
Manuscripts Character Recognition Using Machine Learning and Deep Learning


Abstract
:1. Introduction
- We have built our own dataset from Beowulf’s large electronic images by cropping each character manually.
- We have conducted a comparative study about the performance of different Machine Learning models on different sizes of the dataset against our proposed model.
- We assembled a CNN model, which performs very well on manuscript character images recognition (compared to other well-established classifiers), and achieved benchmark accuracy on the MNIST dataset.
2. Related Work
3. Dataset
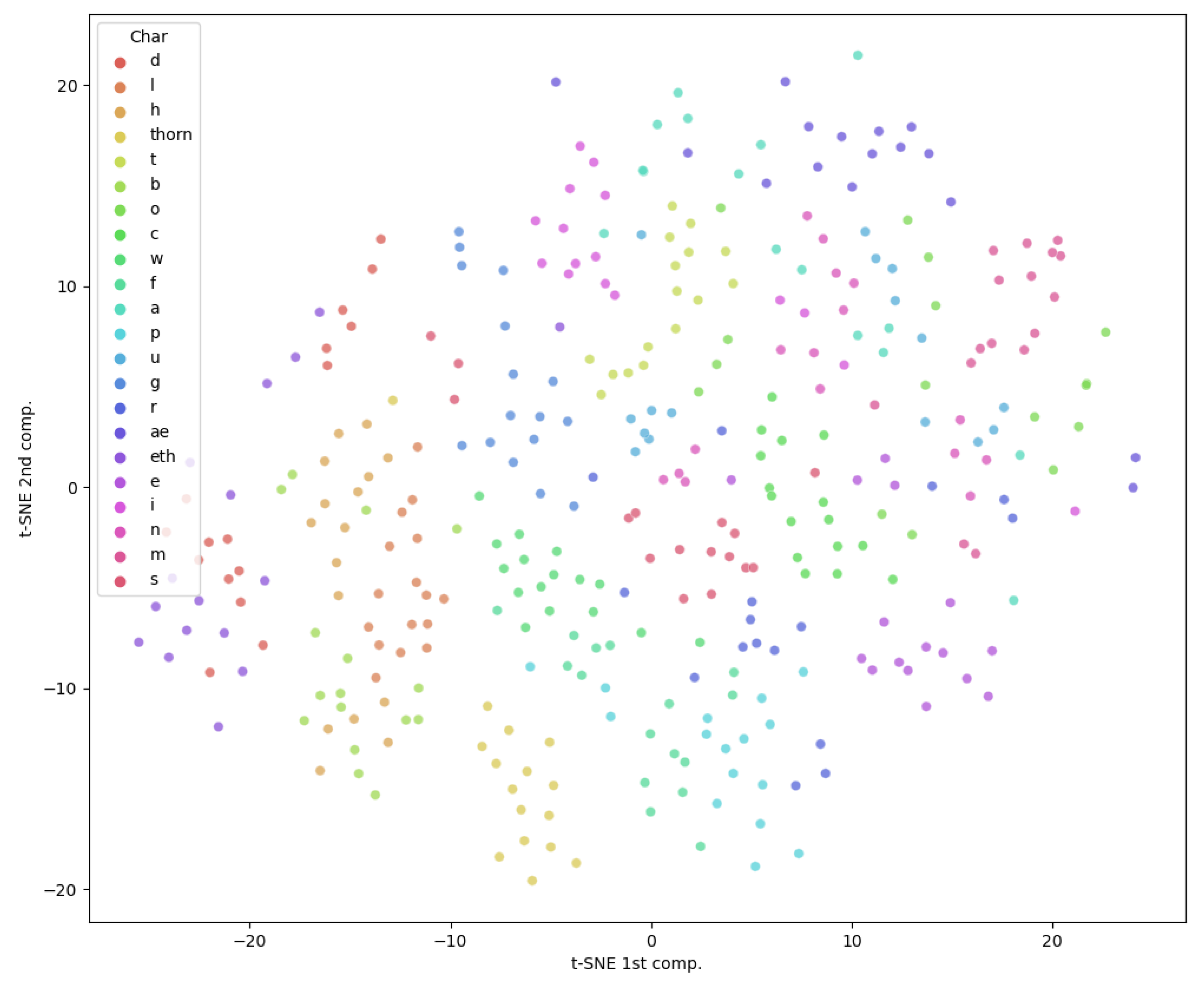
3.1. The Beowulf Manuscript Dataset
3.2. The MNIST Dataset
4. Methodology
4.1. Support Vector Machine
4.2. K-Nearest Neighbor
4.3. Decision Tree
4.4. Random Forest
4.5. XGBoost
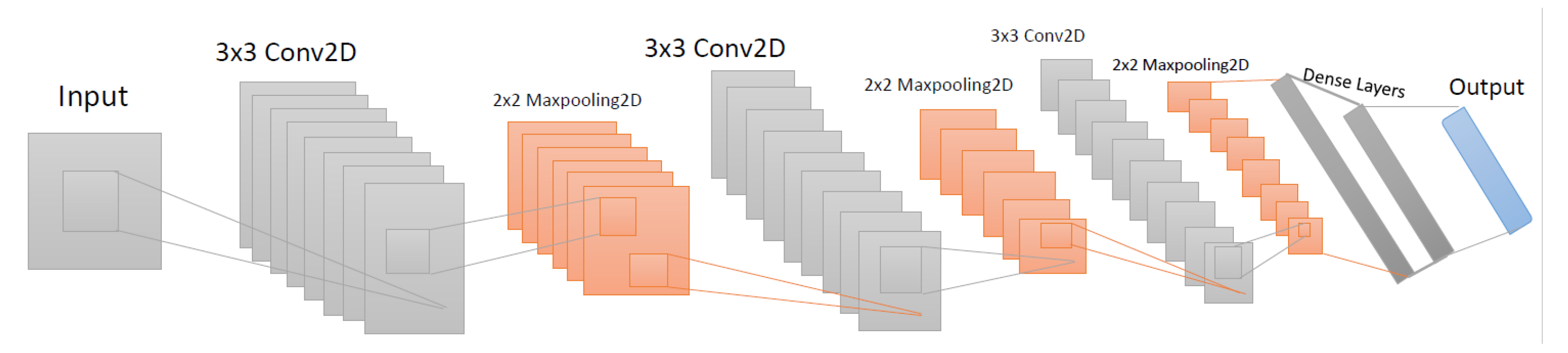
4.6. Proposed Convolutional Neural Network (CNN) Model
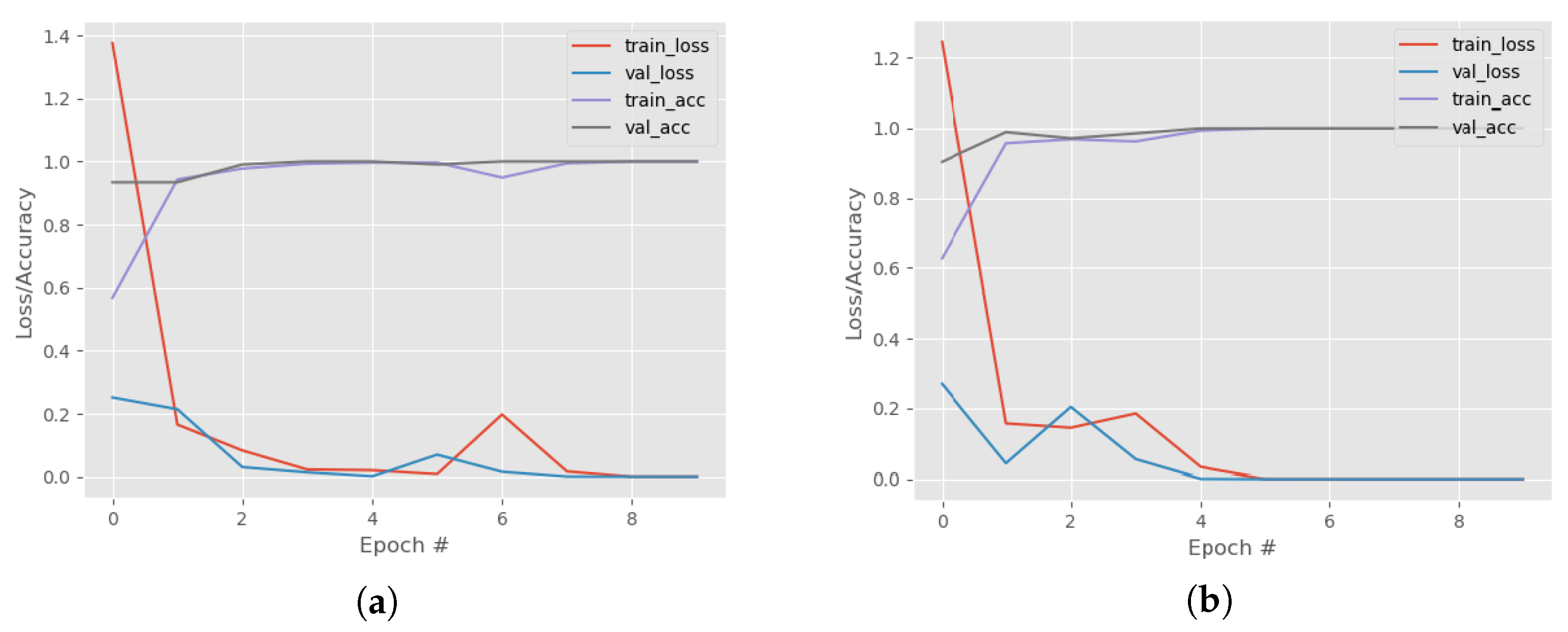
4.7. Model Training and Testing
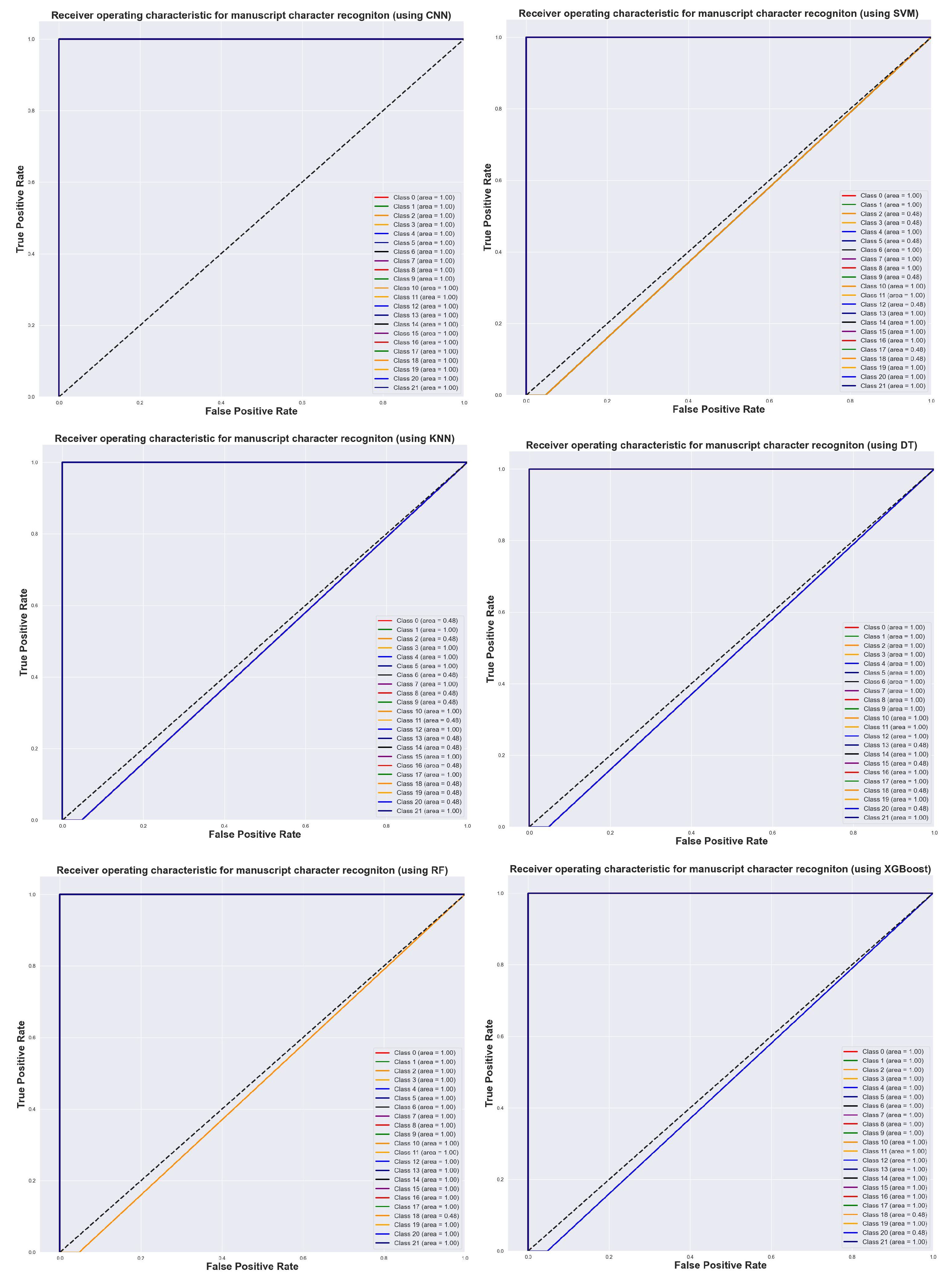
4.8. Model Evaluation
- Recall is another popular evaluation metric for measuring whether a certain model’s performance is consistent or not. The recall is calculated by Equation (3), which quantifies the true positives out of all actual positives.Table 1 shows the recall values for the ML models we used in this study.
- Precision is an evaluation metric that also measures the performance of the model. Precision quantifies true positives computed by a model out of all predicted positives, which is shown by Equation (4).Table 1 shows the precision values for the ML models we use in this study.
- -score is a very important measure to verify the test’s accuracy. The harmonic mean of the recall and precision is considered as -score.
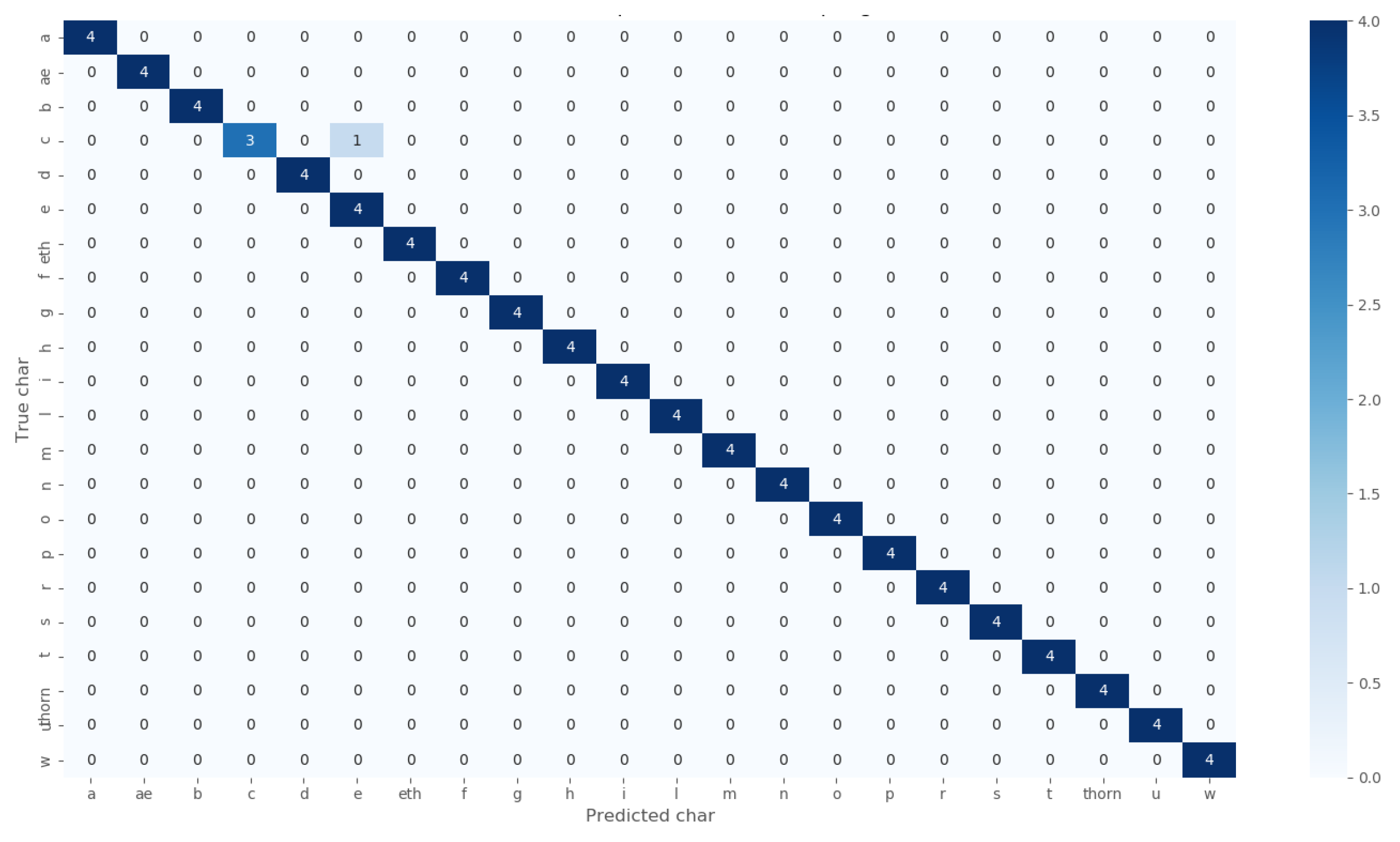
5. Results and Discussion
5.1. Beowulf Manuscript Character Recognition Using ML Models
5.1.1. Resampling 1
5.1.2. Resampling 2
5.1.3. Resampling 3
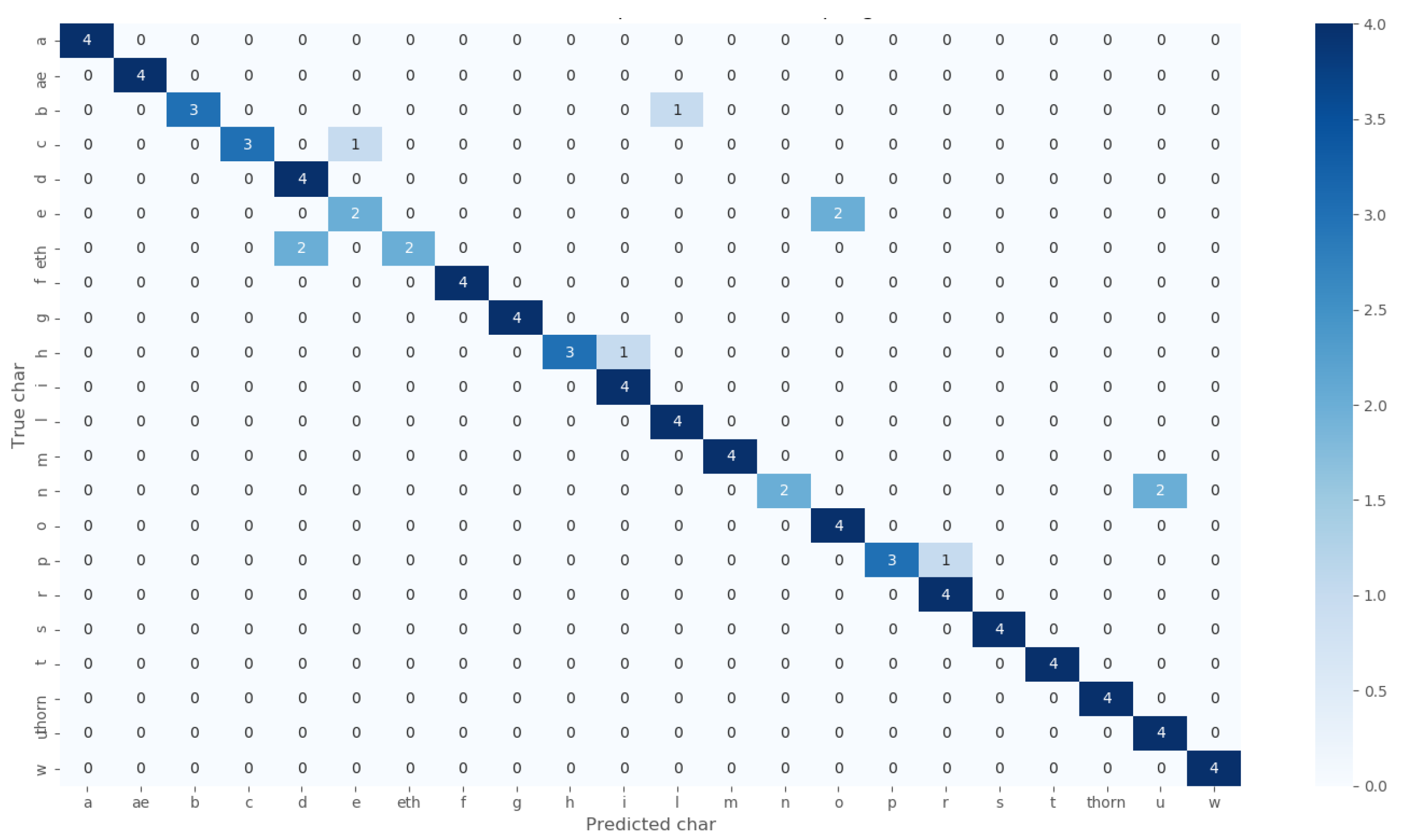
5.2. Beowulf Manuscript Character Recognition Using Proposed CNN Model
5.2.1. Resampling 1
5.2.2. Resampling 2
5.2.3. Resampling 3
5.3. Proposed CNN Model Validation Using MNST Dataset
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saqib, N.; Haque, K.F.; Yanambaka, V.P.; Abdelgawad, A. Convolutional-Neural-Network-Based Handwritten Character Recognition: An Approach with Massive Multisource Data. Algorithms 2022, 15, 129. [Google Scholar] [CrossRef]
- Alom, M.Z.; Sidike, P.; Hasan, M.; Taha, T.M.; Asari, V.K. Handwritten bangla character recognition using the state-of-the-art deep convolutional neural networks. Comput. Intell. Neurosci. 2018, 2018, 6747098. [Google Scholar] [CrossRef] [PubMed]
- Artese, M.T.; Gagliardi, I. Methods, Models and Tools for Improving the Quality of Textual Annotations. Modelling 2022, 3, 224–242. [Google Scholar] [CrossRef]
- Kiernn, K.; Iacob, I.E. Electronic Beowulf, CD-ROM, British Library, 3rd edition, October 2011. Available online: https://ebeowulf.uky.edu/ (accessed on 28 February 2023).
- Library, B. British Library Collection Items. Available online: https://www.bl.uk/collection-items/beowulf(Website) (accessed on 28 February 2023).
- Wikipedia. Wikipedia, Historical Background. Available online: https://en.wikipedia.org/wiki/Beowulf (accessed on 28 February 2023).
- Harrison, J.A.; Sharp, R. The Project Gutenberg eBook of Beowulf. 2003. Available online: https://www.gutenberg.org/files/9700/9700-h/9700-h.htm (accessed on 28 February 2023).
- Sutradhar, S. Old English Character Recognition Using Neural Networks 2018. Electronic Theses and Dissertations, Georgia Southern University. Available online: https://digitalcommons.georgiasouthern.edu/etd/1783/ (accessed on 28 February 2023).
- Islam, M.A. Reduced Dataset Neural Network Model for Manuscript Character Recognition 2020. Electronic Theses and Dissertations, Georgia Southern University. Available online: https://digitalcommons.georgiasouthern.edu/etd/2138/ (accessed on 28 February 2023).
- Kesiman, M.W.A.; Valy, D.; Burie, J.C.; Paulus, E.; Suryani, M.; Hadi, S.; Verleysen, M.; Chhun, S.; Ogier, J.M. Benchmarking of document image analysis tasks for palm leaf manuscripts from southeast asia. J. Imaging 2018, 4, 43. [Google Scholar] [CrossRef]
- Suryani, M.; Paulus, E.; Hadi, S.; Darsa, U.A.; Burie, J.C. The handwritten sundanese palm leaf manuscript dataset from 15th century. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 796–800. [Google Scholar]
- Hidayat, A.A.; Purwandari, K.; Cenggoro, T.W.; Pardamean, B. A convolutional neural network-based ancient sundanese character classifier with data augmentation. Procedia Comput. Sci. 2021, 179, 195–201. [Google Scholar] [CrossRef]
- Sutramiani, N.P.; Suciati, N.; Siahaan, D. MAT-AGCA: Multi Augmentation Technique on small dataset for Balinese character recognition using Convolutional Neural Network. ICT Express 2021, 7, 521–529. [Google Scholar] [CrossRef]
- Sutramiani, N.P.; Suciati, N.; Siahaan, D. Transfer learning on balinese character recognition of lontar manuscript using MobileNet. In Proceedings of the 2020 4th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 10–11 November 2020; pp. 1–5. [Google Scholar]
- Hazra, A.; Choudhary, P.; Inunganbi, S.; Adhikari, M. Bangla-Meitei Mayek scripts handwritten character recognition using convolutional neural network. Appl. Intell. 2021, 51, 2291–2311. [Google Scholar] [CrossRef]
- Hoq, M.N.; Nipa, N.A.; Islam, M.M.; Shahriar, S. Bangla handwritten character recognition: An overview of the state of the art classification algorithm with new dataset. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–6. [Google Scholar]
- Rahman, M.M.; Akhand, M.; Islam, S.; Shill, P.C.; Rahman, M. Bangla handwritten character recognition using convolutional neural network. Int. J. Image Graph. Signal Process. IJIGSP 2015, 7, 42–49. [Google Scholar] [CrossRef]
- Alif, M.A.R.; Ahmed, S.; Hasan, M.A. Isolated Bangla handwritten character recognition with convolutional neural network. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; pp. 1–6. [Google Scholar]
- Chowdhury, R.R.; Hossain, M.S.; ul Islam, R.; Andersson, K.; Hossain, S. Bangla handwritten character recognition using convolutional neural network with data augmentation. In Proceedings of the 2019 Joint 8th International Conference on Informatics, Electronics & Vision (ICIEV) and 2019 3rd International Conference on Imaging, Vision & Pattern Recognition (icIVPR); IEEE: Piscataway, NJ, USA, 2019; pp. 318–323. [Google Scholar]
- Sazal, M.M.R.; Biswas, S.K.; Amin, M.F.; Murase, K. Bangla handwritten character recognition using deep belief network. In Proceedings of the 2013 International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 13–15 February 2014; pp. 1–5. [Google Scholar]
- Nongmeikapam, K.; Wahengbam, K.; Meetei, O.N.; Tuithung, T. Handwritten Manipuri Meetei-Mayek classification using convolutional neural network. ACM Trans. Asian Low Resour. Lang. Inf. Process. TALLIP 2019, 18, 1–23. [Google Scholar] [CrossRef]
- Devi, S.G.; Vairavasundaram, S.; Teekaraman, Y.; Kuppusamy, R.; Radhakrishnan, A. A Deep Learning Approach for Recognizing the Cursive Tamil Characters in Palm Leaf Manuscripts. Comput. Intell. Neurosci. 2022. [Google Scholar] [CrossRef]
- Sudarsan, D.; Joseph, S. A novel approach for handwriting recognition in malayalam manuscripts using contour detection and convolutional neural nets. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 1818–1824. [Google Scholar]
- Alrehali, B.; Alsaedi, N.; Alahmadi, H.; Abid, N. Historical Arabic manuscripts text recognition using convolutional neural network. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 4–5 March 2020; pp. 37–42. [Google Scholar]
- Singh, A.K.; Kadhiwala, B.; Patel, R. Hand-written Hindi Character Recognition-A Comprehensive Review. In Proceedings of the 2021 2nd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 1–3 October 2021; pp. 1–5. [Google Scholar]
- Wibowo, M.A.; Soleh, M.; Pradani, W.; Hidayanto, A.N.; Arymurthy, A.M. Handwritten javanese character recognition using descriminative deep learning technique. In Proceedings of the 2017 2nd International Conferences on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 1–2 November 2017; pp. 325–330. [Google Scholar]
- Meier, U.; Ciresan, D.C.; Gambardella, L.M.; Schmidhuber, J. Better digit recognition with a committee of simple neural nets. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1250–1254. [Google Scholar]
- Adak, C.; Chaudhuri, B.B.; Blumenstein, M. Offline cursive Bengali word recognition using CNNs with a recurrent model. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 429–434. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 11 May 2022).
- Baldominos, A.; Saez, Y.; Isasi, P. A survey of handwritten character recognition with MNIST and EMNIST. Appl. Sci. 2019, 9, 3169. [Google Scholar] [CrossRef]
- Sayeed, A.; Shin, J.; Hasan, M.A.M.; Srizon, A.Y.; Hasan, M.M. BengaliNet: A Low-Cost Novel Convolutional Neural Network for Bengali Handwritten Characters Recognition. Appl. Sci. 2021, 11, 6845. [Google Scholar] [CrossRef]
- Tensmeyer, C.; Saunders, D.; Martinez, T. Convolutional neural networks for font classification. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 985–990. [Google Scholar]
- Kausar, T.; Manzoor, S.; Kausar, A.; Lu, Y.; Wasif, M.; Ashraf, M.A. Deep Learning Strategy for Braille Character Recognition. IEEE Access 2021, 9, 169357–169371. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Nogra, J.A.; Romana, C.L.S.; Balakrishnan, E. Baybáyin character recognition using convolutional neural network. Int. J. Mach. Learn. Comput. 2020, 10, 169–186. [Google Scholar] [CrossRef]
- Ahlawat, S.; Choudhary, A.; Nayyar, A.; Singh, S.; Yoon, B. Improved handwritten digit recognition using convolutional neural networks (CNN). Sensors 2020, 20, 3344. [Google Scholar] [CrossRef]
- Bala, D.; Mynuddin, M.; Hossain, M.I.; Islam, M.A.; Hossain, M.A.; Abdullah, M.I. A Robust Plant Leaf Disease Recognition System Using Convolutional Neural Networks. In Proceedings of the 2022 International Conference on Engineering and Emerging Technologies (ICEET), Kuala Lumpur, Malaysia, 27–28 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Bala, D.; Islam, M.A.; Hossain, M.I.; Mynuddin, M.; Hossain, M.A.; Hossain, M.S. Automated Brain Tumor Classification System using Convolutional Neural Networks from MRI Images. In Proceedings of the 2022 International Conference on Engineering and Emerging Technologies (ICEET), Kuala Lumpur, Malaysia, 27–28 October 202; pp. 1–6. [CrossRef]
- Elmansouri, M.; Makhfi, N.E.; Aghoutane, B. Toward classification of arabic manuscripts words based on the deep convolutional neural networks. In Proceedings of the 2020 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 9–11 June 2020; pp. 1–5. [Google Scholar]
- Liu, X.; Hu, B.; Chen, Q.; Wu, X.; You, J. Stroke sequence-dependent deep convolutional neural network for online handwritten chinese character recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4637–4648. [Google Scholar] [CrossRef]
- Diem, M.; Fiel, S.; Garz, A.; Keglevic, M.; Kleber, F.; Sablatnig, R. ICDAR 2013 competition on handwritten digit recognition (HDRC 2013). In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1422–1427. [Google Scholar]
- Ahmed, S.B.; Naz, S.; Razzak, M.I.; Yousaf, R. Deep learning based isolated Arabic scene character recognition. In Proceedings of the 2017 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France, 3–5 April 2017; pp. 46–51. [Google Scholar]
- Manocha, S.K.; Tewari, P. Devanagari Handwritten Character Recognition using CNN as Feature Extractor. In Proceedings of the 2021 International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON), Pune, India, 29–30 October 2021; pp. 1–5. [Google Scholar]
- Tamir, K. Handwritten Amharic characters recognition using CNN. In Proceedings of the 2019 IEEE AFRICON, Accra, Ghana, 25–27 September 2019; pp. 1–4. [Google Scholar]
- Narang, S.R.; Kumar, M.; Jindal, M.K. DeepNetDevanagari: A deep learning model for Devanagari ancient character recognition. Multimed. Tools Appl. 2021, 80, 20671–20686. [Google Scholar] [CrossRef]
- Jangid, M.; Srivastava, S. Handwritten devanagari character recognition using layer-wise training of deep convolutional neural networks and adaptive gradient methods. J. Imaging 2018, 4, 41. [Google Scholar] [CrossRef]
- Warkhad, A.; Mandhare, S.; Thombre, Y.; Korhale, P.; Deore, S.; Ingle, S. Hybrid Approach For Handwritten Devanagari Character Recognition Using CNN and KNN 2021. Available online: https://www.irjet.net/archives/V8/i2/IRJET-V8I2176.pdf (accessed on 15 November 2022).
- Bala, R.; Singh, C. An optimized CNN-based handwritten gurmukhi character recognition from punjabi script image. Int. J. Sci. Res. Comput. Sci. Appl. Manag. Stud. 2020, 9, 1–10. [Google Scholar]
- Alrasheed, N.; Rao, P.; Grieco, V. Character Recognition of Seventeenth-Century Spanish American Notary Records Using Deep Learning. Digit. Humanit. Q. 2021, 15. Available online: http://www.digitalhumanities.org/dhq/vol/15/4/000581/000581.html (accessed on 28 February 2023).
- Ranzato, M.; Poultney, C.; Chopra, S.; Cun, Y. Efficient learning of sparse representations with an energy-based model. Adv. Neural Inf. Process. Syst. 2006, 19, 1137–1144. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Gambardella, L.M.; Schmidhuber, J. Convolutional neural network committees for handwritten character classification. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1135–1139. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Le Cun, Y.; Fergus, R. Regularization of neural networks using dropconnect. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 16–21 June 2013; pp. 1058–1066. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Vijayan, V.K.; Bindu, K.; Parameswaran, L. A comprehensive study of text classification algorithms. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Manipal, Karnataka, India, 13–16 September 2017; pp. 1109–1113. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Silva, I.; Eugenio Naranjo, J. A Systematic Methodology to Evaluate Prediction Models for Driving Style Classification. Sensors 2020, 20, 1692. [Google Scholar] [CrossRef]
- Buldin, I.D.; Ivanov, N.S. Text Classification of Illegal Activities on Onion Sites. In Proceedings of the 2020 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), St. Petersburg and Moscow, Russia, 27–30 January 2020; pp. 245–247. [Google Scholar]
- Tan, Y. An improved KNN text classification algorithm based on K-medoids and rough set. In Proceedings of the 2018 10th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 25–26 August 2018; Volume 1, pp. 109–113. [Google Scholar]
- Song, Y.Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System; Association for Computing Machinery: New York, NY, USA, 2016; Volume KDD’16; pp. 785–794. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Published Online and Open Source. Image Classification on MNIST. 2022. Available online: https://paperswithcode.com/sota/image-classification-on-mnist (accessed on 20 April 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pre-Trained | Resampling | Evaluation | SVM | KNN | Decision | RF | XGBoost |
|---|---|---|---|---|---|---|---|
| Models | Metrices | Tree | |||||
| VGG16 | 1 | Recall | 0.58 | 0.60 | 0.66 | 0.78 | 0.73 |
| Precision | 0.53 | 0.65 | 0.68 | 0.83 | 0.76 | ||
| F1-score | 0.57 | 0.60 | 0.65 | 0.79 | 0.73 | ||
| 2 | Recall | 0.66 | 0.73 | 0.84 | 0.90 | 0.88 | |
| Precision | 0.71 | 0.75 | 0.85 | 0.91 | 0.89 | ||
| F1-score | 0.68 | 0.72 | 0.84 | 0.90 | 0.88 | ||
| 3 | Recall | 0.70 | 0.78 | 0.92 | 0.94 | 0.93 | |
| Precision | 0.74 | 0.81 | 0.92 | 0.95 | 0.94 | ||
| F1-score | 0.71 | 0.78 | 0.91 | 0.94 | 0.93 | ||
| MobileNet | 1 | Recall | 0.51 | 0.58 | 0.69 | 0.74 | 0.73 |
| Precision | 0.64 | 0.75 | 0.76 | 0.80 | 0.78 | ||
| F1-score | 0.59 | 0.60 | 0.69 | 0.74 | 0.75 | ||
| 2 | Recall | 0.54 | 0.65 | 0.79 | 0.82 | 0.81 | |
| Precision | 0.60 | 0.69 | 0.81 | 0.84 | 0.83 | ||
| F1-score | 0.54 | 0.65 | 0.79 | 0.82 | 0.81 | ||
| 3 | Recall | 0.56 | 0.62 | 0.89 | 0.89 | 0.90 | |
| Precision | 0.69 | 0.71 | 0.90 | 0.89 | 0.91 | ||
| F1-score | 0.58 | 0.63 | 0.88 | 0.88 | 0.90 | ||
| ResNet50 | 1 | Recall | 0.60 | 0.63 | 0.77 | 0.81 | 0.82 |
| Precision | 0.58 | 0.70 | 0.82 | 0.85 | 0.81 | ||
| F1-score | 0.61 | 0.65 | 0.78 | 0.81 | 0.79 | ||
| 2 | Recall | 0.61 | 0.75 | 0.87 | 0.91 | 0.91 | |
| Precision | 0.64 | 0.77 | 0.88 | 0.92 | 0.92 | ||
| F1-score | 0.63 | 0.75 | 0.89 | 0.91 | 0.91 | ||
| 3 | Recall | 0.57 | 0.74 | 0.92 | 0.95 | 0.94 | |
| Precision | 0.64 | 0.77 | 0.92 | 0.95 | 0.94 | ||
| F1-score | 0.58 | 0.74 | 0.92 | 0.95 | 0.94 |
| Beowulf Manuscript’s Dataset | MNIST Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | Resmp | SVM | KNN | DT | RF | XGBoost | CNN | CNN | |
| VGG16 | 1 | 52.16 | 56.84 | 66.10 | 78.81 | 73.72 | Res. 1 | 88.67 | 99.03 |
| 2 | 66.86 | 73.37 | 80.61 | 83.53 | 82.98 | ||||
| 3 | 70.91 | 77.73 | 86.82 | 91.09 | 90.63 | ||||
| MobileNet | 1 | 51.55 | 58.54 | 69.17 | 74.44 | 73.68 | >Res. 2 | 90.91 | |
| 2 | 54.08 | 65.56 | 79.88 | 82.24 | 81.88 | ||||
| 3 | 56.59 | 61.82 | 89.09 | 89.09 | 90.45 | ||||
| ResNet50 | 1 | 56.39 | 63.91 | 76.44 | 79.63 | 79.20 | Res. 3 | 98.86 | |
| 2 | 61.53 | 75.74 | 80.57 | 84.12 | 83.12 | ||||
| 3 | 57.27 | 74.09 | 92.72 | 93.45 | 92.54 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.A.; Iacob, I.E. Manuscripts Character Recognition Using Machine Learning and Deep Learning. Modelling 2023, 4, 168-188. https://doi.org/10.3390/modelling4020010
Islam MA, Iacob IE. Manuscripts Character Recognition Using Machine Learning and Deep Learning. Modelling. 2023; 4(2):168-188. https://doi.org/10.3390/modelling4020010
Chicago/Turabian StyleIslam, Mohammad Anwarul, and Ionut E. Iacob. 2023. "Manuscripts Character Recognition Using Machine Learning and Deep Learning" Modelling 4, no. 2: 168-188. https://doi.org/10.3390/modelling4020010