


Exploring the Effect of Balanced and Imbalanced Multi-Class Distribution Data and Sampling Techniques on Fruit-Tree Crop Classification Using Different Machine Learning Classifiers



Abstract
:1. Introduction
2. Materials and Methods
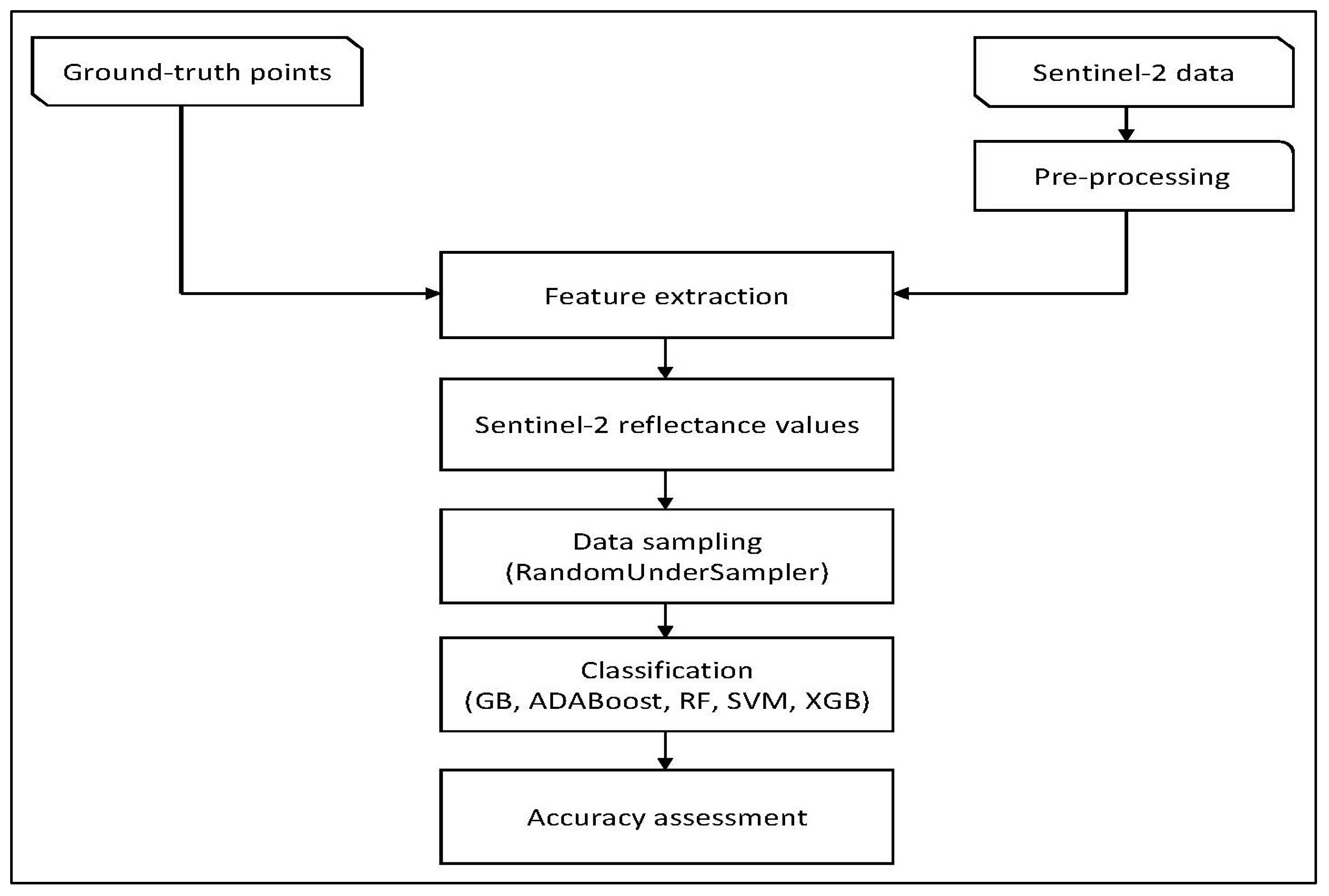
2.1. Methods Overview
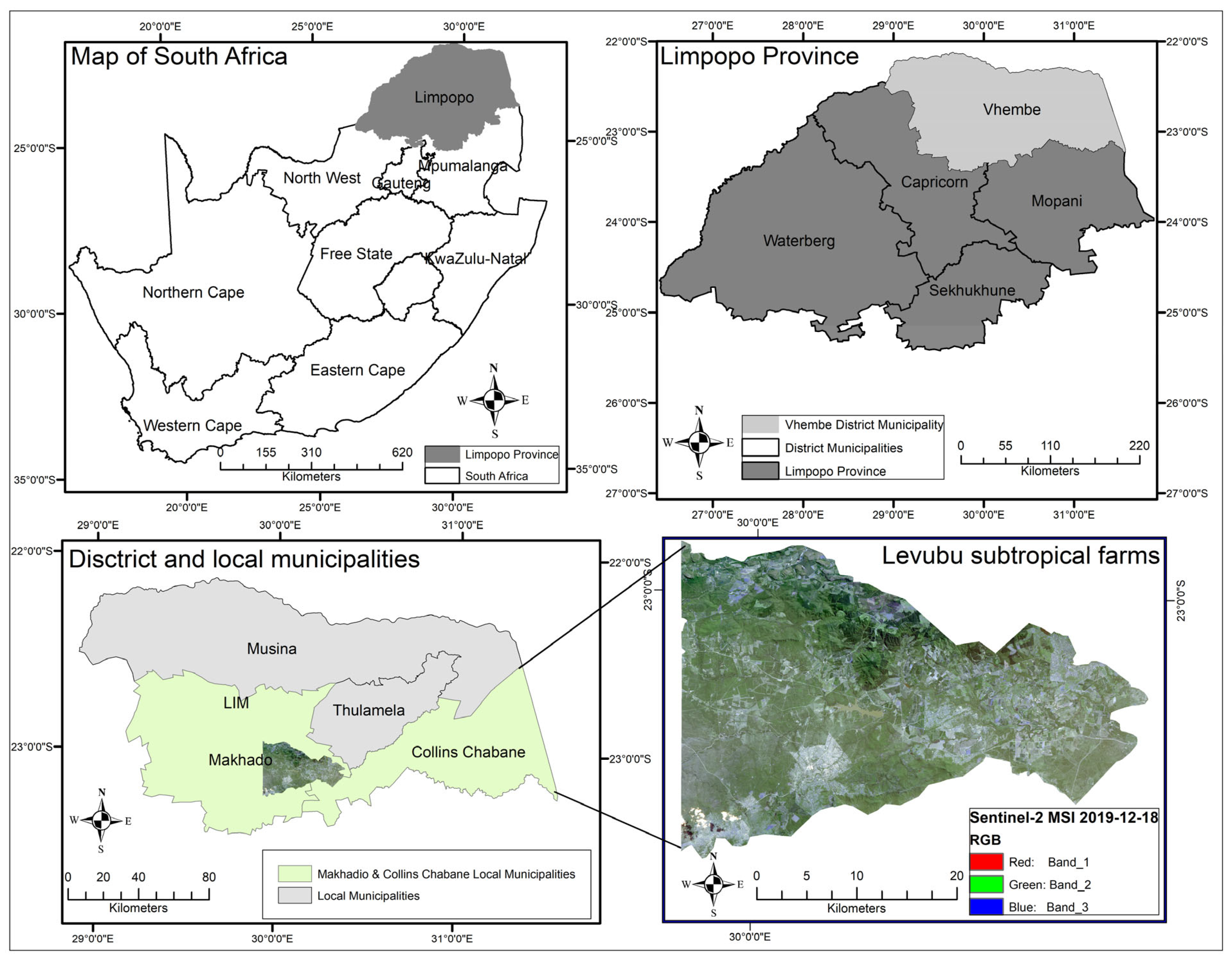
2.2. Study Region
2.3. Data Collection and Processing
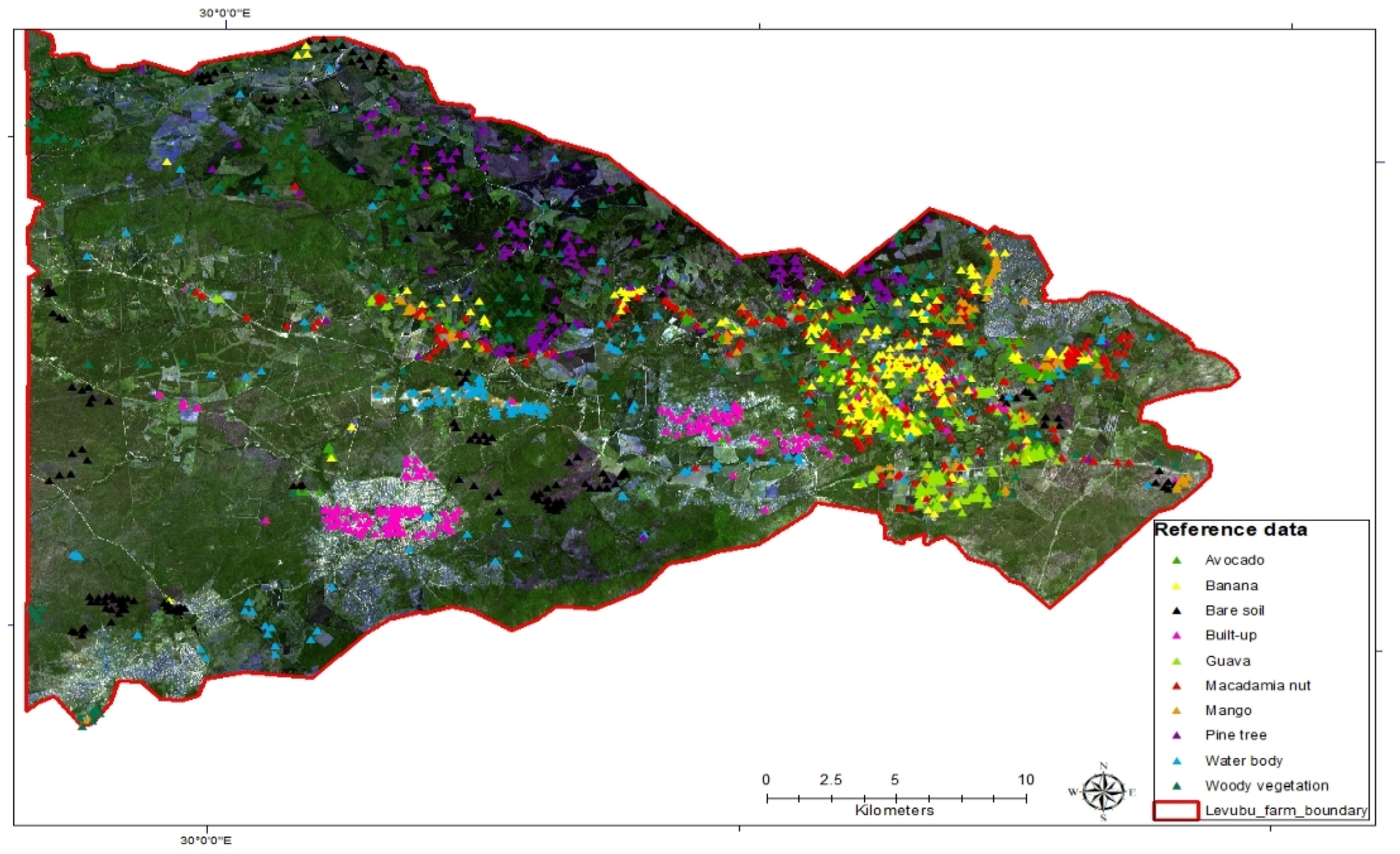
2.3.1. Ground Truth Data
2.3.2. Data Sampling
2.3.3. Remote Sensing Data Acquisition and Pre-Processing
2.4. Machine Learning Classification Algorithms
2.4.1. Random Forest (RF)
2.4.2. Support Vector Machine (SVM)
2.4.3. Gradient Boosting (GB)
2.4.4. Adaptive Boosting (AdaBoost)
2.4.5. eXtreme Gradient Boosting (XGBoost)
2.5. Mapping Accuracy Assessment
3. Results
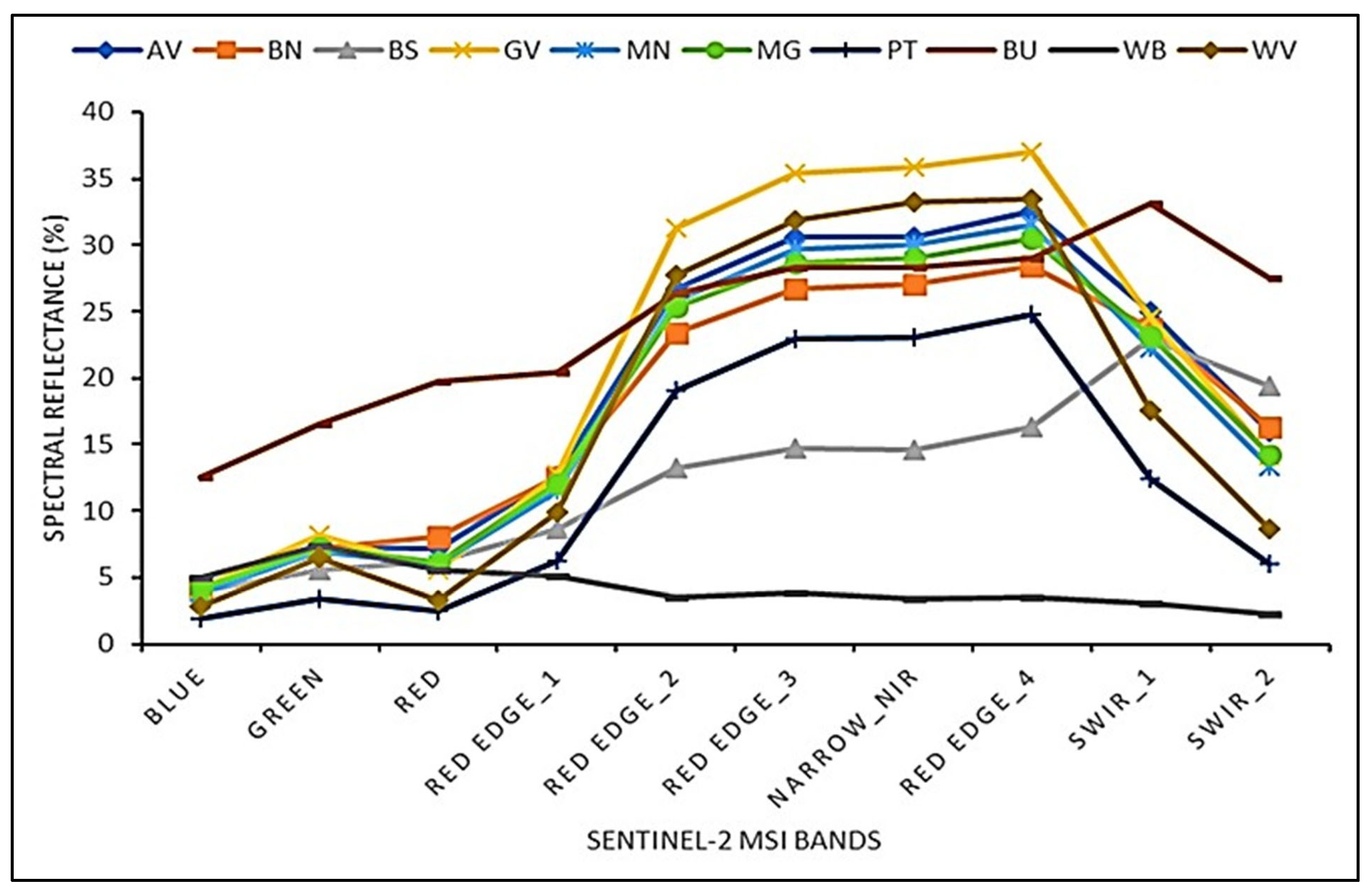
3.1. Spectral Separability of Fruit-Tree Crops and Co-Existing Land-Use Types
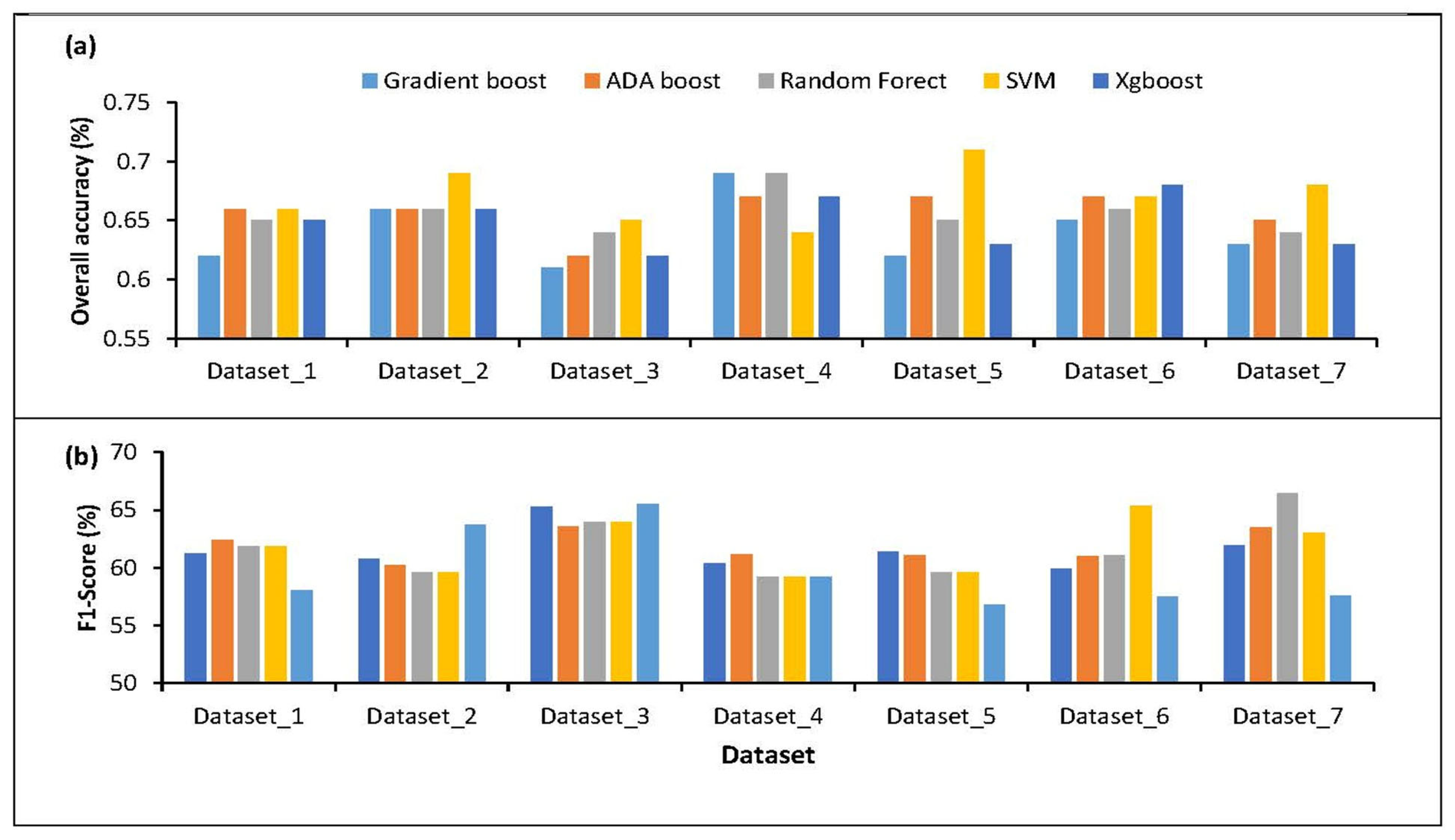
3.2. Fruit-Tree Crops Mapping Using Machine Learning Algorithms
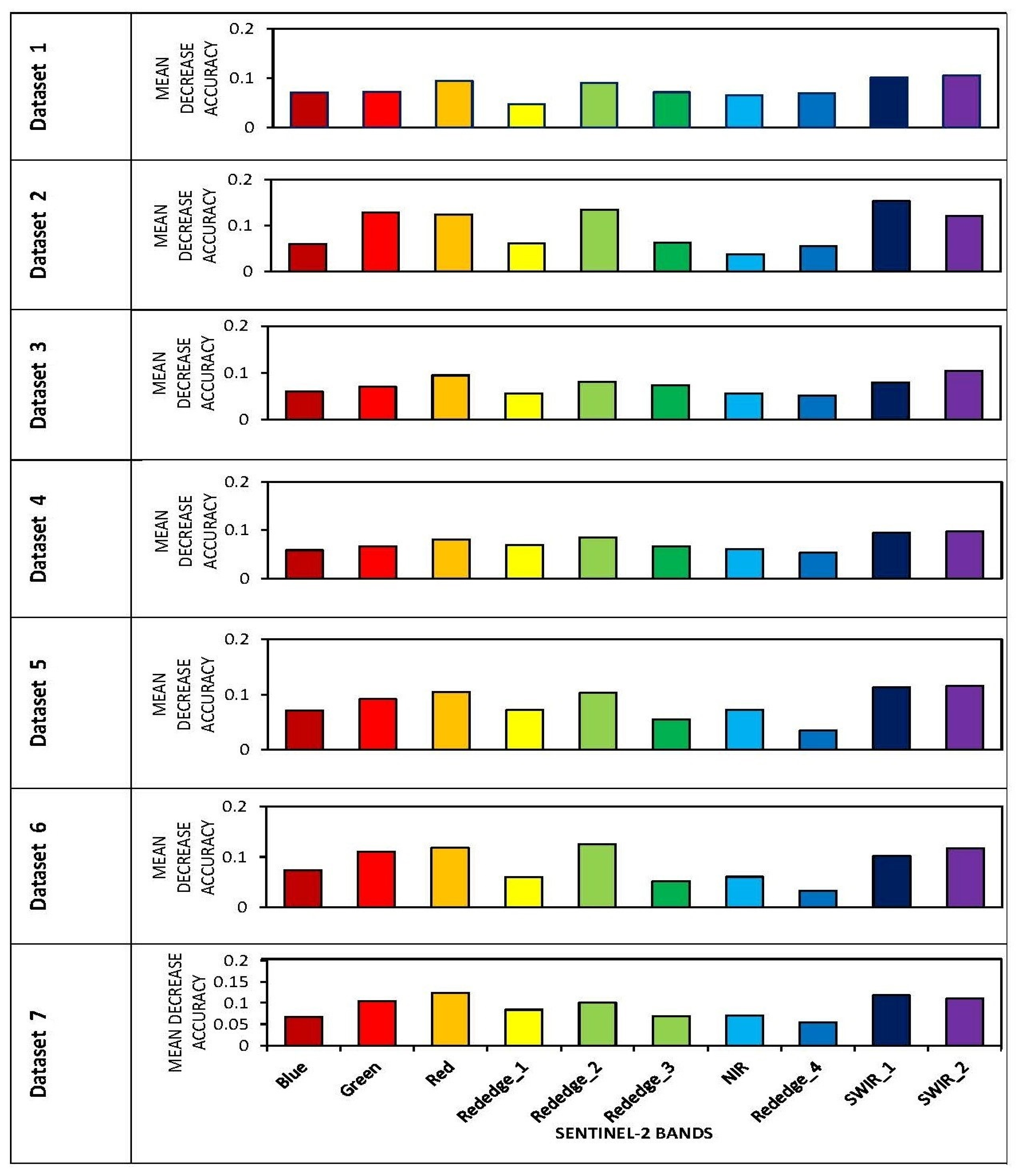
3.3. The Variable Importance
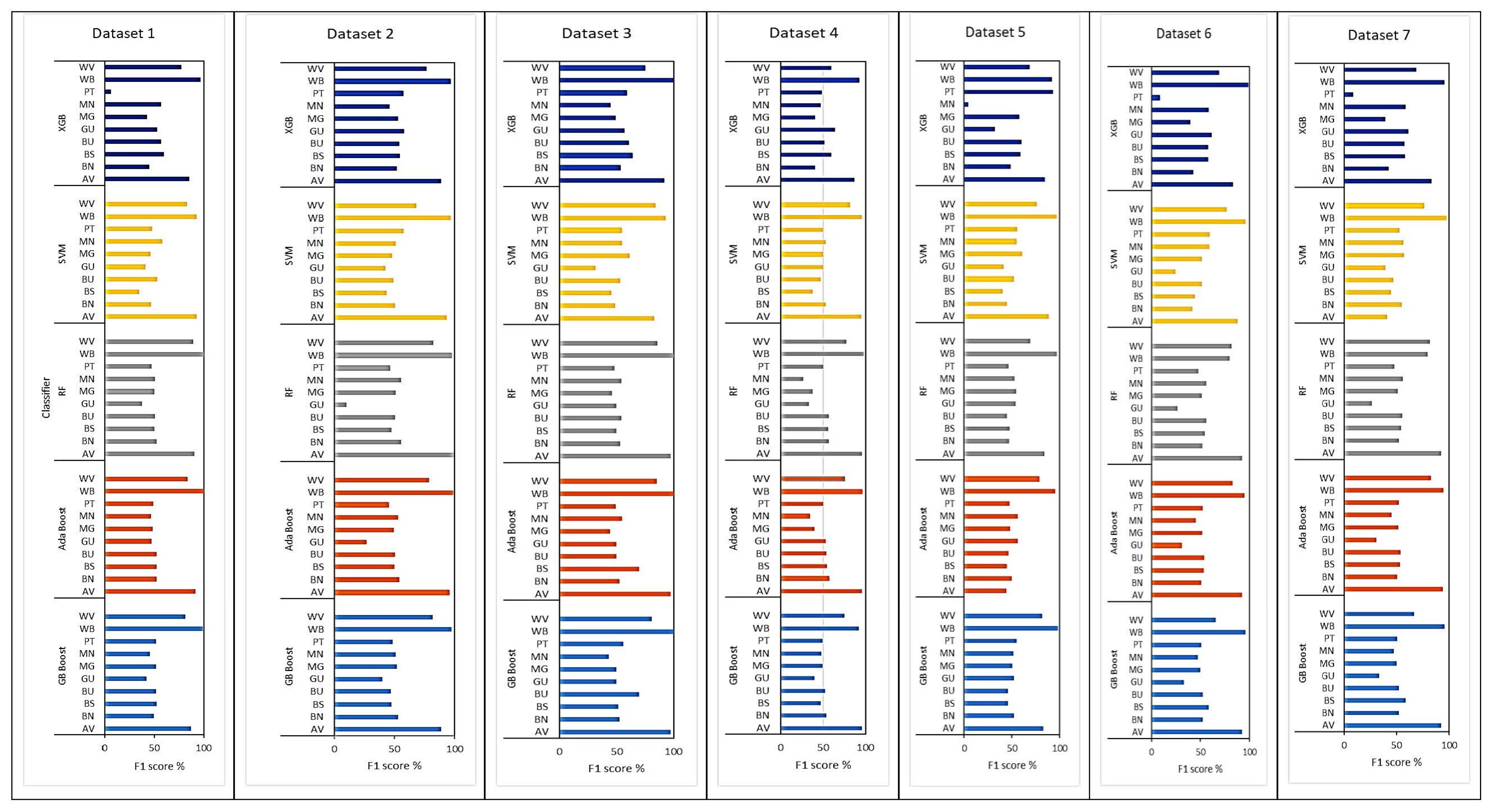
3.4. The Class Accuracies
The F1 Scores
3.5. Statistical Comparison of ML Classifiers from Seven Datasets
4. Discussion
4.1. The Effect of Sampling Size on the Performance of Machine Learning Algorithms
4.2. The Statistical Comparison of the Classifiers among and within the Classifiers
4.3. Comparison of Individual Class Accuracies
4.4. Importance of Variables in Mapping Fruit-Tree Crops and Co-Existing Land-Use Types
5. Conclusions
- Data sampling and selecting appropriate classification algorithms are essential for accurately mapping fruit trees in a horticultural environment characterized by complex and heterogeneous landscapes.
- Sentinel-2 offers similar classification accuracy and can be used for crop type inventories; these reduce the need for extensive data collection.
- The Sentinel-2 Red-Edge_2, SWIR_2, SWIR_1 (B11), and red (B4) bands are the most crucial predictor variables for crop classification using all datasets.
- The S2 Red-Edge bands are centered in the biomass region and contribute more to biomass studies.
- The best overall accuracy was achieved using the SVM and the dataset sampled at 60% (i.e., Dataset 7), while the class accuracies were stable when the dataset was sampled at 40% and 50%, respectively (i.e., Dataset 3 and Dataset 4).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification ☆. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Wang, S.; Azzari, G.; Lobell, D.B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar] [CrossRef]
- Robert, P.C. Precision agriculture: A challenge for crop nutrition management. Plant Soil. 2002, 247, 143–149. [Google Scholar] [CrossRef]
- United Nations. World Population Prospects: The 2015 Revision; Key Findings and Advance Tables; United Nations: New York, NY, USA, 2015; Volume 4, pp. 88–100. [Google Scholar]
- FAO. The Future of Food and Agriculture: Trends and Challenges; FAO: Rome, Italy, 2014; Volume 4. [Google Scholar]
- Foley, J.A.; Ramankutty, N.; Brauman, K.A.; Cassidy, E.S.; Gerber, J.S.; Johnston, M.; Mueller, N.D.; O’Connell, C.; Ray, D.K.; West, P.C.; et al. Solutions for a cultivated planet. Nature 2011, 478, 337–342. [Google Scholar] [CrossRef] [Green Version]
- De Oliveira Santos, C.L.M.; Lamparelli, R.A.C.; Figueiredo, G.K.D.A.; Dupuy, S.; Boury, J.; Luciano, A.C.S.; da Silva Torres, R.; le Maire, G. Classification of crops, pastures, and tree plantations along the season with multi-sensor image time series in a subtropical agricultural region. Remote Sens. 2019, 11, 334. [Google Scholar] [CrossRef] [Green Version]
- Lahlou, O.; Benmansour, S.; Zennayi, Y.; Bourzeix, F. CerealNet: A Hybrid Deep Learning Architecture for Cereal Crop Mapping Using Sentinel-2 Time-Series. Informatics 2022, 9, 96. [Google Scholar]
- Shi, W.; Wang, M.; Liu, Y. Crop yield and production responses to climate disasters in China. Sci. Total Environ. 2021, 750, 141147. [Google Scholar] [CrossRef]
- Hao, P.; Wu, W.; Niu, Z.; Wang, L.; Zhan, Y. Estimation of different data compositions for early-season crop type classification. PeerJ 2018, 6, e4834. [Google Scholar] [CrossRef]
- Yang, H.; Li, H.; Wang, W.; Li, N.; Zhao, J.; Pan, B. Spatio-Temporal Estimation of Rice Height Using Time Series Sentinel-1 Images. Remote Sens. 2022, 14, 546. [Google Scholar] [CrossRef]
- Gourlay, S.; Kilic, T.; Lobell, D. Could Debate Be Over? Errors Farmer-Reported Prod. Their Implic. Inverse Scale-Productivity Relatsh. Uganda; SSRN: Rochester, NY, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Waldner, F.; Fritz, S.; Di Gregorio, A.; Defourny, P. Mapping priorities to focus cropland mapping activities: Fitness assessment of existing global, regional and national cropland maps. Remote Sens. 2015, 7, 7959–7986. [Google Scholar] [CrossRef]
- Preidl, S.; Lange, M.; Doktor, D. Introducing APiC for regionalised land cover mapping on the national scale using Sentinel-2A imagery. Remote Sens. Environ. 2020, 240, 111673. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. Remote Sensing of Environment A high-performance and in-season classi fi cation system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Devi, D.; Biswas, S.; Purkayastha, B. Learning in presence of class imbalance and class overlapping by using one-class SVM and undersampling technique. Conn. Sci. 2019, 31, 105–142. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Yang, X.; Cui, S.; Yang, Q.; Yang, X.; Li, J.; Shen, Y. Developing sustainable cropping systems by integrating crop rotation with conservation tillage practices on the Loess Plateau, a long-term imperative. Field Crops Res. 2018, 222, 164–179. [Google Scholar] [CrossRef]
- Zhu, L.; Radeloff, V.; Ives, A.R. Improving the mapping of crop types in the Midwestern U.S. by fusing Landsat and MODIS satellite data. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 1–11. [Google Scholar] [CrossRef]
- Prins, A.J.; Van Niekerk, A. Crop type mapping using LiDAR, Sentinel-2 and aerial imagery with machine learning algorithms. Geo-Spatial Inf. Sci. 2020, 24, 1–13. [Google Scholar] [CrossRef]
- Mashaba-Munghemezulu, Z.; Chirima, G.; Munghemezulu, C. Mapping Smallholder Maize Farms Using Multi-Temporal Sentinel-1 Data in Support of the Sustainable Development Goals. Remote Sens. 2021, 13, 1666. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop Classification on Single Date Sentinel-2 Imagery Using Random Forest and Suppor Vector Machine. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 5, 683–688. [Google Scholar] [CrossRef] [Green Version]
- Bouras, E.; Jarlan, L.; Er-Raki, S.; Balaghi, R.; Amazirh, A.; Richard, B.; Khabba, S. Cereal yield forecasting with satellite drought-based indices, weather data and regional climate indices using machine learning in morocco. Remote Sens. 2021, 13, 3101. [Google Scholar] [CrossRef]
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral Image Classification with Imbalanced Data Based on Orthogonal Complement Subspace Projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Tu, Y.H.; Phinn, S.; Johansen, K.; Robson, A.; Wu, D. Optimising drone flight planning for measuring horticultural tree crop structure. ISPRS J. Photogramm. Remote Sens. 2020, 160, 83–96. [Google Scholar] [CrossRef] [Green Version]
- Feyisa, G.; Palao, L.; Nelson, A. Characterizing and mapping cropping patterns in a complex agro-ecosystem: An iterative participatory mapping procedure using machine learning algorithms and MODIS vegetation indices. Comput. Electron. Agric. 2019, 175, 105595. [Google Scholar] [CrossRef]
- Naboureh, A.; Li, A.; Bian, J.; Lei, G.; Amani, M. A hybrid data balancing method for classification of imbalanced training data within google earth engine: Case studies from mountainous regions. Remote Sens. 2020, 12, 3301. [Google Scholar] [CrossRef]
- Waldner, F.; Chen, Y.; Lawes, R.; Hochman, Z. Remote Sensing of Environment Needle in a haystack: Mapping rare and infrequent crops using satellite imagery and data balancing methods. Remote Sens. Environ. 2019, 233, 111375. [Google Scholar] [CrossRef]
- Azadbakht, M.; Fraser, C.; Khoshelham, K. Synergy of sampling techniques and ensemble classifiers for classification of urban environments using full-waveform LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 277–291. [Google Scholar] [CrossRef]
- Ghaseminik, F.; Aghamohammadi, H.; Azadbakht, M. Land cover mapping of urban environments using multispectral LiDAR data under data imbalance. Remote Sens. Appl. Soc. Environ. 2021, 21, 100449. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Schmidt, K.; Eftekhari, K.; Behrens, T.; Jamshidi, M.; Davatgar, N.; Toomanian, N.; Scholten, T. Synthetic resampling strategies and machine learning for digital soil mapping in Iran. Eur. J. Soil Sci. 2020, 71, 352–368. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data. 2020, 7, 52. [Google Scholar] [CrossRef]
- Maponya, P.; Mpandeli, S. Climate Change and Agricultural Production in South Africa: Impacts and Adaptation options. J. Agric. Sci. 2012, 4, 49–60. [Google Scholar] [CrossRef]
- Chabalala, Y.; Adam, E. Machine Learning Classification of Fused Sentinel-1 and Sentinel-2 Image Data towards Mapping Fruit Plantations in Highly Heterogenous Landscapes. Remote Sens. 2022, 14, 2621. [Google Scholar] [CrossRef]
- Louw, D.; Flandorp, C. Horticultural Development Plan for the Thulamela Local Municipality: Agricultural Overview; OABS Development (Pty) Ltd.: Western Cape, South Africa, 2017; Volume 27. [Google Scholar]
- Weier, S.M.; Grass, I.; Linden, V.; Tscharntke, T.; Taylor, P.J. Natural vegetation and bug abundance promote insectivorous bat activity in macadamia orchards, South Africa. Biol. Conserv. 2018, 226, 16–23. [Google Scholar] [CrossRef]
- Mukwada, G.; Mazibuko, S.; Moeletsi, M.; Robinson, G.M. Can famine be averted? A spatiotemporal assessment of the impact of climate change on food security in the luvuvhu river catchment of South Africa. Land 2021, 10, 527. [Google Scholar] [CrossRef]
- Fraser, A. White farmers’ dealings’ with land reform in Soutth Africa: Evidence from Northern Limpopo Province. Tijdschr. Voor Econ. En Soc. Geogr. 2008, 99, 24–36. [Google Scholar] [CrossRef] [Green Version]
- DAFF. Department of Agriculture, Forestry and Fisheries. 2012, pp. 1–44. Available online: https://www.daff.gov.za/docs/AMCP/MaizeMVCP2011.pdf (accessed on 18 October 2022).
- Chen, Y.; Song, X.; Wang, S.; Huang, J.; Mansaray, L.R. Impacts of spatial heterogeneity on crop area mapping in Canada using MODIS data. ISPRS J. Photogramm. Remote Sens. 2016, 119, 451–461. [Google Scholar] [CrossRef]
- Brownlee, J. Imbalanced Classification with Python. In Machine Learning Mastery; Python: Wilmington, DE, USA, 2020; p. 463. [Google Scholar]
- Quan, Y.; Zhong, X.; Feng, W.; Chan, J.; Li, Q.; Xing, M. Smote-based weighted deep rotation forest for the imbalanced hyperspectral data classification. Remote Sens. 2021, 13, 464. [Google Scholar] [CrossRef]
- Khaldoon, A.; Sujan, R.; Ali, A.; Agrawal, D.P. Enhancing Imbalanced Dataset by Utilizing (K-NN Based SMOTE_3D Algorithm). Ann. Robot. Autom. 2020, 4, 001–006. [Google Scholar] [CrossRef]
- Waldner, F.; Bellemans, N.; Hochman, Z.; Newby, T.; de Abelleyra, D.; Verón, S.R.; Bartalev, S.; Lavreniuk, M.; Kussul, N.; Le Maire, G.; et al. Roadside collection of training data for cropland mapping is viable when environmental and management gradients are surveyed. Int. J. Appl. Earth Obs. Geoinf. 2019, 80, 82–93. [Google Scholar] [CrossRef]
- Wang, W.; Liu, X.; Chan, W.K.V. Imbalanced classification problem using data-driven and random forest method. ACM Int. Conf. Proceeding Ser. 2020, 26–30. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Kiyohara, S.; Miyata, T.; Mizoguchi, T. Prediction of grain boundary structure and energy by machine learning. Sci. Adv. 2015, 18, 1–5. [Google Scholar] [CrossRef]
- Djamai, N.; Fernandes, R. Comparison of SNAP-Derived Sentinel-2A L2A Product to ESA Product over Europe. Remote Sens. 2018, 10, 926. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kganyago, M.; Mhangara, P.; Adjorlolo, C. Estimating Crop Biophysical Parameters Using Machine Learning Algorithms and Sentinel-2 Imagery. Remote Sens. 2021, 13, 4314. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 1995; p. 334. Available online: https://ci.nii.ac.jp/naid/10020951890 (accessed on 6 October 2022).
- Chabalala, Y.; Adam, E.; Oumar, Z.; Ramoelo, A. Exploiting the capabilities of Sentinel-2 and RapidEye for predicting grass nitrogen across different grass communities in a protected area. Appl. Geomatics. 2020, 12, 379–395. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Funnction Approximation: A gradient Boosting Machine. Ann. Stat. 2001, 148, 148–162. [Google Scholar]
- Woodruff, K. Introduction to boosted decision trees. In Proceedings of the Machine Learning Group Meeting, New Mexico State University, Las Cruces, NM, USA, 29 September 2017; pp. 1–11. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Barrow, D.K.; Crone, S.F. A comparison of AdaBoost algorithms for time series forecast combination. Int. J. Forecast. 2016, 32, 1103–1119. [Google Scholar] [CrossRef] [Green Version]
- Cao, J.; Kwong, S.; Wang, R. A noise-detection based AdaBoost algorithm for mislabeled data. Pattern Recognit. 2012, 45, 4451–4465. [Google Scholar] [CrossRef]
- Peng, T.; Zhou, J.; Zhang, C.; Zheng, Y. Multi-step ahead wind speed forecasting using a hybrid model based on two-stage decomposition technique and AdaBoost-extreme learning machine. Energy Convers. Manag. 2017, 153, 589–602. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Fang, H. Machine Learning on Greenest Pixels for Crop Mapping. EarthArXiv, 2020; preprint. [Google Scholar] [CrossRef]
- Patil, B.M.; Burkpalli, V. A Perspective View of Cotton Leaf Image Classification Using Machine Learning Algorithms Using WEKA. Adv. Human-Computer Interact. 2021, 2021, 9367778. [Google Scholar] [CrossRef]
- Rumora, L.; Miler, M.; Medak, D. Impact of various atmospheric corrections on sentinel-2 land cover classification accuracy using machine learning classifiers. ISPRS Int. J. Geo-Inf. 2020, 9, 277. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Gradient Boosted Trees with XGBoost and Scikit-Learn; Packt Publishing: Birmingham, UK, 2021; Volume 148, pp. 148–162. [Google Scholar]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Vanino, S.; Nino, P.; De Michele, C.; Bolognesi, S.F.; D’Urso, G.; Di Bene, C.; Pennelli, B.; Vuolo, F.; Farina, R.; Pulighe, G.; et al. Capability of Sentinel-2 data for estimating maximum evapotranspiration and irrigation requirements for tomato crop in Central Italy. Remote Sens. Environ. 2018, 215, 452–470. [Google Scholar] [CrossRef]
- Chen, Y.; Hou, J.; Huang, C.; Zhang, Y.; Li, X. Mapping maize area in heterogeneous agricultural landscape with multi-temporal sentinel-1 and sentinel-2 images based on random forest. Remote Sens. 2021, 13, 2988. [Google Scholar] [CrossRef]
- Dietterich, T.G. Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Master Machine Learning Algorithms: Discover how they work and implement them from scratch. In Machine Learning Mastery; Python: Wilmington, DE, USA, 2016; pp. 1–163. Available online: http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/ (accessed on 14 September 2022).
- Zhou, T.; Pan, J.; Zhang, P.; Wei, S.; Han, T. Mapping winter wheat with multi-temporal SAR and optical images in an urban agricultural region. Sensors 2017, 17, 1210. [Google Scholar] [CrossRef]
- Grabska, E.; Frantz, D.; Ostapowicz, K. Evaluation of machine learning algorithms for forest stand species mapping using Sentinel-2 imagery and environmental data in the Polish Carpathians. Remote Sens. Environ. 2020, 251, 112103. [Google Scholar] [CrossRef]
- Forkuor, G.; Dimobe, K.; Serme, I.; Tondoh, J.E. Landsat-8 vs. Sentinel-2: Examining the added value of sentinel-2’s red-edge bands to land-use and land-cover mapping in Burkina Faso. GIScience Remote Sens. 2018, 55, 331–354. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Gašparović, M.; Dobrinić, D. Comparative assessment of machine learning methods for urban vegetation mapping using multitemporal Sentinel-1 imagery. Remote Sens. 2020, 12, 1952. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop classification in a heterogeneous agricultural environment using ensemble classifiers and single-date Sentinel-2A imagery. Geocarto Int. 2021, 36, 2141–2159. [Google Scholar] [CrossRef]
- Baumann, M.; Levers, C.; Macchi, L.; Bluhm, H.; Waske, B.; Gasparri, N.I.; Kuemmerle, T. Mapping continuous fields of tree and shrub cover across the Gran Chaco using Landsat 8 and Sentinel-1 data. Remote Sens. Environ. 2018, 216, 201–211. [Google Scholar] [CrossRef]
- Zhou, Z.; Huang, J.; Wang, J.; Zhang, K.; Kuang, Z.; Zhong, S.; Song, X. Object-oriented classification of sugarcane using time-series middle-resolution remote sensing data based on AdaBoost. PLoS ONE 2015, 10, e0142069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ayyagari, M.R. Classification of Imbalanced Datasets using One-Class SVM, k-Nearest Neighbors and CART Algorithm. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 1–5. [Google Scholar] [CrossRef]
- Sun, F.; Fang, F.; Wang, R.; Wan, B.; Guo, Q.; Li, H.; Wu, X. An impartial semi-supervised learning strategy for imbalanced classification on VHR images. Sensors 2020, 20, 6699. [Google Scholar] [CrossRef] [PubMed]
- Noi, P.T.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Yousefi, D.M.; Rafie, A.M.; Aziz, S.A.; Azrad, S.; Masri, M.M.M.; Shahi, A.; Marzuki, O. Classification of oil palm female inflorescences anthesis stages using machine learning approaches. Inf. Process. Agric. 2021, 8, 537–549. [Google Scholar] [CrossRef]
- Ustuner, M.; Sanli, F.; Abdikan, S. Balanced vs imbalanced training data: Classifying rapideye data with support vector machines. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2016, 41, 379–384. [Google Scholar] [CrossRef] [Green Version]
- Maldonado, S.; López, J. Imbalanced data classification using second-order cone programming support vector machines. Pattern Recognit. 2014, 47, 2070–2079. [Google Scholar] [CrossRef]
- Hong-xia, L.U.O.; Sheng-pei, D.; Mao-fen, L.; En-ping, L.; Qian, Z.; Ying-ying, H.U. Comparison of machine learning algorithms for mapping mango plantations based on Gaofen-1 imagery. J. Integr. Agric. 2020, 19, 2815–2828. [Google Scholar] [CrossRef]
- Richard, K.; Abdel-Rahman, E.M.; Subramanian, S.; Nyasani, J.O.; Thiel, M.; Jozani, H.; Borgemeister, C.; Landmann, T. Maize cropping systems mapping using rapideye observations in agro-ecological landscapes in Kenya. Sensors 2017, 17, 2537. [Google Scholar] [CrossRef] [Green Version]
- Sivasankar, T.; Kumar, D.; Srivastava, H.; Patel, P. Advances in radar remote sensing of agricultural crops: A review. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1126–1137. [Google Scholar] [CrossRef] [Green Version]
- Johansen, K.; Duan, Q.; Tu, Y.-H.; Searle, C.; Wu, D.; Phinn, S.; Robson, A.; McCabe, M.F. Mapping the condition of macadamia tree crops using multi-spectral UAV and WorldView-3 imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 28–40. [Google Scholar] [CrossRef]
- Gutierrez-Coarite, R.; Mollinedo, J.; Cho, A.; Wright, M.G. Canopy management of macadamia trees and understory plant diversification to reduce macadamia felted coccid (Eriococcus ironsidei) populations. Crop Prot. 2018, 113, 75–83. [Google Scholar] [CrossRef]
- Darvishzadeh, R.; Skidmore, A.; Abdullah, H.; Cherenet, E.; Ali, A.; Wang, T.; Nieuwenhuis, W.; Heurich, M.; Vrieling, A.; O’Connor, B.; et al. Mapping leaf chlorophyll content from Sentinel-2 and RapidEye data in spruce stands using the invertible forest reflectance model. Int. J. Appl. Earth Obs. Geoinf. 2019, 79, 58–70. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Liu, H.; Lu, L.; Liu, Z.; Kong, F.; le Zhang, X. Monthly composites from Sentinel-1 and Sentinel-2 images for regional major crop mapping with Google Earth Engine. J. Integr. Agric. 2021, 20, 1944–1957. [Google Scholar] [CrossRef]
- Liu, M.; Wang, T.; Skidmore, A.; Liu, X. Heavy metal-induced stress in rice crops detected using multi-temporal Sentinel-2 satellite images. Sci. Total Environ. 2018, 637–638, 18–29. [Google Scholar] [CrossRef]
- Cui, B.; Zhao, Q.; Huang, W.; Song, X.; Ye, H.; Zhou, X. Leaf chlorophyll content retrieval of wheat by simulated RapidEye, Sentinel-2 and EnMAP data. J. Integr. Agric. 2019, 18, 1230–1245. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tree Species and Other Land Use Classes | Reference Data | Total | |
|---|---|---|---|
| Training | Testing | ||
| Avocado | 109 | 47 | 156 |
| Banana | 181 | 77 | 258 |
| Bare soil | 120 | 52 | 172 |
| Built-up | 122 | 52 | 174 |
| Guava | 154 | 66 | 220 |
| Macadamia nut | 113 | 48 | 161 |
| Mango | 160 | 68 | 228 |
| Pine tree | 117 | 50 | 167 |
| Waterbody | 128 | 53 | 181 |
| Woody vegetation | 126 | 54 | 180 |
| Total sample size = 1897 | |||
| Crop Name | Abbreviation | Balanced Datasets (#1 and 2) | Percentages Undersampled Datasets (#3–6) | Unsampled Imbalanced Dataset (#7) | ||||
|---|---|---|---|---|---|---|---|---|
| Dataset 1 | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5 | Dataset 6 | Dataset 7 | ||
| Avocado | AV | 100 | 150 | 62 | 78 | 94 | 109 | 156 |
| Banana | BN | 100 | 150 | 103 | 52 | 154 | 181 | 258 |
| Bare soil | BS | 100 | 150 | 69 | 86 | 103 | 120 | 172 |
| Guava | GV | 100 | 150 | 70 | 87 | 104 | 121 | 174 |
| Macadamia nut | MN | 100 | 150 | 88 | 110 | 132 | 154 | 220 |
| Mango | MG | 100 | 150 | 64 | 81 | 97 | 113 | 161 |
| Pine tree | PT | 100 | 150 | 91 | 114 | 137 | 160 | 228 |
| Built-up | BU | 100 | 150 | 69 | 86 | 100 | 117 | 167 |
| Waterbody | WB | 100 | 150 | 72 | 91 | 109 | 127 | 181 |
| Woody vegetation | WV | 100 | 150 | 72 | 90 | 108 | 126 | 180 |
| Total number of instances | 1000 | 1500 | 760 | 875 | 1138 | 1328 | 1897 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chabalala, Y.; Adam, E.; Ali, K.A. Exploring the Effect of Balanced and Imbalanced Multi-Class Distribution Data and Sampling Techniques on Fruit-Tree Crop Classification Using Different Machine Learning Classifiers. Geomatics 2023, 3, 70-92. https://doi.org/10.3390/geomatics3010004
Chabalala Y, Adam E, Ali KA. Exploring the Effect of Balanced and Imbalanced Multi-Class Distribution Data and Sampling Techniques on Fruit-Tree Crop Classification Using Different Machine Learning Classifiers. Geomatics. 2023; 3(1):70-92. https://doi.org/10.3390/geomatics3010004
Chicago/Turabian StyleChabalala, Yingisani, Elhadi Adam, and Khalid Adem Ali. 2023. "Exploring the Effect of Balanced and Imbalanced Multi-Class Distribution Data and Sampling Techniques on Fruit-Tree Crop Classification Using Different Machine Learning Classifiers" Geomatics 3, no. 1: 70-92. https://doi.org/10.3390/geomatics3010004