1. Introduction
The prevalence of diabetes is rising all over the world. According to the statistics from the International Diabetes Federation (IDF), about 425 million adults worldwide were diagnosed with diabetes in 2017. Following this trend, it is estimated that by 2045, the number of diabetic patients in the world will exceed 629 million [
1]. Diabetes is a major cause of blindness, kidney failure, heart attack, stroke and lower-limb amputation, bringing huge inconvenience to the patients and even being life-threatening in severe cases. If it can be detected early and intensive treatment be offered, about half of those diabetes patients can go into remission.
At present, machine learning is an important research direction due to its high efficiency, accuracy, and extraordinary learning speed, and it plays a huge role in many fields, such as computer vision [
2], natural language processing [
3,
4], stock market analysis [
5], etc. In the 1980s, machine learning was used to predict diabetes. In 1988, Smith [
6] constructed an early neural network model to study diabetes prediction in Pima Indians. He compared and analyzed the results with Logistic Regression (LR) and Linear Perceptron (LP). In 2004, Meiland [
7] established a model based on LR to predict the presence of asymptomatic bacteriuria in diabetic women according to clinical indicators such as medical history and white blood cell count. In 2011, Ahmad A [
8] compared the performance of decision trees and neural networks in diabetes prediction. In 2013, Kumari [
9] used the backpropagation algorithm to provide an effective method for the automated examination of diabetes. In 2017, Maniruzzaman et al. [
10] proposed a Gaussian Process (GP)-based model for diabetic classification of existing techniques such as Naive Bayes (NB), Linear Discriminant Analysis (LDA) and Quadratic Discriminant Analysis (QDA). In 2018, Swapna and Vinaya Kumar [
11] used a deep learning method for detecting diabetes. In their study, Long Short-Term Memory (LSTM), Convolutional Neural Network (CNN) and a combination thereof were adopted to obtain dynamic features and then pipelined to Support Vector Machine (SVM) for classification.
All these studies have improved the prediction performance of diabetes. However, they are only based on a single small dataset. Considering that a single dataset contains limited information and there are many diabetes datasets, an effective method to promote diabetes prediction performance should be combining the multiple heterogeneous datasets. It should be noted that the process of combining datasets is also a feature-fusion process. Different datasets contain different feature information, and the features contained in different datasets will be fused when combined with different datasets. For feature fusion, many datasets are multi-dimensional. For example, the characteristics of a flower can be shape, color, and so on. These characteristics determine which breed it belongs to. We can also infer its species by its smell, flowering period, and geographical distribution. Therefore, if we combine these characteristics together, then the prediction of the flower varieties should be more accurate. In fact, this process can be viewed as multi-view learning [
12,
13,
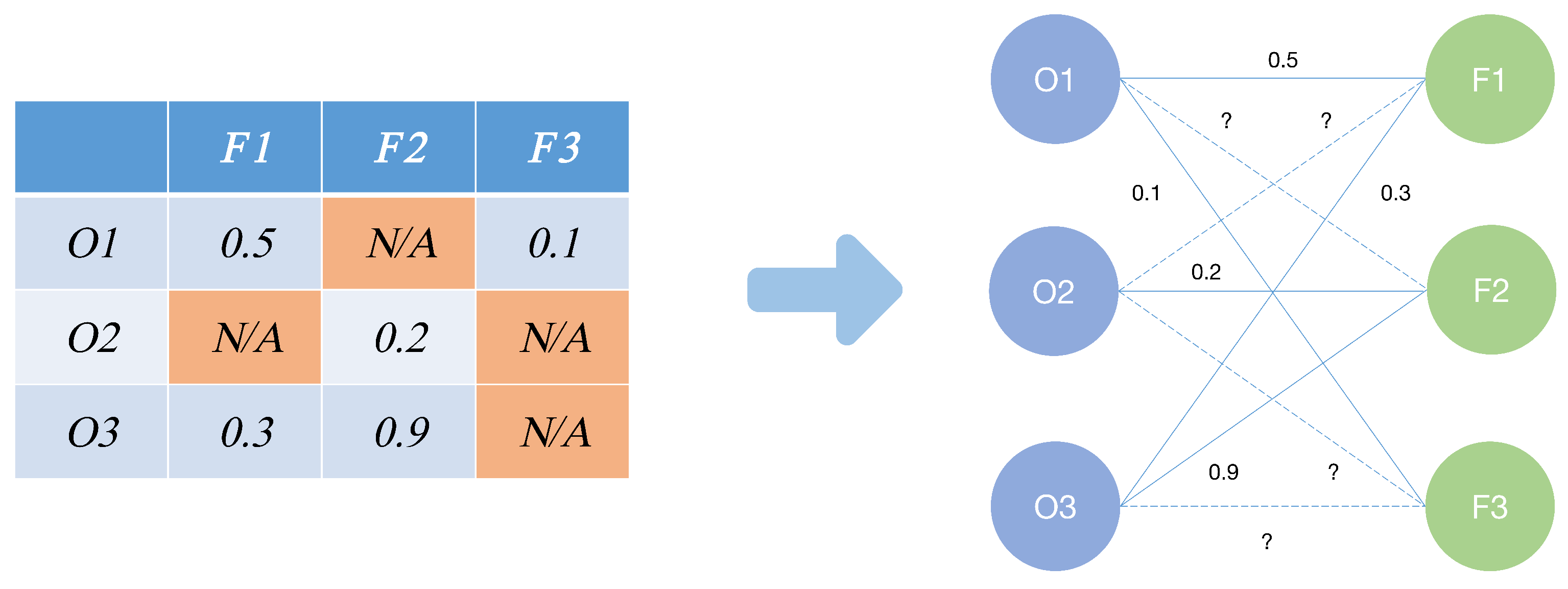
14]. In the process of feature fusion, the common features of heterogeneous datasets are directly integrated. Some specific features will be missed during the fusion process. Thus, some missing-value handling methods are needed to solve this problem and form a complete dataset.
For missing value handling strategies, there are three categories of approaches to deal with missing values. The first category is to remove all samples with missing values [
15]. This is simple and intuitive; it will encounter huge problems when a large number of data values are missing. Unlike the first category, the second category chooses to impute the missing values. There are many common imputation methods, including Mean Imputation [
16], Random Imputation within Classes [
17], Gaussian copula imputation [
18], etc. Commonly used ones include Regression Imputation [
19], Support Vector Machine Imputation (SVM) [
20], Multiple Imputation (MI) [
21], Genetic Algorithm [
22], graph-based imputation [
23], etc. These imputation methods can effectively impute the missing values, but the imputation effect is different. The third category uses the indicator matrix to indicate the position of the missing values in the dataset, ignoring the marked missing values in the subsequent training and prediction process, and only uses the non-missing parts [
24,
25]. The second category is the most commonly used one among these three categories, and multiple imputation is the most popular one among the methods based on imputation.
As for diabetes prediction, besides the most critical glycemic indicator, different hospitals or institutions will also consider other indicators to help them determine whether a patient has diabetes. These indicators may be differentiated and of different dimensions. In other words, there is heterogeneity between datasets. Since different indicators in the heterogeneous datasets all reflect some information related to diabetes, from the perspective of feature fusion, it is necessary to fuse them together. After fusion, the new dataset contains the characteristics of the original two datasets, which theoretically improves the prediction effect of diabetes. Therefore, in this paper, we will propose a new diabetes prediction system that can combine heterogeneous data sources. The system fused the common and special features within two data sources and missing values occurred during this process. For the missing value handling problem, we adopt multiple imputation and the graph representation learning model to impute the data to feed LR [
26] to train and predict diabetes. To further improve the prediction results, we also introduce ensemble learning framework stacking [
27,
28], and finally further improve the prediction performance.
The main contributions of this paper are summarized as follows:
Explore and improve diabetes prediction by fusing two heterogeneous datasets from different sources, which can be generalized to more than two data sources and different application domains.
Taking the uncertainty of the missing values into consideration, graph representation learning is adopted to impute the missing values within the fused dataset.
Compared with the prediction results of the original dataset, the prediction results of the fused dataset are improved, and the stacking strategy further improves the performance.
The rest of this paper is organized as follows:
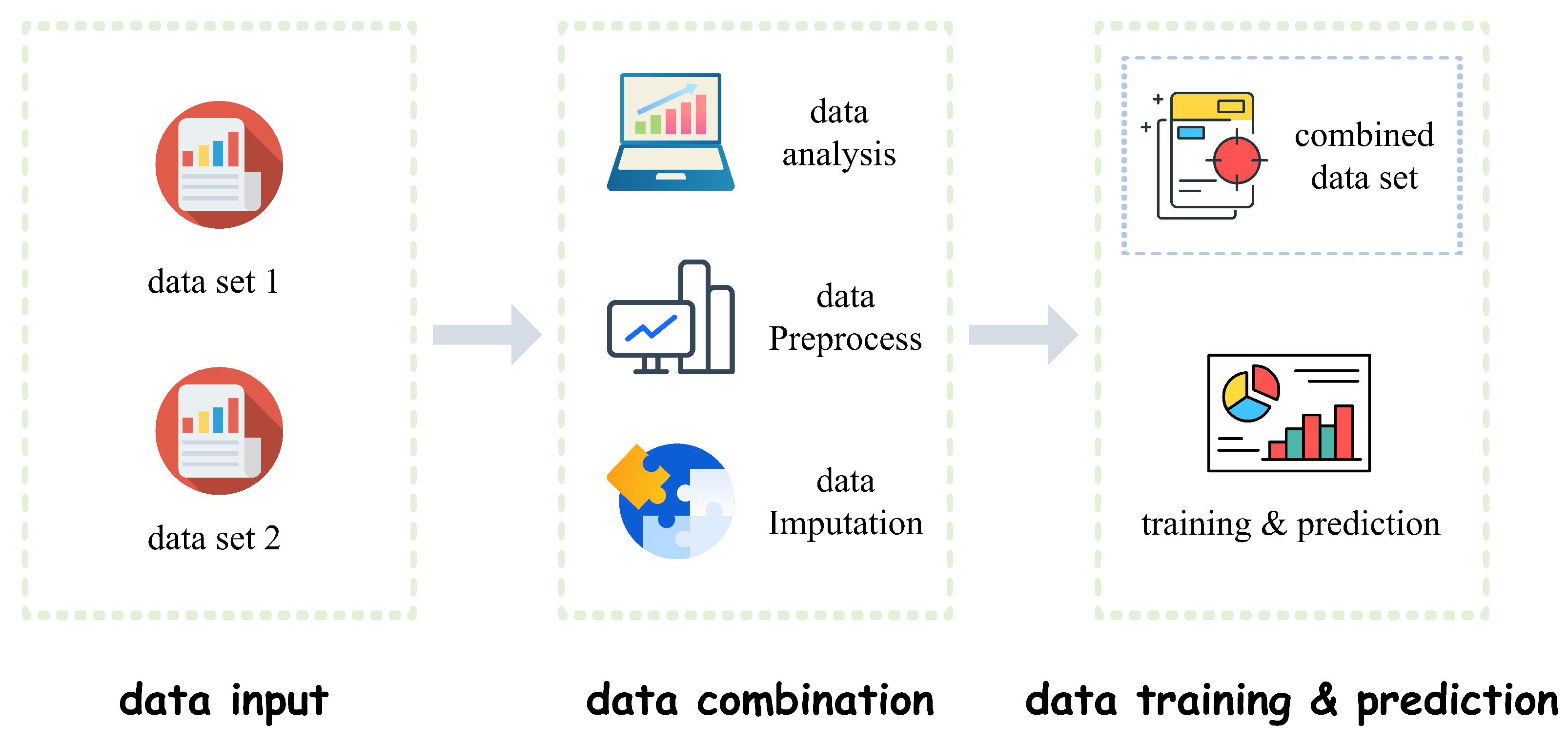
Section 2 elaborates the overall framework of the system, introducing the specific functions of each module.
Section 3 demonstrates the experiments, including dataset description, experimental settings, experimental evaluation metrics, experimental results and the analysis. In
Section 4, we discuss the experimental results. Finally,
Section 5 concludes the paper.
3. Experiment
3.1. Dataset Description
There are two datasets used in this experiment, namely the Weihai Municipal Hospital(WMH) Diabetes Dataset and the Pima Indian Diabetes Dataset. The WMH dataset comes from a municipal hospital in Weihai City, Shandong Province, China. It records 12 diabetes-related diagnostic indicators of 118 local patients in Weihai, including gender, age, BMI, family history, insulin, blood sugar, serum C-peptide, and so on. The Pima dataset contains diabetes indicators including Pregnancies, Glucose, Insulin, Blood Pressure, Skin Thickness, Diabetes Pedigree Function, BMI, etc. of 768 Pima Indian women with potential diabetes from Phoenix, Arizona [
36]. Both datasets contain the diagnosis labels of each patient (ill or not). According to the advice from doctors and some conclusions from previous research [
37], six important features (gender, age, BMI, blood glucose, proinsulin and Cp120) are selected from the former dataset and five features (gender, age, BMI, blood glucose and diabetes pedigree) from the latter one to form seven common features. The features shared by the two datasets include gender, age, BMI, and blood glucose.
Table 1 is a detailed description of the features.
3.2. Experimental Settings
After the dataset fusion process, we selected the multiple imputation and the GRAPE model to fill in the datasets, and obtained two complete fused datasets. The LR model and the stacking model in the ensemble learning framework are selected to train and predict whether the person is diabetic. Five basic models—random forest, decision tree, LDA, KNN, and Naive Bayes—and a meta-model LR are adopted in the stacking model. To verify the effectiveness of the proposed methods, five performance evaluation metrics—accuracy, precision, recall, F1-score, AUC (Area Under Curve)—are used in our experiments, and five-fold cross-validation is adopted to run the experiments. The average results and standard deviations are reported. Cross-validation can decrease the impact brought about by the different distributions of training data and test data.
Experiment 1. Use the LR model to train and predict on the original dataset.
Experiment 2. Use the multiple imputation model and GRAPE model for data imputation on the fused dataset, and use LR model and stacking model for training and prediction. Train the models on the training set containing both WMH and Pima samples, and then predict the WMH samples and Pima samples in the test set, respectively.
Experiment 3. Use the multiple imputation model and GRAPE model for data imputation on the fused dataset, and use LR model and stacking model for training and prediction. Split the fused dataset into the WMH samples and Pima samples, and then train and predict on WMH samples and Pima samples, respectively.
Experiment 4. Compare the methods “Complete GRAPE” and “GRAPE”. When the GRAPE model is used to impute the missing values, in fact, it will impute all the values including the existing values and the missing values. When we adopt LR to do the training, and use the complete data obtained after GRAPE, we call this method “Complete GRAPE”. If the dataset keeps the existing values and just replaces missing values with the imputed values obtained from GRAPE, we call the method employed on this dataset “GRAPE”. We will use them to predict the labels of WMH samples, Pima samples, and all samples in the test set.
Experiment 5. Compare the methods “LR+GRAPE” and “GRAPE”. For the basic model LR, the data after GRAPE imputation is divided into training and test sets, LR is trained on the training set and prediction is performed on the test set. This method is named “LR+GRAPE”. It is noted that GRAPE can predict the label in the test set without the help of any additional classification model. In
Figure 2, running GRAPE with the label as node, the label corresponding to each sample in the test set will be given. This method is named “GRAPE”. We will use them to predict the labels of WMH samples, Pima samples, and all samples in the test set.
Since we use five-fold CV, all the above experiments are run five times, and the mean and standard deviation of the five results are taken as the final result.
3.3. Evaluation Metrics
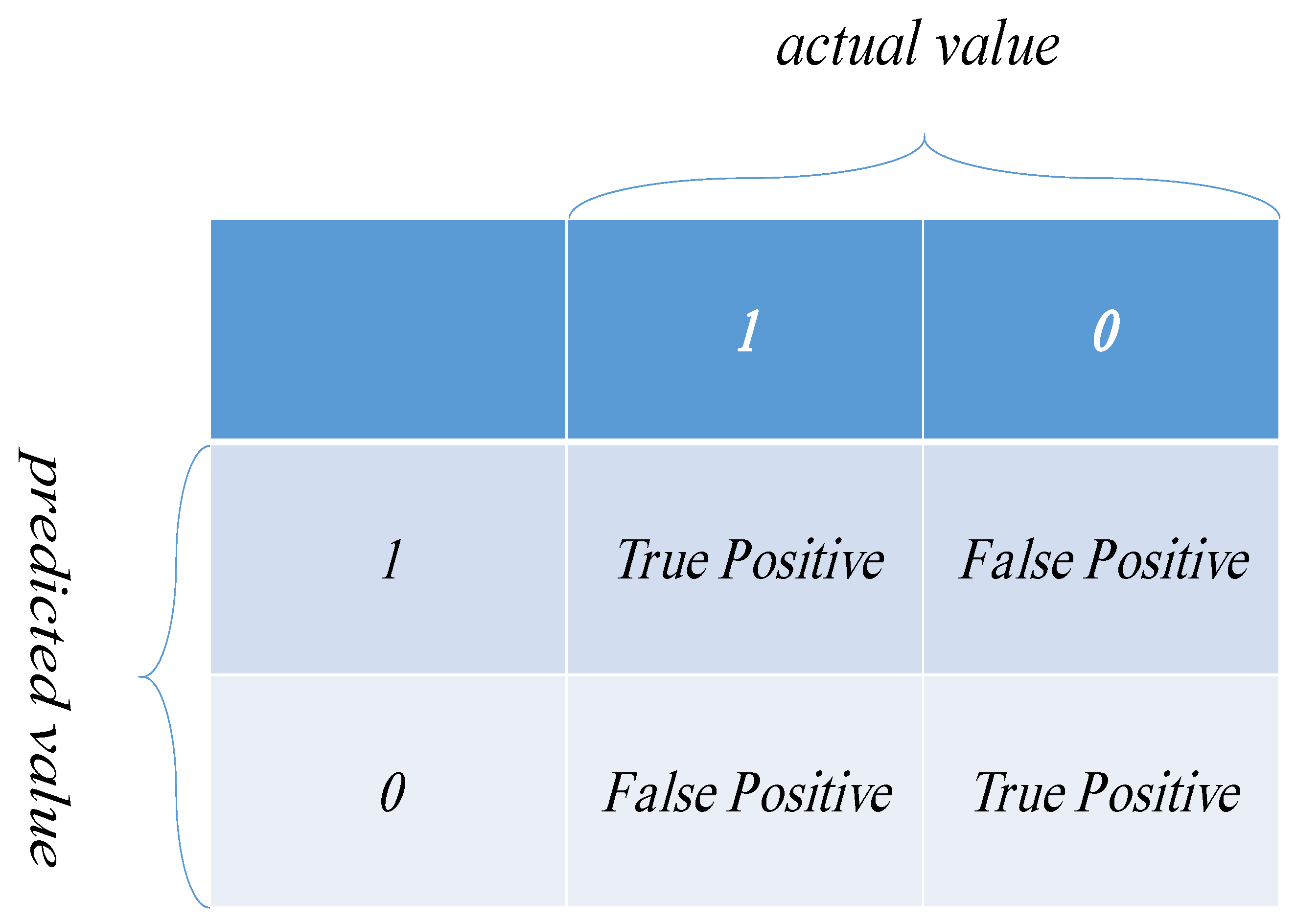
Five evaluation metrics—accuracy, precision, recall, F1-score, and AUC (Area Under Curve)—are adopted in the experimental comparison. Since the first four are based on the confusion matrix, we will introduce the confusion matrix first.
Figure 3 is the structure of the confusion matrix. The confusion matrix is a two-dimensional matrix, which is mainly used to evaluate binary classification problems and reflect the difference between the predicted result and the actual result [
38]. It can be seen from the matrix that there are two types of category (0 and 1), and the difference between the category predicted by the model and the true categories forms four indicators, respectively. They are true positive (TP), false positive (FP), false negative (FN) and true negative (TN). TP represents the number of samples whose predicted result is 1 and the true result is 1, and FP represents the number of samples whose predicted result is 1 but the actual result is 0. TN represents the number of samples whose predicted result is 0 and the true result is 0, and FN represents the number of samples whose predicted result is 0 but the actual result is 1.
The calculation formula for accuracy is
It reflects the proportion of the correctly predicted sample to the total sample.
The calculation formula of precision is
It reflects the accuracy of the positive class and measures the correctness of the prediction of the positive class.
The calculation formula of recall is
It indicates how many samples with positive labels are predicted correctly.
Precision and recall are often relative. Sometimes precision is high but recall is low, so F1-score is introduced to provide a trade-off. F1-score is an evaluation index that combines precision and recall. Its calculation formula is
It is the harmonic mean of precision and recall.
The last one, AUC, refers to the area between the ROC (Receiver Operating Characteristic) curve and the x-axis. It can quantitatively display the classification of the model. Generally, the larger the value of AUC, the better the classification performance on the dataset.
In the context of medicine, especially in clinical decision support, the AUC is often too general in that it assesses all decision thresholds, including unrealistic ones. Conversely, accuracy, precision, recall, positive predictive value, and the F1 score are too specific; they are measured against a single threshold that is optimal for some cases but not for others, which is not fair. Thus, each measure has its limit, all of them will be adopted to evaluate the result. A very recent work [
39] describes a deep ROC analysis to measure performance in multiple groups of predicted risk or in groups of TP rate or FP rate. It is interesting that these authors also provide a Python toolkit.
3.4. Experimental Results
The results of Experiment 1 and Experiment 2 are shown in
Figure 4,
Table 2 and
Table 3. From
Table 2, we can find that both the MICE filling model and the GRAPE imputation model have improved the prediction results of WMH samples slightly, and the performance obtained using the stacking model is better than that obtained by the LR model. Regarding the WMH data, it achieves the best performance with an accuracy of 92.5% using the GRAPE model for data imputation and the stacking model for training and prediction. From
Table 3, it can be seen that compared to the WMH dataset, Pima’s prediction results are slightly improved. On the whole, for Pima dataset, it can be improved slightly using the MICE filling model to impute and using the stacking model to predict.
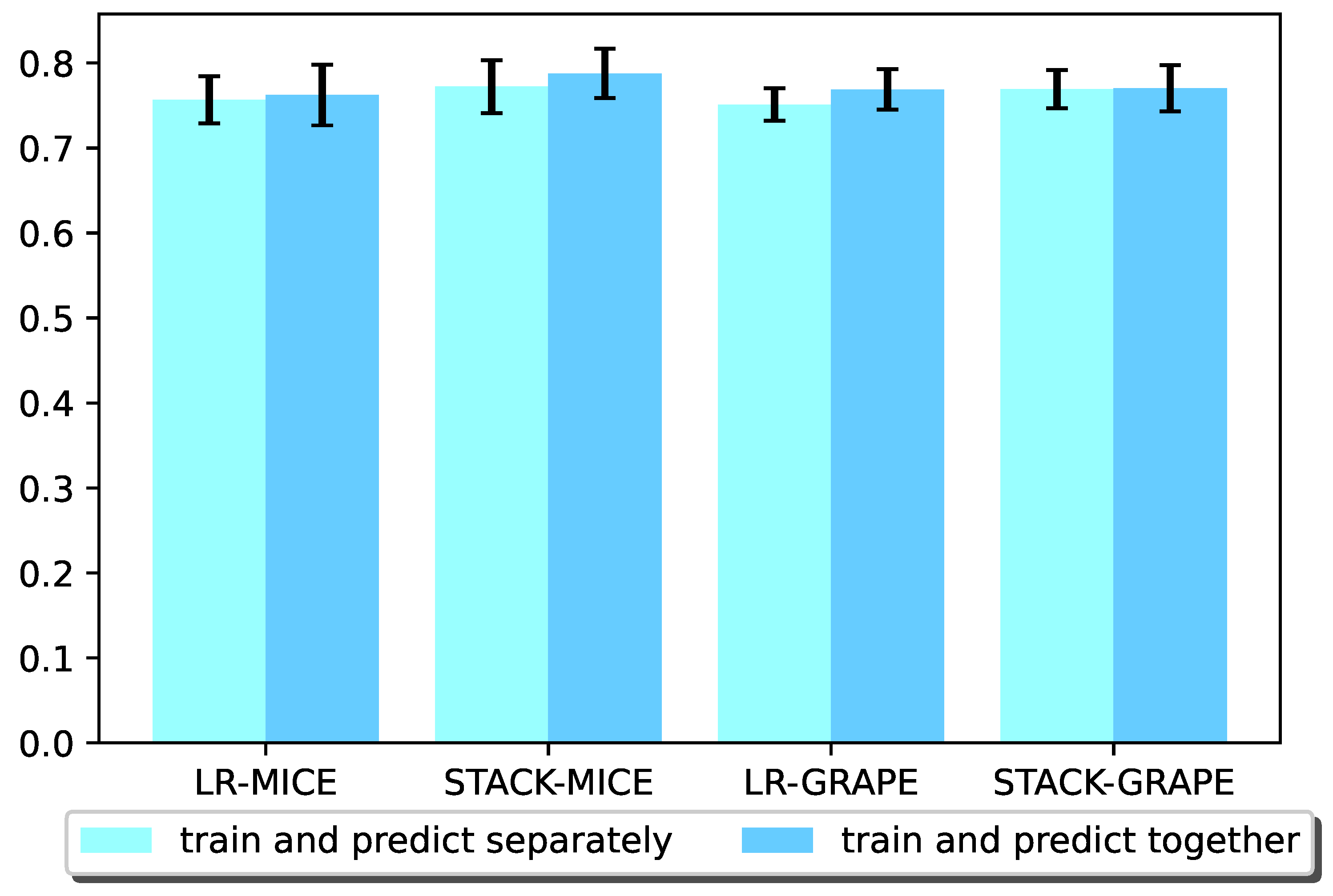
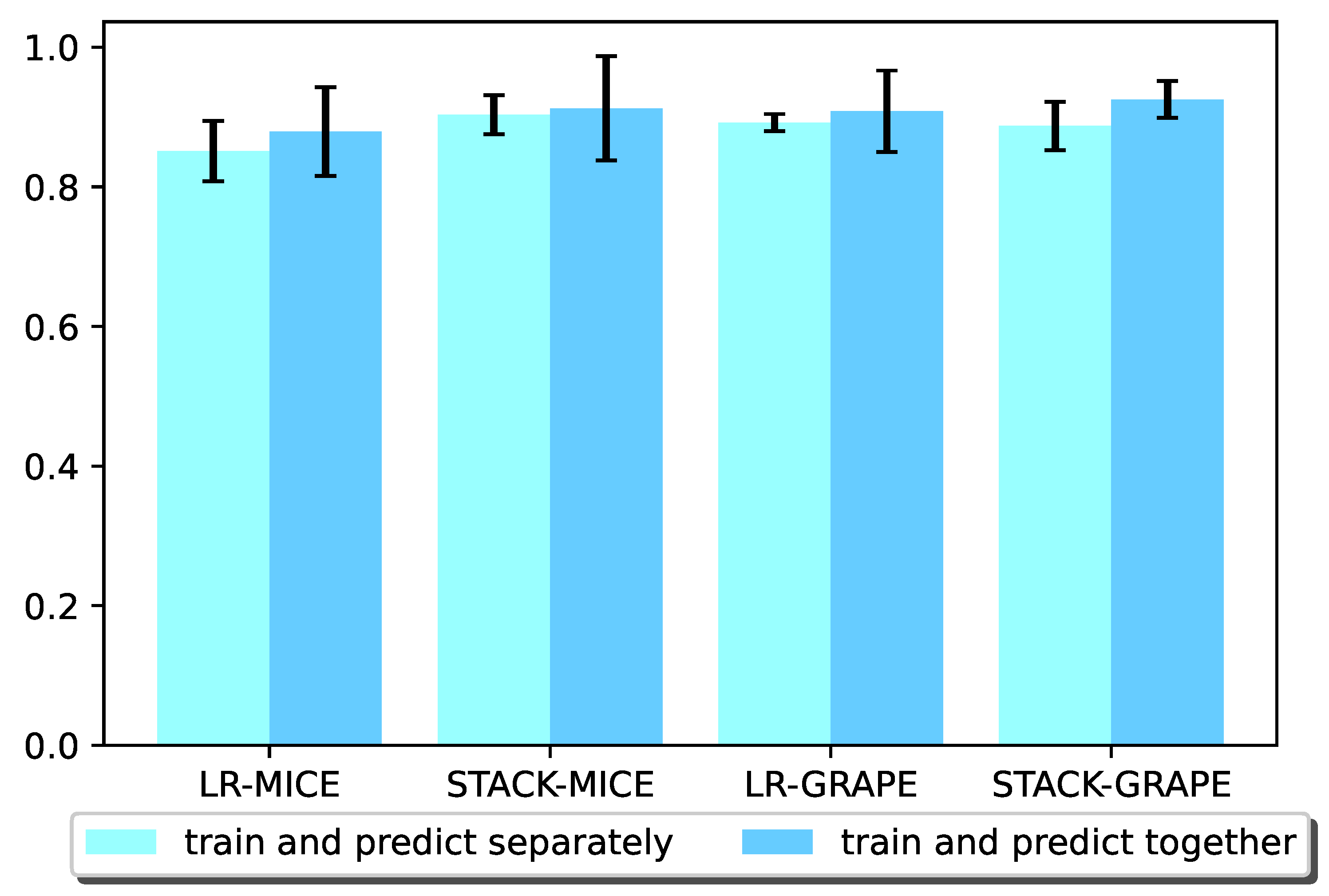
For Experiment 3,
Figure 5 shows the result comparison of training on fused training samples to predict Pima test samples and separate training on Pima training samples and then predicting Pima test samples.
Figure 6 shows the result comparison of training on fused training samples to predict WMH test samples and separately training on WMH samples and then predicting WMH test samples. It can be seen from the results that for both Pima samples and WMH samples, the results of separate training and prediction are generally not as good as those results obtained with training and predicting together.
For Experiment 4,
Table 4 and
Table 5 demonstrate the results of the two methods “GRAPE” and “Complete GRAPE”. From these two tables, we can see that it is slightly better to use the imputed dataset obtained from “Complete GRAPE” for WMH dataset than that obtained from “GRAPE” in recall, but slightly worse in precision, F1-score and AUC. For Pima data, it seems that “Complete GRAPE” performs worse than “GRAPE” in most of the evaluation metrics. On all data, “Complete GRAPE” performs slightly better than or as well as “GRAPE”. In summary, it seems that “Complete GRAPE” performs as well as “GRAPE”. This is indeed reasonable, because the imputed result of the GRAPE model for the position that already exists is very close to the actual value. It indicates that this has little influence on the prediction effect.
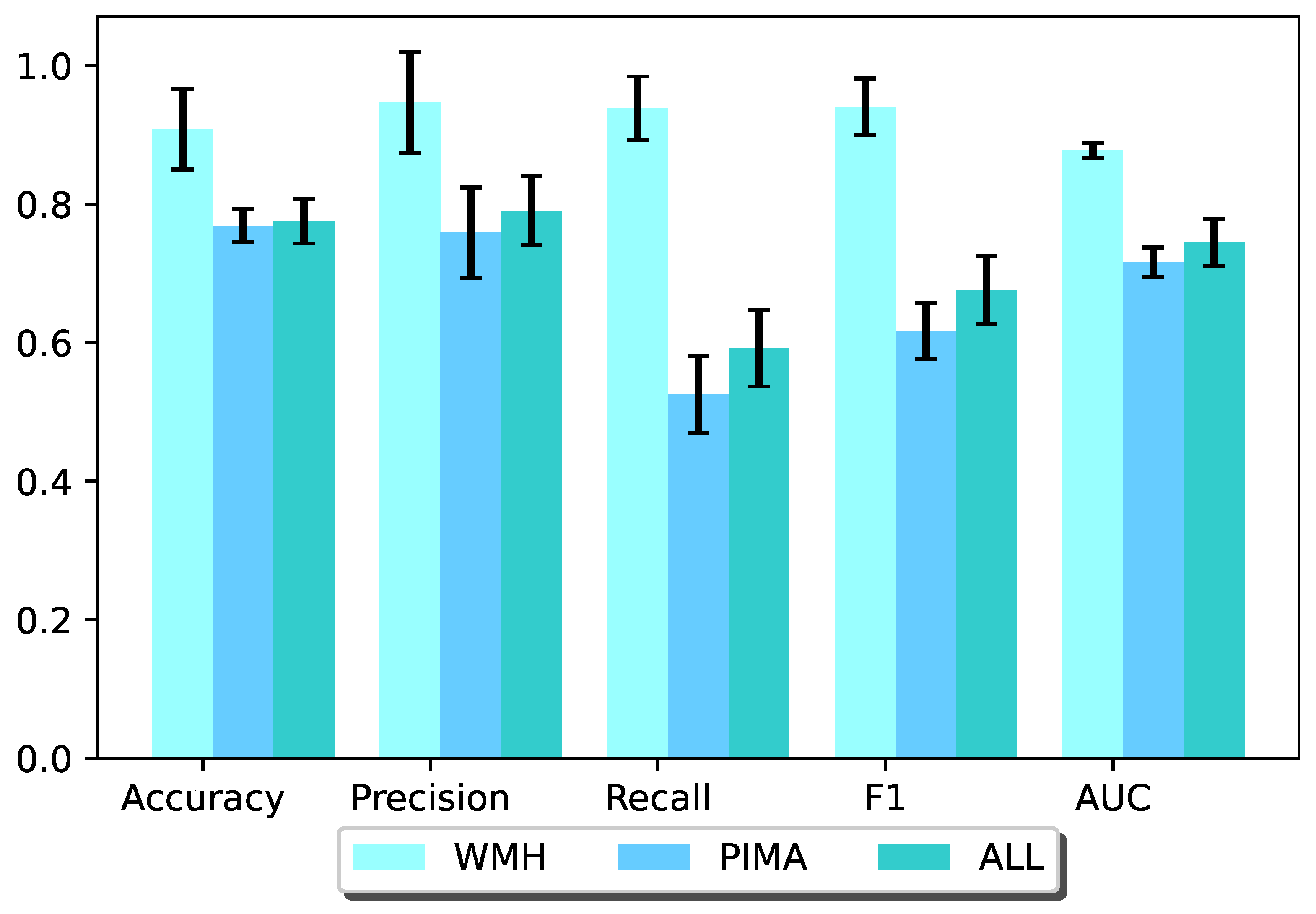
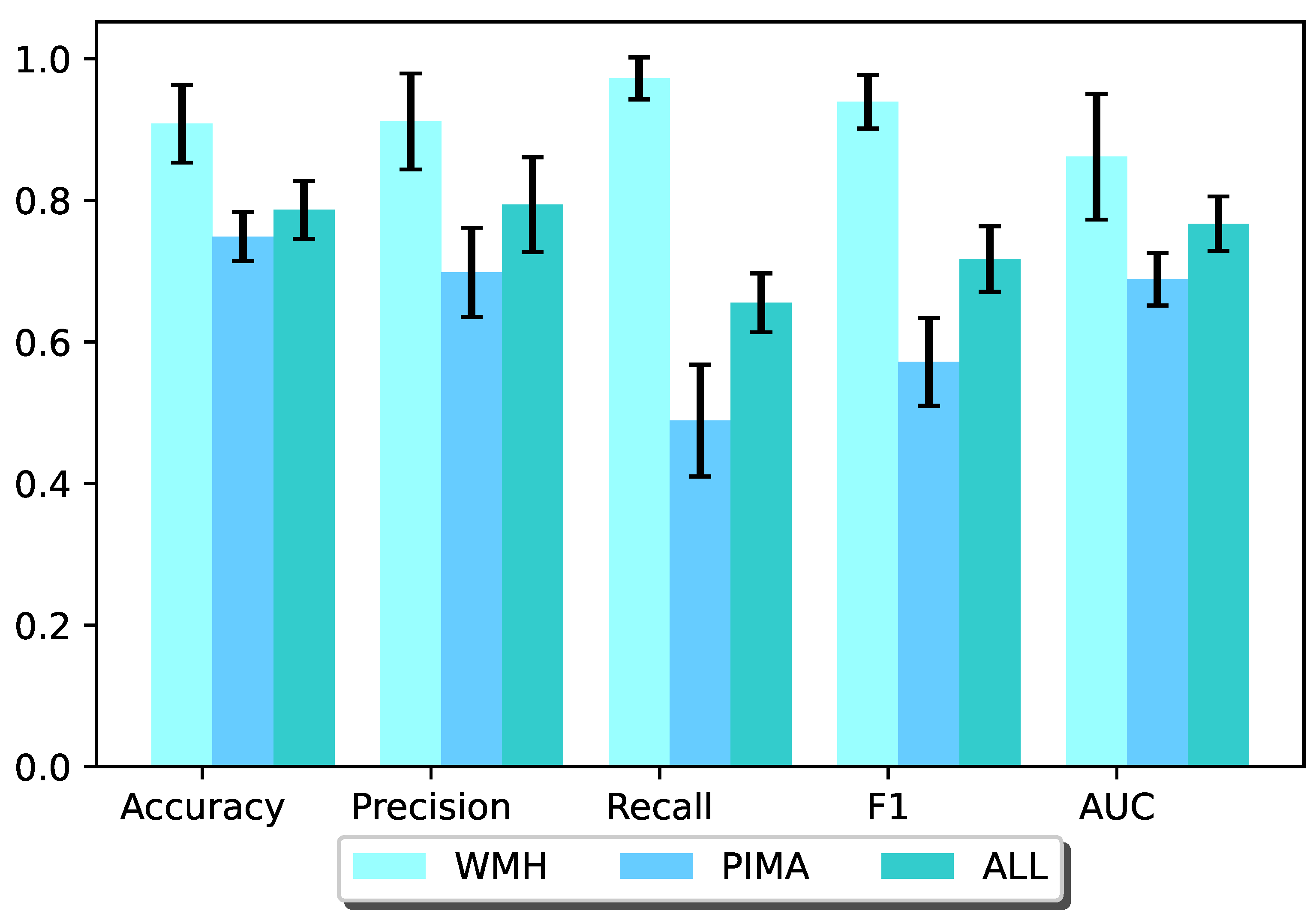
For Experiment 5,
Figure 7 and
Figure 8 show the predicted results of the two methods “GRAPE” and “LR+GRAPE”. From the results, we can find that the prediction results obtained from “GRAPE” are slightly better than or as well as that obtained from “LR+GRAPE”. Thus, it is better to directly use “GRAPE” to impute and predict than to run LR on the data after “GRAPE” imputation.
To see the boundary of the proposed method, we run the STACK-GRAPE on fused datasets with three missing ratios: 30%, 50% and 80%. For our fused dataset, its missing ratio is about 30%. We assume our fused dataset to be
with the size 986 × 7, to generate a dataset with missing ratios 50% and 80%, 20% and 50% of 6902 (986 × 7) entries are randomly removed from those observed positions. STACK-GRAPE is then run on these generated datasets. The results are shown in
Table 6. From this result, we can see that the performance of STACK-GRAPE decreases when missing ratios increase, but even in the missing ratio 80%, the accuracy is still 0.676. Thus, this method applies to the high missing ratio.
Since ensemble learning framework stacking is used to predict diabetes, to understand the stacking model better, additional experiments with each sub-model are conducted and the results are shown in
Table 7. From the results, we can find that Naive Bayes performs the worst, and random forest performs the best among the sub-models. The ensemble model STACK-GRAPE outperforms all the sub-models in the average cases.
4. Discussion
From the above experiments, it can be seen that the imputation model and the classifier adopted have an impact on the prediction performance of the fused datasets. As for the filling model, the more basic filling models such as mean filling and KNN filling are not suitable for multiple regression imputation. The deep-learning imputation model GRAPE seems the best option to impute the missing values in the fused dataset. GRAPE, a deep-learning imputation model, can act as a classifier besides the imputation model, and it performs well. In addition, the ensemble learning model stacking can boost the performance further, and some previous works [
40,
41] also verified this conclusion. However, these works cannot deal with missing-value problems, thus comparison cannot be done on prediction on incomplete datasets. In the process of fusing heterogeneous datasets, it is important to choose a suitable filling model. The better the filling model used, the more effective the information contained in the fusion dataset. With such a dataset, coupled with a good prediction model, the final prediction result will be satisfactory.
For the imputation model, besides multiple imputation and GRAPE, several other models are proposed to deal with missing values, such as LSTM [
42]. Due to the introduction of a gating mechanism, LSTM is outstanding in the processing of the missing values of time-series problems. Compared with LSTM, GRAPE can deal with any missing case in any data. The idea of combining heterogeneous datasets and imputing the missing values incurred in the combining process is not only applicable to the problem of diabetes prediction, but also to all the disease prediction problems [
43], even those outside the medical field. It is also interesting to consider missing-value imputation and diabetes prediction as multitask learning [
44].
Although the proposed methods show their effectiveness, there is a limit for them. If the different data sources do not have common features, the proposed method cannot be directly uses. However, in real-world applications, different data sources collected with the same goal normally have some features in common, as well as some special features. Thus, when combining, it is better to make full use of their complementary and consensus information. It can be seen as multi-view learning [
45,
46] or multi-source learning. Thus, the tools used in those related areas can be borrowed to serve the current goal. In addition, we fused two data sources in this work, and in fact it is easy to extend to more than two data sources.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}