

Performance Evaluation of Federated Learning for Residential Energy Forecasting



Abstract
:1. Introduction
- The feasibility of exploiting federated learning for energy forecast prediction is assessed via a realistic set of experiments that compare the performance of federated learning against a centralized approach.
- Multiple edge-computing/federated-learning architectures with different privacy levels are evaluated to measure the overhead of each configuration and the provided level of accuracy.
2. Related Work
3. Technical Background
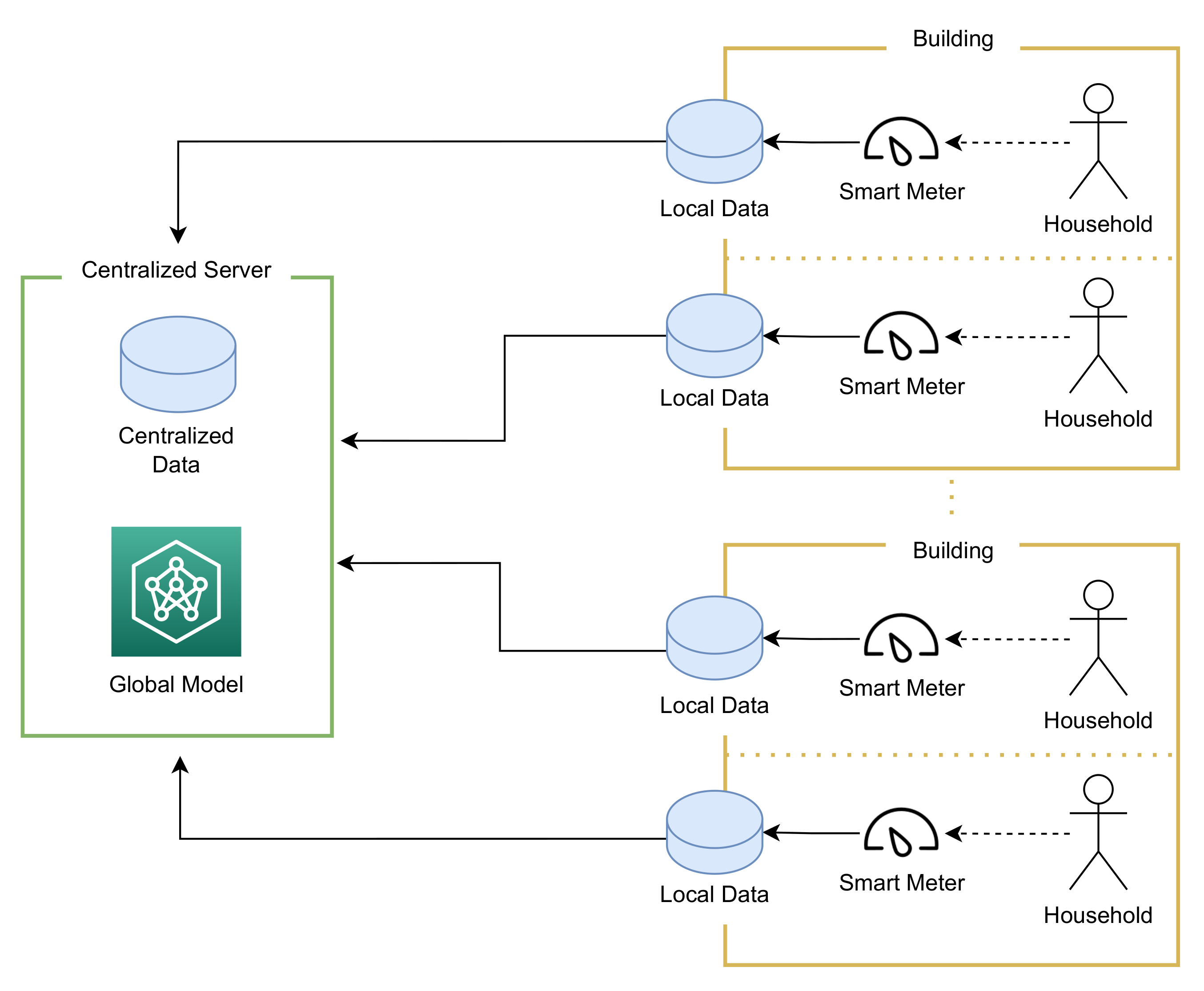
3.1. Federated Learning
- The server selects a subset of the clients (or all) that participate in the next training round.
- The server distributes the current global model weights to the selected clients. In addition, the server provides the instructions on how the training should be performed (e.g., number of local epochs).
- The selected clients receive the model weights, configure its local model with those weights and train it on their local data set, according to the instructions received. When the training is concluded, each client sends back the updated model weights to the server.
- The server receives all the updated models and aggregates them. Subsequently, the old global model is replaced with the new aggregated weights.

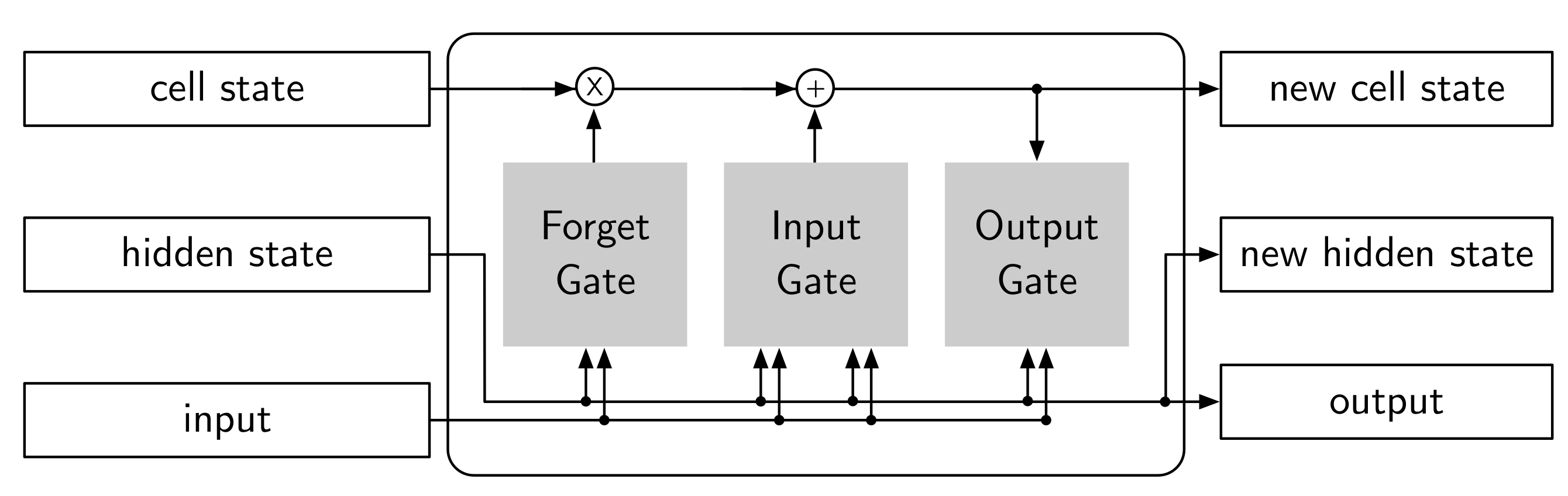
3.2. Long Short-Term Memory Network
- Input Gate: decides the new information that will be stored in the long-term memory.
- Forget Gate: decides which information from the long-term memory should be kept or discarded.
- Output Gate: regulates the flow of information to the rest of the network.

4. Dataset and Methodology
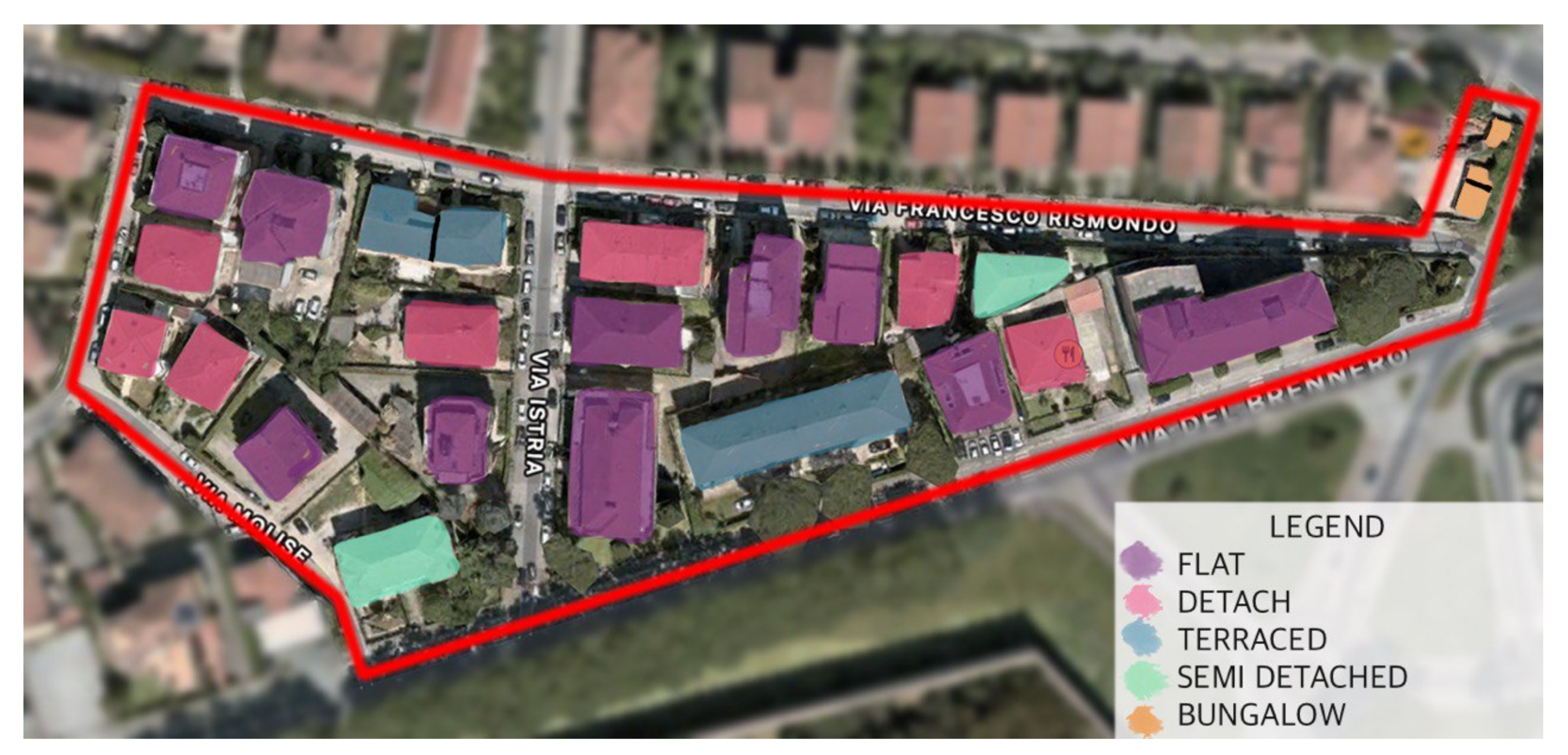
4.1. Dataset
- Bungalow: a small house or cottage that is either single-story or has a second story built into a sloping roof.
- Detached House: a stand-alone residential structure that does not share outside walls with another house or building.
- Flat: a set of rooms for living, usually on one floor and part of a larger building. A flat usually includes bedrooms, a kitchen and a bathroom.
- Terraced House: a house built as part of a continuous row in a uniform style.
- Semi Detached House: a single family duplex dwelling house that shares one common wall with the next house.
4.2. Neural Network Setup
4.3. Flower
5. Results
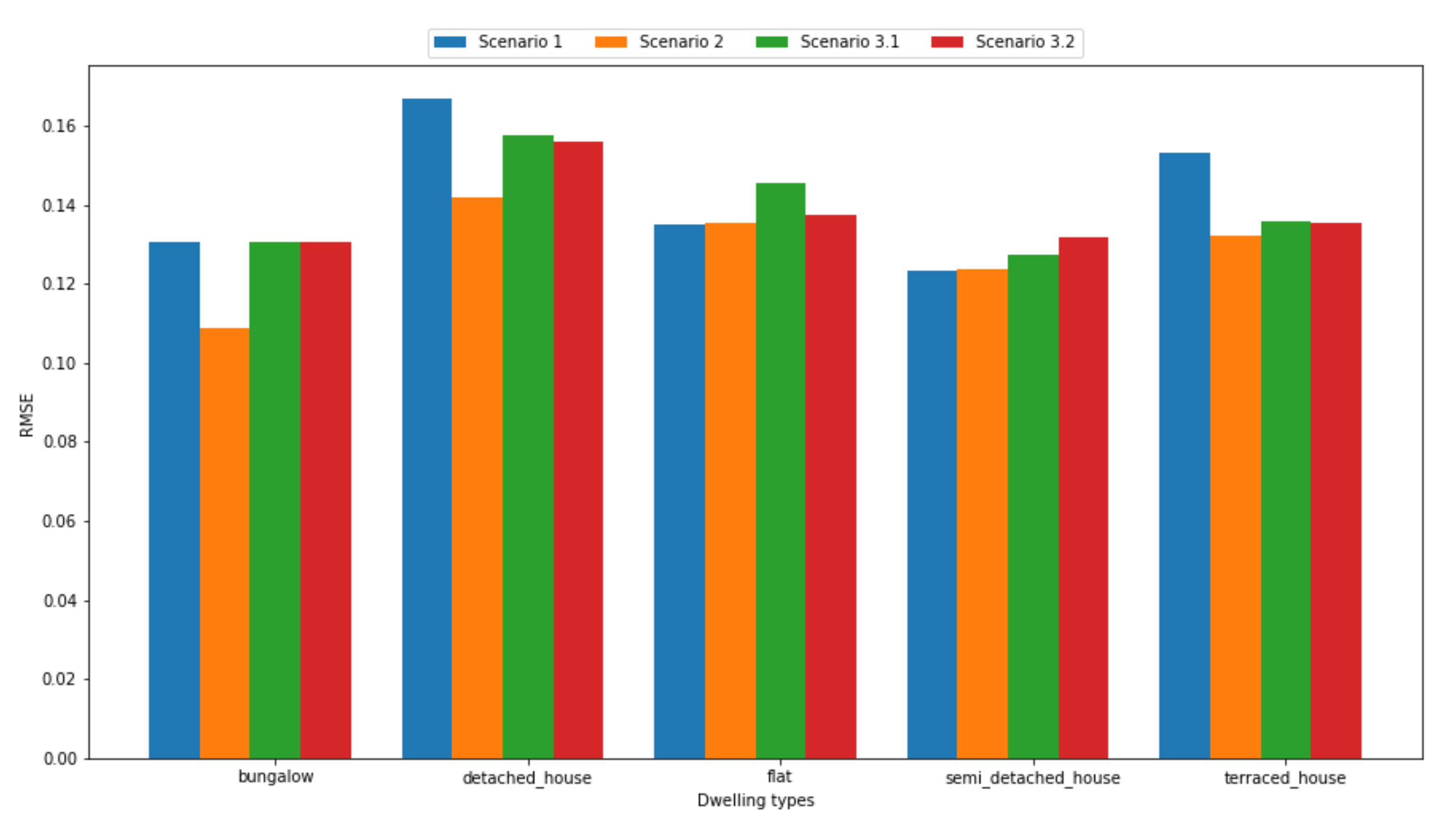
5.1. Experimental Scenarios
5.1.1. Scenario 0: Centralized Server
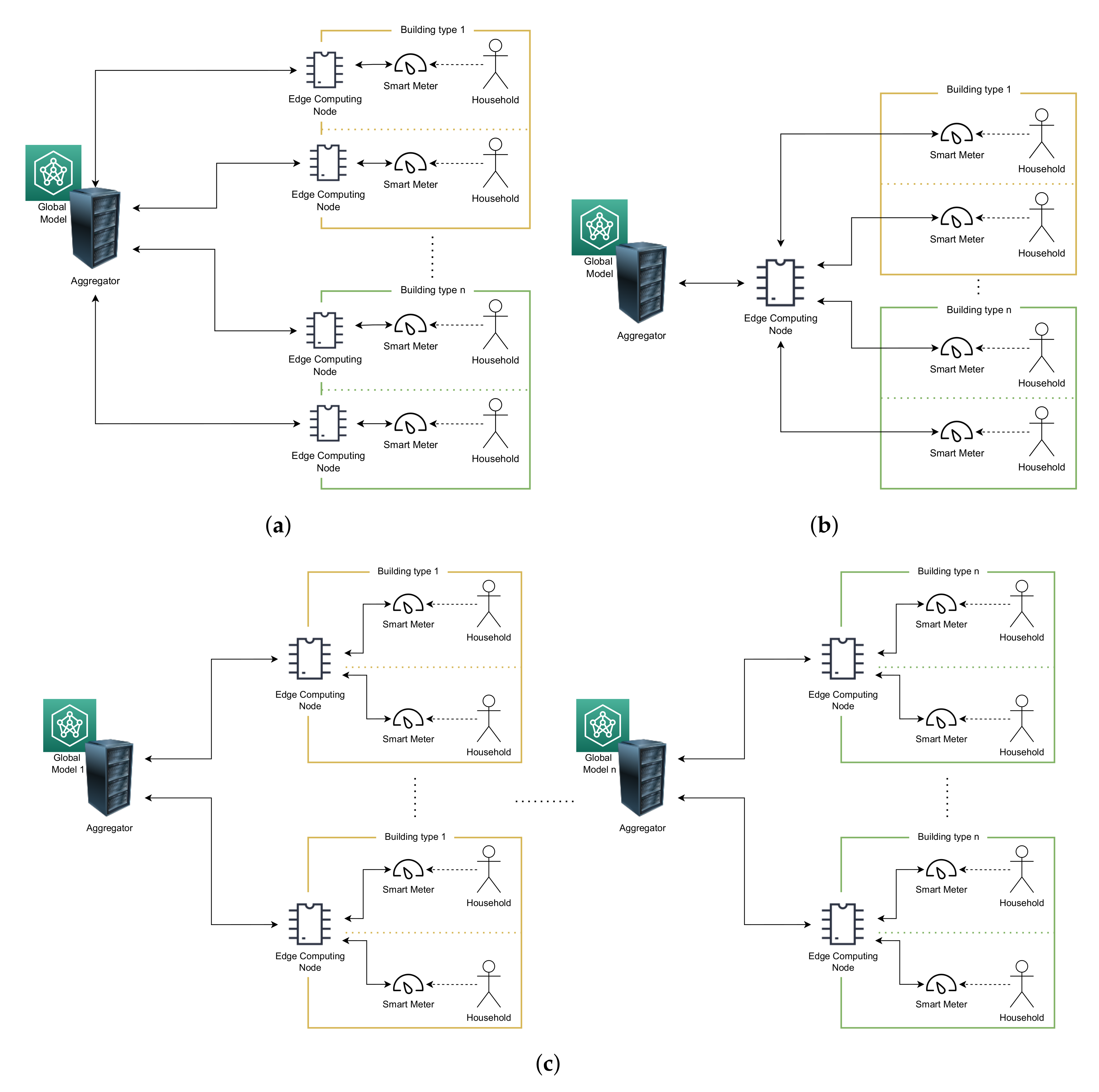
5.1.2. Scenario 1: One Edge-Computing Node per Household
5.1.3. Scenario 2: One Edge-Computing Node per Neighbourhood
5.1.4. Scenario 3: One Edge-Computing Node per Building
- Flat: from 6 to 22 households.
- Detached house: from two to four households.
- Terraced house: from 3 to 12 households.
- Semi-detached house: from three to four households.
- Bungalows house: from one to three households.
- Scenario 3.1—average household density: for each building in the map, the number of households corresponds to the average number of household depending on the dwelling type.
- Scenario 3.2—random household density: for each building in the map, the number of households is sampled uniformly at random depending on the dwelling type.

5.2. Research Questions
- RQ1: What are the performance of the LSTM model(s) trained on a cloud server w.r.t. the LSTM model(s) trained on edge servers with federated learning considering different configurations?
- RQ2: What are the performance of the LSTM models learned with federated learning by varying the reference scenario and/or the dwelling type?
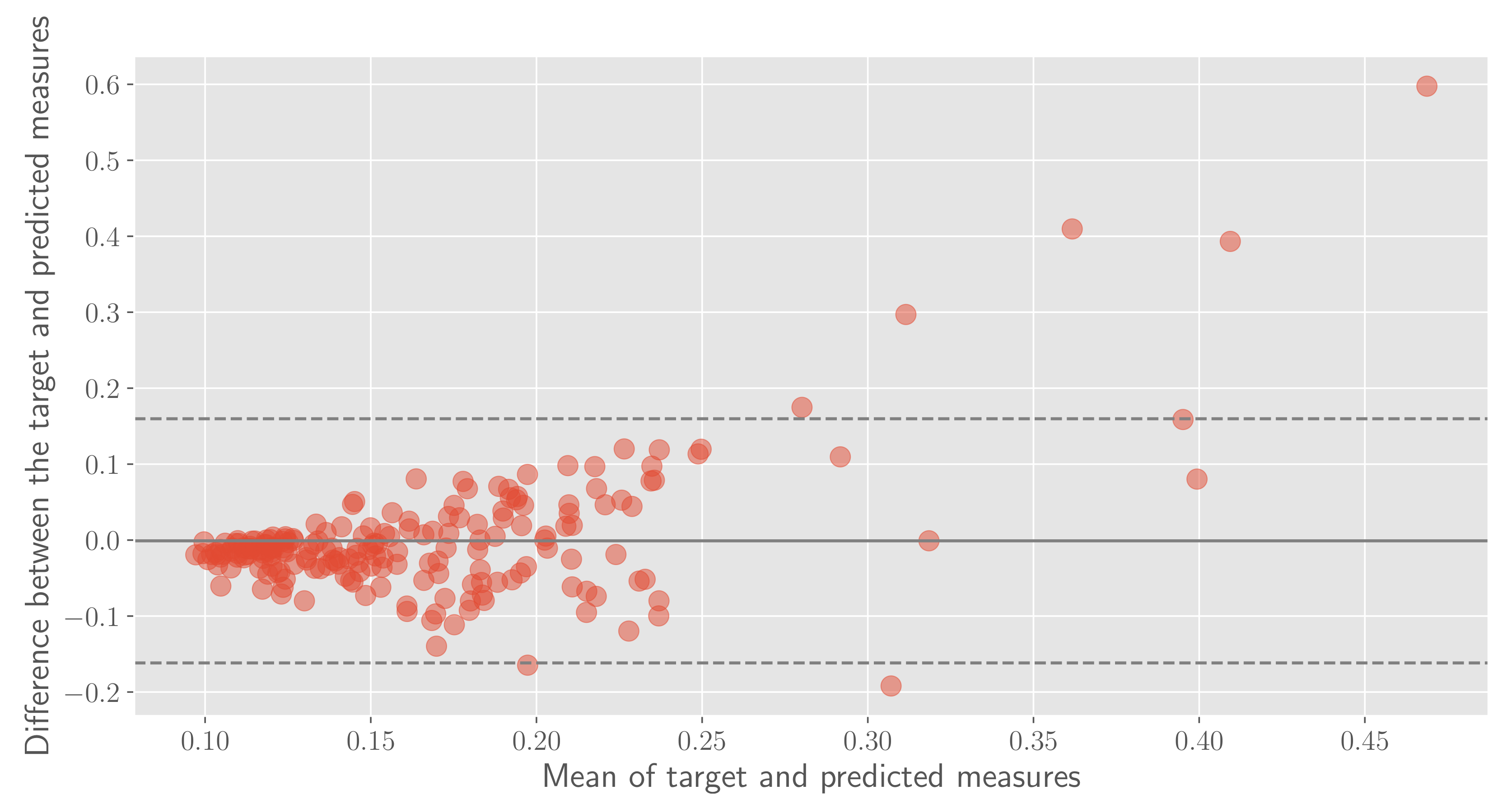
- RQ3: Do we have evidence of the most difficult data sample to predict?
- RQ4: What is the impact of federated learning in the training process, in terms of both time and network overhead?
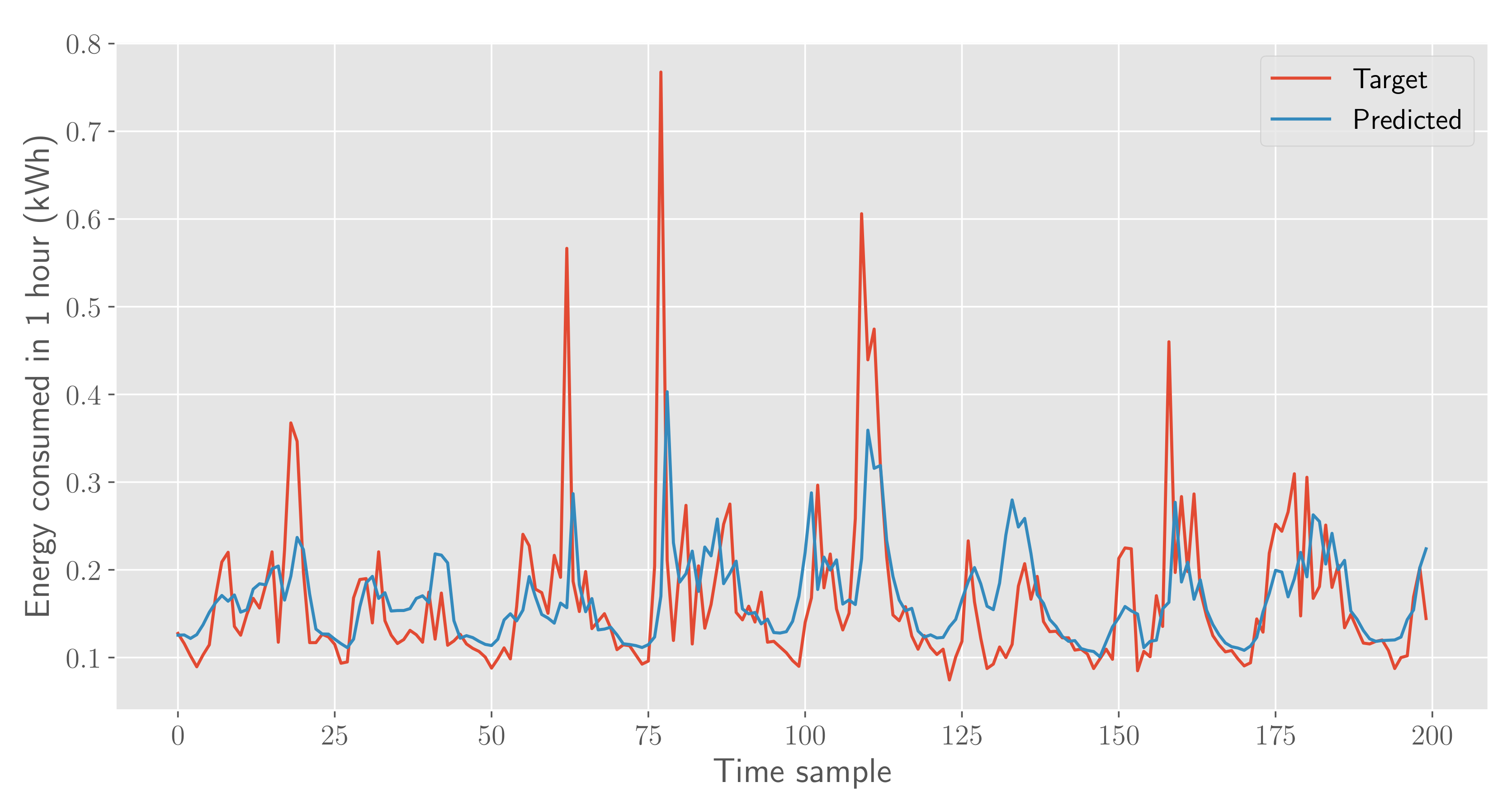
5.3. Results Analysis
5.4. Results Summary
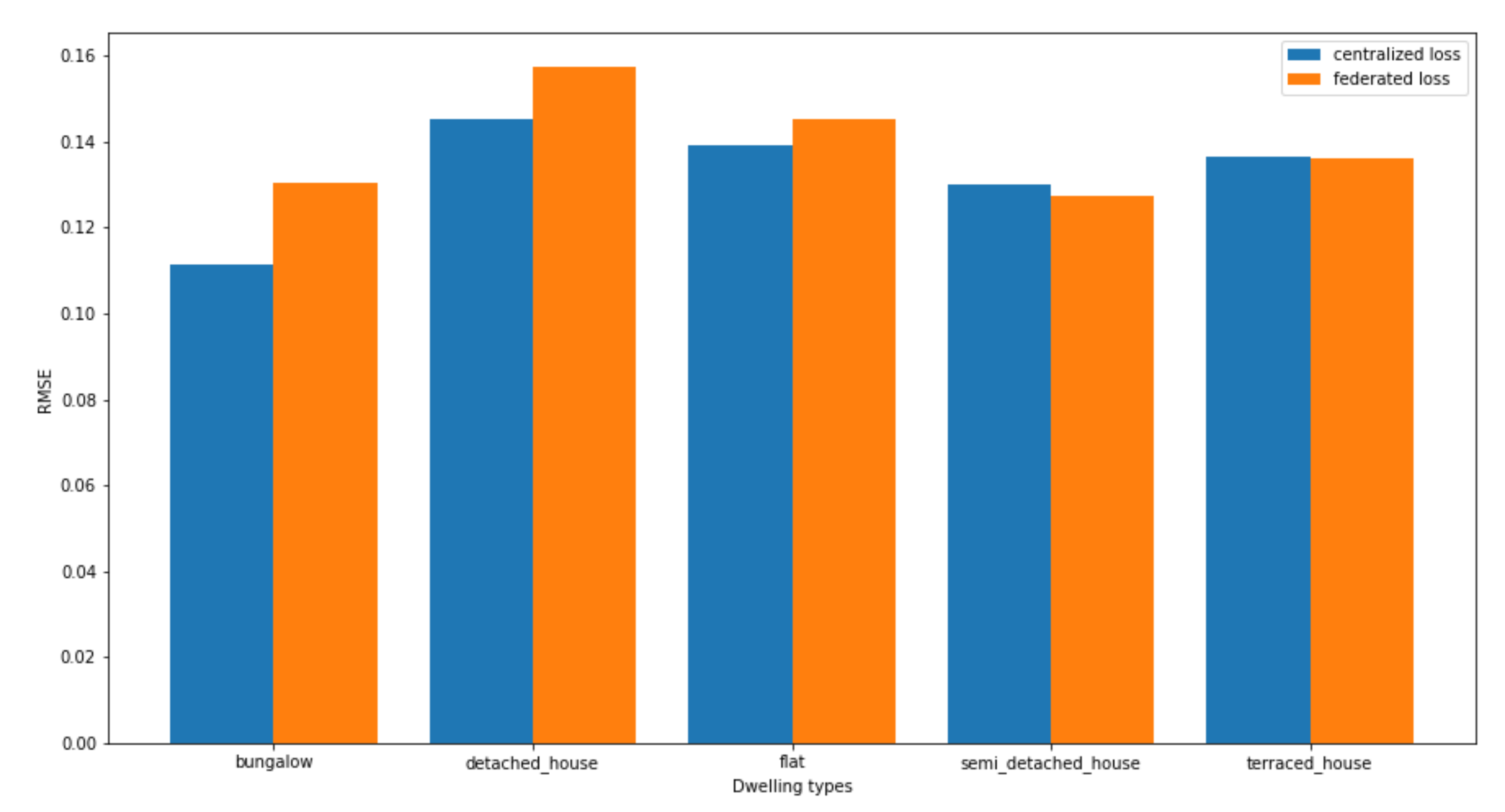
- Centralized vs. Federated. In terms of the accuracy, the centralized solution results in better predictions than any federated configuration. This loss of performance is due to the partitioning of the overall dataset among the different edge-computing nodes. Consequently, a centralized solution results in a better accuracy, however, at the cost of a lower level of privacy.
- Different federated configurations. Different federated configurations with different privacy levels result in different levels of accuracy depending on how the overall data is partitioned across different edge-computing nodes. Generally, the higher the level of privacy, the lower the accuracy. This is due to the fact that increasing the level of privacy, e.g., by installing one edge node per household, means reducing the amount of data available for the model training. The federated approach can help in mitigating this loss, which is, however, still noticeable in our results. If we compare the loss of accuracy in absolute terms, however, we can notice that the loss is not very significant, and consequently the adoption of a federated approach is still feasible.
- Overhead. Although a federated-learning solution results in a higher network overhead, the overall data transmitted in the network is low, and it can be supported by any wide area network technology with a small cost.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ahmad, T.; Zhang, H.; Yan, B. A review on renewable energy and electricity requirement forecasting models for smart grid and buildings. Sustain. Cities Soc. 2020, 55, 102052. [Google Scholar] [CrossRef]
- Podgorelec, V.; Karakatič, S.; Fister, I.; Brezočnik, L.; Pečnik, Š.; Vrbančič, G. Digital Transformation Using Artificial Intelligence and Machine Learning: An Electrical Energy Consumption Case. In International Conference “New Technologies, Development and Applications”; Springer: Berlin/Heidelberg, Germany, 2022; pp. 498–504. [Google Scholar]
- Khan, W.Z.; Ahmed, E.; Hakak, S.; Yaqoob, I.; Ahmed, A. Edge computing: A survey. Future Gener. Comput. Syst. 2019, 97, 219–235. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. arXiv 2019, arXiv:abs/1912.04977. [Google Scholar]
- Gassar, A.A.A.; Cha, S.H. Energy prediction techniques for large-scale buildings towards a sustainable built environment: A review. Energy Build. 2020, 224, 110238. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, T.; Liu, H.; He, R. Power Consumption Predicting and Anomaly Detection Based on Long Short-Term Memory Neural Network. In Proceedings of the 2019 IEEE fourth International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 12–15 April 2019; pp. 487–491. [Google Scholar] [CrossRef]
- Mpawenimana, I.; Pegatoquet, A.; Roy, V.; Rodriguez, L.; Belleudy, C. A comparative study of LSTM and ARIMA for energy load prediction with enhanced data preprocessing. In Proceedings of the 2020 IEEE Sensors Applications Symposium (SAS), Kuala Lumpur, Malaysia, 9–11 March 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Tovar, M.; Robles, M.; Rashid, F. PV Power Prediction, Using CNN-LSTM Hybrid Neural Network Model. Case of Study: Temixco-Morelos, México. Energies 2020, 13, 6512. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Cinelli, L.; Fortino, G.; Savaglio, C.; Terracina, G.; Ursino, D.; Virgili, L. An approach to compute the scope of a social object in a Multi-IoT scenario. Pervasive Mob. Comput. 2020, 67, 101223. [Google Scholar] [CrossRef]
- Nicolazzo, S.; Nocera, A.; Ursino, D.; Virgili, L. A privacy-preserving approach to prevent feature disclosure in an IoT scenario. Future Gener. Comput. Syst. 2020, 105, 502–519. [Google Scholar] [CrossRef]
- Saputra, Y.M.; Hoang, D.T.; Nguyen, D.N.; Dutkiewicz, E.; Mueck, M.D.; Srikanteswara, S. Energy Demand Prediction with Federated Learning for Electric Vehicle Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Sater, R.A.; Hamza, A.B. A Federated Learning Approach to Anomaly Detection in Smart Buildings. ACM Trans. Internet Things 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Fekri, M.N.; Grolinger, K.; Mir, S. Distributed Load Forecasting Using Smart Meter Data: Federated Learning With Recurrent Neural Networks. Int. J. Electr. Power Energy Syst. 2022, 137, 107669. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Triguero, I. FUZZ-IEEE Competition on Explainable Energy Prediction. 2020. Available online: https://ieee-dataport.org/competitions/fuzz-ieee-competition-explainable-energy-prediction (accessed on 5 July 2022).
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Parcollet, T.; Lane, N.D. Flower: A Friendly Federated Learning Research Framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečný, J.; Kumar, S.; McMahan, H.B. Adaptive Federated Optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Housing Type | Number of Smart Meters | Distribution |
|---|---|---|
| Bungalow | 141 | 17% |
| Detached House | 160 | 19% |
| Flat | 38 | 5% |
| Semi Detached | 321 | 39% |
| Terraced House | 161 | 20% |
| All | 821 | 100% |
| Housing Type | Hidden Layer Size |
|---|---|
| Bungalow | 20 |
| Detached House | 40 |
| Flat | 40 |
| Semi Detached | 50 |
| Terraced House | 40 |
| All | 30 |
| Parameter Name | Value |
|---|---|
| Number of centralized epochs | 50 |
| Number of federated epochs | 3 |
| Number of federated rounds | 50 |
| Learning rate | |
| Drop out | 0.2 |
| Early stop threshold | 5 |
| Early stop tolerance |
| Dataset | Mean Aggr. Time (s) | Std. Dev. | Confidence Interval |
|---|---|---|---|
| Bungalow | 0.1237 | 0.0307 | [0.1149 0.1325] |
| Flat | 0.0031 | 0.0004 | [0.003 0.0032] |
| Semi Detached House | 0.0854 | 0.0651 | [0.0667 0.1040 ] |
| Detached House | 0.0419 | 0.0037 | [0.0409 0.0430 ] |
| Terraced House | 0.0153 | 0.0022 | [0.0147 0.0159] |
| Dataset | Centralized Overhead (MB) | Federated Overhead (MB) |
|---|---|---|
| Flat | 3.15 | 55.38 |
| Detached House | 3.57 | 79.20 |
| Bungalow | 0.84 | 4.65 |
| Semi Detached House | 7.17 | 207.06 |
| Terraced House | 3.60 | 16.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrangeli, E.; Tonellotto, N.; Vallati, C. Performance Evaluation of Federated Learning for Residential Energy Forecasting. IoT 2022, 3, 381-397. https://doi.org/10.3390/iot3030021
Petrangeli E, Tonellotto N, Vallati C. Performance Evaluation of Federated Learning for Residential Energy Forecasting. IoT. 2022; 3(3):381-397. https://doi.org/10.3390/iot3030021
Chicago/Turabian StylePetrangeli, Eugenia, Nicola Tonellotto, and Carlo Vallati. 2022. "Performance Evaluation of Federated Learning for Residential Energy Forecasting" IoT 3, no. 3: 381-397. https://doi.org/10.3390/iot3030021