
On 3D Reconstruction Using RGB-D Cameras




Abstract
:1. Introduction
1.1. Motivation
1.2. Scope and Contribution
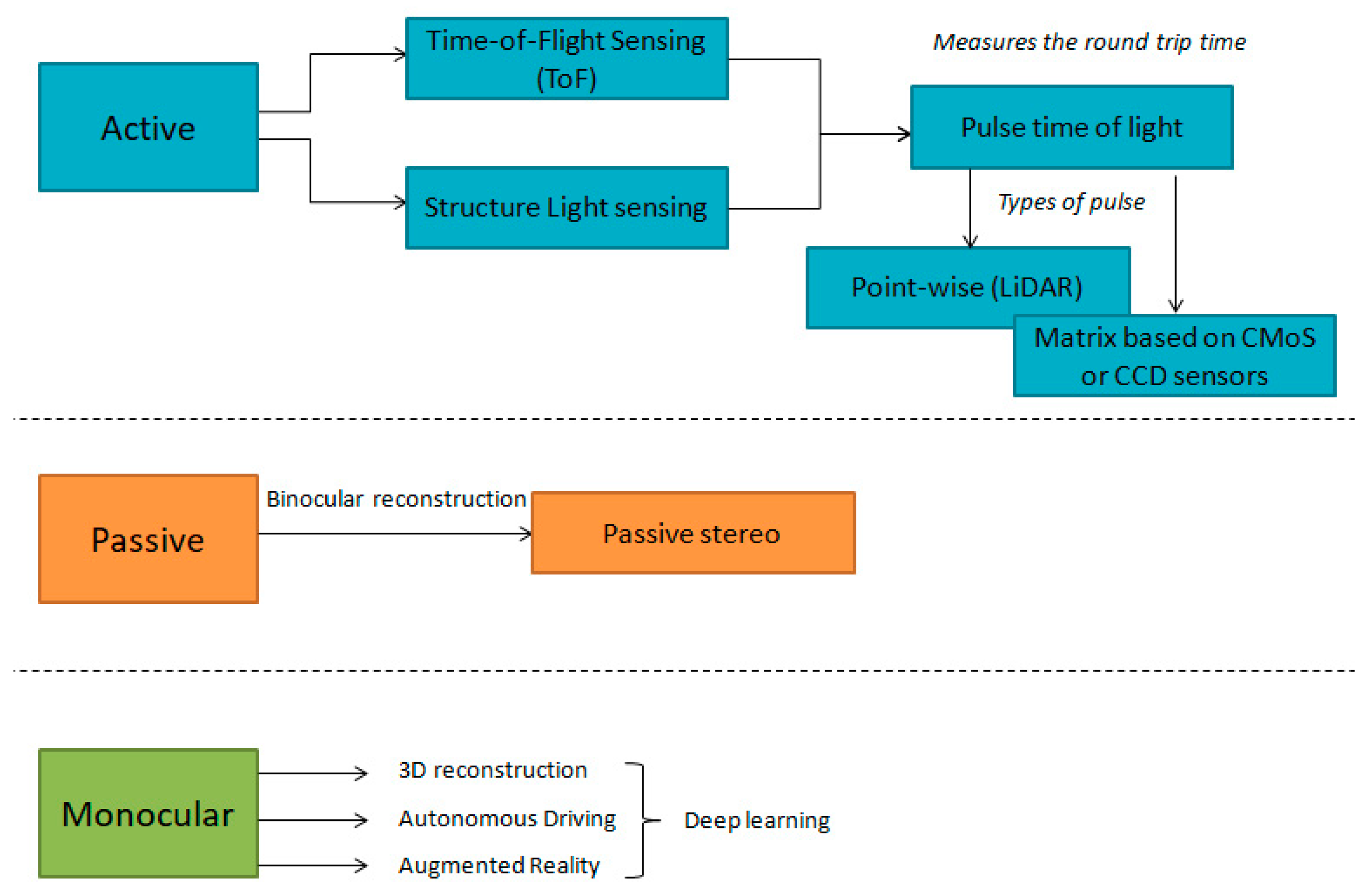
- What is RGB-D camera technology?
- What kind of data is acquired from the RGB-D camera?
- What algorithms are applied for applications?
- What are the benefits and limitations of the RGB-D camera?
- Why is a depth map important?
1.3. Related Work
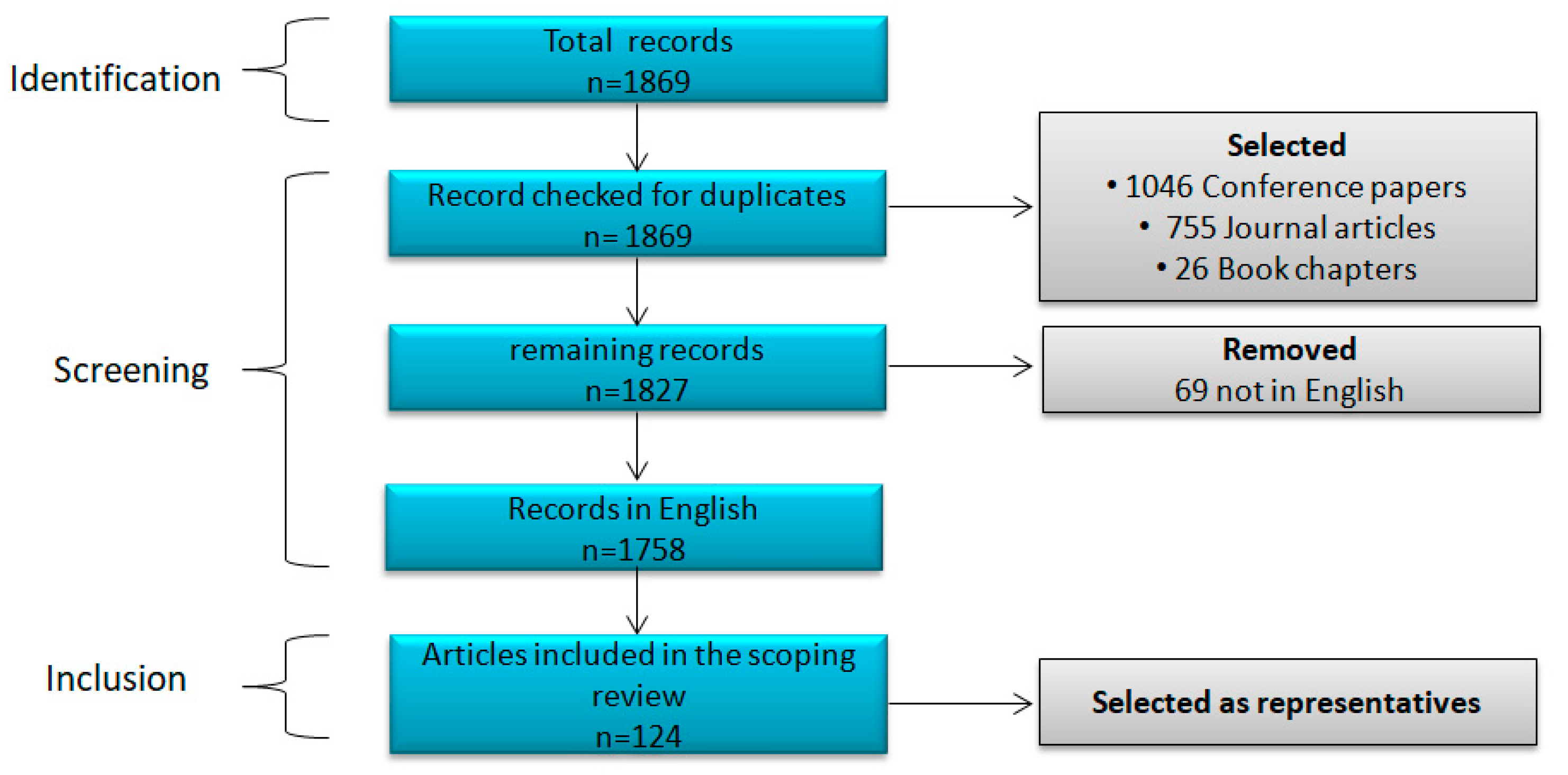
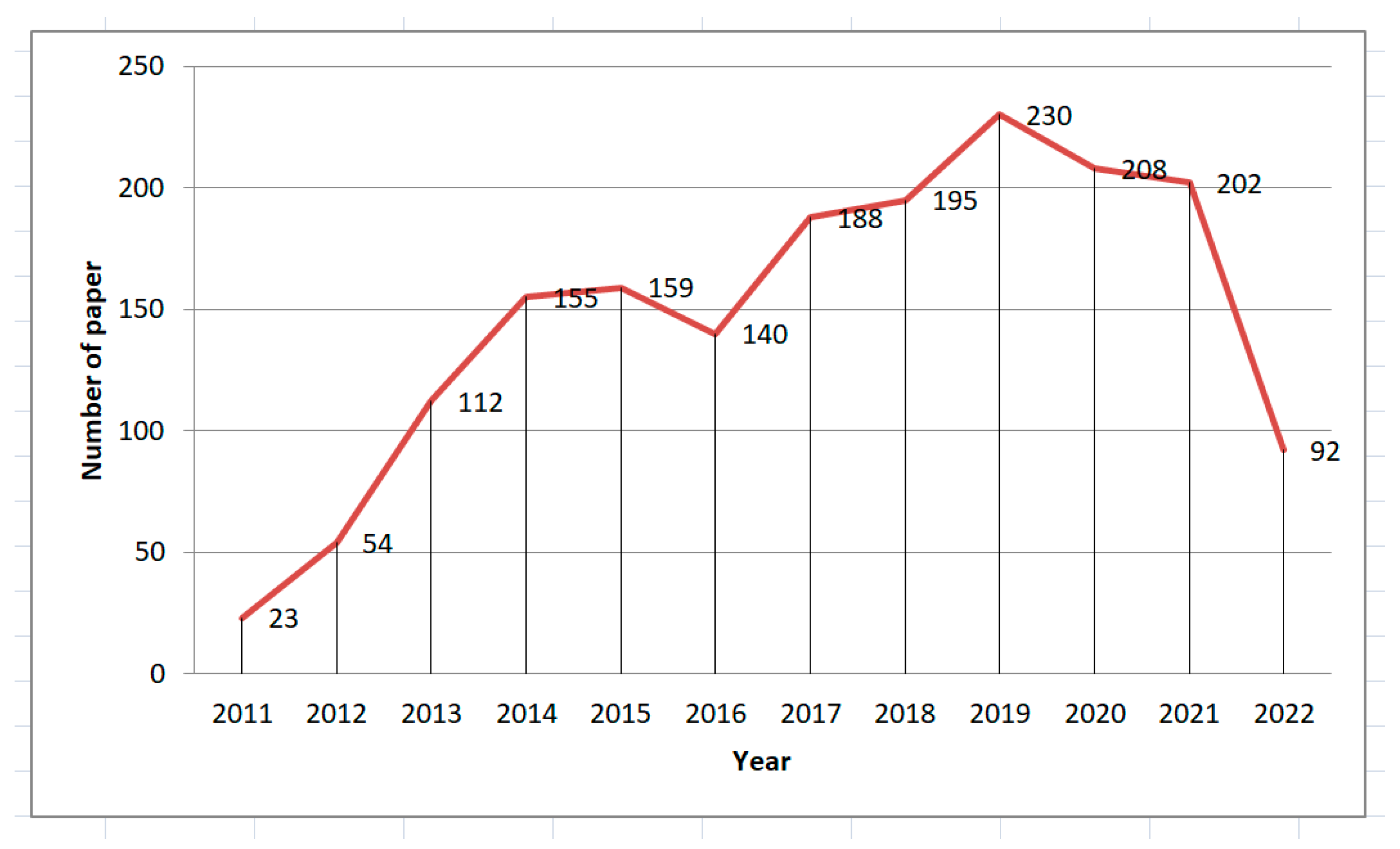
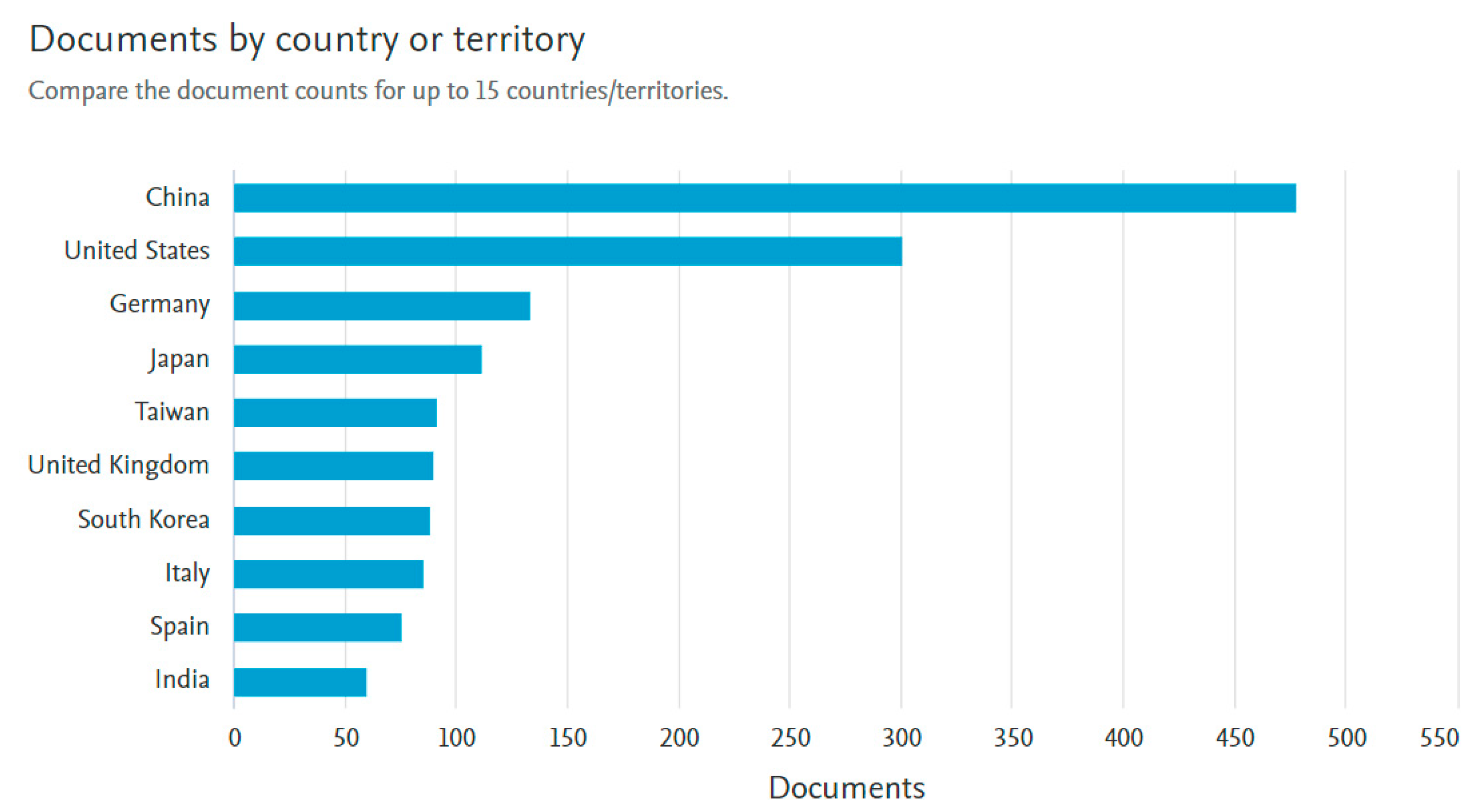
1.4. Methodology of Research Strategy
Data Sources and Search
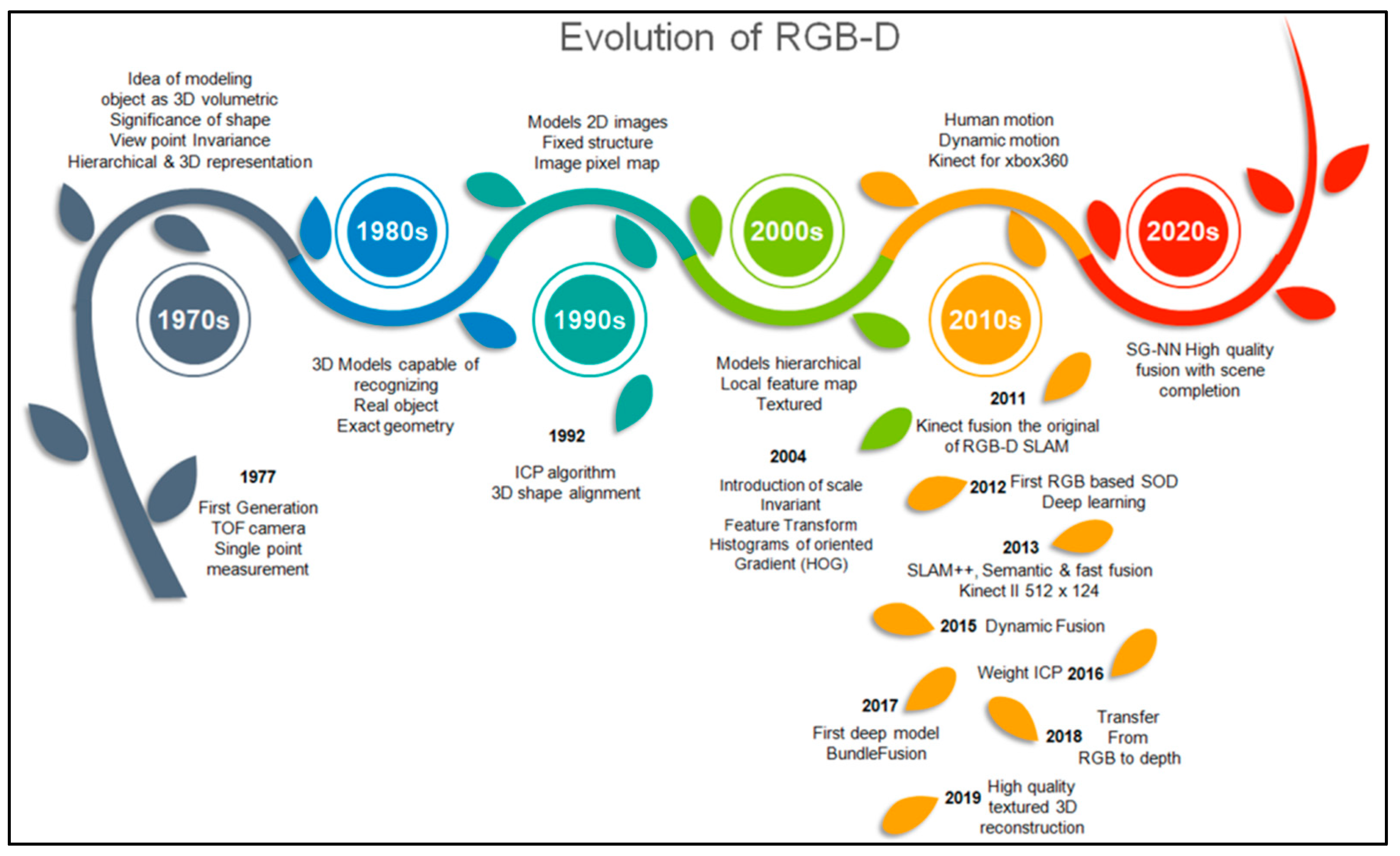
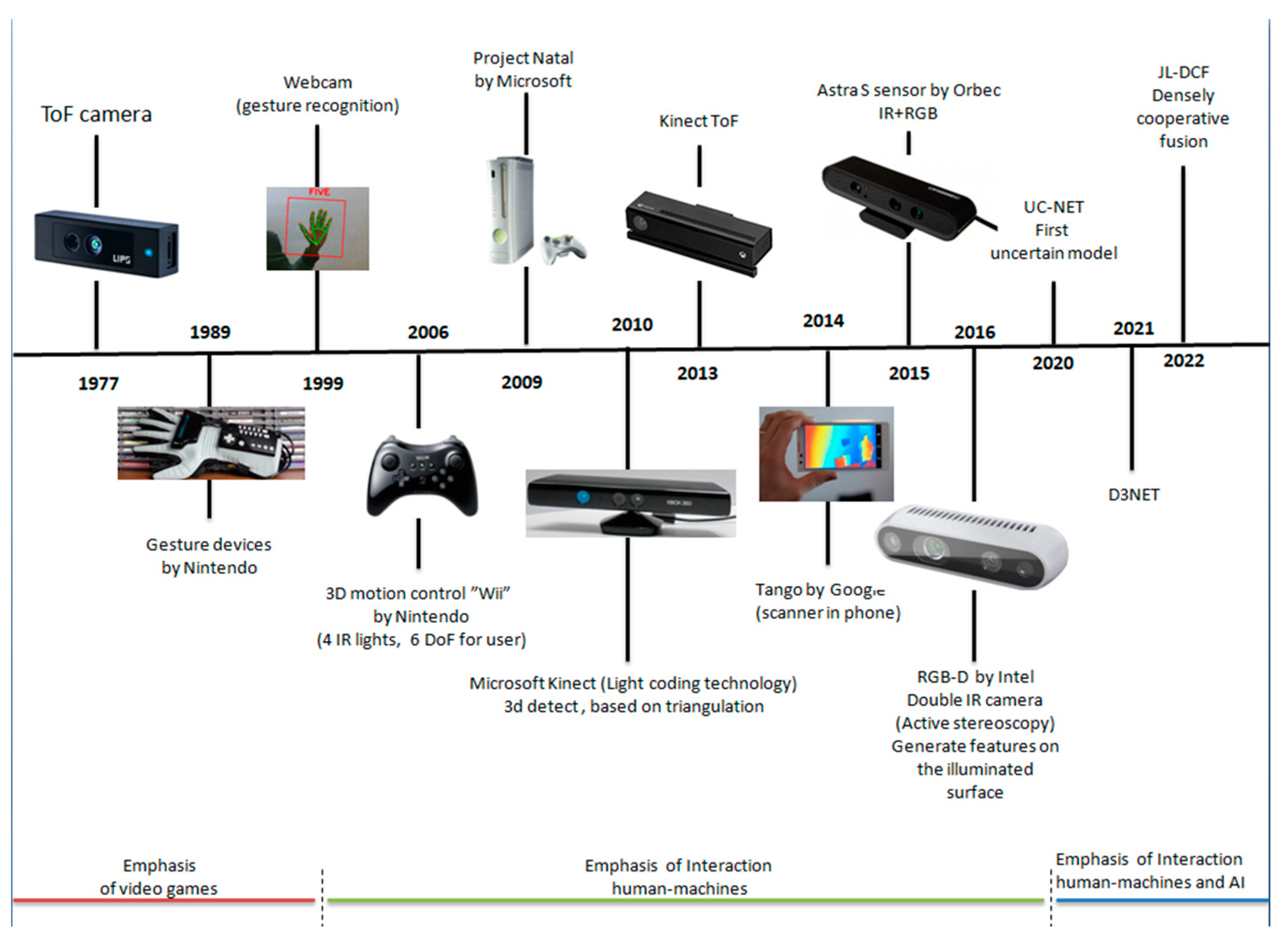
2. History of RGB and 3D Scene Reconstruction
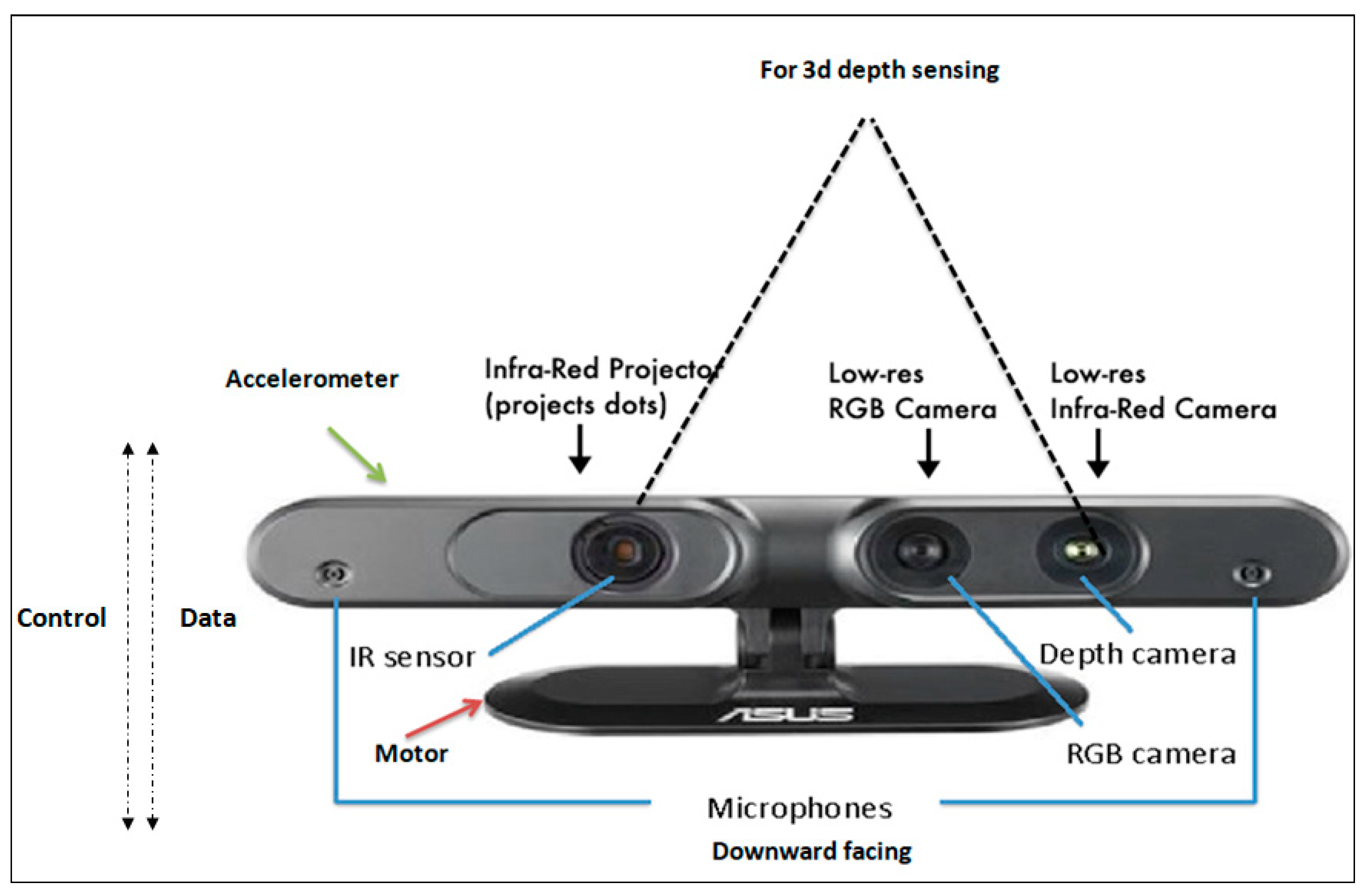
3. Hardware and Basic Technology of RGB-D
4. Conceptual Framework of 3D Reconstruction
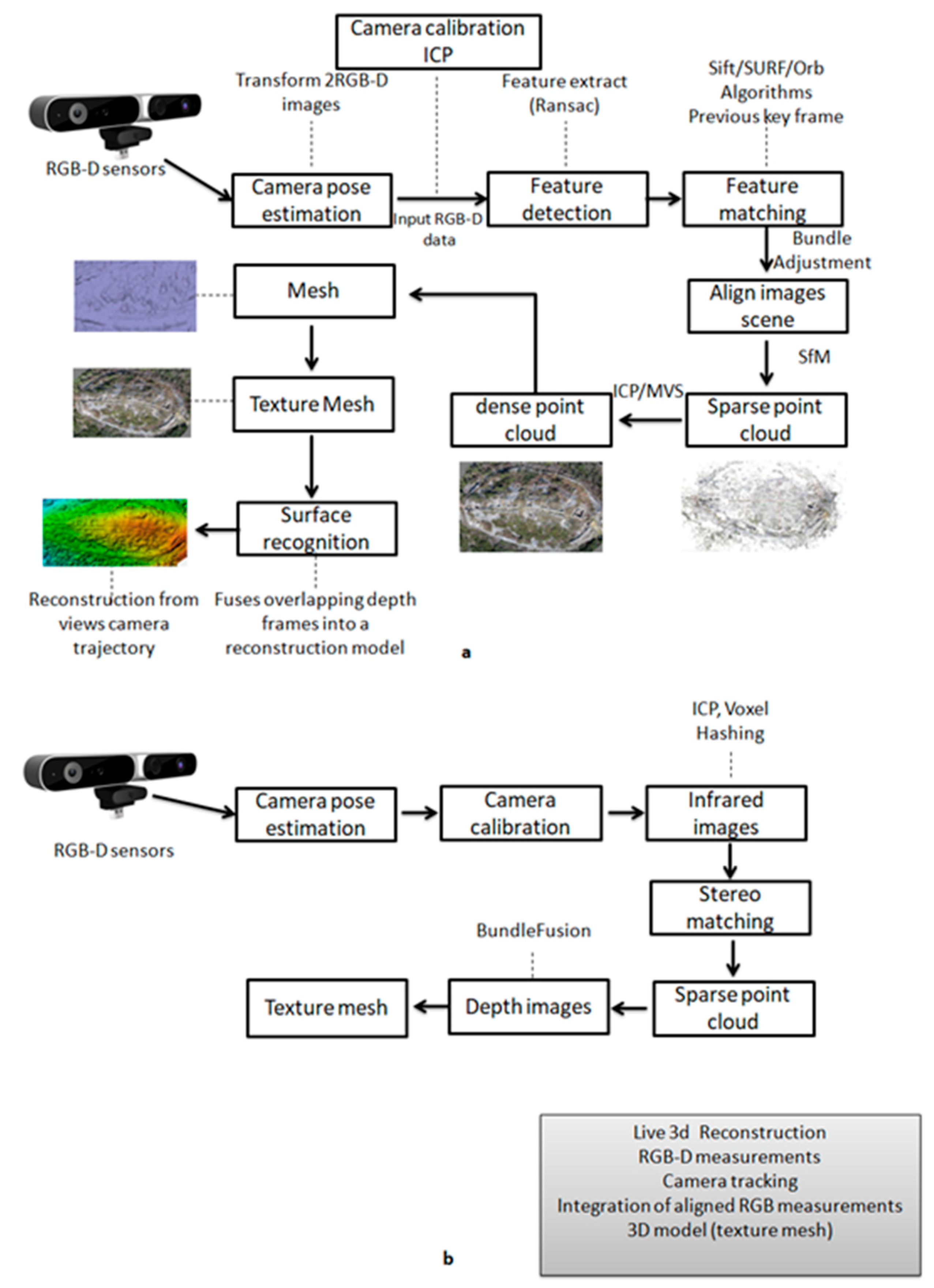
4.1. Approaches to 3D Reconstruction (RGB Mapping)
4.2. Multi-View RGB-D Reconstruction Systems That Use Multiple RGB-D Cameras
4.3. RGB-D SLAM Methods for 3D Reconstruction
5. Data Acquisition and Processing
5.1. RGB-D Sensors and Evolution
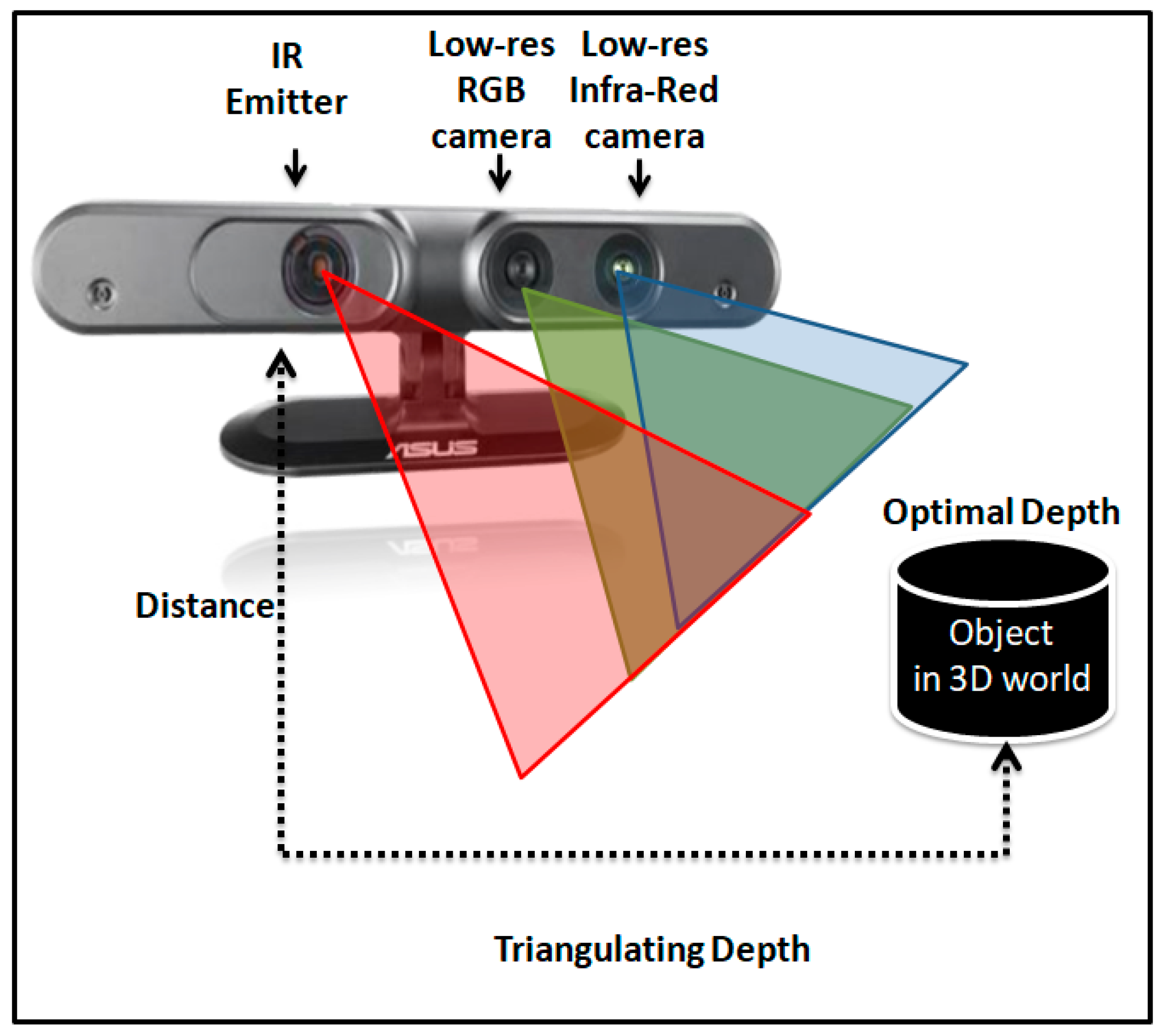
5.2. Sensing Techniques of RGB-D Cameras
5.3. Depth Image Processing (Depth Map)
- Recording the first surface seen cannot obtain information for refracted surfaces;
- Noise from the reflective surface viewing angle. Occlusion boundaries blur the edges of objects;
- Single-channel depth maps cannot convey multiple distances when multiple objects are in the location of the same pixel (grass, hair);
- May represent the perpendicular distance between an object and the plane of the scene camera and the actual distances from the camera to the plane surface seen in the corners of the image as being greater than the distances to the central area;
- In the case of missing depth data, many holes are created. To address this issue, a median filter is used, but sharp depth edges are corrupted;
- Cluttered spatial configuration of objects can create occlusions and shadows.
5.4. RGB-D Datasets
6. Advantages and Limitations of RGB-D
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Orts-Escolano, S.; Rhemann, C.; Fanello, S.; Chang, W.; Kowdle, A.; Degtyarev, Y.; Kim, D.; Davidson, P.L.; Khamis, S.; Dou, M.; et al. Holoportation: Virtual 3D teleportation in real-time. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 741–754. [Google Scholar] [CrossRef]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar] [CrossRef]
- Seitz, S.M.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A comparison and evaluation of multi-view stereo reconstruction algorithms. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Volume 1 (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 519–528. [Google Scholar] [CrossRef]
- Finlayson, G.; Fredembach, C.; Drew, M.S. Detecting illumination in images. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004; pp. 239–241. [Google Scholar] [CrossRef]
- Martinez, M.; Yang, K.; Constantinescu, A.; Stiefelhagen, R. Helping the Blind to Get through COVID-19: Social Distancing Assistant Using Real-Time Semantic Segmentation on RGB-D Video. Sensors 2020, 20, 5202. [Google Scholar] [CrossRef]
- Vlaminck, M.; Quang, L.H.; van Nam, H.; Vu, H.; Veelaert, P.; Philips, W. Indoor assistance for visually impaired people using a RGB-D camera. In Proceedings of the IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Santa Fe, NM, USA, 6–8 March 2016; pp. 161–164. [Google Scholar] [CrossRef]
- Palazzolo, Ε.; Behley, J.; Lottes, P.; Giguere, P.; Stachniss, C. ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 7855–7862. [Google Scholar] [CrossRef]
- Zollhöfer, M.; Stotko, P.; Görlitz, A.; Theobalt, C.; Nießner, M.; Klein, R.; Kolb, A. State of the Art on 3D reconstruction with RGB-D Cameras. Comput. Graph. Forum 2018, 37, 625–652. [Google Scholar] [CrossRef]
- Verykokou, S.; Ioannidis, C.; Athanasiou, G.; Doulamis, N.; Amditis, A. 3D Reconstruction of Disaster Scenes for Urban Search and Rescue. Multimed Tools Appl. 2018, 77, 9691–9717. [Google Scholar] [CrossRef]
- He, Y.B.; Bai, L.; Aji, T.; Jiang, Y.; Zhao, J.M.; Zhang, J.H.; Shao, Y.M.; Liu, W.Y.; Wen, H. Application of 3D Reconstruction for Surgical Treatment of Hepatic Alveolar Ehinococcosis. World J. Gastroenterol. WJG 2015, 21, 10200–10207. [Google Scholar] [CrossRef] [PubMed]
- Gomes, L.; Regina Pereira Bellon, O.; Silva, L. 3D Reconstruction Methods for Digital Preservation of Cultural Heritage: A Survey. Pattern Recognit. Lett. 2014, 50, 3–14. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. DynamicFusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015; pp. 343–352. [Google Scholar] [CrossRef]
- Seichter, D.; Köhler, M.; Lewandowski, B.; Wengefeld, T.; Gross, H.-M. Efficient RGB-D semantic segmentation for indoor scene analysis. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13525–13531. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating depth into semantic segmentation via fusion-based CNN architecture. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 213–228. [Google Scholar]
- Jiang, J.; Zheng, L.; Luo, F.; Zhang, Z. RedNet: Residual Encoder-Decoder Network for indoor RGB-D Semantic Segmentation. arXiv 2018, arXiv:1806.01054. [Google Scholar]
- Zhong, Y.; Dai, Y.; Li, H. 3D geometry-aware semantic labeling of outdoor street scenes. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20 August 2018; pp. 2343–2349. [Google Scholar]
- Xing, Y.; Wang, J.; Chen, X.; Zeng, G. 2.5D Convolution for RGB-D semantic segmentation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22 September 2019; pp. 1410–1414. [Google Scholar]
- Xing, Y.; Wang, J.; Zeng, G. Malleable 2.5D convolution: Learning receptive fields along the depth-axis for RGB-D scene parsing. In Proceedings of the European Conference on Computer Vision 2(ECCV), Glasgow, UK, 23 August 2020; pp. 555–571. [Google Scholar]
- Wang, W.; Neumann, U. Depth-aware CNN for RGB-D segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 144–161. [Google Scholar]
- Chen, L.Z.; Lin, Z.; Wang, Z.; Yang, Y.L.; Cheng, M.M. Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation. arXiv 2020, arXiv:2004.04534. [Google Scholar] [CrossRef]
- Chen, Y.; Mensink, T.; Gavves, E. 3D Neighborhood convolution: Learning DepthAware features for RGB-D and RGB semantic segmentation. In Proceedings of the International Conference on 3D Vision (3DV), Quebeck City, QC, Canada, 16–19 September 2019; pp. 173–182. [Google Scholar]
- Cao, J.; Leng, H.; Lischinski, D.; Cohen-Or, D.; Tu, C.; Li, Y. ShapeConv: Shape-aware convolutional layer for indoor RGB-D semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Chen, X.; Lin, K.Y.; Wang, J.; Wu, W.; Qian, C.; Li, H.; Zeng, G. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 561–577. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. ACNet: Attention based network to exploit complementary features for RGBD semantic segmentation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Hu, J.; Zhao, G.; You, S.; Kuo, C.C.J. Evaluation of multimodal semantic segmentation using RGB-D data. In Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications III; SPIE: Budapest, Hungary, 2021. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, Z.; Lin, W. RGB-D Semantic segmentation: A review. In Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, J.; Yang, K.; Hu, X.; Stiefelhagen, R. CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers. arXiv 2022, arXiv:2203.04838. [Google Scholar]
- Xing, Y.; Wang, J.; Chen, X.; Zeng, G. Coupling two-stream RGB-D semantic segmentation network by idempotent mappings. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 16–19 October 2019; pp. 1850–1854. [Google Scholar]
- Park, S.J.; Hong, K.S.; Lee, S. RDFNet: RGB-D multi-level residual feature fusion for indoor semantic segmentation. In Proceedings of the IEEE International Conference On Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4990–4999. [Google Scholar]
- Valada, A.; Mohan, R.; Burgard, W. Self-supervised model adaptation for multimodal semantic segmentation. Int. J. Comput. Vis. (IJCV) 2019, 128, 1239–1285. [Google Scholar] [CrossRef]
- Fooladgar, F.; Kasaei, S. Multi-Modal Attention-based Fusion Model for Semantic Segmentation of RGB-Depth Images. arXiv 2019, arXiv:1912.11691. [Google Scholar]
- Penelle, B.; Schenkel, A.; Warzée, N. Geometrical 3D reconstruction using real-time RGB-D cameras. In Proceedings of the 2011 International Conference on 3D Imaging (IC3D), Liege, Belgium, 7–8 December 2011; pp. 1–8. [Google Scholar] [CrossRef]
- Bakator, M.; Radosav, D.J.M.T. Deep learning and medical diagnosis: A review of literature. Multimodal Technol. Interact. 2018, 2, 47. [Google Scholar] [CrossRef]
- Lundervold, A.S.; Lundervold, A. An Overview of Deep Learning in Medical Imaging Focusing on MRI. Z. Für Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef]
- Yaqub, M.; Jinchao, F.; Arshid, K.; Ahmed, S.; Zhang, W.; Nawaz, M.Z.; Mahmood, T. Deep Learning-Based Image Reconstruction for Different Medical Imaging Modalities. Comput. Math. Methods Med. 2022, 8750648. [Google Scholar] [CrossRef]
- Pain, C.D.; Egan, G.F.; Chen, Z. Deep Learning-Based Image Reconstruction and Post-Processing Methods in Positron Emission Tomography for Low-Dose Imaging and Resolution Enhancement. Eur. J. Nucl. Med. Mol. Imaging 2022, 49, 3098–3118. [Google Scholar] [CrossRef] [PubMed]
- Lopes, A.; Souza, R.; Pedrini, H. A Survey on RGB-D Datasets. Comput. Vis. Image Underst. 2022, 103489, 222. [Google Scholar] [CrossRef]
- Elmenreich, W. An Introduction to Sensor Fusion. Research Report 47/2001. Available online: https://www.researchgate.net/profile/Wilfried_Elmenreich/publication/267771481_An_Introduction_to_Sensor_Fusion/links/55d2e45908ae0a3417222dd9/AnIntroduction-to-Sensor-Fusion.pdf (accessed on 1 August 2022).
- Nguyen, C.V.; Izadi, S.; Lovell, D. Modeling kinect sensor noise for improved 3D reconstruction and tracking. In Proceedings of the 2nd International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 524–530. [Google Scholar] [CrossRef]
- Morell-Gimenez, V.; Saval-Calvo, M.; Azorin-Lopez, J.; Garcia-Rodriguez, J.; Cazorla, M.; Orts-Escolano, S.; Fuster-Guillo, A. A comparative study of Registration Methods for RGB-D Video of Static Scenes. Sensors 2014, 14, 8547–8576. [Google Scholar] [CrossRef] [PubMed]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique signatures of histograms for local surface description. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 356–369. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar] [CrossRef]
- Chen, Y.; Medioni, G. Object modeling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Wang, R.; Wei, L.; Vouga, E.; Huang, Q.; Ceylan, D.; Medioni, G.; Li, H. Capturing dynamic textured surfaces of moving targets. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–14 September 2016; Springer: Cham, Switzerland, 2016; pp. 271–288. [Google Scholar] [CrossRef]
- Li, J.; Gao, W.; Wu, Y.; Liu, Y.; Shen, Y. High-quality indoor scene 3D reconstruction with RGB-D cameras: A brief review. Comput. Vis. Media 2022, 8, 369–393. [Google Scholar] [CrossRef]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D Mapping: Using Kinect-Style Depth Cameras for Dense 3D Modeling of Indoor Environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Zaharescu, A.; Boyer, E.; Varanasi, K.; Horaud, R. Surface feature detection and description with applications to mesh matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 373–380. [Google Scholar] [CrossRef]
- Knopp, J.; Prasad, M.; Willems, G.; Timofte, R.; Gool, L.V. Hough transform and 3D SURF for robust three dimensional classification. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Springer: Berlin, Heidelberg, 2010; Volume 6316, pp. 589–602. [Google Scholar] [CrossRef]
- Salti, S.; Petrelli, A.; Tombari, F.; di Stefano, L. On the affinity between 3D detectors and descriptors. In Proceedings of the 2nd International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 424–431. [Google Scholar] [CrossRef]
- Steinbrücker, F.; Sturm, J.; Cremers, D. Real-time visual odometry from dense RGB-D images. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 719–722. [Google Scholar] [CrossRef]
- Gao, F.; Sun, Q.; Li, S.; Li, W.; Li, Y.; Yu, J.; Shuang, F. Efficient 6D object pose estimation based on attentive multi-scale contextual information. IET Comput. Vis. 2022, 2022, cvi2.12102. [Google Scholar] [CrossRef]
- Rodriguez, J.S. A comparison of an RGB-D cameras performance and a stereo camera in relation to object recognition and spatial position determination. ELCVIA. Electron. Lett. Comput. Vis. Image Anal. 2021, 20, 16–27. [Google Scholar] [CrossRef]
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual odometry and mapping for autonomous flight using an RGB-D camera. In Robotics Research; Springer: Cham, Switzerland, 2016; pp. 235–252. ISBN 978-3-319-29362-2. [Google Scholar] [CrossRef]
- Jaimez, M.; Kerl, C.; Gonzalez-Jimenez, J.; Cremers, D. Fast odometry and scene flow from RGB-D cameras based on geometric clustering. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3992–3999. [Google Scholar] [CrossRef]
- Yigong, Z.; Zhixing, H.; Jian, Y.; Hui, K. Maximum clique based RGB-D visual odometry. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2764–2769. [Google Scholar] [CrossRef]
- Yang, J.; Gan, Z.; Gui, X.; Li, K.; Hou, C. 3-D geometry enhanced superpixels for RGB-D data. In Proceedings of the Pacific-Rim Conference on Multimedia Springer, Nanjing, China, 13–16 December 2013; Springer: Cham, Switzerland; Volume 8294, pp. 35–46. [Google Scholar] [CrossRef]
- Hu, G.; Huang, S.; Zhao, L.; Alempijevic, A.; Dissanayake, G. A robust RGB-D slam algorithm. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 1714–1719. [Google Scholar] [CrossRef]
- Maisto, M.; Panella, M.; Liparulo, L.; Proietti, A. An accurate algorithm for the identification of fingertips using an RGB-D camera. IEEE J. Emerg. Sel. Top. Circuits Syst. 2013, 3, 272–283. [Google Scholar] [CrossRef]
- Berger, M.; Tagliasacchi, A.; Seversky, L.M.; Alliez, P.; Levine, J.A.; Sharf, A.; Silva, C.T. State of the art in surface reconstruction from point clouds. Eurographics State Art Rep. 2014, 1, 161–185. [Google Scholar] [CrossRef]
- Weinmann, M.; Klein, R. Exploring material recognition for estimating reflectance and illumination from a single image. In Proceedings of the Eurographics Workshop on Material Appearance Modeling, Dublin, Ireland, 22 June 2016; pp. 27–34. [Google Scholar] [CrossRef]
- Curless, B.; Levoy, M. A volumetric method for building complex models from range images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar] [CrossRef]
- Chen, J.; Bautembach, D.; Izadi, S. Scalable real-time volumetric surface reconstruction. ACM Trans. Graph. (ToG) 2013, 32, 113. [Google Scholar] [CrossRef]
- Zollhöfer, M.; Nießner, M.; Izadi, S.; Rehmann, C.; Zach, C.; Fisher, M.; Wu, C.; Fitzgibbon, A.; Loop, C.; Theobalt, C.; et al. Real-time non-rigid reconstruction using an RGB-D camera. ACM Trans. Graph. (ToG) 2014, 33, 156. [Google Scholar] [CrossRef]
- Jia, Q.; Chang, L.; Qiang, B.; Zhang, S.; Xie, W.; Yang, X.; Sun, Y.; Yang, M. Real-time 3D reconstruction method based on monocular vision. Sensors 2021, 21, 5909. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Schuon, S.; Chan, D.; Thrun, S.; Theobalt, C. 3D shape scanning with a time-of-flight camera. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1173–1180. [Google Scholar] [CrossRef]
- Kim, P.; Lim, H.; Kim, H.J. Robust visual odometry to irregular illumination changes with RGB-D camera. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 3688–3694. [Google Scholar] [CrossRef]
- Camplani, M.; Hannuna, S.; Mirmehdi, M.; Damen, D.; Paiement, A.; Tao, L.; Burghardt, T. Real-time RGB-D tracking with depth scaling kernelised correlation filters and occlusion handling. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015; pp. 145.1–145.11. [Google Scholar] [CrossRef]
- Liu, Y.; Jing, X.-Y.; Nie, J.; Gao, H.; Liu, J.; Jiang, G.-P. Context-aware three-dimensional mean-shift with occlusion handling for robust object tracking in RGB-D videos. IEEE Trans. Multimed. 2019, 21, 664–677. [Google Scholar] [CrossRef]
- Sarkar, S.; Venugopalan, V.; Reddy, K.; Ryde, J.; Jaitly, N.; Giering, M. Deep learning for automated occlusion edge detection in RGB-D frames. J. Signal Process. Syst. 2017, 88, 205–217. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. High-accuracy stereo depth maps using structured light. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 16–22 June 2003; pp. 195–202. [Google Scholar] [CrossRef]
- Tang, S.; Zhu, Q.; Chen, W.; Darwish, W.; Wu, B.; Hu, H.; Chen, M. Enhanced RGB-D Mapping Method for Detailed 3D Indoor and Outdoor Modeling. Sensors 2016, 16, 1589. [Google Scholar] [CrossRef]
- Kočevar, T.N.; Tomc, H.G. Modelling and visualisation of the optical properties of cloth. In Computer Simulation; Cvetkovic, D., Ed.; InTech: London, UK, 2017. [Google Scholar] [CrossRef]
- Langmann, B.; Hartmann, K.; Loffeld, O. Depth camera technology comparison and performance evaluation. In Proceedings of the 1st International Conference on Pattern Recognition Applications and Method, Vilamura, Algarve, Portugal, 6–8 February 2012; pp. 438–444. [Google Scholar] [CrossRef]
- Tran, V.-L.; Lin, H.-Y. Accurate RGB-D camera based on structured light techniques. In Proceedings of the International Conference on System Science and Engineering (ICSSE), Ho Chi Minh City, Vietnam, 21–23 July 2017; pp. 235–238. [Google Scholar] [CrossRef]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. BundleFusion: Real-Time Globally Consistent 3D Reconstruction Using On-the-Fly Surface Reintegration. ACM Trans. Graph. 2017, 36, 76a. [Google Scholar] [CrossRef]
- Nießner, M.; Zollhöfer, M.; Izadi, S.; Stamminger, M. Real-time 3D reconstruction at scale using voxel hashing. ACM Trans. Graph. (ToG) 2013, 32, 169. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 511–518. [Google Scholar] [CrossRef]
- Maier, R.; Sturm, J.; Cremers, D. Submap-based bundle adjustment for 3D reconstruction from RGB-D data. In Proceedings of the Conference on Pattern Recognition, Münster, Germany, 2–5 September 2014; Springer: Cham, Switzerland; pp. 54–65. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Fusing points and lines for high performance tracking. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 2, pp. 1508–1515. [Google Scholar] [CrossRef]
- Wang, X.; Zou, J.; Shi, D. An improved ORB image feature matching algorithm based on SURF. In Proceedings of the 3rd International Conference on Robotics and Automation Engineering (ICRAE), Guangzhou, China, 17–19 November 2018; pp. 218–222. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Derpanis, K.G. Overview of the RANSAC Algorithm. Image Rochester NY 2010, 4, 2–3. [Google Scholar]
- Kim, D.-H.; Kim, J.-H. Image-based ICP algorithm for visual odometry using a RGB-D sensor in a dynamic environment. In Robot Intelligence Technology and Applications 2012; Advances in Intelligent Systems and Computing; Kim, J.-H., Matson, E.T., Myung, H., Xu, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 208, pp. 423–430. [Google Scholar] [CrossRef]
- Yariv, L.; Gu, J.; Kasten, Y.; Lipman, Y. Volume Rendering of Neural Implicit Surfaces. Adv. Neural Inf. Process. Syst. 2021, 34, 4805–4815. [Google Scholar] [CrossRef]
- Minh, P.; Hoai, V.; Quoc, L. WSDF: Weighting of Signed Distance Function for Camera Motion Estimation in RGB-D Data. Int. J. Adv. Res. Artif. Intell. 2016, 5, 27–32. [Google Scholar] [CrossRef]
- Huang, P.-H.; Matzen, K.; Kopf, J.; Ahuja, N.; Huang, J.-B. Deepmvs: Learning multi-view stereopsis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2821–2830. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, G.; Bao, H. Robust 3D reconstruction with an RGB-D camera. IEEE Trans. Image Process. 2014, 23, 4893–4906. [Google Scholar] [CrossRef]
- Du, H.; Henry, P.; Ren, X.; Cheng, M.; Goldman, D.B.; Seitz, S.M.; Fox, D. Interactive 3D modeling of indoor environments with a consumer depth camera. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011; pp. 75–84. [Google Scholar] [CrossRef]
- Xu, H.; Hou, J.; Yu, L.; Fei, S. 3D Reconstruction System for Collaborative Scanning Based on Multiple RGB-D Cameras. Pattern Recognit. Lett. 2019, 128, 505–512. [Google Scholar] [CrossRef]
- Shang, Z.; Shen, Z. Real-time 3D reconstruction on construction site using visual SLAM and UAV. In Construction Research Congress; American Society of Civil Engineers: New Orleans, LA, USA, 2018; pp. 305–315. [Google Scholar] [CrossRef]
- Shekhar, S.; Xiong, H.; Zhou, H.; Eds, Χ. Visual odometry. In Encyclopedia of GIS; Springer International Publishing: Cham, Switzerland, 2017; p. 2425. [Google Scholar] [CrossRef]
- Bailey, T.; Durrant-Whyte, H. Simultaneous Localization and Mapping (SLAM): Part II. IEEE Robot. Automat. Mag 2016, 13, 108–117. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous Localization and Mapping: Part I. IEEE Robot. Automat. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Artieda, J.; Sebastian, J.M.; Campoy, P.; Correa, J.F.; Mondragón, I.F.; Martínez, C.; Olivares, M. Visual 3-D SLAM from UAVs. J. Intell. Robot. Syst. 2009, 55, 299–321. [Google Scholar] [CrossRef]
- Cao, F.; Zhuang, Y.; Zhang, H.; Wang, W. Robust Place Recognition and Loop Closing in Laser-Based SLAM for UGVs in Urban Environments. IEEE Sens. J. 2018, 18, 4242–4252. [Google Scholar] [CrossRef]
- Hahnel, D.; Triebel, R.; Burgard, W.; Thrun, S. Map building with mobile robots in dynamic environments. In Proceedings of the IEEE International Conference on Robotics and Automation (Cat. No.03CH37422), Taipei, Taiwan, 14–19 September 2003; pp. 1557–1563. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, S.; Xiong, R.; Wu, J. A Framework for Multi-Session RGBD SLAM in Low Dynamic Workspace Environment. CAAI Trans. Intell. Technol. 2016, 1, 90–103. [Google Scholar] [CrossRef]
- Alliez, P.; Bonardi, F.; Bouchafa, S.; Didier, J.-Y.; Hadj-Abdelkader, H.; Munoz, F.I.; Kachurka, V.; Rault, B.; Robin, M.; Roussel, D. Real-time multi-SLAM system for agent localization and 3D mapping in dynamic scenarios. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020; pp. 4894–4900. [Google Scholar] [CrossRef]
- Yang, Q.; Tan, K.-H.; Culbertson, B.; Apostolopoulos, J. Fusion of active and passive sensors for fast 3d capture. In Proceedings of the IEEE International Workshop on Multimedia Signal Processing, Saint-Malo, France, 4–6 October 2010; pp. 69–74. [Google Scholar] [CrossRef]
- Kooij, J.F.P.; Liem, M.C.; Krijnders, J.D.; Andringa, T.C.; Gavrila, D.M. Multi-modal human aggression detection. Comput. Vis. Image Underst. 2016, 144, 106–120. [Google Scholar] [CrossRef]
- Kahn, S.; Bockholt, U.; Kuijper, A.; Fellner, D.W. Towards precise real-time 3D difference detection for industrial applications. Comput. Ind. 2013, 64, 1115–1128. [Google Scholar] [CrossRef]
- Salvi, J.; Pages, J.; Batlle, J. Pattern Codification Strategies in Structured Light Systems. Pattern Recognit. 2004, 37, 827–849. [Google Scholar] [CrossRef]
- Alexa, M. Differential coordinates for local mesh morphing and deformation. Vis. Comput. 2003, 19, 105–114. [Google Scholar] [CrossRef]
- Beltran, D.; Basañez, L. A comparison between active and passive 3d vision sensors: Bumblebeexb3 and Microsoft Kinect. In Proceedings of the Robot 2013: First Iberian Robotics Conference, Madrid, Spain, 28 November 2013; pp. 725–734. [Google Scholar] [CrossRef]
- Lee, J.-H.; Kim, C.-S. Monocular depth estimation using relative depth maps. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9721–9730. [Google Scholar] [CrossRef]
- Ibrahim, M.M.; Liu, Q.; Khan, R.; Yang, J.; Adeli, E.; Yang, Y. Depth map artefacts reduction: A review. IET Image 2020, 14, 2630–2644. [Google Scholar] [CrossRef]
- Kadambi, A.; Bhandari, A.; Raskar, R. 3D depth cameras in vision: Benefits and limitations of the hardware. In Computer Vision and Machine Learning with RGB-D Sensors; Advances in Computer Vision and Pattern Recognition; Shao, L., Han, J., Kohli, P., Zhang, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 3–26. [Google Scholar] [CrossRef]
- Patias, P. Introduction to Photogrammetry; Ziti Publications: Thessaloniki, Greece, 1991; ISBN 960-431-021-6.691991. (In Greek) [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar] [CrossRef]
- Khoshelham, K.; Elberink, S.O. Accuracy and Resolution of Kinect Depth Data for Indoor Mapping Applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef]
- Malleson, C.; Hilton, A.; Guillemaut, J.-Y. Evaluation of kinect fusion for set modelling. In Proceedings of the European Conference on Visual Media Production (CVMP 2012), London, UK, 5–6 December 2012. [Google Scholar]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the 1998 Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar] [CrossRef]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-Annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- McCormac, J.; Handa, A.; Leutenegger, S.; Davison, A.J. SceneNet RGB-D: Can 5M synthetic images beat generic ImageNet pre-training on indoor segmentation? In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2697–2706. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Wang, P.; Ogunbona, P.; Liu, S.; Tang, C. A large scale RGB-D dataset for action recognition. In Understanding Human Activities Through 3D Sensors; Lecture Notes in Computer, Science; Wannous, H., Pala, P., Daoudi, M., Flórez-Revuelta, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 10188, pp. 101–114. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In Computer Vision—ECCV 2012; Lecture Notes in Computer, Science; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7576, pp. 746–760. [Google Scholar] [CrossRef]
- Silberman, N.; Fergus, R. Indoor scene segmentation using a structured light sensor. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 601–608. [Google Scholar] [CrossRef]
- Gupta, S.; Arbelaez, P.; Malik, J. Perceptual organization and recognition of indoor scenes from RGB-D images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 564–571. [Google Scholar]
- Janoch, A.; Karayev, S.; Jia, Y.; Barron, J.T.; Fritz, M.; Saenko, K.; Darrell, T. A category-level 3d object dataset: Putting the kinect to work. In Consumer Depth Cameras for Computer Vision; Springer: London, UK, 2013; pp. 141–165. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2d-3d-semantic data for indoor scene understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Roberts, M.; Ramapuram, J.; Ranjan, A.; Kumar, A.; Bautista, M.A.; Paczan, N.; Webb, R.; Susskind, J.M. Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding. arXiv 2020, arXiv:2011.02523. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Features/Operation |
|---|---|
| Bundle Fusion | Optimization pose algorithm |
| Voxel Hashing | Real-time reconstruction and easy-to detect scene changes |
| SIFT | Provides uniform scaling and orientation, illumination changes and rotation, measures key points DoG, image translation, uses affine transformation, descriptor type integer vector |
| SURF | Allows a rapid differentiation of light characteristic points in dark background and inverse, key points Hessian, descriptor type real vector, unchanged in various scaling and rotations |
| ORB | Performance in noise scenes, descriptor type binary string |
| FAST | Checks corner points in image block, faster than SIFT/SURF, does not detects orientation of feature points |
| RANCSANC | Copes with outliers in the input image, uses the minimum number of data points |
| ICP | Based on combining images for the dynamic environment and an image with the 3D position information of the feature |
| SDF | Describes geometrical shapes, gives a distance of point X from the boundary of a surface, and determines if a point lies inside or outside the boundary |
| Approaches of 3D Reconstruction | |
|---|---|
| Techniques and Methods | Characteristics |
| Align the current frame to the previous frame with the ICP algorithm [47] | For large-scale scenes, creates error propagation [33] |
| Weighted average of multi-image blending [78] | Motion blur and sensitive to light change |
| Sub-mapping-based BA [79] | High reconstruction accuracies and low computational complexity |
| Design a global 3D model, which is updated and combined with live depth measurements for the volumetric representation of the scene reconstructed [87] | High memory consumption |
| Visual and geometry features, combines SFM without camera motion and depth [88] | Accuracy is satisfactory, cannot be applied to real-time applications |
| Design system that provides feedback, is tolerate in human errors and alignment failures [89] | Scans large area (50 m) and preserves details about accuracy |
| Design system that aligns and maps large indoor environments in near real time and handles featureless corridors and dark rooms [47] | Estimates the appropriate color, implementation of RGB-D mapping is not real time |
| Limitation of RGB-D in Dynamic Scenes | Proposed Solutions |
|---|---|
| High-quality surface modeling | Surface modeling, no points |
| Global model consistency | When the scale changes, errors and distortions are corrected at the same time |
| Robust camera tracking | If the camera does not fail in areas with lack of features, then incremental errors will not occur. Does not consider preceding frames exclusively |
| On-the-fly model updates | Updates model with new poses each time |
| Real-time rates | Camera pose feedback in new spontaneous data |
| Scalability | Scanning in small- and large-scale areas, especially in the robotics sector and virtual reality applications, that are unexpectedly changing. Additionally, maintains local accuracy |
| Cons of Depth Maps | Countermeasures |
|---|---|
| Low accuracy | Apply bilateral filter [106] |
| Noise | Convolutional deep autoencoder denoising [107] |
| (HR) RGB but (LR) depth images | Super-resolution techniques, high-resolution color images [83]. CNN to downsample an HR image sampling and LR depth image [87] |
| Featureless region | Polarization-based methods (reveal surface normal information) [102] |
| Shiny surfaces, bright, transparency | TSDF to voxelize the space [105], ray-voxel pairs [106] |
| Dataset | Year | Sensor Type | Apps | Images/Scenes |
|---|---|---|---|---|
| NYU Depth | (V1) 2011 | Structured light | SS | 64 scenes (108,617 frames) with 2347 labeled RGB-D frames |
| (V2) 2012 | Structured light | SS | 464 scenes (407,024 frames) with 1449 labeled aligned RGB-D images | |
| SUN RGB-D | 2015 | Structured light and TOF | SS, OD, P | 10335 images |
| Stanford2D3D | 2016 | Structured light | SS, NM | 6 large-scale indoor areas (70,496 images) |
| ScanNet | 2017 | Structured light | 3D SvS | 1513 sequences (over 2.5 million frames) |
| Hypersim | 2021 | Synthetic | NM, IS, DR | 461 scenes (77,400 images) |
| Advantages Active & Passive techniques |
| |
| Limitations of RGB-D cameras | Active
| Passive
|
| Limitations of Active sensors | ToF
| Structure Light Sensing
|
| Systematic & Random Errors of Sensors |
| |
| Measurements inaccuracies | Pose estimation of RGB-D
| RGB-D camera itself
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tychola, K.A.; Tsimperidis, I.; Papakostas, G.A. On 3D Reconstruction Using RGB-D Cameras. Digital 2022, 2, 401-421. https://doi.org/10.3390/digital2030022
Tychola KA, Tsimperidis I, Papakostas GA. On 3D Reconstruction Using RGB-D Cameras. Digital. 2022; 2(3):401-421. https://doi.org/10.3390/digital2030022
Chicago/Turabian StyleTychola, Kyriaki A., Ioannis Tsimperidis, and George A. Papakostas. 2022. "On 3D Reconstruction Using RGB-D Cameras" Digital 2, no. 3: 401-421. https://doi.org/10.3390/digital2030022