
Measuring Gender Bias in Contextualized Embeddings †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Bias Detection in Non-Contextual Word Embeddings
2.2. Bias Detection in Contextualized Word Embeddings
Bias Detection in Contextualized Embeddings Using Non-Contextualized Word Embeddings
2.3. Bias Detection in Swedish Language Models
3. Methods
3.1. Extrinsic Evaluation of Gender Bias in T5 and mT5
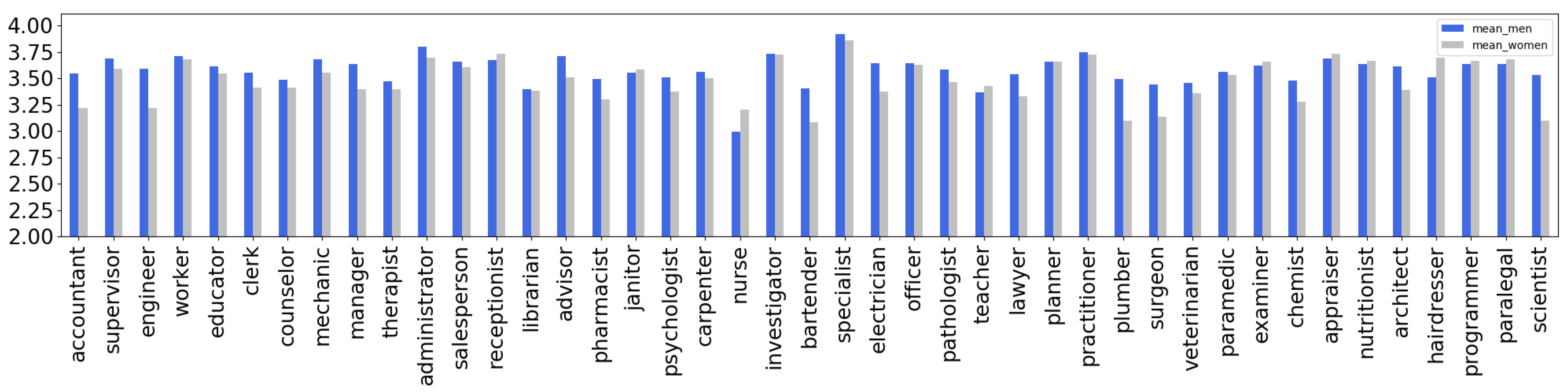
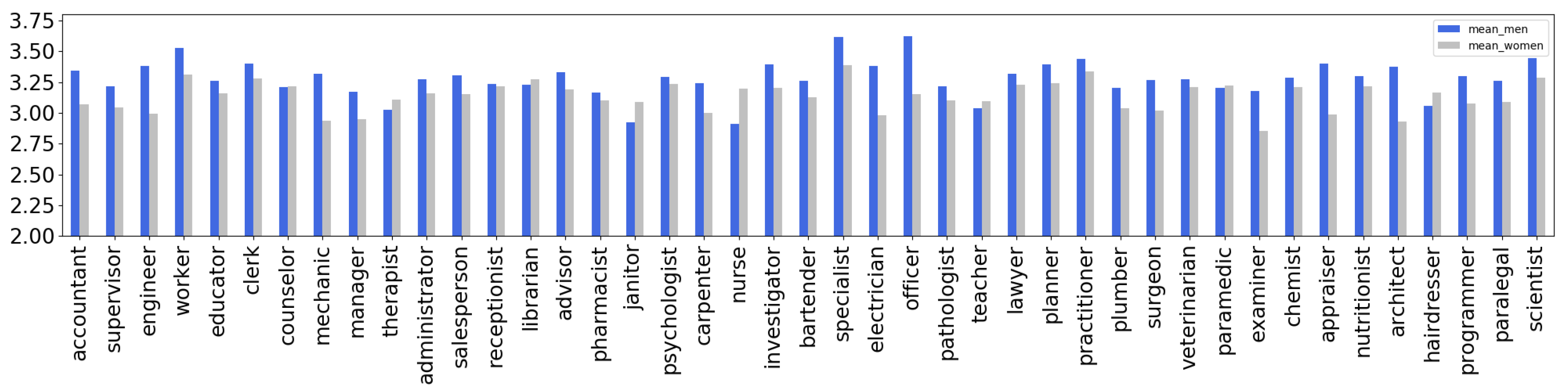
3.1.1. Dataset Creation
3.1.2. Experimental Design
3.2. Intrinsic Evaluation of Gender Bias in T5
4. Results
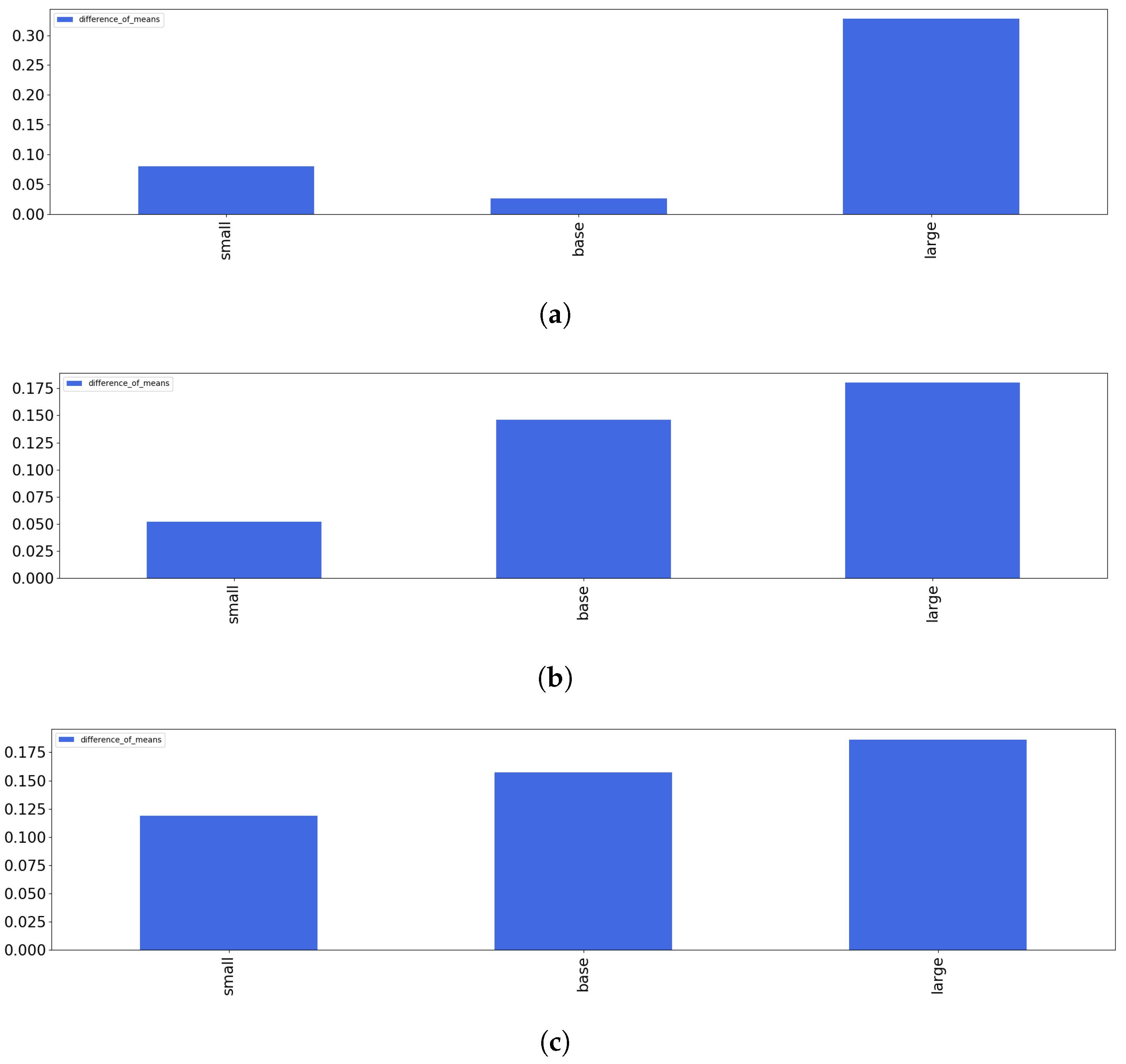
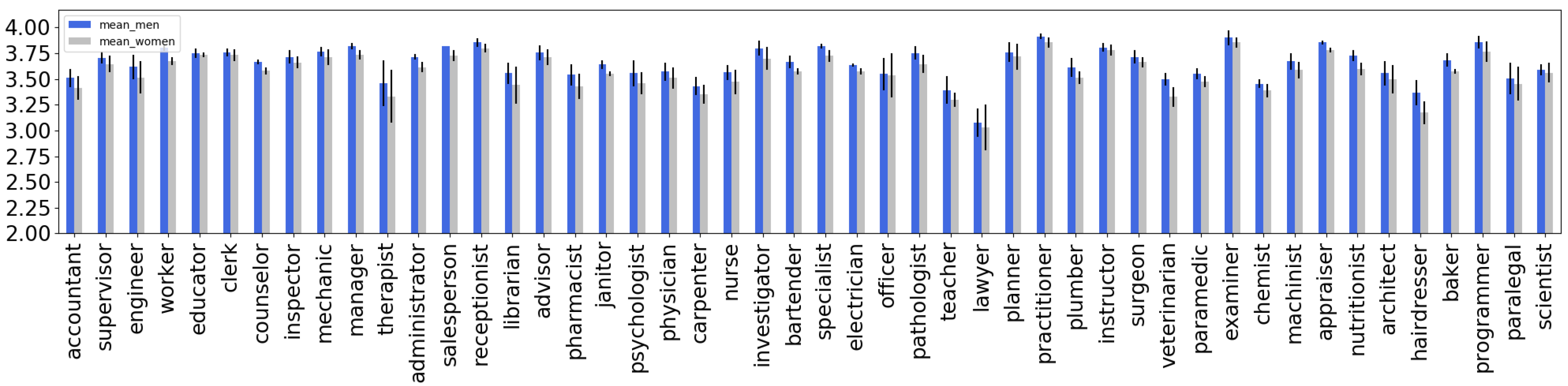
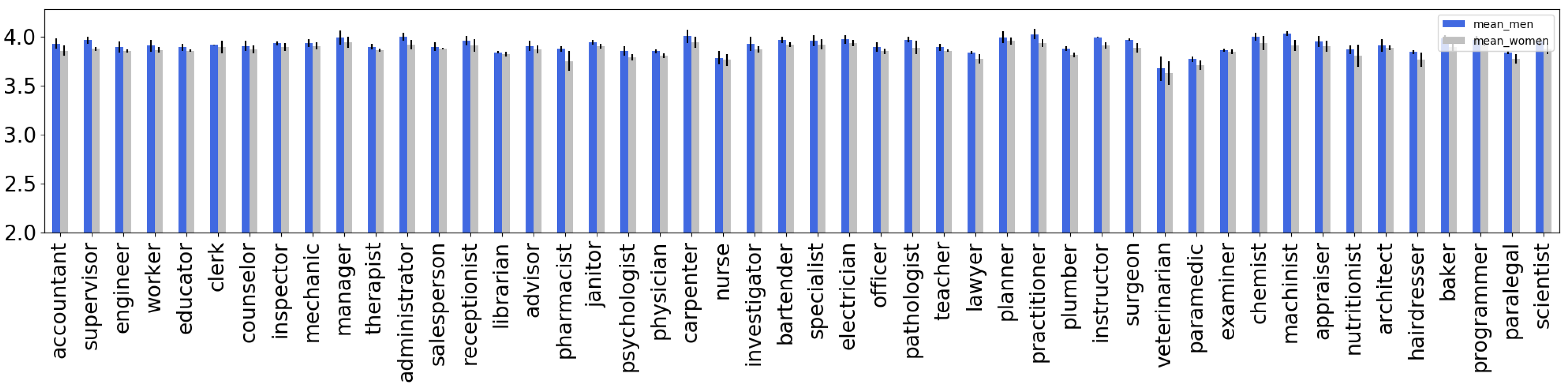
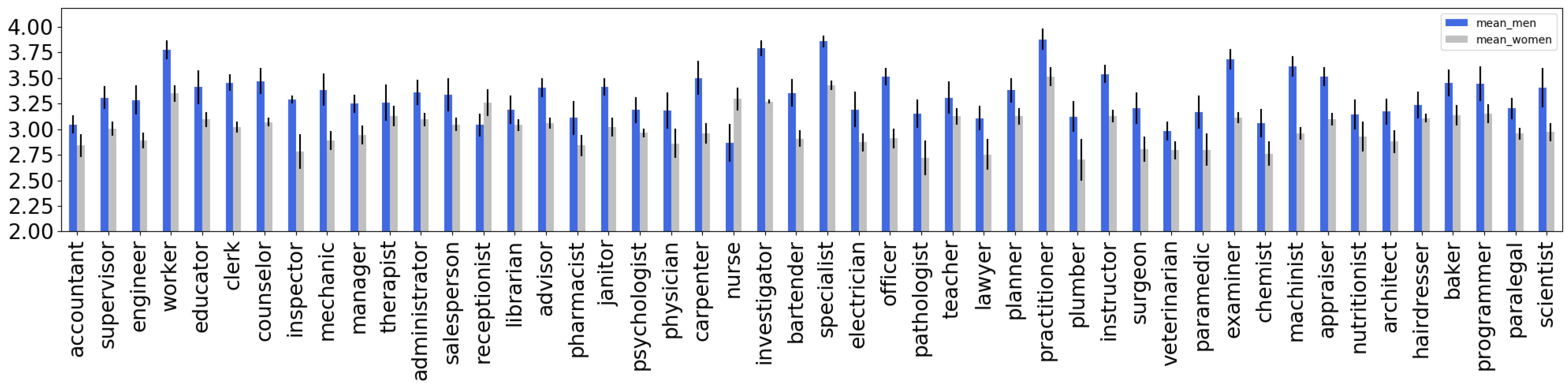
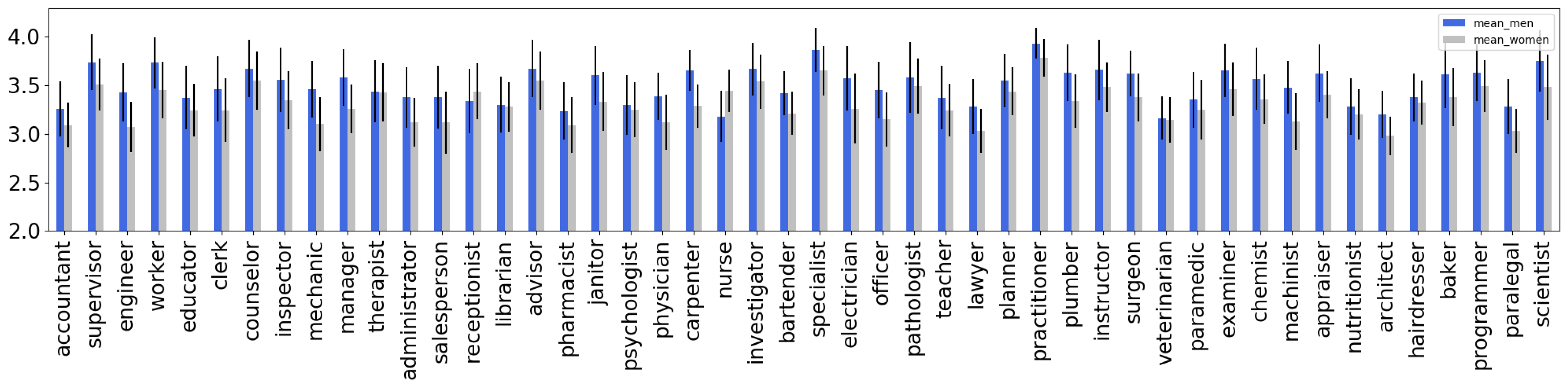
4.1. Extrinsic Evaluation of Gender Bias in T5 and mT5
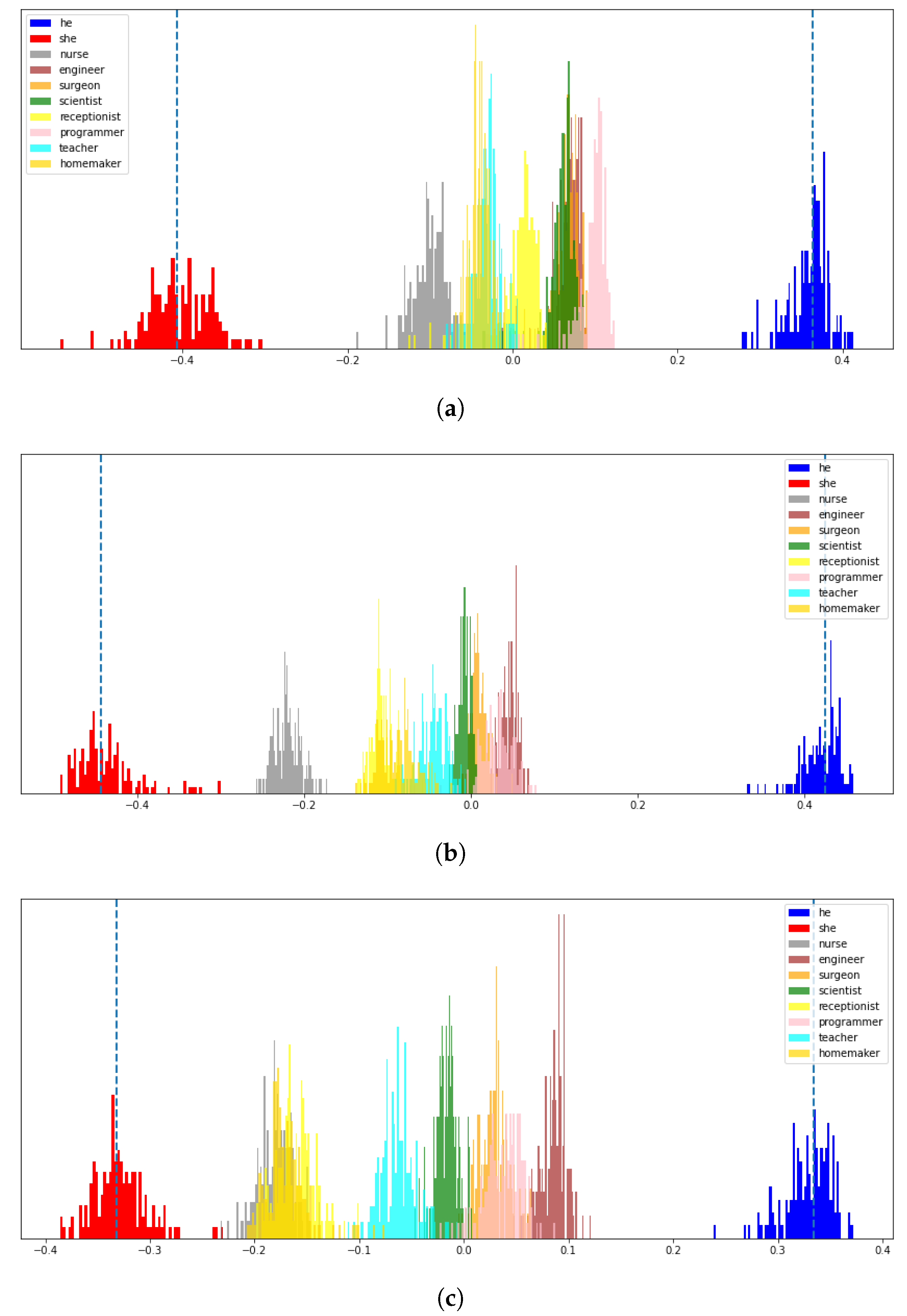
4.2. Intrinsic Evaluation of Gender Bias in T5
5. Discussion
6. Ethics Statement
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A









References
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Zhao, J.; Zhou, Y.; Li, Z.; Wang, W.; Chang, K.W. Learning Gender-Neutral Word Embeddings. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4847–4853. [Google Scholar] [CrossRef] [Green Version]
- Bolukbasi, T.; Chang, K.W.; Zou, J.Y.; Saligrama, V.; Kalai, A.T. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Adv. Neural Inf. Process. Syst. 2016, 26, 4349–4357. [Google Scholar]
- Burstein, J.; Doran, C.; Solorio, T. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019, Volume 1 (Long and Short Papers); Association for Computational Linguistic: Minneapolis, MN, USA, 2019. [Google Scholar]
- Kurita, K.; Vyas, N.; Pareek, A.; Black, A.; Tsvetkov, Y. Measuring Bias in Contextualized Word Representations. In Proceedings of the First Workshop on Gender Bias in Natural Language Processing, Florence, Italy, 2 August 2019; pp. 166–172. [Google Scholar] [CrossRef]
- Caliskan, A.; Bryson, J.J.; Narayanan, A. Semantics derived automatically from language corpora contain human-like biases. Science 2017, 356, 183–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Nangia, N.; Vania, C.; Bhalerao, R.; Bowman, S.R. CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. arXiv 2020, arXiv:2010.00133. [Google Scholar]
- Nadeem, M.; Bethke, A.; Reddy, S. StereoSet: Measuring stereotypical bias in pretrained language models. arXiv 2020, arXiv:2004.09456. [Google Scholar]
- Webster, K.; Wang, X.; Tenney, I.; Beutel, A.; Pitler, E.; Pavlick, E.; Chen, J.; Petrov, S. Measuring and Reducing Gendered Correlations in Pre-trained Models. arXiv 2020, arXiv:2010.06032. [Google Scholar]
- Dhamala, J.; Sun, T.; Kumar, V.; Krishna, S.; Pruksachatkun, Y.; Chang, K.W.; Gupta, R. Bold: Dataset and metrics for measuring biases in open-ended language generation. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual Event, 3–10 March 2021; pp. 862–872. [Google Scholar]
- Guo, W.; Caliskan, A. Detecting Emergent Intersectional Biases: Contextualized Word Embeddings Contain a Distribution of Human-like Biases. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, Virtual Event, 19–21 May 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 122–133. [Google Scholar] [CrossRef]
- Sahlgren, M.; Olsson, F. Gender Bias in Pretrained Swedish Embeddings. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 30 September–2 October 2019; Linköping University Electronic Press: Linköping, Sweden; pp. 35–43. [Google Scholar]
- Prècenth, R. Word Embeddings and Gender Stereotypes in Swedish and English. Ph.D. Thesis, Uppsala University, Uppsala, Sweden, 2019. [Google Scholar]
- Kurpicz-Briki, M. Cultural Differences in Bias? Origin and Gender Bias in Pre-Trained German and French Word Embeddings. In Proceedings of the 5th Swiss Text Analytics Conference and the 16th Conference on Natural Language Processing, SwissText/KONVENS 2020, Online, 23–25 June 2020; Ebling, S., Tuggener, D., Hürlimann, M., Cieliebak, M., Volk, M., Eds.; CEUR Workshop Proceedings: Zurich, Switzerland, 2020; Volume 2624. [Google Scholar]
- Matthews, A.; Grasso, I.; Mahoney, C.; Chen, Y.; Wali, E.; Middleton, T.; Njie, M.; Matthews, J. Gender Bias in Natural Language Processing Across Human Languages. In Proceedings of the First Workshop on Trustworthy Natural Language Processing, Online, 10 June 2021; Association for Computational Linguistics: Barcelona, Spain, 2021; pp. 45–54. [Google Scholar] [CrossRef]
- Bartl, M.; Nissim, M.; Gatt, A. Unmasking Contextual Stereotypes: Measuring and Mitigating BERT’s Gender Bias. In Proceedings of the Second Workshop on Gender Bias in Natural Language Processing, Barcelona, Spain, 13 December 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1–16. [Google Scholar]
- Isbister, T.; Sahlgren, M. Why Not Simply Translate? A First Swedish Evaluation Benchmark for Semantic Similarity. arXiv 2020, arXiv:2009.03116. [Google Scholar]
- Lu, K.; Mardziel, P.; Wu, F.; Amancharla, P.; Datta, A. Gender Bias in Neural Natural Language Processing. arXiv 2019, arXiv:1807.11714. [Google Scholar]
- Garg, N.; Schiebinger, L.; Jurafsky, D.; Zou, J. Word embeddings quantify 100 years of gender and ethnic stereotypes. Proc. Natl. Acad. Sci. USA 2018, 115, E3635–E3644. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Basta, C.; Costa-jussà, M.R.; Casas, N. Evaluating the Underlying Gender Bias in Contextualized Word Embeddings. In Proceedings of the First Workshop on Gender Bias in Natural Language Processing, Florence, Italy, 2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 33–39. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 3615–3620. [Google Scholar] [CrossRef]
- Hutchinson, B.; Prabhakaran, V.; Denton, E.; Webster, K.; Zhong, Y.; Denuyl, S.C. Social Biases in NLP Models as Barriers for Persons with Disabilities. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5491–5501. [Google Scholar]
- Sheng, E.; Chang, K.W.; Natarajan, P.; Peng, N. The woman worked as a babysitter: On biases in language generation. arXiv 2019, arXiv:1909.01326. [Google Scholar]
- Zhang, H.; Lu, A.X.; Abdalla, M.; McDermott, M.; Ghassemi, M. Hurtful words: Quantifying biases in clinical contextual word embeddings. In Proceedings of the ACM Conference on Health, Inference, and Learning, Toronto, ON, Canada, 2–4 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 110–120. [Google Scholar]
- Zhou, P.; Shi, W.; Zhao, J.; Huang, K.H.; Chen, M.; Cotterell, R.; Chang, K.W. Examining Gender Bias in Languages with Grammatical Gender. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5276–5284. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katsarou, S.; Rodríguez-Gálvez, B.; Shanahan, J. Measuring Gender Bias in Contextualized Embeddings. Comput. Sci. Math. Forum 2022, 3, 3. https://doi.org/10.3390/cmsf2022003003
Katsarou S, Rodríguez-Gálvez B, Shanahan J. Measuring Gender Bias in Contextualized Embeddings. Computer Sciences & Mathematics Forum. 2022; 3(1):3. https://doi.org/10.3390/cmsf2022003003
Chicago/Turabian StyleKatsarou, Styliani, Borja Rodríguez-Gálvez, and Jesse Shanahan. 2022. "Measuring Gender Bias in Contextualized Embeddings" Computer Sciences & Mathematics Forum 3, no. 1: 3. https://doi.org/10.3390/cmsf2022003003