
Bayesian Estimation of Latent Space Item Response Models with JAGS, Stan, and NIMBLE in R



Abstract
:1. Introduction
2. Background
2.1. Latent Space Item Response Model
2.2. Bayesian Estimation of LSIRM
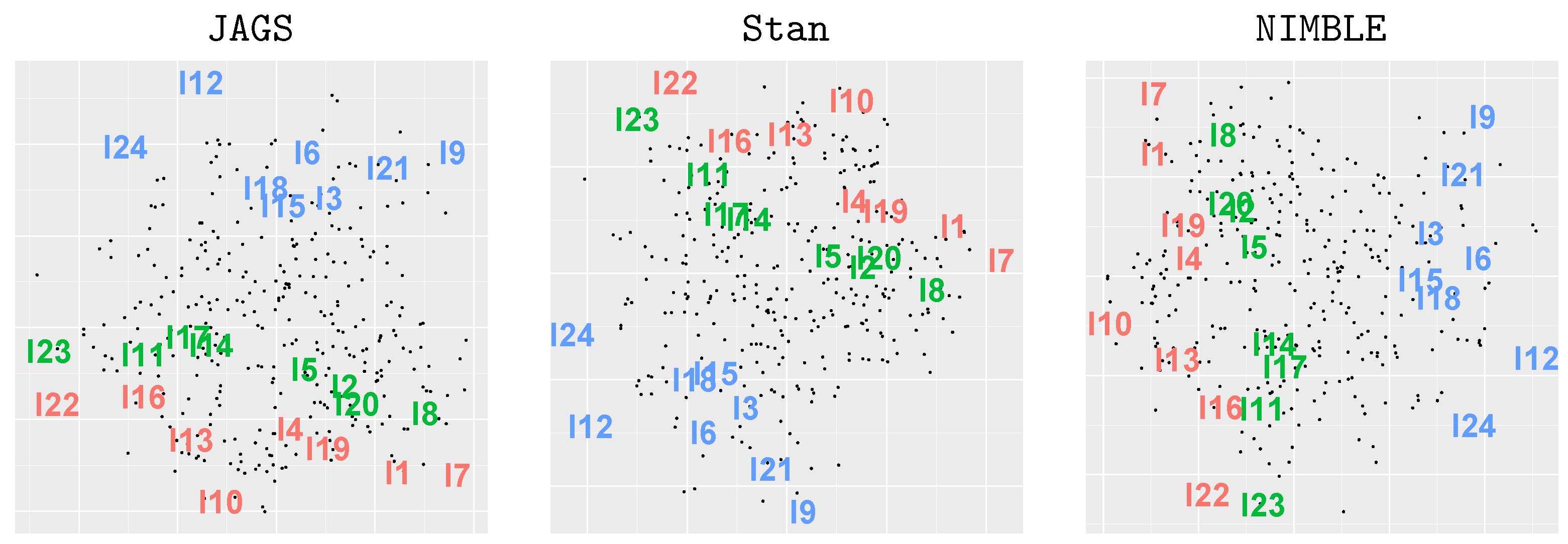
2.3. Interaction Map
3. General-Purpose Bayesian Estimation Packages
3.1. JAGS
3.2. Stan
3.3. NIMBLE
4. Estimating LSIRM with JAGS, Stan, and NIMBLE
4.1. Example Data
| Listing 1: Data loading. |
 |
4.2. LSIRM Estimation in JAGS
Model Specification
| Listing 2: LSIRM model specification in JAGS. |
  |
- Line 9 and line 14 specify normal priors for item intercept () and person intercept (), respectively. The BUGS language defines a normal density asdnorm(mean, precision), where the precision is equal to 1/variance. In the code above, 1/tau_beta^2 indicates the precision where tau_beta is the standard deviation of . Similarly, 1/sigma2 indicates the precision where sigma2 is the variance of .
- Line 10 and line 15 specify bivariate normal priors for the person and item latent positions, respectively, assuming a two-dimensional latent space. The specification can be adjusted if the model specifies a higher-dimensional latent space.
- Lines 19 and 20 set the variance parameter of respondents’ latent trait to follow an Inverse Gamma distribution with the function invsigma ~ dgamma(a_sigma, b_sigma). We then use the reciprocal of invsigma to obtain the desired Inverse Gamma distribution for sigma2.
- Lines 34 to 36 save the log-likelihood.
4.3. Run MCMC in JAGS
| Listing 3: Run MCMC in JAGS. |
  |
- Line 4 reads the specified model from BUGS code (listed in Listing 2).
- Lines 6 to 8 integrate the item response data (r), respondent and item sample size information (N and I) in a list format, which is used in the model specification.
- Lines 12 to 17 set the random numbers and initial values for MCMC estimation.
- Line 19 defines the parameters to monitor and, therefore, to be saved in the posterior samples.
- Lines 21 to 26 generate a compiled model for MCMC estimation in JAGS.
- Lines 28 to 34 execute MCMC and obtain the posterior samples of the parameters specified in the monitor vector (parameters).
- Line 35 uses the window() function to save the posterior samples after completing adaptation (1000 iterations) and the burn-in period (40,000 iterations). That is, the posterior samples are saved starting with the 41,001-th iteration.
| Listing 4: A Wrapper function for JAGS. |
 |
4.4. LSIRM Estimation in Stan
4.4.1. Model Specification
| Listing 5: LSIRM model specification in Stan. |
 |
- Lines 1 to 13 display the data block, where data and hyperparameters are defined. Note that it is mandatory to specify the data type, such as: int as an integer, real as a real number, cov_matrix as a covariance matrix. This follows the convention of programming languages like C++.
- Lines 14 to 21 contain the parameters block, where the parameters to estimate are defined with the type and range of values.
- The range of values that each object can take can be defined inside the symbol. For instance, we know that the number of respondents and items, tau_gamma and tau_beta can only be positive, so the lower bound is set to 0, while, for responses, the lower bound is set to 0 and the upper bound to 1.
- Lines 22 to 39 define the model. Note that the normal distribution in Stan is parameterized with mean and standard deviation, while the inverse gamma distribution is specified with shape and scale.
- Lines 41 to 47 present the generated quantity block that computes the log-likelihood.
- The code in Listing 5 can be used in different ways, depending on the choice of MCMC sampling function. It can be written within brackets in the R script, saved in a mymodel object, for Stan model compilation with the stan_model() function. Users can also save it as mymodel.stan file, and directly call the model from stan() (wrapper) function. We demonstrate the two procedures in Listings 6 and 7.
4.4.2. Run MCMC in Stan
| Listing 6: Run MCMC in Stan. |
 |
- In Line 4, inside the “ ”, the code for the model specification that we presented in Listing 5 should be copied as text.
- From Lines 6 to 15 data and hyperparameters are set
- In Lines 19 to 24 the two chains of MCMC are initialized with the same set of values.
- In Lines 30 to 38 the MCMC algorithm is run to sample from the posterior distribution of the model parameters, given the data. The samples are stored in an object of class stanfit.
| Listing 7: A Wrapper function for Stan. |
 |
4.5. LSIRM Estimation in NIMBLE
| Listing 8: LSIRM model specification in NIMBLE. |
 |
4.5.1. Model Specification
- Lines 11 and 17 specify bivariate normal priors for the person and item latent positions in a two-dimensional latent space.
- Line 15 specifies dnorm(mean, var) parameterization for the normal prior for . NIMBLE uses dnorm(mean, sd). Here, we use the var parameterization to be consistent with the original specification used by Jeon et al. in [1].
- Line 19 uses a normal prior for log(gamma). One can also directly use dlnorm() in NIMBLE, as shown in Listing 2 with JAGS.
- Lines 22 to 26 save the log-likelihood.
4.5.2. Run MCMC in NIMBLE
| Listing 9: Run MCMC in NIMBLE. |
 |
- Lines 6 to 14 define the constants used in the model specification and pos_mu and pos_covmat define the two-dimensional identity matrix.
- Lines 18 to 24 provide the initial values for the MCMC estimation. In NIMBLE, log(gamma) is treated as an independent parameter log_gamma. Therefore, an initial value is provided for log_gamma.
- Line 26 defines an array of parameters of interest to be saved in the posterior samples.
- In Lines 28 to 31, the nimbleModel() function processes the model code, constants, data, and initial values and returns a NIMBLE model. NIMBLE checks the model specification, model sizes, and dimensions at this step.
- Line 32 compileNimble() compiles the specified model.
- Lines 33 to 35 create and return an uncompiled executable MCMC function.
- Line 36 compiles the executable MCMC function regarding the complied specified model.
- Lines 38 to 44 run MCMC, and save the posterior samples of the parameters specified in myparams vector.
| Listing 10: A Wrapper function for NIMBLE. |
 |
5. Model Evaluation
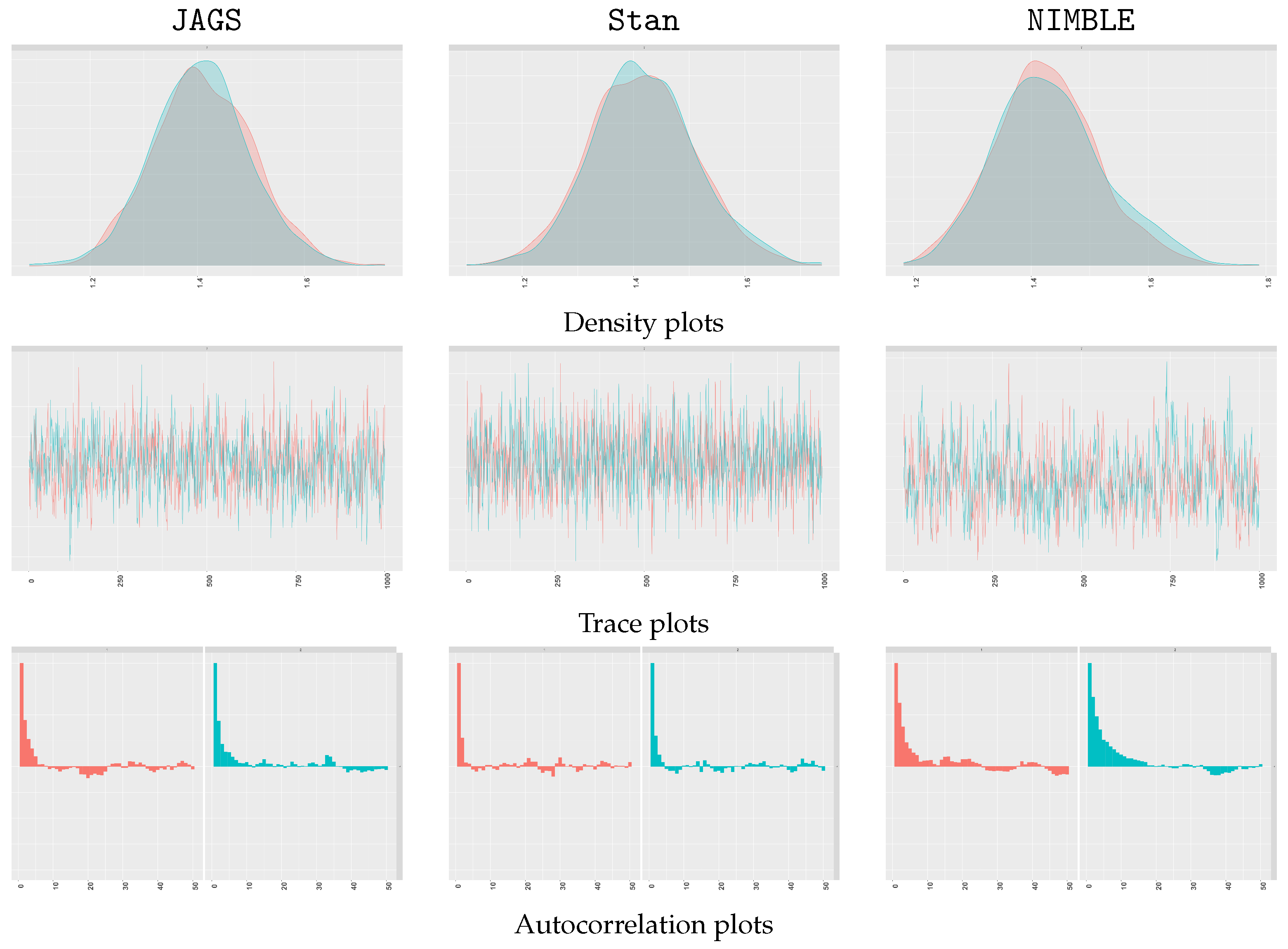
5.1. MCMC Convergence Diagnostics
| Listing 11: Convergence checking with ggmcmc. |
 |
5.2. Model Fit Indices: WAIC and LPPD
| Listing 12: Model fit indices from loo. |
  |
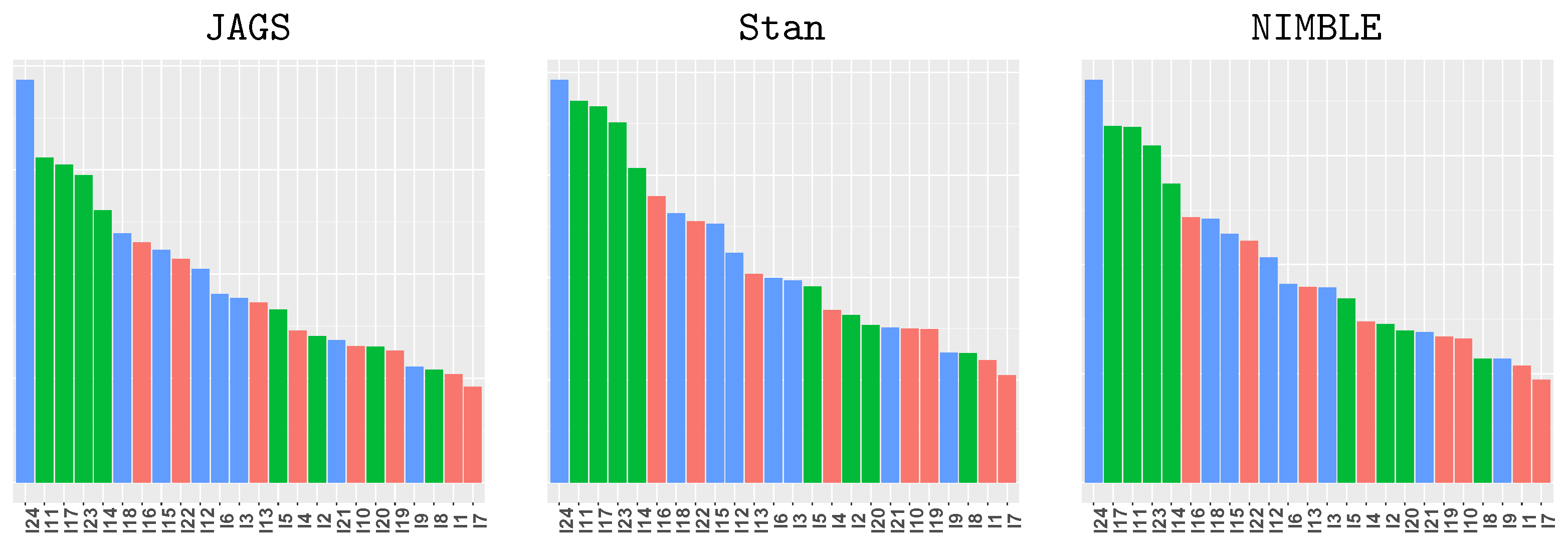
5.3. Effective Sample Size, Run Time, and Sampling Efficiency
| Listing 13: Effective sample size from coda. |
 |
6. Estimated Results
6.1. Model Parameters
| Listing 14: Extracting information from MCMC chains. |
 |
6.2. Interaction Map Visualization
| Listing 15: Procrustes matching and visualization of interaction map and strength (inverse distance) plots. |
 |
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jeon, M.; Jin, I.H.; Schweinberger, M.; Baugh, S. Mapping Unobserved Item–Respondent Interactions: A Latent Space Item Response Model with Interaction Map. Psychometrika 2021, 86, 378–403. [Google Scholar] [CrossRef] [PubMed]
- Rasch, G. On General Laws and the Meaning of Measurement in Psychology. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 4: Contributions to Biology and Problems of Health, Oakland, CA, USA, 20 June–30 July 1961; pp. 321–333. [Google Scholar]
- Ken Kellner, M.M. jagsUI: A Wrapper around ’rjags’ to Streamline ’JAGS’ Analyses; R Package Version 1.5.2; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- Plummer, M. rjags: Bayesian Graphical Models Using MCMC; R Package Version 4-13; R Core Team: Vienna, Austria, 2022. [Google Scholar]
- Plummer, M. JAGS: A Program for Analysis of Bayesian Graphical Models Using Gibbs Sampling. In Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003), Vienna, Austria, 20–22 March 2003; pp. 1–10. [Google Scholar]
- Gelman, A.; Lee, D.; Guo, J. Stan: A Probabilistic Programming Language for Bayesian Inference and Optimization. J. Educ. Behav. Stat. 2015, 40, 530–543. [Google Scholar] [CrossRef]
- Stan Development Team. RStan: The R Interface to Stan; R Package Version 2.21.8; Stan Development Team: Scarborough, OT, USA, 2023. [Google Scholar]
- De Valpine, P.; Turek, D.; Paciorek, C.; Anderson-Bergman, C.; Temple Lang, D.; Bodik, R. Programming with Models: Writing Statistical Algorithms for General Model Structures with NIMBLE. J. Comput. Graph. Stat. 2017, 26, 403–413. [Google Scholar] [CrossRef]
- De Valpine, P.; Paciorek, C.; Turek, D.; Michaud, N.; Anderson-Bergman, C.; Obermeyer, F.; Wehrhahn Cortes, C.; Rodrìguez, A.; Temple Lang, D.; Paganin, S. NIMBLE: MCMC, Particle Filtering, and Programmable Hierarchical Modeling; R Package Version 0.12.1; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar] [CrossRef]
- Hoff, P.D.; Raftery, A.E.; Handcock, M.S. Latent Space Approaches to Social Network Analysis. J. Am. Stat. Assoc. 2002, 97, 1090–1098. [Google Scholar] [CrossRef]
- Shortreed, S.; Handcock, M.S.; Hoff, P. Positional Estimation Within a Latent Space Model for Networks. Methodology 2006, 2, 24–33. [Google Scholar] [CrossRef]
- Gower, J.C. Generalized Procrustes Analysis. Psychometrika 1975, 40, 33–51. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Park, J.H.; Cameletti, M.; Pang, X.; Quinn, K.M. CRAN Task View: Bayesian Inference; Comprehensive R Archive Network (CRAN): Vienna, Austria, 2022. [Google Scholar]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence Diagnosis and Output Analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Depaoli, S.; Clifton, J.P.; Cobb, P.R. Just Another Gibbs Sampler(JAGS): Flexible Software for MCMC Implementation. J. Educ. Behav. Stat. 2016, 41, 628–649. [Google Scholar] [CrossRef]
- Curtis, S.M. BUGS Code for Item Response Theory. J. Stat. Softw. 2010, 36, 1–34. [Google Scholar] [CrossRef]
- Zhan, P.; Jiao, H.; Man, K.; Wang, L. Using JAGS for Bayesian Cognitive Diagnosis Modeling: A Tutorial. J. Educ. Behav. Stat. 2019, 44, 473–503. [Google Scholar] [CrossRef]
- Qiu, M. A Tutorial on Bayesian Latent Class Analysis Using JAGS. J. Behav. Data Sci. 2022, 2, 127–155. [Google Scholar] [CrossRef]
- Merkle, E.C.; Furr, D. Bayesian Comparison of Latent Variable Models: Conditional versus Marginal Likelihoods. Psychometrika 2019, 84, 802–829. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z. Handling Ignorable and Non-ignorable Missing Data through Bayesian Methods in JAGS. J. Behav. Data Sci. 2022, 2, 99–126. [Google Scholar] [CrossRef]
- Ciminelli, J.T.; Love, T.; Wu, T.T. Social Network Spatial Model. Spat. Stat. 2019, 29, 129–144. [Google Scholar] [CrossRef]
- Metropolis, N.; Ulam, S. The Monte Carlo Method. J. Am. Stat. Assoc. 1949, 44, 335–341. [Google Scholar] [CrossRef]
- Hoffman, S. Zero Benefit: Estimating the Effect of Zero Tolerance Discipline Polices on Racial Disparities in School Discipline. Educ. Policy 2014, 28, 69–95. [Google Scholar] [CrossRef]
- Neal, D.T.; Wood, W.; Wu, M.; Kurlander, D. The Pull of the Past: When Do Habits Persist Despite Conflict with Motives? Personal. Soc. Psychol. Bull. 2011, 37, 1428–1437. [Google Scholar] [CrossRef] [PubMed]
- Monnahan, C.C.; Thorson, J.T.; Branch, T.A. Faster Estimation of Bayesian Models in Ecology Using Hamiltonian Monte Carlo. Methods Ecol. Evol. 2017, 8, 339–348. [Google Scholar] [CrossRef]
- Bølstad, J. How Efficient is Stan Compared to JAGS? Conjugacy, Pooling, Centering, and Posterior Correlations. Playing with Numbers: Notes on Bayesian Statistics. 2019. Available online: https://www.boelstad.net/post/stan_vs_jags_speed/ (accessed on 1 May 2023).
- Salter-Townshend, M.; McCormick, T.H. Latent Space Models for Multiview Network Data. Ann. Appl. Stat. 2017, 11, 1217. [Google Scholar] [CrossRef]
- Salter-Townshend, M.; Murphy, T.B. Variational Bayesian Inference for the Latent Position Cluster Model for Network Data. Comput. Stat. Data Anal. 2013, 57, 661–671. [Google Scholar] [CrossRef]
- Beraha, M.; Falco, D.; Guglielmi, A. JAGS, NIMBLE, Stan: A detailed comparison among Bayesian MCMC software. arXiv 2021, arXiv:2107.09357. [Google Scholar]
- Paganin, S.; Paciorek, C.J.; Wehrhahn, C.; Rodríguez, A.; Rabe-Hesketh, S.; de Valpine, P. Computational Strategies and Estimation Performance with Bayesian Semiparametric Item Response Theory Models. J. Educ. Behav. Stat. 2023, 48, 147–188. [Google Scholar] [CrossRef]
- Wang, W.; Kingston, N. Using Bayesian Nonparametric Item Response Function Estimation to Check Parametric Model Fit. Appl. Psychol. Meas. 2020, 44, 331–345. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Chen, G. Bayesian Semiparametric Latent Variable Model with DP Prior for Joint Analysis: Implementation with NIMBLE. Stat. Model. 2020, 20, 71–95. [Google Scholar] [CrossRef]
- Gelman, A.; Simpson, D.; Betancourt, M. The prior can often only be understood in the context of the likelihood. Entropy 2017, 19, 555. [Google Scholar] [CrossRef]
- Depaoli, S.; Winter, S.D.; Visser, M. The importance of prior sensitivity analysis in Bayesian statistics: Demonstrations using an interactive Shiny App. Front. Psychol. 2020, 11, 608045. [Google Scholar] [CrossRef]
- Zitzmann, S.; Lüdtke, O.; Robitzsch, A.; Hecht, M. On the performance of Bayesian approaches in small samples: A comment on Smid, McNeish, Miocevic, and van de Schoot (2020). Struct. Equ. Model. Multidiscip. J. 2021, 28, 40–50. [Google Scholar] [CrossRef]
- Smid, S.C.; McNeish, D.; Miočević, M.; van de Schoot, R. Bayesian versus frequentist estimation for structural equation models in small sample contexts: A systematic review. Struct. Equ. Model. Multidiscip. J. 2020, 27, 131–161. [Google Scholar] [CrossRef]
- De Boeck, P.; Wilson, M. (Eds.) Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach; Springer: New York, NY, USA, 2004; pp. 7–10. [Google Scholar] [CrossRef]
- Magis, D.; Beland, S.; Tuerlinckx, F.; De Boeck, P. A General Framework and an R Package for the Detection of Dichotomous Differential Item Functioning. Behav. Res. Methods 2010, 42, 847–862. [Google Scholar] [CrossRef]
- Jeon, M.; Rijmen, F. A Modular Approach for Item Response Theory Modeling with the R Package Flirt. Behav. Res. Methods 2016, 48, 742–755. [Google Scholar] [CrossRef]
- Gabry, J.; Simpson, D.; Vehtari, A.; Betancourt, M.; Gelman, A. Visualization in Bayesian Workflow. J. R. Stat. Soc. A 2019, 182, 389–402. [Google Scholar] [CrossRef]
- Betancourt, M. A conceptual introduction to Hamiltonian Monte Carlo. arXiv 2017, arXiv:1701.02434. [Google Scholar]
- Betancourt, M.; Girolami, M. Hamiltonian Monte Carlo for Hierarchical Models. Curr. Trends Bayesian Methodol. Appl. 2015, 79, 2–4. [Google Scholar] [CrossRef]
- Gabry, J.; Veen, D. Shinystan: Interactive Visual and Numerical Diagnostics and Posterior Analysis for Bayesian Models; R Package Version 2.6.0; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- RStudio Team. RStudio: Integrated Development for R; RStudio, PBC: Boston, MA, USA, 2020. [Google Scholar]
- Fernández-i-Marín, X. ggmcmc: Analysis of MCMC Samples and Bayesian Inference. J. Stat. Softw. 2016, 70, 1–20. [Google Scholar] [CrossRef]
- Valero-Mora, P.M. ggplot2: Elegant Graphics for Data Analysis. J. Stat. Softw. Book Rev. 2010, 35, 1–3. [Google Scholar] [CrossRef]
- Watanabe, S. Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory. J. Mach. Learn. Res. 2010, 11, 3571–3594. [Google Scholar] [CrossRef]
- Gelman, A.; Hwang, J.; Vehtari, A. Understanding Predictive Information Criteria for Bayesian Models. Stat. Comput. 2014, 24, 997–1016. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; van der Linde, A. Bayesian Measures of Model Complexity and Fit. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2002, 64, 583–639. [Google Scholar] [CrossRef]
- Vehtari, A.; Gelman, A.; Gabry, J. Practical Bayesian Model Evaluation Using Leave-One-Out Cross-Validation and WAIC. Stat. Comput. 2017, 27, 1413–1432. [Google Scholar] [CrossRef]
- Vehtari, A.; Gabry, J.; Magnusson, M.; Yao, Y.; Bürkner, P.C.; Paananen, T.; Gelman, A. loo: Efficient Leave-One-Out Cross-Validation and WAIC for Bayesian Models; R Package Version 2.5.1; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Boca Raton, FL, USA, 2013; pp. 286–287. [Google Scholar] [CrossRef]
- Zitzmann, S.; Hecht, M. Going beyond convergence in Bayesian estimation: Why precision matters too and how to assess it. Struct. Equ. Model. Multidiscip. J. 2019, 26, 646–661. [Google Scholar] [CrossRef]
- Hecht, M.; Weirich, S.; Zitzmann, S. Comparing the MCMC Efficiency of JAGS and Stan for the Multi-Level Intercept-Only Model in the Covariance- and Mean-Based and Classic Parametrization. Psych 2021, 3, 751–779. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Index | JAGS | Stan | NIMBLE |
|---|---|---|---|
| WAIC | 7166.86 | 7168.14 | 7168.63 |
| () | (672.42) | (674.19) | (675.24) |
| LPPD | −2911.01 | −2909.88 | −2909.07 |
| Time | JAGS | Stan | NIMBLE |
|---|---|---|---|
| Compilation (min) | 6.99 | 0.67 | 4.28 |
| Sampling: one core (h) | 4.52 | 3.16 | 0.87 |
| Sampling: parallel on two cores (h) | 1.85 | 1.04 | 0.29 |
| JAGS | Stan | NIMBLE | ||||
|---|---|---|---|---|---|---|
| ESS | ESS/Time | ESS | ESS/Time | ESS | ESS/Time | |
| 808.81 | 1.19 | 1521.01 | 9.78 | 688.38 | 5.26 | |
| 1944.10 | 37.75 | 1970.61 | 166.78 | 1920.58 | 193.21 | |
| 1842.28 | 0.11 | 1560.23 | 0.42 | 1480.57 | 0.47 | |
| 633.11 | 0.04 | 1105.40 | 0.30 | 336.79 | 0.11 | |
| JAGS | Stan | NIMBLE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Post.m | 95 %CI | Post.m | 95 %CI | Post.m | 95 %CI | ||||
| 4.01 | 3.17 | 5.20 | 4.05 | 3.22 | 5.15 | 4.03 | 3.21 | 5.17 | |
| 2.54 | 2.08 | 3.11 | 2.55 | 2.08 | 3.17 | 2.56 | 2.09 | 3.14 | |
| 2.33 | 1.75 | 3.19 | 2.34 | 1.79 | 3.19 | 2.36 | 1.78 | 3.23 | |
| 4.00 | 3.36 | 4.96 | 4.03 | 3.38 | 4.97 | 4.06 | 3.41 | 4.94 | |
| 2.55 | 2.13 | 3.01 | 2.57 | 2.15 | 3.03 | 2.58 | 2.15 | 3.03 | |
| 2.59 | 1.87 | 3.67 | 2.59 | 1.89 | 3.65 | 2.60 | 1.87 | 3.63 | |
| 3.67 | 2.72 | 4.86 | 3.67 | 2.72 | 4.93 | 3.61 | 2.70 | 4.84 | |
| 1.60 | 0.94 | 2.49 | 1.60 | 0.95 | 2.55 | 1.57 | 0.94 | 2.57 | |
| 1.27 | 0.32 | 2.59 | 1.30 | 0.33 | 2.59 | 1.28 | 0.33 | 2.62 | |
| 3.85 | 2.89 | 4.99 | 3.93 | 2.97 | 5.22 | 3.96 | 2.98 | 5.11 | |
| 1.76 | 1.18 | 2.63 | 1.79 | 1.22 | 2.60 | 1.79 | 1.20 | 2.70 | |
| 2.02 | 1.10 | 3.43 | 2.03 | 1.05 | 3.37 | 2.01 | 1.03 | 3.27 | |
| 3.75 | 3.00 | 4.85 | 3.70 | 2.96 | 4.80 | 3.71 | 3.00 | 4.74 | |
| 2.28 | 1.84 | 2.84 | 2.27 | 1.83 | 2.77 | 2.28 | 1.82 | 2.81 | |
| 1.12 | 0.60 | 1.81 | 1.12 | 0.58 | 1.87 | 1.12 | 0.59 | 1.88 | |
| 3.40 | 2.66 | 4.46 | 3.34 | 2.63 | 4.34 | 3.34 | 2.65 | 4.41 | |
| 1.85 | 1.37 | 2.43 | 1.86 | 1.39 | 2.44 | 1.87 | 1.39 | 2.50 | |
| 0.51 | −0.09 | 1.26 | 0.53 | −0.06 | 1.31 | 0.53 | −0.06 | 1.40 | |
| 1.96 | 1.36 | 2.94 | 1.92 | 1.34 | 2.80 | 1.91 | 1.33 | 2.84 | |
| 0.32 | −0.21 | 1.03 | 0.31 | −0.20 | 0.97 | 0.30 | −0.21 | 1.02 | |
| −0.72 | −1.68 | 0.77 | −0.69 | −1.67 | 0.84 | −0.71 | −1.71 | 0.75 | |
| 3.85 | 2.90 | 5.03 | 3.83 | 2.88 | 5.08 | 3.86 | 2.89 | 5.15 | |
| 2.45 | 1.61 | 3.58 | 2.46 | 1.59 | 3.69 | 2.47 | 1.59 | 3.71 | |
| 0.63 | −0.29 | 1.96 | 0.66 | −0.27 | 2.09 | 0.61 | −0.30 | 1.86 | |
| 2.42 | 1.88 | 3.02 | 2.41 | 1.86 | 3.04 | 2.40 | 1.89 | 3.04 | |
| 1.41 | 1.24 | 1.59 | 1.42 | 1.24 | 1.62 | 1.43 | 1.26 | 1.63 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; De Carolis, L.; Zeng, B.; Jeon, M. Bayesian Estimation of Latent Space Item Response Models with JAGS, Stan, and NIMBLE in R. Psych 2023, 5, 396-415. https://doi.org/10.3390/psych5020027
Luo J, De Carolis L, Zeng B, Jeon M. Bayesian Estimation of Latent Space Item Response Models with JAGS, Stan, and NIMBLE in R. Psych. 2023; 5(2):396-415. https://doi.org/10.3390/psych5020027
Chicago/Turabian StyleLuo, Jinwen, Ludovica De Carolis, Biao Zeng, and Minjeong Jeon. 2023. "Bayesian Estimation of Latent Space Item Response Models with JAGS, Stan, and NIMBLE in R" Psych 5, no. 2: 396-415. https://doi.org/10.3390/psych5020027