
PCIer: Pavement Condition Evaluation Using Aerial Imagery and Deep Learning


1
Department of Civil, Construction and Environmental Engineering, Marquette University, Milwaukee, WI 53233, USA
2
Department of Construction and Operations Management, South Dakota State University, Brookings, SD 57007, USA
3
Department of Built Environment, North Carolina A&T State University, Greensboro, NC 27411, USA
*
Authors to whom correspondence should be addressed.
Geographies 2023, 3(1), 132-142; https://doi.org/10.3390/geographies3010008
Submission received: 31 October 2022
/
Revised: 29 January 2023
/
Accepted: 30 January 2023
/
Published: 1 February 2023
(This article belongs to the Special Issue Advanced Technologies in Spatial Data Collection and Analysis)
Abstract
:This paper aims to explore and evaluate aerial imagery and deep learning technology in pavement condition evaluation. A convolutional neural network (CNN) model, named PCIer, was designed to process aerial images and produce pavement condition index (PCI) estimations, which are classified into four scales of Good (PCI ≥ 70), Fair (50 ≤ PCI < 70), Poor (25 ≤ PCI < 50), and Very Poor (PCI < 25). In the experiment, the PCI datasets were retrieved from the published pavement condition report by the City of Sacramento, CA. Following the retrieved datasets, the authors also collected the corresponding aerial image datasets containing 100 images for each PCI grade from Google Earth. An 80% proportion of datasets were used for PCIer model training, and the remaining were used for testing. Comparisons showed using a 128-channel heatmap layer in the proposed PCIer model and saving the PCIer model with the best validation accuracy would yield the best performance, with a testing accuracy of 0.97, and a weighted average precision, recall, and F1-score of 0.98, 0.97, and 0.97, respectively. Moreover, future research recommendations are provided in the discussion for improving the effectiveness of pavement evaluation via aerial imagery and deep learning.
1. Introduction
Pavement evaluations (e.g., visual condition surveys, non-destructive testing, destructive testing) are conducted to determine functional and structural conditions of a highway/street section, either for purposes of routine monitoring or planned corrective action [1,2,3,4]. The Pavement Condition Index (PCI) is a numerical value representing roads’ and parking lots’ pavement status [5]. In ASTM D6433, “Standard Practice for Roads and Parking Lots Pavement Condition Index Surveys,” the PCI has a value from 0 to 100, which is rated based on visual inspection of pavement distress type, severity, and quantity [5]. The Flexible Pavement Visual Survey Condition categories include Rutting, Patching, Failures, Block Cracking, Alligator Cracking, Longitudinal Cracking, Transverse Cracking, Raveling, and Flushing [5].
Before deep learning-based pavement defect detection emerged in the field, researchers identified pavement defections, i.e., cracks, through various Digital Image Processing (DIP) methods, such as thresholding and edge detection, with four steps of preprocessing, image enhancement, image transformation, and image classification and analysis [6,7,8]. These procedures focused on standardizing a specific defect, extracting it as a feature, and performing a rule-based inspection to determine which features are included [9]. However, in the traditional DIP approach, a person should manually process all the filter tasks that extract visual features, and then the completed filters are collected and stored as a banked dataset.
Convolutional operation transforms the tiresome DIP process into a more straightforward process through deep learning. It generates thousands of filters automatically optimized for targeted data that previously could not be made by human effort. In addition, a deeper network model can generate more powerful features since it will cover a wide range of trained datasets with a deeper understanding of complicated abstraction [10,11]. Typically, a Convolutional Neural Network (CNN) model starts with a convolutional layer, while its hidden layers contain multiple max-pooling layers, convolutional layers, and fully connected layers (FC or dense layers). To conduct classification tasks, the CNN ends with an FC layer with a SoftMax activation function to normalize the output of a network to a probability distribution over predicted output classes [12]. The effectiveness of CNN models in pavement distress detection and classification has been proven in several studies and experiment results [12,13,14,15,16,17,18,19].
The ASTM D6433 also scales PCI into several ratings of good (85–100), satisfactory (70–85), fair (55–70), poor (40–55), very poor (25–40), serious (10–25), and failed (0–10), which could be treated as a classification task. Therefore, in this research, a feasibility study of CNN-based PCI estimation was conducted on aerial imagery (Google Earth) to rate the PCI at the multi-level as well. Compared to ASTM D6433, the proposed method in this paper skipped the time-consuming and labor-consuming pavement distress type, severity, and quantity condition survey processes [5].
2. Deep Learning for Pavement Condition Evaluation
The pavement surface of a roadway section is a relatively flat plane, which makes it feasible to use 2D imagery (e.g., top-view and drone photogrammetric orthophotos [20]) to represent the pavement’s spectral features (Red, Green, and Blue). In addition, 3D imagery (e.g., surface-height plot [21], depth map [22], and range image [16,23]) can represent the pavement’s elevation features. Moreover, 2D and 3D images can be further aligned to the same pixel coordinates and merged as integrated features [20]. Based on those 2D/3D data sources, previous studies used the following machine learning and deep learning-based methods to achieve the pavement condition evaluation objectives.
Machine learning methods, such as Support Vector Machine (SVM) [20] and Random Forest (RF) [24], can output numerical values as classification results. In study [20], a set of spectral features (RGB and mean), textural features (contrast, correlation, energy, and homogeneity), and geometrical features (extent, eccentricity, minor axis length major axis length, and orientation) were generated from the drone photogrammetric orthophoto. The results showed that using the combination features had an accuracy of 92% in crack/non-crack classification. Only using textural features had the lowest accuracy of 81%, as cracks are not significantly different from non-cracks in asphalt pavement. Using spectral and structural features separately had an accuracy of about 85%, because cracks, in color and shape, are different from non-cracks [20]. Moreover, CrackForest [24], a RF classifier, also used an integral channel feature (three color, two magnitude, and eight orientation channels) for road image crack detection.
Deep learning approaches, such as Artificial Neural Networks (ANNs), or Neural Networks (NNs) can also perform the classification task. NNs have the architecture of multiple layers, including an input layer, hidden layers, and an output layer. By using different hidden layers to connect the input and output layers, the NNs can generate anything from numerical values to free-form elements such as images, texts, and sounds. Multilayer Perceptron (MLP) is a class of feedforward ANN which typically has 1D vector input data, such as a GPR trace with 128 samples [25] or 300 samples [26]. The hidden layers usually are fully connected layers (FC or dense layers), dropout layers, and activation functions. The output layer contains a SoftMax activation function to generate a 1D binary class vector for classification tasks, where the size of the output vector depends on the number of classes, such as normal signal and abnormal signal-2 classes [25], and pavement thickness (equal to the samples) of 300 classes [26]. Then, the additional Argmax function is required to return the index of the maximum value in the binary class vector as the final numerical value (classification) output [12].
Beyond structured data, the most common type of input data for NNs in the reviewed studies are 2D imagery data, which results in CNNs and FCNs (Fully Convolutional Networks) being the most widely used data analysis method for pavement evaluation. A CNN starts with a convolutional layer, while its hidden layers contain multiple max-pooling layers, convolutional layers, and FCs. A CNN typically ends with an FC with the SoftMax activation function for conducting classification tasks, which generates a numerical value (classification) output, the same as MLP [12]. That is the major difference from FCNs, because an FCN model typically does not contain FC, but it uses a convolutional layer with a Sigmoid activation function as the network’s end layer for generating the same-sized output results as the input images [27]. Furthermore, CNNs can be used with the sliding window scheme (or overlapping small patches [12,14]) to perform crack and non-crack binary classification tasks [14,15,16,17] and pavement cracking category classification tasks [15] in each small patch of a large-resolution 2D/3D image. Moreover, when the size of the window patches is very small, for example, 13 × 13 pixels [14], the CNN-based image patch classification results would be properly annotating cracks on the large-resolution images [14,16]. Moreover, a previous study [18] also utilized the bilateral filter to smooth 227 × 227-pixel small patches with cracks, and implemented a k-means clustering-based image segmentation algorithm to achieve a pixel accuracy of 98.70%.
Therefore, considering the effectiveness of CNN models in pavement distress detection and classification in the previous studies and experiment results, a feasibility study of aerial imagery and CNN-based PCI estimation (by rating PCI at a multi-level) was conducted in this research project. The success of the proposed method can skip the time-consuming and labor-consuming pavement condition survey processes for pavement distress type classification, severity determination, and quantity measurement.
3. PCIer: The Proposed PCI Estimator
3.1. CNN Model for Classification and Visualization
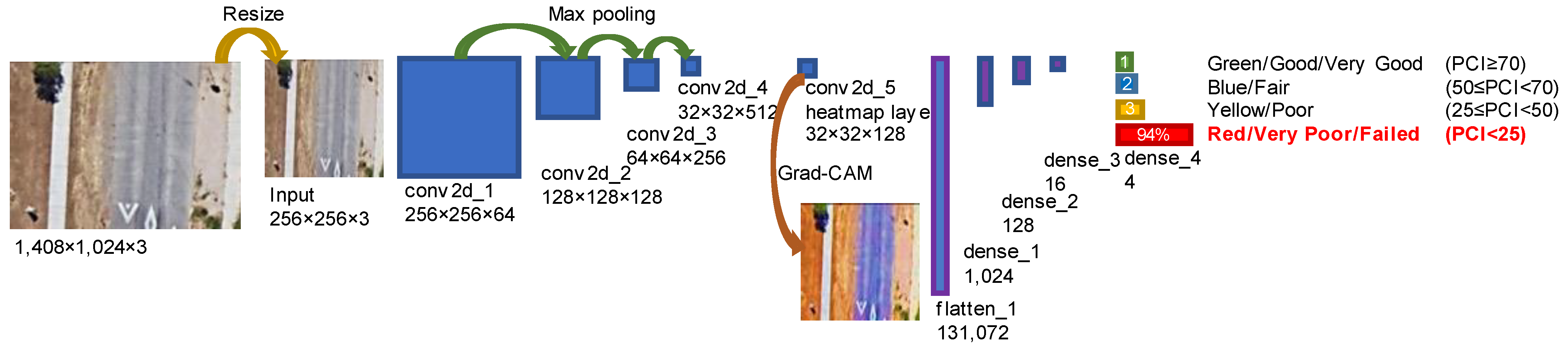
The proposed CNN model, named PCIer, is shown in Figure 1, with detailed model layers and parameters in Table 1. The collected large-dimension aerial images are first resized down to 256 × 256-pixel images as the model inputs. Then, the inputs are processed by four 2D convolutional layers and three max-pooling layers; then, the fifth convolutional layer (named “heatmap layer”) uses the 1 × 1 convolutional operation to reduce the 512 channels feature-maps to small numbers of channels. In this paper, the heatmap layers are compared in the options of 64 and 128 channels. In addition, the heatmap layer has a size of 32 × 32 pixels, which is designed to generate the heatmap via the Grad-CAM (gradient class activation map), a visualization technique for deep learning networks [28].
The generated heatmaps have the same size as convolutional outputs; thus, to make heatmaps’ sizes close to 256 × 256 pixels as in the original CNN inputs, there is no pooling layer between the fourth and fifth convolutional layers (heatmap layer) in the proposed CNN (see Figure 1). The resized heatmaps indicate the regions of the image that contribute to the CNN’s classification results. Moreover, after the heatmap layer, the flatten layer (operation) converts the 32 × 32 × 128 features to a 1D vector of 131,072 elements (or 32 × 32 × 64 features to a 1D vector of 65,536 elements). Then, the four dense layers reduce the dimension of the 1D vector to 1024, 128, 16, and 4 features, respectively.
The proposed CNN model has four dropout layers before four dense layers, which are used to avoid model overfitting. The ReLU activation function is used in the CNN model’s hidden layers (Feature Learning and Classification Blocks in Table 1), because ReLU is faster than other activation functions, such as Sigmoid [12,27]. The CNN model’s output layer uses the SoftMax activation function to generate the probabilities of PCI grades, such as 1% for Green/Good/Very Good (PCI ≥ 70), 2% for Blue/Fair (50 ≤ PCI < 70), 3% for Yellow/Poor (25 ≤ PCI < 50), and 94% for Red/Very Poor/Failed (PCI < 25), as the example shows in Figure 1. Hence, the PCI image datasets of pavement in very poor/failed condition (PCI < 25), poor condition (25 ≤ PCI < 50), fair condition (50 ≤ PCI < 70), and good/very good condition (PCI ≥ 70) need to be prepared, in which images are set with the class label of 0, 1, 2, and 3, respectively.
3.2. Data Augmentation
The proposed Data Augmentation (DA) strategies aim to obtain a well-trained CNN using a limited number of datasets. Figure 2 illustrates the proposed DA strategies, which integrate image transformations of scaling (in a range of 0.5 to 1.5), stretch (scaling in either width or height direction), rotation, flipping, and reflection. The ratios of scaling and stretch are randomly generated. When ratios are larger than one, only the central regions are kept. When ratios are less than one, the small-sized images are padded with reflection operations (alternative to constant padding). In addition, the image color adjustments are randomly determined in the adjustments of brightness, contrast, saturation, and sharpness [29].
3.3. Evaluation Metrics
The following metrics are used to measure the classification performance of the proposed CNN model and DA strategies:
Accuracy Equation (1), the ratio of number of correct predictions to the total number of testing images.
Precision Equation (2), the number of correct positive results divided by the number of positive results predicted by the CNN model.
Recall Equation (3), the number of correct positive results divided by the number of all relevant images (all images that should have been identified as positive).
F1 Score Equation (4), the harmonic mean between precision and recall. The range for the F1 Score is between 0 and 1, which indicates how precise the CNN model is (how many images it classifies correctly), as well as how robust it is (it does not miss a significant number of images).
4. Experiments and Results
4.1. Dataset Preparation
The City of Sacramento (California, CA, USA) rated and mapped the condition of the streets with the following standards: a PCI score of 70 to 100 is considered “Excellent/Good”, 50 to 69 is “Fair”, 25 to 49 is “Poor”, and 0 to 24 is “Very Poor” [30]. One-hundred images were collected from the Google Earth web version for each PCI grade via a Google Earth Screenshot Tool developed in the previous research [11]. Table 2 lists the collected PCI images (and parameters) from five streets in Sacramento. An example of the collected PCI image is shown on the left of Figure 1. The prepared training and testing datasets can be accessed in [31]. For each PCI grade, 80 images were used for CNN model training, and the remaining 20 images were used for CNN model testing. By applying the proposed DA for one time, an original image would be transformed into eight styles, as shown in Figure 2. By running the random DA for ten rounds, the original image would be extended to 80 (=1 × 8 × 10) images. Thus, the collected 320 (=80 × 4) images generated a training dataset with 25,600 (=80 × 320) images.
4.2. Model Training
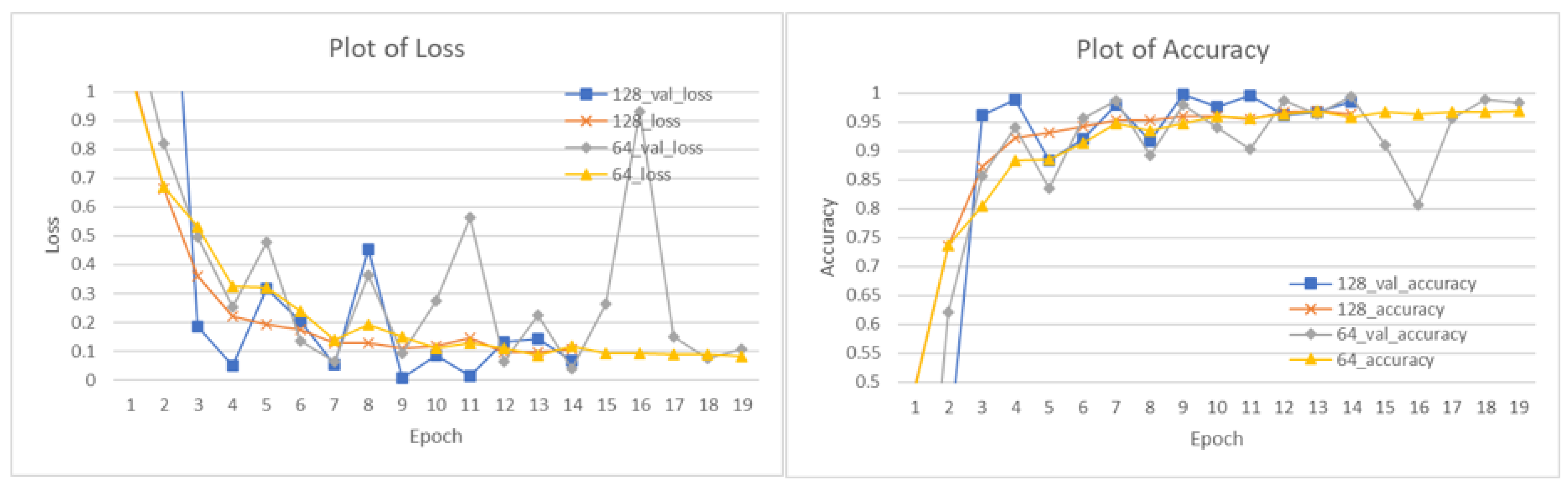
Since the expected output is the probabilities for the four PCI grades of Very Poor, Poor, Fair, and Good, the loss function “categorical_crossentropy” was used in CNN model training. In addition, the “validation_split” was set at 0.20, which means 20% (5120) samples were used for validating the model, and another 80% (20,480) samples were used for model training. The maximum training epoch (an epoch is one full cycle through the entire training dataset) was set at 50 epochs. To avoid model overfitting, the training process was stopped early via monitoring validation accuracy (closer to one is better) where it had not been improved in the previous five epochs.
The plots of accuracy and loss (closer to zero is better) are shown in Figure 3. They indicate that both models (one model has 64 channels in the heatmap layer and another model with a 128-channel heatmap layer) stopped training earlier than the maximum epoch due to activation of the early stopping as described previously. In detail, the 128-channel model stopped at the 14th epoch with a “final” validation accuracy of 0.9846 and the “best” validation accuracy of 0.9979 at the 9th epoch. The 64-channel model stopped at the 19th epoch with a “final” validation accuracy of 0.9836 and the “best” validation accuracy of 0.9936 at the 14th epoch.
4.3. Model Testing
The “best” model (at the best validation accuracy epoch) and the “final” model (at the end epoch) were both saved and tested using the collected testing dataset (which has 20 images for each PCI grade and a total of 80 images) with the selected performance evaluation metrics.
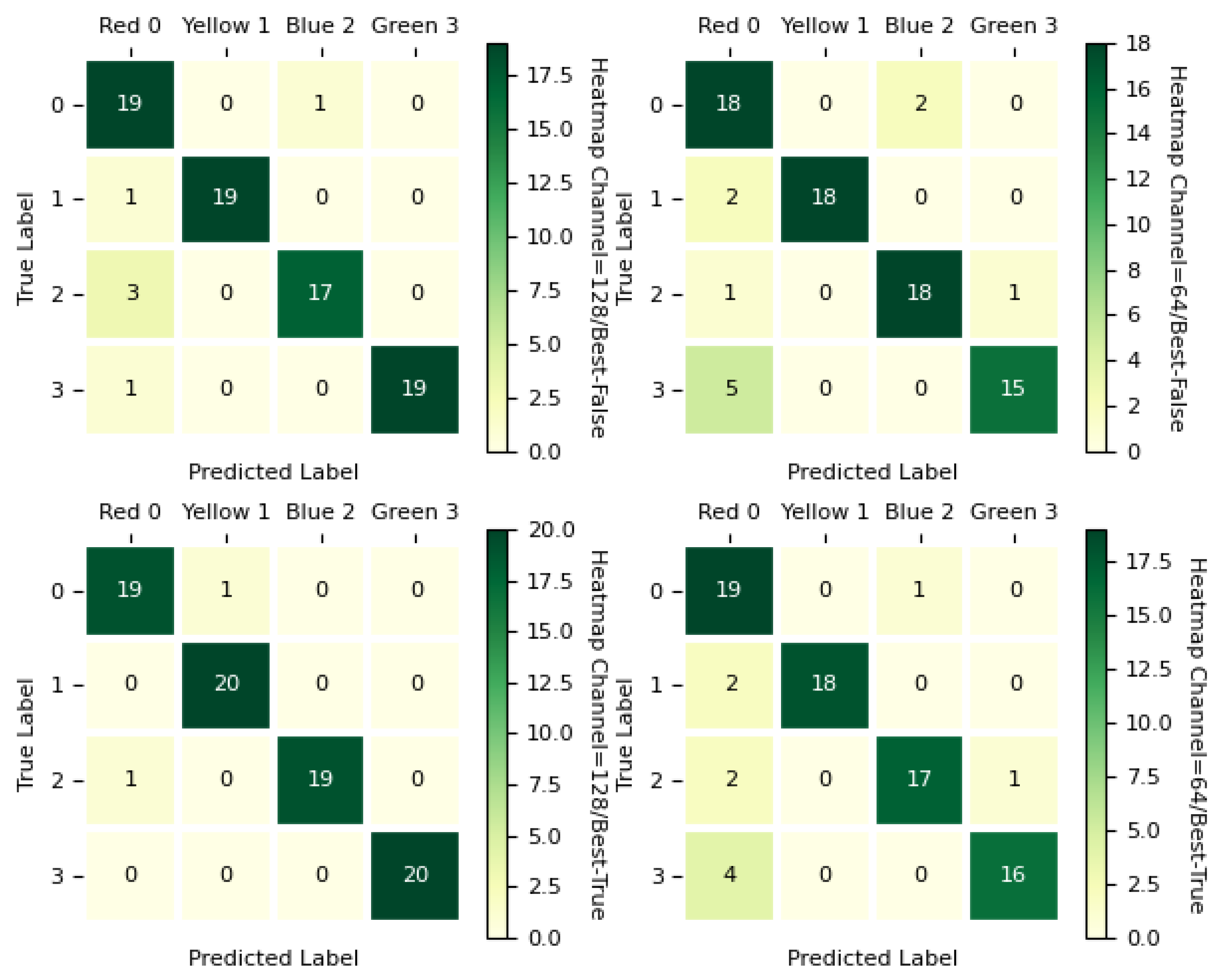
The testing results are listed in Table 3 for the four CNN models (including the 128-channel final model, 128-channel best model, 64-channel final model, and 64-channel best model) and the four PCI grades of Very Poor, Poor, Fair, and Good. In addition, the confusion matrices in Figure 4 indicate the detailed classification results, where the label “Red 0” is the “Very Poor”, “Yellow 1” is the “Poor”, “Blue 2” is the “Fair”, and “Green 3” is the “Good” PCI grade.
5. Discussion
5.1. Performance Comparison
With the training, validation, and testing results, it is safe to conclude that the proposed CNN model with a 128-channel heatmap layer (average testing accuracy of 0.95) performs better than the 64-channel model (average testing accuracy of 0.87), and the “best” model (average testing accuracy of 0.925) has better performance than the “final” model (average testing accuracy of 0.895). In addition, as shown in Table 3, the testing has an accuracy of 0.97, and weighted average precision, recall, and F1-score of 0.98, 0.97, and 0.97, respectively. Thus, the PCIer with a 128-channel heatmap layer is recommended for PCI grade estimation for future applications. The detailed model layers and parameters are shown in Table 1. Moreover, saving the well-trained model with the best validation accuracy can further improve PCIer performance.
5.2. Limitations
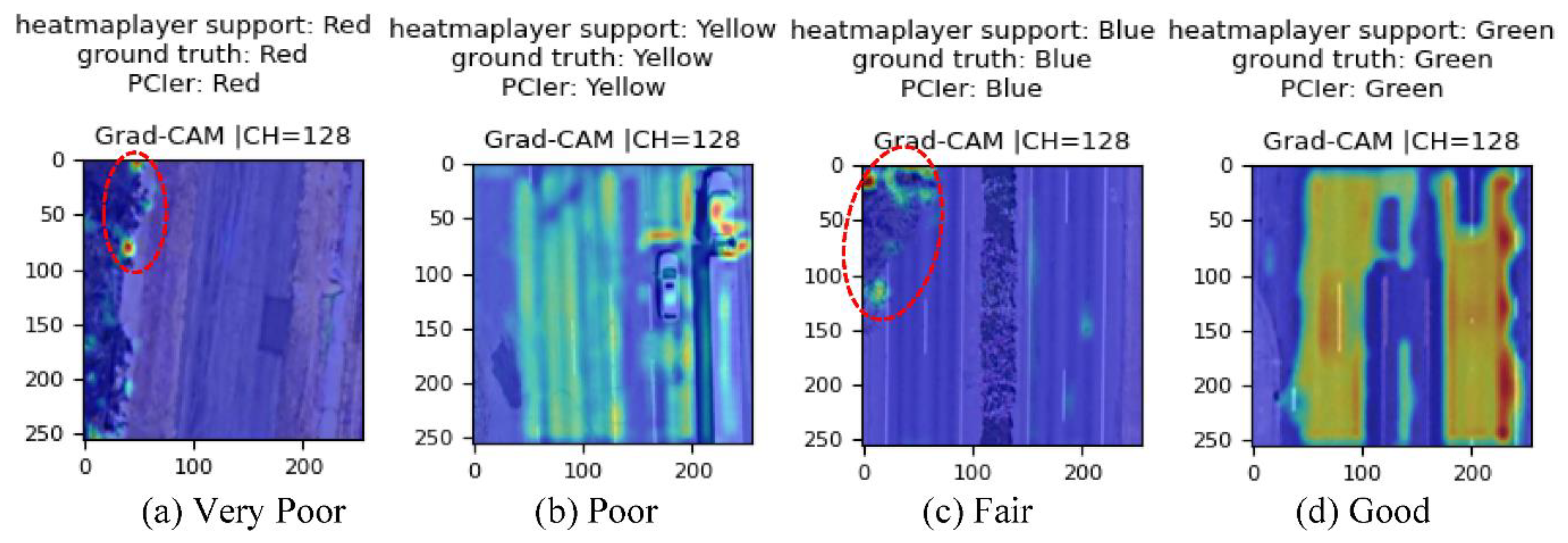
Examples of PCI grade prediction results are shown in Figure 5, where the well-trained CNN model’s (PCIer, 128-channel in heatmap layer) predictions are all matched with the ground truths. The Grad-CAM visualization results are shown in Figure 5 as well. For the Poor (Figure 5b) and Good (Figure 5d) PCI grades, the heatmap generated by the Grad-CAM indicates that the street pavement contributes to those PCI grade classification results. In addition, a demonstration video of real-time PCI estimation and Grad-CAM visualization results of the Power Inn Rd (Sacramento, CA, USA) can be accessed in [31].
However, for the Very Poor (Figure 5a) and Fair (Figure 5c) PCI grades, the heatmap contains the vegetation zone that contributed to the PCI grade classification results (see the annotation in Figure 5a,c). Hence, for future applications, the vegetation zones’ affection could be reduced by the following approaches:
- (1)
- Collect more images for CNN model training to reduce the impact of non-street object obstruction on the classification results. In this approach, additional convolution layers (and channels) and dense layers may need to be added to the proposed CNN model for feature learning. Then, the complicated model might discard the vegetation zone.
- (2)
- Remove non-street (pavement) surfaces from the collected image. In this approach, the vegetation zone would be cropped, and only the street surface would show in the input images for the proposed CNN model.
5.3. Recommendation
The reviewed previous studies with CNN modeling are either input spectral features (red, green, blue, RGB imagery) or input elevation features (3D imagery) [32]. Then, convolutional layers are used to generate complex feature maps based on the input images. However, the traditional methods, such as SVM [20] and RF classifiers, are preferred to input structured combination features and reach high accuracy performance. Thus, for future application of the proposed CNN models, concatenating RGB three-channel and an elevation one-channel to form a four-channel input image may have better performance in PCI estimation. Since considering the elevations, the impacts of vegetation zones would be eliminated as well.
Additionally, this research assumed the Google Earth images are up-to-date high-resolution aerial images (or existing commercial high-resolution aerial imagery) for the target road project or network. The pavement condition evaluation would be more efficient with them by skipping the time-consuming and labor-consuming aerial imagery acquisition operations by the infrastructure management agency-self. Otherwise, another feasible approach would program drones to automatically capture top-view images of the targeted street or highway section, or extract keyframes from a drone’s video. Then, the photogrammetric orthophoto (which provides the spectral features) and point cloud (that provides the elevation features) would improve the PCIer performance.
6. Conclusions
This paper developed a CNN and Google Earth-based PCI estimation and visualization method, which is named as PCIer, and presented the feasibility study results. In the experimental evaluations, the ground truth PCI datasets via the ASTM D6433 pavement distress protocols were collected from the publicly published pavement condition report by the City of Sacramento, CA [30]. The aerial image datasets of five streets in Sacramento, CA were collected via the Google Earth Screenshot Tool [11]. The performance comparisons showed that using a 128-channel heatmap layer for the developed PCIer model and the saved model with the best validation accuracy has the best performance of testing accuracy of 0.97, and weighted average precision, recall, and F1-score of 0.98, 0.97, 0.97, respectively.
Compared to ASTM D6433, the developed PCIer can quickly generate PCI estimations and avoid the time-consuming and labor-consuming pavement condition survey processes for the classification of distress type, determination of distress severity, and measurement of distress quantity. Local infrastructure management agencies can use publicly accessible aerial images for the initial pavement condition evaluation and then send crews to check the likely poor-condition sections. In addition, the developed PCIer can also process the oblique images captured by vehicle-mounted cameras. Infrastructure management agencies can easily deploy the PCIer for their pavement evaluation projects with their own datasets of historical PCI data and the associated images.
Author Contributions
Conceptualization: S.H. and Y.J.; data collection: I.-H.C.; investigation: S.H.; methodology: S.H. and Y.J.; software: Y.J.; supervision: Y.J.; writing—original draft: S.H., I.-H.C. and Y.J.; writing—review and editing: Y.J. and B.U. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Training and Testing Datasets are available in [31].
Acknowledgments
The authors are grateful to the reviewers for their valuable suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Texas Department of Transportation Pavement Manual. Available online: http://onlinemanuals.txdot.gov/txdotmanuals/pdm/index.htm (accessed on 14 January 2023).
- Fuentes, L.; Camargo, R.; Martínez-Arguelles, G.; Komba, J.J.; Naik, B.; Walubita, L.F. Pavement Serviceability Evaluation Using Whole Body Vibration Techniques: A Case Study for Urban Roads. Int. J. Pavement Eng. 2021, 22, 1238–1249. [Google Scholar] [CrossRef]
- Fuentes, L.; Taborda, K.; Hu, X.; Horak, E.; Bai, T.; Walubita, L.F. A Probabilistic Approach to Detect Structural Problems in Flexible Pavement Sections at Network Level Assessment. Int. J. Pavement Eng. 2022, 23, 1867–1880. [Google Scholar] [CrossRef]
- Matlack, G.R.; Horn, A.; Aldo, A.; Walubita, L.F.; Naik, B.; Khoury, I. Measuring Surface Texture of In-Service Asphalt Pavement: Evaluation of Two Proposed Hand-Portable Methods. Road Mater. Pavement Des. 2023, 24, 592–608. [Google Scholar] [CrossRef]
- ASTM D6433 2020; ASTM International Standard Practice for Roads and Parking Lots Pavement Condition Index Surveys. ASTM: West Conshohocken, PA, USA.
- Chambon, S.; Moliard, J.M. Automatic Road Pavement Assessment with Image Processing: Review and Comparison. Int. J. Geophys. 2011, 2011, 989354. [Google Scholar] [CrossRef]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An Integrated Approach to Automatic Pixel-Level Crack Detection and Quantification of Asphalt Pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Wang, W.; Wang, M.; Li, H.; Zhao, H.; Wang, K.; He, C.; Wang, J.; Zheng, S.; Chen, J. Pavement Crack Image Acquisition Methods and Crack Extraction Algorithms: A Review. J. Traffic Transp. Eng. 2019, 6, 535–556. [Google Scholar] [CrossRef]
- Kheradmandi, N.; Mehranfar, V. A Critical Review and Comparative Study on Image Segmentation-Based Techniques for Pavement Crack Detection. Constr. Build. Mater. 2022, 321, 126162. [Google Scholar] [CrossRef]
- Li, W.; Huyan, J.; Gao, R.; Hao, X.; Hu, Y.; Zhang, Y. Unsupervised Deep Learning for Road Crack Classification by Fusing Convolutional Neural Network and K_Means Clustering. J. Transp. Eng. Part B Pavements 2021, 147, 04021066. [Google Scholar] [CrossRef]
- Jiang, Y.; Han, S.; Bai, Y. Development of a Pavement Evaluation Tool Using Aerial Imagery and Deep Learning. J. Transp. Eng. Part B Pavements 2021, 147, 04021027. [Google Scholar] [CrossRef]
- Jiang, Y.; Bai, Y.; Han, S. Determining Ground Elevations Covered by Vegetation on Construction Sites Using Drone-Based Orthoimage and Convolutional Neural Network. J. Comput. Civ. Eng. 2020, 34, 04020049. [Google Scholar] [CrossRef]
- Zhang, C.; Nateghinia, E.; Miranda-Moreno, L.F.; Sun, L. Pavement Distress Detection Using Convolutional Neural Network (CNN): A Case Study in Montreal, Canada. Int. J. Transp. Sci. Technol. 2021, 11, 298–309. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Stathaki, T. Automatic Crack Detection for Tunnel Inspection Using Deep Learning and Heuristic Image Post-Processing. Appl. Intell. 2019, 49, 2793–2806. [Google Scholar] [CrossRef]
- Maniat, M.; Camp, C.V.; Kashani, A.R. Deep Learning-Based Visual Crack Detection Using Google Street View Images. Neural Comput. Appl. 2021, 33, 14565–14582. [Google Scholar] [CrossRef]
- Zhou, S.; Song, W. Deep Learning-Based Roadway Crack Classification Using Laser-Scanned Range Images: A Comparative Study on Hyperparameter Selection. Autom. Constr. 2020, 114, 103171. [Google Scholar] [CrossRef]
- Ali, L.; Valappil, N.K.; Kareem, D.N.A.; John, M.J.; Al Jassmi, H. Pavement Crack Detection and Localization Using Convolutional Neural Networks (CNNs). In Proceedings of the 2019 International Conference on Digitization (ICD), Sharjah, United Arab Emirates, 18–19 November 2019; pp. 217–221. [Google Scholar]
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road Crack Detection Using Deep Convolutional Neural Network and Adaptive Thresholding. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; Volume 2019, pp. 474–479. [Google Scholar]
- Jiang, Y. Remote Sensing and Neural Network-Driven Pavement Evaluation: A Review. In Proceedings of the The 12th International Conference on Construction in the 21st Century (CITC-12), Amman, Jordan, 16–19 May 2022; pp. 335–345. [Google Scholar]
- Dadrasjavan, F.; Zarrinpanjeh, N.; Ameri, A.; Engineering, G.; Branch, Q. Automatic Crack Detection of Road Pavement Based on Aerial UAV Imagery. Preprints 2019, 2019070009. [Google Scholar] [CrossRef]
- Edmondson, V.; Woodward, J.; Lim, M.; Kane, M.; Martin, J.; Shyha, I. Improved Non-Contact 3D Field and Processing Techniques to Achieve Macrotexture Characterisation of Pavements. Constr. Build. Mater. 2019, 227, 116693. [Google Scholar] [CrossRef]
- Roberts, R.; Inzerillo, L.; Di Mino, G. Exploiting Low-Cost 3D Imagery for the Purposes of Detecting and Analyzing Pavement Distresses. Infrastructures 2020, 5, 6. [Google Scholar] [CrossRef]
- Zhou, S.; Song, W. Robust Image-Based Surface Crack Detection Using Range Data. J. Comput. Civ. Eng. 2020, 34, 04019054. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Tong, Z.; Yuan, D.; Gao, J.; Wei, Y.; Dou, H. Pavement-Distress Detection Using Ground-Penetrating Radar and Network in Networks. Constr. Build. Mater. 2020, 233, 117352. [Google Scholar] [CrossRef]
- Sukhobok, Y.A.; Verkhovtsev, L.R.; Ponomarchuk, Y.V. Automatic Evaluation of Pavement Thickness in GPR Data with Artificial Neural Networks. IOP Conf. Ser. Earth Environ. Sci. 2019, 272, 022202. [Google Scholar] [CrossRef]
- Jiang, Y.; Bai, Y. Estimation of Construction Site Elevations Using Drone-Based Orthoimagery and Deep Learning. J. Constr. Eng. Manag. 2020, 146, 04020086. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 128, pp. 618–626. [Google Scholar]
- Haeberli, P.; Voorhies, D. Image Processing By Interp and Extrapolation. Available online: http://www.graficaobscura.com/interp/index.html (accessed on 28 July 2021).
- Moore, R.; Montanez, J.; Smith, G.; Saenz, R. Pavement Condition Report. Available online: https://www.cityofsacramento.org/-/media/Corporate/Files/Public-Works/Maintenance-Services/Sacramento-2020-Pavement-Update---FINAL-3-25-20.pdf?la=en (accessed on 5 April 2022).
- Jiang, Y. PCIer—Pavement Condition Index Estimation. Available online: https://www.yuhanjiang.com/research/IM/PA/PCI (accessed on 15 January 2023).
- Zhang, A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Chen, C.; Yang, G.; Li, J.Q.; Yang, E.; Qiu, S. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces with a Recurrent Neural Network. Comput. Civ. Infrastruct. Eng. 2019, 34, 213–229. [Google Scholar] [CrossRef]
Figure 1.
PCIer: a CNN model architecture.

Figure 2.
Data augmentation (original image cropped from Google Earth).

Figure 3.
Plots of training and validation results.

Figure 4.
Confusion matrices, where Best-False refers to the “final” model and Best-True is the “best” model.
Figure 4.
Confusion matrices, where Best-False refers to the “final” model and Best-True is the “best” model.

Figure 5.
Grad-CAM visualization results.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
PCIer: model layers and parameters.
| Block | Layer | Filter and Size | Stride | Padding | Activation | Output Shape |
|---|---|---|---|---|---|---|
| Input | - | - | - | - | - | (256, 256, 3) |
| Feature learning | conv2d_1 | 64, 3, 3 | 1 | Same | ReLU | (256, 256, 64) |
| max_pooling2d_1 | 2, 2 | 2 | - | - | (128, 128, 64) | |
| conv2d_2 | 128, 3, 3 | 1 | Same | ReLU | (128, 128, 128) | |
| max_pooling2d_2 | 2, 2 | 2 | - | - | (64, 64, 128) | |
| conv2d_3 | 256, 3, 3 | 1 | Same | ReLU | (64, 64, 256) | |
| max_pooling2d_3 | 2, 2 | 2 | - | - | (32, 32, 256) | |
| conv2d_4 | 512, 3, 3 | 1 | Same | ReLU | (32, 32, 512) | |
| heatmap_layer (conv2d_5) | 128, 1, 1 or 64, 1, 1 | 1 | Same | ReLU | (32, 32, 128) or (32, 32, 64) | |
| Classification | flatten_1 | - | - | - | - | 131,072 or 65,536 |
| dropout_1 | 0.5 | - | - | - | 131,072 or 65,536 | |
| dense_1 | 1024 | - | - | ReLU | 1024 | |
| dropout_2 | 0.5 | - | - | - | 1024 | |
| dense_2 | 128 | - | - | ReLU | 128 | |
| dropout_3 | 0.5 | - | - | - | 128 | |
| dense_3 | 16 | - | - | ReLU | 16 | |
| dropout_4 | 0.5 | - | - | - | 16 | |
| Output | dense_4 | 4 | - | - | SoftMax | 4 |
| - | - | - | - | Argmax | 1 (Prediction) |
Table 2.
CNN model training and testing dataset.
| Street Name | PCI Grade | Collected Image | Training | Testing | Original Image Size | Image Size |
|---|---|---|---|---|---|---|
| College Town Dr | Very Poor (PCI < 25) | 55 | 45 | 10 | 1408 × 1024-pixel | 256 × 256-pixel |
| Main Avenue | Very Poor (PCI < 25) | 45 | 35 | 10 | 1408 × 1024-pixel | 256 × 256-pixel |
| Florin Perkins Rd | Poor (25 ≤ PCI < 50) | 100 | 80 | 20 | 1408 × 1024-pixel | 256 × 256-pixel |
| Freeport Blvd | Fair (50 ≤ PCI < 70) | 100 | 80 | 20 | 1408 × 1024-pixel | 256 × 256-pixel |
| Power Inn Rd | Good (PCI ≥ 70) | 100 | 80 | 20 | 1408 × 1024-pixel | 256 × 256-pixel |
Table 3.
Comparison of CNN testing results.
| PCI Grade | 128-Channel Final Model | 64-Channel Final Model | 128-Channel Best Model | 64-Channel Best Model | Support | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | ||
| Very Poor | 0.79 | 0.95 | 0.86 | 0.69 | 0.90 | 0.78 | 0.95 | 0.95 | 0.95 | 0.70 | 0.95 | 0.81 | 20 |
| Poor | 1.00 | 0.95 | 0.97 | 1.00 | 0.90 | 0.95 | 0.95 | 1.00 | 0.98 | 1.00 | 0.90 | 0.95 | 20 |
| Fair | 0.94 | 0.85 | 0.89 | 0.90 | 0.90 | 0.90 | 1.00 | 0.95 | 0.97 | 0.94 | 0.85 | 0.89 | 20 |
| Good | 1.00 | 0.95 | 0.97 | 0.94 | 0.75 | 0.83 | 1.00 | 1.00 | 1.00 | 0.94 | 0.80 | 0.86 | 20 |
| accuracy | 0.93 | 0.86 | 0.97 | 0.88 | 80 | ||||||||
| macro avg | 0.93 | 0.93 | 0.93 | 0.88 | 0.86 | 0.87 | 0.98 | 0.97 | 0.97 | 0.90 | 0.88 | 0.88 | 80 |
| weighted avg | 0.93 | 0.93 | 0.93 | 0.88 | 0.86 | 0.87 | 0.98 | 0.97 | 0.97 | 0.90 | 0.88 | 0.88 | 80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Han, S.; Chung, I.-H.; Jiang, Y.; Uwakweh, B. PCIer: Pavement Condition Evaluation Using Aerial Imagery and Deep Learning. Geographies 2023, 3, 132-142. https://doi.org/10.3390/geographies3010008
AMA Style
Han S, Chung I-H, Jiang Y, Uwakweh B. PCIer: Pavement Condition Evaluation Using Aerial Imagery and Deep Learning. Geographies. 2023; 3(1):132-142. https://doi.org/10.3390/geographies3010008
Chicago/Turabian StyleHan, Sisi, In-Hun Chung, Yuhan Jiang, and Benjamin Uwakweh. 2023. "PCIer: Pavement Condition Evaluation Using Aerial Imagery and Deep Learning" Geographies 3, no. 1: 132-142. https://doi.org/10.3390/geographies3010008