2.1. Background
Usually, to increase serial code performance, parallelization and loop tiling are applied to the source code. Parallelism allows us to use many threads to execute code, while loop tiling improves code locality and increases parallel code granularity that is crucial for improving multi-threaded code performance.
Loop tiling is a reordering loop transformation that allows data to be accessed in blocks (tiles), with the block size defined as a parameter of this transformation. Each loop is transformed in two loops: one iterating inside each block (intratile) and the other one iterating over the blocks (intertile).
As far as loop tiling is concerned, it is very important to generate target code with maximal tile dimension, which is defined with the maximal number of loops in the loop nest. If one or more the innermost loops remain un-tiled, resulting tiles are unbounded along those untiled loops. This makes tiles also unbounded that reduces tiled code locality because it is not possible to hold in cache all the data associated with a single unbounded tile [
15,
16]. If one or more of the outermost loops are untiled, they should be executed serially. This reduces target code parallelism and introduces additional synchronization events reducing target code performance [
10,
13].
Each iteration in the loop nest iteration space is represented with an iteration vector. All iteration vectors of a given loop statement form the iteration space of that statement.
Code can expose dependences among iterations in a code iteration space. A dependence is a situation when two different iterations access the same memory location and at least one of these accesses is written. Each dependence is represented by its source and destination.
To extract dependences and generate target code, we use PET [
17] and the iscc calculator [
18]. The iscc calculator is an interactive tool for manipulating sets and relations of integer tuples bounded by affine constraints over the set variables, parameters and existentially quantified variables. PET is a library for extracting a polyhedral model from a C source. Such a model consists of an iteration space, access relations, and a schedule, each of which is described using affine constraints. A PET schedule specifies the original execution order of loop nest statement instances.
PET extracts dependences in the form of relations, where the input tuple of each relation represents iteration vectors of dependence sources and the output tuple represents those of the corresponding dependence destinations; that is, the dependence relation,
R, is presented in the following form:
where
is the list of all parameters of affine
imposed on
and
.
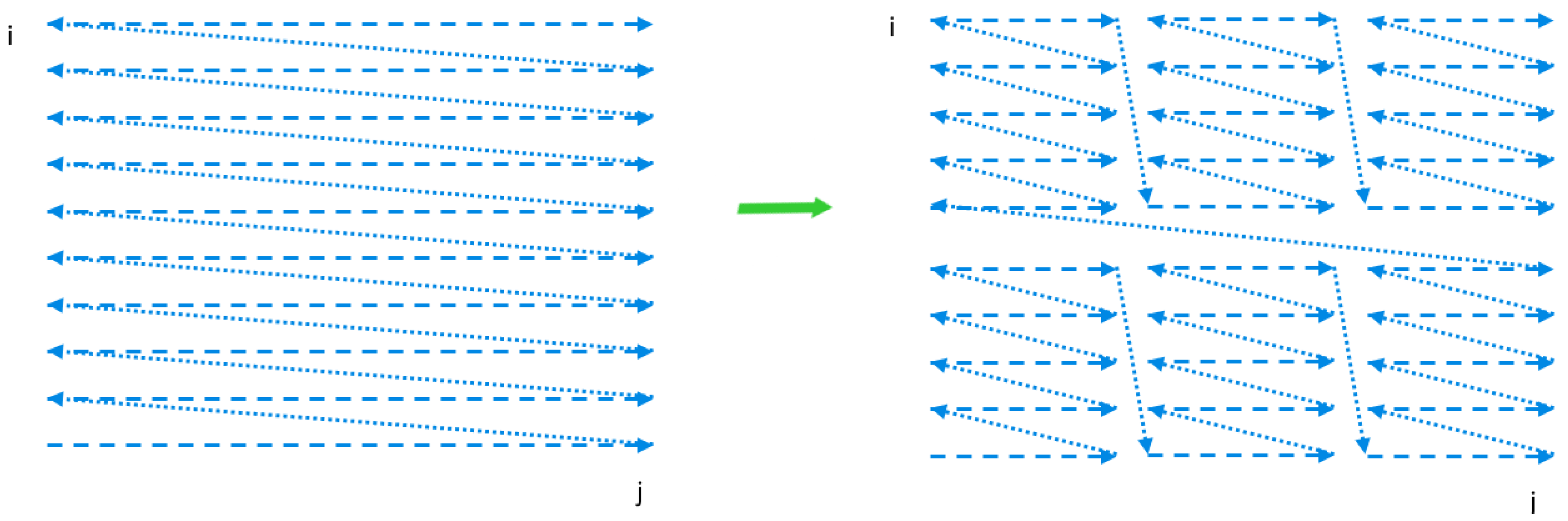
For the dependence, a distance vector is the difference between the iteration vector of its destination and that of its source. Calculating such a difference is possible when both abovementioned vectors are of the same length. This is true for perfectly nested loops where all statements are surrounded with all loops. Otherwise, loops are imperfectly nested, that is, the dimensions of iteration spaces of loop nest statements are different and we cannot directly calculate a distance vector.
In such a case, to calculate distance vectors, we normalize the iteration space of each statement so that all the iteration spaces are of the same dimension. Normalization consists in applying a global schedule extracted with PET for each loop nest statement to an iteration space of the statement. The entire global schedule corresponds to the original execution order of a loop nest. As a result, the iteration spaces of each statement become of the same dimension in the global iteration space and we are able to calculate all distance vectors. We present details of normalization in the following subsection.
To tile and parallelize source codes, we should form time partition constraints [
10] that state that if iteration
I of statement
depends on iteration
J of statement
, then
I must be assigned to a time partition that is executed no earlier than the partition containing
J, that is, schedule (
I) ≤ schedule (
J), where schedule (
I) and schedule (
J) denote the discrete execution time of iterations
I and
J, respectively.
Linear independent solutions to time partition constraints are applied to generate schedules for statement instances of original code. Those affine schedules are used to parallelize and tile an original loop nest.
We strived to extract as many linear independent solutions to time partition constraints as possible because the number of those solutions defines the dimension of generated tiles [
10].
The affine transformation framework comprises the above considerations and includes the following steps: (i) extracting dependence relations, (ii) forming time partition constraints on the basis of dependence relations, (iii) resolving the time partition constraints striving to find as many linearly independent solutions as possible, (iv) forming affine transformations on the basis of the independent solutions, and (v) generating parallel tiled code.
Details of the affine transformation framework can be found in the Ref. [
13]. In the same paper, implementation details of the PLUTO compiler based on the affine transformation are presented.
An alternative approach to generate parallel tiled code is based on applying the transitive closure of a dependence graph. This approach is introduced in the Ref. [
14]. It envisages the following steps: (i) extracting dependence relations, (ii) forming a dependence graph as the union of all dependence relations, (iii) calculating the transitive closure of the dependence graph, (iv) applying transitive closure to form valid tiles, and (v) generating parallel tiled code. This approach does not form and apply any affine transformation. The approach is implemented in the TRACO compiler.
2.2. 3D Tiled Code Generation
For the original loop nest in Listing 1, PET returns the following iteration spaces,
and
, for statements
and
, respectively.
As we can see, the dimensions of the iteration spaces of
and
are different, so we could not directly calculate distance vectors. To normalize the iteration spaces, we applied the following global schedules returned with PET:
to sets
and
, respectively, and obtained the following global spaces:
It is worth noting that if a statement appears in a sequence of statements, PET extends the global schedule for these statements with a constant representing a global schedule dimension. The values of these dimensions correspond to the order of the statements in the sequence. If a statement appears as the body of a loop, then the schedule is extended with both an initial domain dimension and an initial range dimension. In schedules and , in the output (right) tuples in the third positions, constants 0 and 1 are inserted, while in the fourth position of the output tuple of , constant 0 is inserted because statement is not surrounded with iterator k.
In the same way, we transform dependence relations returned with PET and presented in original iteration spaces to dependence relations presented in the global iteration space, where all relation tuples are of the same dimension. Applying the deltas operator of the iscc calculator, which calculates the difference between the output and input tuples of dependence relations in the global iteration space, we obtained the following distance vectors represented with sets.
To simplify extracting affine transformations, we approximate the distance vectors above with a single distance vector, which represents each distance vector presented above:
It is worth noting that the constraints of D are the logical conjunction of all the constraints of and .
The time partition constraint formed on the basis of vector
D is the following.
where
are unknowns, and
is the constraints of set
D.
Because variable is unbounded, that is, , we conclude that should be equal to 0 to satisfy constraint (2). We also conclude that unknown should be 0 because variable is not any loop iterator, it represents global schedule constants, which should not be transformed; they are used only to properly generate target code (correctly place loop statements in target code).
Taking into account the conclusions above, we consummate that there exist only two linearly independent solutions to constraint (2), for example, and .
Thus, for the code in Listing 1, by means of affine transformations, we are able to generate only 2D tiles (see Background).
Next, we use the concept of a loop nest statement instance schedule, which specifies the order in which those instances are executed in target code. To improve the features of the dependences of the code presented in Listing 1, we suggest applying to the loop nest statements a schedule formed according to the data flow concept DFC): first, the readiness time for each operand of each statement should be defined, for example, if are k discrete times of the readiness of k operands of statement i, then the schedule of statement i is defined as follows: . On the right of that formula, the first term defines the maximal time among all operand readiness times of statement i, and “+1” means that statement i can be executed at the next discrete time after all its operands are ready (already calculated).
DFC schedules should be defined and applied to all the statements of the source loop nest to generate a transformed serial loop.
Analyzing the operands
and
of statement
in Listing 1 as well as the bounds of loops
i and
j, we may conclude that their readiness times are
and
, respectively. We also take into account that element
can be updated many times for different values of
k, and the final value of
is formed in time
. Thus, according to DFC, statement
is to be executed at time
for variables
i and
j satisfying the constraint
. The last constraint means that element
formed with statement
can be updated many times at time
t, satisfying the condition
. Thus, taking into account the global schedule of statement
represented with relation
, we obtain the following DFC schedule,
.
Analyzing statement
, we may conclude that it should be executed when for given
i and
j, loop
k is terminated, that is, the calculation of the value of element
is terminated, that is, at time
. Thus, we obtained the following schedule for statement
taking into account the global schedule for
presented with relation
above.
The constraint means that statement can be updated only when loop k is terminated. Constant 1 in the third position of the tuple guarantees that statement should be executed after terminating all the iterations of loop k.
Applying schedules and to statements and , by means of the codegen iscc operator, we obtain the transformed code presented in Listing 4.
| Listing 4. Transformed C code implementing the counting algorithm |
- 1
for (int c0 = 1; c0 < N − 1; c0 += 1) - 2
for (int c1 = −N + c0 + 1; c1 < 0; c1 += 1) - 3
for (int c2 = c0 − c1 + 1; c2 <= min(N, 2 ∗ c0 − c1 + 1); c2 += 1) { - 4
if (2 ∗ c0 >= c1 + c2) - 5
{ - 6
c[−c1][c2] += paired(−c0 + c2 − 1, c2) ? c[−c1][−c0 + c2 − 1 − 1] + c[−c0 + c2 − 1 + 1][c2 − 1] : 0; - 7
} - 8
c[−c1][c2] += paired(c0 − c1, c2) ? c[−c1][c0 − c1 − 1] + c[c0 − c1 + 1][c2 − 1] : 0; - 9
if (c1 + c2 == c0 + 1) - 10
{ - 11
c[−c1][c0 − c1 + 1] = c[−c1][c0 − c1 + 1] + c[−c1][c0 − c1 + 1 − 1]; - 12
} - 13
}
|
That code respects all dependences available in the code in Listing 1 due to the following reason. In the code in Listing 1, we distinguish two types of dependences: standard ones and reductions. If the loop nest statement uses an associative and commutative operation such as addition, we recognize the dependence between two references of this statement as a reduction dependence [
19]. For example, in the code in Listing 1, statement
causes reduction dependences regarding to reads and writes of element
.
We may allow them to be reordered provided that a new order is serial, that is, reduction dependences do not impose an ordering constraint; in the code in Listing 4, reduction dependences are respected due to the serial execution of loop nest statement instances.
Standard dependences available in the code in Listing 1 are respected via implementing the DFC concept.
To prove the validity of the applied schedules to generate the code in Listing 4 in a formal way, we use the schedule validation technique presented in the Ref. [
20].
Given relation
F representing all the dependences to be respected, schedule
S is valid if the following inequality is true:
where
is the operator that maps a relation to the differences between image and domain elements.
The result of the composition is a relation where the input (left) and output (right) tuples represent dependence sources and destinations, respectively, in the transformed iteration space. A schedule is valid (respects all the dependences available in an original loop nest) if the vector whose elements are the differences between the image and domain elements of relation R is lexicographically non-negative (). In such a case, each standard dependence in the original loop nest is respected in the transformed loop nest.
To apply the schedule validity technique above, we extract dependence relations
F by means of PET. Then we eliminate from
F all reduction dependences, taking into account the fact that such dependences cause only statement
. We present reduction dependences by means of the following relation:
Next, applying the iscc calculator, we obtain a relation, R, as the result of the composition , where S is the union of schedules and defined above to generate the target code.
To check whether each vector represented with set is lexicographically non-negative, we form the following set that represents all lexicographically negative vectors in the unbounded 5D space.
Then, we calculate the intersection of sets C and . That intersection is the empty set, that means that all vectors of C are lexicographically non-negative. This proves the validity of schedules and .
For the code presented in Listing 4, by means of PET and the iscc calculator, we obtained the following distance vectors.
,
,
,
,
,
.
To simplify extracting affine transformations, we approximate the distance vectors above with a single distance vector, which represents each distance vector presented above.
. The time partitions constraint formed on the basis of the vector above is the following.
where
are unknowns, and
represent the constraints of set
D above.
Taking into account that unknown should be 0 because variable is not any loop iterator, it represents global schedule constants and it should not be transformed. There exist three linearly independent solutions to constraint (3), for example, and .
Applying the DAPT optimizing compiler [
21], which automatically extracts and applies the affine transformations to the code in Listing 4 to tile and parallelize that code by means of the wave-front technique [
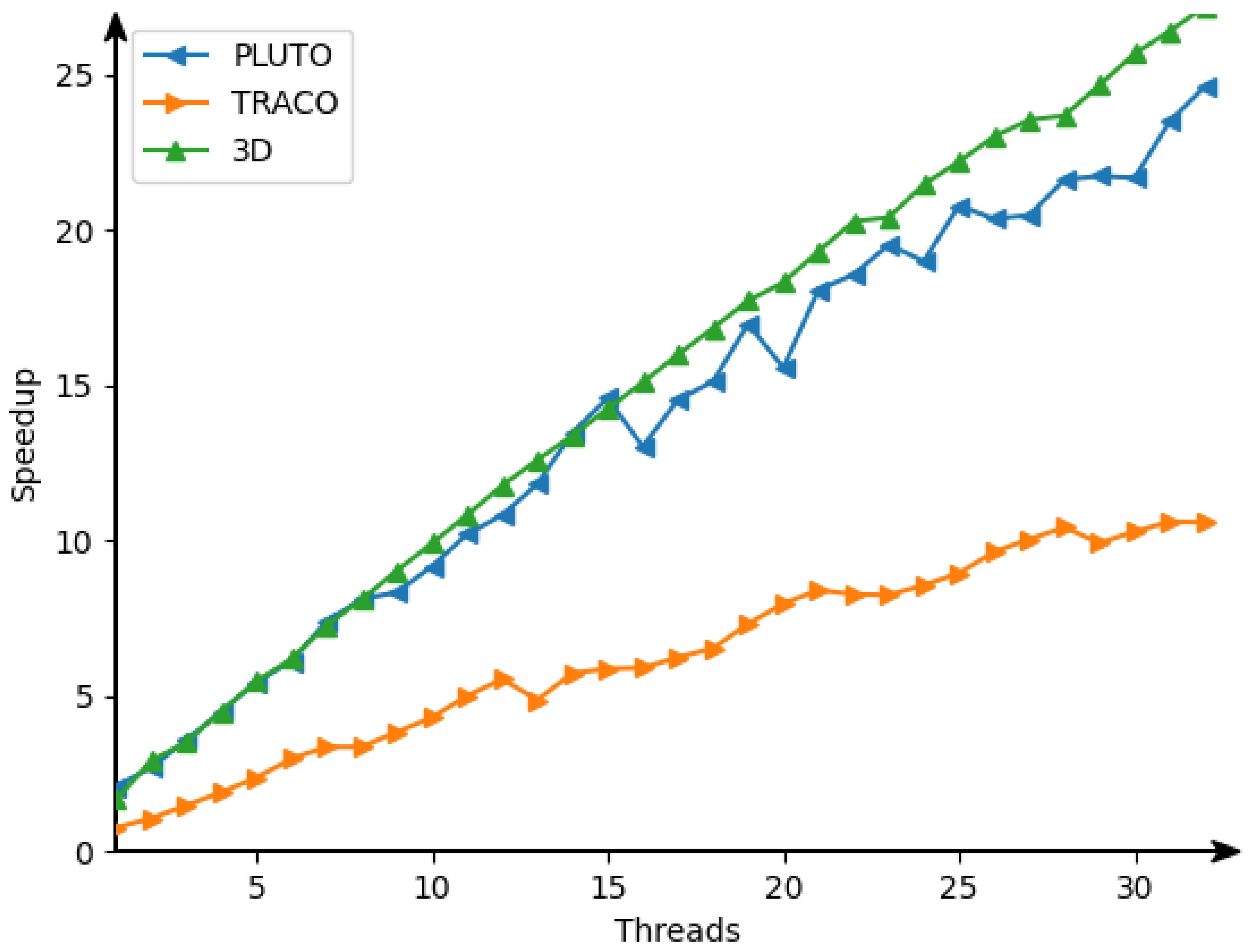
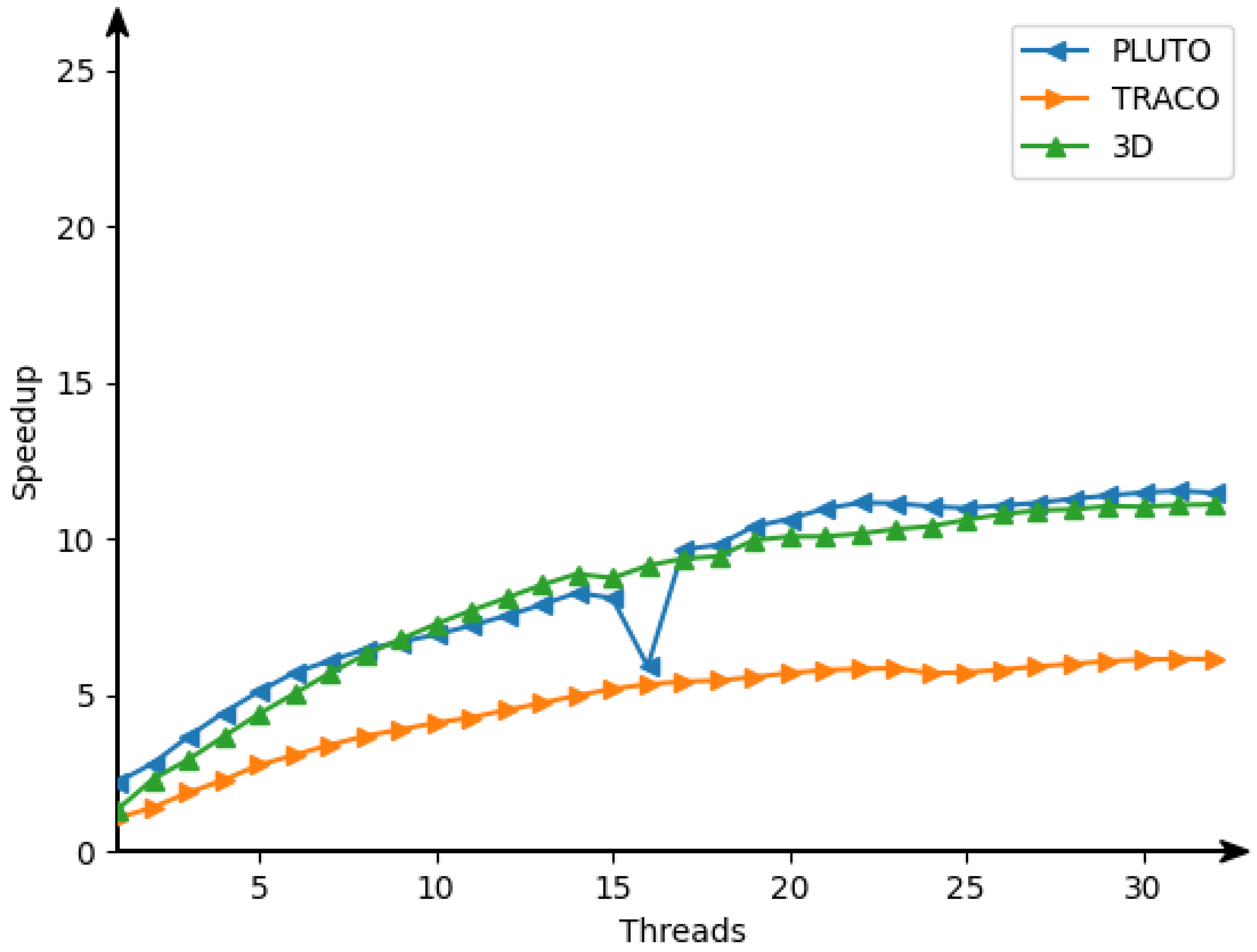
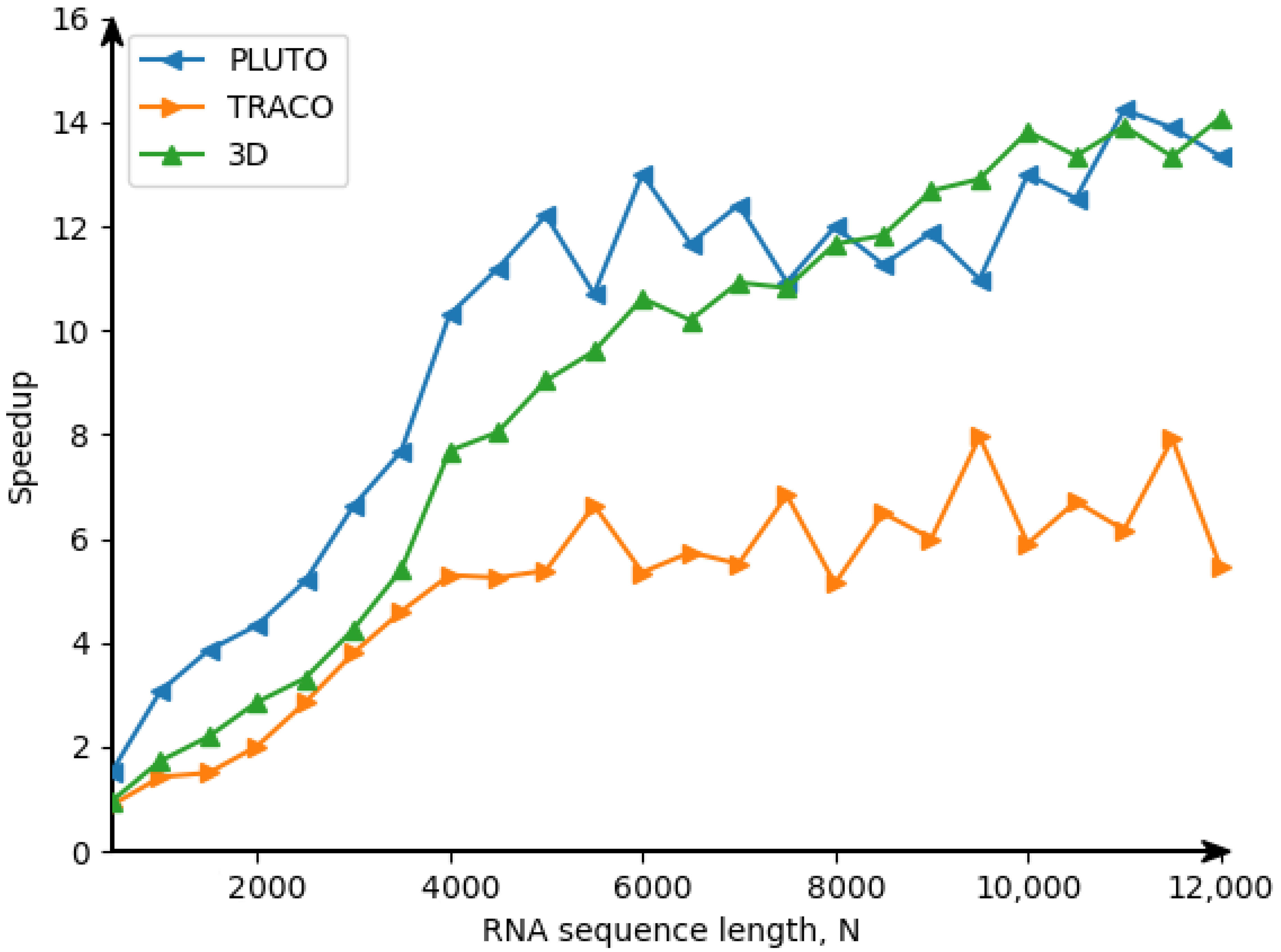
22], we obtain the following target 3D tiled parallel code (Listing 5) with tiles of size 16 × 32 × 40. By means of experiments, this size was defined by us as the optimal one regarding tiled code performance.
In that code, the first three loops enumerate tiles, while the remaining three loops scan statement instances within each tile. The OpenMP [
23] directive
makes the loop
for (int h0=...) parallel.
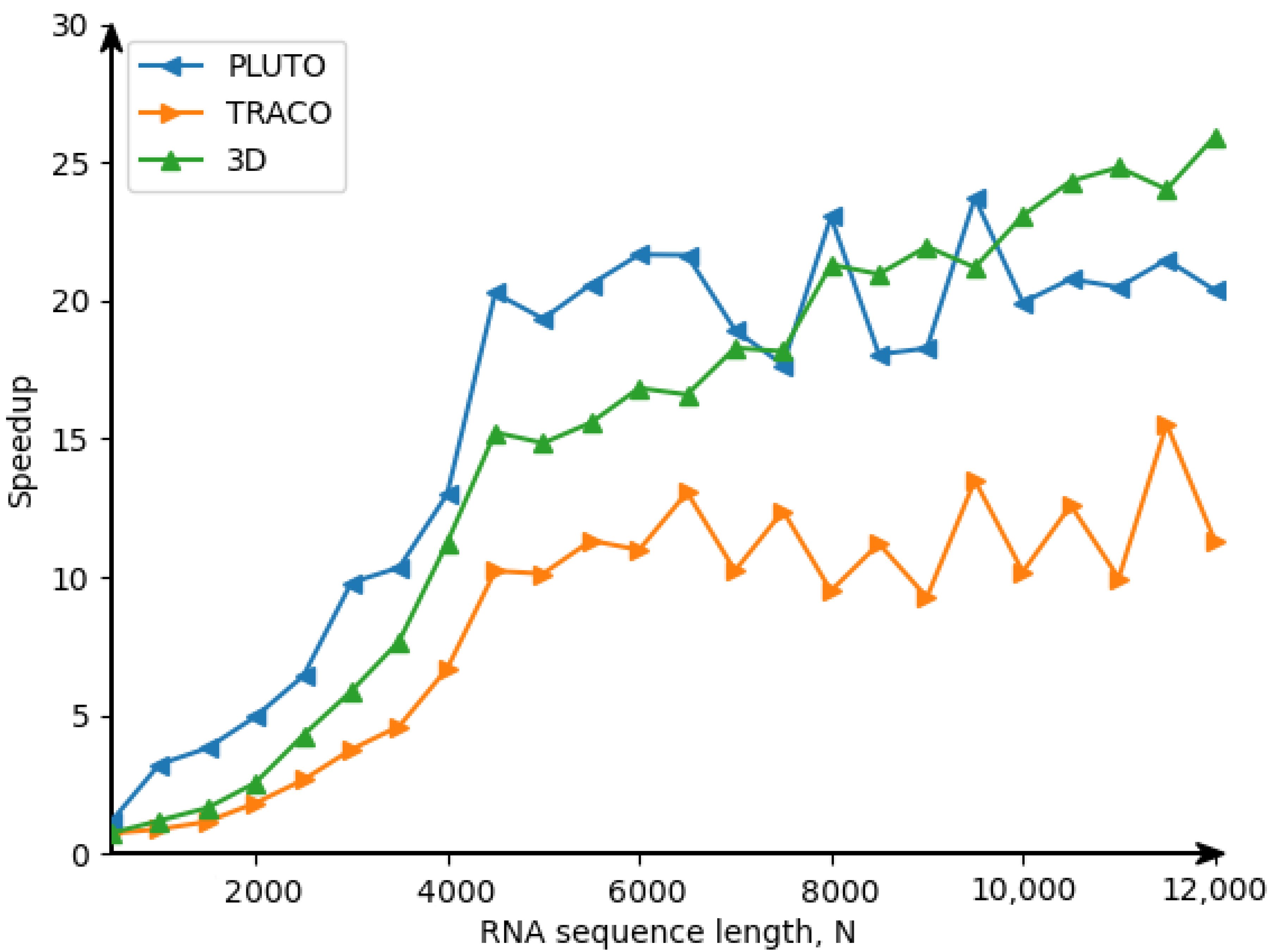
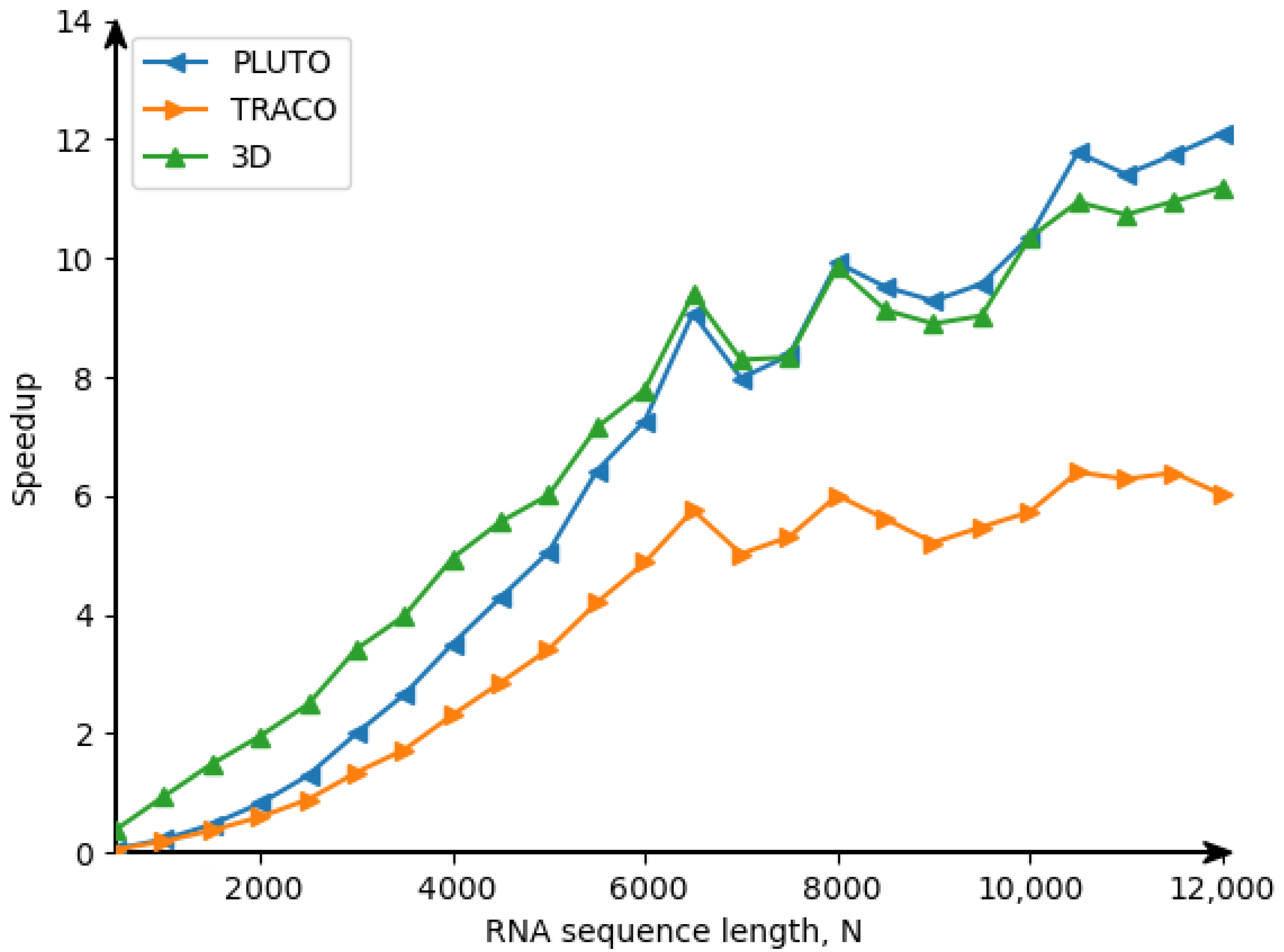
The Ref. [
24] illustrates the advantage of 3D tiled codes in comparison with 2D tiled ones which implement RNA Nussinov’s algorithm [
25]. However, there are the following differences between the approaches used for code generation for the Nussinov problem [
24] and for the counting problem considered in the current paper. The code for the Nussinov problem is derived on the idea of a calculation model based on systolic arrays (first figure in the Nussinov paper), while code for the counting problem is based on the data flow concept (DFC). The approach presented in the current paper uses the validity technique of the applied schedules to generate target code, while the approach presented in the Nussinov paper does not envisage any formal validation of applied schedules.
| Listing 5. 3D tiled parallel code |
- 1
for (int w0 = floord(−N + 34, 160) − 1; w0 < floord(7 ∗ N − 10, 80); w0 += 1) { - 2
#pragma omp parallel for - 3
for (int h0 = max(max(0, w0 − (N + 40) / 40 + 2), w0 + floord(−4 ∗ w0 − 3, 9) + 1); h0 <= min((N − 2) / 16, w0 + floord(N − 80 ∗ w0 + 46, 240) + 1); h0 += 1) { - 4
for (int h1 = max(max(max(5 ∗ w0 − 9 ∗ h0 − 3, −((N + 29) / 32)), w0 − h0 − (N + 40) / 40 + 1), −((N − 16 ∗ h0 + 30) / 32)); h1 <= min(−1, 5 ∗ w0 − 7 ∗ h0 + 8); h1 += 1) { - 5
for (int i0 = max(max(1, 16 ∗ h0), 20 ∗ w0 − 20 ∗ h0 − 4 ∗ h1); i0 <= min(min(16 ∗ h0 + 15, N + 32 ∗ h1 + 30), 40 ∗ w0 − 40 ∗ h0 − 8 ∗ h1 + 69); i0 += 1) { - 6
for (int i1 = max(max(32 ∗ h1, −40 ∗ w0 + 40 ∗ h0 + 40 ∗ h1 + i0 − 38), −N + i0 + 1); i1 <= min(32 ∗ h1 + 31, −40 ∗ w0 + 40 ∗ h0 + 40 ∗ h1 + 2 ∗ i0 + 1); i1 += 1) { - 7
for (int i2 = max(40 ∗ w0 − 40 ∗ h0 − 40 ∗ h1, i0 − i1 + 1); i2 <= min(min(N, 40 ∗ w0 − 40 ∗ h0 − 40 ∗ h1 + 39), 2 ∗ i0 − i1 + 1); i2 += 1) { - 8
{ - 9
if (2 ∗ i0 >= i1 + i2) { - 10
c[−i1][i2] += (paired((−i0 + i2 − 1), (i2)) ? (c[−i1][−i0 + i2 − 2] + c[−i0 + i2][i2 − 1]) : 0); - 11
} - 12
c[−i1][i2] += (paired((i0 − i1), (i2)) ? (c[−i1][i0 − i1 − 1] + c[i0 − i1 + 1][i2 − 1]) : 0); - 13
if (i1 + i2 == i0 + 1) { - 14
c[−i1][i0 − i1 + 1] = (c[−i1][i0 − i1 + 1] + c[−i1][i0 − i1]); - 15
} - 16
} - 17
} - 18
} - 19
} - 20
} - 21
} - 22
}
|


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






