
DRLLA: Deep Reinforcement Learning for Link Adaptation

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Related Work
3. Background
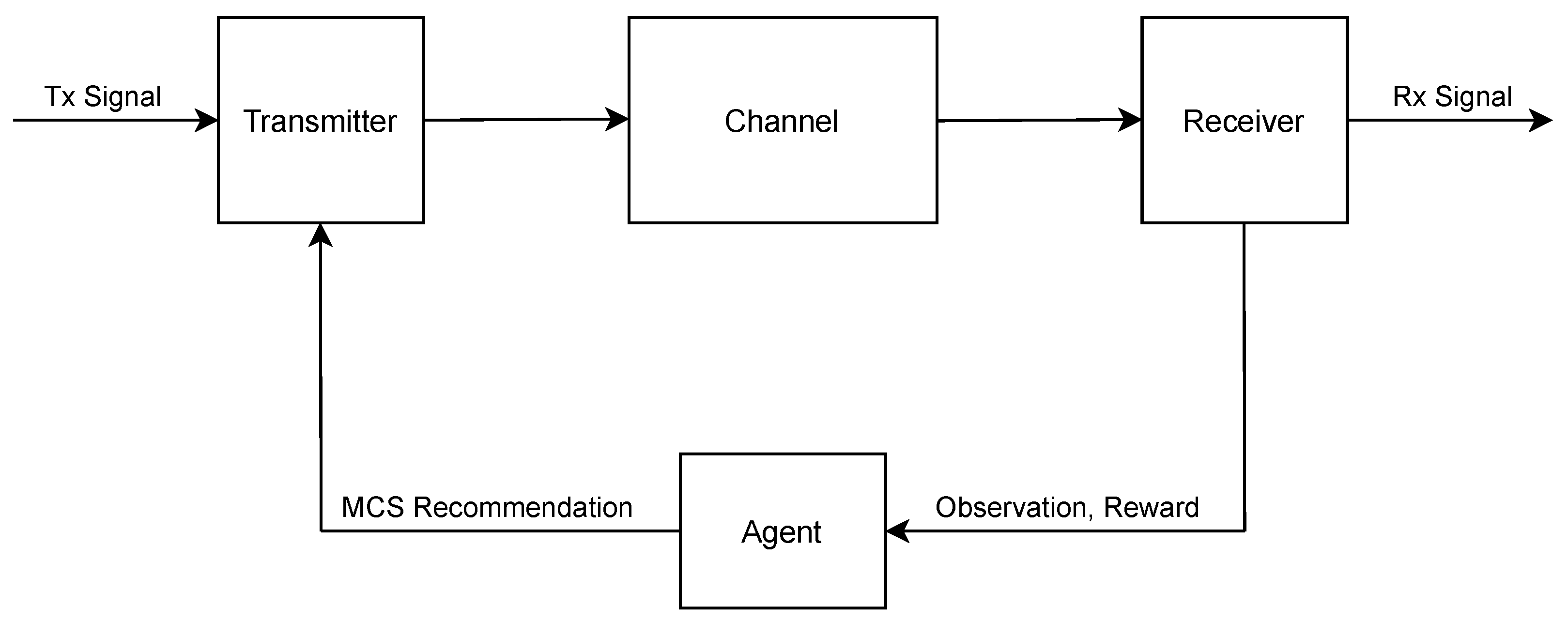
3.1. Link Adaptation
3.2. Reinforcement Learning
- The agent receives an observable state S, provided by the environment.
- The agent executes an action A, based on the received observation.
- The environment provides a reward R, indicating how favorable the performed action was.
- The agent uses the reward R to tune its action selection process by maximizing the cumulative return.
3.3. Tools
3.3.1. GNU Radio
3.3.2. OpenAI Gym
3.3.3. GrGym
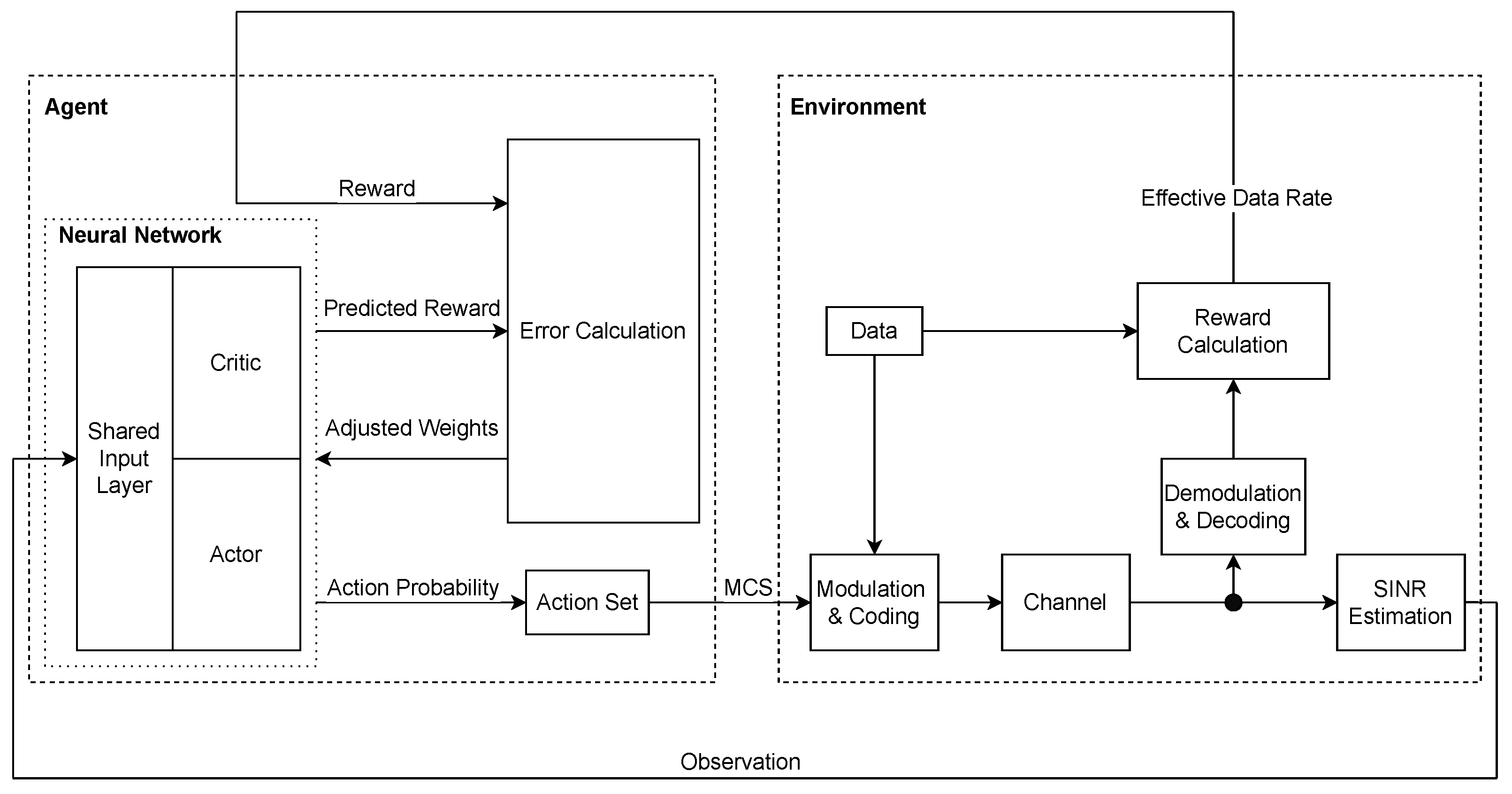
4. Method
4.1. RL Algorithms
4.1.1. Natural Actor-Critic (NAC)
4.1.2. Proximal Policy Optimization (PPO)
4.2. Channels
4.2.1. Additive White Gaussian Noise (AWGN)
4.2.2. Non-Line-of-Sight (NLOS)
4.2.3. Real World
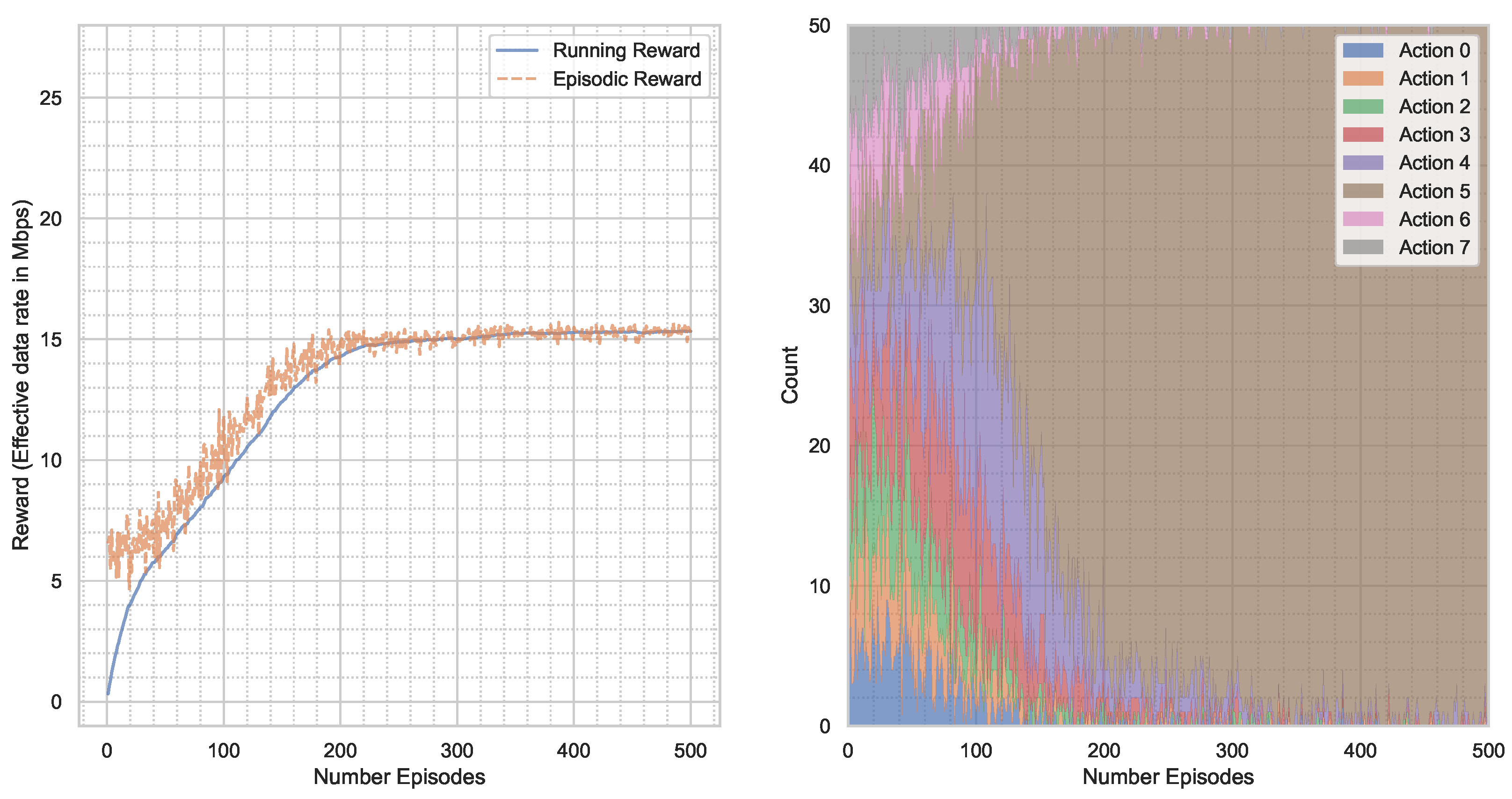
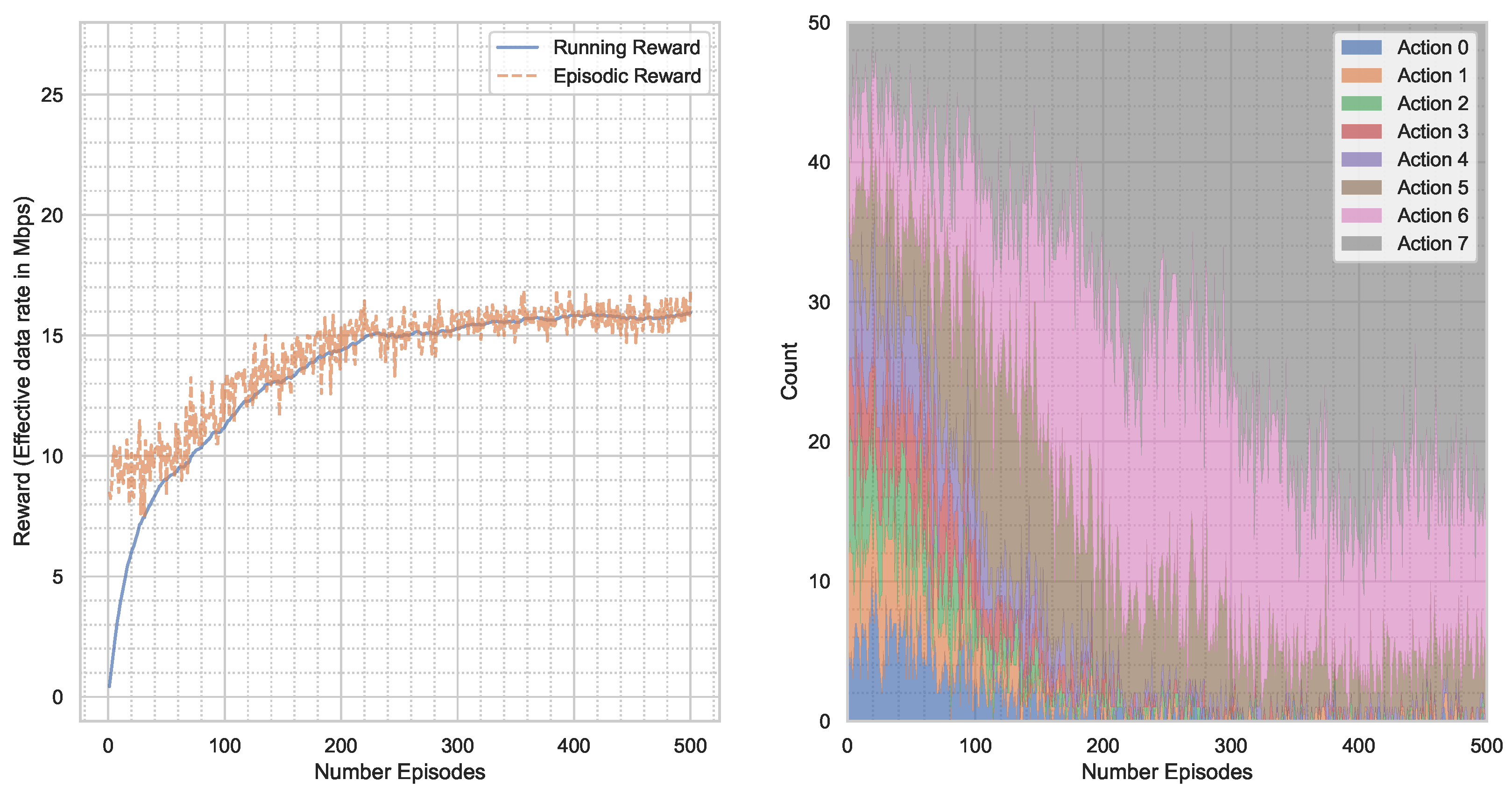
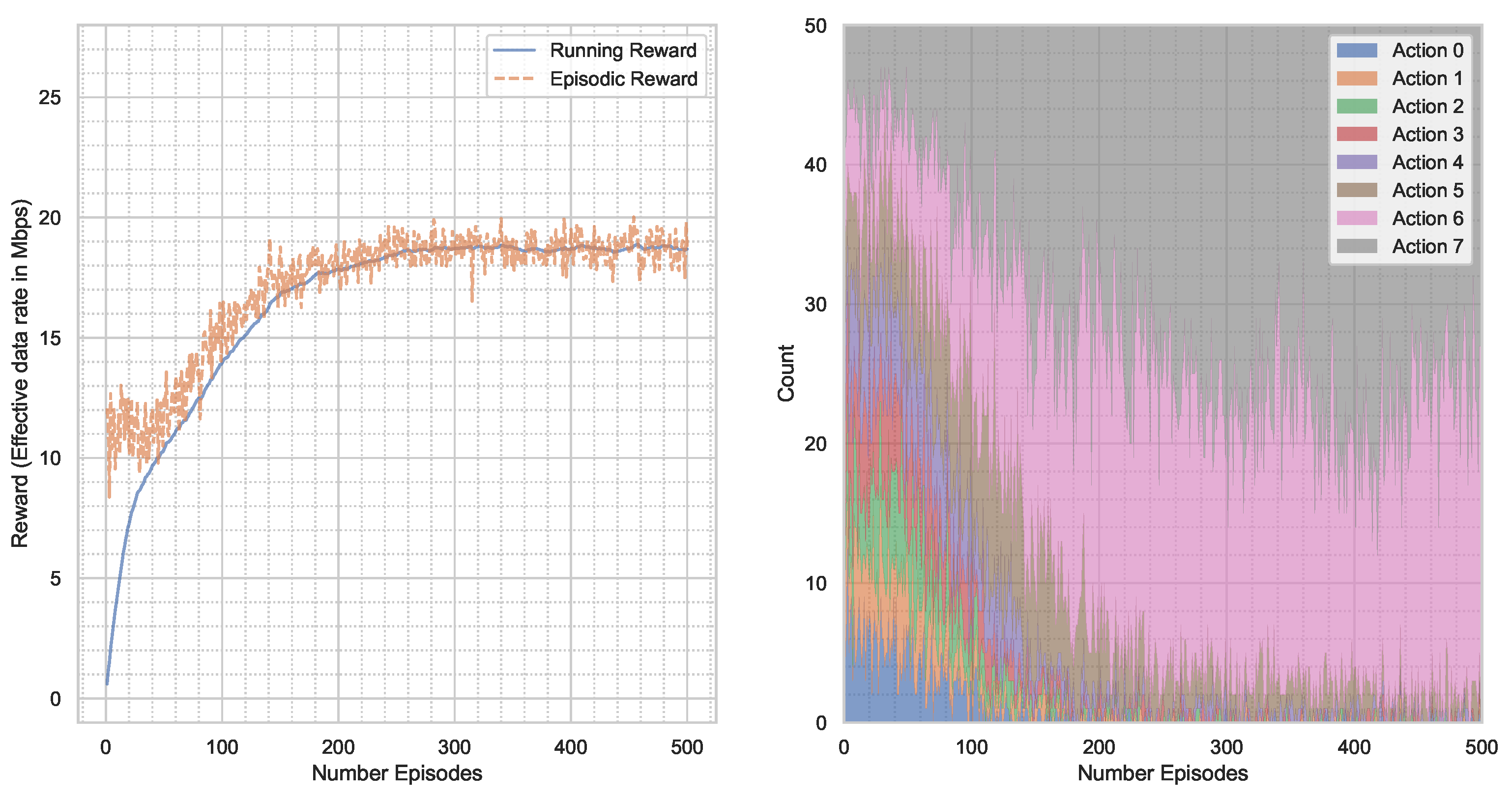
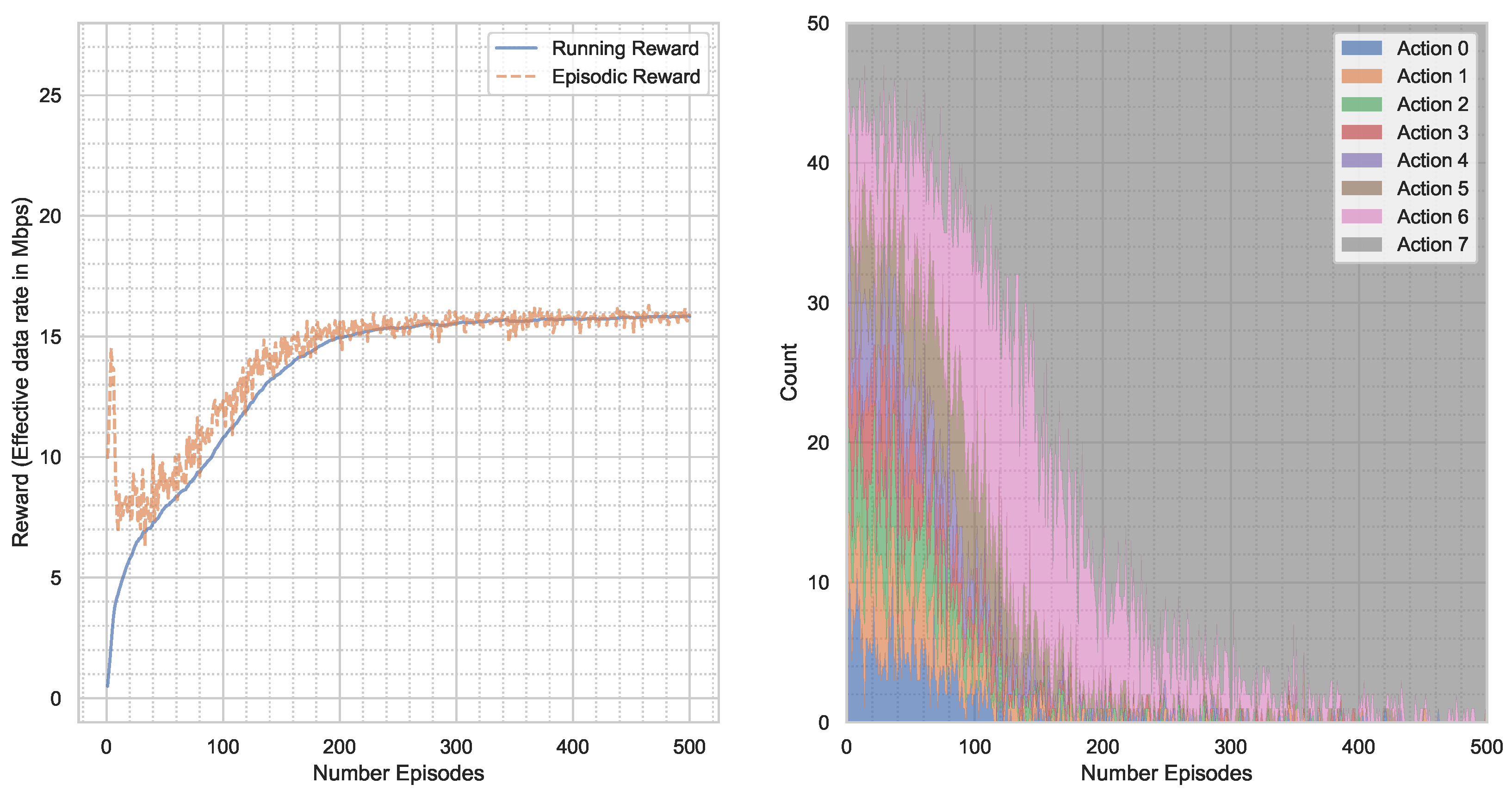
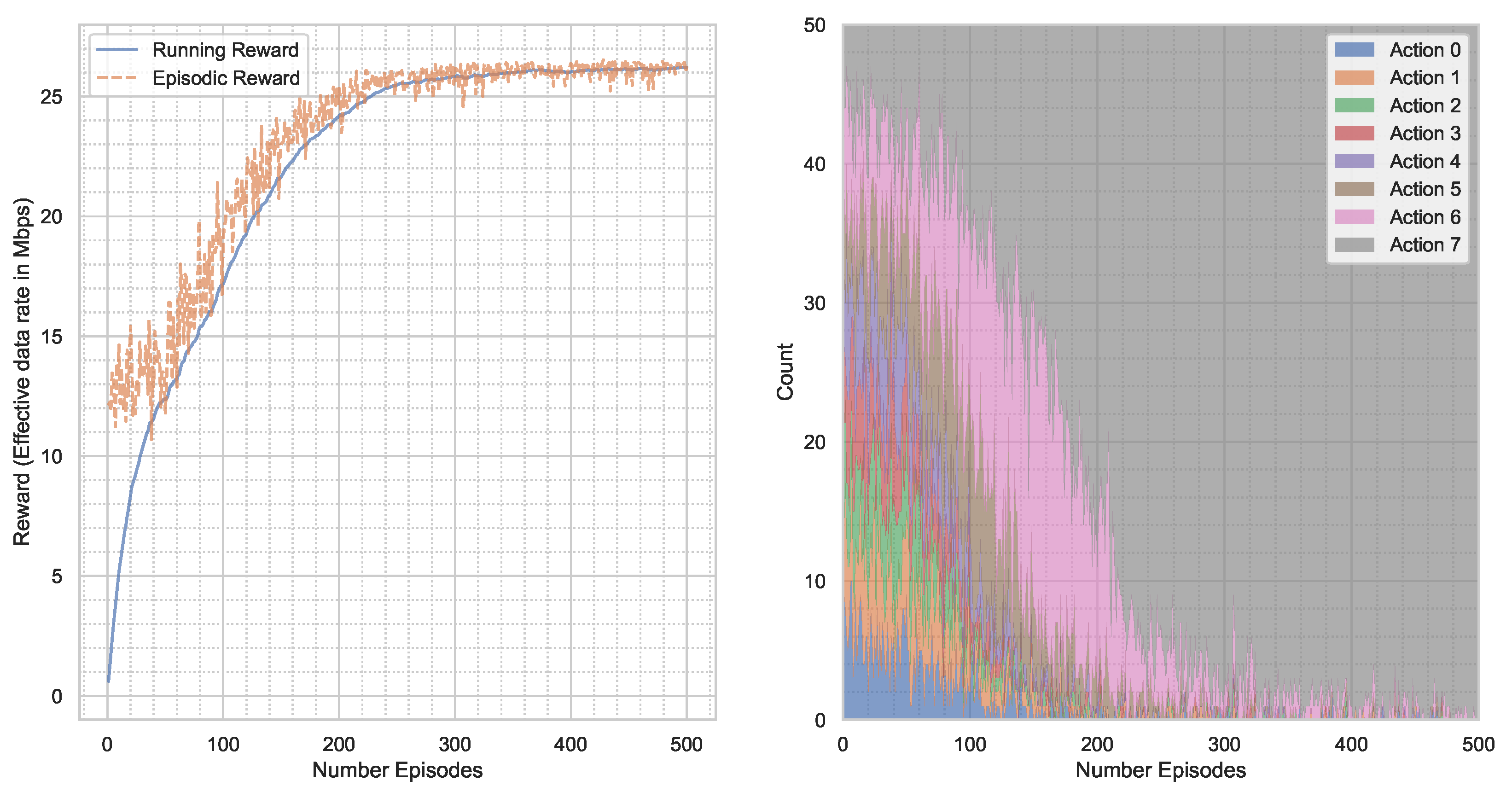
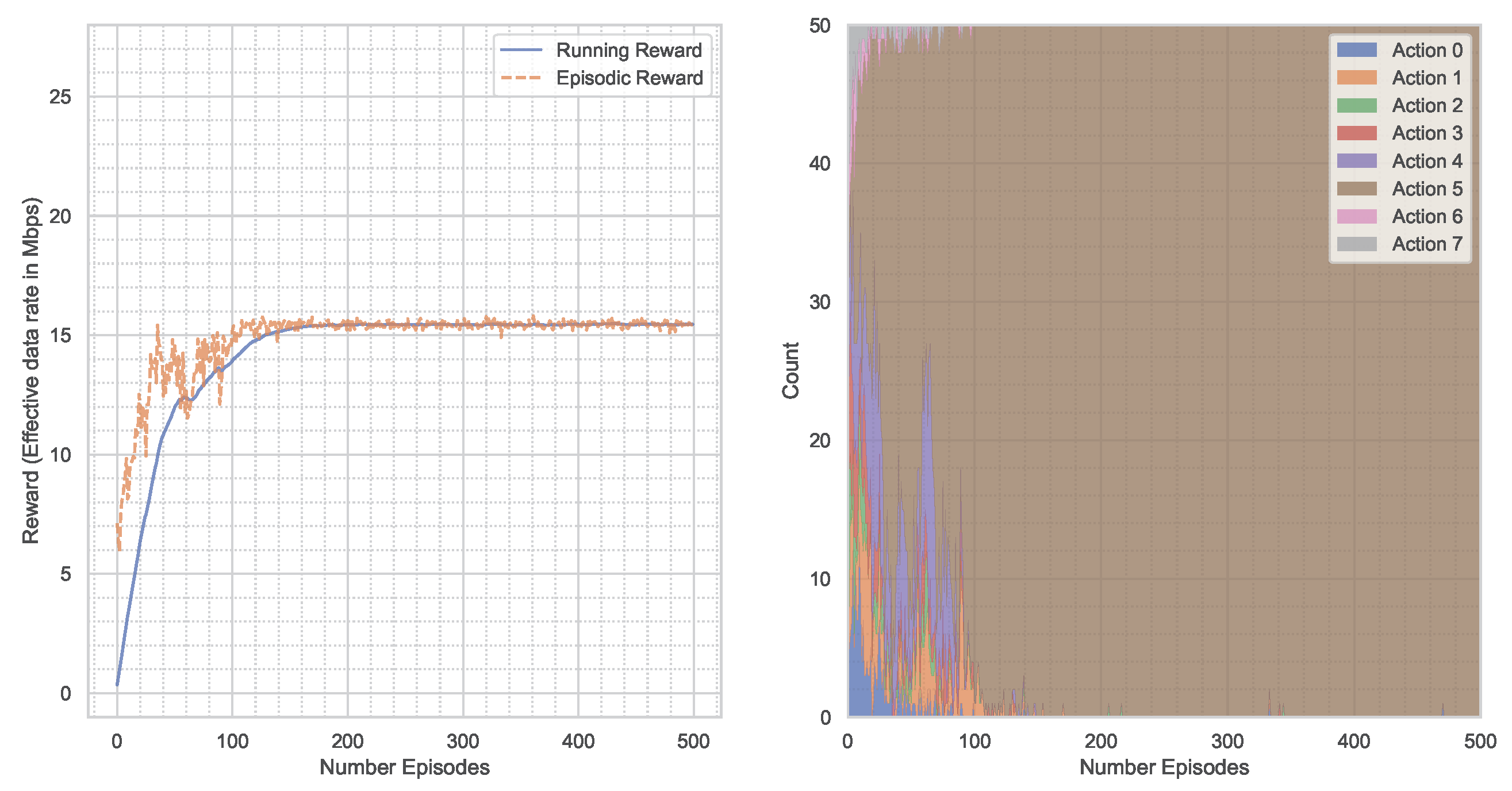
5. Results
5.1. AWGN Channel
5.2. NLOS Channel
5.3. Real-World Channel
5.4. PPO-Algorithm
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AC | Actor Critic. |
| AWGN | Additive White Gaussian Noise. |
| CBR | Coded Bit Rate. |
| CCT | CQI Correction Term. |
| CDR | Coded Data Rate. |
| CQI | Channel Quality Indicator. |
| CR | Code Rate. |
| CRC | Cyclic Redundancy Check. |
| DRL | Deep Reinforcement Learning. |
| DRLLA | Deep Reinforcement Learning for Link Adaptation. |
| GR | GNU Radio. |
| HMM | Hidden Markow Model. |
| LA | Link Adaptation. |
| LTS | Latent Thompson Sampling. |
| MCS | Modulation and Coding Scheme. |
| MIMO | Multiple Input and Multiple Output. |
| mMIMO | Massive MIMO. |
| ML | Machine Learning. |
| NAC | Natural Actor Critic. |
| NLOS | Non-Line of Sight. |
| NN | Neural Network. |
| NR | New Radio. |
| OFDM | Orthogonal Frequency-Division Multiplexing. |
| OLLA | Outer Loop Link Adaptation. |
| Probability Density Function. | |
| PER | Packet Error Rate. |
| PPO | Proximal Policy Optimization. |
| PSR | Packet Success Rate. |
| RL | Reinforcement Learning. |
| RSSI | Received Signal Strength Indicator. |
| SC | Sub carrier. |
| SINR | Signal to Interference plus Noise Ratio. |
| SISO | Single Input and Single Output. |
| SNR | Signal to Noise Ratio. |
| TROLL | Training of Outer Loop Link Adaptation. |
| UE | User Equipment. |
References
- Saxena, V.; Tullberg, H.; Jaldén, J. Reinforcement Learning for Efficient and Tuning-Free Link Adaptation. IEEE Trans. Wirel. Commun. 2022, 21, 768–780. [Google Scholar] [CrossRef]
- Nanda, S.; Rege, K.M. Frame error rates for convolutional codes on fading channels and the concept of effective Eb/N0. IEEE Trans. Veh. Technol. 1998, 47, 1245–1250. [Google Scholar] [CrossRef]
- Nakamura, M.; Awad, Y.; Vadgama, S. Adaptive control of link adaptation for high speed downlink packet access (HSDPA) in W-CDMA. In Proceedings of the 5th International Symposium on Wireless Personal Multimedia Communications, Honolulu, HI, USA, 27–30 October 2002; Volume 2, pp. 382–386. [Google Scholar]
- Morales, D.; Sanchez, J.J.; Gomez, G.; Aguayo-Torres, M.; Entrambasaguas, J. Imperfect adaptation in next generation OFDMA cellular systems. J. Internet Eng. 2009, Volume 3, 202–209. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Blossom, E. GNU Radio: Tools for Exploring the Radio Frequency Spectrum. Linux J. 2004, 122, 1075–3583. [Google Scholar]
- Park, C.S.; Park, S. Implementation of a Fast Link Rate Adaptation Algorithm for WLAN Systems. Electronics 2021, 10, 91. [Google Scholar] [CrossRef]
- Shariatmadari, H.; Li, Z.; Uusitalo, M.; Iraji, S.; Jäntti, R. Link Adaptation Design for Ultra-Reliable Communications. In Proceedings of the IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; Volume 201, pp. 1–5. [Google Scholar]
- Mandelli, S.; Weber, A.; Baracca, P.; Mohammadi, J. TROLL: Training of Outer Loop Link Adaptation in Wireless Networks via Back-propagation. In Proceedings of the WSA 2021, French Riviera, France, 10–12 November 2021. [Google Scholar]
- Ramezani, M.; Mohammadi, J.; Mandelli, S.; Weber, A. CQI Prediction via Hidden Markov Model for Link Adaptation in Ultra Reliable Low Latency Communications. In Proceedings of the WSA 2021, French Riviera, France, 10–12 November 2021. [Google Scholar]
- Zubow, A.; Roesler, S.; Gawlowicz, P.; Dressler, F. GrGym: When GNU Radio goes to (AI) Gym. In Proceedings of the Hotmobile, Austin, TX, USA, 24–26 February 2021; pp. 8–14. [Google Scholar]
- Jiang, D.; Delgrossi, L. IEEE 802.11p: Towards an International Standard for Wireless Access in Vehicular Environments. In Proceedings of the IEEE Vehicular Technology Conference, Singapore, 11–14 May 2008; pp. 2036–2040. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Sutton, R.; Ghavamzadeh, M.; Lee, M. Natural Actor-Critic Algorithms. Automatica 2008, 71, 1180–1190. [Google Scholar] [CrossRef] [Green Version]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv 2018, arXiv:1506.02438. [Google Scholar]
- Clarke, H. A statistical theory of mobile-radio reception. Bell Syst. Tech. J. 1968, 47, 957–1000. [Google Scholar] [CrossRef]
- Study on evaluation methodology of new Vehicle-to-Everything (V2X) use cases for LTE and NR. In ETSI: 3GPP TR 37.885; 5GAA Automotive Association: Munich Germany, 2018; Volume 15.
- Phan-Huy, D.; Wesemann, S.; Bjoersell, J.; Sternad, M. Adaptive Massive MIMO for fast moving connected vehicles: It will work with Predictor Antennas! In Proceedings of the WSA 2018, Bochum, Germany, 14–16 March 2018; pp. 1–8. [Google Scholar]
- Hellings, C.; Dehmani, A.; Wesemann, S.; Koller, M.; Utschick, W. Evaluation of Neural-Network-Based Channel Estimators Using Measurement Data. In Proceedings of the WSA 2019, Vienna, Austria, 24–26 April 2019. [Google Scholar]
- Arena, F.; Pau, G.; Severino, A. A Review on IEEE 802.11p for Intelligent Transportation Systems. J. Sens. Actuator Netw. 2020, 9, 22. [Google Scholar] [CrossRef]
- Fan, A.; Lewis, M.; Dauphin, Y. Hierarchical Neural Story Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 889–898. [Google Scholar]
- Holtzman, A.; Buys, J.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. arXiv 2019, arXiv:1904.09751. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MCS | CDR in Mbps | Modulation | CR | CBR in Mbps |
|---|---|---|---|---|
| 0 | 3 | BPSK | 1/2 | 6 |
| 1 | 4.5 | BPSK | 3/4 | 6 |
| 2 | 6 | QPSK | 1/2 | 12 |
| 3 | 9 | QPSK | 3/4 | 12 |
| 4 | 12 | 16QAM | 1/2 | 24 |
| 5 | 18 | 16QAM | 3/4 | 24 |
| 6 | 24 | 64QAM | 2/3 | 36 |
| 7 | 27 | 64QAM | 3/4 | 36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geiser, F.; Wessel, D.; Hummert, M.; Weber, A.; Wübben, D.; Dekorsy, A.; Viseras, A. DRLLA: Deep Reinforcement Learning for Link Adaptation. Telecom 2022, 3, 692-705. https://doi.org/10.3390/telecom3040037
Geiser F, Wessel D, Hummert M, Weber A, Wübben D, Dekorsy A, Viseras A. DRLLA: Deep Reinforcement Learning for Link Adaptation. Telecom. 2022; 3(4):692-705. https://doi.org/10.3390/telecom3040037
Chicago/Turabian StyleGeiser, Florian, Daniel Wessel, Matthias Hummert, Andreas Weber, Dirk Wübben, Armin Dekorsy, and Alberto Viseras. 2022. "DRLLA: Deep Reinforcement Learning for Link Adaptation" Telecom 3, no. 4: 692-705. https://doi.org/10.3390/telecom3040037