
A Metric for Questions and Discussions Identifying Concerns in Software Reviews

Abstract
:1. Introduction
2. Software Reviews
3. Effective Questions in Reviews
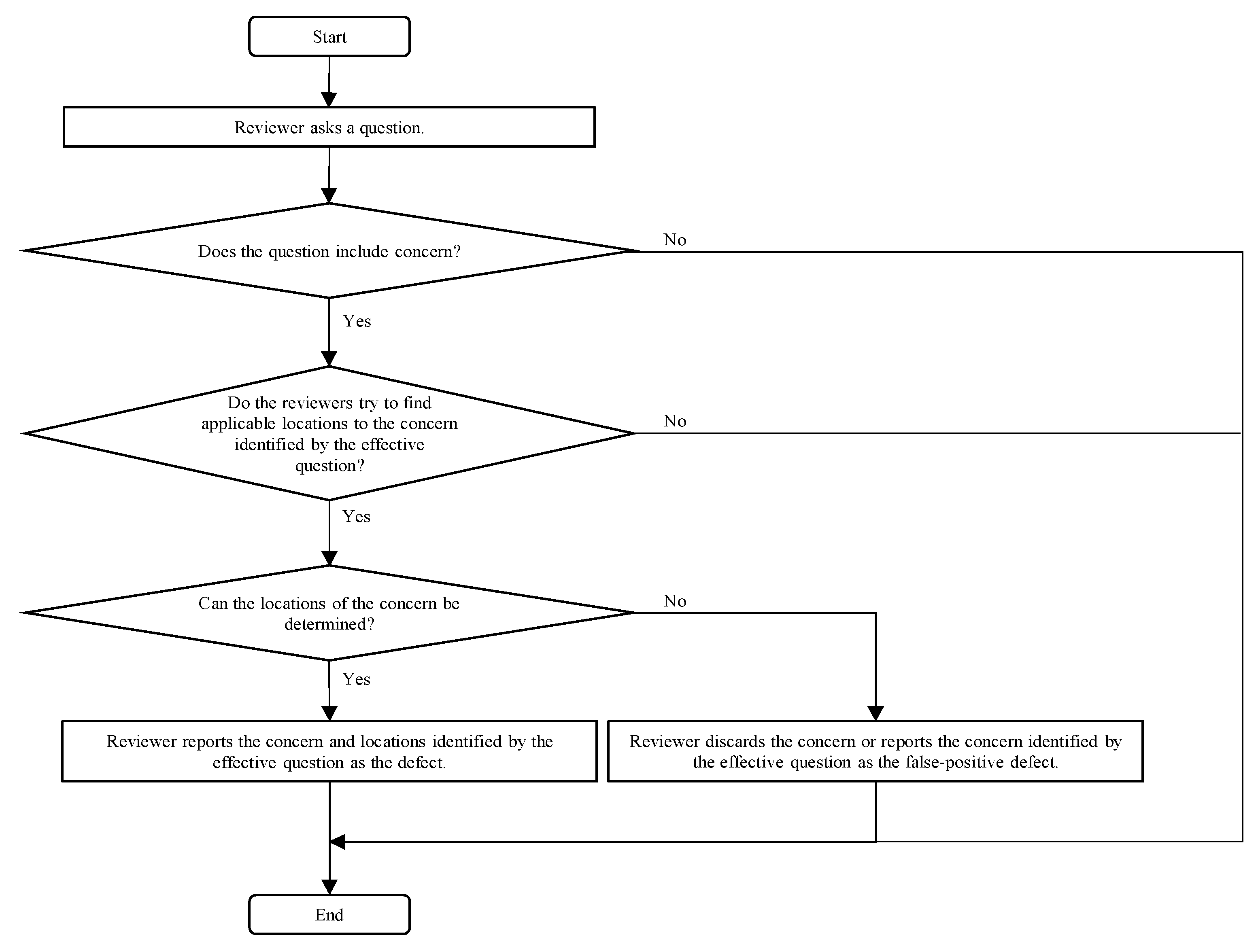
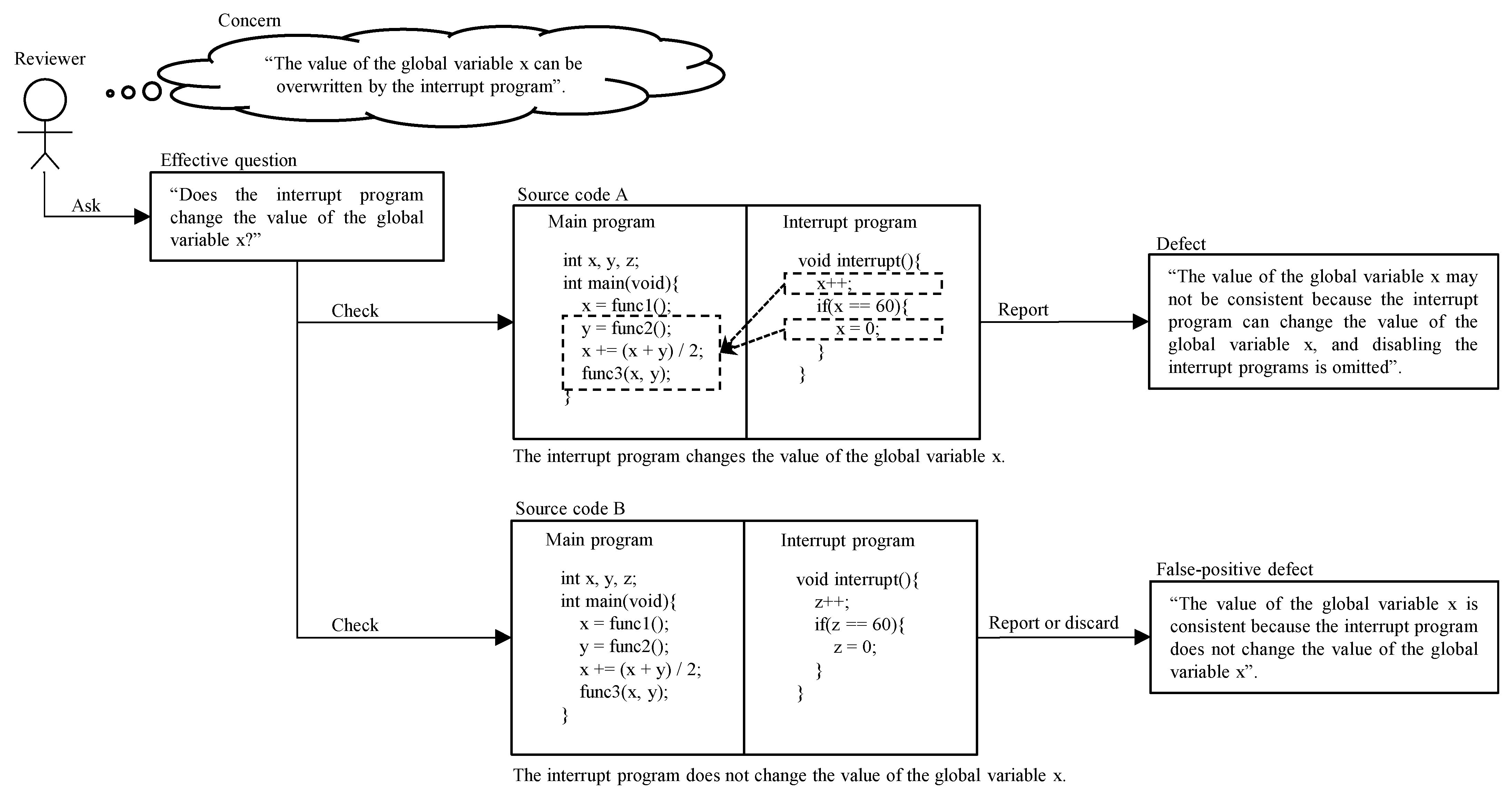
3.1. Definition
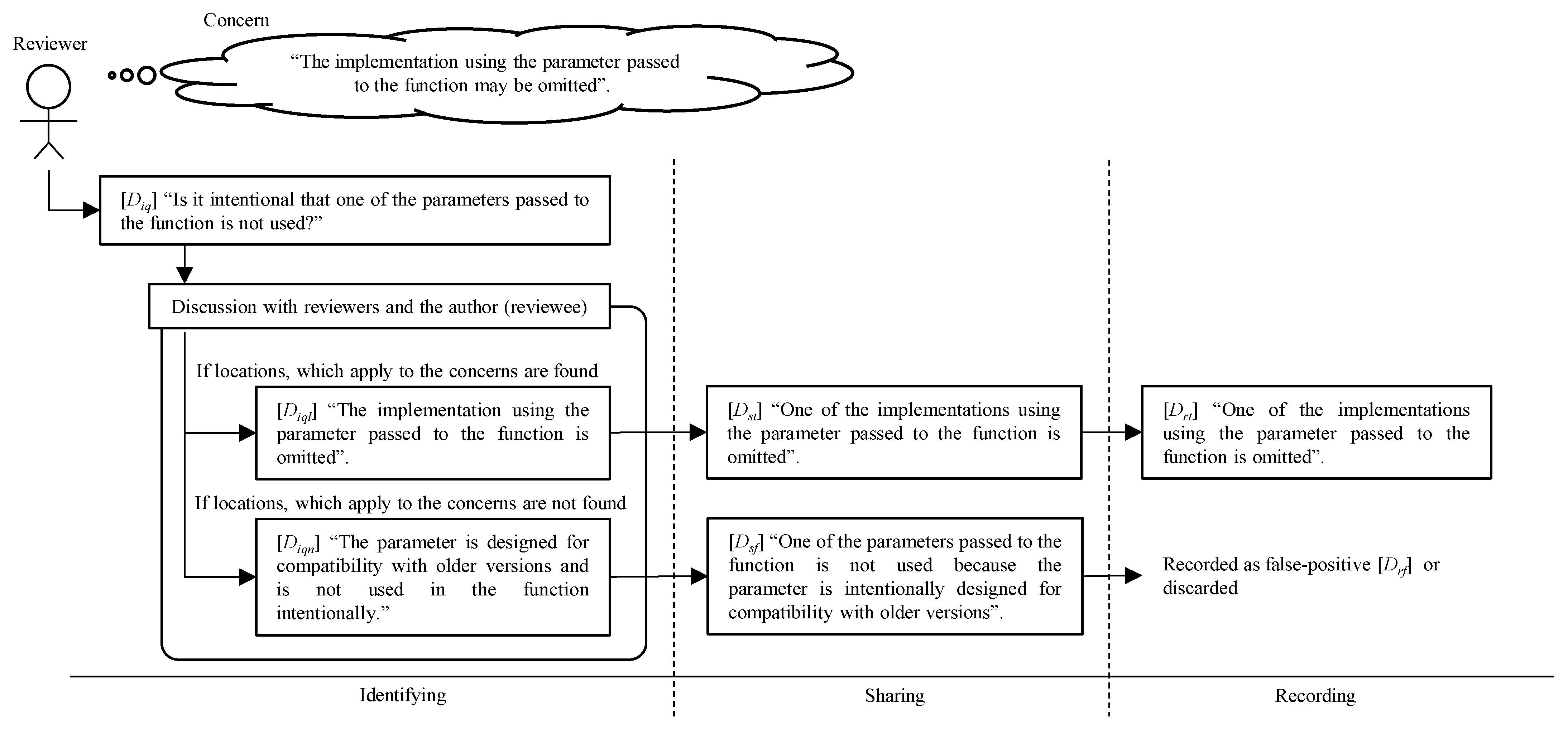
3.2. Defect Category and Effective Questions in Review Process
- -
- Identifying
- -
- Sharing
- -
- Recording
3.3. Literature Review
4. Case Study
4.1. Goal
4.2. Projects
4.3. Metrics and Procedure
4.4. Results
5. Discussion
5.1. RQ: Does the Number of Effective Questions in a Review Affect the Quality of Subsequent Testing?
5.2. Implications for Practitioners
5.3. Threats to Validity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Fagan, M.E. Design and code inspections to reduce errors in program development. IBM Syst. J. 1976, 15, 182–211. [Google Scholar] [CrossRef]
- IEEE Std 1028-2008; IEEE Standard for Software Reviews and Audits. Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2008; pp. 1–53. [CrossRef]
- Boehm, B.; Basili, V.R. Top 10 list [software development]. IEEE Comput. 2001, 34, 135–137. [Google Scholar] [CrossRef]
- De Souza, B.P.; Motta, R.C.; Costa, D.D.O.; Travassos, G.H. An IoT-based scenario description inspection technique. In Proceedings of the XVIII Brazilian Symposium on Software Quality, Fortaleza, Brazil, 28 October–1 November 2019; pp. 20–29. [Google Scholar]
- Tian, J. Software Quality Engineering: Testing, Quality Assurance, and Quantifiable Improvement; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Parnas, D.L.; Lawford, M. The role of inspection in software quality assurance. IEEE Trans. Softw. Eng. 2003, 29, 674–676. [Google Scholar] [CrossRef]
- Olalekan, A.S.; Osofisan, A. Empirical study of factors affecting the effectiveness of software inspection: A preliminary report. Eur. J. Sci. Res. 2008, 19, 614–627. [Google Scholar]
- Suma, V.; Nair, T.R.G. Four-step approach model of inspection (FAMI) for effective defect management in software development. InterJRI Sci. Technol. 2012, 3, 29–41. [Google Scholar] [CrossRef]
- Porter, A.A.; Johnson, P.M. Assessing software review meetings: Results of a comparative analysis of two experimental studies. IEEE Trans. Softw. Eng. 1997, 23, 129–145. [Google Scholar] [CrossRef]
- Bosu, A.; Greiler, M.; Bird, C. Characteristics of useful code reviews: An empirical study at Microsoft. In Proceedings of the IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015; pp. 146–156. [Google Scholar]
- Ebert, F.; Castor, F.; Novielli, N.; Serebrenik, A. Communicative intention in code review questions. In Proceedings of the IEEE International Conference on Software Maintenance and Evolution (ICSME), Madrid, Spain, 23–29 September 2018; pp. 519–523. [Google Scholar]
- Huet, G.; Culley, S.J.; McMahon, C.A.; Fortin, C. Making sense of engineering design review activities. Artif. Intell. Eng. Des. Anal. Manuf. 2007, 21, 243–266. [Google Scholar] [CrossRef]
- Robillard, P.N.; d’Astous, P.; Détienne, F.; Visser, W. An empirical method based on protocol analysis to analyze technical review meetings. In Proceedings of the Conference of the Centre for Advanced Studies on Collaborative Research, Toronto, ON, Canada, 30 November–3 December 1998; pp. 1–12. [Google Scholar]
- d’Astous, P.; Detienne, F.; Visser, W.; Robillard, P. On the use of functional and interactional approaches for the analysis of technical review meetings. In Proceedings of the 12th Annual Workshop of the Psychology of Programming Interest Group, Cosenza, Italy, 10–13 April 2000; pp. 155–170. [Google Scholar]
- Hasan, M.; Iqbal, A.; Islam, M.R.U.; Rahman, A.J.M.I.; Bosu, A. Using a balanced scorecard to identify opportunities to improve code review effectiveness: An industrial experience report. Empir. Softw. Eng. 2021, 26, 129–163. [Google Scholar] [CrossRef]
- Runeson, P.; Wohlin, C. An experimental evaluation of an experience-based capture-recapture method in software code inspections. Empir. Softw. Eng. 1998, 3, 381–406. [Google Scholar] [CrossRef]
- Briand, L.C.; El Emam, K.; Frelmut, B.; Laitenberger, O. Quantitative evaluation of capture-recapture models to control software inspections. In Proceedings of the Eighth International Symposium on Software Reliability Engineering, Albuquerque, NM, USA, 2–5 November 1997; pp. 234–244. [Google Scholar]
- Taba, N.H.; Ow, S.H. A web-based model for inspection inconsistencies resolution: A new approach with two case studies. Malays. J. Comput. Sci. 2019, 32, 1–17. [Google Scholar] [CrossRef]
- Rahman, M.M.; Roy, C.K.; Kula, R.G. Predicting usefulness of code review comments using textual features and developer experience. In Proceedings of the IEEE/ACM 14th International Conference on Mining Software Repositories (MSR), Buenos Aires, Argentina, 20–21 May 2017; pp. 215–226. [Google Scholar]
- Wakimoto, M.; Morisaki, S. Goal-oriented software design reviews. IEEE Access 2022, 10, 32584–32594. [Google Scholar] [CrossRef]
- Basili, V.R.; Green, S.; Laitenberger, O.; Lanubile, F.; Shull, F.; Sørumgård, S.; Zelkowitz, M.V. The empirical investigation of perspective-based reading. Empir. Softw. Eng. 1996, 1, 133–164. [Google Scholar] [CrossRef]
- Ciolkowski, M.; Laitenberger, O.; Biffl, S. Software reviews, the state of the practice. IEEE Softw. 2003, 20, 46–51. [Google Scholar] [CrossRef]
- Porter, A.; Votta, L. Comparing detection methods for software requirements inspections: A replication using professional subjects. Empir. Softw. Eng. 1998, 3, 355–379. [Google Scholar] [CrossRef]
- Porter, A.A.; Votta, L.G.; Basili, V.R. Comparing detection methods for software requirements inspections: A replicated experiment. IEEE Trans. Softw. Eng. 1995, 21, 563–575. [Google Scholar] [CrossRef]
- Shull, F.; Rus, I.; Basili, V. How perspective-based reading can improve requirements inspections. IEEE Comput. 2000, 33, 73–79. [Google Scholar] [CrossRef]
- Thelin, T.; Runeson, P.; Regnell, B. Usage-based reading—An experiment to guide reviewers with use cases. Inf. Softw. Technol. 2001, 43, 925–938. [Google Scholar] [CrossRef]
- Thelin, T.; Runeson, P.; Wohlin, C. An experimental comparison of usage-based and checklist-based reading. IEEE Trans. Softw. Eng. 2003, 29, 687–704. [Google Scholar] [CrossRef]
- Ebad, S.A. Inspection reading techniques applied to software artifacts—A systematic review. Comput. Syst. Sci. Eng. 2017, 32, 213–226. [Google Scholar]
- De Souza, B.P.; Motta, R.C.; Travassos, G.H. The first version of SCENARIotCHECK. In Proceedings of the XXXIII Brazilian Symposium on Software Engineering, Salvador, Brazil, 23–27 September 2019. [Google Scholar]
- Travassos, G.; Shull, F.; Fredericks, M.; Basili, V.R. Detecting defects in object-oriented designs: Using reading techniques to increase software quality. ACM SIGPLAN Not. 1999, 34, 47–56. [Google Scholar] [CrossRef]
- Laitenberger, O. Cost-effective detection of software defects through perspective-based Inspections. Empir. Softw. Eng. 2001, 6, 81–84. [Google Scholar] [CrossRef]
- Shull, F. Developing Techniques for Using Software Documents: A Series of Empirical Studies. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 1998. [Google Scholar]
- Votta, L.G. Does every inspection need a meeting? ACM SIGSOFT Softw. Eng. Notes 1993, 18, 107–114. [Google Scholar] [CrossRef]
- Murphy, P.; Miller, J. A process for asynchronous software inspection. In Proceedings of the Eighth IEEE International Workshop on Software Technology and Engineering Practice incorporating Computer Aided Software Engineering, London, UK, 14–18 July 1997; pp. 96–104. [Google Scholar]
- Laitenberger, O.; DeBaud, J.-M. An encompassing life cycle centric survey of software inspection. J. Syst. Softw. 2000, 50, 5–31. [Google Scholar] [CrossRef]
- Johnson, P.M.; Tjahjono, D. Does every inspection really need a meeting? Empir. Softw. Eng. 1998, 3, 9–35. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, H.; Yin, G.; Wang, T. Reviewer recommendation for pull-requests in GitHub: What can we learn from code review and bug assignment? Inf. Softw. Technol. 2016, 74, 204–218. [Google Scholar] [CrossRef]
- Thongtanunam, P.; Hassan, A.E. Review dynamics and their impact on software quality. IEEE Trans. Softw. Eng. 2020, 2698–2712. [Google Scholar] [CrossRef]
- Mantyla, M.V.; Lassenius, C. What types of defects are really discovered in code reviews? IEEE Trans. Softw. Eng. 2009, 35, 430–448. [Google Scholar] [CrossRef]
- Chillarege, R.; Bhandari, I.S.; Chaar, J.K.; Halliday, M.J.; Moebus, D.S.; Ray, B.K.; Wong, M.-Y. Orthogonal defect classification-a concept for in-process measurements. IEEE Trans. Softw. Eng. 1992, 18, 943–956. [Google Scholar] [CrossRef]
- IBM. Orthogonal Defect Classification v 5.2 for Software Design and Code; IBM: Armonk, NY, USA, 2013. [Google Scholar]
- Fernandez, A.; Abrahao, S.; Insfran, E. Empirical validation of a usability inspection method for model-driven Web development. J. Syst. Softw. 2013, 86, 161–186. [Google Scholar] [CrossRef]
- Regnell, B.; Runeson, P.; Thelin, T. Are the perspectives really different?—Further experimentation on scenario-based reading of requirements. Empir. Softw. Eng. 2000, 5, 331–356. [Google Scholar] [CrossRef]
- Lanubile, F.; Mallardo, T. An empirical study of Web-based inspection meetings. In Proceedings of the International Symposium on Empirical Software Engineering, Rome, Italy, 30 September–1 October 2003; pp. 244–251. [Google Scholar]
- Calefato, F.; Lanubile, F.; Mallardo, T. A controlled experiment on the effects of synchronicity in remote inspection meetings. In Proceedings of the First International Symposium on Empirical Software Engineering and Measurement (ESEM 2007), Madrid, Spain, 20–21 September 2007; pp. 473–475. [Google Scholar]
- Porter, A.; Siy, H.; Mockus, A.; Votta, L. Understanding the sources of variation in software inspections. ACM Trans. Softw. Eng. Methodol. 1998, 7, 41–79. [Google Scholar] [CrossRef] [Green Version]
- Macdonald, F.; Miller, J. A comparison of tool-based and paper-based software inspection. Empir. Softw. Eng. 1998, 3, 233–253. [Google Scholar] [CrossRef]
- Thelin, T.; Runeson, P.; Wohlin, C.; Olsson, T.; Andersson, C. Evaluation of usage-based reading—Conclusions after three experiments. Empir. Softw. Eng. 2004, 9, 77–110. [Google Scholar] [CrossRef]
- Land, L.P.W.; Tan, B.; Bin, L. Investigating training effects on software reviews: A controlled experiment. In Proceedings of the International Symposium on Empirical Software Engineering, Noosa Heads, Australia, 17–18 November 2005; pp. 356–366. [Google Scholar]
- Sabaliauskaite, G.; Kusumoto, S.; Inoue, K. Assessing defect detection performance of interacting teams in object-oriented design inspection. Inf. Softw. Technol. 2004, 46, 875–886. [Google Scholar] [CrossRef]
- Briand, L.; Falessi, D.; Nejati, S.; Sabetzadeh, M.; Yue, T. Traceability and SysML design slices to support safety inspections. ACM Trans. Softw. Eng. Methodol. 2014, 23, 9. [Google Scholar] [CrossRef]
- Wong, Y.; Wilson, D. An empirical investigation of the important relationship between software review meetings process and outcomes. In Proceedings of the IASTED International Conference on Software Engineering, Innsbruck, Austria, 17–19 February 2004; pp. 422–427. [Google Scholar]
- Soltanifar, B.; Erdem, A.; Bener, A. Predicting defectiveness of software patches. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real, Spain, 8–9 September 2016; pp. 1–10. [Google Scholar]
- Carver, J.; Shull, F.; Basili, V. Can observational techniques help novices overcome the software inspection learning curve? An empirical investigation. Empir. Softw. Eng. 2006, 11, 523–539. [Google Scholar] [CrossRef]
- Land, L.P.W. Software group reviews and the impact of procedural roles on defect detection performance. Empir. Softw. Eng. 2002, 7, 77–79. [Google Scholar] [CrossRef]
- Sandahl, K.; Blomkvist, O.; Karlsson, J.; Krysander, C.; Lindvall, M.; Ohlsson, N. An extended replication of an experiment for assessing methods for software requirements inspections. Empir. Softw. Eng. 1998, 3, 327–354. [Google Scholar] [CrossRef]
- Albayrak, Ö.; Carver, J.C. Investigation of individual factors impacting the effectiveness of requirements inspections: A replicated experiment. Empir. Softw. Eng. 2014, 19, 241–266. [Google Scholar] [CrossRef]
- Fagan, M.E. Advances in software inspections. IEEE Trans. Softw. Eng. 1986, 744–751. [Google Scholar] [CrossRef]
- Highsmith, J.; Cockburn, A. Agile software development: The business of innovation. Computer 2001, 34, 120–127. [Google Scholar] [CrossRef] [Green Version]
- Abrahamsson, P.; Warsta, J.; Siponen, M.T.; Ronkainen, J. New directions on agile methods: A comparative analysis. In Proceedings of the 25th International Conference on Software Engineering, Portland, OR, USA, 3–10 May 2003. [Google Scholar]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R.J. Sentiment analysis of Twitter data. In Proceedings of the Workshop on Language in Social Media (LSM 2011), Portland, OR, USA, 23 June 2011; pp. 30–38. [Google Scholar]
- Feldman, R. Techniques and applications for sentiment analysis. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Ahmed, T.; Bosu, A.; Iqbal, A.; Rahimi, S. SentiCR: A customized sentiment analysis tool for code review interactions. In Proceedings of the ASE 2017 32nd IEEE/ACM International Conference on Automated Software Engineering, Urbana, IL, USA, 30 October–3 November 2017; pp. 106–111. [Google Scholar]
- Vrzakova, H.; Begel, A.; Mehtätalo, L.; Bednarik, R. Affect recognition in code review: An in-situ biometric study of reviewer’s affect. J. Syst. Softw. 2020, 159, 110434. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Text Referring the Defect Categories in the Previous Studies |
|---|---|
| Did ∩ Dst | To support decision making, discussants can also vote by rating any potential defect as true defect [44]. Collated defects: the number of defects merged from individual findings to be discussed during the meeting. True defects: the number of defects for which consensus was reached during the meeting in considering them as true defects [45]. We used the information from the repair form and interviews with the author to classify each issue as a true defect (if the author was required to make an execution affecting change to resolve it) [46]. |
| Did ∩ Dsf | False positives are items reported by subjects as defects, when in fact no defect exists [47]. |
| Did ∩ (Dst ∪ Dsf) | In addition to the instructions from the preparation phase, the instructions in the meeting phase were: use the individual inspection record and decide which are faults and which are false positives [48]. |
| Dst | True defects: the number of defects for which consensus was reached during the meeting in considering them as true defects [45]. |
| Dsf | Removed false positives: the number of defects for which consensus was reached during the meeting in considering them as not true defects, thus as false positives [45]. |
| Dst ∩ Drf | In the Discrimination stage, discussion takes place asynchronously as in a discussion forum. When a consensus has been reached, the moderator can mark potential defects as false positives, thus removing them from the list that will go to the author for rework (potential defects marked as false positives appear strikethrough in Figure 4) [44]. |
| Drf | False positives were issues that were identified in the meeting but that were discovered not to be defects either during the meeting or after. The decision whether a defect was a false positive was done by the code review team [39]. |
| Article | Definitions of False-Positive Defects | Percentages of False-Positive Defects | Definitions of True Defects |
|---|---|---|---|
| [9] | False positives (issues raised as defects that are not actual defects) False positives, the number of invalid defects recorded by the group | 22% | Defects, the total number of distinct, valid defects detected by a group |
| [36] | False positives (issues raised as defects that are not actual defects) | 22% | Actual defects |
| [39] | False positives were issues that were identified in the meeting but that were discovered not to be defects either during the meeting or after | 22% | If the code review team finds an issue and agrees that it is a deviation from quality, the issue is counted as a defect |
| [42] | False positives (no real usability problems) | 43.10% | Real usability problem |
| [43] | False positives (reported defects that were not considered to be actual defects) | - | Actual defects |
| [44] | False positives (non-true defects) False positives (defects erroneously reported as such by inspectors) | 46% | True defects |
| [45] | For which consensus was reached during the meeting in considering them as not true defects, thus as false positives | - | True defects: the number of defects for which consensus was reached during the meeting in considering them as true defects |
| [46] | False positive (any issue which required no action) | 20% | True defect (if the author was required to make an execution affecting change to resolve it), soft maintenance issue (any other issue which the author fixed) |
| [47] | False positives are items reported by subjects as defects, when in fact no defect exists | - | Defects |
| [49] | A false positive is a description which is not a true defect, i.e., does not require rework | - | A true defect is a description of a positively identified defect which requires rework; it causes the program to fail, and violates the given specifications and design |
| [50] | False positives (erroneously identified defects) False positives are the non-true defects—defects that require no repair | 42.62% | True defects |
| [51] | It classifies too many consistent designs as inconsistent (false positives) | - | True positive |
| [52] | False positive (FA)—defects that do not exist but were wrongly identified | - | True defects (TR)—defects that actually exist and have been successfully detected |
| [53] | False defect estimations, known as false positive | - | The number of true defect estimations, known as true positive |
| [54] | False positive rate: the percentage of issues reported by an inspector that turn out not to represent real quality problems in the artifact | 80% | Defect detection rate: the percentage of known defects in a given software artifact that are found during the inspection |
| [55] | False positives (not identified from preparation) | - | True defects Net defects |
| [56] | A false positive—an obviously wrong statement of the document. | - | True defect |
| [57] | False positive—items pointed by the subjects that do not correspond to a defect of the RD RD: the Requirements Document | - | Defects—items that really are defects of the RD RD: the Requirements Document |
| Name | Description | |
|---|---|---|
| Lines of code | New (nLOC) | Lines of code newly developed, excluding headers and comments |
| Changed (cLOC) | Lines of code changed from the code base or reused source code, excluding headers and comments | |
| Reused (rLOC) | Lines of code reused from the code base or another product, excluding headers and comments | |
| Product size (SZ) | Product size for assessing development effort consumption in the project management defined by the standard development process. SZ = nLOC + cLOC + rLOC × coefficient (where the coefficient is determined by the project attributes) | |
| Number of defects and questions in reviewed | True defects (rNOD) | Sum of the number of defects detected in software architecture design, software detailed design, and code reviews |
| Effective questions categorized as false-positive defects (NOQf) | Sum of the number of effective questions subsequently categorized as false-positive defects detected in software architecture design, software detailed design, and code reviews | |
| Number of defects detected in the test (tNOD) | Sum of numbers of defects detected in the unit test, software integration test, and software qualification test | |
| Name | Description | |
|---|---|---|
| Q | Proportion of the number of defects detected in testing to the product size | tNOD/SZ |
| p1 | Proportion of the reused lines of code to the lines of code | rLOC/(nLOC + cLOC + rLOC) |
| p2 | Proportion of the number of true defects to the product size | rNOD/SZ |
| p3 | Proportion of the number of effective questions categorized as false-positive defects to the product size | NOQf/SZ |
| p4 | Proportion of the number of effective questions categorized as false-positive defects to the sum of the number of defects and effective questions categorized as false-positive defects | NOQf/(rNOD + NOQf) |
| SZ | rNOD | NOQf | tNOD | |
|---|---|---|---|---|
| max | 110,5000 | 1871 | 384 | 711 |
| min | 1330 | 32 | 0 | 3 |
| median | 144,390 | 589 | 99 | 171 |
| Q | p1 | p2 | p3 | p4 | |
|---|---|---|---|---|---|
| max | 6.50 | 0.97 | 46.29 | 7.90 | 0.29 |
| min | 0.54 | 0.00 | 0.55 | 0.00 | 0.00 |
| median | 2.61 | 0.75 | 12.03 | 1.42 | 0.17 |
| Estimate (b) | Std. Error | t Value | Pr (>|t|) | VIF | |
|---|---|---|---|---|---|
| p1 | 2.53 | 0.88 | 2.89 | 0.01 | 1.07 |
| p3 | 0.42 | 0.15 | 2.91 | 0.01 | 1.38 |
| p4 | −9.68 | 3.69 | −2.63 | 0.02 | 1.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wakimoto, M.; Morisaki, S. A Metric for Questions and Discussions Identifying Concerns in Software Reviews. Software 2022, 1, 364-380. https://doi.org/10.3390/software1030016
Wakimoto M, Morisaki S. A Metric for Questions and Discussions Identifying Concerns in Software Reviews. Software. 2022; 1(3):364-380. https://doi.org/10.3390/software1030016
Chicago/Turabian StyleWakimoto, Michiyo, and Shuji Morisaki. 2022. "A Metric for Questions and Discussions Identifying Concerns in Software Reviews" Software 1, no. 3: 364-380. https://doi.org/10.3390/software1030016