

Acoustic Sensing and Supervised Machine Learning for In Situ Classification of Semi-Autogenous (SAG) Mill Feed Size Fractions Using Different Feature Extraction Techniques
Abstract
:Highlights
- Laboratory SAG mill acoustics are sensitive to different feed size fractions.
- Supervised classification models and acoustic emissions were suitable for predicting different feed size fractions in laboratory SAG mills.
- SAG mill acoustics can serve as online proxy tool for providing more insight into different feed size fractions in the mill.
- The practical implication of the study could be beneficial to SAG mill operators by predicting a sudden change in feed size in real-time.
Abstract

1. Introduction
- (a)
- Which statistical features can best describe acoustic signal variations?
- (b)
- What is the response of varying AG/SAG mill feed size fractions in terms of acoustic emission?
- (c)
- What are the performances of the various extraction techniques used in the study for predicting different feed size distributions inside the laboratory-scale AG/SAG mill?
- (d)
- Which signal extraction technique and classification can best predict different feed size fractions within the mill?
- (e)
- What is the overall practical overview of the study?
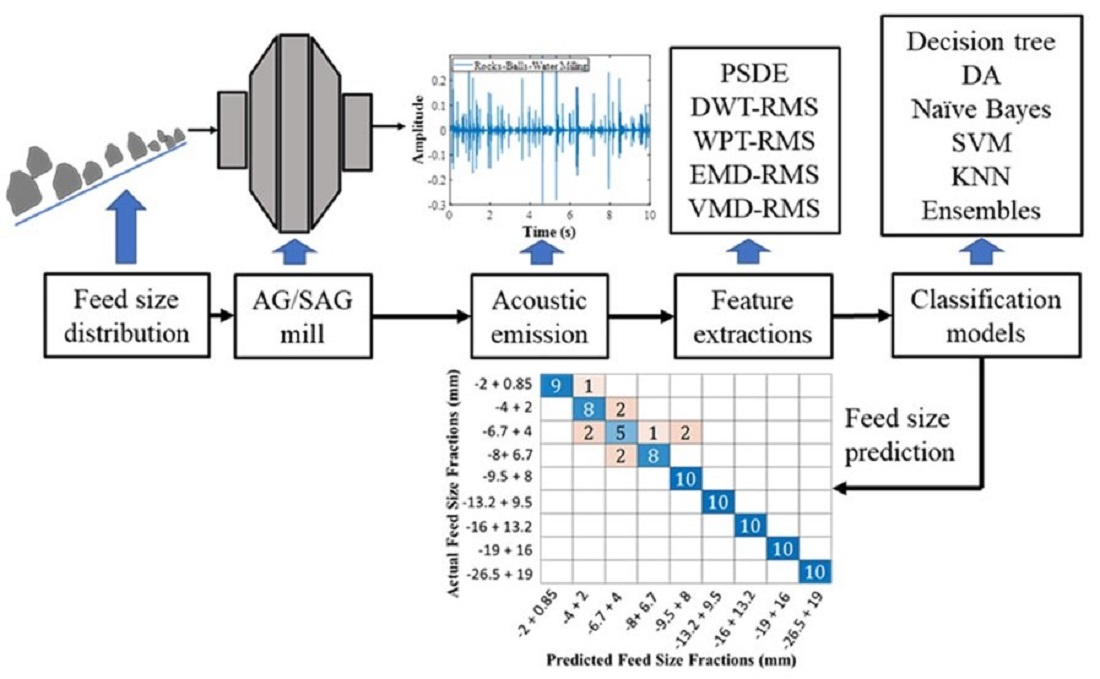
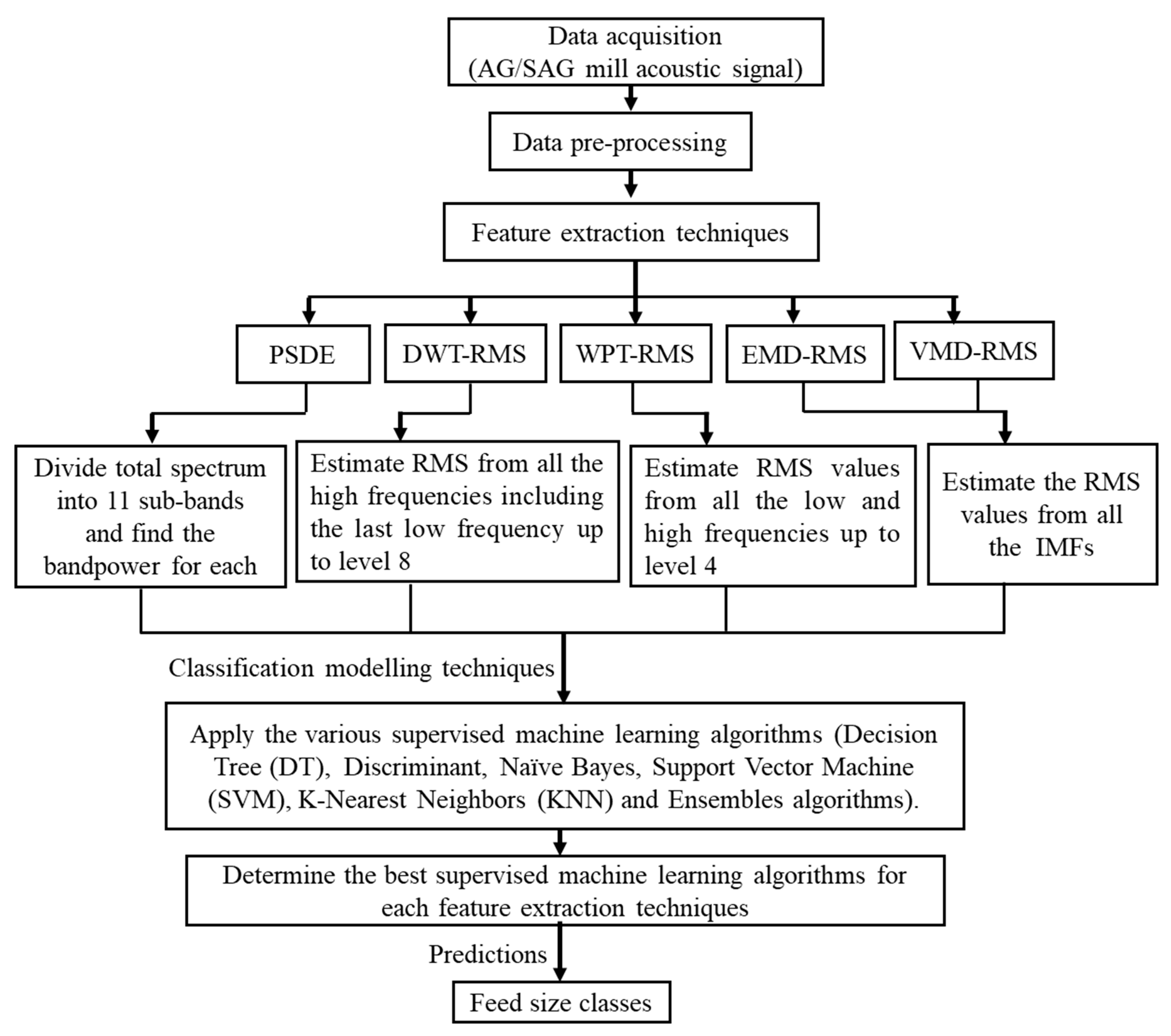
2. Experimental Method
2.1. Feed Size Variations, Grinding Studies, and Acoustic Measurements
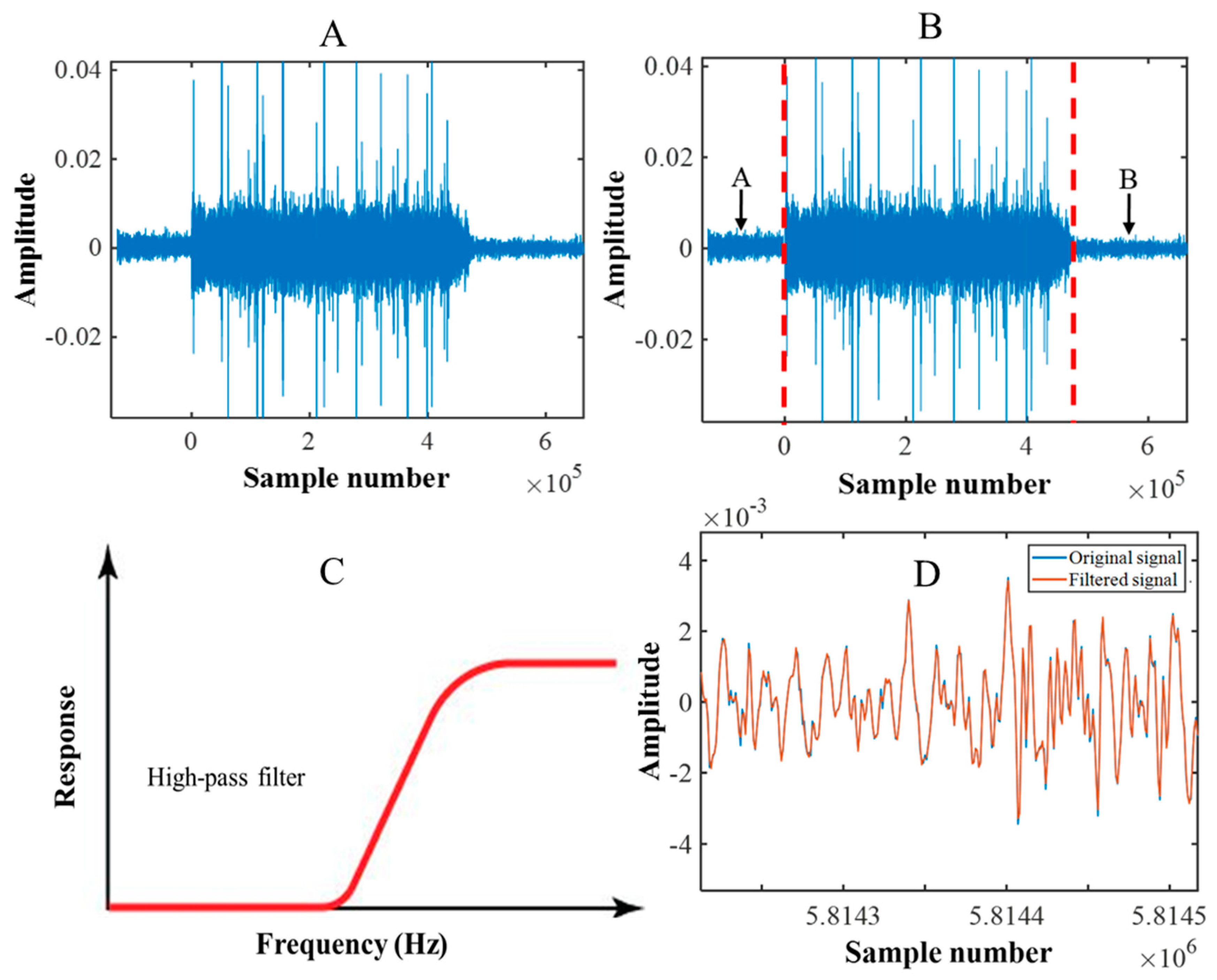
2.2. Acoustic Signal Data Collection and Pre-Processing
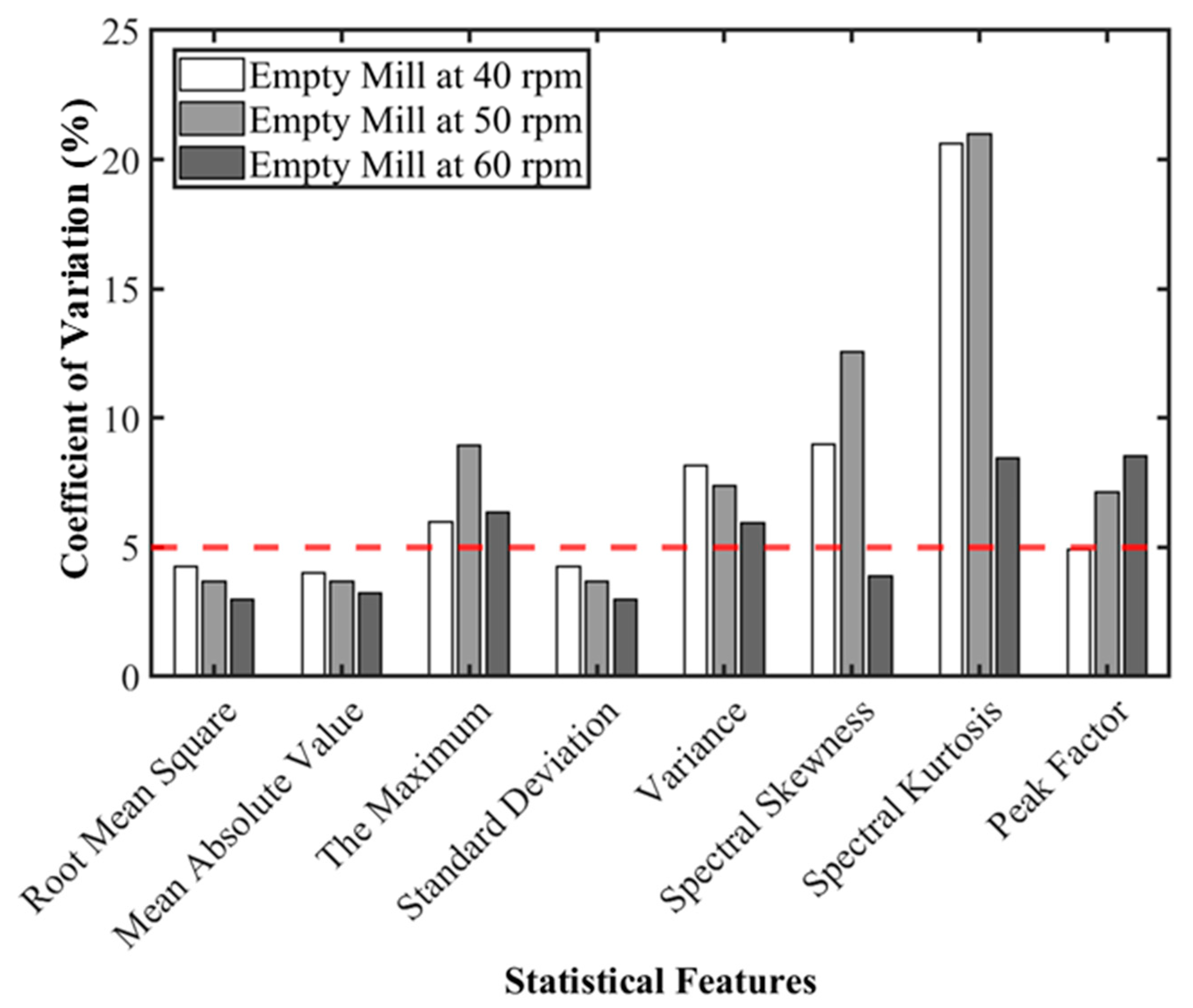
3. Preliminary Statistical Feature Extraction
4. Feature Extraction Techniques for Mill Feed Size Acoustic Estimation
4.1. Power Spectral Density Estimate (PSDE)
4.2. Discrete Wavelet Transform (DWT)
4.3. Wavelet Packet Transform (WPT)
4.4. Empirical Mode Decomposition (EMD)
- Determine all the local minima and maxima (extrema) of the given signal y(t).
- Estimate the lower envelope, emin(t), and upper envelope, emax(t), by interpolation of the extrema.
- The local average or mean, r(t) = [emin(t) + emax(t)]/2 of the envelope as the “low-pass” center, also known as the residual, is computed.
- Extract the first high-frequency component (IMF), as known as the detail component as d(t) = y(t) − r(t).
- Iterate the procedure on the residual r(t) until all the IMFs are acquired.
4.5. Variational Mode Decomposition (VMD)
5. Machine Learning Classification Models’ Intuition
5.1. Decision Tree
5.2. Discriminant Analysis
5.3. Naïve Bayes
5.4. Support Vector Machine
5.5. K-Nearest Neighbours
5.6. Ensembles
6. Methodology: Model Development Using Supervised Machine Learning Algorithms
Classification Model Performance Evaluation Metrics
7. Results and Discussion
7.1. Statistical Feature Selection
7.2. Confusion Matrix for Feed Size Classification
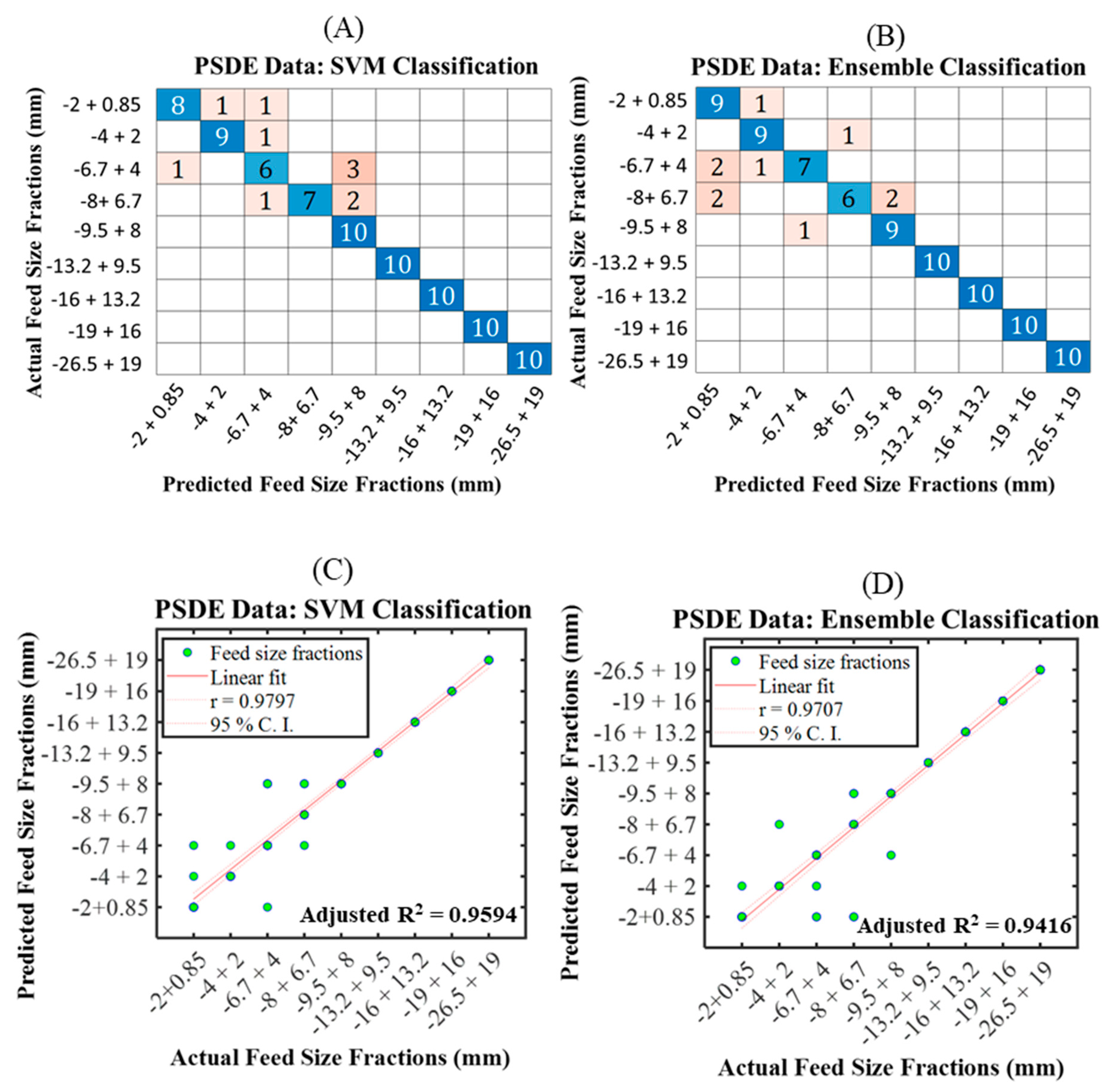
7.2.1. Model 1 with PSDE
7.2.2. Model 2 with DWT–RMS
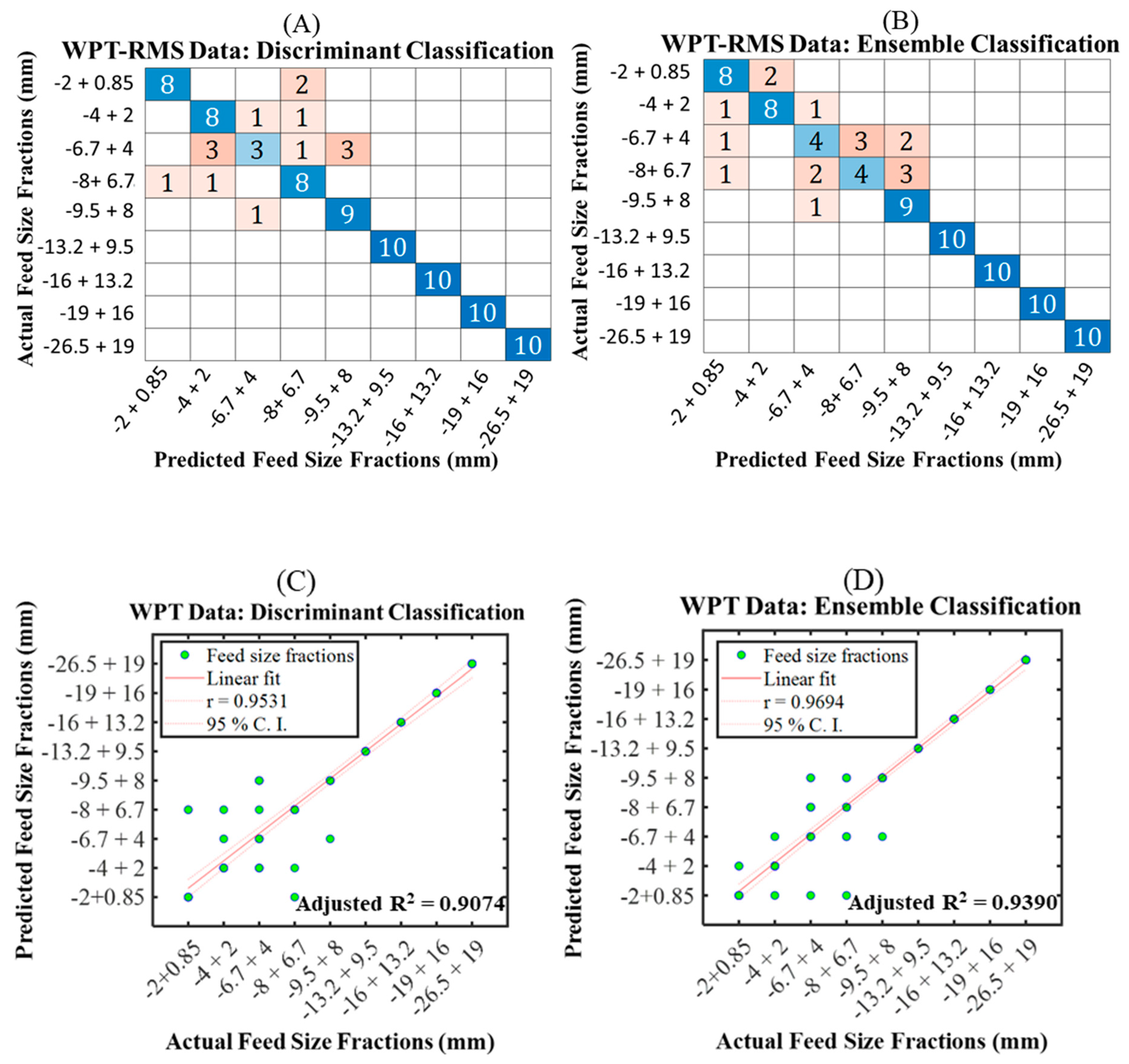
7.2.3. Model 3 with WPT–RMS
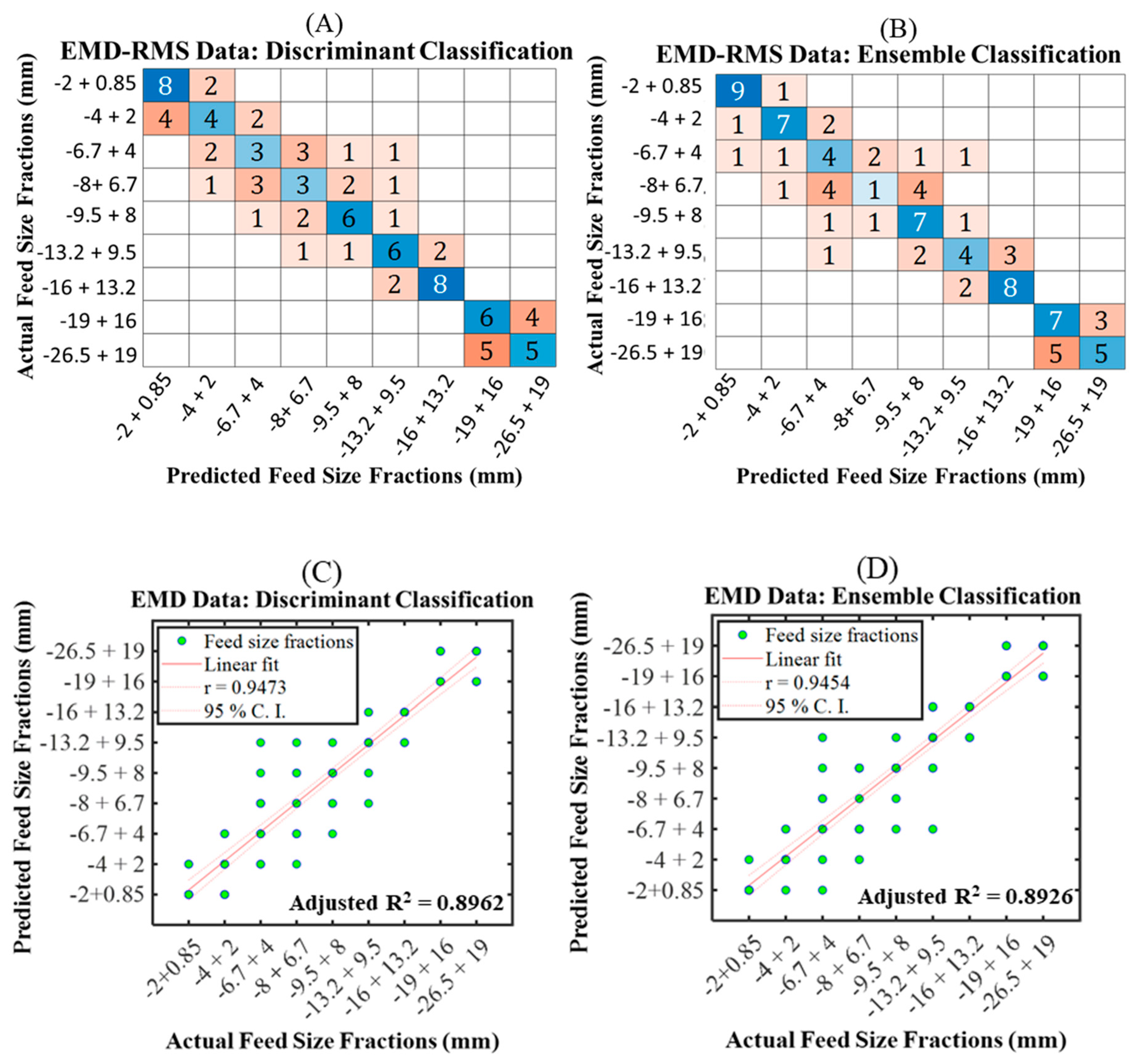
7.2.4. Model 4 with EMD–RMS
7.2.5. Model 5 with VMD–RMS
7.3. Model Evaluation
8. Conclusions
- (a)
- The root mean square (RMS), mean absolute value (MAV), and standard deviation (SD) were identified as the most suitable statistical features for representing the mill acoustic signal with minimal variance.
- (b)
- The mill acoustic emission response is sensitive to different mill feed size fractions, such that an increase in the mill feed size ranges increases the acoustic emission.
- (c)
- All feature extraction techniques (PSDE, DWT, WPT, and VMD), except the EMD, were identified to give improved performance in classifying different feed size distributions inside AG/SAG mill.
- (d)
- The suitable extraction techniques and their respective classification algorithms for improved SAG mill feed size prediction are observed as follows: PSDE–SVM, DWT–LDA, WPT–LDA, EMD-ensemble, and VMD–LDA. The LDA and ensemble classifiers were noted to provide promising algorithms for improving feed size distribution in almost all the signal feature extraction techniques. The data extraction with PSDE combined with SVM classifier demonstrated the best degree of prediction for a sudden change in feed size fraction inside the SAG mill using the performance evaluation metrics such as accuracy, precision, sensitivity, and F1 score.
- (e)
- Mill acoustic emission and supervised machine-learning classification models can be used to provide more insight into the changing feed size distribution of SAG mills. The study’s findings could be beneficial to the comminution circuit by serving as a proxy measure for predicting the sudden feed size fluctuations in real time and assessing the efficiency of upstream processes like crushing and screening. This can result in faster decision-making and more timely intervention by mill operators. Though the current work is constrained to (i) A batch sample rather than continuous feed (blending); and (ii) A small-scale mill rather than an industrial mill, the study provides directions for future applications in large-scale AG/SAG mills.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Morrell, S. The influence of feed size on autogenous and semi-autogenous grinding and the role of blasting in its manipulation. In Proceedings of the XXII International Mineral Processing Congress, Cape Town, South Africa, 29 September–3 October 2003. [Google Scholar]
- Hahne, R.; Pålsson, B.I.; Samskog, P.O. Ore characterisation for—And simulation of—Primary autogenous grinding. Miner. Eng. 2003, 16, 13–19. [Google Scholar] [CrossRef]
- Morrell, S.; Valery, W. Influence of feed size on AG/SAG mill performance. In Proceedings of the SAG2001, Vancouver, BC, Canada, 30 September–3 October 2001; pp. 203–214. [Google Scholar]
- Núñez, F.; Silva, D.; Cipriano, A. Characterization and Modeling of Semi-Autogenous Mill Performance Under Ore Size Distribution Disturbances. IFAC Proc. Vol. 2011, 44, 9941–9946. [Google Scholar] [CrossRef]
- Asamoah, R.K.; Baawuah, E.; Greet, C.; Skinner, W. Characterisation of Metal Debris in Grinding and Flotation Circuits. Miner. Eng. 2021, 171, 107074. [Google Scholar] [CrossRef]
- Joseph-Soly, S.; Asamoah, R.K.; Skinner, W.; Addai-Mensah, J. Superabsorbent dewatering of refractory gold concentrate slurries. Adv. Powder Technol. 2020, 31, 3168–3176. [Google Scholar] [CrossRef]
- Forson, P.; Zanin, M.; Abaka-Wood, G.; Skinner, W.; Asamoah, R.K. Flotation of auriferous arsenopyrite from pyrite using thionocarbamate. Miner. Eng. 2022, 181, 107524. [Google Scholar] [CrossRef]
- Asamoah, R.K.; Skinner, W.; Addai-Mensah, J. Pulp mineralogy and chemistry, leaching and rheological behaviour relationships of refractory gold ore dispersions. Chem. Eng. Res. Des. 2019, 146, 87–103. [Google Scholar] [CrossRef]
- Asamoah, R.K.; Zanin, M.; Skinner, W.; Addai-Mensah, J. Refractory gold ores and concentrates part 2: Gold mineralisation and deportment in flotation concentrates and bio-oxidised products. Miner. Process. Extr. Metall. 2019, 130, 269–282. [Google Scholar] [CrossRef]
- Forson, P.; Zanin, M.; Skinner, W.; Asamoah, R. Differential flotation of pyrite and arsenopyrite: Effect of hydrogen peroxide and collector type. Miner. Eng. 2021, 163, 106808. [Google Scholar] [CrossRef]
- Nayak, D.K.; Das, D.P.; Behera, S.K.; Das, S.P. Monitoring the fill level of a ball mill using vibration sensing and artificial neural network. Neural Comput. Appl. 2020, 32, 1501–1511. [Google Scholar] [CrossRef]
- Behera, B.; Mishra, B.; Murty, C. Experimental analysis of charge dynamics in tumbling mills by vibration signature technique. Miner. Eng. 2007, 20, 84–91. [Google Scholar] [CrossRef]
- Thornton, A.; Pethybridge, T.; Dunn, R.; Rivett, T. SAG Mill Control at Northparkes Mines (Not So Hard after All); MIPAC Report; MIPAC: Albion, QLD, Australia, 2005. [Google Scholar]
- Spencer, S.; Sharp, V.; Campbell, J.J.; Holmes, R.J.; Rowlands, T.; Barker, D.G.; Davey, K.J.; Phillips, P.L. Prediction of AG/SAG mill variables from surface vibrations. In Proceedings of the XXIII International Mineral Processing Congress, Turkish Mining Development Foundation, Istanbul, Turkey, 3–8 September 2006. [Google Scholar]
- Wei, D.; Craig, I.K. Grinding mill circuits—A survey of control and economic concerns. Int. J. Miner. Process. 2009, 90, 56–66. [Google Scholar] [CrossRef]
- Owusu, K.B.; Karageorgos, J.; Greet, C.; Zanin, M.; Skinner, W.; Asamoah, R.K. Predicting mill feed grind characteristics through acoustic measurements. Miner. Eng. 2021, 171, 107099. [Google Scholar] [CrossRef]
- Aldrich, C.; Theron, D.A. Acoustic estimation of the particle size distributions of sulphide ores in a laboratory ball mill. J. S. Afr. Inst. Min. Metall. 2000, 100, 243–248. [Google Scholar]
- Zeng, Y.; Forssberg, E. Effects of operating parameters on vibration signal under laboratory scale ball grinding conditions. Int. J. Miner. Process. 1992, 35, 273–290. [Google Scholar] [CrossRef]
- Zeng, Y.; Forssberg, E. Application of digital signal processing and multivariate data analysis to vibration signals from ball-mill grinding. Trans. Inst. Min. Sect. C-Miner. Process. Extr. Metall. 1993, 102, 39–43. [Google Scholar]
- Zeng, Y.; Forssberg, E. Application of vibration signals to monitoring crushing parameters. Powder Technol. 1993, 76, 247–252. [Google Scholar] [CrossRef]
- Zeng, Y.; Forssberg, E. Monitoring grinding parameters by signal measurements for an industrial ball mill. Int. J. Miner. Process. 1993, 40, 1–16. [Google Scholar] [CrossRef]
- Zeng, Y. Vibration Signal Analysis in Comminution. Ph.D. Thesis, Luleå Tekniska Universitet, Luleå, Sweden, 1994. [Google Scholar]
- Zeng, Y.; Forssberg, K. Vibration signal emission from mono-size particle breakage. Int. J. Miner. Process. 1996, 44–45, 59–69. [Google Scholar] [CrossRef]
- Das, S.P.; Das, D.P.; Behera, S.K.; Mishra, B.K. Interpretation of mill vibration signal via wireless sensing. Miner. Eng. 2011, 24, 245–251. [Google Scholar] [CrossRef]
- Owusu, K.B.; Zanin, M.; Skinner, W.; Asamoah, R.K. AG/SAG mill acoustic emissions characterisation under different operating conditions. Miner. Eng. 2021, 171, 107098. [Google Scholar] [CrossRef]
- Owusu, K.B.; Skinner, W.; Asamoah, R. Feed hardness and acoustic emissions of autogenous/semi-autogenous (AG/SAG) mills. Miner. Eng. 2022, 187, 107781. [Google Scholar] [CrossRef]
- Owusu, K.B.; Skinner, W.; Asamoah, R. Acoustic Sensor Frequencies and Mill Feed Properties—A Brief Review; Engineers Australia: Barton, ACT, Australia, 2021. [Google Scholar]
- Owusu, K.B.; Greet, C.J.; Skinner, W.; Asamoah, R.K. Influence of lifter height on mill acoustics and performance. In Proceedings of the 5th International Future Mining Conference 2021, Online, 6–10 December 2021. [Google Scholar]
- Dhall, D.; Kaur, R.; Juneja, M. Machine Learning: A Review of the Algorithms and Its Applications. In Proceedings of ICRIC 2019; Springer: Cham, Switzerland, 2020; pp. 47–63. [Google Scholar] [CrossRef]
- Meylan, B.; Shevchik, S.A.; Parvaz, D.; Mosaddeghi, A.; Simov, V.; Wasmer, K. Acoustic emission and machine learning for in situ monitoring of a gold–copper ore weakening by electric pulse. J. Clean. Prod. 2021, 280, 124348. [Google Scholar] [CrossRef]
- Al-Zubaidi, S.; Ghani, J.A.; Haron, C.H.C. Application of ANN in Milling Process: A Review. Model. Simul. Eng. 2011, 2011, 696275. [Google Scholar] [CrossRef]
- Amankwaa-Kyeremeh, B.; Zhang, J.; Zanin, M.; Skinner, W.; Asamoah, R.K. Feature selection and Gaussian process prediction of rougher copper recovery. Miner. Eng. 2021, 170, 107041. [Google Scholar] [CrossRef]
- Li, Y.; Bao, J.; Yu, A.; Yang, R. ANN prediction of particle flow characteristics in a drum based on synthetic acoustic signals from DEM simulations. Chem. Eng. Sci. 2021, 246, 117012. [Google Scholar] [CrossRef]
- Zeng, Y.; Forssberg, E. Monitoring grinding parameters by vibration signal measurement—A primary application. Miner. Eng. 1994, 7, 495–501. [Google Scholar] [CrossRef]
- Acharya, D.; Rani, A.; Agarwal, S.; Singh, V. Application of adaptive Savitzky–Golay filter for EEG signal processing. Perspect. Sci. 2016, 8, 677–679. [Google Scholar] [CrossRef] [Green Version]
- Guiñón, J.L.; Ortega, E.; García-Antón, J.; Pérez-Herranz, V. Moving average and Savitzki-Golay smoothing filters using Mathcad. In Proceedings of the International Conference on Engineering Education, ICEE 2007, Coimbra, Portugal, 3–7 September 2007; pp. 1–4. [Google Scholar]
- Liu, Y.; Dang, B.; Li, Y.; Lin, H.; Ma, H. Applications of Savitzky-Golay Filter for Seismic Random Noise Reduction. Acta Geophys. 2016, 64, 101–124. [Google Scholar] [CrossRef] [Green Version]
- Mathew, S.K.; Zhang, Y. Acoustic-Based Engine Fault Diagnosis Using WPT, PCA and Bayesian Optimization. Appl. Sci. 2020, 10, 6890. [Google Scholar] [CrossRef]
- Owusu, K.B.; Karageorgos, J.; Greet, C.; Zanin, M.; Skinner, W.; Asamoah, R.K. Acoustic Monitoring of Mill Pulp Densities. In Proceedings of the 6th UMaT Biennial International Mining and Mineral Conference, Tarkwa, Ghana, 4–7 August 2020. [Google Scholar]
- Rangel-Magdaleno, J.; Peregrina-Barreto, H.; Ramirez-Cortes, J.; Morales-Caporal, R.; Cruz-Vega, I. Vibration Analysis of Partially Damaged Rotor Bar in Induction Motor under Different Load Condition Using DWT. Shock Vib. 2016, 2016, 3530464. [Google Scholar] [CrossRef]
- Ospina, R.; Marmolejo-Ramos, F. Performance of Some Estimators of Relative Variability. Front. Appl. Math. Stat. 2019, 5, 43. [Google Scholar] [CrossRef]
- Same, M.H.; Gandubert, G.; Gleeton, G.; Ivanov, P.; Landry, R., Jr. Simplified Welch Algorithm for Spectrum Monitoring. Appl. Sci. 2021, 11, 86. [Google Scholar] [CrossRef]
- Kılıç, R.; Kumbasar, N.; Oral, E.A.; Ozbek, I.Y. Drone classification using RF signal based spectral features. Eng. Sci. Technol. Int. J. 2021, 28, 101028. [Google Scholar] [CrossRef]
- Solomon, O., Jr. PSD Computations Using Welch’s Method; Power Spectral Density (PSD); Sandia National Lab.: Albuquerque, NM, USA, 1991; p. 23584. [Google Scholar]
- Welch, P.D. The use of fast Fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, M.O.; Reversat, J.H.; Reynoso, L.A. Wavelet Transform Analysis to Applications in Electric Power Systems. In Wavelet Transform and Complexity; InTech Open: London, UK, 2019; pp. 1–17. [Google Scholar] [CrossRef] [Green Version]
- Plaza, E.G.; López, P.N. Analysis of cutting force signals by wavelet packet transform for surface roughness monitoring in CNC turning. Mech. Syst. Signal Process. 2018, 98, 634–651. [Google Scholar] [CrossRef]
- Yen, G.; Lin, K.-C. Wavelet packet feature extraction for vibration monitoring. IEEE Trans. Ind. Electron. 2000, 47, 650–667. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Wang, Y.; Wang, K. Fault diagnosis and prognosis using wavelet packet decomposition, Fourier transform and artificial neural network. J. Intell. Manuf. 2013, 24, 1213–1227. [Google Scholar] [CrossRef]
- Huang, F.; Wu, P.; Ziggah, Y. GPS Monitoring Landslide Deformation Signal Processing using Time-series Model. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 321–332. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Labate, D.; La Foresta, F.; Occhiuto, G.; Morabito, F.C.; Lay-Ekuakille, A.; Vergallo, P. Empirical mode decomposition vs. wavelet decomposition for the extraction of respiratory signal from single-channel ECG: A comparison. IEEE Sens. J. 2013, 13, 2666–2674. [Google Scholar] [CrossRef]
- Huang, Q.; Liu, X.; Li, Q.; Zhou, Y.; Yang, T.; Ran, M. A parameter-optimized variational mode decomposition method using salp swarm algorithm and its application to acoustic-based detection for internal defects of arc magnets. AIP Adv. 2021, 11, 065216. [Google Scholar] [CrossRef]
- Vanitha, V.; Sophia, J.G.; Resmi, R.; Raphel, D. Artificial intelligence-based wind forecasting using variational mode decomposition. Comput. Intel. 2020, 37, 1034–1046. [Google Scholar]
- Soofi, A.A.; Awan, A. Classification Techniques in Machine Learning: Applications and Issues. J. Basic Appl. Sci. 2017, 13, 459–465. [Google Scholar] [CrossRef]
- Tewari, K.; Vandita, S.; Jain, S. Predictive Analysis of Absenteeism in MNCS Using Machine Learning Algorithm. In Proceedings of ICRIC 2019; Springer: Cham, Switzerland, 2020; pp. 3–14. [Google Scholar] [CrossRef]
- Singh, P.; Chahal, D.; Kharb, L. Predictive Strength of Selected Classification Algorithms for Diagnosis of Liver Disease. In Proceedings of ICRIC 2019; Springer: Cham, Switzerland, 2020; pp. 239–255. [Google Scholar] [CrossRef]
- Paul, Y.; Kumar, N. A Comparative Study of Famous Classification Techniques and Data Mining Tools. In Proceedings of ICRIC 2019; Springer: Cham, Switzerland, 2020; pp. 627–644. [Google Scholar] [CrossRef]
- Zhu, G.; Blumberg, D.G. Classification using ASTER data and SVM algorithms;: The case study of Beer Sheva, Israel. Remote Sens. Environ. 2002, 80, 233–240. [Google Scholar] [CrossRef]
- Sahu, S.K.; Mohapatra, D.P. A Review on Scalable Learning Approaches on Intrusion Detection Dataset. In Proceedings of ICRIC 2019; Springer: Cham, Switzerland, 2020; pp. 699–714. [Google Scholar]
- Han, S.; Li, M.; Ren, Q. Discriminating among tectonic settings of spinel based on multiple machine learning algorithms. Big Earth Data 2019, 3, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Fatourechi, M.; Ward, R.K.; Mason, S.G.; Huggins, J.; Schlögl, A.; Birch, G.E. Comparison of Evaluation Metrics in Classification Applications with Imbalanced Datasets. In Proceedings of the 2008 Seventh International Conference On Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008. [Google Scholar] [CrossRef]
- Patro, V.M.; Patra, M.R. Augmenting Weighted Average with Confusion Matrix to Enhance Classification Accuracy. Trans. Mach. Learn. Artif. Intell. 2014, 2, 77–91. [Google Scholar] [CrossRef] [Green Version]
- Deniz, V. A study on the effect of ball diameter on breakage properties of clinker and limestone. Indian J. Chem. Technol. 2021, 19, 180–184. [Google Scholar]
- Nava, J.V.; Llorens, T.; Menéndez-Aguado, J.M. Kinetics of Dry-Batch Grinding in a Laboratory-Scale Ball Mill of Sn–Ta–Nb Minerals from the Penouta Mine (Spain). Metals 2020, 10, 1687. [Google Scholar] [CrossRef]
- Starkey, J.H.; Hindstrom, S.; Orser, T. Choosing a SAG mill to achieve design performance. In Proceedings of the CMP Conference, Ottawa, ON, Canada, 17–19 January 2023. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Feed Size Fractions (mm) |
|---|---|
| 1 | −2 + 0.85 |
| 2 | −4 + 2 |
| 3 | −6.7 + 4 |
| 4 | −8 + 6.7 |
| 5 | −9.5 + 8 |
| 6 | −13.2 + 9.5 |
| 7 | −16 + 13.2 |
| 8 | −19 + 16 |
| 9 | −26.5 + 19 |
| Statistical Features | Equations | Number |
|---|---|---|
| Root mean square (RMS) | (1) | |
| Mean absolute value (MAV) | (2) | |
| Maximum (Max) | The maximum peak or value of a given acoustic signal | - |
| Standard deviation (SD) | (3) | |
| Variance (Var) | (4) | |
| Skewness (SS) | (5) | |
| Kurtosis (SKur) | (6) | |
| Peak factor (PF) | (7) |
| Feature Extraction Techniques | Suitable Classification Models | Model Performance Indicators | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Sensitivity/Recall | F1 Score | ||
| PSDE | SVM (Quadratic) | 88.89 | 90.25 | 88.89 | 89.56 |
| Ensemble (subspace discriminant) | 88.89 | 89.56 | 88.89 | 89.23 | |
| DWT-RMS | LDA | 88.89 | 88.95 | 88.89 | 88.92 |
| Ensemble (subspace discriminant) | 85.56 | 85.46 | 85.56 | 85.51 | |
| WPT-RMS | LDA | 84.44 | 84.14 | 84.44 | 84.29 |
| Ensemble (subspace discriminant) | 81.11 | 80.46 | 81.11 | 80.79 | |
| EMD-RMS | LDA | 54.44 | 53.60 | 54.44 | 54.02 |
| Ensemble (subspace discriminant) | 57.78 | 55.97 | 57.78 | 56.86 | |
| VMD-RMS | LDA | 83.33 | 84.21 | 83.33 | 83.77 |
| Ensemble (subspace discriminant) | 83.33 | 83.74 | 83.33 | 83.54 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Owusu, K.B.; Skinner, W.; Asamoah, R.K. Acoustic Sensing and Supervised Machine Learning for In Situ Classification of Semi-Autogenous (SAG) Mill Feed Size Fractions Using Different Feature Extraction Techniques. Powders 2023, 2, 299-322. https://doi.org/10.3390/powders2020018
Owusu KB, Skinner W, Asamoah RK. Acoustic Sensing and Supervised Machine Learning for In Situ Classification of Semi-Autogenous (SAG) Mill Feed Size Fractions Using Different Feature Extraction Techniques. Powders. 2023; 2(2):299-322. https://doi.org/10.3390/powders2020018
Chicago/Turabian StyleOwusu, Kwaku Boateng, William Skinner, and Richmond K. Asamoah. 2023. "Acoustic Sensing and Supervised Machine Learning for In Situ Classification of Semi-Autogenous (SAG) Mill Feed Size Fractions Using Different Feature Extraction Techniques" Powders 2, no. 2: 299-322. https://doi.org/10.3390/powders2020018