




Agronomy 2024, 14(4), 719; https://doi.org/10.3390/agronomy14040719 - 29 Mar 2024
Viewed by 558
Abstract
►
Show Figures
Machine learning is a widespread technology that plays a crucial role in digitalisation and aims to explore rules and patterns in large datasets to autonomously solve non-linear problems, taking advantage of multiple source data. Due to its versatility, machine learning can be applied
[...] Read more.
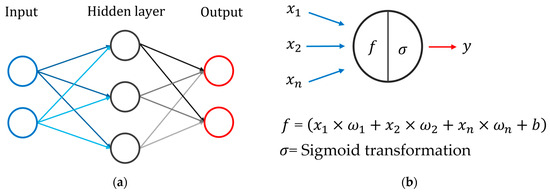
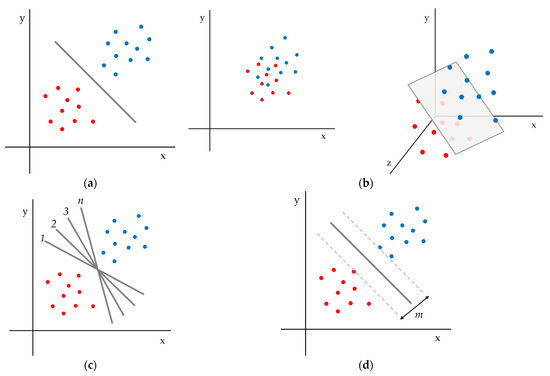
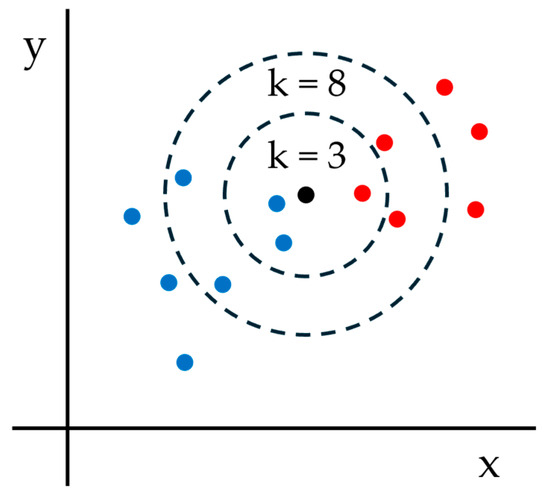
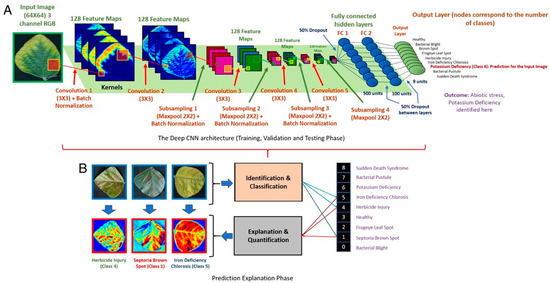
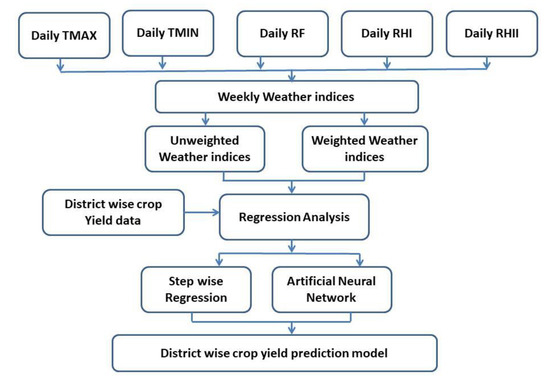
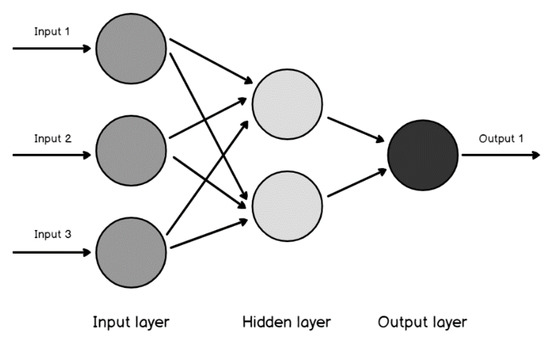
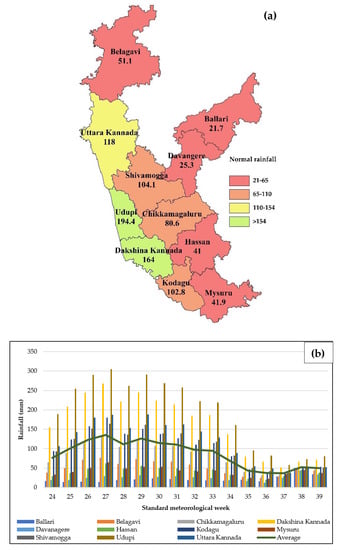
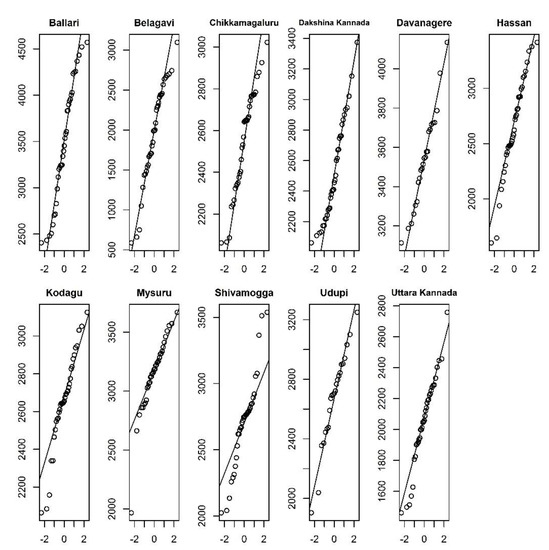
Machine learning is a widespread technology that plays a crucial role in digitalisation and aims to explore rules and patterns in large datasets to autonomously solve non-linear problems, taking advantage of multiple source data. Due to its versatility, machine learning can be applied to agriculture. Better crop management, plant health assessment, and early disease detection are some of the main challenges facing the agricultural sector. Plant phenotyping can play a key role in addressing these challenges, especially when combined with machine learning techniques. Therefore, this study reviews available scientific literature on the applications of machine learning algorithms in plant phenotyping with a specific focus on sunflowers. The most common algorithms in the agricultural field are described to emphasise possible uses. Subsequently, the overview highlights machine learning application on phenotyping in three primaries areas: crop management (i.e., yield prediction, biomass estimation, and growth stage monitoring), plant health (i.e., nutritional status and water stress), and disease detection. Finally, we focus on the adoption of machine learning techniques in sunflower phenotyping. The role of machine learning in plant phenotyping has been thoroughly investigated. Artificial neural networks and stacked models seems to be the best way to analyse data.
Full article
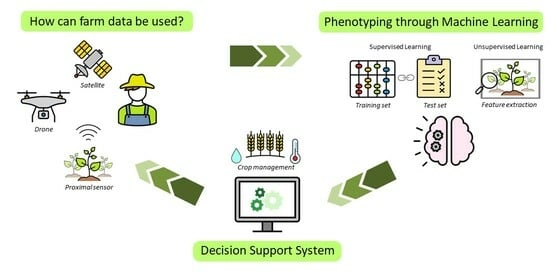
Graphical abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}