
Vision-Autocorrect: A Self-Adapting Approach towards Relieving Eye-Strain Using Facial-Expression Recognition

Abstract
:1. Introduction
2. Related Work
2.1. Facial Expression Recognition
2.2. Machine Learning Techniques for FER
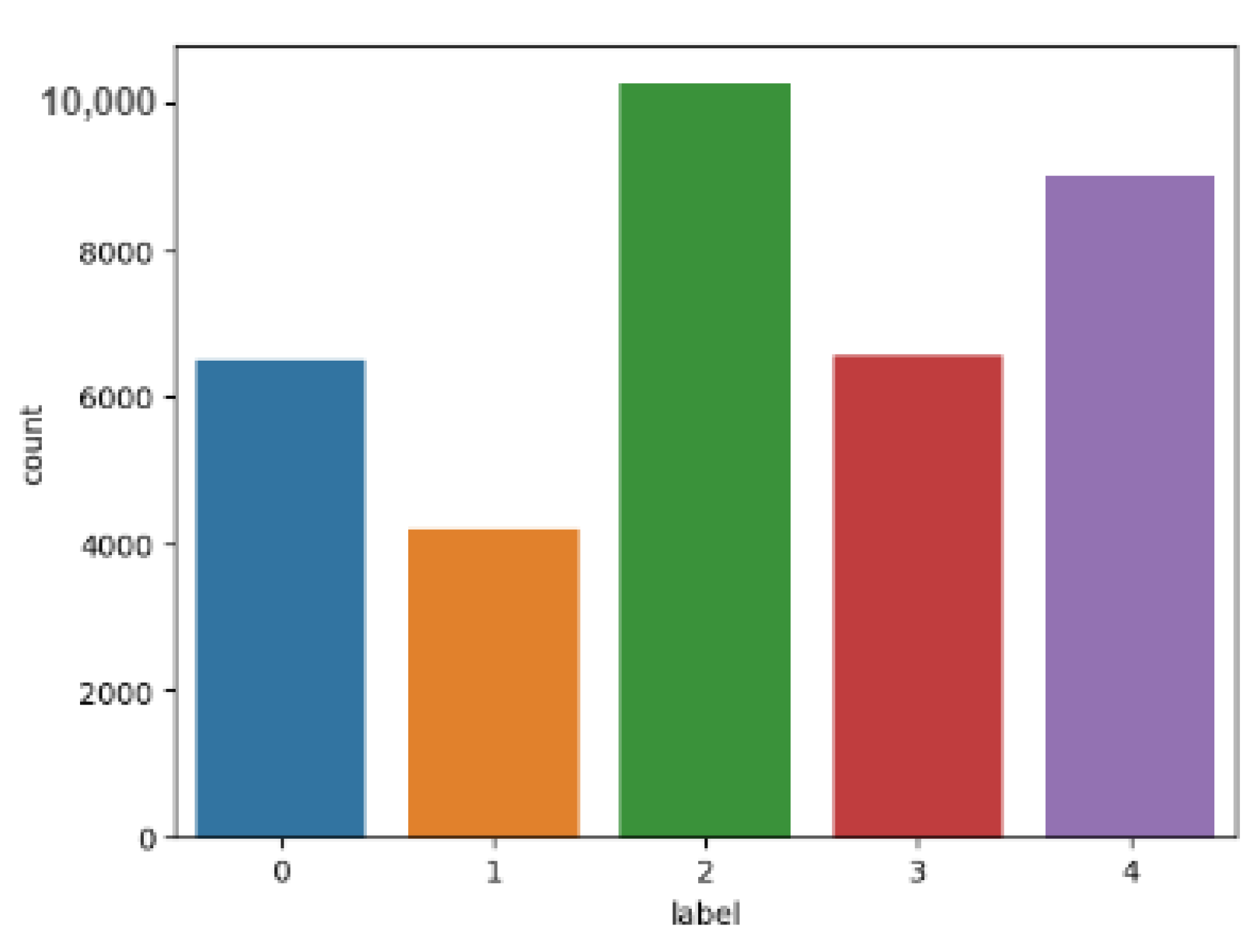
2.2.1. FER Datasets
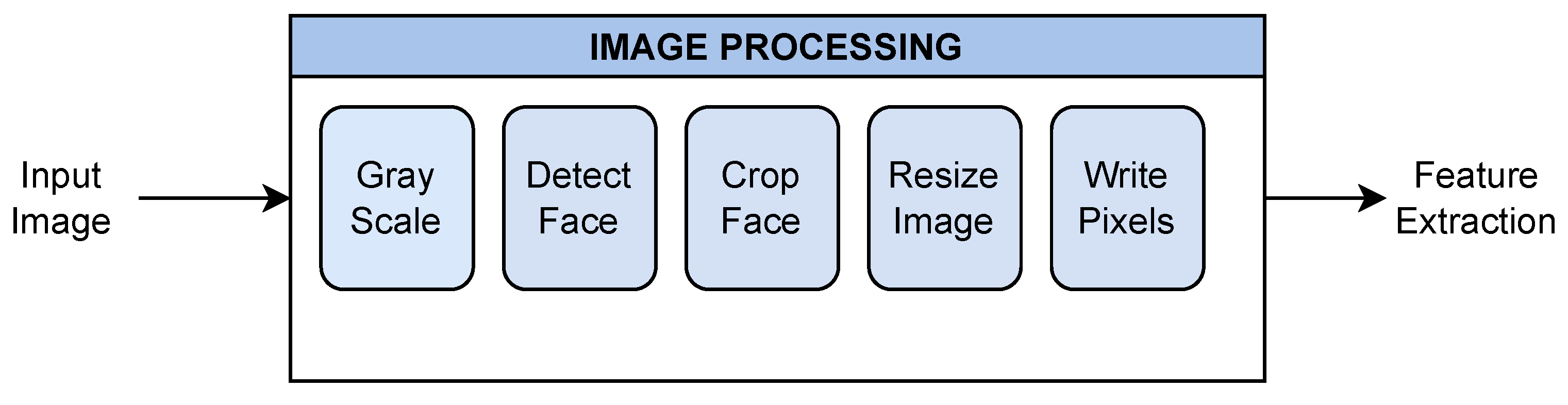
2.2.2. Image Processing and Feature Extraction
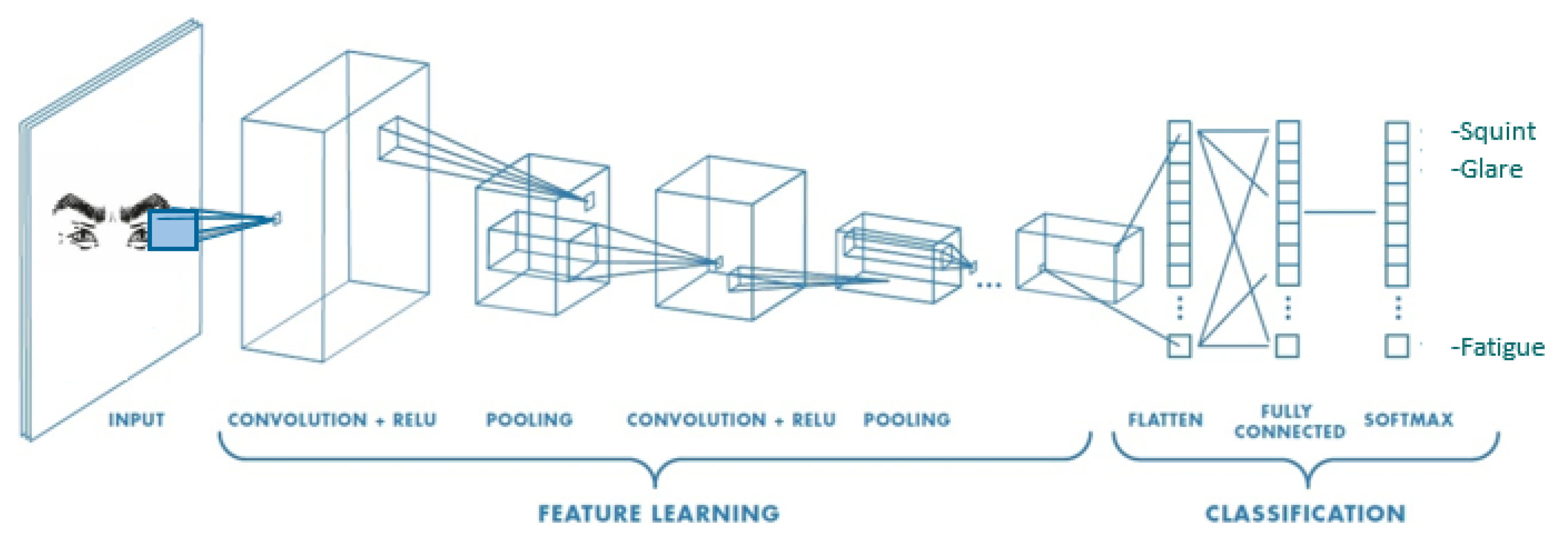
2.2.3. FER Algorithms
3. Solution Design
3.1. Developing the Machine Learning Model
3.1.1. Data Labeling
3.1.2. Model Development
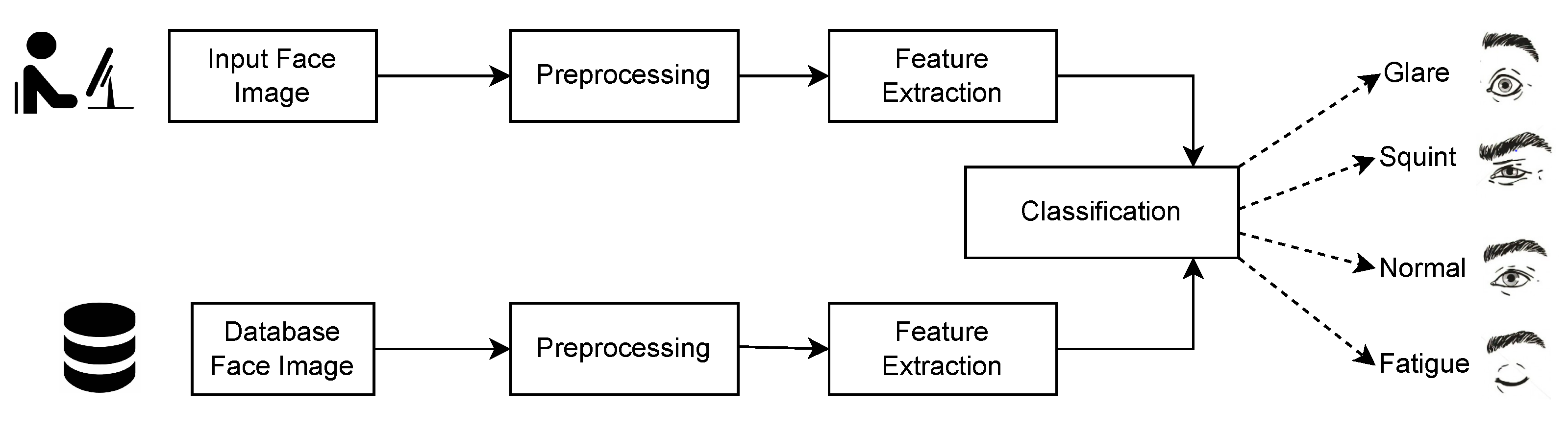
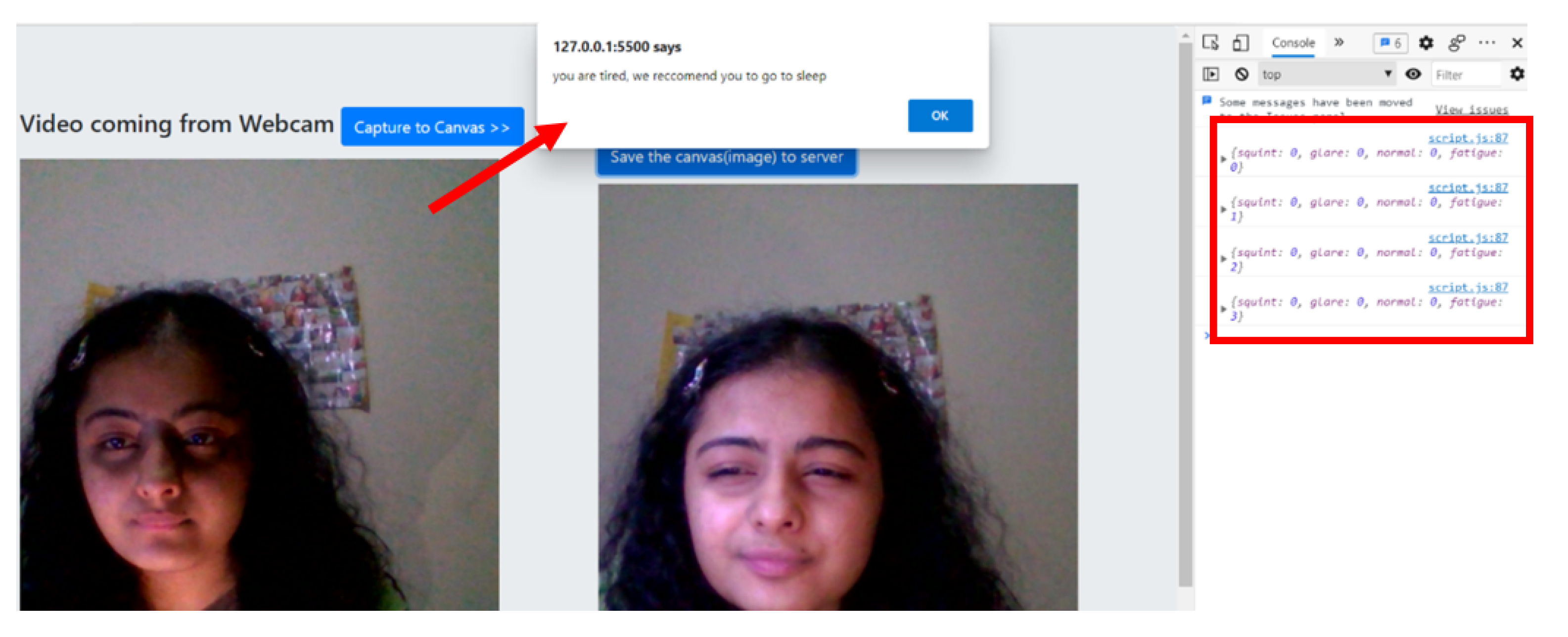
3.2. Digital Eye Strain Expression Recognition
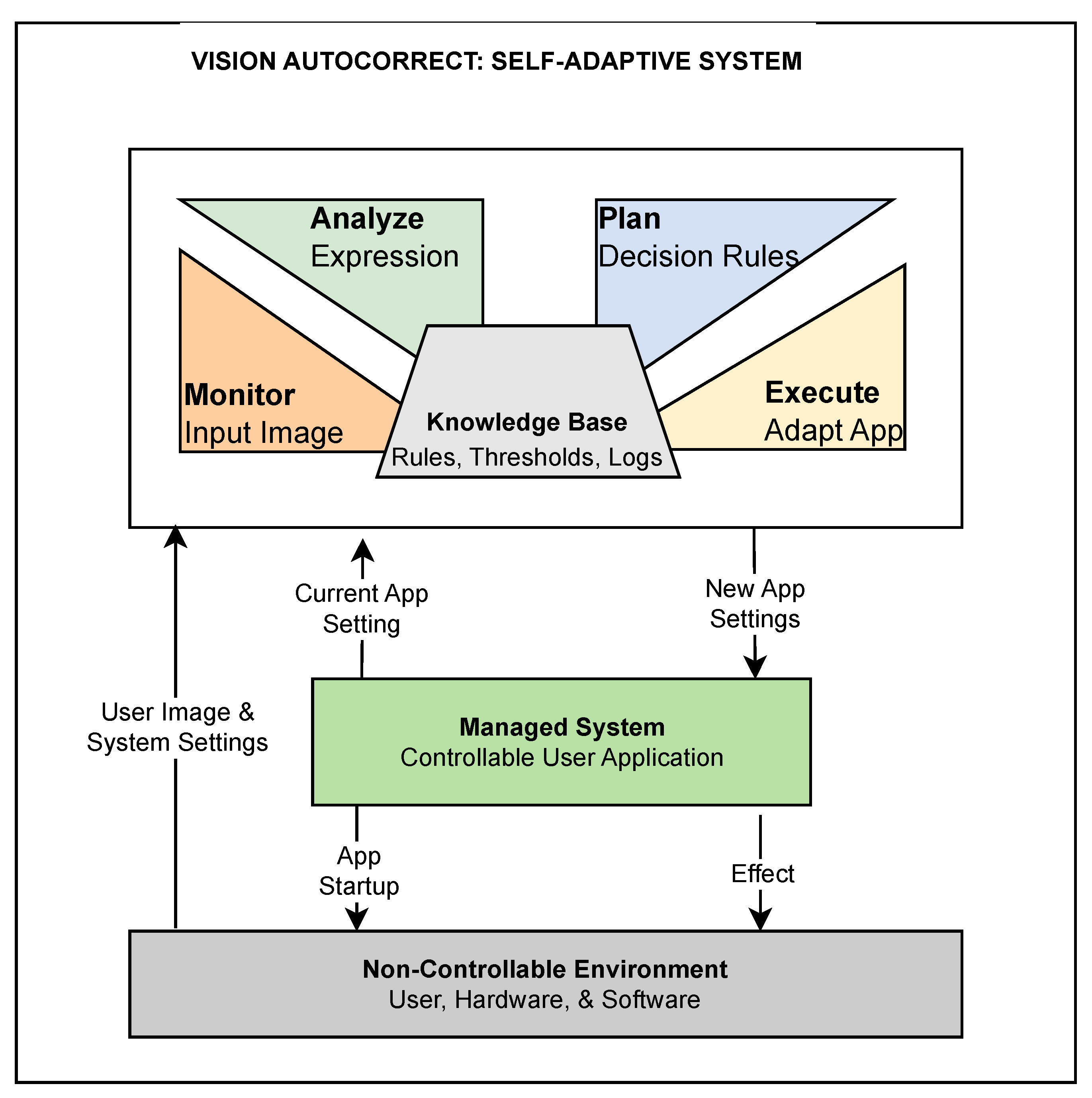
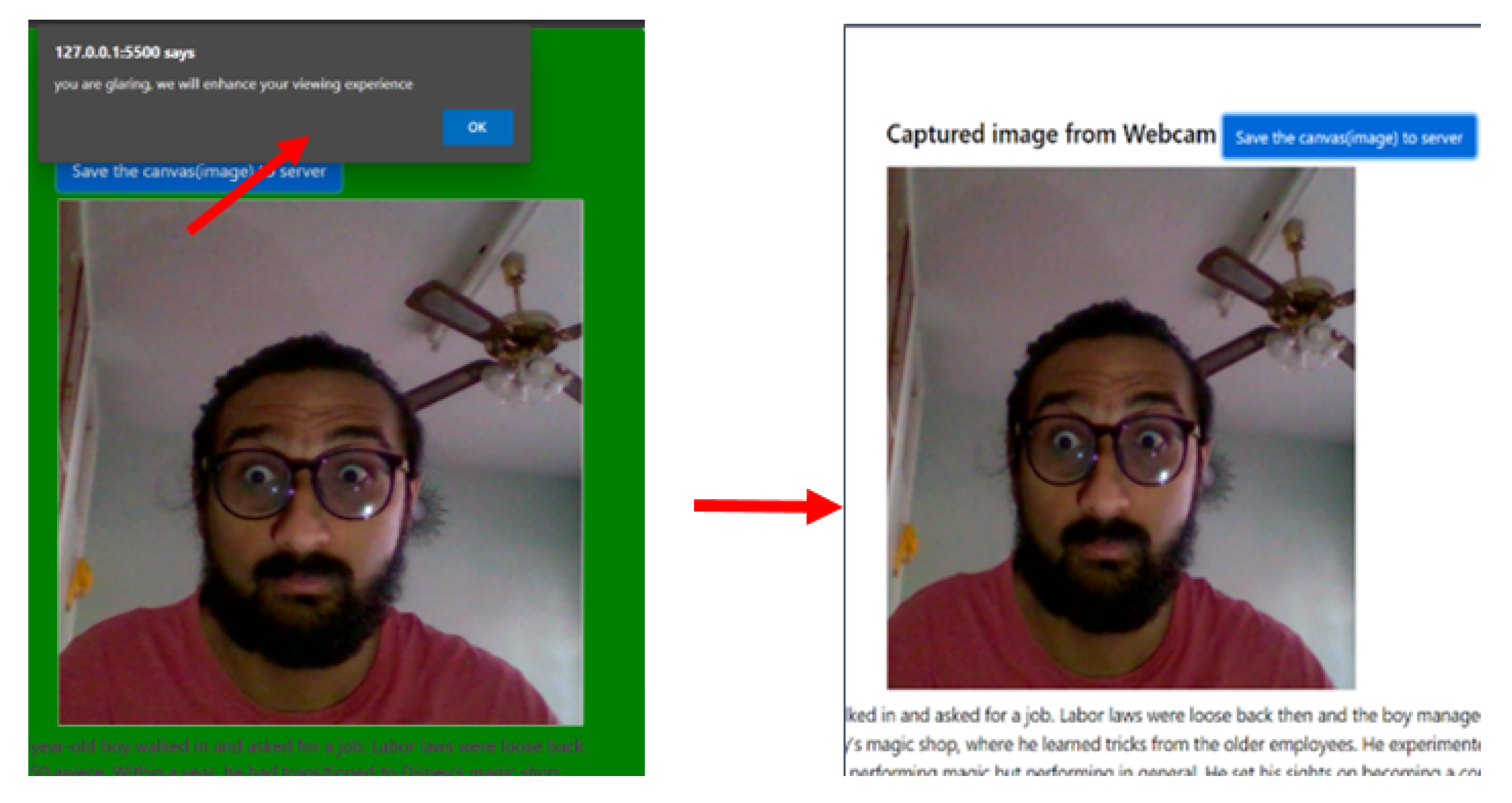
3.3. Self-Adaptation System
3.3.1. Design and Implementation
3.3.2. Decision Rules
4. Experimental Results and Discussion
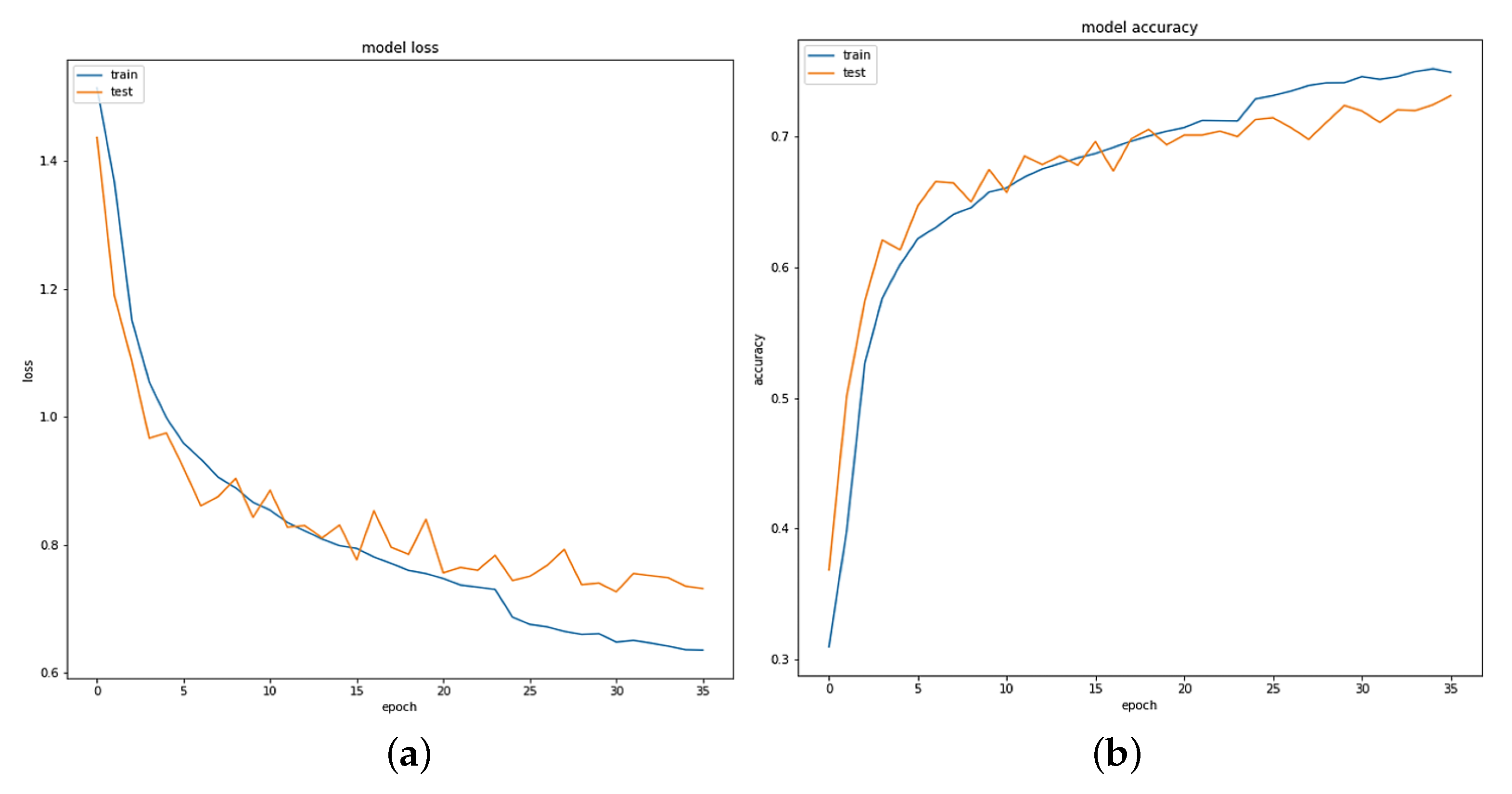
4.1. Model Evaluation
 ,
,  ,
,  and
and  are used to represent the accuracy status ranging from the least to the most models respectively as perceived by the users. The results revealed that Model ID 6 was the most accurate according to both users and the training results obtained. Based on this, Model ID 6 was used to develop the final application, available as a Jupyter notebook for reproducibility on: https://github.com/Jeetg57/VisionAutocorrect/blob/main/Model%206/6R1/Model%206R1.html (accessed on 10 March 2023).
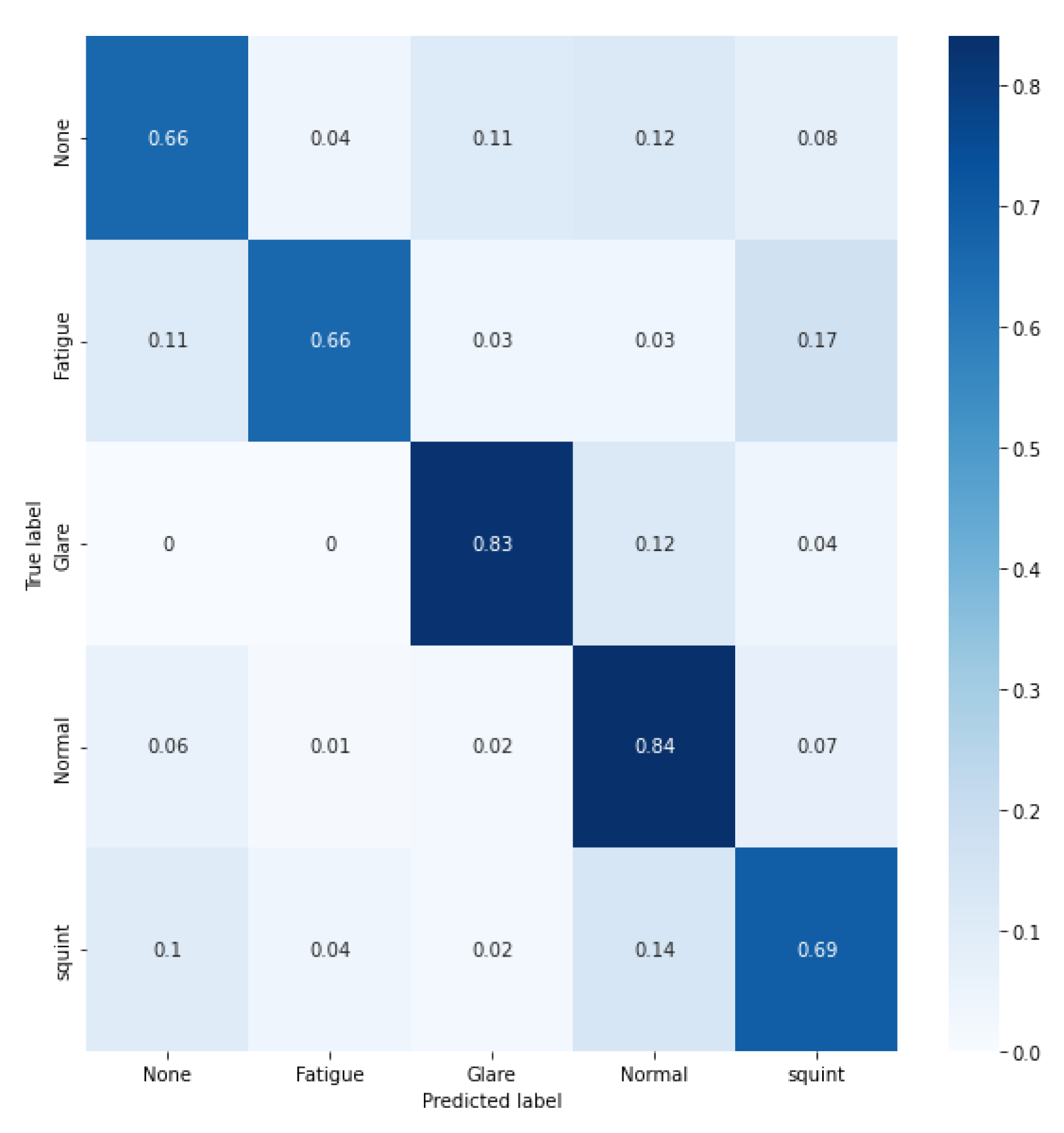
are used to represent the accuracy status ranging from the least to the most models respectively as perceived by the users. The results revealed that Model ID 6 was the most accurate according to both users and the training results obtained. Based on this, Model ID 6 was used to develop the final application, available as a Jupyter notebook for reproducibility on: https://github.com/Jeetg57/VisionAutocorrect/blob/main/Model%206/6R1/Model%206R1.html (accessed on 10 March 2023).4.2. Evaluating the Facial Expression Recognition Process
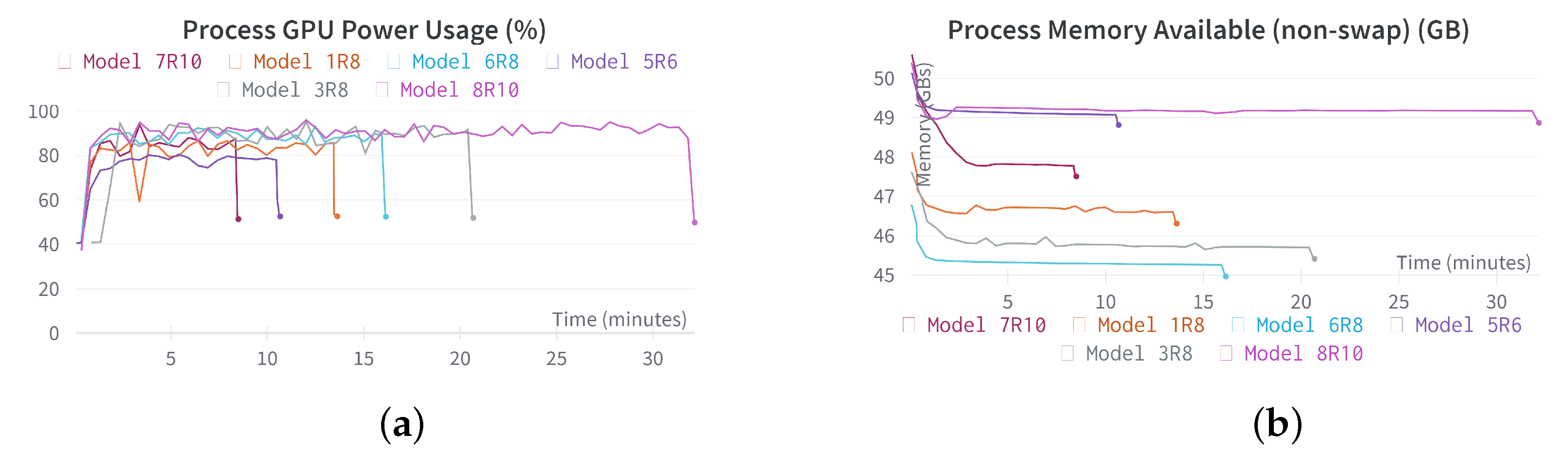
4.3. Evaluating the Self-Adaptation Process
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
- FER2013 - Goodfellow, I.; Erhan, D.; Carrier, P.; Courville, A.; Mirza, M.; Hamner, B. & Zhou, Y. (2013, November). Challenges in representation learning: A report on three machine learning contests. In Proceedings of the International Conference on Neural Information Processing, pp. 117–124.
- CK+ - Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 ieee computer society conference on computer vision and pattern recognition-workshops. IEEE, 2010, pp. 94–101
Acknowledgments
Conflicts of Interest
Appendix A

| Model Data | Model Accuracy | Confusion Matrix | |
|---|---|---|---|
| Model ID | 1 |  |  |
| Early Stopping Epochs | 35 | ||
| Training Accuracy | 0.67 | ||
| User Evaluation | 3 | ||
| Model ID | 3 |  |  |
| Early Stopping Epochs | 30 | ||
| Training Accuracy | 0.74 | ||
| User Evaluation | 2 | ||
| Model ID | 5 |  |  |
| Early Stopping Epochs | 20 | ||
| Training Accuracy | 0.65 | ||
| User Evaluation | 6 | ||
| Model ID | 6 |  |  |
| Early Stopping Epochs | 35 | ||
| Training Accuracy | 0.77 | ||
| User Evaluation | 1 | ||
| Model ID | 7 |  |  |
| Early Stopping Epochs | 20 | ||
| Training Accuracy | 0.75 | ||
| User Evaluation | 5 | ||
| Model ID | 8 |  |  |
| Early Stopping Epochs | 35 | ||
| Training Accuracy | 0.72 | ||
| User Evaluation | 4 |
References
- Elsworthy, E. Average Adult Will Spend 34 Years of Their Life Looking at Screens, Poll Claims. Independent 2020. Available online: https://www.independent.co.uk/life-style/fashion/news/screen-time-average-lifetime-years-phone-laptop-tv-a9508751.html (accessed on 10 March 2023).
- Nugent, A. UK adults spend 40% of their waking hours in front of a screen. Independent 2020. [Google Scholar]
- Bhattacharya, S.; Saleem, S.M.; Singh, A. Digital eye strain in the era of COVID-19 pandemic: An emerging public health threat. Indian J. Ophthalmol. 2020, 68, 1709. [Google Scholar] [CrossRef]
- Siegel, R. Tweens, Teens and Screens: The Average Time Kids Spend Watching Online Videos Has Doubled in 4 Years. The Washington Post, 29 October 2019. [Google Scholar]
- Hussain, J.; Ul Hassan, A.; Muhammad Bilal, H.S.; Ali, R.; Afzal, M.; Hussain, S.; Bang, J.; Banos, O.; Lee, S. Model-based adaptive user interface based on context and user experience evaluation. J. Multimodal User Interfaces 2018, 12, 1–16. [Google Scholar] [CrossRef]
- Plos, O.; Buisine, S.; Aoussat, A.; Mantelet, F.; Dumas, C. A Universalist strategy for the design of Assistive Technology. Int. J. Ind. Ergon. 2012, 42, 533–541. [Google Scholar] [CrossRef] [Green Version]
- Firmenich, S.; Garrido, A.; Paternò, F.; Rossi, G. User interface adaptation for accessibility. In Web Accessibility; Springer: Berlin/Heidelberg, Germany, 2019; pp. 547–568. [Google Scholar]
- Sterritt, R.; Hinchey, M. SPAACE IV: Self-properties for an autonomous & autonomic computing environment—Part IV A Newish Hope. In Proceedings of the 2010 Seventh IEEE International Conference and Workshops on Engineering of Autonomic and Autonomous Systems, Oxford, UK, 22–26 March 2010; pp. 119–125. [Google Scholar]
- Sheedy, J.E. The physiology of eyestrain. J. Mod. Opt. 2007, 54, 1333–1341. [Google Scholar] [CrossRef]
- Agarwal, S.; Goel, D.; Sharma, A. Evaluation of the factors which contribute to the ocular complaints in computer users. J. Clin. Diagn. Res. JCDR 2013, 7, 331. [Google Scholar] [CrossRef] [PubMed]
- Sheppard, A.; Wolffsohn, J. Digital eye strain: Prevalence, measurement and amelioration. BMJ Open Ophthalmol. 2018, 3, e000146. [Google Scholar] [CrossRef] [Green Version]
- Rosenfield, M. Computer vision syndrome (aka digital eye strain). Optom. Pract. 2016, 17, 1–10. [Google Scholar]
- Dachapally, P.R. Facial emotion detection using convolutional neural networks and representational autoencoder units. arXiv 2017, arXiv:1706.01509. [Google Scholar]
- Joseph, A.; Geetha, P. Facial emotion detection using modified eyemap–mouthmap algorithm on an enhanced image and classification with tensorflow. Vis. Comput. 2020, 36, 529–539. [Google Scholar] [CrossRef]
- Li, K.; Jin, Y.; Akram, M.W.; Han, R.; Chen, J. Facial expression recognition with convolutional neural networks via a new face cropping and rotation strategy. Vis. Comput. 2020, 36, 391–404. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial expression recognition: A survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef] [Green Version]
- González-Rodríguez, M.R.; Díaz-Fernández, M.C.; Gómez, C.P. Facial-expression recognition: An emergent approach to the measurement of tourist satisfaction through emotions. Telemat. Inform. 2020, 51, 101404. [Google Scholar] [CrossRef]
- Generosi, A.; Ceccacci, S.; Mengoni, M. A deep learning-based system to track and analyze customer behavior in retail store. In Proceedings of the 2018 IEEE 8th International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 2–5 September 2018; pp. 1–6. [Google Scholar]
- Bouzakraoui, M.S.; Sadiq, A.; Enneya, N. Towards a framework for customer emotion detection. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–6. [Google Scholar]
- Baggio, H.C.; Segura, B.; Ibarretxe-Bilbao, N.; Valldeoriola, F.; Marti, M.; Compta, Y.; Tolosa, E.; Junqué, C. Structural correlates of facial emotion recognition deficits in Parkinson’s disease patients. Neuropsychologia 2012, 50, 2121–2128. [Google Scholar] [CrossRef] [PubMed]
- Norton, D.; McBain, R.; Holt, D.J.; Ongur, D.; Chen, Y. Association of impaired facial affect recognition with basic facial and visual processing deficits in schizophrenia. Biol. Psychiatry 2009, 65, 1094–1098. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.A.; Hussain, S.; Xiaoming, S.; Yang, S. An effective framework for driver fatigue recognition based on intelligent facial expressions analysis. IEEE Access 2018, 6, 67459–67468. [Google Scholar] [CrossRef]
- Xiao, Z.; Hu, Z.; Geng, L.; Zhang, F.; Wu, J.; Li, Y. Fatigue driving recognition network: Fatigue driving recognition via convolutional neural network and long short-term memory units. IET Intell. Transp. Syst. 2019, 13, 1410–1416. [Google Scholar] [CrossRef]
- Munasinghe, M. Facial expression recognition using facial landmarks and random forest classifier. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 423–427. [Google Scholar]
- Reddy, A.P.C.; Sandilya, B.; Annis Fathima, A. Detection of eye strain through blink rate and sclera area using raspberry-pi. Imaging Sci. J. 2019, 67, 90–99. [Google Scholar] [CrossRef]
- Lim, J.Z.; Mountstephens, J.; Teo, J. Emotion recognition using eye-tracking: Taxonomy, review and current challenges. Sensors 2020, 20, 2384. [Google Scholar] [CrossRef]
- Klaib, A.F.; Alsrehin, N.O.; Melhem, W.Y.; Bashtawi, H.O.; Magableh, A.A. Eye tracking algorithms, techniques, tools, and applications with an emphasis on machine learning and Internet of Things technologies. Expert Syst. Appl. 2021, 166, 114037. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Kanade, T.; Cohn, J. Handbook of Face Recognition; Li, S.Z., Jain, A.K., Eds.; Springer: London, UK, 2011. [Google Scholar]
- Kanade, T.; Cohn, J.F.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the fourth IEEE International Conference on Automatic Face and Gesture Recognition (cat. No. PR00580), Grenoble, France, 28–30 March 2000; pp. 46–53. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the Neural Information Processing: 20th International Conference, ICONIP 2013, Daegu, Korea, 3–7 November 2013; Proceedings, Part III 20. Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Petrou, M.M.; Petrou, C. Image Processing: The Fundamentals; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Russ, J.C. The Image Processing Handbook; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Joshi, P. OpenCV with Python by Example; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef]
- Liliana, D.Y.; Basaruddin, T. Review of automatic emotion recognition through facial expression analysis. In Proceedings of the 2018 International Conference on Electrical Engineering and Computer Science (ICECOS), Pangkal, Indonesia, 2–4 October 2018; pp. 231–236. [Google Scholar]
- Lopes, A.T.; De Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Facial expression recognition with convolutional neural networks: Coping with few data and the training sample order. Pattern Recognit. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Georgescu, M.I.; Ionescu, R.T.; Popescu, M. Local learning with deep and handcrafted features for facial expression recognition. IEEE Access 2019, 7, 64827–64836. [Google Scholar] [CrossRef]
- Pecoraro, R.; Basile, V.; Bono, V. Local multi-head channel self-attention for facial expression recognition. Information 2022, 13, 419. [Google Scholar] [CrossRef]
- Aouayeb, M.; Hamidouche, W.; Soladie, C.; Kpalma, K.; Seguier, R. Learning vision transformer with squeeze and excitation for facial expression recognition. arXiv 2021, arXiv:2107.03107. [Google Scholar]
- Meng, D.; Peng, X.; Wang, K.; Qiao, Y. Frame attention networks for facial expression recognition in videos. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3866–3870. [Google Scholar]
- Pourmirzaei, M.; Montazer, G.A.; Esmaili, F. Using self-supervised auxiliary tasks to improve fine-grained facial representation. arXiv 2021, arXiv:2105.06421. [Google Scholar] [CrossRef]
- Gacav, C.; Benligiray, B.; Topal, C. Greedy search for descriptive spatial face features. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1497–1501. [Google Scholar]
- Antoniadis, P.; Filntisis, P.P.; Maragos, P. Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; Available online: http://xxx.lanl.gov/abs/2106.03487 (accessed on 12 January 2023).
- Ryumina, E.; Dresvyanskiy, D.; Karpov, A. In search of a robust facial expressions recognition model: A large-scale visual cross-corpus study. Neurocomputing 2022, 514, 435–450. [Google Scholar] [CrossRef]
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 15 June 2019; pp. 6105–6114. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Minhas, R.A.; Javed, A.; Irtaza, A.; Mahmood, M.T.; Joo, Y.B. Shot classification of field sports videos using AlexNet Convolutional Neural Network. Appl. Sci. 2019, 9, 483. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Chen, X.; Xie, L.; Wu, J.; Tian, Q. Progressive darts: Bridging the optimization gap for nas in the wild. Int. J. Comput. Vis. 2021, 129, 638–655. [Google Scholar] [CrossRef]
- Al-Sabaawi, A.; Ibrahim, H.M.; Arkah, Z.M.; Al-Amidie, M.; Alzubaidi, L. Amended convolutional neural network with global average pooling for image classification. In Intelligent Systems Design and Applications. ISDA 2020. Advances in Intelligent Systems and Computing; Abraham, A., Piuri, V., Gandhi, N., Siarry, P., Kaklauskas, A., Madureira, A., Eds.; Springer: Cham, Switzerland, 2020; Volume 1351, pp. 171–180. [Google Scholar]
- Liu, D.; Liu, Y.; Dong, L. G-ResNet: Improved ResNet for brain tumor classification. In Neural Information Processing. ICONIP 2019. Lecture Notes in Computer Science; Gedeon, T., Wong, K., Lee, M., Eds.; Springer: Cham, Switzerland, 2019; Volume 11953, pp. 535–545. [Google Scholar]
- Wang, S.; Peng, G.; Zheng, Z.; Xu, Z. Capturing emotion distribution for multimedia emotion tagging. IEEE Trans. Affect. Comput. 2019, 12, 821–831. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Vijayalakshmi, K.A.A. Comparison of viola-jones and kanade-lucas-tomasi face detection algorithms. Orient. J. Comput. Sci. Technol. 2017, 10, 151–159. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












| Model ID | Architecture | Number of Convolutional Layers |
|---|---|---|
| 3 | AlexNets [42] | 4 |
| 7 | 4 | |
| 8 | 8 | |
| 1 | VGGNets [43] | 6 |
| 6 | 9 | |
| 5 | ResNets [44] | 7, 8 Separable |
| Training Results | User Tests Results | ||||||
|---|---|---|---|---|---|---|---|
| Model ID | Attempt | Accuracy | Squint | Glare | Fatigue | Normal | Rank |
| Model 1 | 1 | 0.634043694 | | | | | 5 |
| 2 | 0.651729226 | | | | | 4 | |
| 3 | 0.674306452 | | | | | 1 | |
| 4 | 0.660965323 | | | | | 2 | |
| 5 | 0.655970991 | | | | | 3 | |
| Model 3 | 1 | 0.692402422 | | | | | 4 |
| 2 | 0.676529944 | | | | | 5 | |
| 3 | 0.738822579 | | | | | 1 | |
| 4 | 0.705298781 | | | | | 2 | |
| 5 | 0.694386482 | | | | | 3 | |
| Model 5 | 1 | 0.648308396 | | | | | 1 |
| 2 | 0.69226557 | | | | | 2 | |
| 3 | 0.652721226 | | | | | 3 | |
| 4 | 0.666575432 | | | | | 4 | |
| 5 | 0.647453249 | | | | | 5 | |
| Model 6 | 1 | 0.747887671 | | | | | 2 |
| 2 | 0.771764815 | | | | | 1 | |
| 3 | 0.702151656 | | | | | 5 | |
| 4 | 0.708172262 | | | | | 4 | |
| 5 | 0.738788366 | | | | | 3 | |
| Model 7 | 1 | 0.732459903 | | | | | 3 |
| 2 | 0.724934161 | | | | | 4 | |
| 3 | 0.719495118 | | | | | 5 | |
| 4 | 0.750555873 | | | | | 1 | |
| 5 | 0.746450901 | | | | | 2 | |
| Model 8 | 1 | 0.745014191 | | | | | 3 |
| 2 | 0.655389428 | | | | | 5 | |
| 3 | 0.728560209 | | | | | 4 | |
| 4 | 0.726165652 | | | | | 2 | |
| 5 | 0.723497391 | | | | | 1 | |
| Key: Accurate, Partially Accurate, Partially Inaccurate, Inaccurate | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mutanu, L.; Gohil, J.; Gupta, K. Vision-Autocorrect: A Self-Adapting Approach towards Relieving Eye-Strain Using Facial-Expression Recognition. Software 2023, 2, 197-217. https://doi.org/10.3390/software2020009
Mutanu L, Gohil J, Gupta K. Vision-Autocorrect: A Self-Adapting Approach towards Relieving Eye-Strain Using Facial-Expression Recognition. Software. 2023; 2(2):197-217. https://doi.org/10.3390/software2020009
Chicago/Turabian StyleMutanu, Leah, Jeet Gohil, and Khushi Gupta. 2023. "Vision-Autocorrect: A Self-Adapting Approach towards Relieving Eye-Strain Using Facial-Expression Recognition" Software 2, no. 2: 197-217. https://doi.org/10.3390/software2020009