1. Introduction
Machine Learning models are used to solve problems in several different areas. The techniques have several knobs that must be chosen before the training procedure to create the model. The choice of these values, known as hyper-parameters, is a highly complex task and directly impacts the model performance. It depends on the user experience with the technique and knowledge about the data itself. Also, it is generally difficult for non-experts in modelling and the problem to be solved due to a lack of knowledge of the specific problem. The user usually has to perform several experiments with different hyper-parameter values to maximize the model’s performance to find the best set of hyper-parameters. Depending on the size of the model and the data, this can be very challenging.
The hyper-parameter search can be performed manually or using search algorithms. The manual hyper-parameter search can be done by simply testing different sets of hyper-parameters. One of the most common approaches is to use a grid search. The grid-search process assesses the models by testing all the possible combinations given a set of hyper-parameters and their values. Search algorithms can also be applied by using knowledge of previous runs to test promising hyper-parameter space during the next iteration, such as evolutionary and swarm algorithms, Gaussian processes [
1]. In this paper, we focus on the hyper-parameter search for Artificial Neural Networks since it is an effective and flexible technique due to its universal approximator capabilities [
2] applied to tabular datasets since it is a prevalent type of data used in the real world by several companies.
The best set of hyper-parameters could be chosen if the technique could be assessed using all the possible values for each variable. However, this is usually prohibitive due to the model training time. Two paths can be taken to accelerate the process: (i) reducing the training time of each model or (ii) assessing the model in the most promising points of the hyper-parameter space. The second point can be challenging because it is hard to perform a thorough search using a few points.
GPUs are ubiquitous when training Neural Networks, especially Deep Neural Networks. Given the computational capacity that we have today, we can leverage the parallelization power of CPUs that contain several cores and threads and GPUs with their CUDA [
3] cores to minimize the training time. The parallelization is commonly applied during matrix multiplication procedures, increasing the overall speed of the training process. However, if the data and the model that is being used do not produce big matrices, GPUs can decrease the training time if compared to CPUs due to the cost of CPU-GPU memory transfers [
4]. Also, the GPUs might not saturate their usage when using small operations. If we aggregate several MLPs as a single network with independent sub-networks, the matrices become more extensive, and we can increase the GPU usage, consequentially increasing the training speed. In this paper, we designed a single MLP architecture that takes advantage of caching mechanisms to increase speed in CPUs or GPUs environment, called ParallelMLPs from now on, that contains several independent internal MLPs and allow us to leverage the parallelization power of CPUs and GPUs to train individual and independent Neural Networks, containing different architectures (number of hidden neurons and activation functions) simultaneously. This is an embarrassingly parallel alternative to train MLPs as the internal subnetworks’ results and computations are performed independently of each other.
3. Materials and Methods
In order to facilitate the methodology explanation, we will write the tensors in capital letters. Their respective dimensions can be presented as subscripts such as meaning a two-dimensional tensor with three rows and four columns.
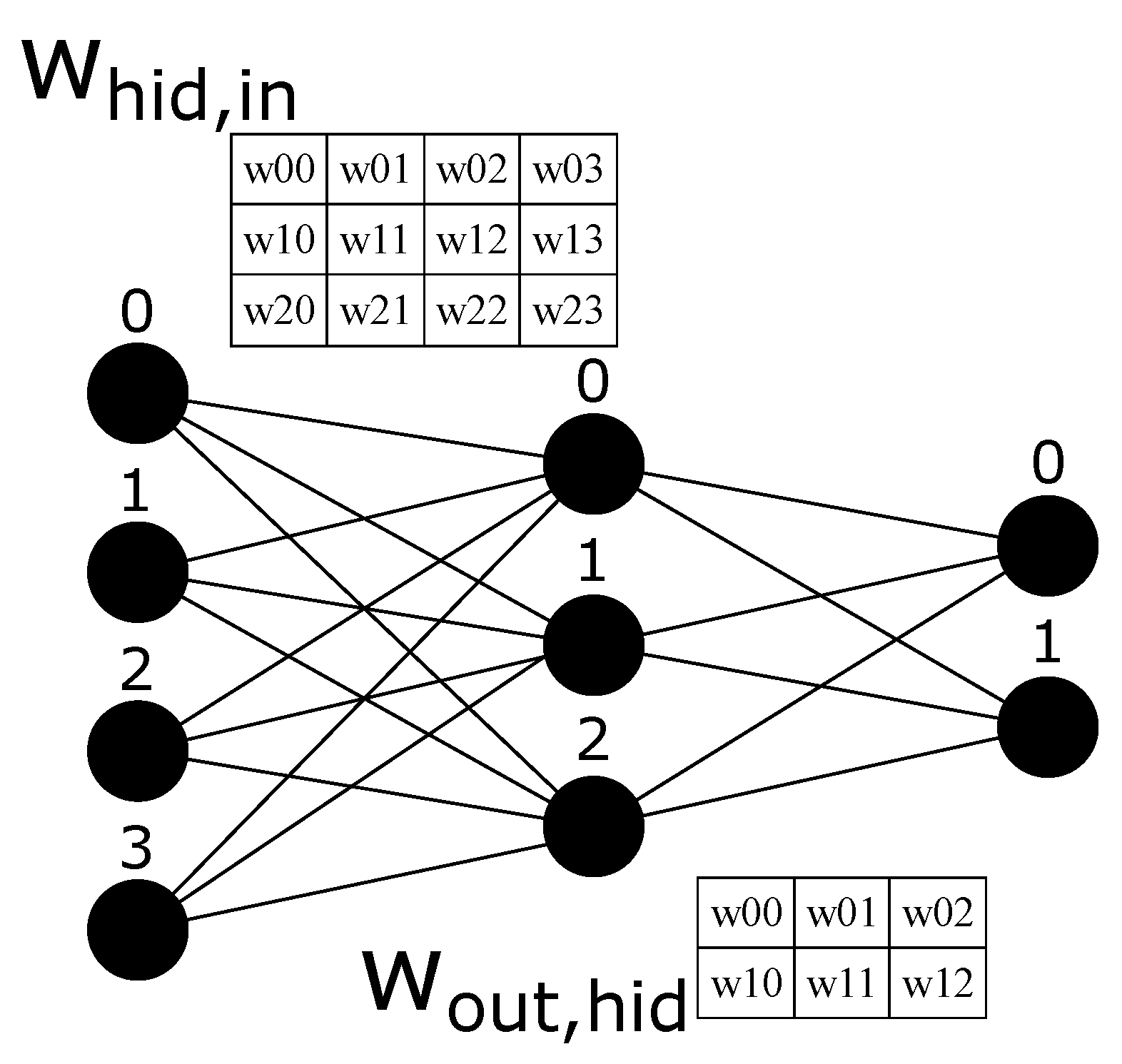
An example of a MLP architecture with 4 inputs, 3 hidden neurons and 2 outputs (
) can be seen in
Figure 1. The weights are also explicit with notation
meaning a connection from neuron
j in the current layer to neuron
i in the next layer. The first weight matrix with shape
projects the input representation (4 dimensions) into the hidden representation (3 dimensions). In contrast, the second matrix with shape
projects the hidden representation (3 dimensions) into the output representation (2 dimensions).
The training procedure of an MLP is usually performed by the Backpropagation algorithm [
12]. It is divided into two phases. We perform several non-linear projections in the forward phase until we reach the final representation in the backward phase. Then, we can calculate the error using a loss function to backpropagate them using the gradient vector of the error w.r.t. the parameters to update the parameters of the network in order to minimize its error.
The forward calculation can be described as two consecutive non-linear projections of the type . and . We need two different weight matrices with shape and with shape . We also would want two bias vectors, but we will not use them to facilitate the explanations and figures.
The forward phase in our example can be visualized as a three-step procedure.
Input to hidden matrix multiplication, .
Hidden activation function application, .
Hidden activated to output matrix multiplication, .
To train the model, we need to apply a loss function to compare the numbers in step 3 against the targets which the model is trying to learn. After the loss calculation, the gradient of each parameter w.r.t. the loss is estimated and used to update the parameters of the network.
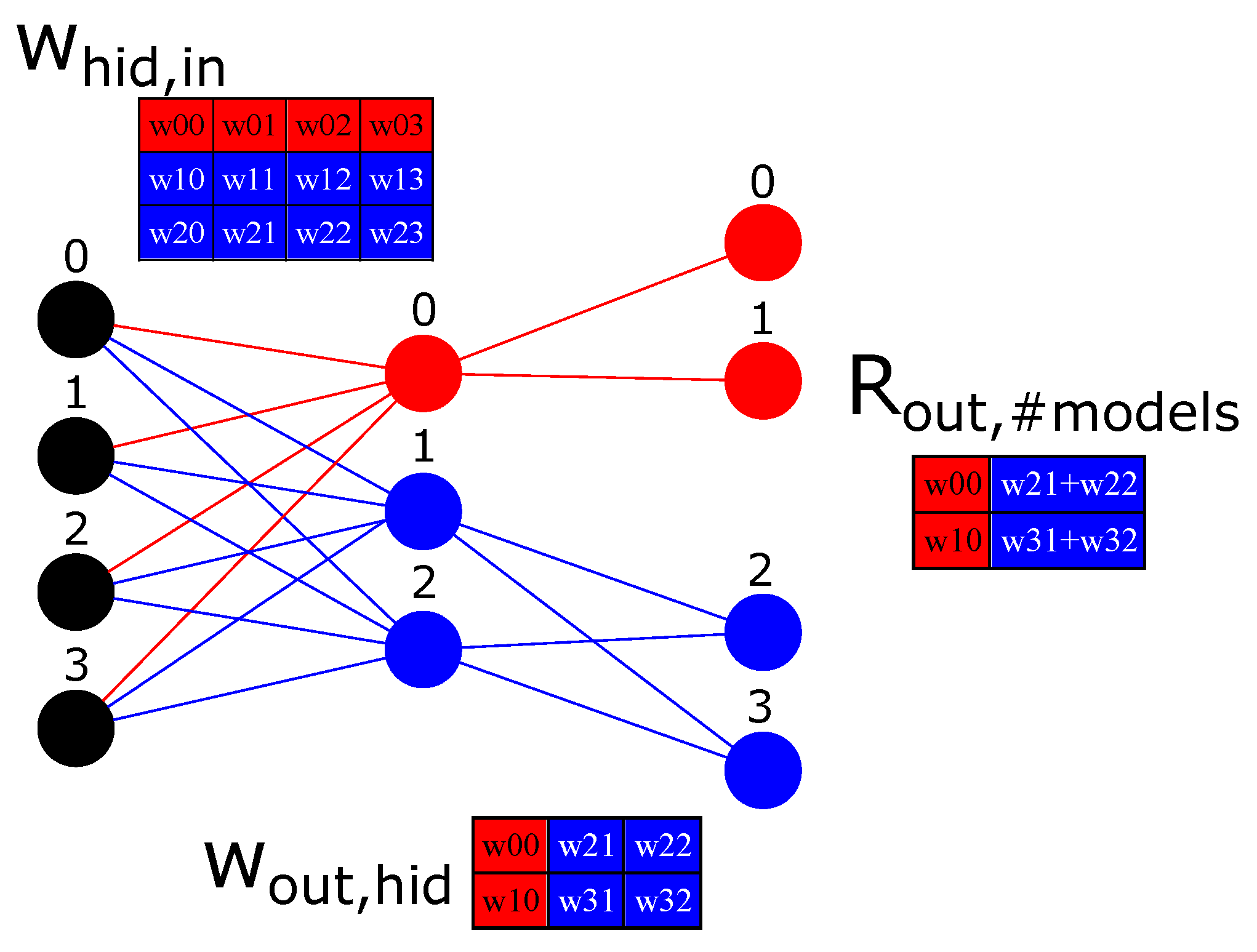
Since MLP architectures usually do not saturate GPUs, we can change the architecture to create MLPs that share the same matrix instance but have their own independent set of parameters. It allows them to train in parallel. Suppose we want to train two MLPs in the same dataset with architectures
and
. To leverage the GPU parallelization, we can fuse both architectures as a single architecture (ParallelMLPs), in the form
. In
Figure 2 we can see both internal networks represented as a single architecture (ParallelMLPs) with different colours. The number of inputs does not change; the number of hidden neurons is summed, while the number of output neurons is multiplied by the number of independent MLPs we want to train. The layout of ParallelMLP was designed to take advantage of temporal and spatial locality principles in caching [
10] and overall parallelization mechanisms.
In order to maintain the internal MLPs independent of each other, we cannot follow the same steps previously described because, in that case, we would mix the gradients of all the internal models during the backpropagation. The matrix multiplication can be understood as two consecutive operations: (i) element-wise vector multiplication (rows ∗ columns) and (ii) reduced sum of the previous vectors. We need to change how we perform the matrix multiplication in step 3. The main idea is to divide the matrix multiplication into two procedures: (i) matrix element-wise multiplication and (ii) summation. However, the summation needs to be carefully designed such that we do not reduce-sum the entire vector but different portions of the axis. We can use broadcast techniques implemented in every tensor library, and a special case of summation called Scatter Add to make these two procedures memory efficient. We will refer to this procedure as Modified Matrix Multiplication (M3) [
13].
This M3 procedure might be useful to handle sparse NN. Most of the time, sparsity is treated with masking. Masking tends to be a waste of resources since the original amount of floating point calculations are still being done, and additional masking floating point operations are being added to the process.
The Scatter Add () operation takes a dimension D to apply the operation and two tensors as inputs. The source tensor S contains the numbers that we want to sum up and the indices tensor I, which informs which elements in the source tensor must be summed and stored in the result tensor. When applied to two-dimensional tensors as , the result tensor R (initialized as zeros) can be calculated as:
if dimension = 0
if dimension = 1
A very simple example of the scatter add operation would be when:
,
,
,
,
with
I informing how to accumulate values in the destination tensor
R, with the first element (0) accumulating only the first element of
S, the second destination element (1) accumulating the second and third values of
S, and the latest element (2) accumulating the fourth, fifth and sixth element of
S. This operation is implemented in parallel in any popular GPU tensor library. In our architecture represented in
Figure 2, in order to have the two separated outputs, one for each internal MLP, we would have to sum across the lines using a matrix
I as follows:
It would generate an output matrix where each line is related to each internal/individual MLP.
The Scatter Add operation is responsible for keeping the gradients after the loss function application not mixed during the backpropagation algorithm, allowing us to train thousands of MLPs simultaneously in an independent manner.
To summarize, the steps to perform the parallel training of independent MLPs are:
Input to hidden matrix multiplication, .
Hidden activation function application, .
Hidden activated element-wise multiplication with multi-output projection matrix, (broadcasted element-wise multiplication)
Finally, the Scatter Add operation to construct the independent outputs
After that, a loss function is applied to calculate the gradients and update all the internal MLPs parameters independently.
We can go further and use not only a single activation function that should be applied to all the internal MLPs, but several of them by repeating the original number of architectures as many times as we have for activation functions. Since this is often not enough to use all the GPU resources, one can also have repetitions of the same architecture and activation function. In order to use several activation functions, the last step must be modified such that we can apply different activation functions to different portions of the matrix O. This can be done using a tensor split operation, applying each activation function iterativelly in different continuous portions of the representations, and finally concatenating the activated representations again.
| Pseudocode 1: High-level description of the ParallelMLPs operations. |
![Ai 04 00002 i001]()
![Ai 04 00002 i002]() |
3.1. Experiments
Simulations were performed in order to compare the speed of the Parallel training against the Sequential approach.
3.1.1. Computing Environment
A Machine with 16 GB RAM, 11 GB NVIDIA GTX 1080 Ti, and an I7-8700K CPU @ 3.7 GHz containing 12 threads were used to perform the simulations. All the code was written using PyTorch [
14].
3.1.2. Model Architectures
We have created architectures starting with one neuron at the hidden layer until 100, resulting in 100 different possibilities. For each architecture, we have assessed ten different activation functions: Identity, Sigmoid, Tanh, ReLU, ELU, SeLU, GeLU, LeakyReLU, Hardshrink, Mish. It increases the number of independent architectures to . We have repeated each architecture 10 times, totalling models. It is worth mentioning that this design is not limited to these circumstances. One could create arbitrary MLP architectures such as 3 different networks with 3, 19, and 200 hidden neurons and still would be able to leverage the speedup from ParallelMLPs.
3.1.3. Datasets
We have created controlled training datasets with 100, 1000, and 10,000 samples. With 5, 10, 50, and 100 features. Giving a combination of 12 different datasets. For all the simulations, 12 epochs were used, ignoring the first two epochs as a warm-up period. For the MNIST dataset, we kept the same amount of model architectures, and investigated only the GPU approach with batch size of 64 due to memory restrictions as the number of features increased to 784.
3.1.4. Training Details
All the samples are stored in GPU at the beginning of the process to not waste much time of GPU-CPU transfers. It favours the Sequential processing speed more than the Parallel since the former would have 10,000 more CPU-GPU transfers throughout the entire experiment.
The data is used only as train splits because this phase is where the gradients are calculated, and the two operations of forward and backward are used. Therefore, the training split processing is much more expensive than validation and test splits.
5. Discussion
Suppose one is training for 100 epochs of the previously mentioned 10,000 models in a dataset with 10,000 samples and 100 features with 32 as the batch size. In that case, CPU-Sequential can take more than 32 h (), while CPU-Parallel only 2 h ( would be necessary to perform the same training. The same case with batch size of 256 samples, we would have approximately 14 h and 1.5 h for CPU-Sequential and CPU-Parallel, respectively. In this case, the CPU-Parallel is for the first scenario and for the second scenario times faster than CPU-Sequential. The CPU-Parallel experiments took between 3.9% and 10.3% of the CPU-Sequential time, considering all the variations we have performed. As one can see, the CPU speed improves when using larger batch sizes probably to better exploration of the principle of locality.
If we analyze the same experiments in GPUs, more than 51 h () would be necessary for GPU-Sequential, and 7.4 min when using GPU-ParallelMLPs for the 32 batch experiment and 15.5 h for GPU-Sequential and 4.6 min for the 256 batch size. It gives us a speed improvement on GPU-Parallel of and times, respectively, when compared to GPU-Sequential. The GPU-Parallel experiments range from 0.017% to 0.486% of the GPU-Sequential time for all the assessed experiments. As one can see, the GPU speed improves when using larger batch sizes probably to better exploration of the principle of locality and also a better parallelization in the GPU kernel.
At first glance, the GPU training time should be faster than the CPU training time. However, when we compare GPU-Sequential against the CPU-Sequential, the GPU version is slower than CPU one. This slowness may be explained by the high number of function/kernel calls to perform cheap operations (small matrix multiplications). As the single-core of a CPU is optimized to perform a specific computation very quickly (high clock rate) and the single-core of a GPU is much slower than CPU, it is reasonable that CPUs can take advantage in this scenario. On the other hand, GPUs contain much more cores than the CPU, and they can run computations in parallel, therefore we can see huge differences as this is often the scenario in which GPUs will outperform CPUs. As we increase the size of matrices to be multiplied in GPU-ParallelMLP (with more architectures or bigger batch sizes), a considerable amount of speed can be delivered compared to CPU-ParallelMLP.
It is essential to mention that the GPU memory consumption of the 10,000 parallel models using 100 features and batch size of 256 (the worst case scenario for our experiments w.r.t. memory allocation) was less than 4.8 GB, meaning that (i) simpler GPUs can be used and still take advantage of our approach, and (ii) is probably possible to improve the speed if using more models in parallel to make a better usage of the GPU memory.
As we can perform a very efficient grid-search in the discrete hyper-parameters space that will define the network architecture, it is much easier for the user to select a suitable model since several number of neurons and activation functions can be trained in parallel, mainly for beginners in the field who have difficulties to guess the best number of neurons and activation function, since the hyper-parameter definition is highly dependent on the user experience. Also, researchers that use any search method that proposes an MLP architecture in a specific problem can now train the models in parallel. The ParalleMLPs can be applied for both classification and regression tasks. We believe this M3 operation can be optimized and lead to even more speed improvements if a specialized CUDA kernel could be written.
7. Future Works
We believe the ideas proposed in this paper can inspire other researchers to develop parallelization of other necessary core operations/modules such as Convolutions, Attention Mechanisms, and Ensemble fusion of heterogeneous MLPs.
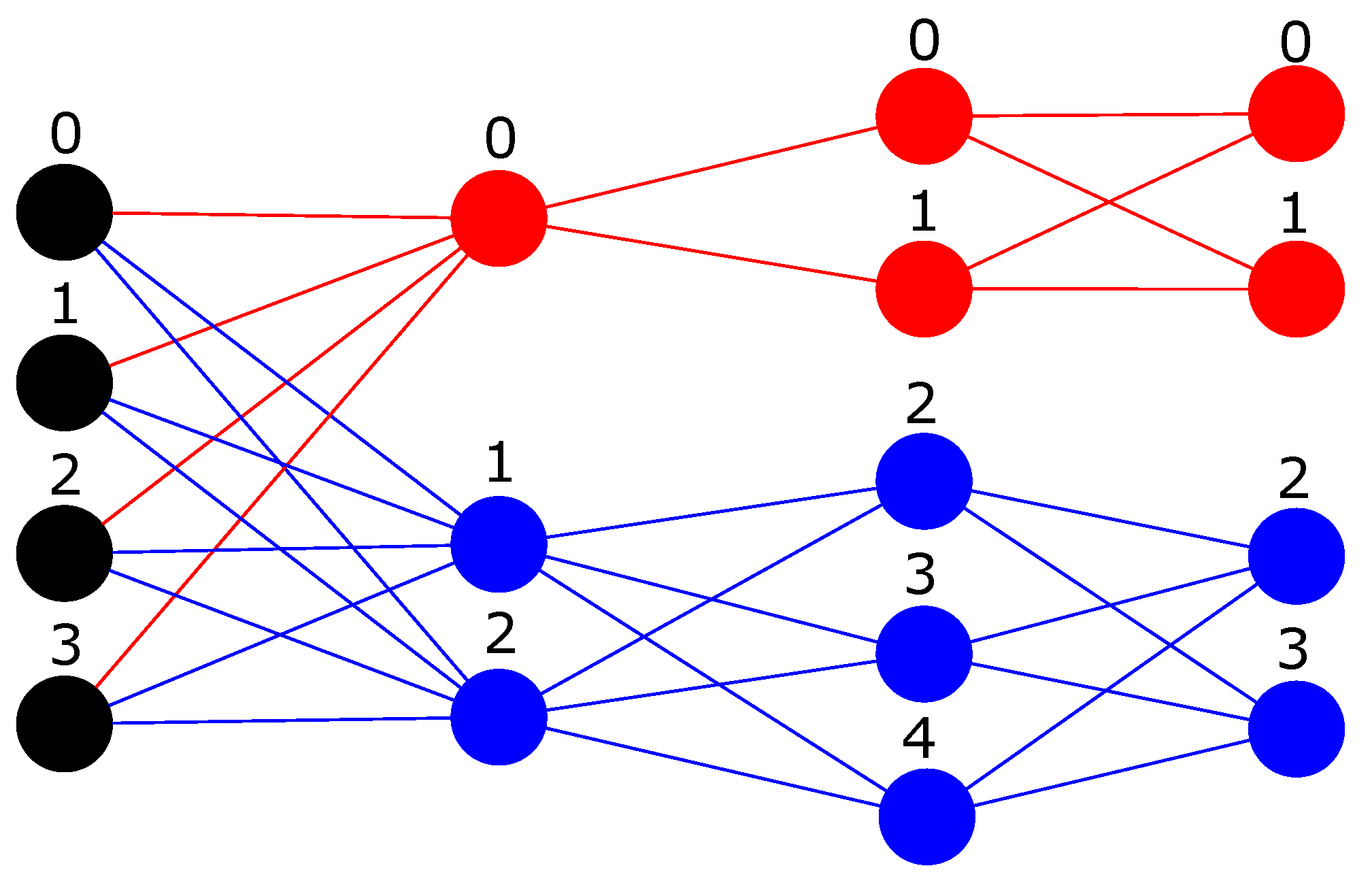
In future works, we would like to investigate if the M3 operation can be used from the second transformation until the last layer to train MLPs with more than one hidden layer since only during the first transformation (from input to the first hidden layer) all the previous neurons are sum-reduced instead of a sparse version of them. We can see an example of this idea into
Figure 3.
An interesting work would be to perform feature selection using ParallelMLPs by repeating the MLP architecture and creating a mask tensor to be applied to the inputs before the first input to hidden projection. We also plan to perform model selection in the large pool of trained MLPs in a specific dataset. Also, we plan to automatize the number of neurons and the number of layers. After we finish the ParallelMLP training, we can (i) remove the output layer or (ii) use the output layer as the new representation of the dataset to be the input of a new series of ParallelMLP training. It is also possible to use the original features concatenated with the previously mentioned outputs like residual connections [
15]. After each ParallelMLP training, we can pick the best MLP to create the current layer, continuously increasing the number of layers until no more improvements are perceived. A further investigation is needed to verify if similar ideas could be used for convolutional and pooling layers since they are basic building blocks for several Deep Learning architectures. We also would like to investigate what happens if an architecture containing a backbone representing the input space into a latent space and MLP at the end, such as [
16] to perform the classification would be replaced by a parallel layer with several independent set of outputs, but sharing the backbone’s parameters. One hypothesis is that the backbone would be regularized by different update signals from a heterogeneous set of MLP heads. This technique can also be similar to a Random Forest [
17] of MLPs where during the training phase, the inputs could be masked depending on the individual network to mimic bagging or mask specific features, or even simulate a Random Subspace [
18]. Our technique can be used to find the best random initialized model given that [
19] was able to found good sub-networks without any training–extending the idea of Lottery Ticket Hypothesis [
20]. There is space to parallelize even more hyper-parameters such as batch size, learning rate, weight decay, and initialization strategies. One straightforward way is to use boolean masks to treat each case or hooks to change the gradients directly, but it might not be the most efficient way. A handy extension of our proposition would be to automatically calculate the hyper-parameter space to saturate the GPU.










{kind=link}
{kind=link}
{kind=link}