1. Introduction
The development of maintenance strategies for multicomponent systems is an increasingly important topic in the field of reliability. In the industrial field, choices must be made between different maintenance options such as those regarding the nature of the maintenance (preventive or corrective) and the frequency or type of maintenance action to perform. When a single-component system is considered, maintenance optimization seems “simple” (the optimization is then a strategy of finding the best times to intervene while accounting for the dynamics of system degradation and constraints relating to availability, safety, maintainability, etc.), but the problem increases in complexity as the size of the system increases. Complexity is added when there are interactions (economic, stochastic, etc.) between the components of the system. In this case, the optimal solution for a multicomponent system can be very far from a “stacking” of the individual optimal strategies characterizing each component considered alone. Research on maintenance optimization dates to the 1960s, and many works try to deal with some aspects of this particularly hard and complex problem: from modeling the degradation processes to taking on constraints such as reliability, staff availability, costs, etc., or more recently, taking advantage of the advancements in monitoring or new technologies such as artificial intelligence, machine learning, big data, and the Internet of Things. For more details, readers could refer to the last literature review on maintenance optimization proposed by Pincirolli et al. [
1].
To optimize the maintenance cost of a multicomponent system, approaches that group maintenance actions are generally proposed. These groupings are beneficial from an economic perspective (in particular, grouping reduces fixed costs), but also ensure that the system functions well overall. In recent years, many maintenance strategies have been proposed that bundle maintenance tasks. Several papers have discussed this problem; see, for example, Refs. [
2,
3,
4,
5]. The aim of these strategies is to minimize maintenance costs and ensure system availability. For example, Dekker et al. reviewed the literature on multicomponent system maintenance strategies considering the economic dependence between systems’ components [
2]. They listed different types of strategies: stationary politics with a long-term stable situation and dynamic strategies that account for the modification of the system in the short term. Those strategies handle either corrective or preventive maintenance or, in some cases, combined corrective and preventive maintenance actions. The operational nature of the system indicates the type of planning horizon. In [
5], most grouping policies are concerned with series systems because the shutdown of one component leads to the total shutdown of the system. Then, authors proposed a maintenance strategy for multicomponent systems with dynamic contexts and a finite horizon model to optimize online the maintenance strategy in dynamic contexts. The paper neglects the maintenance duration and the impacts of the grouped maintenance on the production systems. The proposed strategy was applied to a numerical example of a 16-component system. The results highlight the preference and robustness of the proposed maintenance grouping strategy.
Proposing a maintenance grouping strategy for a system with several components starts with the proposal of an individual preventive maintenance plan for each component. In industry, preventive maintenance is the act of periodically performing a maintenance action to fix or replace a component before its failure. Different preventive maintenance approaches exist. A systematic approach identifies an optimal maintenance path in accordance with the lifetime of the component and the maintenance cost; see, for example, [
6]. The aim of a conditional policy is to determine an optimal preventive degradation threshold according to the degradation model, maximum degradation threshold, and maintenance cost [
7]. The last preventive maintenance type is the predictive approach. This approach is like the conditional approach, but the preventive threshold is replaced by a failure risk as the remaining useful life [
8]. This paper considers the systematic approach.
To evaluate the state of a system S at time t, a decision variable is assigned for each component to identify whether it has failed or is operating, and since the maintenance strategy proposed in this paper is based on reliability, it is necessary to identify the state space of the system. In our study, the decision variables are therefore the ones that provide the renewal (or repair) times. In the literature, two approaches have generally been considered. The state space Dℶ of a given component denoted i can be either continuous (e.g., the percentage of pavement cracked) or discrete with a finite number of states. In this study, the states can be reduced to two: respectively, the operating and failure states.
In the case in which the decision variable is continuous, a component is considered to have failed if this variable exceeds a set failure threshold. In this work, the condition of each component
i is periodically inspected (an inspection step is set), and the decision variable is continuous. With this approach, the exact date when the component crosses the failure threshold is not known. Then, the inspection data are said to be censored. The censored data are categorized into three types: left censored, interval censored, and right censored. Thus, to address this kind of problem, the literature proposes three families of algorithms: expectation–maximization (EM) [
9,
10], stochastic expectation–maximization (SEM) [
11,
12], and Bayesian restoration maximization (BRM) [
13,
14,
15]. In this work, an EM algorithm is considered.
Although there are several papers in the literature that study the maintenance of road infrastructure, no studies take into consideration all the components of the road infrastructure (pavement and marker lines). The main goal of this paper is, therefore, to propose an optimal maintenance plan of all the marker lines of a given road infrastructure regarding a grouping approach. To achieve this goal, a specific data processing and analysis approach is proposed. This study is motivated by the needs of autonomous and connected vehicles for road infrastructure.
2. Introduction to the Problem and the Use Case
Preventive maintenance has been discussed by many authors. In industry, preventive maintenance is the act of periodically performing a maintenance action to x or replace a component before its failure. In the literature, many preventive maintenance strategies exist. In [
16], two types of preventive maintenance policies are considered. The first is useful for maintaining simple equipment, and the second is useful for maintaining complex systems. In the same context, Valdez-Flores et al. included optimization models for the repair, replacement, and inspection of systems subject to stochastic deterioration [
17]. In 2002, Wang proposed different types of preventive maintenance: the age replacement policy, random age replacement policy, block replacement policy, and repair cost limit policy [
18]. Finally, Barlo and Proshan concluded that the age replacement policy is an economical way to determine block replacement age [
19]. Under this policy, a component is replaced at age
T* or after failure. Refs. [
20,
21] introduced another type of preventive maintenance policy (imperfect maintenance) with minimal repair. This policy is equivalent to a perfect repair with probability
p and a minimal repair with probability 1 −
p. After imperfect maintenance, the component is not as good as new but is younger. In the same context, Ref. [
22] discussed conditional preventive maintenance. This type of policy is based on controls and inspections to guarantee the optimal availability of a component. This paper considered an age replacement policy.
Then, the optimization of maintenance strategies is also a key issue. As many papers can easily be found in the literature, we chose to focus on works dedicated to road infrastructure. Thus, Guan et al. proposed a multi-objective optimization model considering the interactions between pavement condition and traffic dynamics for the planning of multi-year road network maintenance considering a genetic algorithm [
23]. In [
24], authors proposed a multiple Markov decision process model and a priority-based two-stage method for determining optimal maintenance decisions for road infrastructure. In [
25], based on a semi-Markov approach to model the road deterioration through a Weibull model, linear programing models were proposed to define optimal maintenance policies to minimize the lifecycle cost of a road.
As mentioned in
Section 1, our work focuses on multicomponent systems that refer to a mixture of a few components which may interact with each other. These components are structured in different configurations: serial, parallel, or a complex combination of serial and parallel structures. The structure of the system represents the way in which the components are arranged to perform a common function. The modeling of the system structure is vital because it conditions the overall functioning of the system. A serial system works if all its components work, but a parallel system works if at least one of its components works.
In industry, grouping maintenance is a way to minimize preventive maintenance costs. The aim of the method is to identify the optimal time to simultaneously maintain a complex system’s components. According to [
2], the dependencies between the system’s components are classified into stochastic, structural, and economic. Many grouped maintenance policies are presented, and most consider only economic dependence.
Nguyen introduced two types of grouped maintenance policies: dynamic policies that allow maintenance plans to be updated in a dynamic context and stationary policies that do not consider the dynamic context [
26]. However, grouping maintenance actions can also be conducted in a dynamic context [
4,
5]. In this case, some changes both in the costs during the planning horizon and in the system’s structure must be introduced. Ref. [
27] proposed a stationary grouped maintenance strategy for systems with complex structures. The grouping methodology is presented as a policy for making the maintenance cost cheaper than separately performing the maintenance activities. In the same context, [
3] proposed a grouped maintenance optimization for series systems subject to reliability constraints. Most of the grouping strategies are based on genetic algorithms, and some recent papers explored other operational research solutions. Thus, a particle swarm optimization algorithm was proposed for both optimizing the availability of a system and minimizing the cost of its preventive maintenance through a grouping strategy [
28]. More recently, a clustering approach was proposed for optimal grouping maintenance strategies for complex structure systems [
29]. Finally, some grouping strategies tried to take constraints into account. Up to now, only one constraint is generally introduced in grouping policies, mainly connected to maintenance teams. Thus, Do et al. proposed a dynamic maintenance grouping strategy, optimized on a rolling horizon using a genetic algorithm, under both availability and limited repairmen constraints [
30]. In a road context, Jha et al. considered a cost minimization problem considering work shift and overtime constraints. An algorithm using Floyd’s shortest path method was developed to optimize the time and paths for efficient inspection of highway assets [
31].
In our paper, the proposed methodology considers the interdependence existing between components. In conclusion, the main aim of this study is to propose a grouped maintenance policy for multicomponent systems in a finite planning horizon.
For some systems, the components do not really fail but reach a serviceability threshold. Therefore, even for serial systems, if a component reaches a serviceability limit state, the entire system remains in operation. Thus, it is important to inspect the system to know the condition of each component. As introduced in
Section 1, the aim of this paper is to determine an optimal maintenance strategy for road marking considering a grouping approach. For this, a specific data processing approach to analyze the feedback data of multicomponent systems is defined and introduced. The contribution of this study is summarized in
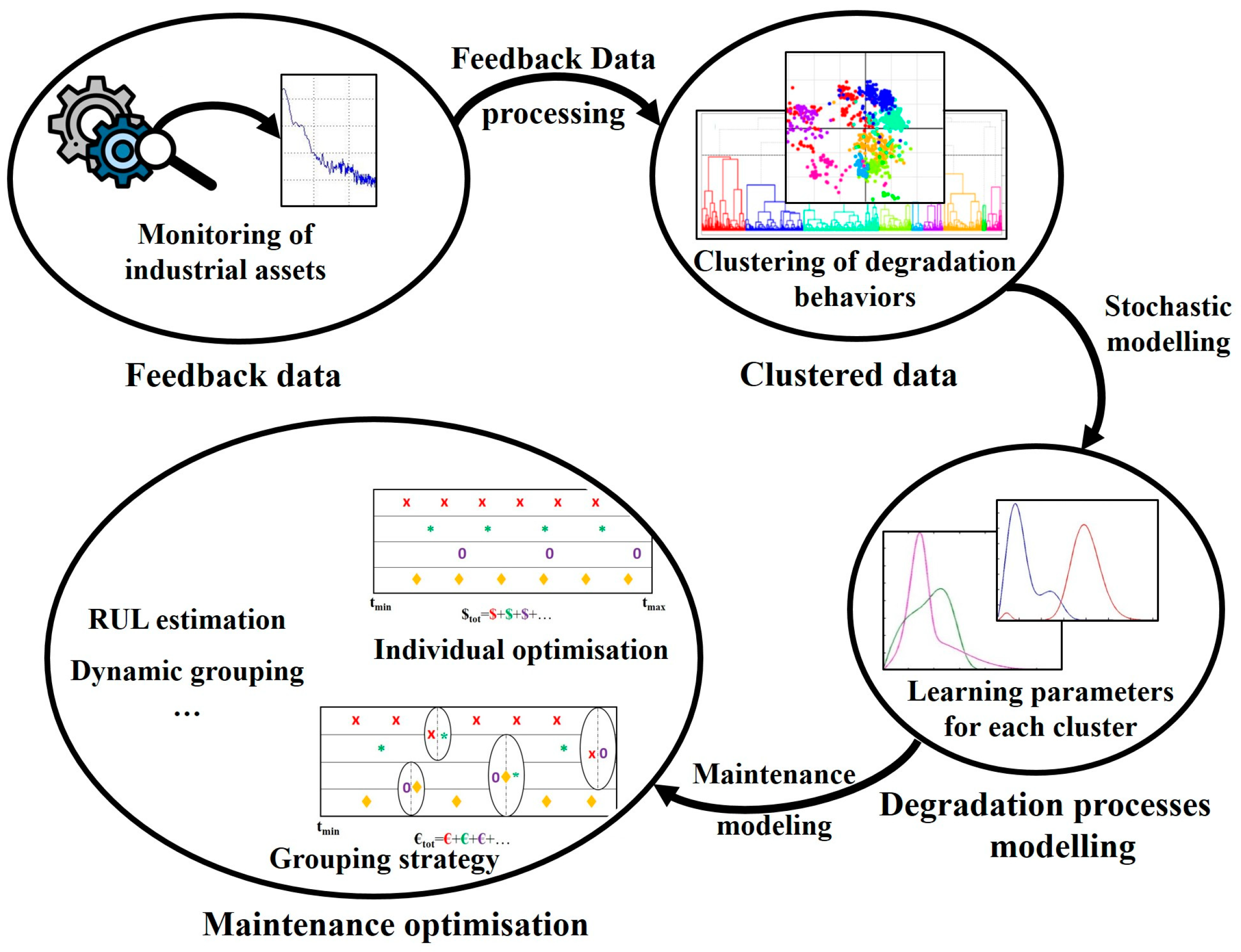
Figure 1, which introduces our contribution and all the algorithms used. As illustrated in
Figure 1, the proposed grouping strategy involves four main steps:
Data collection and analysis;
Classification of system components into several clusters according to their degradation process;
Individual maintenance optimization for each cluster;
Maintenance action grouping, considering the interactions between the system components.
The contributions of this paper focus on the last three steps previously introduced. Each of these steps will be discussed and detailed in the next sections.
The proposed strategy is applied to periodically inspected feedback data. The exact failure time is not generally observed, and the feedback data contain multiple types of censoring: left censoring, interval censoring, and right censoring. To address this kind of data, a Weibull analysis is proposed for estimating the failure time using maximum likelihood estimation (MLE).
In 2007, Hunter suggested using the EM algorithm to estimate the date of failure [
8]. In the case of incomplete or missing data, an EM algorithm is a useful method for finding the maximum likelihood. A Weibull analysis is a commonly used methodology for performing life data analysis. Indeed, it is an effective method for determining reliability characteristics and has demonstrated a good “agility” to fit the behavior of a population. Ducros and Pamphile proposed EM, SEM, and BRM algorithms for estimating the Weibull parameters [
14]. In the second section of this paper, an extension of the EM algorithm for processing left- and right-censored data is presented. The proposed algorithm is applicable to all observation vectors independent of the nature of the censoring.
In this paper, the EM algorithm proposed by M. Redondin is used. According to the work of Sathyanarayanan, this algorithm is suitable for the simulation of road marking degradation [
32]. To simplify the study, the components of the system are clustered into groups according to their degradation level. Then, a maintenance strategy is proposed for each cluster.
In data mining, two types of classification exist: supervised and unsupervised. Supervised classification is the data mining algorithm most often used for quantitative analysis. In the literature, supervised classification algorithms are often used with image data. In this case study, agglomerative hierarchical clustering (AHC) combined with a factor analysis of mixed data (FAMD) is considered since its use has been proven relevant for road markings [
33]. This strategy is introduced in
Section 4.
In this article, the feedback data (the inspection date t and the level of degradation of a component) are classified in a state space marked D. In this framework, the data are censored, so the state space is divided into four subspaces according to the nature of the censoring. D = DE ∪ DL ∪ DI ∪ DR, where DE represents the exact data, DL the left-censored data, DI the interval-censored, data and DR the right-censored data. Then, the data collected during inspections are clustered into k clusters according to their degradation model. To correct the censoring of each cluster Cj with j ∈ {1, …, k}, an EM algorithm is applied to estimate the exact dates of failure and assign a probability distribution for the degradation model for each cluster Cj with j ∈ {1, …, k}. Once the parameters of the Weibull distribution (αj, βj) are estimated and the various maintenance costs are set, an optimal replacement period Tj∗ is defined for each cluster Cj. For minimizing maintenance costs, a bundling strategy is applied to identify a maintenance date that bundles several maintenance actions together.
This paper considers an example structured as a series system whose components are independent and periodically inspected. The decision variable is continuous.
In conclusion, although the case study is limited to serial systems, the minimum requirement to apply this grouping strategy is to have an inspection history of the different components of the system. The feedback data process and grouped maintenance strategy, illustrated in
Figure 1, is proposed for:
This paper is structured as follows. In
Section 3, a strategic clustering of the system components is discussed. The aim is to group the components that degrade in the same way in order to assign a maintenance strategy to each cluster. The feedback data considered in this paper are censored. Instead of correcting the censoring for each component, it is corrected for each cluster by applying an EM algorithm, presented in
Section 4. The maintenance policy chosen (for each cluster) in this paper is an age-based policy. It is discussed in detail in
Section 5. To minimize the preventive maintenance cost of a given system, a grouping policy is proposed in
Section 6, and its application is discussed in
Section 7.
8. Application of the Grouping Strategy to Road Markings
As mentioned above, serial systems are considered in the study case, and the components are periodically inspected. To highlight the proposed grouping process, the proposed strategy is applied to the retroreflective road markings of French National Road 4 (NR4) connecting Paris to Strasbourg.
The retroreflective road markings on road lanes can reflect the light from a vehicle’s headlight back to the driver. The retroreflectivity of road markings is used to improve the quality of road lanes in low-light and night conditions. These markings provide visual guidance for drivers.
According to NF EN 1436, the French standard for road markings—the retroreflection luminance of markings—is a standard measure used for evaluating marking degradation. This road section is managed by the DIR Est. To evaluate the state of the markings, one inspection per year, in late September, is conducted. The retroreflectivity level of a marking is measured in millicandela per square meter and by luminance (mcd/m
2/lx). For simplicity, a measurement is generally interpreted as a single marking, a point of reference (PR), located by a landmark (e.g., a mile marker). According to Tidjani et al., a road marking is considered to have “failed” and must be replaced if its retroreflectivity level is less than 150 mcd/m
2/lx [
33]. In this case, the replacement is the only maintenance action.
The NR4 generally consists of three lines: the median strip line (MSL), emergency line (EL), and broken center line (BCL). The road marking is then represented by a serial system, denoted S, with three components.
As mentioned above, road markings are periodically inspected. Thus, the exact failure time is unknown. In this case, the feedback data contain many censored data points. The EM algorithm is then applied to the PR of each line. To simplify the study, the PR values of all the lines are clustered into
g clusters according to the retroreflectivity level degradation using the AHC introduced in
Section 3. This methodology shows that each line can be clustered into nine clusters.
Figure 10 directly presents all these nine clusters on the map (each color represents a cluster).
Projecting the clustering results on the map, we can see that it is mainly based on different characteristics of the road (type of pavement, type of lanes, and location: city, village, etc.).
The first cluster, represented in black on the map, contains 9% of the PRs of the NR4. It appears that the road markings in this cluster are laid on 2 × 2 lanes and two-lane single pavements in excellent condition. On these sections, some grading, interchanges, and planes are noticed.
Cluster 2, presented in yellow on the map, contains 12% of the marking lines. The pavement is generally paved with very thin modified bitumen, and is a 2 × 2 lane-divided pavement. In this cluster, there is the presence of unevenness, and the markings have exhibited rather stable evolution over time.
Cluster 3 groups together only the pavements in poor condition, and this is essentially a 2 × 2 lane-divided pavement surfaced with very thin modified bitumen.
Cluster 4 represents 11% of the road lines. A significant number of markings belonging to this cluster have poor pavement conditions. This includes markings on single four-lane roadways paved with very thin modified asphalt. The intersection in the plan is remarkable.
In cluster 5, The road markings have acceptable conditions and are primarily placed on single two-lane roadways. This is the only cluster that contains a portion of three-lane single pavement.
Cluster 6 focuses on 2 × 2 lane-divided roadways paved with very thin modified bitumen and in acceptable condition. There is a significant presence of gradients and interchanges.
Cluster 7 consists mostly of single two-lane pavement paved with pure thin bitumen in acceptable condition. It is the only cluster in which there are no special crossings, and its asphalt is the oldest of all and has the lowest daily traffic rate.
Cluster 8 is the only cluster where all road markings are in excellent condition. It contains, in particular, 2 × 2 lane-divided roads. Apart from the presence of gradients and planes in this cluster, a fairly high percentage of interchanges is noted.
Finally, cluster 9 has a significant percentage of grade separation. Single two-lane pavements and 2 × 2 lane-divided pavements, semi-gritty bitumen, and acceptable condition are observed. All three types of markings in this cluster show a similar pattern.
The literature shows that the Weibull distribution is suitable for analyzing the reliability of road markings. Thus, to correct the censored data, the EM algorithm is applied to each cluster
j ∈ {1…
g} with
g = 9. For each cluster
Cj, a Weibull analysis is applied using the EM algorithm presented in
Section 4. The aim of this analysis is to determine the parameters of the Weibull distribution for each cluster.
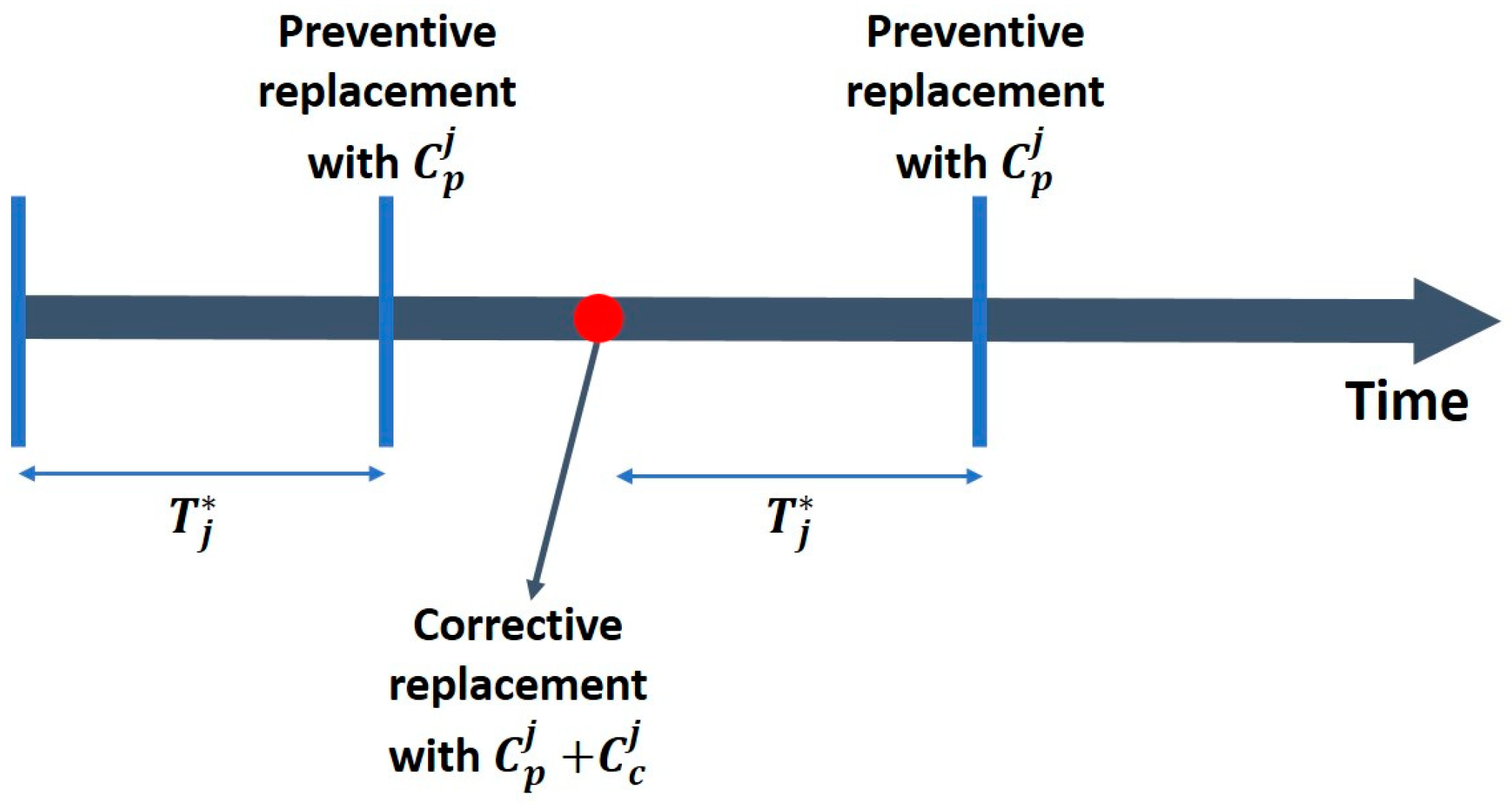
Let and be, respectively, the preventive and corrective maintenance costs of cluster Cj. The preventive maintenance cost allocated for road markings is Cp = 10 K, and the corrective maintenance cost is arbitrarily defined as Cc = 3∗Cp. This global budget is distributed equitably according to the size of the clusters. With these costs in mind, the optimal maintenance path is defined using age-based maintenance.
Table 1,
Table 2 and
Table 3 show the Weibull parameters
αj and
βj of each cluster
Cj and the optimal maintenance replacement path for each of the three lines (respectively, broken center line, emergency line, and median strip line). Note that colors in the first column refer to the clustering of the roadmap introduced in
Figure 10.
The first column presents the number of the PRs that belong to each cluster with their frequency. The second one shows the associated Weibull parameters estimated by the EM algorithm. The third column presents the average operating time, and the last one lists the optimum replacement period associated with each cluster.
The replacement interval for the axial line varies between 8 and 18 months, that of the EL varies between 9 and 28 months, and that of the MSL varies between 11 and 45 months. The difference in replacement frequency is due to the nature of the road section and its location.
As an illustration, we take the first cluster as an example. It represents 9% of the PRs of NR4. The lifetime model associated with the BCL is Ω(21.84, 2.01). The preventive maintenance cost is estimated to be 940 units, and the corrective maintenance cost is defined as three times the preventive cost. According to the age-based replacement strategy, the PRs belonging to this cluster must be replaced every 19 months. The same methodology is applied to the other lines, which shows that the EL and MSL can be replaced every 12 and 19 months, respectively.
According to Tidjani et al., the clustering algorithm is followed by a FAMD to analyze the clusters or the strategic maintenance areas [
33]. The FAMD proposes data management and identifies different correlations between variables. However, the FAMD considers only the CBL and EL because those of the MSL are not available everywhere on NR4.
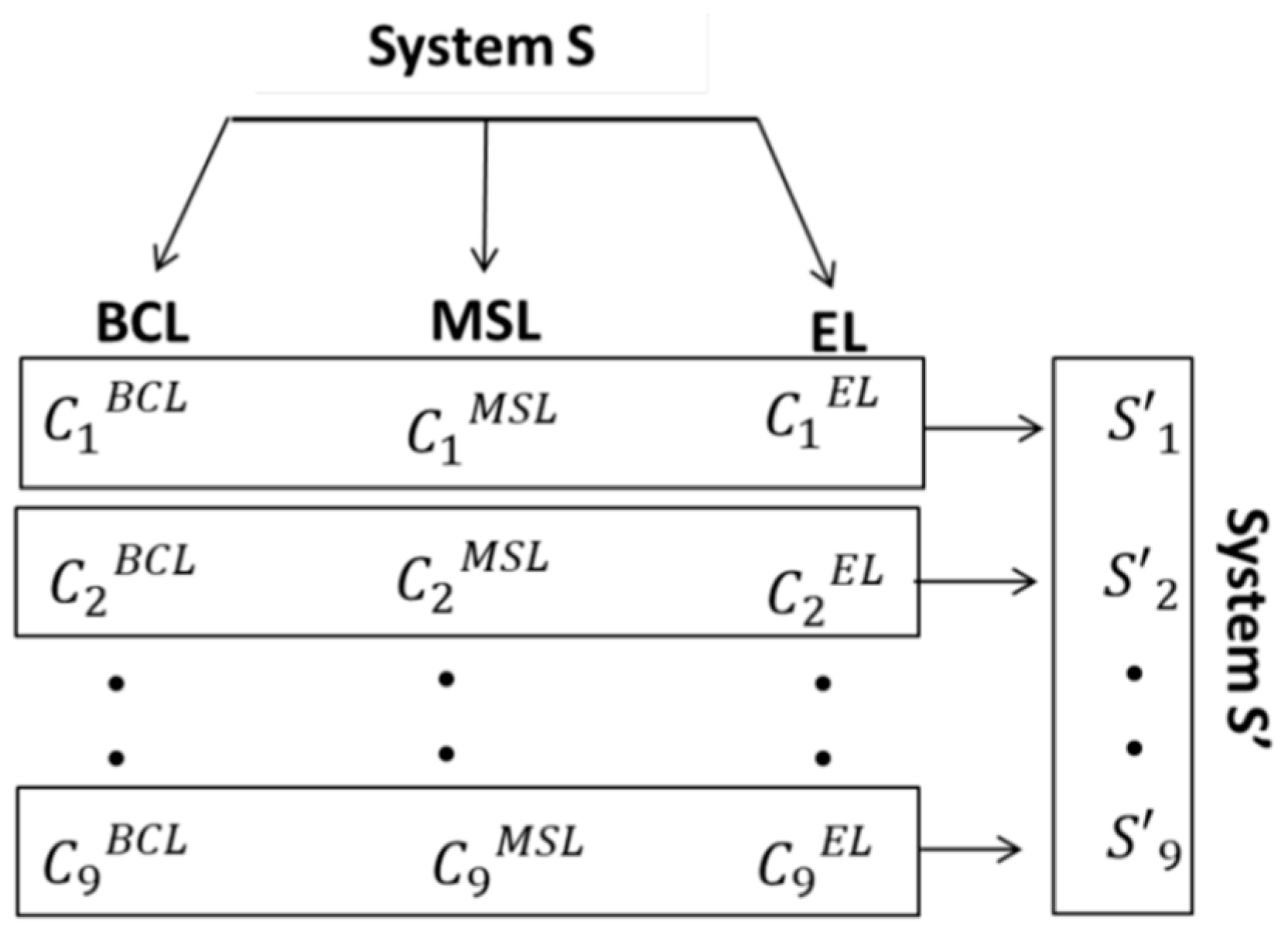
To minimize the preventive maintenance cost of the system
S, we assume that each cluster represents a component of a new system denoted
S′. Then,
S′ is a system consisting in nine subsystems,
S1′,
S2′ …
S9′, construed as illustrated in
Figure 11.
To minimize the preventive maintenance cost, the grouping methodology presented in this paper is applied to the components of each subsystem Si′, where i ∈ {1… 9}. The aim is to determine an optimal maintenance time for replacing the three types of road markings (BCL, EL, and MSL).
It is assumed that the components have just been held and that the planning time fence starts at time t = 0 (Tbegin = 0). This strategy is applied to the rst subspace, and the planning horizon thus becomes HZ = [0,19]. At this horizon, each component must be replaced only once. For determining the optimal grouping structure, the previously introduced GA presented is considered.
Then, an initial population has to first be generated, and then the GA can be applied. The maintenance actions over the planning horizon are {1
(1), 2
(1), 3
(1)}. As an illustration, we consider two examples of grouping structures with two groups:
G1 = {1
(1), 3
(1)} and
G2 = {2
(1)} or
G1 = {1
(1), 2
(1)} and
G2 = {3
(1)}, as illustrated
Figure 12.
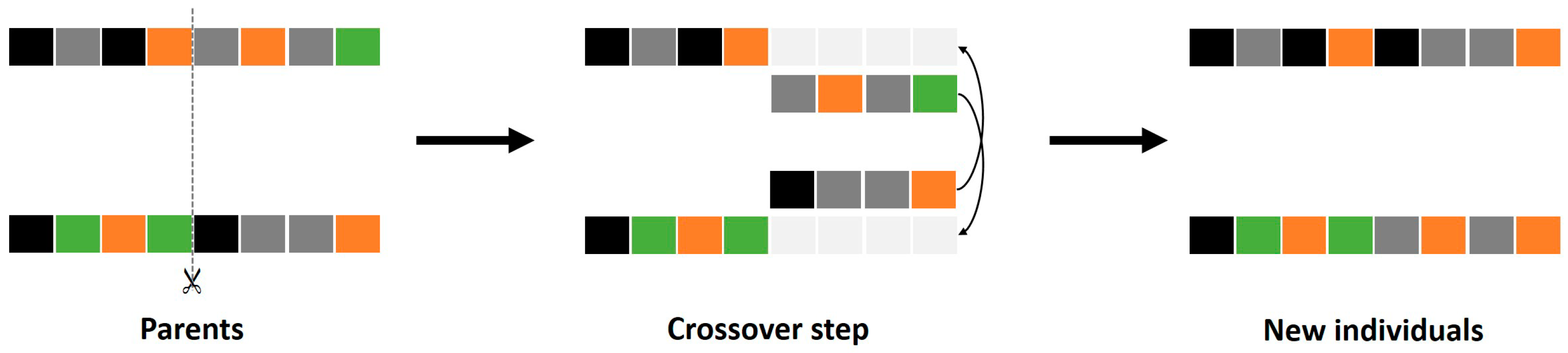
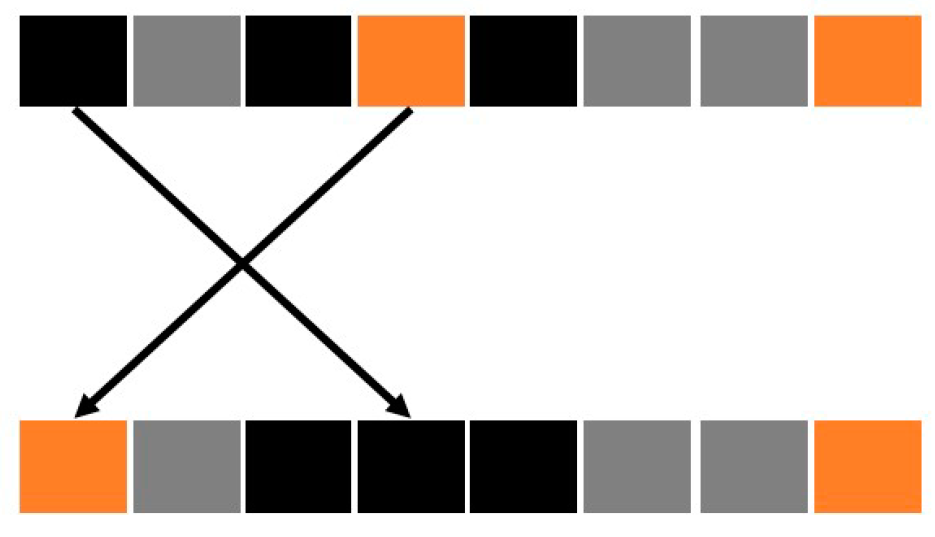
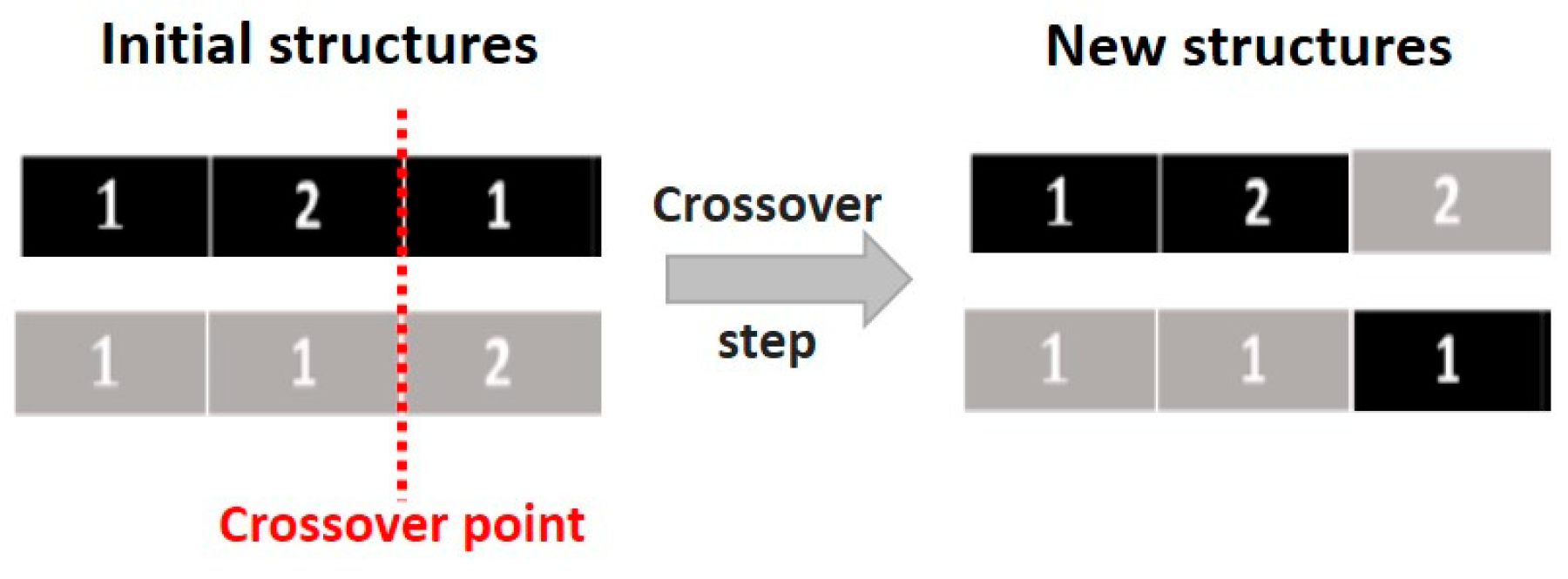
The two considered candidate solutions are encoded considering the method introduced in the previous section. Then, to generate new candidate solutions, the crossover step has to be considered. A random crossover point is chosen (e.g., point 2), and the new solutions are constructed, as represented in
Figure 13.
The other steps of the GA are then applied, and other solutions are thus generated. In each iteration, the economic profit is calculated, and the best solutions are selected for the next iteration (generation). The economic benefit is calculated for each solution, and the optimal one is the candidate with the greatest total economic benefit.
Table 4 shows the optimal grouping structure for each iteration and the associated economic profit with the optimal grouping time. The best economic profit is obtained when all the maintenance actions are performed 13 months after the last replacement. This represents a 10% gain in the total maintenance cost.
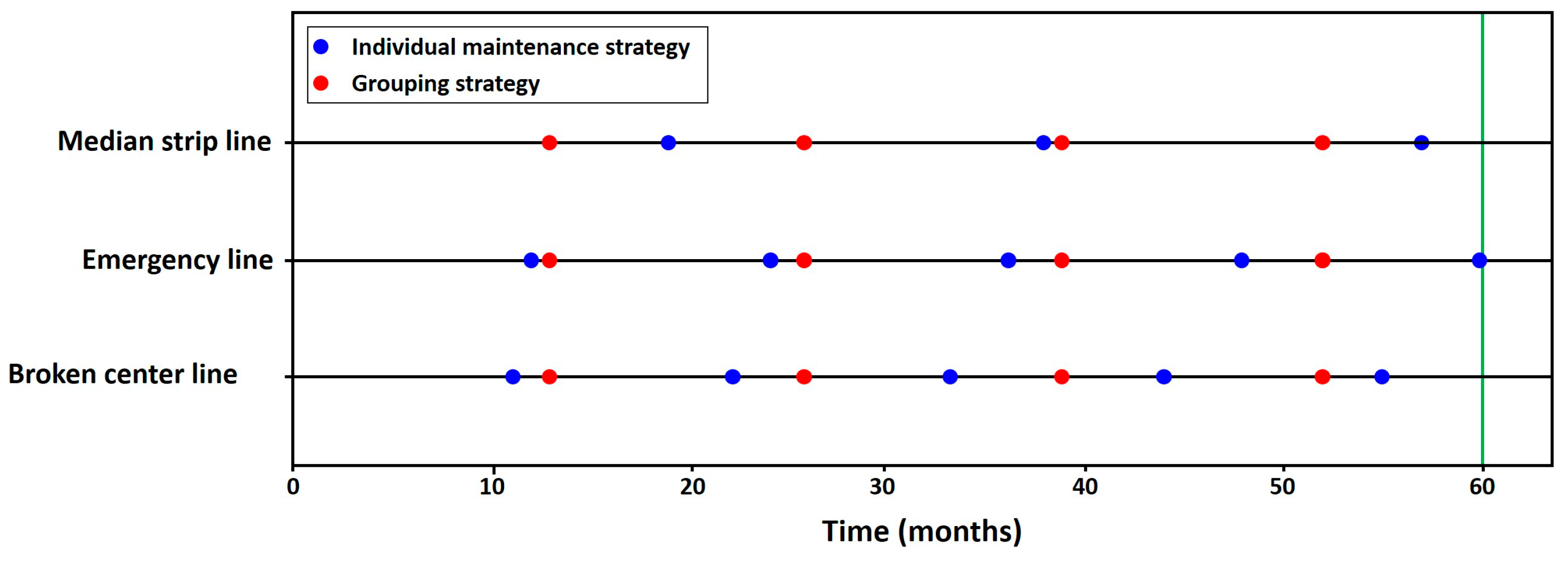
To evaluate the reliability of the system in the case of grouped maintenance, we apply the maintenance strategies over a planning horizon of 60 months (5 years).
Figure 14 presents a comparison between the individual maintenance plan and one with a grouping strategy. The blue points indicate the maintenance action for the individual optimal plan, and the red ones are the maintenance times for the grouped strategy. For this cluster, each component is maintained only once per cycle, and the cluster plan indicates that all three components can be maintained simultaneously every 13 months.
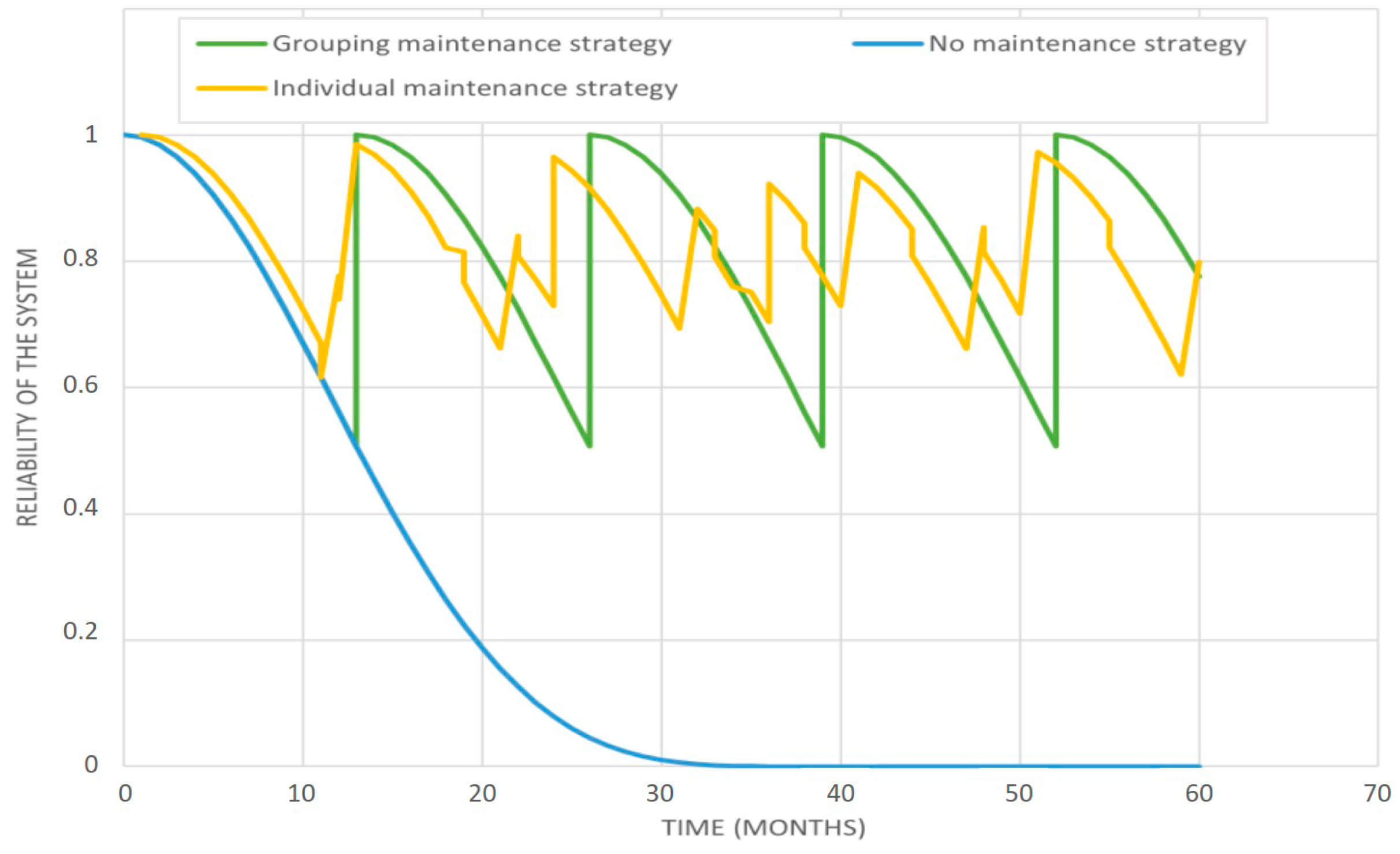
To assess the effectiveness of the bundled maintenance plan, the reliability of the system was studied under three different maintenance strategies, as shown in
Figure 15:
The blue graph represents the reliability of the system when no maintenance is performed. In this case, the reliability drops to 0.2 after 20 months, and the system is considered to have failed (nil reliability) after 30 months. The yellow graph represents the reliability of the system when an individual strategy is considered. The reliability varies between 1 and 0.6. After the first maintenance actions, the reliability is no longer equal to 1 because the components are no longer maintained simultaneously. Since the maintenance times are quite close (11, 12, and 19 months), reliability remains high. Finally, the green curve shows the behavior of the reliability when a grouping strategy is applied. In this case, the reliability of the system remains periodic: the three marker lines are maintained simultaneously, and their age is initialized to 0 after each replacement. As the maintenance instants are moved after each replacement (as presented in
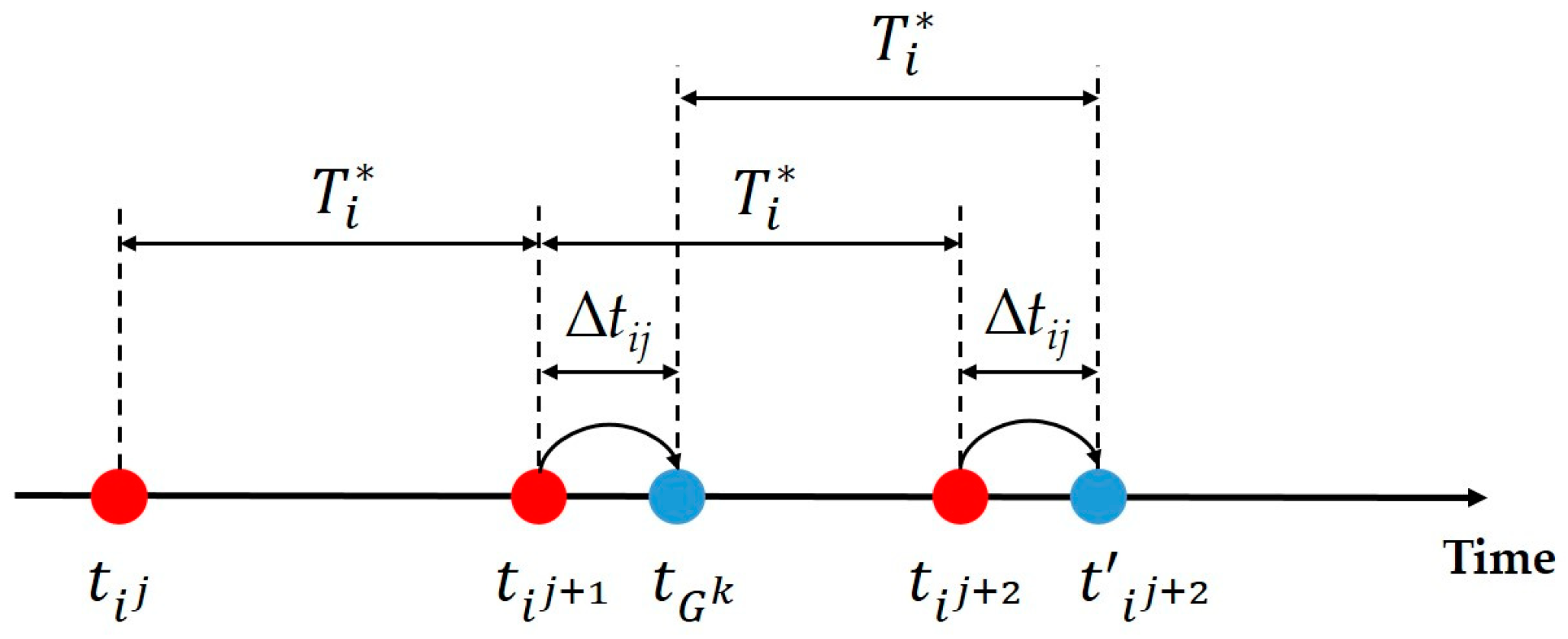
Figure 4), the same time interval between maintenance actions is always considered, hence the periodicity of reliability.
The green curve encompasses the yellow one. Even if in the case of grouped maintenance, we tolerate a lower reliability than in the case of a strategy with individual maintenance, but from an economic perspective, we save 10% of the budget allocated to maintenance for each cycle. In this case, without any constraints imposed by the infrastructure manager, the grouping strategy remains the most interesting. Moreover, both approaches have the same mean value for reliability, and even if the individual approach provides a better variance, it is easy to understand that the availability of infrastructure will be optimized with the grouped approach.
Table 5 shows the optimal grouping strategy for each cluster and the associated economic profit. We consider cluster 5 as an example. On the planning horizon, the EL and the BCL have to be replaced many times. Whenever maintenance actions are grouped together, the next maintenance instances are shifted, and only those remaining on the planning horizon are taken into consideration. For this cluster, the grouping strategy allows a 16% gain in the TEP in comparison with an individual optimization approach.
In
Table 6, the average reliability for each cluster under the three considered different maintenance strategies is introduced. If no maintenance action is performed, the average reliability does not exceed 0.24%, which is perfectly understandable since the road markings performance decrease to zero and then stay null up to the end of the time horizon. We can notice that, as previously introduced, the average reliability for the considered two maintenance strategies is quite close and generally better for the grouped approach (even if we also noticed that the variance is generally better for the individual approach). However, in terms of economic perspectives, the grouped maintenance strategy systematically provides an interesting economic benefit. In this case, the grouped maintenance strategy is more interesting. Moreover, we noticed that the availability of infrastructures is necessarily better with grouped actions than with individual strategies, which is a not-negligible advantage.
9. Conclusions and Prospects
The aim of this study was to determine the optimal maintenance plan for all the road markings of an infrastructure. For this, we first proposed a feedback data process to identify several degradation profiles and cluster the infrastructure. The systems considered in this study are periodically inspected. The monitoring data are generally triply censored with right, left, and interval censoring. In this paper, the proposed maintenance grouping policy was applied to road markings by considering road infrastructure as a three-component serial system. In our case study, the whole infrastructure was considered as a set a sections characterized by their own degradation process (influenced by the typology of the section, the nature of the pavement, its location, etc.). To group the road sections that degrade in the same way, the unsupervised clustering algorithm AHC was applied. This clustering grouped the road marking lines into nine clusters. Each cluster grouped the components that have the same evolution or degradation over time. In this case, instead of correcting the censoring and assigning a maintenance plan for each marking, the proposed analysis was applied to each cluster. We thus applied an extension of the EM algorithm to estimate the failure time and assign a Weibull distribution to each cluster.
Then, the grouped maintenance strategy started by identifying an optimal individual maintenance period for each cluster. An age-based maintenance replacement was considered in this paper. Since simultaneously performing all maintenance tasks is not always the optimal solution, a GA was used to determine the optimal solution by grouping several actions. This algorithm offers better results than dynamic programming and entails a reasonable execution time. This grouping strategy considers budget constraints and the previously described life duration model. It demonstrated a significant decrease in the budget allocated to preventive maintenance. The advantages and strengths of the proposed process lie in the fact that it can address highly censored data. This type of data is often encountered when a system is periodically inspected and maintained. The maintenance process proposed in this paper is based on individual optimization with clustering of the monitoring database. In our case study, the clustering was very useful to the infrastructure manager because it helped to better understand the road network behavior.
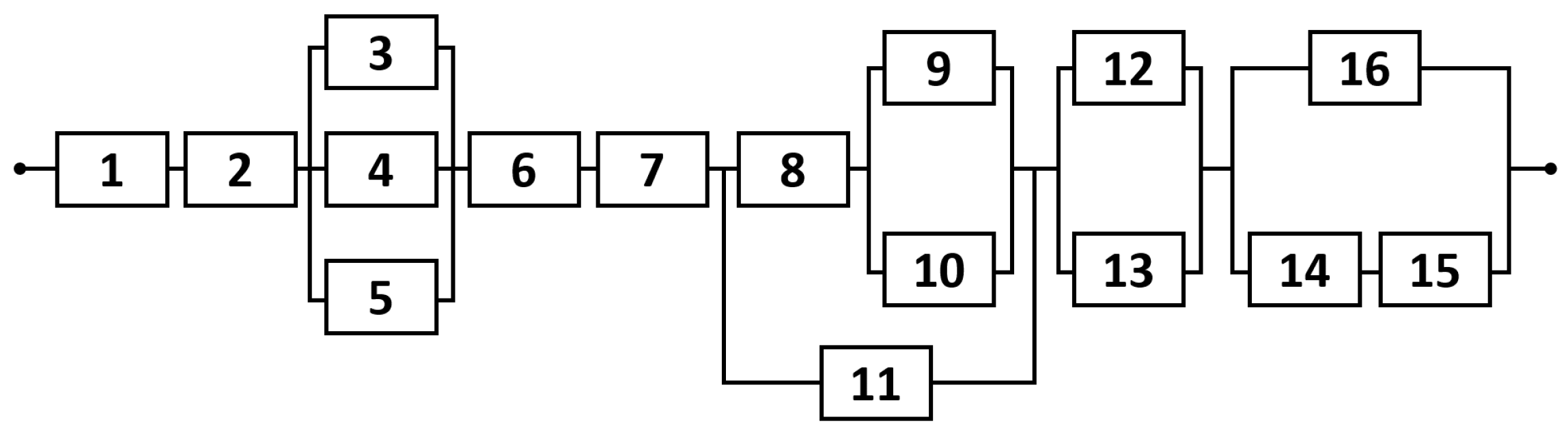
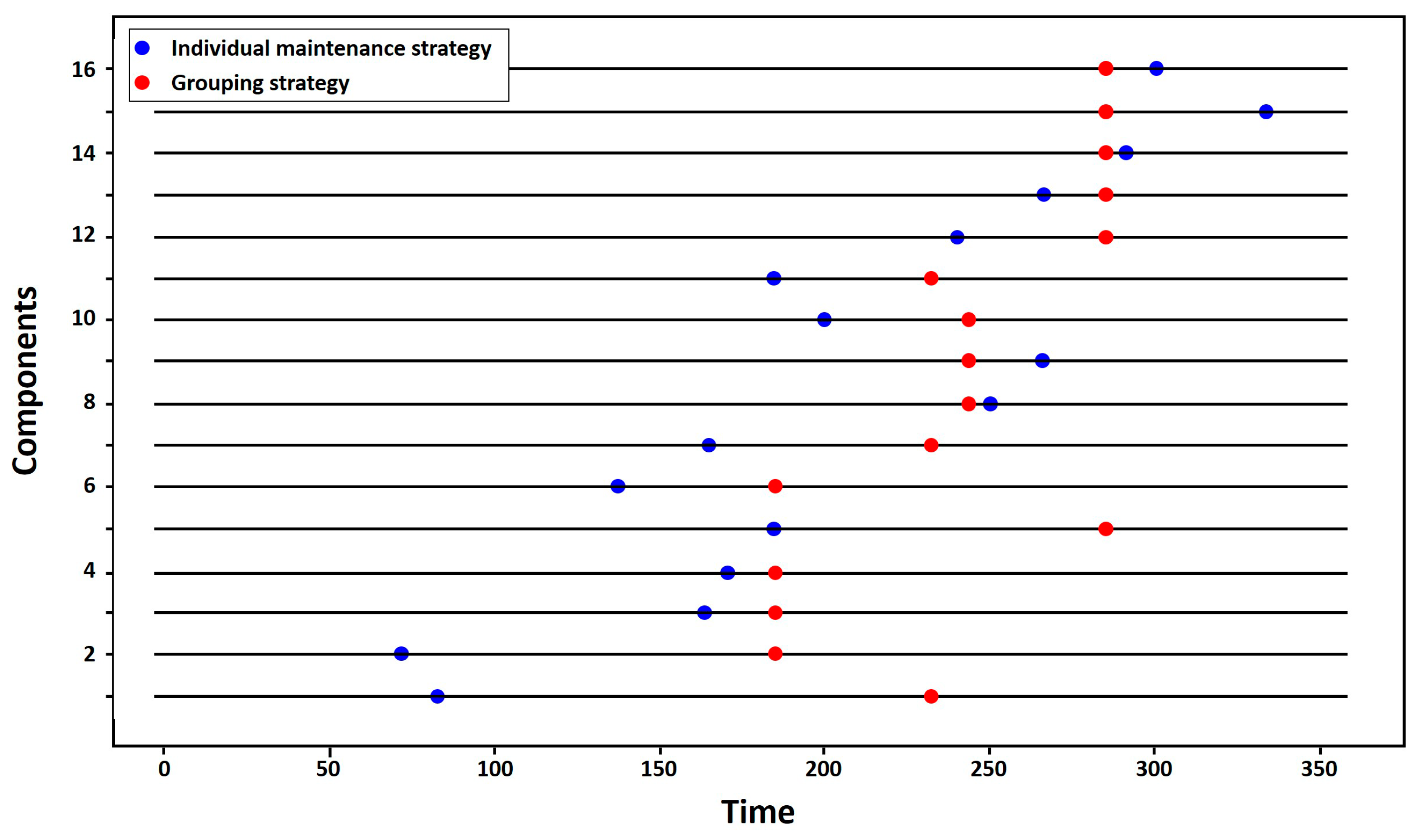
Although the case study, which is the main objective of this work, is a simple system, our approach has demonstrated its applicability to even more complex structures through its application to a 16-component complex structure system from the literature.
On the other hand, the strategy has some limitations. First, the optimal grouped maintenance clearly depends on the planning horizon, which, in our case, is finite. The definition of this horizon, in an optimal way, could depend on budget and availability constraints. Future works could deal with defining the value of the time horizon with respect to such constraints. Moreover, the literature has shown that, in general, the GA is the most-used algorithm to optimize a grouping maintenance strategy; however, other works such as [
29] have shown that other optimization approaches offer interesting solutions (mainly in terms of complexity). Indeed, GA generally faces some limitations when the system has a complex structure, and other algorithms such as PSO and clustering optimization seem to be more efficient and could be added to our work.
Finally, the last limitation, but not the least important, deals with taking constraints into account in the optimization process. The next step of this study is currently in progress through two new PhD projects, taking into account new constraints such as maintenance action durations and resource constraints (maintenance staff and maintenance equipment), but also some availability constraints connected with operating needs. Indeed, the literature review underlines that no previous study has considered more than one of these constraints in its maintenance optimization process for complex systems.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
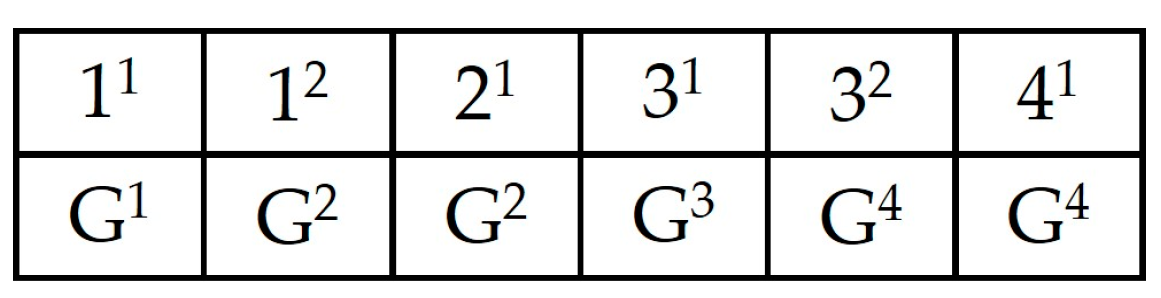{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}