
An Understanding of the Vulnerability of Datasets to Disparate Membership Inference Attacks

Abstract
:1. Introduction
1.1. Previous Work
1.2. Contributions
2. Methodology
2.1. Data
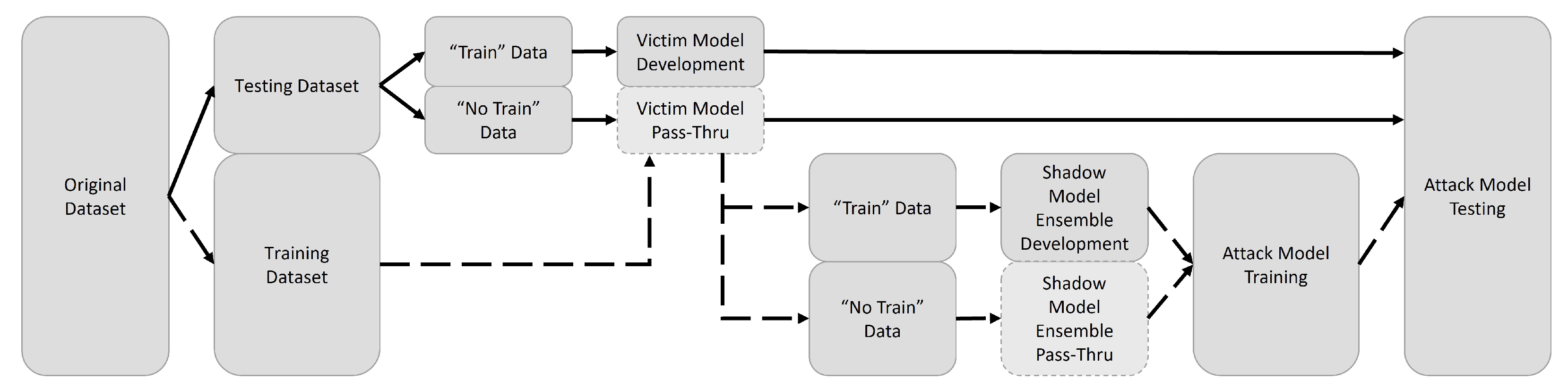
2.2. Membership Inference Attack
2.2.1. Development and Standardization of Victim Models
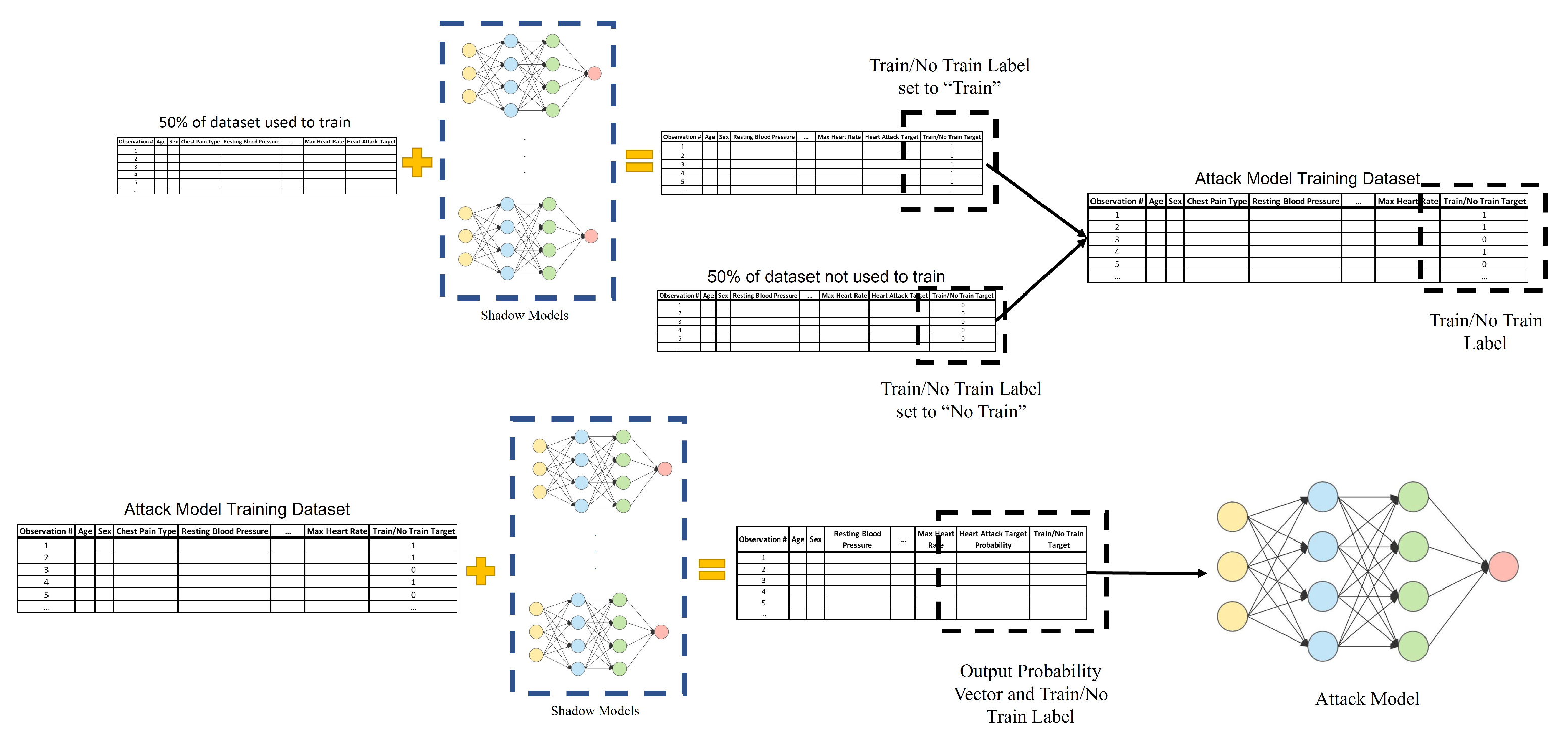
2.2.2. Development and Standardization of Shadow Models
2.2.3. Development and Standardization of the Attack Model
2.3. Understanding of Labeling
2.4. Development of Dataset Features
2.5. Feature Selection
2.6. Vulnerability Classification
2.7. Hardening Exploration
3. Results of Vulnerability Classification
3.1. In-Label Distance Measures
3.2. Width Ratio
3.3. Proportion of Binary Features
4. Results of Hardening Exploration
5. Discussion of Vulnerabilities to Disparate Membership Inference Attack
6. Discussion of Hardening Exploration
7. Summary and Future Efforts
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| Number of Observations (Macro and Disparate) | The quantity of observations within the original dataset. |
| Class Entropy | Entropy as defined through the number of observations in each class. |
| Number of Classes | The number of classes. |
| Number of Features | The number of features in the original dataset. |
| Number of Features After One Hot Encoding | The number of features after the dataset has been processed using one-hot encoding on categorical features. |
| Proportion of Categorical Features | The proportion of categorical features in respect to the original number of features. |
| Proportion of Binary Features | The proportion of binary features in respect to the original number of features. |
| Proportion of Numerical Features | The proportion of numerical features in respect to the original number of features. |
| Variance of the Entropy of Features (Macro and Disparate) | An entropy is calculated for each feature. This is the variance of that array. |
| Maximum of the Entropy of Features (Macro and Disparate) | An entropy is calculated for each feature. This is the maximum value of that array. |
| Minimum of the Entropy of Features (Macro and Disparate) | An entropy is calculated for each feature. This is the minimum value of that array. |
| Mean of the Entropy of Features (Macro and Disparate) | An entropy is calculated for each feature. This is the mean of that array. |
| Maximum of the Numerical Feature Range (Macro and Disparate) | The maximum range of values of the numerical features. |
| Minimum of the Numerical Feature Range (Macro and Disparate) | The minimum range of values of the numerical features. |
| Global Maximum of the Numerical Feature Range (Macro and Disparate) | The global maximum range of values of the numerical features as defined by the largest numerical value minus the smallest numerical value across all numerical features. |
| Global Minimum of the Numerical Feature Range (Macro and Disparate) | The global minimum range of values of the numerical features as defined by the smallest, upper numerical value minus the largest, lower numerical value across all numerical feature ranges. |
| Mean of Mean Label Distances | The distances of observations within each label were calculated using cityblock distances and then averaged within that label. This feature is the mean of those averages. |
| Variance of Mean Label Distances | The distances of observations within each label were calculated using cityblock distances and then averaged within that label. This feature is the variance of those averages. |
| Mean of Mean Label Minimum Distances | The distances of observations within each label were calculated using cityblock distances. This feature is the mean of the minimum of distances for each label. |
| Variance of Mean Label Minimum Distances | The distances of observations within each label were calculated using cityblock distances. This feature is the variance of the minimum of distances for each label. |
| Mean of Mean Label Maximum Distances | The distances of observations within each label were calculated using cityblock distances. This feature is the mean of the maximum of distances for each label. |
| Variance of Mean Label Maximum Distances | The distances of observations within each label were calculated using cityblock distances. This feature is the variance of the maximum of distances for each label. |
| Mean of Feature–Feature Correlation (Macro and Disparate) | This feature is the mean of feature to feature correlation values. |
| Maximum of Feature–Feature Correlation (Macro and Disparate) | This feature is the maximum value of feature to feature correlation values. |
| Minimum of Feature–Feature Correlation (Macro and Disparate) | This feature is the minimum value of feature to feature correlation values. |
| Mean of Variance of Feature–Feature Correlation (Macro and Disparate) | This feature is the mean of the variance of feature to feature correlation values. |
| Variance of the Mean of Feature–Feature Correlation (Macro and Disparate) | This feature is the variance of the means of feature to feature correlation values. |
| Number of PCAs Required to Explain Variance | The number of principal components required to explain of the variance of the dataset. |
| Cond num 2norm (Macro and Disparate) | Condition number of 2-norm. |
| Width Ratio (Macro and Disparate) | The ratio of the number of observations of the original dataset to the number of features of the original dataset. |
| Width Ratio of One Hot Encoding (Macro and Disparate) | The number of observations of the original dataset to the number of features after one-hot encoding the categorical variables. |
| Maximum Number of Categories (Macro and Disparate) | The maximum number of categories that any categorical feature in the original dataset contained. |
| Minimum Number of Categories (Macro and Disparate) | The minimum number of categories that any categorical feature in the original dataset contained. |
| Mean Number of Categories (Macro and Disparate) | The average number of categories for each categorical feature in the original dataset. |
| Variance of Number of Categories (Macro and Disparate) | The variance of the number of categories for each categorical feature in the original dataset. |
| Mean Feature–Feature Correlation Grouped by Label | The mean of the feature to feature correlation when grouped by label. |
| Maximum Feature–Feature Correlation Grouped by Label | The maximum of the feature to feature correlation when grouped by label. |
| Minimum Feature–Feature Correlation Grouped by Label | The minimum of the feature to feature correlation when grouped by label. |
| Mean of the Variance of Feature–Feature Correlation Grouped by Label | The average of the variance of feature to feature correlations when grouped by label. |
| Variance of the Means of Feature–Feature Correlation Grouped by Label | The variance of the means of the feature to feature correlations when grouped by label. |
| Canonical Correlation (Macro and Disparate) | Canonical correlation. |
| Maximum Feature Skewness (Macro and Disparate) | The maximum skewness of the features in the dataset. |
| Minimum Feature Skewness (Macro and Disparate) | The minimum skewness of the features in the dataset. |
| Mean Feature Skewness (Macro and Disparate) | The mean skewness of the features in the dataset. |
| Variance Feature Skewness (Macro and Disparate) | The variance skewness of the features in the dataset. |
| Maximum Feature Kurtosis (Macro and Disparate) | The maximum kurtosis of the features in the dataset. |
| Minimum Feature Kurtosis (Macro and Disparate) | The minimum kurtosis of the features in the dataset. |
| Mean Feature Kurtosis (Macro and Disparate) | The mean kurtosis of the features in the dataset. |
| Variance Feature Kurtosis (Macro and Disparate) | The variance kurtosis of the features in the dataset. |
| Standard Deviation Ratio of Features (Macro and Disparate) | The geometric mean ratio of standard deviations of the individual populations to the pooled standard deviation. |
| Maximum Standard Deviation Ratio of Features by Label | The maximum of the standard deviation ratios of features as described above but grouped by label. |
| Minimum Standard Deviation Ratio of Features by Label | The minimum of the standard deviation ratios of features as described above but grouped by label. |
| Mean of the Standard Deviation Ratio of Features by Label | The mean of the standard deviation ratios of features as described above but grouped by label. |
| Variance of the Standard Deviation Ratio of Features by Label | The variance of the standard deviation ratios of features as described above but grouped by label. |
| Mean Mutual Information of Features (Macro and Disparate) | The mean mutual information of features. |
| Maximum Mutual Information of Features (Macro and Disparate) | The maximum mutual information of features. |
| Minimum Mutual Information of Features (Macro and Disparate) | The minimum mutual information of features. |
| Variance of the Mutual Information of Features (Macro and Disparate) | The variance of the mutual information of features. |
| Mean Mutual Information of Features Grouped by Label | The mean mutual information of features grouped by label. |
| Maximum Mutual Information of Features Grouped by Label | The maximum mutual information of features grouped by label. |
| Minimum Mutual Information of Features Grouped by Label | The minimum mutual information of features grouped by label. |
| Variance of the Mutual Information of Features Grouped by Label | The variance of the mutual information of features grouped by label. |
| Equivalent Number of Attributes | Entropy of class divided by the mean mutual information of class and attributes. |
References
- Veale, M.; Binns, R.; Edwards, L. Algorithms that remember: Model inversion attacks and data protection law. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2018, 376, 20180083. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. Adversarial attacks and defences: A survey. arXiv 2018, arXiv:1810.00069. [Google Scholar] [CrossRef]
- He, Y.; Meng, G.; Chen, K.; Hu, X.; He, J. Towards Privacy and Security of Deep Learning Systems: A Survey. arXiv 2019, arXiv:1911.12562. [Google Scholar]
- Qiu, S.; Liu, Q.; Zhou, S.; Wu, C. Review of artificial intelligence adversarial attack and defense technologies. Appl. Sci. 2019, 9, 909. [Google Scholar] [CrossRef] [Green Version]
- Calandrino, J.A.; Kilzer, A.; Narayanan, A.; Felten, E.W.; Shmatikov, V. “You might also like:” Privacy risks of collaborative filtering. In Proceedings of the 2011 IEEE Symposium on Security and Privacy, Washington, DC, USA, 22–25 May 2011; pp. 231–246. [Google Scholar]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Fredrikson, M.; Lantz, E.; Jha, S.; Lin, S.; Page, D.; Ristenpart, T. Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing. In Proceedings of the 23rd USENIX Security Symposium (USENIX Security 14), San Diego, CA, USA, 20–22 August 2014; pp. 17–32. [Google Scholar]
- Narayanan, A.; Shmatikov, V. Robust De-anonymization of Large Datasets (How to Break Anonymity of the Netflix Prize Dataset). The University of Texas at Austin. In Proceedings of the 29th IEEE Symposium on Security and Privacy, Oakland, CA, USA, 18–21 May 2008; pp. 111–125. [Google Scholar]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models. arXiv 2018, arXiv:1806.01246. [Google Scholar]
- Hilprecht, B.; Härterich, M.; Bernau, D. Monte carlo and reconstruction membership inference attacks against generative models. Proc. Priv. Enhancing Technol. 2019, 2019, 232–249. [Google Scholar] [CrossRef] [Green Version]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Kuppa, A.; Le-Khac, N.A. Adversarial xai methods in cybersecurity. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4924–4938. [Google Scholar] [CrossRef]
- Huang, W.; Zhou, S.; Liao, Y. Unexpected Information Leakage of Differential Privacy Due to the Linear Property of Queries. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3123–3137. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. An Efficient Subpopulation-based Membership Inference Attack. arXiv 2022, arXiv:2203.02080. [Google Scholar]
- Tan, J.; Mason, B.; Javadi, H.; Baraniuk, R.G. Parameters or Privacy: A Provable Tradeoff between Overparameterization and Membership Inference. arXiv 2022, arXiv:2202.01243. [Google Scholar]
- Ateniese, G.; Mancini, L.V.; Spognardi, A.; Villani, A.; Vitali, D.; Felici, G. Hacking smart machines with smarter ones: How to extract meaningful data from machine learning classifiers. Int. J. Secur. Netw. 2015, 10, 137–150. [Google Scholar] [CrossRef]
- Long, Y.; Bindschaedler, V.; Wang, L.; Bu, D.; Wang, X.; Tang, H.; Gunter, C.A.; Chen, K. Understanding membership inferences on well-generalized learning models. arXiv 2018, arXiv:1802.04889. [Google Scholar]
- Long, Y.; Wang, L.; Bu, D.; Bindschaedler, V.; Wang, X.; Tang, H.; Gunter, C.A.; Chen, K. A Pragmatic Approach to Membership Inferences on Machine Learning Models. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 7–11 September 2020; pp. 521–534. [Google Scholar]
- Tonni, S.M.; Farokhi, F.; Vatsalan, D.; Kaafar, D. Data and Model Dependencies of Membership Inference Attack. arXiv 2020, arXiv:2002.06856. [Google Scholar]
- Truex, S.; Liu, L.; Gursoy, M.E.; Yu, L.; Wei, W. Demystifying membership inference attacks in machine learning as a service. IEEE Trans. Serv. Comput. 2019, 14, 2073–2089. [Google Scholar] [CrossRef]
- Yaghini, M.; Kulynych, B.; Troncoso, C. Disparate vulnerability: On the unfairness of privacy attacks against machine learning. arXiv 2019, arXiv:1906.00389. [Google Scholar]
- Bagdasaryan, E.; Poursaeed, O.; Shmatikov, V. Differential privacy has disparate impact on model accuracy. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 15479–15488. [Google Scholar]
- Chang, H.; Shokri, R. On the Privacy Risks of Algorithmic Fairness. arXiv 2020, arXiv:2011.03731. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 30 April 2021).
- Abdelhamid, N.; Ayesh, A.; Thabtah, F. Phishing detection based associative classification data mining. Expert Syst. Appl. 2014, 41, 5948–5959. [Google Scholar] [CrossRef]
- Abid, F.; Izeboudjen, N. Predicting Forest Fire in Algeria Using Data Mining Techniques: Case Study of the Decision Tree Algorithm. In Proceedings of the International Conference on Advanced Intelligent Systems for Sustainable Development, Marrakech, Morocco, 8–11 July 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 363–370. [Google Scholar]
- Abreu, N.G.C.F.M. Análise do Perfil do Cliente Recheio e Desenvolvimento de um Sistema Promocional. Ph.D. Thesis, Iscte-Instituto Universitário de Lisboa, Lisbon, Portugal, 2011. Available online: http://hdl.handle.net/10071/4097 (accessed on 5 October 2022).
- Adak, M.F.; Lieberzeit, P.; Jarujamrus, P.; Yumusak, N. Classification of alcohols obtained by QCM sensors with different characteristics using ABC based neural network. Eng. Sci. Technol. Int. J. 2020, 23, 463–469. [Google Scholar] [CrossRef]
- Ahmed, M.; Jahangir, M.; Afzal, H.; Majeed, A.; Siddiqi, I. Using crowd-source based features from social media and conventional features to predict the movies popularity. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 273–278. [Google Scholar]
- Alzahrani, A.; Sadaoui, S. Clustering and labeling auction fraud data. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 269–283. [Google Scholar]
- Antal, B.; Hajdu, A. An ensemble-based system for automatic screening of diabetic retinopathy. Knowl.-Based Syst. 2014, 60, 20–27. [Google Scholar] [CrossRef] [Green Version]
- Benítez-Mata, B.; Castro, C.; Castañeda, R.; Vargas, E.; Flores, D.L. Prediction of Breast Cancer Diagnosis by Blood Biomarkers Using Artificial Neural Networks. In Proceedings of the VIII Latin American Conference on Biomedical Engineering and XLII National Conference on Biomedical Engineering, Cancún, Mexico, 2–5 October 2020; González Díaz, C.A., Chapa González, C., Laciar Leber, E., Vélez, H.A., Puente, N.P., Flores, D.L., Andrade, A.O., Galván, H.A., Martínez, F., García, R., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 47–55. [Google Scholar]
- Blachnik, M.; Sołtysiak, M.; Dąbrowska, D. Predicting Presence of Amphibian Species Using Features Obtained from GIS and Satellite Images. ISPRS Int. J. Geo-Inf. 2019, 8, 123. [Google Scholar] [CrossRef] [Green Version]
- Chicco, D.; Jurman, G. Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Med. Informatics Decis. Mak. 2020, 20, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J. Modeling wine preferences by data mining from physicochemical properties. Decis. Support Syst. 2009, 47, 547–553. [Google Scholar] [CrossRef] [Green Version]
- De Stefano, C.; Maniaci, M.; Fontanella, F.; di Freca, A.S. Reliable writer identification in medieval manuscripts through page layout features: The “Avila” Bible case. Eng. Appl. Artif. Intell. 2018, 72, 99–110. [Google Scholar] [CrossRef]
- Elter, M.; Schulz-Wendtland, R.; Wittenberg, T. The prediction of breast cancer biopsy outcomes using two CAD approaches that both emphasize an intelligible decision process. Med. Phys. 2007, 34, 4164–4172. [Google Scholar] [CrossRef] [PubMed]
- Fehrman, E.; Muhammad, A.K.; Mirkes, E.M.; Egan, V.; Gorban, A.N. The five factor model of personality and evaluation of drug consumption risk. In Data Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 231–242. [Google Scholar]
- Fernandes, K.; Vinagre, P.; Cortez, P. A proactive intelligent decision support system for predicting the popularity of online news. In Proceedings of the Portuguese Conference on Artificial Intelligence, Coimbra, Portugal, 8–11 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 535–546. [Google Scholar]
- Fernandes, K.; Cardoso, J.S.; Fernandes, J. Transfer learning with partial observability applied to cervical cancer screening. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Faro, Portugal, 20–23 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 243–250. [Google Scholar]
- Guyon, I.; Gunn, S.; Ben-Hur, A.; Dror, G. Result analysis of the nips 2003 feature selection challenge. Adv. Neural Inf. Process. Syst. 2004, 17, 545–552. [Google Scholar]
- Gyamfi, K.S.; Brusey, J.; Hunt, A.; Gaura, E. Linear dimensionality reduction for classification via a sequential Bayes error minimisation with an application to flow meter diagnostics. Expert Syst. Appl. 2018, 91, 252–262. [Google Scholar] [CrossRef]
- Higuera, C.; Gardiner, K.J.; Cios, K.J. Self-organizing feature maps identify proteins critical to learning in a mouse model of down syndrome. PLoS ONE 2015, 10, e0129126. [Google Scholar] [CrossRef]
- Hussain, S.; Atallah, R.; Kamsin, A.; Hazarika, J. Classification, clustering and association rule mining in educational datasets using data mining tools: A case study. In Proceedings of the Computer Science On-line Conference, Vsetin, Czech Republic, 25–28 April 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 196–211. [Google Scholar]
- Hussain, S.; Dahan, N.A.; Ba-Alwib, F.M.; Ribata, N. Educational data mining and analysis of students’ academic performance using WEKA. Indones. J. Electr. Eng. Comput. Sci. 2018, 9, 447–459. [Google Scholar] [CrossRef]
- Johnson, B.A. High-resolution urban land-cover classification using a competitive multi-scale object-based approach. Remote Sens. Lett. 2013, 4, 131–140. [Google Scholar] [CrossRef]
- Johnson, B.A.; Iizuka, K. Integrating OpenStreetMap crowdsourced data and Landsat time-series imagery for rapid land use/land cover (LULC) mapping: Case study of the Laguna de Bay area of the Philippines. Appl. Geogr. 2016, 67, 140–149. [Google Scholar] [CrossRef]
- Johnson, B.; Tateishi, R.; Xie, Z. Using geographically weighted variables for image classification. Remote Sens. Lett. 2012, 3, 491–499. [Google Scholar] [CrossRef]
- Johnson, B.; Xie, Z. Classifying a high resolution image of an urban area using super-object information. ISPRS J. Photogramm. Remote Sens. 2013, 83, 40–49. [Google Scholar] [CrossRef]
- Kahraman, H.T.; Sagiroglu, S.; Colak, I. The development of intuitive knowledge classifier and the modeling of domain dependent data. Knowl.-Based Syst. 2013, 37, 283–295. [Google Scholar] [CrossRef]
- Khomtchouk, B.B. Codon usage bias levels predict taxonomic identity and genetic composition. bioRxiv 2020. [Google Scholar] [CrossRef]
- Koklu, M.; Ozkan, I.A. Multiclass classification of dry beans using computer vision and machine learning techniques. Comput. Electron. Agric. 2020, 174, 105507. [Google Scholar] [CrossRef]
- Moro, S.; Cortez, P.; Rita, P. A data-driven approach to predict the success of bank telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef] [Green Version]
- Palechor, F.M.; de la Hoz Manotas, A. Dataset for estimation of obesity levels based on eating habits and physical condition in individuals from Colombia, Peru and Mexico. Data Brief 2019, 25, 104344. [Google Scholar] [CrossRef]
- Sakar, C.O.; Polat, S.O.; Katircioglu, M.; Kastro, Y. Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Comput. Appl. 2019, 31, 6893–6908. [Google Scholar] [CrossRef]
- Sikora, M. Application of rule induction algorithms for analysis of data collected by seismic hazard monitoring systems in coal mines. Arch. Min. Sci. 2010, 55, 91–114. [Google Scholar]
- Tsanas, A.; Xifara, A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Velloso, E.; Bulling, A.; Gellersen, H.; Ugulino, W.; Fuks, H. Qualitative activity recognition of weight lifting exercises. In Proceedings of the fourth Augmented Human International Conference, Stuttgart, Germany, 7–8 March 2013; pp. 116–123. [Google Scholar]
- Wang, T.; Rudin, C.; Doshi-Velez, F.; Liu, Y.; Klampfl, E.; MacNeille, P. A bayesian framework for learning rule sets for interpretable classification. J. Mach. Learn. Res. 2017, 18, 2357–2393. [Google Scholar]
- Yeh, I.C.; Lien, C.h. The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients. Expert Syst. Appl. 2009, 36, 2473–2480. [Google Scholar] [CrossRef]
- Yeh, I.C.; Yang, K.J.; Ting, T.M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Zikeba, M.; Tomczak, J.M.; Lubicz, M.; Świkatek, J. Boosted SVM for extracting rules from imbalanced data in application to prediction of the post-operative life expectancy in the lung cancer patients. Appl. Soft Comput. 2014, 14, 99–108. [Google Scholar]
- Zikeba, M.; Tomczak, S.K.; Tomczak, J.M. Ensemble Boosted Trees with Synthetic Features Generation in Application to Bankruptcy Prediction. Expert Sys. Appl. 2016, 58, 93–101. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Brazdil, P.; Gama, J.; Henery, B. Characterizing the applicability of classification algorithms using meta-level learning. In Proceedings of the European Conference on Machine Learning, Catania, Italy, 6–8 April 1994; Springer: Berlin/Heidelberg, Germany, 1994; pp. 83–102. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 7335–7345. [Google Scholar]
- Mani, I.; Zhang, I. kNN approach to unbalanced data distributions: A case study involving information extraction. In Proceedings of the Workshop on Learning from Imbalanced Datasets, ICML, 2003, Washington, DC, USA, 21–24 August 2003; Volume 126, pp. 1–7. [Google Scholar]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the surprising behavior of distance metrics in high dimensional space. In Proceedings of the International Conference on Database Theory, London, UK, 1–4 January 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 420–434. [Google Scholar]


| Victim Model | Shadow Models | Attack Model |
|---|---|---|
| Neural Network | Neural Network | Neural Network |
| Neural Network | Neural Network | Random Forest |
| Random Forest | Random Forest | Random Forest |
| Random Forest | Random Forest | Neural Network |
| Logistic Regression | Logistic Regression | Logistic Regression |
| Logistic Regression | Logistic Regression | Neural Network |
| Logistic Regression | Logistic Regression | Random Forest |
| Support Vector Machine | Support Vector Machine | Support Vector Machine |
| Support Vector Machine | Support Vector Machine | Neural Network |
| Support Vector Machine | Support Vector Machine | Random Forest |
| Naive Bayes | Naive Bayes | Naive Bayes |
| Naive Bayes | Naive Bayes | Neural Network |
| Naive Bayes | Naive Bayes | Random Forest |
| Model Type | Hyperparameter | Potential Values |
|---|---|---|
| Random Forest | Number of Estimators | 100, 500, 1000 |
| Depth | 10, 50, 100, None | |
| Neural Net | Number of Hidden Layers | 1 |
| Number of Nodes in Layer | 64, 128, 256 | |
| Logistic Regression | Penalty | L1, L2 |
| Solver | newton-cg, sag, lbfgs, saga | |
| SVM | Kernel | rbf, poly, sigmoid |
| Gamma | scale, auto | |
| Naive Bayes | Alpha | 1, 0 |
| Priors | True, False |
| Statistic | Disparate Attack |
|---|---|
| Mean | 0.617 |
| Standard Deviation | 0.111 |
| Minimum | 0.324 |
| Quartile | 0.530 |
| Quartile | 0.582 |
| Quartile | 0.697 |
| Maximum | 0.915 |
| Feature |
|---|
| Average of Label Minimum Distances |
| Variance of Label Minimum Distances |
| Variance of Label Mean Distances |
| Proportion of Binary Features |
| Average of Label Mean Distances |
| Average of Label Maximum Distances |
| Width Ratio After One Hot Encoding on Class Subsets |
| Metric | LOOCV Training Data | Test Data |
|---|---|---|
| Precision of Vulnerable Class | 0.819 | 0.819 |
| Recall of Vulnerable Class | 0.762 | 0.759 |
| F1 of Vulnerable Clas | 0.789 | 0.788 |
| Accuracy | 0.846 | 0.845 |
| Feature | Descriptive Statistic | Full Dataset | Non-Vulnerable | Vulnerable |
|---|---|---|---|---|
| Average of Label Minimum Distances | Mean | 19.85 | 0.62 | 48.80 |
| Standard Deviation | 41.13 | 5.41 | 52.95 | |
| Minimum | 0.00 | 0.00 | 0.00 | |
| Quartile | 0.00 | 0.00 | 0.00 | |
| Quartile | 0.00 | 0.00 | 4.15 | |
| Quartile | 2.00 | 0.07 | 111.35 | |
| Maximum | 111.35 | 103.22 | 111.35 | |
| Variance of Label Minimum Distances | Mean | 260.81 | 5.76 | 644.85 |
| Standard Deviation | 552.29 | 91.81 | 711.89 | |
| Minimum | 0.00 | 0.00 | 0.00 | |
| Quartile | 0.00 | 0.00 | 0.00 | |
| Quartile | 0.00 | 0.00 | 0.19 | |
| Quartile | 0.01 | 0.00 | 1409.65 | |
| Maximum | 1536.01 | 1536.01 | 1536.01 | |
| Variance of Label Mean Distances | Mean | 293.26 | 9.08 | 721.16 |
| Standard Deviation | 621.88 | 121.66 | 801.77 | |
| Minimum | 0.00 | 0.00 | 0.00 | |
| Quartile | 0.47 | 0.22 | 1.11 | |
| Quartile | 1.11 | 1.11 | 8.16 | |
| Quartile | 8.16 | 1.11 | 1521.40 | |
| Maximum | 2282.77 | 2282.77 | 2282.77 | |
| Average of Label Mean Distances | Mean | 41.39 | 8.04 | 91.60 |
| Standard Deviation | 70.95 | 12.02 | 90.60 | |
| Minimum | 0.26 | 0.26 | 0.65 | |
| Quartile | 7.15 | 4.20 | 8.73 | |
| Quartile | 8.73 | 8.73 | 10.81 | |
| Quartile | 10.92 | 8.73 | 191.09 | |
| Maximum | 191.51 | 191.51 | 191.51 | |
| Average of Label Maximum Distances | Mean | 65.17 | 17.45 | 137.01 |
| Standard Deviation | 101.79 | 19.58 | 129.68 | |
| Minimum | 2.14 | 2.14 | 2.31 | |
| Quartile | 13.13 | 11.50 | 18.92 | |
| Quartile | 18.92 | 18.92 | 23.77 | |
| Quartile | 23.77 | 18.92 | 273.40 | |
| Maximum | 325.20 | 325.20 | 325.20 |
| Descriptive Statistic | Full Dataset | Non-Vulnerable | Vulnerable |
|---|---|---|---|
| Mean | 0.21 | 0.13 | 0.34 |
| Standard Deviation | 0.49 | 0.32 | 0.65 |
| Minimum | 0.00 | 0.00 | 0.01 |
| Quartile | 0.01 | 0.01 | 0.06 |
| Quartile | 0.05 | 0.02 | 0.24 |
| Quartile | 0.28 | 0.10 | 0.31 |
| Maximum | 5.36 | 4.32 | 5.36 |
| Descriptive Statistic | Full Dataset | Non-Vulnerable | Vulnerable |
|---|---|---|---|
| Mean | 0.21 | 0.03 | 0.47 |
| Standard Deviation | 0.39 | 0.13 | 0.49 |
| Minimum | 0.00 | 0.00 | 0.00 |
| Quartile | 0.00 | 0.00 | 0.00 |
| Quartile | 0.00 | 0.00 | 0.13 |
| Quartile | 0.13 | 0.00 | 1.00 |
| Maximum | 1.00 | 1.00 | 1.00 |
| Hardening Method | Class-Based Subsets Hardened (Original Datasets) | Subsets Unchanged | Subsets Which Became More Secure | Subsets Which Became More Vulnerable | Change in Victim Model Accuracy on Average | Change in Victim Model F1 Score on Average | Change in Disparate Attack Accuracy on Average |
|---|---|---|---|---|---|---|---|
| Feature Reduction via Correlation | 439 (97) | 85.9 | 7.5 | 6.6 | Insignificant | Insignificant | −0.01 |
| Feature Reduction via Manifold Theory | 355 (77) | 82.5 | 16.1 | 1.4 | −0.03 | −0.04 | −0.04 |
| Class Balancing via Oversampling | 436 (96) | 86.9 | 7.6 | 5.5 | +0.02 | +0.02 | +0.01 |
| Class Balancing via Undersampling | 621 (102) | 87.1 | 4.8 | 8.1 | +0.02 | +0.02 | +0.02 |
| Correlation-Based Feature Reduction with Oversampling | 239 (63) | 81.6 | 13.0 | 5.4 | Insignificant | −0.01 | −0.01 |
| Manifold Theory-Based Feature Reduction with Oversampling | 208 (57) | 79.8 | 19.2 | 1.0 | −0.01 | Insignificant | −0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moore, H.D.; Stephens, A.; Scherer, W. An Understanding of the Vulnerability of Datasets to Disparate Membership Inference Attacks. J. Cybersecur. Priv. 2022, 2, 882-906. https://doi.org/10.3390/jcp2040045
Moore HD, Stephens A, Scherer W. An Understanding of the Vulnerability of Datasets to Disparate Membership Inference Attacks. Journal of Cybersecurity and Privacy. 2022; 2(4):882-906. https://doi.org/10.3390/jcp2040045
Chicago/Turabian StyleMoore, Hunter D., Andrew Stephens, and William Scherer. 2022. "An Understanding of the Vulnerability of Datasets to Disparate Membership Inference Attacks" Journal of Cybersecurity and Privacy 2, no. 4: 882-906. https://doi.org/10.3390/jcp2040045