1. Introduction
The major issue in terms of data privacy in today’s world stems from the fact that machine learning (ML) algorithms strongly depend on the use of large datasets to work efficiently and accurately. Along with the highly increased deployment of ML, its privacy aspect rightfully became a cause of concern, since the collection of such large datasets makes users vulnerable to fraudulent use of personal, (possibly) sensitive information. This vulnerability is aimed to be mitigated by privacy enhancing technologies that are designed to protect data privacy of users.
Differential privacy (DP) has been proposed to address this vulnerability and it has furthermore been used to develop practical methods for protecting private user-data. Dwork’s original definition of DP in [
1] emanates from a notion of statistical indistinguishability of two different probability distributions which is achieved through randomization of the data prior to their publication. The outputs of two differentially private mechanisms are indistinguishable for two datasets that only differ in one user’s data, i.e., neighbors. In other words, DP guarantees that the output of the mechanism is
statistically indifferent to changes made in a single row of the dataset proportional to its privacy budget. The reader is referred to [
2,
3,
4] for surveys of results.
Let us imagine a scenario where it is possible to weaponize privacy protection methods by adversaries in order to avoid being detected by the defender. Adversarial classification/anomaly detection is an application of the ML approach, statistical classification, to detect misclassification attacks where adversaries shield themselves by using DP to remain undetected. This paper studies adversarial classification in differentially private mechanisms to establish the trade-off between the probability distribution of the noise and the impact of the attack to remain indistinguishable. This is achieved by employing both statistical and information-theoretic tools. In this setting, we consider an adversary who not only aims to discover the information of a dataset but also wants to harm it by inserting data into the original dataset. Accordingly, we establish stochastic and information-theoretic relations between the impact of the adversary’s attack and the privacy budget of the DP mechanism.
1.1. Related Work and Methodology
This part is reserved for a discussion on related work and background of the addressed problem emphasizing the differences between the existing literature and the current paper along with the methodology that is used in this paper.
The addressed problem in this work differs from existing work on DP which considers an adversary model where the goal of the attacker is to solely discover some information about the dataset. For instance, the assumption in [
5] is that the adversary has the knowledge of the entire dataset except for one entry. This translates to the implicit strong adversary assumption. In this paper, our aim is to extend this model with a stronger adversary who also wants to harm the dataset and the output of the mechanism. We consider an adversary who is able to modify (add, replace, delete, etc.) the published information from a differentially private mechanism which is a noisy version of the output. The adversary’s goal in this model is to maximize the possible damage (the induced bias or additional variance) while remaining undetected. Thus, there are two sides of what the adversary wants to achieve: (i) s/he gives false data with the biggest possible difference from the real data, (ii) this modification has to be achieved without being detected. On the defender’s end, the mechanism wants to preserve DP and correctly detect the attack.
A simpler version of the described problem is addressed by [
6] from an adversarial perspective and the two conflicting goals of the adversary is formulated as an optimization problem where maximizing the bias induced by the adversary is the objective function. However, the privacy parameter does not take part in the formulation of this optimization problem, instead, DP is used in conjunction with anomaly detection for preserving privacy afterward. We seek a characterization of the trade-off between the attack (the change in the output induced by the adversary) and the privacy parameter. On the other hand, in [
7], the authors show that the sensitivity of a mechanism has also an impact on the differentially private output. The noise to be added on the output is calibrated accordingly as a function of the noise distribution. Such a characterization of the problem described in this paper introduces a third element as the value of the attack to be included in this adjustment of the DP noise with respect to (w.r.t.) the sensitivity of the system. This will allow us to be able to determine a threshold for detecting the attacker, alternatively, for the attacker to remain undetected.
As for the methodology, we will use the framework of statistical hypothesis testing in a similar vein to [
8] where the authors determine an appropriate value of the privacy parameter as a function of false alarm and mis-detection probabilities in deciding on the presence or absence of a particular record in a dataset. Similarly, in [
9], the author studies the differentially private hypothesis testing in the local setting where users locally add the DP noise on their personal data before submitting them to the dataset. In this paper, we tailor this approach as a first attempt for a solution for anomaly detection in Laplace and Gaussian mechanisms under global DP where the personal sensitive data are transmitted to a central server by the users and the server applies DP noise on the data before their release. The major difference from the existing literature that employs statistical inference to differential privacy lies in our new attacker model which considers an adversary who not only aims to discover but also wants to alter the information in the dataset. We present a statistical threshold of detecting the attacker as a function of the impact of the attack (the effect of the additional data on the overall dataset) and the privacy parameter(s). Additionally, in the case of Laplace mechanism, we propose an interval for the privacy budget, so that the defender detects the attack.
For the case of Gaussian mechanism, besides the aforementioned statistical approach, we also derive the mutual information between the datasets before and after the attack (considered as neighbors) in order to bound the second-order statistics of the additional data. This yields an information-theoretic threshold for correctly detecting the attack. Originally, the lossy source-coding approach in the information-theoretic DP literature has mostly been used to quantify the privacy guarantee [
10] or the leakage [
11,
12]. Ref. [
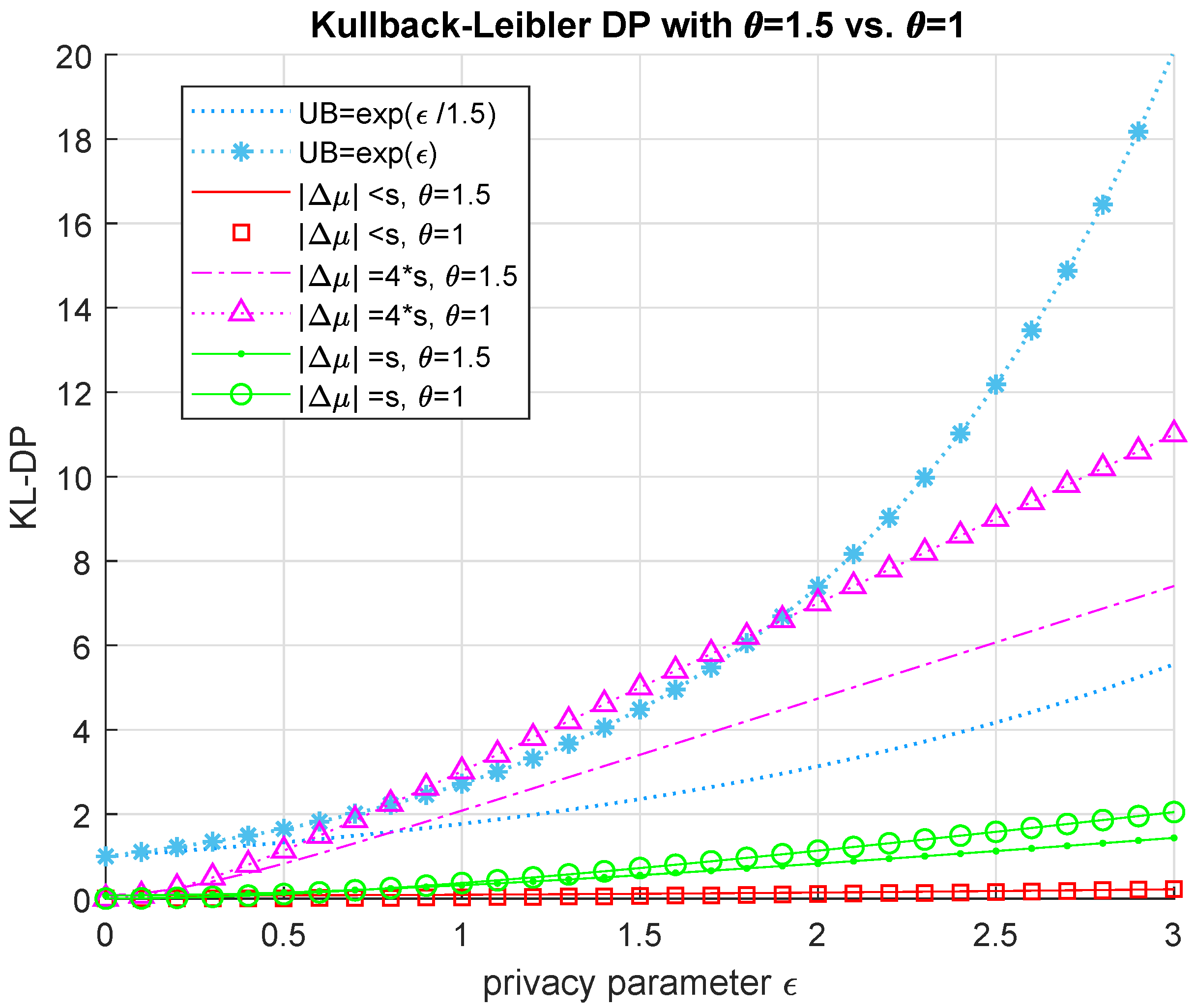
13] stands out in the way that the rate-distortion perspective is applied to DP, where various fidelity criteria is set to determine how fast the empirical distribution converges to the actual source distribution. We present an adaptation of the so-called Kullback–Leibler (KL)-DP [
5] for detecting misclassification attacks in Laplace and Gaussian mechanisms, where the corresponding distributions in relative entropy were considered as the differentially private noise with and without the adversary’s advantage. Lastly, this work introduces a novel DP metric based on Chernoff information along with its application to adversarial classification.
Aside from statistical and information-theoretic approaches as employed in this paper, the literature on adversarial examples and attempts to correctly classify and detect them is rather rich. For instance, ref. [
14] offers a game-theory-based risk analysis approach that was originally introduced by [
15], whereas [
16] introduce efficient algorithms for reverse engineering linear classifiers for adversarial classification. Adversarial classification dates back to [
17], which assumes (somewhat unrealistically) that the adversary has the perfect knowledge of the classifier and attempt to detect these attacks by computation of the adversary’s optimal strategy. The novelty of the current paper lies in its methodology that makes use of information-theoretic quantities to solve a privacy and security problem.
1.2. Contributions and Outline
Our contributions are summarized in the following list.
We consider a new attacker model whereby the adversary takes advantage of the underlying differentially private mechanism in order to remain undetected.
We derive a trade-off between the privacy protected adversary’s advantage and the security of the system for the adversary to remain undetected while giving as much damage as possible to the system or, alternatively, for the defender to preserve the privacy of the system and detect the attacker. This trade-off is defined in the framework of statistical hypothesis testing similarly to [
8].
We adopt the Kullback–Leibler DP definition of [
5] to the addressed problem for adversarial classification in differentially private mechanisms and present numerical comparisons of different cases where the sensitivity of the system is less and greater than the bias induced by the adversary on the published information.
We apply a source-coding approach to anomaly detection under differential privacy to bound the variance of the additional data by the sensitivity of the mechanism and the original data’s statistics by deriving the mutual information between the neighboring datasets.
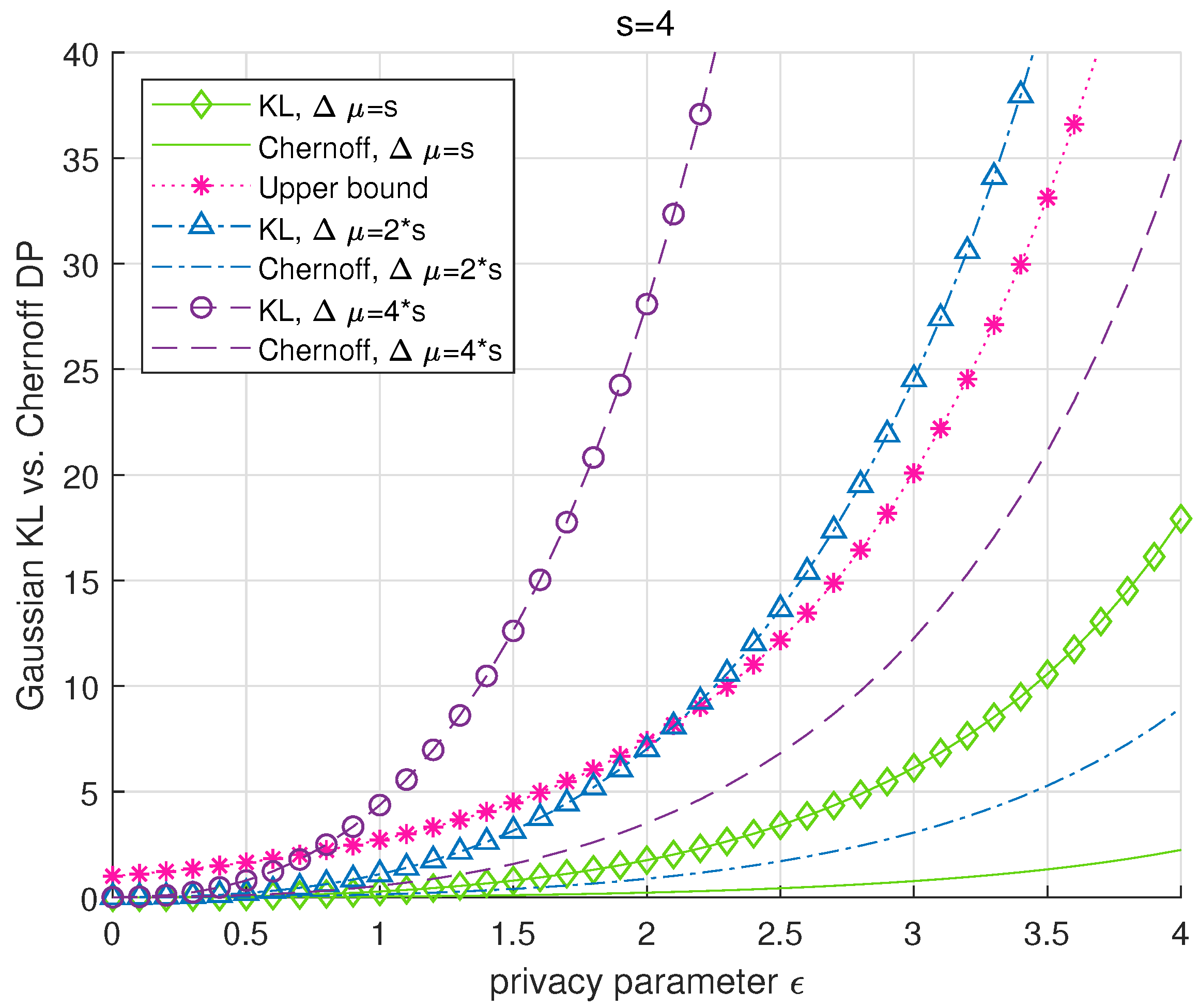
We introduce a new DP metric, that is called Chernoff DP, as a stronger alternative to the well-known -DP and KL-DP for the Gaussian mechanism. Chernoff DP is also adapted for adversarial classification and numerically shown to outperform KL-DP.
The outline of the paper is as follows. In the upcoming section, we remind the reader of some important preliminaries from the DP literature which will be used throughout this paper along with the detailed problem definition and performance criteria. In
Section 3 and
Section 4, we present statistical and information-theoretic thresholds for anomaly detection in Laplace and Gaussian mechanisms, respectively.
Section 5 introduces divergence-based definitions of DP adapted for anomaly detection. We present numerical evaluation results in
Section 6 and draw our final conclusions in
Section 7.
2. System Model and Its Components
In this part, we revisit certain notions from the literature on DP which will also be employed in this paper. These preliminaries will be followed by a detailed definition of the addressed problem. We begin with defining the notion of neighborhood between datasets and sensitivity of DP.
Definition 1 (Neighboring datasets).
Any two datasets that differ only in one row are called neighbors [4]. For two neighboring datasets, the following equality holdswhere denotes the Hamming (or ) distance between two datasets. Definition 2 (
norm sensitivity [
7]).
Global sensitivity, denoted by s of a function (or a query) q: is the smallest possible upper bound on the distance between the images of q when applied to two neighboring datasets, i.e., the distance is bounded by . Basically, sensitivity of a DP mechanism is the smallest possible upper bound on the images of a query function for neighbors. Hence it is a function of the type of the query having an opposite relationship with the privacy. Higher sensitivity of the query refers to a stronger requirement for privacy guarantee, consequently more noise is needed to achieve that guarantee.
Definition 3 (
-DP [
4]).
A randomized algorithm is -differentially private if and for all neighboring datasets x and within the domain of the following inequality holds. Next, we remind the reader of the Laplace distribution and Laplace mechanism. A differentially private system is named after the probability distribution of the perturbation applied onto the query output in the global setting. The Laplace distribution, also known as the double exponential distribution, is defined as
with the location parameter equal to its mean
and variance
where
denotes the scale parameter.
Definition 4. Laplace mechanism [7] is defined for a function (or a query) as followswhere , denote i.i.d. Laplace random variables. We will refer to the parameters and as privacy budget throughout the paper. Next definition reminds the reader of the norm global sensitivity.
Definition 5. norm sensitivity denoted s refers to the smallest possible upper bound on the distance between the images of a query when applied to two neighboring datasets and as Definition 6. Gaussian mechanism [7] is defined for a function (or a query) as followswhere , denote independent and identically distributed (i.i.d.) Gaussian random variables with the variance . Theorem 1 ([
4]).
The Laplace mechanism satisfies -differential privacy. Theorem 2 ([
4]).
For any , the Gaussian mechanism satisfies -differential privacy. Application of Gaussian noise results in a more relaxed privacy guarantee contrary to Laplace mechanism, which brings about -DP.
2.1. Problem Definition
Within the scope of this paper, we use two different approaches to study adversarial classification under differential privacy, namely the statistical approach to bound the first-order statistics of the additional data and an information-theoretic approach to characterize the second-order statistics of the attack. We define the original dataset in the following form . The query function takes the aggregation of this dataset as and the DP-mechanism adds Laplacian or Gaussian noise Z on the query output leading to the noisy output in the following form . This public information is altered by an adversary, who adds a single record denoted to this dataset. The modified output of the DP-mechanism becomes . The reader should note that, we do not make any assumptions on the value of .
2.1.1. First-Order Statistics of
Our first approach is inspired by [
8] where the authors determine statistical thresholds for the adversary’s hypothesis problem which is set to decide a given dataset entry is included in a dataset
D or its neighbor
. This approach is adapted to the problem of detecting a strong adversary who does not only want to discover all the entries of a dataset but also wants to harm it. Accordingly, we set the following hypotheses where the null and alternative hypotheses are respectively translated into DP noise distribution with and without the bias induced by the attacker.
The hypothesis testing problem defined above in (
7) can be translated into deciding on the DP noise distribution with its parameters. Here
and
correspond to DP noise following the probability distributions
with mean
and
with mean
, respectively. Therefore, the decision boils down to choosing between
and
. Hence the shift in the location due to the addition of
to the dataset is
. The corresponding likelihood ratio for this problem yields.
where
denotes the likelihood function for the corresponding hypothesis and
is some positive number to be determined. Such a threshold defines the critical region in statistical hypothesis tests where the null hypothesis is rejected. This approach results in a precise trade-off between the attacker’s advantage (or the bias induced by the adversary)
, the sensitivity
s and the privacy parameter
of the differentially private mechanism to characterize the threshold for rejecting the null hypothesis, i.e., detecting the attack, as a function of the error probabilities.
and
respectively denote type I and type II error probabilities which are defined for the hypothesis testing problem in (
7) as follows:
Based on the definition of
, also called the
probability of false-alarm, we denote its complement by
. Similarly, due to (
10), the complement of type II error probability (or the
probability of mis-detection) is denoted by
. The probability of detection
(i.e., correctly deciding
) is also called the
power of the test in the statistics or the recall in machine learning terminology.
According to the Neyman–Pearson Theorem [
18], the likelihood ratio compared against some positive integer defines the best critical region of size
for testing a simple hypothesis against an alternative simple hypothesis with the largest (or equally largest) power of the test. An extension of this result to testing against a composite alternative hypothesis is also possible. Such an extension is called
uniformly most powerful test since such a test with the best critical region of size
is conducted for each possible value of the alternative hypothesis. Once we define the critical region for deciding between
and
in (
7) as a function of
, the privacy parameter
and the sensitivity
s, we will derive the error probabilities and the power of the test analytically as well as compute and depict them numerically.
2.1.2. Second-Order Statistics of -Information-Theoretic Approach
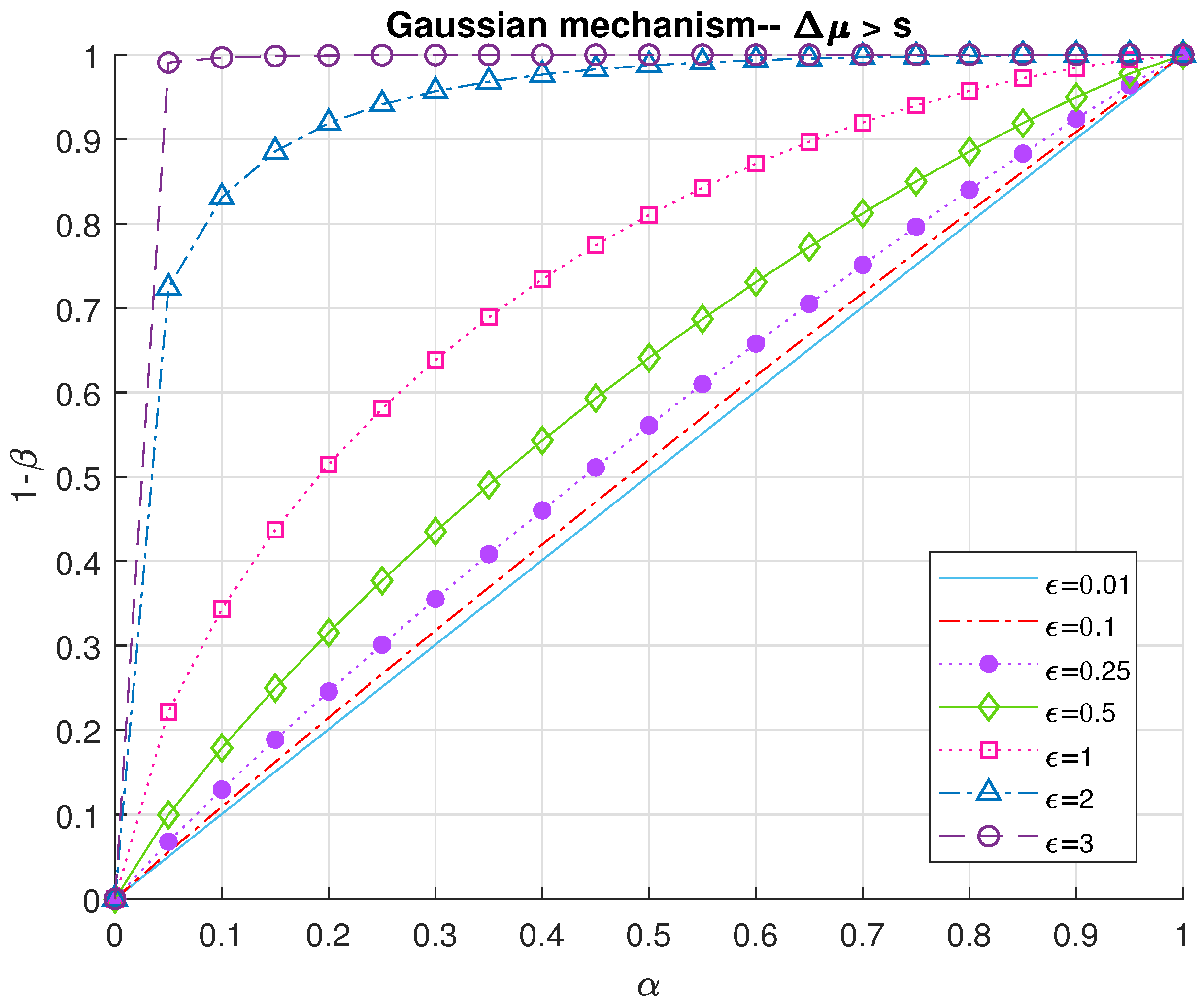
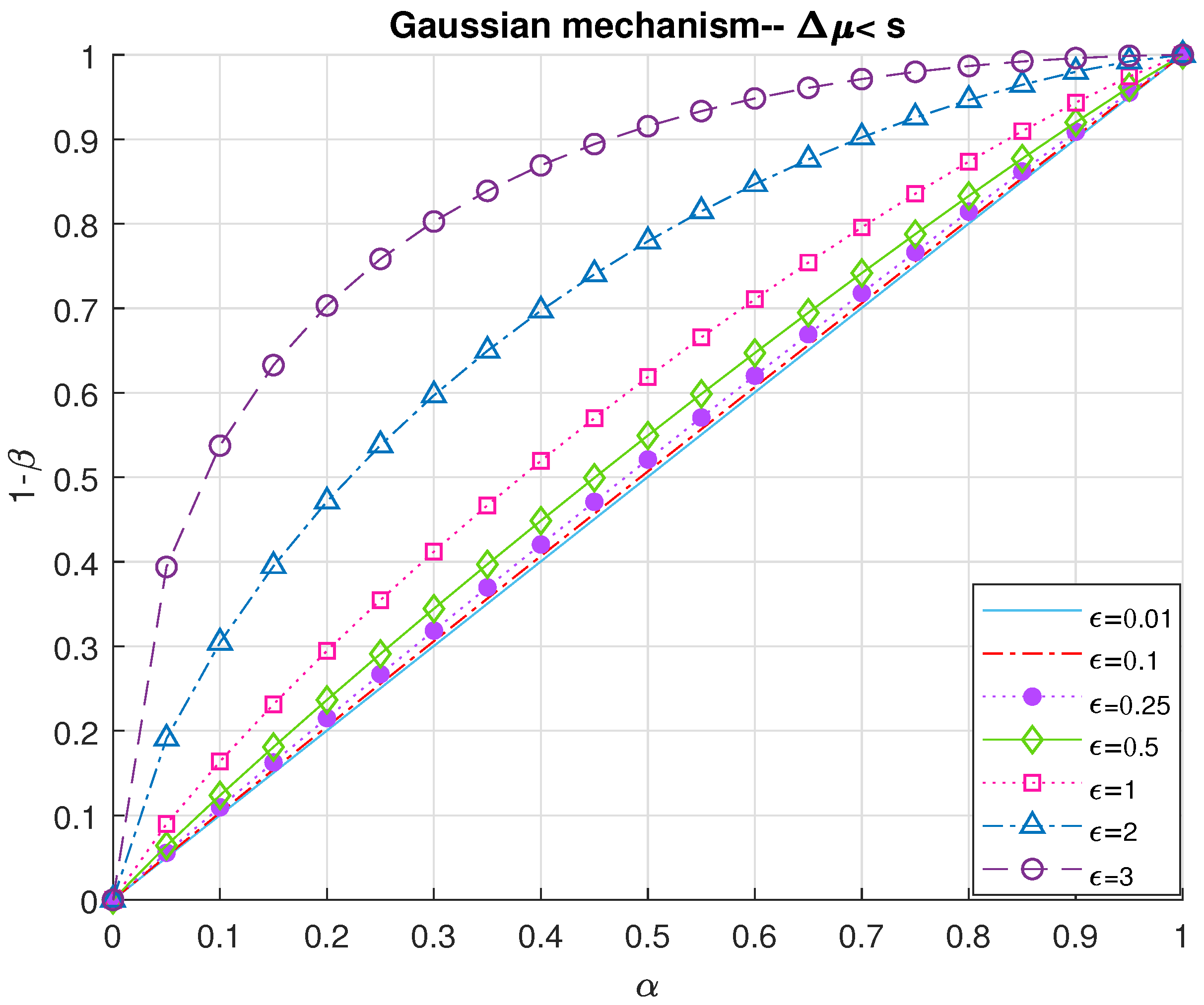
Our second approach is inspired by rate-distortion theory. For Gaussian mechanism, we employ the biggest possible difference between the images of the query for the datasets with and without the additional data (i.e., neighboring inputs) as the fidelity criterion (Definition 5). Accordingly, we derive the mutual information between the original dataset and its neighbor in order to bound the additional data’s second-order statistics so that the defender fails to detect the attack. We assume that follows a normal distribution with the variance . To simplify our derivations, we also assume that the original dataset and its neighbor have the same dimension n. Alternatively, the attack would change the size of the dataset as where the additional data are not added to either of the ’s.
3. Adversarial Classification in Laplace Mechanisms
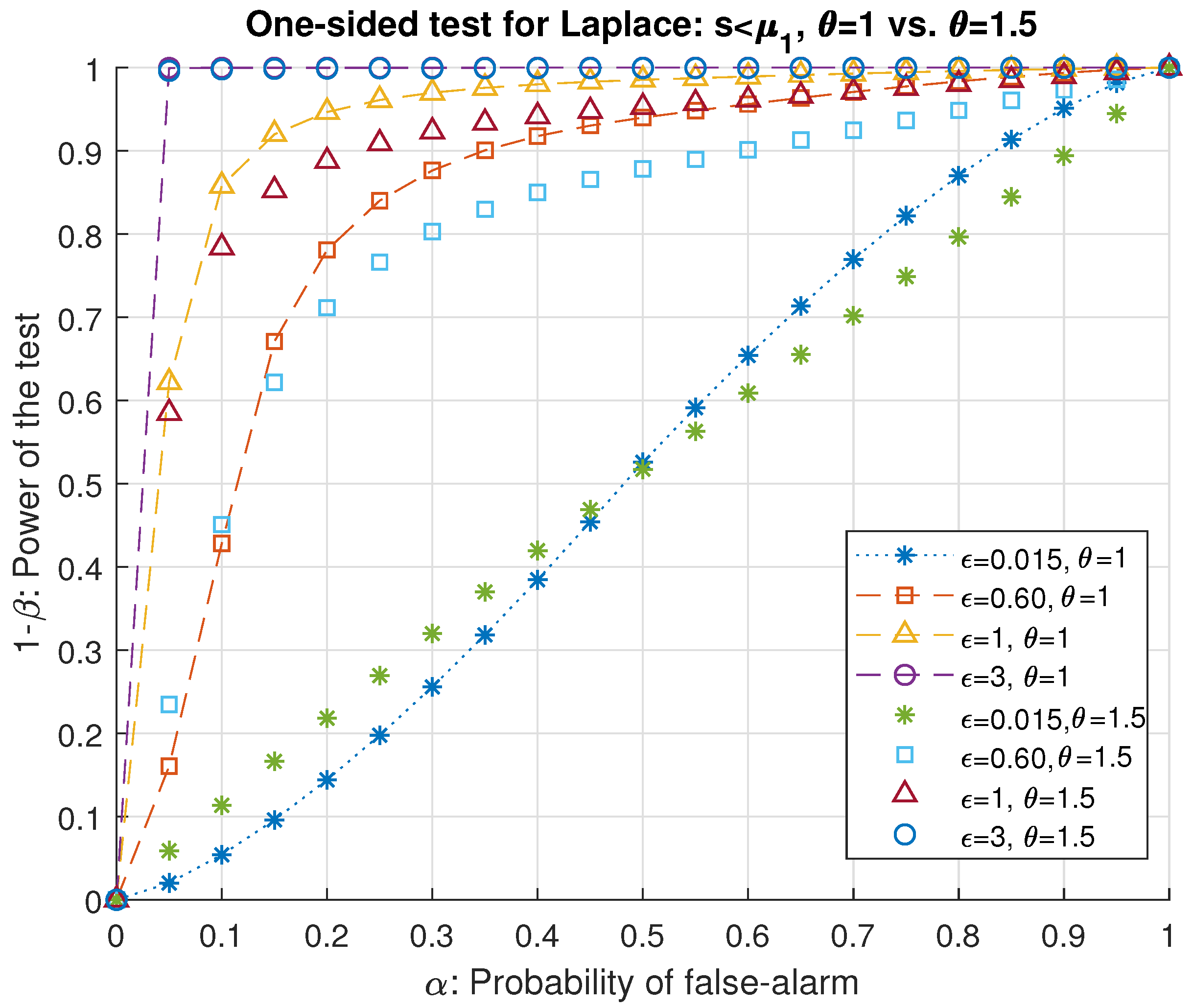
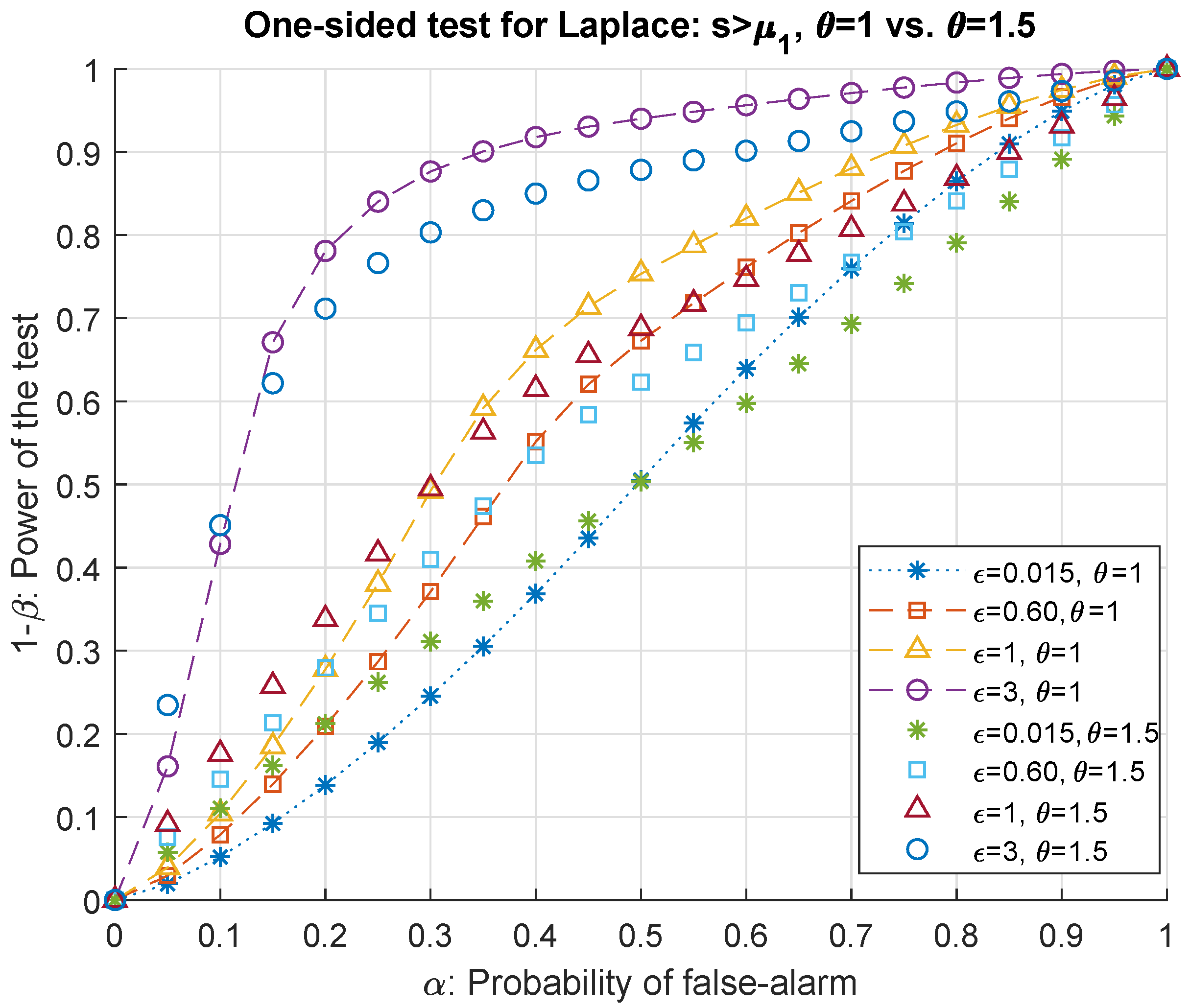
We separate our results in two main groups for -DP in Laplace mechanisms for one-sided and two-sided hypothesis tests.
We will investigate both cases of setting the alternative hypothesis
as either
(i.e.,
) or
(i.e.,
). This corresponds to a one-sided hypothesis testing problem. The decision of choosing between the hypotheses in (
7) boils down to deciding between
and
where
as the measure of the change in the privacy budget of the system whereas
s and
denote the sensitivity and privacy parameter, respectively. It should be noted that setting
translates the hypothesis test in (
7) into testing only the location parameter of the Laplacian DP noise. Our goal is to derive a relationship between the privacy parameter, the significance level (or the probability of false alarm), type II error probability (or the probability of mis-detection) for the attacker to be successful, i.e., to fail to reject
, as a function of the bias
. The corresponding likelihood ratio to (
7) is given by
where
is some positive number to be determined and
for
represent the location and scale parameters of the distributions to be tested.
The next theorem states our first main result which presents a threshold of correctly detecting the adversary for a given level of privacy budget, sensitivity and type I error probability.
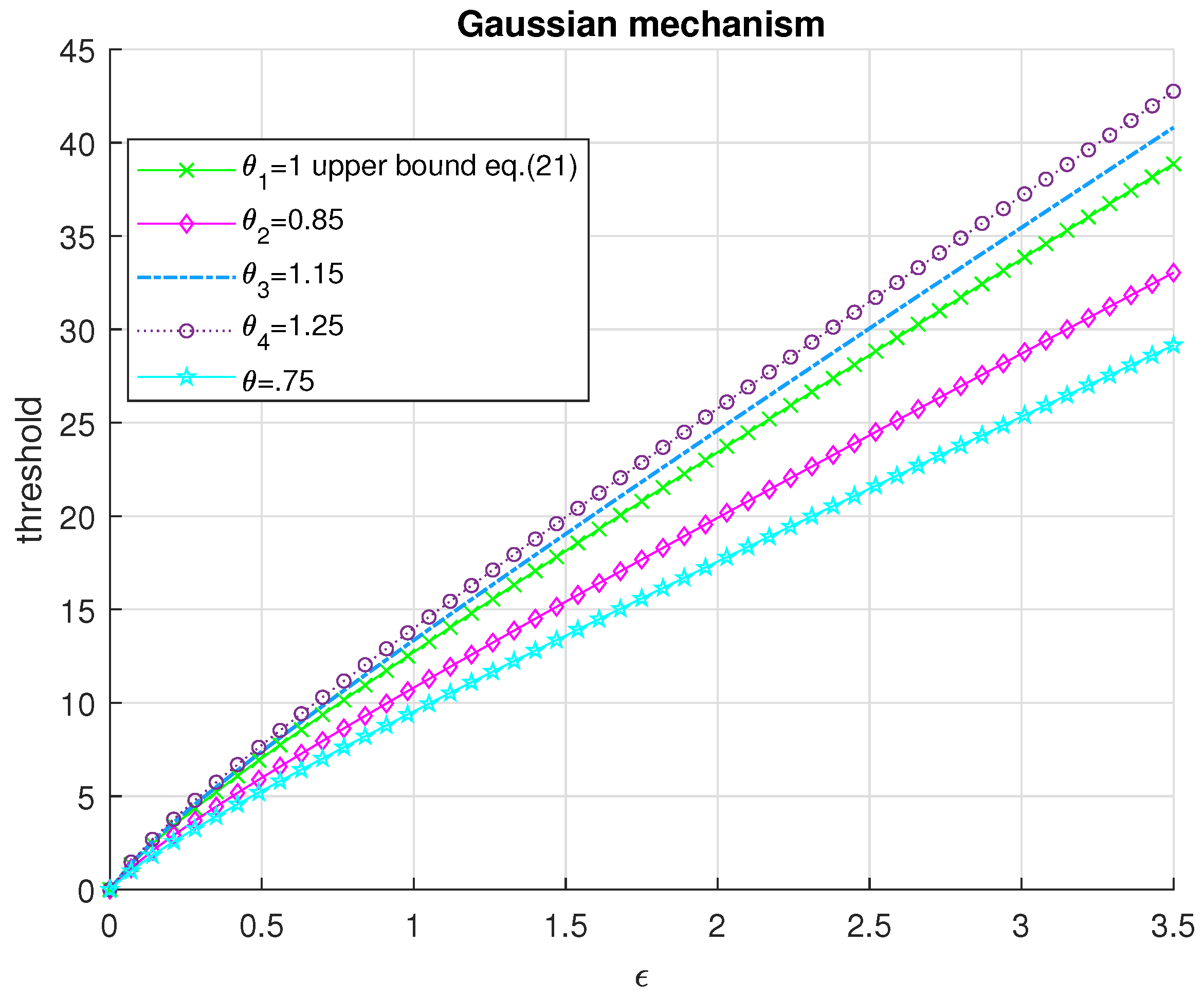
Theorem 3. The threshold of the best critical region of size α defined in (9) for deciding between the null hypothesis and its alternative of the one-sided hypothesis testing problem in (7) for a Laplace mechanism with the largest power is given as a function of the probability of false alarm α, privacy parameter ϵ and global sensitivity s as follows Then according to the adversary’s hypothesis testing problem, the defender detects the attack for if the output of the Laplace mechanism exceeds where is the noiseless query output. Similarly, for , the attack is detected if .
Remark 1. The decision rule given by Theorem 3 is equivalent to comparing the Laplace noise to the threshold k as it will be shown by the following proof. For positive bias, the critical region becomes thus, ![Jcp 02 00042 i003]() . By analogy if , the critical region for the Laplace noise becomes .
. By analogy if , the critical region for the Laplace noise becomes . Proof. According to the Neyman–Pearson theorem [
18], each point where
composes the best critical region of size α as defined in (
9) for this simple hypothesis testing problem. Using the ratio in (
11), we will determine the threshold
k as a function of the best critical region, the power of the test, the privacy budget and lastly, the attack.
The likelihood ratio in (
13) can be summarized by the following piecewise function based on the possible relationships between
and
z due to the absolute value in the exponent of the probability distribution for
.
Equivalently,
is confined in the interval
On the other hand, for
, the corresponding likelihood ratio for the hypotheses in (
7) yields
To be able to determine a threshold for deciding between the hypotheses in (
7), we compute the false alarm rate
α and the mis-detection error
β (and the power of the test, that is
) applying the Neyman–Pearson lemma that guarantees maximizing the power of the hypothesis test for a given false alarm rate
α.
Based on the definition in (
9), for
the probability of raising a false-alarm is derived by integrating the following probability distribution over the critical region
which is further expanded out in two possible ways. First for
, we get
Second, we have for
Rewriting (
20) and (
22) as an equality for
k, we obtain the piecewise function (
12) as the threshold in Theorem 3 as a function of
α. If the bias induced by the adversary is negative, i.e.,
, then the conditions to obtain (
20) and (
22) are swapped. For
and
, we get (
22) for the probability of false-alarm.
According to the piecewise expansions of likelihood ratio functions in (
16) and (
15) respectively for
and
, we have the intervals for
κ given by (
23) and (
24) on top of the next page since
![Jcp 02 00042 i004]()
.
Therefore, the null hypothesis is rejected for
or
Due to the threshold of the critical region defined in Theorem 3, we finally get
κ as follows
□
The power of the hypothesis test is the probability of rejecting the null hypothesis
given that the alternative hypothesis
is true. Let
denote the complement of the type II error
β, we have using the definition in (
10) for
and
As for
, the power function becomes
On the contrary for negative bias
, the conditions based on
k and
to obtain (
29) and (
32) are swapped. In
Section 6, we present numerical evaluation results for Theorem 3 using the probability of false-alarm
and power of the test
to draw receiving operating characteristic curves (ROC) as performance analysis.
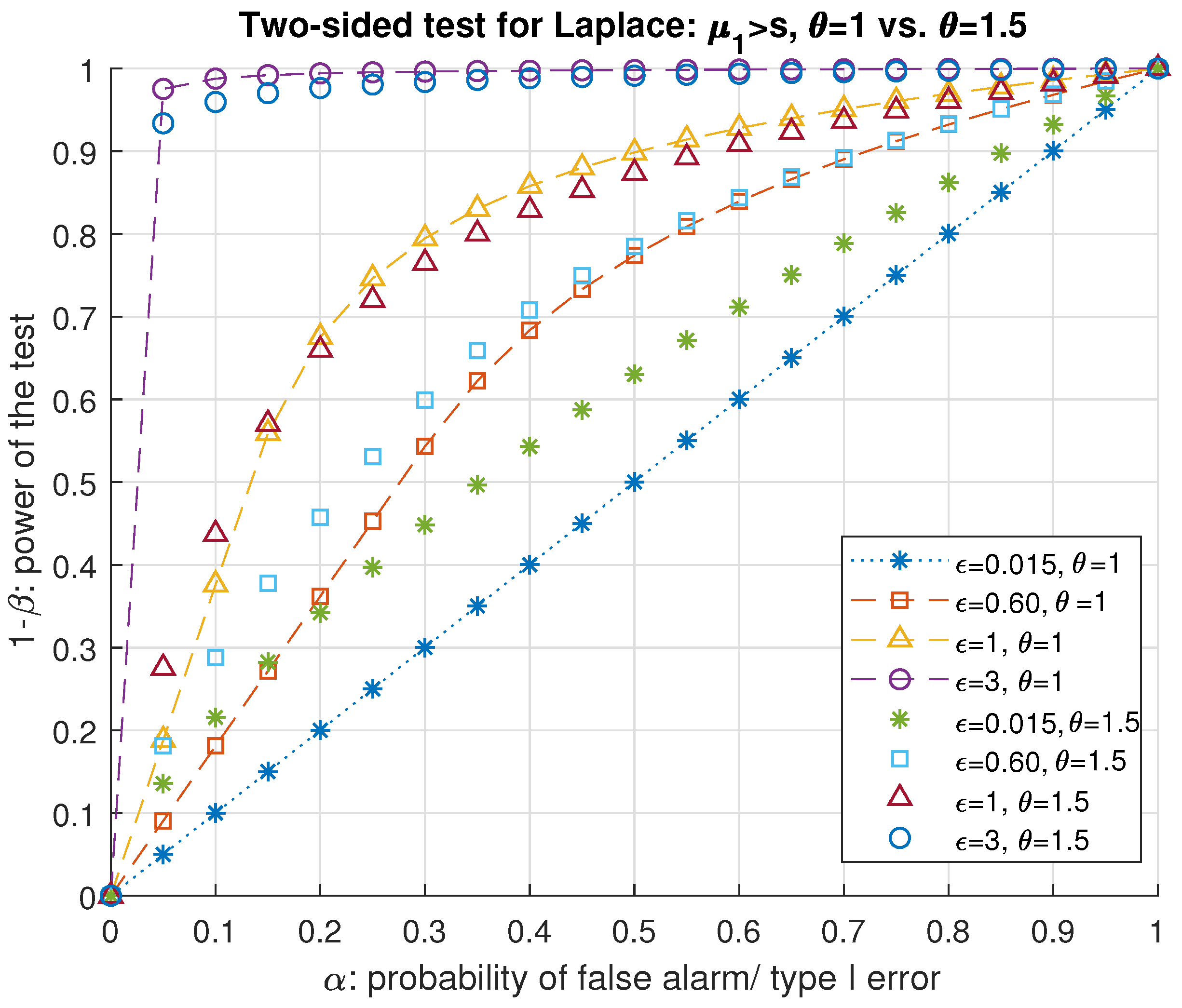
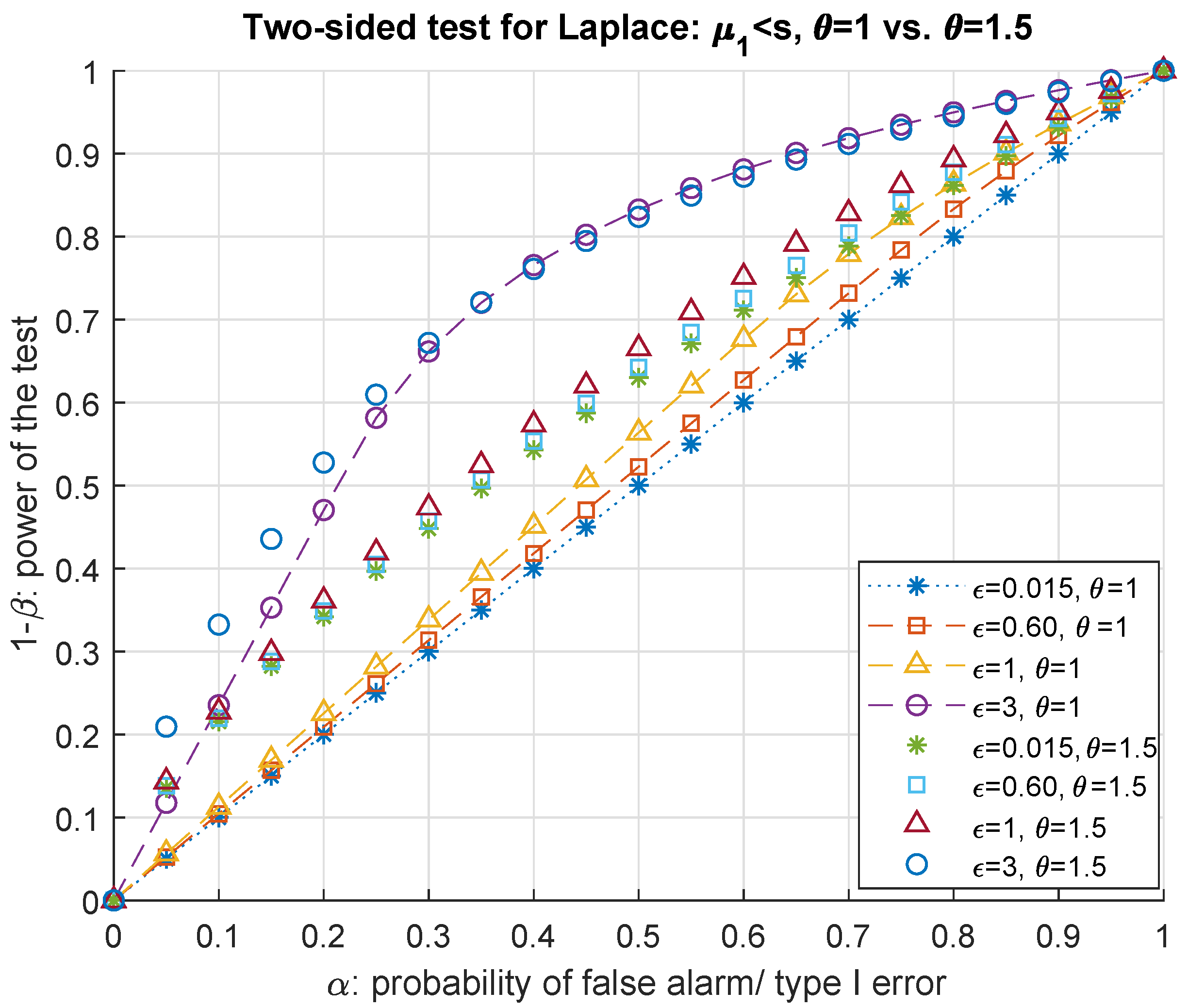
Remark 2. Special case of and : Setting in (13), it can be easily observed that both likelihood ratios in (15) and in (16) are included in the following interval . Applying also onto the likelihood ratio Λ in (13), we get which is the -DP. 3.1. Two-Sided Test
As an alternative solution to the same problem of detecting the attacker through determining the shifts and changes in the location and deviation of the DP noise using a one-sided hypothesis test, a two-sided test could provide a more realistic solution where it is not possible to assume the direction of the shift induced by the adversary. Hence the hypothesis test in (
7) can be conducted for determining the (possible) change in the distribution of the DP noise in both directions where the null hypothesis remains the same as
to test against the alternative
.
This translates to choosing between
where
μ denotes the location parameter and
b denoted the scale parameter of any Laplace distribution. The alternative hypothesis can also be stated with the parameters
,
where
.
In this two-sided test, there are two thresholds on each side of the origin to be determined for the critical region each with a size of . Let and denote the threshold greater and smaller than the origin, respectively. The next theorem presents the thresholds for detecting the attack as a function of the probability of false-alarm and the privacy budget of the differentially private mechanism as its one-sided counterpart given by Theorem 3.
Theorem 4. The threshold of the best critical region of size α defined in (9) for choosing between the null hypothesis and its alternative of the two-sided hypothesis testing problem in (34) and (35) for a Laplace mechanism with the largest power is Then according to the adversary’s hypothesis testing problem, the defender fails to detect the attack when the output of the Laplace mechanism is confined in where is the noiseless query output.
Proof. The null hypothesis cannot be rejected if the noisy output of the Laplace mechanism is confined in the interval
. First, we begin with the derivation of threshold for the output of the DP mechanism. The probability of raising a false-alarm or having a type I error is derived as follows.
Each addend of
α corresponds to one half of the probability of false-alarm. Equating each integral to
and rewriting the equalities in terms of
and
, we get the thresholds in (
37). □
3.2. A Trade-off between , s and for Detecting the Attacker-Two-Sided Test
Using the threshold presented in Theorem 4, we can determine an interval to confine the mean of the attacker’s advantage to be detected by the DP mechanism, i.e., for the null hypothesis to be rejected. Alternatively, such an interval can be converted for the privacy parameter ϵ as a function of error probabilities, the attack and the sensitivity. The following result, Corollary 1, presents upper and lower bounds on the attacker’s advantage so that the defender detects the attack.
There are two possible cases w.r.t. the relationship between and . The alternative hypothesis in this two-sided test also states that these two parameters are unequal. As we have discussed earlier in the derivation of the threshold for determining the critical region in Laplace mechanisms, whether or directly effects the likelihood ratio function, and thus the condition to reject the null hypothesis. Let us then consider the first possible case of . In this case, we have either or . On the contrary for , we have for the thresholds either of the cases or . These different cases can be used for deriving an interval to include as a function of the error probabilities, privacy budget and the sensitivity.
Corollary 1. The absolute bias induced by the adversary is confined in the following interval so that the defender detects and preserves - DPfor where α and respectively are the significance level and the power of the test of (35). Proof. We begin with deriving the power of the two-sided test (
35) as a function of the thresholds of the critical region. The probability of correctly detecting the attacker is as follows.
Each addend in (
41) corresponds to
and can be rewritten for the thresholds as functions of the power of the test as
and
. Combining this with
for the case
, the bias is lower bounded as follows
As for the upper bound we have
By analogy, we get the swapped upper and lower bound for
for the second case of
. Finally, we get the interval for the absolute bias as given by (
40). This concludes the proof of the corollary. □




 . By analogy if , the critical region for the Laplace noise becomes .
. By analogy if , the critical region for the Laplace noise becomes . .
.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

