
E-Eye Solution for the Discrimination of Common and Niche Celery Ecotypes


Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples
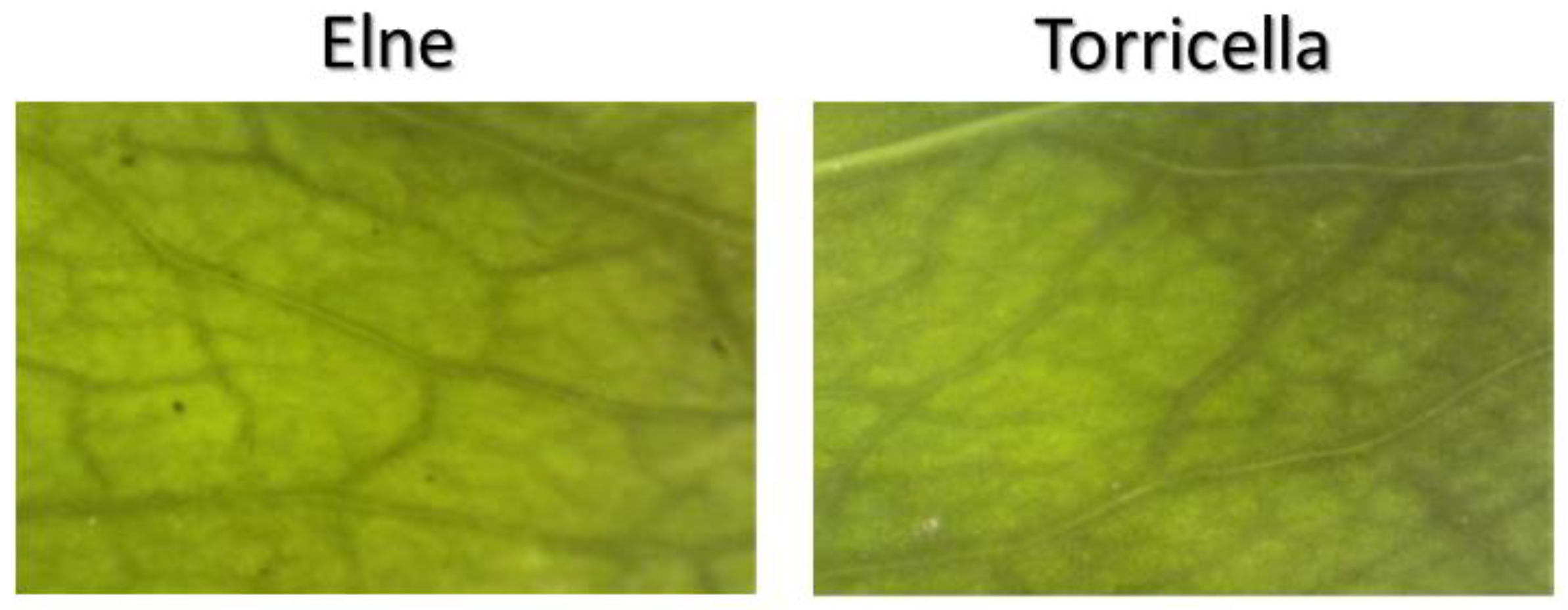
2.2. E-Eye Analysis
2.3. Chemometric Analysis
3. Results
3.1. Exploratory Analysis
3.2. Discriminant Classification
3.2.1. SPORT Analysis
3.2.2. SO-CovSel Analysis
3.3. Class-Modelling Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Torricelli, R.; Tiranti, B.; Spataro, G.; Castellini, G.; Albertini, E.; Falcinelli, M.; Negri, V. Differentiation and structure of an Italian landrace of celery (Apium graveolens L.): Inferences for on farm conservation. Genet. Resour. Crop Evol. 2013, 60, 995–1006. [Google Scholar] [CrossRef]
- Raffo, A.; Sinesio, F.; Moneta, E.; Nardo, N.; Peparaio, M.; Paoletti, F. Internal quality of fresh and cold stored celery petioles described by sensory profile, chemical and instrumental measurements. Eur. Food Res. Technol. 2006, 222, 590–599. [Google Scholar] [CrossRef]
- Yao, Y.; Sang, W.; Zhou, M.; Ren, G. Phenolic Composition and Antioxidant Activities of 11 Celery Cultivars. J. Food Sci. 2010, 75, C9–C13. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Zhuang, L.; Song, D.; Lu, C.; Xu, X. Isolation, purification, and identification of the main phenolic compounds from leaves of celery (Apium graveolens L. var. dulce Mill./Pers.). J. Sep. Sci. 2017, 40, 472–479. [Google Scholar] [CrossRef]
- Wang, X.J.; Luo, Q.; Li, T.; Meng, P.H.; Pu, Y.T.; Liu, J.X.; Zhang, J.; Liu, H.; Tan, G.F.; Xiong, A.S. Origin, evolution, breeding, and omics of Apiaceae: A family of vegetables and medicinal plants. Hortic. Res. 2022, 9, uhac076. [Google Scholar] [CrossRef]
- Ingallina, C.; Capitani, D.; Mannina, L.; Carradori, S.; Locatelli, M.; Di Sotto, A.; Di Giacomo, S.; Toniolo, C.; Pasqua, G.; Valletta, A.; et al. Phytochemical and biological characterization of Italian “sedano bianco di Sperlonga” Protected Geographical Indication celery ecotype: A multimethodological approach. Food Chem. 2020, 309, 125649. [Google Scholar] [CrossRef]
- Tirillini, B.; Pellegrino, R.; Pagiotti, R.; Pocceschi, N.; Menghini, L. Volatile compounds in different cultivars of Apium graveolens L. Ital. J. Food Sci. 2004, 16, 477–482. [Google Scholar]
- Reale, S.; Di Cecco, V.; Di Donato, F.; Di Martino, L.; Manzi, A.; Di Santo, M.; D’Archivio, A.A. Characterization of the Volatile Profile of Cultivated and Wild-Type Italian Celery (Apium graveolens L.) Varieties by HS-SPME/GC-MS. Appl. Sci. 2021, 11, 5855. [Google Scholar] [CrossRef]
- Salvucci, G.; Pallottino, F.; De Laurentiis, L.; Del Frate, F.; Manganiello, R.; Tocci, F.; Vasta, S.; Figorilli, S.; Bassotti, B.; Violino, S.; et al. Fast olive quality assessment through RGB images and advanced convolutional neural network modelling. Eur. Food Res. Technol. 2022, 248, 1395–1405. [Google Scholar] [CrossRef]
- Godoy, A.C.; dos Santos, P.D.S.; Nakano, A.Y.; Bini, R.A.; Siepmann, D.A.B.; Schneider, R.; Gaspar, P.A.; Pfrimer, F.W.D.; da Paz, R.F.; Santos, O.O. Analysis of Vegetable Oil from Different Suppliers by Chemometric Techniques to Ensure Correct Classification of Oil Sources to Deal with Counterfeiting. Food Anal. Methods 2020, 13, 1138–1147. [Google Scholar] [CrossRef]
- Agarwal, A.; Dutta Gupta, S. Assessment of spinach seedling health status and chlorophyll content by multivariate data analysis and multiple linear regression of leaf image features. Comput. Electron. Agric. 2018, 152, 281–289. [Google Scholar] [CrossRef]
- Venora, G.; Grillo, O.; Shahin, M.A.; Symons, S.J. Identification of Sicilian landraces and Canadian cultivars of lentil using an image analysis system. Food Res. Int. 2007, 40, 161–166. [Google Scholar] [CrossRef]
- Ropelewska, E.; Sabanci, K.; Aslan, M.F. Authentication of tomato (Solanum lycopersicum L.) cultivars using discriminative models based on texture parameters of flesh and skin images. Eur. Food Res. Technol. 2022, 248, 1959–1976. [Google Scholar] [CrossRef]
- Antonelli, A.; Cocchi, M.; Fava, P.; Foca, G.; Franchini, G.C.; Manzini, D.; Ulrici, A. Automated evaluation of food colour by means of multivariate image analysis coupled to a wavelet-based classification algorithm. Anal. Chim. Acta 2004, 515, 3–13. [Google Scholar] [CrossRef]
- Roger, J.-M.; Biancolillo, A.; Marini, F. Sequential preprocessing through ORThogonalization (SPORT) and its application to near infrared spectroscopy. Chemom. Intell. Lab. Syst. 2020, 199, 103975. [Google Scholar] [CrossRef]
- Foschi, M.; D’Addario, A.; Antonio D’Archivio, A.; Biancolillo, A. Future foods protection: Supervised chemometric approaches for the determination of adulterated insects’ flours for human consumption by means of ATR-FTIR spectroscopy. Microchem. J. 2022, 183, 108021. [Google Scholar] [CrossRef]
- Biancolillo, A.; Di Donato, F.; Merola, F.; Marini, F.; D’Archivio, A.A. Sequential data fusion techniques for the authentication of the P.G.I. senise (“crusco”) bell pepper. Appl. Sci. 2021, 11, 1709. [Google Scholar] [CrossRef]
- Maraphum, K.; Saengprachatanarug, K.; Wongpichet, S.; Phuphuphud, A.; Posom, J. Achieving robustness across different ages and cultivars for an NIRS-PLSR model of fresh cassava root starch and dry matter content. Comput. Electron. Agric. 2022, 196, 106872. [Google Scholar] [CrossRef]
- Giannetti, V.; Mariani, M.B.; Marini, F.; Torrelli, P.; Biancolillo, A. Grappa and Italian spirits: Multi-platform investigation based on GC–MS, MIR and NIR spectroscopies for the authentication of the Geographical Indication. Microchem. J. 2020, 157, 104896. [Google Scholar] [CrossRef]
- Schiavone, S.; Marchionni, B.; Bucci, R.; Marini, F.; Biancolillo, A. Authentication of Grappa (Italian grape marc spirit) by Mid and Near Infrared spectroscopies coupled with chemometrics. Vib. Spectrosc. 2020, 107, 103040. [Google Scholar] [CrossRef]
- Biancolillo, A.; Foschi, M.; D’Archivio, A.A. Geographical Classification of Italian Saffron (Crocus sativus L.) by Multi-Block Treatments of UV-Vis and IR Spectroscopic Data. Molecules 2020, 25, 2332. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yang, S.; Wang, Y.; Zhang, J. Multi-platform integration based on NIR and UV–Vis spectroscopies for the geographical traceability of the fruits of Amomum tsao-ko. Spectrochim. Acta-Part A Mol. Biomol. Spectrosc. 2021, 258, 119872. [Google Scholar] [CrossRef] [PubMed]
- Jiménez-Carvelo, A.M.; González-Casado, A.; Bagur-González, M.G.; Cuadros-Rodríguez, L. Alternative data mining/machine learning methods for the analytical evaluation of food quality and authenticity—A review. Food Res. Int. 2019, 122, 25–39. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I. Principal Component Analysis. In Encyclopedia of Statistics in Behavioral Science; American Cancer Society: Atlanta, GA, USA, 2005; ISBN 9780470013199. [Google Scholar]
- Biancolillo, A.; Marini, F.; Ruckebusch, C.; Vitale, R. Chemometric strategies for spectroscopy-based food authentication. Appl. Sci. 2020, 10, 6544. [Google Scholar] [CrossRef]
- Li Vigni, M.; Durante, C.; Cocchi, M. Exploratory Data Analysis. In Data Handling in Science and Technology; Marini, F., Ed.; Elsevier: Amsterdam, The Netherlands, 2013; Volume 28, pp. 55–126. [Google Scholar]
- Cocchi, M.; Biancolillo, A.; Marini, F. Chemometric Methods for Classification and Feature Selection. In Comprehensive Analytical Chemistry; Jaumot, J., Bedia, C., Tauler, R., Eds.; Elsevier B.V.: Amsterdam, The Netherlands, 2018; Volume 82, pp. 265–299. ISBN 9780444640444. [Google Scholar]
- Picca, A.; Ponziani, F.R.; Calvani, R.; Marini, F.; Biancolillo, A.; Coelho-Junior, H.J.; Gervasoni, J.; Primiano, A.; Putignani, L.; Del Chierico, F.; et al. Gut microbial, inflammatory and metabolic signatures in older people with physical frailty and sarcopenia: Results from the BIOSPHERE study. Nutrients 2020, 12, 65. [Google Scholar] [CrossRef] [Green Version]
- Næs, T.; Tomic, O.; Mevik, B.-H.; Martens, H. Path modelling by sequential PLS regression. J. Chemom. 2011, 25, 28–40. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Indahl, U.G.; Martens, H.; Næs, T. From dummy regression to prior probabilities in PLS-DA. J. Chemom. 2007, 21, 529–536. [Google Scholar] [CrossRef]
- Biancolillo, A.; Næs, T. The Sequential and Orthogonalized PLS Regression for Multiblock Regression: Theory, Examples, and Extensions. Data Handl. Sci. Technol. 2019, 31, 157–177. [Google Scholar] [CrossRef]
- Roger, J.M.; Palagos, B.; Bertrand, D.; Fernandez-Ahumada, E. CovSel: Variable selection for highly multivariate and multi-response calibration. Application to IR spectroscopy. Chemom. Intell. Lab. Syst. 2011, 106, 216–223. [Google Scholar] [CrossRef] [Green Version]
- Biancolillo, A.; Marini, F.; Roger, J.-M. SO-CovSel: A novel method for variable selection in a multiblock framework. J. Chemom. 2020, 34, e3120. [Google Scholar] [CrossRef]
- Wold, S. Sjöström, M. SIMCA: A method for analysing chemical data in terms of similarity and analogy. In Chemometrics, Theory and Application; Kowalski, B.R., Ed.; American Chemical Society: Washington, DC, USA, 1977; pp. 243–282. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pretreatment | Modelled Class | PCs | Sensitivity (%CV) | Specificity (%CV) | Efficiency (%CV) |
|---|---|---|---|---|---|
| Mean-Centering | Elne | 10 | 79.7 | 40.9 | 57.1 |
| Autoscaling | Elne | 10 | 81.1 | 24.6 | 44.7 |
| Mean-Centering | Torricella | 9 | 50.7 | 57.3 | 53.9 |
| Autoscaling | Torricella | 10 | 62.2 | 44.0 | 52.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biancolillo, A.; Foschi, M.; D’Archivio, A.A. E-Eye Solution for the Discrimination of Common and Niche Celery Ecotypes. AppliedChem 2023, 3, 1-10. https://doi.org/10.3390/appliedchem3010001
Biancolillo A, Foschi M, D’Archivio AA. E-Eye Solution for the Discrimination of Common and Niche Celery Ecotypes. AppliedChem. 2023; 3(1):1-10. https://doi.org/10.3390/appliedchem3010001
Chicago/Turabian StyleBiancolillo, Alessandra, Martina Foschi, and Angelo Antonio D’Archivio. 2023. "E-Eye Solution for the Discrimination of Common and Niche Celery Ecotypes" AppliedChem 3, no. 1: 1-10. https://doi.org/10.3390/appliedchem3010001