The morphology of particles can be described by
d-dimensional descriptor vectors
, where
is some integer and the entries of
x either characterize the shape or size of the particles. The entirety of particle descriptor vectors associated with particles of the feed material observed by MLA measurements can be modeled by a number-weighted multidimensional probability density, which will be denoted by
in the following. Analogously, the descriptor vectors for particles in the concentrate can be modeled by a number-weighted multidimensional probability density
. Then, the number-weighted multivariate Tromp function
(also referred to as multivariate separation function) is given by
for each
, where
and
denote the number of particles in the concentrate and the feed, respectively. Note that in the case of 2D-image data it is reasonable to use number-weighted probability densities in order to describe particle systems. However, different measurement techniques obey varying physical principles which may result in differently weighted probability densities. For example, when considering aerodynamic lenses for the separation of airborne particles [
20], particle systems in the separation process are described by mass-weighted probability densities. Thus, Tromp functions are then defined by mass-weighted probability densities [
13,
14].
In the following we show how the value
of the Tromp function given by Equation (
1) can be interpreted as the separation probability of a particle having the descriptor vector
x, to be separated into the concentrate, and we discuss the equivalence of number-weighted and mass-weighted Tromp functions, see
Section 2.4.1. Then, in
Section 2.4.2 we explain how computational issues can be solved in case of computing Tromp functions from image measurements. Moreover, in
Section 2.4.3 we propose a method for computing Tromp functions when only partial information about the fractions in separation processes is available, e.g., when only the feed and a single separated fraction is measured. In
Section 2.4.4, we present a scheme that constrains the set of admissible particle descriptors for which we compute the separation probability.
2.4.1. Interpretation of Multivariate Tromp Functions as Separation Probabilities
To begin with, we provide a reasoning which shows why the value
of the Tromp function given by Equation (
1) can be interpreted as the separation probability of a particle having the descriptor vector
x, to be separated into the concentrate. Let
X be a
d-dimensional random vector, whose probability distribution is given by the density
. Thus,
X can be interpreted as a (random) particle descriptor vector of the “typical particle” in the feed. Note that integration of the density
allows for the computation of probabilities that the random particle descriptor vector
X belongs to some cuboidal sets
, i.e., such probabilities are given by
Normally, the probability density
is determined from measurements, see
Section 2.5.
Furthermore, let
Z be a binary random variable with values in the set
such that the event
corresponds to the case where the typical particle is separated into the concentrate. One method to determine the distribution of
Z is to compute the probability of the event
, which can be done by considering the ratio of the number of particles in the concentrate and feed, respectively, i.e.,
The value of
can be interpreted as the probability that a particle taken at random from the feed is separated into the concentrate. Note that the separation outcome typically depends on particle descriptors (e.g., large particles might have a larger separation probability than smaller particles). Therefore, the (conditional) probability
of the event
can change when conditioning it with respect to some specific deterministic descriptor vector
x. The values
for
can be interpreted as a separation probability function which assigns each particle with a descriptor vector
x its corresponding separation probability. In order to determine
, we make use of the probability density
of descriptor vectors for particles in the concentrate.
More precisely, using the notion of the typical particle
X and the separation outcome
Z, the distribution of descriptor vectors for particles in the concentrate is given by conditioning on the event
, i.e., by
for each cuboidal set
. Since we additionally assumed that the distribution of descriptor vectors associated with the concentrate has the density
, we get that
On the other hand, we can represent such probabilities by
where the first equation is true due to the definition of conditional probabilities and the second equation holds due to the law of total probability. In both Equations (
4) and (
5), the probability
has a representation as an integral on the domain
B, for any cuboidal set
. Consequently, we can assume that the integrands coincide, i.e., we get
Therefore, we immediately get a formula for the separation probability
, i.e., we get
Now, comparing the right-hand side of this equation with the right-hand side of Equation (
1), and taking Equation (
3) into account, we get that
for each
. In other words, the value
of the Tromp function as defined in Equation (
1) can be interpreted as the separation probability.
Note that the computational formula given in Equation (
1) requires number-weighted probability densities
and
. However, some measurement techniques yield so-called mass-weighted probability densities of descriptor vectors. In such a scenario it is a common approach to determine mass-weighted multivariate Tromp functions which are defined by a (scaled) fraction of mass-weighted probability densities. We now show that such mass-weighted Tromp functions approximately coincide with the number-weighted Tromp function given in Equation (
1) and, consequently, can also be interpreted as a separation probability.
Therefore, let
be a function which maps a descriptor vector
x of particles onto their mass
, see e.g., [
21]. Then, the mass-weighted probability densities
of descriptor vectors of particles in the feed and concentrate, respectively, are given by
for each
assuming that
and
are finite positive numbers, respectively. Furthermore, the mass-weighted multivariate Tromp function
of a separation process is given by
for each
, where
is the yield (i.e., the total mass
of particles in the concentrate divided by the total mass
of particles in the feed).
The Tromp functions
T and
given in Equations (
1) and (
7), respectively, take on similar values, i.e., it holds that
for each
. Indeed, inserting the definitions of the mass-weighted probability densities
and
given in Equation (
6) into Equation (
7), we get that
Note that the total mass
of particles in the feed can be approximated by the number of particles
times the expected mass of particles in the feed which is given by
, i.e.,
. Analogously, we get that
. Inserting these expressions for
and
into Equation (
8) we obtain that
for each
.
2.4.2. Reconstructing the Density of Descriptor Vectors for Particles in the Feed
The computation of Tromp functions as quotients of probability densities by means of Equation (
1) or (
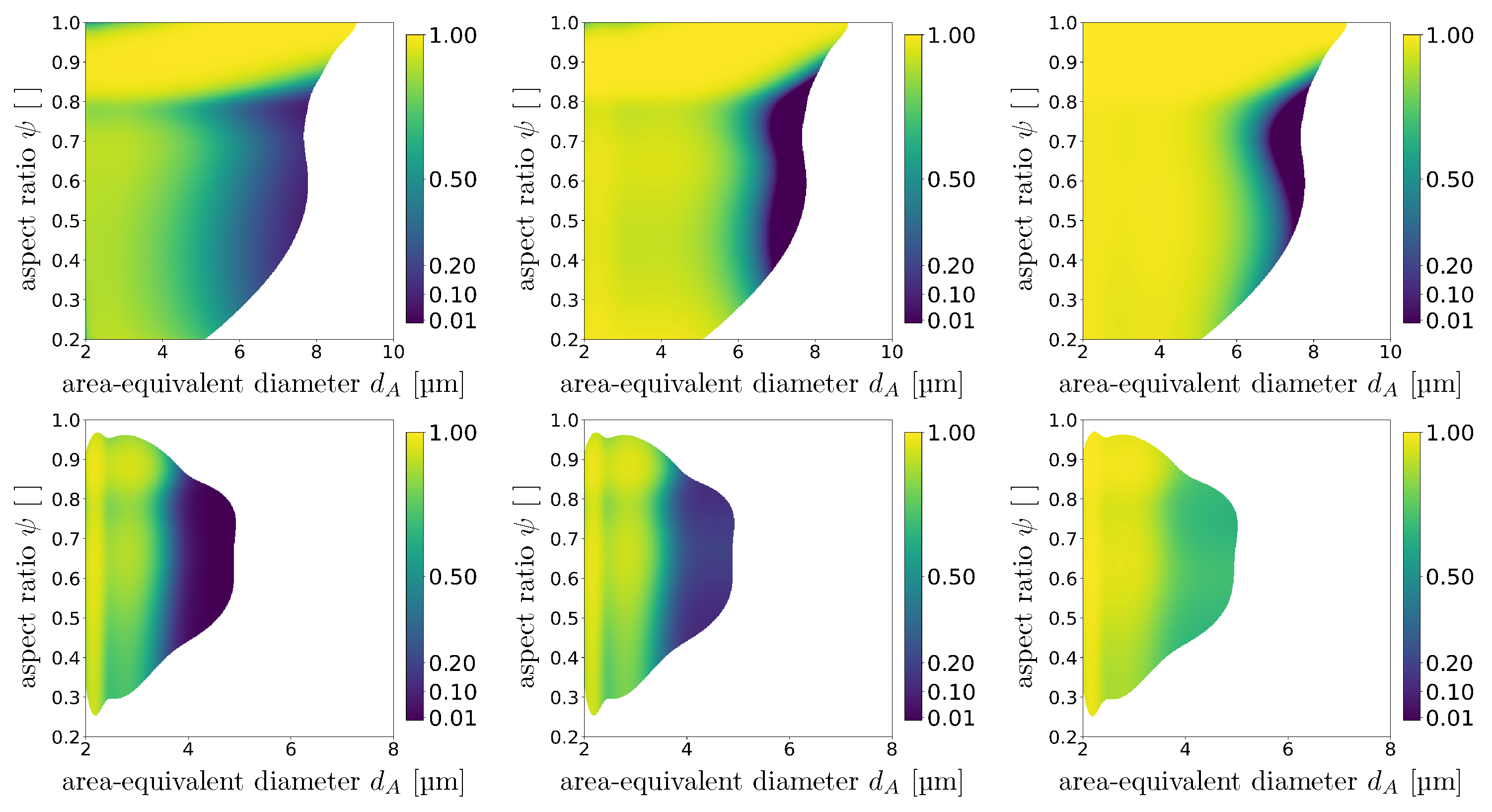
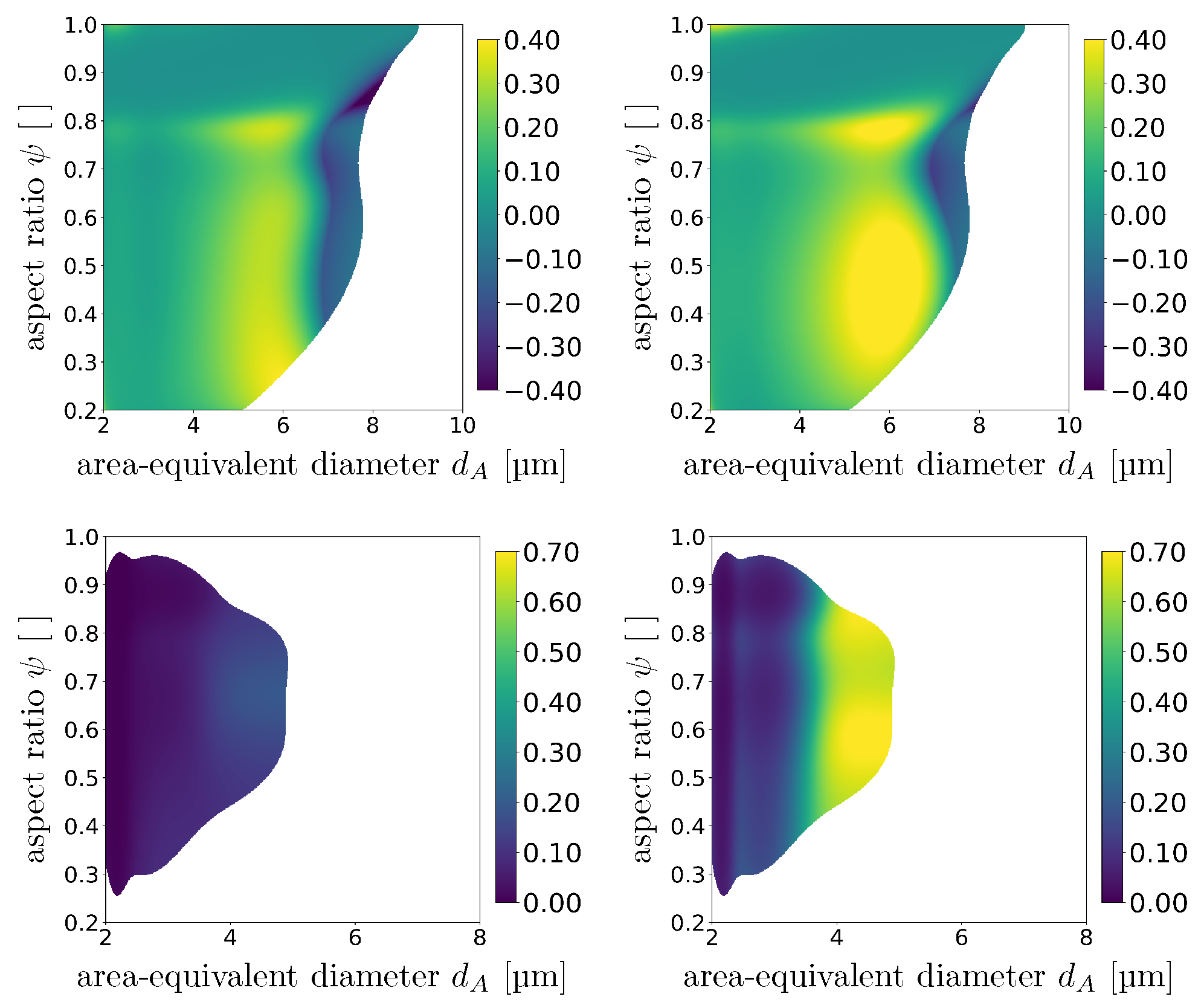
7) is often problematic because we have to ensure that this function only takes values between zero and one. When computing Tromp functions via quotients, numerical instabilities can occur which can cause a Tromp function to take values greater than one. This is due to a Tromp function being rather sensitive to denominator values which are close to zero, e.g., when there are relatively few particles with certain descriptor vectors within the feed, yet such particles can be enriched within the concentrate. In addition, it should be noted that the image measurements of feed, concentrate and tailings are only a statistically representative sample for the corresponding particle systems. More precisely, in theory the union set of particle descriptors corresponding to all particles within the concentrate and tailings should be equal to the set of particle descriptors associated with feed particles. However, in image data solely, small traces of feed/concentrate/tailings particles are observed such that the validity of this equality can be violated.
In order to avoid this issue, it is useful to have in mind that the probability density of descriptor vectors of particles in the feed can be considered to be a convex combination of the probability densities
and
[
15]. Namely, the probability density
can be given by
for all
with some mixing parameter
, which describes the ratio of particles in the concentrate and tailings. In case of number-weighted probability densities, the mixing parameter
is given by
In the case of mass-weighted probability densities, this parameter corresponds to the yield given by the weighting constant in Equation (
7).
Using Equation (
9), the Tromp function given in Equation (
1) can be written as
for all
. The representation of Tromp functions by Equation (
11) has several advantages, because
can then be computed without information regarding particles in the feed. It is enough to obtain image measurements of the concentrate and the tailings. Moreover, using Equation (
11), the Tromp function takes values between zero and one and its computation is numerically stable, in comparison to the computation of Tromp functions by means of Equation (
1). This is due to the replacement of the critical denominator in Equation (
1) by the robust reconstructed probability density
given in Equation (
9).
2.4.3. Computation of Tromp Functions for Partially Available Separated Fractions
Tromp functions can be computed by means of Equation (
11) if image measurements are available for the concentrate and tailings. However, in practice, MLA measurements of concentrate or tailings are often unavailable or incomplete. For example, in the flotation-based separation process described in
Section 2.2 (and analyzed in
Section 3.2), the problem arises that the concentrate consists of several fractions of concentrates. Thus, to compute the Tromp function for the complete concentrate (i.e., the union of all single concentrate fractions), all concentrate fractions must be mixed in the measurement process to obtain a single measured fraction for the concentrate. This would lead to a loss of information regarding the individual concentrate fractions. Alternatively, the probability densities of the descriptor vectors of particles in the complete concentrate could be computed as a convex combination of the probability densities of the descriptor vectors of particles in the individual concentrates. However, this method would be rather time consuming because for an increasing number of output fractions, the effort required for MLA measurements and the estimation procedure of the probability densities of particle descriptors for each individual concentrate increases significantly.
Therefore, we present an approach to compute Tromp functions when no measurements are available for some of the separated fractions by solving a minimization problem. In particular, we consider the case when image measurements are available only for feed and tailings, using the probability densities
and
instead of
and
. To redeem the numerical issues, which can occur when estimating the probability density
from image measurements as described in
Section 2.4.2, we exploit the fact that
can be expressed as a convex combination of
and
, where we replace the (unknown) probability density
of descriptor vectors associated with particles in the complete concentrate by some parametric approximation
. More precisely, we assume that
is a member of a parametric family
of multivariate probability densities, e.g., the density of a multivariate normal distribution or a copula-based distribution model as described in
Section 2.5, where
denotes the set of admissible parameters for some integer
. Then,
can be determined by solving the following minimization problem:
i.e., the function
minimizes the integral on the right-hand side of Equation (
12).
Note that the number-weighted mixing parameter
in Equation (
12) cannot be computed directly if there is no information on the concentrate available. Instead we can determine
by solving the equation
We also remark that in case of using Equation (
12) to obtain an approximation for
and then computing the Tromp function
T utilizing Equation (
11),
T takes values between zero and one by definition.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}