1. Introduction
Trafficking in persons is one of the most harmful criminal industries internationally. Its prevalence continues to rise each year and it is currently identified as the second-most profitable illegal trade, after drug trafficking [
1]. According to the U.S. Department of State’s 2022 Trafficking in Persons Report [
2], 1111 federal (or joint federal-local/state) investigations of human trafficking were opened during the fiscal year 2021, with the Department of Justice initiating prosecution in 228 cases, the majority of which (221) concerned sex—as opposed to labor—trafficking. At the local/state level, 2203 human trafficking offenses were reported by participating jurisdictions (U.S. Department of State 2022). These figures, however, are thought to grossly underestimate the true extent of the problem. For instance, 11,500 cases of human trafficking were reported to the National Human Trafficking Hotline during 2019 [
3]. These calls led to the identification of 22,326 victims and survivors, of whom 14,597 (65%) had been sex trafficked, with an additional 1048 (5%) having been subjected to both sex and labor trafficking.
Federal law defines sex trafficking as “the recruitment, harboring, transporting, provision, obtaining, patronizing or soliciting of a person for the purposes of a commercial sex act, in which the commercial sex act is induced, through the use of force, fraud, or coercion, or in which the person induced to perform such an act has not attained 18 years of age”. This means that, if the victim is under the age of 18, force, fraud, or coercion are not required to prove trafficking. Human trafficking is often conflated with human smuggling, but smuggling requires the movement of an individual across international borders. “Trafficking” in this sense refers to the illegal commodification of an individual and their entrance into the stream of commerce, akin to weapons or drug trafficking, as opposed to the movement of a commodity.
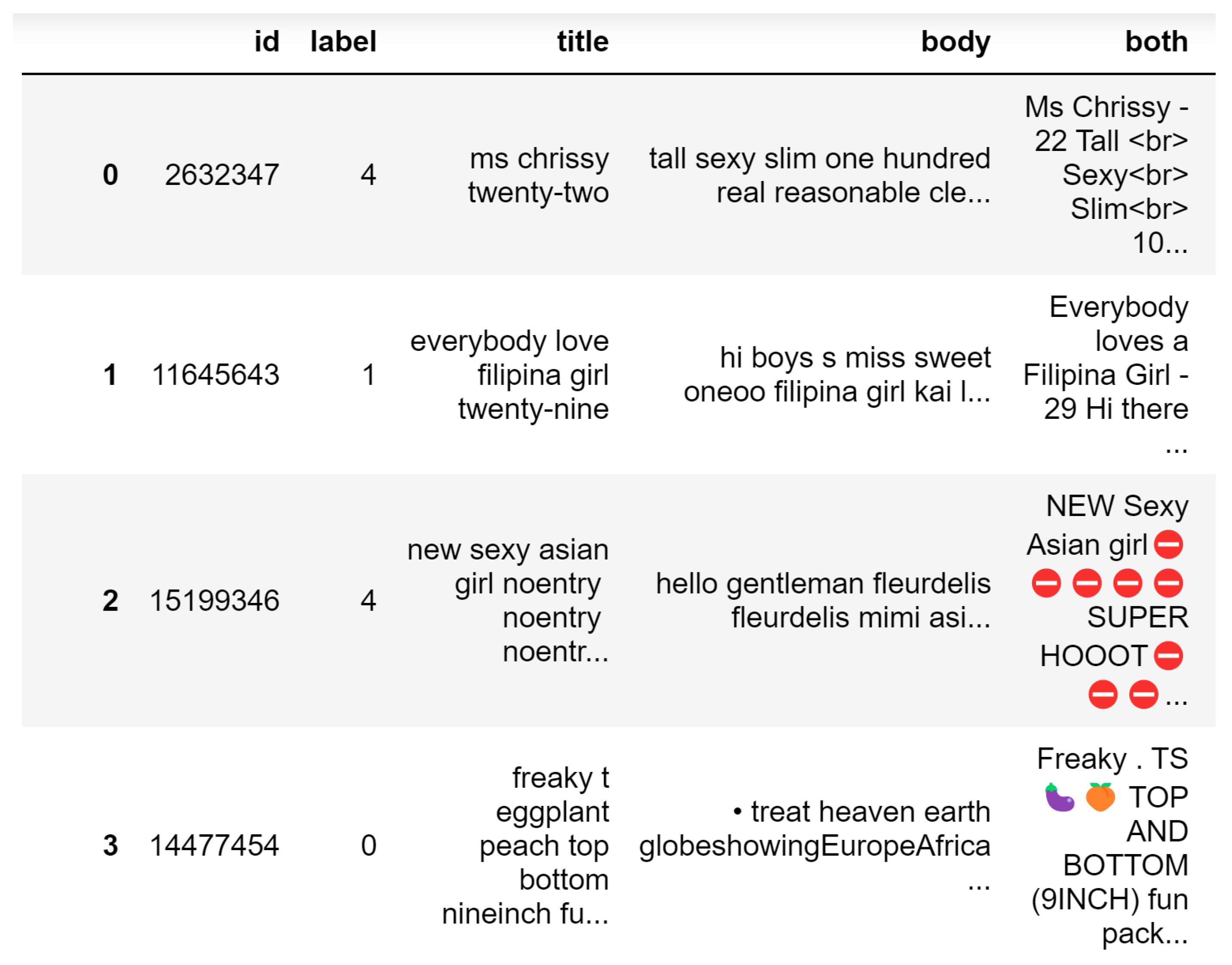
Sex trafficking (ST) can be promulgated through information and communications technologies (ICT) such as the Internet and, more specifically, online escort advertisements [
4,
5,
6]. These ads are typically very brief and contain a provocative photo, a description of the seller/victim, and language to describe or indicate the advertisement is for commercial sex [
7]. However, thinly coded terms and/or other characteristics may be indicative of commercial exploitation. For example, a phrase such as “new in town” may indicate victims being moved around (often an indication of sex trafficking), a crown emoji or image may signify services managed by a pimp, and emojis displaying a growing heart, a cherry, or a cherry blossom emoji may signify a minor in the ad [
8,
9]. The ads usually appear to be posted by the individual in the ad, but traffickers often post and pay for the ads themselves [
7].
While easily accessible to both the public and law enforcement, the sheer volume of ads, the frequency with which the posting location changes, along with the use of obfuscation tactics by those posting and hosting the advertisements, make it difficult for law enforcement to identify, react, and respond [
8]. Traffickers and buyers, along with the technology used itself, evolve at a rapid rate, and this demands that law enforcement, prosecutors, and legislatures come up with creative responses to combat the advances in technology (which is inherent to the covert nature of the crime itself). Thus, these stakeholders require accurate, productionalized, and cost-free methods for classifying websites likely engaged in illicit ST to target enforcement [
10].
Machine learning (ML) has shown promise in the automated classification of websites—both escort and third-party review sites—that facilitate sex trafficking. Tong and colleagues (2017) were one of the first to apply these classification-supervised learning methods to online escort ads, with the goal of identifying likely sex trafficking activity [
11]. They collaborated with law enforcement officials to annotate more than 10,000 escort ads from Backpage (a dominant escort advertisement site that is no longer active) along a seven-point Likert scale to indicate their likely involvement in sex trafficking activity. Based on these, the authors developed a deep model that considered the text, emojis, and images in the ads. This model outperformed all baselines considered (e.g., keywords, bag of words, random forest, logistic regression, and linear support vector machine, or SVM, models) in identifying those ads suspected of being associated with sex trafficking, highlighting the value of the methodology.
Since then, other studies have followed that have employed the Trafficking-10k and other datasets. For example, Alvari et al. [
12] also used law enforcement experts to manually label a large portion of crawled data from Backpage. They extended the existing Laplacian SVM model by adding a regularization term to the optimization equation and ultimately reported that their approach had the highest F1 scores (91). In a separate study, an ordinal regression neural network approach yielded a model that outperformed previous conventional regression models [
13].
Esfahani and colleagues [
14] developed a centralized, semi-automatic tool that utilized natural language processing (NLP) techniques, among others, to identify trafficking ads—the classifiers developed had a significantly better performance than any single feature/variable set alone. The full model utilizing the full feature set (under U-BERT) provided 26% recall improvement over the three individual ones (e.g., 69% vs. 28–42%; recall, or sensitivity, is the model’s true positive rate) when precision (positive predictive value) was set to 85%. Zhu et al. [
15], using the Trafficking-10k dataset, developed a language selection model and showed improvement against Tong et al.’s human trafficking deep network (HTDN) model [
11], with a precision of 66.2% and recall of 73.4%. The application of the model went further than prior research by using the model to identify unknown trafficking organizations and assign a risk score. However, this model only examined the text of the ads (and not the emojis or images).
Convolutional neural networks (CNN) have become a commonplace approach for image (and other) analyses. Granizo et al. compared SVM and CNN models to estimate the gender and age of individuals on a known public repository where sex services were advertised [
16]. The training data set consisted of labeled images (
n = 4096 posts). Accuracy rates for age classification were 80.6% (SVM) vs. 97.3% (CNN) for faces and 82.1% (SVM) vs. 51.4% (CNN) for upper body images.
More recently, Wiriyakun and Kurutach [
17,
18] utilized a feature selection approach and compared three updated ML models against the original work of Tong et al. [
11] with the Trafficking-10k dataset, namely random forest, logistic regression, and linear SVM. These models significantly outperformed Tong et al.’s [
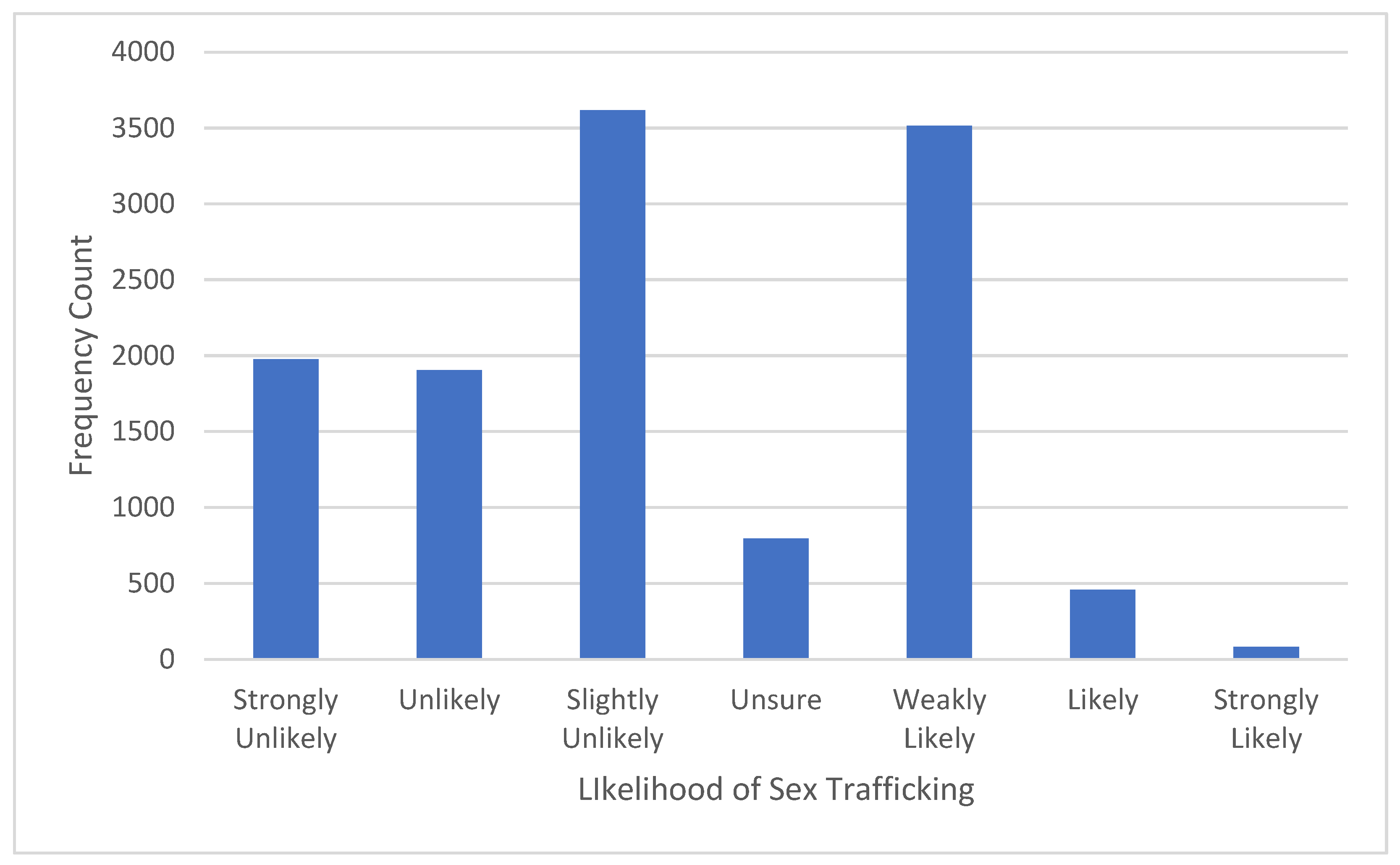
11] bag of words approach, with F1 scores of 63.3%, 64.8%, and 61.3%, respectively, as compared to 24.5%. These results are relevant because the authors dichotomized the labels in the Trafficking-10k dataset, which is the approach adopted in the present study.
Table 1 provides a summary of the results from related work.
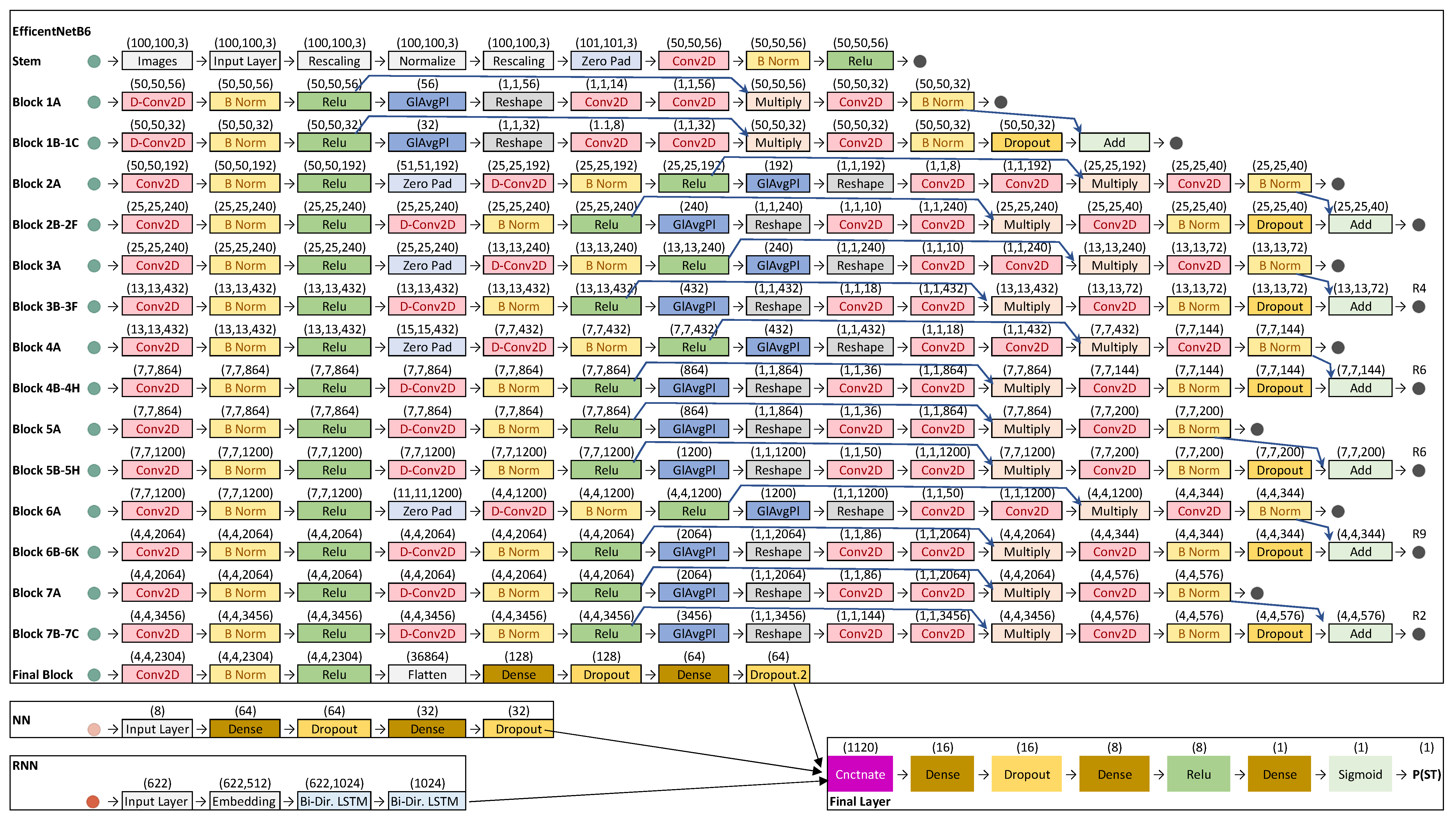
As ML methods advance and classification modeling improves, the need to determine the extent to which these higher-performance models apply in different contexts arises. This study attempts to improve on earlier methods via the provision of a high-performance deep learning model that includes text and imagery inputs. This has the potential to alleviate resource constraints placed on law enforcement by creating a model that can identify sex trafficking-related online escort ads with both high accuracy and precision, thus maximizing the efficiency of criminal investigators.
4. Discussion
This study has shown that recent advances in deep learning for classification allow us to more accurately and precisely identify online escort ads that may be associated with sex trafficking activity. High-precision models are particularly favored in that wasted effort by investigators with limited time resources should be avoided; the complete multi-input model (NN + RNN + ENET) developed here achieved 77% precision (as compared to the original 71% precision reported by Tong et al. [
11]), and this increased to almost 96% when only the ads associated with the highest positive classification probabilities (>0.90) were considered. Other model metrics for this complete model were comparable to Tong et al.’s [
11], demonstrating the increased precision was not associated with a trade-off deterioration in other metrics.
These results are based on the analysis of texts, emoticons, and emojis. Unfortunately, the advertisements’ photographic images could not be accessed and incorporated into the model. It is, therefore, possible (if not likely) that even better results could be obtained if the images of the ads were available for analysis.
As with any other research study, this one suffered from certain shortcomings. The Trafficking-10k dataset is aging, so the results reported here would need to be replicated using newly harvested data. While manually labeling ads can be time consuming and expensive, automatic classification based on widely accepted indicators of sex trafficking activity (e.g., movement of sex providers, apparently minor providers) may be performed in its place (see [
9]). Further, the multi-input model developed was complex, which yielded greater accuracy but obscured its theoretical underpinnings. Future research could develop and test a more theoretically sound model, then fit neural nets to the residuals to increase the model’s accuracy, using expert ratings to annotate the ads.
Although the binary reclassification of the original outcome labels in Tong et al.’s [
11] Trafficking-10k dataset could be perceived as a disadvantage, as it would arguably lead to a loss in granularity, our best accuracy score was comparable to those reported by [
13], who applied ordinal regression neural network (ORNN) models to this same dataset. The advantage of our binary outcome model is that it estimates the probability of a given online escort ad being associated with ST, which is much easier to interpret than coefficients or estimates from an ordinal model. Such functionality could then be productionalized to allow criminal investigators to identify the ads with the highest probability values. This would allow law enforcement to prioritize such ads, which we have shown to have precision scores as high as 96–100%.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}