

When BERT Started Traveling: TourBERT—A Natural Language Processing Model for the Travel Industry

Abstract
:1. Introduction
2. Literature Review
3. Methodology and Results
3.1. Pre-Training TourBERT
3.2. TourBERT Model Evaluation
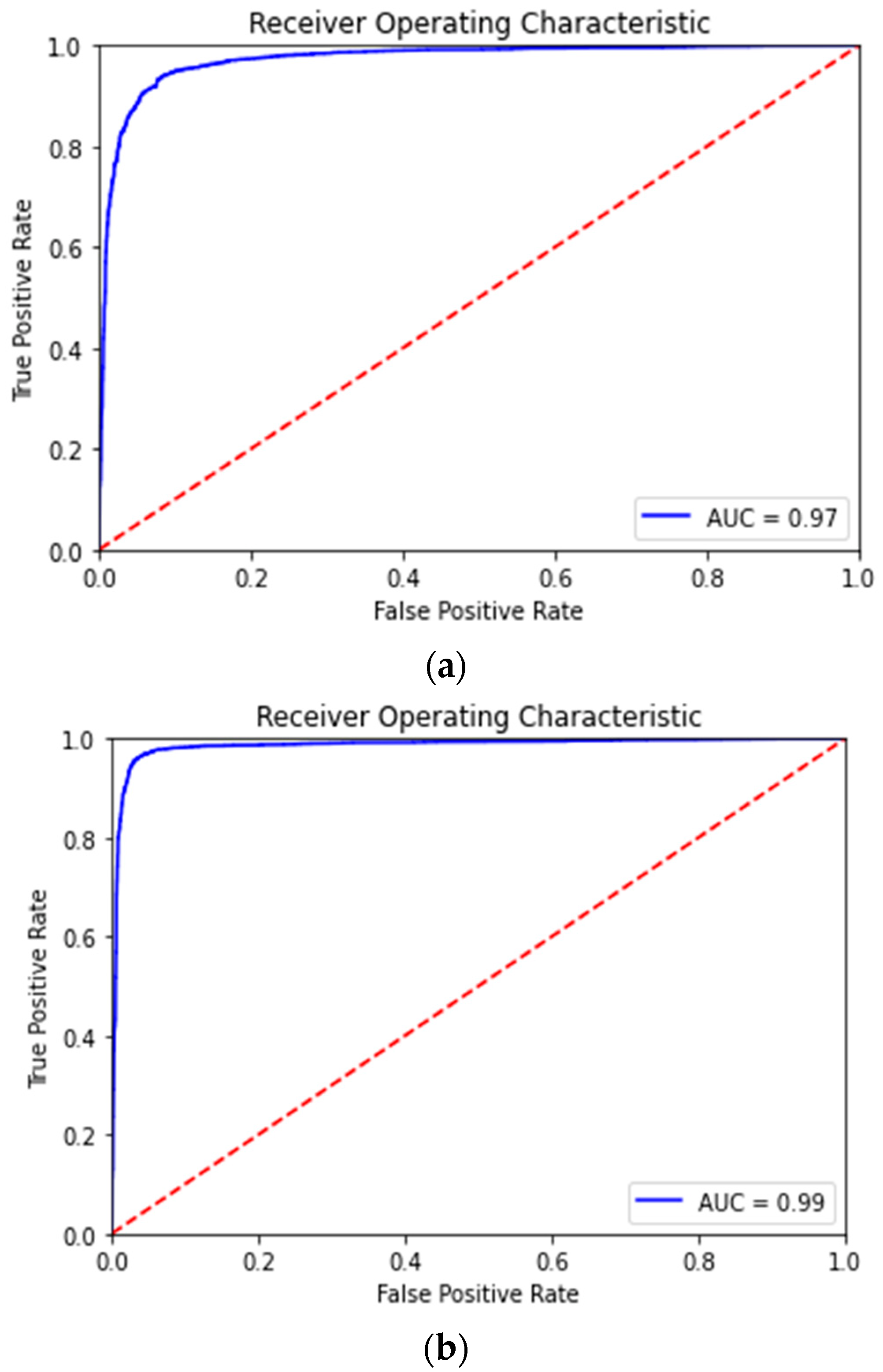
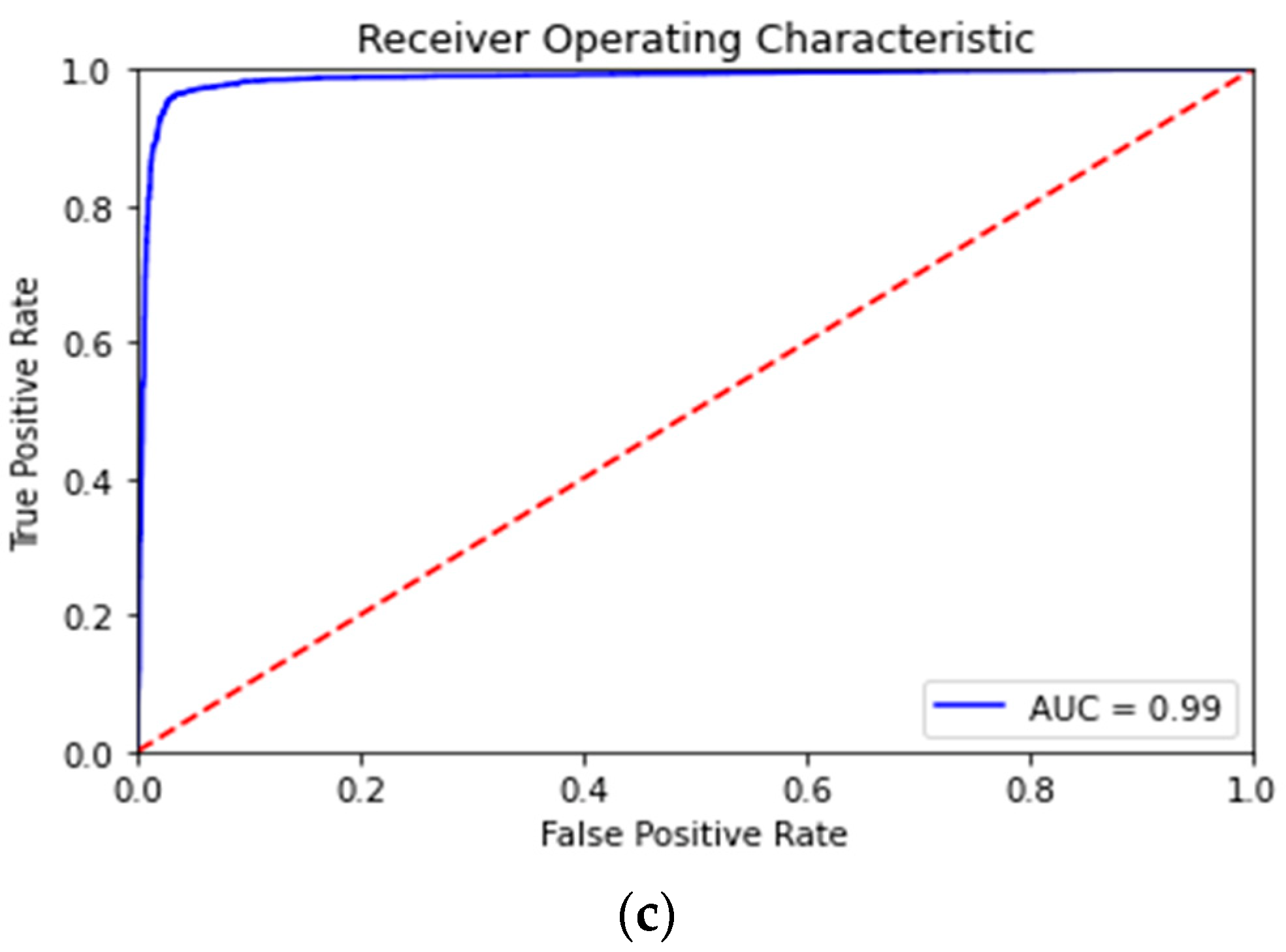
3.2.1. Supervised Evaluation: Sentiment Classification
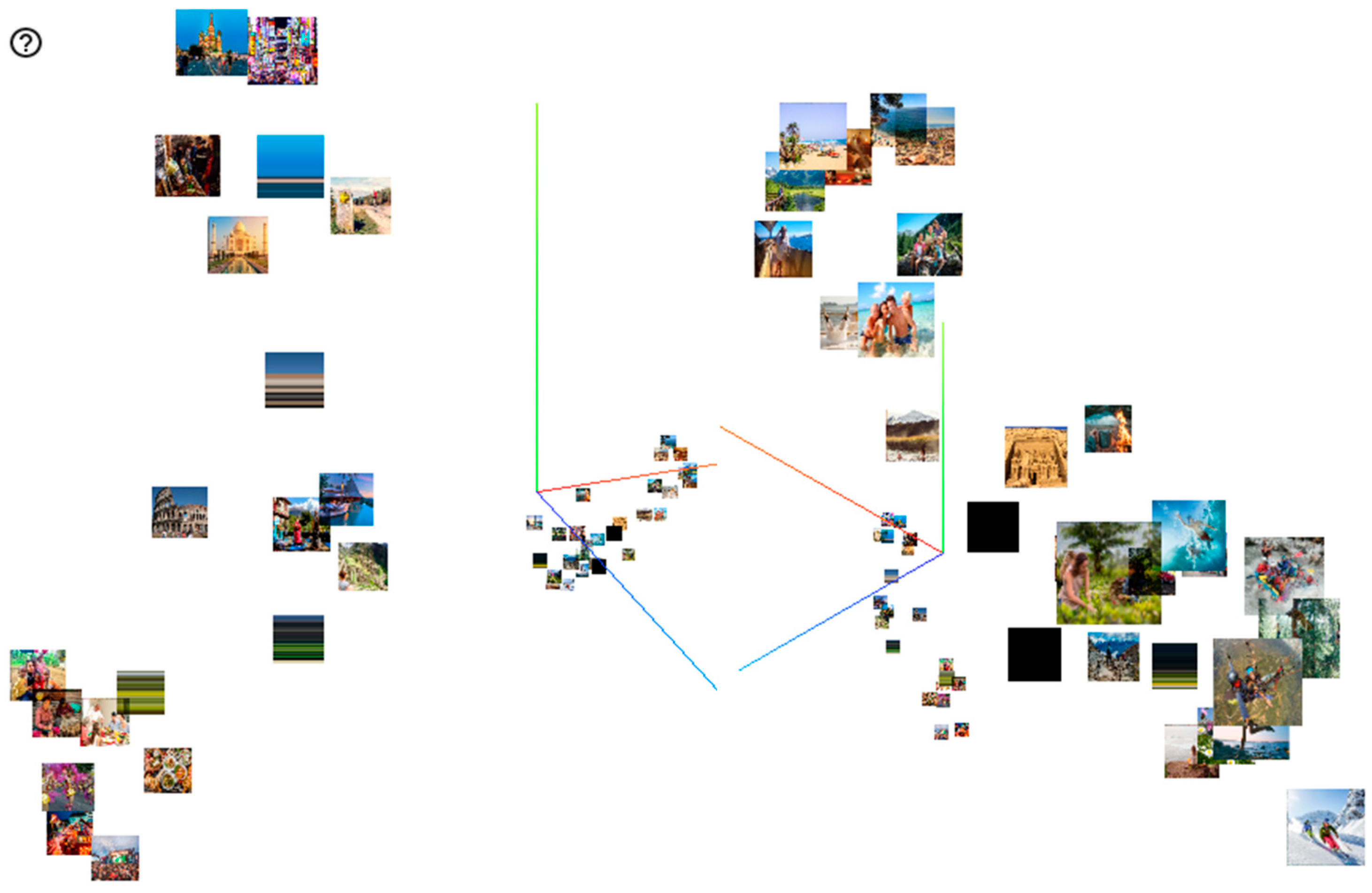
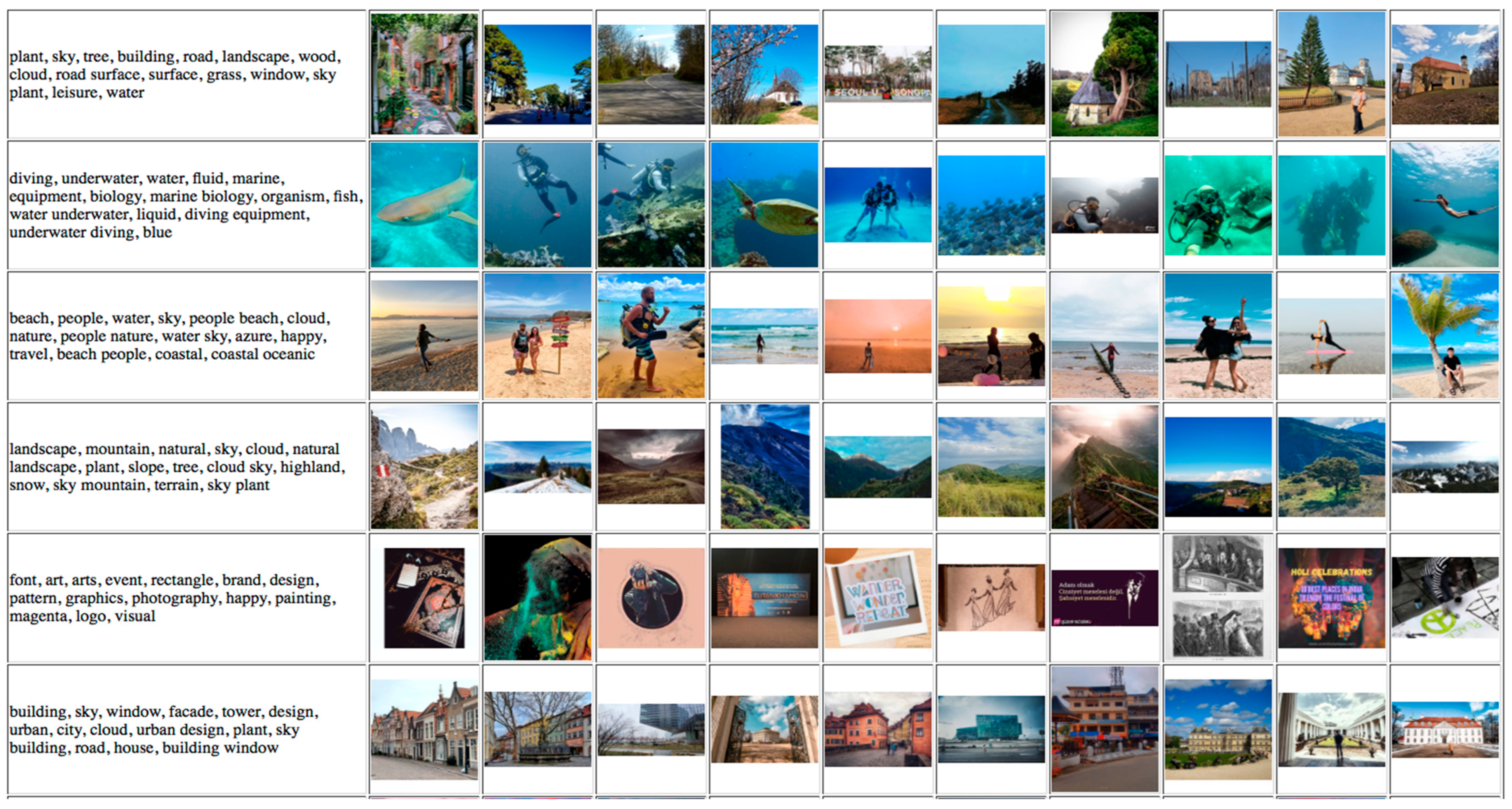
3.2.2. Unsupervised Evaluation: Visualization of Photo Annotations
3.2.3. Unsupervised Evaluation: Topic Modeling
3.2.4. Unsupervised Evaluation: User Study
3.2.5. Unsupervised Evaluation: Synonyms Search
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Doolin, B.; Burgess, L.; Cooper, J. Evaluating the use of the Web for tourism marketing: A case study from New Zealand. Tour. Manag. 2002, 23, 557–561. [Google Scholar] [CrossRef]
- Yu, J.; Egger, R. Tourist Experiences at Overcrowded Attractions: A Text Analytics Approach. In Information and Communication Technologies in Tourism 2021; Springer: Cham, Switzerland, 2021; pp. 231–243. [Google Scholar]
- Daxböck, J.; Dulbecco, M.L.; Kursite, S.; Nilsen, T.K.; Rus, A.D.; Yu, J.; Egger, R. The Implicit and Explicit Motivations of Tourist Behaviour in Sharing Travel Photographs on Instagram: A Path and Cluster Analysis. In Information and Communication Technologies in Tourism 2021; Springer: Cham, Switzerland, 2021; pp. 244–255. [Google Scholar]
- Saraiva, J.P.D.P.M. Web 2.0 in restaurants: Insights regarding TripAdvisor’s use in Lisbon. Doctoral Dissertation, Universidade Catolica Protugesa, Lisboa, Portugal, 2013. [Google Scholar]
- Egger, R.; Gokce, E. Natural Language Processing: An Introduction. In Applied Data Science in Tourism. Interdisciplinary Approaches, Methodologies and Applications; Egger, R., Ed.; Springer: Berlin/Heidelberg, Germany, 2022; pp. 307–334. [Google Scholar]
- Wennker, P. Künstliche Intelligenz in der Praxis. In Anwendung in Unternehmen und Branchen: KI wettbewerbs- und zukunftsorientiert Einsetzen; Springer Gabler: Wiesbaden, Germany, 2020; Available online: https://ebookcentral.proquest.com/lib/kxp/detail.action?docID=6326361 (accessed on 23 May 2022).
- Poon, A. Tourism, Technology and Competitive Strategies; CAB International: Wallingford, UK, 1993. [Google Scholar]
- Egger, R. Text Representations and Word Embeddings. Vectorizing Textual Data. In Applied Data Science in Tourism. Interdisciplinary Approaches, Methodologies and Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 335–361. [Google Scholar]
- Tenney, I.; Dipanjan, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Edwards, A.; Camacho-Collados, J.; De Ribaupierre, H.; Preece, A. Go simple and pre-train on domain-specific corpora: On the role of training data for text classification. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 5522–5529. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t stop pretraining: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Araci, D. Finbert: Financial sentiment analysis with pre-trained language models. arXiv 2019, arXiv:1908.10063. [Google Scholar]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.H.; Jin, D.; Naumann, T.; McDermott, M. Publicly available clinical BERT embeddings. arXiv 2019, arXiv:1904.03323. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beltagy, I.; Lo, K.; Cohan, A. Scibert: A pretrained language model for scientific text. arXiv 2019, arXiv:1903.10676. [Google Scholar]
- Avishek Garain. Hotel Reviews from around the world with Sentiment Values and Review Ratings in different Categories for Natural Language Processing. IEEE Dataport. Available online: https://ieee-dataport.org/documents/hotel-reviews-around-world-sentiment-values-and-review-ratings-different-categories (accessed on 22 April 2020).
- Liu, J. 515K Hotel Reviews Data in Europe. 2019. Available online: https://www.kaggle.com/jiashenliu/515k-hotel-reviews-data-in-europe (accessed on 2 June 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
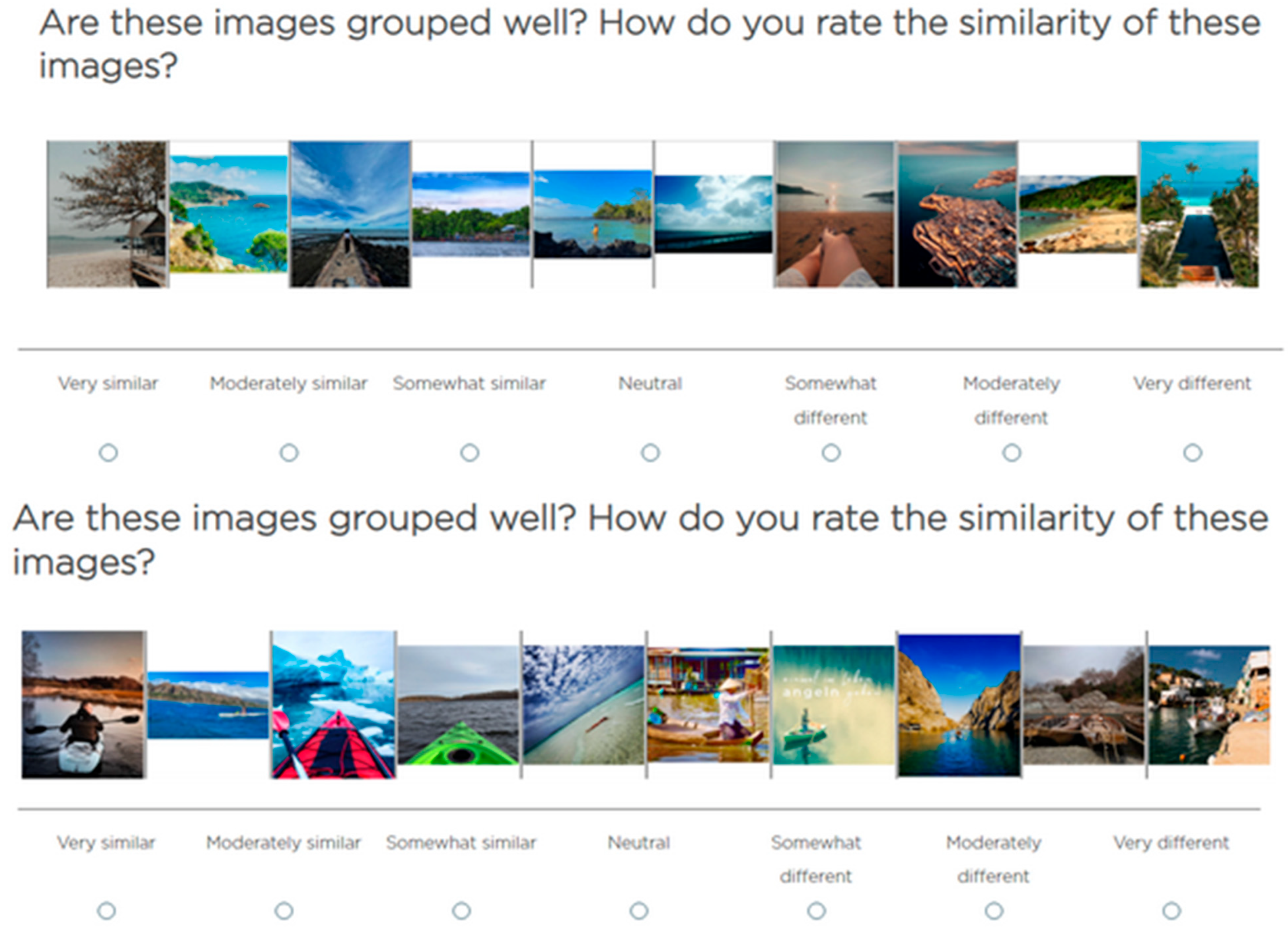{kind=link}
| Validation Set | Test Set | |||||
|---|---|---|---|---|---|---|
| Loss | Accuracy | Accuracy | Precision | Recall | F1 | |
| BERT-Base | 0.4250 | 0.8190 | 0.81 | 0.66 | 0.4 | 0.42 |
| TourBERT (WordPiece) | 0.3146 | 0.8708 | 0.86 | 0.7 | 0.65 | 0.68 |
| TourBERT (SentencePiece) | 0.3166 | 0.8712 | 0.87 | 0.7 | 0.65 | 0.68 |
| Validation Set | Test Set | |||
|---|---|---|---|---|
| Loss | Accuracy | Accuracy | AUC | |
| BERT-Base | 0.2296 | 0.9218 | 0.9279 | 0.97 |
| TourBERT (WordPiece) | 0.1371 | 0.9569 | 0.9633 | 0.99 |
| TourBERT (SentencePiece) | 0.1329 | 0.9586 | 0.9626 | 0.99 |
| Topic | Words |
|---|---|
| 0 | fashion, sleeve, shoulder, flash, flash photography, photography, street, street fashion, smile, hair, neck, eyewear, eyebrow, happy, sky |
| 1 | shades, tints, tints shades, plant, black, sky, shirt, bicycle, photography, white, font, sleeve, wood, building, automotive |
| 2 | sky, nature, water, landscape, plant, natural, cloud, people, tree, people nature, natural landscape, water sky, happy, cloud sky, azure |
| 3 | automotive, vehicle, sky, tire, font, plant, landscape, design, wood, art, building, rectangle, cloud, water, lighting |
| 4 | plant, natural, water, landscape, natural landscape, sky, ecoregion, cloud, tree, mountain, nature, cloud sky, highland, community, plant community |
| 5 | water, landforms, sky, coastal, coastal oceanic, oceanic, oceanic landforms, landscape, cloud, natural, beach, water sky, natural landscape, azure, plant |
| 6 | people, nature, sky, smile, people nature, sunglasses, flash, flash photography, photography, water, sleeve, care, vision, vision care, eyewear |
| 7 | landscape, sky, plant, cloud, natural, natural landscape, water, tree, building, nature, cloud sky, mountain, vehicle, people, blue |
| 8 | water, sky, cloud, landscape, plant, natural, natural landscape, resources, water resources, building, tree, mountain, cloud sky, water sky, nature |
| 9 | landscape, plant, natural, sky, water, natural landscape, nature, cloud, tree, grass, people, people nature, cloud sky, sky plant, wood |
| 10 | fashion, happy, sky, people, nature, photography, flash, flash photography, eyewear, smile, people nature, care, vision, vision care, plant |
| 11 | plant, sky, water, natural, landscape, ecoregion, tree, natural landscape, cloud, photography, fashion, flash, flash photography, smile, happy |
| 12 | plant, natural, landscape, water, natural landscape, sky, tree, dog, nature, grass, cloud, terrestrial, wood, people, landforms |
| 13 | building, sky, plant, window, vehicle, facade, tree, wood, design, house, automotive, tire, cloud, road, city |
| 14 | vehicle, automotive, sky, building, plant, tire, font, design, art, window, cloud, tree, wood, rectangle, lighting |
| 15 | plant, shades, tints, tints shades, sky, wood, black, fashion, bicycle, photography, rectangle, people, white, building, font |
| 16 | plant, water, natural, sky, landscape, natural landscape, cloud, ecoregion, mountain, tree, cloud sky, community, plant community, resources, water resources |
| 17 | landscape, plant, water, sky, natural, natural landscape, shades, tints, tints shades, tree, cloud, landforms, wood, coastal, coastal oceanic |
| 18 | fashion, sleeve, flash, flash photography, photography, street, street fashion, lip, shoulder, eyelash, eyebrow, smile, hairstyle, sky, neck |
| 19 | water, sky, equipment, cloud, equipment supplies, supplies, boating, boating equipment, boats, boats boating, landforms, boat, watercraft, coastal, coastal oceanic |
| 20 | water, landscape, natural, plant, sky, cloud, natural landscape, mountain, tree, nature, cloud sky, azure, highland, resources, water resources |
| 21 | plant, water, sky, nature, landscape, natural, cloud, tree, people, natural landscape, people nature, grass, cloud sky, mountain, building |
| 22 | sky, plant, cloud, water, landscape, building, natural, tree, natural landscape, mountain, cloud sky, window, nature, travel, road |
| 23 | plant, natural, sky, landscape, water, natural landscape, tree, cloud, nature, terrestrial, terrestrial plant, flower, grass, petal, wood |
| 24 | food, sky, cuisine, ingredient, recipe, tableware, dish, food tableware, ingredient recipe, water, tableware ingredient, staple, staple food, plate, produce |
| Topic | Words |
|---|---|
| 0 | plant, sky, tree, building, road, landscape, wood, cloud, road surface, surface, grass, window, sky plant, leisure, water |
| 1 | diving, underwater, water, fluid, marine, equipment, biology, marine biology, organism, fish, water underwater, liquid, diving equipment, underwater diving, blue |
| 2 | beach, people, water, sky, people beach, cloud, nature, people nature, water sky, azure, happy, travel, beach people, coastal, coastal oceanic |
| 3 | landscape, mountain, natural, sky, cloud, natural landscape, plant, slope, tree, cloud sky, highland, snow, sky mountain, terrain, sky plant |
| 4 | font, art, arts, event, rectangle, brand, design, pattern, graphics, photography, happy, painting, magenta, logo, visual |
| 5 | building, sky, window, facade, tower, design, urban, city, cloud, urban design, plant, sky building, road, house, building window |
| 6 | water, sky, afterglow, cloud, dusk, atmosphere, landscape, natural, natural landscape, sky atmosphere, cloud sky, sunlight, sunset, water sky, tree |
| 7 | tableware, drinkware, table, bottle, cup, dishware, food, glass, wood, plant, furniture, device, stemware, kitchen, wine |
| 8 | people, nature, sky, people nature, flash, flash photography, photography, happy, water, smile, plant, cloud, leg, gesture, tree |
| 9 | water, sky, equipment, boat, watercraft, cloud, vehicle, lake, supplies, boating, boating equipment, boats, boats boating, equipment supplies, water sky |
| 10 | care, vision, vision care, sunglasses, sleeve, eyewear, goggles, glasses, sky, dress, fashion, smile, shirt, flash, flash photography |
| 11 | automotive, vehicle, tire, bicycle, wheel, motor, motor vehicle, automotive tire, vehicle automotive, sky, lighting, automotive lighting, car, plant, tire wheel |
| 12 | plant, landscape, natural, natural landscape, sky, tree, nature, grass, community, plant community, cloud, people, people nature, water, sky plant |
| 13 | sky, water, cloud, landscape, natural, atmosphere, cloud sky, blue, natural landscape, azure, plant, nature, tree, horizon, sunlight |
| 14 | water, natural, landscape, sky, natural landscape, cloud, plant, nature, mountain, resources, water resources, ecoregion, tree, cloud sky, water sky |
| 15 | temple, sky, building, architecture, plant, facade, city, cloud, art, travel, tree, leisure, sculpture, world, monument |
| 16 | nature, plant, people nature, people, sky, happy, tree, landscape, cloud, natural, water, grass, natural landscape, travel, leisure |
| 17 | wood, design, building, rectangle, interior, interior design, window, shades, tints, tints shades, property, font, furniture, flooring, plant |
| 18 | food, cuisine, ingredient, tableware, recipe, dish, food tableware, ingredient recipe, produce, staple, staple food, cuisine dish, tableware ingredient, plate, cake |
| 19 | fashion, street, street fashion, sleeve, eyewear, flash, flash photography, photography, shirt, happy, waist, smile, dress, design, shoe |
| 20 | lip, eyebrow, eyelash, smile, hair, chin, shoulder, skin, nose, forehead, hairstyle, neck, eye, lip chin, facial |
| 21 | plant, flower, tree, terrestrial, twig, landscape, terrestrial plant, natural, petal, natural landscape, branch, grass, wood, sky, flowering |
| 22 | water, natural, plant, landscape, landforms, natural landscape, fluvial, fluvial landforms, landforms streams, streams, resources, water resources, sky, watercourse, water water |
| 23 | water, landscape, landforms, natural, sky, coastal, coastal oceanic, oceanic, oceanic landforms, cloud, natural landscape, water sky, azure, resources, water resources |
| 24 | dog, plant, animal, carnivore, breed, dog breed, fawn, sky, terrestrial, working, working animal, companion, companion dog, collar, grass |
| Paired Samples Statistics | ||||||||
| Mean | N | Std. Deviation | Std. Error Mean | |||||
| Pair 1 | BERT | 3.7759 | 82 | 0.71655 | 0.07913 | |||
| TourBERT | 2.5239 | 82 | 0.61724 | 0.06816 | ||||
| Paired Sample Test | ||||||||
| Mean | SD | Std. EM | t | df | Sig. (2-tailed) | |||
| Pair 1 | BERT—TourBERT | 1.252 | 0.51773 | 0.0571 | 21.898 | 81 | 0.000 | |
| Paired Samples Effect Sizes | ||||||||
| Standardizer | Point Estimate | 95% Confidence Interval | ||||||
| Lower | Upper | |||||||
| Pair 1 | BERT—TourBERT | Cohen’s d | 0.51773 | 2.418 | 1.986 | 2.846 | ||
| Hedges’ correction | 0.52015 | 2.407 | 1.977 | 2.833 | ||||
| Authenticity | Experience | Entrance | Attraction | Ticket | Destination | Guide | Transfer | Sightseeing | Service |
|---|---|---|---|---|---|---|---|---|---|
| legitimacy | teach | shelter | attractions | tickets | dying | companion | recovery | trees | vessel |
| sincerity | heal | entrances | restaurant | fare | choice | entry | exchange | fireworks | authority |
| competence | communicate | archway | hotel | fares | lame | visit | imaging | shops | headquarters |
| authorship | consume | gate | exhibit | card | address | database | restoring | pacing | facility |
| flexibility | learn | roof | pavilion | trains | exit | forum | sale | comedy | workshop |
| integrity | eat | causeway | nightclub | bus | partner | workshop | comparison | prostitutes | circulation |
| conscience | consider | tenants | mall | metro | correction | access | recovering | sidewalk | companion |
| characterization | experiences | exit | ballroom | freight | priorities | screening | nights | operation |
| Authenticity | Experience | Entrance | Attraction | Ticket | Destination | Guide | Transfer | Sightseeing | Service |
|---|---|---|---|---|---|---|---|---|---|
| uniqueness | experince | entry | destination | tickets | spot | ##guide | transfers | exploring | sevice |
| ambience | expereince | enterance | feature | entry | attraction | guides | transport | sights | services |
| originality | experiance | admittance | landmark | entrance | place | tourguide | pickup | attractions | staff |
| intimacy | adventure | admission | place | wristband | point | guid | transportation | exploration | personnel |
| charm | experiences | ticket | institution | admission | itinerary | driver | journey | nightlife | hospitality |
| accuracy | enjoyment | fee | museum | fee | hotspot | interpreter | limousine | hiking | personel |
| flare | opportunity | carpark | spot | pass | venture | guiding | shuttle | outings | frontdesk |
| warmth | expere | payment | site | tix | hangout | narrator | pickups | excursions | housekeeping |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arefeva, V.; Egger, R. When BERT Started Traveling: TourBERT—A Natural Language Processing Model for the Travel Industry. Digital 2022, 2, 546-559. https://doi.org/10.3390/digital2040030
Arefeva V, Egger R. When BERT Started Traveling: TourBERT—A Natural Language Processing Model for the Travel Industry. Digital. 2022; 2(4):546-559. https://doi.org/10.3390/digital2040030
Chicago/Turabian StyleArefeva, Veronika, and Roman Egger. 2022. "When BERT Started Traveling: TourBERT—A Natural Language Processing Model for the Travel Industry" Digital 2, no. 4: 546-559. https://doi.org/10.3390/digital2040030