
A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method

South Huaxi Avenue, School of Mathematics and Statistics, Guizhou University, No. 2708, Guiyang 550025, China
*
Author to whom correspondence should be addressed.
AppliedMath 2023, 3(1), 98-116; https://doi.org/10.3390/appliedmath3010008
Submission received: 10 January 2023
/
Revised: 1 February 2023
/
Accepted: 2 February 2023
/
Published: 13 February 2023
Abstract
:A multilevel Monte Carlo (MLMC) method is applied to simulate a stochastic optimal problem based on the gradient projection method. In the numerical simulation of the stochastic optimal control problem, the approximation of expected value is involved, and the MLMC method is used to address it. The computational cost of the MLMC method and the convergence analysis of the MLMC gradient projection algorithm are presented. Two numerical examples are carried out to verify the effectiveness of our method.
1. Introduction
The stochastic optimal control problem has been widely used in engineering, finance and economics. Many scholars have studied the stochastic optimal control problem for different controlled systems. Because it is difficult to find analytical solutions for these problems, the application of numerical approximation is a good choice. As with numerical methods for determining optimal control problems (see, e.g., [1,2,3,4,5,6]), numerical methods for stochastic optimal control problems have also been extensively studied. For optimal control problems governed by PDE with a random coefficient, the authors of [7,8,9] studied numerical approximations using different methods for different problems. For SDE optimal control problems, the stochastic maximum principle in [10,11], Bellman dynamic programming principle in [12] and Martingale method in [13] have been used to study numerical approximation in recent years.
The gradient projection method is a common numerical optimization method. In [14,15,16,17], the gradient projection method is used. For the numerical simulation of stochastic optimal control problems, whether gradient projection or other optimization methods are used, the approximation of expected value is always involved. For a class stochastic optimal control problem, the authors of [16] combined the gradient projection method with conditional expectation (which was used to solve forward and backward stochastic differential equations) to solve the stochastic optimal control problem. This method is difficult because it involves conditional expectation and numerical methods of solving forward and backward stochastic differential equations. In [15], the expectation was calculated using the Monte Carlo (MC) method, which is easy to understand and implement. However, the convergence speed of the MC method is slow. If we want it to produce a relatively small allowable error, we need to use a large sample. The MLMC method is a commonly used method of improving the slow convergence rate. For the MLMC method and its application, we can refer to the literature [7,18,19,20,21,22,23,24]. It is worth mentioning that in reference [18], an MLMC method is proposed for the robust optimization of PDEs with random coefficients. The MLMC method can effectively overcome adverse effects when the iterative solution is near the exact solution. However, the proof of the convergence for the gradient algorithm is not given.
In this work, we apply the gradient projection method with the MLMC method to solve a stochastic optimal control problem. An expected value is needed to compute in the simulation of the stochastic optimal control problem. To reduce the influence of statistical and discrete errors brought about by the calculation of the gradient, we use the MLMC method to estimate the gradient in each iteration. In the process of iteration, the mean square error (MSE) is dynamically updated. We prove the convergence of the gradient projection method combined with MLMC, and also extend the theory of MLMC which is suitable for our stochastic optimal control problem.
The rest of this paper is organized as follows. We describe the stochastic optimal control problem in Section 2. In Section 3, we review the gradient projection method and MLMC theory. In Section 4, we expand the existing MLMC theory and apply it to the gradient projection method for the stochastic optimal problem. The convergence analysis is also presented in this section. Some numerical experiments are carried out to verify the validity of our method in Section 5. Main contributions and future work are presented in Section 6.
2. Stochastic Optimal Control Problem
Let be a complete probability space and be a real-valued square-integrable -adapted process space such that where is a natural filtration generated by a one-dimensional standard Brownian motion , and
The objective function of the optimal control problem that we consider is
where are first-order continuous derivative functions. is a deterministic control. is a closed convex control set in the control space . stands for expectation, which is defined by . The stochastic process is generated by the following stochastic differential equation:
Assume that f is a continuous differentiable function with respect to ; and g is a continuous differentiable function with respect to . Under these continuous differentiable assumptions, we can find that for the problem (3) there exists a unique solution with (this can be seen in [25]). Here, is a function of . For the optimal control problem (2)–(3) there exists a unique solution. Let be the optimal solution.
In the following, C denotes different positive constants at different occurrences, and is independent of discrete parameters, sample parameters and iteration times.
3. Review of Gradient Projection Method and MLMC Method
The gradient projection method is a common numerical method for optimization problems. The gradient projection method for stochastic optimal control problems usually contains expectation, and MLMC is an important method for calculating expectations. This section introduces the gradient projection and MLMC methods.
3.1. Gradient Projection Method
Let , where is the solution of (3). We assume that is a convex function, is a Hilbert space and K is a closed convex subset of U. Let be a symmetric and positive definite bilinear form and define by . Combining the first order optimization condition with the projection operator , we can obtain (see [15,16])
where is the Gâteaux derivative of , is a positive constant.
We introduce a uniform partition for time intervals: Let . The piecewise constant space is denoted by
where is the characteristic function of . can be approximated by:
where . Based on the analysis of (4)–(6), we can get an iterative scheme for the numerical approximation of (2)–(3) as below:
where is the iterative step size, and is the numerical approximation of . The error between and is represented by the following formula:
Lemma 1.
Assume that is Lipschitz continuous and uniformly monotone in the neighborhood of and , i.e., there exist positive constants c and C such that
Suppose that
and can be chosen such that for some constant . Then the iteration scheme (7) is convergent, i.e.,
In the iterative scheme (7), the gradient of the objective function (2) needs to be calculated. Using the stochastic maximum principle, the gradient is solved more conveniently by introducing an adjoint equation:
The detail deduction can be seen in [26,27]. Thus the derivative of can be denoted by
According to the Riesz representation theorem, we can get
3.2. MLMC Method
In [19,20,21], the quantities of interest in the MLMC method are scalar value. The authors of [18,21]) make an extension of the MLMC theory to fit function value. In the gradient projection algorithm, the quantities of interest are unknown functions. In this section, we will first briefly review the theoretical knowledge of MLMC. Then, we discuss in detail how to estimate the expectation for the gradient projection method.
3.2.1. Scalar-Valued Quantities of Output
The quantity we are interested in is . Generally, the exact sample of A is not known. We can only get an approximate sample . It is assumed that A has an order weak convergence property, i.e.,
and the computational cost satisfies
where is a positive constant. Usually, depend on the algorithm itself.
For the MLMC method (see, e.g., [19,21]), we consider the multiple approximations , ⋯, of A, where () represents time step size at the lth level. Here, is a positive integer (in the later numerical experiments, ). The expectation of can be defined by
where . For each , we apply the standard MC method to estimate. If the sample number is , we can obtain
In order to maintain a high correlation between samples under fine and coarse meshes, we must produce samples in the same Brownian motion path. Combining (19) and (20), we can get the multilevel estimation Because the expectation operator is linear, and each expectation is estimated independently, we have
Moreover, Y is known as an approximation of , and its mean square error (MSE) can be described as:
where the first term is the statistical error and the second term is the algorithm error. To make the MSE less than , we may let both terms be less than . Denote the cost of taking a sample of by , and the sample size by . The total cost can be represented as
How should we choose such that the multilevel estimated variance is less than ? In [21], we find that the optimal sample number can be selected as
Here the symbol indicates rounding up.
The complexity theorem for the MLMC is given in [19,20,21] when the quantities of interest are scalar. Usually, l can not be taken from 0, because when the grid is too coarse, the correlation of equation (SDE, SPDE) is lost. Especially when the quantity is a function, an interpolation operator is needed. If the grid is too coarse, interpolation can cause large errors.
3.2.2. Function Valued Quantities of Output
When the interest quantity is a function in Equation (16), a natural problem is how to apply classical MLMC theory.
When the samples are a vector or matrix, the discrete time step size of each level is different. and are not compatible. Thus they cannot be subtracted directly. The most natural idea is processed by interpolation and compression. Reference [28] introduced an abstract operator for one-dimensional cases. If , the operator is a bounded linear prolongation operator. If , the operator is a bounded linear compression operator. If , it is an identity operator. We also require . In real applications, is often a linear interpolation operator. However, in order to be consistent with the previous control space (5), we define . Redefine
and
where , . The MLMC theory of extending to vectors or functions can be found in [18,21]. The MSE of each A is less than , i.e.,
The optimal sample number is determined by the maximum variance. Thus, the optimal sample number can be revised as follows:
Next we consider the termination condition of the MLMC method, when the bias term is less than (see, e.g., [20]). if and only if and . Choosing , we may assume that
where is a bounded linear prolongation operator, such as linear interpolation. Using the inverse triangle inequality, we can obtain
From (30)–(31), we can derive
Furthermore, we get
Combining Equation (32) with (33), we can derive the following error estimate,
To ensure that the bias term can be less than , we use the following formula:
Based on the above analysis, the complexity theorem of MLMC is given below.
Theorem 1.
Suppose that there are positive constants , , and
Then, there exists a positive integer L and a sequence such that, for any
and the cost
The proof of Theorem 1 is similar to that of Theorem 3.1 in [20]. The norm can be replaced by , .
Next, we introduce a combination of the MLMC method with the gradient projection method.
4. MLMC Method Based on Gradient Projection
For the expectation form in formula (16), a more general expectation estimation form may occur in the numerical approximation of stochastic optimal control problems. We consider the expectation formula
where y, p are the solutions of the state equation and the adjoint equation, respectively. We assume that f, g have continuous derivatives. The numerical approximation is denoted by . Before the theoretical analysis, we first make the following assumptions:
Hypothesis 1 (H1).
Assume that the error estimate of state y is as
Hypothesis 2 (H2).
Assume that the error estimate of the adjoint state p is as
Hypothesis 3 (H3).
where the first and second terms are costs in sampling y, p, respectively.Assume that the cost of calculating approximate sample A is as
4.1. Classic Monte Carlo Method
Let . is estimated by the average value of the sample, i.e.,
where . For a fixed M, we have . Because the exact sample is taken here, there is only statistical error (see, e.g., [7,22]). The statistical error can be given by the following lemma.
Lemma 2.
Assume that . Then, for any , we have
The approximation of can be defined by
where , is independent and identically distributed. From the formula (45), we can obviously find that there are two sources of error: one is statistical error, and the other is discrete error. The detailed error estimate is described as follows.
Theorem 2.
Let assumptions H1–H2 hold and f, g be Lipschitz continuous. Then we have
where .
Proof.
From Theorem 2, we can find that the numbers of statistical samples are affected by the step size. Based on this, the complexity theorem of MC is given below:
Theorem 3.
Let assumptions H1–H3 hold, and f, g be Lipschitz continuous. Then, the MC sample number M can be derived as
the error bound yields
and the total cost satisfies
4.2. Multilevel Monte Carlo Method
According to Equations (26) and (27), a multilevel estimator is established for A in the following theorem.
Theorem 4.
Proof.
Using the triangle inequality, we get
where
Now, the aim is to estimate the terms and . For , employing Theorem 2, we can obtain
For the term , using the triangle inequality, Lemma 2, Cauchy–Schwarz inequality and Lipschitz continuity, we get
where is used in the above derivation. Hence, substituting estimates of , into equation (53), we derive
which is the desired result. □
The formula (52) shows that is selected by balancing discrete and statistical errors. We choose sample number such that
and the total cost is as little as possible. According to [7], this is a convex optimization minimization problem. Therefore, there exists an optimal sample number at each level. Thus, we introduce a Lagrange function as
Letting the derivative of with respect to be zero, we can derive
Based on the above analysis, the complexity theorem of the MLMC method based on gradient projection is given as follows.
Theorem 5.
Let assumptions H1–H3 hold, and f, g be Lipschitz continuous. Then, the MLMC estimator (27) can be obtained by the following choice of ,
where
Then the error bound is yielded as
And the total computational cost is asymptotically bounded by
4.3. Gradient Projection Based on Optimization
Following the analysis of the former parts, the numerical iterative algorithm for the optimal control problem (2)–(3) is given in [15].
From Lemma 1, Corollary 3.2 of [16], we know that their algorithm is convergent. The error of the scheme in [15] has two main sources. One is the error caused by estimating the expected ; the other is caused by the Euler scheme, which cannot be ignored. The error of the estimation for expectation has little effect on the step size at the initial iteration step. When is small, the estimated error from expectations may completely distort the gradient direction. This causes the algorithm to be unable to converge, i.e., the iterative error does not subsequently decrease.
To make the gradient valid, it is necessary that the MSE satisfies , where ( is determined by the optimal control problem). To reduce the influence of statistical error, discrete error and unnecessary computation cost, we use MLMC to estimate expectation.
4.4. MLMC Gradient Projection Algorithm
For the algorithm presented in [15], the MSE cannot decrease for a fixed time step size, no matter how much the number of samples is increased, because it is a biased estimate. Therefore, in an efficient algorithm, the time step size will not be fixed. Here we apply the MLMC method to estimate the gradient, which can ensure that the MSE of each iteration is within an allowable range. The detail step is presented in Algorithm 1. Norm is induced by the inner product . is the MLMC approximation of (16). The definition of Y can be seen in (27). Here, is involved in (28), Theorems 4 and 5.
| Algorithm 1: MLMC gradient projection based optimization |
1: input , , , , 2: for i = 1, do 3: estimate 4: estimate 5: if then 6: return 7: end if 8: if or then 9: or 10: else 11: 12: end if 13: end for |
Line 1: is the iterative permissible error; is the given initial MSE; is the max iterative steps; is the initial control function; is a given parameter.
Line 3: We use the MLMC method to estimate gradient according to MSE .
Line 4: We use the gradient projection formula (7) to update the control function. To determine the new optimal iterative step size , we need to calculate the objective function. After a small number of iterations, the change of the objective function value is small, which makes the MSE very small and the computation cost of MLMC very large, especially through the Armijio search method. So for the iterative step size here we simply use , where d is a positive constant.
Lines 8–12 determine the MSE of the next iteration, ensure that the MSE of the MLMC estimation gradient will not affect the iterative error of each iteration, and also ensure that the MSE cannot be less than the iterative error of each iteration. This avoids the waste of unnecessary samples; especially when the iteration is close to termination, a very small error change will lead to a large sample number difference.
Noting that the sample number and max level are related to , and
from Algorithm 1, we can see
hold.
4.5. Convergence Analysis of the Algorithm
First of all, we consider the accuracy of applying MLMC to estimate a gradient. For the accuracy of the gradient estimate, Theorem 6.1 of [18] is discussed in detail. The gradient estimated by MLMC is the exact gradient of a discrete objective function. When the objective function is convex, the MLMC estimation remains convex.
Algorithm 1 eliminates the impact of from discrete and statistical errors as far as possible. According to formula (16), line 3 and line 9 in Algorithm 1, we have
where is the MLMC estimate of the .
From Lemma 1, Corollary 3.2 of [16] and Theorem 1 of [15], we know that Algorithm 1 is convergent and that the final iterative error is not affected by discrete or statistical errors. We have the following convergence theorem as :
Theorem 6.
Suppose all the conditions of Lemma 1 hold,
and satisfies , where . Then, Algorithm 1 based on multilevel estimation is convergent, i.e.,
Proof.
Triangle inequality implies
where the definition of can be seen (6). Let , , . Then, for the second term of the right hand side (RHS) of (75), we have
For the first term of the RHS of (76), we can get
The second term of the RHS of (77) can be written as
Using (11), (72) and Cauchy–Schwartz inequality, we can obtain for the second term of the RHS of (78)
Substituting (77)–(79) into (76), we have
Triangle inequality and (80) imply
Choosing appropriate , we can get
Combining (75) with (76) and (82), we have
It is known from Theorem 3.1 of [16] that
When , according to the assumption and (71), we have . The fact that is dense in K () implies that and . This completes the proof. □
5. Numerical Experiments
In this section, two numerical examples are presented. The effectiveness of Algorithm 1 is analyzed numerically.
5.1. Example 1
This example comes from the literature [16]. It is as follows:
The optimal control problem is equivalent to
The exact solution of the optimal control problem is
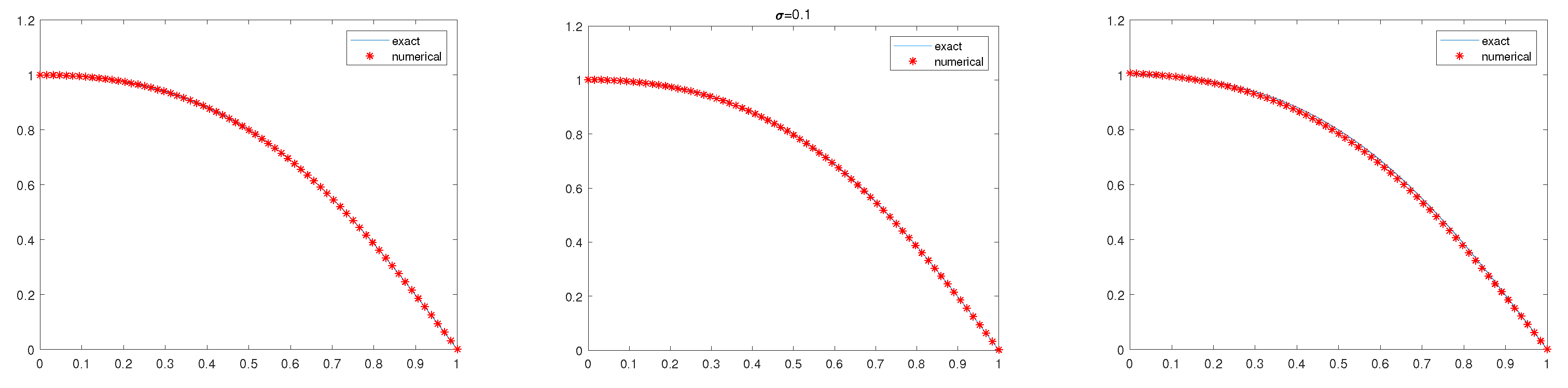
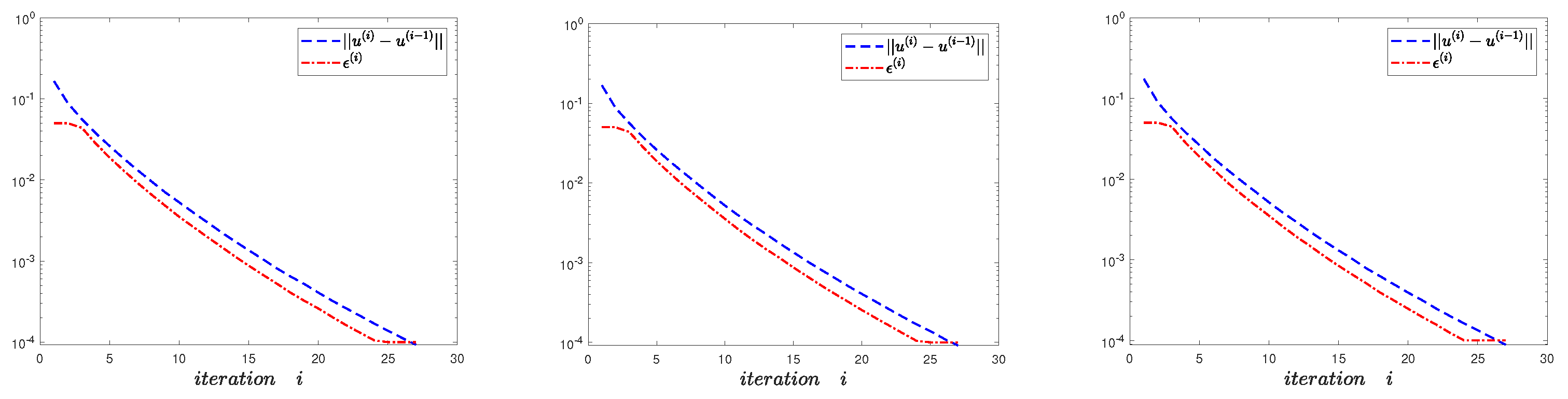
The parameters are chosen as , , , , , , . Firstly, the parameters need to be simulated when MLMC is used to estimate the gradient. Because the Euler algorithm is used for numerically simulating adjoint equation and state equation, the relevant parameters have been determined theoretically (the details are referred to in [20,29,30]). Therefore, , , . The experimental results are shown in Figure 1, Figure 2 and Figure 3 with . The final error values are , , , respectively.
Partial information about the computation process when is listed in Table 1. In the table, is the number of samples, k means time step . The total time of iteration is s for .
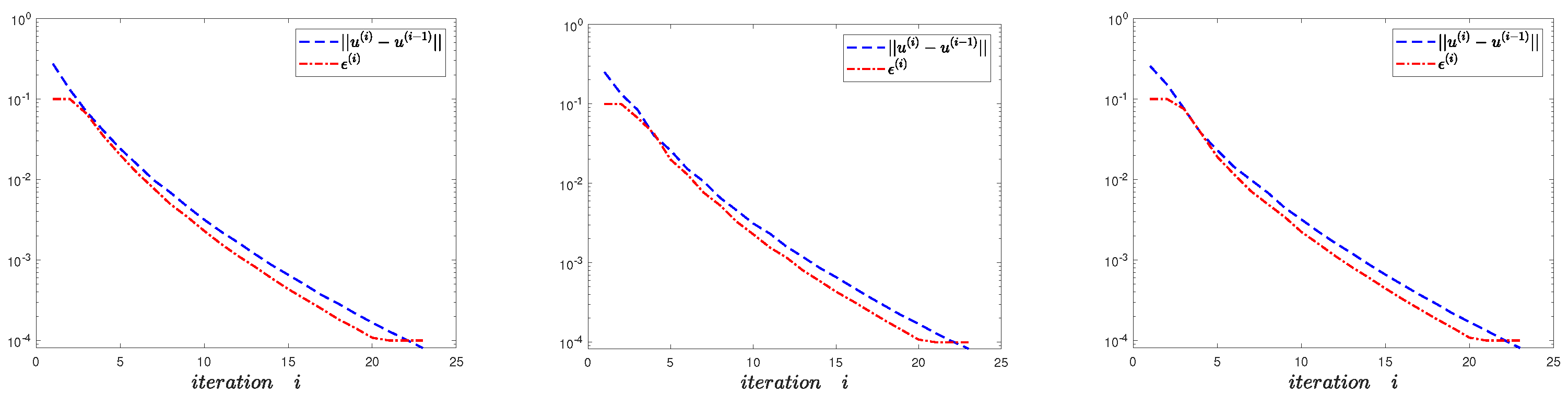
From Figure 1, Figure 2 and Figure 3 and Table 1, it can be seen that , Algorithm 1 is convergent, and the MLMC method is efficient.
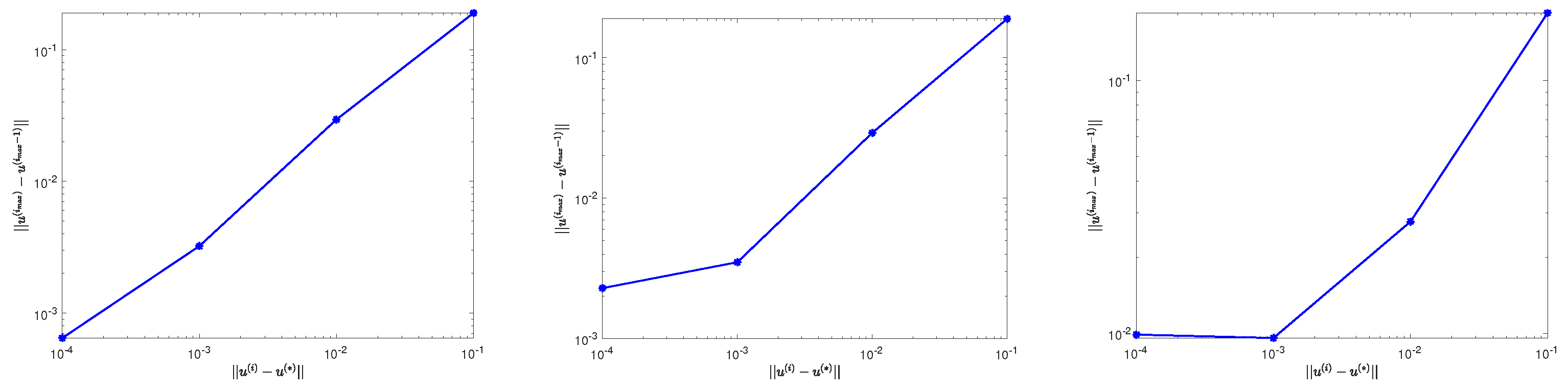
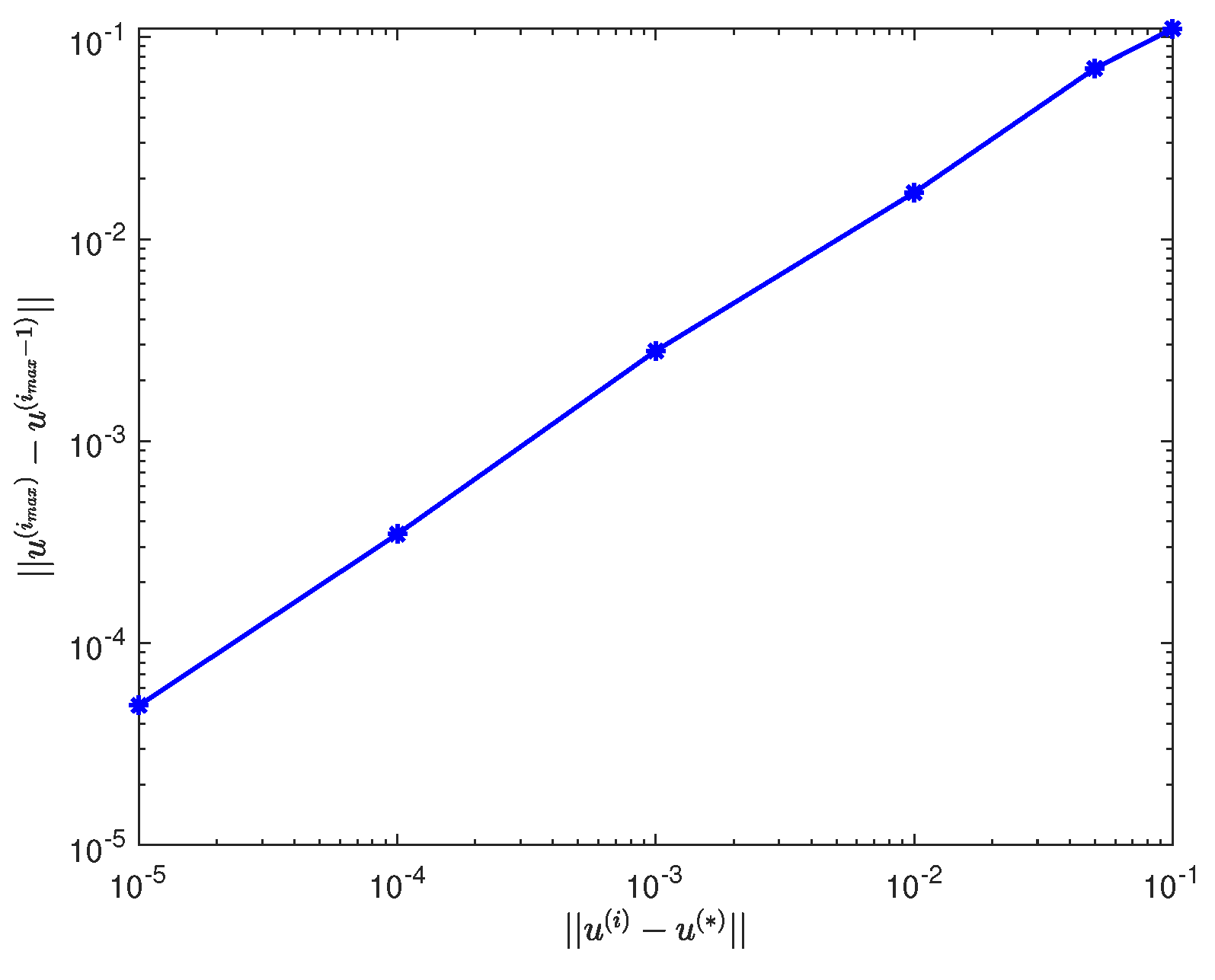
From Figure 3, we can see that when the gradually decreases, the error decreases slowly (). This is mainly caused by the direction we choose is the negative gradient direction, which is the disadvantage of the gradient descent method itself.
5.2. Example 2
This example comes from [15]; it is as follows:
This optimal control problem is equivalent to:
where
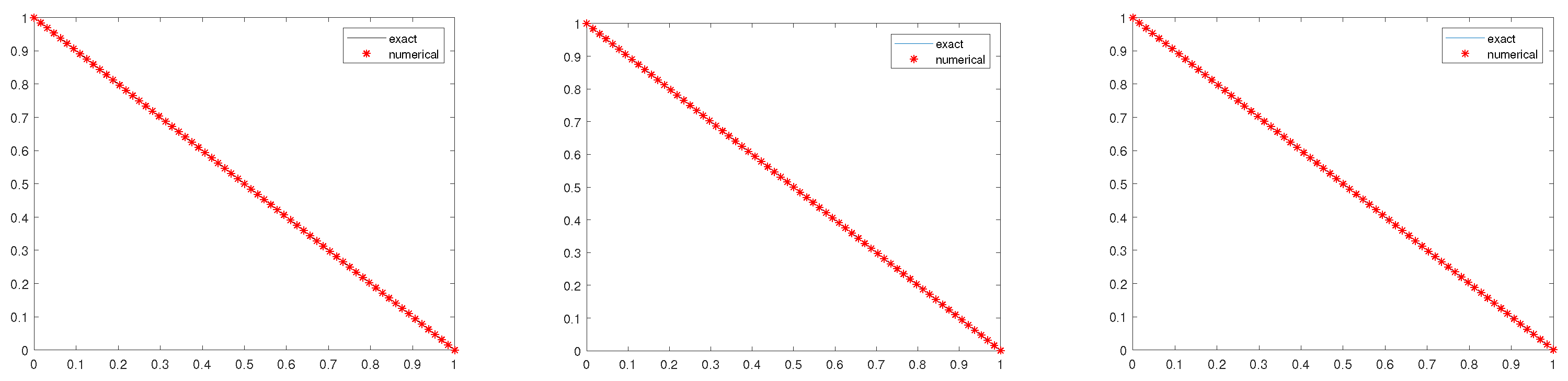
The parameters are selected as , , , , , . The computational results are shown in Figure 4, Figure 5 with . The final error values are , , respectively.
When , partial information about the computation process is listed in Table 2. In this table, has the same meaning as in Table 1. The total time of iteration is s when .
From Figure 4, Figure 5 and Figure 6 and Table 2, it can also be seen that , Algorithm 1 is convergent, and the MLMC method is efficient.
In the numerical approximation of the stochastic optimal control problem, statistical error (or MSE) and discrete error have a great influence on the convergence of the gradient projection method. If we use a Monte Carlo method as in [15], the optimization iteration method (gradient projection method) may not converge for a fixed large time step. In order to ensure the convergence of the iteration (gradient projection method), it is necessary to select a small time step size h and a large sample size M. This means that each optimization iteration will take a lot of time.
Our Algorithm 1 is actually an MLMC method with variable step size. The number of samples in each iteration step is different, and the sample size is also different with different time step sizes. It is optimal in a sense, just as the MLMC is superior to the MC method. Compared with the method in [16], our method is much simpler.
6. Conclusions
In this paper, an MLMC method based on gradient projection is used to approximate a stochastic optimal control problem. One of the contributions is that MLMC method is used to compute expectation, reducing the influence of statistical and discrete errors on the convergence of the gradient projection algorithm. The other contribution is that the convergence proof of Algorithm 1 is given; to the best of our knowledge, this is not found elsewhere. Two numerical examples are carried out to verify the effectiveness of the proposed algorithm.
Our method can be applied to simulate other stochastic optimal control problems with expected value in the optimality conditions (optimal control of SDE or SPDE).
The MLMC is used to reduce the MSE. Other methods include the most important sampling method (see, e.g., [31,32]), quasi-Monte Carlo method and multilevel quasi-Monte Carlo method (see, e.g., [33,34]). In future work, we can use the importance sampling MLMC method and the multi-level quasi-Monte Carlo method to approximate the stochastic optimal control problem with gradient projection or other optimization methods.
Author Contributions
Methodology, X.L.; software, C.Y.; validation, X.L. and C.Y.; formal analysis, C.Y. and X.L.; investigation, C.Y.; writing—original draft preparation, C.Y.; writing—review and editing, X.L.; visualization, C.Y.; supervision, X.L.; project administration, X.L.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Foundation of China (Granted No. 11961008).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cerone, V.; Regruto, D.; Abuabiah, M.; Fadda, E. A kernel- based nonparametric approach to direct data-driven control of LTI systems. IFAC-PapersOnLine 2018, 51, 1026–1031. [Google Scholar] [CrossRef]
- Hinze, M.; Pinnau, R.; Ulbrich, M.; Ulbrich, S. Optimization with PDE Constraints; Springer: New York, NY, USA, 2009. [Google Scholar]
- Liu, W.; Yan, N. Adaptive Finite Element Methods: Optimal Control Governed by PDEs; Science Press: Beijing, China, 2008. [Google Scholar]
- Luo, X. A priori error estimates of Crank-Nicolson finite volume element method for a hyperbolic optimal control problem. Numer. Methods Partial Differ. Equ. 2016, 32, 1331–1356. [Google Scholar] [CrossRef]
- Luo, X.; Chen, Y.; Huang, Y.; Hou, T. Some error estimates of finite volume element method for parabolic optimal control problems. Optim. Control Appl. Methods 2014, 35, 145–165. [Google Scholar] [CrossRef]
- Luo, X.; Chen, Y.; Huang, Y. A priori error estimates of finite volume element method for hyperbolic optimal control problems. Sci. China Math. 2013, 56, 901–914. [Google Scholar] [CrossRef]
- Ali, A.A.; Ullmann, E.; Hinze, M. Multilevel Monte Carlo analysis for optimal control of elliptic PDEs with random coefficients. SIAM/ASA J. Uncertain. Quantif. 2016, 5, 466–492. [Google Scholar] [CrossRef]
- Borzi, A.; Winckel, G. Multigrid methods and sparse-grid collocation techniques for parabolic optimal control problems with random coefficients. SIAM J. Sci. Comput. 2009, 31, 2172–2192. [Google Scholar] [CrossRef]
- Sun, T.; Shen, W.; Gong, B.; Liu, W. A priori error estimate of stochastic Galerkin method for optimal control problem governed by random parabolic PDE with constrained control. J. Sci. Comput. 2016, 67, 405–431. [Google Scholar] [CrossRef]
- Archibald, R.; Bao, F.; Yong, J.; Zhou, T. An efficient numerical algorithm for solving data driven feedback control problems. J. Sci. Comput. 2020, 85, 51. [Google Scholar] [CrossRef]
- Haussmann, U.G. Some examples of optimal stochastic controls or: The stochastic maximum principle at work. SIAM Rev. 1981, 23, 292–307. [Google Scholar] [CrossRef]
- Kushner, H.J.; Dupuis, P. Numerical Methods for Stochastic Control Problems in Continuous Time, 2nd ed.; Springer: New York, NY, USA, 2001. [Google Scholar]
- Korn, R.; Kraft, H. A stochastic control approach to portfolio problems with stochastic interest rates. SIAM J. Control Optim. 2001, 40, 1250–1269. [Google Scholar] [CrossRef] [Green Version]
- Archibald, R.; Bao, F.; Yong, J. A stochastic gradient descent approach for stochastic optimal control. East Asian J. Appl. Math. 2020, 10, 635–658. [Google Scholar] [CrossRef]
- Du, N.; Shi, J.; Liu, W. An effective gradient projection method for stochastic optimal control. Int. J. Numer. Anal. Model. 2013, 10, 757–774. [Google Scholar]
- Gong, B.; Liu, W.; Tang, T. An efficient gradient projection method for stochastic optimal control problems. SIAM J. Numer. Anal. 2017, 55, 2982–3005. [Google Scholar] [CrossRef]
- Wang, Y. Error analysis of a discretization for stochastic linear quadratic control problems governed by SDEs. IMA J. Math. Control Inf. 2021, 38, 1148–1173. [Google Scholar] [CrossRef]
- Barel, A.V.; Vandewalle, S. Robust optimization of PDEs with random coefficients using a multilevel Monte Carlo method. SIAM/ASA J. Uncertain. Quantif. 2017, 7, 174–202. [Google Scholar] [CrossRef]
- Cliffe, K.A.; Giles, M.B.; Scheichl, R.; Teckentrup, A.L. Multilevel Monte Carlo methods and applications to elliptic PDEs with random coefficients. Comput. Vis. Sci. 2011, 14, 3–15. [Google Scholar] [CrossRef]
- Giles, M.B. Multilevel Monte Carlo Path Simulation. Oper. Res. 2008, 56, 607–617. [Google Scholar] [CrossRef]
- Giles, M.B. Multilevel Monte Carlo methods. Acta Numer. 2015, 24, 259–328. [Google Scholar] [CrossRef]
- Kornhuber, R.; Schwab, C.; Wolf, M.W. Multilevel Monte Carlo finite element methods for stochastic elliptic variational inequalities. SIAM J. Numer. Anal. 2014, 52, 1243–1268. [Google Scholar] [CrossRef]
- Li, M.; Luo, X. An MLMCE-HDG method for the convection diffusion equation with random diffusivity. Comput. Math. Appl. 2022, 127, 127–143. [Google Scholar] [CrossRef]
- Li, M.; Luo, X. Convergence analysis and cost estimate of an MLMC-HDG method for elliptic PDEs with random coefficients. Mathematics 2021, 9, 1072. [Google Scholar] [CrossRef]
- Ikeda, N.; Watanabe, S. Stochastic Differential Equations and Diffusion Processes, 2nd ed.; North-Holland Publishing Company: New York, NY, USA, 1989. [Google Scholar]
- Ma, J.; Yong, J. Forward-Backward Stochastic Differential Equations and their Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 51–79. [Google Scholar]
- Peng, S. Backward stochastic differential equations and applications to optimal control. Appl. Math. Optim. 1993, 27, 125–144. [Google Scholar] [CrossRef]
- Brenner, S.C.; Scott, L.R. The Mathematical Theory of Finite Element Methods, 3rd ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Li, T.; Vanden-Eijnden, E. Applied Stochastic Analysis; AMS: Providengce, RI, USA, 2019. [Google Scholar]
- Lord, G.J.; Powell, C.E.; Shardlow, T. An Introduction to Computational Stochastic PDEs; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Alaya, M.B.; Hajji, K.; Kebaier, A. Adaptive importance sampling for multilevel Monte Carlo Euler method. Stochastics 2022. [Google Scholar] [CrossRef]
- Kebaier, A.; Lelong, J. Coupling importance sampling and multilevel Monte Carlo using sample average approximation. Methodol. Comput. Appl. Probab. 2018, 20, 611–641. [Google Scholar] [CrossRef]
- Giles, M.B.; Waterhouse, B.J. Multilevel quasi-Monte Carlo path simulation. In Advanced Financial Modeling; Albrecher, H., Runggaldier, W.J., Schachermayer, W., Eds.; de Gruyter: New York, NY, USA, 2009; pp. 165–181. [Google Scholar]
- Kuo, F.Y.; Schwab, C.; Sloan, I.H. Multi-level quasi-Monte Carlo finite element methods for a class of elliptic partial differential equation with random coefficients. Found. Comput. Math. 2015, 15, 411–449. [Google Scholar] [CrossRef]
Figure 1.
The exact solution and the numerical solutions (Left: . Middle . Right: ).

Figure 2.
The changing process of and with iteration number i (Left: . Middle . Right: ).

Figure 3.
The changing process of with the iterative error (Left: . Middle . Right: ).

Figure 4.
The exact solution and the numerical solutions (Left: . Middle . Right: ).

Figure 5.
The changing process of and with iteration number i (Left: . Middle . Right: ).

Figure 6.
The changeing process of with the iterative error ().


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Behavior of MLMC gradient projection-based optimization ().
| i | ||||||||
|---|---|---|---|---|---|---|---|---|
| 3 | 178 | 3 | 1 | 0.08 | ||||
| 7 | 4273 | 55 | 10 | 0.09 | ||||
| 11 | 53,203 | 749 | 126 | 0.20 | ||||
| 15 | 508,312 | 6715 | 1181 | 254 | 1.70 | |||
| 19 | 3,816,292 | 51,158 | 8526 | 1880 | 463 | 11.63 | ||
| 23 | 23,879,767 | 321,838 | 54,732 | 11,887 | 2892 | 67.07 |
Table 2.
Behavior of MLMC gradient projection-based optimization ().
| i | |||||||
|---|---|---|---|---|---|---|---|
| 3 | 2785 | 19 | 3 | 0.05 | |||
| 7 | 329,983 | 2050 | 267 | 0.56 | |||
| 11 | 6,642,693 | 42,434 | 5277 | 9.23 | |||
| 15 | 85,982,855 | 549,800 | 69,370 | 119.30 | |||
| 19 | 821,441,011 | 5,264,257 | 656,891 | 82,911 | 1160.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ye, C.; Luo, X. A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method. AppliedMath 2023, 3, 98-116. https://doi.org/10.3390/appliedmath3010008
AMA Style
Ye C, Luo X. A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method. AppliedMath. 2023; 3(1):98-116. https://doi.org/10.3390/appliedmath3010008
Chicago/Turabian StyleYe, Changlun, and Xianbing Luo. 2023. "A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method" AppliedMath 3, no. 1: 98-116. https://doi.org/10.3390/appliedmath3010008