
Automation in Regional Economic Synthetic Index Construction with Uncertainty Measurement

Abstract
:1. Introduction
2. Background
3. Methods
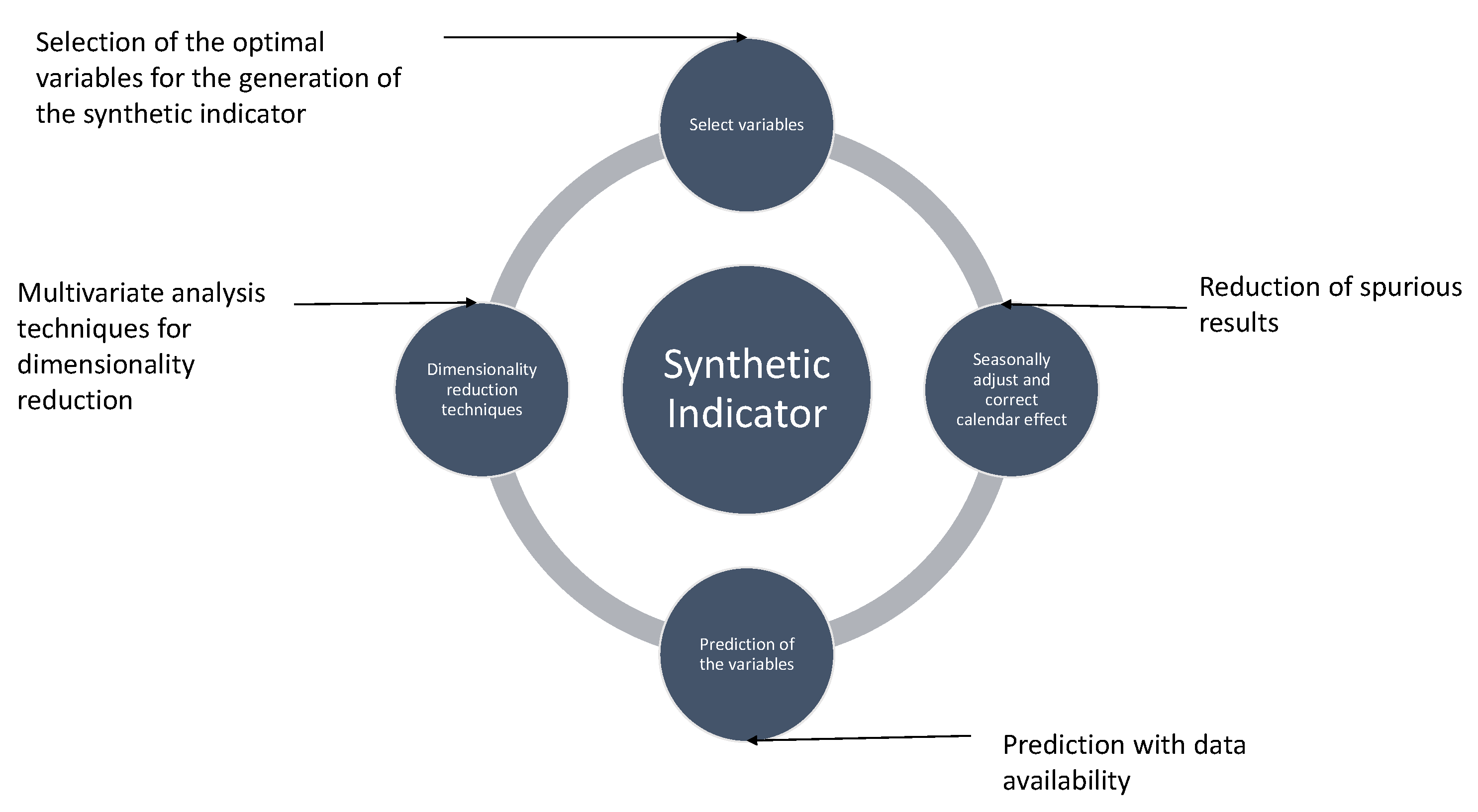
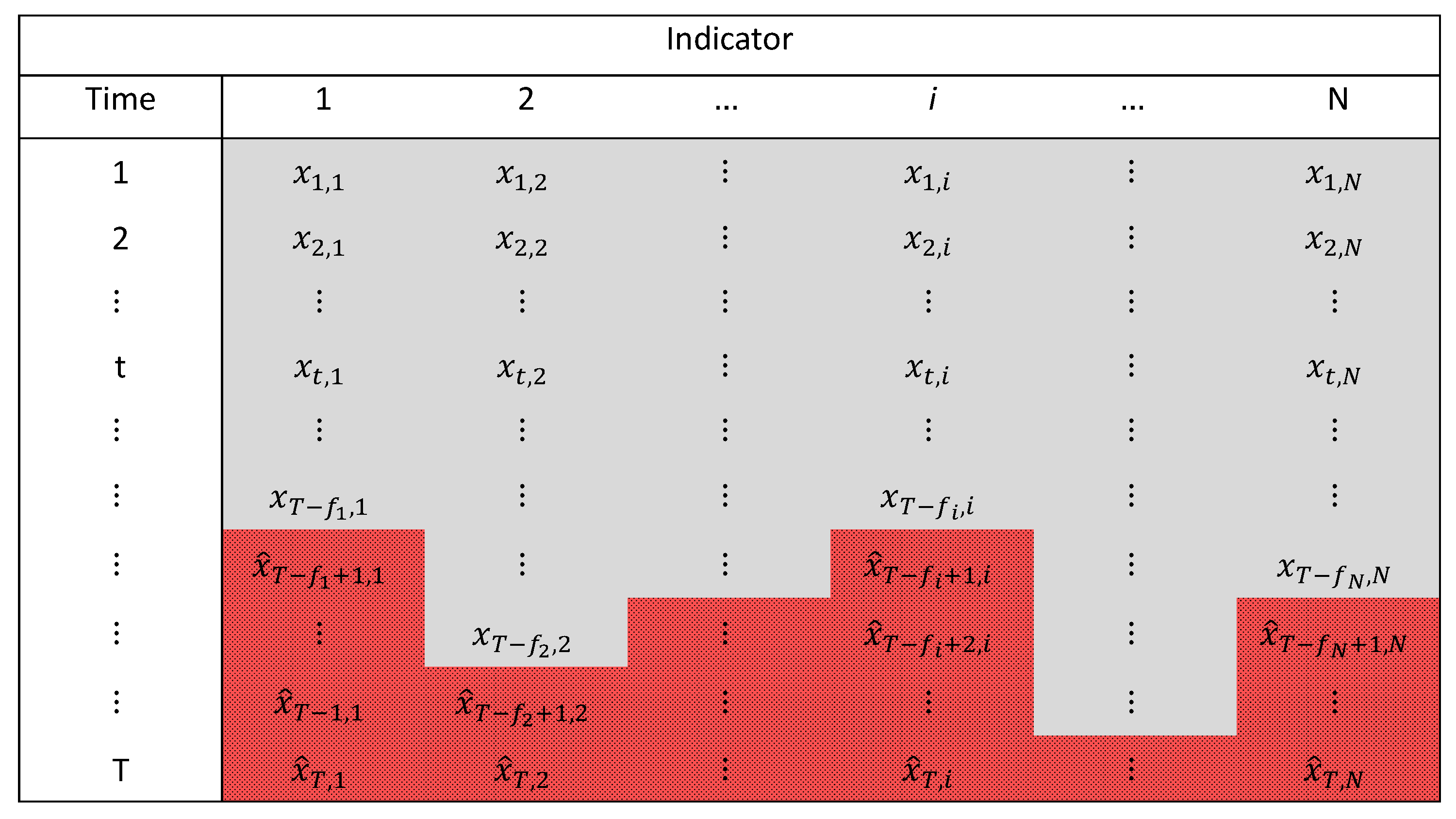
3.1. Synthetic Index
3.2. Uncertainty Measurement
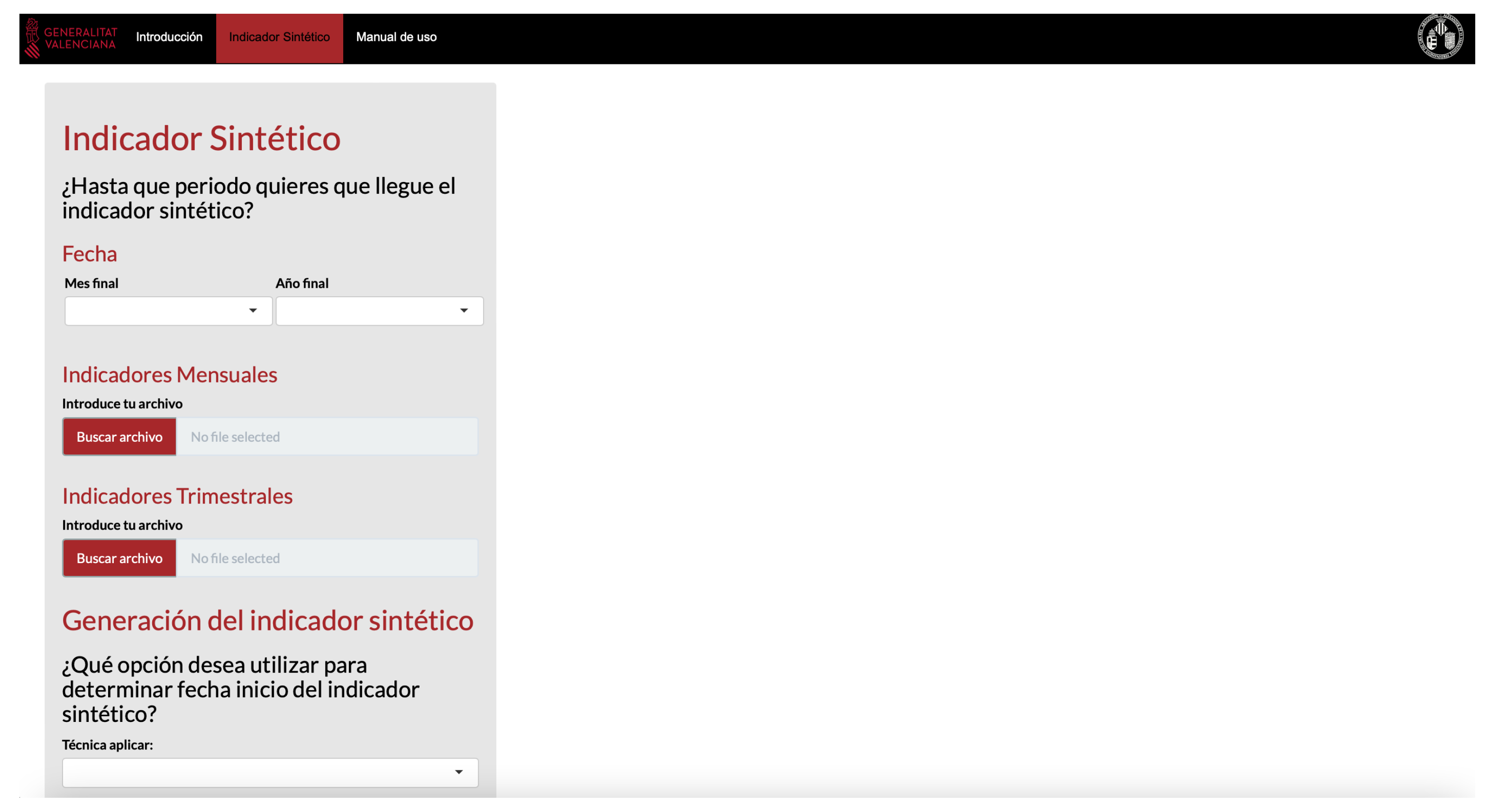
4. Synthetic Index: Web Application
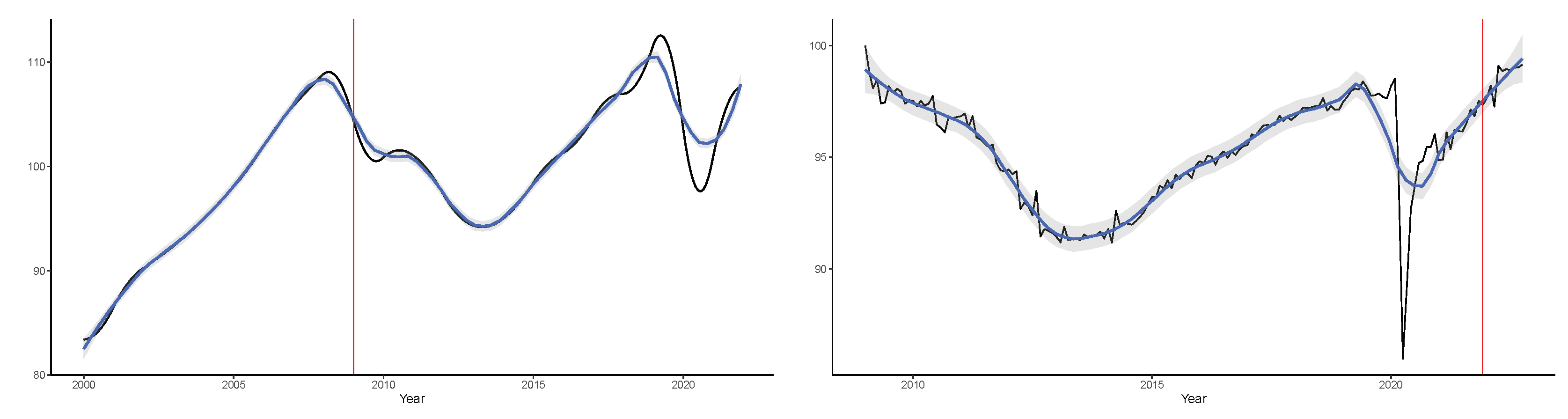
5. Empirical Application
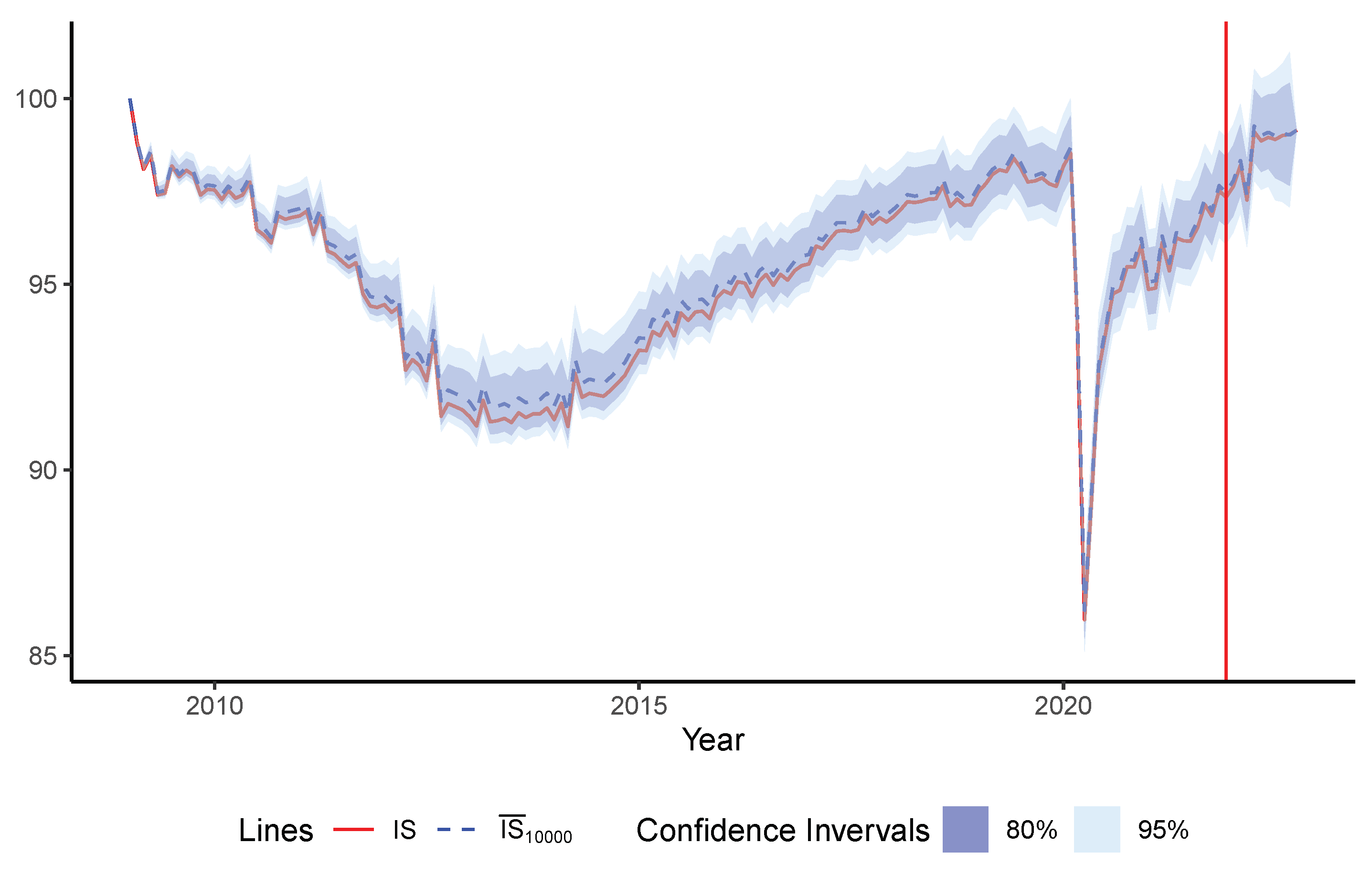
6. Measuring the Uncertainty
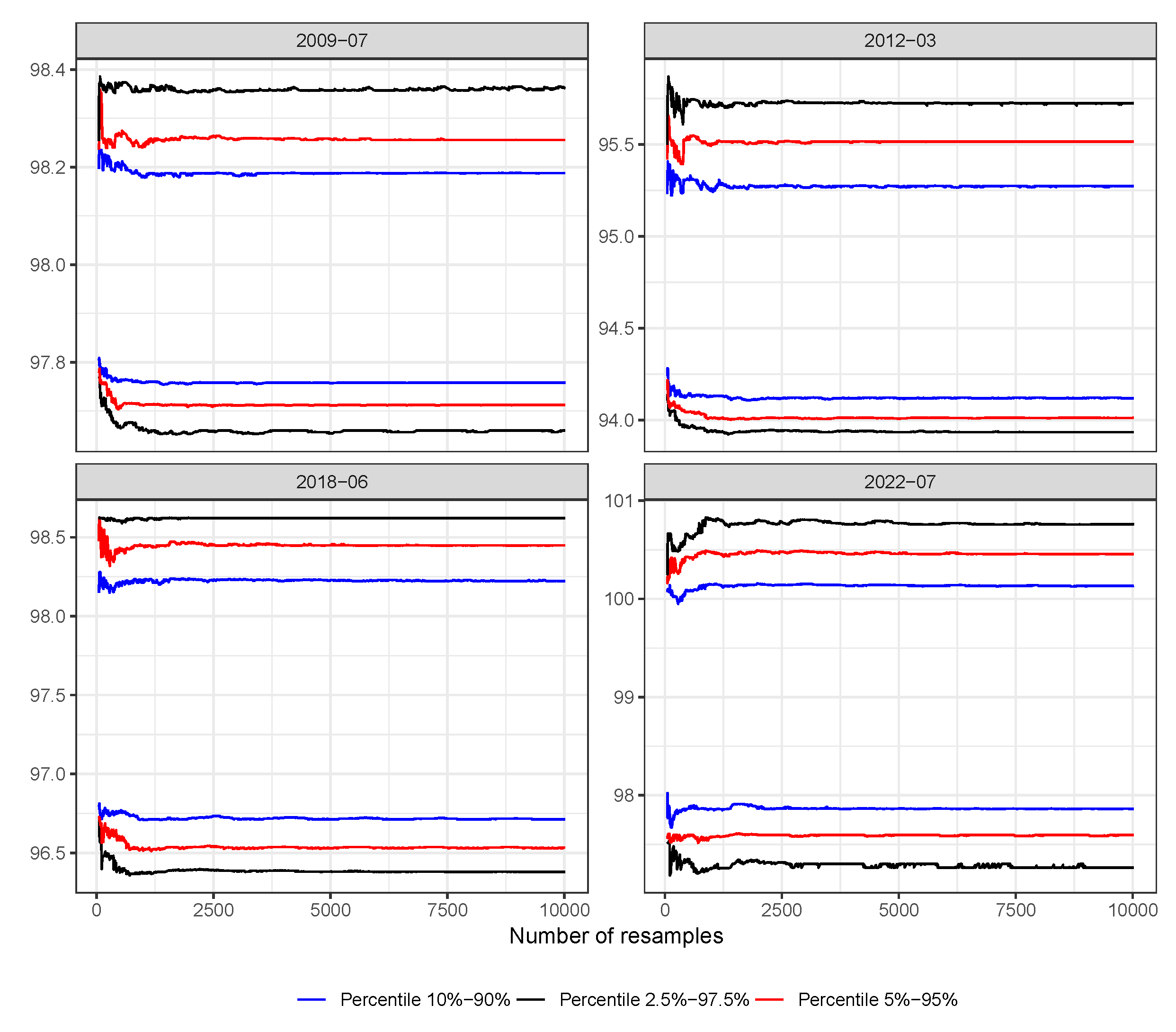
7. How Many Resamples? An Analysis of Sensitivity
8. Summary and Final Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stigler, S.M. The History of Statistics: The Measurement of Uncertainty Before 1900; Harvard University Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Petropoulos, F.; Apiletti, D.; Assimakopoulos, V.; Babai, M.Z.; Barrow, D.K.; Ben Taieb, S.; Bergmeir, C.; Bessa, R.J.; Bijak, J.; Boylan, J.E.; et al. Forecasting: Theory and Practice. Int. J. Forecast. 2022, 38, 705–871. [Google Scholar] [CrossRef]
- Dauphin, J.F.; Dybczak, K.; Maneely, M.; Sanjani, M.T.; Suphaphiphat, N.; Wang, Y.; Zhang, H. Nowcasting GDP-A Scalable Approach Using DFM, Machine Learning and Novel Data, Applied to European Economies; International Monetary Fund: Washington, DC, USA, 2022. [Google Scholar]
- Ballester, L.; López, J.; Pavía, J.M. European Systemic Credit Risk Transmission Using Dynamic Bayesian Networks. Res. Int. Bus. Financ. 2023, 65, 101914. [Google Scholar] [CrossRef]
- Khan, S.A.R.; Razzaq, A.; Yu, Z.; Shah, A.; Sharif, A.; Janjua, L. Disruption in Food Supply Chain and Undernourishment Challenges: An Empirical Study in the Context of Asian Countries. Socio-Econ. Plan. Sci. 2022, 82, 101033. [Google Scholar] [CrossRef]
- Sifat, I.; Zarei, A.; Hosseini, S.; Bouri, E. Interbank Liquidity Risk Transmission to Large Emerging Markets in Crisis Periods. Int. Rev. Financ. Anal. 2022, 82, 102200. [Google Scholar] [CrossRef]
- Szczygielski, J.J.; Brzeszczyński, J.; Charteris, A.; Bwanya, P.R. The COVID-19 Storm and the Energy Sector: The Impact and Role of Uncertainty. Energy Econ. 2022, 109, 105258. [Google Scholar] [CrossRef]
- Tao, Y. Research on the Impact of Trade Uncertainty on National Grain Supply and Risk Cost Control. Acta Agric. Scand. Sect. B—Soil Plant Sci. 2022, 72, 92–104. [Google Scholar] [CrossRef]
- Chernis, T.; Cheung, C.; Velasco, G. A three-frequency dynamic factor model for nowcasting Canadian provincial GDP growth. Int. J. Forecast. 2020, 36, 851–872. [Google Scholar] [CrossRef]
- Chow, H.K.; Fei, Y.; Han, D. Forecasting GDP with many predictors in a small open economy: Forecast or information pooling? Empir. Econ. 2023. [Google Scholar] [CrossRef]
- Hall, S.G.; Tavlas, G.S.; Wang, Y. Forecasting inflation: The use of dynamic factor analysis and nonlinear combinations. Ournal Forecast. 2023, 42, 514–529. [Google Scholar] [CrossRef]
- Antipa, P.; Barhoumi, K.; Brunhes-Lesage, V.; Darné, O. Nowcasting German GDP: A comparison of bridge and factor models. J. Policy Model. 2012, 34, 864–878. [Google Scholar] [CrossRef]
- Hakura, D. What Is Debt Sustainability? 2020. Available online: https://www.imf.org/en/Publications/fandd/issues/2020/09/what-is-debt-sustainability-basics (accessed on 12 December 2022).
- Kuck, K.; Schweikert, K. Forecasting Baden-Württemberg’s GDP growth: MIDAS regressions versus dynamic mixed-frequency factor models. J. Forecast. 2021, 40, 861–882. [Google Scholar] [CrossRef]
- Andreini, P.; Hasenzagl, T.; Reichlin, L.; Senftleben-König, C.; Strohsal, T. Nowcasting German GDP: Foreign factors, financial markets, and model averaging. Int. J. Forecast. 2023, 39, 298–313. [Google Scholar] [CrossRef]
- Bitetto, A.; Cerchiello, P.; Mertzanis, C. On the efficient synthesis of short financial time series: A Dynamic Factor Model approach. Financ. Res. Lett. 2023, 53, 103678. [Google Scholar] [CrossRef]
- Gil, M.; Leiva-Leon, D.; Pérez, J.J.; Urtasun, A. An Application of Dynamic Factor Models to Nowcast Regional Economic Activity in Spain; Banco de España: Madrid, Spain, 2019. [Google Scholar] [CrossRef]
- Kuznets, S. Economic Growth and Income Inequality. Am. Econ. Rev. 1955, 45, 1–28. [Google Scholar]
- Camacho, M.; Perez-Quiros, G. Introducing the Euro-Sting: Short-Term Indicator of Euro Area Growth. J. Appl. Econom. 2010, 25, 663–694. [Google Scholar] [CrossRef]
- Cuevas, A.; Pérez-Quirós, G.; Quilis, E.M. Integrated Model of Short-Term Forecasting of the Spanish Economy (MIPRED Model). Rev. Econ. Apl. 2017, 25, 5–25. [Google Scholar]
- Burns, A.F.; Mitchell, W.C. Measuring Business Cycles; National Bureau of Economic Research: Cambridge, MA, USA, 1946. [Google Scholar]
- Liang, R.; Wang, F.; Xu, J. Nowcasting China’s PPI inflation using low-frequency and mixed-frequency dynamic factor models. J. Financ. Res. 2021, 494, 22–41. [Google Scholar] [CrossRef]
- Anesti, N.; Galvão, A.B.; Miranda-Agrippino, S. Uncertain Kingdom: Nowcasting Gross Domestic Product and its revisions. J. Appl. Econom. 2022, 37, 42–62. [Google Scholar] [CrossRef]
- Mumtaz, H.; Musso, A. The Evolving Impact of Global, Region-Specific, and Country-Specific Uncertainty. J. Bus. Econ. Stat. 2021, 39, 466–481. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Meyer, J.S.; Ingersoll, C.G.; McDonald, L.L.; Boyce, M.S. Estimating Uncertainty in Population Growth Rates: Jackknife vs. Bootstrap Techniques. Ecology 1986, 67, 1156–1166. [Google Scholar] [CrossRef]
- Hasni, M.; Aguir, M.; Babai, M.; Jemai, Z. Spare Parts Demand Forecasting: A Review on Bootstrapping Methods. Int. J. Prod. Res. 2019, 57, 4791–4804. [Google Scholar] [CrossRef]
- Fresoli, D. Bootstrap VAR Forecasts: The Effect of Model Uncertainties. J. Forecast. 2022, 41, 279–293. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Hesterberg, T. Bootstrap. WIREs Comput. Stat. 2011, 3, 497–526. [Google Scholar] [CrossRef]
- Dagum, E.B.; Cholette, P.A. The Cholette-Dagum Regression-Based Benchmarking Method—The Additive Model. In Benchmarking, Temporal Distribution, and Reconciliation Methods for Time Series; Lecture Notes in Statistics; Springer: New York, NY, USA, 2006; pp. 51–84. [Google Scholar] [CrossRef]
- Hothorn, T.; Hornik, K.; Zeileis, A. Unbiased Recursive Partitioning: A Conditional Inference Framework. J. Comput. Graph. Stat. 2006, 15, 651–674. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and Variable Selection Via the Elastic Net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Cabrer Borrás, B. Indicadores Económicos y su Problemática: Una Visión de Síntesis. In Análisis Regional: El Proyecto Hispalink; Cabrer Borrás, B., Ed.; Mundi Prensa Libros: Madrid, Spain, 2001; pp. 259–275. [Google Scholar]
- Cuevas, A.; Quilis, E.M.; Espasa, A. Quarterly Regional GDP Flash Estimates by Means of Benchmarking and Chain Linking. J. Off. Stat. 2015, 31, 627–647. [Google Scholar] [CrossRef]
- Mondéjar-Jiménez, J.; Vargas-Vargas, M. Indicadores Sintéticos: Una Revisión de los Métodos de Agregación. Econ. Soc. Territ. 2008, 8, 565–585. [Google Scholar] [CrossRef]
- Domínguez Serrano, M.; Blancas Peral, F.J.; Guerrero Casas, F.M.; González Lozano, M. Una Revisión Crítica para la Construcción de Indicadores Sintéticos. Rev. MéTodos Cuantitativos Econ. Empresa 2011, 11, 41–70. [Google Scholar]
- Cuevas, A.; Quilis, E.M. A Factor Analysis for the Spanish Economy. SERIEs 2012, 3, 311–338. [Google Scholar] [CrossRef]
- Doz, C.; Fuleky, P. Dynamic Factor Models; Springer International Publishing: Berlin, Germany, 2020; pp. 27–64. [Google Scholar] [CrossRef]
- Grudkowska, S.D. JDemetra+ Reference Manual Version 2.1; Narodowy Bank Polski Education: Warsaw, Poland, 2017. [Google Scholar]
- Maravall, A.; Gómez, V.; Caporello, G. Statistical and Econometrics Software: TRAMO and SEATS. In Statistical and Econometrics Software; Banco de España: Madrid, Spain, 2015. [Google Scholar]
- US Census Bureau. X-13ARIMA-SEATS Reference Manual; US Census Bureau: Washington, DC, USA, 2017. [Google Scholar]
- IVE. Estándar del SEEDS de la Generalitat Valenciana para la Corrección de Efectos Estacionales y de Calendario en las Series Coyunturales; Generalitat Valenciana: Valencia, Spain, 2016. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- Wan Ahmad, W.K.A.; Ahmad, S. Arima Model and Exponential Smoothing Method: A Comparison. AIP Conf. Proc. 2013, 1522, 1312–1321. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R. Bootstrap Methods for Standard Errors, Confidence Intervals, and Other Measures of Statistical Accuracy. Stat. Sci. 1986, 1, 54–75. [Google Scholar] [CrossRef]
- Valliant, R.; Dorfman, A.; Royall, R. Finite Population Sampling and Inference: A Prediction Approach; John Wiley & Sons: New York, NY, USA, 2000; Number 4. [Google Scholar]
- Veres-Ferrer, E.J.; Pavía, J.M. Elasticity as a Measure for Online Determination of Remission Points in Ongoing Epidemics. Stat. Med. 2021, 40, 865–884. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Chang, W.; Cheng, J.; Allaire, J.; Sievert, C.; Schloerke, B.; Xie, Y.; Allen, J.; McPherson, J.; Dipert, A.; Borges, B. Shiny: Web Application Framework for R; R Package Version 1.7.4.9002; 2023. Available online: https://rstudio.github.io/shiny/authors.html (accessed on 6 March 2023).
- Wilcox, R.R. The Bootstrap. In Fundamentals of Modern Statistical Methods: Substantially Improving Power and Accuracy; Wilcox, R.R., Ed.; Springer: New York, NY, USA, 2010; pp. 87–108. [Google Scholar] [CrossRef]
- Davidson, R.; MacKinnon, J.G. Bootstrap Tests: How Many Bootstraps? Econom. Rev. 2000, 19, 55–68. [Google Scholar] [CrossRef]
- Chernick, M.R. Bootstrap Methods: A Guide for Practitioners and Researchers; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar]
- Pavía-Miralles, J.M.; Cabrer-Borrás, B. On Estimating Contemporaneous Quarterly Regional GDP. Ournal Forecast. 2007, 26, 155–170. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Description |
|---|---|
| AFSST | Total affiliated to the social security system |
| AFSSC | Total affiliated to the social security system in the construction sector |
| CPPT | Consumption of petroleum products |
| CVV | Property sales |
| EXPORT | Exports |
| GTOTUR | Tourist spending |
| IASS | Service sector activity indicator |
| ICMG | Retail turnover index |
| IMPORT | Imports |
| IPI | Industrial production index |
| MATTUR | Vehicle registrations |
| MATVC | Heavy-duty vehicle registrations |
| PHT | Total overnight stays in hotel establishments |
| VET | Total approvals of building certificates |
| Model | N | Predictors | Adj. | AIC | |
|---|---|---|---|---|---|
| 9908 | 8 | AFSST GTOTUR IASS ICMG | 0.94 | 0.94 | 15.31 |
| IMPORT MATTUR MATVC PHT | |||||
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| 16,383 | 14 | AFSST AFSSC CPPT CVV EXPORT | 0.94 | 0.94 | 23.12 |
| EXPORT GTOTUR IASS ICMG IMPORT | |||||
| IPI MATTUR MATVC PHT VET | |||||
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| 14 | 1 | CPPT | 0.13 | 0.12 | 361.72 |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| 25 | 50 | 399 | 599 | 1000 | 10,000 | 25 | 50 | 399 | 599 | 1000 | 10,000 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25 | 0.1018 | 0.0991 | 0.1001 | 0.1034 | 0.0985 | 0.1058 | 0.1029 | 0.1040 | 0.1074 | 0.1023 | |||
| 50 | 0.1171 | 0.0352 | 0.0439 | 0.0629 | 0.0590 | 0.1232 | 0.0365 | 0.0456 | 0.0653 | 0.0612 | |||
| 399 | 0.0969 | 0.0688 | 0.0195 | 0.0460 | 0.0405 | 0.1020 | 0.0724 | 0.0203 | 0.0477 | 0.0420 | |||
| 599 | 0.0954 | 0.0683 | 0.0098 | 0.0312 | 0.0260 | 0.1005 | 0.0719 | 0.0103 | 0.0324 | 0.0270 | |||
| 1000 | 0.1124 | 0.0682 | 0.0254 | 0.0247 | 0.0114 | 0.1183 | 0.0718 | 0.0267 | 0.0260 | 0.0118 | |||
| 10,000 | 0.1079 | 0.0704 | 0.0181 | 0.0177 | 0.0106 | 0.1136 | 0.0742 | 0.0191 | 0.0186 | 0.0112 |
| 25 | 50 | 399 | 599 | 1000 | 10,000 | 25 | 50 | 399 | 599 | 1000 | 10,000 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25 | 0.0858 | 0.1149 | 0.1373 | 0.1270 | 0.1260 | 0.0890 | 0.1190 | 0.1422 | 0.1315 | 0.1305 | |||
| 50 | 0.0623 | 0.0701 | 0.0904 | 0.0951 | 0.0963 | 0.0656 | 0.0726 | 0.0936 | 0.0985 | 0.0997 | |||
| 399 | 0.0855 | 0.0868 | 0.0396 | 0.0518 | 0.0508 | 0.0901 | 0.0915 | 0.0410 | 0.0537 | 0.0526 | |||
| 599 | 0.0892 | 0.0837 | 0.0205 | 0.0595 | 0.0578 | 0.0940 | 0.0883 | 0.0217 | 0.0616 | 0.0598 | |||
| 1000 | 0.1006 | 0.0861 | 0.0438 | 0.0305 | 0.0119 | 0.1061 | 0.0908 | 0.0463 | 0.0322 | 0.0123 | |||
| 10000 | 0.0999 | 0.0887 | 0.0345 | 0.0232 | 0.0140 | 0.1053 | 0.0936 | 0.0364 | 0.0245 | 0.0148 |
| 25 | 50 | 399 | 599 | 1000 | 10,000 | 25 | 50 | 399 | 599 | 1000 | 10,000 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25 | 0.1178 | 0.1112 | 0.1160 | 0.1437 | 0.1483 | 0.1219 | 0.1150 | 0.1199 | 0.1485 | 0.1532 | |||
| 50 | 0.1031 | 0.1263 | 0.1241 | 0.1280 | 0.1310 | 0.1085 | 0.1305 | 0.1282 | 0.1323 | 0.1354 | |||
| 399 | 0.0911 | 0.0859 | 0.0238 | 0.0558 | 0.0618 | 0.0961 | 0.0906 | 0.0246 | 0.0577 | 0.0638 | |||
| 599 | 0.0970 | 0.0874 | 0.0191 | 0.0970 | 0.0874 | 0.1024 | 0.0922 | 0.0202 | 0.0487 | 0.0531 | |||
| 1000 | 0.1029 | 0.0926 | 0.0245 | 0.0181 | 0.0142 | 0.1087 | 0.0978 | 0.0258 | 0.0191 | 0.0147 | |||
| 10,000 | 0.1059 | 0.0913 | 0.0286 | 0.0212 | 0.0126 | 0.1119 | 0.0964 | 0.0302 | 0.0224 | 0.0133 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Espinosa, P.; Pavía, J.M. Automation in Regional Economic Synthetic Index Construction with Uncertainty Measurement. Forecasting 2023, 5, 424-442. https://doi.org/10.3390/forecast5020023
Espinosa P, Pavía JM. Automation in Regional Economic Synthetic Index Construction with Uncertainty Measurement. Forecasting. 2023; 5(2):424-442. https://doi.org/10.3390/forecast5020023
Chicago/Turabian StyleEspinosa, Priscila, and Jose M. Pavía. 2023. "Automation in Regional Economic Synthetic Index Construction with Uncertainty Measurement" Forecasting 5, no. 2: 424-442. https://doi.org/10.3390/forecast5020023