
Monitoring of Iron Ore Quality through Ultra-Spectral Data and Machine Learning Methods

Abstract
:1. Introduction
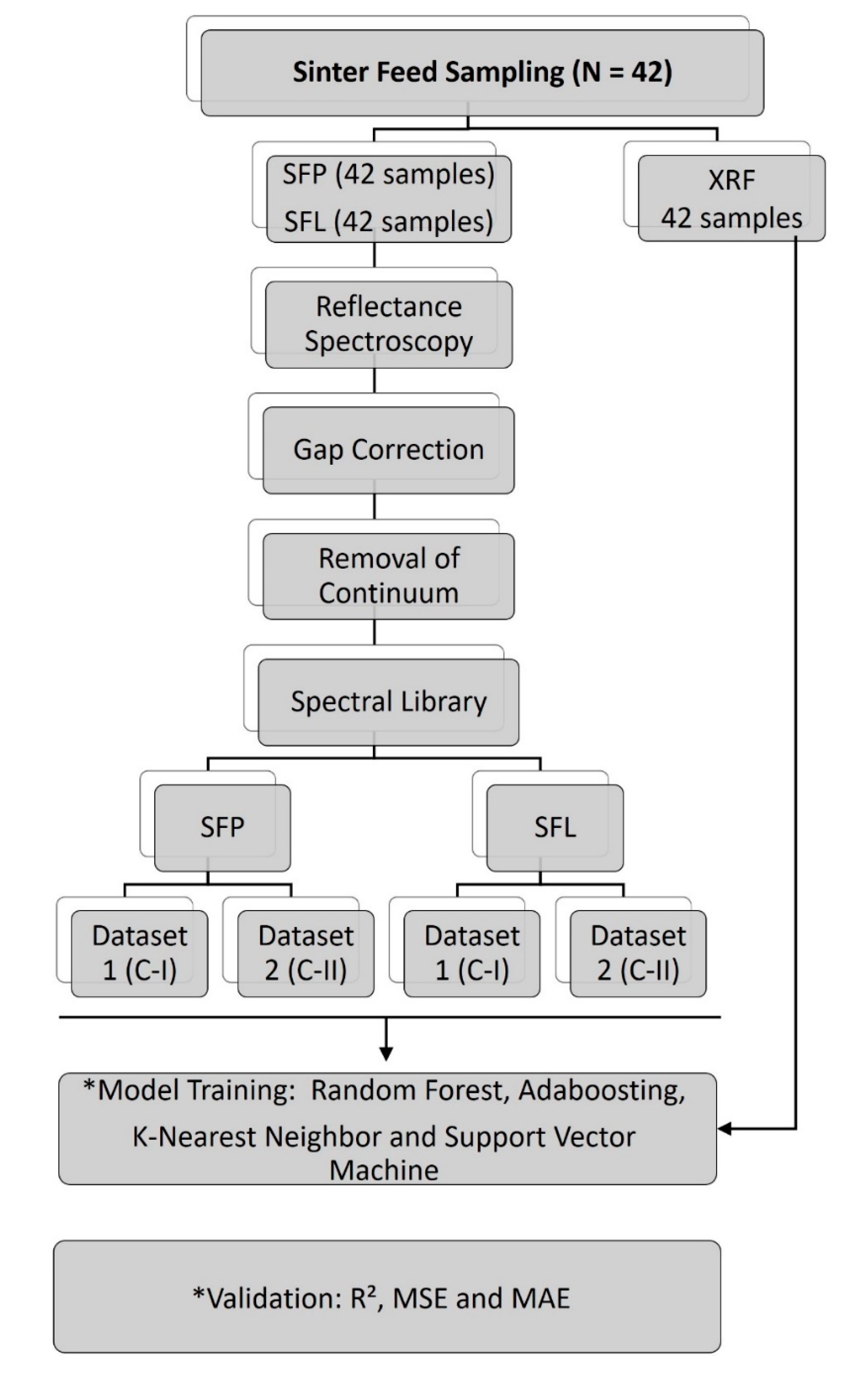
2. Materials and Methods
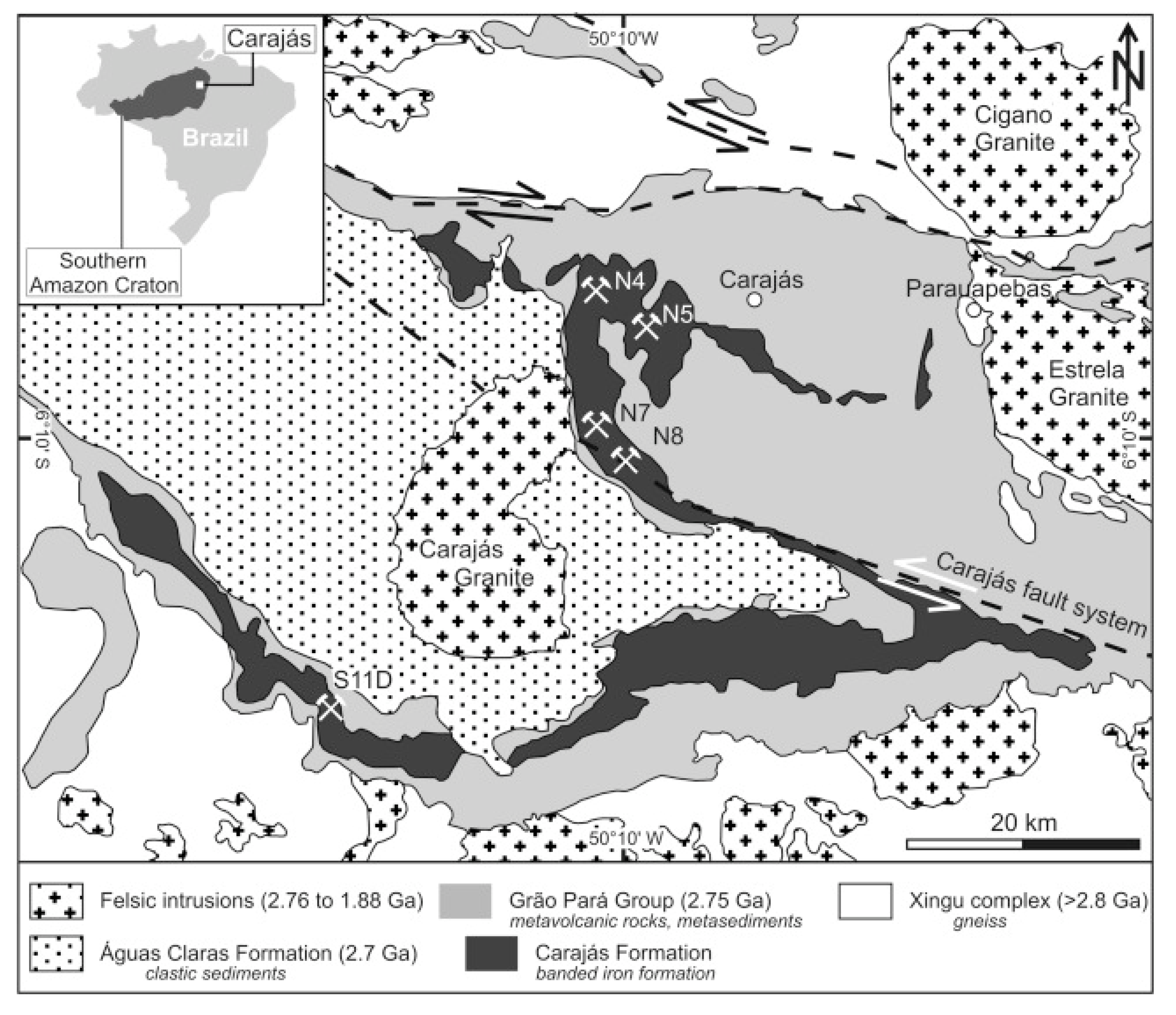
2.1. Sinter Feed Samples
2.2. Acquisition and Processing of Reflectance Spectra
2.3. Datasets
2.3.1. Modeling Procedures
2.3.2. Random Forest (RF)
2.3.3. Adaboosting (ADB)
2.3.4. K-Nearest Neighbor (kNN)
2.3.5. Support Vector Machine (SVM)
2.4. Validation of Predication Models
3. Results
3.1. Physical and Spectral Characterization of the Sinter Feed
3.2. Iron Estimation Models
4. Discussion
5. Conclusions
- -
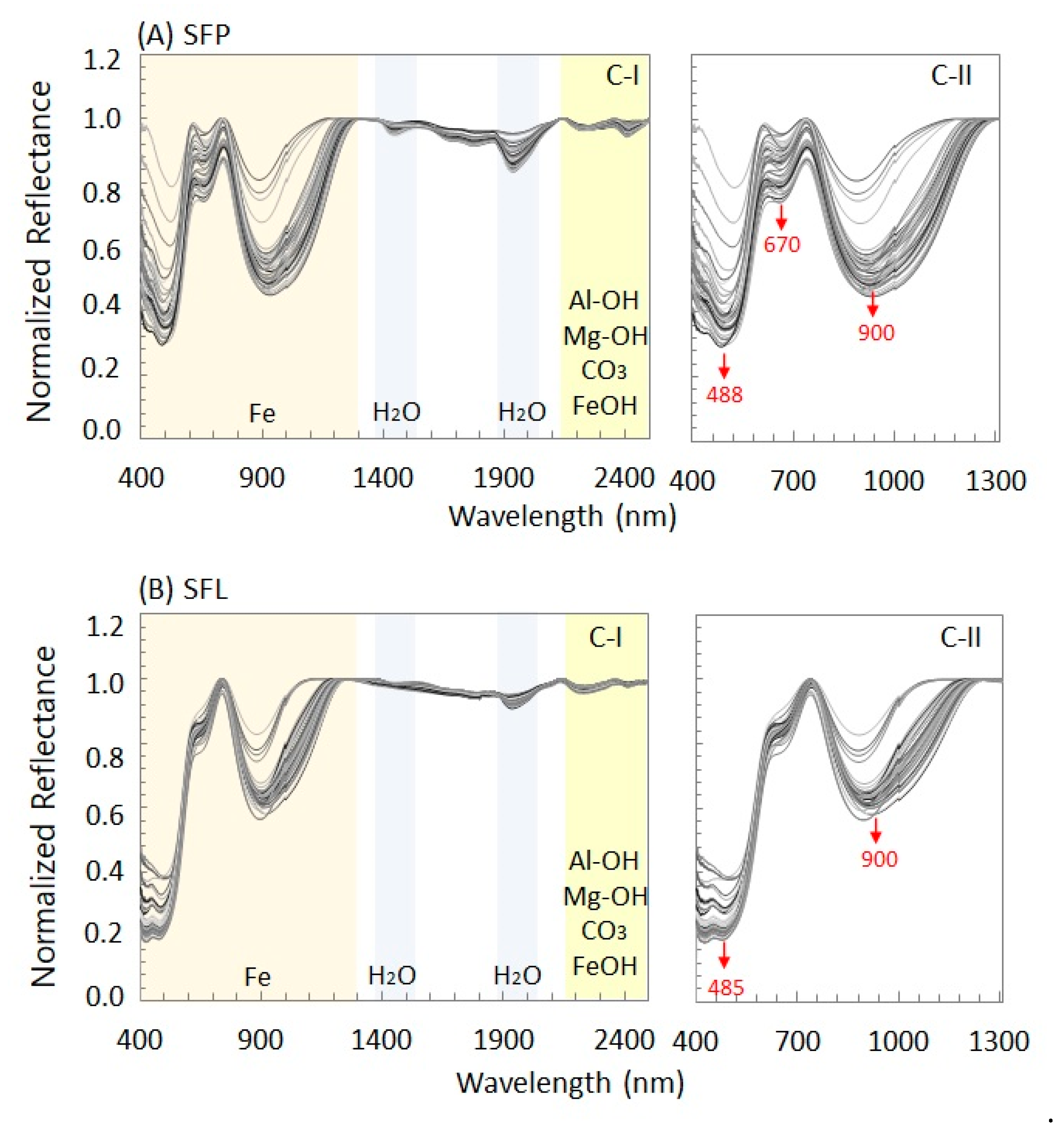
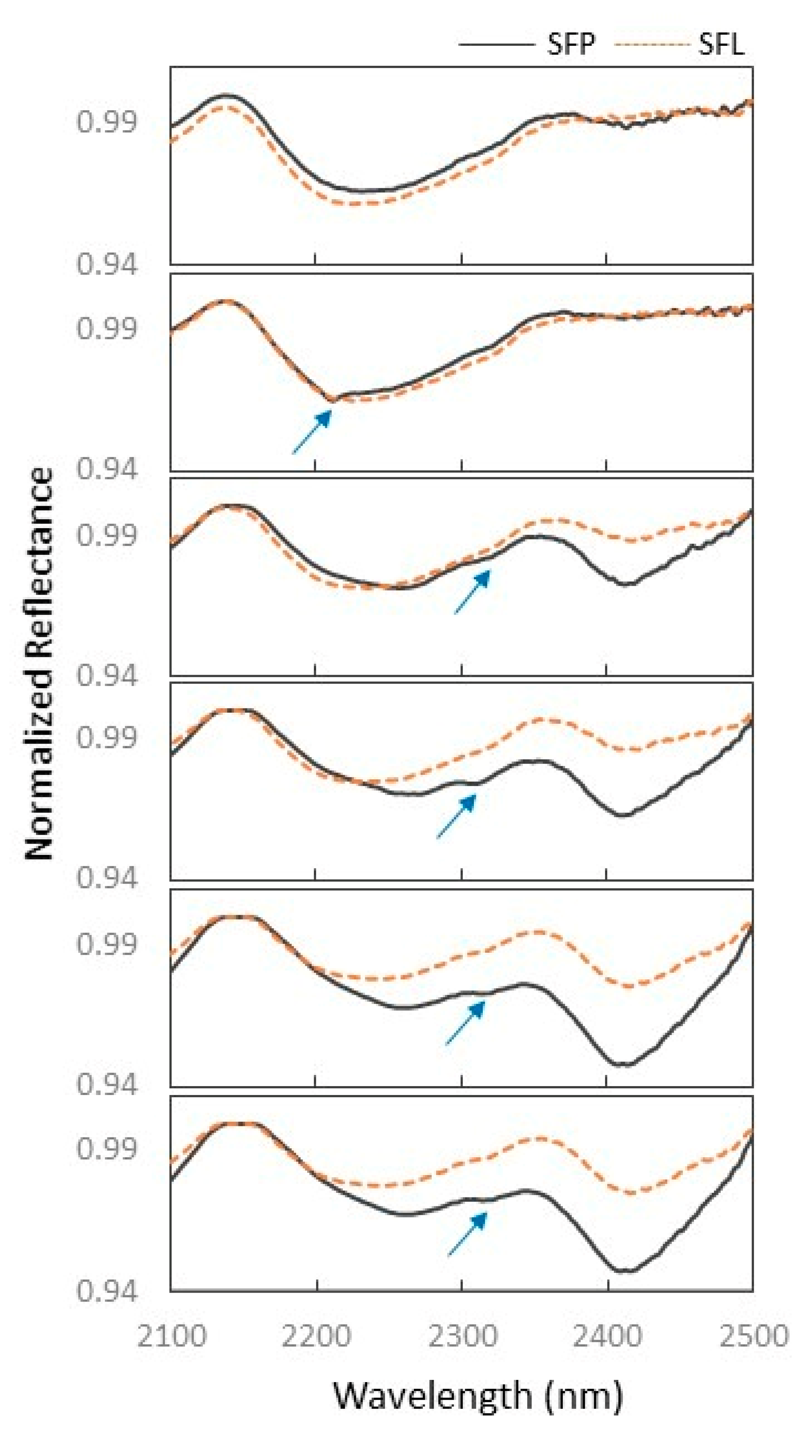
- Spectrally, there were no gains with the preparation of the Sinter Feed samples in the laboratory as with the drying and spraying procedures, the particle size of these samples became more homogeneous, thus attenuating the VSWIR absorption features used for qualitative and quantitative analyses of the physicochemical and mineralogical properties of the Sinter Feed.
- -
- The absorption features located in the VNIR region (~860 nm) enabled the identification of more hematitic (CN_10585, CN_10584 and CN_10564) and goethite samples, starting at 900 nm (CN_10563, CN_10556 and CN_10550). This information corroborated the physical characterization of the Sinter Feed, in which the hematitic samples were described as the most friable material with fine to medium particle sizes and colors between red to black (when product) and dark red (when sprayed). On the other hand, the goethite samples had coarser particle sizes and colors varying in shades of red, both for the Sinter Feed product samples and for the samples prepared in the laboratory.
- -
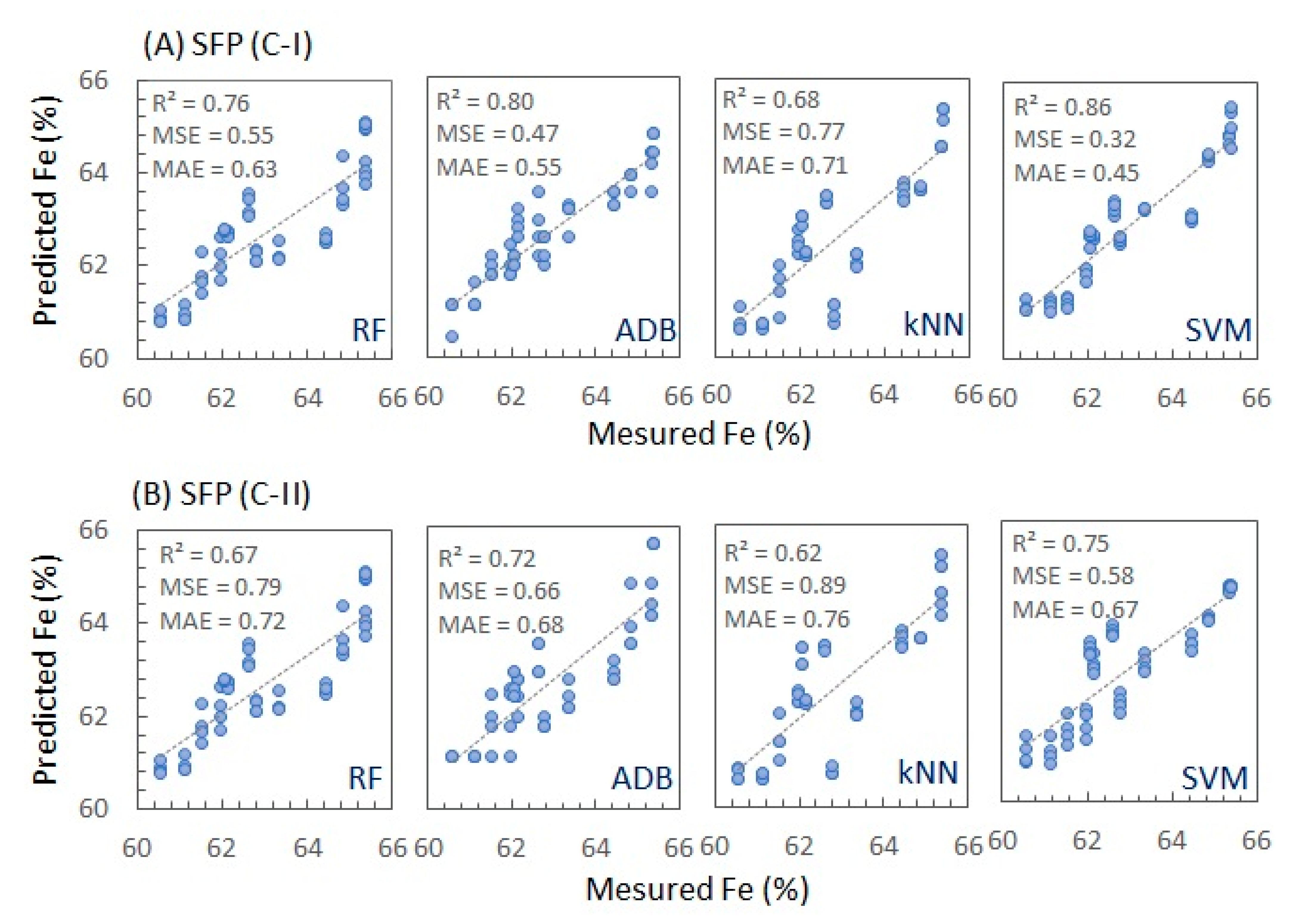
- The best Fe estimates for SFP were made with the ADB and SVM models, using only the C-I dataset, which is in the spectral range of 400 to 2500 nm.
- -
- For SFL, the RF, ADB and SVM models were more efficient for estimating Fe using both the C-I and C-II libraries. Conversely, kNN is the least recommended for this application.
- -
- The possibility of calibrating models, such as SVM and ADB, using only the Sinter Feed spectra without sample preparation opens space to discuss the operationalization of these methods in the processing plant routine.
- -
- Finally, we suggest calibration and evaluation of models using reflectance spectroscopy and XRF to estimate contaminants, such as phosphorus, silica, manganese and alumina. We also suggest that other algorithms could be tested to improve the results presented here, such as decision trees and artificial neural networks.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yellishetty, M.; Werner, T.T.; Weng, Z. Iron Ore in Australia and the World: Resources, Production, Sustainability, and Future Prospects. In Iron Ore; Woodhead Publishing: Cambridge, UK, 2022; pp. 711–750. [Google Scholar]
- Banco de Desenvolvimento de Minas Gerais. Minas Gerais Do Século XXI. Vol.IX. Belo Horizonte: Rona Editora. 2002. Available online: https://silo.tips/download/minas-gerais-do-seculo-xxi-2 (accessed on 23 March 2022).
- Grainger, C.J.; Groves, D.I.; Tallarico, F.H.; Fletcher, I.R. Metallogenesis of the Carajás mineral province, southern Amazon craton, Brazil: Varying styles of Archean through Paleoproterozoic to Neoproterozoic base-and precious-metal mineralisation. Ore Geol. Rev. 2008, 33, 451–489. [Google Scholar] [CrossRef]
- Juliani, C.; Monteiro, L.V.S.; Fernandes, C.M.D. Potencial Mineral: Cobre. In Recursos Minerais no Brasil: Problemas e Desafios; Melfi, A.J., Misi, A., Campos, D.d.A., Cordani, U.G., Eds.; Academia Brasileira de Ciências: Rio de Janeiro, Brazil, 2006; pp. 134–149. [Google Scholar]
- Cabral, A.; Creaser, R.; Nägler, T.; Lehmann, B.; Voegelin, A.; Belyatsky, B.; Pašava, J.; Gomes, A.S.; Galbiatti, H.; Böttcher, M.E.; et al. Trace-element and multi-isotope geochemistry of Late-Archean black shales in the Carajás iron-ore district, Brazil. Chem. Geol. 2013, 362, 91–104. [Google Scholar] [CrossRef]
- Xiao, D.; Le, B.T.; Ha, T.T.L. Iron ore identification method using reflectance spectrometer and a deep neural network framework. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 248, 119168. [Google Scholar] [CrossRef] [PubMed]
- Lobo, A.; Garcia, E.; Barroso, G.; Martí, D.; Fernandez-Turiel, J.-L.; Ibáñez-Insa, J. Machine Learning for Mineral Identification and Ore Estimation from Hyperspectral Imagery in Tin–Tungsten Deposits: Simulation under Indoor Conditions. Remote Sens. 2021, 13, 3258. [Google Scholar] [CrossRef]
- Tuşa, L.; Kern, M.; Khodadadzadeh, M.; Blannin, R.; Gloaguen, R.; Gutzmer, J. Evaluating the performance of hyperspectral short-wave infrared sensors for the pre-sorting of complex ores using machine learning methods. Miner. Eng. 2020, 146, 106150. [Google Scholar] [CrossRef]
- Barra, I.; Haefele, S.M.; Sakrabani, R.; Kebede, F. Soil spectroscopy with the use of chemometrics, machine learning and pre-processing techniques in soil diagnosis: Recent advances—A review. TrAC Trends Anal. Chem. 2021, 135, 116166. [Google Scholar] [CrossRef]
- Brown, D.J.; Shepherd, K.D.; Walsh, M.G.; Mays, M.D.; Reinsch, T.G. Global soil characterization with VNIR diffuse reflectance spectroscopy. Geoderma 2006, 132, 273–290. [Google Scholar] [CrossRef]
- Chen, S.H.; Jakeman, A.J.; Norton, J.P. Artificial Intelligence techniques: An introduction to their use for modelling environmental systems. Math. Comput. Simul. 2008, 78, 379–400. [Google Scholar] [CrossRef]
- Richter, N.; Jarmer, T.; Chabrillat, S.; Oyonarte, C.; Hostert, P.; Kaufmann, H. Free Iron Oxide Determination in Mediterranean Soils using Diffuse Reflectance Spectroscopy. Soil Sci. Soc. Am. J. 2009, 73, 72–81. [Google Scholar] [CrossRef]
- Rossel, R.V.; Behrens, T. Using data mining to model and interpret soil diffuse reflectance spectra. Geoderma 2010, 158, 46–54. [Google Scholar] [CrossRef]
- Khosravi, V.; Ardejani, F.D.; Yousefi, S.; Aryafar, A. Monitoring soil lead and zinc contents via combination of spectroscopy with extreme learning machine and other data mining methods. Geoderma 2018, 318, 29–41. [Google Scholar] [CrossRef]
- Hu, P.; Liu, X.; Cai, Y.; Cai, Z. Band Selection of Hyperspectral Images Using Multiobjective Optimization-Based Sparse Self-Representation. IEEE Geosci. Remote Sens. Lett. 2018, 16, 452–456. [Google Scholar] [CrossRef]
- Pabón, R.E.C.; Filho, C.R.D.S.; de Oliveira, W.J. Reflectance and imaging spectroscopy applied to detection of petroleum hydrocarbon pollution in bare soils. Sci. Total Environ. 2019, 649, 1224–1236. [Google Scholar] [CrossRef] [PubMed]
- Cardoso-Fernandes, J.; Silva, J.; Lima, A.; Teodoro, A.C.; Perrotta, M.; Cauzid, J.; Roda-Robles, E.; Ribeiro, M.D.A. Reflectance spectroscopy to validate remote sensing data/algorithms for satellite-based lithium (Li) exploration (Central East Portugal). In Earth Resources and Environmental Remote Sensing/GIS Applications XI; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; Volume 11534. [Google Scholar]
- Jia, X.; O’Connor, D.; Shi, Z.; Hou, D. VIRS based detection in combination with machine learning for mapping soil pollution. Environ. Pollut. 2021, 268, 115845. [Google Scholar] [CrossRef]
- Parent, E.J.; Parent, S.É.; Parent, L.E. Machine learning prediction of particle-size distribution from infrared spectra, methodologies and soil features. bioRxiv 2020. [Google Scholar] [CrossRef]
- Silva, A.C.P. Monitoramento da Qualidade de Sinter Feed Através de Dados Espectrais Associados a Aprendizado de Máquina–estudo de Caso: Mina De Carajás Serra Sul (S11D). Master’s Thesis, UFOP, ITV, Ouro Preto, Minas Gerais, Brazil, 2021. Available online: https://www.itv.org/wp-content/uploads/2022/01 (accessed on 20 January 2022).
- ASD FieldSpec® 4 Hi-Res: Espectrorradiômetro de Alta Resolução, Malvern Panalytical. Available online: https://www.malvernpanalytical.com/br/products/product-range/asd-range/fieldspec-range (accessed on 17 January 2022).
- Clark, R.N.; Roush, T.L. Reflectance spectroscopy: Quantitative analysis techniques for remote sensing applications. J. Geophys. Res. Earth Surf. 1984, 89, 6329–6340. [Google Scholar] [CrossRef]
- Kokaly, R.F. Investigating a Physical Basis for Spectroscopic Estimates of Leaf Nitrogen Concentration. Remote Sens. Environ. 2001, 75, 153–161. [Google Scholar] [CrossRef]
- Ozaki, Y.; McClure, W.F.; Christy, A.A. (Eds.) Near-Infrared Spectroscopy in Food Science and Technolog; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Orange Data Mining. Available online: https://github.com/biolab/orange3 (accessed on 15 January 2022).
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 157–175. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Borges, F.A.; Rabelo, R.A.; Araujo, M.A.; Fernandes, R.A. Metodologia baseada no algoritmo adaboost combinado com rede reural Para localização do distúrbio de afundamento de tensão. In Congresso Brasileiro de Automática-CBA; Cidade Universitária Zeferino Vaz: Campinas, Brazil, 2019; Volume 1. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Linden, R. Técnicas de Agrupamento. Rev. Sist. Inf. FSMA 2009, 4, 18–36. [Google Scholar]
- Lantz, B. Machine Learning with R: Expert Techniques for Predictive Modeling; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Filgueiras, P.R. Regressão Por Vetores de Suporte Aplicado na Determinação de Propriedades Físico-Químicas de Petróleo e Biocombustíveis. Ph.D. Thesis, Instituto de Química, Universidade Estadual de Campinas, Campinas, Brazil, 2014. [Google Scholar]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef] [Green Version]
- De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean absolute percentage error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Clout, J.; Manuel, J. Mineralogical, chemical, and physical characteristics of iron ore. In Iron Ore; Woodhead Publishing: Cambridge, UK, 2015; pp. 45–84. [Google Scholar] [CrossRef]
- Dalstra, H.; Guedes, S. Giant hydrothermal hematite deposits with Mg-Fe metasomatism: A comparison of the carajas, hamersley, and other iron ores. Econ. Geol. 2004, 99, 1793–1800. [Google Scholar] [CrossRef]
- Upadhyay, R.; Venkatesh, A.S. Current strategies and future challenges on exploration, beneficiation and value addition of iron ore resources with special emphasis on iron ores from Eastern India. Appl. Earth Sci. 2006, 115, 187–195. [Google Scholar] [CrossRef]
- Van Der Meer, F. Analysis of spectral absorption features in hyperspectral imagery. Int. J. Appl. Earth Obs. Geoinf. 2004, 5, 55–68. [Google Scholar] [CrossRef]
- Pontual, S.; Merry, N.; Gamson, P. Spectral Interpretation-Field Manual. GMEX. Spectral Analysis Guides for Mineral Exploration; AusSpec International Pty. Ltd.: Warrnambool, VIC, Australia, 2008; p. 189. [Google Scholar]
- Townsend, T.E. Discrimination of iron alteration minerals in visible and near-infrared reflectance data. J. Geophys. Res. Earth Surf. 1987, 92, 1441–1454. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample | Fe | SiO2 | P | Al2O3 | Mn | TiO2 | CaO | MgO | K2O |
|---|---|---|---|---|---|---|---|---|---|
| CN_10551 | 61.12 | 0.39 | 0.43 | 2.82 | 0.018 | 0.402 | 0.006 | 0.030 | 0.006 |
| CN_10552 | 61.76 | 0.40 | 0.46 | 2.49 | 0.018 | 0.407 | 0.006 | 0.027 | 0.007 |
| CN_10554 | 61.99 | 0.43 | 0.41 | 2.44 | 0.019 | 0.253 | 0.006 | 0.027 | 0.006 |
| CN_10556 | 60.45 | 0.35 | 0.52 | 2.90 | 0.018 | 0.482 | 0.006 | 0.026 | 0.005 |
| CN_10558 | 60.46 | 0.32 | 0.54 | 2.93 | 0.018 | 0.497 | 0.006 | 0.025 | 0.005 |
| CN_10560 | 61.13 | 0.34 | 0.46 | 2.42 | 0.018 | 0.404 | 0.006 | 0.026 | 0.007 |
| CN_10561 | 62.56 | 0.45 | 0.32 | 1.94 | 0.020 | 0.190 | 0.006 | 0.028 | 0.007 |
| CN_10563 | 63.26 | 0.48 | 0.26 | 1.69 | 0.020 | 0.245 | 0.006 | 0.034 | 0.008 |
| CN_10564 | 64.00 | 0.67 | 0.21 | 1.47 | 0.022 | 0.176 | 0.006 | 0.035 | 0.010 |
| CN_10566 | 63.56 | 0.59 | 0.25 | 1.58 | 0.020 | 0.167 | 0.006 | 0.027 | 0.011 |
| CN_10568 | 61.93 | 0.41 | 0.41 | 2.15 | 0.018 | 0.424 | 0.006 | 0.025 | 0.007 |
| CN_10569 | 62.45 | 0.40 | 0.32 | 1.77 | 0.018 | 0.197 | 0.006 | 0.025 | 0.007 |
| CN_10573 | 63.94 | 0.89 | 0.21 | 1.52 | 0.011 | 0.200 | 0.006 | 0.025 | 0.004 |
| CN_10574 | 63.89 | 0.63 | 0.22 | 1.44 | 0.015 | 0.192 | 0.006 | 0.030 | 0.004 |
| CN_10576 | 61.61 | 0.58 | 0.37 | 1.88 | 0.008 | 0.239 | 0.006 | 0.025 | 0.004 |
| CN_10577 | 62.77 | 0.93 | 0.27 | 1.45 | 0.012 | 0.215 | 0.006 | 0.025 | 0.004 |
| CN_10578 | 63.18 | 0.46 | 0.26 | 1.43 | 0.008 | 0.219 | 0.006 | 0.025 | 0.004 |
| CN_10579 | 62.18 | 0.58 | 0.23 | 2.68 | 0.010 | 0.279 | 0.008 | 0.025 | 0.004 |
| CN_10580 | 63.54 | 0.66 | 0.21 | 1.45 | 0.015 | 0.204 | 0.006 | 0.025 | 0.004 |
| CN_10581 | 62.43 | 0.63 | 0.18 | 2.45 | 0.010 | 0.231 | 0.006 | 0.025 | 0.004 |
| CN_10582 | 61.98 | 9.65 | 0.01 | 0.41 | 0.112 | 0.042 | 0.006 | 0.100 | 0.004 |
| CN_10583 | 58.21 | 14.91 | 0.01 | 0.60 | 0.134 | 0.048 | 0.006 | 0.105 | 0.004 |
| CN_10584 | 41.41 | 39.45 | 0.01 | 0.37 | 0.023 | 0.067 | 0.006 | 0.096 | 0.004 |
| CN_10585 | 68.24 | 1.21 | 0.01 | 0.22 | 0.038 | 0.040 | 0.006 | 0.124 | 0.004 |
| CN_10759 | 62.92 | 0.58 | 0.35 | 2.27 | 0.010 | 0.190 | 0.007 | 0.050 | 0.009 |
| CN_10760 | 64.37 | 0.63 | 0.36 | 1.33 | 0.015 | 0.084 | 0.007 | 0.057 | 0.012 |
| CN_10762 | 65.66 | 0.72 | 0.14 | 0.97 | 0.013 | 0.082 | 0.008 | 0.062 | 0.016 |
| CN_10764 | 64.80 | 0.56 | 0.17 | 1.18 | 0.011 | 0.131 | 0.008 | 0.046 | 0.009 |
| CN_10765 | 66.11 | 0.71 | 0.06 | 0.60 | 0.016 | 0.068 | 0.008 | 0.064 | 0.010 |
| CN_10553 | 61.97 | 0.39 | 0.38 | 2.25 | 0.018 | 0.257 | 0.006 | 0.027 | 0.007 |
| CN_10557 | 62.15 | 0.57 | 0.36 | 2.29 | 0.018 | 0.160 | 0.006 | 0.031 | 0.007 |
| CN_10559 | 61.12 | 0.36 | 0.46 | 2.44 | 0.018 | 0.410 | 0.006 | 0.025 | 0.006 |
| CN_10562 | 63.34 | 0.47 | 0.29 | 1.61 | 0.019 | 0.190 | 0.006 | 0.028 | 0.007 |
| CN_10565 | 64.44 | 0.49 | 0.23 | 1.29 | 0.020 | 0.139 | 0.006 | 0.034 | 0.007 |
| CN_10567 | 62.06 | 0.51 | 0.35 | 2.41 | 0.019 | 0.418 | 0.006 | 0.027 | 0.008 |
| CN_10575 | 62.62 | 0.82 | 0.22 | 1.97 | 0.015 | 0.224 | 0.006 | 0.025 | 0.004 |
| CN_10757 | 62.78 | 0.56 | 0.45 | 1.90 | 0.010 | 0.126 | 0.006 | 0.043 | 0.009 |
| CN_10761 | 64.85 | 0.60 | 0.26 | 1.27 | 0.009 | 0.099 | 0.007 | 0.045 | 0.013 |
| CN_10763 | 65.35 | 0.62 | 0.13 | 0.98 | 0.010 | 0.094 | 0.007 | 0.046 | 0.010 |
| CN_10766 | 65.38 | 0.61 | 0.13 | 1.11 | 0.014 | 0.131 | 0.007 | 0.056 | 0.008 |
| CN_10550 | 60.55 | 0.38 | 0.47 | 3.03 | 0.017 | 0.436 | 0.006 | 0.028 | 0.004 |
| CN_10555 | 63.26 | 0.48 | 0.26 | 1.69 | 0.020 | 0.245 | 0.006 | 0.034 | 0.008 |
| Min | 41.41 | 0.32 | 0.01 | 0.22 | 0.008 | 0.040 | 0.006 | 0.025 | 0.004 |
| Max | 68.24 | 39.45 | 0.54 | 3.03 | 0.134 | 0.497 | 0.008 | 0.124 | 0.016 |
| Average | 62.42 | 2.04 | 0.28 | 1.74 | 0.021 | 0.222 | 0.006 | 0.040 | 0.007 |
| (A) SFP | |||
|---|---|---|---|
| * C-I: 400 to 2500 nn | |||
| Model | R2 | MSE | MAE |
| RF | 0.768 | 0.559 | 0.638 |
| ADB | 0.801 | 0.479 | 0.554 |
| kNN | 0.680 | 0.771 | 0.717 |
| SVM | 0.865 | 0.325 | 0.450 |
| * C-II: 400 to 1310 nm | |||
| RF | 0.670 | 0.795 | 0.728 |
| ADB | 0.725 | 0.662 | 0.685 |
| kNN | 0.627 | 0.898 | 0.760 |
| SVM | 0.758 | 0.584 | 0.676 |
| (B) SFL | |||
| * C-I: 400 to 2500 nm | |||
| Model | R2 | MSE | MAE |
| RF | 0.777 | 0.536 | 0.567 |
| ADB | 0.837 | 0.392 | 0.507 |
| kNN | 0.724 | 0.664 | 0.677 |
| SVM | 0.878 | 0.295 | 0.451 |
| * C-II: 400 to 1310 nm | |||
| RF | 0.884 | 0.280 | 0.452 |
| ADB | 0.872 | 0.308 | 0.935 |
| kNN | 0.732 | 0.647 | 0.650 |
| SVM | 0.795 | 0.493 | 0.569 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, A.C.P.; Coimbra, K.T.Z.; Filho, L.W.R.; Pessin, G.; Correa-Pabón, R.E. Monitoring of Iron Ore Quality through Ultra-Spectral Data and Machine Learning Methods. AI 2022, 3, 554-570. https://doi.org/10.3390/ai3020032
Silva ACP, Coimbra KTZ, Filho LWR, Pessin G, Correa-Pabón RE. Monitoring of Iron Ore Quality through Ultra-Spectral Data and Machine Learning Methods. AI. 2022; 3(2):554-570. https://doi.org/10.3390/ai3020032
Chicago/Turabian StyleSilva, Ana Cristina Pinto, Keyla Thayrinne Zoppi Coimbra, Levi Wellington Rezende Filho, Gustavo Pessin, and Rosa Elvira Correa-Pabón. 2022. "Monitoring of Iron Ore Quality through Ultra-Spectral Data and Machine Learning Methods" AI 3, no. 2: 554-570. https://doi.org/10.3390/ai3020032