
Semantic Communities from Graph-Inspired Visual Representations of Cityscapes
 , , and
, , and 
Abstract
:
1. Introduction
- A robust model to generate semantic communities in an urban challenging environment based on a community detection algorithm of graph-inspired topometric descriptors of observed entities;
- The creation of graph-based description vectors, for which we semantically segment every input image and produce the corresponding descriptor in the form of an undirected graph;
- A novel dataset recorded in the city of Xanthi, Greece, with a moving car that contains distinct semantic regions with consistent visual information, in order to validate our system.
2. Related Literature
3. Approach
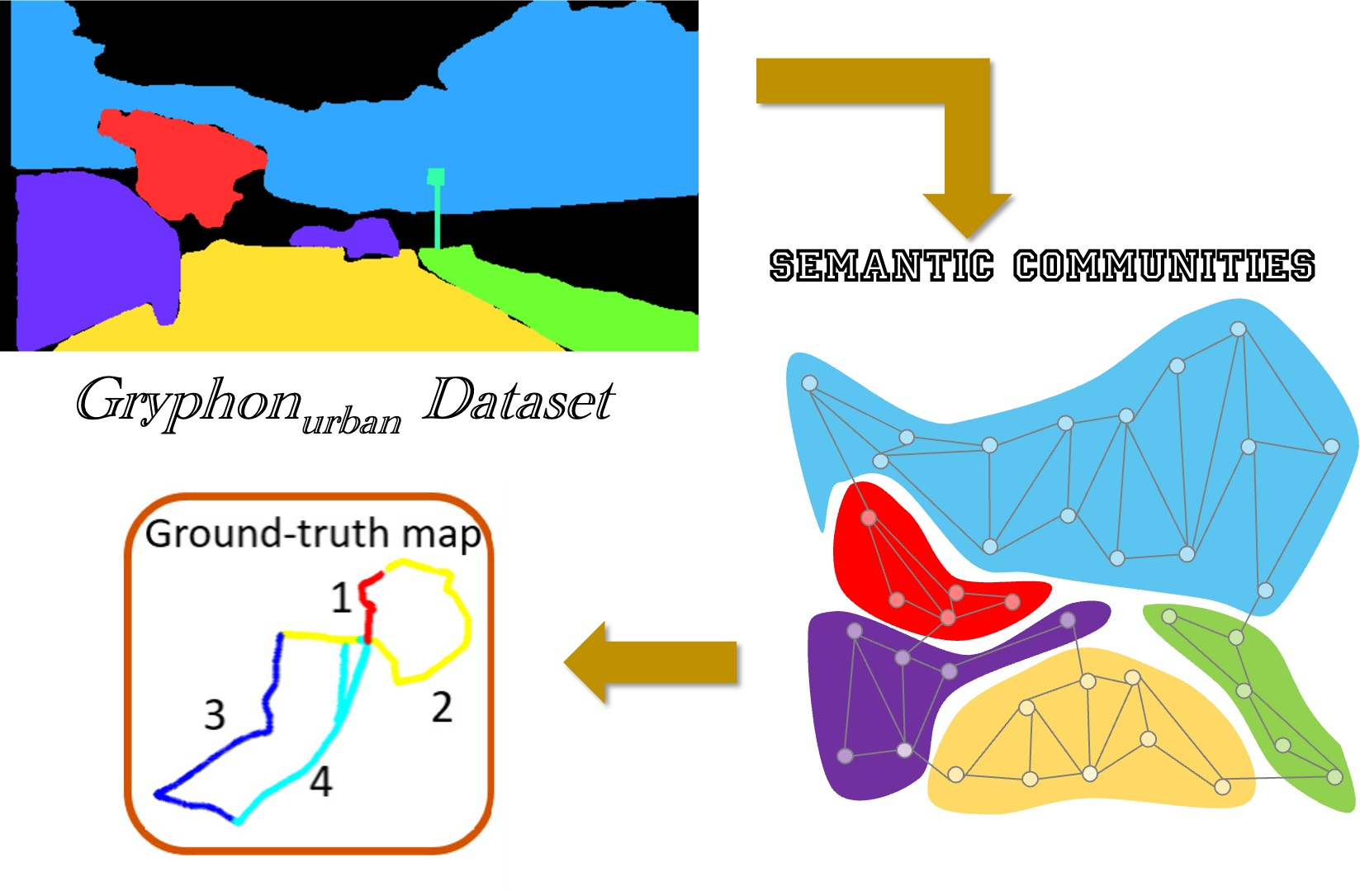
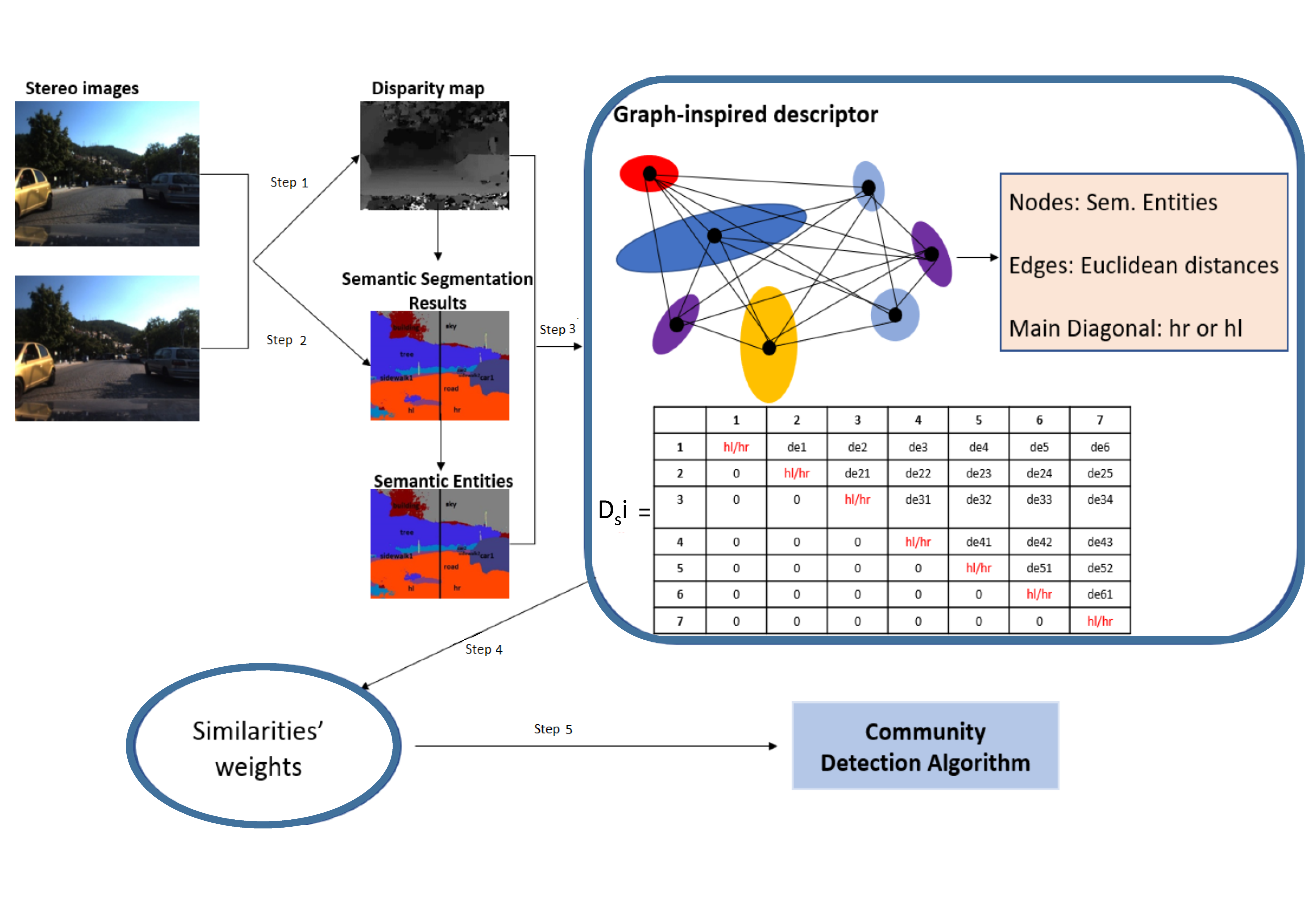
3.1. Generation of Graph-Based Descriptors
| Algorithm 1: Pseudocode algorithm for the creation of the proposed graph-based description vector. |
1 Input: A: l or r labels and e: number of entities 2 Output: description vector 3 for
do 4 if ‘l’ then 5 6 else 7 8 end if 9 for do 10 11 12 end for 13 end for 14 // vectorisation of |
3.2. Generation of Semantic Communities
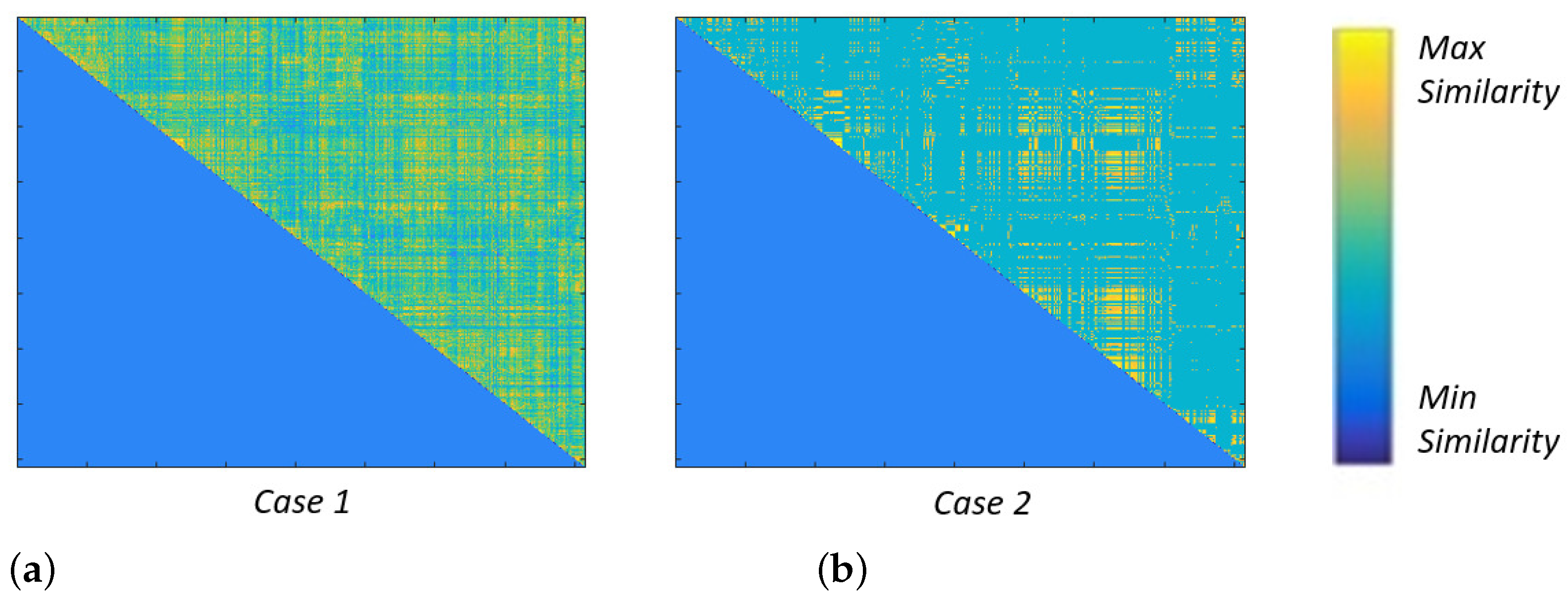
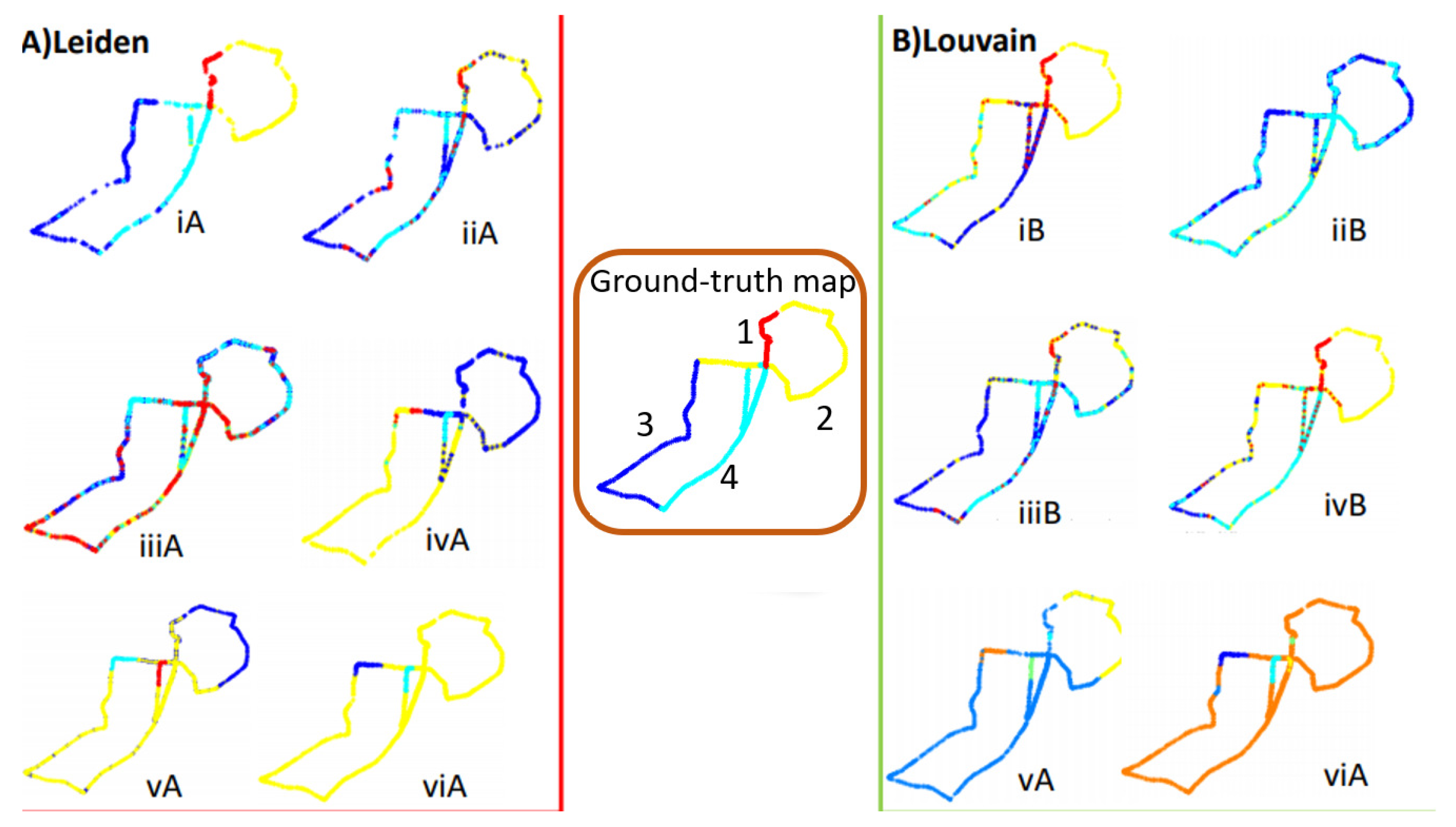
4. Results
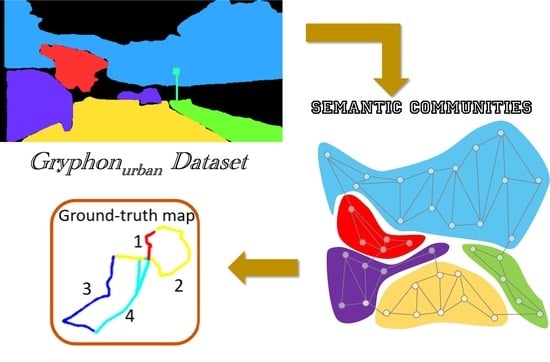
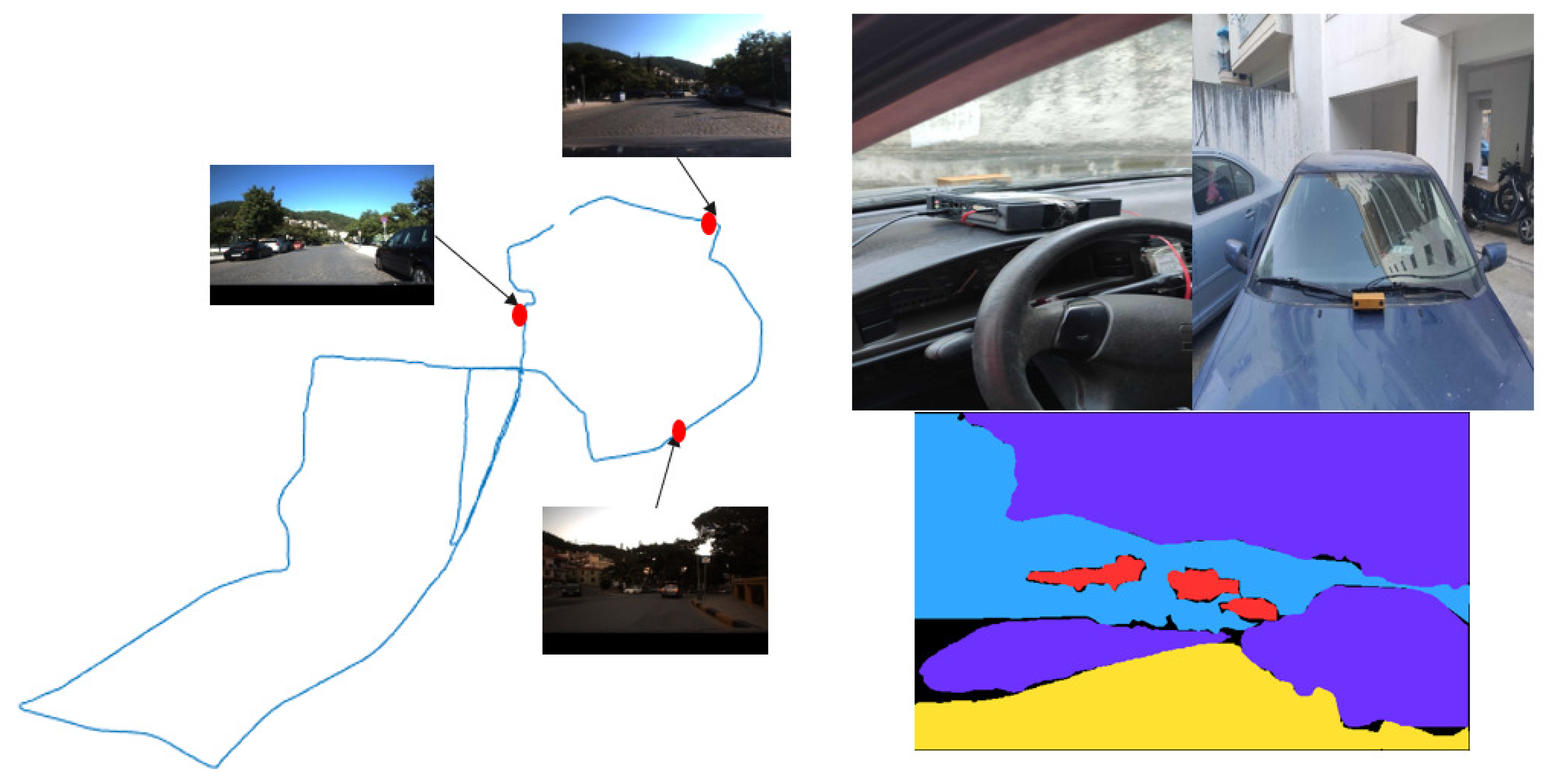
4.1. Dataset Formulation
4.2. Performance Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| mIoU | Mean Intersection of Union |
| SLINK | Single Linkage |
| SAD | Sum of Absolute Differences |
| ROS | Robotic Operation System |
| SBC | Single Board Computer |
| SGM | Semi-Global Matching |
| LD | Census Transform Histogram |
| OLTSM | Topological Semantic Map |
| BoW | Bag-of-Words |
| LaCDA | Louvain Community Detection Algorithm |
| LeCDA | Leiden Community Detection Algorithm |
References
- Balaska, V.; Bampis, L.; Katsavounis, S.; Gasteratos, A. Generating Graph-Inspired Descriptors by Merging Ground-Level and Satellite Data for Robot Localization. Cybern. Syst. 2022, 1–19. [Google Scholar] [CrossRef]
- Balaska, V.; Bampis, L.; Gasteratos, A. Self-localization based on terrestrial and satellite semantics. Eng. Appl. Artif. Intell. 2022, 111, 104824. [Google Scholar] [CrossRef]
- Konstantinidis, F.K.; Balaska, V.; Symeonidis, S.; Mouroutsos, S.G.; Gasteratos, A. AROWA: An autonomous robot framework for Warehouse 4.0 health and safety inspection operations. In Proceedings of the 2022 30th Mediterranean Conference on Control and Automation (MED), Vouliagmeni, Greece, 28 June–1 July 2022; pp. 494–499. [Google Scholar]
- Balaska, V.; Bampis, L.; Kansizoglou, I.; Gasteratos, A. Enhancing satellite semantic maps with ground-level imagery. Robot. Auton. Syst. 2021, 139, 103760. [Google Scholar] [CrossRef]
- Tas, M.O.; Yavuz, H.S.; Yazici, A. High-definition map update framework for intelligent autonomous transfer vehicles. J. Exp. Theor. Artif. Intell. 2021, 33, 847–865. [Google Scholar] [CrossRef]
- Pantazi, X.E.; Tamouridou, A.A.; Alexandridis, T.; Lagopodi, A.L.; Kashefi, J.; Moshou, D. Evaluation of hierarchical self-organising maps for weed mapping using UAS multispectral imagery. Comput. Electron. Agric. 2017, 139, 224–230. [Google Scholar] [CrossRef]
- Karaoguz, H.; Bozma, H.I. Reliable topological place detection in bubble space. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 697–702. [Google Scholar]
- Papapetros, I.T.; Balaska, V.; Gasteratos, A. Multi-layer map: Augmenting semantic visual memory. In Proceedings of the 2020 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 1–4 September 2020; pp. 1206–1212. [Google Scholar]
- Balaska, V.; Bampis, L.; Boudourides, M.; Gasteratos, A. Unsupervised semantic clustering and localization for mobile robotics tasks. Robot. Auton. Syst. 2020, 131, 103567. [Google Scholar] [CrossRef]
- Lu, C.; van de Molengraft, M.J.G.; Dubbelman, G. Monocular semantic occupancy grid mapping with convolutional variational encoder–decoder networks. IEEE Robot. Autom. Lett. 2019, 4, 445–452. [Google Scholar] [CrossRef] [Green Version]
- Roddick, T.; Cipolla, R. Predicting semantic map representations from images using pyramid occupancy networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11138–11147. [Google Scholar]
- Hiller, M.; Qiu, C.; Particke, F.; Hofmann, C.; Thielecke, J. Learning topometric semantic maps from occupancy grids. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4190–4197. [Google Scholar]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Trenčanová, B.; Proença, V.; Bernardino, A. Development of Semantic Maps of Vegetation Cover from UAV Images to Support Planning and Management in Fine-Grained Fire-Prone Landscapes. Remote Sens. 2022, 14, 1262. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, Y.; Liu, Y.; Lv, G. Semantic loop closure detection based on graph matching in multi-objects scenes. J. Vis. Commun. Image Represent. 2021, 76, 103072. [Google Scholar] [CrossRef]
- Guo, X.; Hu, J.; Chen, J.; Deng, F.; Lam, T.L. Semantic histogram based graph matching for real-time multi-robot global localization in large scale environment. IEEE Robot. Autom. Lett. 2021, 6, 8349–8356. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, C.; Tang, F.; Jiang, H.; Wu, Y.; Liu, Y. Lightweight Object-level Topological Semantic Mapping and Long-term Global Localization based on Graph Matching. arXiv 2022, arXiv:2201.05977. [Google Scholar]
- Sengupta, S.; Sturgess, P.; Ladickỳ, L.; Torr, P.H. Automatic dense visual semantic mapping from street-level imagery. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 857–862. [Google Scholar]
- Ranganathan, A. PLISS: Labeling places using online changepoint detection. Auton. Robots 2012, 32, 351–368. [Google Scholar] [CrossRef]
- Kostavelis, I.; Charalampous, K.; Gasteratos, A.; Tsotsos, J.K. Robot navigation via spatial and temporal coherent semantic maps. Eng. Appl. Artif. Intell. 2016, 48, 173–187. [Google Scholar] [CrossRef]
- Liu, M.; Colas, F.; Siegwart, R. Regional topological segmentation based on mutual information graphs. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3269–3274. [Google Scholar]
- Cowley, A.; Taylor, C.J.; Southall, B. Rapid multi-robot exploration with topometric maps. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1044–1049. [Google Scholar]
- Erkent, Ö.; Karaoguz, H.; Bozma, H.I. Hierarchically self-organizing visual place memory. Adv. Robot. 2017, 31, 865–879. [Google Scholar] [CrossRef]
- Sibson, R. SLINK: An Optimally Efficient Algorithm For The Single-Link Cluster Method. Comput. J. 1973, 16, 30–34. [Google Scholar] [CrossRef]
- Guillaume, H.; Dubois, M.; Emmanuelle, F.; Tarroux, P. Temporal bag-of-words-a generative model for visual place recognition using temporal integration. In Proceedings of the VISAPP—International Conference on Computer Vision Theory and Applications, Algarve, Portugal, 5–7 March 2011. [Google Scholar]
- Demidova, E.; Dsouza, A.; Gottschalk, S.; Tempelmeier, N.; Yu, R. Creating knowledge graphs for geographic data on the web. ACM SIGWEB Newsl. 2022, 1–8. [Google Scholar] [CrossRef]
- Tempelmeier, N.; Feuerhake, U.; Wage, O.; Demidova, E. Mining Topological Dependencies of Recurrent Congestion in Road Networks. ISPRS Int. J. Geo-Inf. 2021, 10, 248. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Vakalopoulou, M.; Paragios, N.; Karantzalos, K. Stacked Encoder-Decoders for Accurate Semantic Segmentation of Very High Resolution Satellite Datasets. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6927–6930. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recogn. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Liu, T.; Moore, A.W.; Yang, K.; Gray, A.G. An investigation of practical approximate nearest neighbor algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 1 December 2004; pp. 825–832. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Roy, A.; Todorovic, S. Monocular depth estimation using neural regression forest. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5506–5514. [Google Scholar]
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 807–814. [Google Scholar]
- Bampis, L.; Amanatiadis, A.; Gasteratos, A. Fast loop-closure detection using visual-word-vectors from image sequences. Int. J. Robot. Res. 2018, 37, 62–82. [Google Scholar] [CrossRef]
- Traag, V.A.; Waltman, L.; van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balaska, V.; Bampis, L.; Gasteratos, A. Graph-based semantic segmentation. In International Conference on Robotics in Alpe-Adria Danube Region; Springer: Cham, Switzerland, 2018; pp. 572–579. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Reichardt, J.; Bornholdt, S. When are networks truly modular? Phys. D Nonlinear Phenom. 2006, 224, 20–26. [Google Scholar] [CrossRef] [Green Version]
- Kruger, L.E.; Wohler, C.; Wurz-Wessel, A.; Stein, F. In-factory calibration of multiocular camera systems. In Proceedings of the Optical Metrology in Production Engineering, Strasbourg, France, 27–30 April 2004; Volume 5457, pp. 126–137. [Google Scholar]
- Patidar, A.K.; Agrawal, J.; Mishra, N. Analysis of different similarity measure functions and their impacts on shared nearest neighbor clustering approach. Int. J. Comput. Appl. 2012, 40, 1–5. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Lowe, G. Sift-the scale invariant feature transform. Int. J. 2004, 2, 2. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LeCDA | LaCDA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Semantic Areas | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |
| Case 1 | L2-score | 25% | 67% | 60% | 51% | 34% | 56% | 62% | 49% |
| Jaccard | 20% | 50% | 30% | 51% | 23% | 15% | 40% | - | |
| SAD | 31% | 75% | 62% | 32% | 22% | 79% | 58% | 45% | |
| Case 2 | L2-score | 55% | 100% | 92% | 71% | 42% | 60% | 74% | 56% |
| Jaccard | 20% | 50% | 30% | 51% | 23% | 15% | 40% | - | |
| SAD | 49% | 88% | 76% | 32% | 31% | 85% | 67% | 48% | |
| Case 3 | L2-score | 20% | 59% | 60% | 50% | 34% | 56% | 62% | 45% |
| Jaccard | 20% | 50% | 26% | 51% | 23% | 15% | 37% | - | |
| SAD | 27% | 73% | 60% | 30% | 18% | 75% | 55% | 39% | |
| Case 4 | L2-score | 22% | 65% | 60% | 51% | 30% | 50% | 60% | 49% |
| Jaccard | 18% | 47% | 28% | 51% | 23% | 15% | 40% | - | |
| SAD | 30% | 75% | 60% | 31% | 20% | 77% | 58% | 45% | |
| LeCDA | LaCDA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Semantic Areas | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |
| Ours (Case 2) | L2-score | 55% | 100% | 92% | 71% | 42% | 60% | 74% | 56% |
| Jaccard | 20% | 50% | 30% | 51% | 23% | 15% | 40% | - | |
| SAD | 49% | 88% | 76% | 32% | 31% | 85% | 67% | 48% | |
| SURF | 20% | - | 20% | 0% | 22% | 0% | 15% | 0% | |
| SIFT | 49% | 20% | 32% | 20% | 41% | 10% | 36% | 18% | |
| ORB | 16% | 0% | 22% | 0% | 19% | 0% | 15% | 0% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balaska, V.; Theodoridis, E.; Papapetros, I.-T.; Tsompanoglou, C.; Bampis, L.; Gasteratos, A. Semantic Communities from Graph-Inspired Visual Representations of Cityscapes. Automation 2023, 4, 110-122. https://doi.org/10.3390/automation4010008
Balaska V, Theodoridis E, Papapetros I-T, Tsompanoglou C, Bampis L, Gasteratos A. Semantic Communities from Graph-Inspired Visual Representations of Cityscapes. Automation. 2023; 4(1):110-122. https://doi.org/10.3390/automation4010008
Chicago/Turabian StyleBalaska, Vasiliki, Eudokimos Theodoridis, Ioannis-Tsampikos Papapetros, Christoforos Tsompanoglou, Loukas Bampis, and Antonios Gasteratos. 2023. "Semantic Communities from Graph-Inspired Visual Representations of Cityscapes" Automation 4, no. 1: 110-122. https://doi.org/10.3390/automation4010008