

Characterizing the Impact of Data-Damaged Models on Generalization Strength in Intrusion Detection

Abstract
:1. Introduction
1.1. Problem Statement
1.2. Research Contribution
1.3. Article Outline
1.4. Related Work
1.4.1. Practical: Lack of Interoperable Datasets
1.4.2. Experimental: Defining the Scope of Generalization
1.4.3. Theoretical and Fundamental Critiques of ML-NIDS
1.4.4. Reaching Generalization by Augmenting Datasets
2. Materials and Methods
2.1. Included Data Sets
2.1.1. CIC-IDS2017
2.1.2. CSE-CIC-IDS2018
2.2. Training and Evaluation Procedure
2.2.1. Included Algorithms
- Tree-based methods:
- Decision tree (dtree);
- Decision trees with bagging (bag);
- Adaboost (ada);
- Gradient-boosted trees (gradboost);
- Regularized gradient boosting (xgboost);
- Random forest (rforest);
- Randomized decision trees (extratree).
- Neighbor methods:
- K-nearest-neighbors (knn);
- Nearest-centroid (ncentroid).
- Other methods:
- Linear kernel SVM (linsvc);
- RBF-kernel SVM (rbfsvc);
- Logistic regression (binlr).
2.2.2. Increasing the Learning Difficulty
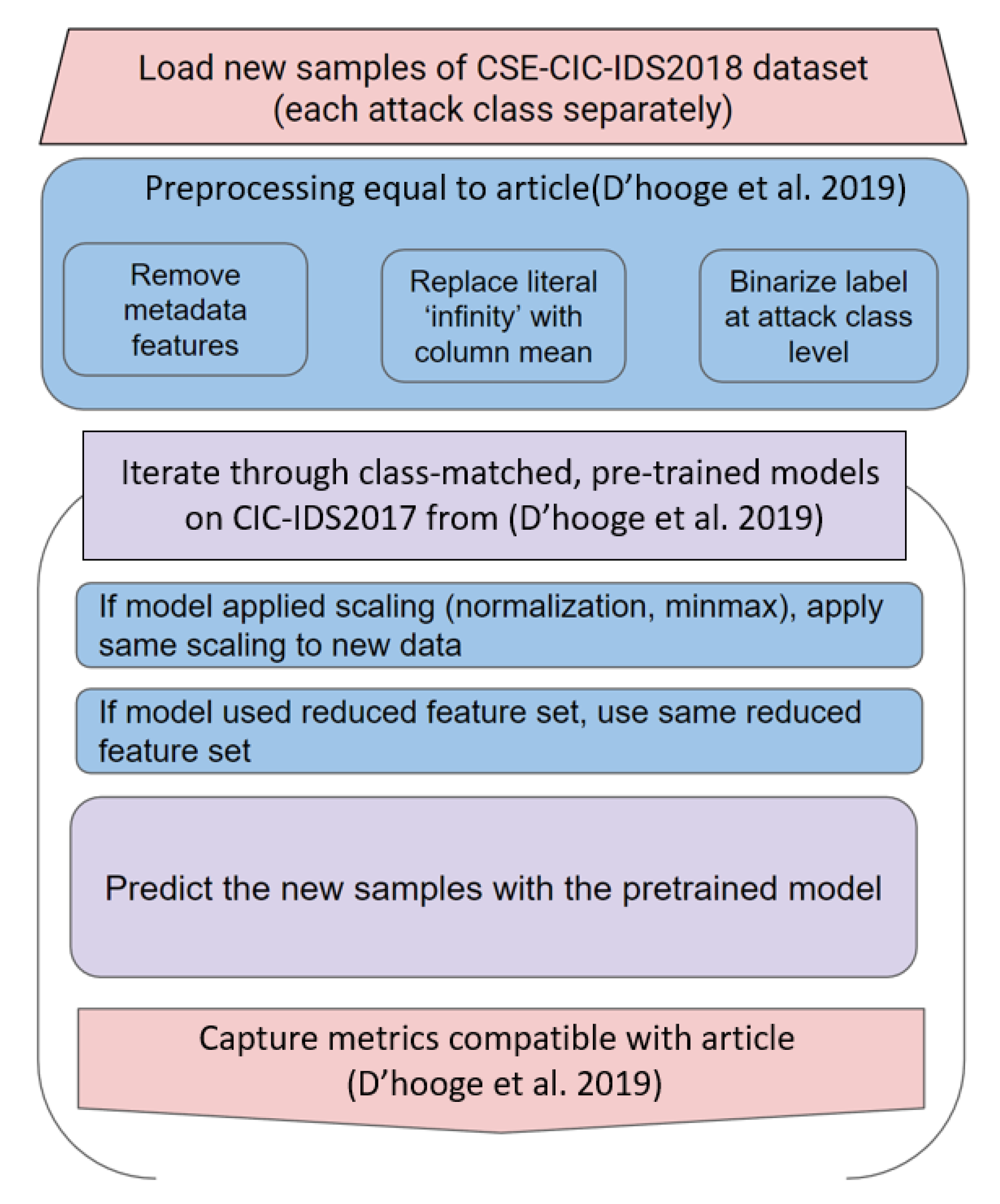
3. Note on Obtained Results and Graphics
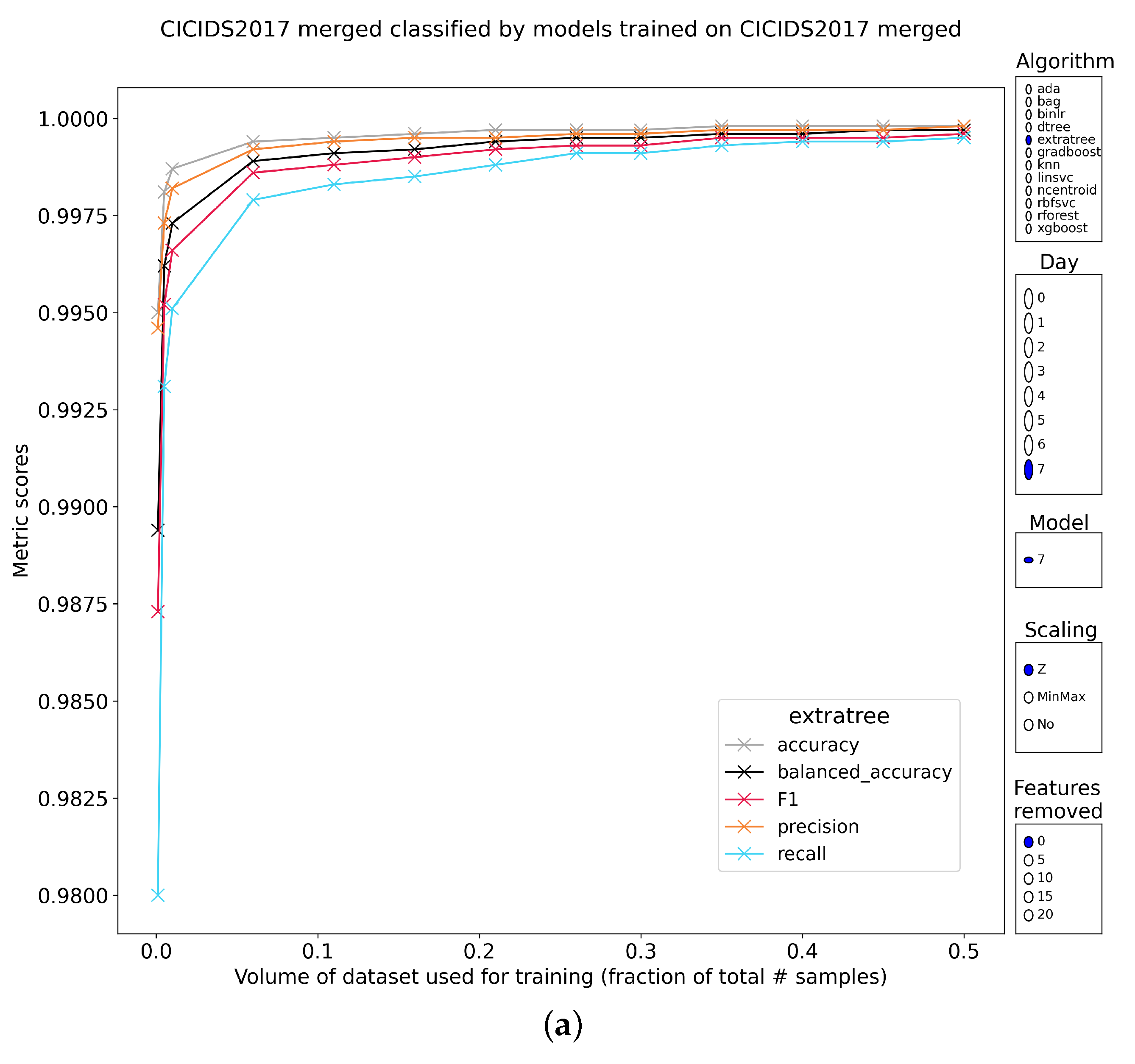
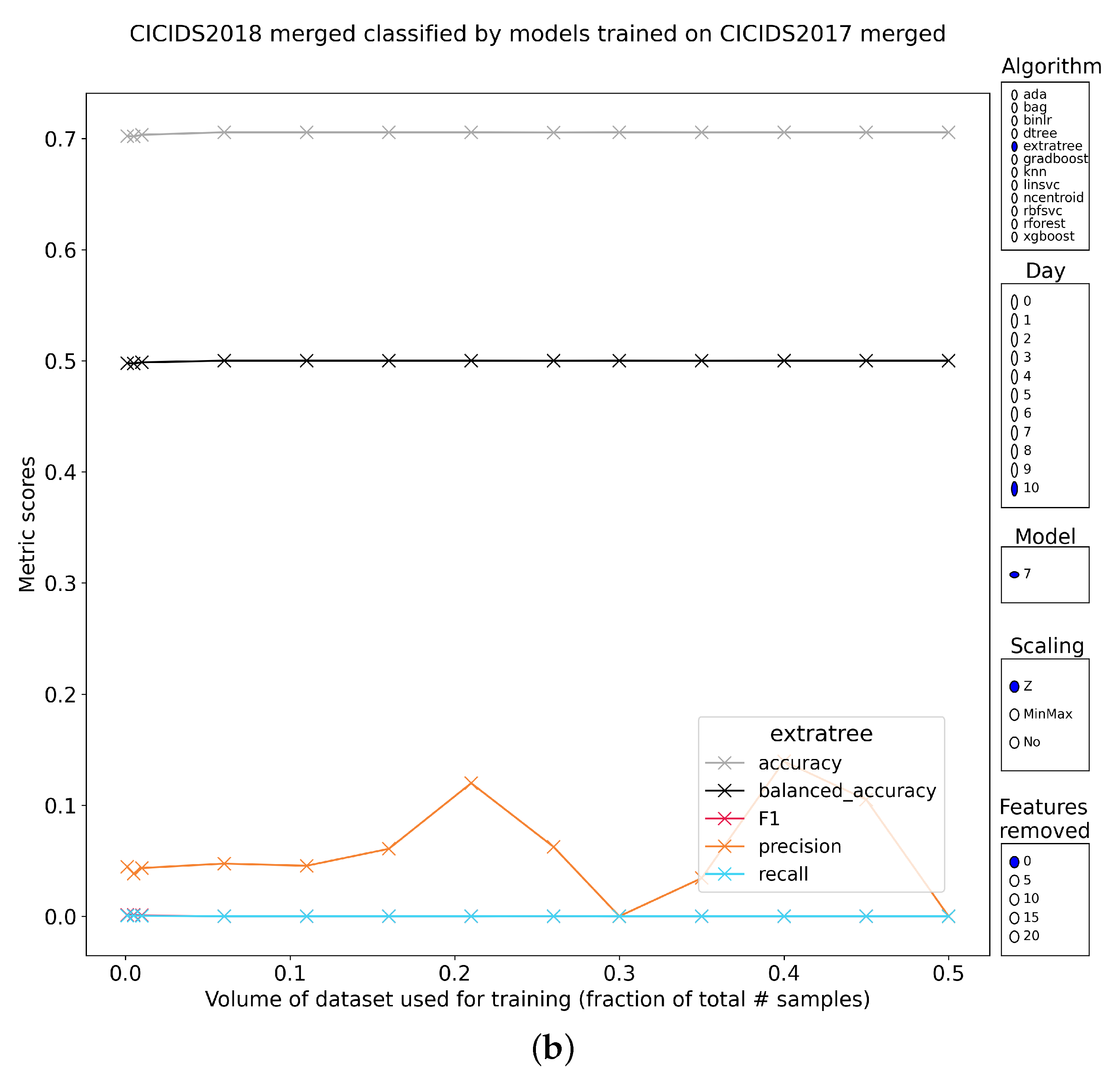
4. Results of Global Two-Class Models
4.1. Internal Retest
4.2. Exposure to Unseen Data
4.2.1. Tree-Based Classifiers
4.2.2. Neighbor-Based Classifiers
4.2.3. Other Classifiers
4.2.4. Intermediate Conclusion
5. Results of Attack-Specific Two-Class Models
5.1. Internal Retest
5.2. Exposure to Unseen Data
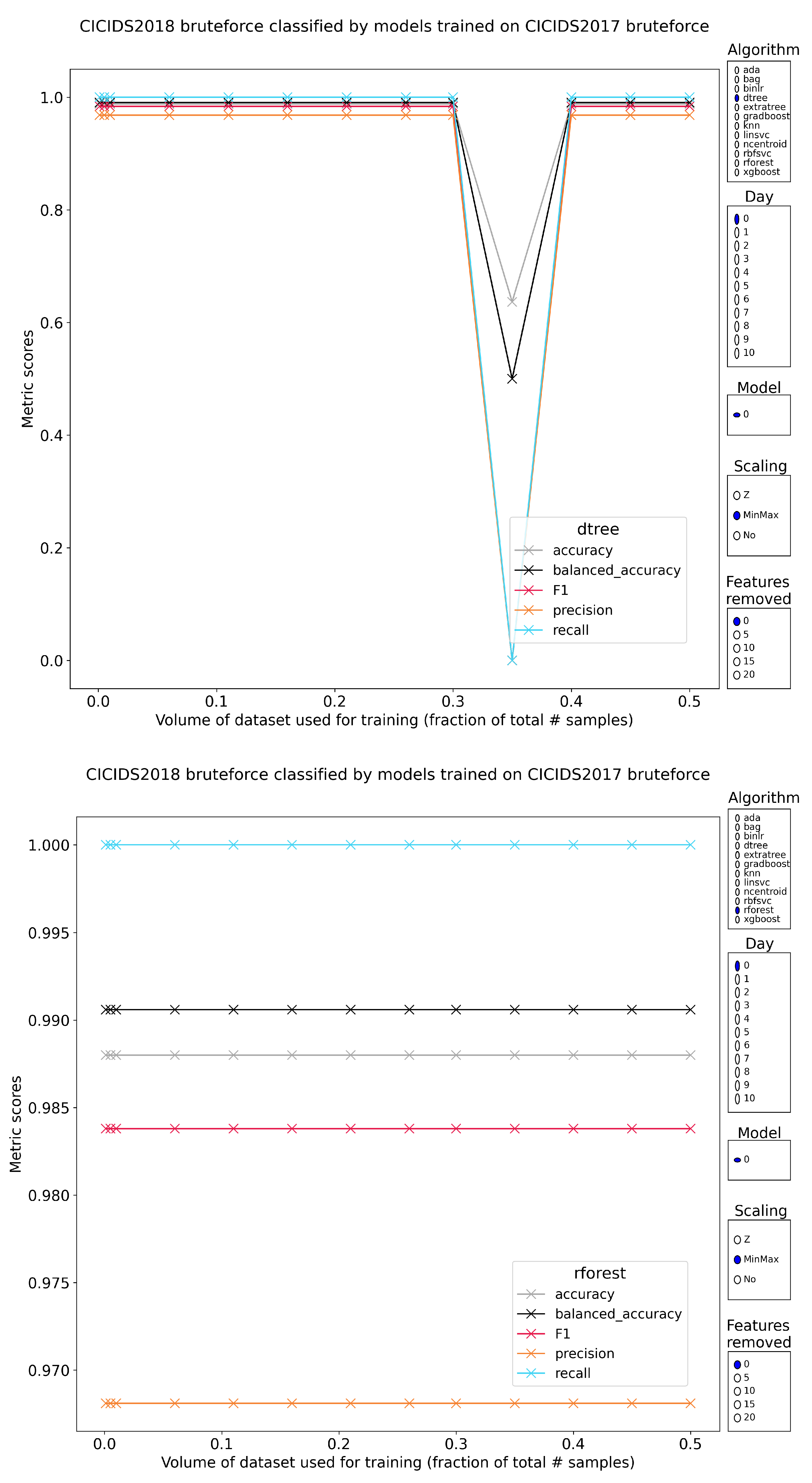
5.2.1. FTP/SSH Brute Force
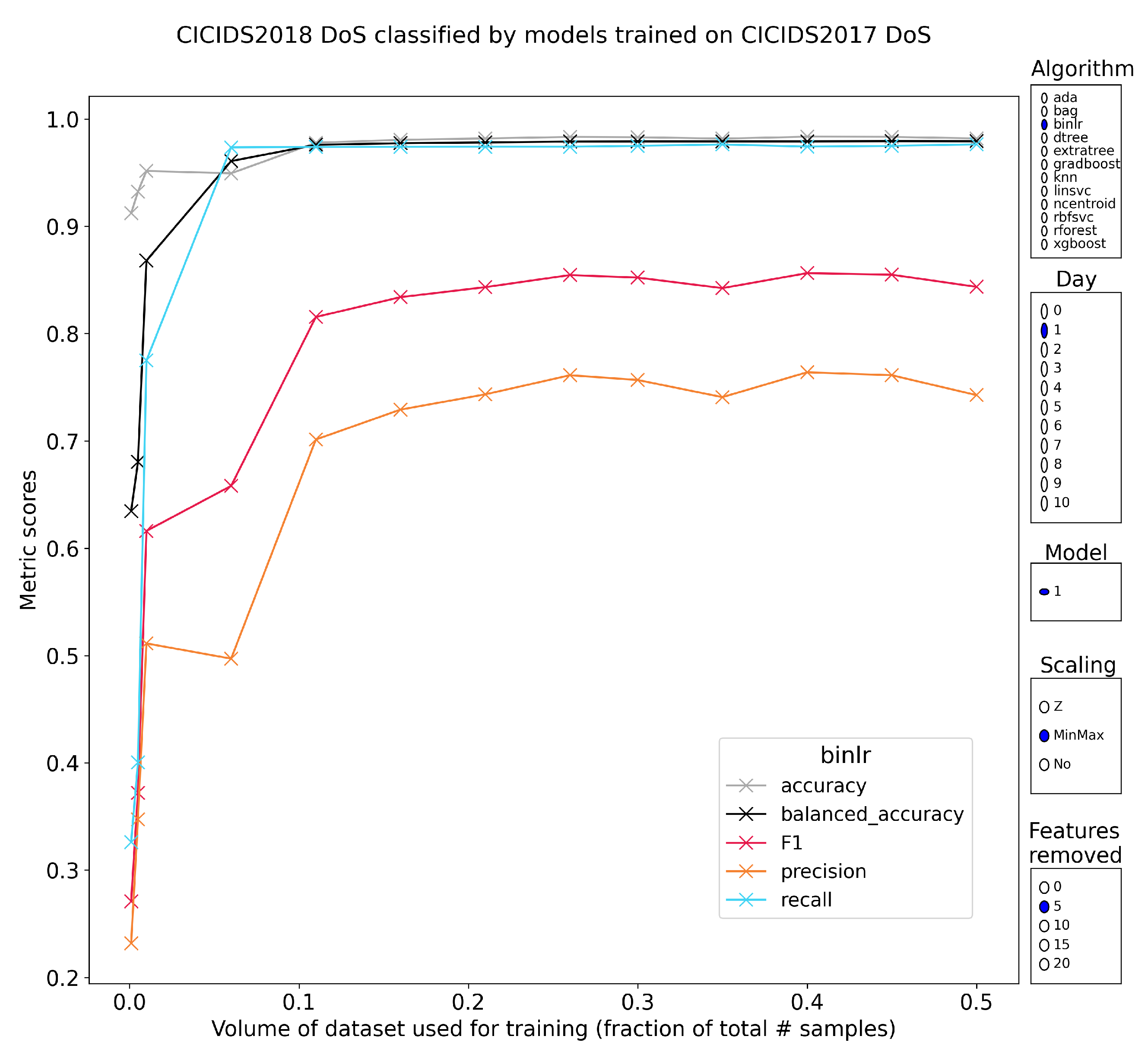
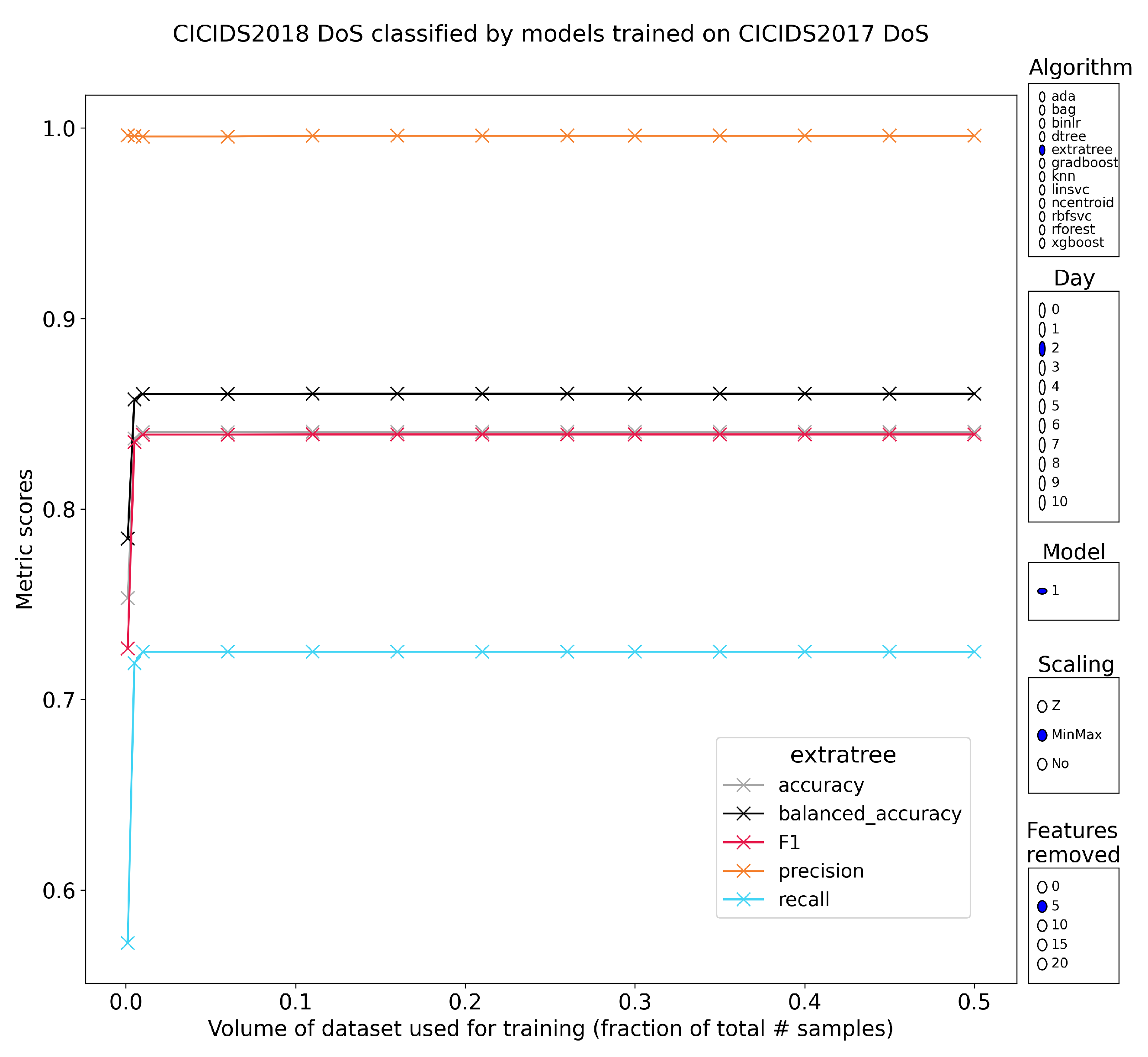
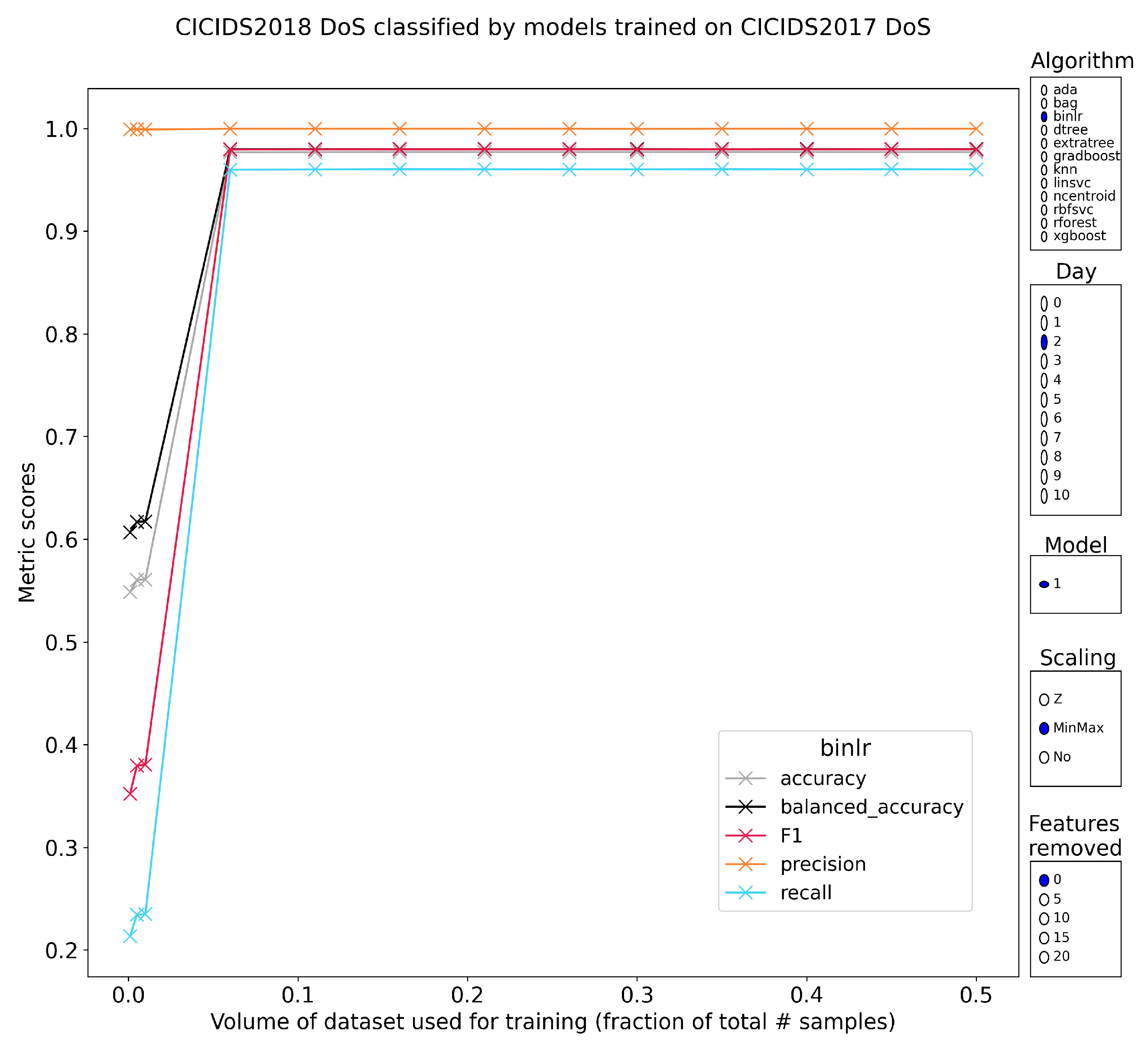
5.2.2. Layer-7 Denial of Service
5.2.3. DoS Heartbleed
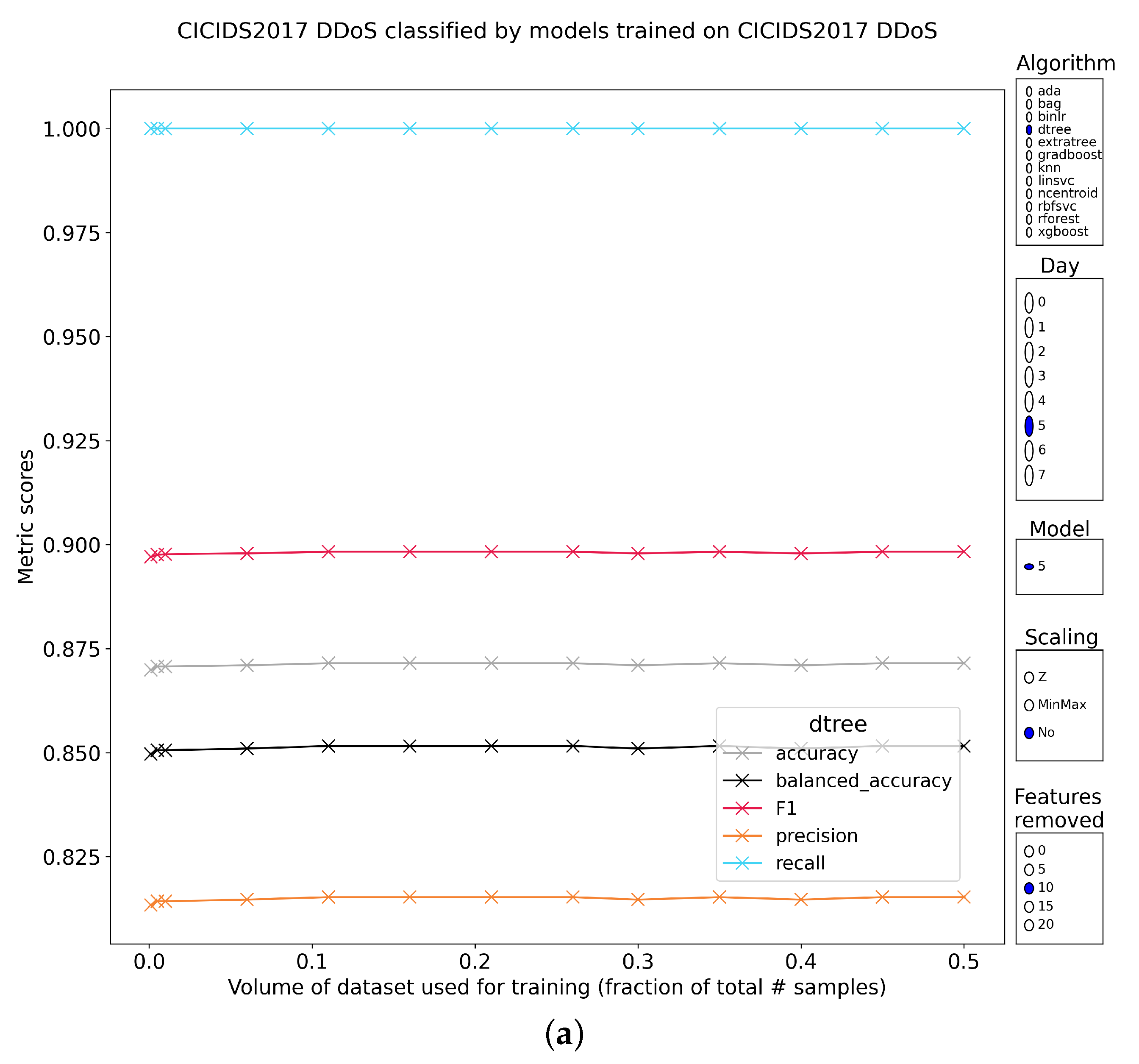
5.2.4. DDoS Part 1
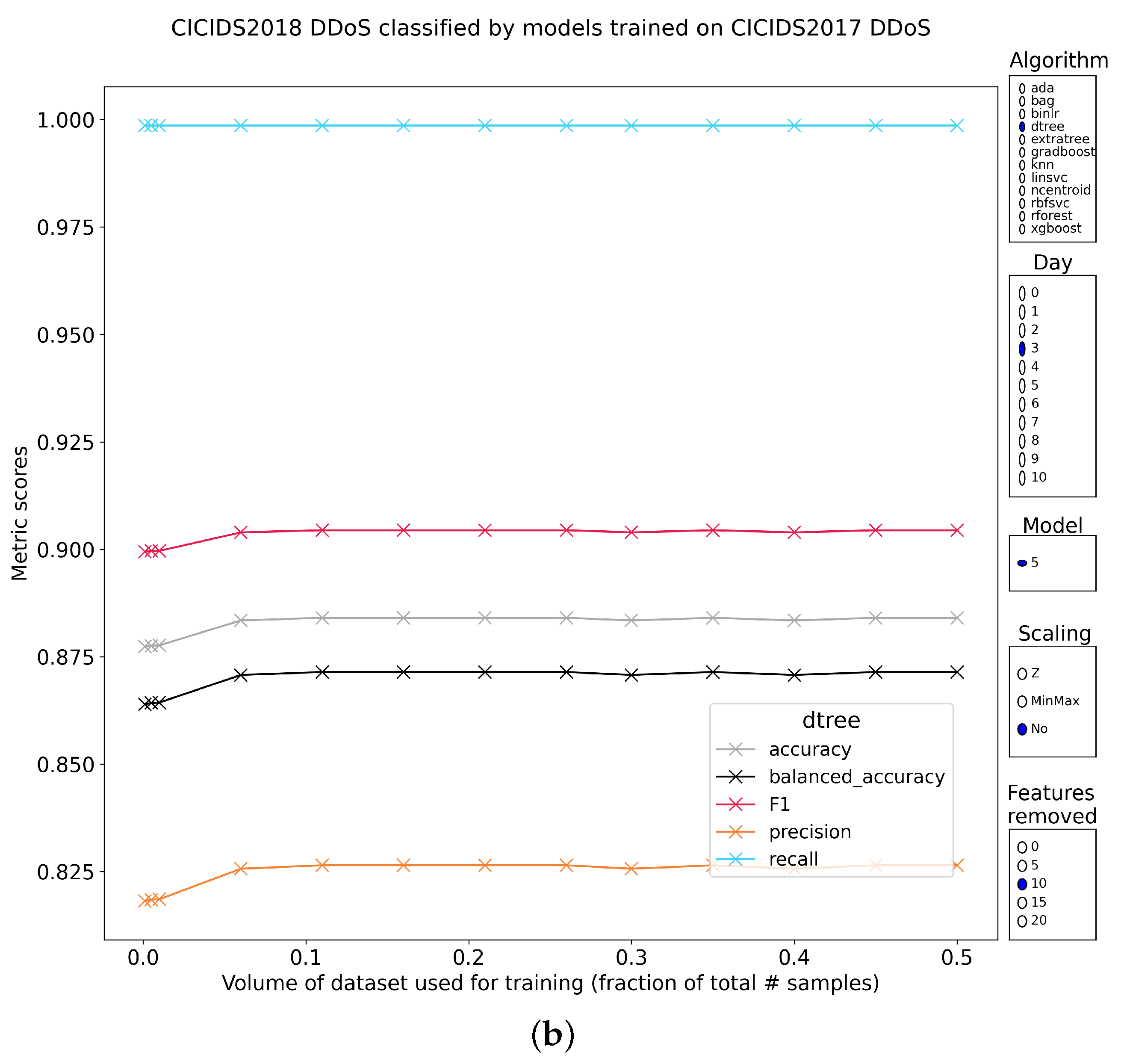
5.2.5. DDoS Part 2
5.2.6. Web Attacks
5.2.7. Infiltration
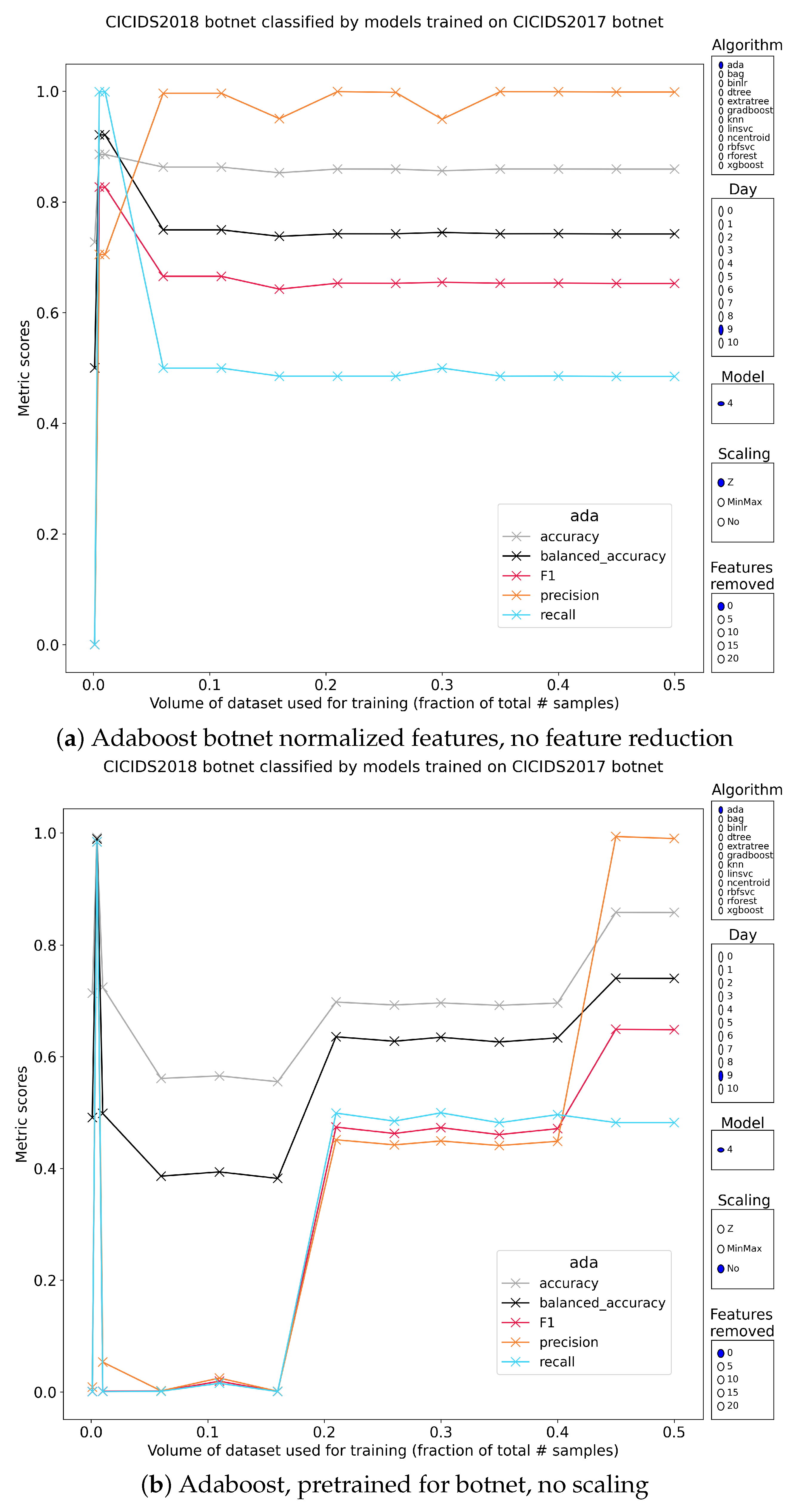
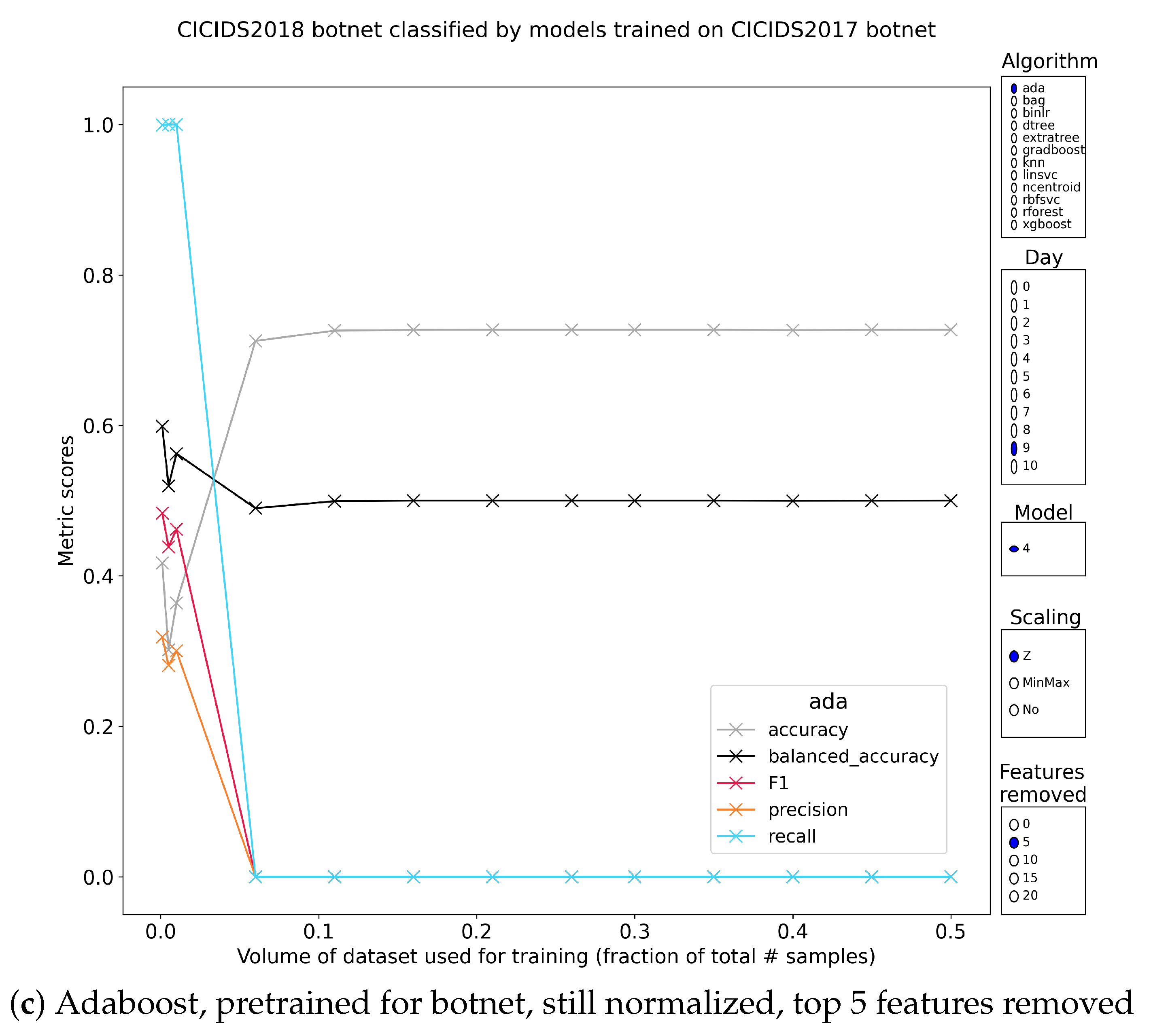
5.2.8. Botnet Traffic
5.2.9. Intermediate Conclusion
6. Discussion
7. Conclusions and Future Work
Future Work and Hypotheses
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Denning, D.; Neumann, P.G. Requirements and Model for IDES-a Real-Time Intrusion-Detection Expert System. SRI International: Menlo Park, CA, USA, 1985; Volume 8. [Google Scholar]
- Denning, D.E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, 13, 222–232. [Google Scholar] [CrossRef]
- Duessel, P.; Gehl, C.; Flegel, U.; Dietrich, S.; Meier, M. Detecting zero-day attacks using context-aware anomaly detection at the application-layer. Int. J. Inf. Secur. 2017, 16, 475–490. [Google Scholar] [CrossRef]
- Kolias, C.; Kolias, V.; Kambourakis, G. TermID: A distributed swarm intelligence-based approach for wireless intrusion detection. Int. J. Inf. Secur. 2017, 16, 401–416. [Google Scholar] [CrossRef]
- Shone, N.; Ngoc, T.N.; Phai, V.D.; Shi, Q. A deep learning approach to network intrusion detection. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 41–50. [Google Scholar] [CrossRef] [Green Version]
- Sethi, K.; Sai Rupesh, E.; Kumar, R.; Bera, P.; Venu Madhav, Y. A context-aware robust intrusion detection system: A reinforcement learning-based approach. Int. J. Inf. Secur. 2020, 19, 657–678. [Google Scholar] [CrossRef]
- Quadir, M.A.; Christy Jackson, J.; Prassanna, J.; Sathyarajasekaran, K.; Kumar, K.; Sabireen, H.; Ubarhande, S.; Vijaya Kumar, V. An efficient algorithm to detect DDoS amplification attacks. J. Intell. Fuzzy Syst. 2020, 39, 8565–8572. [Google Scholar] [CrossRef]
- Kannari, P.R.; Shariff, N.C.; Biradar, R.L. Network intrusion detection using sparse autoencoder with swish-PReLU activation model. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 1–13. [Google Scholar] [CrossRef]
- Badji, J.C.J.; Diallo, C. A CNN-based Attack Classification versus an AE-based Unsupervised Anomaly Detection for Intrusion Detection Systems. In Proceedings of the 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), Prague, Czech Republic, 20–22 July 2022; pp. 1–7. [Google Scholar] [CrossRef]
- D’hooge, L.; Wauters, T.; Volckaert, B.; De Turck, F. Inter-dataset generalization strength of supervised machine learning methods for intrusion detection. J. Inf. Secur. Appl. 2020, 54, 102564. [Google Scholar] [CrossRef]
- D’hooge, L.; Wauters, T.; Volckaert, B.; De Turck, F. Classification hardness for supervised learners on 20 years of intrusion detection data. IEEE Access 2019, 7, 167455–167469. [Google Scholar] [CrossRef]
- Sharafaldin, I.; CIC. CIC-IDS2017. 2017. Available online: https://www.unb.ca/cic/datasets/ids-2017.html (accessed on 15 November 2022).
- Sharafaldin, I.; CIC. CIC-IDS2018. 2018. Available online: https://www.unb.ca/cic/datasets/ids-2018.html (accessed on 15 November 2022).
- Sharafaldin, I.; CIC. CIC-DDoS2019. 2019. Available online: https://www.unb.ca/cic/datasets/ddos-2019.html (accessed on 15 November 2022).
- Sharafaldin, I.; Lashkari, A.H.; Hakak, S.; Ghorbani, A.A. Developing realistic distributed denial of service (DDoS) attack dataset and taxonomy. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; pp. 1–8. [Google Scholar]
- Govindarajan, M.; Chandrasekaran, R. Intrusion detection using an ensemble of classification methods. In Proceedings of the World Congress on Engineering and Computer Science (WCECS), San Francisco, CA, USA, 24–26 October 2012; Volume 1, pp. 459–464. [Google Scholar]
- Lu, L.; Teng, S.; Zhang, W.; Zhang, Z.; Fei, L.; Fang, X. Two-Layer Intrusion Detection Model Based on Ensemble Classifier. In Proceedings of the CCF Conference on Computer Supported Cooperative Work and Social Computing, Kunming, China, 16–18 August 2019; Springer: Singapore, 2019; pp. 104–115. [Google Scholar]
- Kuang, F.; Xu, W.; Zhang, S.; Wang, Y.; Liu, K. A novel approach of KPCA and SVM for intrusion detection. J. Comput. Inf. Syst. 2012, 8, 3237–3244. [Google Scholar]
- Wickramasinghe, C.S.; Marino, D.L.; Amarasinghe, K.; Manic, M. Generalization of deep learning for cyber-physical system security: A survey. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 745–751. [Google Scholar]
- Sommer, R.; Paxson, V. Outside the closed world: On using machine learning for network intrusion detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 16–19 May 2010; pp. 305–316. [Google Scholar]
- Gates, C.; Taylor, C. Challenging the anomaly detection paradigm: A provocative discussion. In Proceedings of the 2006 Workshop on NEW Security Paradigms, Schloss Dagstuhl, Germany, 19–22 September 2006; pp. 21–29. [Google Scholar]
- Małowidzki, M.; Berezinski, P.; Mazur, M. Network intrusion detection: Half a kingdom for a good dataset. In Proceedings of the NATO STO SAS-139 Workshop, Lisbon, Portugal, 1 December 2015. [Google Scholar]
- Vasilomanolakis, E.; Cordero, C.G.; Milanov, N.; Mühlhäuser, M. Towards the creation of synthetic, yet realistic, intrusion detection datasets. In Proceedings of the NOMS 2016-2016 IEEE/IFIP Network Operations and Management Symposium, Istanbul, Turkey, 25–29 April 2016; pp. 1209–1214. [Google Scholar]
- Ring, M.; Wunderlich, S.; Scheuring, D.; Landes, D.; Hotho, A. A survey of network-based intrusion detection data sets. Comput. Secur. 2019, 86, 147–167. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Das, A.; Zhou, J. Model generalization and its implications on intrusion detection. In Proceedings of the International Conference on Applied Cryptography and Network Security, New York, NY, USA, 7–10 June 2005; pp. 222–237. [Google Scholar]
- Lin, Z.; Shi, Y.; Xue, Z. Idsgan: Generative adversarial networks for attack generation against intrusion detection. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Chengdu, China, 16–19 May 2022; pp. 79–91. [Google Scholar]
- Newlin, M.; Reith, M.; DeYoung, M. Synthetic Data Generation with Machine Learning for Network Intrusion Detection Systems. In Proceedings of the European Conference on Cyber Warfare and Security, Coimbra, Portugal, 4– 5 July 2019; p. 785-XVII. [Google Scholar]
- Recht, B.; Roelofs, R.; Schmidt, L.; Shankar, V. Do imagenet classifiers generalize to imagenet? In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5389–5400. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Sharafaldin, I.; Gharib, A.; Lashkari, A.H.; Ghorbani, A.A. Towards a reliable intrusion detection benchmark dataset. Softw. Netw. 2018, 2018, 177–200. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- D’hooge, L.; Wauters, T.; Volckaert, B.; De Turck, F. In-depth comparative evaluation of supervised machine learning approaches for detection of cybersecurity threats. In Proceedings of the 4th International Conference on Internet of Things, Big Data and Security (IoTBDS), Crete, Greece, 2–4 May 2019; pp. 125–136. [Google Scholar]
- Sweetsoftware. Ares. 2017. Available online: https://github.com/sweetsoftware/Ares (accessed on 18 November 2022).
- Touyachrist. Evo-Zeus. 2017. Available online: https://github.com/touyachrist/evo-zeus (accessed on 18 November 2022).
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. IntelligenCe Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mighan, S.N.; Kahani, M. A novel scalable intrusion detection system based on deep learning. Int. J. Inf. Secur. 2021, 20, 387–403. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Class | 2017 | Tools | 2018 | Tools |
|---|---|---|---|---|
| FTP/SSH brute force | 0 | Patator.py (FTP/SSH) | 0 | Patator.py (FTP/SSH) |
| DoS layer-7 | 1 | Slowloris Slowhttptest Hulk Goldeneye | 1 | Slowloris Slowhttptest Hulk Goldeneye |
| Heartbleed | 1 | Heartleech | 2 | Heartleech |
| Web attacks | 2 | Custom Selenium XSS+bruteforce, SQLi vs. DVWA | 5 | same types, tools undocumented |
| Web attacks | 2 | Custom Selenium XSS+bruteforce, SQLi vs. DVWA | 6 | same types, tools undocumented |
| Infiltration | 3 | Metasploit, Dropbox download, cool disk MAC | 7 | Nmap, Dropbox download |
| Infiltration | 3 | Metasploit, Dropbox download, cool disk MAC | 8 | Nmap, Dropbox download |
| Botnet | 4 | ARES | 9 | Zeus, ARES |
| DDoS | 5 | Low Orbit Ion Cannon (LOIC) HTTP | 3 | LOIC HTTP |
| DDoS | 5 | LOIC HTTP | 4 | LOIC-UDP, High Orbit Ion Cannon (HOIC) |
| Port scan | 6 | Various Nmap commands | - | - |
| Dataset | Most Discriminative | |
|---|---|---|
| CIC-IDS2017 | 1–5 | Timestamp, Init Win bytes forward, Destination Port, Flow IAT Min, Fwd Packets/s |
| 5–10 | Fwd Packet Length Std, Avg Fwd Segment Size, Flow Duration, Fwd IAT Min, ECE Flag Count | |
| 10–15 | Fwd IAT Mean, Init Win bytes backward, Bwd Packets/s, Idle Max, Fwd IAT Std | |
| 15–20 | FIN Flag Count, Fwd Header Length, SYN Flag Count, Fwd Packet Length Max, Flow Packets | |
| B/G | Class | Algorithm | Balanced Acc. | F1 | Precision | Recall | Scaling | Reduction | % Train |
|---|---|---|---|---|---|---|---|---|---|
| B | 0.Bruteforce | gradboost | 99.84 | 99.06 | 98.40 | 99.73 | No | 0 | 0.5 |
| extratree | 99.63 | 99.24 | 99.21 | 99.28 | Z | 0 | 0.5 | ||
| extratree | 99.64 | 99.63 | 99.97 | 99.28 | Z | 0 | 1.0 | ||
| G | 0.Bruteforce | xgboost | 100 | 100 | 100 | 100 | No | 0 | 0.5 |
| xgboost | 99.97 | 99.95 | 99.90 | 100 | No | 0 | 1.0 | ||
| gradboost | 99.06 | 98.38 | 96.81 | 100 | MinMax | 0 | 0.1 | ||
| B | 1.L7-DoS | xgboost | 99.85 | 99.79 | 99.71 | 99.88 | No | 0 | 0.5 |
| xgboost | 99.85 | 99.77 | 99.66 | 99.89 | Z | 0 | 0.5 | ||
| xgboost | 99.84 | 99.76 | 99.61 | 99.91 | MinMax | 0 | 0.5 | ||
| G | 1.L7-DoS | linsvc | 97.80 | 82.59 | 71.57 | 97.63 | MinMax | 5 | 1.0 |
| linsvc | 97.98 | 84.93 | 75.14 | 97.65 | MinMax | 5 | 6.0 | ||
| linsvc | 97.75 | 81.63 | 70.10 | 97.70 | MinMax | 5 | 11.0 | ||
| G | 2.L7-DoS (HeartBleed) | rforest | 99.75 | 99.81 | 99.65 | 99.78 | Z | 20 | 1.0 |
| linsvc | 99.49 | 99.50 | 99.95 | 99.04 | MinMax | 0 | 0.5 | ||
| gradboost | 99.65 | 99.72 | 99.60 | 99.85 | MinMax | 10 | 1 | ||
| B | 2.Web Attacks | xgboost | 97.58 | 96.92 | 98.72 | 95.18 | MinMax | 0 | 1.0 |
| xgboost | 98.83 | 98.75 | 99.86 | 97.66 | MinMax | 0 | 6.0 | ||
| extratree | 98.89 | 98.27 | 98.75 | 97.80 | MinMax | 0 | 6.0 | ||
| G | 5.Web Attacks | gradboost | 64.23 | 43.37 | 91.15 | 28.45 | No | 10 | 0.5 |
| dtree | 77.74 | 38.69 | 29.69 | 55.52 | No | 0 | 11.0 | ||
| ada | 64.36 | 41.35 | 73.76 | 28.73 | No | 0 | 1.0 | ||
| G | 6.Web Attacks | extratree | 61.75 | 38.05 | 100 | 23.50 | MinMax | 5 | 0.5 |
| gradboost | 61.66 | 36.92 | 88.59 | 23.32 | No | 10 | 0.5 | ||
| xgboost | 61.66 | 36.82 | 87.42 | 23.32 | MinMax | 10 | 0.5 | ||
| B | 3.Infiltration | dtree | 88.89 | 71.79 | 66.67 | 77.78 | MinMax | 10 | 11.0 |
| xgboost | 93.06 | 91.18 | 96.88 | 86.11 | Z | 0 | 35.0 | ||
| extratree | 88.89 | 86.15 | 96.55 | 77.78 | MinMax | 15 | 26.0 | ||
| G | 7.Infiltration | ncentroid | 50.19 | 17.50 | 11.33 | 38.42 | Z | 20 | 6.0 |
| binlr | 50.46 | 14.86 | 11.71 | 20.34 | Z | 0 | 6.0 | ||
| binlr | 49.93 | 15.22 | 11.18 | 23.82 | Z | 20 | 6.0 | ||
| G | 8.Infiltration | ncentroid | 57.75 | 42.42 | 35.74 | 52.16 | Z | 20 | 6.0 |
| binlr | 55.23 | 43.21 | 31.58 | 68.38 | MinMax | 15 | 11.0 | ||
| linsvc | 51.09 | 43.11 | 28.62 | 87.29 | MinMax | 10 | 11.0 | ||
| B | 4.Botnet | xgboost | 98.42 | 98.19 | 99.58 | 96.85 | MinMax | 0 | 6.0 |
| xgboost | 98.14 | 97.65 | 99.06 | 96.29 | Z | 0 | 6.0 | ||
| xgboost | 97.53 | 97.32 | 99.68 | 95.07 | No | 0 | 6.0 | ||
| G | 9.Botnet | ada | 98.90 | 98.40 | 98.39 | 98.41 | No | 0 | 0.5 |
| gradboost | 92.11 | 82.67 | 70.51 | 99.91 | Z | 0 | 0.5 | ||
| ada | 92.11 | 82.67 | 70.51 | 99.91 | Z | 0 | 0.5 | ||
| B | 5.DDoS | extratree | 99.89 | 99.89 | 99.96 | 99.82 | Z | 5 | 0.1 |
| extratree | 99.87 | 99.88 | 99.96 | 99.79 | Z | 10 | 0.1 | ||
| extratree | 99.84 | 99.86 | 99.88 | 99.83 | No | 10 | 0.1 | ||
| G | 3.DDoS | dtree | 96.30 | 96.75 | 96.09 | 97.42 | Z | 0 | 0.5 |
| ada | 96.30 | 96.75 | 96.09 | 97.42 | Z | 0 | 1.0 | ||
| bag | 95.96 | 96.49 | 95.58 | 97.42 | Z | 0 | 0.5 | ||
| G | 4.DDoS | binlr | 99.86 | 99.87 | 99.99 | 99.75 | MinMax | 0 | 0.1 |
| binlr | 99.86 | 99.87 | 99.99 | 99.75 | MinMax | 5 | 0.1 | ||
| binlr | 99.86 | 99.87 | 99.99 | 99.75 | MinMax | 10 | 0.1 | ||
| B | 7.Global | xgboost | 99.82 | 99.73 | 99.75 | 99.70 | No | 0 | 0.5 |
| xgboost | 99.68 | 99.62 | 99.84 | 99.40 | Z | 0 | 0.5 | ||
| xgboost | 99.86 | 99.80 | 99.85 | 99.75 | Z | 0 | 1.0 | ||
| G | 10.Global | knn | 81.36 | 71.98 | 64.46 | 81.47 | Z | 0 | 0.1 |
| knn | 79.23 | 69.06 | 60.65 | 80.18 | Z | 10 | 1.0 | ||
| knn | 79.03 | 68.45 | 58.49 | 82.50 | Z | 10 | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’hooge, L.; Verkerken, M.; Wauters, T.; De Turck, F.; Volckaert, B. Characterizing the Impact of Data-Damaged Models on Generalization Strength in Intrusion Detection. J. Cybersecur. Priv. 2023, 3, 118-144. https://doi.org/10.3390/jcp3020008
D’hooge L, Verkerken M, Wauters T, De Turck F, Volckaert B. Characterizing the Impact of Data-Damaged Models on Generalization Strength in Intrusion Detection. Journal of Cybersecurity and Privacy. 2023; 3(2):118-144. https://doi.org/10.3390/jcp3020008
Chicago/Turabian StyleD’hooge, Laurens, Miel Verkerken, Tim Wauters, Filip De Turck, and Bruno Volckaert. 2023. "Characterizing the Impact of Data-Damaged Models on Generalization Strength in Intrusion Detection" Journal of Cybersecurity and Privacy 3, no. 2: 118-144. https://doi.org/10.3390/jcp3020008