
The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning †

Department of Computer Science, Stanford University, Stanford, CA 94035, USA
*
Author to whom correspondence should be addressed.
†
Presented at the AAAI Workshop on Artificial Intelligence with Biased or Scarce Data (AIBSD), Online, 28 February 2022.
‡
These authors contributed equally to this work.
Comput. Sci. Math. Forum 2022, 3(1), 4; https://doi.org/10.3390/cmsf2022003004
Published: 15 April 2022
(This article belongs to the Proceedings of AAAI Workshop on Artificial Intelligence with Biased or Scarce Data (AIBSD))
Abstract
:Supervised contrastive learning optimizes a loss that pushes together embeddings of points from the same class while pulling apart embeddings of points from different classes. Class collapse—when every point from the same class has the same embedding—minimizes this loss but loses critical information that is not encoded in the class labels. For instance, the “cat” label does not capture unlabeled categories such as breeds, poses, or backgrounds (which we call “strata”). As a result, class collapse produces embeddings that are less useful for downstream applications such as transfer learning and achieves suboptimal generalization error when there are strata. We explore a simple modification to supervised contrastive loss that aims to prevent class collapse by uniformly pulling apart individual points from the same class. We seek to understand the effects of this loss by examining how it embeds strata of different sizes, finding that it clusters larger strata more tightly than smaller strata. As a result, our loss function produces embeddings that better distinguish strata in embedding space, which produces lift on three downstream applications: 4.4 points on coarse-to-fine transfer learning, 2.5 points on worst-group robustness, and 1.0 points on minimal coreset construction. Our loss also produces more accurate models, with up to 4.0 points of lift across 9 tasks.
1. Introduction
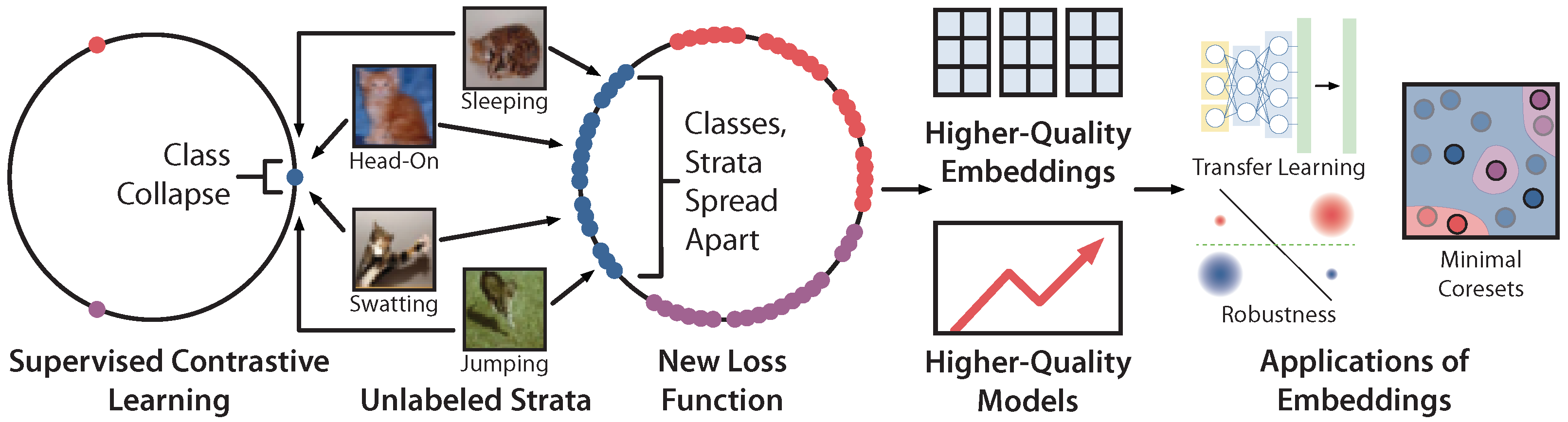
Supervised contrastive learning has emerged as a promising method for training deep models, with strong empirical results over traditional supervised learning [1]. Recent theoretical work has shown that under certain assumptions, class collapse—when the representation of every point from a class collapses to the same embedding on the hypersphere, as in Figure 1—minimizes the supervised contrastive loss [2]. Furthermore, modern deep networks, which can memorize arbitrary labels [3], are powerful enough to produce class collapse.
Although class collapse minimizes and produces accurate models, it loses information that is not explicitly encoded in the class labels. For example, consider images with the label “cat.” As shown in Figure 1, some cats may be sleeping, some may be jumping, and some may be swatting at a bug. We call each of these semantically-unique categories of data—some of which are rarer than others, and none of which are explicitly labeled—a stratum. Distinguishing strata is important; it empirically can improve model performance [4] and fine-grained robustness [5]. It is also critical in high-stakes applications such as medical imaging [6]. However, maps the sleeping, jumping, and swatting cats all to a single “cat” embedding, losing strata information. As a result, these embeddings are less useful for common downstream applications in the modern machine learning landscape, such as transfer learning.
In this paper, we explore a simple modification to that prevents class collapse. We study how this modification affects embedding quality by considering how strata are represented in embedding space. We evaluate our loss both in terms of embedding quality, which we evaluate through three downstream applications, and end model quality.
In Section 3, we present our modification to , which prevents class collapse by changing how embeddings are pushed and pulled apart. pushes together embeddings of points from the same class and pulls apart embeddings of points from different classes. In contrast, our modified loss includes an additional class-conditional InfoNCE loss term that uniformly pulls apart individual points from within the same class. This term on its own encourages points from the same class to be maximally spread apart in embedding space, which discourages class collapse (see Figure 1 middle). Even though does not use strata labels, we observe that it still produces embeddings that qualitatively appear to retain more strata information than those produced by (see Figure 2).
In Section 4, motivated by these empirical observations, we study how well preserves distinctions between strata in the representation space. Previous theoretical tools that study the optimal embedding distribution fail to characterize the geometry of strata. Instead, we propose a simple thought experiment considering the embeddings that the supervised contrastive loss generates when it is trained on a partial sample of the dataset. This setup enables us to distinguish strata based on their sizes by considering how likely it is for them to be represented in the sample (larger strata are more likely to appear in a small sample). In particular, we find that points from rarer and more distinct strata are clustered less tightly than points from common strata, and we show that this clustering property can improve embedding quality and generalization error.
In Section 5, we empirically validate several downstream implications of these insights. First, we demonstrate that produces embeddings that retain more information about strata, resulting in lift on three downstream applications that require strata recovery:
- We evaluate how well ’s embeddings encode fine-grained subclasses with coarse-to-fine transfer learning. achieves up to 4.4 points of lift across four datasets.
- We evaluate how well embeddings produced by can recover strata in an unsupervised setting by evaluating robustness against worst-group accuracy and noisy labels. We use our insights about how embeds strata of different sizes to improve worst-group robustness by up to 2.5 points and to recover 75% performance when 20% of the labels are noisy.
- We evaluate how well we can differentiate rare strata from common strata by constructing limited subsets of the training data that can achieve the highest performance under a fixed training strategy (the coreset problem). We construct coresets by subsampling points from common strata. Our coresets outperform prior work by 1.0 points when coreset size is 30% of the training set.
2. Background
We present our generative model for strata (Section 2.1). Then, we discuss supervised contrastive learning—in particular the SupCon loss from [1] and its optimal embedding distribution [2]—and the end model for classification (Section 2.2).
2.1. Data Setup
We have a labeled input dataset , where for and . For a particular data point x, we denote its label as with distribution . We assume that data is class-balanced such that for all . The goal is to learn a model on to classify points.
Data points also belong to categories beyond their labels, called strata. Following [5], we denote a stratum as a latent variable z, which can take on values in . can be partitioned into disjoint subsets such that if , then its corresponding y label is equal to k. Let denote the deterministic label corresponding to stratum c. We model the data generating process as follows. First, the latent stratum is sampled from distribution . Then, the data point x is sampled from the distribution , and its corresponding label is (see Figure 2 of [5]). We assume that each class has m strata, and that there exist at least two strata, , where and .
2.2. Supervised Contrastive Loss
Supervised contrastive loss pushes together pairs of points from the same class (called positives) and pulls apart pairs of points from different classes (called negatives) to train an encoder . Following previous works, we make three assumptions on the encoder: (1) we restrict the encoder output space to be , the unit hypersphere; (2) we assume , which allows Graf et al. [2] to recover optimal embedding geometry; and (3) we assume the encoder f is “infinitely powerful”, meaning that any distribution on is realizable by .
2.2.1. SupCon and Collapsed Embeddings
We focus on the SupCon loss from [1]. Denote , where is a temperature hyperparameter. Let be the set of batches of labeled data on and be the points in B with the same label as . For an anchor , the SupCon loss is , where forms positive pairs and forms negative pairs.
The optimal embedding distribution that minimizes has one embedding per class, with the per-class embeddings collectively forming a regular simplex inscribed in the hypersphere Graf et al. [2]. Formally, if , then for all . makes up the regular simplex, defined by: (a) ; (b) ; and (c) s.t. for . We describe this property as class collapse and define the distribution of that satisfies these conditions as collapsed embeddings.
2.2.2. End Model
After the supervised contrastive loss is used to train an encoder, a linear classifier is trained on top of the representations by minimizing cross-entropy loss over softmax scores. We assume that for each . The end model’s empirical loss can be defined as . The model uses softmax scores constructed with and W to generate predictions , which we also write as . Finally, the generalization error of the model on is the expected cross-entropy between and , namely .
3. Method
We now highlight some theoretical problems with class collapse under our generative model of strata (Section 3.1). We then propose and qualitatively analyze the loss function (Section 3.2).
3.1. Theoretical Motivation
We show that the conditions under which collapsed embeddings minimize generalization error on coarse-to-fine transfer and the original task do not hold when distinct strata exist.
Consider the downstream coarse-to-fine transfer task of using embeddings learned on to classify points by fine-grained strata. Formally, coarse-to-fine transfer involves learning an end model with weight matrix and fixed (as described in Section 2.2) on points , where we assume the data are class-balanced across z.
Observation 1.
Class collapse minimizes if for all x, (1) , meaning that each x is deterministically assigned to one class, and (2) where . The second condition implies that for all , meaning that there is no distinction among strata from the same class. This contradicts our data model described in Section 2.1.
Similarly, we characterize when collapsed embeddings are optimal for the original task .
Observation 2.
Class collapse minimizes if, for all x, . This contradicts our data model.
Proofs are in Appendix D.1. We also analyze transferability of f on arbitrary new distributions information-theoretically in Appendix C.1, finding that a one-to-one encoder obeys the Infomax principle [7] better than collapsed embeddings on . These observations suggest that a distribution over the embeddings that preserves strata distinctions and does not collapse classes is more desirable.
3.2. Modified Contrastive Loss
We introduce the loss , a weighted sum of two contrastive losses and . is a supervised contrastive loss, while encourages intra-class separation. For ,
For a given anchor , define as an augmentation of the same point as x. Define the set of negative examples for i to be . Then,
is a variant of the SupCon loss, which encourages class separation in embedding space as suggested by Graf et al. [2]. is a class-conditional InfoNCE loss, where the positive distribution consists of augmentations and the negative distribution consists of i.i.d samples from the same class. It encourages points within a class to be spread apart, as suggested by the analysis of the InfoNCE loss by Wang and Isola [8].
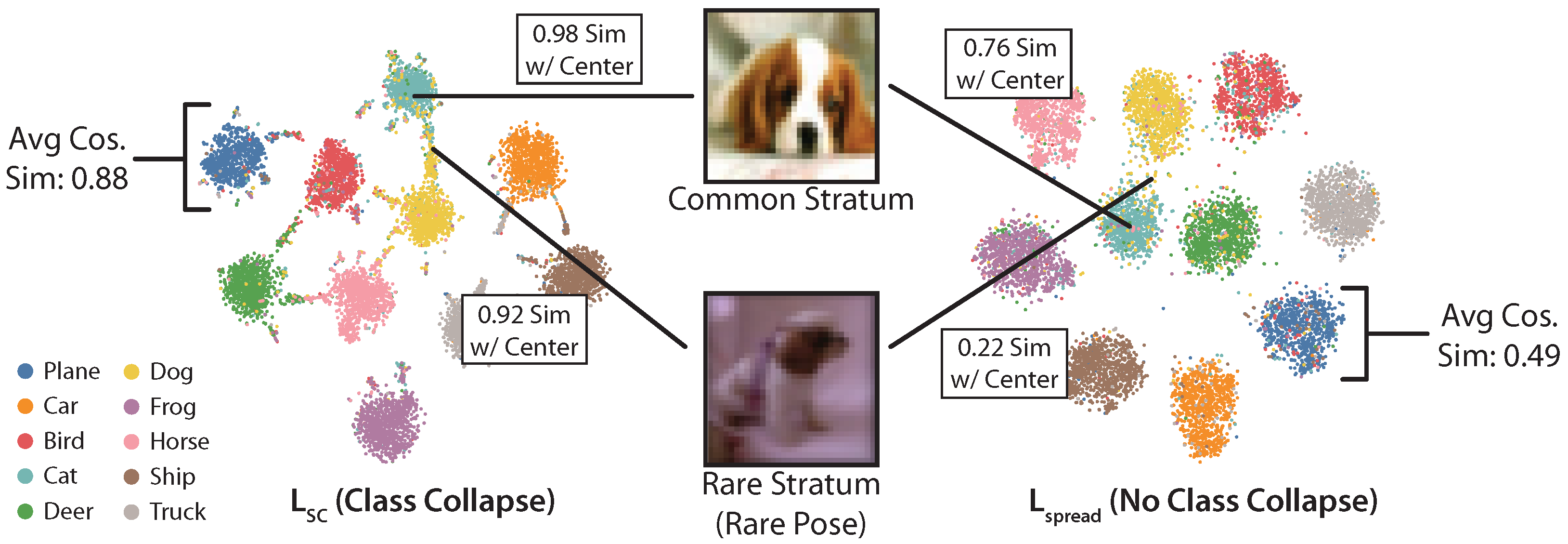
Qualitative Evaluation
Figure 2 shows t-SNE plots for embeddings produced with versus on the CIFAR10 test set. produces embeddings that are more spread out than those produced by and avoids class collapse. As a result, images from different strata can be better differentiated in embedding space. For example, we show two dogs, one from a common stratum and one from a rare stratum (rare pose). The two dogs are much more distinguishable by distance in the embedding space, which suggests that it helps preserve distinctions between strata.
4. Geometry of Strata
We first discuss some existing theoretical tools for analyzing contrastive loss geometrically and their shortcomings with respect to understanding how strata are embedded. In Section 4.2, we propose a simple thought experiment about the distances between strata in embedding space when trained under a finite subsample of data to better understand our prior qualitative observations. Then, in Section 4.3, we discuss implications of representations that preserve strata distinctions, showing theoretically how they can yield better generalization error on both coarse-to-fine transfer and the original task and empirically how they allow for new downstream applications.
4.1. Existing Analysis
Previous works have studied the geometry of optimal embeddings under contrastive learning [2,8,9], but their techniques cannot analyze strata because strata information is not directly used in the loss function. These works use the infinite encoder assumption, where any distribution on is realizable by the encoder f applied to the input data. This allows the minimization of the contrastive loss to be equivalent to an optimization problem over probability measures on the hypersphere. As a result, solving this new problem yields a distribution whose characterization is solely determined by information in the loss function (e.g., labels information [2,9]) and is decoupled from other information about the input data x and hence decoupled from strata.
More precisely, if we denote the measure of as , minimizing the contrastive loss over the mapping f is equal (at the population level) to minimizing over the pushforward measure . The infinite encoder assumption allows us to relax the problem and instead consider optimizing over any in the Borel set of probability measures on the hypersphere. Then, the optimal learned is independent of the distribution of the input data beyond what is in the relaxed objective function.
This approach using the infinite encoder assumption does not allow for analysis of strata. Strata are unknown at training time and thus cannot be incorporated explicitly into the loss function. Their geometries will not be reflected in the characterization of the optimal distribution obtained from previous theoretical tools. Therefore, we need additional reasoning for our empirical observations that strata distinctions are preserved in embedding space under .
4.2. Subsampling Strata
We propose a simple thought experiment based on subsampling the dataset—randomly sampling a fraction of the training data—to analyze strata. Consider the following: we subsample a fraction of a training set of N points from . We use this subsampled dataset to learn an encoder , and we study the average distance under between two strata z and as t varies.
The average distance between z and is and depends on whether z and are both in the subsampled dataset. We study when z and belong to the same class. We have three cases (with probabilities stated in Appendix C.2) based on strata frequency and t—when both, one, or neither of the strata appears in :
- Both strata appear in The encoder is trained on both z and . For large N, we can approximate this setting by considering trained on infinite data from these strata. Points belonging to these strata will be defined in the optimal embedding distribution on the hypersphere, which can be characterized by prior theoretical approaches [2,8,9]. With , depends on , which controls the extent of spread in the embedding geometry. With , points from the two strata would asymptotically map to one location on the hypersphere, and would converge to 0. This case occurs with probability increasing in and t.
- One stratum but not the other appears in Without loss of generality, suppose that points from z appear in but no points from do. To understand , we can consider how the end model learned using the “source” distribution containing z performs on the “target” distribution of stratum since this downstream classifier is a function of distances in embedding space. Borrowing from the literature in domain adaptation, the difficulty of this out-of-distribution problem depends on both the divergence between source z and target distributions and the capacity of the overall model. The -divergence from Ben-David et al. [10,11], which is studied in lower bounds in Ben-David and Urner [12], and the discrepancy difference from Mansour et al. [13] capture both concepts. Moreover, the optimal geometries of and induce different end model capacities and prediction distributions, with data being more separable under , which can help explain why better preserves strata distances. This case occurs with probability increasing in and decreasing in and t.
- Neither strata appears in The distance in this case is at most (total variation distance) regardless of how the encoder is trained, although differences in transfer from models learned on to z versus can be further analyzed. This case occurs with probability decreasing in and t.
We make two observations from these cases. First, if z and are both common strata, then as t increases, the distance between them depends on the optimal asymptotic distribution. Therefore, if we set in , these common strata will collapse. Second, if z is a common strata and is uncommon, the second case occurs frequently over randomly sampled , and thus the strata are separated based on the difficulty of the respective out-of-distribution problem. We thus arrive at the following insight from our thought experiment:
Common strata are more tightly clustered together, while rarer and more semantically distinct strata are far away from them.
Figure 3 demonstrates this insight. It shows a t-SNE visualization of embeddings from training on CIFAR100 with coarse superclass labels, and with artifically imbalanced subclasses. We show points from the largest subclasses in dark blue and points from the smallest subclasses in light blue. Points from the largest subclasses (dark blue) cluster tightly, whereas points from small subclasses (light blue) are scattered throughout the embedding space.
4.3. Implications
We discuss theoretical and practical implications of our subsampling argument. First, we show that on both the coarse-to-fine transfer task and the original task , embeddings that preserve strata yield better generalization error. Second, we discuss practical implications arising from our subsampling argument that enable new applications.
4.3.1. Theoretical Implications
Consider , the encoder trained on with all N points using , and suppose a mean classifier is used for the end model, e.g., and . On coarse-to-fine transfer, generalization error depends on how far each stratum center is from the others.
Lemma 1.
There exists such that the generalization error on the coarse-to-fine transfer task is at most
where is the average distance between strata z and defined in Section 4.2.
The larger the distances between strata, the smaller the upper bound on generalization error. We now show that a similar result holds on the original task , but there is an additional term that penalizes points from the same class being too far apart.
Lemma 2.
There exists such that the generalization error on the original task is at most
This result suggests that maximizing distances between strata of different classes is desirable, but less so for distances between strata of the same class as suggested by the first term in the expression. Both results illustrate that separating strata to some extent in the embedding space results in better bounds on generalization error. In Appendix C.3, we provide proofs of these results and derive values of the generalization error for these two tasks under class collapse for comparison.
4.3.2. Practical Implications
Our discussion in Section 4.2 suggests that training with better distinguishes strata in embedding space. As a result, we can use differences between strata of different sizes for downstream applications. For example, unsupervised clustering can help recover pseudolabels for unlabeled, rare strata. These pseudolabels can be used as inputs to worst-group robustness algorithms, or used to detect noisy labels, which appear to be rare strata during training (see Section 5.3 for examples). We can also train over subsampled datasets to heuristically distinguish points that come from common strata from points that come from rare strata. We can then downsample points from common strata to construct minimal coresets (see Section 5.4 for examples).
5. Experiments
This section evaluates on embedding quality and model quality:
- First, in Section 5.2, we use coarse-to-fine transfer learning to evaluate how well the embeddings maintain strata information. We find that achieves lift across four datasets.
- In Section 5.3, we evaluate how well can detect rare strata in an unsupervised setting. We first use to detect rare strata to improve worst-group robustness by up to 2.5 points. We then use rare strata detection to correct noisy labels, recovering 75% performance under 20% noise.
- In Section 5.4, we evaluate how well can distinguish points from large strata versus points from small strata. We downsample points from large strata to construct minimal coresets on CIFAR10, outperforming prior work by 1.0 points at 30% labeled data.
- Finally, in Section 5.5, we show that training with improves model quality, validating our theoretical claims that preventing class collapse can improve generalization error. We find that improves performance in 7 out of 9 cases.
5.1. Datasets and Models
Tabel Table 1 lists all the datasets we use in our evaluation. CIFAR10, CIFAR100, and MNIST are the standard computer vision datasets. We also use coarse versions of each, wherein classes are combined to create coarse superclasses (animals/vehicles for CIFAR10, standard superclasses for CIFAR100, and <5, ≥5 for MNIST). In CIFAR100-Coarse-U, some subclasses have been artificially imbalanced. Waterbirds, ISIC and CelebA are image datasets with documented hidden strata [5,14,15,16]. We use a ViT model [17] (4 × 4, 7 layers) for CIFAR and MNIST and a ResNet50 for the rest. For the ViT models, we jointly optimize the contrastive loss with a cross entropy loss head. For the ResNets, we train the contrastive loss on its own and use linear probing on the final layer. More details in Appendix E.
5.2. Coarse-to-Fine Transfer Learning
In this section, we use coarse-to-fine transfer learning to evaluate how well retains strata information in the embedding space. We train on coarse superclass labels, freeze the weights, and then use transfer learning to train a linear layer with subclass labels. We use this supervised strata recovery setting to isolate how well the embeddings can recover strata in the optimal setting. For baselines, we compare against training with and the SimCLR loss .
Table 2 reports the results. We find that produces better embeddings for coarse-to-fine transfer learning than and . Lift over varies from 0.2 points on MNIST (16.7% error reduction), to 23.6 points of lift on CIFAR10. also produces better embeddings than , since does not encode superclass labels in the embedding space.
5.3. Robustness against Worst-Group Accuracy and Noise
In this section, we use robustness to measure how well can recover strata in an unsupervised setting. We use clustering to detect rare strata as an input to worst-group robustness algorithms, and we use a geometric heuristic over embeddings to correct noisy labels.
To evaluate worst-group accuracy, we follow the experimental setup and datasets from Sohoni et al. [5]. We first train a model with class labels. We then cluster the embeddings to produce pseudolabels for hidden strata, which we use as input for a Group-DRO algorithm to optimize worst-group robustness [14]. We use both and cross entropy loss [5] for training the first stage as baselines.
To evaluate robustness against noise, we introduce noisy labels to the contrastive loss head on CIFAR10. We detect noisy labels with a simple geometric heuristic: points with incorrect labels appear to be small strata, so they should be far away from other points of the same class. We then correct noisy points by assigning the label of the nearest cluster in the batch. More details can be found in Appendix E.
Table 3 shows the performance of unsupervised strata recovery and downstream worst-group robustness. We can see that outperforms both and Sohoni et al. [5] on strata recovery. This translates to better worst-group robustness on Waterbirds and CelebA.
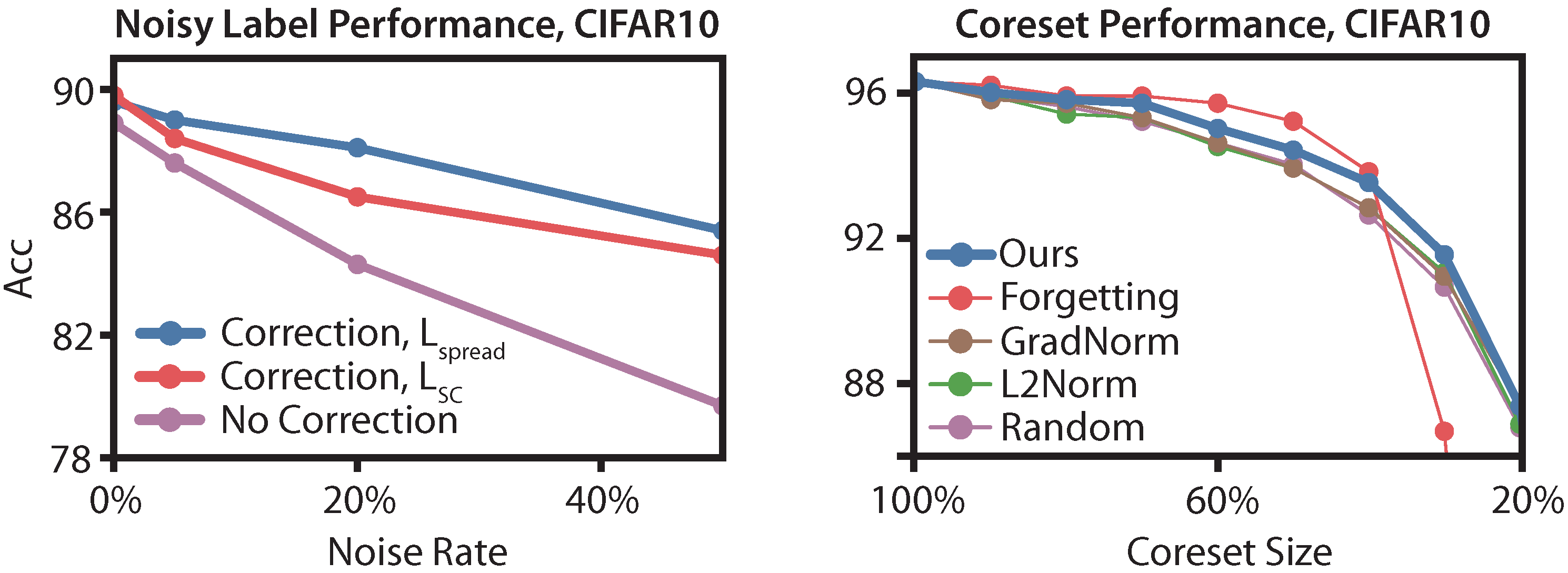
Figure 4 (left) shows the effect of noisy labels on performance. When noisy labels are uncorrected (purple), performance drops by up to 10 points at 50% noise. Applying our geometric heuristic (red) can recover 4.8 points at 50% noise, even without using . However, recovers an additional 0.9 points at 50% noise, and an additional 1.6 points at 20% noise (blue). In total, recovers 75% performance at 20% noise, whereas only recovers 45% performance.
5.4. Minimal Coreset Construction
Now we evaluate how well training on fractional samples of the dataset with can distinguish points from large versus small strata by constructing minimal coresets for CIFAR10. We train a ResNet18 on CIFAR10, following Toneva et al. [18], and compare against baselines from Toneva et al. [18] (Forgetting) and Paul et al. [19] (GradNorm, L2Norm). For our coresets, we train with on subsamples of the dataset and record how often points are correctly classified at the end of each run. We bucket points in the training set by how often the point is correctly classified. We then iteratively remove points from the largest bucket in each class. Our strategy removes easy examples first from the largest coresets, but maintains a set of easy examples in the smallest coresets.
Figure 4 (right) shows the results at various coreset sizes. For large coresets, our algorithm outperforms both methods from Paul et al. [19] and is competitive with Toneva et al. [18]. For small coresets, our method outperforms the baselines, providing up to 5.2 points of lift over Toneva et al. [18] at 30% labeled data. Our analysis helps explain this gap; removing too many easy examples hurts performance, since then the easy examples become rare and hard to classify.
5.5. Model Quality
Finally, we confirm that produces higher-quality models and achieves better sample complexity than both and the SimCLR loss from [20]. Table 4 reports the performance of models across all our datasets. We find that achieves better overall performance compared to models trained with and in 7 out of 9 tasks, and matches performance in 1 task. We find up to 4.0 points of lift over (Waterbirds), and up to 2.2 points of lift (AUROC) over (ISIC). In Appendix F, we additionally evaluate the sample complexity of contrastive losses by training on partial subsamples of CIFAR10. outperforms and throughout.
6. Related Work and Discussion
From work in contrastive learning, we take inspiration from [21], who use a latent classes view to study self-supervised contrastive learning. Similarly, [22] considers how minimizing the InfoNCE loss recovers a latent data generating model. We initially started from a debiasing angle to study the effects of noise in supervised contrastive learning inspired by [23], but moved to our current strata-based view of noise instead. Recent work has also analyzed contrastive learning from the information-theoretic perspective [24,25,26], but does not fully explain practical behavior [27], so we focus on the geometric perspective in this paper because of the downstream applications. On the geometric side, we are inspired by the theoretical tools from [8] and [2], who study representations on the hypersphere along with [9].
Our work builds on the recent wave of empirical interest in contrastive learning [20,28,29,30,31] and supervised contrastive learning [1]. There has also been empirical work analyzing the transfer performance of contrastive representations and the role of intra-class variability in transfer learning. [32] find that combining supervised and self-supervised contrastive loss improves transfer learning performance, and they hypothesize that this is due to both inter-class separation and intra-class variability. [33] find that combining cross entropy and self-supervised contrastive loss improves coarse-to-fine transfer, also motivated by preserving intra-class variability.
We derive from similar motivations to losses proposed in these works, and we futher theoretically study why class collapse can hurt downstream performance. In particular, we study why preserving distinctions of strata in embedding space may be important, with theoretical results corroborating their empirical studies. We further propose a new thought experiment for why a combined loss function may lead to better separation of strata.
Our treatment of strata is strongly inspired by [5,6], who document empirical consequences of hidden strata. We are inspired by empirical work that has demonstrated that detecting subclasses can be important for performance [4,34] and robustness [14,35,36].
Each of our downstream applications is a field in itself, and we take inspiration from recent work from each. Our noise heuristic is similar to the ELR [37] and takes inspiration from a various work using contrastive learning to correct noisy labels and for semi-supervised learning [38,39,40]. Our coreset algorithm is inspired by recent work in coresets for modern deep networks [19,41,42], and takes inspiration from [18] in particular.
7. Conclusions
We propose a new supervised contrastive loss function to prevent class collapse and produce higher-quality embeddings. We discuss how our loss function better maintains strata distinctions in embedding space and explore several downstream applications. Future directions include encoding label hierarchies and other forms of knowledge in contrastive loss functions and extending our work to more modalities, models, and applications. We hope that our work inspires further work in more fine-grained supervised contrastive loss functions and new theoretical approaches for reasoning about generalization and strata.
Author Contributions
Conceptualization, D.Y.F. and M.F.C.; methodology, D.Y.F. and M.F.C.; software, D.Y.F.; validation, D.Y.F. and M.Z.; formal analysis, M.F.C.; investigation, D.Y.F., M.F.C. and M.Z.; resources, D.Y.F. and M.F.C.; data curation, D.Y.F.; writing—original draft preparation, D.Y.F., M.F.C. and M.Z.; writing—review and editing, D.Y.F., M.F.C. and M.Z.; visualization, D.Y.F.; supervision, K.F. and C.R.; project administration, D.Y.F. and M.F.C.; funding acquisition, D.Y.F. and M.F.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by NIH under No. U54EB020405 (Mobilize), NSF under Nos. CCF1763315 (Beyond Sparsity), CCF1563078 (Volume to Velocity), and 1937301 (RTML); ONR under No. N000141712266 (Unifying Weak Supervision); ONR N00014-20-1-2480: Understanding and Applying Non-Euclidean Geometry in Machine Learning; N000142012275 (NEPTUNE); the Moore Foundation, NXP, Xilinx, LETI-CEA, Intel, IBM, Microsoft, NEC, Toshiba, TSMC, ARM, Hitachi, BASF, Accenture, Ericsson, Qualcomm, Analog Devices, the Okawa Foundation, American Family Insurance, Google Cloud, Salesforce, Total, the HAI-GCP Cloud Credits for Research program, the Stanford Data Science Initiative (SDSI), Department of Defense (DoD) through the National Defense Science and Engineering Graduate Fellowship (NDSEG) Program, and members of the Stanford DAWN project: Facebook, Google, and VMWare. The Mobilize Center is a Biomedical Technology Resource Center, funded by the NIH National Institute of Biomedical Imaging and Bioengineering through Grant P41EB027060. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views, policies, or endorsements, either expressed or implied, of NIH, ONR, or the U.S. Government.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
Datasets used in this paper are publicly available and described in Appendix E.
Acknowledgments
We thank Nimit Sohoni for helping with coreset and robustness experiments, and we thank Beidi Chen and Tri Dao for their helpful comments.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
We provide a glossary in Appendix A. Then we provide definitions of terms in Appendix B. We discuss additional theoretical results in Appendix C. We provide proofs in Appendix D. We discuss additional experimental details in Appendix E. Finally, we provide additional experimental results in Appendix F.
Appendix A. Glossary
The glossary is given in Table A1 below.

{kind=link}
{kind=link}
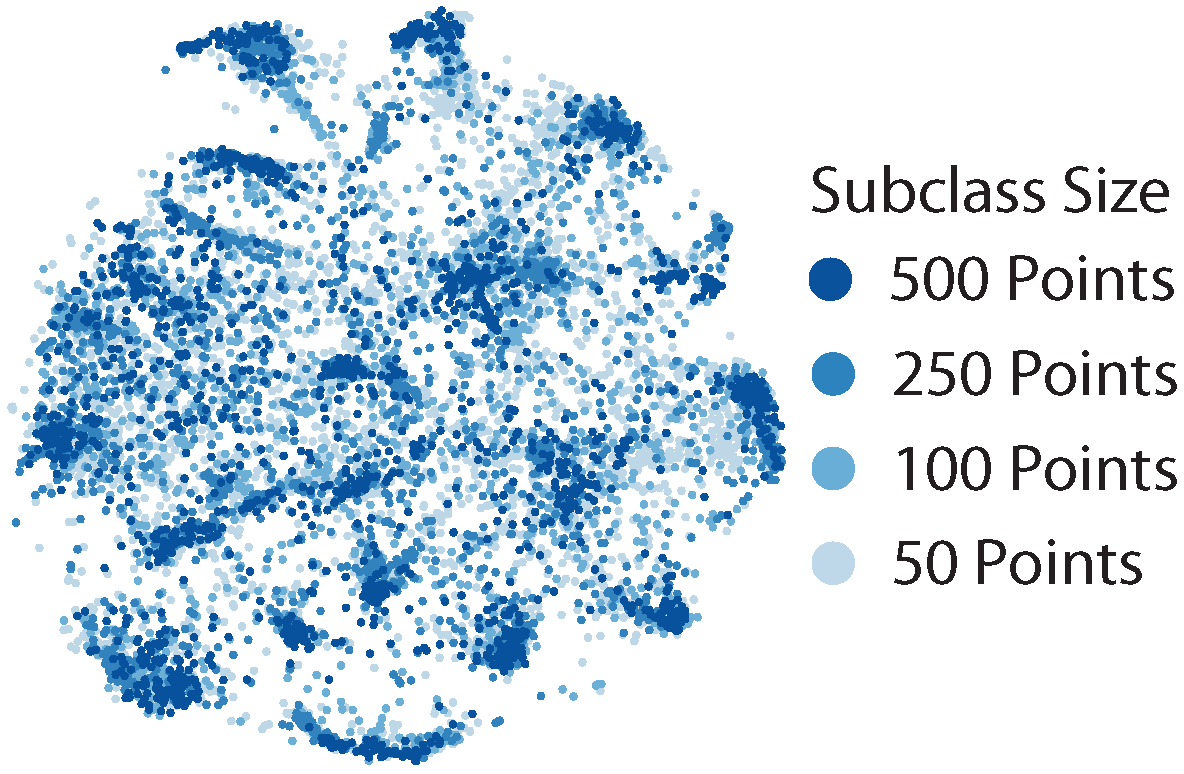{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Glossary of variables and symbols used in this paper.
| Symbol | Used for |
|---|---|
| SupCon (see Section 2.2), a supervised contrastive loss introduced by [1]. | |
| Our modified loss function defined in Section 3.2. | |
| x | Input data . |
| y | Class label . |
| Dataset of N points drawn i.i.d. from . | |
| The class that x belongs to, i.e., is a label drawm from . This label | |
| information is used as input in the supervised contrastive loss. | |
| The end model’s predicted distribution over y given x. | |
| z | A stratum is a latent variable that further categorizes data |
| beyond labels. | |
| The set of all strata corresponding to label k (deterministic). | |
| The label corresponding to strata c (deterministic). | |
| The distribution of input data belonging to stratum z, i.e., . | |
| m | The number of strata per class. |
| d | Dimension of the embedding space. |
| f | The encoder maps input data to an embedding space and is learned by |
| minimizing the contrastive loss function. | |
| The unit hypersphere, formally . | |
| Temperature hyperparameter in contrastive loss function. | |
| Notation for . | |
| Set of batches of labeled data on . | |
| Points in B with the same label as , formally . | |
| A regular simplex inscribed in the hypersphere (see Definition A1). | |
| W | The weight matrix that parametrizes the downstream linear classifier |
| (end model) learned on . | |
| The empirical cross entropy loss used to learn W over dataset (see (A1)). | |
| The generalization error of the end model of predicting output y on x using | |
| encoder f (see (A2) and (A3)). | |
| A variant on SupCon that is used in that pushes points of a class together | |
| (see (2)). | |
| A class-conditional InfoNCE loss that is used in to pull apart points | |
| within a class (see ()). | |
| Hyperparameter controls how to balance and . | |
| An augmentation of data point x. | |
| Points in B with a label different from that of , formally . | |
| t | Fraction of training data that is varied in our thought experiment. |
| Randomly sampled dataset from with size equal to fraction of . | |
| Encoder trained on sampled dataset . | |
| The distance between centers of strata z and under encoder , | |
| namely . |
Appendix B. Definitions
We restate definitions used in our proofs.
Definition A1
(Regular Simplex). The points form a regular simplex inscribed in the hypersphere if
- 1.
- 2.
- for all i
- 3.
- s.t. for
Definition A2
(Downstream model). Once an encoder is learned, the downstream model consists of a linear classifier trained using the cross-entropy loss:
Define . Then, the end model’s outputs are the probabilities
and the generalization error is
Appendix C. Additional Theoretical
Appendix C.1. Transfer Learning on
We now show an additional transfer learning result on new tasks . Formally, recall that we learn the encoder f on . We wish to use it on a new task with target distribution . We find that an injective encoder is more appropriate to be used on new distributions than collapsed embeddings based on the Infomax principle [7].
Observation A1.
Define as the mapping to collapsed embeddings and as an injective mapping, both learned on . Construct a new variable with joint distribution and suppose that . Then, by the data processing inequality, it holds that where is the mutual information between two random variables. We apply to and to to get that
Therefore, obeys the Infomax principle [7] better on than . Via Fano’s inequality, this statement implies that the Bayes risk for learning from is lower using than .
Appendix C.2. Probabilities of Strata Appearing in Subsampled Dataset
As discussed in Section 4.2, the distance between strata z and in embedding space depends on if these strata appear in the subsampled dataset that the encoder was trained on. We define the exact probabilities of the three cases presented. Let be the probability that both strata are seen, be the probability that only z is seen, and be the probability that neither are seen.
First, the probability of neither strata appearing in is easy to compute. In particular, we have that . This quantity decreases in and , confirming that it is less likely for two common strata to not appear in .
Second, the probability of z being in and not being in can be expressed as . is equal to , and . Finally, note that . Putting this together, we get that , and we can similarly construct . This quantity depends on the difference between and , so this case is common when one stratum is common and one is rare.
Lastly, the probability of both z and being in is thus . This quantity increases in and .
Appendix C.3. Performance of Collapsed Embeddings on Coarse-to-Fine Transfer and Original Task
Lemma A1.
Denote to be the encoder that collapses embeddings such that for any . Then, the generalization error on the coarse-to-fine transfer task using and a linear classifier learned using cross entropy loss is at least
where is the dot product of any two different class-collapsed embeddings. The generalization error on the original task under the same setup is at least
Proof.
We first bound generalization error on the coarse-to-fine transfer task. For collapsed embeddings, when , where is information available at training time that follows the distribution . We thus denote the embedding as . Therefore, we write the generalization error with an expectation over and factorize the expectation according to our generative model.
Furthermore, since the W learned over collapsed embeddings satisfies for , we have that for any y, and our expected generalization error is
This tells us that the generalization error is at most and at least .
For the original task, we can apply this same approach to the case where to get that the average generalization error is
This is at least and at most . □
Appendix D. Proofs
Appendix D.1. Proofs for Theoretical Motivation
We provide proofs for Section 3.1. First, we characterize the optimal linear classifier (for both the coarse-to-fine transfer task and the original task) learned on the collapsed embeddings. Note that this result appears similar to Corollary 1 of [2], but their result minimizes the cross entropy loss over both the encoder and downstream weights (i.e., in a classical supervised setting where only cross entropy is used in training).
Lemma A2
(Downstream linear classifier for coarse-to-fine task). Suppose the dataset is class-balanced across z, and the embeddings satisfy if where form the regular simplex. Then the optimal weight matrix that minimizes satisfies for .
Proof.
Formally, the convex optimization problem we are solving is
The Lagrangian of this optimization problem is
and the stationarity condition w.r.t. is
Substituting , we get . Using the fact that for all , this equals . Next, recall that . Then, , satisfying the dual constraint. We can further verify complementary slackness and primal feasibility, since , to confirm that an optimal weight matrix satisfies for . □
Corollary A1.
When we apply the above proof to the case when , we recover that the optimal weight matrix that minimizes for the original task on satisfies for all .
We now prove Observation 1 and 2. Then, we present an additional result on transfer learning on collapsed embeddings to general tasks of the form .
Proof of Observation 1.
We write out the generalization error for the downstream task, using our conditions that and .
To minimize this, should be the same across all x where is the same value, since does not change across fixed and thus varying will not further decrease the value of this expression. Therefore, we rewrite as . Using the fact that y is class balanced, our loss is now
We claim that and for all minimizes this convex function. The corresponding Lagrangian is
The stationarity condition with respect to is the same as (A6), and we have already demonstrated that the feasibility constraints and complementary slackness are satisfied on W. The stationarity condition with respect to is
Substituting in and , we get . From the regular simplex definition, this is . We thus have that , and the feasibility constraints are satisfied. Therefore, for minimizes the generalization error when and .
and , so . being class balanced means that . Therefore, this condition suggests that there is no distinction among the strata within a class. □
Proof of Observation 2.
This observation follows directly from Observation 1 by repeating the proof approach with .
Lastly, suppose it is not true that . Then, the generalization error on the original task is , which is minimized when . Intuitively, a model constructed with label information, , will not improve over one that uses x itself to approximate . □
Appendix D.2. Proofs for Theoretical Implications
We provide proofs for Section 4.3.
Proof of Lemma 1.
The generalization error is
Using the definition of the mean classifier,
Since is bounded, there exists a constant such that
We can also rewrite the dot product between mean embeddings per strata in terms of the distance between them:
This directly gives us our desired bound. □
Proof of Lemma 2.
The generalization error is
We substitute in the definition of the mean classifier to get
We can rewrite the dot product between mean embeddings per strata in terms of the distance between them:
We can write in the above expression as , which we have analyzed:
From our previous proof, there exists such that this is at most
We can write each weighted summation over and as an expectation and use the definition of to obtain our desired bound. □
Appendix E. Additional Experimental Details
Appendix E.1. Datasets
We first describe all the datasets in more detail:
- CIFAR10, CIFAR100, and MNIST are all the standard computer vision datasets.
- CIFAR10-Coarse consists of two superclasses: animals (dog, cat, deer, horse, frog, bird) and vehicles (car, truck, plane, boat).
- CIFAR100-Coarse consists of twenty superclasses. We artificially imbalance subclasses to create CIFAR100-Coarse-U. For each superclass, we select one subclass to keep all 500 points, select one subclass to subsample to 250 points, select one subclass to subsample to 100 points, and select the remaining two to subsample to 50 points. We use the original CIFAR100 class index to select which subclasses to subsample: the subclass with the lowest original class index keeps all 500 points, the next subclass keeps 250 points, etc.
- MNIST-Coarse consists of two superclasses: <5 and ≥5.
- Waterbirds [14] is a robustness dataset designed to evaluate the effects of spurious correlations on model performance. The waterbirds dataset is constructed by cropping out birds from photos in the Caltech-UCSD Birds dataset [43], and pasting them on backgrounds from the Places dataset [44]. It consists of two categories: water birds and land birds. The water birds are heavily correlated with water backgrounds and the land birds with land backgrounds, but 5% of the water birds are on land backgrounds, and 5% of the land birds are on water backgrounds. These form the (imbalanced) hidden strata.
- ISIC is a public skin cancer dataset for classifying skin lesions [15] as malignant or benign. 48% of the benign images contain a colored patch, which form the hidden strata.
Appendix E.2. Hyperparameters
For all model quality experiments for , we first fixed and swept . We then took the two best-performing values and swept . For and , we swept . Final hyperparameter values for for were for CIFAR10, for CIFAR10-coarse, for CIFAR100, for CIFAR100-Coarse, for CIFAR100-Coarse-U, for MNIST, for MNIST-coarse, for ISIC, and for waterbirds.
For coarse-to-fine transfer learning, we fixed for all losses and swept . Final hyperparameter values for were for CIFAR10-Coarse, for CIFAR100-Coarse, for CIFAR100-Coarse-U, and for MNIST-Coarse.
Appendix E.3. Applications
We describe additional experimental details for the applications.
Appendix E.3.1. Robustness against Worst-Group Performance
We follow the evaluation of [5]. First, we train a model on the standard class labels. We evaluate different loss functions for this step, including , , and the cross entropy loss . Then we project embeddings of the training set using a UMAP projection [45], and cluster points to discover unlabeled subgroups. Finally, we use the unlabeled subgroups in a Group-DRO algorithm to optimize worst-group robustness [14].
Appendix E.3.2. Robustness against Noise
We use the same training setup as we use to evaluate model quality, and introduce symmetric noise into the labels for the contrastive loss head. We train the cross entropy head with a fraction of the full training set. In Section 5.3, we report results from training with 20% labels to cross entropy. We report additional levels in Appendix F.
We detect noisy labels with a simple geometric heuristic: for each point, we compute the cosine similarity between the embedding of the point and the center of all the other points in the batch that have the same class. We compare this similarity value to the average cosine similarity with points in the batch from every other class, and rank the points by the difference between these two values. Points with incorrect labels have a small difference between these two values (they appear to be small strata, so they are far away from points of the same class). Given the noise level as an input, we rank the points by this heuristic and mark the fraction of the batch with the smallest scores as noisy. We then correct their labels by adopting the label of the closest cluster center.
Appendix E.3.3. Minimal Coreset Construction
We use the publicly-available evaluation framework for coresets from [18] (https://github.com/mtoneva/example_forgetting, accessed on 1 October 2021). We use the official repository from [19] (https://github.com/mansheej/data_diet, accessed on 1 October 2021) to recreate their coreset algorithms.
Our coreset algorithm proceeds in two parts. First, we give each point a difficulty rating based on how likely we are to classify it correctly under partial training. Then we subsample the easiest points to construct minimal coresets.
First, we mirror the set up from our thought experiment and train with on random samples of of the CIFAR10 training set, taking three random samples for each of (and we train the cross entropy head with 1% labeled data). For each run, we record which points are classified correctly by the cross entropy head at the end of training, and bucket points the training set by how often the point was correctly classified. To construct a coreset of size , we iteratively remove points from the largest bucket in each class. Our strategy removes easy examples first from the largest coresets, but maintains a set of easy examples in the smallest coresets.
Appendix F. Additional Experimental Results
In this section, we report three sets of additional experimental results: the performance of using on its own to train models, sample complexity of compared to , and additional noisy label results (including a bonus de-noising algorithm).
Appendix F.1. Performance of
In an early iteration of this project, we experienced success with using on its own to train models, before realizing the benefits of adding in an additional term to prevent class collapse. As an ablation, we report on the performance of using on its own in Table A2. can outperform , but outperforms both. We do not report the results here, but also performs significantly worse than on downstream applications, since it more direclty encourages class collapse.
Table A2.
Performance of compared to and using on its own. Best in bold.
| End Model Perf. | ||||
|---|---|---|---|---|
| Dataset | ||||
| CIFAR10 | 89.7 | 90.9 | 91.3 | 91.5 |
| CIFAR100 | 68.0 | 67.5 | 68.9 | 69.1 |
Appendix F.2. Sample Complexity
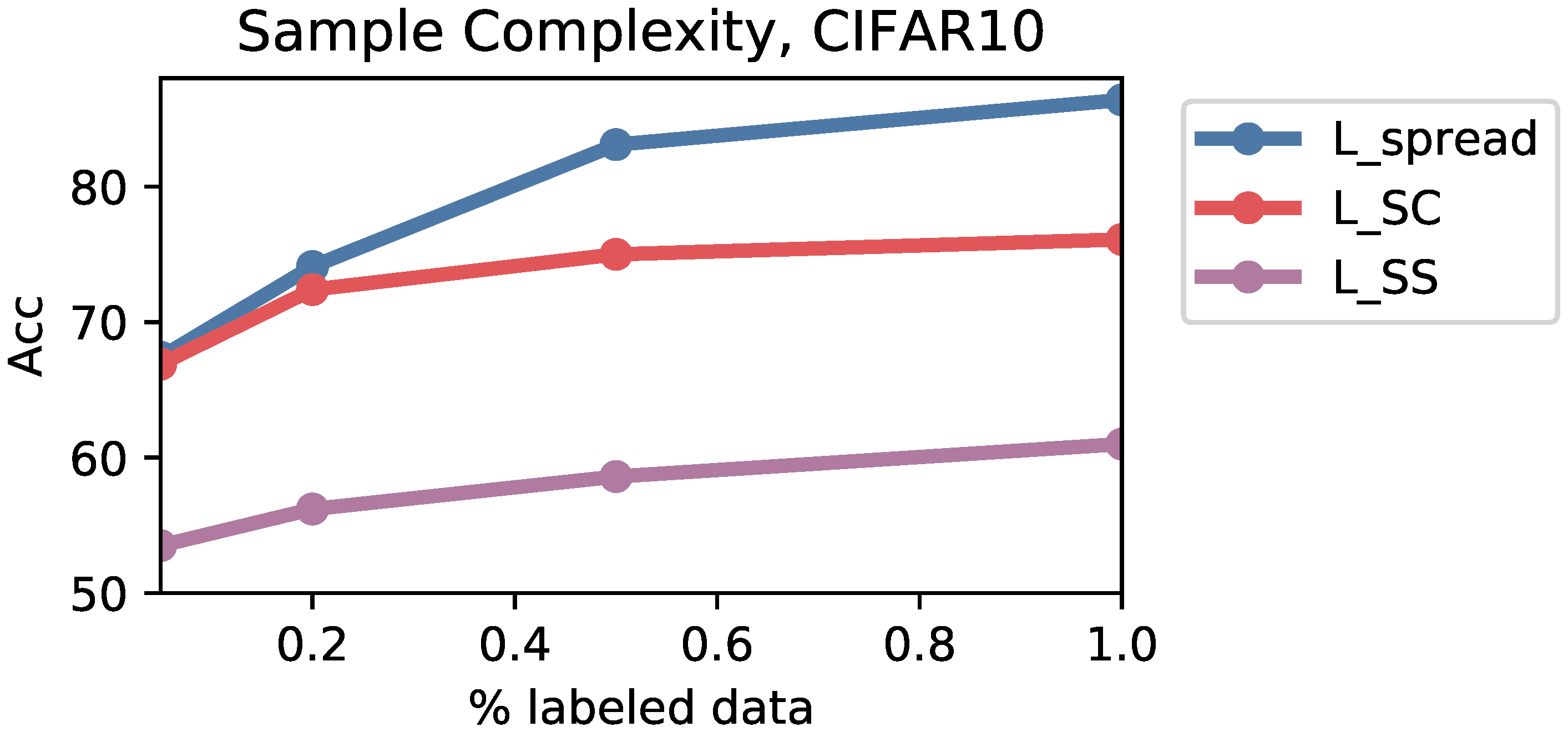
Figure A1 shows the performance of training ViT models with various amounts of labeled data for , , and . In these experiments, we train the cross entropy head with 1% labeled data to isolate the effect of training data on the contrastive losses themselves.
outperforms and throughout. At 10% labeled data, outperforms by 13.9 points, and outperforms by 0.5 points. By 100% labeled data (for the contrastive head), outperforms by 25.4 points, and outperforms by 10.3 points.
Figure A1.
Performance of training ViT with compared to training with and on CIFAR10 at various amounts of labeled data. outperforms the baselines at each point. The cross entropy head here is trained with 1% labeled data to isolate the effect of training data on the contrastive losses.
Figure A1.
Performance of training ViT with compared to training with and on CIFAR10 at various amounts of labeled data. outperforms the baselines at each point. The cross entropy head here is trained with 1% labeled data to isolate the effect of training data on the contrastive losses.

Appendix F.3. Noisy Labels
In Section 5.3, we reported results from training the contrastive loss head with noisy labels and the cross entropy loss with clean labels from 20% of the training data.
In this section, we first discuss a de-noising algorithm inspired by [23] that we initially developed to correct for noisy labels, but that we did not observe strong empirical results from. We hope that reporting this result inspires future work into improving contrastive learning.
We then report additional results with larger amounts of training data for the cross entropy head.
Appendix F.3.1. Debiasing Noisy Contrastive Loss
First, we consider the triplet loss and show how to debias it in expectation under noise. Then we present an extension to supervised contrastive loss.
Noise-Aware Triplet Loss
Consider the triplet loss:
Now suppose that we do not have access to true labels but instead have noisy labels denoted by the weak classifier . We adopt a simple model of symmetric noise where .
We use to construct and as and . For simplicity, we start by looking at how the triplet loss in (A7) is impacted when noise is not addressed in the binary setting. Define as used with and .
Lemma A3.
When class-conditional noise is uncorrected, is equivalent to
Proof.
We split depending on if the noisy positive and negative pairs are truly positive and negative.
Define . Note that
(i.e., all three points are correct or all reversed, such that their relative pairings are correct). In addition, the other three probabilities above are all equal to . □
We now show that there exists a weighted loss function that in expectation equals .
Lemma A4.
Define
where
Then, .
Proof.
We evaluate and the other terms separately. Using the same probabilities as computed in Lemma A3,
We evaluate the remaining terms:
and
Examining the coefficients, we see that
which shows that only the term persists. This completes our proof. □
We now show the general case for debiasing , which uses more negative samples.
Proposition A1.
Define (as the “batch size” in the denominator), and
and are defined in the same was as before. is the solution to the system where is the standard basis vector in where the 2nd index is 1 and all others are 0. The th element of is where
Then, .
We do not present the proof for Proposition A1, but the steps are very similar to the proof for the triplet loss case. We also note that a different form of must be computed for the multi-class case, which we do not present here (but can be derived through computation).
Observation A2.
Note that the values of have high variance in the noise rate as m increases. Additionally, note that the number of terms in the summation of increase combinatorially with m. We found this de-noising algorithm very unstable as a result.
Appendix F.3.2. Additional Noisy Label Results
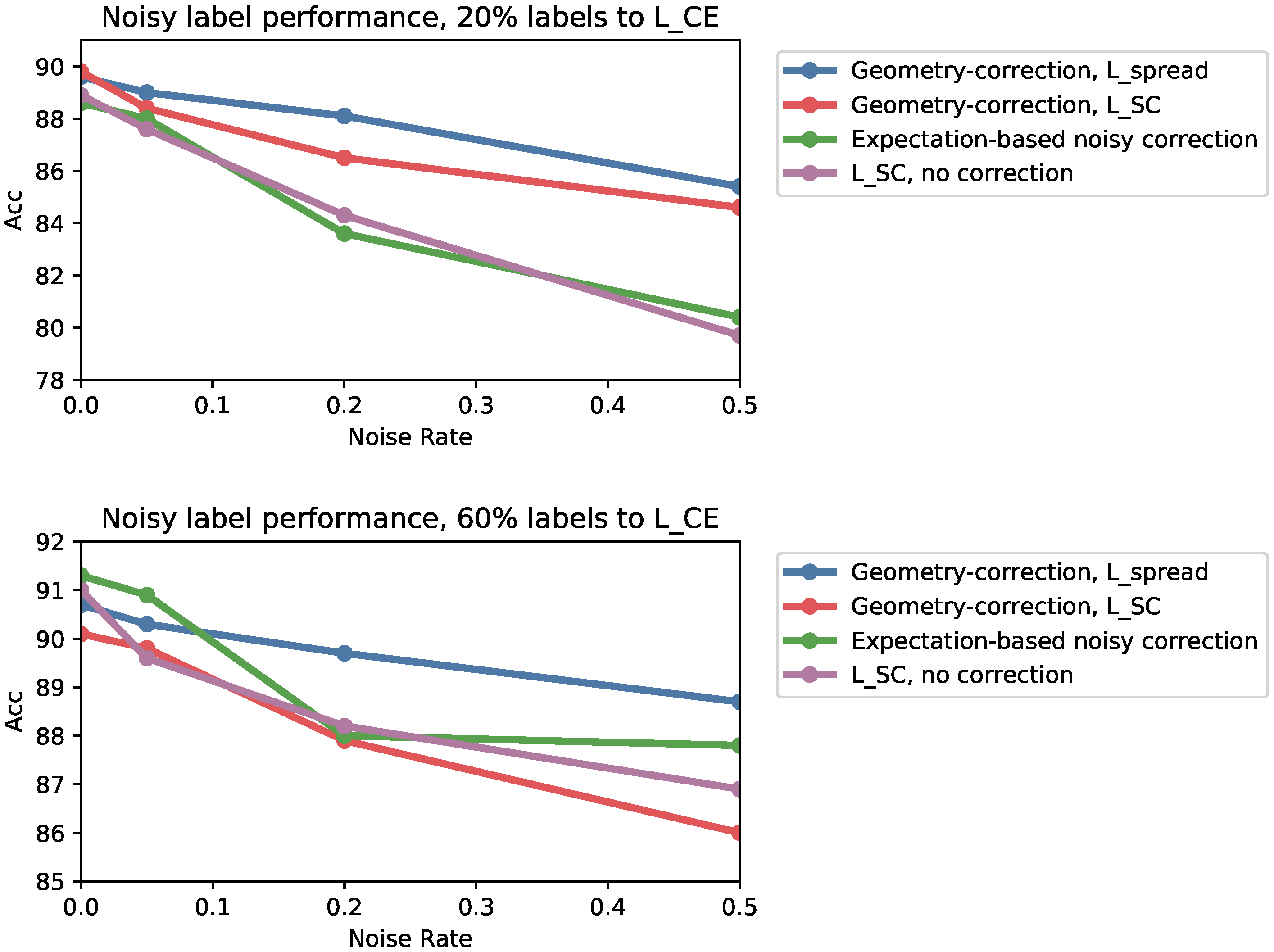
Now we report the performance of denoising algorithms with additional amounts of labeled data for the cross entropy loss head. We also report the performance of using to debias noisy labels.
Figure A2 shows the results. Our geometric correction together with works the most consistently. Using the geometric correction with can be unreliable, since can learn memorize noisy labels early on in training. The expectation-based debiasing algorithm occasionally shows promise but is unreliable, and is very sensitive to having the correct noise rate as an input.
Figure A2.
Performance of models under various amounts of label noise for the contrastive loss head, and various amounts of clean training data for the cross entropy loss.
Figure A2.
Performance of models under various amounts of label noise for the contrastive loss head, and various amounts of clean training data for the cross entropy loss.

References
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Mschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Graf, F.; Hofer, C.; Niethammer, M.; Kwitt, R. Dissecting Supervised Constrastive Learning. Proc. Int. Conf. Mach. Learn. PMLR. 2021, 139, 3821–3830. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. Commun. ACM 2016, 64, 107–115. [Google Scholar] [CrossRef]
- Hoffmann, A.; Kwok, R.; Compton, P. Using subclasses to improve classification learning. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2001; pp. 203–213. [Google Scholar]
- Sohoni, N.; Dunnmon, J.; Angus, G.; Gu, A.; Ré, C. No Subclass Left Behind: Fine-Grained Robustness in Coarse-Grained Classification Problems. Adv. Neural Inf. Process. Syst. 2020, 33, 19339–19352. [Google Scholar]
- Oakden-Rayner, L.; Dunnmon, J.; Carneiro, G.; Ré, C. Hidden stratification causes clinically meaningful failures in machine learning for medical imaging. In Proceedings of the Proceedings of the ACM conference on Health, Inference, and Learning, Toronto, ON, Canada, 2–4 April 2020; pp. 151–159. [Google Scholar]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. Proc. Int. Conf. Mach. Learn. PMLR 2020, 119, 9929–9939. [Google Scholar]
- Robinson, J.; Chuang, C.Y.; Sra, S.; Jegelka, S. Contrastive learning with hard negative samples. arXiv 2020, arXiv:2010.04592. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. Adv. Neural Inf. Process. Syst. 2007, 19, 137. [Google Scholar]
- Ben-David, S.; Urner, R. On the Hardness of Domain Adaptation and the Utility of Unlabeled Target Samples. In Proceedings of the 23rd International Conference, Lyon, France, 29–31 October 2012; Bshouty, N.H., Stoltz, G., Vayatis, N., Zeugmann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 139–153. [Google Scholar]
- Mansour, Y.; Mohri, M.; Rostamizadeh, A. Domain adaptation: Learning bounds and algorithms. arXiv 2009, arXiv:0902.3430. [Google Scholar]
- Sagawa, S.; Koh, P.W.; Hashimoto, T.B.; Liang, P. Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization. arXiv 2019, arXiv:1911.08731. [Google Scholar]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the Proceedings of International Conference on Computer Vision (ICCV), Santiago, Chile, 7 December 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Toneva, M.; Sordoni, A.; des Combes, R.T.; Trischler, A.; Bengio, Y.; Gordon, G.J. An Empirical Study of Example Forgetting during Deep Neural Network Learning. arXiv 2018, arXiv:1812.05159. [Google Scholar]
- Paul, M.; Ganguli, S.; Dziugaite, G.K. Deep Learning on a Data Diet: Finding Important Examples Early in Training. arXiv 2021, arXiv:2107.07075. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. Proc. Int. Conf. Mach. Learn. PMLR 2020, 119, 1597–1607. [Google Scholar]
- Arora, S.; Khandeparkar, H.; Khodak, M.; Plevrakis, O.; Saunshi, N. A theoretical analysis of contrastive unsupervised representation learning. arXiv 2019, arXiv:1902.09229. [Google Scholar]
- Zimmermann, R.S.; Sharma, Y.; Schneider, S.; Bethge, M.; Brendel, W. Contrastive Learning Inverts the Data Generating Process. arXiv 2021, arXiv:2012.08850. [Google Scholar]
- Chuang, C.Y.; Robinson, J.; Torralba, A.; Jegelka, S. Debiased Contrastive Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 8765–8775. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Tian, Y.; Sun, C.; Poole, B.; Krishnan, D.; Schmid, C.; Isola, P. What makes for good views for contrastive learning? arXiv 2020, arXiv:2005.10243. [Google Scholar]
- Tsai, Y.H.H.; Wu, Y.; Salakhutdinov, R.; Morency, L.P. Self-supervised Learning from a Multi-view Perspective. arXiv 2020, arXiv:2006.05576. [Google Scholar]
- Tschannen, M.; Djolonga, J.; Rubenstein, P.K.; Gelly, S.; Lucic, M. On Mutual Information Maximization for Representation Learning. arXiv 2019, arXiv:1907.13625. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. arXiv 2019, arXiv:1911.05722. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Goyal, P.; Caron, M.; Lefaudeux, B.; Xu, M.; Wang, P.; Pai, V.; Singh, M.; Liptchinsky, V.; Misra, I.; Joulin, A.; et al. Self-supervised Pretraining of Visual Features in the Wild. arXiv 2021, arXiv:2103.01988. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Islam, A.; Chen, C.F.; Panda, R.; Karlinsky, L.; Radke, R.; Feris, R. A Broad Study on the Transferability of Visual Representations with Contrastive Learning. arXiv 2021, arXiv:2103.13517. [Google Scholar]
- Bukchin, G.; Schwartz, E.; Saenko, K.; Shahar, O.; Feris, R.; Giryes, R.; Karlinsky, L. Fine-grained Angular Contrastive Learning with Coarse Labels. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19 June 2021; 2021. [Google Scholar] [CrossRef]
- d’Eon, G.; d’Eon, J.; Wright, J.R.; Leyton-Brown, K. The Spotlight: A General Method for Discovering Systematic Errors in Deep Learning Models. arXiv 2021, arXiv:2107.00758. [Google Scholar]
- Duchi, J.; Hashimoto, T.; Namkoong, H. Distributionally robust losses for latent covariate mixtures. arXiv 2020, arXiv:2007.13982. [Google Scholar]
- Goel, K.; Gu, A.; Li, Y.; Re, C. Model Patching: Closing the Subgroup Performance Gap with Data Augmentation. arXiv 2020, arXiv:2008.06775. [Google Scholar]
- Liu, S.; Niles-Weed, J.; Razavian, N.; Fernandez-Granda, C. Early-Learning Regularization Prevents Memorization of Noisy Labels. Adv. Neural Inf. Process. Syst. 2020, 33, 20331–20342. [Google Scholar]
- Li, J.; Xiong, C.; Hoi, S.C. Semi-supervised Learning with Contrastive Graph Regularization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11 October 2021. [Google Scholar]
- Ciortan, M.; Dupuis, R.; Peel, T. A Framework using Contrastive Learning for Classification with Noisy Labels. arXiv 2021, arXiv:2104.09563. [Google Scholar] [CrossRef]
- Li, J.; Socher, R.; Hoi, S.C. DivideMix: Learning with Noisy Labels as Semi-supervised Learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- Ju, J.; Jung, H.; Oh, Y.; Kim, J. Extending Contrastive Learning to Unsupervised Coreset Selection. arXiv 2021, arXiv:2103.03574. [Google Scholar] [CrossRef]
- Sener, O.; Savarese, S. Active Learning for Convolutional Neural Networks: A Core-Set Approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200. In Technical Report CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition using Places Database. Adv. Neural Inf. Process. Syst. 2014, 27, 487–495. [Google Scholar]
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3. [Google Scholar] [CrossRef]
Figure 1.
Classes contain critical information that is not explicitly encoded in the class labels. Supervised contrastive learning (left) loses this information, since it maps unlabeled strata such as sleeping cats, jumping cats, and swatting cat to a single embedding. We introduce a new loss function that prevents class collapse and maintains strata distinctions. produces higher-quality embeddings, which we evaluate with three downstream applications.
Figure 1.
Classes contain critical information that is not explicitly encoded in the class labels. Supervised contrastive learning (left) loses this information, since it maps unlabeled strata such as sleeping cats, jumping cats, and swatting cat to a single embedding. We introduce a new loss function that prevents class collapse and maintains strata distinctions. produces higher-quality embeddings, which we evaluate with three downstream applications.

Figure 2.
produces embeddings that are qualitatively better than those produced by . We show t-SNE visualizations of embeddings for the CIFAR10 test set and report cosine similarity metrics (average intracluster cosine similarities, and similarities between individual points and the class cluster). produces lower intraclass cosine similarity and embeds images from rare strata further out over the hypersphere than .
Figure 2.
produces embeddings that are qualitatively better than those produced by . We show t-SNE visualizations of embeddings for the CIFAR10 test set and report cosine similarity metrics (average intracluster cosine similarities, and similarities between individual points and the class cluster). produces lower intraclass cosine similarity and embeds images from rare strata further out over the hypersphere than .

Figure 3.
Points from large subclasses cluster tightly; points from small subclasses scatter (CIFAR100-Coarse, unbalanced subclasses).
Figure 3.
Points from large subclasses cluster tightly; points from small subclasses scatter (CIFAR100-Coarse, unbalanced subclasses).

Figure 4.
(Left) Performance of models under various amounts of label noise for the contrastive loss head. (Right) Performance of a ResNet18 trained with coresets of various sizes. Our coreset algorithm is competitive with the state-of-the-art in the large coreset regime (from 40–90% coresets), but maintains performance for small coresets (smaller than 40%). At the 10% coreset, our algorithm outperforms [18] by 32 points and matches random sampling.
Figure 4.
(Left) Performance of models under various amounts of label noise for the contrastive loss head. (Right) Performance of a ResNet18 trained with coresets of various sizes. Our coreset algorithm is competitive with the state-of-the-art in the large coreset regime (from 40–90% coresets), but maintains performance for small coresets (smaller than 40%). At the 10% coreset, our algorithm outperforms [18] by 32 points and matches random sampling.

Table 1.
Summary of the datasets we use for evaluation.
| Dataset | Notes |
|---|---|
| CIFAR10 | Standard computer vision dataset |
| CIFAR10-Coarse | CIFAR10 with animal/vehicle coarse labels |
| CIFAR100 | Standard computer vision dataset |
| CIFAR100-Coarse | CIFAR100 with standard coarse labels |
| CIFAR100-Coarse-U | CIFAR100 with standard coarse labels, but with some fine classes |
| sub-sampled | |
| MNIST | Standard computer vision dataset |
| MNIST-Coarse | MNIST with <5 and ≥5 coarse labels |
| Waterbirds | Robustness dataset mixing up images of birds and their |
| backgrounds [14] | |
| ISIC | Images of skin lesions [15] |
| CelebA | Images of celebrity faces [16] |
Table 2.
Performance of coarse-to-fine transfer on various datasets compared against contrastive baselines. In these tasks, we first train a model on coarse task labels, then freeze the representation and train a model on fine-grained subclass labels. produces embeddings that transfer better across all datasets. Best in bold.
Table 2.
Performance of coarse-to-fine transfer on various datasets compared against contrastive baselines. In these tasks, we first train a model on coarse task labels, then freeze the representation and train a model on fine-grained subclass labels. produces embeddings that transfer better across all datasets. Best in bold.
| Coarse-to-Fine Transfer | |||
|---|---|---|---|
| Dataset | |||
| CIFAR10-Coarse | 71.7 | 52.5 | 76.1 |
| CIFAR100-Coarse | 62.0 | 62.4 | 63.9 |
| CIFAR100-Coarse-U | 61.9 | 59.5 | 62.4 |
| MNIST-Coarse | 97.1 | 98.8 | 99.0 |
Table 3.
Unsupervised strata recovery performance (top, F1), and worst-group performance (AUROC for ISIC, Acc for others) using recovered strata. Best in bold.
Table 3.
Unsupervised strata recovery performance (top, F1), and worst-group performance (AUROC for ISIC, Acc for others) using recovered strata. Best in bold.
| Sub-Group Recovery | |||
|---|---|---|---|
| Dataset | Sohoni et al. [5] | ||
| Waterbirds | 56.3 | 47.2 | 59.0 |
| ISIC | 74.0 | 92.5 | 93.8 |
| CelebA | 24.2 | 19.4 | 24.8 |
| Worst-Group Robustness | |||
| Waterbirds | 88.4 | 86.5 | 89.0 |
| ISIC | 92.0 | 93.3 | 92.6 |
| CelebA | 55.0 | 66.1 | 67.8 |
Table 4.
End model performance training with on various datasets compared against contrastive baselines. All metrics are accuracy except for ISIC (AUROC). produces the best performance in 7 out of 9 cases, and matches the best performance in 1 case. Best in bold.
Table 4.
End model performance training with on various datasets compared against contrastive baselines. All metrics are accuracy except for ISIC (AUROC). produces the best performance in 7 out of 9 cases, and matches the best performance in 1 case. Best in bold.
| End Model Perf. | |||
|---|---|---|---|
| Dataset | |||
| CIFAR10 | 89.7 | 90.9 | 91.5 |
| CIFAR10-Coarse | 97.7 | 96.5 | 98.1 |
| CIFAR100 | 68.0 | 67.5 | 69.1 |
| CIFAR100-Coarse | 76.9 | 77.2 | 78.3 |
| CIFAR100-Coarse-U | 72.1 | 71.6 | 72.4 |
| MNIST | 99.1 | 99.3 | 99.2 |
| MNIST-Coarse | 99.1 | 99.4 | 99.4 |
| Waterbirds | 77.8 | 73.9 | 77.9 |
| ISIC | 87.8 | 88.7 | 90.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Fu, D.Y.; Chen, M.F.; Zhang, M.; Fatahalian, K.; Ré, C. The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning. Comput. Sci. Math. Forum 2022, 3, 4. https://doi.org/10.3390/cmsf2022003004
AMA Style
Fu DY, Chen MF, Zhang M, Fatahalian K, Ré C. The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning. Computer Sciences & Mathematics Forum. 2022; 3(1):4. https://doi.org/10.3390/cmsf2022003004
Chicago/Turabian StyleFu, Daniel Y., Mayee F. Chen, Michael Zhang, Kayvon Fatahalian, and Christopher Ré. 2022. "The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning" Computer Sciences & Mathematics Forum 3, no. 1: 4. https://doi.org/10.3390/cmsf2022003004