

An Efficient Information Retrieval System Using Evolutionary Algorithms



Abstract
:1. Introduction
- Proposing a novel indexing technique called the advanced document indexing method (ADIM) applied to large IRS-indexed files joined with modified GA and CA for retrieving relevant documents to the user queries;
- Reducing the amount of storage required for the produced ADIM;
- Modifying genetic algorithm (MGA) and integrating with culture algorithm (CA) to retrieve relevant documents.
2. Background and Literature Review
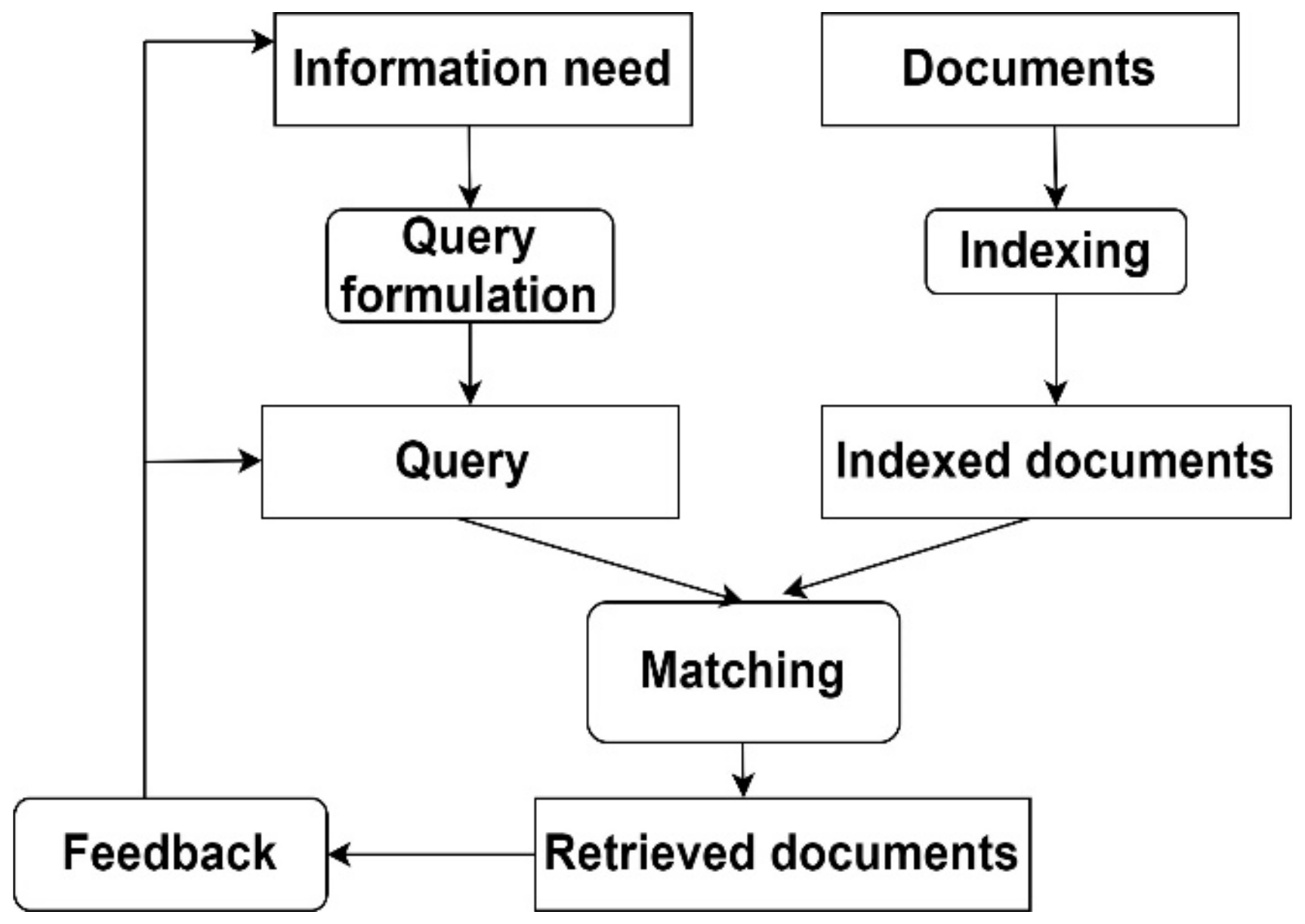
2.1. Information Retrieval System (IRS) Concept
2.1.1. IRSs Models
2.1.2. Indexed Techniques
2.2. Evolutionary Models (Search Techniques) Overview
2.2.1. Genetic Algorithms (GA) Overview and Related Work
2.2.2. Culture Algorithms (CA) Overview
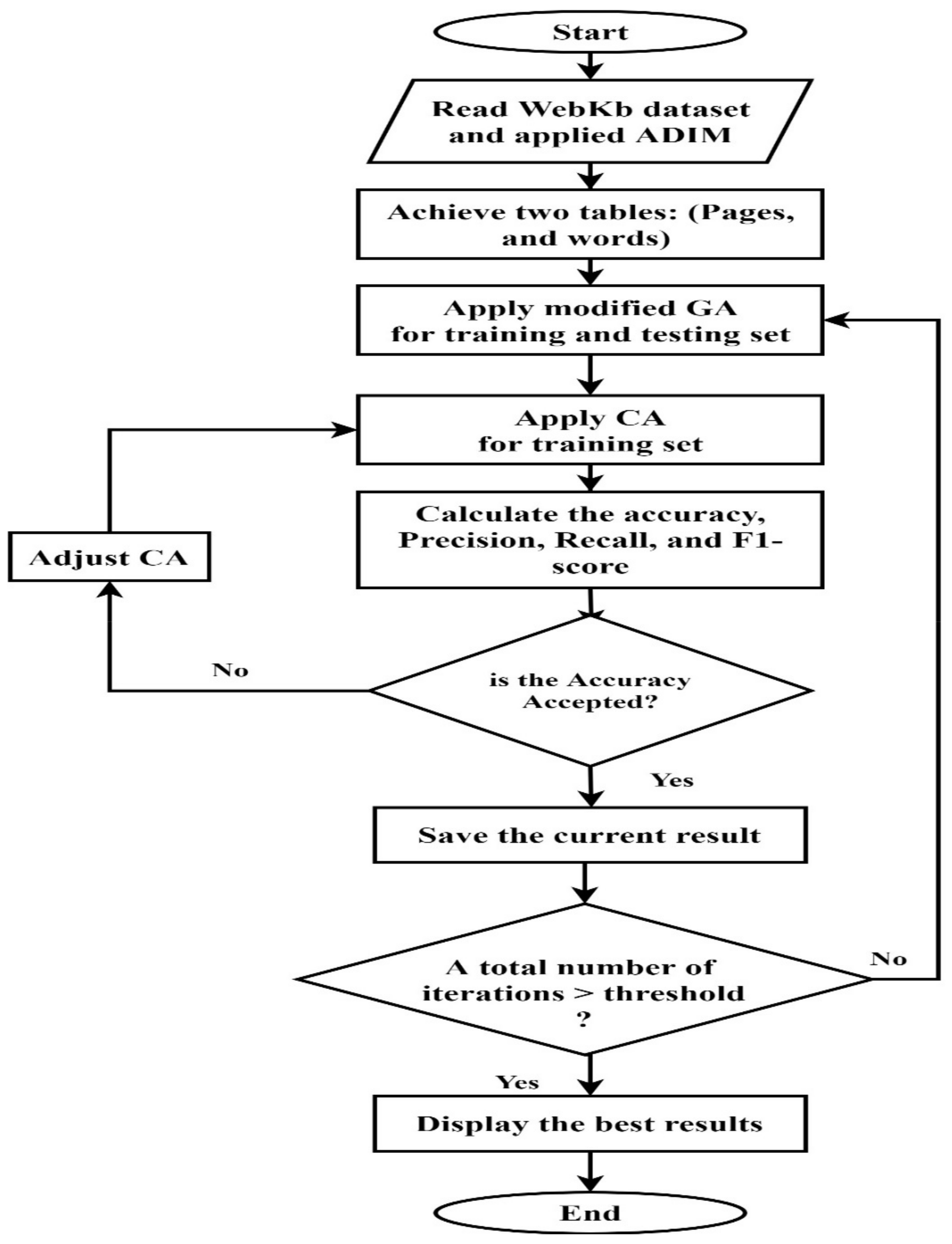
3. Methodology
3.1. Advanced Document Indexing Method (ADIM) Stage
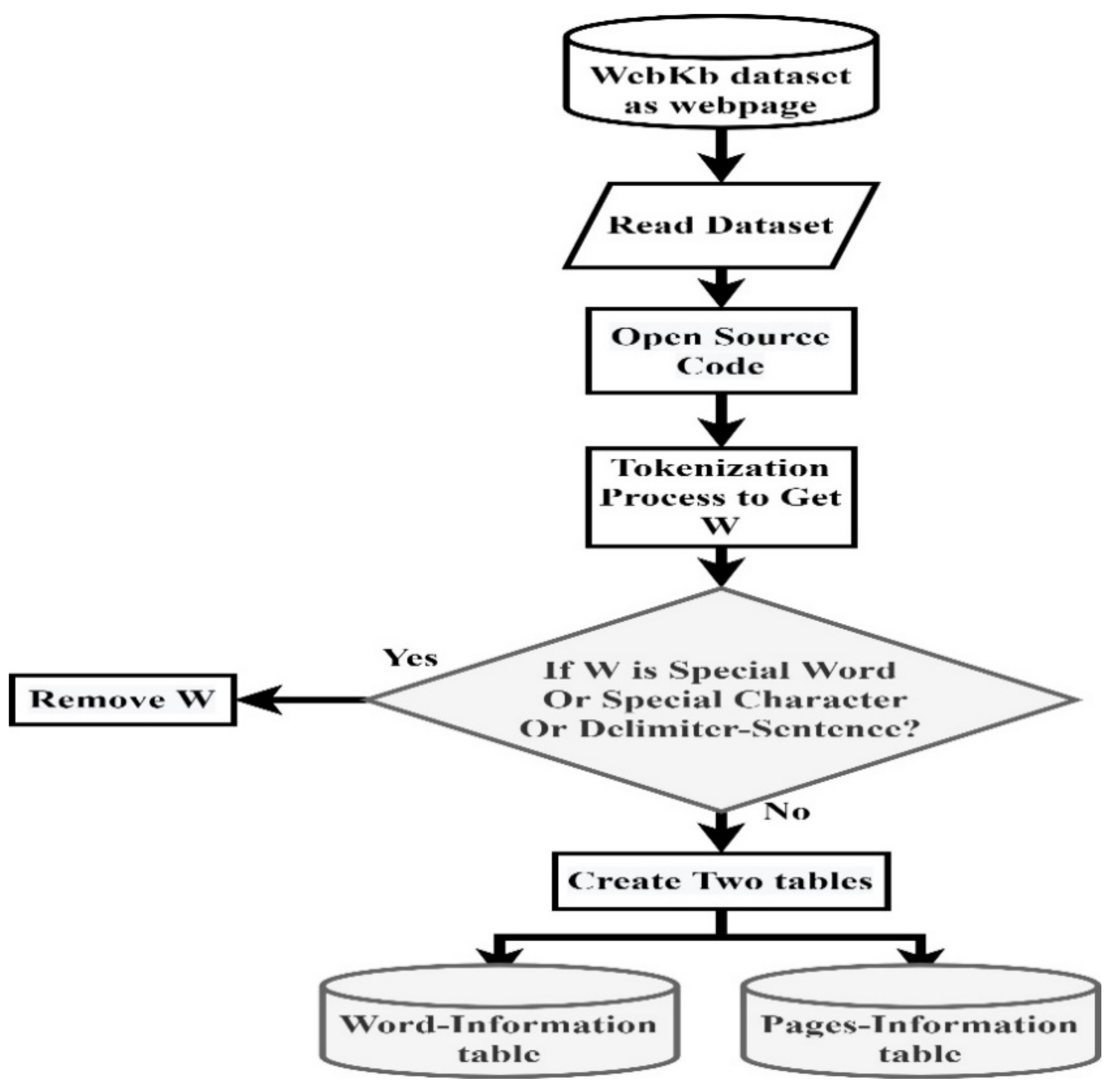
3.1.1. WebKb Dataset Reading
3.1.2. ADIM
| Algorithm 1: Advanced Document Indexing Method |
Begin
|
- The special-word table is constructed by removing (stop words, special characters, and sentence delimiters).
- The HTML tag information table is constructed by removing preferred tags (i.e., HTML, head, sub-headers (h1, h2, h3), body), and generating the weight of the removed tags. Table 6 depicts documents with tags; a document tag represents a specific importance level. It contains the related essential information of the requested user query.
3.2. Query Search Processing Stage
| Algorithm 2: Query Search Algorithm (QSA) |
|
3.3. Evolutionary Algorithm Stage
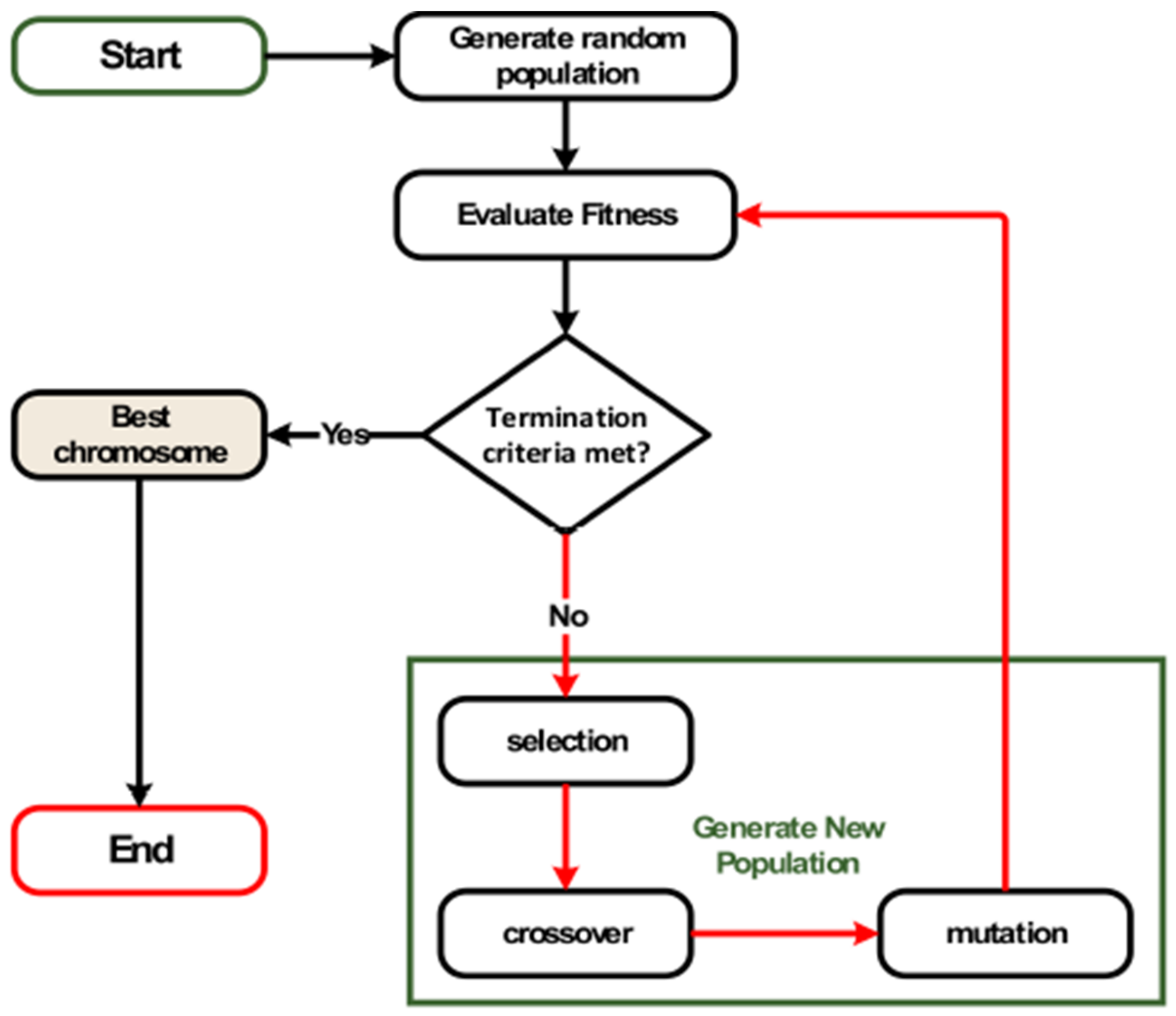
3.3.1. Modify Genetic Algorithm (MGA)
| Algorithm 3: GA- Processes |
|
- A.
- Initial Generation
- B.
- Fitness-Function
- For the first appearance become: 1100 + 0.1 = 1100.1
- For the second appearance becomes: 1100.1 + 0.1 = 1100.2
- For the third appearance becomes: 1100.2 + 0.1 = 1100.3
- For the third appearance becomes: 1100.3 + 0.1 = 1100.4
- C.
- Parent Selection
- D.
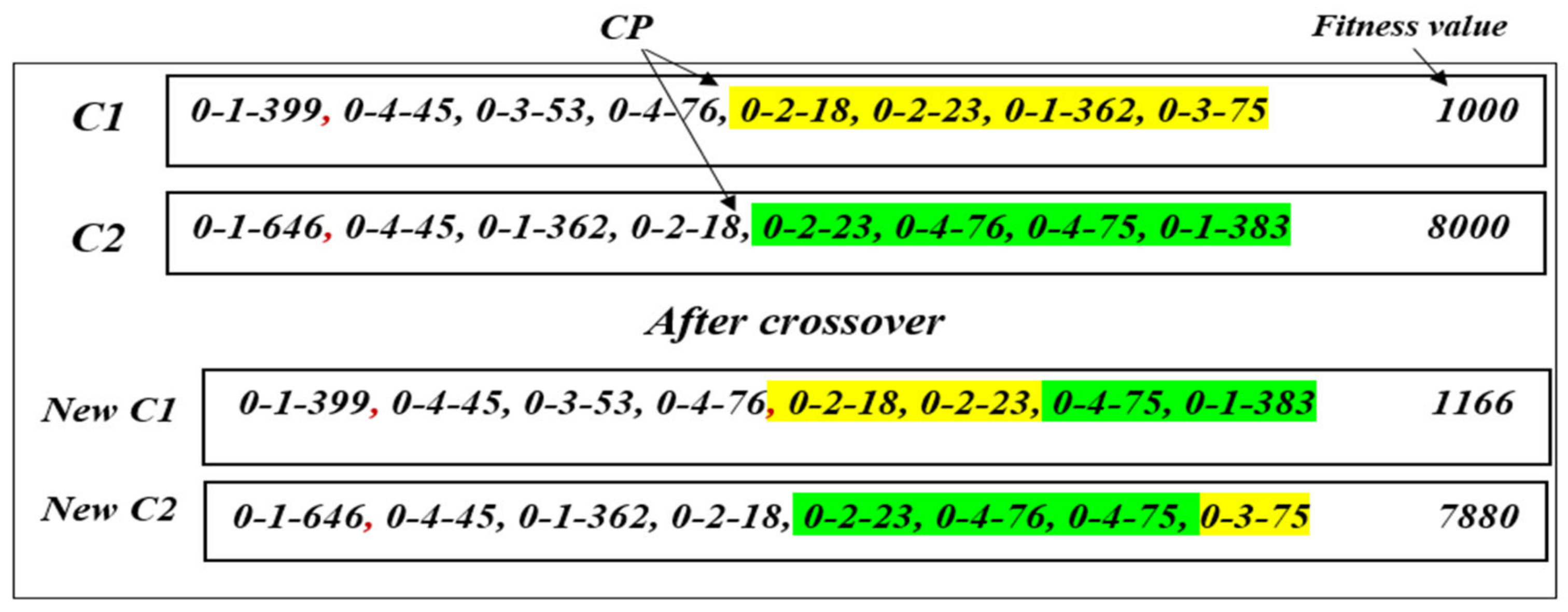
- Crossover Operator (Single-Point)
| Algorithm 4: Pseudo-Code of proposed single-point crossover operation |
|
- E.
- Mutation Operator
- F.
- Stopping Criteria
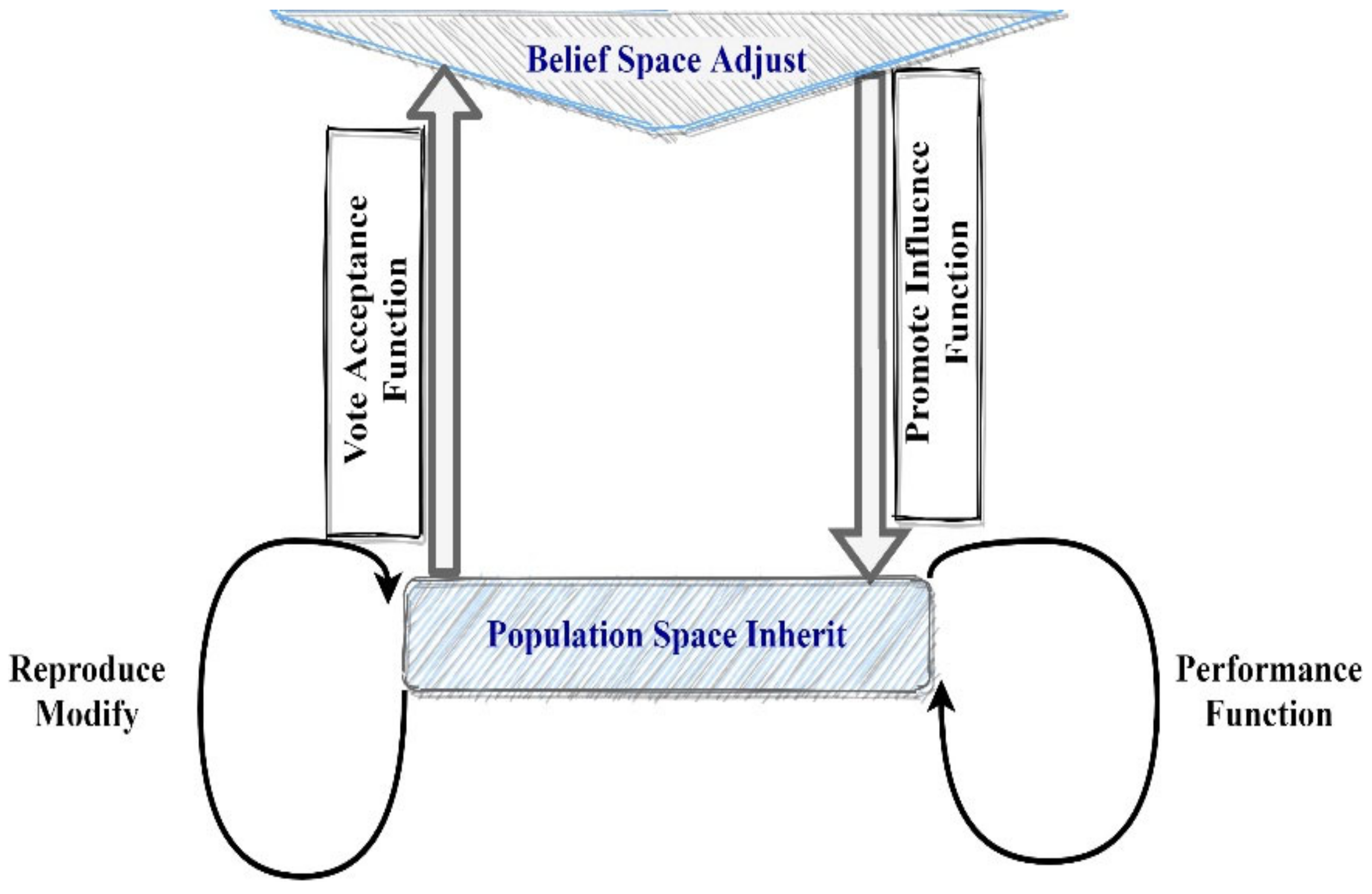
3.3.2. Culture Algorithm (MCA)
3.4. GA and CA Integration
| Algorithm 5: Integration between MGA, and CA |
|
4. Implementation
4.1. ADIM Experimental Results and Memory Efficiency
4.2. Query Length Producer and Results
4.3. Modified GA Procedure and Results
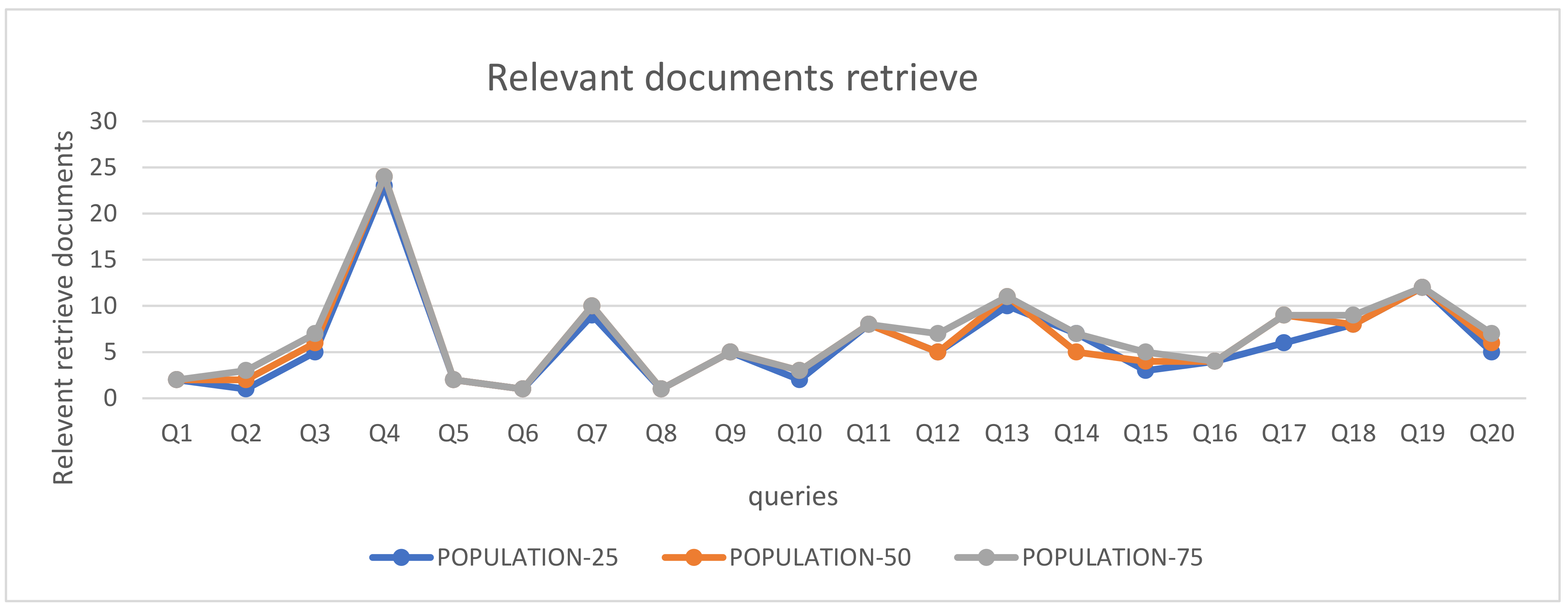
4.4. Experimental Result of Population Size and Discussion
4.5. Comparison with Other Studies
5. Discussions and Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ceri, S.; Bozzon, A.; Brambilla, M.; Della Valle, E.; Fraternali, P.; Quarteroni, S. An Introduction to Information Retrieval. In Web Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–11. [Google Scholar]
- Sarrouti, M.; Ouatik El Alaoui, S. A passage retrieval method based on probabilistic information retrieval and UMLS concepts in biomedical question answering. J. Biomed. Inform. 2017, 68, 96–103. [Google Scholar] [CrossRef] [PubMed]
- Kantemirova, B.I.; Orlova, E.A.; Polunina, O.S.; Chernysheva, E.N.; Abdullaev, M.A.; Sychev, D.A. Pharmacogenetic bases of individual sensitivity and personalized administration of antiplatelet therapy in different ethnic groups. Farmatsiya Farmakol. 2020, 8, 392–404. [Google Scholar] [CrossRef]
- Oleiwi, H.W.; Mhawi, D.N.; Al-Raweshidy, H. MLTs-ADCNs: Machine Learning Techniques for Anomaly Detection in Communication Networks. IEEE Access 2022, 10, 91006–91017. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Erritali, M.; Beni-Hssane, A.; Birjali, M.; Madani, Y. An Approach of Semantic Similarity Measure between Documents Based on Big Data. Int. J. Electr. Comput. Eng. 2016, 6, 2454–2461. [Google Scholar] [CrossRef]
- Kulzer, B. Wie profitieren Menschen mit Diabetes von Big Data und künstlicher Intelligenz? Der Diabetol. 2021, 17, 799–806. [Google Scholar] [CrossRef]
- Han, Y.; Lang, Y.; Cheng, M.; Geng, Z.; Chen, G.; Xia, T. DTaxa: An actor–critic for automatic taxonomy induction. Eng. Appl. Artif. Intell. 2021, 106, 104501. [Google Scholar] [CrossRef]
- Vatansever, D.; Smallwood, J.; Jefferies, E. Varying demands for cognitive control reveals shared neural processes supporting semantic and episodic memory retrieval. Nat. Commun. 2021, 12, 1–11. [Google Scholar] [CrossRef]
- Jabonete, D.S.; De Leon, M.M. Development of an Automatic Document to Digital Record Association Feature for a Cloud-Based Accounting Information System. In Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2022; Volume 283. [Google Scholar]
- Oleiwi, H.W.; Al-Taie, H.L.; Saeed, N.; Mhawi, D.N. A Comparative Investigation on Different QoS Mechanisms in Multi-Homed Networks. Iraqi J. Ind. Res. 2022, 9, 1–11. [Google Scholar] [CrossRef]
- Noor Al-Ufoq Company. Proceedings of the The 3rd International Scientific Conference of Computer Sciences (3SCCS2021), Muscat, Oman, 14 August 2021. Available online: https://www.researchgate.net/publication/358248266_The_3rd_International_Scientific_Conference_of_Computer_Sciences_3SCCS2021 (accessed on 31 August 2022).
- Oleiwi, H.W.; Saeed, N.; Al-Taie, H.L.; Nteesha, D. An Enhanced Interface Selectivity Technique to Improve the QoS for the Multi-homed Node. Eng. Technol. J. 2022, 40, 101–109. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef] [PubMed]
- Kadhm, M.S. An Accurate Diabetes Prediction System Based on K-means Clustering and Proposed Classification Approach. Int. J. Appl. Eng. Res. 2018, 13, 4038–4041. [Google Scholar]
- Alam, T.; Qamar, S.; Dixit, A.; Benaida, M. Genetic algorithm: Reviews, implementations and applications. Int. J. Eng. Pedagog. 2021, 10, 57–77. [Google Scholar] [CrossRef]
- Velliangiri, S.; Karthikeyan, P.; Arul Xavier, V.M.; Baswaraj, D. Hybrid electro search with genetic algorithm for task scheduling in cloud computing. Ain Shams Eng. J. 2021, 12, 631–639. [Google Scholar] [CrossRef]
- Drachal, K.; Pawłowski, M. A review of the applications of genetic algorithms to forecasting prices of commodities. Economies 2021, 9, 6. [Google Scholar] [CrossRef]
- Delyová, I.; Frankovský, P.; Bocko, J.; Trebuňa, P.; Živčák, J.; Schürger, B.; Janigová, S. Sizing and topology optimization of trusses using genetic algorithm. Materials 2021, 14, 715. [Google Scholar] [CrossRef]
- Ren, J.; Wang, H.; Liu, T. Information retrieval based on knowledge-enhanced word embedding through dialog: A case study. Int. J. Comput. Intell. Syst. 2020, 13, 275–290. [Google Scholar] [CrossRef] [Green Version]
- Mhawi, D.N.; Hashem, S.H. Proposed Hybrid Correlation Feature Selection Forest Panalized Attribute Approach to advance IDSs. Karbala Int. J. Mod. Sci. 2021, 7, 405–420. [Google Scholar] [CrossRef]
- Mhawi, D.N.; Aldallal, A. Advanced Feature-Selection-Based Hybrid Ensemble Learning Algorithms for Network Intrusion Detection Systems. Symmetry 2022, 14, 1461. [Google Scholar] [CrossRef]
- Oleiwi, H.W.; Saeed, N.; Al-taie, H.L.; Mhawi, D.N. Evaluation of Differentiated Services Policies in Multihomed Networks Based on an Interface-Selection Mechanism. Sustainability 2022, 14, 13235. [Google Scholar] [CrossRef]
- El-Bathy, N.; Azar, G.; El-Bathy, M.; Stein, G. Intelligent information retrieval lifecycle architecture based clustering genetic algorithm using SOA for modern medical industries. In Proceedings of the IEEE International Conference on Electro Information Technology, Mankato, MN, USA, 15–17 May 2011. [Google Scholar]
- Zhang, P.; Gao, H.; Hu, Z.; Yang, M.; Song, D.; Wang, J.; Hou, Y.; Hu, B. A bias–variance evaluation framework for information retrieval systems. Inf. Process. Manag. 2022, 59, 102747. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Sharma, S. An automated framework for incorporating fine-grained news data into S&P BSE SENSEX stock trading strategies. Indian J. Sci. Technol. 2016, 9, 97025. [Google Scholar] [CrossRef]
- Wang, F.; Liu, J.; Wang, H. Sequential Text-Term Selection in Vector Space Models. J. Bus. Econ. Stat. 2021, 39, 82–97. [Google Scholar] [CrossRef]
- Hassan, A.K.; Enteesha mhawi, D. Enhance Inverted Index Using in Information Retrieval. Eng. Tech. J. 2016, 34, 302–310. [Google Scholar]
- Karim Abdul Hassan, A.; Enteesha mhawi, D. A Proposed Method for Documents Indexing. Diyala J. Pure Sci. 2017, 13, 43–56. [Google Scholar] [CrossRef]
- El Guemmat, K.; Ouahabi, S. A literature review of indexing and searching techniques implementation in educational search engines. Int. J. Inf. Commun. Technol. Educ. 2018, 14, 72–83. [Google Scholar] [CrossRef]
- Bukar, A.L.; Tan, C.W.; Said, D.M.; Dobi, A.M.; Ayop, R.; Alsharif, A. Energy management strategy and capacity planning of an autonomous microgrid: Performance comparison of metaheuristic optimization searching techniques. Renew. Energy Focus 2022, 40, 48–66. [Google Scholar] [CrossRef]
- Lee, J.Y.; Cho, S.B. Sparse fitness evaluation for reducing user burden in interactive genetic algorithm. In Proceedings of the IEEE International Conference on Fuzzy Systems, Seoul, Korea, 22–25 August 1999; Volume 2. [Google Scholar]
- Shirakawa, M.; Arakawa, M. Multi-objective optimization system for plant layout design (3rd report, Interactive multi-objective optimization technique for pipe routing design). J. Adv. Mech. Des. Syst. Manuf. 2018, 12, JAMDSM0053. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Gong, D. Surrogate model-assisted interactive genetic algorithms with individual’s fuzzy and stochastic fitness. J. Control Theory Appl. 2010, 8, 189–199. [Google Scholar] [CrossRef]
- Pal, S.K.; Bandyopadhyay, S.; Biswas, S. Pattern Recognition and Machine Intelligence—First International Conference, PReMI 2005, Proceedings; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3776 LNCS, ISBN 3540305068. [Google Scholar]
- Liaw, R.T. A cooperative coevolution framework for evolutionary learning and instance selection. Swarm Evol. Comput. 2021, 62, 100840. [Google Scholar] [CrossRef]
- Rychtyckyj, N.; Reynolds, R.G. Using Cultural Algorithms to Improve Knowledge Base. IEEE Congr. Evol. Comput. 1998, 3, 1405–1412. [Google Scholar]
- Ohsaki, M. An input method using discrete fitness values for interactive GA. J. Intell. Fuzzy Syst. 1998, 6, 131–145. [Google Scholar]
- Oleiwi, H.W.; Al-Raweshidy, H. SWIPT-Pairing Mechanism for Channel-Aware Cooperative H-NOMA in 6G Terahertz Communications. Sensors 2022, 22, 6200. [Google Scholar] [CrossRef] [PubMed]
- Aldallal, A.; Alisa, F. Effective intrusion detection system to secure data in cloud using machine learning. Symmetry 2021, 13, 2306. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | General Description | Limitations |
|---|---|---|
| Boolean | It uses a theory set, which is Boolean algebra. It has three elements (i.e., the NOT, the OR, and the AND) to form a query. |
|
| Vector Space | It aims to order documents according to how closely each one resembles the user query. Documents and user queries are represented as a vector, whereas the angle between the two vectors is calculated using a cosine function. The vector space model has been introducing a term-weight scheme named the tf-idf weighting. |
|
| Probabilistic | It is initiated to order documents according to how likely they are to be relevant given a user query. Vectors d and q, which are binary vectors, represent both documents and user queries. |
|
| Indexed Technique | General Description | Limitations |
|---|---|---|
| Signature File | Compared to the original file, it is significantly smaller. It also has a greater search rate. |
|
| Inverted Index | Every document is composed of a list, which depicts the contents of the document for retrieval purposes. Fast retrieval is obtained if one can invert those keywords. All the reference words are stored alphabetically in a file called an index file. For each keyword, a list can be kept of pointers to the characterized documents in the postings file. |
|
| Searching Technique | General Description | Disadvantages |
|---|---|---|
| Linear | It is a fundamental method for discovering a certain word or keyword from a list of words or array that sequentially and individually verifies each element’s presence. It is the least complicated technique. |
|
| Brute Force | It is a well-known technique, itemizing all potential participants to the resolution, determining whether each participant reveals problem statements. |
|
| Binary | It finds the position of a particular input value (i.e., the search key) within an array sorted by some key value. The given array needs to be arranged in an ascending or descending order. The middle element key value of the provided arranged array is compared to the search key value using this technique. When both keys’ values matched, a matching item is discovered and indexed. |
|
| Directory Name | Number of Documents |
|---|---|
| Departments | 1641 |
| Students | 181 |
| Faculty | 930 |
| Courses | 1124 |
| Projects | 3763 |
| Staffs | 504 |
| Others | 137 |
| Total | 8280 |
| University Name | Number of Documents |
|---|---|
| Cornell | 867 |
| Texas | 827 |
| Washington | 1263 |
| Misc. | 1205 |
| Wisconsin | 4120 |
| Tag-name | Weight | How Many Tags Occur on Page | Description |
|---|---|---|---|
| title | 6 | appear only one time and not repeated | It is the most important tag because contains terms near to the request of the UQ. |
| header & sub-header (h1, h2, and h3) | 5 | appear n times | words found within the tags deliver structural information. |
| An anchor | 4 | appear n times | This tag contains a word this word points to another word or link. |
| Italic (I) & bold (B) | 3 | appear n times | gives the descriptions of the document and the score. |
| body | 1 | appear only one time and not repeated | less important tag that contains the plain text. |
| ID | Query | Query Length | No. of Related Doc. |
|---|---|---|---|
| 1 | WOODROW BLEDSOE | 2 | 2 |
| 2 | OPAL PROJECT | 2 | 3 |
| 3 | PASCAL PROGRAMMING | 2 | 9 |
| 4 | WERNER VOGELS | 2 | 25 |
| 5 | SOFTWARE TESTING TECHNIQUES | 3 | 2 |
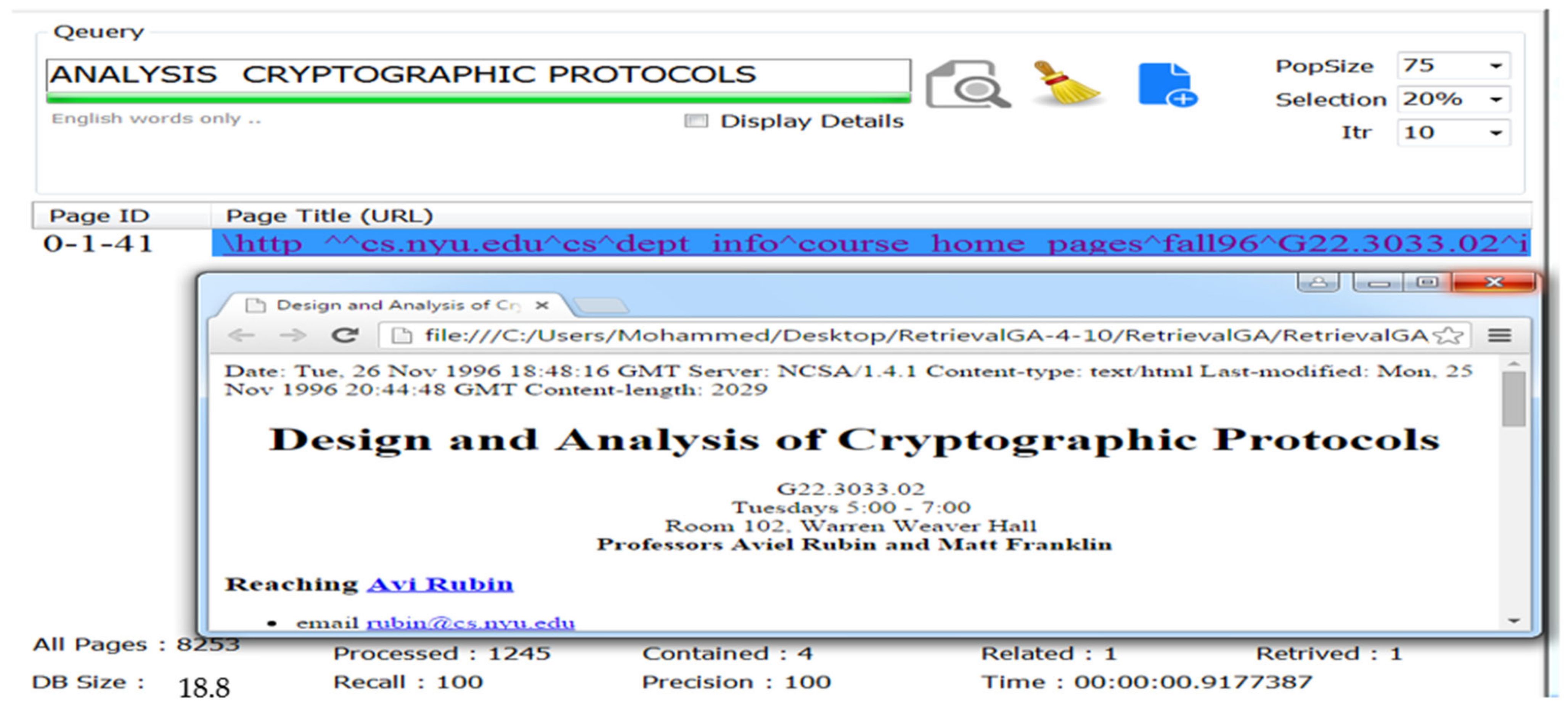
| 6 | ANALYSIS CRYPTOGRAPHIC PROTOCOLS | 3 | 1 |
| 7 | LAUREN BRICKER | 2 | 10 |
| 8 | VLSI PLACEMENT ROUTING ALGORITHMS | 4 | 1 |
| 9 | DENNIS LEE | 2 | 8 |
| 10 | CAD VLSI RESEARCH GROUP | 3 | 3 |
| 11 | WAYNE OHLRICH | 2 | 10 |
| 12 | PAUL FRANKLIN | 2 | 10 |
| 13 | TED ROMER | 2 | 13 |
| 14 | MIKE DAHLIN | 2 | 10 |
| 15 | DAVID ZUCKERMAN | 2 | 8 |
| 16 | WEB OPERATING SYSTEMS | 3 | 5 |
| 17 | SOFTWARE ENGINEERING PROJECT | 3 | 10 |
| 18 | BENJAMIN KUIPERS | 2 | 11 |
| 19 | LORENZO ALVISI | 2 | 12 |
| 20 | COMPUTER COMMUNICATION NETWORKS | 3 | 9 |
| 21 | DANIEL WELD | 2 | 7 |
| 22 | CRAIG CHAMBERS | 2 | 31 |
| 23 | PROGRAMMING SOLUTIONS | 2 | 3 |
| 24 | CARL EBELING | 2 | 36 |
| 25 | STEVE HANKS | 2 | 18 |
| 26 | STEVEN TANIMOTO | 2 | 9 |
| 27 | PAUL YOUNG | 2 | 3 |
| 28 | EFFICIENT PARALLEL ALGORITHMS | 3 | 8 |
| 29 | NANCY LEVESON | 2 | 14 |
| 30 | DISCRETE STRUCTURES COMPUTER SCIENCE | 4 | 5 |
| 31 | ADVANCED PROGRAMMING LANGUAGES | 3 | 15 |
| 32 | OLVI MANGASARIAN | 2 | 15 |
| 33 | MIRON LIVNY | 2 | 25 |
| 34 | SCIENTIFIC COMPUTATION | 2 | 30 |
| 35 | PROGRAMMING LANGUAGES COMPILERS | 3 | 19 |
| 36 | ADVANCED DIGITAL DESIGN | 3 | 7 |
| 37 | CALTECH COMPUTER SCIENCE DEPARTMENT | 4 | 5 |
| 38 | OPAL PROJECT | 2 | 3 |
| 39 | MESH GENERATION-RELATED SOFTWARE | 4 | 2 |
| 40 | INTRODUCTORY COMPUTER PROGRAMMING | 3 | 2 |
| 41 | PROBLEM-SOLVING USING COMPUTERS | 4 | 7 |
| 42 | INTRODUCTION TO NATURAL LANGUAGE UNDERSTANDING | 4 | 3 |
| 43 | SYSTEM PROGRAMMER | 2 | 3 |
| 44 | JAVA-RELATED ITEMS | 3 | 1 |
| 45 | PROGRAMMING LANGUAGES IMPLEMENTATION | 3 | 2 |
| 46 | NEURAL NETWORKS INFORMATION | 3 | 2 |
| 47 | DIGITAL SYSTEMS DESIGN | 3 | 25 |
| 48 | NETWORKS DISTRIBUTED PROCESSING | 3 | 1 |
| 49 | NUMERICAL ANALYSIS COMPUTING | 3 | 1 |
| 50 | PARALLEL LANGUAGES COMPILERS | 3 | 1 |
| ID | Parameters | Value |
|---|---|---|
| 1 | Population size | 75 by experiment |
| 2 | Chromosome length (dynamic) | Dynamic (depending on the intersection between words of a query with web pages (shared pages)). |
| 3 | Number of iterations | 15 by experiment |
| ID | Query | Recall Measures | ||
|---|---|---|---|---|
| 25 | 50 | 75 | ||
| 1 | WOODROW BLEDSOE | 100% | 100% | 100% |
| 2 | OPAL PROJECT | 33.33% | 66.66% | 100% |
| 3 | PASCAL PROGRAMMING | 55.55% | 66.66% | 77.77% |
| 4 | WERNER VOGELS | 92% | 96% | 96% |
| 5 | SOFTWARE TESTING TECHNIQUES | 100% | 100% | 100% |
| 6 | ANALYSIS CRYPTOGRAPHIC PROTOCOLS | 100% | 100% | 100% |
| 7 | LAUREN BRICKER | 90% | 100% | 100% |
| 8 | VLSI PLACEMENT ROUTING ALGORITHMS | 100% | 100% | 100% |
| 9 | DENNIS LEE | 62.5% | 62.5% | 62.5% |
| 10 | CAD VLSI RESEARCH GROUP | 66.66% | 100% | 100% |
| 11 | WAYNE OHLRICH | 88.88% | 88.88% | 88.88% |
| 12 | PAUL FRANKLIN | 50% | 50% | 70% |
| 13 | TED ROMER | 76.69% | 84.46% | 84.46% |
| 14 | MIKE DAHLIN | 70% | 50% | 70% |
| 15 | DAVID ZUCKERMAN | 37.5% | 50% | 62.5% |
| 16 | WEB OPERATING SYSTEMS | 80% | 80% | 80% |
| 17 | SOFTWARE ENGINEERING PROJECT | 60% | 90% | 90% |
| 18 | BENJAMIN KUIPERS | 72.72% | 72.72% | 81.81% |
| 19 | LORENZO ALVISI | 100% | 100% | 100% |
| 20 | COMPUTER COMMUNICATION NETWORKS | 55.55% | 66.66% | 77.77% |
| ID | Query | Semantic Results | Recall | Precision |
|---|---|---|---|---|
| 1 | WOODROW BLEDSOE | 2 of 2 | 100% | 100% |
| 2 | OPAL PROJECT | 3 of 3 | 100% | 100% |
| 3 | PASCAL PROGRAMMING | 9 of 9 | 100% | 100% |
| 4 | WERNER VOGELS | 25 of 25 | 100% | 100% |
| 5 | SOFTWARE TESTING TECHNIQUES | 2 of 2 | 100% | 100% |
| 6 | ANALYSIS CRYPTOGRAPHIC PROTOCOLS | 1 of 1 | 100% | 100% |
| 7 | LAUREN BRICKER | 10 of 10 | 100% | 100% |
| 8 | VLSI PLACEMENT ROUTING ALGORITHMS | 1 of 1 | 100% | 100% |
| 9 | DENNIS LEE | 8 of 8 | 100% | 100% |
| 10 | CAD VLSI RESEARCH GROUP | 3 of 3 | 100% | 100% |
| 11 | WAYNE OHLRICH | 9 of 9 | 100% | 100% |
| 12 | PAUL FRANKLIN | 9 of 10 | 90% | 100% |
| 13 | TED ROMER | 11 of 13 | 90% | 100% |
| 14 | MIKE DAHLIN | 10 of 10 | 100% | 100% |
| 15 | DAVID ZUCKERMAN | 8 of 8 | 100% | 100% |
| 16 | WEB OPERATING SYSTEMS | 5 of 5 | 100% | 100% |
| 17 | SOFTWARE ENGINEERING PROJECT | 9 of 10 | 90% | 100% |
| 18 | BENJAMIN KUIPERS | 10 of 11 | 90% | 100% |
| 19 | LORENZO ALVISI | 12 of 12 | 100% | 100% |
| 20 | COMPUTER COMMUNICATION NETWORKS | 9 of 9 | 100% | 100% |
| 21 | DANIEL WELD | 6 of 7 | 90% | 100% |
| 22 | CRAIG CHAMBERS | 30 of 31 | 90% | 100% |
| 23 | PROGRAMMING SOLUTIONS | 3 of 3 | 100% | 100% |
| 24 | CARL EBELING | 45 of 36 | 90% | 100% |
| 25 | STEVE HANKS | 17 of 18 | 90% | 100% |
| 26 | STEVEN TANIMOTO | 8 of 9 | 90% | 100% |
| 27 | PAUL YOUNG | 3 of 3 | 100% | 100% |
| 28 | EFFICIENT PARALLEL ALGORITHMS | 8 of 8 | 100% | 100% |
| 29 | NANCY LEVESON | 14 of 14 | 100% | 100% |
| 30 | DISCRETE STRUCTURES COMPUTER SCIENCE | 4 of 5 | 90% | 100% |
| 31 | ADVANCED PROGRAMMING LANGUAGES | 14 of 15 | 90% | 100% |
| 32 | OLVI MANGASARIAN | 15 of 15 | 100% | 100% |
| 33 | MIRON LIVNY | 24 of 25 | 96% | 100% |
| 34 | SCIENTIFIC COMPUTATION | 28 of 30 | 92% | 100% |
| 35 | PROGRAMMING LANGUAGES COMPILERS | 18 of 19 | 90% | 100% |
| 36 | ADVANCED DIGITAL DESIGN | 6 of 7 | 85.71% | 100% |
| 37 | CALTECH COMPUTER SCIENCE DEPARTMENT | 5 of 5 | 100% | 100% |
| 38 | OPAL PROJECT | 3 of 3 | 100% | 100% |
| 39 | MESH GENERATION-RELATED SOFTWARE | 2 of 2 | 100% | 100% |
| 40 | INTRODUCTORY COMPUTER PROGRAMMING | 2 of 2 | 100% | 100% |
| 41 | PROBLEM-SOLVING USING COMPUTERS | 7 of 7 | 100% | 100% |
| 42 | INTRODUCTION TO NATURAL LANGUAGE UNDERSTANDING | 3 of 3 | 100% | 100% |
| 43 | SYSTEM PROGRAMMER | 3 of 3 | 100% | 100% |
| 44 | JAVA-RELATED ITEMS | 1 of 1 | 100% | 100% |
| 45 | PROGRAMMING LANGUAGES IMPLEMENTATION | 2 of 2 | 100% | 100% |
| 46 | NEURAL NETWORKS INFORMATION | 2 of 2 | 100% | 100% |
| 47 | DIGITAL SYSTEMS DESIGN | 23 of 25 | 97% | 100% |
| 48 | NETWORKS DISTRIBUTED PROCESSING | 1 of 1 | 100% | 100% |
| 49 | NUMERICAL ANALYSIS COMPUTING | 1 of 1 | 100% | 100% |
| 50 | PARALLEL LANGUAGES COMPILERS | 1 of 1 | 100% | 100% |
| Average | 98.5236% | 100% | ||
| Item | Proposed | Ref. [20] | Traditional |
|---|---|---|---|
| Documents indexing method | ADIM | Enhance inverted index | Inverted index |
| Memory space for the doc. indexing | 18.8 MB | 100 MB | 895.186 MB |
| Average Recall | 98.5% | 84% | N/A |
| Average of Precision | 100% | 86% | N/A |
| Response time in milliseconds | 00.46.74.78 ms | N/A | Measured by minutes |
| Displaying the most relevant document | based on the fitness function | first 10 ranked documents | ranking method |
| Optimal solution convergence | 15 iterations | 22 iterations | N/A |
| Population size | 75 | 125 | N/A |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mhawi, D.N.; Oleiwi, H.W.; Saeed, N.H.; Al-Taie, H.L. An Efficient Information Retrieval System Using Evolutionary Algorithms. Network 2022, 2, 583-605. https://doi.org/10.3390/network2040034
Mhawi DN, Oleiwi HW, Saeed NH, Al-Taie HL. An Efficient Information Retrieval System Using Evolutionary Algorithms. Network. 2022; 2(4):583-605. https://doi.org/10.3390/network2040034
Chicago/Turabian StyleMhawi, Doaa N., Haider W. Oleiwi, Nagham H. Saeed, and Heba L. Al-Taie. 2022. "An Efficient Information Retrieval System Using Evolutionary Algorithms" Network 2, no. 4: 583-605. https://doi.org/10.3390/network2040034