mining method was modified to cater to the specific domain in question. The challenge being, that the more complex a domain is the harder it is to make good predictions, as more implicit domain knowledge is required that is not always available. This is especially true in complex domains where there are soft factors like the interaction of the conflicting and cooperating objectives of the stakeholders and system dynamics play a significant role. The challenge in a business context is that one would like to see (i) how the algorithms can be repeatable in the real world, (ii) how the patterns mined can be utilized by the business and (iii) how the resulting model can be understood and utilized in the business environment. Furthermore, the idea is to identify the variables that impact the goal variable but to do so with the data, interestingness, deployment and general domain (business) constraints of the domain.
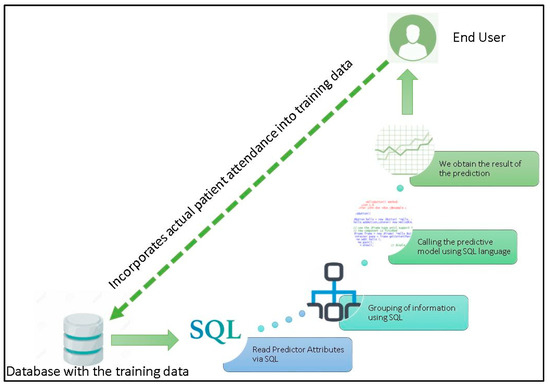
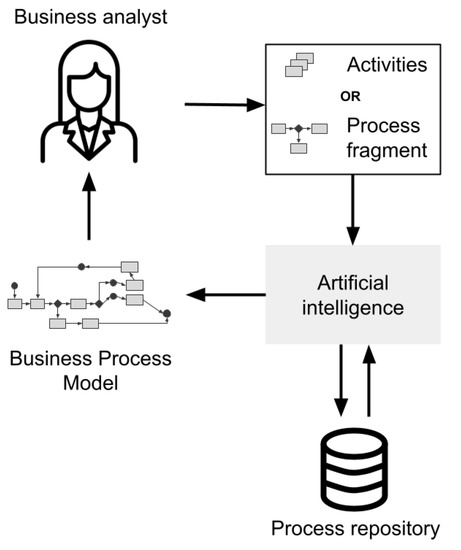
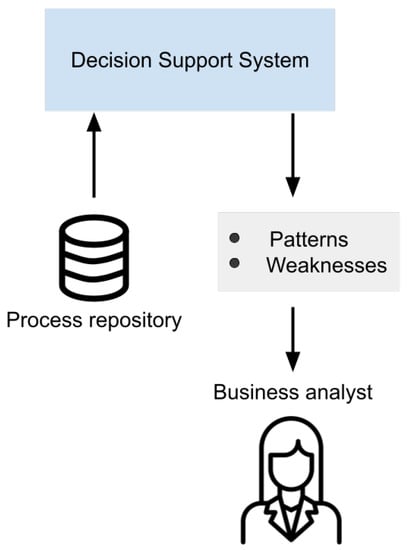
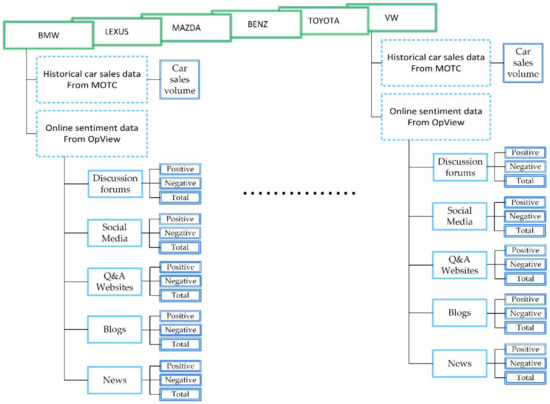
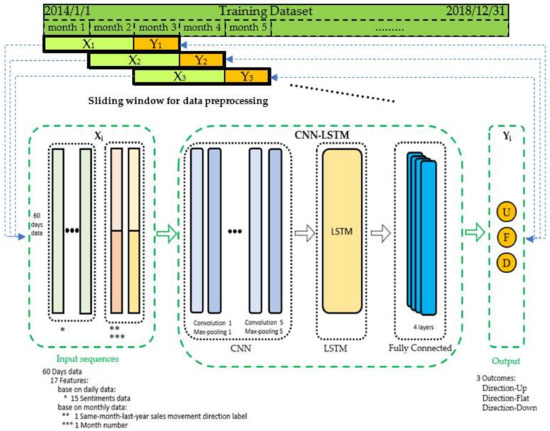
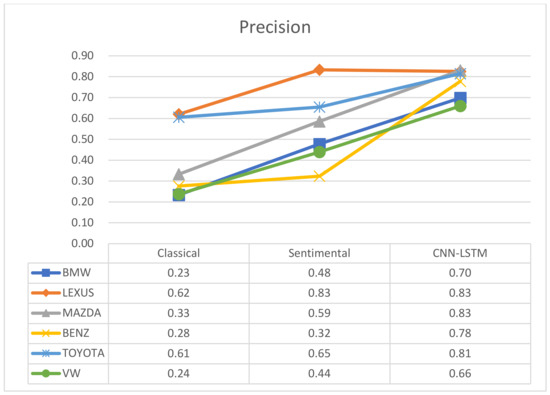
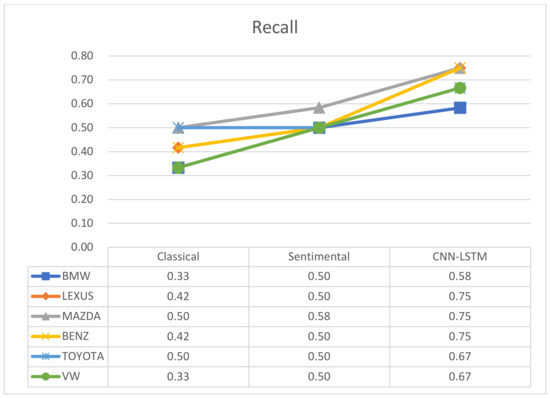
One of the methods to analyse a complex domain is by using a method called intelligence meta-synthesis. Intelligence synthesis is the collection and creation of perceived or understood (i.e. not necessarily objective) information. Meta-synthesis is the collection and creation of knowledge and information from collected intelligences. The goal of this approach is to design and develop predictive models, that could eventually be incorporated into a business intelligence dashboard. As a result, one would (i) understand the nature and origin of data that allows the system user to determine the quality of the data, to perform the data cleaning; (ii) understand the factors in the domain that influence the predicted variable, leading the developer to determine which variables need to be included in the predictive model; (iii) develop predictive models that are usable and interesting within the domain in terms of predictive power, integrating with existing infrastructure, and integrating with business rules & processes; and finally (iv) use the predicted data to find the optimize business processes in the particular domain.
The main goal of this collection is to bring together researchers, participants, academic scientists and contributors to share their experiences, present and discuss ongoing and latest research results that cover several aspects of original research as regards to existing theoretical, methodological contributions as well as the development of new methods/approaches in data mining in business domains.
Dr. Chintan Amrit
Dr. Asad Abdi
Guest Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Applied Sciences is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
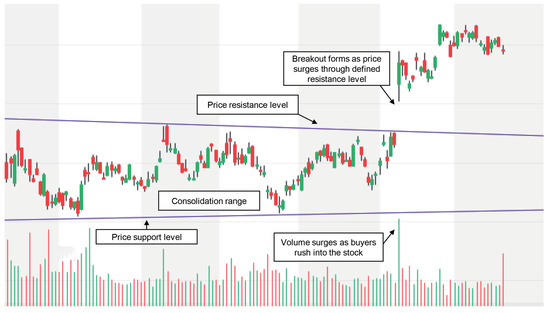{kind=link}
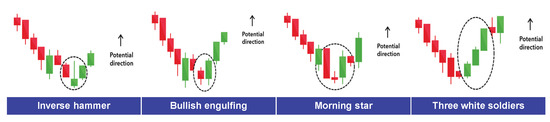{kind=link}
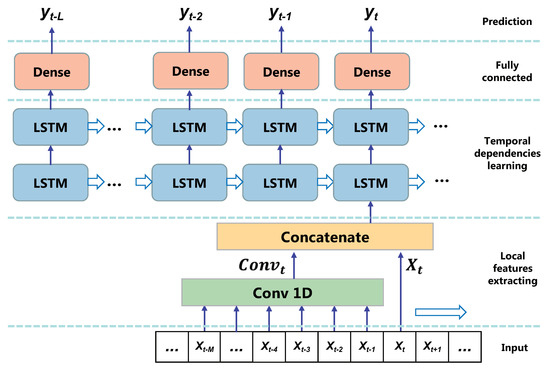{kind=link}
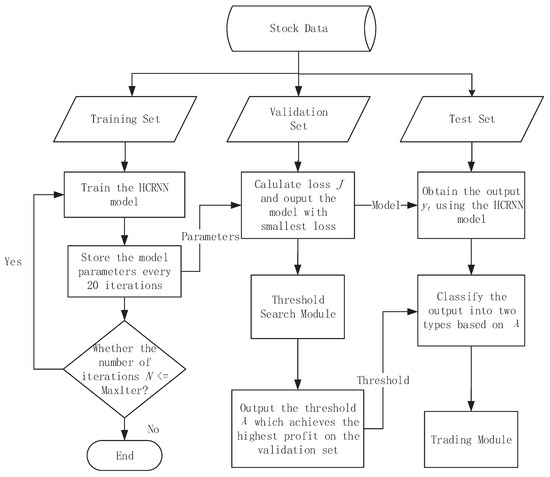{kind=link}
{kind=link}
{kind=link}
{kind=link}