1. Introduction
In medical imaging, magnetic resonance imaging (MRI) is commonly used because it can capture the anatomical structure of the human body without exposing subjects to radiation. MRI scanners that generate a strong magnetic field can scan images with a higher spatial and contrast resolution than commonly used scanners. These high-resolution MR images are preferred in both the clinical and research fields since more information can be obtained from a single scanning session, leading doctors to diagnose diseases earlier or computers to analyze images more precisely.
3T MRI scanners provide high spatial resolution and contrast images and are widely used in clinical practice and research studies. Moreover, 7T ultra-high-field scanners are now becoming available for research use, providing ultra-high resolution images that depict fine anatomical structures in unprecedented detail and with higher contrast. Such ultra-high resolution MRI is attractive because it has the potential to capture mild disease-related anatomical changes that are difficult to identify with 3T MRI. Alternatively, obtaining high-definition images with commonly used scanners requires longer scanning times and places a burden on the patient. In such a situation, super-resolving techniques draw attention, which translates low-resolution (LR) MR images to high-resolution (HR) MR images [
1].
Resolution enhancing methods for MRI can be categorized into two groups: (1) processing the raw signal from the MRI scanner to improve the resolution to be reconstructed and (2) translating already reconstructed LR images into HR-like images, so-called super-resolution (SR).
From a practical point of view, we chose a post-processing method instead of processing the raw signal from the scanner. The choice is for the following three reasons: (1) MR images are usually stored as rendered image files, while the raw signal data are discarded immediately after each scan. In this approach, an extensive archive of legacy MR images can be used. (2) Post-processing can be used to perform super-resolution. (3) This approach is independent of specific scanner hardware and scan protocols, and can be applied to many MRI contrasts, such as T1-MRI, T2-MRI, diffusion MRI, and functional MRI.
Although these deep-learning (DL) methods, including recent generative adversarial network (GAN) -based ones, have many desirable features from non-DL techniques, they have not yet been able to synthesize images as if they were taken by a high-field scanner. This is because most of their methods are designed to be trained with pairs of ordinary resolution MRI and its shrunken version. Therefore, the conventional SR methods can only learn to translate low-resolution images to normal-resolution images and cannot perform normal-to-high translation, which is an essential demand by clinicians and researchers.
What makes the normal-to-high translation difficult is the limited number of high-definition training images. Deep neural networks, especially GANs, require a large number of training samples to achieve desired performance. Due to the limitation of not having access to images taken by high-end scanners, it is virtually impossible to apply existing DL-based algorithms.
This paper proposes a simple yet effective GAN-based super-resolution method. Compared to the existing DL-based super-resolution methods, the proposed method requires significantly less training of MR images (dozens of data) and generates high-quality SR images. The proposed method comprises two techniques: stochastic patch sampling (SPS) and artifact suppressing discriminator (ASD). The SPS partitions input LR MR images into several smaller patches (i.e., cubes) first. After the partitioning, the ESRGAN-based neural network takes each LR patch as an input, and then outputs the corresponding upscaled HR patch. Here, the ASD eliminates discontinuities in the joints of each patch and generates natural-looking high-resolution images. In our experiments to evaluate the performance of our SR method using 7T MR images of 37 patients, peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) were significantly improved from 16.19 to 26.92 and 0.766 to 0.944, respectively, compared with baseline ESRGAN. In addition, the diagnostic performance of the Alzheimer’s disease discriminator trained on super-resolution processed images improved from 80.31% to 83.85%.
2. Related Works
In the last decade, the accuracy of single image super-resolution for general (non-medical) images has increased significantly along with the advancement of DL-based algorithms [
2]. Originating from the super-resolution convolutional neural networks (SRCNNs) [
3], a very first successful attempt to utilize convolutional neural networks to perform super-resolution, many studies have proposed DL-based SR techniques. Very-deep super-resolution (VDSR) [
4] extended SRCNN with a deeper network to improve the accuracy. Enhanced deep residual networks for single image super-resolution (EDSR) [
5] also introduced a deeper network with residual connection from ResNet [
6]. In more recent years, significant quality improvements have been achieved by several generative adversarial network (GAN)-based SR methods [
7]. A super-resolution generative adversarial network (SRGAN) [
8] achieved significant improvement in pixel-wise accuracy by introducing a discriminator to their ResNet-like SR network. An enhanced super-resolution generative adversarial network (ESRGAN) [
9] made even more improvements with a DenseNet-like generator [
10] and Relativistic discriminator [
11].
Along with the advancement of super-resolution methods for general images, studies for applying SR for medical images have also been made. Pham et al. [
12] applied SRCNN to MR images to enhance spatial resolution. The improvement with GAN-based techniques has also been applied to medical imaging fields [
13]. Sánchez and Vilaplana [
14] utilized a simplified version of SRGAN to MR images. Yamashita and Markov [
15] improved the quality of optical coherence tomography (OCT) images with ESRGAN.
3. Proposed Method
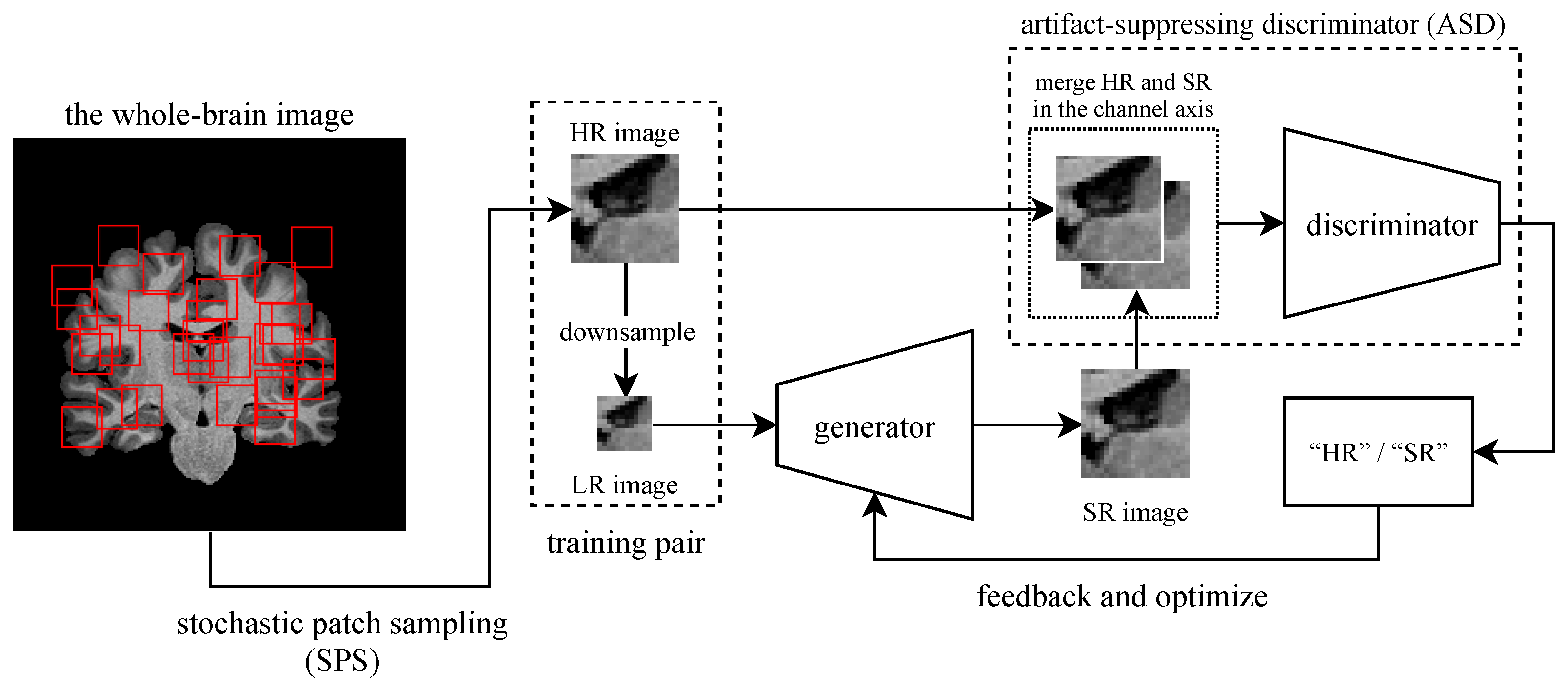
In this paper, we propose a new super-resolution technique for brain MR images with a significantly smaller number of training images. To train the GAN-based super-resolution network, SPS randomly selects many small cubic regions from the input images and feeds them into the network. While the SPS enables the network to be effectively trained with a few images, it also introduces intensity discontinuities around the boundaries of the patches. The ASD suppresses such discontinuities by implicitly knowing the location information of its input patches by referring to both the HR and the generated SR image.
3.1. The Network Architecture
Figure 1 illustrates the schematics of the proposed method. For the network architecture, we used a slightly modified version of the ESRGAN. The modifications we applied are as follows: (1) all the layers such as convolutions, poolings, and pixel-shufflers are changed to their three-dimensional version to process volumetric MR images, and (2) the number of residual-in-residual dense block (RRDB) is reduced from 23 to 5 because the expected input size is smaller than the original ESRGAN.
3.2. Stochastic Patch Sampling (SPS)
Each image is split into a set of smaller three-dimensional cubic patches by randomly choosing the coordinate in the image space. If the patch is sampled from the background and does not contain any brain structure, the patch is automatically rejected and repeatedly re-sampled until sampled from the appropriate coordinate. While the total amount of information fed to the network is theoretically identical, using a collection of sampled patches has several benefits rather than using the whole image at once. Compared to the whole-brain image, the sampled patch is relatively tiny. With this approach, we can use more training samples per batch during mini-batch learning, enabling more stable optimization. The network will also be more robust for unregistered images since the input patches have more significant spatial variances introduced in random sampling. At the inference phase, patches are sampled evenly from the input image with the grid manner. Then, each patch is upscaled by the network and combined into a single image.
3.3. Artifact Suppressing Discriminator (ASD)
Since the network processes small patches separately and performs super-resolution on each one individually, there is no mechanism to sustain the consistency of the final combined image. This lack of consistency causes discontinuities at each patch’s joints, resulting in an unpleasant final image. To address this issue, we introduced ASD, which is an extension of the common GAN discriminator. ASD takes two images; one is always a “real” (or HR, in the context of super-resolution) image, and the other is a generated image or an HR image combined as a two-channel image. Accordingly, the discriminator takes (HR+HR) or (HR+SR) images during training. The proposed ASD can extract more discriminative feature representations by learning the correlation/difference between HR and SR images, while common discriminators take HR and SR images independently.
4. Experiments
The purpose of super-resolution is to aid clinicians or computers in analyzing images more precisely, providing more information on smaller structures. To confirm the effectiveness of the proposed techniques, we investigate the impact of the proposed super-resolution network on disease classification performance in addition to regular image quality evaluation.
4.1. Dataset and Preprocessing
As the high-resolution reference images, we used 37 scans of T1-weighted MR images from the DS000113 (“Forrest Gump”) dataset [
16] and 11 images from the DS002702 dataset [
17], both published by OpenNeuro (
https://openneuro.org/, accessed on 20 September 2020). Both datasets are provided as a collection of functional-MRI (fMRI) images but also contain T1-weighted still MR images we used, which were taken on a high-field 7T scanners. After the skull removal and intensity normalization, each HR image is shrunken to 50% to make an LR image, providing high- and low-resolution training pairs. At the SPS phase during the training, we randomly sampled 2500
patches per one high-resolution image and downsampled them to 50% resolution to make low-resolution images.
4.2. Training of the Network
Since the network input and output are three-dimensional volume data, we cannot use the perceptual loss with a VGG network used in the original SRGAN and ESRGAN because it must be pre-trained with the ImageNet dataset. To train the network to generate images with more fidelity, we added mean-squared error (MSE) of gradients of the images for all directions to capture finer transitions of the intensity.
As for optimization of both networks, we used the Adam optimizer with the same learning rate and parameters with the original ESRGAN.
4.3. Assessing the Image Quality
First, we measure the two most standard metrics for assessing a super-resolution system: (1) peak signal-to-noise ratio (PSNR) and (2) structural similarity (SSIM) between each output image and its corresponding original high-resolution image. In general, SR studies using GAN, Inception Score, and Fréchet Inception Distance (FID) are often used. However, scores are calculated based on low-dimensional representations of two-dimensional images by models trained on everyday objects (e.g., ImageNet) and are unsuitable for this evaluation. We also investigate the line profile of the optic thalamus, which is difficult to see for fine structure with a conventional MR scanner.
4.4. Assessing the Impact on Improving Diagnostic Performance
In addition, the purpose of super-resolution is to aid clinicians or computers in analyzing images more precisely, providing more information on smaller structures. Therefore, we investigate the effectiveness of the proposed SR method on disease classification performance. This way, we can emulate one of the real-world applications of super-resolution for medical images.
In this experiment, we used 650 images from the ADNI2. (Data used in the preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (adni.loni.usc.edu). The ADNI was launched in 2003 as a public-private partnership, led by Principal Investigator Michael W. Weiner, MD. The primary goal of ADNI has been to test whether serial magnetic resonance imaging (MRI), positron emission tomography (PET), other biological markers, and clinical and neuropsychological assessment can be combined to measure the progression of mild cognitive impairment (MCI) and early Alzheimer’s disease (AD). For up-to-date information, see
www.adni-info.org, accessed on 20 September 2020) dataset, containing 360 cognitively normal (CN) images and 290 Alzheimer’s disease (AD) images. Each image is downsampled into 1.4-mm pixel spacing to match the training data after skull removal and intensity normalization. We first performed super-resolution for all images to make pseudo-high-resolution training/validation samples. Then, we trained a three-dimensional version of MobileNetV2 with 90% of the images and evaluated the area-under-curve (AUC) score with the remaining 10% of them.
To confirm that the proposed SR process recovers some of the lost information from low-resolution images, we also trained a classifier with downsampled images. Then, we trained another classifier with super-resolved downsampled images and compared their AUC score. We used 50% and 25% for the downsampling scales and three-dimensional MobileNetV2 for the classifier network.
Here, we defined “recovery ratio” to measure how much information is recovered from a low-resolution image as follows:
where
,
, and
are the AUC score on HR images, LR (
downsampled from HR) images, and SR images, where
super-resolved images are applied for LR images, respectively. Here, we assume that the AUC with the SR images does not exceed that with the HR images, i.e., the AUC with the HR dataset is the upper bound for the resolution.
5. Results
5.1. Image Quality Assessment
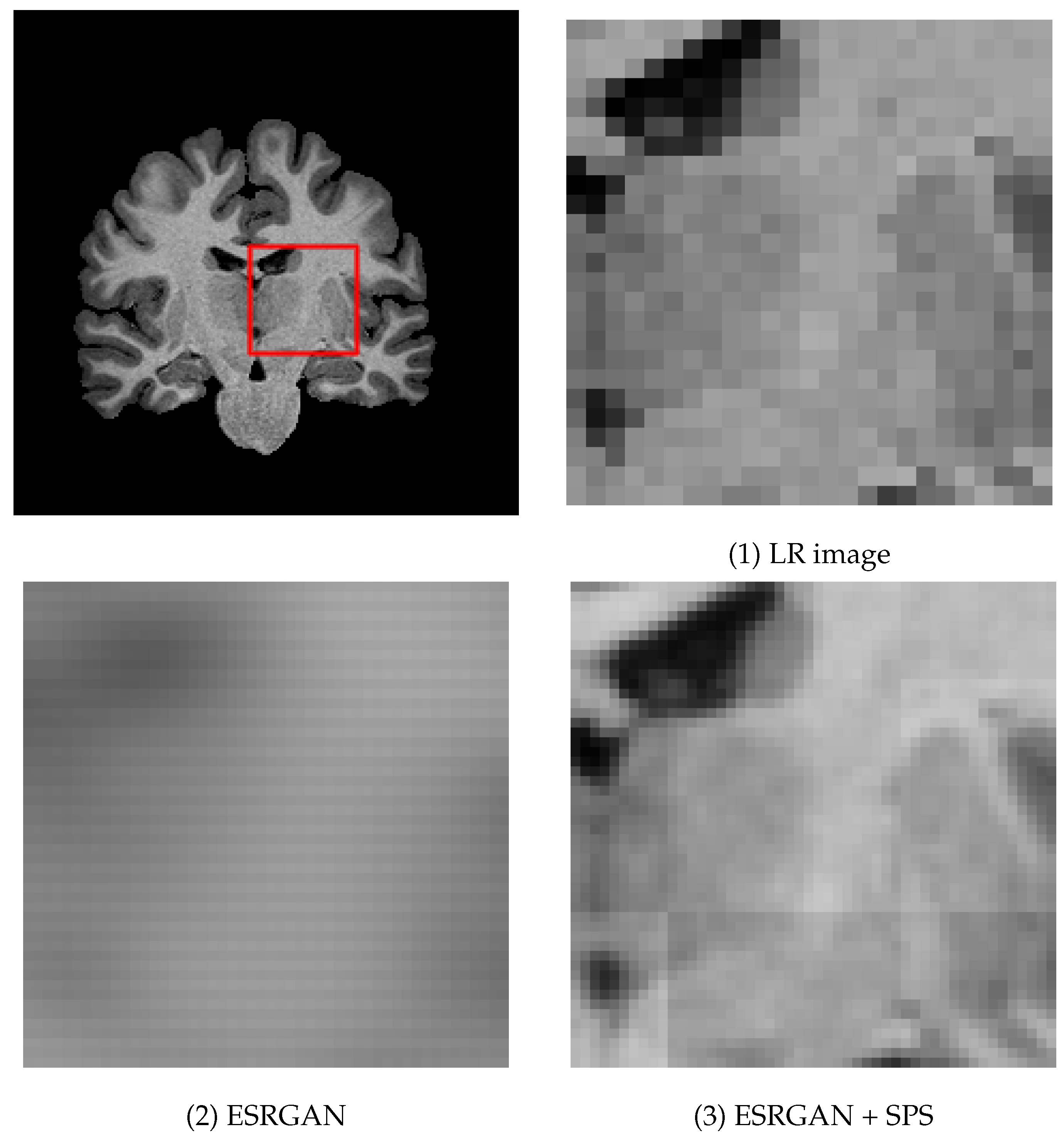
Figure 2 and
Figure 3 show examples of MR images generated by proposed super-resolution networks and their original HR images, and their magnified view, respectively. In
Table 1, the average SSIM and PSNR between super-resolved images using each method and their ground-truth high-resolution images are also summarized.
The output images of the network without SPS, i.e., plain ESRGAN (column (2)), are visibly blurry, and most of the structural features are lost, leading to the lower SSIM/PSNR value. With the proposed SPS (column (3)), generated images are significantly sharper and visibly natural-looking. However, grid-shaped intensity shifts appear at the joints of each patch (
Figure 3 (3)). On the other hand, almost all the intensity shifts are suppressed with the images with the proposed discriminator (column (4)).
5.2. Effectiveness on Classification Performance
Table 2 shows the diagnostic performances of the Alzheimer’s disease classifier trained and tested with the super-resolved images. The performance of pure ESRGAN is abysmal because it fails to generate images, and the proposed method outperforms the other methods.
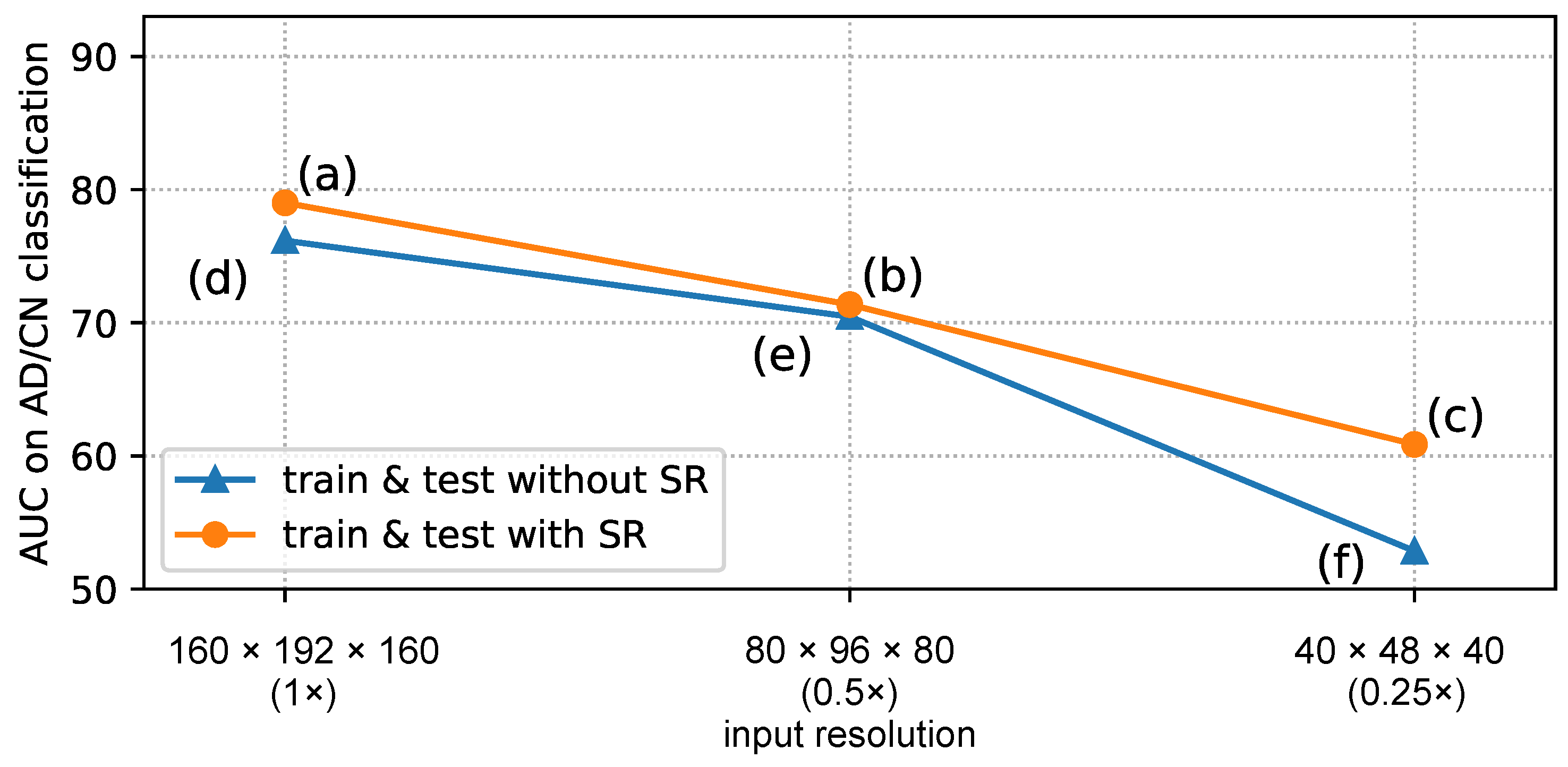
Table 3 and
Figure 4 summarize the classification accuracies with the downsampled images with/without super-resolution. For the sake of better comparison, results on original (non-downsampled) images are also listed/plotted in them.
6. Discussion
6.1. Qualities of Generated SR Images
ESRGAN, a sophisticated super-resolution method based on GAN that requires many training images, could not generate any images at all with about 30 training images. This result is worse than the result from the bi-cubic interpolation of LR images. By introducing patch learning with the proposed SPS, we can confirm that it is possible to generate images with a certain level of accuracy. However, as mentioned earlier, discontinuities between patches are noticeable.
With the introduction of the proposed ASD, the discontinuities are mostly suppressed and achieved to generate more natural-looking super-resolution images. Besides the quantitative metrics such as PSNR and SSIM, the line-profile shown in
Figure 5 shows that the proposed method can generate the details of finer tissues, which are known to be more challenging to capture with conventional MRI scanners.
In regular GAN training, a generator and a discriminator are trained adversarially. The discriminator indirectly lets the generator learn to make more natural images by trying to identify whether the input is “real” or “fake” (i.e., HR or SR). On the other hand, the proposed ASD takes a two-channeled input, which always contains a HR image in one of the channels. Therefore, in addition to the usual effect, the discriminator itself learns the SR image closer to the HR by implicitly giving the information of the relative location of a patch in a whole-brain image. In this regard, an overfitting effect could be expected because of more information given to the networks during training. Nevertheless, from our experiment with different patients, no adverse effect was confirmed.
6.2. Impact of Super-Resolution on the Disease Classification Problem
The removal of unwanted boundary discontinuities by ASD resulted in an improved AUC score by 5.4% in diagnosing Alzheimer’s disease. The increased visibility of essential structures, as shown in
Figure 5, is thought to have contributed to the improved diagnostic performance.
In the experiment with downsampled images, first, we confirmed that the AUC score drops as the input resolution decreases, as we intuitively expected. From
Table 3, it can be said that the images enhanced by the proposed method can boost the performance up to 45% closer to the possible upper bound of score.
6.3. Limitations and Future Work
In the proposed method, a low-resolution training image is obtained by simply downsampling the corresponding high-resolution image. However, the actual differences between images with high-field scanners and ordinary ones are not just image resolution but also intensity contrasts, the amount of noise, and so on. The network would perform better if we trained it with high-field and actual ordinary scanners. In the future, we will use more HR images to develop a better method.
7. Conclusions
In this paper, we propose a new super-resolution method for brain MR images with a significantly smaller number of training images. Our method is GAN-based super-resolution with two essential proposed techniques: the SPS and ASD. These proposed techniques succeeded in generating super-resolution images from the training of only about 30 brain MR images. The images generated in this way showed an overall improvement in image quality and an increase in the resolution of critical diagnostic regions, which helped to improve the disease diagnostic performance of the CNN-based classifier built on these images.
Author Contributions
Conceptualization, methodology, K.I., H.I.; software, K.I.; validation, K.I., H.I., K.O.; resources, data curation, K.O.; writing—original draft preparation, K.I.; writing—review and editing, K.I., H.I., K.O.; supervision, H.I., K.O.; project administration, H.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the Ministry of Education, Science, Sports and Culture of Japan (JSPS KAKENHI), Grant-in-Aid for Scientific Research (C), 21K12656, 2021–2023.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
We used a brain MR image dataset published by the OpenNeuro and Alzheimer’s Disease Neuroimaging Initiative (ADNI) project.
Acknowledgments
The MRI data collection and sharing for this project was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (
www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Greenspan, H. Super-resolution in Medical Imaging. Comput. J. 2009, 52, 43–63. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep Learning for Image Super-resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-resolution using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 26 July 2017; pp. 136–144. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, arXiv:1406.2661. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic Single Image Super-resolution using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. ESRGAN: Enhanced Super-resolution Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Jolicoeur-Martineau, A. The Relativistic Discriminator: A Key Element Missing From Standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Pham, C.H.; Ducournau, A.; Fablet, R.; Rousseau, F. Brain MRI Super-resolution Using Deep 3D Convolutional Networks. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 197–200. [Google Scholar]
- Yi, X.; Walia, E.; Babyn, P. Generative Adversarial Network in Medical Imaging: A Review. Med. Image Anal. 2019, 58, 101552. [Google Scholar] [CrossRef] [Green Version]
- Sánchez, I.; Vilaplana, V. Brain MRI Super-resolution Using 3D Generative Adversarial Networks. arXiv 2018, arXiv:1812.11440. [Google Scholar]
- Yamashita, K.; Markov, K. Medical Image Enhancement Using Super Resolution Methods. In Proceedings of the International Conference on Computational Science, Las Vegas, NV, USA, 16–18 December 2020; pp. 496–508. [Google Scholar]
- Hanke, M.; Baumgartner, F.J.; Ibe, P.; Kaule, F.R.; Pollmann, S.; Speck, O.; Zinke, W.; Stadler, J. Forrest Gump. OpenNeuro. 2018. Available online: https://openneuro.org/datasets/ds000113/versions/1.3.0 (accessed on 20 September 2020). [CrossRef]
- Kay, K.; Jamison, K.W.; Vizioli, L.; Zhang, R.; Margalit, E.; Ugurbil, K. High-Field 7T Visual fMRI Datasets. OpenNeuro. 2020. Available online: https://openneuro.org/datasets/ds002702/versions/1.0.1 (accessed on 20 September 2020). [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}