
On Deceiving Malware Classification with Section Injection


Abstract
:1. Introduction
Any software that does something that causes harm to a user, computer, or network can be considered malware […]
- Random injection:
- inserting random bytes, so that we do not require any knowledge about the systems to be deceived
- Adversarial injection:
- inserting bytes taken from families different from the sample being evaluated.
- We provide a framework to inject data into PE files that leverages all the alignments required to preserve its functionality. It can inject any sort of data (either random or from a different file) in multiple positions of the file, not only at the end (padding).
- We evaluate how different deep neural networks architectures proposed for malware classification behave in multiclass classification scenarios. We want to assess the difficulties behind separating a given sample from other samples of the same kind.
- We evaluate how the aforementioned networks behave when dealing with injected samples. Our goal here is to assess how our attacks impact the classification of these networks in regard to both the location and also the amount of injected data.
- We evaluate different augmentation strategies for defending against our data injection scheme, amplifying the robustness of malware classification techniques using raw bytes.
2. Background
3. Related Works
3.1. Malware Classification
3.2. Malware Injection
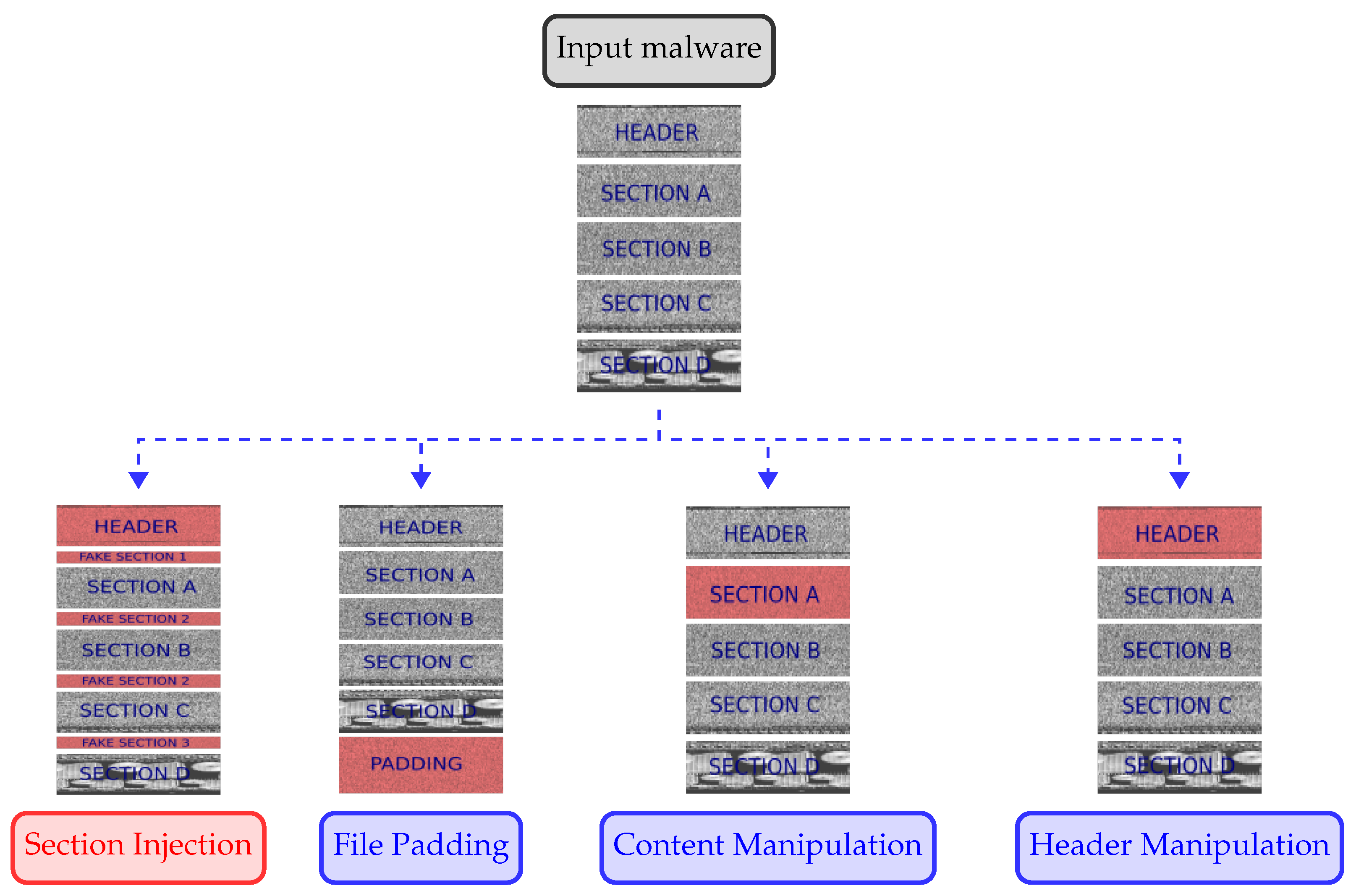
4. Data Injection
4.1. File Header
4.2. Section Header
4.3. Injected Data
4.4. Workarounds
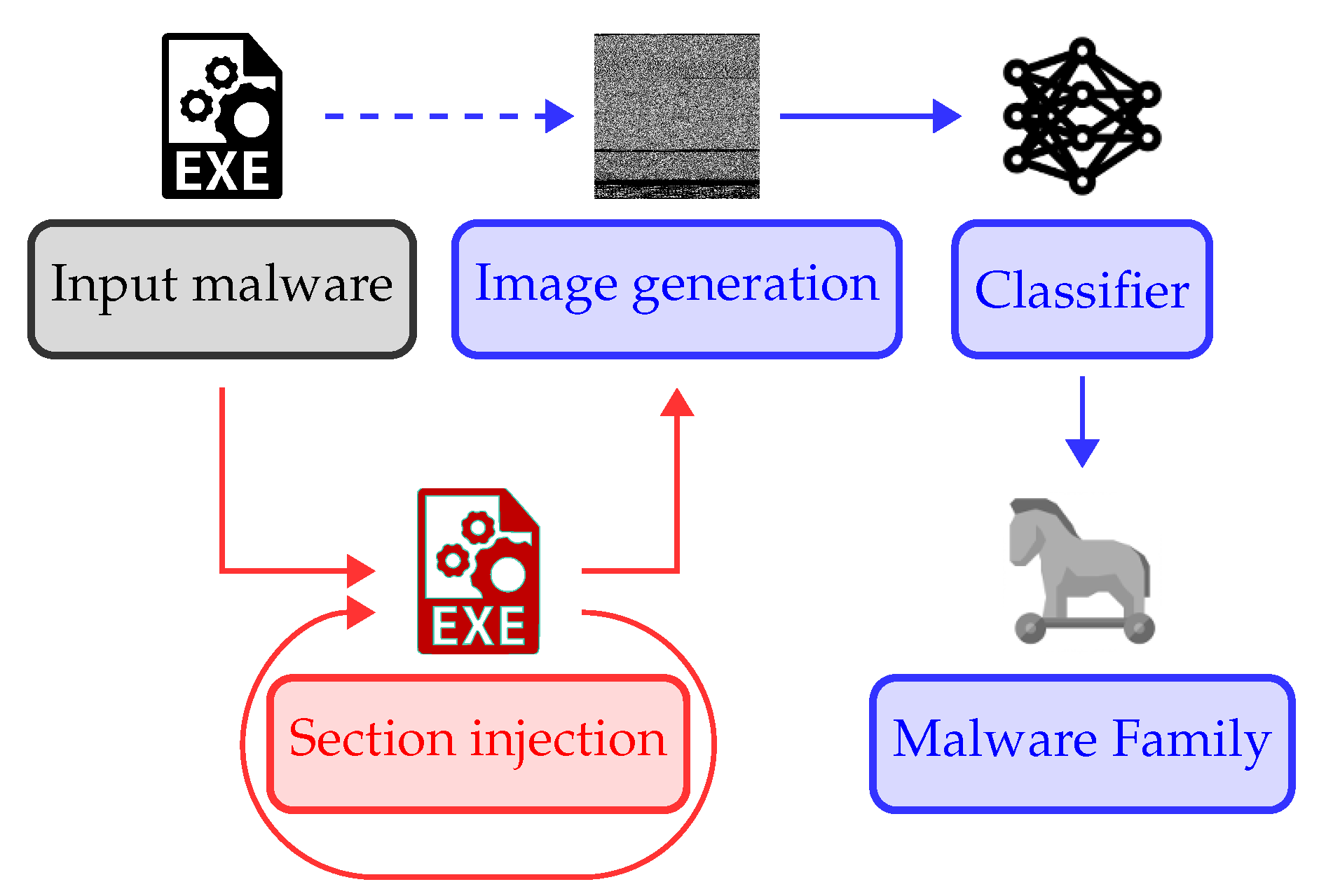
5. Malware Classification
5.1. Image Generation
5.2. Classification
5.2.1. GIST + KNN
5.2.2. CNNs
- Le et al. [17] present three models. A simple model with three 1D-CNN layers before a fully connected layer is referred to as Le-CNN. A second model with an LSTM layer before the fully connected one is referred to as Le-CNN-LSTM. A third model with a bidirectional LSTM before the fully connected layer is referred to as Le-CNN-BiLSTM. For all of them, we employ the same input size of 10 k bytes, a batch size of 512, and train the model for at most 60 epochs (early stopping if the accuracy does not improve for 10 epochs). Optimization is performed with the Adam algorithm [55] with a learning rate of 1e-4.
- Raff et al. [16] present the model referred to as MalConv. This model employs a gated convolution network, i.e., an embedding layer followed by two separate 1D-CNN layers that are multiplied and passed on for two fully connected layers. For this model, we use training protocol similar to Lucas et al. [23]: an input size of 1 MB and training for a total of 10 epochs without early stopping with a batch size of 16 due to memory constraints. Optimization is performed using the Stochastic Gradient Descent (SGD) algorithm with a Nesterov momentum [56] of 9e-1, weight decay of 1e-3, and a learning rate of 1e-2.
6. Results
6.1. Dataset
6.2. Metrics
- Accuracy curves: where each data point represents the accuracy (e.g., percentage of correctly classified samples over total number of samples) of the network in a given scenario—as described by Equation (5), where True Positive (TP), True Negative (TN), False Positive (FP) and False Negative (FN) are used.
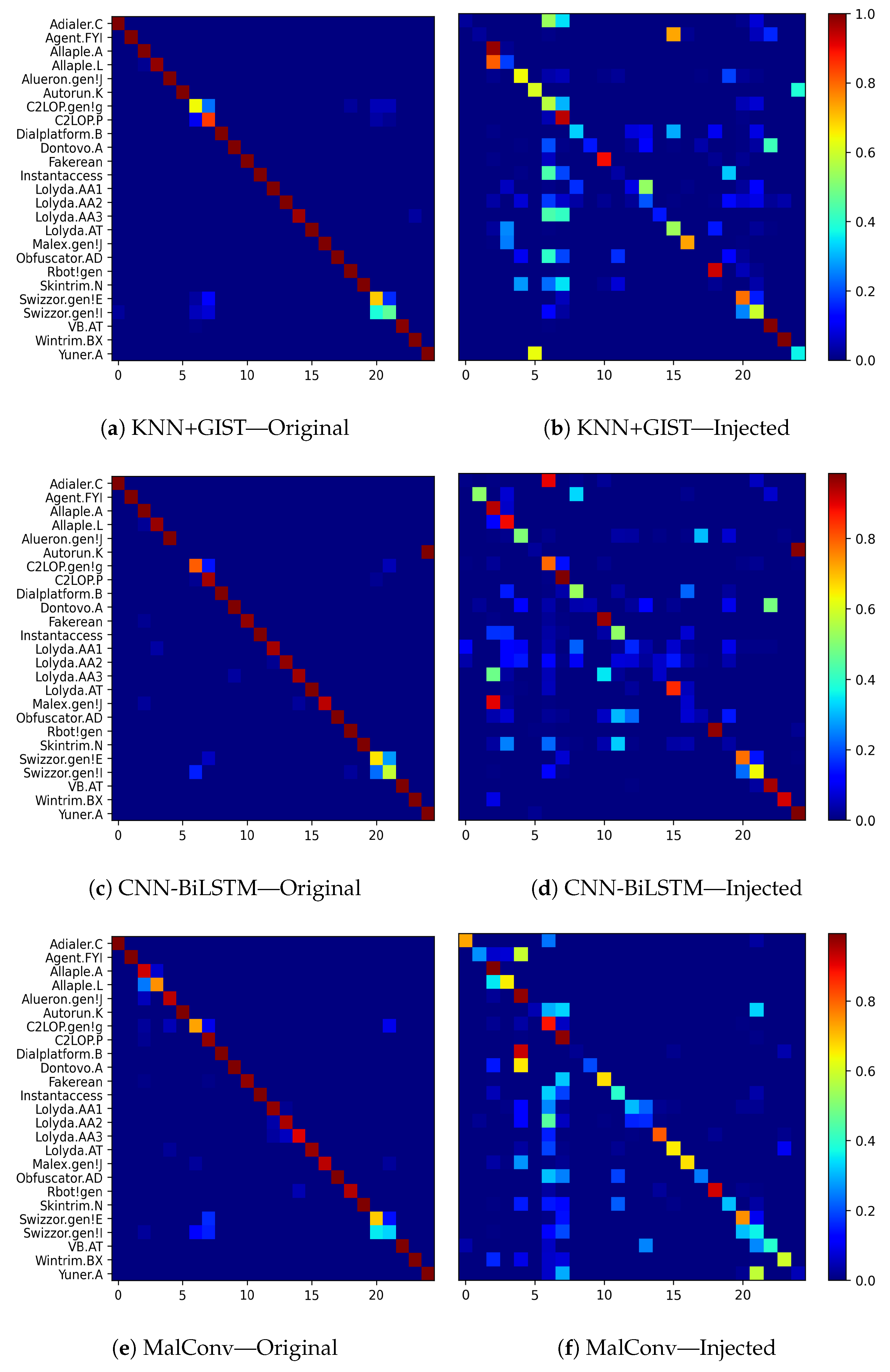
- Confusion Matrices: used to understand how similar the classes are before and after the injection of data, which might give a clue on the weights given to each class by the evaluated algorithms.
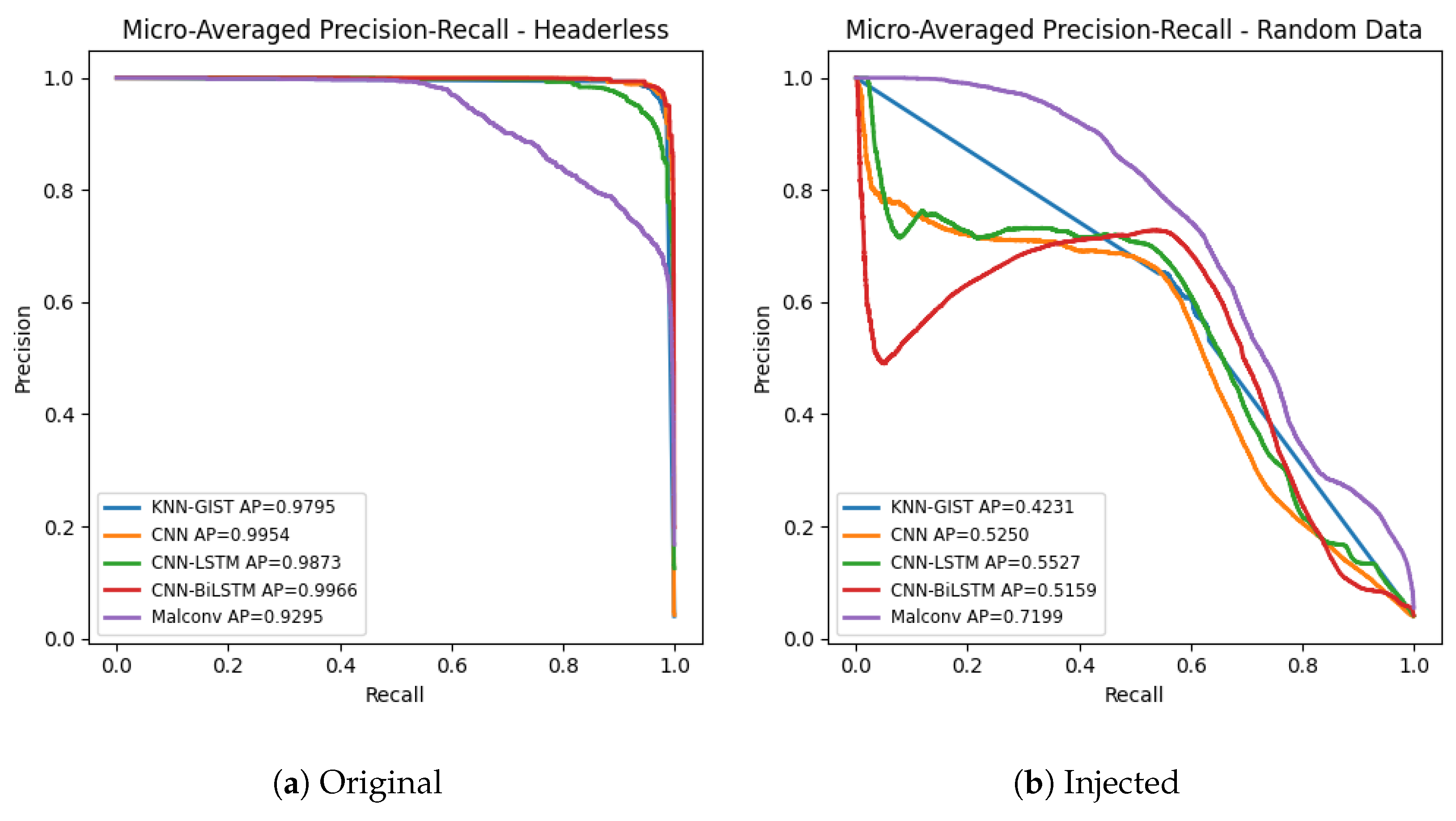
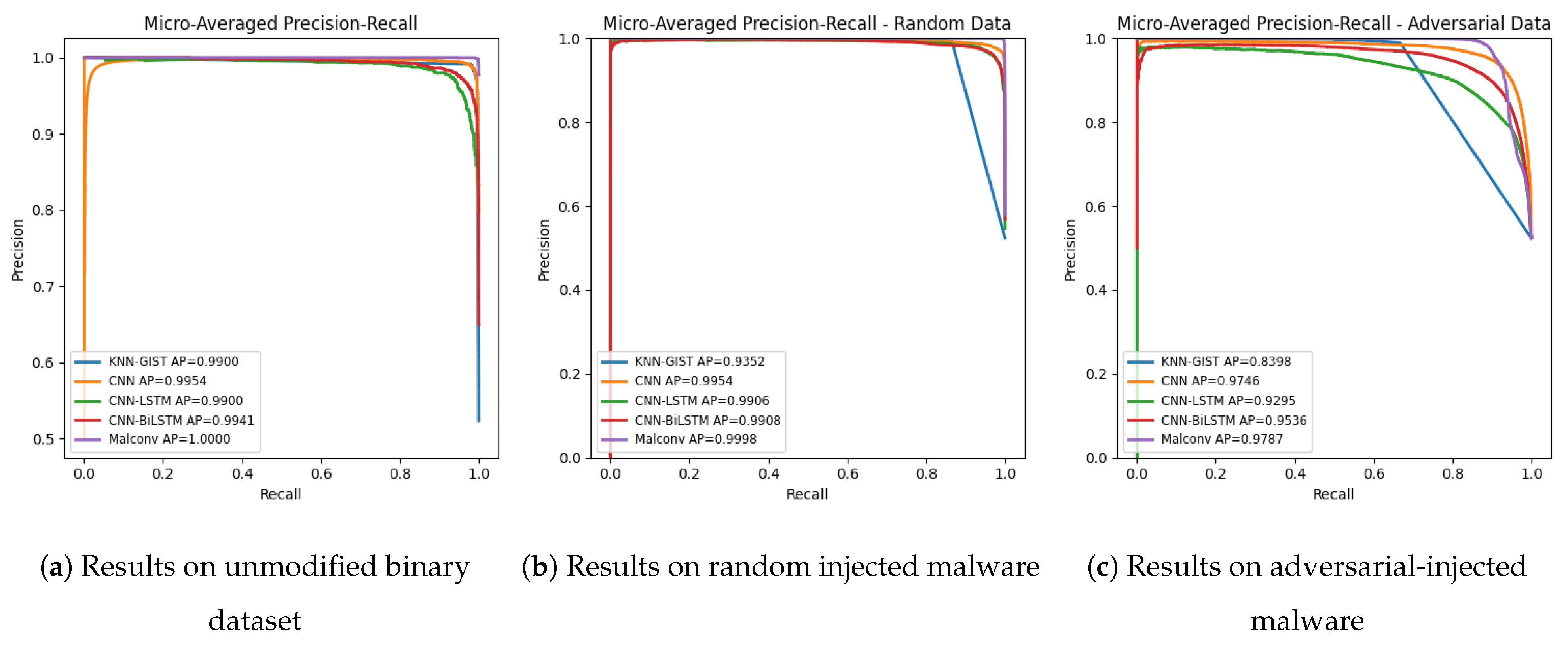
- Precision–Recall curves: as mentioned in Section 6.1, we are dealing with a highly imbalanced dataset, with some classes having an order of magnitude more examples than others. In those scenarios, precision–recall curves offer a better visualization on the true performance of the models, since it computes the capacity of the model in correctly classifying the target class when it has way fewer samples than the negative class. It is possible for a classifier to achieve high accuracies by learning to categorize based only on the major class if the positive to negative ratio is too low [58,59]. We also compute the average precision (AP) as described by Equation (6). It can be understood as the area under the precision–recall curve. These values are obtained by computing precision (P) and recall (R) over a range of thresholds (n), using the algorithm’s output probabilities.
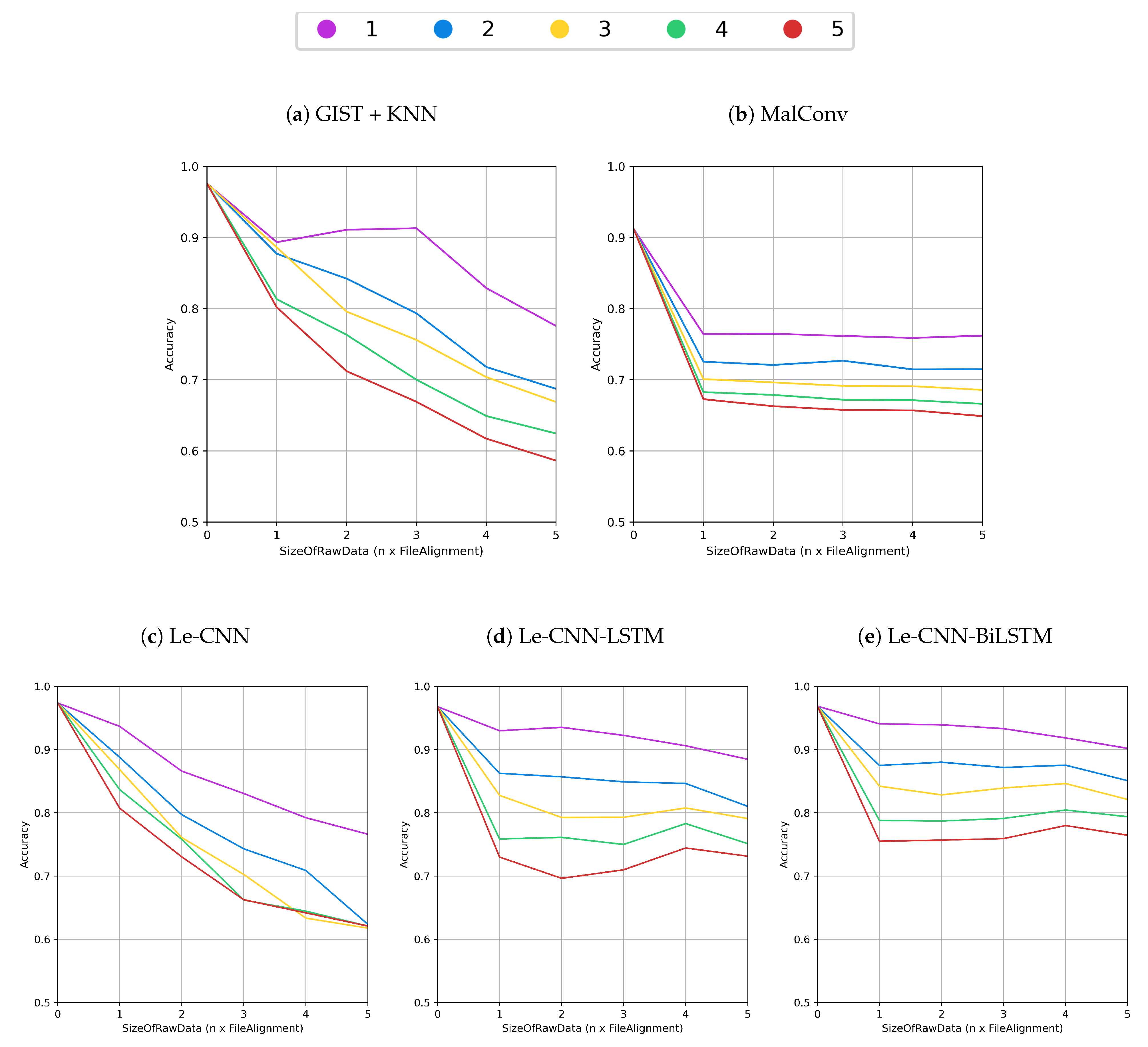
6.3. Injection Attacks with Random Data
6.4. Injection Attacks with Adversarial Data
6.5. Evaluating Samples without Header
6.6. Defending against Data Injection
6.6.1. Augmentation
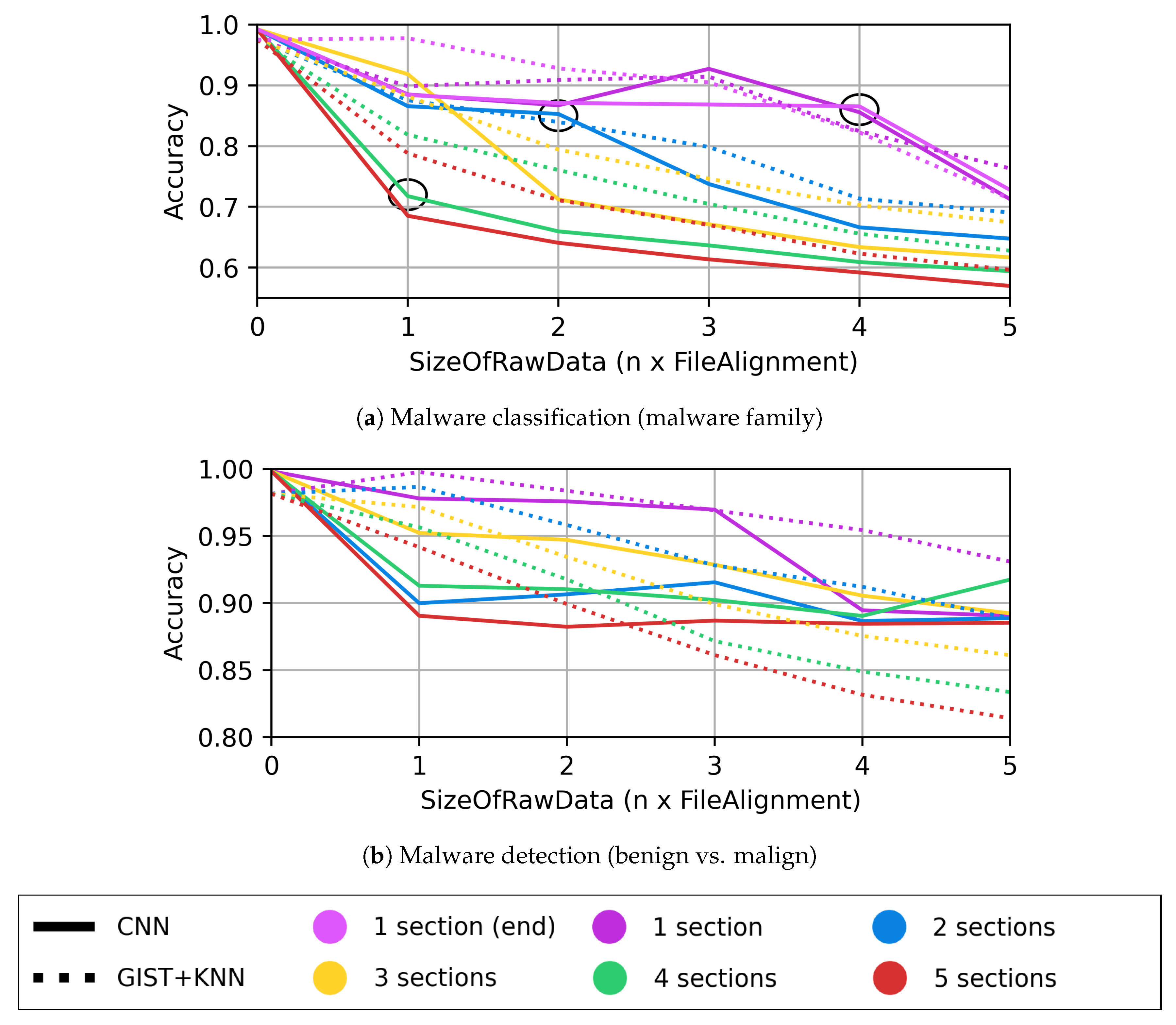
- Section reordering: Since our injection scheme adds new sections in a random position among the existing one, the first augmentation idea was to reorder the sections on the training section. By doing this, we wanted to check if the model could be more robust against data injection without seeing them during training. As shown by Figure 9a–c, this strategy increased a bit the performance of all models when compared to the vanilla results shown by Figure 7.
- Training with injected data: Since data are injected in the test set, a possibility was to include injected samples with random data in the training set as well. By comparing Figure 9d–f against Figure 7, we can see that all models became less vulnerable against random data injection but still struggle against adversarial data. MalConv benefitted the most in this scheme.
6.6.2. Binary Data
6.6.3. Scaling Models
7. Conclusions
- The usage of CNNs is gaining momentum in this research field literatures [9,14,15,17,18,19]. This work shows a simple technique that can make the accuracy in such CNNs drop in almost 50% by adding small perturbations to a malware file. We could observe that methods such as Gated CNN [16] or combining CNN with LSTM [17] can be more robust against the data injection presented here.
- A deeper understanding of how the operating system loads executable files to memory usually helps malware creators. During preliminary tests, we saw that some file format rules are flexible, and malware authors do not follow all of them. It includes files with section headers missing or some sections not aligned to the required flags. We tried our best to keep our generated examples in accordance with the format specified. Malware creators might not have this mentality, so that should be considered when building neural networks with the purpose of detecting malware files that rely on static features from the file.
- Our results show that data dispersion might be just as important as the amount of data being injected. We can use this idea to conduct a more directed attack using our method together with the method proposed by Khormali et al. (2019) [19], injecting FSGM-generated sections in any position of the file.
Challenges and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AOCD | Architecture Object Code Dataset |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CNN | Convolutional Neural Networks |
| CW | Carlini–Wagner |
| FN | False Negaive |
| FP | False Positive |
| FGSM | Fast Gradient Sign Method |
| GAMMA | Genetic Adversarial Machine learning Malware Attack |
| GBDT | Gradient Boost Decision Tree |
| GIST | Global Image Descriptor |
| IPR | In-Place Randomization |
| KNN | K-Nearest Neighbors |
| LSTM | Long Short-Term Memory |
| PE | Portable Executable |
| SGD | Stochastic Gradient Descent |
| TN | True Negative |
| TP | True Positive |
References
- Sikorski, M.; Honig, A. Practical Malware Analysis: The Hands-On Guide to Dissecting Malicious Software, 1st ed.; No Starch Press: San Francisco, CA, USA, 2012. [Google Scholar]
- Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-rimy, B.A.S.; Eisa, T.A.E.; Elnour, A.A.H. Malware Detection Issues, Challenges, and Future Directions: A Survey. Appl. Sci. 2022, 12, 8482. [Google Scholar] [CrossRef]
- Naseer, M.; Rusdi, J.F.; Shanono, N.M.; Salam, S.; Muslim, Z.B.; Abu, N.A.; Abadi, I. Malware detection: Issues and challenges. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1807, p. 012011. [Google Scholar]
- Alenezi, M.N.; Alabdulrazzaq, H.; Alshaher, A.A.; Alkharang, M.M. Evolution of malware threats and techniques: A review. Int. J. Commun. Netw. Inf. Secur. 2020, 12, 326–337. [Google Scholar] [CrossRef]
- Li, Y.; Caragea, D.; Hall, L.; Ou, X. Experimental Study of Machine Learning based Malware Detection Systems’ Practical Utility. In Hicss Symposium On Cybersecurity Big Data Analytics; 2020. Available online: https://par.nsf.gov/biblio/10178634-experimental-study-machine-learning-based-malware-detection-systems-practical-utility (accessed on 10 January 2023).
- Microsoft Corporation. Microsoft Security Intelligence Report Volume 24; Technical Report; Microsoft Corporation: Redmond, WA, USA, 2019; Available online: https://www.microsoft.com/security/blog/2019/02/28/microsoft-security-intelligence-report-volume-24-is-now-available/ (accessed on 11 October 2022).
- Symantec Corporation. Internet Security Threat Report Volume 24; Technical Report; Symantec Corporation: Tempe, AZ, USA, 2019; Available online: https://docs.broadcom.com/doc/istr-24-2019-en (accessed on 11 October 2022).
- Microsoft 365 Defender Threat Intelligence Team. Microsoft Researchers Work with Intel Labs to Explore New Deep Learning Approaches for Malware Classification. 2020. Available online: https://www.microsoft.com/security/blog/2020/05/08/microsoft-researchers-work-with-intel-labs-to-explore-new-deep-learning-approaches-for-malware-classification/ (accessed on 19 February 2022).
- Chen, L.; Sahita, R.; Parikh, J.; Marino, M. STAMINA: Scalable deep learning approach for malware classification. Intel White Paper 2020, 1, 3. [Google Scholar]
- Anderson, H.S.; Kharkar, A.; Filar, B.; Roth, P. Evading machine learning malware detection. Black Hat 2017, 2017. Available online: https://www.blackhat.com/docs/us-17/thursday/us-17-Anderson-Bot-Vs-Bot-Evading-Machine-Learning-Malware-Detection-wp.pdf (accessed on 10 January 2023).
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware Images: Visualization and Automatic Classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, VizSec ’11. Pittsburgh, PA, USA, 20 July 2011; ACM: New York, NY, USA, 2011; pp. 4:1–4:7. [Google Scholar] [CrossRef]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial perturbations against deep neural networks for malware classification. arXiv 2016, arXiv:1606.04435. [Google Scholar]
- Athiwaratkun, B.; Stokes, J.W. Malware classification with LSTM and GRU language models and a character-level CNN. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2482–2486. [Google Scholar]
- Yue, S. Imbalanced malware images classification: A CNN based approach. arXiv 2017, arXiv:1708.08042. [Google Scholar]
- Chen, L. Deep transfer learning for static malware classification. arXiv 2018, arXiv:1812.07606. [Google Scholar]
- Raff, E.; Barker, J.; Sylvester, J.; Brandon, R.; Catanzaro, B.; Nicholas, C. Malware detection by eating a whole exe. arXiv 2017, arXiv:1710.09435. [Google Scholar]
- Le, Q.; Boydell, O.; Namee, B.M.; Scanlon, M. Deep learning at the shallow end: Malware classification for non-domain experts. Digit. Investig. 2018, 26, S118–S126. [Google Scholar] [CrossRef]
- Su, J.; Vasconcellos, V.D.; Prasad, S.; Daniele, S.; Feng, Y.; Sakurai, K. Lightweight Classification of IoT Malware Based on Image Recognition. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 664–669. [Google Scholar] [CrossRef] [Green Version]
- Khormali, A.; Abusnaina, A.; Chen, S.; Nyang, D.; Mohaisen, A. COPYCAT: Practical adversarial attacks on visualization-based malware detection. arXiv 2019, arXiv:1909.09735. [Google Scholar]
- Benkraouda, H.; Qian, J.; Tran, H.Q.; Kaplan, B. Attacks on Visualization-Based Malware Detection: Balancing Effectiveness and Executability. In International Workshop on Deployable Machine Learning for Security Defense; Springer: Cham, Switerlands, 2021; pp. 107–131. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Al-Dujaili, A.; Huang, A.; Hemberg, E.; O’Reilly, U. Adversarial Deep Learning for Robust Detection of Binary Encoded Malware. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 76–82. [Google Scholar] [CrossRef] [Green Version]
- Demetrio, L.; Biggio, B.; Lagorio, G.; Roli, F.; Armando, A. Explaining vulnerabilities of deep learning to adversarial malware binaries. arXiv 2019, arXiv:1901.03583. [Google Scholar]
- Demetrio, L.; Coull, S.E.; Biggio, B.; Lagorio, G.; Armando, A.; Roli, F. Adversarial exemples: A survey and experimental evaluation of practical attacks on machine learning for windows malware detection. ACM Trans. Priv. Secur. (TOPS) 2021, 24, 1–31. [Google Scholar] [CrossRef]
- Lucas, K.; Sharif, M.; Bauer, L.; Reiter, M.K.; Shintre, S. Malware Makeover: Breaking ML-based static analysis by modifying executable bytes. In Proceedings of the Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Virtual Event, 7–11 June 2021; pp. 744–758. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, M.A.; Xu, Z.; Dickerson, J.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial training for free! In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Zhang, J.; Dong, Y.; Liu, B.; Ouyang, B.; Zhu, J.; Kuang, M.; Wang, H.; Meng, Y. The art of defense: Letting networks fool the attacker. arXiv 2021, arXiv:2104.02963. [Google Scholar]
- Ho, C.H.; Vasconcelos, N. DISCO: Adversarial Defense with Local Implicit Functions. arXiv 2022, arXiv:2212.05630. [Google Scholar]
- Yoo, K.; Kim, J.; Jang, J.; Kwak, N. Detection of Word Adversarial Examples in Text Classification: Benchmark and Baseline via Robust Density Estimation. arXiv 2022, arXiv:2203.01677. [Google Scholar]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft Malware Classification Challenge. 2018. Available online: http://xxx.lanl.gov/abs/1802.10135 (accessed on 10 January 2023).
- Agarap, A.F.; Pepito, F.J.H. Towards Building an Intelligent Anti-Malware System: A Deep Learning Approach using Support Vector Machine (SVM) for Malware Classification. arXiv 2018, arXiv:1801.00318. [Google Scholar]
- Liu, Y.s.; Lai, Y.K.; Wang, Z.H.; Yan, H.B. A New Learning Approach to Malware Classification Using Discriminative Feature Extraction. IEEE Access 2019, 7, 13015–13023. [Google Scholar] [CrossRef]
- Pascanu, R.; Stokes, J.W.; Sanossian, H.; Marinescu, M.; Thomas, A. Malware classification with recurrent networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 1916–1920. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. Deep neural network based malware detection using two dimensional binary program features. In Proceedings of the 2015 10th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 20–22 October 2015; pp. 11–20. [Google Scholar] [CrossRef]
- Anderson, H.S.; Roth, P. Ember: An open dataset for training static pe malware machine learning models. arXiv 2018, arXiv:1804.04637. [Google Scholar]
- İbrahim, M.; Issa, B.; Jasser, M.B. A Method for Automatic Android Malware Detection Based on Static Analysis and Deep Learning. IEEE Access 2022, 10, 117334–117352. [Google Scholar] [CrossRef]
- Gao, Y.; Hasegawa, H.; Yamaguchi, Y.; Shimada, H. Malware Detection by Control-Flow Graph Level Representation Learning With Graph Isomorphism Network. IEEE Access 2022, 10, 111830–111841. [Google Scholar] [CrossRef]
- Raff, E.; Zak, R.; Cox, R.; Sylvester, J.; Yacci, P.; Ward, R.; Tracy, A.; McLean, M.; Nicholas, C. An investigation of byte n-gram features for malware classification. J. Comput. Virol. Hacking Tech. 2018, 14, 1–20. [Google Scholar] [CrossRef]
- HaddadPajouh, H.; Dehghantanha, A.; Khayami, R.; Choo, K.K.R. A deep Recurrent Neural Network based approach for Internet of Things malware threat hunting. Future Gener. Comput. Syst. 2018, 85, 88–96. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.; Poornachandran, P.; Venkatraman, S. Robust intelligent malware detection using deep learning. IEEE Access 2019, 7, 46717–46738. [Google Scholar] [CrossRef]
- Uysal, D.T.; Yoo, P.D.; Taha, K. Data-driven malware detection for 6G networks: A survey from the perspective of continuous learning and explainability via visualisation. IEEE Open J. Veh. Technol. 2022, 4, 61–71. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Pappas, V.; Polychronakis, M.; Keromytis, A.D. Smashing the gadgets: Hindering return-oriented programming using in-place code randomization. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012. [Google Scholar]
- Koo, H.; Polychronakis, M. Juggling the gadgets: Binary-level code randomization using instruction displacement. In Proceedings of the Asia Conference on Computer and Communications Security (AsiaCCS), Xi’an China, 30 May 2016–3 June 2016. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef] [Green Version]
- Coull, S.E.; Gardner, C. Activation analysis of a byte-based deep neural network for malware classification. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW). IEEE, San Francisco, CA, USA, 19–23 May 2019; pp. 21–27. [Google Scholar]
- Clemens, J. Automatic classification of object code using machine learning. Digit. Investig. 2015, 14, S156–S162. [Google Scholar] [CrossRef] [Green Version]
- Krčál, M.; Švec, O.; Bálek, M.; Jašek, O. Deep convolutional malware classifiers can learn from raw executables and labels only. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018; Available online: https://openreview.net/pdf?id=HkHrmM1PM (accessed on 10 January 2023).
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep learning for classification of malware system call sequences. In Australasian Joint Conference on Artificial Intelligence; Springer: Cham, Switerlands, 2016; pp. 137–149. [Google Scholar]
- Sarvam. Supervised Classification with k-fold Cross Validation on a Multi Family Malware Dataset. 2014. Available online: https://sarvamblog.blogspot.com/2014/08/supervised-classification-with-k-fold.html (accessed on 10 January 2023).
- CeADAR Ireland. Deep Learning at the Shallow End: Malware Classification for Non-Domain Experts. 2018. Available online: https://bitbucket.org/ceadarireland/deeplearningattheshallowend/src/master (accessed on 10 January 2023).
- Elastic. Elastic Malware Benchmark for Empowering Researchers. 2017. Available online: https://github.com/elastic/ember (accessed on 10 January 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv arXiv:1412.6980, 2014. [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; Volume 28, pp. 1139–1147. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 10 January 2023).
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. Proceedings Of The 23rd International Conference On Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Saito, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLOS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Catak, F.O.; Ahmed, J.; Sahinbas, K.; Khand, Z.H. Data augmentation based malware detection using convolutional neural networks. PeerJ Comput. Sci. 2021, 7, e346. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving deep learning with generic data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Technique | Dataset |
|---|---|---|
| Nataraj et al. (2011) [11] | GIST + KNN | malimg [11] |
| Pascanu et al. (2015) [34] | Echo State Network (ESN) + Logistic Regression | Private |
| Athiwaratkun and Stokes (2017) [13] | LSTM + Multilayer Perceptron (MLP) | Private |
| Yue (2017) [14] | CNN | malimg [11] |
| Raff (2017) [16] | Embedding + CNN | Private |
| Anderson (2018) [36] | Embedding + CNN | Ember [36] |
| Su et al. (2018) [18] | CNN | Private |
| HaddadPajouh et al. (2018) [40] | LSTM | Private |
| Liu et al. (2018) [33] | Multilayer SIFT | malimg [11], BIG 2015 [31] |
| Agarap and Pepito (2018) [32] | Gated Recurrent UNIT (GRU) + Support Vector Machines (SVM) | malimg [11] |
| Le (2018) [17] | CNN-BiLSTM | BIG 2015 [31] |
| Chen (2018) [15] | Inception-V1 [44] | malimg [11], BIG 2015 [31] |
| Vinayakumar et al. (2019) [41] | CNN | malimg [11], Ember [36], Private |
| Chen (2020) [9] | Inception-V1 [44] | Private |
| Gao et al. (2022) [38] | Graph Isomorphism Network (GIN) | Private |
| Author | Methods | Targets | Dataset |
|---|---|---|---|
| Anderson et al. [10] | Set of Manipulations | GBDT [36] | Private |
| Khormali et al. [19] | Padding | 3-layer CNN | BIG 2015 [31] + Private IoT dataset |
| Demetrio et al. [23] | Set of Manipulations | MalConv [16], GBDT [36] | Private |
| Demetrio et al. [24] | Partial DOS, Full DOS, Extend, Shift, FGSM, Padding | MalConv [16], DNN [48], GBDT [36] | Private |
| Lucas et al. [25] | IPR, Disp | AvastNet [50], MalConv [16], GBDT [36] | Private |
| Benkraouda et al. [20] | Adversarial Generation + Optimization | CNN [19,51] | Private (combination of malimg [11] and AOCD [49]) |
| Flag Name | Description |
|---|---|
| Number of sections in the file | |
| Section size in bytes is a multiple of this flag | |
| Memory address of a section is a multiple of this flag | |
| Memory size of all sections in bytes | |
| Address of the first byte when the file is loaded to memory (default value is 0x00400000) |
| Flag Name | Size | Description |
|---|---|---|
| 8 bytes | Section name | |
| 4 bytes | Section size in bytes on memory | |
| 4 bytes | Section offset on memory relative to | |
| 4 bytes | Section size in bytes on disk | |
| 4 bytes | Section offset on disk relative to the beginning of the file | |
| 4 bytes | Section characteristics like usage and permissions |
| Size (kB) | Width (px) |
|---|---|
| <10 | 32 |
| 10–30 | 64 |
| 30–60 | 128 |
| 60–100 | 256 |
| 100–200 | 384 |
| 200–500 | 512 |
| 500–1000 | 768 |
| 1000–2000 | 1024 |
| >2000 | 2048 |
| # | Family | # Samples | Average Size (kB) |
|---|---|---|---|
| 1 | Adialer.C | 122 | 209.82 |
| 2 | Agent.FYI | 116 | 16.07 |
| 3 | Allaple.A | 2949 | 72.64 |
| 4 | Allaple.L | 1591 | 57.75 |
| 5 | Alueron.gen!J | 198 | 101.27 |
| 6 | Autorun.K | 106 | 524.54 |
| 7 | C2LOP.P | 146 | 386.92 |
| 8 | C2LOP.gen!g | 200 | 524.04 |
| 9 | Dialplatform.B | 177 | 13.98 |
| 10 | Dontovo.A | 162 | 34.50 |
| 11 | Fakerean | 381 | 110.62 |
| 12 | Instantaccess | 431 | 173.07 |
| 13 | Lolyda.AA1 | 213 | 27.43 |
| 14 | Lolyda.AA2 | 184 | 35.13 |
| 15 | Lolyda.AA3 | 123 | 244.80 |
| 16 | Lolyda.AT | 159 | 24.66 |
| 17 | Malex.gen!J | 136 | 82.96 |
| 18 | Obfuscator.AD | 142 | 162.82 |
| 19 | Rbot!gen | 158 | 241.04 |
| 20 | Skintrim.N | 80 | 192.98 |
| 21 | Swizzor.gen!E | 128 | 336.74 |
| 22 | Swizzor.gen!I | 132 | 320.77 |
| 23 | VB.AT | 408 | 666.80 |
| 24 | Wintrim.BX | 97 | 408.74 |
| 25 | Yuner.A | 800 | 524.54 |
| Total | 25 families | 9339 samples | 176.29kB size |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
da Silva, A.A.; Pamplona Segundo, M. On Deceiving Malware Classification with Section Injection. Mach. Learn. Knowl. Extr. 2023, 5, 144-168. https://doi.org/10.3390/make5010009
da Silva AA, Pamplona Segundo M. On Deceiving Malware Classification with Section Injection. Machine Learning and Knowledge Extraction. 2023; 5(1):144-168. https://doi.org/10.3390/make5010009
Chicago/Turabian Styleda Silva, Adeilson Antonio, and Mauricio Pamplona Segundo. 2023. "On Deceiving Malware Classification with Section Injection" Machine Learning and Knowledge Extraction 5, no. 1: 144-168. https://doi.org/10.3390/make5010009