
Efficient Non-DHT-Based RC-Based Architecture for Fog Computing in Healthcare 4.0

Abstract
:1. Introduction
Our Contribution
2. Distributed Hash Table P2P vs. RC-Based P2P
2.1. DHT-Based P2P
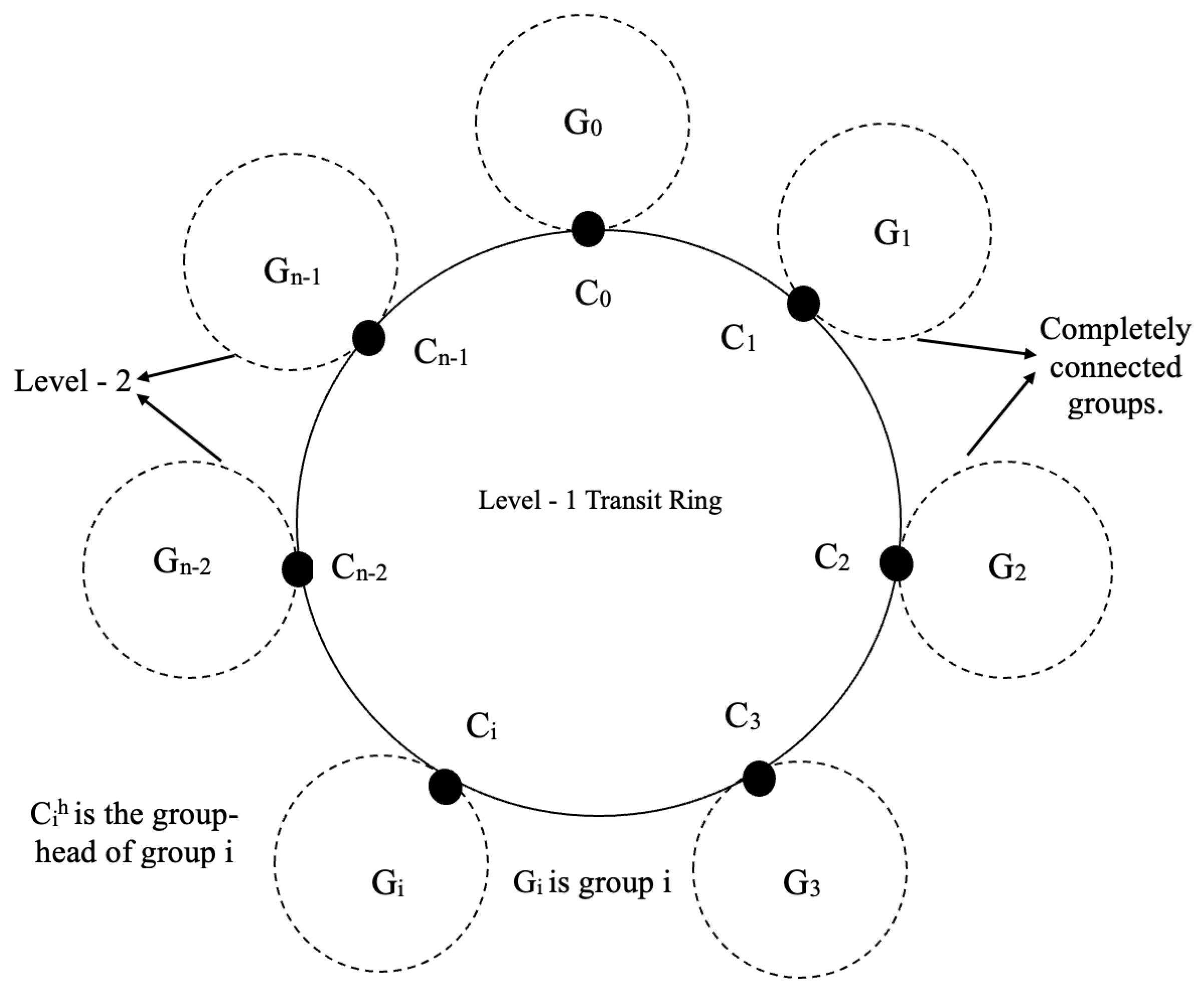
2.2. RC-Based P2P Architecture [20]
- 1.
- At level 1, there is a ring network consisting of the peers (). The ring has n peers, which corresponds to the number of different resource kinds. This ring network is known as a transit ring since it is utilized for quick data search.
- 2.
- There are n totally linked networks (groups) of peers at level 2. Each of these groups, say , is made up of the peers of the subset , in such a way that all of the peers (∈) are logically connected and the network has a diameter of 1. Each has a group-head that connects it to the transit ring network.
- 3.
- Each peer on the transit ring network maintains a global resource table (GRT) that consists of n number of tuples. GRT contains one tuple per group and each tuple is of the form <Group-Head Logical address, IP address>, where Group-Head Logical Address refers to the architecture. Additionally, Resource Code is the same as the group-head logical address.
- 4.
- Each group-head also maintains a local resource table (LRT) that consists of k number of tuples, where k is equal to the number of members present in that group . LRT contains a tuple of the form <Group member Logical address, IP address>. This LRT is also maintained by all the group-members of .
- 5.
- Any communication between a peer ∈ group and ∈ group takes place only through the corresponding group-heads and .
2.2.1. Relevant Properties of Modular Arithmetic
2.2.2. Assignments of Overlay Addresses
- 1.
- Logical addresses of peers in a subset (i.e., group ): It will be shown how to use these addresses to support the claim that all peers (∈) are (logically) directly linked to one another, producing an overlay network of diameter 1. Each , as used in graph theory, is a whole graph.
- 2.
- Identifying which peers on the transit ring network are neighbors with one another.
- 3.
- Identifying each distinct resource type with a unique code.
- 1.
- At level 1, the smallest non-negative number (r) of the residue class r (mod n) of the residue system, is assigned to each group-head of group .
- 2.
- At level 2, the group (i.e., the subset ) will be formed by all peers with the same resource type , with the group-head connected to the transit ring network. Given to each new peer that joins group is the group membership address (r + j.n), where j is 1, 2, 3 ….
- 3.
- Resource class possessed by peers in is assigned the code r which is also the logical address of the group-head of group .
- 4.
- A corresponding tuple of <Group-Head Logical Address, IP Address> is added to the global resource table (GRT) each time a new group-head joins.
2.2.3. Salient Features of Overlay Architecture
- 1.
- It is a two − level hierarchical overlay network architecture with a structured network at each level.
- 2.
- A group-head address would be identical to the resource type held by the group using modular arithmetic described in Section 2.2.1.
- 3.
- 4.
- Assume in general that there are already i group-heads (, , …) in the ring. The address i will then be given to the following peer joining the system as the group leader with resource type i. As an illustration, the sixth group-head joining the system will have the logical address 5 and the resource type code 5, respectively.
- 5.
- The diameter of the transit ring network is n/2. Please note that in any P2P network, the total number of peers N >> n.
- 6.
- In level 2, every overlay network is fully connected, i.e., in terms of graph theory, it is a full graph made up of the group peers. Its diameter is therefore just 1. The design provides the lowest feasible search latency inside a group due to its smallest diameter (in terms of overlay hops).
2.2.4. Fault Tolerance of the Architecture
2.2.5. Scalability of the Architecture
2.3. Comparison of Distributed Hash Table P2P vs. RC-Based P2P
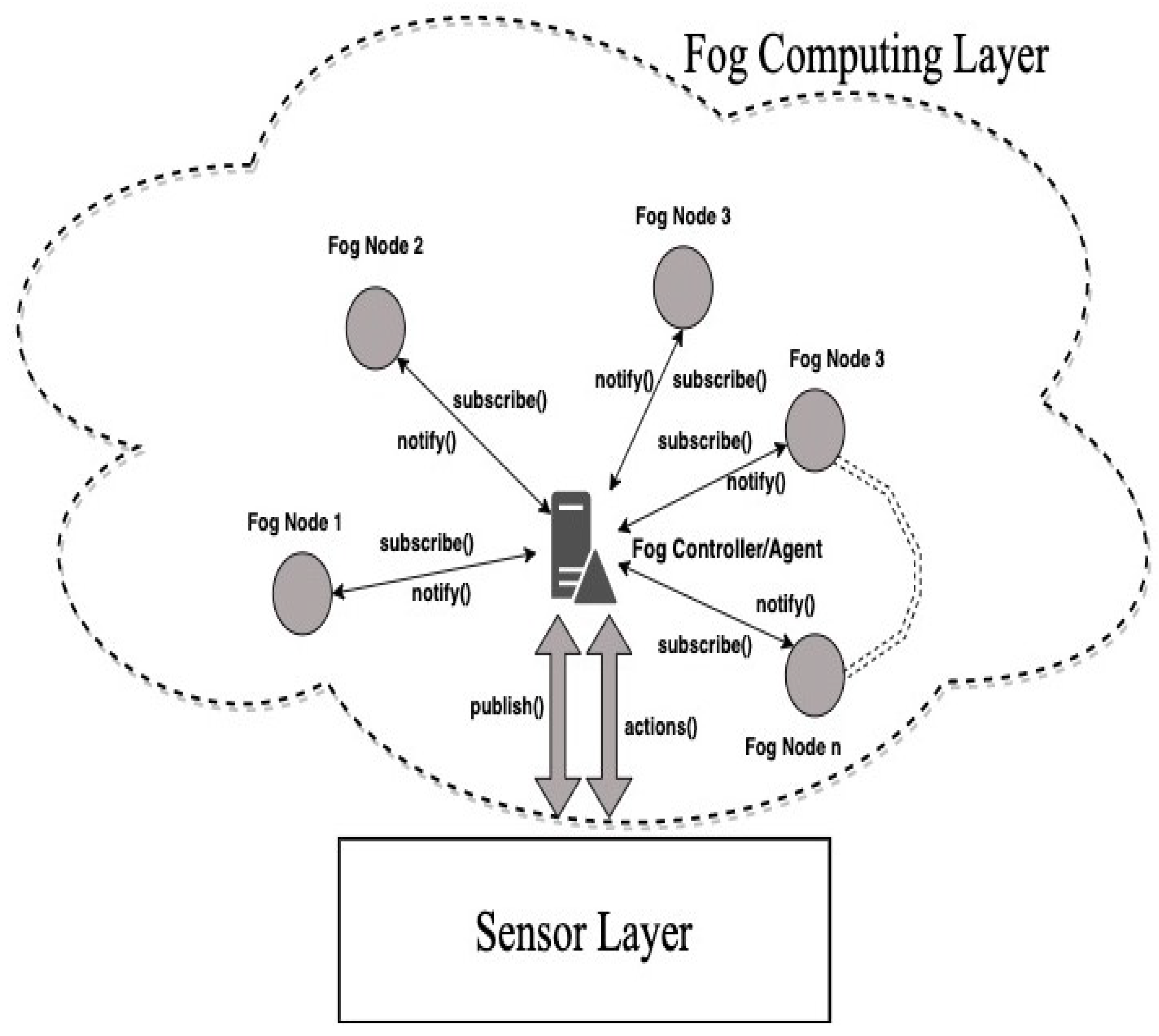
3. Publish/Subscribe and RC-Based P2P Architecture for Fog Computing
3.1. PubSub-Based Fog-Computing Framework
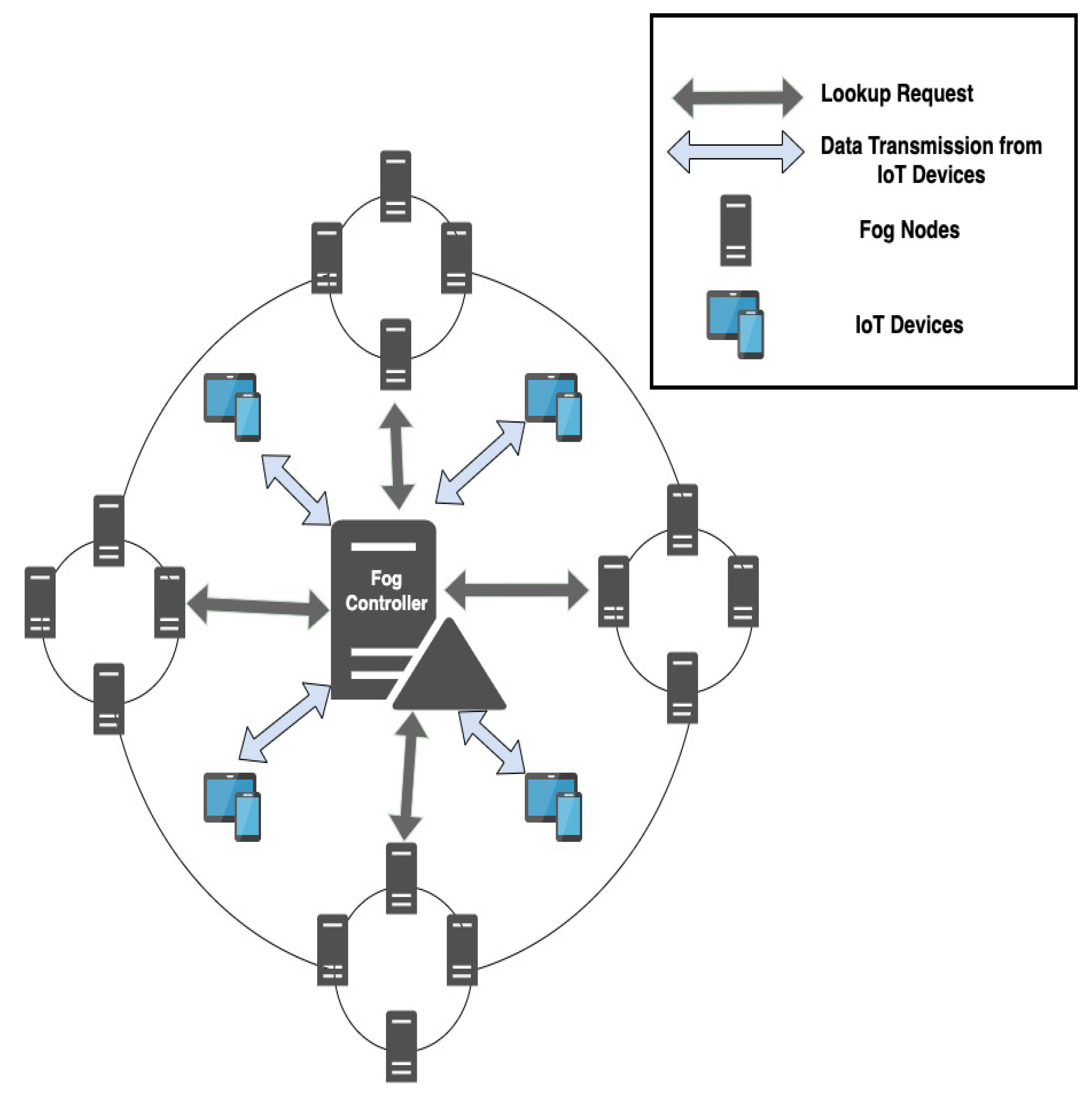
3.2. RC-Based P2P Fog-Computing Architecture
- Scenario 1: The fog node itself has .
- Scenario 2: The fog node who has is the group member of the group .
- Scenario 3: The fog node who has is the group-head of another group .
- Scenario 4: The fog node who has is the group member of another group .

3.2.1. RC-Based Lookup Protocol
- Scenario 1 (Section 3.2): The fog node itself has .
- −
- FC forwards the advertised job to .
- −
- If falls in the computing range and the fog node have the resource it will provide service to FC.
This scenario is presented in Algorithm 1.Algorithm 1 Scenario 1 (Section 3.2): The fog node itself has the resource - 1:
- FC forwards the advertised job to ;
- 2:
- if () ∧ possess then
- 3:
- unicasts service to FC;
- 4:
- else if Scenario 2 or Scenario 3 or Scenario 4 then
- 5:
- Respective Scenario solution
- 6:
- else
- 7:
- informs FC no one has ;
- 8:
- cloud node is contacted by FC for service ;
- 9:
- cloud responds with to FC;
- 10:
- end if
Observation 1: The number of hops required for an FC to find a resource in the proposed overlay P2P architecture for Scenario 1 (Section 3.2) is only 2 which is constant. - Scenario 2 (Section 3.2): The fog node who has is the group member of the group of .
- −
- FC forwards the advertised job to .
- −
- Fog node does not have ,
- −
- If falls in the computing range ,it will broadcast the advertised message in its group using LRT.
- −
- Fog node in who has will reply with the service to the .
- −
- will reply to FC with the service.
This scenario is presented in Algorithm 2.Algorithm 2 Scenario 2 (Section 3.2): The fog node that has the resource is the group member of the group of - 1:
- FC forwards the advertised job to ;
- 2:
- if () ∧ does not possess then
- 3:
- broadcast the advertised message in its group using LRT;
- 4:
- if ∈ possess then
- 5:
- unicasts service to ;
- 6:
- respond to FC with the service ;
- 7:
- else if Scenario 3 or Scenario 4 then
- 8:
- Respective Scenario solution
- 9:
- else
- 10:
- informs FC no one has ;
- 11:
- cloud node is contacted by FC for service ;
- 12:
- cloud responds with to FC;
- 13:
- end if
- 14:
- end if
Observation 2: The number of hops required for an FC to find a resource in the proposed overlay P2P architecture for Scenario 2 (Section 3.2) is only 4 which is constant. - Scenario 3 (Section 3.2): The fog node that has the resource is the group-head of another resource type .
- −
- FC forwards the advertised job to .
- −
- Fog node and any ∈ does not have the resource .
- −
- determines the group-head ’s address code from GRT such that ∈ the computing range for (i = y).
- −
- computes .
- −
- Based upon the value of h, it will forward to its predecessor or its successor.
- −
- Every group-head traversed forwards until i = y.
- −
- If has the resource, it will reply with the service to the .
- −
- will reply to the FC with the service.
This scenario is presented in Algorithm 3.Algorithm 3 Scenario 3 (Section 3.2): The fog node that has the resource is the group-head of another resource type - 1:
- FC forwards the advertised job to ;
- 2:
- if∉then
- 3:
- determines the group-head ’s address code from GRT; ▹∈ the computing range for (i = y)
- 4:
- computes ;
- 5:
- if h > n/2 then ▹ n = total no. of computing ranges
- 6:
- forwards the advertised message along with ’s IP address to its predecessor ;
- 7:
- else
- 8:
- forwards the advertised message along with ’s IP address to its successor ; ▹ Looking for minimum no. of hops along the transit ring network
- 9:
- end if
- 10:
- All intermediate group-heads forwards until i = y ▹ no. of hops along the ring in the worst case is n/2
- 11:
- if possess then
- 12:
- unicasts service to ;
- 13:
- respond to FC with the service ;
- 14:
- else if Scenario 4 then
- 15:
- Respective Scenario solution
- 16:
- else
- 17:
- informs FC no one has ;
- 18:
- cloud node is contacted by FC for service ;
- 19:
- cloud responds with to FC;
- 20:
- end if
- 21:
- end if
Observation 3: The number of hops required for an FC to find a resource in the proposed overlay P2P architecture for Scenario 3 (Section 3.2) is , where n is the total number of computing ranges in the network, the data-lookup complexity is O(n). - Scenario 4 (Section 3.2): The fog node who has is the group member another group .
- −
- FC forwards the advertised job to .
- −
- Fog node and any ∈ does not have .
- −
- determines the group-head ’s address code from GRT such that ∈ the computing range for (i = y).
- −
- computes .
- −
- Based upon the value of h, it will forward to its predecessor or its successor.
- −
- Every group-head traversed forwards until i = y.
- −
- If does not have it will broadcast the message in group .
- −
- Fog node in who has will reply with the service to the .
- −
- will reply to with the service.
- −
- will reply to FC with the service.
This scenario is presented in Algorithm 4.
| Algorithm 4 Scenario 4 (Section 3.2): The fog node that has is the group member of the group of another resource type |
|
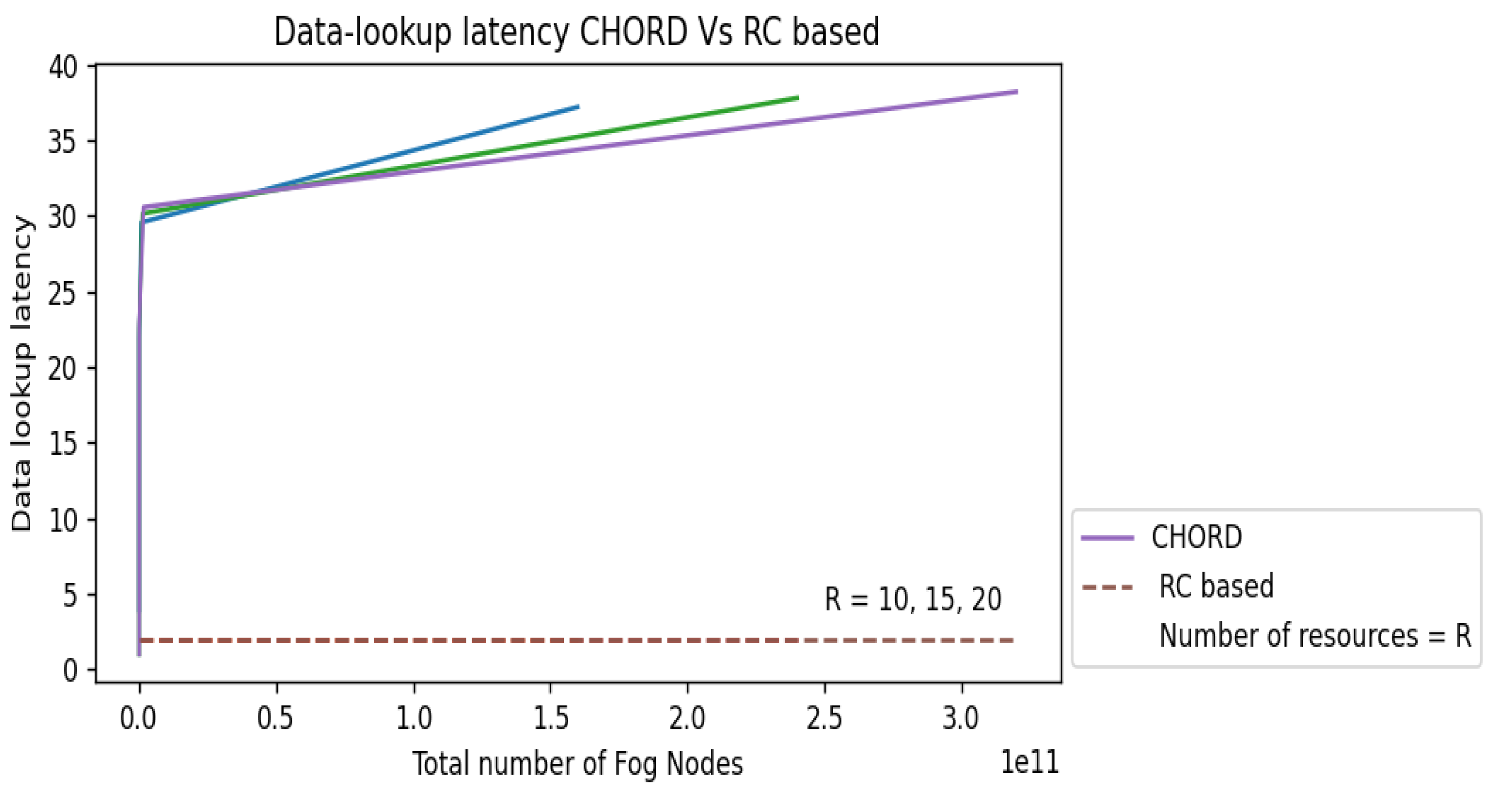
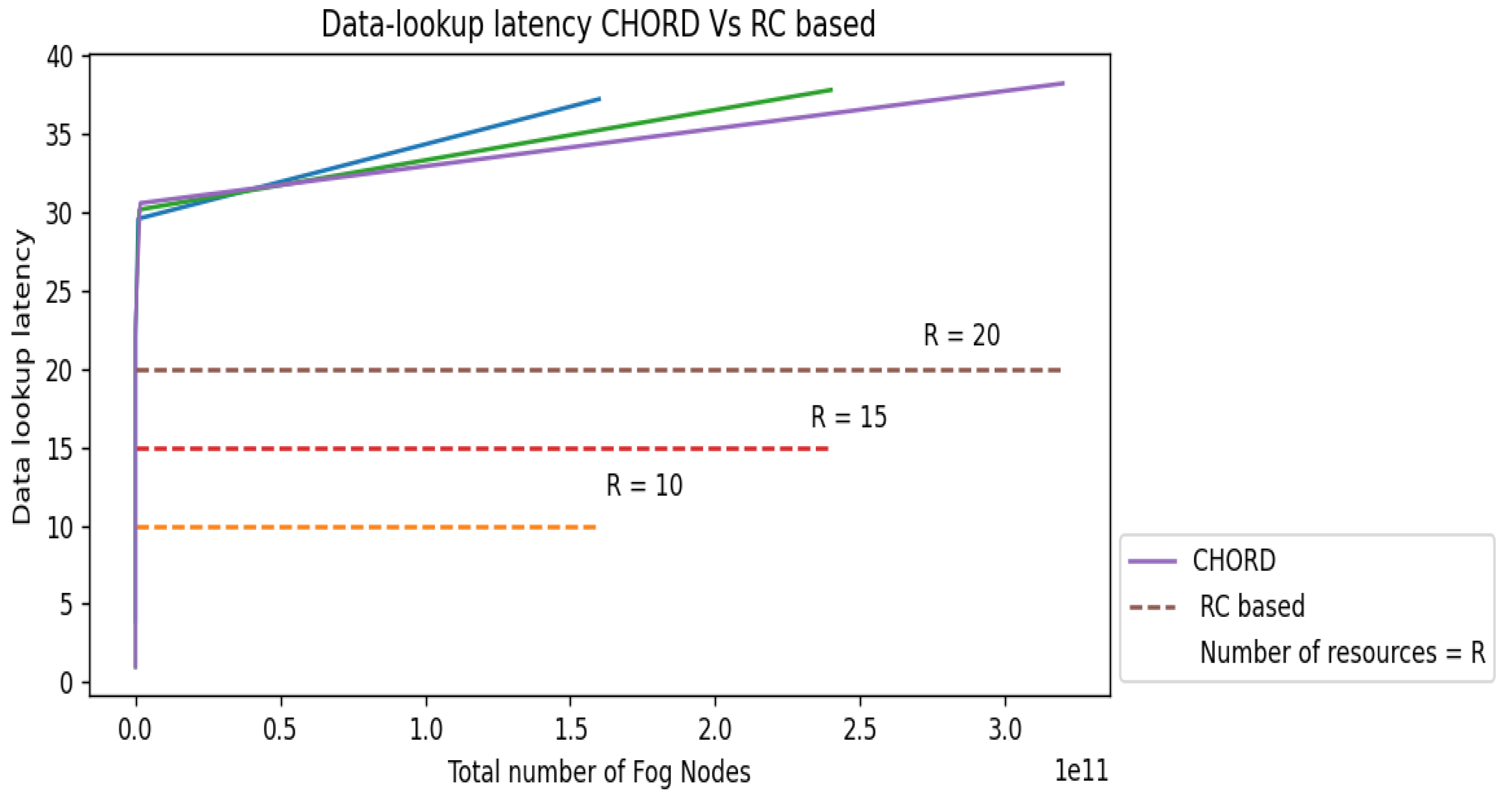
4. Performance Evaluation
Experiments



5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hathaliya, J.J.; Tanwar, S.; Tyagi, S.; Kumar, N. Securing electronics healthcare records in healthcare 4.0: A biometric-based approach. Comput. Electr. Eng. 2019, 76, 398–410. [Google Scholar] [CrossRef]
- Vora, J.; DevMurari, P.; Tanwar, S.; Tyagi, S.; Kumar, N.; Obaidat, M.S. Blind signatures based secured e-healthcare system. In Proceedings of the 2018 International Conference on Computer, Information and Telecommunication Systems (CITS), Colmar, France, 11–13 July 2018. [Google Scholar]
- Vora, J.; Nayyar, A.; Tanwar, S.; Tyagi, S.; Kumar, N.; Obaidat, M.S.; Rodrigues, J.J. BHEEM: A blockchain-based framework for securing electronic health records. In Proceedings of the 2018 IEEE GLOBECOM workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Vora, J.; Italiya, P.; Tanwar, S.; Tyagi, S.; Kumar, N.; Obaidat, M.S.; Hsiao, K.F. Ensuring privacy and security in e-health records. In Proceedings of the 2018 International Conference on Computer, Information and Telecommunication Systems (CITS), Colmar, France, 11–13 July 2018. [Google Scholar]
- Shukla, N.; Gandhi, C. Efficient Resource Discovery and Sharing Framework for Fog Computing in Healthcare 4.0. In Fog Computing for Healthcare 4.0 Environments; Signals and Communication Technology; Tanwar, S., Ed.; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Eugster, P.T.; Felber, P.A.; Guerraoui, R.; Kermarrec, A.M. The many faces of publish/subscribe. ACM Comput. Surv. (CSUR) 2003, 35, 114–131. [Google Scholar] [CrossRef]
- Liang, J.; Kumar, R.; Ross, K. The kazaa overlay: A measurement study. In Proceedings of the 19th IEEE Annual Computer Communications Workshop, Hong Kong, China, 7–11 March 2004; pp. 17–20. [Google Scholar]
- Ripeanu, M. Peer-to-peer architecture case study: Gnutella network. In Proceedings of the First International Conference on Peer-to-Peer Computing, Linköping, Sweden, 27–29 August 2001; pp. 99–100. [Google Scholar]
- Ratnasamy, S.; Francis, P.; Handley, M.; Karp, R.; Shenker, S. A Scalable Contentaddressable Network; ACM: New York, NY, USA, 2001. [Google Scholar]
- Stoica, I.; Morris, R.; Karger, D.; Kaashoek, M.F.; Balakrishnan, H. Chord: A scalable peer-to-peer lookup service for internet applications. ACM Sigcomm. Comput. Commun. Rev. 2001, 31, 149–160. [Google Scholar] [CrossRef]
- Rowstron, A.; Druschel, P. Pastry: Scalable, decentralized object location, and routing for large-scale peer-to-peer systems. In Proceedings of the IFIP/ACM International Conference on Distributed Systems Platforms and Open Distributed Processing, Heidelberg, Germany, 12–16 November 2001; pp. 329–350. [Google Scholar]
- Zhao, B.Y.; Kubiatowicz, J.; Joseph, A.D. Tapestry: An Infrastructure for Fault-Tolerant Wide-Area Location and Routing; University of California at Berkeley: Berkeley, CA, USA, 2001. [Google Scholar]
- Aekaterinidis, I.; Triantafillou, P. Pastrystrings: A comprehensive content-based publish/subscribe DHT network. In Proceedings of the International Conference on Distributed Computing Systems, Lisboa, Portugal, 4–7 July 2006; Volume 6, p. 23. [Google Scholar]
- Rowstron, A.; Kermarrec, A.M.; Castro, M.; Druschel, P. Scribe: The design of a large-scale event notification infrastructure. In Proceedings of the International Workshop on Networked Group Communication, London, UK, 7–9 November 2001; pp. 30–43. [Google Scholar]
- Gupta, A.; Sahin, O.D.; Agrawal, D.; Abbadi, A.E. Meghdoot: Content-based publish/subscribe over p2p networks. In Proceedings of the 5th ACM/IFIP/USENIX International Conference on Middleware, Toronto, ON, Canada, 6 October 2004; pp. 254–273. [Google Scholar]
- Pietzuch, P.R.; Bacon, J.M. Hermes: A distributed event-based middleware architecture. In Proceedings of the 22nd International Conference on Distributed Computing Systems Workshops, Sendai, Japan, 7–9 December 2002; pp. 611–618. [Google Scholar]
- Carlsson, B.; Gustavsson, R. The rise and fall of napster—An evolutionary approach. In Proceedings of the International Computer Science Conference on Active Media Technology, Hong Kong, China, 18–20 December 2001; pp. 347–354. [Google Scholar]
- Gupta, H.; Vahid Dastjerdi, A.; Ghosh, S.K.; Buyya, R. iFogSim: A toolkit for modeling and simulation of resource management techniques in the internet of things, edge 1 and fog computing environments. Softw. Pract. Exp. 2017, 47, 1275–1296. [Google Scholar] [CrossRef]
- Hao, Z.; Novak, E.; Yi, S.; Li, Q. Challenges and software architecture for fog computing. IEEE Internet Comput. 2017, 21, 44–53. [Google Scholar] [CrossRef]
- Kaluvakuri, S.; Maddali, K.; Roy, I.; Rekabdar, B.; Liu, Z.; Gupta, B. Design of RC Based Low Diameter Hierarchical Structured P2P Network Architecture. In Learning and Analytics in Intelligent Systems; EMENA-ISTL; Springer: Berlin/Heidelberg, Germany, 2020; Volume 7, pp. 312–320. [Google Scholar]
- Kaluvakuri, S.; Maddali, K.; Rahimi, N.; Gupta, B.; Debnath, N. Generalization of RC-Based Low Diameter Hierarchical Structured P2P Network Architecture. Int. J. Comput. Appl. (IJCA) 2020, 27, 77–83. [Google Scholar]
- Maddali, K.; Rekabdar, B.; Kaluvakuri, S.; Gupta, B. Efficient Capacity-Constrained Multicast in RC based P2P Networks. In Proceedings of the CAINE2019: 32nd International Conference on Computer Applications in Industry and Engineering, San Diego, CA, USA, 30 September–2 October 2019; Volume 63, pp. 121–129. [Google Scholar]
- Yang, M.; Yang, Y. An Efficient Hybrid Peer-to-Peer System for Distributed Data Sharing. Comput. IEEE Trans. 2010, 59, 1158–1171. [Google Scholar] [CrossRef]
- Mahmud, R.; Pallewatta, S.; Goudarzi, M.; Buyya, R. IFogSim2: An Extended iFogSim Simulator for Mobility, Clustering, and Microservice Management in Edge and Fog Computing Environments. J. Syst. Softw. 2022, 190, 111351. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Can | Chord | Pastry | RC-Based | |
|---|---|---|---|---|
| Architecture | DHT-based | DHT-based | DHT-based | RC-Based |
| Lookup Protocol | {Key, value} pairs to map a point P in the coordinate space using uniform hash functions | Matching Key and NodeID | Matching Key and prefix in NodeID | Inter-Group: Routing through group heads Intra-Group: Complete Graph |
| Parameters | N number of peers in the network, d-number of dimensions | N number of peers in the network | N number of peers in the network, b-number of bits (B = 2b) use for the base of the chosen identifier | n = Number of distinct resource types, N-number of peers in the network, n N |
| Lookup Performance | Inter-Group: , Intra-Group: |
| Global Resource Table (GRT) | ||
|---|---|---|
| Group-Head Logical Address | IP-Address | Computing Range |
| 0 | 172.16.254.1 | |
| 1 | 160.15.244.4 | |
| 2 | 171.10.230.7 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, I.; Mitra, R.; Rahimi, N.; Gupta, B. Efficient Non-DHT-Based RC-Based Architecture for Fog Computing in Healthcare 4.0. IoT 2023, 4, 131-149. https://doi.org/10.3390/iot4020008
Roy I, Mitra R, Rahimi N, Gupta B. Efficient Non-DHT-Based RC-Based Architecture for Fog Computing in Healthcare 4.0. IoT. 2023; 4(2):131-149. https://doi.org/10.3390/iot4020008
Chicago/Turabian StyleRoy, Indranil, Reshmi Mitra, Nick Rahimi, and Bidyut Gupta. 2023. "Efficient Non-DHT-Based RC-Based Architecture for Fog Computing in Healthcare 4.0" IoT 4, no. 2: 131-149. https://doi.org/10.3390/iot4020008