1. Introduction
Recent advances in information and communication technologies (ICT) are enabling Internet of Things (IoT) smart city projects to collect and analyze vast amounts of data in an effort to support more environmentally and economically sustainable communities [
1,
2]. For instance, smart stormwater projects have shown successful IoT-based infrastructure-monitoring applications to address communities’ operation and planning challenges [
3,
4,
5]. As IoT devices become more pervasive, the collected data is expected to play an increasingly central role to inform communities’ decisions and, therefore, it is critical to develop and maintain cyber infrastructure to collect, store, and visualize sensor data.
However, as a growing number of new ICT technologies become available, the task of developing and integrating hardware and software solutions for IoT smart city projects can demand extensive specialized knowledge in different ICT domains [
6,
7], which can be challenging for IoT system designers. To reduce IoT systems’ design effort and to make IoT solutions more accessible, The Things Industry (TTI) [
8] created and sponsored The Things Network (TTN) [
9], a set of open-source tools to provide the basic software infrastructure to deploy IoT sensors based on LoRaWAN [
10,
11], a low-power and wide-area network (LPWAN) wireless communication protocol. This open-source project enables contributors around the globe to publicly share TTN compatible gateways that can connect LoRaWAN sensors to a network server known as The Things Stack, which is maintained by TTI. The use of TTN for smart city projects has been successfully demonstrated in the literature for different applications (e.g., [
3,
12]), while it also benefits communities by creating an open LoRaWAN communication infrastructure that can be leveraged by other IoT projects such as air quality monitoring [
13].
Although deploying an IoT system is greatly simplified by using TTN tools, their goal is to provide only the network server infrastructure and leave the application server to be developed by users. For instance, long-term data storage, graphical user interfaces (e.g., plotting tools), and the capacity to send alarm notifications are functionalities not supported by TTN’s network server. To achieve such functionalities, users need to develop their own application server or adopt third-party service providers such as Ubidots [
14] and myDevices [
15]. Another possible solution is to develop a custom server using a TTN open-source networking solution and modify it to include application layer functionalities; however, this solution implies an increased server workload and code maintenance requirements when compared to only developing and hosting application layer functions.
While third-party application servers might provide great value to many applications, users might still decide to develop their own application server solution to achieve more control over their data, to create customized application solutions, or to reduce recurring costs. However, developing an application server implies selecting, developing, and integrating software modules to achieve the application’s goals, which can be challenging due to the large diversity of architecture options and software solutions currently available as commercial products and open-source modules. In this context, IoT application case studies can offer users a valuable insight into developing and integrating software systems to meet application goals. To help guide users on the path of creating integrated IoT smart city applications, we introduce our use case of a flood warning system for a suburban watershed in Virginia, USA. Our system uses a pressure sensor and two ultrasonic sensors to monitor water levels at three locations on the stream network, and a weather station to monitor precipitation rates. All our monitoring devices use LoRAWAN to communicate to TTN’s network server. We developed and integrated a scalable set of cloud-based application tools to perform long-term data storage, data visualization, and automated alarm notification functionality. We discuss the implementation challenges and insights for our system, as well as a cost analysis using Amazon Web Services (AWS). To support users’ planning and decision-making, we included a cost analysis section where we evaluate how costs currently evolve with time, number of sensors, and data storage requirements.
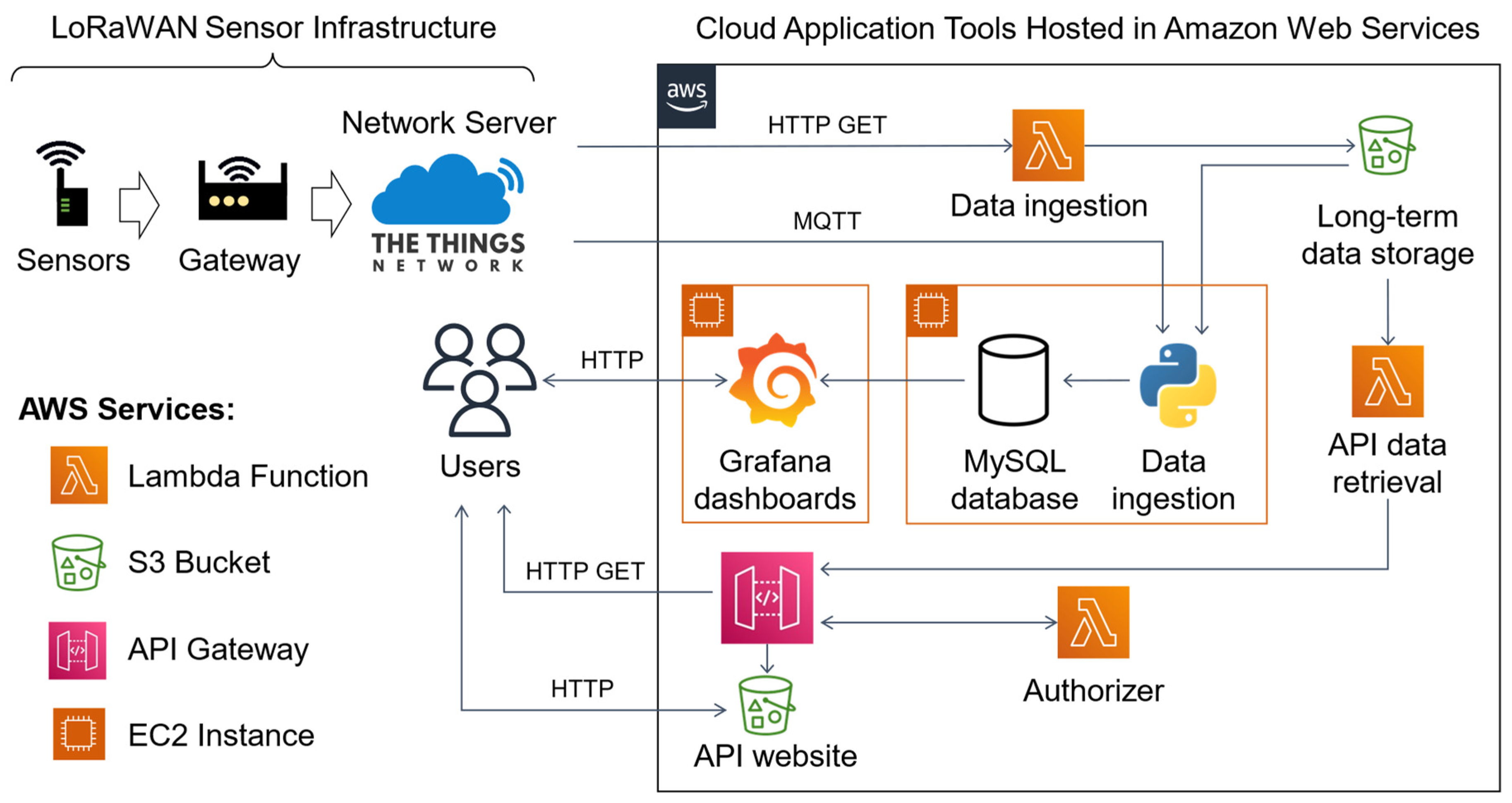
This paper’s main contributions can be summarized as: (1) our work provides practical insights on the development of cloud-based tools for IoT applications, an emerging area that is frequently overlooked in empirical IoT research; (2) we propose a general cloud backend system architecture that can guide IoT developers to quickly prototype smart city applications by using our demonstrated tools such as serverless data ingestion for IoT historical backup data storage, on-demand MySQL database and Grafana servers, and a RESTful API for programmatical data access; and (3) we perform a cost analysis for the first few years of using AWS cloud services in an IoT application, highlighting the cost-effectiveness of our proposed solution, and providing to IoT developers a cost estimate of these cloud services under a varying number of sensors and data rate.
This work is organized as follows: in
Section 2, we present an overview of related works on IoT for smart city projects that share similarities with our solution; in
Section 3, we introduce our example application along with its objective and goals; in
Section 4, we present the use case, the adopted overall system architecture, and the design requirements; in
Section 5, we present our main results and discussion; finally, in
Section 6, we present our final conclusions.
3. Example Application Motivation and Objectives
With the increase in weather variability and flooding [
24], it is vital that communities launch flood mitigation initiatives for the safety and quality of life of their residents. To create a sensing and alert system, we need to collect real-time sensor data from various locations around a city, and parse, store, provide responsive visualization, and transmit alert messages. For preemptive flood management strategies, we also need to collect data about existing infrastructure and land features to model stormwater flow and forecast future flood conditions.
This example application’s main goal was to demonstrate cloud-based application solutions to support the monitoring and alerting of flooding events. The basic features of our application system include data collection, storage, visualization, and alert creation as well as a RESTful API to provide data access to data-driven environmental forecasting and physics-based stormwater flow simulation. Although this use case is focused on flood warning, we describe each component and lessons learned in a general way, so it can be easily translated to other smart city use cases.
6. Conclusions
While data collected by IoT smart city applications are a central asset in supporting management and planning decisions for many communities, designing and deploying IoT solutions is still challenging due to system integration complexity, reliability limitations, and cost. We presented a cloud data storage and visualization system for smart cities, leveraging reliable existing technology to integrate a complete IoT monitoring solution hosted in AWS and costing under USD 26/year for long-term data storage and USD 0.0204/hour of use for MySQL database and Grafana servers. By using this cloud-based solution together with TTN infrastructure and commercial LoRaWAN sensors, users can collect, store, and visualize datasets to address their needs and integrate their own services. We demonstrated the use of the system for a flood warning system application example with river and weather LoRaWAN sensors. The cloud-based system design uses serverless data ingestion to provide a simple and cost-effective data storage solution that is independent of other services such as data visualization. An on-demand database and visualization servers offer flexibility to adapt to application needs while saving costs and simplifying maintenance operations. Furthermore, we explored the different AWS tiers and their respective reliability/cost tradeoff so users can make informed decisions when tailoring our system to their own application. As opposed to focusing mainly on the example application, as commonly seen in the literature, we highlight common tasks that are required by an IoT project and share our insights in leveraging modern cloud services to simplify IoT backend system design and optimize costs.
As a future research avenue, we intend to explore the use of new serverless cloud backend architectures in smart city IoT applications and investigate practical tradeoffs to server solutions. We intend to analyze in particular the on-demand allocation of computational resources as we scale the number of sensors, total sensor data rate, and number of clients connecting to user interfaces in cloud IoT backend systems. We also intend to explore the integration of modeling and simulation tools with IoT data acquisition systems while efficiently allocating computational resources.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}