
Machine Learning Applied to LoRaWAN Network for Improving Fingerprint Localization Accuracy in Dense Urban Areas

Abstract
:1. Introduction
2. LoRaWAN Standard
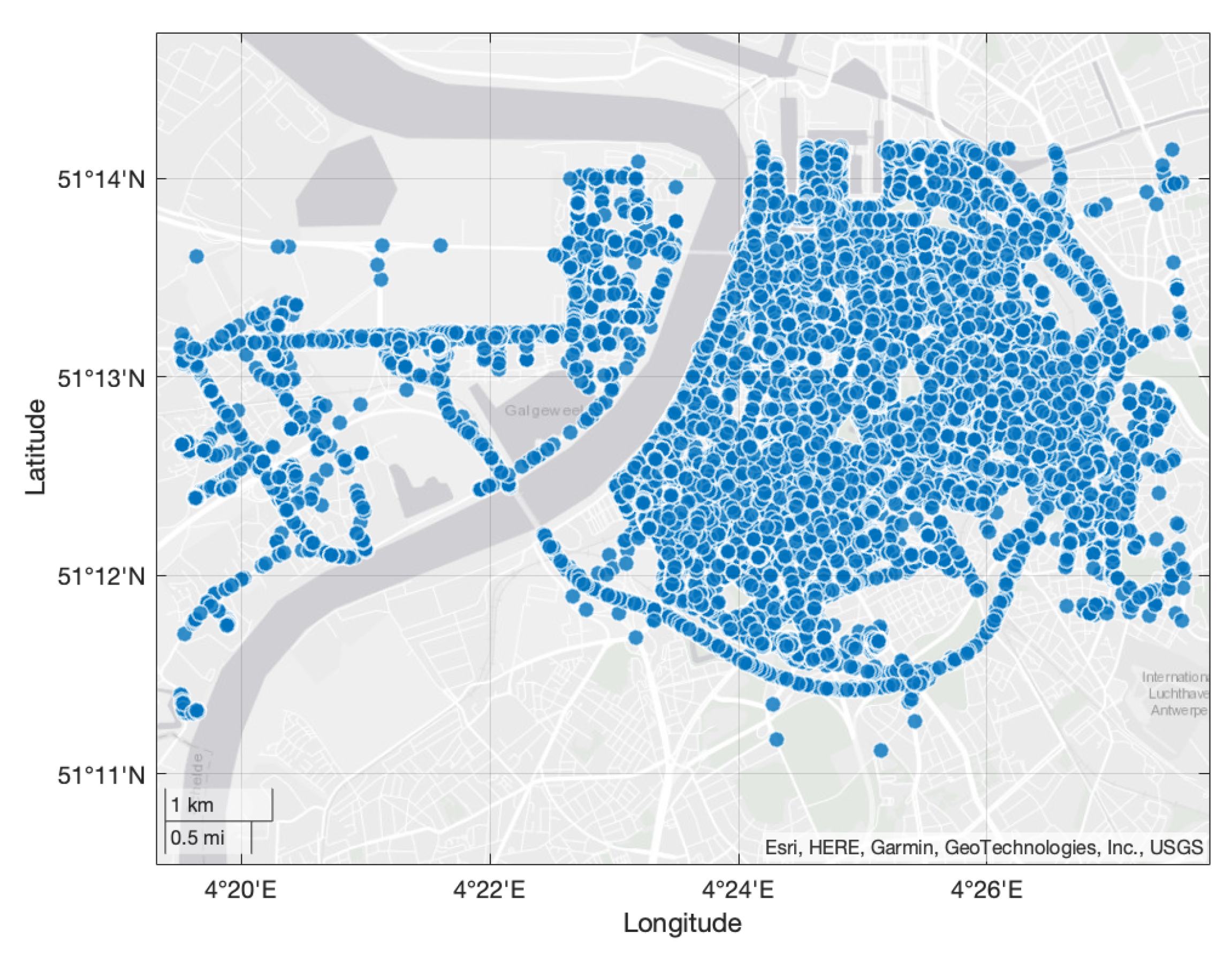
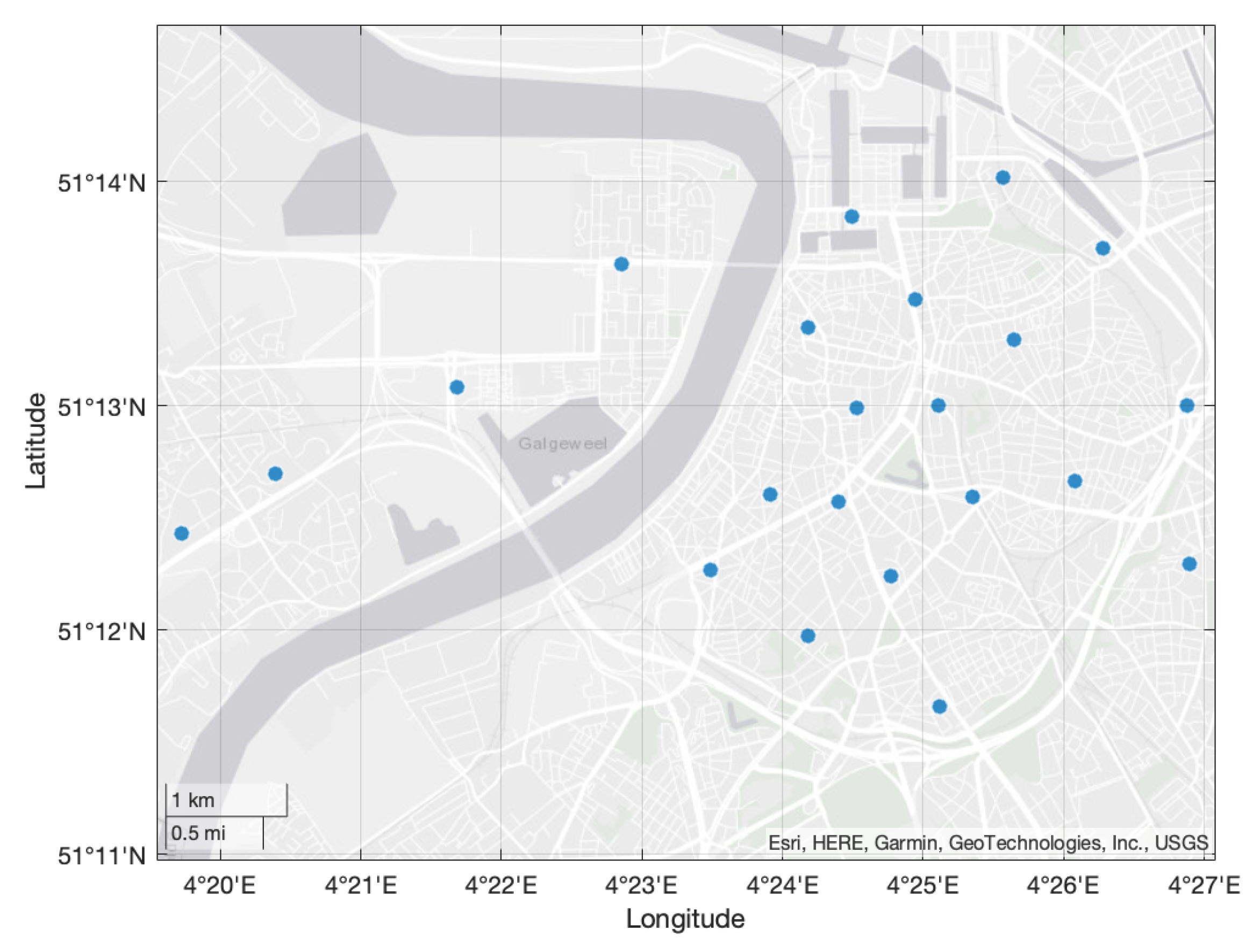
3. Dataset Analysis
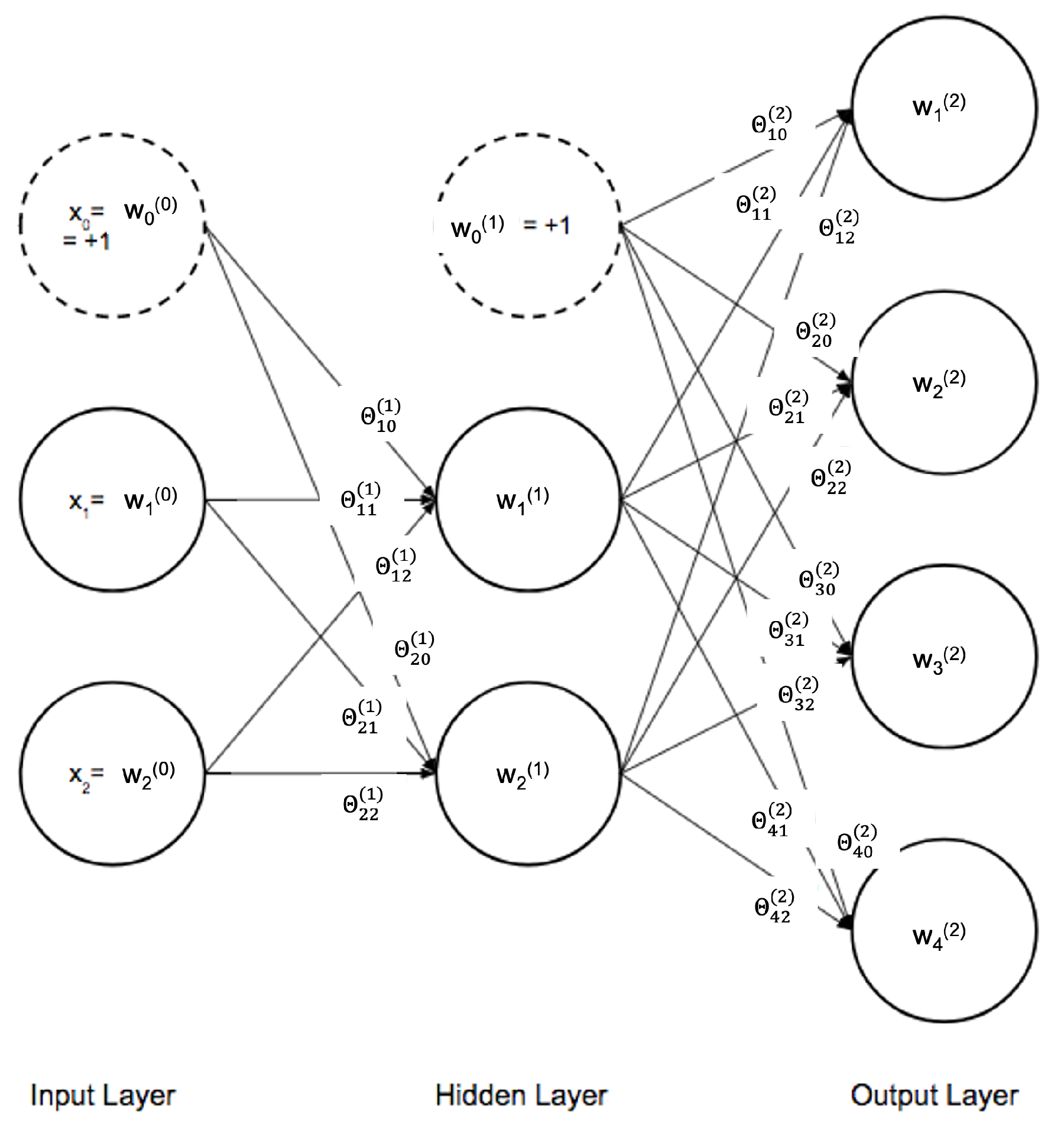
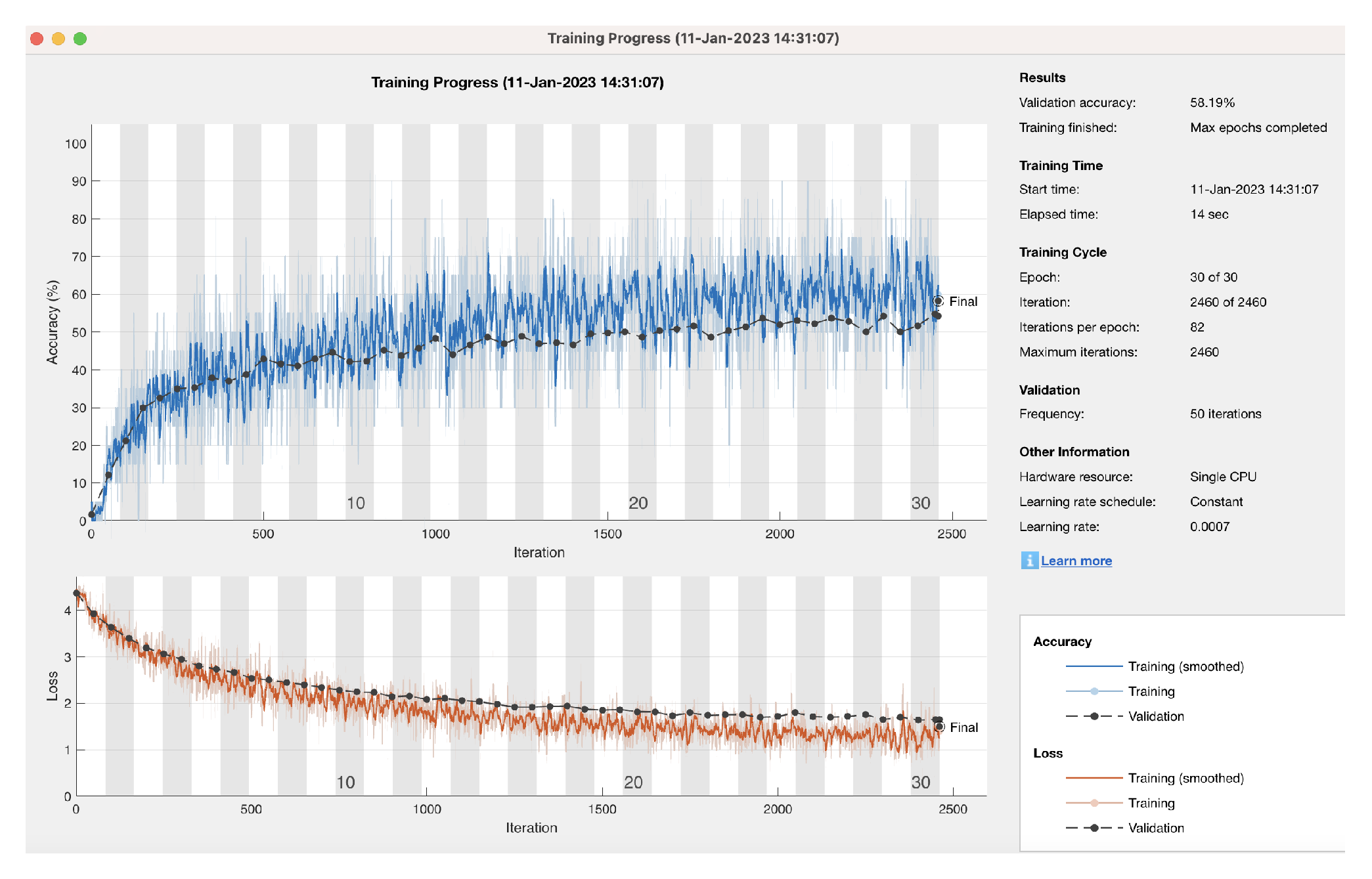
4. Machine Learning Approach
| Algorithm 1 Neural Network Architecture and Training Options. |
| layers = [ featureInputLayer(numFeatures,’Normalization’, ’zscore’) fullyConnectedLayer(70) batchNormalizationLayer reluLayer fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]; miniBatchSize = 20; options = trainingOptions(’adam’, … ’InitialLearnRate’,0.0007,… ’MiniBatchSize’,miniBatchSize, … ’Shuffle’,’every-epoch’, … ’ValidationData’,tblValidation, … ’Plots’,’training-progress’, … ’Verbose’,false); |
4.1. Comparative Analysis between Computational Complexity of Neural Network and Sensor-Based Approach
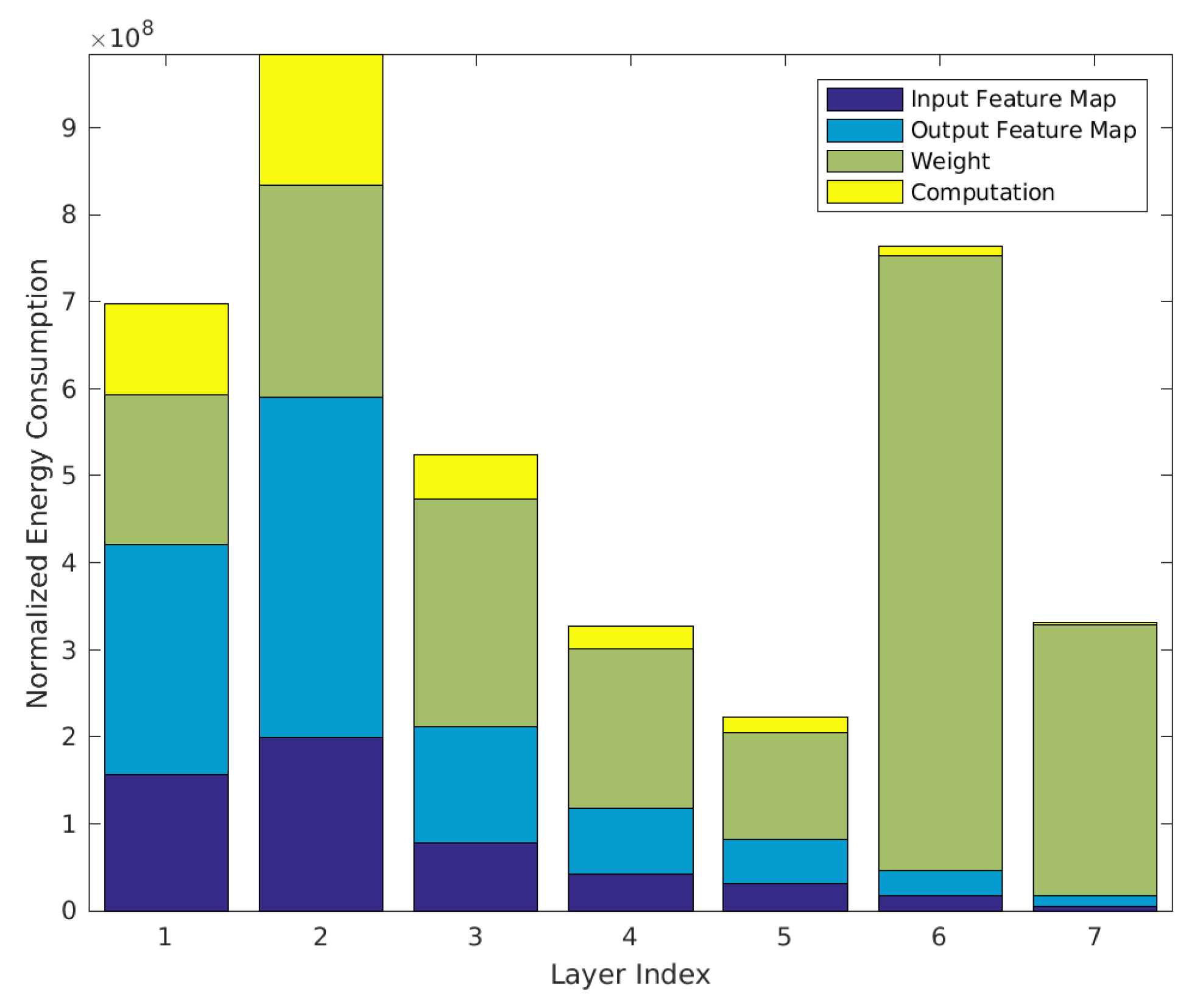
4.2. Comparative Analysis between Power Consumption of Neural Network and Sensor-Based Approach
- A txt file where each row gives the estimated energy dissipation for each layer in terms of the data movement and of the three data types (input feature map, weight and output feature map) and the computation. Energy units are normalized in terms of the energy for a MAC (multiply-and-accumulate) operation (that is, 102 = energy of 100 MACs). The output total energy is the energy required to process the dataset.
- A png file which visualizes the energy estimation result. See Figure 8.
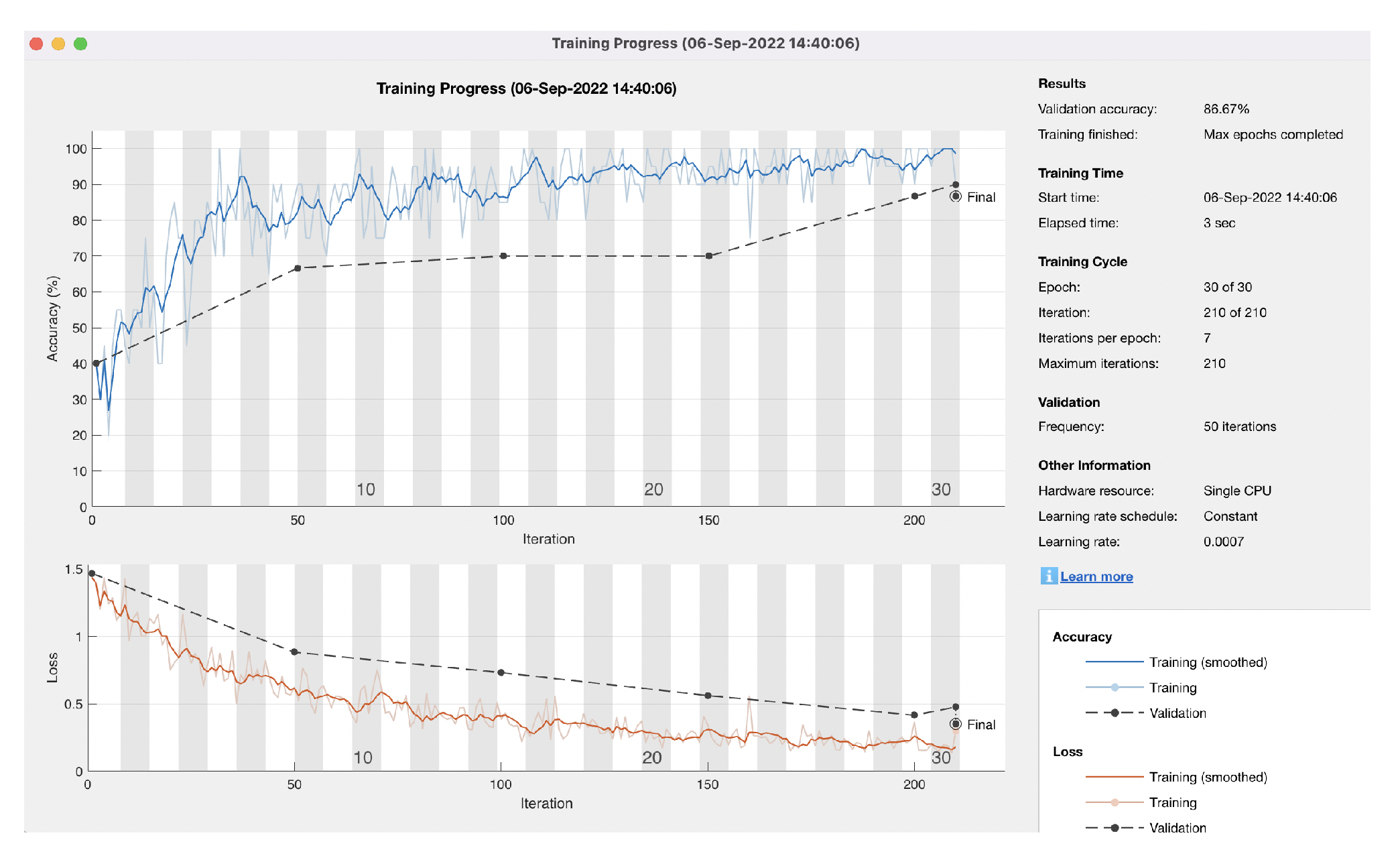
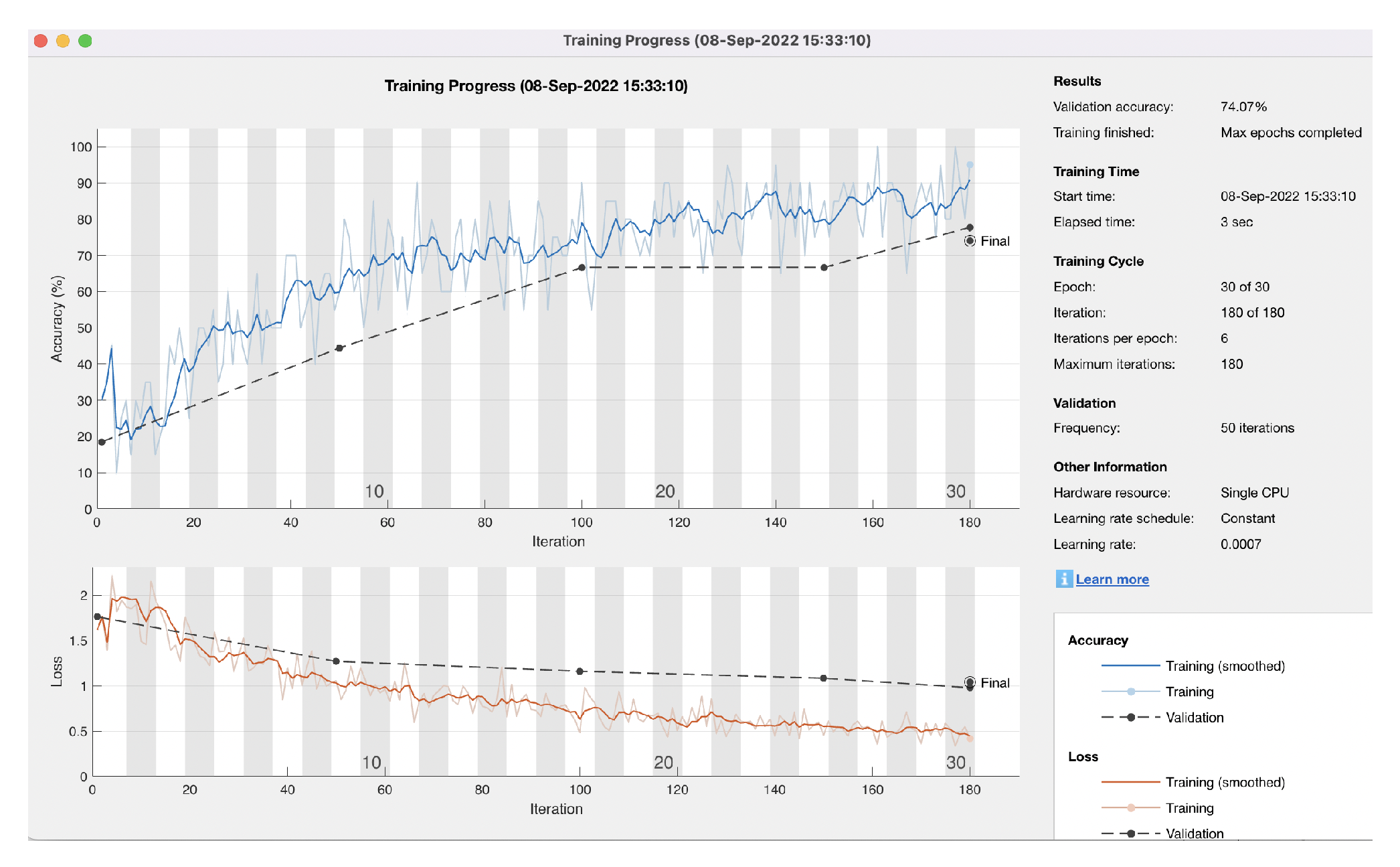
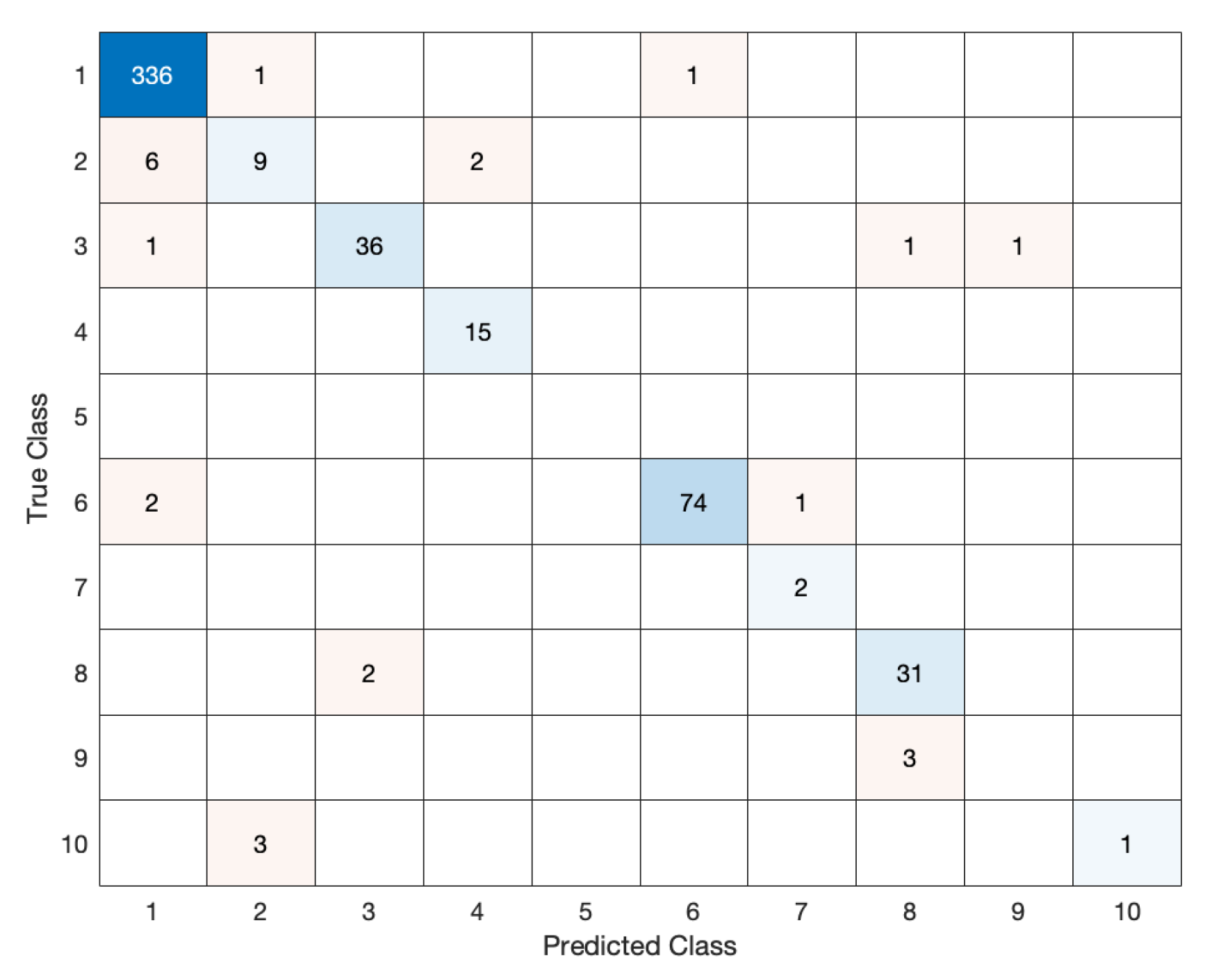
5. Results
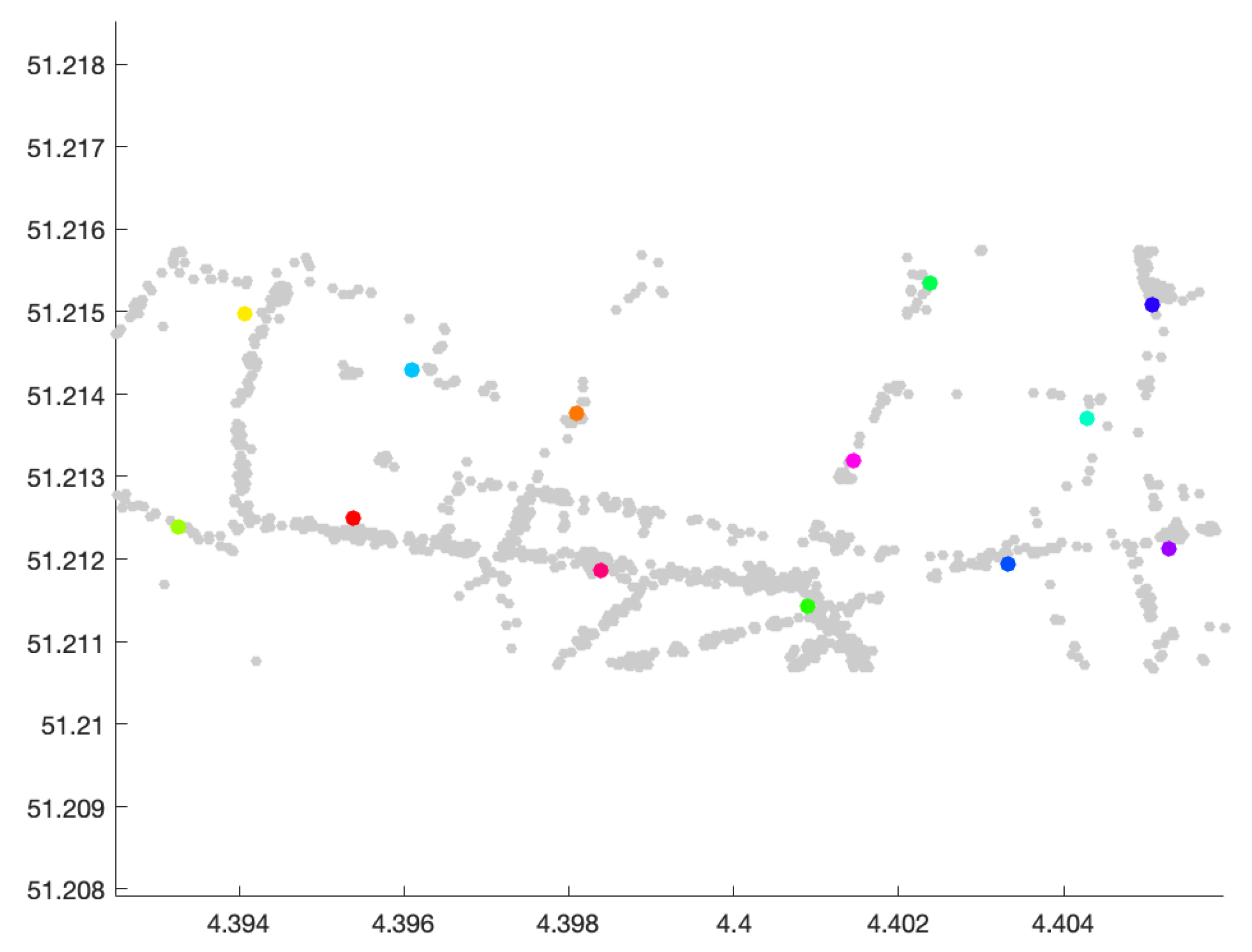
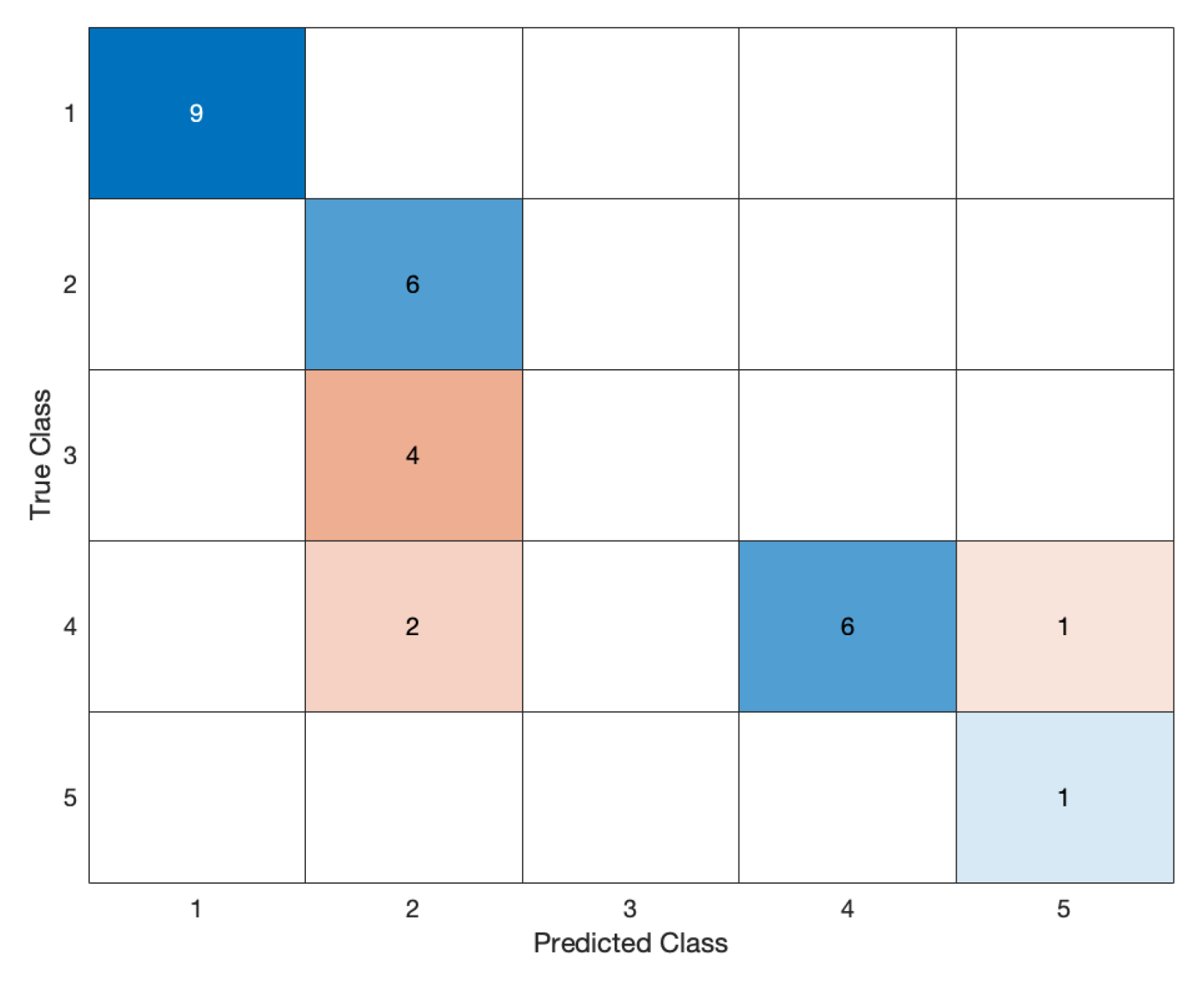
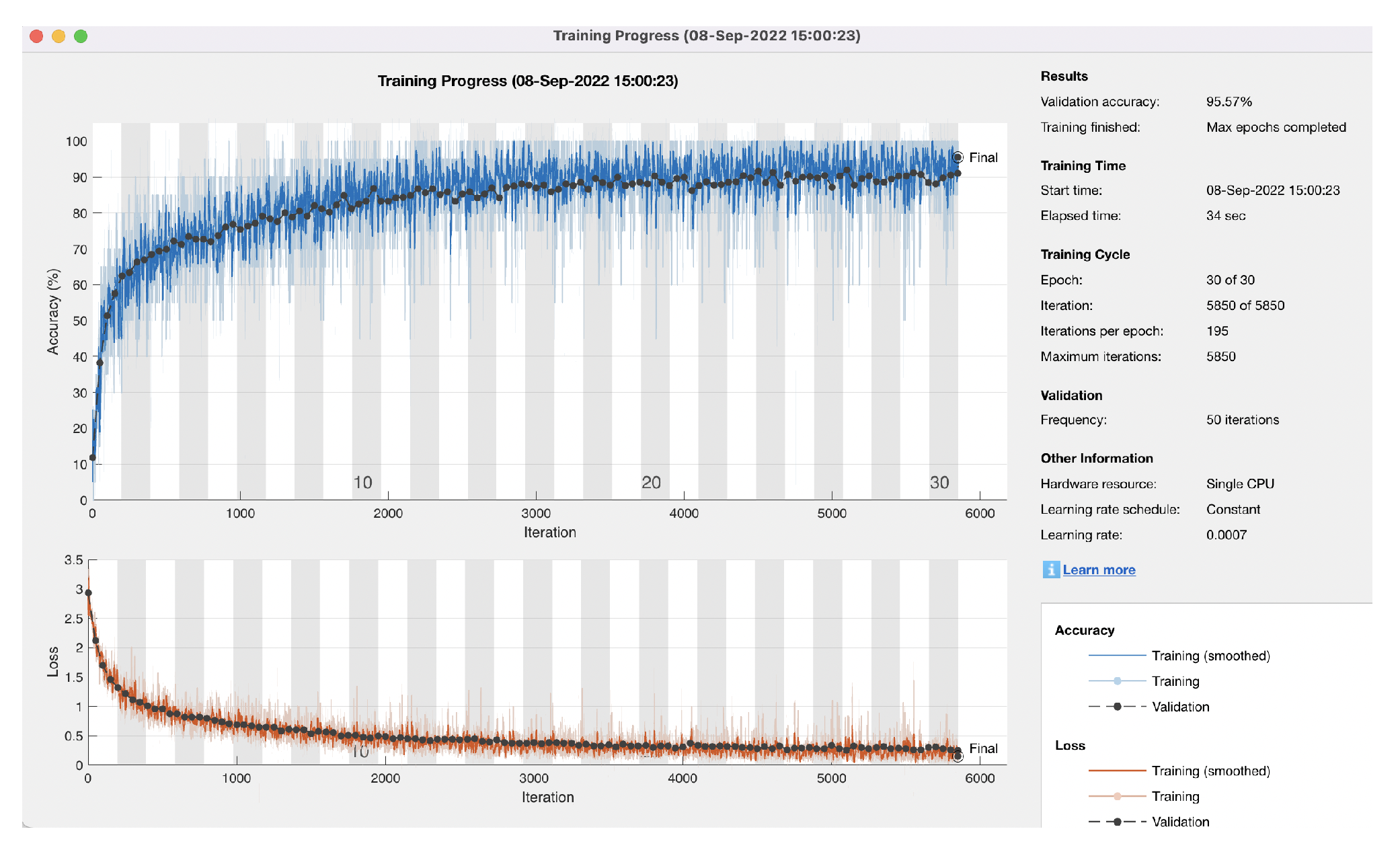
5.1. Low Accuracy
- Number of clusters: 4;
- Size of smallest cluster: 13;
- Size of largest cluster: 123;
- Mean cluster size: 50.500000;
- Median cluster size: 33;
- Number of points that are not part of any cluster: 9.
- Number of clusters: 5;
- Size of smallest cluster: 10;
- Size of largest cluster: 67;
- Mean cluster size: 36;
- Median cluster size: 26;
- Number of points that are not part of any cluster: 18.
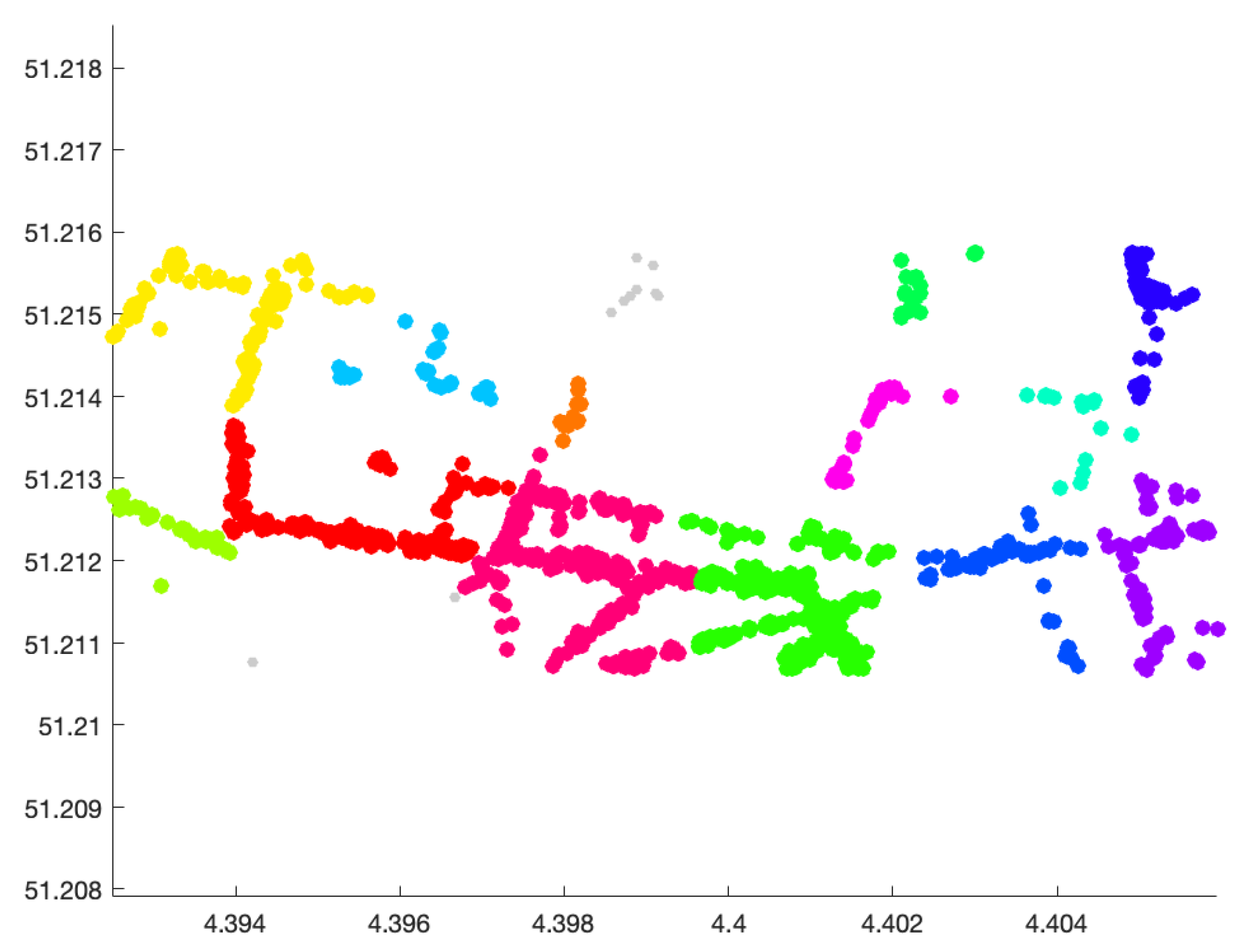
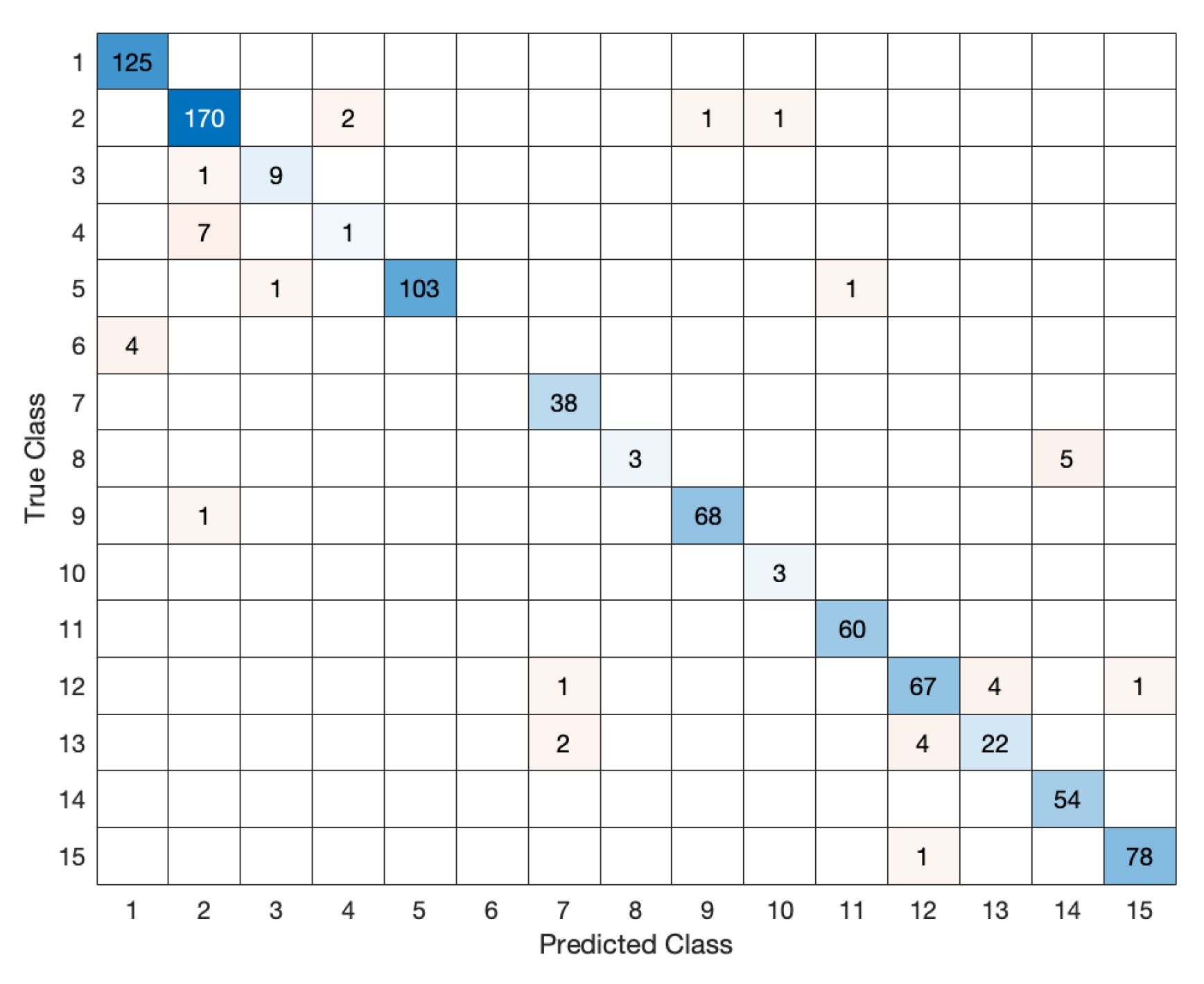
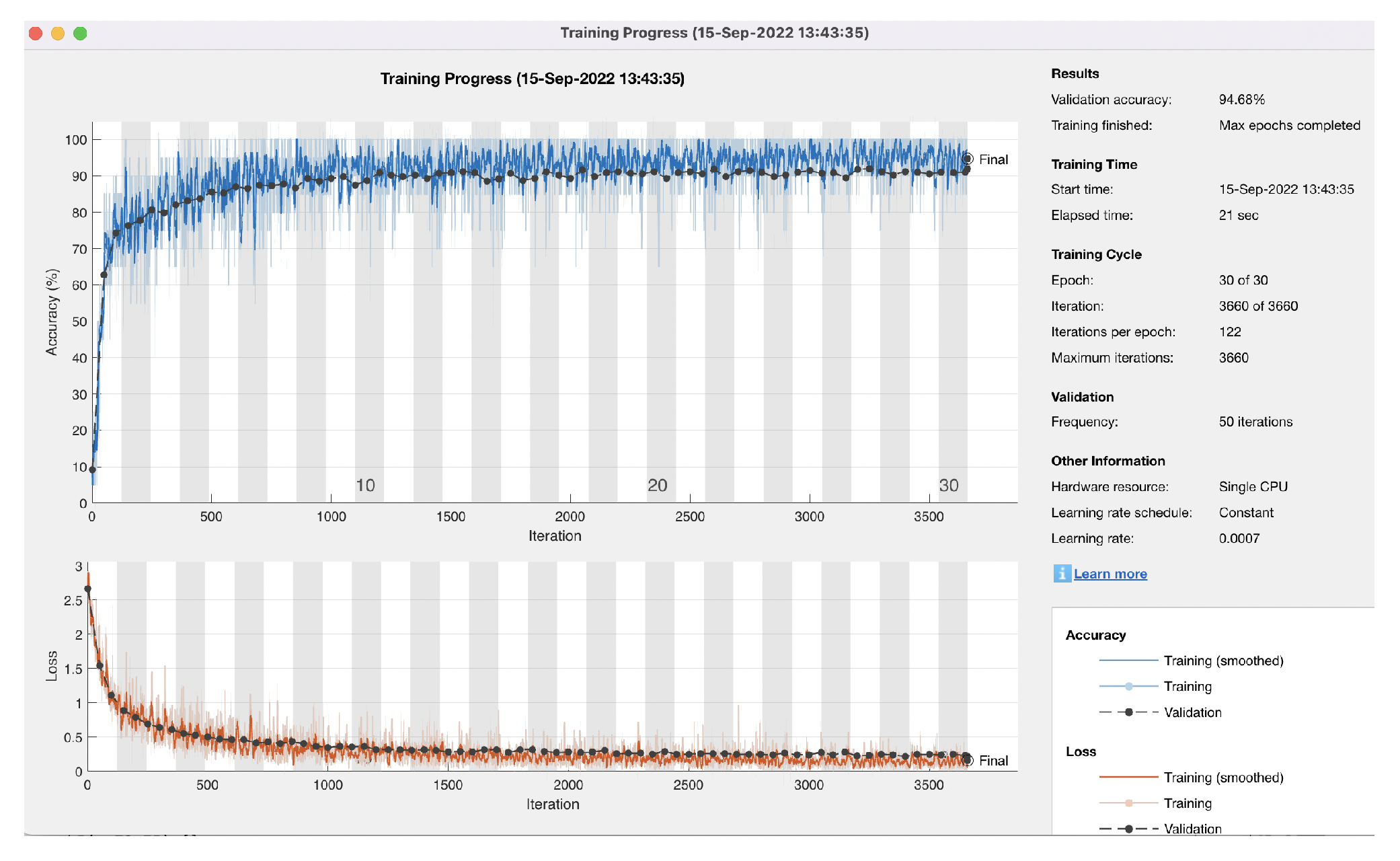
5.2. High Accuracy
- Number of clusters: 15;
- Size of smallest cluster: 16;
- Size of largest cluster: 1175;
- Mean cluster size: 359;
- Median cluster size: 350;
- Number of points that are not part of any cluster: 6.
- Number of clusters: 10;
- Size of smallest cluster: 12;
- Size of largest cluster: 1784;
- Mean cluster size: 299;
- Median cluster size: 121;
- Number of points that are not part of any cluster: 18.
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Augustin, A.; Yi, J.; Clausen, T.; Townsley, W. A study of lora: Long range low power networks for the internet of things. Sensors 2016, 16, 1466. [Google Scholar] [CrossRef] [PubMed]
- Piroddi, A.L. Torregiani, M. Combining Q-Learning and Multi-Layer Perceptron Models on Wireless Channel Quality Prediction. Am. J. Eng. Appl. Sci. 2021, 14, 139–151. [Google Scholar] [CrossRef]
- Anagnostopoulos, G.G.; Kalousis, A. Can I Trust This Location Estimate? Reproducibly Benchmarking the Methods of Dynamic Accuracy Estimation of Localization. Sensors 2022, 22, 1088. [Google Scholar] [CrossRef] [PubMed]
- Fargas, B.C.; Petersen, M.N. GPS-free geolocation using LoRa in low-power WANs. In Proceedings of the 2017 Global Internet of Things Summit (GIoTS), Geneva, Switzerland, 6–9 June 2017; pp. 1–6. [Google Scholar]
- Maróti, M.; Völgyesi, P.; Dóra, S.; Kusy, B.; Nádas, A.; Lédeczi, Á.; Balogh, G.; Molnár, K. Radio interferometric geolocation. In Proceedings of the SenSys’05, San Diego, CA, USA, 2–4 November 2005. [Google Scholar]
- Margelis, G.; Piechocki, R.; Kaleshi, D.; Thomas, P. Low Throughput Networks for the IoT: Lessons learned from industrial implementations. In Proceedings of the IEEE World Forum on Internet of Things (WF-IoT), Milan, Italy, 14–16 December 2015; pp. 181–186. [Google Scholar]
- Thrane, J.; Sliwa, B.; Wietfeld, C.; Christiansen, H.L. Deep learning-based signal strength prediction using geographical images and expert knowledge. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020. [Google Scholar] [CrossRef]
- Yu, X.; Wang, H.; Wu, J. A method of fingerprint indoor localization based on received signal strength difference by using compressive sensing. J. Wirel. Commun. Netw. 2020, 72. [Google Scholar] [CrossRef]
- LoRaWAN Adaptive Data Rate. Available online: https://www.thethingsnetwork.org/docs/lorawan/adaptive-data-rate/ (accessed on 22 November 2022).
- LoRaWANTM 1.1 Specification. Available online: https://lora-alliance.org/wp-content/uploads/2020/11/lorawantm_specification_-v1.1.pdf (accessed on 26 September 2022).
- Aernouts, M.; Berkvens, R.; Vlaenderen, K.V.; Weyn, M. Sigfox and LoRaWAN Datasets for Fingerprint Localization in Large Urban and Rural Areas. Data 2018, 3, 13. [Google Scholar] [CrossRef]
- LoRaWAN Dataset Antwerp. Available online: https://zenodo.org/record/3342253/files/lorawan_antwerp_2019_dataset.csv?download=1 (accessed on 22 November 2022).
- Srinivasan, K.; Levis, P. RSSI Is Under-Appreciated. In Proceedings of the Third Workshop on Embedded Networked Sensors (EmNets), Cambridge, MA, USA, 30–31 May 2006. [Google Scholar]
- Marcon, Y. Distance-Based Clustering of a Set of XY Coordinates. MATLAB Central File Exchange. 2022. Available online: https://www.mathworks.com/matlabcentral/fileexchange/56150-distance-based-clustering-of-a-set-of-xy-coordinates (accessed on 26 October 2022).
- Hernández-Pérez, E.L.; Navarro-Mesa, J.; Martin-Gonzalez, S.; Quintana-Morales, P.; Ravelo-García, A. Path loss factor estimation for RSS-based localization algorithms with wireless sensor networks. In Proceedings of the 19th European Signal Processing Conference, EUSIPCO 2011, Barcelona, Spain, 29 August–2 September 2011; pp. 1994–1998. [Google Scholar]
- Zhang, C.; Patras, P.; Haddadi, H. Deep Learning in Mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Bansal, A.; Gadre, A.; Singh, V.; Rowe, A.; Iannucci, B.; Kumar, S. Owll: Accurate lora localization using the tv whitespaces. In Proceedings of the 20th International Conference on Information Processing in Sensor Networks (Co-Located with CPS-IoT Week 2021), Nashville, TN, USA, 18–21 May 2021; pp. 148–162. [Google Scholar]
- Aernouts, M.; BniLam, N.; Berkvens, R.; Weyn, M. TDAoA: A Combination of TDoA and AoA Localization with LoRaWAN. Internet Things 2020, 11, 100236. [Google Scholar] [CrossRef]
- Podevijn, N.; Plets, D.; Trogh, J.; Martens, L.; Suanet, P.; Hendrikse, K.; Joseph, W. TDoA-based outdoor positioning with tracking algorithm in a public LoRa network. Wirel. Commun. Mob. Comput. 2018, 2018, 1864209. [Google Scholar] [CrossRef]
- Alippi, C.; Vanini, G. A RSSI-based and calibrated centralized localization technique for Wireless Sensor Networks. In Proceedings of the IEEE PerCom Workshops 2006, Pisa, Italy, 13–17 March 2006. [Google Scholar]
- Gholami, M.R.; Vaghefi, R.M.; Ström, E.G. RSS-based sensor localization in the presence of unknown channel parameters. IEEE Trans. Signal Process. 2013, 61, 3752–3759. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.; Hamed, E.; Katabi, D.; Erran Li, L. LTE radio analytics made easy and accessible. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 211–222. [Google Scholar] [CrossRef]
- Sun, G.; Chen, J.; Guo, W.; Liu, K.R. Signal processing techniques in network-aided positioning: A survey of state-of-the-art positioning designs. IEEE Signal Process. Mag. 2005, 22, 12–23. [Google Scholar]
- Kumar, S.; Gil, S.; Katabi, D.; Rus, D. Accurate Indoor Localization with Zero Start-up Cost. In Proceedings of the ACM MobiCom, Maui, HI, USA, 7–11 September 2014. [Google Scholar]
- Vasisht, D.; Kumar, S.; Katabi, D. Decimeter-level localization with a single wifi access point. In Proceedings of the USENIX NSDI, Santa Clara, CA, USA, 16–18 March 2016. [Google Scholar]
- Tomić, I.; Bhatia, L.; Breza, M.J.; McCann, J.A. The Limits of LoRaWAN in Event-Triggered Wireless Networked Control Systems. arXiv 2020, arXiv:2002.01472. [Google Scholar]
- Justus, D.; Brennan, J.; Bonner, S.; McGough, A.S. Predicting the Computational Cost of Deep Learning Models. arXiv 2018, arXiv:1811.11880. [Google Scholar]
- Kon, M.A.; Plaskota, L. Information complexity of neural networks. Neural Netw. 2000, 13, 365–375. [Google Scholar] [CrossRef] [PubMed]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Chen, Y.-H.; Yang, T.-J.; Emer, J.; Sze, V. Understanding the Limitations of Existing Energy-Efficient Design Approaches for Deep Neural Networks. In Proceedings of the SYSML’18, Stanford, CA, USA, 15–16 February 2018. [Google Scholar]
- Yang, T.-J.; Chen, Y.-H.; Sze, V. Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Takruri, M.; Ismail, S.; Awad, M.; Al-Hattab, M.; Hamad, N.A. A comparative study of energy consumption required for localization in wireless sensor networks. Int. J. Commun. Antenna Propag. (IRECAP) 2019, 9, 301. [Google Scholar] [CrossRef]
- Höpfner, H.; Bunse, C. Towards an energy-consumption based complexity classification for resource substitution strategies. In Proceedings of the GvD Workshop’10, Bad Helmstedt, Germany, 25–28 May 2010. [Google Scholar]
- Strassen, V. Matrix Multiplication: Strassen’s Algorithm—stanford.edu. 1969. Available online: https://stanford.edu/~rezab//classes/cme323/S16/notes/Lecture03/cme323_lec3.pdf (accessed on 16 January 2023).
- Mahendran, N. Analysis of memory consumption by neural networks based on hyperparameters. arXiv 2021, arXiv:2110.11424v1. [Google Scholar]
- Micheloni, R.; Marelli, A.; Eshghi, K. Inside Solid State Drives (SSDs); Springer: Heidelberg/Berlin, Germany, 2012. [Google Scholar]
- Plets, D.; Podevijn, N.; Trogh, J.; Martens, L.; Joseph, W. Experimental Performance Evaluation of Outdoor TDoA and RSS Positioning in a Public LoRa Network. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Hancke, G.P.; Silva, B.C.; Hancke, G.P., Jr. The role of advanced sensing in smart cities. Sensors 2012, 13, 393–425. [Google Scholar] [CrossRef]
- Gantelet, E.; Lefauconnier, A. The time looking for a parking space: Strategies, associated nuisances and stakes of parking management in France. In Proceedings of the European Transport Conference (ETC) Association for European Transport (AET), Strasbourg, France, 18–20 September 2006; pp. 1–7. [Google Scholar]
- Balestrieri, E.; Daponte, P.; De Vito, L.; Lamonaca, F. Sensors and Measurements for Unmanned Systems: An Overview. Sensors 2021, 21, 1518. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BS 1 | BS 2 | … | BS 72 | RX Time | SF | Latitude | Longitude |
|---|---|---|---|---|---|---|---|
| −200 | −200 | −200 | −200 | “2019-01” | 8 | 51.23399… | 4.42610… |
| −200 | −118 | −200 | −97 | “2019-01” | 7 | 51.20718… | 4.40368… |
| … | … | … | … | “…” | … | … | … |
| Number of Clusters | Size of Smallest Cluster | Size of Largest Cluster | Mean Cluster Size | Median Cluster Size | Number of Points Not Part of Any Cluster |
|---|---|---|---|---|---|
| 13 | 14 | 880 | 212 | 78 | 10 |
| Technique | Range (m) | Power | Precision (m) | Source |
|---|---|---|---|---|
| OwLL | 500 | Low | ≈9 | [17] |
| Prior LP-WAN | >500 | Low | >100 | [18,19] |
| Sensor-based | ≈50 | Low | ≈5 | [20,21] |
| Cellular | ≈50 | High | 0.085 | [22,23] |
| Wi-Fi | ≈15 | Medium | <0.05 | [24,25] |
| Lambda | Accuracy Result |
|---|---|
| 0.006 | 98% |
| 0.01 | 95% |
| 0.03 | 95% |
| 0.16 | 84% |
| 0.3 | 59% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piroddi, A.; Torregiani, M. Machine Learning Applied to LoRaWAN Network for Improving Fingerprint Localization Accuracy in Dense Urban Areas. Network 2023, 3, 199-217. https://doi.org/10.3390/network3010010
Piroddi A, Torregiani M. Machine Learning Applied to LoRaWAN Network for Improving Fingerprint Localization Accuracy in Dense Urban Areas. Network. 2023; 3(1):199-217. https://doi.org/10.3390/network3010010
Chicago/Turabian StylePiroddi, Andrea, and Maurizio Torregiani. 2023. "Machine Learning Applied to LoRaWAN Network for Improving Fingerprint Localization Accuracy in Dense Urban Areas" Network 3, no. 1: 199-217. https://doi.org/10.3390/network3010010