
Review of Applicable Outlier Detection Methods to Treat Geomechanical Data




Abstract
:1. Introduction
2. Methodology
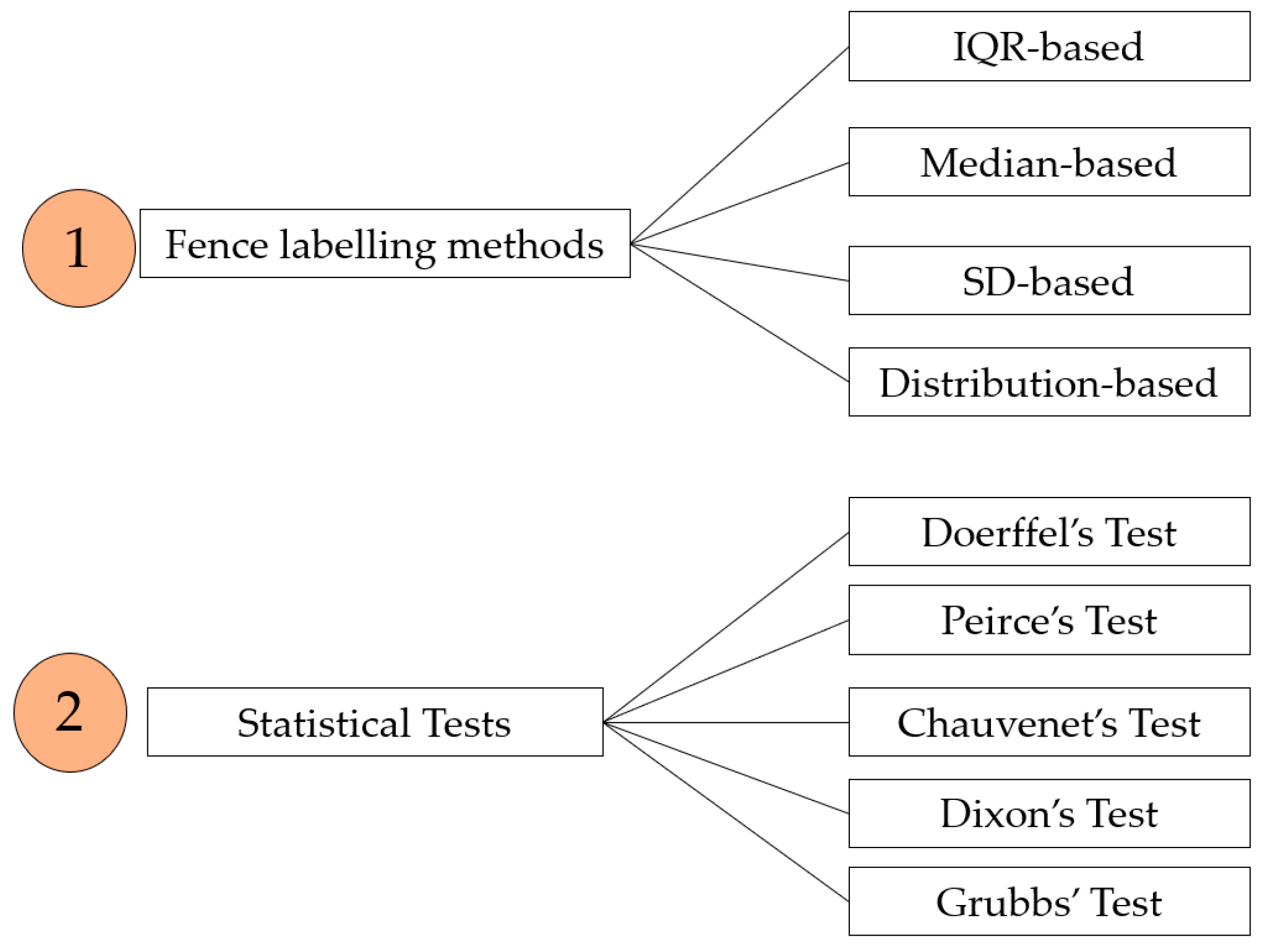
3. Classification of Outlier Detection Methods in Geomechanics
3.1. Fence Labeling Methods
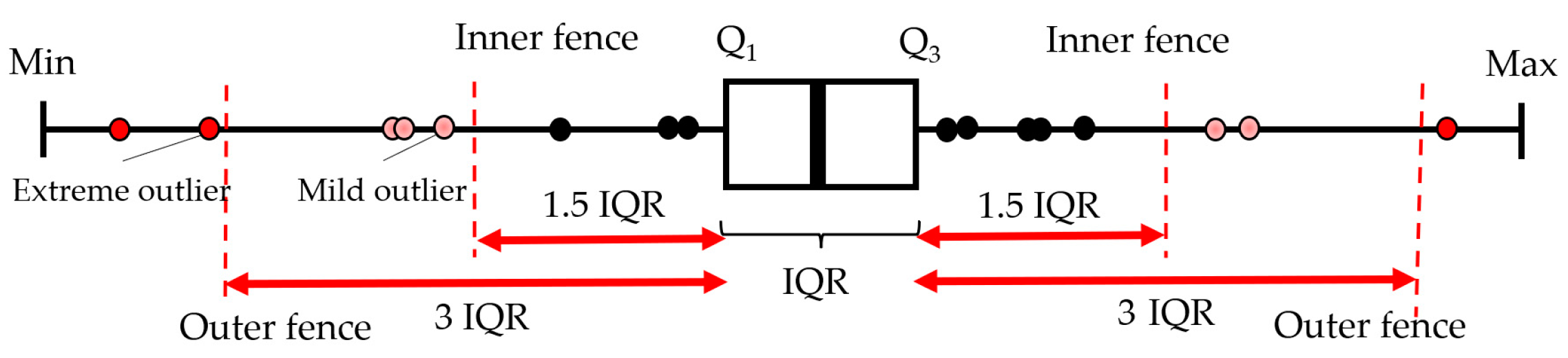
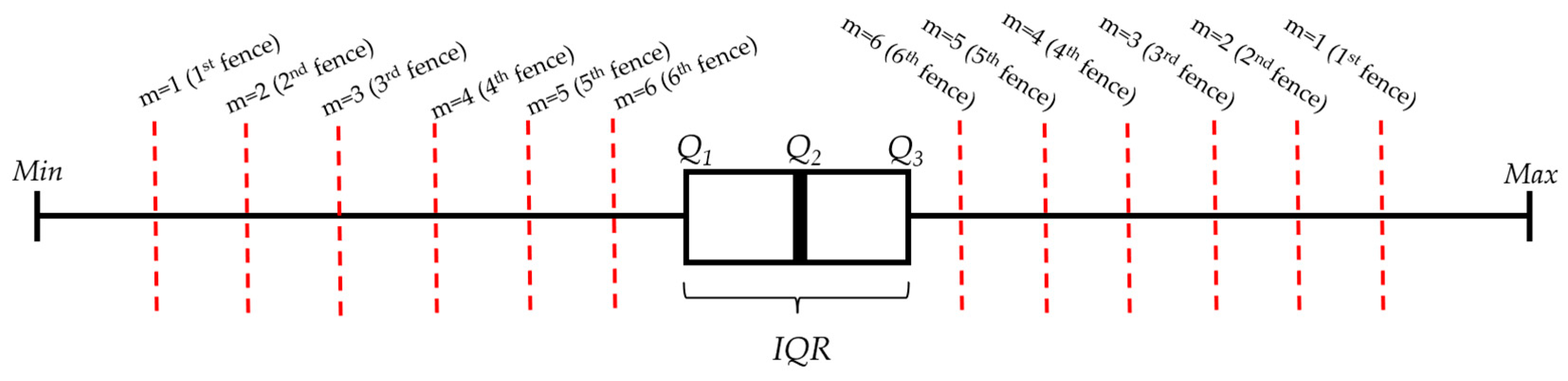
3.1.1. IQR-Based Methods
3.1.2. Median-Based Methods
3.1.3. SD-Based Methods
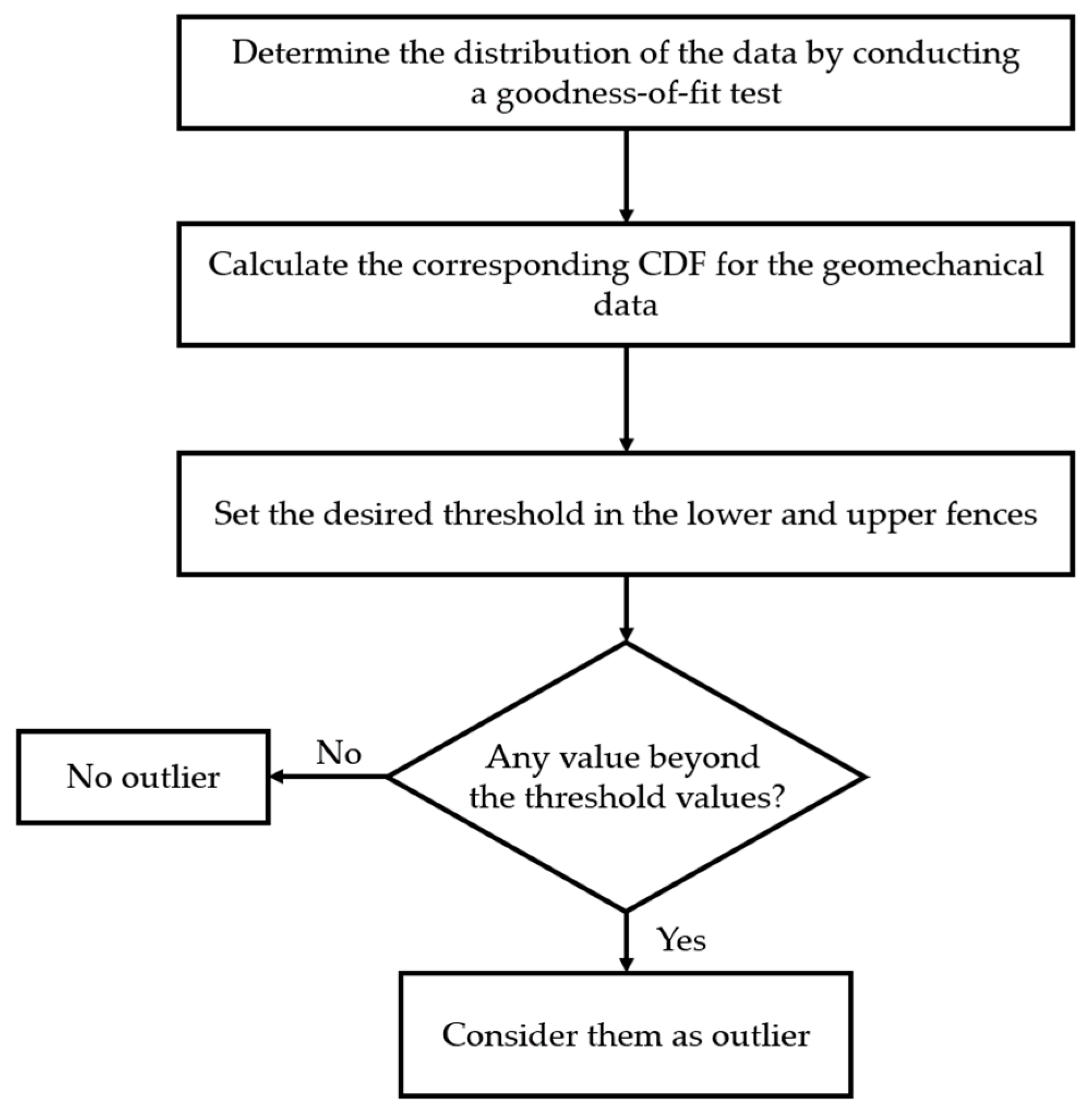
3.1.4. Distribution-Based Approach
3.2. Statistical Tests
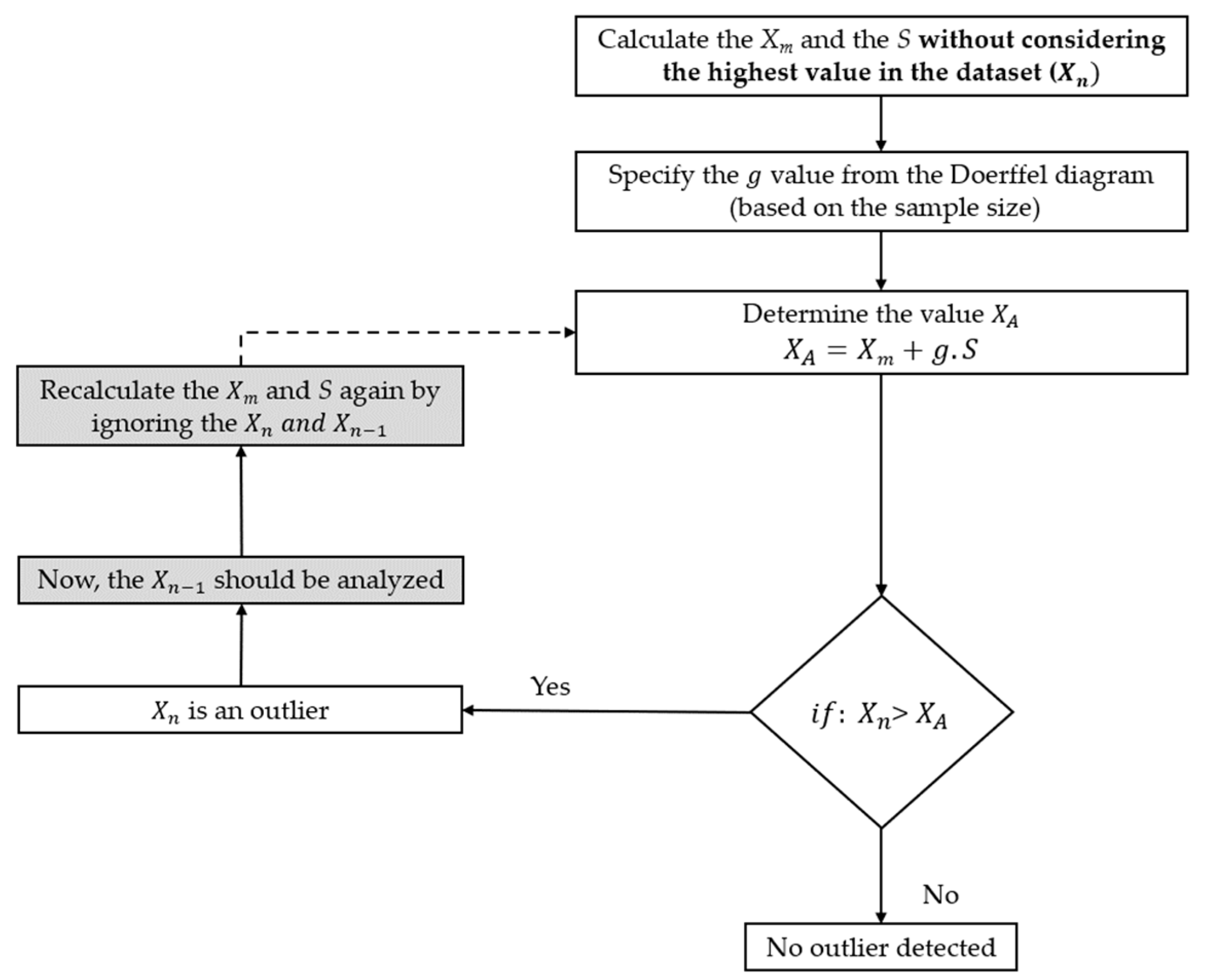
3.2.1. Doerffel’s Test
3.2.2. Peirce’s Test
3.2.3. Chauvenet’s Test
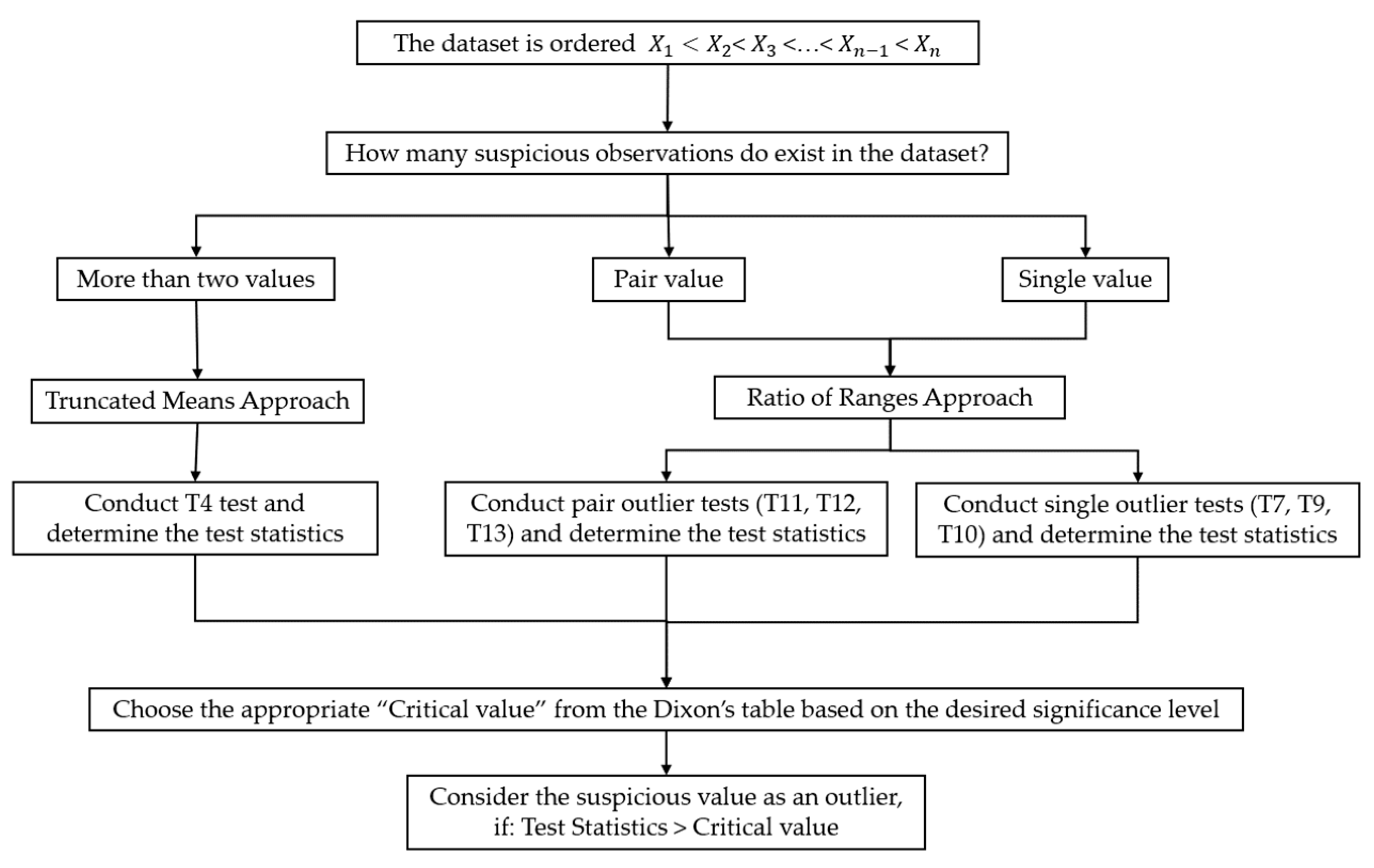
3.2.4. Dixon’s Test
3.2.5. Grubbs’ Test
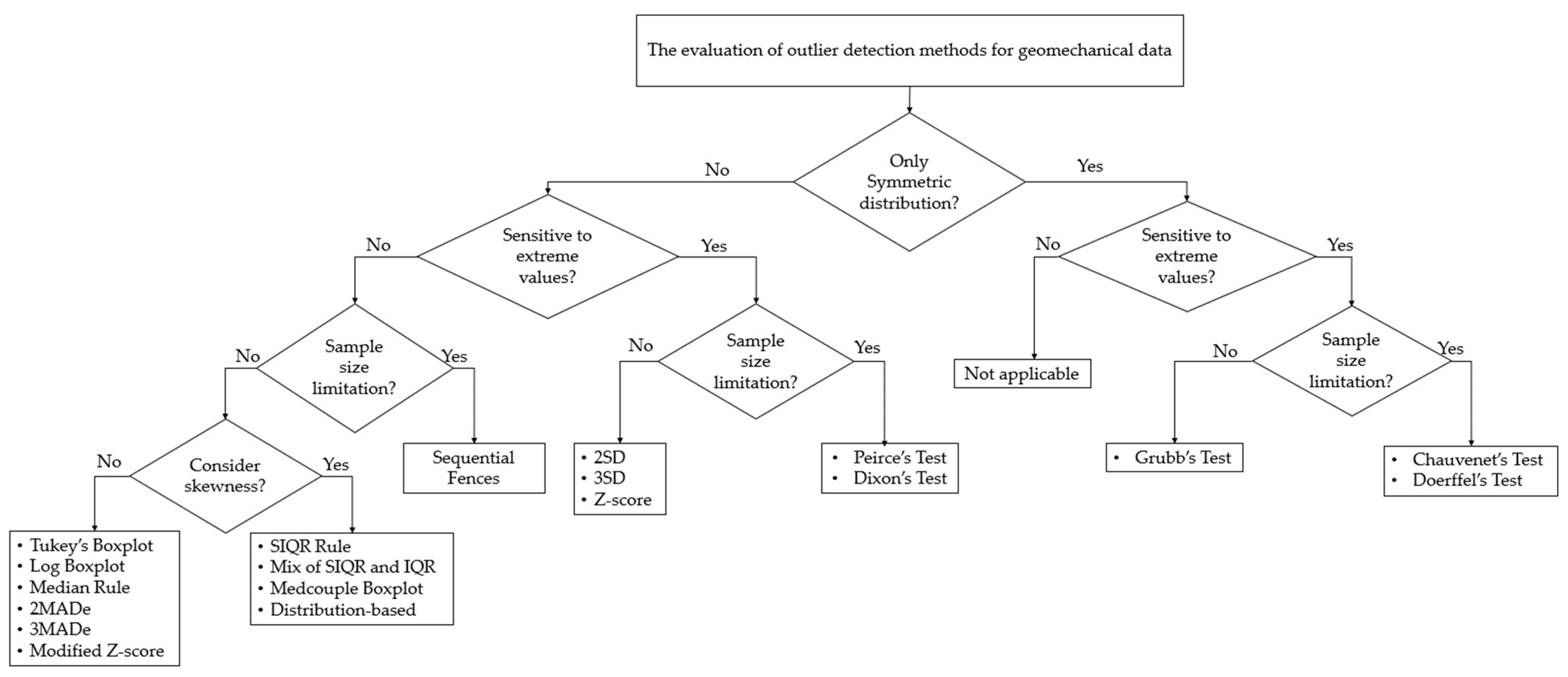
4. Evaluation of Applicability of Outlier Methods in Geomechanics
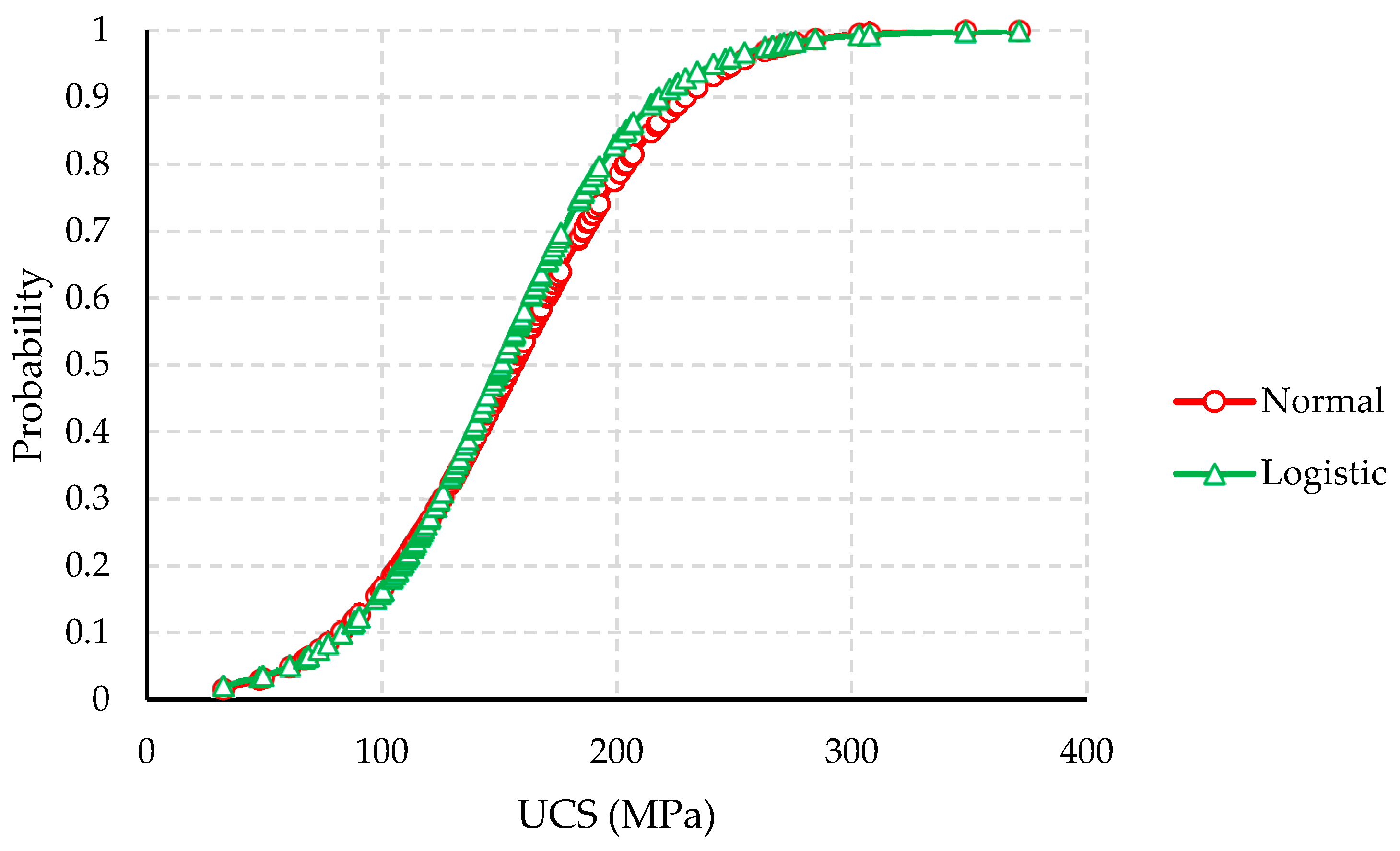
- An important factor to consider in the suitability of outlier detection methods is the shape of data distribution. Geomechanical data are generally assumed to be normally distributed. In reality, however, laboratory test results such as UCS values naturally show large variations, which leads them to be greatly skewed. Thus, the visual shape of the data frequencies should be primarily analyzed. Certain outlier detection methods, such as Doerffel, Chauvenet, and Grubbs, are suitable for symmetrically distributed data only [38,68,79]. Many of the most applicable methods can be used for either symmetric or asymmetric distributions. Although most fence labeling methods do not explicitly consider the data distribution, they rely on several statistics that are related to the distribution. Therefore, methods with no distribution limitations may be better suited for geomechanical data.
- When outlier detection methods are evaluated, their sensitivity to extreme values is an important detail to consider. Deviation-based outlier methods, which incorporate standard deviation in their formulas, are more sensitive to the presence of extreme values in the dataset [4,37]. Thus, they may not be suitable for analyzing geomechanical data. However, some approaches such as IQR-based methods exhibit robustness against outliers. In addition, methods that use the median value instead of the mean value are generally less susceptible to violations of the dataset [35].
- The number of samples in a geomechanical dataset also affects the applicability of outlier detection methods. While geomechanical datasets may not have a large number of samples, certain statistical tests such as Peirce’s test cannot be applied to sample sizes greater than 60 [29]. For larger datasets, IQR- and median-based methods are more suitable because they can be applied to any sample size without being influenced by extreme datapoints [36].
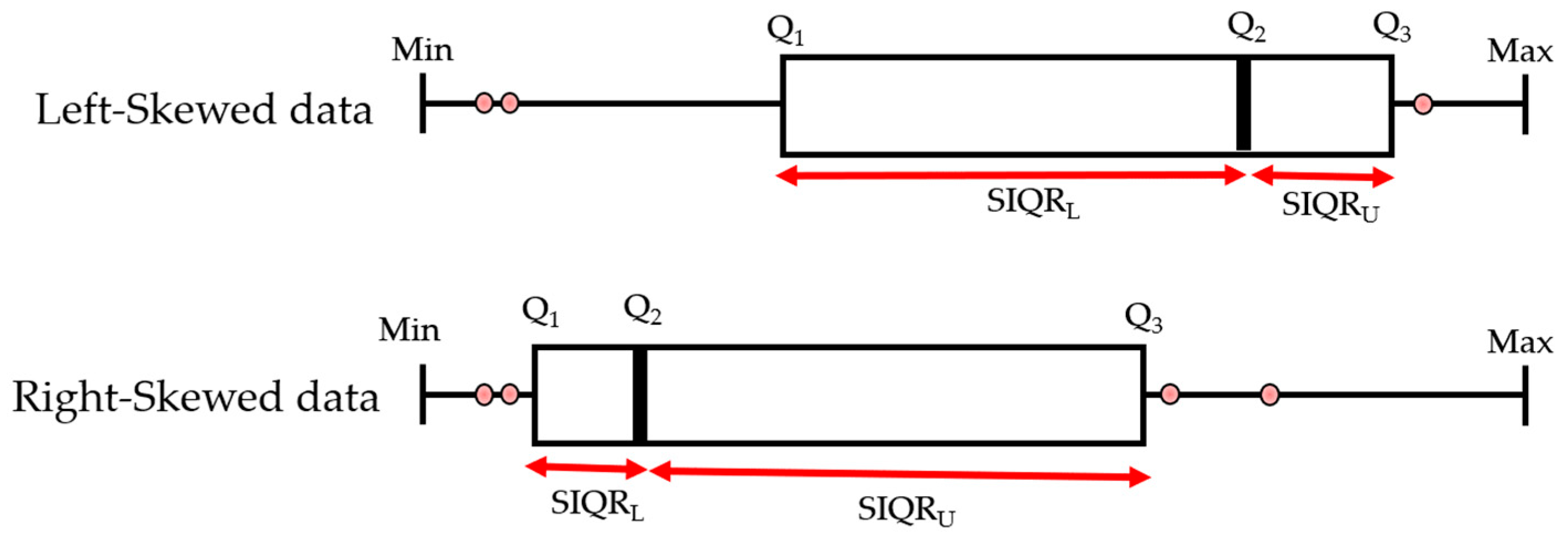
- Geomechanical data tend to be skewed because of their significant inherent variability, which is why a proper outlier method should address the effect of skewness. However, there are a few methods such as MC boxplot, SIQR rule, and the mix of the SIQR and IQR methods which consider the skewness by modifying the fences [31,41]. Furthermore, the distribution-based approach indirectly takes the data skewness into account because it focuses on the distribution tails and can identify extreme outliers that are far away from the rest of the data. However, many outlier methods are still used for heavily skewed data.
Comparison of Various Outlier Detection Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Xm | Mean |
| S | Standard deviation |
| n | Sample size |
| IQR | Interquartile range |
| Semi-interquartile range for lower threshold | |
| Semi-interquartile range for upper threshold | |
| Lower fence | |
| Upper fence | |
| Q1 | First quartile |
| Q2 | Second quartile or median |
| Q3 | Third quartile |
| t | Student’s t-distribution |
| df | Degree of freedom |
| Probability | |
| MC | Medcouple |
| MAD | Median absolute deviation |
| UCS | Uniaxial compressive strength |
| CDF | Cumulative distribution function |
References
- Mazraehli, M.; Zare, S. An application of uncertainty analysis to rock mass properties characterization at porphyry copper mines. Bull. Eng. Geol. Environ. 2020, 79, 3721–3739. [Google Scholar] [CrossRef]
- Han, L.; Wang, L.; Zhang, W. Quantification of statistical uncertainties of rock strength parameters using Bayesian-based Markov Chain Monte Carlo method. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Beijing, China, 19–21 November 2020; IOP Publishing: Bristol, UK, 2020; Volume 570, p. 032051. [Google Scholar]
- Connor Langford, J.; Diederichs, M.S. Quantifying uncertainty in Hoek–Brown intact strength envelopes. Int. J. Rock Mech. Min. Sci. 2015, 74, 91–102. [Google Scholar] [CrossRef]
- Barbato, G.; Barini, E.; Genta, G.; Levi, R. Features and performance of some outlier detection methods. J. Appl. Stat. 2011, 38, 2133–2149. [Google Scholar] [CrossRef]
- Saleem, S.; Aslam, M.; Shaukat, M.R. A review and empirical comparison of univariate outlier detection methods. Pak. J. Stat. 2021, 37, 447–462. [Google Scholar]
- Kannan, K.S.; Manoj, K.; Arumugam, S. Labeling methods for identifying outliers. Int. J. Stat. Syst. 2015, 10, 231–238. [Google Scholar]
- Hadi, A.S.; Imon, A.R.; Werner, M. Detection of outliers. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 57–70. [Google Scholar] [CrossRef]
- Peirce, B. Criterion for the rejection of doubtful observations. Astron. J. 1852, 2, 161–163. [Google Scholar] [CrossRef]
- Tiryaki, B. Predicting intact rock strength for mechanical excavation using multivariate statistics, artificial neural networks, and regression trees. Eng. Geol. 2008, 99, 51–60. [Google Scholar] [CrossRef]
- Heidarzadeh, S.; Saeidi, A.; Lavoie, C.; Rouleau, A. Geomechanical characterization of a heterogenous rock mass using geological and laboratory test results: A case study of the Niobec Mine, Quebec (Canada). SN Appl. Sci. 2021, 3, 640. [Google Scholar] [CrossRef]
- Shirani Faradonbeh, R.; Taheri, A.; Karakus, M. The propensity of the over-stressed rock masses to different failure mechanisms based on a hybrid probabilistic approach. Tunn. Undergr. Space Technol. 2022, 119, 104214. [Google Scholar] [CrossRef]
- Bozorgzadeh, N.; Dolowy-Busch, M.; Harrison, J.P. Obtaining Robust Estimates of Rock Strength for Rock Engineering Design. In Proceedings of the 13th ISRM International Congress of Rock Mechanics, Montreal, QC, Canada, 10–13 May 2015. [Google Scholar]
- Xue, Y.; Bai, C.; Qiu, D.; Kong, F.; Li, Z. Predicting rockburst with database using particle swarm optimization and extreme learning machine. Tunn. Undergr. Space Technol. 2020, 98, 103287. [Google Scholar] [CrossRef]
- Roy, J.; Eberhardt, E.; Bewick, R.; Campbell, R. Application of Data Analysis Techniques to Identify Rockburst Mechanisms, Triggers, and Contributing Factors in Cave Mining. Rock Mech. Rock Eng. 2023, 56, 2967–3002. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, C.; Guo, S.; Wang, W.; Luo, H. Evaluation of rock burst intensity of cloud model based on CRITIC method and order relation analysis method. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Lin, S.; Zheng, H.; Han, C.; Han, B.; Li, W. Evaluation and prediction of slope stability using machine learning approaches. Front. Struct. Civ. Eng. 2021, 15, 821–833. [Google Scholar] [CrossRef]
- Manouchehrian, A.; Gholamnejad, J.; Sharifzadeh, M. Development of a model for analysis of slope stability for circular mode failure using genetic algorithm. Environ. Earth Sci. 2014, 71, 1267–1277. [Google Scholar] [CrossRef]
- Zhou, J.; Li, E.; Yang, S.; Wang, M.; Shi, X.; Yao, S.; Mitri, H.S. Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf. Sci. 2019, 118, 505–518. [Google Scholar] [CrossRef]
- Tomaszewski, D.; Rapiński, J.; Stolecki, L.; Śmieja, M. Switching Edge Detector as a tool for seismic events detection based on GNSS timeseries. Arch. Min. Sci. 2022, 67, 317–332. [Google Scholar]
- Hunt, R.E. Geotechnical Engineering Investigation Handbook; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Pan, J.; Bai, Z.; Cao, Y.; Zhou, W.; Wang, J. Influence of soil physical properties and vegetation coverage at different slope aspects in a reclaimed dump. Environ. Sci. Pollut. Res. 2017, 24, 23953–23965. [Google Scholar] [CrossRef]
- Shao, Z.; Armaghani, D.J.; Bejarbaneh, B.Y.; Mu’azu, M.; Mohamad, E.T. Estimating the friction angle of black shale core specimens with hybrid-ANN approaches. Measurement 2019, 145, 744–755. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y.; Xie, X. Prediction of Uniaxial Compression Strength of Limestone Based on the Point Load Strength and SVM Model. Minerals 2021, 11, 1387. [Google Scholar] [CrossRef]
- Bolla, A.; Paronuzzi, P. UCS field estimation of intact rock using the Schmidt hammer: A new empirical approach. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Turin, Italy, 20–25 September 2021; p. 012014. [Google Scholar]
- Goktan, R.; Gunes, N. A comparative study of Schmidt hammer testing procedures with reference to rock cutting machine performance prediction. Int. J. Rock Mech. Min. Sci. 2005, 42, 466–472. [Google Scholar] [CrossRef]
- Goktan, R.; Ayday, C. A suggested improvement to the Schmidt rebound hardness ISRM suggested method with particular reference to rock machineability. Int. J. Rock Mech. Min. Sci. 1993, 30, 321–322. [Google Scholar] [CrossRef]
- Dindarloo, S.R.; Siami-Irdemoosa, E. Maximum surface settlement based classification of shallow tunnels in soft ground. Tunn. Undergr. Space Technol. 2015, 49, 320–327. [Google Scholar] [CrossRef]
- Carmona, S.; Molins, C.; Aguado, A.; Mora, F. Distribution of fibers in SFRC segments for tunnel linings. Tunn. Undergr. Space Technol. 2016, 51, 238–249. [Google Scholar] [CrossRef]
- Seo, S. A Review and Comparison of Methods for Detecting Outliers in Univariate Data Sets. Master’s Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 2006. [Google Scholar]
- Tukey, J.W. Exploratory Data Analysis; Addison-wesley series in behavioral science-quantitative methods; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Walker, M.L.; Dovoedo, Y.H.; Chakraborti, S.; Hilton, C.W. An Improved Boxplot for Univariate Data. Am. Stat. 2018, 72, 348–353. [Google Scholar] [CrossRef]
- Petrone, P.; Allocca, V.; Fusco, F.; Incontri, P.; De Vita, P. Engineering geological 3D modeling and geotechnical characterization in the framework of technical rules for geotechnical design: The case study of the Nola’s logistic plant (southern Italy). Bull. Eng. Geol. Environ. 2023, 82, 12. [Google Scholar] [CrossRef]
- Almeida, A.P.; Liu, J. Statistical evaluation of design methods for micropiles in Ontario soils. DFI J. J. Deep Found. Inst. 2018, 12, 133–146. [Google Scholar] [CrossRef]
- Sanou, A.-G.; Saeidi, A.; Heidarzadeh, S.; Chavali, R.V.P.; Samti, H.E.; Rouleau, A. Geotechnical Parameters of Landslide-Prone Laflamme Sea Deposits, Canada: Uncertainties and Correlations. Geosciences 2022, 12, 297. [Google Scholar] [CrossRef]
- Hoaglin, D.C.; Iglewicz, B. Fine-Tuning Some Resistant Rules for Outlier Labeling. J. Am. Stat. Assoc. 1987, 82, 1147–1149. [Google Scholar] [CrossRef]
- Dawson, R. How significant is a boxplot outlier? J. Stat. Educ. 2011. [Google Scholar] [CrossRef]
- Gignac, G. How2statsbook (Online Edition 1), Chapter 2; Perth, Australia. 2019. Available online: https://www.how2statsbook.com (accessed on 29 March 2023).
- Schwertman, N.C.; de Silva, R. Identifying outliers with sequential fences. Comput. Stat. Data Anal. 2007, 51, 3800–3810. [Google Scholar] [CrossRef]
- Carling, K. Resistant outlier rules and the non-Gaussian case. Comput. Stat. Data Anal. 2000, 33, 249–258. [Google Scholar] [CrossRef]
- Kimber, A. Exploratory data analysis for possibly censored data from skewed distributions. J. R. Stat. Soc. Ser. C Appl. Stat. 1990, 39, 21–30. [Google Scholar] [CrossRef]
- Hubert, M.; Vandervieren, E. An adjusted boxplot for skewed distributions. Comput. Stat. Data Anal. 2008, 52, 5186–5201. [Google Scholar] [CrossRef]
- Barnett, O.; Cohen, A. The histogram and boxplot for the display of lifetime data. J. Comput. Graph. Stat. 2000, 9, 759–778. [Google Scholar]
- Dovoedo, Y.; Chakraborti, S. Boxplot-based outlier detection for the location-scale family. Commun. Stat. Simul. Comput. 2015, 44, 1492–1513. [Google Scholar] [CrossRef]
- Romão, X.; Vasanelli, E. Identification and Processing of Outliers. In Non-Destructive In Situ Strength Assessment of Concrete: Practical Application of the RILEM TC 249-ISC Recommendations; Springer: Berlin/Heidelberg, Germany, 2021; pp. 161–180. [Google Scholar]
- Yang, M.; Wang, R.; Li, M.; Liao, M. A PSI targets characterization approach to interpreting surface displacement signals: A case study of the Shanghai metro tunnels. Remote Sens. Environ. 2022, 280, 113150. [Google Scholar] [CrossRef]
- Azad, S.T.; Moghaddassi, N.; Sayehbani, M. Digital Shoreline Analysis System improvement for uncertain data detection in measurements. Environ. Monit. Assess. 2022, 194, 646. [Google Scholar] [CrossRef]
- Olewuezi, N. Note on the comparison of some outlier labeling techniques. J. Math. Stat. 2011, 7, 353–355. [Google Scholar]
- Duchnowski, R. Median-based estimates and their application in controlling reference mark stability. J. Surv. Eng. 2010, 136, 47–52. [Google Scholar] [CrossRef]
- Hussain, I.; Uddin, M. Functional and multivariate hydrological data visualization and outlier detection of Sukkur Barrage. Int. J. Comput. Appl. 2019, 178, 20–29. [Google Scholar] [CrossRef]
- Choi, S.-I.; Shim, S.; Kong, S.-M.; Kim, Y.B.; Lee, S.-W. Efficiency Analysis of Filter-Based Calibration Technique to Improve Tunnel Measurement Reliability. KSCE J. Civ. Eng. 2022, 26, 2926–2938. [Google Scholar] [CrossRef]
- Iglewicz, B.; Hoaglin, D.C. How to Detect and Handle Outliers; Asq Press: Milwaukee, WI, USA, 1993; Volume 16. [Google Scholar]
- Wah, W.S.L.; Owen, J.S.; Chen, Y.-T.; Elamin, A.; Roberts, G.W. Removal of masking effect for damage detection of structures. Eng. Struct. 2019, 183, 646–661. [Google Scholar]
- Kottegoda, N.T.; Rosso, R. Applied Statistics for Civil and Environmental Engineers; Blackwell Publishing: Hoboken, NJ, USA, 2008. [Google Scholar]
- Kor, K.; Ertekin, S.; Yamanlar, S.; Altun, G. Penetration rate prediction in heterogeneous formations: A geomechanical approach through machine learning. J. Pet. Sci. Eng. 2021, 207, 109138. [Google Scholar] [CrossRef]
- Yang, H.; Song, K.; Zhou, J. Automated recognition model of geomechanical information based on operational data of tunneling boring machines. Rock Mech. Rock Eng. 2022, 55, 1499–1516. [Google Scholar] [CrossRef]
- Kamari, A.; Khaksar-Manshad, A.; Gharagheizi, F.; Mohammadi, A.H.; Ashoori, S. Robust model for the determination of wax deposition in oil systems. Ind. Eng. Chem. Res. 2013, 52, 15664–15672. [Google Scholar] [CrossRef]
- Monteiro, D.D.; Duque, M.M.; Chaves, G.S.; Ferreira Filho, V.M.; Baioco, J.S. Using data analytics to quantify the impact of production test uncertainty on oil flow rate forecast. Oil Gas Sci. Technol. Rev. D’ifp Energ. Nouv. 2020, 75, 7. [Google Scholar] [CrossRef]
- Shaygan, K.; Jamshidi, S. Prediction of rate of penetration in directional drilling using data mining techniques. Geoenergy Sci. Eng. 2023, 221, 111293. [Google Scholar] [CrossRef]
- Gumbel, E. Statistics of Extremes; Columbia University Press: New York, NY, USA, 1958. [Google Scholar]
- Barnett, V.; Lewis, T. Outliers in Statistical Data; Wiley: New York, NY, USA, 1994; Volume 3. [Google Scholar]
- Doerffel, K. Die Statistische Auswertung von Analysenergebnissen; Springer: Berlin, Germany, 1967; Volume 2. [Google Scholar]
- Afraei, S.; Shahriar, K.; Madani, S.H. Statistical analysis of rock-burst events in underground mines and excavations to present reasonable data-driven predictors. J. Stat. Comput. Simul. 2017, 87, 3336–3376. [Google Scholar] [CrossRef]
- Adel, S.; Mansour, Z.; Ardeshir, H. Geochemical behavior investigation based on k-means and artificial neural network prediction for titanium and zinc, Kivi region, Iran. Bull. Tomsk Polytech. Univ. Geo Assets Eng. 2021, 332, 113–125. [Google Scholar]
- Rochim, A.F.R.F. Chauvenet’s Criterion, Peirce’s Criterion, and Thompson’s Criterion (Literatures Review). Available online: https://www.researchgate.net/publication/299829851 (accessed on 21 March 2016).
- Ross, S.M. Peirce’s criterion for the elimination of suspect experimental data. J. Eng. Technol. 2003, 20, 38–41. [Google Scholar]
- Borosnyói, A. Variability case study based on in-situ rebound hardness testing of concrete: Part 1. Statistical analysis of inherent variability parameters. Építöanyag (Online) 2014, 66, 85. [Google Scholar] [CrossRef]
- Retamales, R.; Davies, R.; Mosqueda, G.; Filiatrault, A. Experimental seismic fragility of cold-formed steel framed gypsum partition walls. J. Struct. Eng. 2013, 139, 1285–1293. [Google Scholar] [CrossRef]
- Chauvenet, W. A Manual of Spherical and Practical Astronomy, (Spherical Astronomy), 5th ed.; Dover Publication: New York, NY, USA, 1960; Volume 1. [Google Scholar]
- Gul, M.; Kotak, Y.; Muneer, T.; Ivanova, S. Enhancement of albedo for solar energy gain with particular emphasis on overcast skies. Energies 2018, 11, 2881. [Google Scholar] [CrossRef]
- Limb, B.J.; Work, D.G.; Hodson, J.; Smith, B.L. The Inefficacy of Chauvenet’s Criterion for Elimination of Data Points. J. Fluids Eng. 2017, 139, 054501. [Google Scholar] [CrossRef]
- García, A.; Castro-Fresno, D.; Polanco, J.; Thomas, C. Abrasive wear evolution in concrete pavements. Road Mater. Pavement Des. 2012, 13, 534–548. [Google Scholar] [CrossRef]
- Mohammadi, Y.; Kaushik, S. Flexural fatigue-life distributions of plain and fibrous concrete at various stress levels. J. Mater. Civ. Eng. 2005, 17, 650–658. [Google Scholar] [CrossRef]
- Bawa, S.; Singh, S.P. Analysis of fatigue life of hybrid fibre reinforced self-compacting concrete. Proc. Inst. Civ. Eng. 2020, 173, 251–260. [Google Scholar] [CrossRef]
- Muscolino, G.; Genovese, F.; Sofi, A. Reliability bounds for structural systems subjected to a set of recorded accelerograms leading to imprecise seismic power spectrum. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A Civ. Eng. 2022, 8, 04022009. [Google Scholar] [CrossRef]
- Dixon, W.J. Analysis of extreme values. Ann. Math. Stat. 1950, 21, 488–506. [Google Scholar] [CrossRef]
- Verma, S.P.; Quiroz-Ruiz, A.; Díaz-González, L. Critical values for 33 discordancy test variants for outliers in normal samples up to sizes 1000, and applications in quality control in Earth Sciences. Rev. Mex. De Cienc. Geológicas 2008, 25, 82–96. [Google Scholar]
- Lach, S. The application of selected statistical tests in the detection and removal of outliers in water engineering data based on the example of piezometric measurements at the Dobczyce dam over the period 2012–2016. In Proceedings of the E3S Web of Conferences, Krakow, Poland, 7–8 June 2018. [Google Scholar]
- Kim, H.-S.; Kim, H.-K.; Shin, S.-Y.; Chung, C.-K. Application of statistical geo-spatial information technology to soil stratification in the Seoul metropolitan area. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2012, 6, 221–228. [Google Scholar] [CrossRef]
- Grubbs, F.E. Sample Criteria for Testing Outlying Observations. Ann. Math. Stat. 1950, 21, 27–58. [Google Scholar] [CrossRef]
- Bao, Y.; Song, C.; Wang, W.; Ye, T.; Wang, L.; Yu, L. Damage Detection of Bridge Structure Based on SVM. Math. Probl. Eng. 2013, 2013, 490372. [Google Scholar] [CrossRef]
- Garces, D.; Rebolledo, H.; Miranda, P. Incorporating vulnerability of hang-ups and secondary breaking to drawpoints availability for short-term cave plans, El Teniente mine. In Proceedings of the MassMin 2020: Proceedings of the Eighth International Conference & Exhibition on Mass Mining, Santiago, Chile, 9–12 December 2020; pp. 988–1001. [Google Scholar]
- Wei, F. Gross error elimination and index determination of shearing strength parameters in triaxial test. In Proceedings of the Applied Mechanics and Materials, Wuhan, China, 24–25 August 2013; Trans Tech Publications: Stafa-Zurich, Switzerland, 2013; Volume 353, pp. 152–158. [Google Scholar]
- Lu, H.; Li, H.; Meng, X. Spatial Variability of the Mechanical Parameters of High-Water-Content Soil Based on a Dual-Bridge CPT Test. Water 2022, 14, 343. [Google Scholar] [CrossRef]
- @Risk; Palisade Corporation, 2022. Available online: https://www.palisade.com/risk/ (accessed on 29 March 2023).
- Minitab; Minitab, LLC, 2021. Available online: https://www.minitab.com/ (accessed on 29 March 2023).
- IBM SPSS Statistics for Windows; IBM Corp: New York, NY, USA, 2022.
- MATLAB R2022a; MathWorks: Natick, MA, USA, 2022.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author (Year) | Method | Formula | Equation |
|---|---|---|---|
| Tukey (1977) [30] | Traditional boxplot | (1) | |
| Barbato et al. (2011) [4] | Log boxplot | (2) | |
| Schwertman and de Silva (2007) [38] | Sequential fences | (3) | |
| (4) | |||
| Carling (2000) [39] | Median rule | (5) | |
| Kimber (1990) [40] | SIQR rule | (6) | |
| (7) | |||
| Walker et al. (2018) [31] | Mix of SIQR and IQR | (8) | |
| (9) | |||
| Hubert and Vandervieren (2008) [41] | MC boxplot | (10) | |
| (11) | |||
| (12) |
| Test Code | Upper-Bound Test Statistic (TS) | Lower-Bound Test Statistic (TS) | Tested Values | |
|---|---|---|---|---|
| T7 | ||||
| T9 | , | |||
| T10 | , | |||
| T11 | , | |||
| T12 | , | |||
| T13 | , | |||
| T4 | Lower bound | |||
| , | ||||
| , , | ||||
| , , | ||||
| Upper bound | ||||
| , | ||||
| , , | ||||
| , , | ||||
| Outlier Detection Method | Confidence Interval (MPa) | Number of Outliers | |
|---|---|---|---|
| LB | UB | ||
| Tukey’s boxplot (1.5 IQR) | 26.10 < UCS < 266.10 | 0 | 10 |
| Tukey’s boxplot (3.0 IQR) | −63.90 < UCS < 356.10 | 0 | 1 |
| Tukey’s boxplot (2.2 IQR) | −15.90 < UCS < 308.10 | 0 | 2 |
| Log boxplot | 15.34 < UCS < 276.86 | 0 | 5 |
| Sequential fences | NA * | NA | NA |
| Median rule | 11.80 < UCS < 287.80 | 0 | 4 |
| MC boxplot | 32.29 < UCS < 271.04 | 0 | 8 |
| SIQR rule | 15.00 < UCS < 255.00 | 0 | 11 |
| Mix of SIQR and IQR | 0.78 < UCS < 246.34 | 0 | 13 |
| 2MADe method | 49.85 < UCS < 249.75 | 3 | 12 |
| 3MADe method | −0.13 < UCS < 349.71 | 0 | 1 |
| 2SD method | 40.86 < UCS < 270.30 | 1 | 8 |
| 3SD method | −16.50 < UCS < 327.67 | 0 | 2 |
| Z-score | −3.00 < Z-score < +3.00 | 0 | 2 |
| Modified Z-score | −3.50 < modified Z-score < +3.50 | 0 | 2 |
| Distribution-based approach | 43.15 < UCS < 268.00 | 1 | 9 |
| Doerffel’s test | Statistical tests identify outliers based on statistical hypotheses | NA | 1 |
| Peirce’s test | NA | NA | |
| Chauvenet’s test | 0 | 1 | |
| Dixon’s test (ratio of ranges) | 0 | 0 | |
| Dixon’s test (truncated means) | 4 | 0 | |
| Grubbs’ test | NA | NA | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dastjerdy, B.; Saeidi, A.; Heidarzadeh, S. Review of Applicable Outlier Detection Methods to Treat Geomechanical Data. Geotechnics 2023, 3, 375-396. https://doi.org/10.3390/geotechnics3020022
Dastjerdy B, Saeidi A, Heidarzadeh S. Review of Applicable Outlier Detection Methods to Treat Geomechanical Data. Geotechnics. 2023; 3(2):375-396. https://doi.org/10.3390/geotechnics3020022
Chicago/Turabian StyleDastjerdy, Behzad, Ali Saeidi, and Shahriyar Heidarzadeh. 2023. "Review of Applicable Outlier Detection Methods to Treat Geomechanical Data" Geotechnics 3, no. 2: 375-396. https://doi.org/10.3390/geotechnics3020022